Post Syndicated from Jon Levine original https://blog.cloudflare.com/workers-analytics-engine/


Today we’re excited to introduce Workers Analytics Engine, a new way to get telemetry about anything using Cloudflare Workers. Workers Analytics Engine provides time series analytics built for the serverless era.
Workers Analytics Engine uses the same technology that powers Cloudflare’s analytics for millions of customers, who generate 10s of millions of events per second. This unique architecture provides significant benefits over traditional metrics systems – and even enables our customers to build analytics for their customers.
Why use Workers Analytics Engine
Workers Analytics Engine can be used to get telemetry about just about anything.
Our initial motivation for building Workers Analytics Engine was to help internal teams at Cloudflare better understand what’s happening in their Workers. For example, one early internal customer is our R2 storage product. The R2 team is using the Analytics Engine to measure how many reads and writes happen in R2, how many users make these requests, how many bytes are transferred, how long the operations take, and so forth.
After seeing quick adoption from internal teams at Cloudflare, we realized that many customers could benefit from using this product.
For example, Workers Analytics Engine can also be used to build custom security rules. You could use it to implement something like fail2ban, a program that can ban malicious traffic. Every time someone logs in, you could record information like their location and IP. On subsequent logins, you could query the rate of login attempts from these attackers, and block them if they’ve attempted to sign in too many times in a given period.
Workers Analytics Engine can even be used to track things in the world that have nothing (yet!) to do with Workers. For example, imagine you have a network of IoT sensors that connect to the Internet to report weather and air quality data, like temperature, air pressure, wind speed, and PM2.5 pollution. Using Workers Analytics Engine, you could deploy a Worker in just a few minutes that collects these reports, and then query and visualize the data using our analytics APIs.
How to use Workers Analytics Engine
There are three steps to get started with Workers Analytics Engine:
- Configure your analytics using Wrangler
- Write data using the Workers Runtime API
- Query your data using our SQL or GraphQL API.
Configuring Workers Analytics Engine in Wrangler
To start using Workers Analytics Engine, you first need to configure it in Wrangler. This is done by creating a binding in wrangler.toml.
[analytics_engine]
bindings = [
{ name = "WEATHER" }
]
Your analytics can be named after the event in the world that they represent. For example, readings from our weather sensor above might be named “WEATHER.”
For our current beta release, customers may only create one binding at a time. In the future, we plan to enable customers to define multiple bindings, or even define them on-the-fly from within the Workers runtime.
Writing data from the Workers runtime
Once a binding is declared in Wrangler, you get a new environment variable in the Workers runtime that represents your Analytics Engine. This variable has a method, writeDataPoint(). A “data point” is a structured event which consists of a vector of labels and a vector of metrics.
A metric is just a “number” type field that can be aggregated in some way – for example, it could be summed, averaged, or quantiled. A label is a “string” type field that can be used for grouping or filtering.
For example, suppose you are collecting air quality samples. Each data point would represent a reading from your weather sensor. Metrics might include numbers like the temperature or air pressure reading. The labels could include the location of the sensor and the hardware identifier of the sensor.
Here’s what this looks like in code:
async fetch(request: Request, env) {
env.WEATHER.writeDataPoint({
labels: ["Seattle", "USA", "pro_sensor_9000”],
metrics: [25, 0.5]
});
return new Response("OK!");
}
In our initial version, developers are responsible for providing fields in a consistent order, so that they have the same semantics when querying. In a future iteration, we plan to let developers name their labels and metrics in the binding, and then use these names when writing data points in the runtime.
Querying and visualizing data
To query your data, Cloudflare provides a rich SQL API. For example:
SELECT label_1 as city, avg(metric_2) as avg_humidity
FROM WEATHER
WHERE metric_1 > 0
ORDER BY avg_humidity DESC
LIMIT 10
The results would show you the top 10 cities that had the highest average humidity readings when the temperature was above 0.
Note that, for our initial version, labels and metrics are accessed via names that have 1-based indexing. In the future, when we let developers name labels and metrics in their binding, these names will also be available via the SQL API.
Workers Analytics Engine is optimized for powering time series analytics that can be visualized using tools like Grafana. Every event written from the runtime is automatically populated with a timestamp field. This makes it incredibly easy to make time series charts in Grafana:
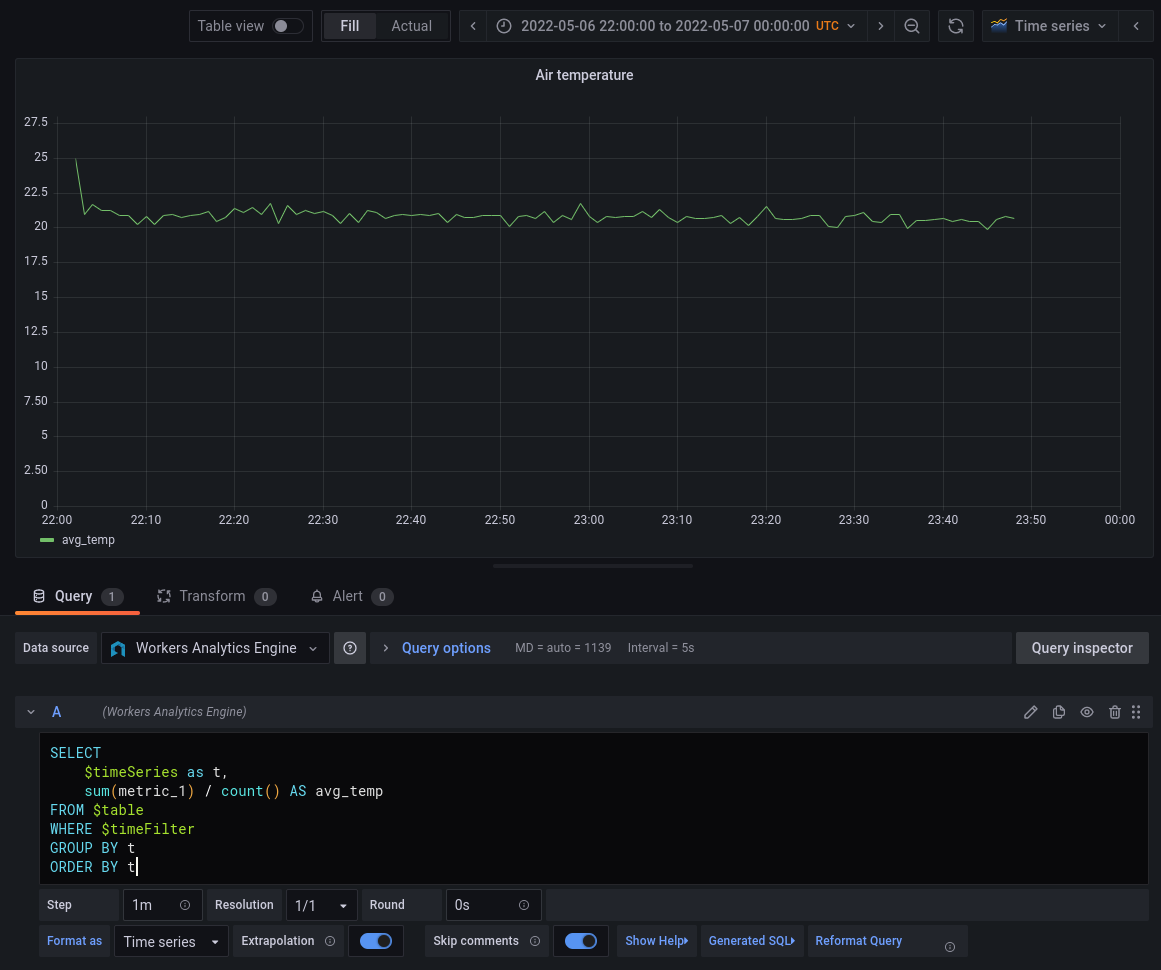
The macro $timeSeries simply expands to intDiv(toUInt32(timestamp), 60) * 60 * 1000 — i.e. the timestamp rounded to the nearest minute (as defined in our \$step parameter) and converted into milliseconds. Grafana also provides \$timeFilter which can be changed at the grafana dashboard level. We could easily add another series here by just “grouping” on another field like “city”.
Data can also be queried using our GraphQL API. At this time, the GraphQL API only supports querying total counts for each named binding.
Finally, the Cloudflare dashboard also provides a high-level count of the total number of data points seen for each binding. In the future, we plan to offer rich analytical abilities through the dashboard.
How is this different from traditional metrics systems?
Many developers are familiar with metrics systems like Prometheus. We built Workers Analytics Engine based on our experience providing analytics for millions of Cloudflare customers. Writing structured event logs and querying them using a relational database model is very different from writing metrics – but it’s also much more powerful.
Here are some of the benefits of our model, compared with metrics systems:
- Unlimited cardinality of label values: In a traditional metrics system, like Prometheus, every time you add a new label value, under the hood you are actually adding a new metric. If you have multiple labels for one data point, this can rapidly increase the number of metrics. Nearly everyone using a metrics system runs into challenges with cardinality. For example, you may start by including a “customer ID” in a label – but what happens when you have thousands or millions of customers? In contrast, when using Workers Analytics Engine, every label value is stored independently – so every data point can have unique label values with no problem.
- Low latency reporting: Pull-based metrics systems must check for new metrics at some fixed interval, known as a scrape interval. Commonly this is set to one minute or longer – and this is the absolute fastest that your data can be collected. With Workers Analytics Engine, we can report on new data points within a few seconds.
- Fast queries at any timescale: Everyone who uses Prometheus knows what happens when you expand that range selector in Grafana to change from looking back 30 minutes to seven days… you wait, and you’re lucky if you get any results at all. Whole new pieces of software exist just for the challenge of storing Prometheus metrics long-term. In contrast, Workers Analytics Engine is superfast at querying anything from the last five minutes of data to the last seven days. Look for yourself to see!
And of course, Workers Analytics Engine runs on Cloudflare’s global network. So rather than worrying about running your own Prometheus server, setting up Thanos, and closely tracking cardinality, you can just write data and query it using our SQL API.
What’s next
Today we’re introducing a closed beta for Workers Analytics Engine. You can join the waitlist by signing up here. We already have many teams at Cloudflare happily using this and would love to get your feedback at this early stage, as we are quickly adding new functionality.
We have an ambitious roadmap ahead of us. One critical use case we plan to support is building analytics and usage-based billing for your customers – so if you’re a platform who is looking to build analytics into your product, we’d love to talk to you!
And of course, if this sounds fun to work on, we’re hiring engineers on the Data team to work in San Francisco, London, or remote locations!




























![[Security Nation] Jim O’Gorman and g0tmi1k on Kali Linux](https://blog.rapid7.com/content/images/2022/05/Jim-800x800.jpg)
![[Security Nation] Jim O’Gorman and g0tmi1k on Kali Linux](https://blog.rapid7.com/content/images/2022/05/image1.jpg)