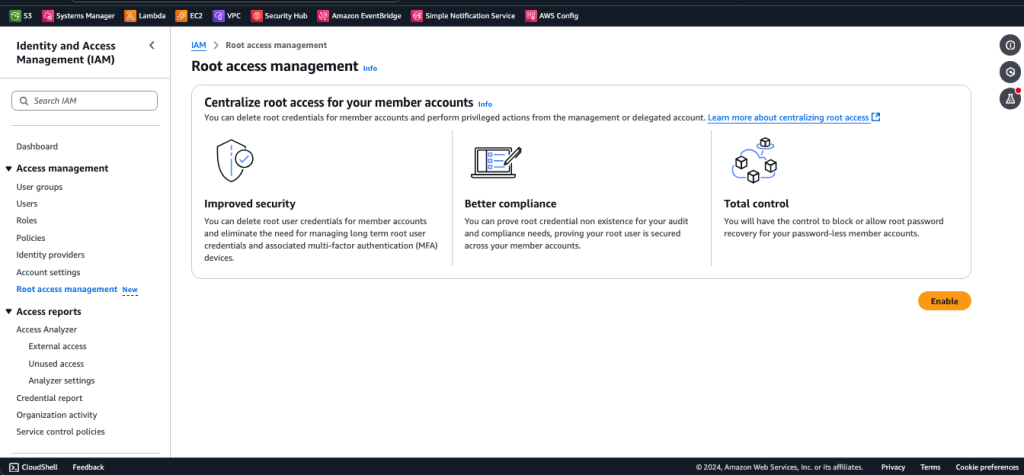
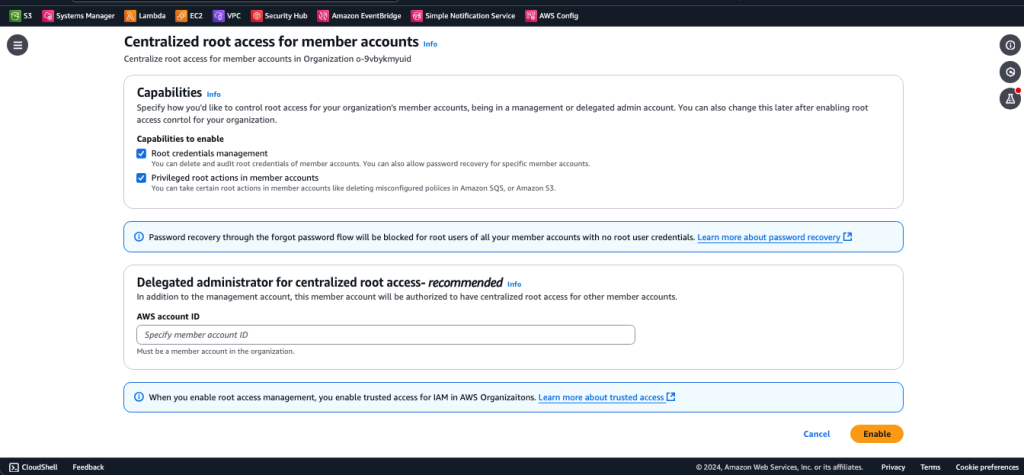
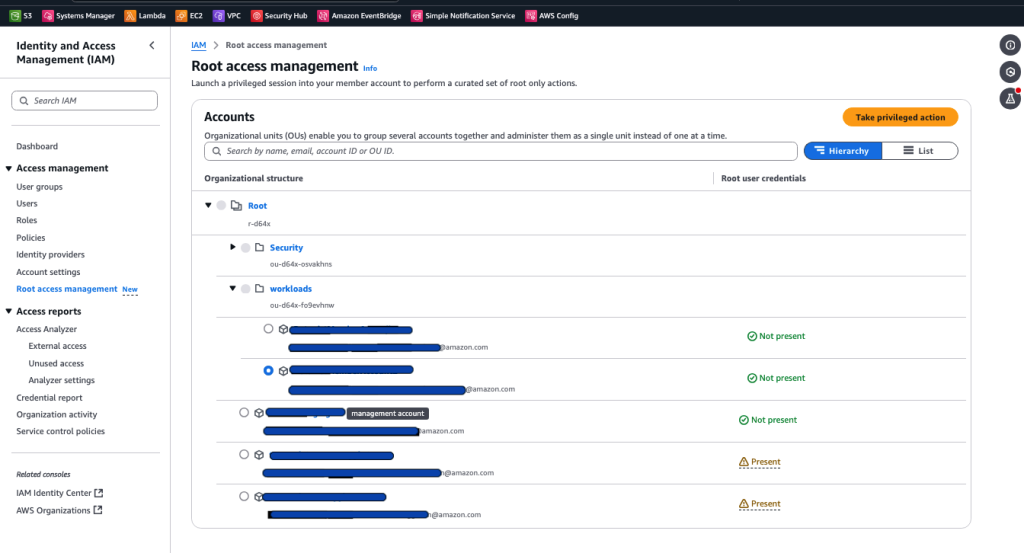
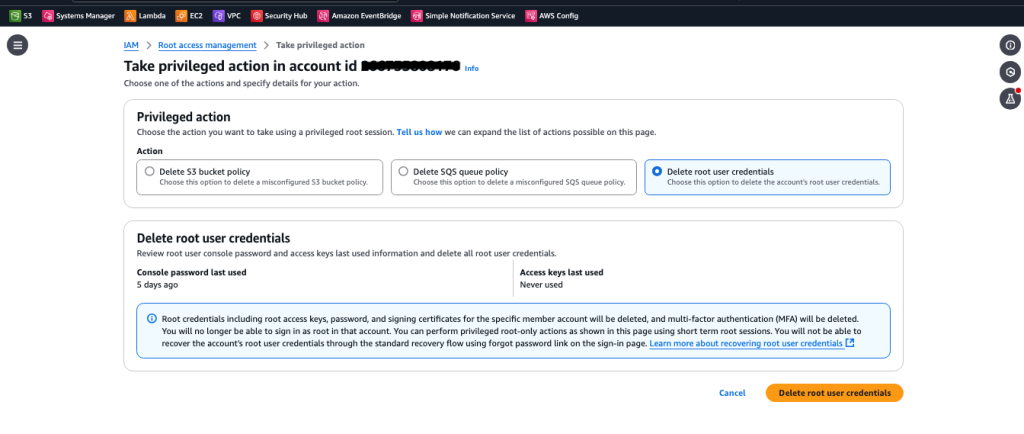
Post Syndicated from Chris McPeek original https://aws.amazon.com/blogs/compute/simplifying-developer-experience-with-variables-and-jsonata-in-aws-step-functions/
This post is written by Uma Ramadoss, Principal Specialist SA, Serverless and Dhiraj Mahapatro, Principal Specialist SA, Amazon Bedrock
AWS Step Functions is introducing variables and JSONata data transformations. Variables allow developers to assign data in one state and reference it in any subsequent steps, simplifying state payload management without the need to pass data through multiple intermediate states. With JSONata, an open source query and transformation language, you now perform advanced data manipulation and transformation, such as date and time formatting and mathematical operations.
This blog post explores the powerful capabilities of these new features, delving deep into simplifying data sharing across states using variables and reducing data manipulation complexity through advanced JSONata expressions.
Overview
Customers choose Step Functions to build complex workflows that involve multiple services such as AWS Lambda, AWS Fargate, Amazon Bedrock, and HTTP API integrations. Within these workflows, you build states to interface with these various services, passing input data and receiving responses as output. While you can use Lambda functions for date, time, and number manipulations beyond Step Functions’ intrinsic capabilities, these methods struggle with increasing complexity, leading to payload restrictions, data conversion burdens, and more state changes. This affects the overall cost of the solution. You use variables and JSONata to address this.
To illustrate these new features, consider the same business use case from the JSONPath blog, a customer onboarding process in the insurance industry. A potential customer provides basic information, including names, addresses, and insurance interests, while signing up. This Know-Your-Customer (KYC) process starts a Step Functions workflow with a payload containing these details. The workflow decides the customer’s approval or denial, followed by sending a notification.
{
"data": {
"firstname": "Jane",
"lastname": "Doe",
"identity": {
"email": "[email protected]",
"ssn": "123-45-6789"
},
"address": {
"street": "123 Main St",
"city": "Columbus",
"state": "OH",
"zip": "43219"
},
"interests": [
{"category": "home", "type": "own", "yearBuilt": 2004, "estimatedValue": 800000},
{"category": "auto", "type": "car", "yearBuilt": 2012, "estimatedValue": 8000},
{"category": "boat", "type": "snowmobile", "yearBuilt": 2020, "estimatedValue": 15000},
{"category": "auto", "type": "motorcycle", "yearBuilt": 2018, "estimatedValue": 25000},
{"category": "auto", "type": "RV", "yearBuilt": 2015, "estimatedValue": 102000},
{"category": "home", "type": "business", "yearBuilt": 2009, "estimatedValue": 500000}
]
}
}
The original workflow diagram illustrates the workflow without new features, while the new workflow diagram shows the workflow built by applying variables and JSONata. Access the workflows in the GitHub repository from the main (original workflow) and jsonata-variables (new workflow) branches.

Figure 1: Original Workflow

Figure 2: New Workflow
Setup
Follow the steps in the README to create this state machine and cleanup once testing is complete.
Simplifying data sharing with variables
Variables allow you to instantiate or assign state results to a variable that is referenced in future states. In a single state, you assign multiple variables with different values, including static data, results of a state, JSONPath or JSONata expressions, and intrinsic functions. The following diagram illustrates how variables are assigned and used inside a state machine:

Figure 3: Variable assignment and scope
Variable scope
In Step Functions, variables have a scope similar to programming languages. You define variables at different levels, with inner scope and outer scope. Inner scope variables are defined inside map, parallel, or nested workflows and these variables are only accessible within their specific scope. Alternatively, you set outer scope variables at the top level. Once assigned, these variables can be accessed from any downstream state irrespective of their order of execution in the future. However, as of the release of this blog, distributed map state cannot reference variables in outer scopes. The user guide on variable scope elaborates on these edge cases.
Variable assignment and usage
To set a variable’s value, use the special field Assign. The JSONata part of this blog post further down explains the purpose of {%%}.
"Assign": {
"inputPayload": "{% $states.context.Execution.Input %}",
"isCustomerValid": "{% $states.result.isIdentityValid and $states.result.isAddressValid %}"
} Use a variable by writing a dollar sign ($) before its name.
{
"TableName": "AccountTable",
"Item": {
"email": {
"S": "{% $inputPayload.data.email %}"
},
"firstname": {
"S": "{% $inputPayload.data.firstname %}"
},....
}
Simplifying data manipulations with JSONata
JSONata is a lightweight query and transformation language for Json data. JSONata offers more capabilities compared to JSONPath within Step Functions.
Setting QueryLanguage to “JSONata” and using {%%} tags for JSONata expressions allows you to leverage JSONata within a state machine. Apply this configuration at the top level of the state machine or at each task level. JSONata at the task level gives you fine-grained control of choosing JSONata vs JSONPath. This approach is valuable for complex workflows where you want to simplify a subset of states with JSONata and continue to use JSONPath for the rest. JSONata provides you with more functions and operators than JSONPath and intrinsic functions in Step Functions. Activating the QueryLanguage attribute as JSONata at the state machine level disables JSONPath, therefore, restricting the use of InputPath, Parameters, ResultPath, ResultSelector, and OutputPath. Instead of these JSONPath parameters, JSONata uses Arguments and Output.
Optimizing simple states
One of the first things to notice in the new state machine is that the Verification process does not use Lambda functions anymore as seen in the following comparison:

Figure 4: Lambda functions replaced with Pass states
In the previous approach, a Lambda function is used to validate email and SSN using regular expressions:
const ssnRegex = /^\d{3}-?\d{2}-?\d{4}$/;
const emailRegex = /^[a-zA-Z0-9._-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4}$/;
exports.lambdaHandler = async event => {
const { ssn, email } = event;
const approved = ssnRegex.test(ssn) && emailRegex.test(email);
return {
statusCode: 200,
body: JSON.stringify({
approved,
message: `identity validation ${approved ? 'passed' : 'failed'}`
})
}
};With JSONata, you define regular expressions directly in the state machine’s Amazon States Language (ASL). You use a Pass state and $match() from JSONata to validate the email and the SSN.
{
"StartAt": "Check Identity",
"States": {
"Check Identity": {
"Type": "Pass",
"QueryLanguage": "JSONata",
"End": true,
"Output": {
"isIdentityValid": "{% $match($states.input.data.identity.email, /^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$/) and $match($states.input.data.identity.ssn, /^(\\d{3}-?\\d{2}-?\\d{4}|XXX-XX-XXXX)$/) %}"
}
}
}
}
The same applies to validate the address inside a Pass state using sophisticated JSONata string functions like $length, $trim, $each, and $not from JSONata:
{
"StartAt": "Check Address",
"States": {
"Check Address": {
"Type": "Pass",
"QueryLanguage": "JSONata",
"End": true,
"Output": {
"isAddressValid": "{% $not(null in $each($states.input.data.address, function($v) { $length($trim($v)) > 0 ? $v : null })) %}"
}
}
}
}
When using JSONata, $states becomes a reserved variable.
Result aggregation
Previously with JSONPath, using an expression outside of a Choice state was not available. That is not the case anymore with JSONata. The parallel state, in the example, gathers identity and address verification results from each sub-step. You merge the results into a boolean variable isCustomerValid.
"Verification": {
"Type": "Parallel",
"QueryLanguage": "JSONata",
...
"Assign": {
"inputPayload": "{% $states.context.Execution.Input %}",
"isCustomerValid": "{% $states.result.isIdentityValid and $states.result.isAddressValid %}"
},
"Next": "Approve or Deny?"
}The crucial part to note here is the access to results via $states.result and use of AND boolean-operator inside {%%}. This ultimately makes the downstream Choice state, which uses this variable, simpler. Operators in JSONata give you flexibility to write expressions like these wherever possible, which reduces the need of a compute layer to process simple data transformations.
Additionally, the Choice state becomes simpler to use with flexible JSONata operators and expressions, as long as the expressions within {%%} result in a true or false value.
"Approve or Deny?": {
"Type": "Choice",
"QueryLanguage": "JSONata",
"Choices": [
{
"Next": "Add Account",
"Condition": "{% $isCustomerValid %}"
}
],
"Default": "Deny Message"
}
Intrinsic functions as JSONata functions
Step Functions provides built-in JSONata functions to enable parity with Step Functions’ intrinsic functions. The DynamoDB putItem step shows how you use $uuid() that has the same functionality as States.UUID() intrinsic function. You also get JSONata specific functions on date and time. The following state shows the use of $now() to get the current timestamp as ISO-8601 as a string before inserting this item to the DynamoDB table.
"Add Account": {
"Type": "Task",
"QueryLanguage": "JSONata",
"Resource": "arn:aws:states:::dynamodb:putItem",
"Arguments": {
"TableName": "AccountTable",
"Item": {
"PK": {
"S": "{% $uuid() %}"
},
"email": {
"S": "{% $inputPayload.data.identity.email %}"
},
"name": {
"S": "{% $inputPayload.data.firstname & ' ' & $inputPayload.data.lastname %}"
},
"address": {
"S": "{% $join($each($inputPayload.data.address, function($v) { $v }), ', ') %}"
},
"timestamp": {
"S": "{% $now() %}"
}
}
},
"Next": "Interests"
}
Notice that you don’t apply the .$ notation in S.$ anymore as JSONata expressions reduces developer pain while building state machine ASL. Explore the additional JSONata functions accessible within Step Functions.
Advanced JSONata
JSONata’s flexibility stems from its pre-built functions, higher-order functions support, and functional programming constructs. With JSONPath, you used the advanced expressions "InputPath": "$..interests[?(@.category==home)]" to filter Home insurance related interests from the interests array. JSONata does much more than filtering. For example, you look for home insurance interests, totalAssetValue of the category type as home, and refer to existing fields like name and email as JSONata variables:
The result JSON will be:
{
"customer": "Jane Doe",
"email": "[email protected]",
"totalAssetValue": 1400000,
"home": {
"own": 2004,
"business": 2009
}
}
By following these steps, you ascend one level by collecting all of the insurance interests and their aggregated results. Notice that the category filter is no longer present.
which results in:
{
"customer": "Jane Doe",
"email": "[email protected]",
"totalAssetValue": 1549000,
"home": {
"own": 2004,
"business": 2009
},
"auto": {
"car": 2012,
"motorcycle": 2018,
"RV": 2015
},
"boat": {
"snowmobile": 2020
}
}
Discovering complex expressions
Use the JSONata playground with your sample data to discover detailed and complex expressions that fit your requirements. The following is an example of using the JSONata playground:

Figure 5: JSONata playground
Considerations
Variable Size
The maximum size of a single variable is 256Kib. This limit helps you bypass the Step Functions payload size restriction by letting you store state outputs in separate variables. While each individual variable can be up to 256Kib in size, the total size of all variables within a single Assign field cannot exceed 256Kib. Use Pass states to workaround this limitation, however, the total size of all stored variables cannot exceed 10MiB per execution.
Variable visibility
Variables are a powerful mechanism to simplify the data sharing across states. Prefer them over ResultPath, OutputPath or JSONata’s Output fields because of their ease of use and flexibility. There are two situations where you might still use Output. First, you can’t access inner-scoped variables in the outer scope. In these cases, fields in Output can help share data between different workflow levels. Second, when sending a response from the final state of the workflow, you may need to use fields in Output fields. The following transition diagram from JSONPath to JSONata provides additional details:

Figure 6: Transition from JSONPath to JSONata
Additionally, variables assigned to a specific state are not accessible in that same state:
"Assign Variables": {
"Type": "Pass",
"Next": "Reassign Variables",
"Assign": {
"x": 1,
"y": 2
}
},
"Reassign Variables": {
"Type": "Pass",
"Assign": {
"x": 5,
"y": 10,
## The assignment will fail unless you define x and y in a prior state.
## otherwise, the value of z will be 3 instead of 15.
"z": "{% $x+$y %}"
},
"Next": "Pass"
}
Best practices
Step Functions’ validation API provides semantic checks for workflows, allowing for early problem identification. To ensure safe workflow updates, it’s best to combine the validation API with versioning and aliases for incremental deployment.
Multi-line expressions in JSONata are not valid JSON. Therefore, use a single line as string delimited by a semicolon “;” where the last line returns the expression.
Mutually exclusive
Use of QueryLanguage type is mutually exclusive. Do not mix JSONPath/intrinsic functions and JSONata during variable assignments. For example, the below task fails because the variable b uses JSONata, whereas c uses an intrinsic function.
"Store Inputs": {
"Type": "Pass",
"QueryLanguage": "JSONata"
"Assign": {
"inputs": {
"a": 123,
"b": "{% $states.input.randomInput %}",
"c.$": "States.MathRandom($.start, $.end)"
}
},
"Next": "Average"
}
To use variables with JSONPath, set the QueryLanguage to JSONPath or remove this attribute from the task definition.
Conclusion
With variables and JSONata, AWS Step Functions now elevates the developer’s experience to write elegant workflows with simpler code in Amazon States Language (ASL) that matches with the normal programming paradigm. Developers can now build faster and write cleaner code by cutting out extra data transformation steps. These capabilities can be used in both new and existing workflows, giving you the flexibility to upgrade from JSONPath to JSONata and variables.
Variables and JSONata are available at no additional cost to customers in all the AWS regions where AWS Step Functions is available. For more information, refer to the user guide for JSONata and variables, as well as the sample application in the jsonata-variables branch.
To expand your serverless knowledge, visit Serverless Land.




 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike. Vishal Kajjam is a Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and using ML/AI for designing and building end-to-end solutions to address customers’ data integration needs. In his spare time, he enjoys spending time with family and friends.
Vishal Kajjam is a Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and using ML/AI for designing and building end-to-end solutions to address customers’ data integration needs. In his spare time, he enjoys spending time with family and friends. Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS. Wei Tang is a Software Development Engineer on the AWS Glue team. She is strong developer with deep interests in solving recurring customer problems with distributed systems and AI/ML.
Wei Tang is a Software Development Engineer on the AWS Glue team. She is strong developer with deep interests in solving recurring customer problems with distributed systems and AI/ML. XiaoRun Yu is a Software Development Engineer on the AWS Glue team. He is working on building new features for AWS Glue to help customers. Outside of work, Xiaorun enjoys exploring new places in the Bay Area.
XiaoRun Yu is a Software Development Engineer on the AWS Glue team. He is working on building new features for AWS Glue to help customers. Outside of work, Xiaorun enjoys exploring new places in the Bay Area. Jake Zych is a Software Development Engineer on the AWS Glue team. He has deep interest in distributed systems and machine learning. In his spare time, Jake likes to create video content and play board games.
Jake Zych is a Software Development Engineer on the AWS Glue team. He has deep interest in distributed systems and machine learning. In his spare time, Jake likes to create video content and play board games. Savio Dsouza is a Software Development Manager on the AWS Glue team. His team works on distributed systems & new interfaces for data integration and efficiently managing data lakes on AWS.
Savio Dsouza is a Software Development Manager on the AWS Glue team. His team works on distributed systems & new interfaces for data integration and efficiently managing data lakes on AWS. Mohit Saxena is a Senior Software Development Manager on the AWS Glue team. His team focuses on building distributed systems to enable customers with interactive and simple-to-use interfaces to efficiently manage and transform petabytes of data across data lakes on Amazon S3, and databases and data warehouses on the cloud.
Mohit Saxena is a Senior Software Development Manager on the AWS Glue team. His team focuses on building distributed systems to enable customers with interactive and simple-to-use interfaces to efficiently manage and transform petabytes of data across data lakes on Amazon S3, and databases and data warehouses on the cloud.




 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike. Keerthi Chadalavada is a Senior Software Development Engineer at AWS Glue, focusing on combining generative AI and data integration technologies to design and build comprehensive solutions for customers’ data and analytics needs.
Keerthi Chadalavada is a Senior Software Development Engineer at AWS Glue, focusing on combining generative AI and data integration technologies to design and build comprehensive solutions for customers’ data and analytics needs. Pradeep Patel is a Software Development Manager on the AWS Glue team. He is passionate about helping customers solve their problems by using the power of the AWS Cloud to deliver highly scalable and robust solutions. In his spare time, he loves to hike and play with web applications.
Pradeep Patel is a Software Development Manager on the AWS Glue team. He is passionate about helping customers solve their problems by using the power of the AWS Cloud to deliver highly scalable and robust solutions. In his spare time, he loves to hike and play with web applications. Chuhan Liu is a Software Engineer at AWS Glue. He is passionate about building scalable distributed systems for big data processing, analytics, and management. He is also keen on using generative AI technologies to provide brand-new experience to customers. In his spare time, he likes sports and enjoys playing tennis.
Chuhan Liu is a Software Engineer at AWS Glue. He is passionate about building scalable distributed systems for big data processing, analytics, and management. He is also keen on using generative AI technologies to provide brand-new experience to customers. In his spare time, he likes sports and enjoys playing tennis. Vaibhav Naik is a software engineer at AWS Glue, passionate about building robust, scalable solutions to tackle complex customer problems. With a keen interest in generative AI, he likes to explore innovative ways to develop enterprise-level solutions that harness the power of cutting-edge AI technologies.
Vaibhav Naik is a software engineer at AWS Glue, passionate about building robust, scalable solutions to tackle complex customer problems. With a keen interest in generative AI, he likes to explore innovative ways to develop enterprise-level solutions that harness the power of cutting-edge AI technologies. Gartner recognized AWS strengths as:
Gartner recognized AWS strengths as:




 Dipal Mahajan is a Lead Consultant with Amazon Web Services based out of India, where he guides global customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings extensive experience on Software Development, Architecture and Analytics from industries like finance, telecom, retail and healthcare.
Dipal Mahajan is a Lead Consultant with Amazon Web Services based out of India, where he guides global customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings extensive experience on Software Development, Architecture and Analytics from industries like finance, telecom, retail and healthcare. Anusha Challa is a Senior Analytics Specialist Solutions Architect focused on Amazon Redshift. She has helped many customers build large-scale data warehouse solutions in the cloud and on premises. She is passionate about data analytics and data science.
Anusha Challa is a Senior Analytics Specialist Solutions Architect focused on Amazon Redshift. She has helped many customers build large-scale data warehouse solutions in the cloud and on premises. She is passionate about data analytics and data science.
 Ricardo Serafim is a Senior Analytics Specialist Solutions Architect at AWS.
Ricardo Serafim is a Senior Analytics Specialist Solutions Architect at AWS.

 Hang (Arthur) Zuo is a Senior Product Manager with Amazon OpenSearch Service. Arthur leads the core experience in the next-gen OpenSearch UI and data migration to Amazon OpenSearch Service. Arthur is passionate about cloud technologies and building data products that help users and businesses gain actionable insights and achieve operational excellence.
Hang (Arthur) Zuo is a Senior Product Manager with Amazon OpenSearch Service. Arthur leads the core experience in the next-gen OpenSearch UI and data migration to Amazon OpenSearch Service. Arthur is passionate about cloud technologies and building data products that help users and businesses gain actionable insights and achieve operational excellence. Chris Helma is a Senior Engineer at Amazon Web Services based in Austin, Texas. He is currently developing tools and techniques to enable users to shift petabyte-scale data workloads into OpenSearch. He has extensive experience building highly-scalable technologies in diverse areas such as search, security analytics, cryptography, and developer productivity. He has functional domain expertise in distributed systems, AI/ML, cloud-native design, and optimizing DevOps workflows. In his free time, he loves to explore specialty coffee and run through the West Austin hills.
Chris Helma is a Senior Engineer at Amazon Web Services based in Austin, Texas. He is currently developing tools and techniques to enable users to shift petabyte-scale data workloads into OpenSearch. He has extensive experience building highly-scalable technologies in diverse areas such as search, security analytics, cryptography, and developer productivity. He has functional domain expertise in distributed systems, AI/ML, cloud-native design, and optimizing DevOps workflows. In his free time, he loves to explore specialty coffee and run through the West Austin hills. Andre Kurait is a Software Development Engineer II at Amazon Web Services, based in Austin, Texas. He is currently working on Migration Assistant for Amazon OpenSearch Service. Prior to joining Amazon OpenSearch, Andre worked within Amazon Health Services. In his free time, Andre enjoys traveling, cooking, and playing in his church sport leagues. Andre holds Bachelor of the Science degrees from the University of Kansas in Computer Science and Mathematics.
Andre Kurait is a Software Development Engineer II at Amazon Web Services, based in Austin, Texas. He is currently working on Migration Assistant for Amazon OpenSearch Service. Prior to joining Amazon OpenSearch, Andre worked within Amazon Health Services. In his free time, Andre enjoys traveling, cooking, and playing in his church sport leagues. Andre holds Bachelor of the Science degrees from the University of Kansas in Computer Science and Mathematics. Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.

 Darshit Thakkar is a Technical Product Manager with AWS and works with the Amazon Athena team.
Darshit Thakkar is a Technical Product Manager with AWS and works with the Amazon Athena team. Selman Ay is a Data Architect in the AWS Professional Services team.
Selman Ay is a Data Architect in the AWS Professional Services team. BP Yau is a Sr Partner Solutions Architect at AWS helping customers architect big data solutions to process data at scale
BP Yau is a Sr Partner Solutions Architect at AWS helping customers architect big data solutions to process data at scale