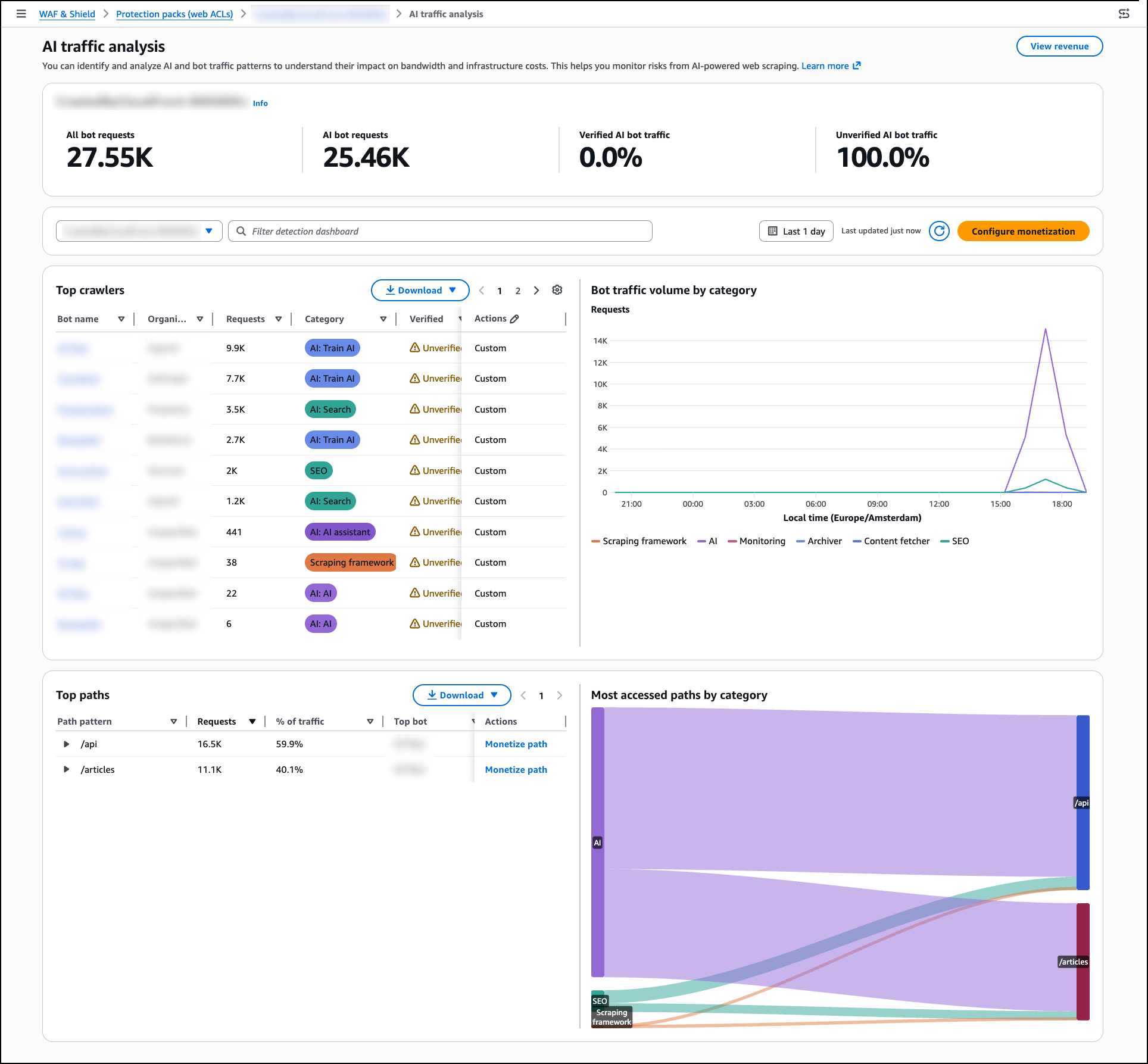
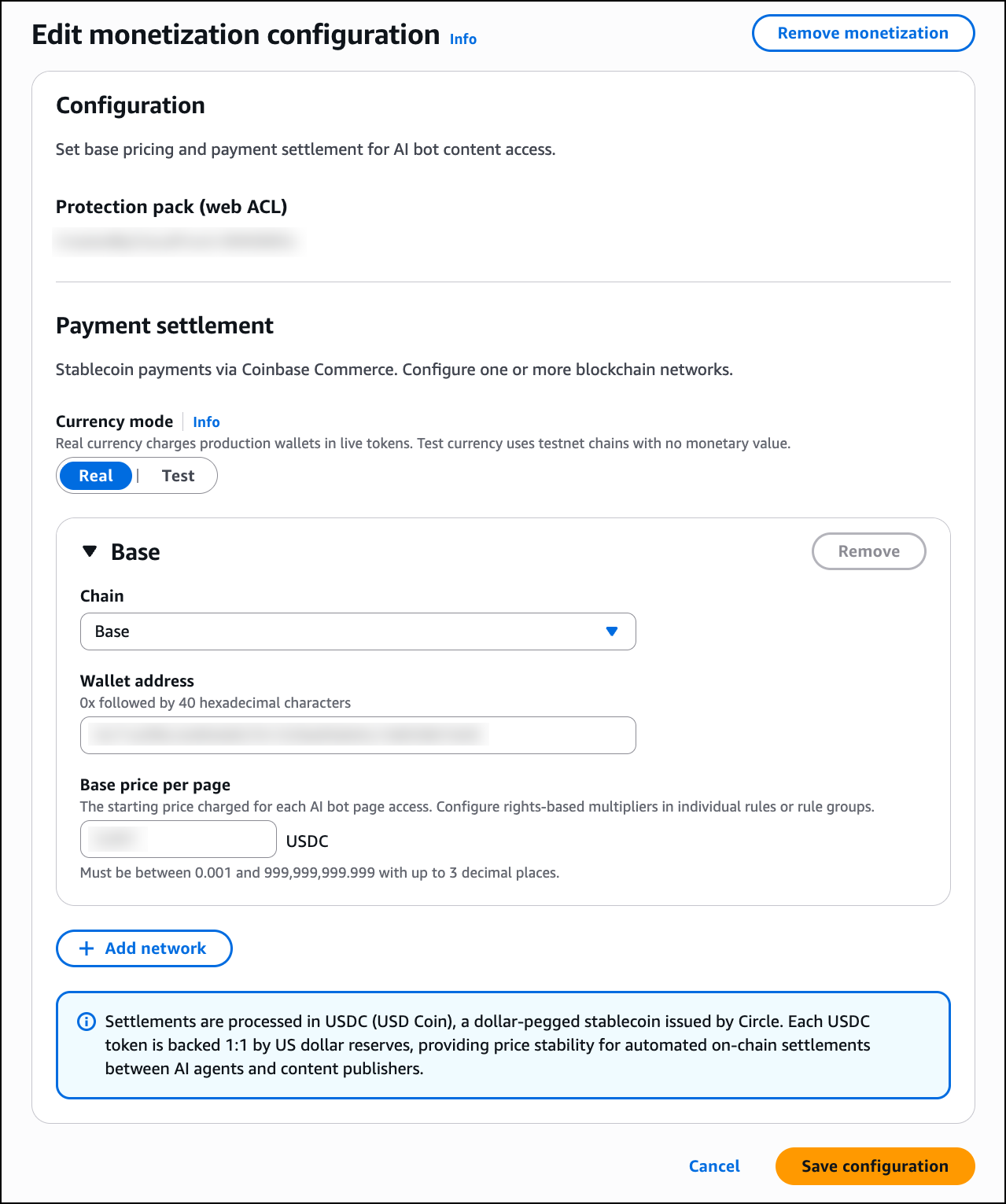
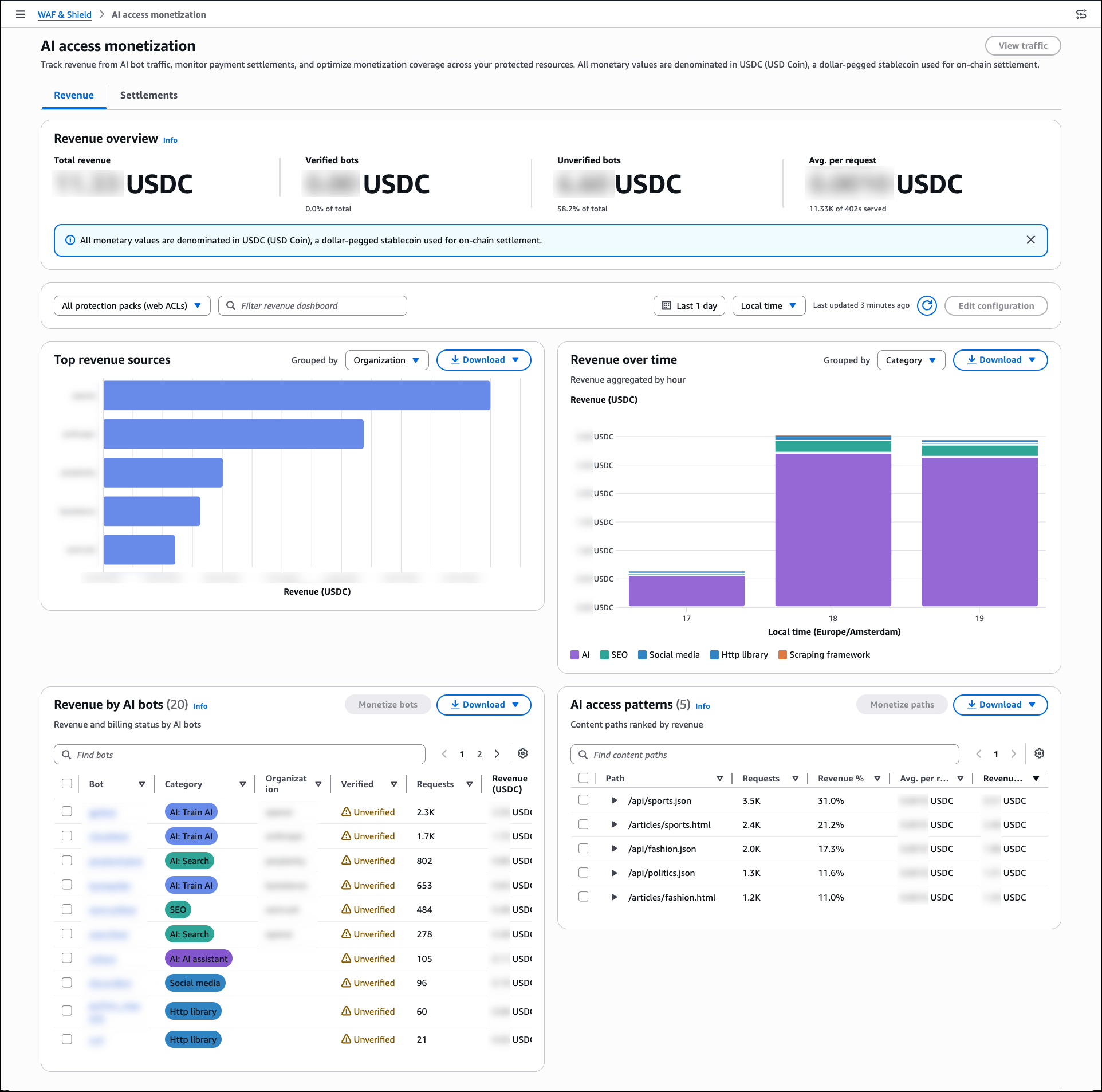
Post Syndicated from Matt Gurr original https://aws.amazon.com/blogs/security/threat-tactic-spotlight-subdomain-takeover/
In this blog post you’ll learn how to detect and prevent subdomain takeover – a tactic where threat actors exploit dangling DNS records to redirect traffic to attacker-controlled resources. We’ll explain the issue, how the situation arises, and how you can use various AWS features and services to help mitigate the impact of this tactic.
Under the shared responsibility model, securing configurations in the cloud is your responsibility. AWS supports you through strong defaults, guidance in the Security Pillar of the Well-Architected Framework, and security services to help you meet that responsibility. The AWS Customer Incident Response Team (AWS CIRT) also monitors for new and trending tactics that threat actors use to exploit specific customer configurations, so that you can make informed design decisions and improve your response plans.
AWS CIRT has observed threat actors actively scanning for public DNS CNAME records that point to resources that no longer exist, looking for subdomain takeover opportunities.
Note: The subdomain takeover tactic does not leverage vulnerabilities of AWS services. It exploits a dangling DNS record to redirect traffic to an attacker-controlled resource.
Quick DNS Primer
CNAME Records: A CNAME (Canonical Name) record is a DNS entry that points one domain name to another. For example, api.example.com can be configured to point to api.example.s3-website-us-east-1.amazonaws.com. This feature of DNS enables users to configure a memorable, human-friendly domain name while the actual resource lives at a longer, machine-generated AWS hostname. A security issue emerges when the target resource is deleted but the CNAME record pointing to it remains – creating a “dangling” record.
Dangling Records: When a resource (like an S3 bucket) is deleted but the DNS record pointing to it is left behind, that DNS record becomes “dangling”, pointing to a resource that no longer exists. For resources in globally shared namespaces, threat actors can potentially reclaim the name of your deleted resource and serve malicious content through your DNS record.
What is subdomain takeover?
A subdomain is a prefix added to a domain that allows you to organize access to your resources. A subdomain takeover occurs when you delete the underlying resource and a threat actor creates a new resource with the same name to take advantage of the DNS records still pointing to it.
A subdomain takeover is possible when a CNAME record points to an AWS resource that uses a globally shared DNS namespace where the resource name can be chosen by any AWS customer. The following AWS resources meet these criteria:
Amazon S3 (global namespace): Bucket names like mybucket.s3.amazonaws.com are globally unique and can be claimed by any account if the bucket is deleted. Note: S3 buckets created with account regional namespaces (launched March 2026) are scoped to your account and are not subject to this issue.
Amazon CloudFront: Distribution domain names like d111111abcdef8.cloudfront.net are assigned by AWS and cannot be chosen by an attacker. However, if you delete a distribution and another customer creates one that happens to receive the same domain name, a dangling CNAME could resolve to their content.
AWS Elastic Beanstalk: Environment names like myapp.elasticbeanstalk.com are globally unique and can be claimed by any account if the environment is terminated.
Resources like Amazon VPC, Amazon EC2 instances, or private hosted zones are not subject to this tactic because they do not expose globally claimable DNS namespaces.
MITRE ATT&CK classifies this technique under T1584.001: Compromise Infrastructure – Domains.
Analyzing an example scenario
Consider the following scenario:
You create a DNS CNAME record pointing to your S3 website endpoint. The subdomain subdomain.example.com now resolves to subdomain.example.s3-website-us-east-1.amazonaws.com, which serves content from the S3 bucket named subdomain.example. If your team deletes the bucket and forgets to delete the DNS record, users that navigate to the site will see an error stating that the bucket doesn’t exist. However, at this point, if a threat actor sees this error and moves in to claim the bucket name, they will be able to set up their own site that users will see when they navigate to the subdomain.example.com site.
Figure 1 shows an S3 bucket named subdomain.example (a globally unique bucket name) configured to host a static website, with the S3 website endpoint subdomain.example.s3-website-us-east-1.amazonaws.com.
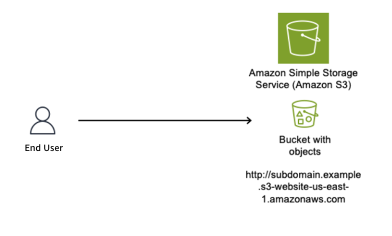
Figure 1: S3 bucket configured as a static website
As shown in Figure 2, we use Amazon Route 53 to create a CNAME record to resolve to our Amazon domain name; to give users a friendly name and so they do not have to remember the long S3 website name in URLs.
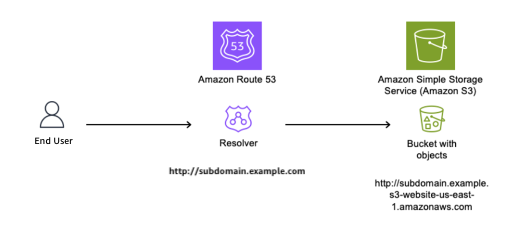
Figure 2: DNS Resolver configured with CNAME record pointing to origin bucket
The customer’s AWS administrator decides to stop serving content from the S3 bucket and deletes it, as shown in Figure 3.
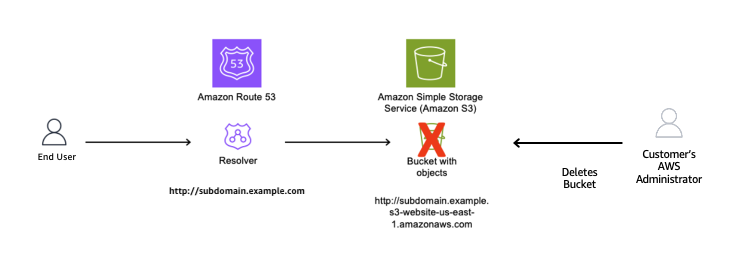
Figure 3: Resource deleted without removing the CNAME record
With the S3 bucket deleted and the CNAME record still in place, the DNS record is now dangling. A threat actor identifies this situation and creates a new S3 bucket with the same global name subdomain.example in an AWS account that the threat actor controls, as shown in Figure 4. The threat actor can now serve content from this new bucket, including potentially malicious content. End users remain unaware of this switch and continue to access subdomain.example.com, trusting the content because it appears to originate from a URL they recognize.
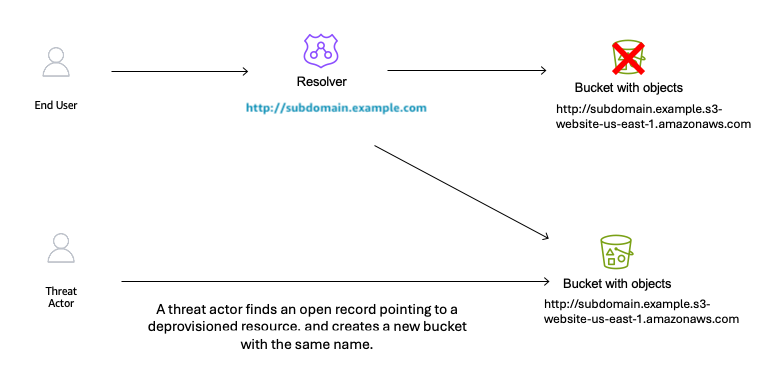
Figure 4: Subdomain takeover happens
Potential impacts of a sub-domain takeover
Consider these potential impacts:
Reputation risk: There is a potential risk to your organization’s reputation, because you don’t control the content being served from the threat actor’s site that your DNS record points to.
Potential exposure to phishing campaigns: Users within your organization might have the subdomain bookmarked in their browser, not knowing the resource is no longer available, then unsuspectingly navigate to the site that now hosts malware or is used to phish user credentials.
Blocking: If the subdomain is flagged by security vendors for malicious activity, it could impact your business operations.
Financial loss: Subdomain takeover incidents can result in a financial impact due to the potential disruption to service delivery as you deal with the event.
Proactive detection
AWS Config for proactive detection
For proactive detection, you can use AWS Config to continuously monitor your Route 53 CNAME records and verify that the target resources exist in your account.
Prerequisite: This approach requires AWS Config recorder to be enabled for the resource types you want to monitor (S3 buckets, CloudFront distributions, Elastic Beanstalk environments). If Config isn’t recording a resource type, it won’t appear in the inventory check. For more information, see Setting up AWS Config with the console.
Why use AWS Config inventory instead of DNS resolution checks?
A common approach is to check whether a CNAME resolves to a valid endpoint. However, this method has a critical flaw: if an attacker has already claimed the resource, DNS resolution will succeed – to their resource, not yours. You would have no indication that you don’t own what’s responding.
By querying AWS Config’s recorded configuration items, you’re checking whether the resource exists in your account inventory, not just whether something responds at that DNS name. This approach correctly identifies dangling CNAMEs even after a takeover has occurred.
Implementation approach:
Account-level vs. organization-level scope
The reference implementation queries AWS Config inventory within a single account. This means that if a CNAME record in Account A points to a resource that legitimately exists in Account B within the same AWS organization, the rule will flag it as NON_COMPLIANT.
For organizations that share resources across accounts, you can modify the solution to use an AWS Config Aggregator, which queries resource inventory across all accounts in your organization. This is similar to how IAM Access Analyzer supports both account-level and organization-level scopes. To use this approach, you need an organization-level Config Aggregator already configured, and the Lambda function’s IAM role needs the config:SelectAggregateResourceConfig permission.
We recommend starting with account-level scope for simplicity, then expanding to organization-level if your environment includes cross-account resource sharing.
The main idea is to create a custom AWS Config rule that queries your Route 53 hosted zones for CNAME records, then parses each CNAME target to determine whether it points to a known AWS resource pattern such as S3, CloudFront, or Elastic Beanstalk. For each match, the rule cross-references the target against your AWS Config inventory to verify that the resource actually exists in your account. If the resource isn’t found, the rule marks the CNAME record as NON_COMPLIANT, surfacing it for review.
The Config rule should focus on known AWS resource patterns:
- S3: *.s3.amazonaws.com, *.s3-website-<region>.amazonaws.com
- CloudFront: *.cloudfront.net
- Elastic Beanstalk: *.elasticbeanstalk.com
Note: CNAME records pointing to external third-party services are outside the scope of this detection mechanism, as those resources won’t appear in your AWS Config inventory.
NON_COMPLIANT findings from your Config rule can be routed to AWS Security Hub for centralized visibility, or trigger SNS notifications to alert your security team.
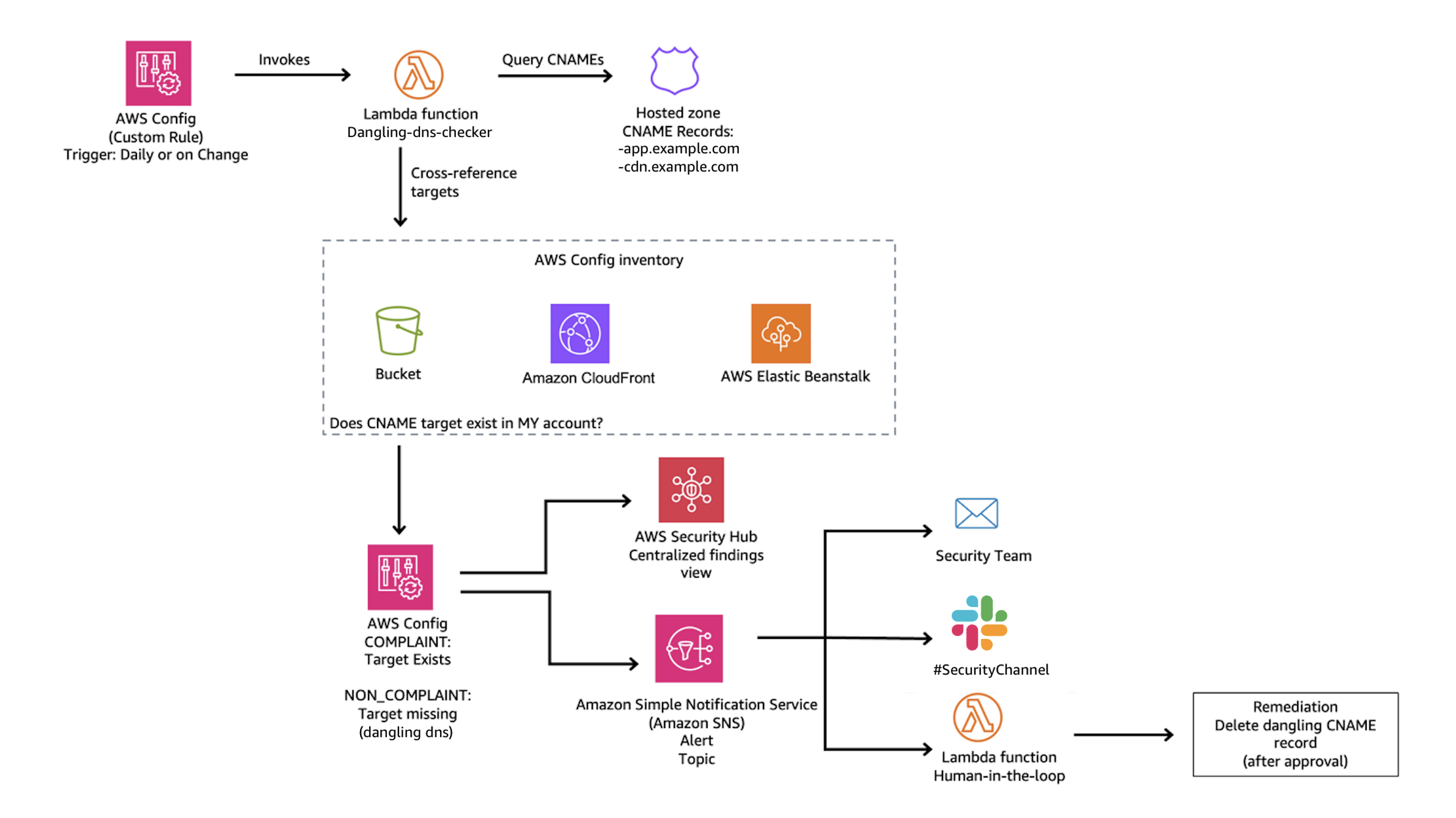
Figure 5: Dangling DNS Detection Solution
Reference implementation:
We’ve published a complete implementation of this detection approach as an open-source solution. The solution deploys a Lambda function that discovers CNAME records across all your Route 53 hosted zones and uses pattern matching to identify targets pointing to S3, CloudFront, and Elastic Beanstalk. It then queries your AWS Config inventory to verify whether each target resource still exists in your account. When a dangling record is detected, the solution generates a HIGH severity finding in Security Hub and can optionally send SNS notifications to alert your security team. A CloudWatch metrics dashboard is also included for ongoing compliance tracking.
Deployment:
The stack creates an AWS Config custom rule that runs on your specified schedule (default: every 24 hours), evaluating all CNAME records and reporting compliance status.
Mitigating the effects
Mitigating subdomain takeover requires both preventive procedures and responsive capabilities.
Prevention: Standard operating procedure
The most effective mitigation is a standard operating procedure for resource deprovisioning that ensures DNS records are removed before the underlying resource:
- Within your DNS zone, delete the CNAME record that points to the fully qualified domain name (FQDN) of the resource that you plan to deprovision.
- Wait for the DNS TTL to expire before deleting the resource. DNS resolvers cache records for the duration of the TTL (for example, a TTL of 3600 means resolvers may serve the old record for up to one hour). If you delete the resource before the TTL expires, a threat actor could claim the resource name while cached CNAME entries are still directing traffic to it.
- Deprovision the resource that you no longer want to use.
- Run a DNS check of the CNAME record that you removed to verify that the resource is no longer resolving.
Key principle: Always delete DNS first, wait for the TTL to expire, then delete the resource. This order eliminates the window where a dangling record could be exploited.
Prevention: S3 account regional namespaces
As mentioned earlier, AWS introduced account regional namespaces for Amazon S3 general purpose buckets in March 2026. While this is a meaningful step toward mitigating the S3-specific takeover vector, there are important operational limitations to be aware of:
Existing buckets are unaffected. Buckets already created in the global namespace cannot be migrated to an account regional namespace. The bucket names remain globally unique and claimable by anyone if the bucket is deleted.
Global namespace is still the default. When creating a new bucket through the console, CLI, or SDK, the global namespace remains the default selection. Users who aren’t aware of the new option will continue creating globally-scoped buckets.
Existing IaC templates require updates. Existing infrastructure-as-code templates (CloudFormation, CDK, Terraform) that don’t explicitly opt in to the account regional namespace will continue provisioning buckets in the global namespace. For CloudFormation, this means setting the BucketNamespace property to account-regional. For other IaC tools, consult their documentation for the equivalent configuration. Organizations need to audit and update their templates to opt in.
For these reasons, the dangling DNS detection approach described in this post remains critical – particularly for organizations with existing S3 infrastructure, and for CloudFront, and Elastic Beanstalk resources where no equivalent namespace scoping exists.
Response: Notification and remediation
When a dangling DNS record is detected, the reference solution described in the Detection section automatically creates a HIGH severity finding in AWS Security Hub and reports the CNAME record as NON_COMPLIANT in AWS Config. If you provide an SNS topic ARN during deployment, the solution also sends notifications to alert your security or operations team via email, Slack, or other channels. For production environments, consider a human-in-the-loop workflow where these notifications are reviewed by a team member who approves the DNS record deletion before it’s executed. This prevents accidental deletion of legitimate records during transient issues.
The reference solution also includes a CloudWatch dashboard for tracking compliance status and evaluation metrics over time, giving your team ongoing visibility into DNS health across your hosted zones.
Note: Fully automated remediation (auto-deleting DNS records) carries risk – a false positive could disrupt legitimate services. We recommend starting with detection and notification, then evaluating automation based on your detection accuracy and operational maturity.
Conclusion
Subdomain takeover is a preventable misconfiguration that can have significant impact on your organization. A layered defense approach provides the best protection:
Prevention: Implement a standard operating procedure that deletes DNS records before deprovisioning the underlying resource.
Detection: Use AWS Config custom rules to proactively identify CNAME records pointing to resources that no longer exist in your account.
Response: Configure notifications through SNS or Security Hub so your team can respond quickly when dangling records are detected.
Monitoring: Maintain ongoing visibility through CloudWatch dashboards to track DNS health and compliance status.
The key insight is that good DNS hygiene – knowing when your CNAME records point to a nonexistent resource – is your first line of defense. Automated detection through AWS Config provides a safety net when operational procedures fail. And if you detect an issue, having a playbook ready to enact your response can lower the impact and your mean time to recovery.
If you have feedback about this post, submit comments in the Comments section below.


![[Topic
list screenshot]](https://lwn.net/images/2026/topiclist.png)