Post Syndicated from Andy Klein original https://www.backblaze.com/blog/backblaze-drive-stats-for-q2-2023/

At the end of Q2 2023, Backblaze was monitoring 245,757 hard drives and SSDs in our data centers around the world. Of that number, 4,460 are boot drives, with 3,144 being SSDs and 1,316 being HDDs. The failure rates for the SSDs are analyzed in the SSD Edition: 2022 Drive Stats review.
Today, we’ll focus on the 241,297 data drives under management as we review their quarterly and lifetime failure rates as of the end of Q2 2023. Along the way, we’ll share our observations and insights on the data presented, tell you about some additional data fields we are now including and more.
Q2 2023 Hard Drive Failure Rates
At the end of Q2 2023, we were managing 241,297 hard drives used to store data. For our review, we removed 357 drives from consideration as they were used for testing purposes or drive models which did not have at least 60 drives. This leaves us with 240,940 hard drives grouped into 31 different models. The table below reviews the annualized failure rate (AFR) for those drive models for Q2 2023.
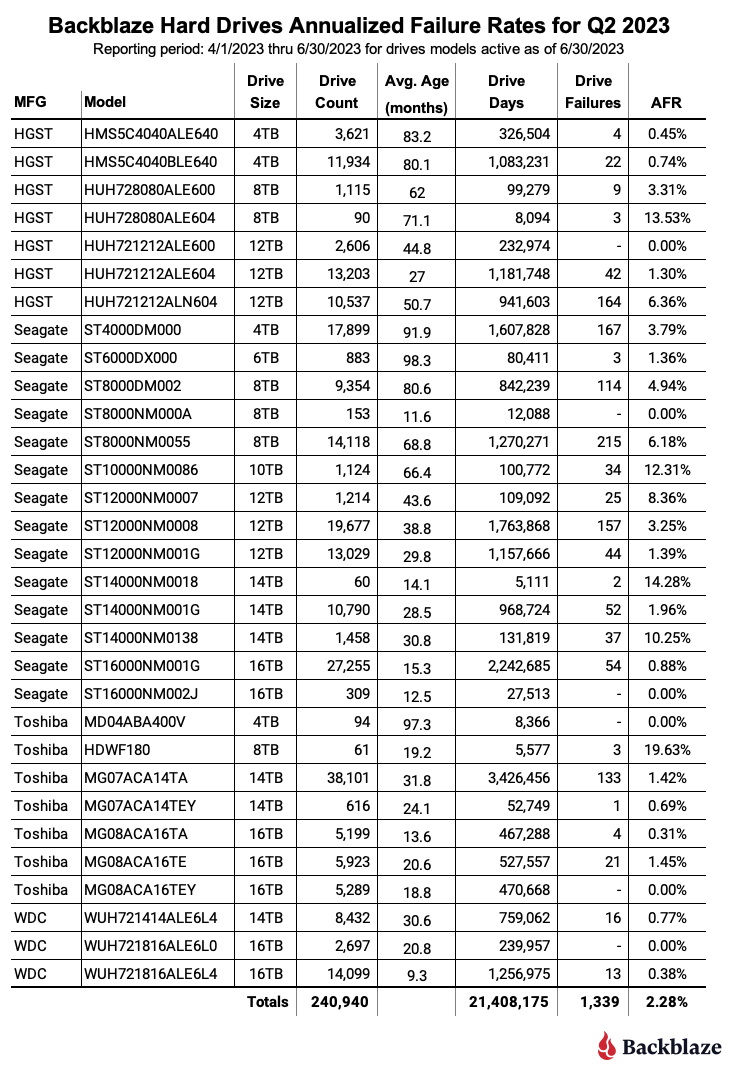
Notes and Observations on the Q2 2023 Drive Stats
- Zero Failures: There were six drive models with zero failures in Q2 2023 as shown in the table below.
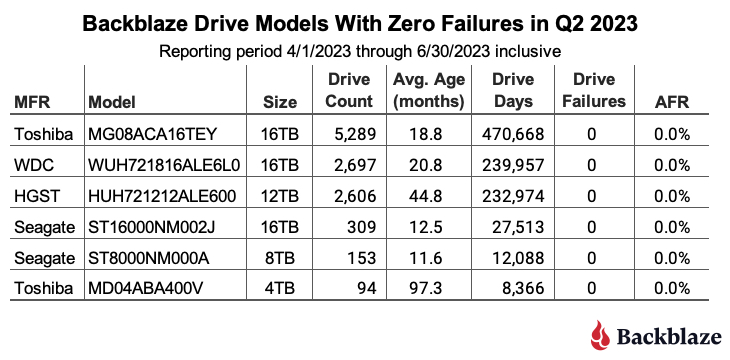
The table is sorted by the number of drive days each model accumulated during the quarter. In general a drive model should have at least 50,000 drive days in the quarter to be statistically relevant. The top three drives all meet that criteria, and having zero failures in a quarter is not surprising given the lifetime AFR for the three drives ranges from 0.13% to 0.45%. None of the bottom three drives has accumulated 50,000 drive days in the quarter, but the two Seagate drives are off to a good start. And, it is always good to see the 4TB Toshiba (model: MD04ABA400V), with eight plus years of service, post zero failures for the quarter.
- The Oldest Drive? The drive model with the oldest average age is still the 6TB Seagate (model: ST6000DX000) at 98.3 months (8.2 years), with the oldest drive of this cohort being 104 months (8.7 years) old.
The oldest operational data drive in the fleet is a 4TB Seagate (model: ST4000DM000) at 105.2 months (8.8 years). That is quite impressive, especially in a data center environment, but the winner for the oldest operational drive in our fleet is actually a boot drive: a WDC 500GB drive (model: WD5000BPKT) with 122 months (10.2 years) of continuous service.
- Upward AFR: The AFR for Q2 2023 was 2.28%, up from 1.54% in Q1 2023. While quarterly AFR numbers can be volatile, they can also be useful in identifying trends which need further investigation. In this case, the rise was expected as the age of our fleet continues to increase. But was that the real reason?
Digging in, we start with the annualized failure rates and average age of our drives grouped by drive size, as shown in the table below.
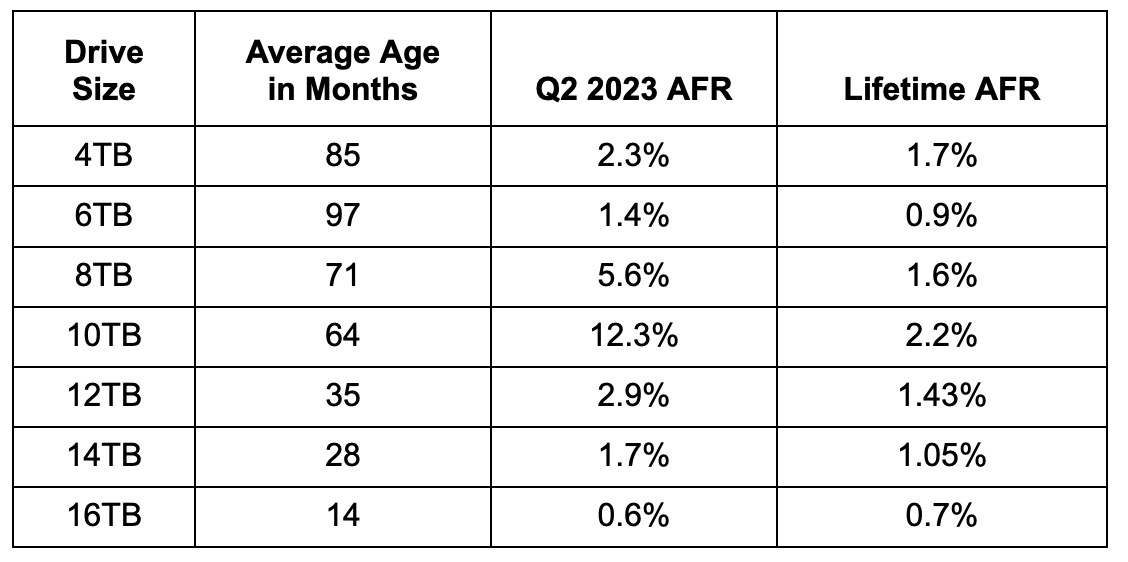
For our purpose, we’ll define a drive as old when it is five years old or more. Why? That’s the warranty period of the drives we are purchasing today. Of course, the 4TB and 6TB drives, and some of the 8TB drives, came with only two year warranties, but for consistency we’ll stick with five years as the point at which we label a drive as “old”.
Using our definition for old drives eliminates the 12TB, 14TB and 16TB drives. This leaves us with the chart below of the Quarterly AFR over the last three years for each cohort of older drives, the 4TB, 6TB, 8TB, and 10TB models.
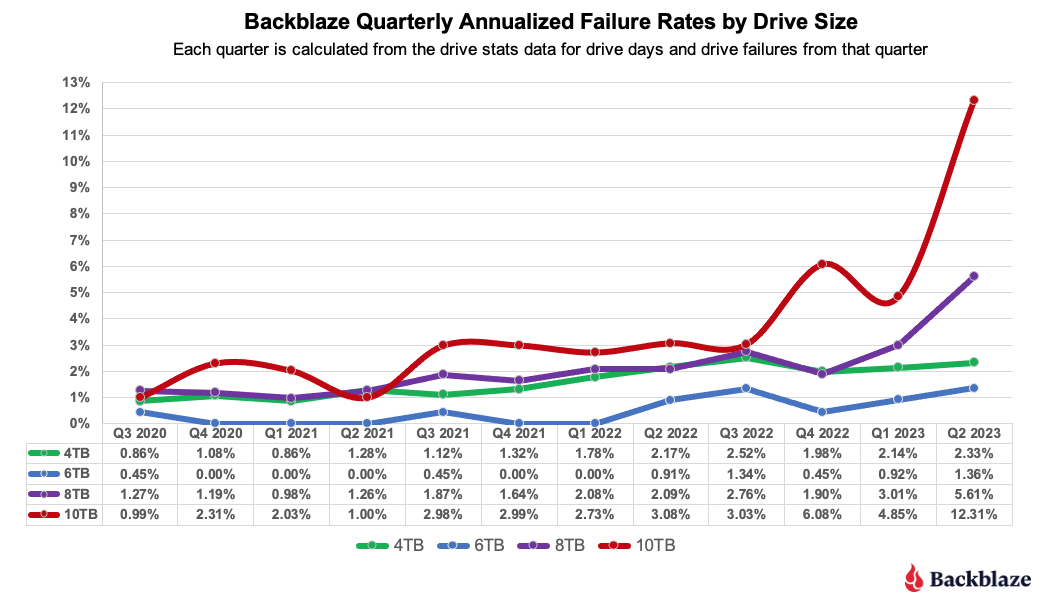
Interestingly, the oldest drives, the 4TB and 6TB drives, are holding their own. Yes, there has been an increase over the last year or so, but given their age, they are doing well.
On the other hand, the 8TB and 10TB drives, with an average of five and six years of service respectively, require further attention. We’ll look at the lifetime data later on in this report to see if our conclusions are justified.
What’s New in the Drive Stats Data?
For the past 10 years, we’ve been capturing and storing the drive stats data and since 2015 we’ve open sourced the data files that we used to create the Drive Stats reports. From time to time, new SMART attribute pairs have been added to the schema as we install new drive models which report new sets of SMART attributes. This quarter we decided to capture and store some additional data fields about the drives and the environment they operate in, and we’ve added them to the publicly available Drive Stats files that we publish each quarter.
The New Data Fields
Beginning with the Q2 2023 Drive Stats data, there are three new data fields populated in each drive record.
- Vault_id: All data drives are members of a Backblaze Vault. Each vault consists of either 900 or 1,200 hard drives divided evenly across 20 storage servers. The vault is a numeric value starting at 1,000.
- Pod_id: There are 20 storage servers in each Backblaze Vault. The Pod_id is a numeric field with values from 0 to 19 assigned to one of the 20 storage servers.
- Is_legacy_format: Currently 0, but will be useful over the coming quarters as more fields are added.
The new schema is as follows:
- date
- serial_number
- model
- capacity_bytes
- failure
- vault_id
- pod_id
- is_legacy_format
- smart_1_normalized
- smart_1_raw
- Remaining SMART value pairs (as reported by each drive model)
Occasionally, our readers would ask if we had any additional information we could provide with regards to where a drive lived, and, more importantly, where it died. The newly-added data fields above are part of the internal drive data we collect each day, but they were not included in the Drive Stats data that we use to create the Drive Stats reports. With the help of David from our Infrastructure Software team, these fields will now be available in the Drive Stats data.
How Can We Use the Vault and Pod Information?
First a caveat: We have exactly one quarter’s worth of this new data. While it was tempting to create charts and tables, we want to see a couple of quarters worth of data to understand it better. Look for an initial analysis later on in the year.
That said, what this data gives us is the storage server and the vault of every drive. Working backwards, we should be able to ask questions like: “Are certain storage servers more prone to drive failure?” or, “Do certain drive models work better or worse in certain storage servers?” In addition, we hope to add data elements like storage server type and data center to the mix in order to provide additional insights into our multi-exabyte cloud storage platform.
Over the years, we have leveraged our Drive Stats data internally to improve our operational efficiency and durability. Providing these new data elements to everyone via our Drive Stats reports and data downloads is just the right thing to do.
There’s a New Drive in Town
If you do decide to download our Drive Stats data for Q2 2023, there’s a surprise inside—a new drive model. There are only four of these drives, so they’d be easy to miss, and they are not listed on any of the tables and charts we publish as they are considered “test” drives at the moment. But, if you are looking at the data, search for model “WDC WUH722222ALE6L4” and you’ll find our newly installed 22TB WDC drives. They went into testing in late Q2 and are being put through their paces as we speak. Stay tuned. (Psst, as of 7/28, none had failed.)
Lifetime Hard Drive Failure Rates
As of June 30, 2023, we were tracking 241,297 hard drives used to store customer data. For our lifetime analysis, we removed 357 drives that were only used for testing purposes or did not have at least 60 drives represented in the full dataset. This leaves us with 240,940 hard drives grouped into 31 different models to analyze for the lifetime table below.
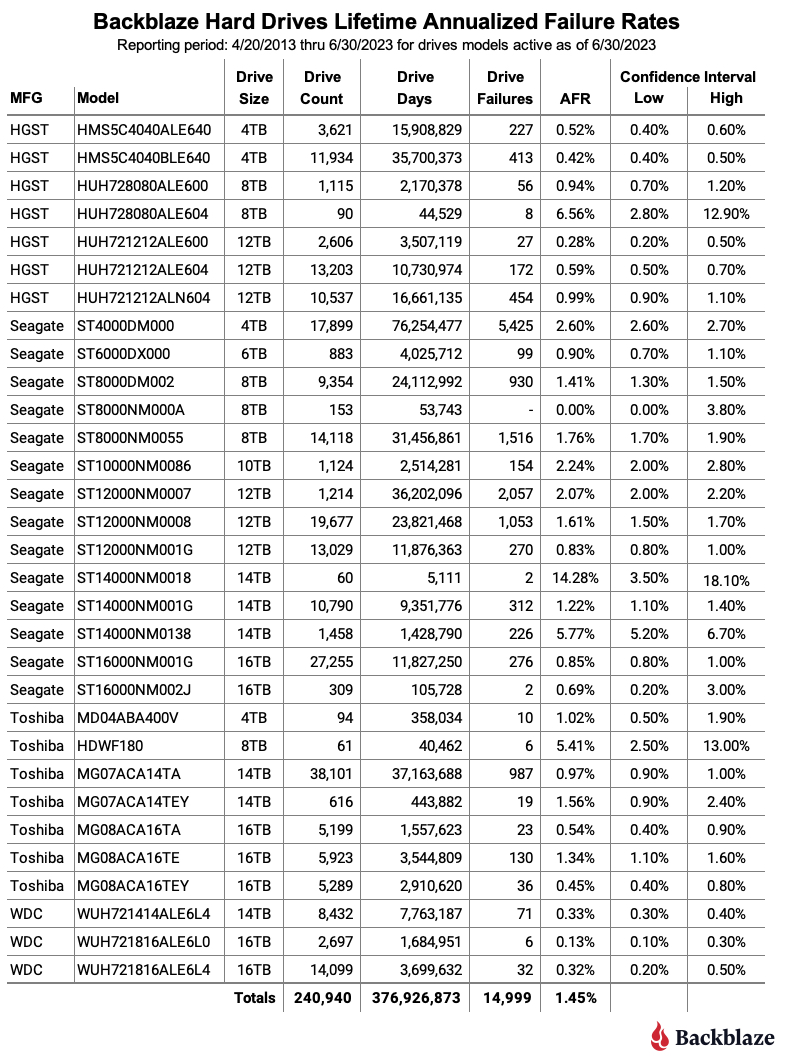
Notes and Observations About the Lifetime Stats
The Lifetime AFR also rises. The lifetime annualized failure rate for all the drives listed above is 1.45%. That is an increase of 0.05% from the previous quarter of 1.40%. Earlier in this report by examining the Q2 2023 data, we identified the 8TB and 10TB drives as primary suspects in the increasing rate. Let’s see if we can confirm that by examining the change in the lifetime AFR rates of the different drives grouped by size.
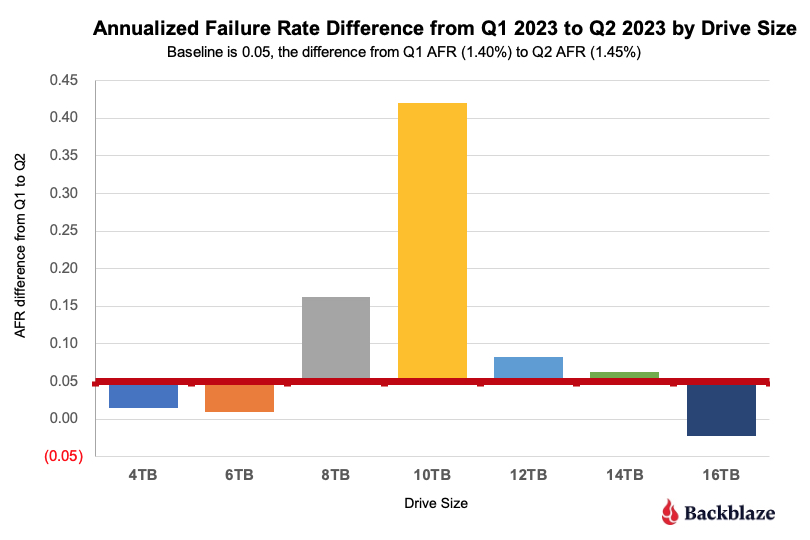
The red line is our baseline as it is the difference from Q1 to Q2 (0.05%) of the lifetime AFR for all drives. Drives above the red line support the increase, drives below the line subtract from the increase. The primary drives (by size) which are “driving” the increased lifetime annualized failure rate are the 8TB and 10TB drives. This confirms what we found earlier. Given there are relatively few 10TB drives (1,124) versus 8TB drives (24,891), let’s dig deeper into the 8TB drives models.
The Lifetime AFR for all 8TB drives jumped from 1.42% in Q1 to 1.59% in Q2. An increase of 12%. There are six 8TB drive models in operation, but three of these models comprise 99.5% of the drive failures for the 8TB drive cohort, so we’ll focus on them. They are listed below.
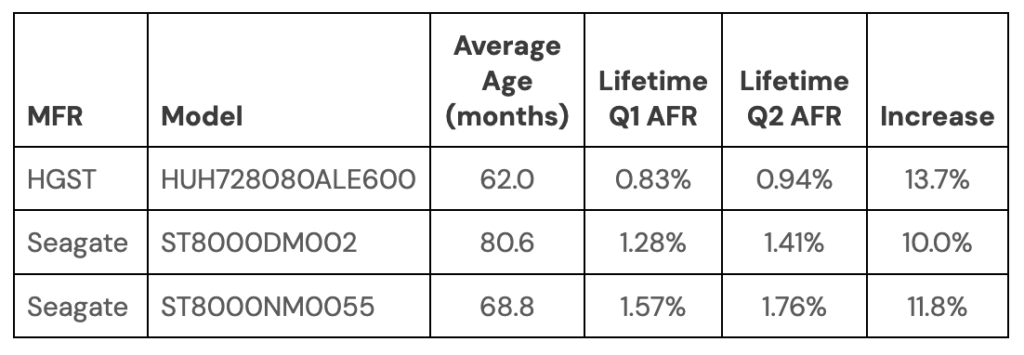
For all three models, the increase of the lifetime annualized failure rate from Q1 to Q2 is 10% or more which is statistically similar to the 12% increase for all of the 8TB drive models. If you had to select one drive model to focus on for migration, any of the three would be a good candidate. But, the Seagate drives, model ST8000DM002, are on average nearly a year older than the other drive models in question.
- Not quite a lifetime? The table above analyzes data for the period of April 20, 2013 through June 30, 2023, or 10 years, 2 months and 10 days. As noted earlier, the oldest drive we have is 10 years and 2 months old, give or take a day or two. It would seem we need to change our table header, but not quite yet. A drive that was installed anytime in Q2 2013 and is still operational today would report drive days as part of the lifetime data for that model. Once all the drives installed in Q2 2013 are gone, we can change the start date on our tables and charts accordingly.
A Word About Drive Failure
Are we worried about the increase in drive failure rates? Of course we’d like to see them lower, but the inescapable reality of the cloud storage business is that drives fail. Over the years, we have seen a wide range of failure rates across different manufacturers, drive models, and drive sizes. If you are not prepared for that, you will fail. As part of our preparation, we use our drive stats data as one of the many inputs into understanding our environment so we can adjust when and as we need.
So, are we worried about the increase in drive failure rates? No, but we are not arrogant either. We’ll continue to monitor our systems, take action where needed, and share what we can with you along the way.
The Hard Drive Stats Data
The complete data set used to create the information used in this review is available on our Hard Drive Stats Data webpage. You can download and use this data for free for your own purpose. All we ask are three things: 1) you cite Backblaze as the source if you use the data, 2) you accept that you are solely responsible for how you use the data, and 3) you do not sell this data to anyone; it is free.
If you want the tables and charts used in this report, you can download the .zip file from Backblaze B2 Cloud Storage which contains an MS Excel spreadsheet with a tab for each of the tables or charts..
Good luck and let us know if you find anything interesting.
The post Backblaze Drive Stats for Q2 2023 appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.






 Thomas Burns,
Thomas Burns,  Aileen Zheng is a Solutions Architect supporting US Federal Civilian Sciences customers at Amazon Web Services (AWS). She partners with customers to provide technical guidance on enterprise cloud adoption and strategy and helps with building well-architected solutions. She is also very passionate about data analytics and machine learning. In her free time, you’ll find Aileen doing pilates, taking her dog Mumu out for a hike, or hunting down another good spot for food! You’ll also see her contributing to projects to support diversity and women in technology.
Aileen Zheng is a Solutions Architect supporting US Federal Civilian Sciences customers at Amazon Web Services (AWS). She partners with customers to provide technical guidance on enterprise cloud adoption and strategy and helps with building well-architected solutions. She is also very passionate about data analytics and machine learning. In her free time, you’ll find Aileen doing pilates, taking her dog Mumu out for a hike, or hunting down another good spot for food! You’ll also see her contributing to projects to support diversity and women in technology.






 Rupesh Tiwari is a Senior Solutions Architect at AWS in New York City, with a focus on Financial Services. He has over 18 years of IT experience in the finance, insurance, and education domains, and specializes in architecting large-scale applications and cloud-native big data workloads. In his spare time, Rupesh enjoys singing karaoke, watching comedy TV series, and creating joyful moments with his family.
Rupesh Tiwari is a Senior Solutions Architect at AWS in New York City, with a focus on Financial Services. He has over 18 years of IT experience in the finance, insurance, and education domains, and specializes in architecting large-scale applications and cloud-native big data workloads. In his spare time, Rupesh enjoys singing karaoke, watching comedy TV series, and creating joyful moments with his family. Sheel Saket is a Senior Data Science Manager at FIS in Chicago, Illinois. He has over 11 years of IT experience in the finance, insurance, and e-commerce domains, and specializes in architecting large-scale AI solutions and cloud MLOps. In his spare time, Sheel enjoys listening to audiobooks, podcasts, and watching movies with his family.
Sheel Saket is a Senior Data Science Manager at FIS in Chicago, Illinois. He has over 11 years of IT experience in the finance, insurance, and e-commerce domains, and specializes in architecting large-scale AI solutions and cloud MLOps. In his spare time, Sheel enjoys listening to audiobooks, podcasts, and watching movies with his family.











{kind=link}
.PNG){kind=link}
{kind=link}