Security updates have been issued by Debian (chromium and firefox-esr), Fedora (firefox, redis, samba, and xen), Oracle (python39:3.9, python39-devel:3.9), Slackware (mozilla and xorg), and SUSE (libnbd, open-vm-tools, python, sox, vorbis-tools, and zchunk).
Customers using Amazon CodeWhisperer often want to enable their developers to sign in using existing identity providers (IdP), such as Okta. CodeWhisperer provides support for authentication either through AWS Builder Id or AWS IAM Identity Center. AWS Builder ID is a personal profile for builders. It is designed for individual developers, particularly when working on personal projects or in cases when organization does not authenticate to AWS using the IAM Identity Center. IAM Identity Center is better suited for enterprise developers who use CodeWhisperer as employees of organizations that have an AWS account. The IAM Identity Center authentication method expands the capabilities of IAM by centralizing user administration and access control. Many customers prefer using Okta as their external IdP for Single Sign-On (SSO). They aim to leverage their existing Okta credentials to seamlessly access CodeWhisperer. To achieve this, customers utilize the IAM Identity Center authentication method.
Trained on billions of lines of Amazon and open-source code, CodeWhisperer is an AI coding companion that helps developers write code by generating real-time whole-line and full-function code suggestions in their Integrated Development Environments (IDEs). CodeWhisperer comes in two tiers—the Individual Tier is free for individual use, and the Professional Tier offers administrative features, like SSO and IAM Identity Center integration, policy control for referenced code suggestions, and higher limits on security scanning. Customers enable the professional tier of CodeWhisperer for their developers for a business use. When using CodeWhisperer with the professional tier, developers should authenticate with the IAM Identity Center. We will also soon introduce the Enterprise Tier, offering the additional capability to customize CodeWhisperer to generate more relevant recommendations by making it aware of your internal libraries, APIs, best practices, and architectural patterns.
In this blog, we will show you how to set up Okta as an external IdP for IAM Identity Center and enable access to CodeWhisperer using existing Okta credentials.
How it works
The flow for accessing CodeWhisperer through the IAM Identity Center involves the authentication of Okta users using Security Assertion Markup Language (SAML) 2.0 authentication.
Figure 1: Architecture diagram for sign-in process
The sign-in process follows these steps:
IAM Identity Center synchronizes users and groups information from Okta into IAM Identity Center using the System for Cross-domain Identity Management (SCIM) v2.0 protocol.
Developer with an Okta account connects to CodeWhisperer through IAM Identity Center.
If the developer isn’t already authenticated, they will be redirected to the Okta account login. The developer will sign in using their Okta credentials.
If the sign-in is successful, Okta processes the request and sends a SAML response containing the developer’s identity and authentication status to IAM Identity Center.
If the SAML response is valid and the developer is authenticated, IAM Identity Center grants access to CodeWhisperer.
The developer can now securely access and use CodeWhisperer.
Prerequisites
For this walkthrough, you should have the following prerequisites:
Under Identity source, select Change identity source from the Actions drop-down menu
On the next page, select External identity provider, then click Next.
Configure the external identity provider:
IdP SAML metadata: Click Choose file to upload Okta’s IdP SAML metadata you saved in the previous section Step 6.
Make a copy of the AWS access portal sign-in URL, IAM Identity Center ACS URL, and IAM Identity Center issuer URL values. You’ll need these values later on.
Click Next.
Review the list of changes. Once you are ready to proceed, type ACCEPT, then click Change identity source.
Step 3: Configure Okta with IAM Identity Center Sign On details
In Okta, select the Sign On tab IAM Identity Center SAML app, then click Edit:
Enter AWS IAM Identity Center SSO ACS URL and AWS IAM Identity Center SSO issuer URL values that you copied in previous section step 5b into the corresponding fields.
Application username format: Select one of the options from the drop-down menu.
Click Save.
Step 4: Enable provisioning in IAM Identity Center
On the Settings page, locate the Automatic provisioning information box, and then choose Enable. This immediately enables automatic provisioning in IAM Identity Center and displays the necessary SCIM endpoint and access token information.
Figure 5: IAM Identity Center Settings for Automatic provisioning
In the Inbound automatic provisioning dialog box, copy each of the values for the following options. You will need to paste these in later when you configure provisioning in Okta.
SCIM endpoint
Access token
Choose Close.
Step 5: Configure provisioning in Okta
In a separate browser window, log in to the Okta admin portal and navigate to the IAM Identity Center app.
On the IAM Identity Center app page, choose the Provisioning tab, and then choose Integration.
Choose Configure API Integration and then select the check box next to Enable API integration to enable provisioning.
Paste SCIM endpoint copied in previous step into the Base URL field. Make sure that you remove the trailing forward slash at the end of the URL.
Paste Access token copied in previous step into the API Token field.
Choose Test API Credentials to verify the credentials entered are valid.
Choose Save.
Under Settings, choose To App, choose Edit, and then select the Enable check box for each of the Provisioning Features you want to enable.
Choose Save.
Step 6: Assign access for groups in Okta
In the Okta admin console, navigate to the IAM Identity Center app page, choose the Assignments tab.
In the Assignments page, choose Assign, and then choose Assign to Groups.
Choose the Okta group or groups that you want to assign access to the IAM Identity Center app. Choose Assign, choose Save and Go Back, and then choose Done. This starts provisioning the users in the group into the IAM Identity Center.
Repeat step 3 for all groups that you want to provide access.
Choose the Push Groups tab. Choose the Okta group or groups that you chose in the previous step.
Then choose Save. The group status changes to Active after the group and its members have successfully been pushed to IAM Identity Center.
Figure 7: Amazon CodeWhisperer Settings Page
Step 7: Provide access to CodeWhisperer
In the CodeWhisperer Console, under Settings add the groups which require access to CodeWhisperer.
Figure 7: Amazon CodeWhisperer Settings Page
Set up AWS Toolkit with IAM Identity Center
To use CodeWhisperer, you will now set up the AWS Toolkit within integrated development environments (IDE) to establish authentication with the IAM Identity Center.
Figure 8: Set up AWS Toolkit with IAM Identity Center
In the IDE, open the AWS extension panel and click Start button under Developer Tools > CodeWhisperer.
In the resulting pane, expand the section titled Have a Professional Tier subscription? Sign in with IAM Identity Center.
Enter the IAM Identity Center URL you previously copied into the Start URL field.
Set the region to us-east-1 and click Sign in button.
Click Copy Code and Proceed to copy the code from the resulting pop-up.
When prompted by the Do you want Code to open the external website? pop-up, click Open.
Paste the code copied in Step 5 and click Next.
Enter your Okta credentials and click Sign in.
Click Allow to grant AWS Toolkit to access your data.
When the connection is complete, a notification indicates that it is safe to close your browser. Close the browser tab and return to IDE.
Depending on your preference, select Yes if you wish to continue using IAM Identity Center with CodeWhisperer while using current AWS profile, else select No.
You are now all set to use CodeWhisperer from within IDE, authenticated with your Okta credentials.
Test Configuration
If you have successfully completed the previous step, you will see the code suggested by CodeWhisperer.
Figure 9: Test Step Configurations
Conclusion
In this post, you learned how to leverage existing Okta credential to access Amazon CodeWhisperer via the IAM Identity Center integration. The post walked through the steps detailing the process of setting up Okta as an external IdP with the IAM Identity Center. You then configured the AWS Toolkit to establish an authenticated connection to AWS using Okta credentials, enabling you to access the CodeWhisperer Professional Tier.
Fascinating story of a covert wiretap that was discovered because of an expired TLS certificate:
The suspected man-in-the-middle attack was identified when the administrator of jabber.ru, the largest Russian XMPP service, received a notification that one of the servers’ certificates had expired.
However, jabber.ru found no expired certificates on the server, as explained in a blog post by ValdikSS, a pseudonymous anti-censorship researcher based in Russia who collaborated on the investigation.
The expired certificate was instead discovered on a single port being used by the service to establish an encrypted Transport Layer Security (TLS) connection with users. Before it had expired, it would have allowed someone to decrypt the traffic being exchanged over the service.
Нови детски градини, нов асфалт, нови тротоари, (нова) канализация… Предизборните обещания са толкова втръснали, колкото са брадясали нерешените проблеми на българските общини. Защо тогава всички са се вторачили в тези местни избори?
Първо, резултатите от тях ще променят баланса на силите в управляващия съюз и оттам дизайна на правителството при ротацията през март. Второ, колко голяма ще стане „Възраждане“ – трета политическа сила след последните парламентарни избори, за която местният вот е и трамплин към вота за Европейски парламент през май догодина. Трето, ще остане ли управляващата коалиция ПП–ДБ само „софийска“ – на предишните местни избори „Демократична България“ спечели осем районни кметове в столицата, но нито един общински. Четвърто, къде и срещу кого ще сработи сглобката на местно ниво.
Пробив при ГЕРБ – но къде и с колко?
Поглед от дрон върху приключващата предизборна кампания очертава центростремителното движение на ПП–ДБ към София и центробежното на ГЕРБ в останалата част от България. Политиката на ГЕРБ и лидера Бойко Борисов да хвърлят сили в провинцията, където държат повечето областни центрове, изглежда правилна предвид факта, че на предишните местни избори през 2019 г. кметицата Йорданка Фандъкова за първи път от осем години не спечели на първи тур. А на балотажа би с близо 20 000 гласа преднина Мая Манолова.
Предвид заявките от нови играчи, в това число инициативни комитети, подозирани във връзки с Президентството, доминацията на ГЕРБ ще се разклати. Въпросът е дали, освен (почти) сигурните кметски позиции в Бургас, Стара Загора, Габрово, Перник, ще успеят да се преборят за кметове във Велико Търново, Пловдив, Варна, където се очертават оспорвани балотажи.
ПП–ДБ се спря до София. А Пловдив?
ПП–ДБ, които консумират всички негативи като управляващи, залагат основно на кметския пост в столицата не само заради липсата на жизнени структури по места. В София, която спечелиха на 2 април, са концентрирани усилията им за пробив, в София шансовете им са най-големи и заради обединението, което формираха със „Спаси София“ и „Екипът на София“. Въпреки това изследване на „Алфа Рисърч“ показва, че резултатът на надпартийния им кандидат Васил Терзиев е с малко, но под този за листата за общински съветници – 29,8% срещу 33,2%. (Впрочем с кандидата на ГЕРБ–СДС Антон Хекимян, който също се явява „външно лице“ за ГЕРБ, положението е сходно – 21,1% при 22,8% за общинската листа.) Мобилизацията на избирателите извън твърдите ядра ще е основното предизвикателство за вота в неделя заради значителния дял колебаещи се дали да гласуват – над 20%.
Вторият най-голям град Пловдив ще е изпитание за ПП–ДБ, издигнали бившия областен управител Ивайло Старибратов. Сигурен е балотажът между него и кандидата на ГЕРБ и кмет на район „Тракия“ от 12 години Костадин Димитров. На парламентарните избори ПП–ДБ спечели Пловдив с 29,18% от гласовете, а сега сондажите дават около 24,9% подкрепа за Старибратов и малко над 30% за Димитров. Третият кандидат е бившият кмет Славчо Атанасов, който има своя здрава група поддръжници – и те ще определят изхода на втория тур.
„Възраждане“ се бори като партия
Стигнала ли е „Възраждане“ тавана си, или ще пробие още нагоре, се питат социолози и политолози.Като партия, която участва за първи път на местни избори и няма ярки кандидати, „Възраждане“ се бори партийно – за пробив в общинските съвети. Затова и основна фигура в клипа, който се върти по телевизиите, е лидерът Костадин Костадинов, най-разпознаваемото лице на партията.
Спечелване на кметско място би било бонус, макар че във Варна, традиционно силен град за учредената там „Възраждане“, кандидатът ѝ Коста Стоянов се конкурира за балотажа с номинирания от ПП–ДБ Благомир Коцев. В София, където бяха трета политическа сила на парламентарните избори през април, „Възраждане“ са и трети в Столичния общински съвет според прогнозни резултати на „Алфа Рисърч“. Така че от кандидата им Деян Николов се иска да поддържа огъня.
Ако не беше Ваня Григорова, кой е чувал за БСП?
В лицето на синдикалистката Ваня Григорова, кандидатка на левицата за кмет на София, някои вече виждат лелеяното модерно ляво. Харизматична популистка, която синдикалната закалка е научила на бърза и непосредствена комуникация с хората и работа на терен, Григорова тръгна от много ниски нива на подкрепа и се изкачи до трета позиция и дори конкуренция на втория – Хекимян. Енергията, акумулирана покрай кампанията за местни избори, със сигурност ще бъде използвана да трасира пътя ѝ в политиката. (В съседна Гърция бившият премиер и бивш лидер на лявата СИРИЗА Алексис Ципрас тръгна от профсъюзите.)
Появата на Григорова, чиято програма е микс от соцносталгия и синдикално бодрячество, увлича мнозина и е сигнал, че и в София, където безработицата е най-ниска, а средните заплати най-високи, има значителна група обедняващи, недоволни и маргинализирани хора. Кандидатката на левицата няма нищо общо с партийните бюрократи от „Позитано“ 20, а и какво по-естествено от това синдикалист да е левичар. Лидерът на БСП Корнелия Нинова не припознава Григорова за „своя“ и се е дистанцирала от кампанията в столицата. Вероятно за добро, защото прогнозните резултати на лявата кандидатка за кметския пост надхвърлят тези на партийната листа за общински съветници.
Както на всички избори, въпросът за ДПС е къде извън традиционните си крепости в Лудогорието, Източните Родопи и Благоевградско ще осъществят нови пробиви. Вече са завоювали позиции в Северозапада – в районите на Видин, Враца и Монтана. В тази кампания пресцентърът на ДПС отразяваше повече изявленията на съпредседателя на парламентарната група Делян Пеевски, отколкото на лидера Мустафа Карадайъ.
Участието в управленския модел извади ГЕРБ от изолация, а заради конституционните промени ДПС вече е необходимо зло. Местните избори ще изострят апетитите им за още власт, но едва ли ще разпаднат настоящата управленска формула.
Първо броихме жертви. После гледахме ужасяващи видеа в Telegram. След това дойдоха конспиративните теории. И накрая всички се оказахме безкрайно компетентни по въпросите на Близкия изток и на всички конфликти в Обетованата земя.
За това какво се случи, защо сега и как ще се развие ситуацията оттук нататък за Израел, Европа и света, решихме да поговорим с доц. Искрен Иванов от СУ „Св. Климент Охридски“.
Искрен Иванов е завършил Софийския университет, а след това има и няколко специализации в Европа и САЩ, сред които по противодействие на тероризма, международна сигурност и американска политика в Принстънския университет, „Йейл“ и „Уест Пойнт“. От 2014 г. е част от преподавателския екип на катедра „Политология“ на Философския факултет в СУ „Св. Климент Охридски“. Бил е гост-лектор в Университета в Остин, в Сорбоната и в Католическия университет в Лил. Сред дисциплините, които преподава, са „Управление на конфликти“, „Въведение в американската политика“, „Международни отношения и външна политика на САЩ“. Автор е на три книги и на над 20 публикации. Снимка: личен архив
Доц. Иванов, според Вас международната общност даваше ли си сметка, че това, което стана в Израел, е възможно?
Международната общност не си даваше сметка какво се случва, защото част от нея все още отказва да признае очевидната истина, че светът става двуполюсен. От едната страна имаме лагера на Съединените щати и на Европейския съюз, към който се ориентира понастоящем и България. От другата страна са Русия, Китай и актьори, ориентиращи се към по-засилено сътрудничество с тях. Същевременно има държави, които се опитват да балансират между двата лагера. Като Саудитска Арабия, която гледа да поддържа добри отношения с Америка предвид икономическите си интереси там, но и с Русия и Китай по линия на инициативата „Един пояс, един път“. Напоследък саудитският принц има приказка и с руския президент вероятно заради желанието на саудитите да развиват енергийното си сътрудничество с Москва.
Нашата съседка Турция има голямо желание да е медиатор по различни глобални въпроси. Тя от държавите, опитващи се да балансират между лагерите, ли е?
Република Турция е твърдо позиционирана в лагера на НАТО. Да, тя флиртува с Русия от време на време, но е много зависима от американската икономика. А и Ердоган добре знае, че членството на Турция в НАТО гарантира липсата на ескалация от страна на кюрдите.
Всъщност мечтата на турския президент е Турция да бъде глобален актьор, а не просто регионална сила. Но истината е, че засега няма този потенциал просто защото ясно е позиционирана като част от западния лагер. Русия не би допуснала Анкара да бъде медиатор между нея и Украйна в едни бъдещи, но все по-невероятни мирни преговори. Съвсем друг е въпросът, че членството на Турция в НАТО всъщност гарантира, че утре кюрдите няма да си направят държава, а да не говорим пък, че гарантира добрите отношения с България и останалите балкански държави предвид историческото минало на Балканите.
Та в контекста на това глобално поделяне и преразпределение на баланса на силите се нагорещиха всички онези конфликти, които по време на еднополюсния свят Америка успяваше с едно обаждане или с едно изпращане на дипломати да циментира. Ще дам пример с конфликта в Нагорни Карабах. Много дълго време Алиев (президентът на Азербайджан Илхам Алиев, б.р.) не си позволяваше такива провокации към Армения. Но когато започна разместването на геополитическия баланс, той стана много по-уверен. И всъщност точно това ще продължи да се случва, ако Америка се разколебае в подкрепата за съюзниците си. Още много конфликти ще се активизират и още много като Алиев ще си позволят действия, които не са предприемали досега, просто защото ще видят, че силата на Америка лека-полека се балансира със силата на Русия и Китай.
Терористичните мрежи видяха, че Америка е фокусирана да сдържа Русия в Украйна, и решиха отново да хвърлят Близкия изток в хаос.
От това пък могат да се възползват актьори като Русия, която също има трайни интереси да вземе част от региона, защото в момента Сирия е бастионът на нейното влияние. Иран също ѝ помага, макар че там има други интереси. Но пък Русия винаги има интерес да вземе повече, отколкото притежава.
Конфликтът между „Хамас“ и Израел е част от една много по-голяма геополитическа игра, свързана с преходния период от еднополюсен към двуполюсен модел. А историята е доказала, че подобен период неминуемо е съпроводен с войни и конфликти, докато се наместят пластовете.
Тогава, ако четем историята като нещо, което се повтаря, какво предстои да се случи сега?
Онова, което не трябва да се случва, е Трета световна война, защото в нея няма да има победители. Историята сочи, че държавите винаги са намирали някаква формула за мир, но с появата на ядреното оръжие този баланс на силите, който познаваме и от системата на Вестфалските договори, и от Първата и Втората световна война, не е приложим към сегашните обстоятелства.
Така че по-скоро трябва да се намери трайна формула, в рамките на която тези два полюса да постигнат консенсус по три точки. Първата точка – по нея вече има консенсус, за щастие, – това е, че ядрена война не може да бъде спечелена и не трябва да бъде водена. Втората точка е ясно да се разграничат сферите на влияние. Това ще отнеме години, най-малкото защото Америка няма да отстъпи традиционни сфери на влияние, а в момента Русия и особено Китай разширяват своите, което води до напрежение.
И третата точка е върху какви принципи ще стъпва този нов свят.
Най-важното е да запазим все пак Хартата на ООН във вида, в който съществува в момента, а именно че най-висшите ценности, въпреки всички търкания между Великите сили, въпреки всички атентати и всички конфликти, са човешкият живот и човешките права.
Ето върху тази точка глобалните сили трябва да се фокусират най-много, защото, ако тя не значи нищо, тогава се връщаме обратно в онзи предмодерен свят, където важи законът на джунглата.
В момента изглежда точно така – че човешкият живот не значи нищо.
Така изглежда, защото дълго след края на Студената война доминираше тезата, че светът е навлязъл в състояние, бележещо края на историята. И в рамките на това състояние най-усъвършенстваният човек е човекът на демокрацията. Оттук се даде зелена светлина на либералната демокрация, чиято идея беше нейният модел да бъде изнасян така, щото да бъде универсално приложен. Тук, в Източна Европа, демокрацията си я разбираме по балкански, но някак си може да се случат нещата. Обаче същото не важи в Близкия изток, в арабския свят. Няма как да се приложи там просто защото страните имат коренно различна политическа култура и те демокрацията си я разбират по техен много различен начин.
Излиза, че демокрацията не е франчайз, който може да вирее навсякъде?
Точно така. Ако питате руснаците, ще ви кажат, че и Путин говори за суверенна демокрация. Но да вземем либералната демокрация в най-чистия ѝ вид – такава, каквато я виждаме в Европа например. За да стигне до нея, Европа преминава през културните феномени на Ренесанса, на Просвещението, на класицизма, през Лок, Хобс, Бърк, които впоследствие оказват много силно влияние върху американските бащи основатели.
А сега да обърнем поглед към Китай. Той минал ли е през тези периоди на културно развитие? Не. Китай е древна цивилизация на 5000 години. В продължение на почти 5000 години там е управлявал императорът, който е Син на Небето и съгласно конфуцианската традиция има мандата на Небето да бъде абсолютен управник. Когато Мао Дзъдун извършва революцията след гражданската война, създава Китайската народна република и започва да говори за демокрация, за пръв път китайците виждат, че някой нещо ги пита. Макар че за нас, европейците, е едва ли не безумие да говорим за демокрация, в която избирателите просто се съгласяват с политиците си, за китайците е огромен пробив.
Същото е и в арабския свят. Как доктрината за човешките права на либералната демокрация ще сработи в Саудитска Арабия в контекста на уахабизма и уахабитската култура? Няма как да стане. Е, да, обаче имаше един период, в който Саудитска Арабия председателстваше Съвета по правата на човека в ООН със съгласието на президента Барак Обама.
Тогава защо при тези големи културни различия и исторически натрупвания немалка част от хората от близкия и по-далечен Изток търсят живот и препитание на Запад?
Защото болезнената истина е, че демокрацията дава възможност за възникването на онзи феномен, наречен средна класа. Когато имаме една много богата държава, това богатство невинаги се дължи на нейния жизнен стандарт и на средната класа. Една държава може да бъде много богата, но това богатство да отива при олигархията – 2–3% милионери и милиардери, а всички останали живеят на прага на бедността. Тази държава може да бъде много силна военно, политически, икономически, културно, но в нея хората не живеят добре.
Демокрацията, и по-конкретно европейската демокрация и европейската социална държава, дава възможност за възникването на средна класа, от която произтичат безплатното здравеопазване, безплатното образование, достъпът до много услуги, на които в азиатската политическа традиция, че дори в Америка се гледа като на привилегия.
Едно от нещата, което подразни Запада, е, че Китай със своя модел за пръв път започна да формира някаква средна класа. Да, по начина, по който там я разбират, но започна да се формира. Докато в Русия такава класа няма и никога не се е формирала, защото има олигархия, съсредоточена около президента, и останалото са бедни хора.
Хващам се за думите Ви, че Западът се е „подразнил“. Защо, при положение че китайците се опитват да постигнат модела, който Западът счита за най-добър?
Когато бях специализант в Америка, питах много американци кой им е любимият президент. Защото в Източна Европа хората казват: „Любимият ни президент е Роналд Рейгън. Той събори Съветския съюз и сега ние живеем в демокрация.“ За американците любим президент се оказа Джон Кенеди. „Искаме си 60-те години“, казват те. И като ги попитах защо, отговорът беше: „Защото тогава в Америка имаше социална държава. Имаше си здравеопазване, имаше достъп до социални услуги.“ През 90-те години тази социална държава беше напълно унищожена.
В Европа идват много имигранти, защото европейската социална демокрация и европейският капитализъм не целят създаването на армия. Аз много се смея, като слушам, че трябва да създадем европейска армия.
Целта на европейския проект е хората да живеят добре, да няма войни и да няма конфликти. И затова нашата демокрация е социална. Тя цели добър живот, а не налагането на универсален модел на всички общества.
В този ред на мисли и гледайки към конфликта между Израел и „Хамас“, Израел като каква държава се позиционира?
Израел е държава с много специфична политическа култура. Тук ще си позволя да вмъкна малко религия – няма как да дефинираме политическата култура на Израел без това. В сърцето на еврейската политическа култура, както казва и Даниел Елазар, стои концепцията за завета между Бог и Неговия народ; идеята за избрания народ, който населява тази част на земята и в този смисъл я има за свой свещен дълг. Казано с други думи, тук говорим за култура, при която, когато по някакъв начин еврейското политическо цяло е заплашено, то се сплотява, независимо кой е начело на държавата.
Едва 22% от израелците подкрепяха премиера Нетаняху. Когато „Хамас“ удари, вече всички го подкрепят. Такъв прецедент имаше в Съединените щати, когато терористите удариха на 11 септември Вашингтон и Ню Йорк.
Да, знаем колко много хора всъщност не харесваха Буш-младши тогава, но го избраха за втори мандат.
Спомням си думите на един миньор, който тогава работеше по разчистването на останките от Кулите, към Буш. Човекът беше демократ, защото в Ню Йорк републиканците не са популярни, и въпреки това му каза: „Сър, не Ви харесвам, не гласувах за Вас, но ще гласувам за Вас на следващите избори.“
Затова няма значение каква държава е Израел. Нетаняху не може да си позволи да не отговори на удара, защото това ще означава, че пренебрегва основния принцип на еврейското политическо цяло. Кой ще го избере за премиер след това? За него като израелец това е въпрос на принципи, а като политик е въпрос на оцеляване.
Това, между другото, е една от основните причини да се стигне дотук. Всеки път, когато държавата е била разделена, са ги сполетявали подобни нападения. Но сега Израел трябва да има предвид поне две неща. Първо, не бива да се допускат грешките на САЩ след 11 септември, когато американците влязоха във вражеските територии, останаха дълго там и после имаха вътрешнополитически проблеми. Предвид технологиите, с които Израел разполага, нещо подобно е малко вероятно, освен ако конфликтът не се разлее. Другата опасност е, разбира се, Иран. Никой не знае дали Иран няма да удари в гръб.
Всъщност отговорихте на въпроса, който си задавахме настойчиво от първия миг – защо израелските служби, които са нарицателно за най-високо ниво на разузнаване, проспаха това, което би трябвало да знаят, че ще се случи.
Байдън обаче направи скоростна визита няколко дни след нападението на 7 октомври.
В Съединените щати има закон за лобизма и той казва, че всяко лоби има правото да влияе директно върху външнополитическия процес на страната. Еврейското лоби е най-влиятелно в американската външна политика. Още повече че Израел е апетитен съюзник и за него ще се борят и двата лагера – нека не забравяме, че в Израел живеят два милиона руски евреи. Въпреки че за мен шансовете на Русия рязко намаляха, след като тя започна да говори за създаването на независима палестинска държава. Това Израел няма да го забрави лесно.
И все пак имаше моменти, в които изглеждаше, че Путин и Нетаняху си имат приказката.
Те имаха много добра приказка, дотам че бяха станали доста съмнителни. Но Нетаняху разбра, че не може да вярва на Путин, а Русия си даде сметка, че няма как да подкрепи американски съюзник, колкото и да е критична ситуацията в момента.
Какво ще се случи оттук нататък?
Това, което в момента се случва в региона, може да бъде най-точно дефинирано с думите „прокси война“. Иран действа чрез „Хизбулла“ или чрез „Хамас“. Дава им средства, помага им да държат Израел настрана. Израел изстрелва някакви ракети, действа чрез свои агенти в ивицата Газа така, че да не се стигне до директна конфронтация.
По неофициална информация Израел разполага с тактически ядрени бойни глави, а Иран също разработва своя ядрен потенциал. Ако се стигне до война между двата актьора, тогава дилемата става ядрена и е почти сигурно, че Америка ще се намеси, за да свали аятоласите в Техеран, а и защото никой не иска ядрена ескалация в региона.
Ако се случи нещо подобно, войната в Украйна ще ни се стори като дребен регионален конфликт. Не се ли действа сега срещу трансграничните терористични мрежи, утре ще пламне Египет, защото ислямистите ще свалят Сиси и ще вдигнат във въздуха египетските пирамиди. После ще пламне Сирия, защото, да, в Сирия има предимно сунити, но Башар Асад е алауит. След това ще пламне Саудитска Арабия. Хората там са уахабити, обаче последния път, когато ИДИЛ говори за Саудитска Арабия, каза, че били много либерални. Разбира се, трябва да се гарантира животът на цивилните, но ако не се реагира бързо на тази криза, тя ще обхване целия регион.
Какво значи да се реагира бързо в тази ситуация?
Мисля, че трябва да се направят три неща. Първо, да се прокарат транспортни коридори, за да може цивилните да напуснат най-бързо зоната на военните действия. Добре е да има актьор, който да бъде гарант на тези коридори. Може да бъде Египет, може да бъде Турция, но по-добре би било това да е държава, която има глобално влияние – може би САЩ.
Второто нещо: не се съмнявам, че Израел ще извърши успешна операция, но тя трябва да е организирана така, че да не повтори онова свръхразпростиране, което Америка направи след 11 септември и за което говорих вече. Израел трябва да разграфи точно колко ресурс иска да отдели, за кой регион, къде ще остане и откъде ще се изтегли. Третата стъпка е да се избегне ядрена ескалация и превантивен удар от страна на Иран. А това, уви, в момента не е във властта на актьорите в региона. Ако американски войски стъпят още веднъж там, това почти сигурно означава, че Иран ще реагира. И тогава дори руснаците няма да могат да убедят иранците да не се намесват.
В момента не гледаме към Украйна, но как изглежда тази война в настоящия контекст? Ще се задълбочи ли?
Това зависи единствено и само от Вашингтон. Ако американският Конгрес продължи да отпуска пари в равна степен и за Украйна, и за Израел, ако президентът Байдън е склонен да продължи политиката на офшорно балансиране, така че ресурси да отиват и за Украйна, и за Израел, мисля, че ситуацията ще се задържи така, както е в момента. (Няколко часа след вземането на това интервю американският президент Джо Байдън направи специално обръщение, в което заяви, че подкрепата за Украйна и Израел е от съществена важност за американската сигурност – б.а.)
Но докога Американският конгрес ще подкрепя воденето на война на два фронта, предстои да видим, защото пък и на Байдън му предстоят избори. Тръмп става все по-популярен в Америка, което в един момент може да наложи компромиси.
Рейтингът на Байдън играе и не се знае какво би се случило, ако Тръмп отново стане президент. Тогава преходът към двуполюсен свят може да приключи много по-бързо, отколкото ни се иска.
Възможни ли са съвсем преки, директни и ясни разговори между САЩ и Китай, в които да се стигне до някакъв баланс?
Такива разговори винаги е имало и продължава да има. Америка е последователна в спазването на Политиката на единен Китай. Тя има някакви отношения с Тайван, които в момента дразнят Китай най-вече поради факта, че се пращат оръжия за Тайван. Но на хартия Америка продължава да спазва тази политика.
А на практика?
Факт е действително, че в последно време Вашингтон модифицира част от Политиката на единен Китай – негласно, разбира се. Виждаме, че връзките между Америка и Тайван са все по-силни. Виждаме посещения на американски официални лица в Тайван, което откровено дразни Китай. Но Китай няма да реагира поне докато не видим директна военна помощ за Тайван. Защото неоконфуцианската дипломация почива върху презумпцията, че конфликти и войни трябва да бъдат избягвани.
Китай не обича да воюва и не иска да воюва, затова до последно ще избягва директна военна конфронтация със Съединените щати. Ако обаче Америка разположи военни сили в Тайван или се опита по някакъв начин да наруши този интегритет и Политиката на единен Китай, тогава съгласно закона, който самият Китай прие, вероятно ще се стигне до конфликт между Пекин и Вашингтон. А това е много лош сценарий, защото тогава цялата глобална икономика просто ще рухне.
Тук трябва да обърна внимание на коментарите, които се правят от мнозина, че и Америка, и Китай имат проблеми с икономиката. Америка – защото залязва, Китай – защото го управляват хардлайнери. Нищо такова. Това, че еднополюсният свят си е отишъл, не означава, че Америка залязва. Просто вече не е толкова силна, че да командва какво се случва по света. Що се отнася до Китай, там в момента на власт може да са хардлайнерите, но тези управляващи продължават да генерират мощна средна класа, която гарантира високия жизнен стандарт на китайците.
В момента американската и китайската икономика се откачат една друга, а това води до ефекта на бумеранга. Когато Америка налага санкции на Китай, те се връщат срещу нея и обратното. Тази взаимозависимост, наречете го политическо тайдзи, води до ситуацията, в която се намираме в момента.
Как изглежда Европа на този фон?
Най-важното за Европа е да гарантира сигурността си. Въпросът за Европа е един: по какъв начин да намери баланса между това да създаде армия или по-скоро сили за бързо реагиране, които да ни помагат по-ефективно да охраняваме границите си.
И още нещо: да запазим социалния модел, който ни дава възможност да имаме блага като здравеопазване, осигуряване, пенсии. Съвсем друг е въпросът какво би се случило, ако човек като Тръмп отново застане начело на Щатите. Такива хора обикновено казват, че не биха защитили страна членка на НАТО.
Доколкото си спомням, тъкмо той държеше Европа да си прави армия.
Точно така. Истината е, че тези неща не ги решава президентът. Парите ги отпуска Конгресът. За щастие. По конституция той решава ще има ли война и какви войски ще бъдат изпратени. Така че който и да е президентът на САЩ, той ще трябва да се съобразява с Конгреса, който дава парите.
Какво не чухте, а трябваше да се каже според Вас след нападението на 7 октомври?
Каквото можа, се каза. По-скоро въпросът е какво остана свръхизказано. Няколко са наративите. Първият наратив е, че Нетаняху е виновен за всичко. Вторият е, че случващото се в Близкия изток става, защото някой е платил на друг. И третата конспирация е, че всичко това работи в полза на Русия.
Не може цялата едноличната отговорност да се стоварва върху Нетаняху, защото той беше принуден шест месеца да се оправя с протестите, които парализираха Израел. Да, балансът на силите обективно се променя, но нека не влизаме в конспирации, че някой нарочно е проспал атентата или че американците и руснаците са платили, за да може Израел да отиде в западния лагер.
Трябва да вярваме на суровите емпирични факти. А те са, че от едната страна е актьор като Израел с военна доктрина, наречена „Дахая“, според която винаги когато има асиметрична война срещу страната, евреите се обединяват, за да приложат диспропорционална сила спрямо противника си и да го смажат. Така е било в миналото, така е и сега. От другата са групировките, които осъществяват политически мотивирано насилие, а то, независимо от религията на осъществяващите го, на езика на международната сигурност се нарича тероризъм. Няма смисъл да ровим в конспиративни теории.
Истината е, че в целия регион живеят хора, които се мразят. Тук не става въпрос просто за политически конфликти, а за междурелигиозен, междуетнически и междукултурен диалог. Такива конфликти решаване нямат, защото от едната страна имаме хора, които искат политическо оцеляване, а от другата – такива, които искат физическо оцеляване. Има и трети, които искат просто насилие. За Иран това е въпрос на политическо оцеляване. За Израел – на културно-религиозно и физическо оцеляване. За терористите е въпрос на насилие.
Периодът до 14-тата седмица от живота на ембриона е известен сред учените като „черната кутия“ на човешкото развитие. Законите и етичните норми позволяват лабораторните изследвания само в рамките на този времеви отрязък. С помощта на синтетично създадени ембриони можем да извлечем много повече информация за началните процеси на развитие, като се елиминира необходимостта от използването на истински ембриони.
Ембрионално развитие при човека
Ембрионалното развитие започва с оплождането. От уроците по биология в училище знаем, че това е процесът на обединяване на женската и мъжката гамета (половите клетки) – яйцеклетка и сперматозоид. Дали възниква естествено в репродуктивната система на жената, или с помощта на т.нар. асистирана репродукция извън човешкото тяло, резултатът е формирането на структура, наречена зигота. Когато жената е в период на овулация, се отделя една яйцеклетка във фалопиевите тръби (или повече – в случаите на двуяйчни близнаци). Оплодената яйцеклетка (зиготата) се придвижва към матката и започва да се дели до образуването на бластоцист.
Бластоцистът е съставен от две групи клетки, изграждащи вътрешната (еритробласт) и външната му част (трофобласт). Той е обграден от защитен слой по време на развитието си, наречен зона пелуцида (zona pellucida), подобна на черупка на яйце. Клетките от външната страна са разположени под това покритие и в следващите стадии образуват плацентата и обграждащите я тъкани. Клетките във вътрешността се превръщат в различните тъкани и органи на човешкото тяло.
При човека клетките на бластоциста се делят бързо в първите няколко дни от развитието преди имплантирането му в матката. След това обвивката се разрушава и освобождава бластоциста, който се придвижва през фалопиевите тръби и се имплантира в матката на десетия ден. Когато бластоцистът стигне до финалните стъпки на имплантиране, той се превръща в ембрион. Развиват се структури като уста, долна челюст, гърло. По това време започват да се формират също кръвоносната система и сърцето. Развиват се ушите, ръцете, краката, пръстите и се оформят очите. На този етап главният и гръбначният мозък вече са формирани, а храносмилателната система и сензорните органи тепърва започват да се развиват. Първите образувани кости лека-полека заместват хрущяла.
Между 10-тата и 12-тата седмица на бременността ембрионът преминава към последната фаза на развитие – фетус. Органите продължават да се развиват и растат и фетусът се превръща в бебе на осмия месец. Към края на бременността през деветия месец бебето реагира на стимули, може да движи цялото си тяло и започва да му става тясно.
Стволови клетки
Стволовите клетки са уникални заради възможността си да се превръщат в различни видове специализирани клетки. Всички органи в човешкото тяло водят началото си от ембрионалните стволови клетки (ESC). ESC са полезен инструмент за изучаването на комплексните механизми, участващи в развитието на специализирани клетки и на органни структури.
Стволовите клетки могат и да се самообновяват. Те могат да се реплицират много пъти, за разлика например от нервните или мускулните клетки. Деленето на стволовите клетки бива два вида: симетрично и асиметрично. При симетричното се получават две дъщерни стволови клетки, а при несиметричното – една стволова и една диференцирана.
Как стволови клетки остават в недиференцирано състояние, вълнува немалка част от учените, които се занимават с изследвания на ембрионалното развитие, стареенето, регенеративните процеси и др. От друга страна, стои въпросът какво предизвиква една стволова клетка да се превърне в определен специализиран вид клетка. Част от сигналите, които провокират този процес, са фактори (най-често различни видове хормони), секретирани от заобикалящите клетки, физически контакт със съседни клетки и определени молекули в микросредата.
Синтетичен модел на човешкия ембрион
По-рано тази година изследователи от научния институт „Вайцман“ публикуваха статия, описваща създаването на първия човешки синтетичен ембрион. Техният модел на ембрион е създаден от стволови клетки без участието на яйцеклетка и сперматозоид. Изкуственият ембрион се развива до 14-тата седмица и изглежда като перфектния пример по учебник. Ембрионът се намира в клетъчна култура. Част от изследването включва и провеждане на тест за бременност чрез вземане на проба от средата, в която „живее“ ембрионът. Тестът е положителен, тъй като създаденият ембрион освобождава характерните за този период хормони.
Изкуственият ембрион успява точно да имитира структурите, характерни за ранните етапи на ембрионалното развитие. За да постигнат това, учените използват определени химични стимули, с които подканват стволовите клетки да се превърнат в точно определен вид диференцирани клетки: епибласт (който накрая се превръща във фетус), трофобласт (който образува плацентата), хипобласт (който образува хориона) и екстраембрионален мезодерм. Избрани са 120 от тези клетки в определено съотношение и са събрани в едно. Само малка част от тази смес започва самостоятелно да се подрежда, диференцира и разраства, докато накрая не заприличва на копие (ненапълно съвършено) на истински човешки ембрион.
Учените от екипа описват феномена като „изключително фина архитектура“. Но за какво ни е всъщност да имитираме природата? Надеждата на учените е, че този тип модели ще позволят да се изяснят конкретните механизми, чрез които се формират органите в човешкото тяло, а също така да се подобрят инвитро процедурите за оплождане. Друго приложение е тестването на лекарства, за да се провери дали приемането им е безопасно по време на бременност.
Въпреки това ембрионалните модели технически и законово не са истински ембриони и не подлежат на същите закони. Тук стои въпросът дали е редно да се правят опити за създаване на технология, с която изкуственият ембрион да може да расте и след 14-тата седмица, с цел да научим повече за началните стадии на човешкото развитие. Учените тепърва разработват нови правила за работа със синтетични ембриони. Тези модели биха позволили да се изяснят причините за често срещаните загуби на бременността в най-ранния етап на развитието на ембриона, както и за епигенетични, генетични и хромозомни болести.
Заглавно изображение: Човешки ембриони в ранен стадий на развитие. Източник: Flickr.com
Like virtually all customers, you want to spend as little as possible while getting the best possible performance. This means you need to pay attention to price-performance. With Amazon Redshift, you can have your cake and eat it too! Amazon Redshift delivers up to 4.9 times lower cost per user and up to 7.9 times better price-performance than other cloud data warehouses on real-world workloads using advanced techniques like concurrency scaling to support hundreds of concurrent users, enhanced string encoding for faster query performance, and Amazon Redshift Serverless performance enhancements. Read on to understand why price-performance matters and how Amazon Redshift price-performance is a measure of how much it costs to get a particular level of workload performance, namely performance ROI (return on investment).
Because both price and performance enter into the price-performance calculation, there are two ways to think about price-performance. The first way is to hold price constant: if you have $1 to spend, how much performance do you get from your data warehouse? A database with better price-performance will deliver better performance for each $1 spent. Therefore, when holding price constant when comparing two data warehouses that cost the same, the database with better price-performance will run your queries faster. The second way to look at price-performance is to hold performance constant: if you need your workload to finish in 10 minutes, what will it cost? A database with better price-performance will run your workload in 10 minutes at a lower cost. Therefore, when holding performance constant when comparing two data warehouses that are sized to deliver the same performance, the database with better price-performance will cost less and save you money.
Finally, another important aspect of price-performance is predictability. Knowing how much your data warehouse is going to cost as the number of data warehouse users grows is crucial for planning. It should not only deliver the best price-performance today, but also scale predictably and deliver the best price-performance as more users and workloads are added. An ideal data warehouse should have linear scale—scaling your data warehouse to deliver twice the query throughput should ideally cost twice as much (or less).
In this post, we share performance results to illustrate how Amazon Redshift delivers significantly better price-performance compared to leading alternative cloud data warehouses. This means that if you spend the same amount on Amazon Redshift as you would on one of these other data warehouses, you will get better performance with Amazon Redshift. Alternatively, if you size your Redshift cluster to deliver the same performance, you will see lower costs compared to these alternatives.
Price-performance for real-world workloads
You can use Amazon Redshift to power a very wide diversity of workloads, from batch-processing of complex extract, transform, and load (ETL)-based reports, and real-time streaming analytics to low-latency business intelligence (BI) dashboards that need to serve hundreds or even thousands of users at the same time with subsecond response times, and everything in between. One of the ways we continually improve price-performance for our customers is to constantly review the software and hardware performance telemetry from the Redshift fleet, looking for opportunities and customer use cases where we can further improve Amazon Redshift performance.
Some recent examples of performance optimizations driven by fleet telemetry include:
String query optimizations – By analyzing how Amazon Redshift processed different data types in the Redshift fleet, we found that optimizing string-heavy queries would bring significant benefit to our customers’ workloads. (We discuss this in more detail later in this post.)
Automated materialized views – We found that Amazon Redshift customers often run many queries that have common subquery patterns. For example, several different queries may join the same three tables using the same join condition. Amazon Redshift is now able to automatically create and maintain materialized views and then transparently rewrite queries to use the materialized views using the machine-learned automated materialized view autonomics feature in Amazon Redshift. When enabled, automated materialized views can transparently increase query performance for repetitive queries without any user intervention. (Note that automated materialized views were not used in any of the benchmark results discussed in this post).
High-concurrency workloads – A growing use case we see is using Amazon Redshift to serve dashboard-like workloads. These workloads are characterized by desired query response times of single-digit seconds or less, with tens or hundreds of concurrent users running queries simultaneously with a spiky and often unpredictable usage pattern. The prototypical example of this is an Amazon Redshift-backed BI dashboard that has a spike in traffic Monday mornings when a large number of users start their week.
High-concurrency workloads in particular have very broad applicability: most data warehouse workloads operate at concurrency, and it’s not uncommon for hundreds or even thousands of users to run queries on Amazon Redshift at the same time. Amazon Redshift was designed to keep query response times predictable and fast. Redshift Serverless does this automatically for you by adding and removing compute as needed to keep query response times fast and predictable. This means a Redshift Serverless-backed dashboard that loads quickly when it’s being accessed by one or two users will continue to load quickly even when many users are loading it at the same time.
To simulate this type of workload, we used a benchmark derived from TPC-DS with a 100 GB data set. TPC-DS is an industry-standard benchmark that includes a variety of typical data warehouse queries. At this relatively small scale of 100 GB, queries in this benchmark run on Redshift Serverless in an average of a few seconds, which is representative of what users loading an interactive BI dashboard would expect. We ran between 1–200 concurrent tests of this benchmark, simulating between 1–200 users trying to load a dashboard at the same time. We also repeated the test against several popular alternative cloud data warehouses that also support scaling out automatically (if you’re familiar with the post Amazon Redshift continues its price-performance leadership, we didn’t include Competitor A because it doesn’t support automatically scaling up). We measured average query response time, meaning how long a user would wait for their queries to finish (or their dashboard to load). The results are shown in the following chart.
Competitor B scales well until around 64 concurrent queries, at which point it is unable to provide additional compute and queries begin to queue, leading to increased query response times. Although Competitor C is able to scale automatically, it scales to lower query throughput than both Amazon Redshift and Competitor B and is not able to keep query runtimes low. In addition, it doesn’t support queueing queries when it runs out of compute, which prevents it from scaling beyond around 128 concurrent users. Submitting additional queries beyond this are rejected by the system.
Here, Redshift Serverless is able to keep the query response time relatively consistent at around 5 seconds even when hundreds of users are running queries at the same time. The average query response times for Competitors B and C increase steadily as load on the warehouses increases, which results in users having to wait longer (up to 16 seconds) for their queries to return when the data warehouse is busy. This means that if a user is trying to refresh a dashboard (which may even submit several concurrent queries when reloaded), Amazon Redshift would be able to keep dashboard load times far more consistent even if the dashboard is being loaded by tens or hundreds of other users at the same time.
Because Amazon Redshift is able to deliver very high query throughput for short queries (as we wrote about in Amazon Redshift continues its price-performance leadership), it’s also able to handle these higher concurrencies when scaling out more efficiently and therefore at a significantly lower cost. To quantify this, we look at the price-performance using published on-demand pricing for each of the warehouses in the preceding test, shown in the following chart. It’s worth noting that using Reserved Instances (RIs), especially 3-year RIs purchased with the all upfront payment option, has the lowest cost to run Amazon Redshift on Provisioned clusters, resulting in the best relative price-performance compared to on-demand or other RI options.
So not only is Amazon Redshift able to deliver better performance at higher concurrencies, it’s able to do so at significantly lower cost. Each data point in the price-performance chart is equivalent to the cost to run the benchmark at the specified concurrency. Because the price-performance is linear, we can divide the cost to run the benchmark at any concurrency by the concurrency (number of Concurrent Users in this chart) to tell us how much adding each new user costs for this particular benchmark.
The preceding results are straightforward to replicate. All queries used in the benchmark are available in our GitHub repository and performance is measured by launching a data warehouse, enabling Concurrency Scaling on Amazon Redshift (or the corresponding auto scaling feature on other warehouses), loading the data out of the box (no manual tuning or database-specific setup), and then running a concurrent stream of queries at concurrencies from 1–200 in steps of 32 on each data warehouse. The same GitHub repo references pregenerated (and unmodified) TPC-DS data in Amazon Simple Storage Service (Amazon S3) at various scales using the official TPC-DS data generation kit.
Optimizing string-heavy workloads
As mentioned earlier, the Amazon Redshift team is continuously looking for new opportunities to deliver even better price-performance for our customers. One improvement we recently launched that significantly improved performance is an optimization that accelerates the performance of queries over string data. For example, you might want to find the total revenue generated from retail stores located in New York City with a query like SELECT sum(price) FROM sales WHERE city = ‘New York’. This query is applying a predicate over string data (city = ‘New York’). As you can imagine, string data processing is ubiquitous in data warehouse applications.
To quantify how often customers’ workloads access strings, we conducted a detailed analysis of string data type usage using fleet telemetry of tens of thousands of customer clusters managed by Amazon Redshift. Our analysis indicates that in 90% of the clusters, string columns constitute at least 30% of all the columns, and in 50% of the clusters, string columns constitute at least 50% of all the columns. Moreover, a majority of all queries run on the Amazon Redshift cloud data warehouse platform access at least one string column. Another important factor is that string data is very often low cardinality, meaning the columns contain a relatively small set of unique values. For example, although an orders table representing sales data may contain billions of rows, an order_status column within that table might contain only a few unique values across those billions of rows, such as pending, in process, and completed.
As of this writing, most string columns in Amazon Redshift are compressed with LZO or ZSTD algorithms. These are good general-purpose compression algorithms, but they aren’t designed to take advantage of low-cardinality string data. In particular, they require that data be decompressed before being operated on, and are less efficient in their use of hardware memory bandwidth. For low-cardinality data, there is another type of encoding that can be more optimal: BYTEDICT. This encoding uses a dictionary-encoding scheme that allows the database engine to operate directly over compressed data without the need to decompress it first.
To further improve price-performance for string-heavy workloads, Amazon Redshift is now introducing additional performance enhancements that speed up scans and predicate evaluations, over low-cardinality string columns that are encoded as BYTEDICT, between 5–63 times faster (see results in the next section) compared to alternative compression encodings such as LZO or ZSTD. Amazon Redshift achieves this performance improvement by vectorizing scans over lightweight, CPU-efficient, BYTEDICT-encoded, low-cardinality string columns. These string-processing optimizations make effective use of memory bandwidth afforded by modern hardware, enabling real-time analytics over string data. These newly introduced performance capabilities are optimal for low-cardinality string columns (up to a few hundred unique string values).
You can automatically benefit from this new high performance string enhancement by enabling automatic table optimization in your Amazon Redshift data warehouse. If you don’t have automatic table optimization enabled on your tables, you can receive recommendations from the Amazon Redshift Advisor in the Amazon Redshift console on a string column’s suitability for BYTEDICT encoding. You can also define new tables that have low-cardinality string columns with BYTEDICT encoding. String enhancements in Amazon Redshift are now available in all AWS Regions where Amazon Redshift is available.
Performance results
To measure the performance impact of our string enhancements, we generated a 10TB (Tera Byte) dataset that consisted of low-cardinality string data. We generated three versions of the data using short, medium, and long strings, corresponding to the 25th, 50th, and 75th percentile of string lengths from Amazon Redshift fleet telemetry. We loaded this data into Amazon Redshift twice, encoding it in one case using LZO compression and in another using BYTEDICT compression. Finally, we measured the performance of scan-heavy queries that return many rows (90% of the table), a medium number of rows (50% of the table), and a few rows (1% of the table) over these low-cardinality string datasets. The performance results are summarized in the following chart.
Queries with predicates that match a high percentage of rows saw improvements of 5–30 times with the new vectorized BYTEDICT encoding compared to LZO, whereas queries with predicates that match a low percentage of rows saw improvements of 10–63 times in this internal benchmark.
Redshift Serverless price-performance
In addition to the high-concurrency performance results presented in this post, we also used the TPC-DS-derived Cloud Data Warehouse benchmark to compare the price-performance of Redshift Serverless to other data warehouses using a larger 3TB dataset. We chose data warehouses that were priced similarly, in this case within 10% of $32 per hour using publicly available on-demand pricing. These results show that, like Amazon Redshift RA3 instances, Redshift Serverless delivers better price-performance compared to other leading cloud data warehouses. As always, these results can be replicated by using our SQL scripts in our GitHub repository.
We encourage you to try Amazon Redshift using your own proof of concept workloads as the best way to see how Amazon Redshift can meet your data analytics needs.
Find the best price-performance for your workloads
The benchmarks used in this post are derived from the industry-standard TPC-DS benchmark, and have the following characteristics:
The schema and data are used unmodified from TPC-DS.
The queries are generated using the official TPC-DS kit with query parameters generated using the default random seed of the TPC-DS kit. TPC-approved query variants are used for a warehouse if the warehouse doesn’t support the SQL dialect of the default TPC-DS query.
The test includes the 99 TPC-DS SELECT queries. It doesn’t include maintenance and throughput steps.
For the single 3TB concurrency test, three power runs were run, and the best run is taken for each data warehouse.
Price-performance for the TPC-DS queries is calculated as cost per hour (USD) times the benchmark runtime in hours, which is equivalent to the cost to run the benchmark. The latest published on-demand pricing is used for all data warehouses and not Reserved Instance pricing as noted earlier.
We call this the Cloud Data Warehouse benchmark, and you can easily reproduce the preceding benchmark results using the scripts, queries, and data available in our GitHub repository. It is derived from the TPC-DS benchmarks as described in this post, and as such is not comparable to published TPC-DS results, because the results of our tests don’t comply with the official specification.
Conclusion
Amazon Redshift is committed to delivering the industry’s best price-performance for the widest variety of workloads. Redshift Serverless scales linearly with the best (lowest) price-performance, supporting hundreds of concurrent users while maintaining consistent query response times. Based on test results discussed in this post, Amazon Redshift has up to 2.6 times better price-performance at the same level of concurrency compared to the nearest competitor (Competitor B). As mentioned earlier, using Reserved Instances with the 3-year all upfront option gives you the lowest cost to run Amazon Redshift, resulting in even better relative price-performance compared to on-demand instance pricing that we used in this post. Our approach to continuous performance improvement involves a unique combination of customer obsession to understand customer use cases and their associated scalability bottlenecks coupled with continuous fleet data analysis to identify opportunities to make significant performance optimizations.
Each workload has unique characteristics, so if you’re just getting started, a proof of concept is the best way to understand how Amazon Redshift can lower your costs while delivering better performance. When running your own proof of concept, it’s important to focus on the right metrics—query throughput (number of queries per hour), response time, and price-performance. You can make a data-driven decision by running a proof of concept on your own or with assistance from AWS or a system integration and consulting partner.
Stefan Gromoll is a Senior Performance Engineer with Amazon Redshift team where he is responsible for measuring and improving Redshift performance. In his spare time, he enjoys cooking, playing with his three boys, and chopping firewood.
Ravi Animi is a Senior Product Management leader in the Amazon Redshift team and manages several functional areas of the Amazon Redshift cloud data warehouse service including performance, spatial analytics, streaming ingestion and migration strategies. He has experience with relational databases, multi-dimensional databases, IoT technologies, storage and compute infrastructure services and more recently as a startup founder using AI/deep learning, computer vision, and robotics.
Aamer Shah is a Senior Engineer in the Amazon Redshift Service team.
Sanket Hase is a Software Development Manager in the Amazon Redshift Service team.
Orestis Polychroniou is a Principal Engineer in the Amazon Redshift Service team.
От тогава доста хора споделиха в социалните мрежи и коментарите тук какъв е бил опита им. След като минаха летните отпуски, реших да попитам НЗОК все пак колко хора все пак са се възползвали спрямо общия брой изкарани карти. Ето какво научих.
През януари 2022 е подадено едно заявление през ССЕВ – моето. След три месеца увещаване получих картата си през април. Тогава писах за пръв път за случая в twitter. Според предоставените данни, следващите подадени заявления са чак август – общо 12. Три от тях са отново от мен за останалите от семейството ми. След това има между по 2 до 11 между ноември и април 2023. През май тази година пуснах още 4 заявления, за да обновя картите. Още 13 души са подали тогава.
В края на юни пуснах статията си как работи процеса и 58 души са го използвал. През юли вече беше копиран текста от няколко медии и 195 са подали заявление, а през август и септември – още общо 209. Откакто показах, че може и следва да е опция, над 400 души са попълнили заявлението и са получили картите с куриер.
За сравнение, от началото на 2022-ра до края на септември 2023 са били издадени 283625 карти на гише. Приемайки, че в този период някои са били преиздадени, това означава, че поне 164 хиляди души са се редели два пъти почти изцяло в клонове на партньорските им банки, за да си вземат картите от НЗОК.
Подновените карти са 60% от всички издадени. За такива се считат всички карти на хора, които някога са си изваждали ЕЗОК. Забелязва се сериозно покачване на новоиздадените карти през това лято, отчасти заради кампания в медиите колко са полезни всъщност. Интересно е, че немалко количество карти се издават в рамките на цялата година, не само през летните месеци, когато е основният поток от пътувания зад граница. Кривата съвпада доста добре с тази на излизащите от страната с цел почивка. Закономерно се вижда пик през юни и юли, т.е. преди летните отпуски.
Интересно наблюдение е, че немалка част от картите издадени пред 2022-ра не се преиздават скоро след изтичането на едногодишния им срок през 2023-та. Пикът това лято е основно от нови карти. Има обаче поне една група от около 100 хиляди души, които редовно си обновяват картите. Може да свалите всички числа от отговора на НЗОК тук.
Тук отново изниква въпроса защо е нужно всичко това. Обяснението на НЗОК от край време е, за да се пресичат злоупотребите. Попитах колко притежатели на карти са губили здравните си права докато са имали активна карта. Казаха ми, че не знаят. Причината е, че не го следят активно, а при искане за покриване на лечение. Отделно се оказа, че НЗОК нямат справка в реално време кой си плаща здравните вноски и кой не – налага се индивидуално да проверяват всеки за конкретен период през интерфейс на НАП. Това, както сами се сещате, е абсурдно на много нива.
Това, което ми отговориха обаче е, че от 140669 заявления подадени по какъвто и да е начин през 2022-ра, 2371 или 1.69% са били отказани заради прекъснати здравни права. Това число и съответно процент намалява значително откакто има ЕЗОК – от 5662 в 2013, през 4374 през 2018 до наполовина сега спрямо преди 10 години. Така смисълът от краткия срок на тези карти се обезсмисля, предвид, че разходът за издаването всяка година, разпространението и времето, което хората губят е повече, отколкото потенциалните щети за касата.
Докато някой в НЗОК започне да мисли за този и други далеч по-тежки пороци в системата, това, което огромна част от хората губещи време по каси и банки могат да направят е да използват дистанционния вариант. Това, с което Министерството за електронното управление от една страна и здравеопазването от друга могат да спомогнат, е да се направи прост формуляр, което да попълва всичко автоматично. Особено предвид, че 90% от информацията изисквана в наредбата е достъпна служебно правейки наредбата противозаконна.
Към този момент под 0.78% от ЕЗОК издадени след статията ми са били поискани през ССЕВ. Не съм фен на оптимизирането на процеси, които не следва да съществуват на първо място, но това тук е полезно упражнение в комуникация и честно казано – обучение на собствените ни институции. По този начин съм подавал както адресна регистрация, така и искания за акт за раждане, заявления по ЗДОИ и други документи.
From customer interactions on e-commerce platforms to social media trends and from sensor data in internet of things (IoT) devices to financial market updates, streaming data encompasses a vast array of information. This ability to handle real-time flow often distinguishes successful organizations from their competitors. Harnessing the potential of streaming data processing offers organizations an opportunity to stay at the forefront of their industries, make data-informed decisions with unprecedented agility, and gain invaluable insights into customer behavior and operational efficiency.
AWS provides a foundation for building robust and reliable data pipelines that efficiently transport streaming data, eliminating the intricacies of infrastructure management. This shift empowers engineers to focus their talents and energies on creating business value, rather than consuming their time for managing infrastructure.
In a world of exploding data, traditional on-premises analytics struggle to scale and become cost-prohibitive. Modern data architecture on AWS offers a solution. It lets organizations easily access, analyze, and break down data silos, all while ensuring data security. This empowers real-time insights and versatile applications, from live dashboards to data lakes and warehouses, transforming the way we harness data.
This whitepaper guides you through implementing this architecture, focusing on streaming technologies. It simplifies data collection, management, and analysis, offering three movement patterns to glean insights from near real-time data using AWS’s tailored analytics services. The future of data analytics has arrived.
In this workshop, you’ll see how to process data in real-time, using streaming and micro-batching technologies in the context of anomaly detection. You will also learn how to integrate Apache Kafka on Amazon Managed Streaming for Apache Kafka (Amazon MSK) with an Apache Flink consumer to process and aggregate the events for reporting purposes.
Streaming architectures built on Apache Kafka follow the publish/subscribe paradigm: producers publish events to topics via a write operation and the consumers read the events.
This video describes how to offer a real-time financial data feed as a service on AWS. By using Amazon MSK, you can work with Kafka to allow consumers to subscribe to message topics containing the data of interest. The sessions drills down into the best design practices for working with Kafka and the techniques for establishing hybrid connectivity for working at a global scale.
The Samsung SmartThings story is a compelling case study in how businesses can modernize and optimize their streaming data analytics, relieve the burden of infrastructure management, and embrace a future of real-time insights. After Samsung migrated to Amazon Managed Service for Apache Flink, the development team’s focus shifted from the tedium of infrastructure upkeep to the realm of delivering tangible business value. This change enabled them to harness the full potential of a fully managed stream-processing platform.
Software upgrades bring new features and better performance, and keep you current with the software provider. However, upgrades for software services can be difficult to complete successfully, especially when you can’t tolerate downtime and when the new version’s APIs introduce breaking changes and deprecation that you must remediate. This post shows you how to upgrade from Elasticsearch engine to OpenSearch engine on Amazon OpenSearch Service without needing an intermediate upgrade to Elasticsearch 7.10.
OpenSearch Service supports OpenSearch as an engine, with versions in the 1.x through 2.x series. The service also supports legacy versions of Elasticsearch, versions 1.x through 7.10. Although OpenSearch brings many improvements over earlier engines, it can feel daunting to consider not only upgrading versions, but also changing engines in the process. The good news is that OpenSearch 1.0 is wire compatible with Elasticsearch 7.10, making engine changes straightforward. If you’re running a version of Elasticsearch in the 6.x or early 7.x series on OpenSearch Service, you might think you need to upgrade to Elasticsearch 7.10, and then upgrade to OpenSearch 1.3. However, you can easily upgrade your existing Elasticsearch engine running 6.8, 7.1, 7.2, 7.4, 7.9, and 7.10 in OpenSearch Service to the OpenSearch 1.3 engine.
OpenSearch Service runs a variety of checks before running an actual upgrade:
Validation before starting an upgrade
Preparing the setup configuration for the desired version
Provisioning new nodes with the same hardware configuration
Moving shards from old nodes to newly provisioned nodes
Removing older nodes and old node references from OpenSearch endpoints
During an upgrade, AWS takes care of the undifferentiated heavy lifting of provisioning, deploying, and moving the data to new domain. You are responsible to make sure there are no breaking changes that affect the data migration and movement to the newer version of the OpenSearch domain. In this post, we discuss the things you must modify and verify before and after running an upgrade from 6.8, 7.1, 7.2, 7.4, 7.9, and 7.10 version of Elasticsearch to 1.3 OpenSearch Service.
Pre-upgrade breaking changes
The following are pre-upgrade breaking changes:
Dependency check for language clients and libraries – If you’re using the open-source high-level language clients from Elastic, for example the Java, go, or Python client libraries, AWS recommends moving to the open-source, OpenSearch versions of these clients. (If you don’t use a high-level language client, you can skip this step.) The following are a few steps to perform a dependency check:
Determine the client library – Choose an appropriate client library compatible with your programing language. Refer to OpenSearch language clients for a list of all supported client libraries.
Add dependencies and resolve conflicts – Update your project’s dependency management system with the necessary dependencies specified by the client library. If your project already has dependencies that conflict with the OpenSearch client library dependencies, you may encounter dependency conflicts. In such cases, you need to resolve the conflicts manually.
Test and verify the client – Test the OpenSearch client functionality by establishing a connection, performing some basic operations (like indexing and searching), and verifying the results.
Removal of mapping types – Multiple types within an index were deprecated in Elasticsearch version 6.x, and completely removed in version 7.0 or later. OpenSearch indexes can only contain one mapping type. From OpenSearch version 2.x onward, the mapping _type must be _doc. You must check and fix the mapping before upgrading to OpenSearch 1.3.
Complete the following steps to identify and fix mapping issues:
Navigate to dev tools and use the following GET <index> mapping API to fetch the mapping information for all the indexes:
GET /index-name/_mapping
The mapping response will contain a JSON structure that represents the mapping for your index.
Look for the top-level keys in the response JSON; each key represents a custom type within the index.
The _doc type is used for the default type in Elasticsearch 7.x and OpenSearch Service 1.x, but you may see additional types that you defined in earlier versions of Elasticsearch. The following is an example response for an index with two custom types, type1 and type2.
Note that indexes created in 5.x will continue to function in 6.x as they did in 5.x, but indexes created in 6.x only allow a single type per index.
To fix the multiple mapping types in your existing domain, you need to reindex the data, where you can create one index for each mapping. This is a crucial step in the migration process because OpenSearch doesn’t support multiple types within a single index. In the next steps, we convert an index that has multiple mapping types into two separate indexes, each using the _doc type.
You can unify the mapping by using your existing index name as a root and adding the type as a suffix. For example, the following code creates two indexes with myindex as the root name and type1 and type2 as the suffix:
# Create an index for "type1"
PUT /myindex_type1
# Create an index for "type2"
PUT /myindex_type2
Use the _reindex API to reindex the data from the original index into the two new indexes. Alternately, you can reload the data from its source, if you’re keeping it in another system.
If your application was previously querying the original index with multiple types, you’ll need to update your queries to specify the new indexes with _doc as the type. For example, if your client was querying using myindex, which has been reindexed to myindex_type1 and myindex_type2, then change your clients to point to myindex*, which will query across both indexes.
After you have verified that the data is successfully reindexed and your application is working as expected with the new indexes, you should delete the original index before starting the upgrade, because it won’t be supported in the new version. Be cautious when deleting data and make sure you have backups if necessary.
As part of this upgrade, Kibana will be replaced with OpenSearch Dashboards. When you’re done with the upgrade in the next step, you should advocate your users to use the new endpoint, which will be _dashboards. If you use a custom endpoint, be sure to update it to point to /_dashboards.
We recommend that you update your AWS Identity and Access Management (IAM) policies to use the renamed API operations. However, OpenSearch Service will continue to respect existing policies by internally replicating the old API permissions. Service control policies (SCPs) introduce an additional layer of complexity compared to standard IAM. To prevent your SCP policies from breaking, you need to add both the old and the new API operations to each of your SCP policies.
Start the upgrade
The upgrade process is irreversible and can’t be paused or cancelled. You should make sure that everything will go smoothly by running a proof of concept (POC) check. By building a POC, you ensure data preservation, avoid compatibility issues, prevent unwanted bugs, and mitigate risks. You can run a POC with a small domain on the new version, and with a small subset of your data. Deploy and run any front-end code that communicates with OpenSearch Service via API against your test domain. Use your ingest pipeline to send data to your test domain as well, ensuring nothing breaks. Import or rebuild dashboards, alerts, anomaly detectors, and so on. This simple precaution can make your upgrade experience smoother and trouble-free while minimizing potential disruptions.
When OpenSearch Service starts the upgrade, it can take from 15 minutes to several hours to complete. OpenSearch Dashboards might be unavailable during some or all of the duration of the upgrade.
This snapshot serves as a backup that you can restore on a new domain if you want to return to using the prior version.
On the OpenSearch Service console, choose the domain that you want to upgrade.
On the Actions menu, choose Upgrade.
Select the target version as OpenSearch 1.3. If you’re upgrading to an OpenSearch version, then you’ll be able to enable compatibility mode. If you enable this setting, OpenSearch reports its version as 7.10 to allow Elastic’s open-source clients and plugins like Logstash to continue working with your OpenSearch Service domain.
Choose Check Upgrade Eligibility, which helps you identify if there are any breaking changes you still need to fix before running an upgrade.
Choose Upgrade.
Check the status on the domain dashboard to monitor the status of the upgrade.
The following graphic gives a quick demonstration of running and monitoring the upgrade via the preceding steps.
Post-upgrade changes and validations
Now that you have successfully upgraded your domain to OpenSearch Service 1.3, be sure to make the following changes:
Custom endpoint – A custom endpoint for your OpenSearch Service domain makes it straightforward for you to refer to your OpenSearch and OpenSearch Dashboards URLs. You can include your company’s branding or just use a shorter, easier-to-remember endpoint than the standard one. In OpenSearch Service, Kibana has been renamed to dashboards. After you upgrade a domain from the Elasticsearch engine to the OpenSearch engine, the /_plugin/kibana endpoint changes to /_dashboards. If you use the Kibana endpoint to set up a custom domain, you need to update it to include the new /_dashboards endpoint.
SAML authentication for OpenSearch Dashboards – After you upgrade your domain to OpenSearch Service, you need to change all Kibana URLs configured in your identity provider (IdP) from /_plugin/kibana to /_dashboards. The most common URLs are assertion consumer service (ACS) URLs and recipient URLs.
Conclusion
This post discussed what to consider when planning to upgrade your existing Elasticsearch engine in your OpenSearch Service domain to the OpenSearch engine. OpenSearch Service continues to support older engine versions, including open-source versions of Elasticsearch from 1.x through 7.10. By migrating forward to OpenSearch Service, you will be able to take advantage of bug fixes, performance improvements, new service features, and expanded instance types for your data nodes, like AWS Graviton 2 instances.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Harsh Bansal is a Solutions Architect at AWS with Analytics as his area of specialty.He has been building solutions to help organizations make data-driven decisions.
Amazon Redshift is a fast, petabyte-scale, cloud data warehouse that tens of thousands of customers rely on to power their analytics workloads. Data analysts and database developers want to use this data to train machine learning (ML) models, which can then be used to generate insights on new data for use cases such as forecasting revenue, predicting customer churn, and detecting anomalies. Amazon Redshift ML makes it easy for SQL users to create, train, and deploy ML models using SQL commands familiar to many roles such as executives, business analysts, and data analysts. We covered in a previous post how you can use data in Amazon Redshift to train models in Amazon SageMaker, a fully managed ML service, and then make predictions within your Redshift data warehouse.
Redshift ML currently supports ML algorithms such as XGBoost, multilayer perceptron (MLP), KMEANS, and Linear Learner. Additionally, you can import existing SageMaker models into Amazon Redshift for in-database inference or remotely invoke a SageMaker endpoint.
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for ML models. However, one challenge in training a production-ready ML model using SageMaker Feature Store is access to a diverse set of features that aren’t always owned and maintained by the team that is building the model. For example, an ML model to identify fraudulent financial transactions needs access to both identifying (device type, browser) and transaction (amount, credit or debit, and so on) related features. As a data scientist building an ML model, you may have access to the identifying information but not the transaction information, and having access to a feature store solves this.
In this post, we discuss the combined feature store pattern, which allows teams to maintain their own local feature stores using a local Redshift table while still being able to access shared features from the centralized feature store. In a local feature store, you can store sensitive data that can’t be shared across the organization for regulatory and compliance reasons.
We also show you how to use familiar SQL statements to create and train ML models by combining shared features from the centralized store with local features and use these models to make in-database predictions on new data for use cases such as fraud risk scoring.
Overview of solution
For this post, we create an ML model to predict if a transaction is fraudulent or not, given the transaction record. To build this, we need to engineer features that describe an individual credit card’s spending pattern, such as the number of transactions or the average transaction amount, and also information about the merchant, the cardholder, the device used to make the payment, and any other data that may be relevant to detecting fraud.
Train and validate a fraud risk scoring ML model using local feature data and external offline feature store data.
Use the offline feature store and local store for inference.
Dataset
To demonstrate this use case, we use a synthetic dataset with two tables: identity and transactions. They can both be joined by the TransactionID column. The transaction table contains information about a particular transaction, such as amount, credit or debit card, and so on, and the identity table contains information about the user, such as device type and browser. The transaction must exist in the transaction table, but might not always be available in the identity table.
The following is an example of the transactions dataset.
The following is an example of the identity dataset.
Let’s assume that across the organization, data science teams centrally manage the identity data and process it to extract features in a centralized offline feature store. The data warehouse team ingests and analyzes transaction data in a Redshift table, owned by them.
We work through this use case to understand how the data warehouse team can securely retrieve the latest features from the identity feature group and join it with transaction data in Amazon Redshift to create a feature set for training and inferencing a fraud detection model.
Create the offline feature group and ingest data
To start, we set up SageMaker Feature Store, create a feature group for the identity dataset, inspect and process the dataset, and ingest some sample data. We then prepare the transaction features from the transaction data and store it in Amazon S3 for further loading into the Redshift table.
Alternatively, you can author features using Amazon SageMaker Data Wrangler, create feature groups in SageMaker Feature Store, and ingest features in batches using an Amazon SageMaker Processing job with a notebook exported from SageMaker Data Wrangler. This mode allows for batch ingestion into the offline store.
Let’s explore some of the key steps in this section.
On the SageMaker console, under Notebook in the navigation pane, choose Notebook instances.
Locate your notebook instance and choose Open Jupyter.
Choose Upload and upload the notebook you just downloaded.
Open the notebook sagemaker_featurestore_fraud_redshiftml_python_sdk.ipynb.
Follow the instructions and run all the cells up to the Cleanup Resources section.
The following are key steps from the notebook:
We create a Pandas DataFrame with the initial CSV data. We apply feature transformations for this dataset.
identity_data = pd.read_csv(io.BytesIO(identity_data_object["Body"].read()))
transaction_data = pd.read_csv(io.BytesIO(transaction_data_object["Body"].read()))
identity_data = identity_data.round(5)
transaction_data = transaction_data.round(5)
identity_data = identity_data.fillna(0)
transaction_data = transaction_data.fillna(0)
# Feature transformations for this dataset are applied
# One hot encode card4, card6
encoded_card_bank = pd.get_dummies(transaction_data["card4"], prefix="card_bank")
encoded_card_type = pd.get_dummies(transaction_data["card6"], prefix="card_type")
transformed_transaction_data = pd.concat(
[transaction_data, encoded_card_type, encoded_card_bank], axis=1
)
We store the processed and transformed transaction dataset in an S3 bucket. This transaction data will be loaded later in the Redshift table for building the local feature store.
Next, we need a record identifier name and an event time feature name. In our fraud detection example, the column of interest is TransactionID.EventTime can be appended to your data when no timestamp is available. In the following code, you can see how these variables are set, and then EventTime is appended to both features’ data.
# record identifier and event time feature names
record_identifier_feature_name = "TransactionID"
event_time_feature_name = "EventTime"
# append EventTime feature
identity_data[event_time_feature_name] = pd.Series(
[current_time_sec] * len(identity_data), dtype="float64"
)
We then create and ingest the data into the feature group using the SageMaker SDK FeatureGroup.ingest API. This is a small dataset and therefore can be loaded into a Pandas DataFrame. When we work with large amounts of data and millions of rows, there are other scalable mechanisms to ingest data into SageMaker Feature Store, such as batch ingestion with Apache Spark.
identity_feature_group.create(
s3_uri=<S3_Path_Feature_Store>,
record_identifier_name=record_identifier_feature_name,
event_time_feature_name=event_time_feature_name,
role_arn=<role_arn>,
enable_online_store=False,
)
identity_feature_group_name = "identity-feature-group"
# load feature definitions to the feature group. SageMaker FeatureStore Python SDK will auto-detect the data schema based on input data.
identity_feature_group.load_feature_definitions(data_frame=identity_data)
identity_feature_group.ingest(data_frame=identity_data, max_workers=3, wait=True)
We can verify that data has been ingested into the feature group by running Athena queries in the notebook or running queries on the Athena console.
At this point, the identity feature group is created in an offline feature store with historical data persisted in Amazon S3. SageMaker Feature Store automatically creates an AWS Glue Data Catalog for the offline store, which enables us to run SQL queries against the offline data using Athena or Redshift Spectrum.
Create a Redshift table and load local feature data
To build a Redshift ML model, we build a training dataset joining the identity data and transaction data using SQL queries. The identity data is in a centralized feature store where the historical set of records are persisted in Amazon S3. The transaction data is a local feature for training data that needs to made available in the Redshift table.
Let’s explore how to create the schema and load the processed transaction data from Amazon S3 into a Redshift table.
Create the customer_transaction table and load daily transaction data into the table, which you’ll use to train the ML model:
Load the sample data by using the following command. Replace your Region and S3 path as appropriate. You will find the S3 path in the S3 Bucket Setup For The OfflineStore section in the notebook or by checking the dataset_uri_prefix in the notebook.
COPY customer_transaction
FROM '<s3path>/transformed_transaction_data.csv'
IAM_ROLE default delimiter ','
region 'your-region';
Now that we have created a local feature store for the transaction data, we focus on integrating a centralized feature store with Amazon Redshift to access the identity data.
Create an external schema for Redshift Spectrum to access the offline store data
We have created a centralized feature store for identity features, and we can access this offline feature store using services such as Redshift Spectrum. When the identity data is available through the Redshift Spectrum table, we can create a training dataset with feature values from the identity feature group and customer_transaction, joining on the TransactionId column.
This section provides an overview of how to enable Redshift Spectrum to query data directly from files on Amazon S3 through an external database in an AWS Glue Data Catalog.
First, check that the identity-feature-group table is present in the Data Catalog under the sagemamker_featurestore database.
Using Redshift Query Editor V2, create an external schema using the following command:
CREATE EXTERNAL SCHEMA sagemaker_featurestore
FROM DATA CATALOG
DATABASE 'sagemaker_featurestore'
IAM_ROLE default
create external database if not exists;
All the tables, including identity-feature-group external tables, are visible under the sagemaker_featurestore external schema. In Redshift Query Editor v2, you can check the contents of the external schema.
Run the following query to sample a few records—note that your table name may be different:
Select * from sagemaker_featurestore.identity_feature_group_1680208535 limit 10;
Create a view to join the latest data from identity-feature-group and customer_transaction on the TransactionId column. Be sure to change the external table name to match your external table name:
create or replace view public.credit_fraud_detection_v
AS select "isfraud",
"transactiondt",
"transactionamt",
"card1","card2","card3","card5",
case when "card_type_credit" = 'False' then 0 else 1 end as card_type_credit,
case when "card_type_debit" = 'False' then 0 else 1 end as card_type_debit,
case when "card_bank_american_express" = 'False' then 0 else 1 end as card_bank_american_express,
case when "card_bank_discover" = 'False' then 0 else 1 end as card_bank_discover,
case when "card_bank_mastercard" = 'False' then 0 else 1 end as card_bank_mastercard,
case when "card_bank_visa" = 'False' then 0 else 1 end as card_bank_visa,
"id_01","id_02","id_03","id_04","id_05"
from public.customer_transaction ct left join sagemaker_featurestore.identity_feature_group_1680208535 id
on id.transactionid = ct.transactionid with no schema binding;
Train and validate the fraud risk scoring ML model
Redshift ML gives you the flexibility to specify your own algorithms and model types and also to provide your own advanced parameters, which can include preprocessors, problem type, and hyperparameters. In this post, we create a customer model by specifying AUTO OFF and the model type of XGBOOST. By turning AUTO OFF and using XGBoost, we are providing the necessary inputs for SageMaker to train the model. A benefit of this can be faster training times. XGBoost is as open-source version of the gradient boosted trees algorithm. For more details on XGBoost, refer to Build XGBoost models with Amazon Redshift ML.
We train the model using 80% of the dataset by filtering on transactiondt < 12517618. The other 20% will be used for inference. A centralized feature store is useful in providing the latest supplementing data for training requests. Note that you will need to provide an S3 bucket name in the create model statement. It will take approximately 10 minutes to create the model.
CREATE MODEL frauddetection_xgboost
FROM (select "isfraud",
"transactiondt",
"transactionamt",
"card1","card2","card3","card5",
"card_type_credit",
"card_type_debit",
"card_bank_american_express",
"card_bank_discover",
"card_bank_mastercard",
"card_bank_visa",
"id_01","id_02","id_03","id_04","id_05"
from credit_fraud_detection_v where transactiondt < 12517618
)
TARGET isfraud
FUNCTION ml_fn_frauddetection_xgboost
IAM_ROLE default
AUTO OFF
MODEL_TYPE XGBOOST
OBJECTIVE 'binary:logistic'
PREPROCESSORS 'none'
HYPERPARAMETERS DEFAULT EXCEPT(NUM_ROUND '100')
SETTINGS (S3_BUCKET <s3_bucket>);
When you run the create model command, it will complete quickly in Amazon Redshift while the model training is happening in the background using SageMaker. You can check the status of the model by running a show model command:
show model frauddetection_xgboost;
The output of the show model command shows that the model state is TRAINING. It also shows other information such as the model type and the training job name that SageMaker assigned. After a few minutes, we run the show model command again:
show model frauddetection_xgboost;
Now the output shows the model state is READY. We can also see the train:error score here, which at 0 tells us we have a good model. Now that the model is trained, we can use it for running inference queries.
Use the offline feature store and local store for inference
We can use the SQL function to apply the ML model to data in queries, reports, and dashboards. Let’s use the function ml_fn_frauddetection_xgboost created by our model against our test dataset by filtering where transactiondt >=12517618, to predict whether a transaction is fraudulent or not. SageMaker Feature Store can be useful in supplementing data for inference requests.
Run the following query to predict whether transactions are fraudulent or not:
select "isfraud" as "Actual",
ml_fn_frauddetection_xgboost(
"transactiondt",
"transactionamt",
"card1","card2","card3","card5",
"card_type_credit",
"card_type_debit",
"card_bank_american_express",
"card_bank_discover",
"card_bank_mastercard",
"card_bank_visa",
"id_01","id_02","id_03","id_04","id_05") as "Predicted"
from credit_fraud_detection_v where transactiondt >= 12517618;
For binary and multi-class classification problems, we compute the accuracy as the model metric. Accuracy can be calculated based on the following:
accuracy = (sum (actual == predicted)/total) *100
Let’s apply the preceding code to our use case to find the accuracy of the model. We use the test data (transactiondt >= 12517618) to test the accuracy, and use the newly created function ml_fn_frauddetection_xgboost to predict and take the columns other than the target and label as the input:
-- check accuracy
WITH infer_data AS (
SELECT "isfraud" AS label,
ml_fn_frauddetection_xgboost(
"transactiondt",
"transactionamt",
"card1","card2","card3","card5",
"card_type_credit",
"card_type_debit",
"card_bank_american_express",
"card_bank_discover",
"card_bank_mastercard",
"card_bank_visa",
"id_01","id_02","id_03","id_04","id_05") AS predicted,
CASE
WHEN label IS NULL
THEN 0
ELSE label
END AS actual,
CASE
WHEN actual = predicted
THEN 1::INT
ELSE 0::INT
END AS correct
FROM credit_fraud_detection_v where transactiondt >= 12517618),
aggr_data AS (
SELECT SUM(correct) AS num_correct,
COUNT(*) AS total
FROM infer_data)
SELECT (num_correct::FLOAT / total::FLOAT) AS accuracy FROM aggr_data;
Clean up
As a final step, clean up the resources:
Delete the Redshift cluster.
Run the Cleanup Resources section of your notebook.
Conclusion
Redshift ML enables you to bring machine learning to your data, powering fast and informed decision-making. SageMaker Feature Store provides a purpose-built feature management solution to help organizations scale ML development across business units and data science teams.
In this post, we showed how you can train an XGBoost model using Redshift ML with data spread across SageMaker Feature Store and a Redshift table. Additionally, we showed how you can make inferences on a trained model to detect fraud using Amazon Redshift SQL commands.
About the authors
Anirban Sinha is a Senior Technical Account Manager at AWS. He is passionate about building scalable data warehouses and big data solutions working closely with customers. He works with large ISVs customers, in helping them build and operate secure, resilient, scalable, and high-performance SaaS applications in the cloud.
Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse.
Gaurav Singh is a Senior Solutions Architect at AWS, specializing in AI/ML and Generative AI. Based in Pune, India, he focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. In his spare time, Gaurav loves to explore nature, read, and run.
“Кметът в сянка” в гр. Царево Ангел Цигуларов е за пореден път “измъкнат”, вместо да бъде подведен под отговорност, с помощта на местната власт и на Прокуратурата на Република България…
The C programming language is replete with features that seemed like a good
idea at the time (and perhaps even were good ideas then) that have not aged
well. Most would likely agree that string handling, and the use of
NUL-terminated strings, is one of those. Kernel developers have, for
years, tried to improve the handling of strings in an attempt to slow the
flow of bugs and vulnerabilities that result from mistakes in that area.
Now there is an early discussion on the idea of moving away from
NUL-terminated strings in much of the kernel.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
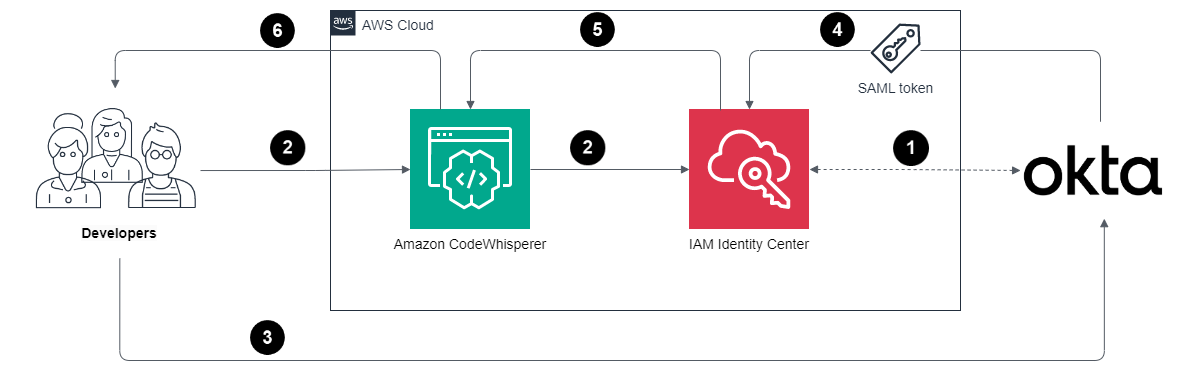
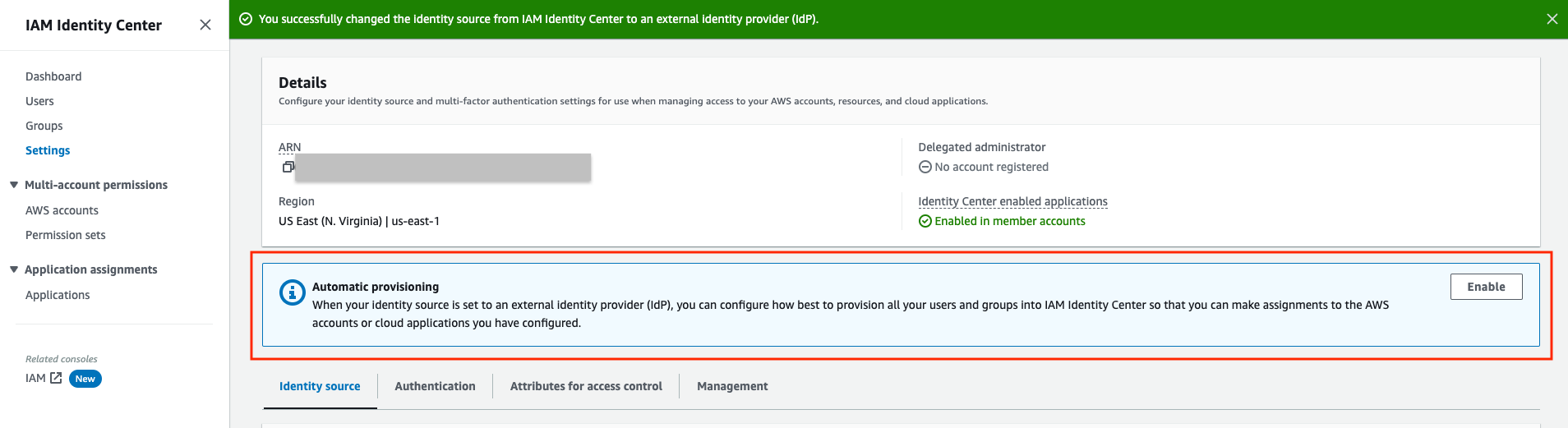







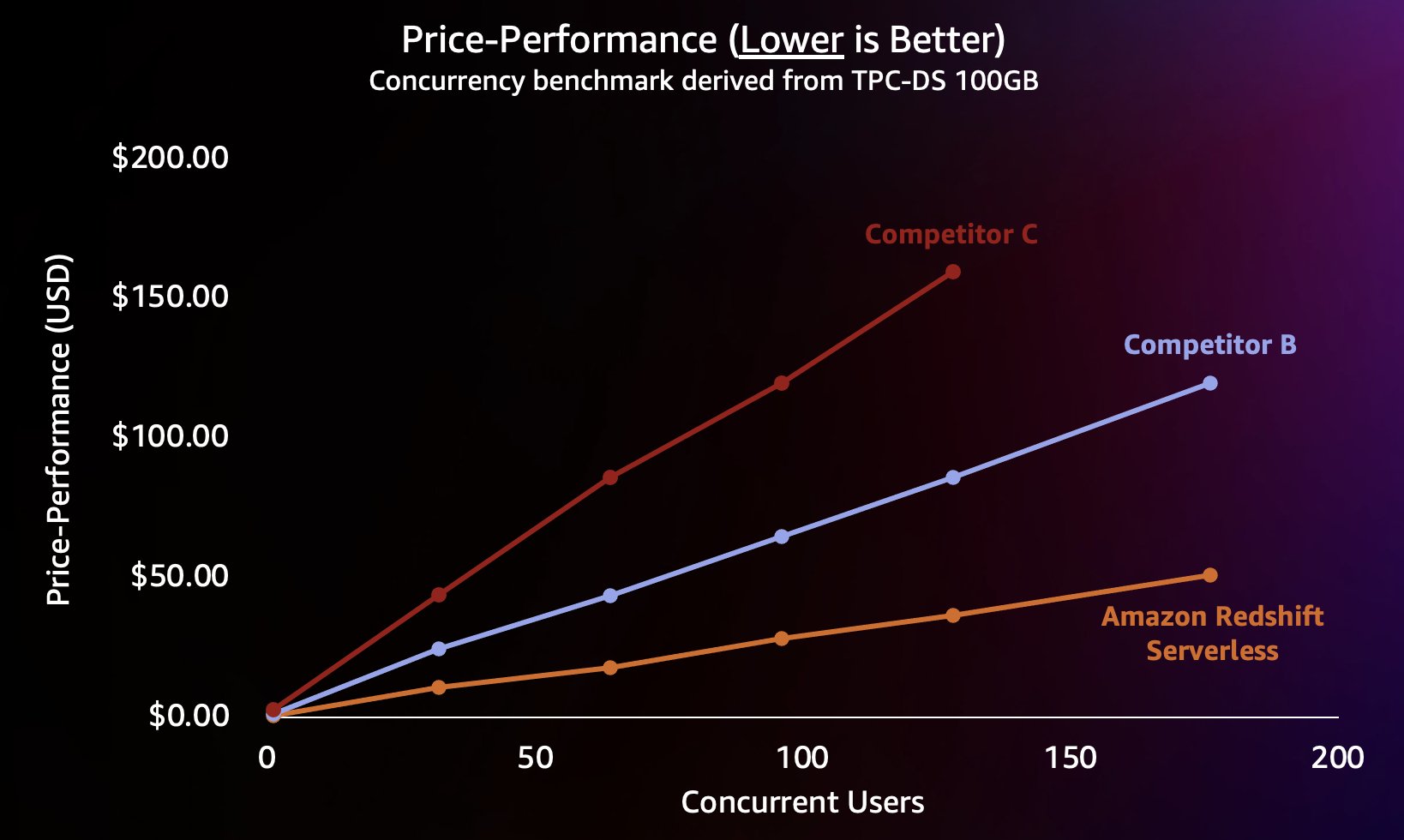

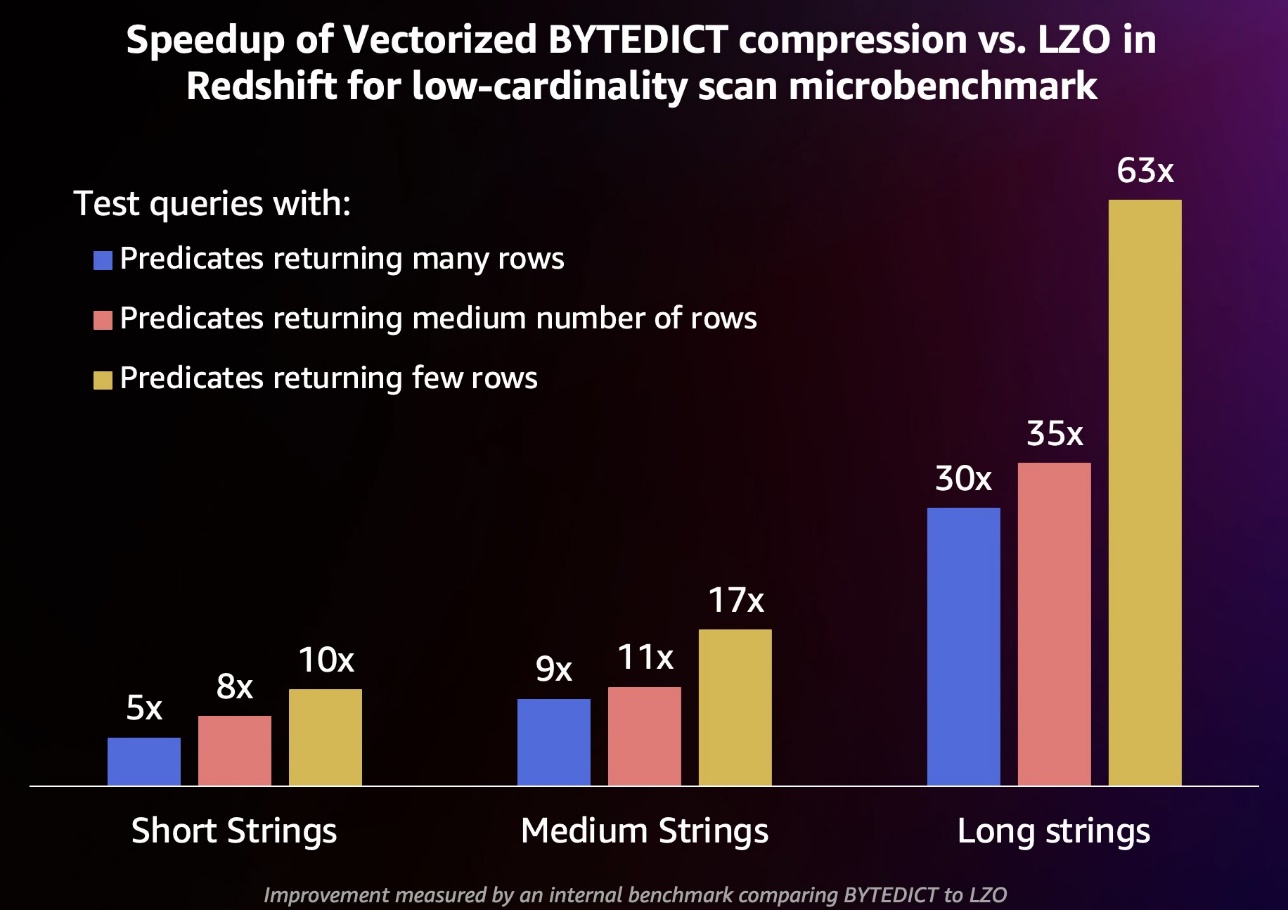

 Stefan Gromoll is a Senior Performance Engineer with Amazon Redshift team where he is responsible for measuring and improving Redshift performance. In his spare time, he enjoys cooking, playing with his three boys, and chopping firewood.
Stefan Gromoll is a Senior Performance Engineer with Amazon Redshift team where he is responsible for measuring and improving Redshift performance. In his spare time, he enjoys cooking, playing with his three boys, and chopping firewood.
 Aamer Shah is a Senior Engineer in the Amazon Redshift Service team.
Aamer Shah is a Senior Engineer in the Amazon Redshift Service team. Sanket Hase is a Software Development Manager in the Amazon Redshift Service team.
Sanket Hase is a Software Development Manager in the Amazon Redshift Service team. Orestis Polychroniou is a Principal Engineer in the Amazon Redshift Service team.
Orestis Polychroniou is a Principal Engineer in the Amazon Redshift Service team.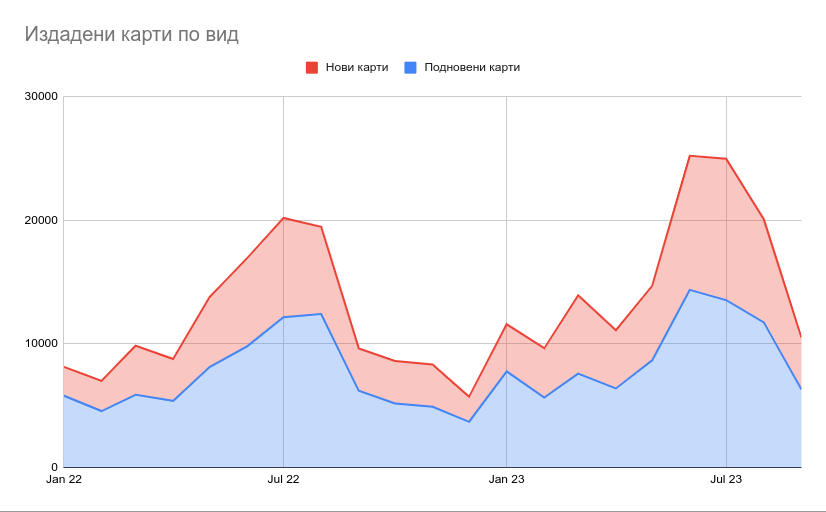
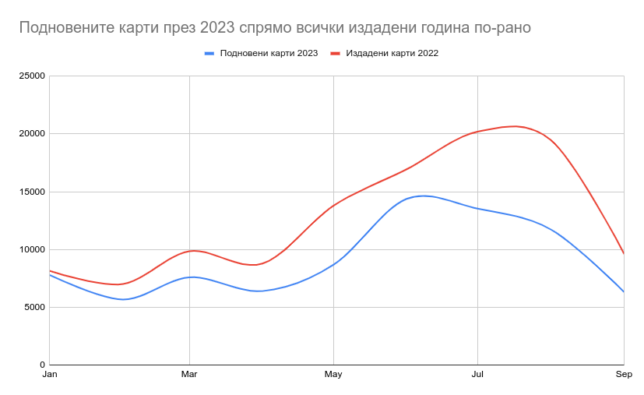




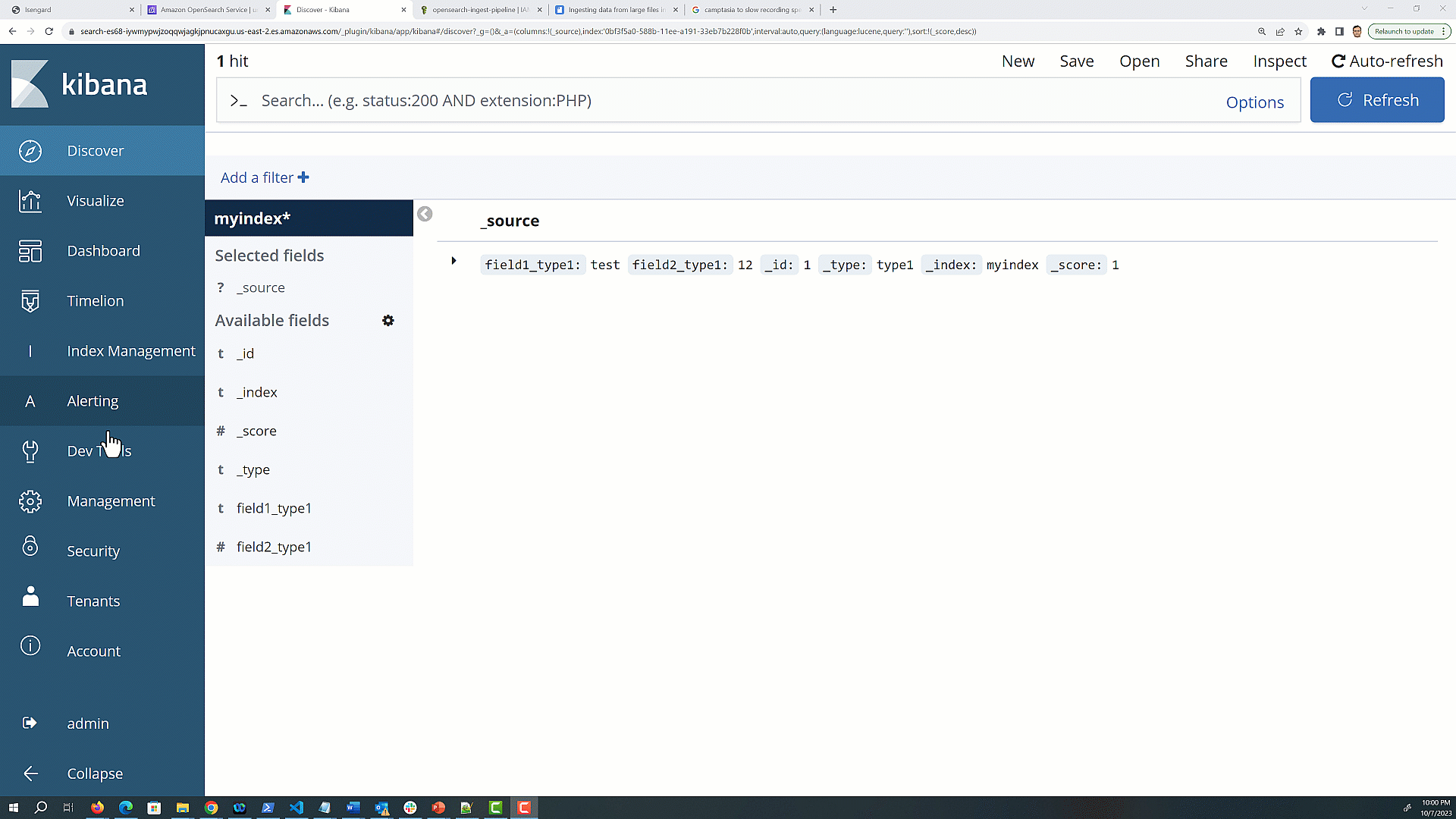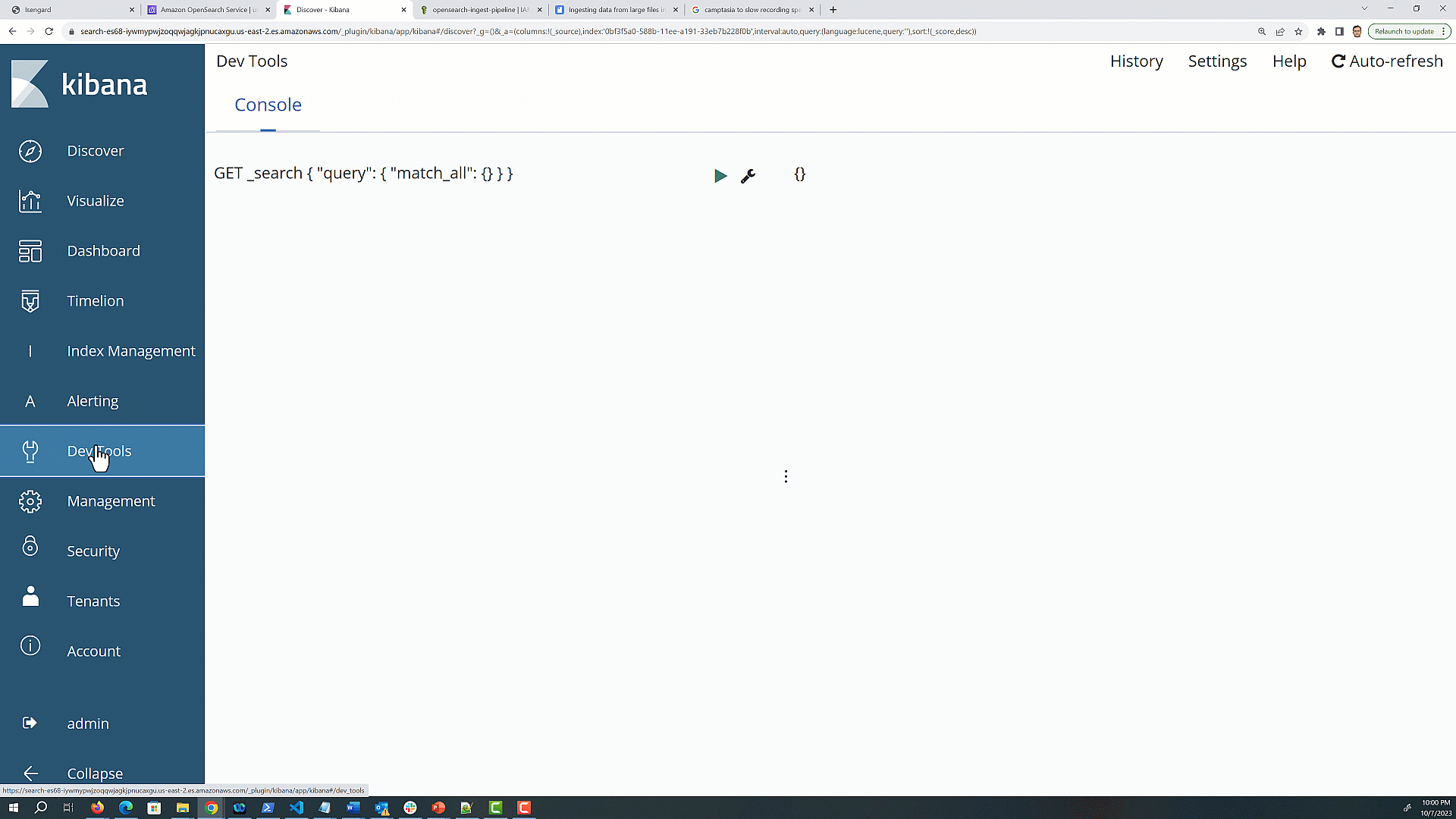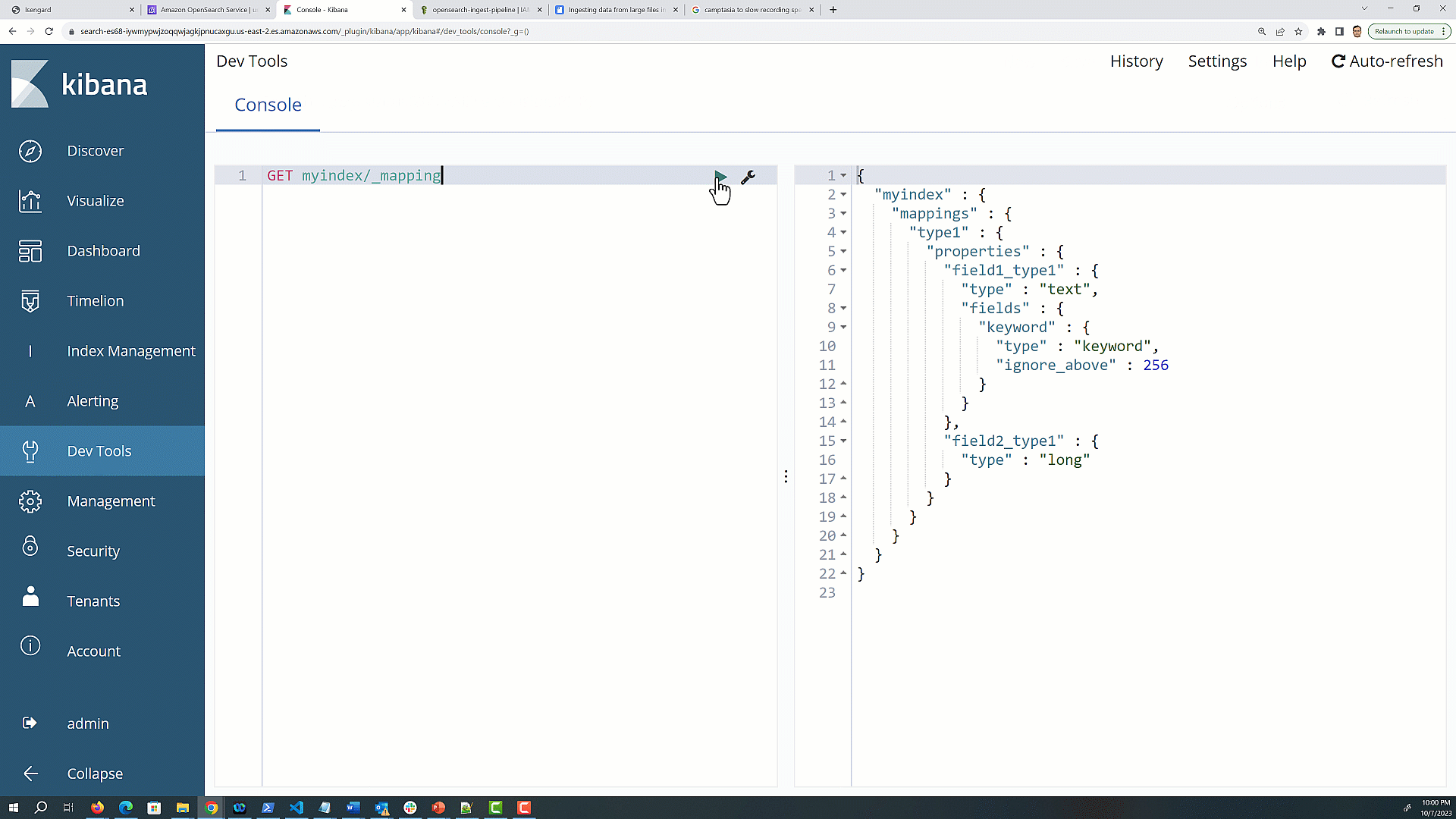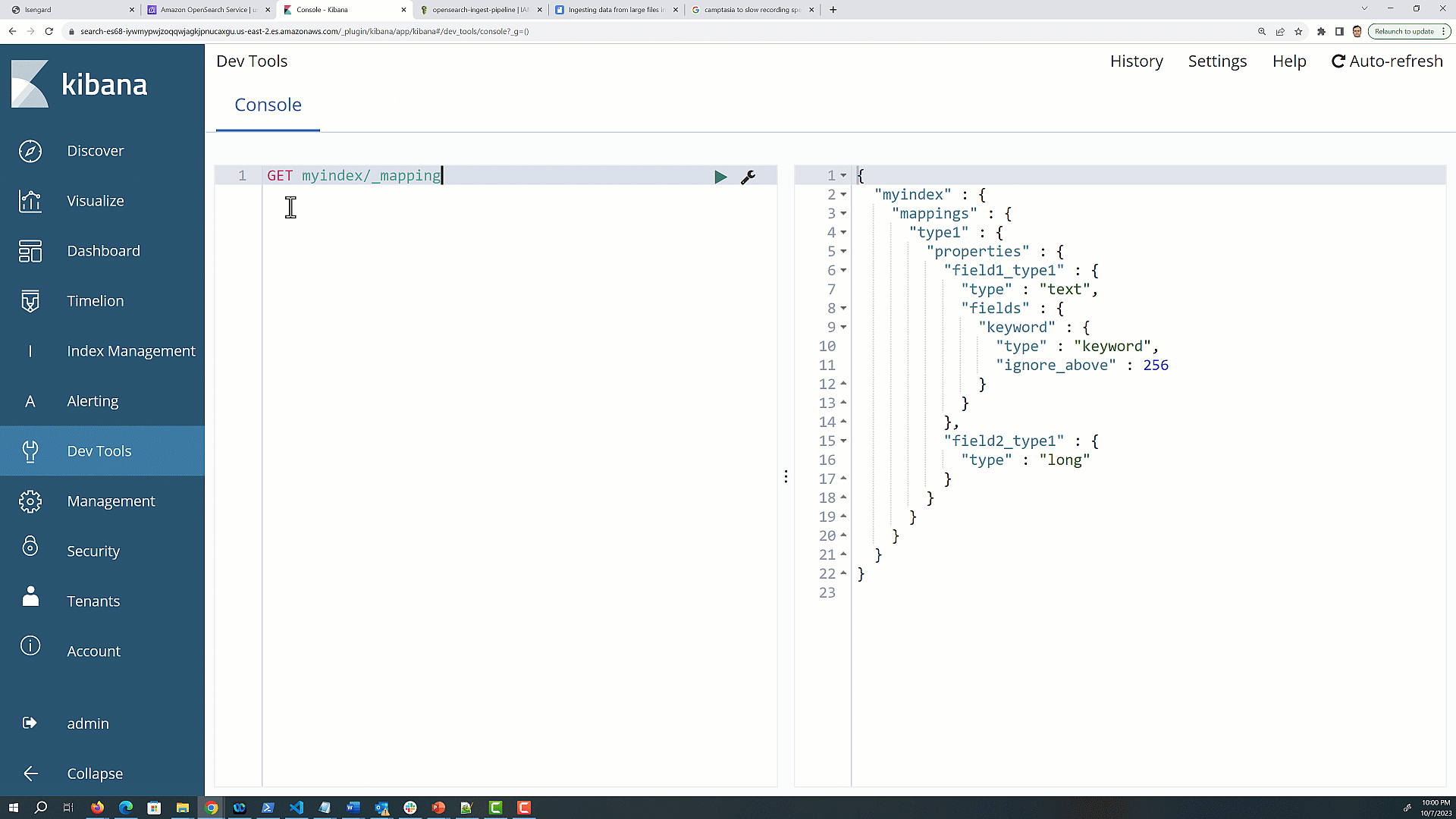
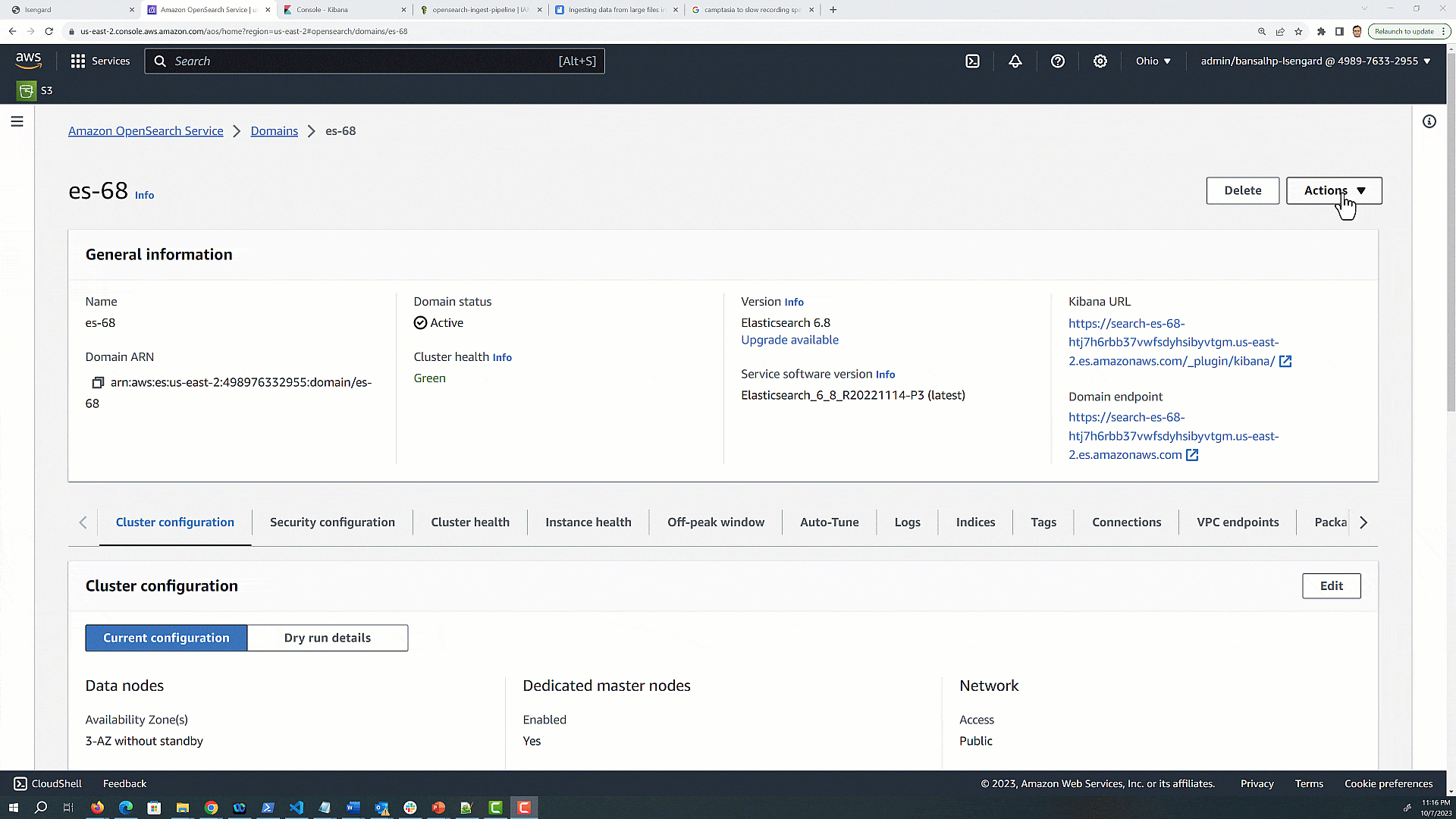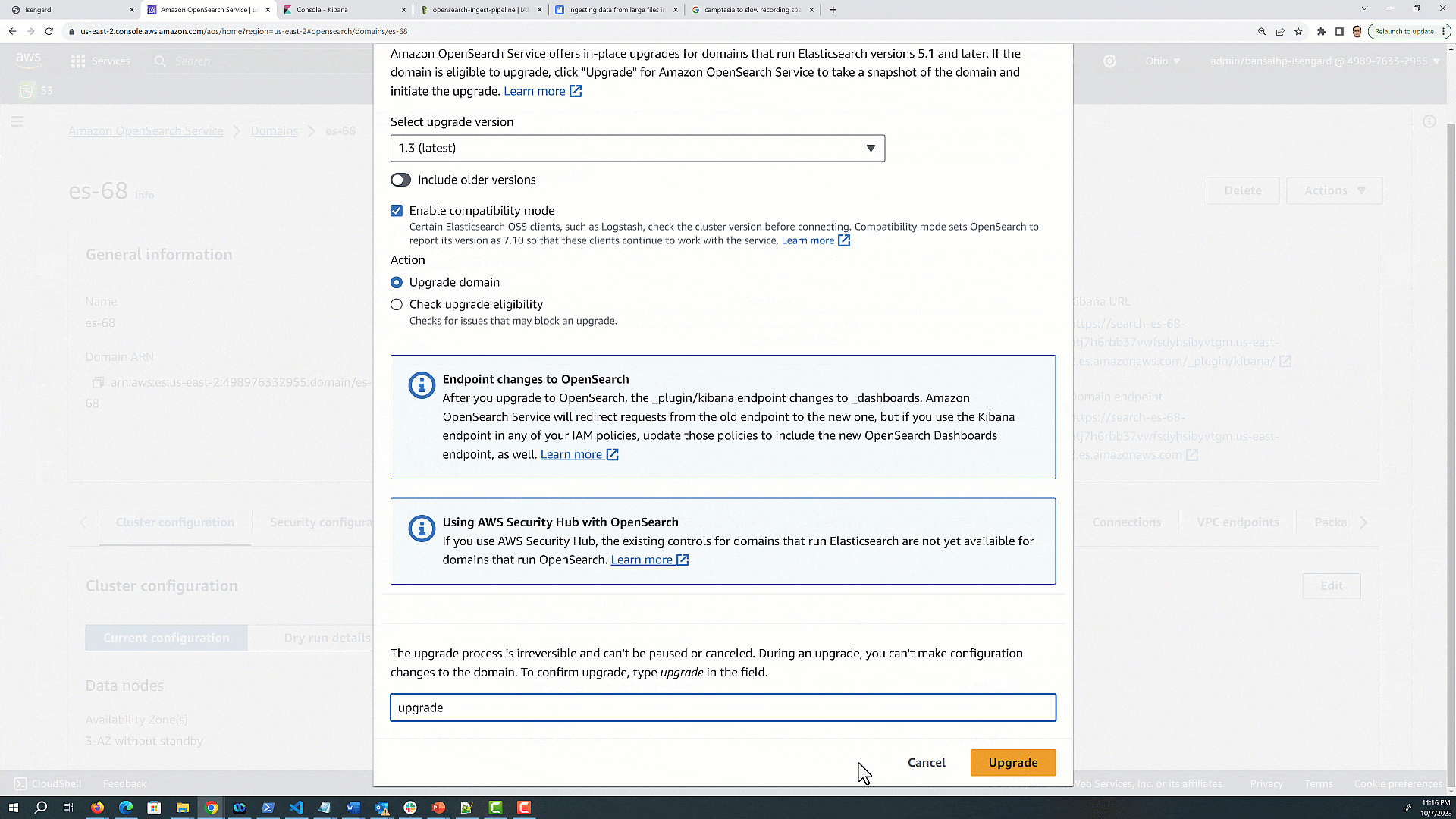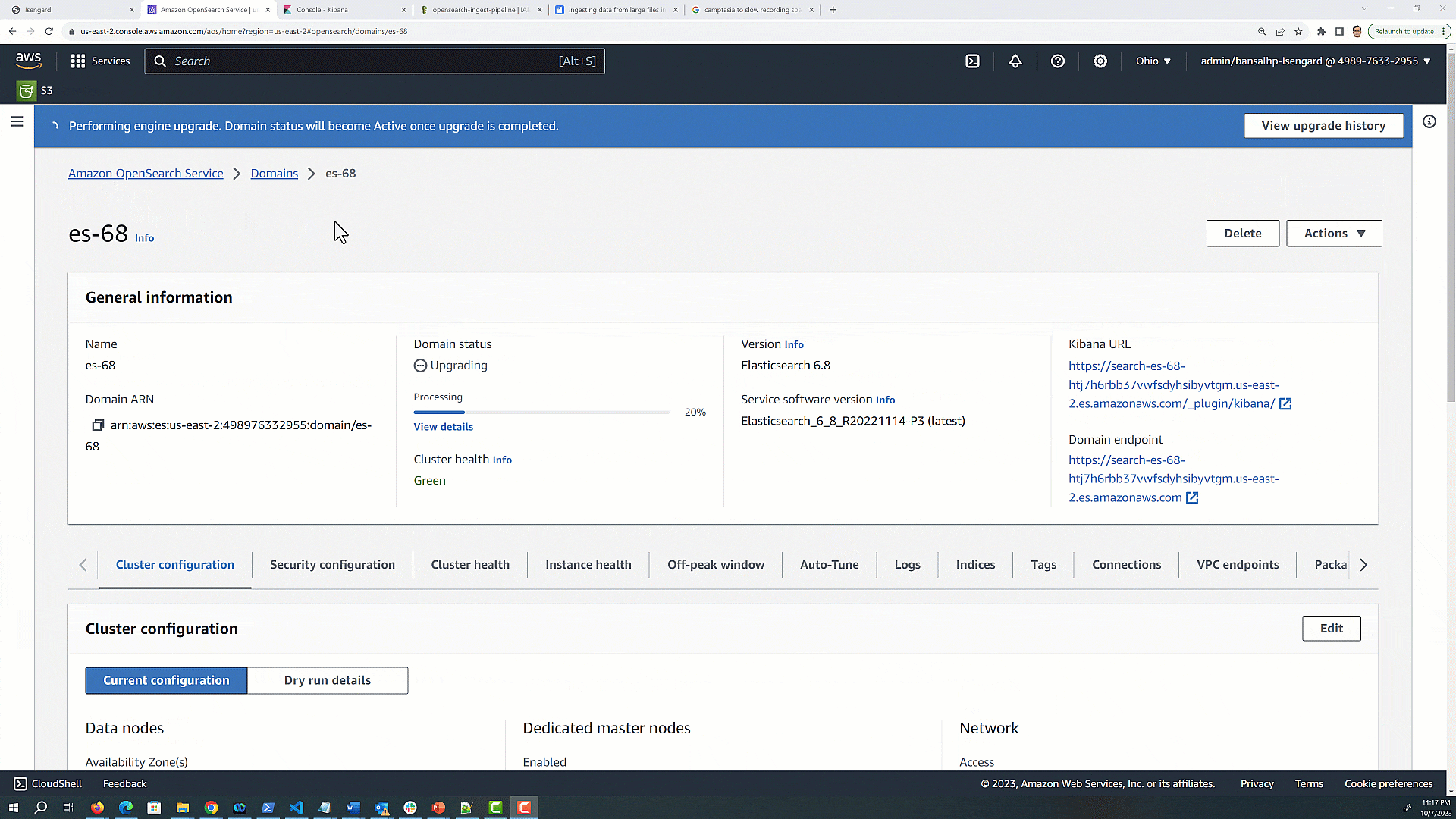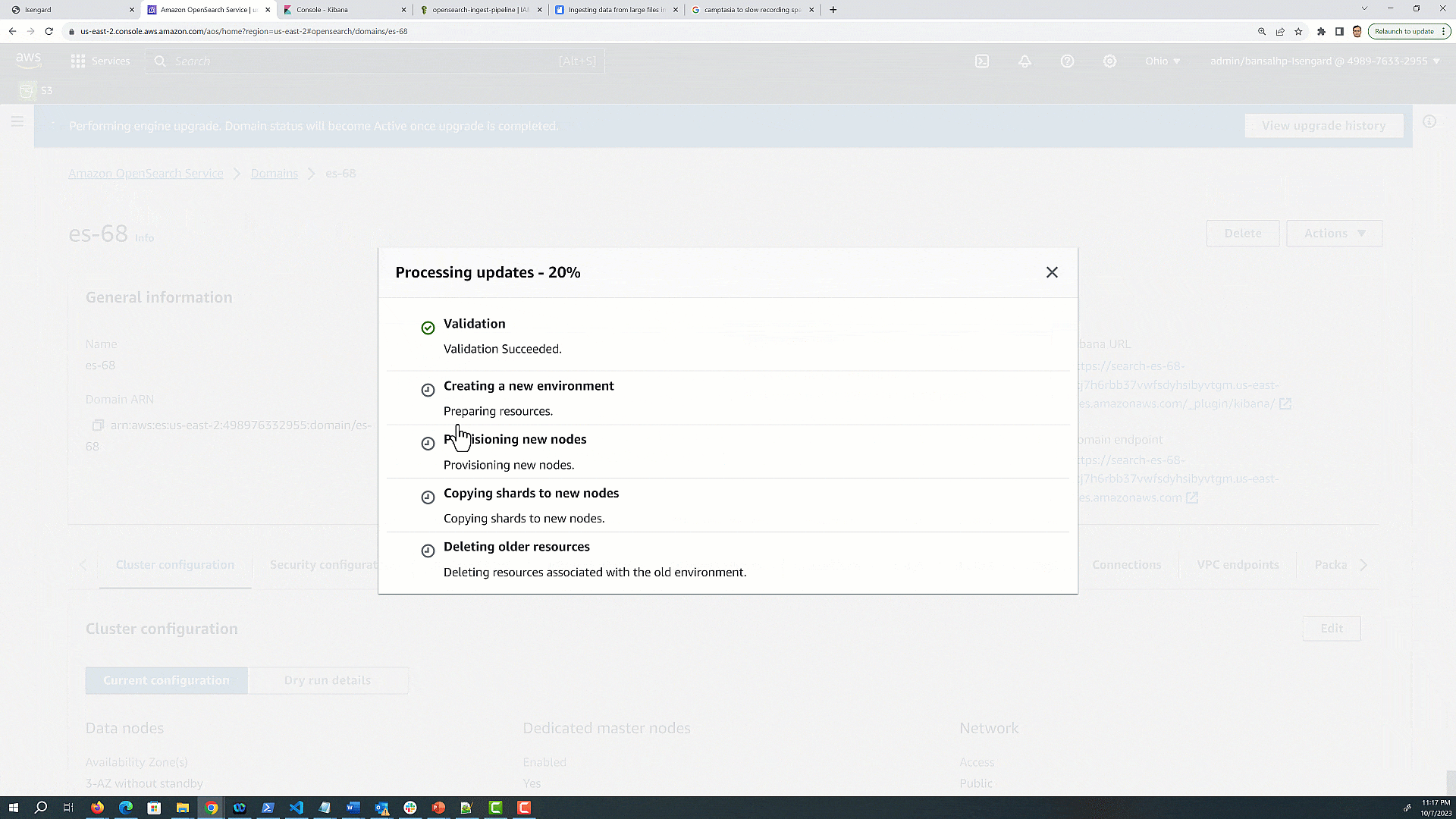
 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.












 Anirban Sinha is a Senior Technical Account Manager at AWS. He is passionate about building scalable data warehouses and big data solutions working closely with customers. He works with large ISVs customers, in helping them build and operate secure, resilient, scalable, and high-performance SaaS applications in the cloud.
Anirban Sinha is a Senior Technical Account Manager at AWS. He is passionate about building scalable data warehouses and big data solutions working closely with customers. He works with large ISVs customers, in helping them build and operate secure, resilient, scalable, and high-performance SaaS applications in the cloud. Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse.
Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse. Gaurav Singh is a Senior Solutions Architect at AWS, specializing in AI/ML and Generative AI. Based in Pune, India, he focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. In his spare time, Gaurav loves to explore nature, read, and run.
Gaurav Singh is a Senior Solutions Architect at AWS, specializing in AI/ML and Generative AI. Based in Pune, India, he focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. In his spare time, Gaurav loves to explore nature, read, and run.