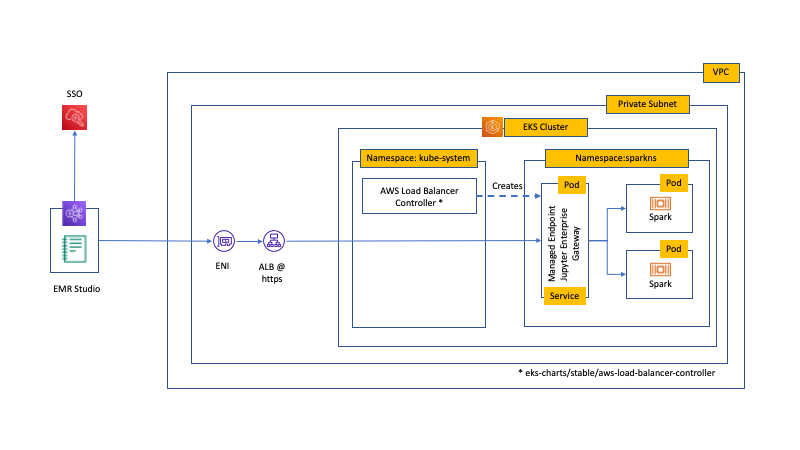
Post Syndicated from Радослав Русев original https://toest.bg/optimistichno-za-vik-otrasula/
Има един сектор в икономиката ни, който рядко генерира положителни новини. По-рядко дори от енергетиката, здравеопазването и образованието, където проблемите са наистина дълбоки. Става дума за водоснабдяването и канализацията, накратко ВиК, като в тази абревиатура влиза и все по-важният (и скъп) компонент „пречистване на отпадъчните води“.
В бранша често цитираме две неприятни азбучни истини: 1) хората се сещат за ВиК-то най-вече когато водата спре, и 2) никой не знае как точно се сформира месечната му сметка за вода, но знае, че е „много висока“ и че „сега пак щели да увеличават цената“.
Ако потребителските нагласи са само една от гледните точки, то нека чуем какво казват и „отговорните институции“. Тук преобладаващите термини са „усвояване“, „съответствие“ и „поносимост“:
„Усвояването“ е процентът от средствата по Оперативна програма „Околна среда“ (ОПОС), тоест колко сме прибрали от ЕС спрямо заложения бюджет, без особено значение за какво сме ги похарчили…
„Съответствието“ е процентът изградени пречиствателни станции за отпадъчни води в градове над 2000 души – нищо че вече имаме областни градове с трайно нарушено питейно водоснабдяване, тоест обективно по-значими инвестиционни приоритети. „Тука водата от чешмата пиете ли я?“ е чест въпрос по тези места.
А „поносимостта“ е съотношението между сметката за вода на едно домакинство и нетния му разполагаем доход за същия период.
И не че тези неща нямат значение (особено последното), но вторачени в клишетата, като че ли забравяме базовите неща – да има вода, тя да става за пиене, да строим качествени тръбопроводи и резервоари с дълъг живот, да прилагаме съвременните технологии и секторът като цяло да е интересен и смислен за 20-те хиляди души (и още поне толкова подизпълнители), пряко ангажирани в него.
Настоящият момент
Нека погледнем и по-тясната конюнктура – какво става във ВиК сектора в края на 2021 г.
Регулаторът (КЕВР) разглежда бизнес планове и тарифи за следващия регулаторен период 2022–2026 г., тоест предложения за инвестиции и нови тарифи.
Навлизаме в новия 7-годишен рамков период на ЕС (2021–2027), но във ВиК отрасъла големите инвестиции по ОПОС за периода 2014–2020 г. тепърва ще се осъществяват заради закъснели подготвителни дейности.
Трети пореден за годината нов парламент ще предлага законодателни промени, като „цената на водата“ е обичаен сюжет за парламентарна активност. Пример: за краткия живот на последния парламент по темата бяха направени три различни законодателни предложения от различни парламентарни групи.
Междувременно рязко повишените цени на електроенергията буквално обричат на фалит част от дружествата, които имат висока консумация на електричество (Добрич, Шумен, Разград, Сливен и други, в някои от които тя може да достигне 50% от всички месечни разходи).
В тази ситуация е логично ВиК отрасълът да не генерира особено положителни новини.
Защо дяволът не е толкова черен
Ако твърде дълго се взираш в бездната, бездната ще се взре в теб.
Ницше
Че пред отрасъла има пропаст, има. Но дали е толкова черна и дълбока, до голяма степен зависи и от аршина на взиращия се. Наскоро говорих с външен за сектора чуждестранен експерт, който смело обобщи: „Абе, не че нямате проблеми, ама какво толкова мрънкате – вода имате (като ресурс в природата), повечето ви големи градове даже си имат язовири, скъпите съоръжения (сондажи, резервоари, станции, довеждащи водопроводи) са изградени, инженерите ви ги знаят по цял свят.“ И е доста прав…
Несъмнено и двете позиции (песимистичната и оптимистичната) имат своите основания. Ако си управител на ВиК дружество и на бюрото ти има непосилна сметка за електроенергия, чийто падеж наближава, логично е да виждаш пропаст. Ако си ВиК консултант или проектен ръководител, който се прибира от Северна Африка или Близкия изток, е лесно да кажеш, че „това не са сериозни проблеми“.
Както обикновено, истината е някъде между двете крайни позиции, но не непременно по средата. Личната ми позиция е, че реалното положение е много по-близко до розовата част на спектъра, поне в сравнение с наистина проблемните сектори в икономиката и обществения живот в България. И ако нещата останат дългосрочно зле, то основната причина е в нашата колективна глупост, алчност и късогледство, а не толкова в климата, бедността и старите тръби.
Какво може – и защо сега
Дори за най-черногледите ни сънародници е ясно, че в момента България има шанс да направи крачки в положителна посока, при това в различни области на обществения живот и икономиката. Бавно и от третия път, но вероятно по Коледа ще имаме ново правителство – и то натоварено със справедливи очаквания за промени.
Във ВиК отрасъла, както навсякъде другаде, е хубаво да внимаваме какво си пожелаваме, защото най-често то се сбъдва. И ако си пожелаем повече „усвояване“, да сме наясно, че това е нещо различно от „чиста вода за пиене“. Някъде тук е време тази статия да завие към няколко предложения. Без претенции, че това са най-важните (или пък спешни) приоритети пред сектора, но те ще ни отклонят от опасното и излишно вторачване в бездната.
-
Да свържем отрасъла с големите теми
От поне десетина години всевъзможни класации (например ежегодната класация на World Economic Forum) поставят водата в топ 3 на световните рискове. Отскоро обаче започват да се виждат някои интересни възможности, които надхвърлят секторната тематика, тоест идентифицират се ВиК решения на проблеми от други сфери на живота. Няколко конкретни примера:
Анализ на отпадъчните води с цел откриване на вируси и бактерии (т.нар. epidemiological surveillance). Тази тема придоби огромна популярност около многобройните проекти за проследяване на разпространението на новия коронавирус и неговите мутации. Истината е, че от години е разпространена технологията за откриване на огнища на други вируси и патогени (причиняващи хепатит, полиомиелит и др.), на прекомерна употреба на опиоиди и антибиотици, и други. Редица страни – Австрия, Холандия, Португалия, Великобритания – въведоха наблюдението на отпадъчни води като основен елемент в националните си планове за управление на пандемията. Вероятно променената Директива за пречистване на градските отпадъчни води (в момента тече обществена консултация) ще наложи подобен мониторинг като задължителен стандарт за страните членки на ЕС.
Гъвкаво управление на консумацията на електричество. Особено в условията на рязко поскъпнала електроенергия ВиК дружествата гледат на доставчиците (включително на т.нар. балансиращи групи) като на основна заплаха. Част от истината е обаче, че ВиК операторите и техните контролни зали могат да бъдат най-добрият приятел на енергийните търговци, като предоставят частична възможност за гъвкаво управление на консумацията. Повечето ВиК дружества разполагат с резервоари, които играят ролята на буфери, тоест потреблението на електричество от сондажи и помпени станции може да бъде интелигентно премествано поне с няколко часа, което да помогне на търговците на електроенергия да управляват своите баланси – ситуация, от която и двете страни могат да спечелят.
Използване на пречистени отпадъчни води за напояване. Идеята не е нова и се прилага в страни със сух климат, включително в Южна Европа (Испания, Португалия и др.). Технологично изглежда просто, но както обикновено, дяволът е в детайлите – да се оставят ли полезни елементи (фосфор и азот) във водата при пречистването, каква дезинфекция да се използва, какви са другите рискове, подходящите поливни култури и т.н. Посоката обаче е ясна и постепенно отпадъчните води (а и утайките) ще стават все по-ценен ресурс за селското стопанство.
Посочените примери са установени практики в редица страни. В ограничен формат подобни пилотни проекти са изпълнявани и у нас, като голяма част от необходимата експертност е налична. Тези примери показват как ВиК секторът помага за попълването на сериозни дефицити в сферата на общественото здраве, енергетиката и селското стопанство, а междувременно решава свои проблеми и генерира приходи. Едно побутване от страна на държавата или браншовите организации – Министерството на регионалното развитие и благоустройството, „Български ВиК холдинг“, Българската асоциация по водите, Съюза на ВиК операторите – ще даде необходимия начален тласък.
-
ВиК секторът като среда за развитие на високи технологии
Водоснабдяването и канализацията са известни като отрасъл с критично ниско, бавно и неадекватно навлизане на технологиите. В по-широката рамка на т.нар. ютилити индустрия експертите в бранша обикновено се шегуваме, че технологиите най-напред навлизат в комуникациите, десетина години след това – в енергетиката, а евентуално след още десет – и при нас.
Тезата е особено вярна в България, но точно сега имаме добър шанс секторът да се превърне в среда за създаване и развиване на високи технологии, а не само да бъде поле за прилагането им. Два са основните фактори за тази възможност: 1) наличието на активна и растяща екосистема от ИТ компании, които жадуват за възможността да прилагат т.нар. интернет на нещата (IoT), анализ на големи масиви данни (big data) и други високотехнологични решения в реална среда, и 2) обективното наличие на огромни масиви неизползвани до момента данни във ВиК отрасъла – за клиенти, активи и процеси.
Накратко: ВиК дружествата са перфектната среда за пилотни проекти на иновативни компании или единични изследователи. Интерес съществува, успешни примери също не липсват, но една заявена държавна подкрепа (или поне позволение) може много да помогне – при това без излишно субсидиране, а изцяло на пазарен принцип. И сега български компании предлагат в чужбина ВиК решения (системи за мониторинг, софтуер, аналитични модули), базирани на пилотни проекти в България. Този прохождащ модел може да стане норма на работа.
-
Повече свобода за експертите
Предвид пословично консервативния сектор с презюмирано високо ниво на корупция, не е пресилено да се каже, че организационната среда в отрасъла е токсична. Чак е учудващо как млади инженери, химици и биолози продължават да постъпват на работа в провинциални ВиК дружества за заплати, по-ниски от тези на касиер в хипермаркет. Но го правят. Било за стаж, било от младежки идеализъм.
Представете си обаче, че институционалната шапка над всички ВиК дружества – „Български ВиК Холдинг“ – създаде програма (не инцидентен проект), в рамките на която ежегодно се одобряват и финансират по няколко десетки предложения, идентифицирани и управлявани от вътрешни за системата кадри. Представете си, че всеки районен началник, главен енергетик или старши лаборант може да предлага решения, с които да се подобри и оптимизира експлоатацията, да се спестят разходи и да се постигне широка полезност за обществото. Именно така ще се задържат в сектора младите инженери, химици и биолози – та дори при заплати, по-ниски от тези на касиер в хипермаркет. (И именно подобни проекти биха им проправили пътя и към по-високи заплати.)
ВиК отрасълът в България може много повече. Първата ни задача обаче е да си го поискаме това много повече. Да си го представим, да го нарисуваме, да го обсъдим помежду си. Политическото и оперативното ръководство на сектора, регулаторът и браншовите организации, както и цялата широка общественост са част от този дебат.