The realtime developers have been working for many years to
create a kernel where the highest-priority task is always able to run
without delay. That has meant a long process of finding and fixing
situations where high-priority tasks might be blocked from running; one of
the persistent problems in this regard has been kernel code that disables
preemption. One tool that the realtime developers have reached for is
disabling migration (moving a process from one CPU to another) rather than
preemption; this approach has not been entirely popular among scheduler
developers, though. Even so, the solution would appear to be this
migration-disable patch set from scheduler developer Peter Zijlstra.
In the weeks leading up to re:Invent, we’ll share conversations we’ve had with people at AWS who will be presenting, and get a sneak peek at their work.
How long have you been at AWS and what do you do in your current role?
I’ve been at Amazon for nearly 4 years, and at AWS for 2 years. I’m a solutions architect with a specialty in security. I work primarily with financial services customers, helping them solve security problems and build out secure foundations for their AWS workloads.
What’s your favorite part of your job?
Working in AWS feels like working in the future. My first job as a software engineer was fixing bugs in 20-year-old legacy C code and writing network support for SNMPv1. Now, I’m on the cutting edge of network design. When I work with my customers, I genuinely feel like I’m helping “Invent and Simplify” the future.
How did you get started in Security?
I’ve been interested in security since college. I took all the crypto and protocol courses in my computer science program from amazing professors like Radia Perlman and Michael Rabin. After college, I worked in software engineering. My real break into the security field came when I got to use my software engineering background to fix security vulnerabilities for Bank of America. After consulting across dozens of companies, I gained depth in application security, pen testing, code review, and architectural analysis. Over 10 years later, I’m using and extending those architectural analysis and AppSec skills to build and improve cloud architecture and design.
How do you explain what you do to non-technical friends or family?
“I work in computer security, helping your bank keep your online data safe and secure.” It’s true! If they are willing to hear more details, then I try to explain what the cloud is, and that you can design a network in good and bad ways to stop people from getting in.
One sad thing about not working for the Amazon.com side of the house is that I can no longer tell people that “I’m a security guard at a bookstore.” That also used to be true for me!
You’re presenting at re:Invent this year – can you give readers a sneak peek of what you’re covering?
Yes! I’ve put together a “Top 10” list to check the health of your AWS Identity foundation. I want every one of our customers to be thoughtful about how they authenticate their users and how they authorize access to their AWS resources. I’m going to talk about how to use account boundaries and AWS Organizations to build strong isolation controls, how to use roles and federation to secure login, and how to build and validate granular permissions that enable least privilege access across your network.
What are you hoping your audience will do differently after your session?
I’m giving you a list of what to do. I literally want you to take that list, one at a time, and ask yourself, “Am I doing this? If not, what would it take to do this?” I know that security can sometimes feel daunting, and in AWS, we all have access to dozens (or hundreds) of different tools you can use to build and layer your secure environment. So here is a short list to get started. I hope this will make it easier to build a strong foundation and use the tools that AWS is giving you.
From your perspective, what’s the biggest thing happening in Identity right now?
I am really excited about how tagging and Attribute Based Access Control (ABAC) can help with scaling. At a base level, Identity and Permissions are really easy. You just say “Becky should have access to the Unicorn database,” and AWS gives you powerful tools for writing a rule like that with our IAM service. But once you have not just Becky, but also Syed and Sean—and then 300 more people, 200 databases, and 1,000 S3 buckets—the sheer number of rules you have to write and keep track of gets hard. And it gets even harder for someone else to come and look at your rules afterwards and figure out if you’re doing it right.
With ABAC, you can now write a rule that says any person from team “red” can access any database that is tagged with ”red.“ That takes potentially hundreds of rules and collapses it into one easy-to-understand statement.
All the Amazon Leadership Principles highlight important facets of how to build successful organizations, but “Have Backbone: Disagree and Commit” is my favorite. It’s more than an LP; it’s a mechanism. It’s a way to build a system of people working toward a common goal, while still keeping our independent ideas and values. It gives us permission to disagree, while at the same time giving us a way out of stalemates and unfruitful perfectionism.
What’s the best career advice you’ve ever received?
My dad is a lifelong academic (who is secretly a little embarrassed that I never got a PhD). Growing up, I watched him in action: creating novel research, taking care of his grad students, and even running academic departments with all their bitter politics and conflicting goals.
Two things that he says about his highly successful career:
The older I get and the more I learn, the less I am confident about anything.
I have never accomplished anything by myself.
This perspective is antithetical, I think, to the standard American career ladder, and it’s been invaluable to me. In my career in tech, I’ve met a lot of brilliant people who know all the answers and tout all their personal accomplishments from any available rooftop. And that is absolutely one way to succeed. But I know intimately that there is another way that can also work, a way that is built on collaboration and scholarship, and constantly learning and questioning your knowledge.
If you could go back, what would you tell yourself at the beginning of your career?
I guess “don’t worry so much” is the least helpful advice ever… I’m sure I wouldn’t have been able to hear it at 22! But here is something I would have understood:
Little Cassia, you’re going to succeed at many things and fail at some things. But no matter what, every single job you tackle is going to teach you something important. You’re going to learn technical skills that will be useful when you least expect them, and you’re also going to learn more about yourself—what you want to do, who you want to surround yourself with, and what you need to thrive. Just keep trying, and I promise life will only keep getting better!
What are you most proud of in your career?
The last time I went to the DEF CON Security Conference, I attended not one, not two, but THREE different talks delivered by former mentees of mine. Getting to help these extraordinary people get started in application security, and then getting to watch them become ever more talented and exceed everything I knew, and then to watch them shine on stage—it was a privilege, and made so much pain worthwhile. Hey, I may not know anything about NFC penetration testing, but Katherine sure does, and she’s teaching the whole damned world.
Among your many degrees from Harvard University, you also have a BA in Ancient Greek. Tell us about that. What started your interest in it?
My love for Ancient Greek and Latin was fostered by some really amazing high school teachers. I went to the kind of boarding school where professors took care of you like family, and the mysterious Dr. Reyes and the two sophisticated Professors Myers took extraordinary care of my fumbling teenage heart and my raging intellectual curiosity. I had a little bit of an advantage in that I had already learned Modern Greek in grade school, since my hometown had a thriving Hellenic community. I have since completely forgotten both, but as my dear professors had me recite: “the shadow of lost knowledge at least protects you from many illusions.”
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
Our first-ever Storage Day in November 2019 (Welcome to AWS Storage Day) was a big success. We were able to take a multitude of significant announcements related to AWS Storage services and summarize them in a single post, with longer and more detailed posts as needed. Today, we are doing it again, so welcome to […]
We launched S3 Intelligent-Tiering two years ago, which added the capability to take advantage of S3 without needing to have a deep understanding of your data access patterns. Today we are launching two new optimizations for S3 Intelligent-Tiering that will automatically archive objects that are rarely accessed. These new optimizations will reduce the amount of […]
Netflix is known for its loosely coupled and highly scalable microservice architecture. Independent services allow for evolving at different paces and scaling independently. Yet they add complexity for use cases that span multiple services. Rather than exposing 100s of microservices to UI developers, Netflix offers a unified API aggregation layer at the edge.
UI developers love the simplicity of working with one conceptual API for a large domain. Back-end developers love the decoupling and resilience offered by the API layer. But as our business has scaled, our ability to innovate rapidly has approached an invisible asymptote. As we’ve grown the number of developers and increased our domain complexity, developing the API aggregation layer has become increasingly harder.
In order to address this rising problem, we’ve developed a federated GraphQL platform to power the API layer. This solves many of the consistency and development velocity challenges with minimal tradeoffs on dimensions like scalability and operability. We’ve successfully deployed this approach for Netflix’s studio ecosystem and are exploring patterns and adaptations that could work in other domains. We’re sharing our story to inspire others and encourage conversations around applicability elsewhere.
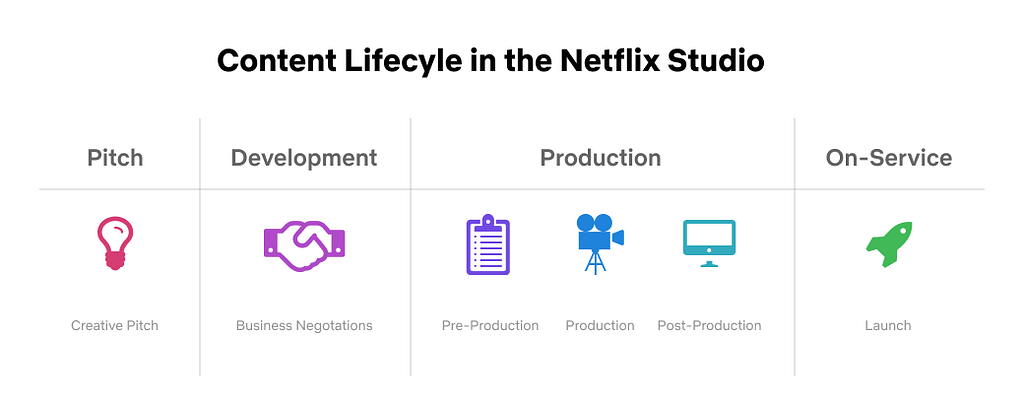
Netflix is producing original content at an accelerated pace. From the time a TV show or a movie is pitched to when it’s available on Netflix, a lot happens behind the scenes. This includes but is not limited to talent scouting and casting, deal and contract negotiations, production and post-production, visual effects and animations, subtitling and dubbing, and much more. Studio Engineering is building hundreds of applications and tools that power these workflows.
Content Lifecycle
Studio API
Looking back to a few years ago, one of the pains in the studio space was the growing complexity of the data and its relationships. The workflows depicted above are inherently connected but the data and its relationships were disparate and existed in myriads of microservices. The product teams solved for this with two architectural patterns.
1) Single-use aggregation layers — Due to the loose coupling, we observed that many teams spent considerable effort building duplicative data-fetching code and aggregation layers to support their product needs. This was either done by UI teams via BFF (Backend For Frontend) or by a backend team in a mid-tier service.
2) Materialized views for data from other teams — some teams used a pattern of building a materialized view of another service’s data for their specific system needs. Materialized views had performance benefits, but data consistency lagged by varying degrees. This was not acceptable for the most important workflows in the Studio. Inconsistent data across different Studio applications was the top support issue in Studio Engineering in 2018.
Graph API: To better address the underlying needs, our team started building a curated graph API called “Studio API”. Its goal was to provide an unified abstraction on top of data and relationships. Studio API used GraphQL as its underlying API technology and created significant leverage for accessing core shared data. Consumers of Studio API were able to explore the graph and build new features more quickly. We also observed fewer instances of data inconsistency across different UI applications, as every field in GraphQL resolves to a single piece of data-fetching code.
Studio API GraphStudio API Architecture
Bottlenecks of Studio API
The One Graph exposed by Studio API was a runaway success; product teams loved the reusability and easy, consistent data access. But new bottlenecks emerged as the number of consumers and amount of data in the graph increased.
First, the Studio API team was disconnected from the domain expertise and the product needs, which negatively impacted the schema’s health. Second, connecting new elements from a back-end into the graph API was manual and ran counter to the rapid evolution promised by a microservice architecture. Finally, it was hard for one small team to handle the increasing operational and support burden for the expanding graph.
We knew that there had to be a better way — unified but decoupled, curated but fast moving.
Returning to Core Principles
To address these bottlenecks, we leaned into our rich history of microservices and breaking monoliths apart. We still wanted to keep the unified GraphQL schema of Studio API but decentralize the implementation of the resolvers to their respective domain teams.
As we were brainstorming the new architecture back in early 2019, Apollo released the GraphQL Federation Specification. This promised the benefits of a unified schema with distributed ownership and implementation. We ran a test implementation of the spec with promising results, and reached out to collaborate with Apollo on the future of GraphQL Federation. Our next generation architecture, “Studio Edge”, emerged with federation as a critical element.
GraphQL Federation Primer
The goal of GraphQL Federation is two-fold: provide a unified API for consumers while also giving backend developers flexibility and service isolation. To achieve this, schemas need to be created and annotated to indicate how ownership is distributed. Let’s look at an example with three core entities:
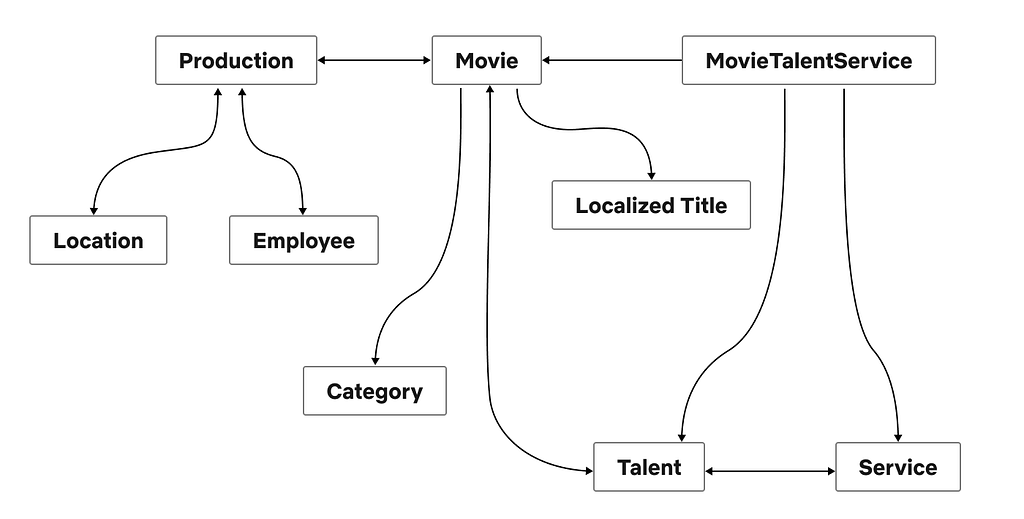
Movie: At Netflix, we make titles (shows, films, shorts etc.). For simplicity, let’s assume each title is a Movie object.
Production: Each Movie is associated with a Studio Production. A Production object tracks everything needed to make a Movie including shooting location, vendors, and more.
Talent: the people working on a Movie are the Talent, including actors, directors, and so on.
These three domains are owned by three separate engineering teams responsible for their own data sources, business logic, and corresponding microservices. In an unfederated implementation, we would have this simple Schema and Resolvers owned and implemented by the Studio API team. The GraphQL Framework would take in queries from clients and orchestrate the calls to the resolvers in a breadth-first traversal.
Schema & Resolvers for Studio API
To transition to a federated architecture, we need to transfer ownership of these resolvers to their respective domains without sacrificing the unified schema. To achieve this, we need to extend the Movie type across GraphQL service boundaries:
Federating Movie
This ability to extend a Movie type across GraphQL service boundaries makes Movie a Federated Type. Resolving a given field requires delegation by a gateway layer down to the owning domain services.
Studio Edge Architecture
Using the ability to federate a type, we envisioned the following architecture:
Studio Edge Architecture
Key Architectural Components
Domain Graph Service (DGS) is a standalone spec-compliant GraphQL service. Developers define their own federated GraphQL schema in a DGS. A DGS is owned and operated by a domain team responsible for that subsection of the API. A DGS developer has the freedom to decide if they want to convert their existing microservice to a DGS or spin up a brand new service.
Schema Registry is a stateful component that stores all the schemas and schema changes for every DGS. It exposes CRUD APIs for schemas, which are used by developer tools and CI/CD pipelines. It is responsible for schema validation, both for the individual DGS schemas and for the combined schema. Last, the registry composes together the unified schema and provides it to the gateway.
GraphQL Gateway isprimarily responsible for serving GraphQL queries to the consumers. It takes a query from a client, breaks it into smaller sub-queries (a query plan), and executes that plan by proxying calls to the appropriate downstream DGSs.
Implementation Details
There are 3 main business logic components that power GraphQL Federation.
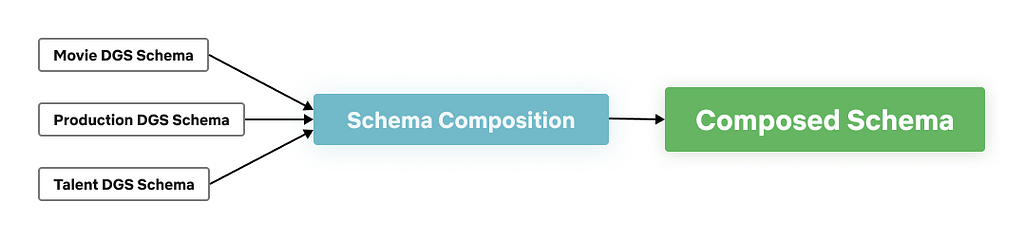
Schema Composition
Composition is the phase that takes all of the federated DGS schemas and aggregates them into a single unified schema. This composed schema is exposed by the Gateway to the consumers of the graph.
Schema Composition Phases
Whenever a new schema is pushed by a DGS, the Schema Registry validates that:
New schema is a valid GraphQL schema
New schema composes seamlessly with the rest of the DGSs schemas to create a valid composed schema
New schema is backwards compatible
If all of the above conditions are met, then the schema is checked into the Schema Registry.
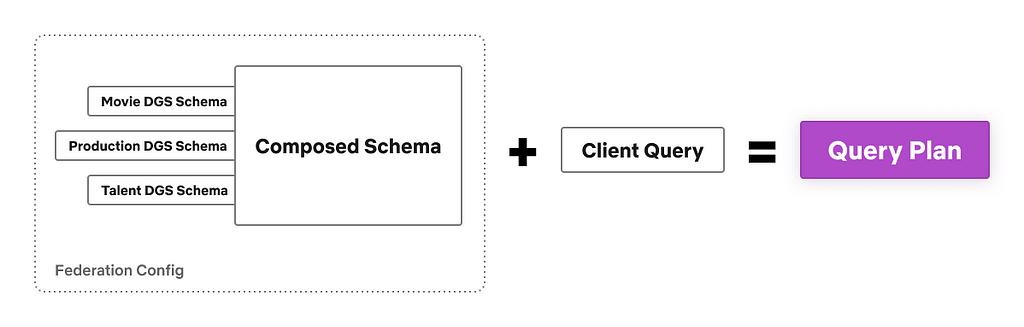
Query Planning and Execution
The federation config consists of all the individual DGS schemas and the composed schema. The Gateway uses the federation config and the client query to generate a query plan. The query plan breaks down the client query into smaller sub-queries that are then sent to the downstream DGSs for execution, along with an execution ordering that includes what needs to be done in sequence versus run in parallel.
Query Plan Inputs
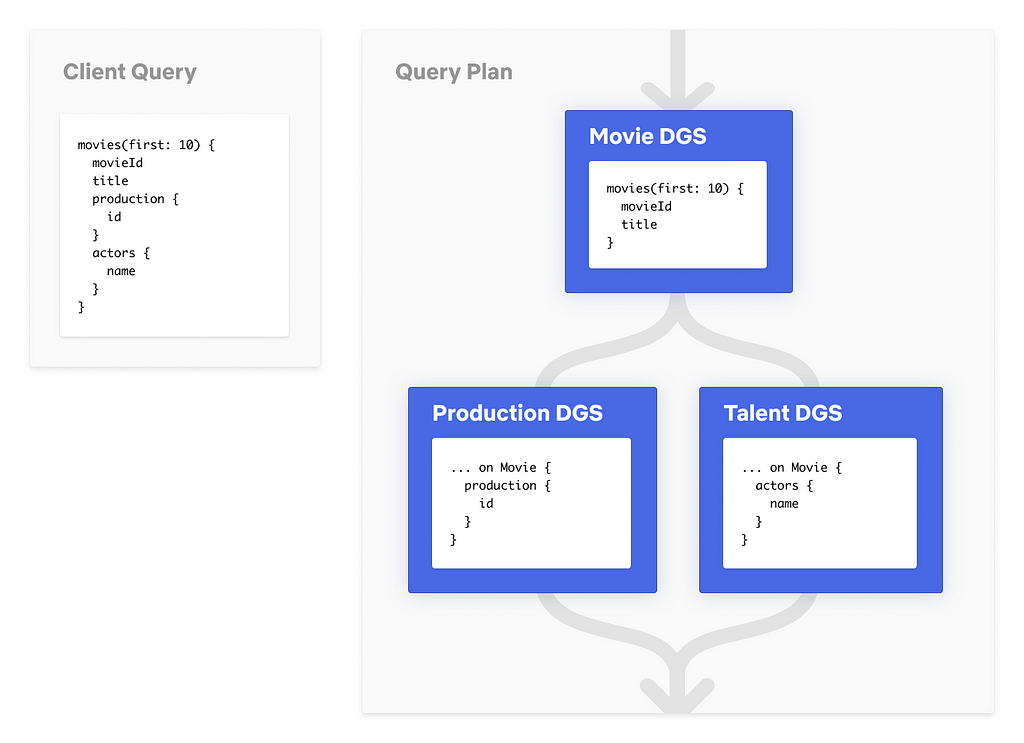
Let’s build a simple query from the schema referenced above and see what the query plan might look like.
Simplified Query Plan
For this query, the gateway knows which fields are owned by which DGS based on the federation config. Using that information, it breaks the client query into three separate queries to three DGSs. The first query is sent to Movie DGS since the root field movies is owned by that DGS. This results in retrieving the movieId and title fields for the first 10 movies in the dataset. Then using the movieIds it got from the previous request, the gateway executes two parallel requests to Production DGS and Talent DGS to fetch the production and actors fields for those 10 movies. Upon completion, the sub-query responses are merged together and the combined data response is returned to the caller.
A note on performance: Query Planning and Execution adds a ~10ms overhead in the worst case. This includes the compute for building the query plan, as well as the deserialization of DGS responses and the serialization of merged gateway response.
Entity Resolver
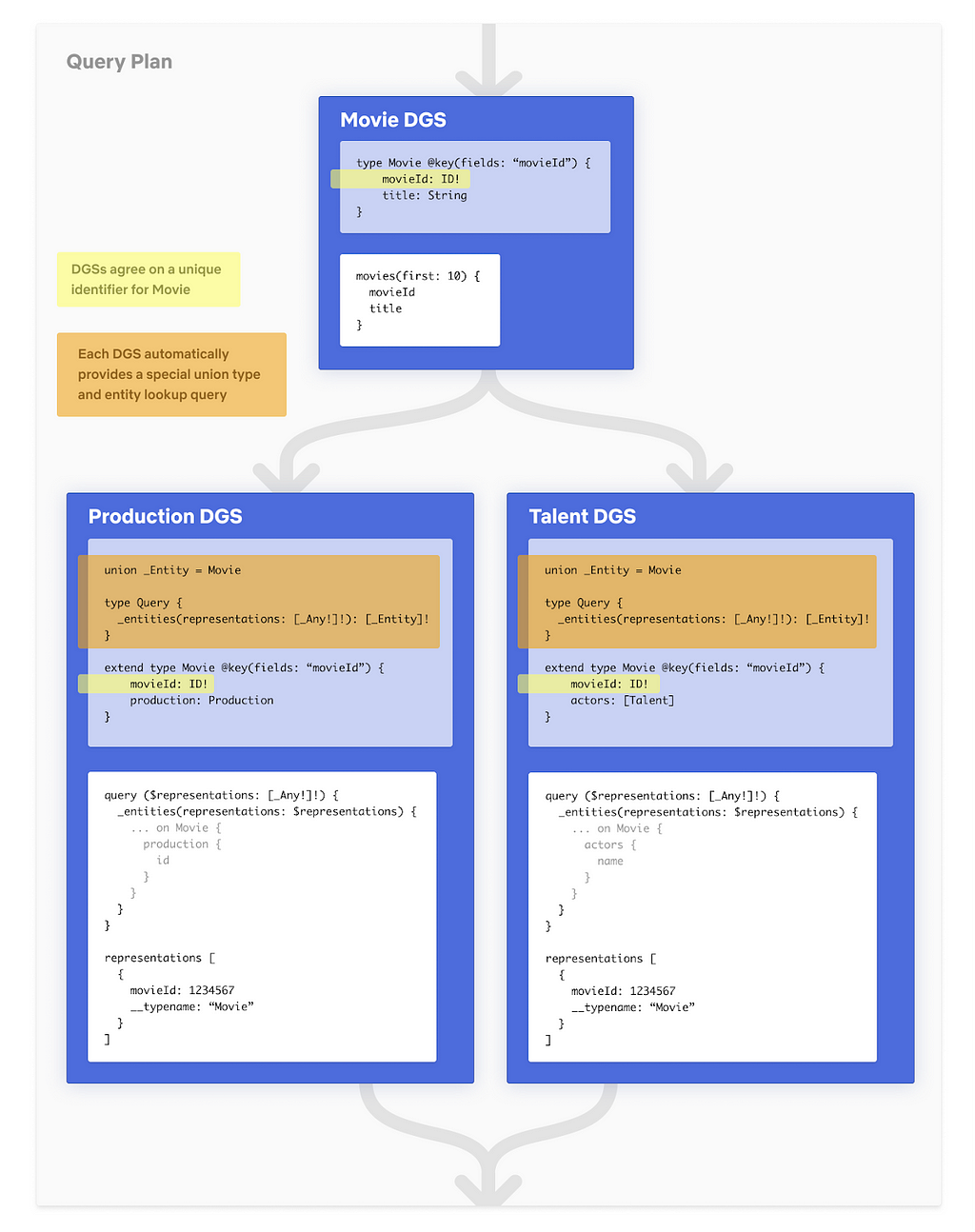
Now you might be wondering, how do the parallel sub-queries to Production and Talent DGS actually work? That’s not something that the DGS supports. This is the final piece of the puzzle.
Let’s go back to our federated type Movie. In order for the gateway to join Movie seamlessly across DGSs, all the DGSs that define and extend the Movie need to agree on one or more fields that define the primary key (e.g. movieId). To make this work, Apollo introduced the @key directive in the Federation Spec. Second, DGSs have to implement a resolver for a generic Query field, _entities. The _entities query returns a union type of all the federated types in that DGS. The gateway uses the _entities query to look up Movie by movieId.
Let’s take a look at how the query plan actually looks like
Detailed Federated Query Plan
The representation object consists of the movieId and is generated from the response of the first request to Movie DGS. Since we requested for the first 10 movies, we would have 10 representation objects to send to Production and Talent DGS.
This is similar to Relay’s Object Identification with a few differences. _Entity is a union type, while Relay’s Node is an interface. Also, with @key, there is support for variable key names and types as well as composite keys while in Relay, the id is a single opaque ID field.
Combined together, these are the ingredients that power the core of a federated API architecture.
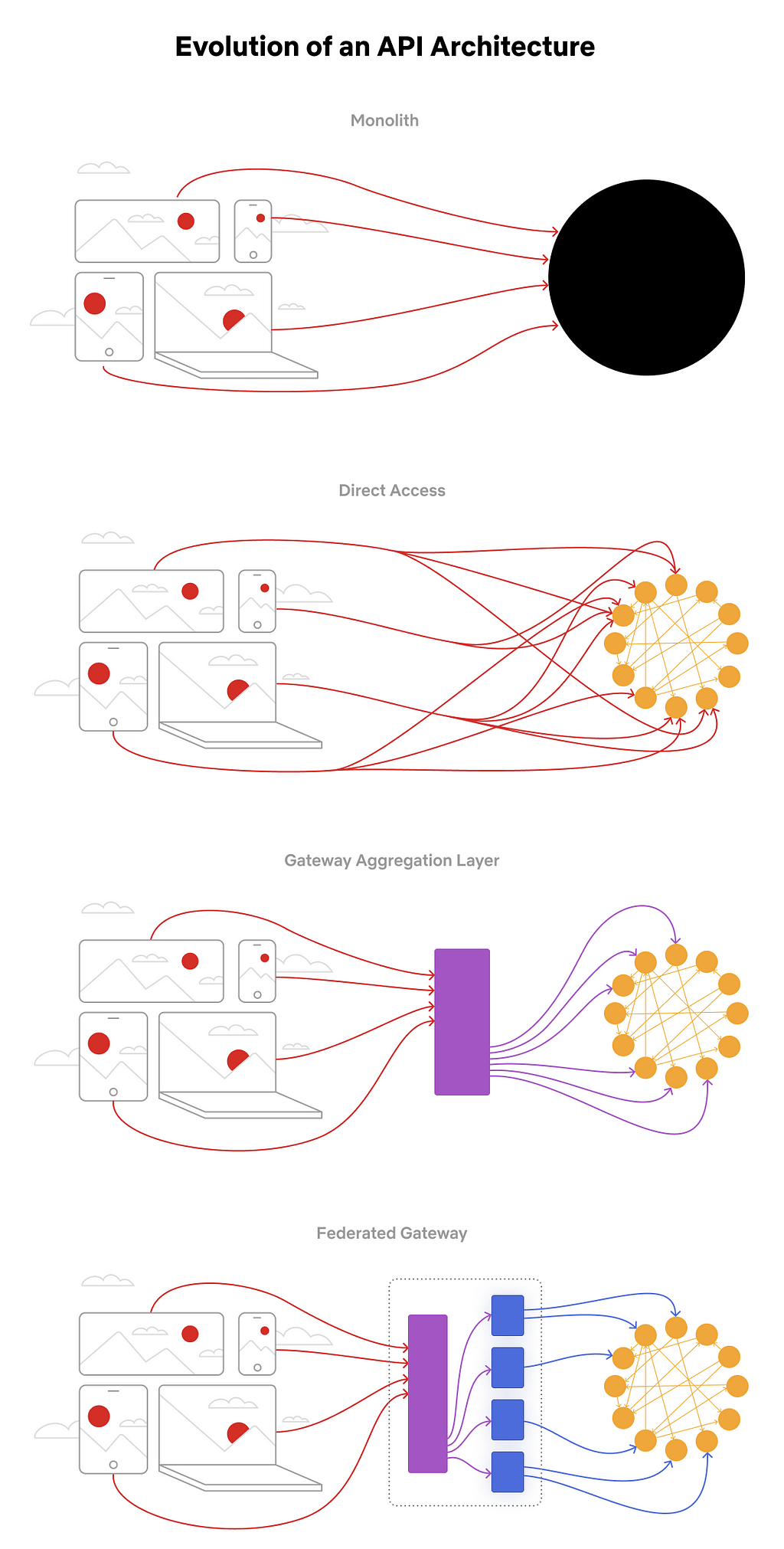
The Journey, Summarized
Our Studio Ecosystem architecture has evolved in distinct phases, all motivated by reducing the time between idea and implementation, improving the developer experience, and streamlining operations. The architectural phases look like:
Evolution of an API Architecture
Stay Tuned
Over the past year we’ve implemented the federated API architecture components in our Studio Edge. Getting here required rapid iteration, lots of cross-functional collaborations, a few pivots, and ongoing investment. We’re live with 70 DGSes and hundreds of developers contributing to and using the Studio Edge architecture. In our next Netflix Tech Blog post, we’ll share what we learned along the way, including the cross-cutting concerns necessary to build a holistic solution.
We want to thank the entire GraphQL open-source community for all the generous contributions and paving the path towards the promise of GraphQL. If you’d like to be a part of solving complex and interesting problems like this at Netflix scale, check out our jobs page or reach out to us directly.
Amazon EventBridge is a serverless event bus used to decouple event producers and consumers. Event producers publish events onto an event bus, which then uses rules to determine where to send those events. The rules determine the targets, and EventBridge routes the events accordingly.
In event-driven architectures, it can be useful for services to access past events. This has previously required manual logging and archiving, and creating a mechanism to parse files and put events back on the event bus. This can be complex, since you may not have access to the applications that are publishing the events.
With the announcement of event replay, EventBridge can now record any events processed by any type of event bus. Replay stores these recorded events in archives. You can choose to record all events, or filter events to be archived by using the same event pattern matching logic used in rules.
You can also configure a retention policy for an archive to store data either indefinitely or for a defined number of days. You can now easily configure logging and replay options for events created by AWS services, your own applications, and integrated SaaS partners.
Event replay can be useful for a number of different use-cases:
Testing code fixes: after fixing bugs in microservices, being able to replay historical events provides a way to test the behavior of the code change.
Testing new features: using historical production data from event archives, you can measure the performance of new features under load.
Hydrating development or test environments: you can replay event archives to hydrate the state of test and development environments. This helps provide a more realistic state that approximates production.
This blog post shows you how to create event archives for an event bus, and then how to replay events. I also cover some of the important features and how you can use these in your serverless applications.
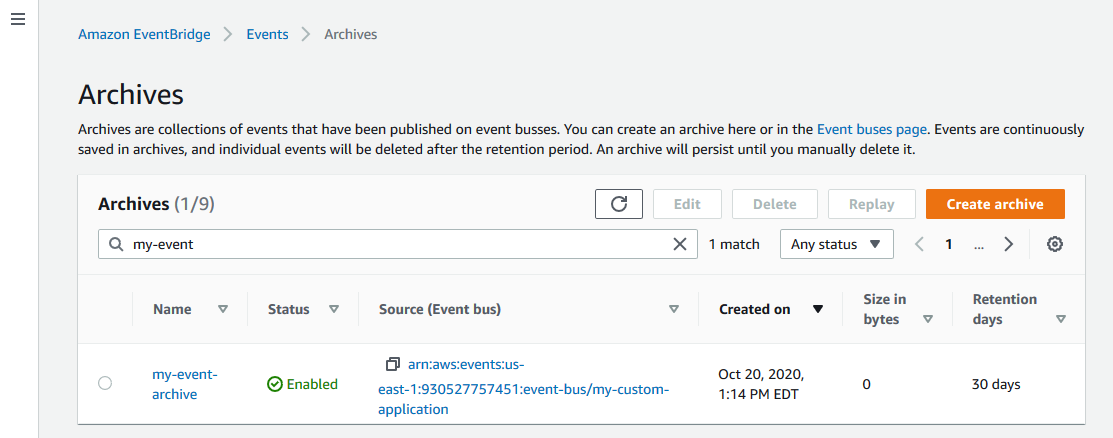
Creating event archives
To create an event archive for an event bus:
Navigate to the EventBridge console and select Archives from the left-hand submenu. Choose the Create Archive button.
In the Define archive details page:
Enter ‘my-event-archive’ for Name and provide an optional description.
Select a source bus from the dropdown (choose default if you want to archive AWS events).
For retention period, enter ‘30’.
Choose Next.
In the Filter events page, you can provide an event pattern to archive a subset of events. For this walkthrough, select No event filtering and choose Create archive.
In the Archives page, you can see the new archive waiting to receive events.
Choose the archive to open the details page. Over time, as more events are sent to the bus, the archive maintains statistics about the number and size of events stored.
You can also create archives using AWS CloudFormation. The following example creates an archive that filters for a subset of events with a retention period of 30 days:
Archives are always sourced from a single event bus. Once you have created an archive, it appears on the event bus details page:
You can make changes to an archive definition once it is created. If you shorten the duration, this deletes any events in the archives that are earlier than the new retention period. This deletion process occurs after a period of time and is not immediate. If you extend the duration, this affects event collection from the current point, but does not restore older events.
Each time you create an archive, this automatically generates a rule on the event bus. This is called a managed rule, which is created, updated, and deleted by the EventBridge service automatically. This rule does not count towards the default 300 rules per event bus service quota.
When you open a managed rule, the configuration is read-only.
This configuration shows an event pattern that is applied to all incoming events, including those that may be replayed from archives. The event pattern excludes events containing a replay-name attribute, which prevents replayed events from being archived multiple times.
Replaying archived events
To replay an archive of events:
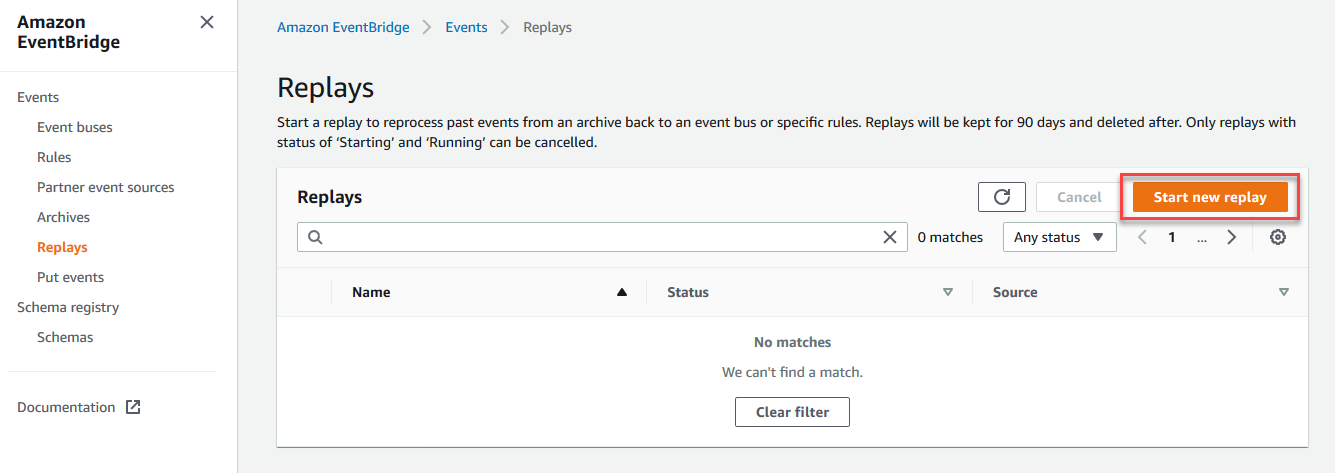
Navigate to the EventBridge console and select Replays from the left-hand submenu. Choose the Create Archive button.
In the Start new replay page:
Enter ‘my-event-replay’ for Name and provide an optional description.
Select a source bus from the dropdown. This must match the source bus for the event archive.
For Specify rule(s), select All rules.
Enter a time frame for the replay. This is the ingestion time for the first and last events in the archive.
Choose Start Replay.
The Replays page shows the new replay in Starting status.
How this works
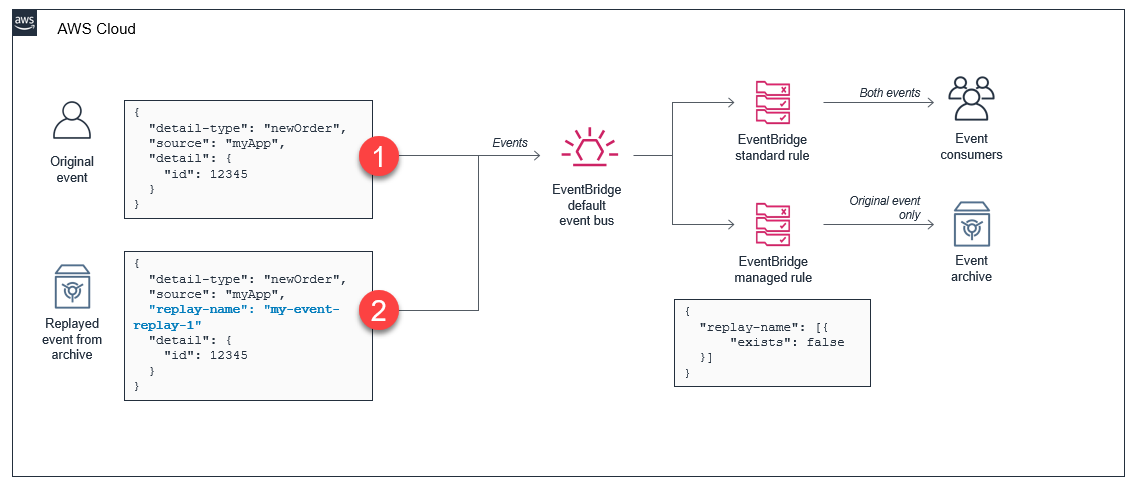
When a replay is started, the service sends the archived event back to the original event bus. It processes these as quickly as possible, with no ordering guarantees. The replay process adds a “replay-name” attribute to the original event. This is the flow of events:
The original event is sent to the event bus. It is received by any existing rules and the managed rule creating the archive. The event is saved to the event archive.
When the archived event is replayed, the JSON object includes the replay-name attribute. The existing rules process the event as in the first step. Since the managed rule does not match the replayed event, it is not forwarded to the archive.
Showing additional replay fields
In the Replays console, choose the preferences cog icon to open the Preferences dialog box.
From here, you can add:
Event start time and end time: Timestamps for the earliest and latest events in the archive that was replayed.
Replay start time and end time: shows the time filtering parameters set for the listed replay.
Last replayed: a timestamp of when the final replay event occurred.
You can sort on any of these additional fields.
Advanced routing of replayed events
In this simple example, a replayed archive matches the same rules that the original events triggered. Additionally, replayed events must be sent to the original bus where they were archived from. As a result, a basic replay allows you to duplicate events and copy the rule matching behaviors that occurred originally.
However, you may want to trigger different rules for replayed events or send the events to another bus. You can make use of the replay-name attribute in your own rules to add this advanced routing functionality. By creating a rule that filters for the presence of the “replay-name” event, it ignores all events that are not replays. When you create the replay, instead of targeting all rules on the bus, only target this one rule.
The original event is put on the event bus. The replay rule is evaluated but does not match.
The event is played from the archive, targeting only the replay rule. All other rules are excluded automatically by the replay service. The replay rule matches and forwards events onto the rule’s targets.
The target of the replay rule may be typical rule target, including an AWS Lambda function for customized processing, or another event bus.
Conclusion
In event-driven architectures, it can be useful for services to access past events. The new event replay feature in Amazon EventBridge enables you to automatically archive and replay events on an event bus. This can help for testing new features or new code, or hydrating services in development and test to more closely approximate a production environment.
This post shows how to create and replay event archives. It discusses how the archives work, and how you can implement these in your own applications. To learn more about using Amazon EventBridge, visit the learning path for videos, blogs, and other resources.
For more serverless learning resources, visit Serverless Land.
When we think back to our school days, we can all recall that one teacher who inspired us, believed in us, and made all the difference to how we approached a particular subject. It was someone we maybe took for granted at the time and so we only realised (much) later how amazing they were.
I hope this post makes you think of a teacher or mentor who has made a key difference in your life!
Here computer science student Jonathan Alderson and our team’s Ben Garside talk to me about how Ben supported and inspired Jonathan in his computer science classroom.
The teacher: Ben Garside. The student: Jonathan Alderson.
Hi Jonathan! How did you get into computing?
Jonathan: My first memories of using a computer were playing 3D Pinball, Club Penguin, and old Disney games, so nothing productive there…or so I thought! I was always good at IT and Maths at school, and Computing seemed to be a cross between the two, so I thought it would be good.
Jonathan and Ben, can you remember your time working together? It’s been a while now!
Jonathan: I met Mr Garside at the start of sixth form. Our school didn’t have a computer science course, so a few of us would walk between schools twice a week. Mr Garside really made me feel welcome in a place where I didn’t know anyone.
When learning computer science, it’s difficult to understand the importance of new concepts like recursion, classes, or linked lists when the examples are so small. Mr Garside’s teaching made me see the relevance of them and how they could fit into other projects; it’s easy to go a long time without using concepts because you don’t necessarily need them, even when it would make your life a lot easier.
Mr Garside really made me feel welcome in a place where I didn’t know anyone. […] Mr Garside’s teaching made me see the relevance of [new computer science concepts] and how they could fit into other projects.
Jonathan Alderson
Ben: It was a real pleasure to teach Jonathan. He stands out as being one of the most inquisitive students that I have taught. If something wasn’t clear to him, he’d certainly let me know and ask relevant questions so that he could fully understand. Jonathan was also constantly working on his own programming projects outside of lessons. During his A level, I remember him taking it upon himself to write a program that played chess. Each week he would demonstrate the progress he had made to the class. It was a perfect example of decomposition as he tackled the project in small sections and had a clear plan as to what he wanted to achieve. By the end of his project, not only did he have a program that played chess, but it was capable of playing against real online users including making the mouse clicks on the screen!
Moving from procedural to object-oriented programming (OOP) can be a sticking point for a lot of learners, and I remember Jonathan finding this difficult at first. I think what helped Jonathan in particular was getting him to understand that this wasn’t as new a concept as he first thought. OOP was just a different paradigm where he could still apply all of the coding structures that he was already confident in using.
That sounds like a very cool project. What other projects did you make, Jonathan? And how did Ben help you?
Jonathan: My final-year project, [a video game] called Vector Venture, ended up becoming quite a mammoth task! I didn’t really have a clue about organising large projects, what an IDE was, or you could split files apart. Mr Garside helped me spend enough time on the final report and get things finished. He was very supportive of me releasing the game and got me a chance to speak at the Python North East group, which was a great opportunity.
Ben: Vector Venture was a very ambitious project that Jonathan undertook, but I think by then he had learned a lot about how to tackle a project of that size from previous projects such as the chess program. The key to his success was that whilst he was learning, he was picking projects to undertake that he had a genuine interest in and enjoyed developing. I would also tell my A level students to pick as a project something that they will enjoy developing. Jonathan clearly enjoyed developing games, but I also had students who picked projects to develop programs that would solve problems. For example, one of my students developed a system that would take online bookings for food orders and manage table allocation for a local restaurant.
I would tell my A level students to pick as a project something that they will enjoy developing.
Ben Garside
I think that point about having fun while learning something challenging like programming is really important to highlight. So what are you doing now, Jonathan?
Jonathan: I have just completed my undergraduate degree at the University of Leeds (UoL) with a place on the Dean’s List and am staying to complete a Masters in High Performance Graphics.
During my time at UoL, I’ve had three summer placements creating medical applications and new systems for the university. This helped me understand the social benefits of computer science; it was great to work on something that is now benefitting so many people. My dissertation was on music visualisation, mapping instrument attributes of a currently playing song to control parameters inside sharers on the GPU to produce reactive visualisations. I’ve just completed an OpenGL project to create procedural underwater scenes, with realistic lighting, reflections, and fish simulations. I’m now really looking forward to completing my Game Engine project for my masters and graduating.
Teachers are often brilliant at taking something complicated and presenting it in a clearer way. Are those moments of clarity part of what motivates you to teach, Ben?
Ben: There are lots of things that excite me about teaching computer science. Before I worked for the Raspberry Pi Foundation, there was a phrase I heard Carrie Anne Philbin say when I attended a Picademy: we are teaching young people to be digital makers, logical thinkers, and problem solvers, not just to be consumers of technology. I felt this really summed up how great it is to teach our subject. Teaching computer science means that we’re educating young people about the world around them and how technology plays its part in their lives. By doing this, we are empowering them to solve problems and to make educated choices about how they use technology.
Teaching computer science means that we’re educating young people about the world around them and how technology plays its part in their lives.
Ben Garside
As for my previous in-school experiences, I loved those lightbulb moments when something suddenly made sense to a student and a loud “Yesssss!” would break the silence of a quietly focused classroom. I loved teaching something that regularly sparked their imaginations; give them a single lesson on programming, and they would start to ask questions like: “Now I’ve made it do that…does this mean I could make it do this next?“. It wasn’t uncommon for students to want to do more outside of the classroom that wasn’t a homework activity. That, for me, was the ultimate win!
How about you?
Who was the teacher who helped shape your future when you were at school? Tell us about them in the comments below.
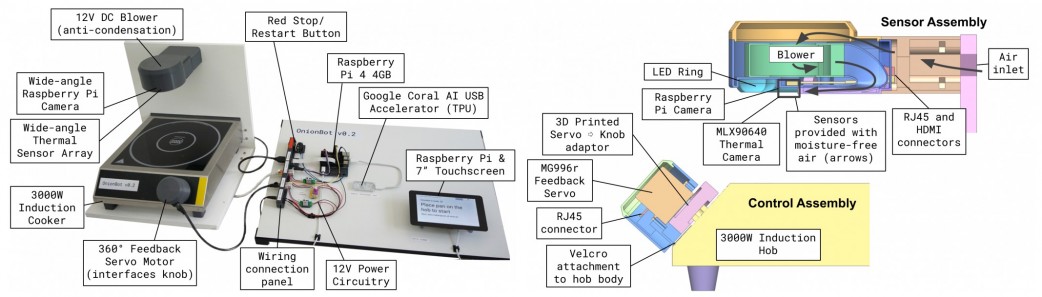
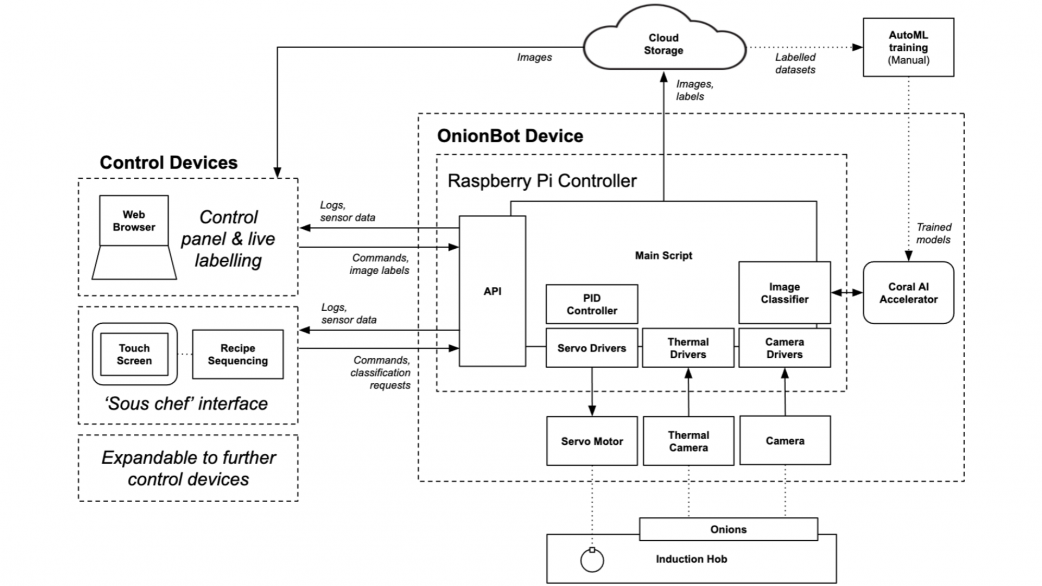
Design Engineering student Ben Cobley has created a Raspberry Pi–powered sous-chef that automates the easier pan-cooking tasks so the head chef can focus on culinary creativity.
Ben named his invention OnionBot, as the idea came to him when looking for an automated way to perfectly soften onions in a pan while he got on with the rest of his dish. I have yet to manage to retrieve onions from the pan before they blacken so… *need*.
The full setup (you won’t need a laptop while you’re cooking, so you’ll have counter space)
Ben’s affordable solution is much better suited to home cooking than the big, expensive robotic arms used in industry. Using our tiny computer also allowed Ben to create something that fits on a kitchen counter.
What can OnionBot do?
Tells you on-screen when it is time to advance to the next stage of a recipe
Autonomously controls the pan temperature using PID feedback control
Detects when the pan is close to boiling over and automatically turns down the heat
Reminds you if you haven’t stirred the pan in a while
A thermal sensor array suspended above the stove detects the pan temperature, and the Raspberry Pi Camera Module helps track the cooking progress. A servo motor controls the dial on the induction stove.
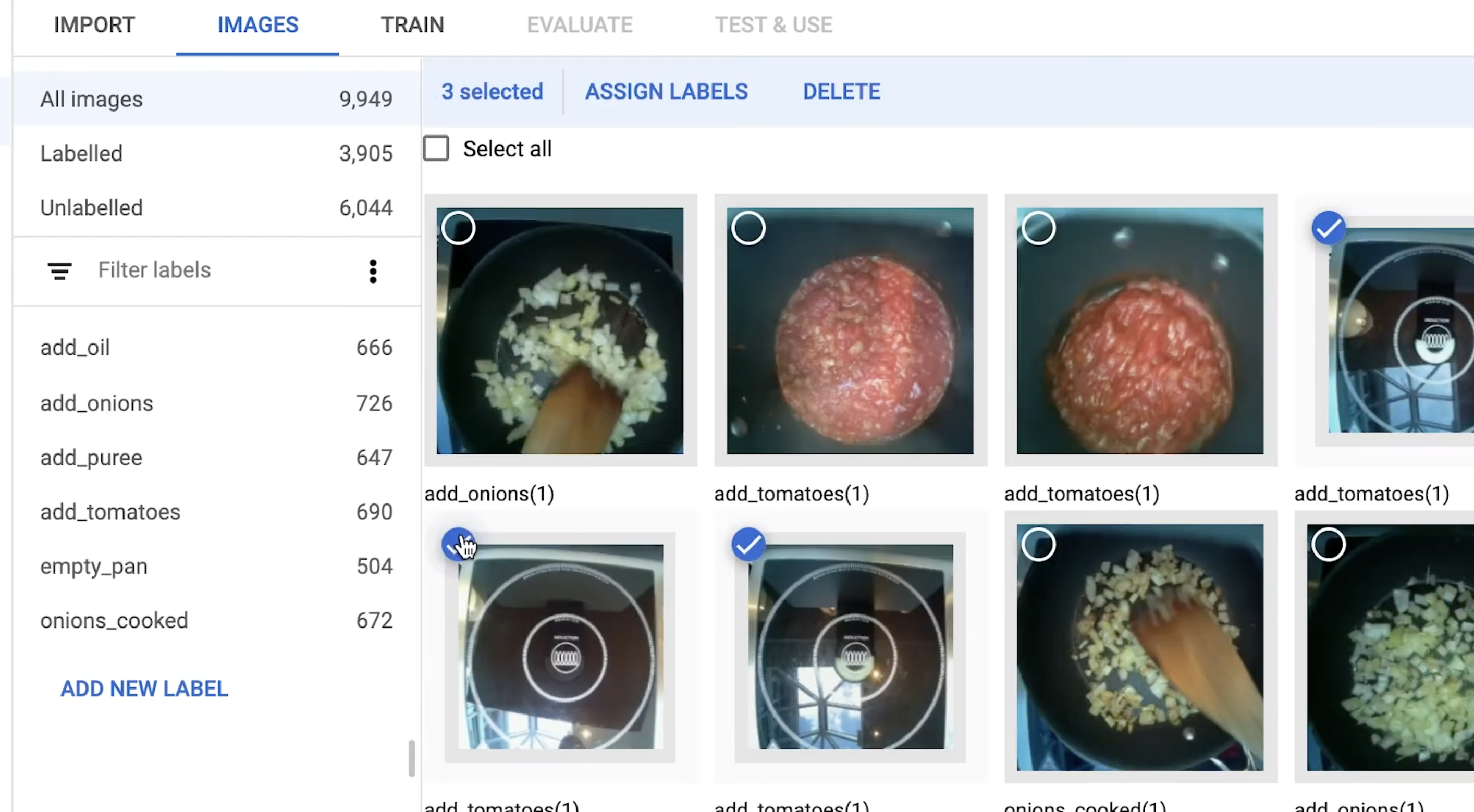
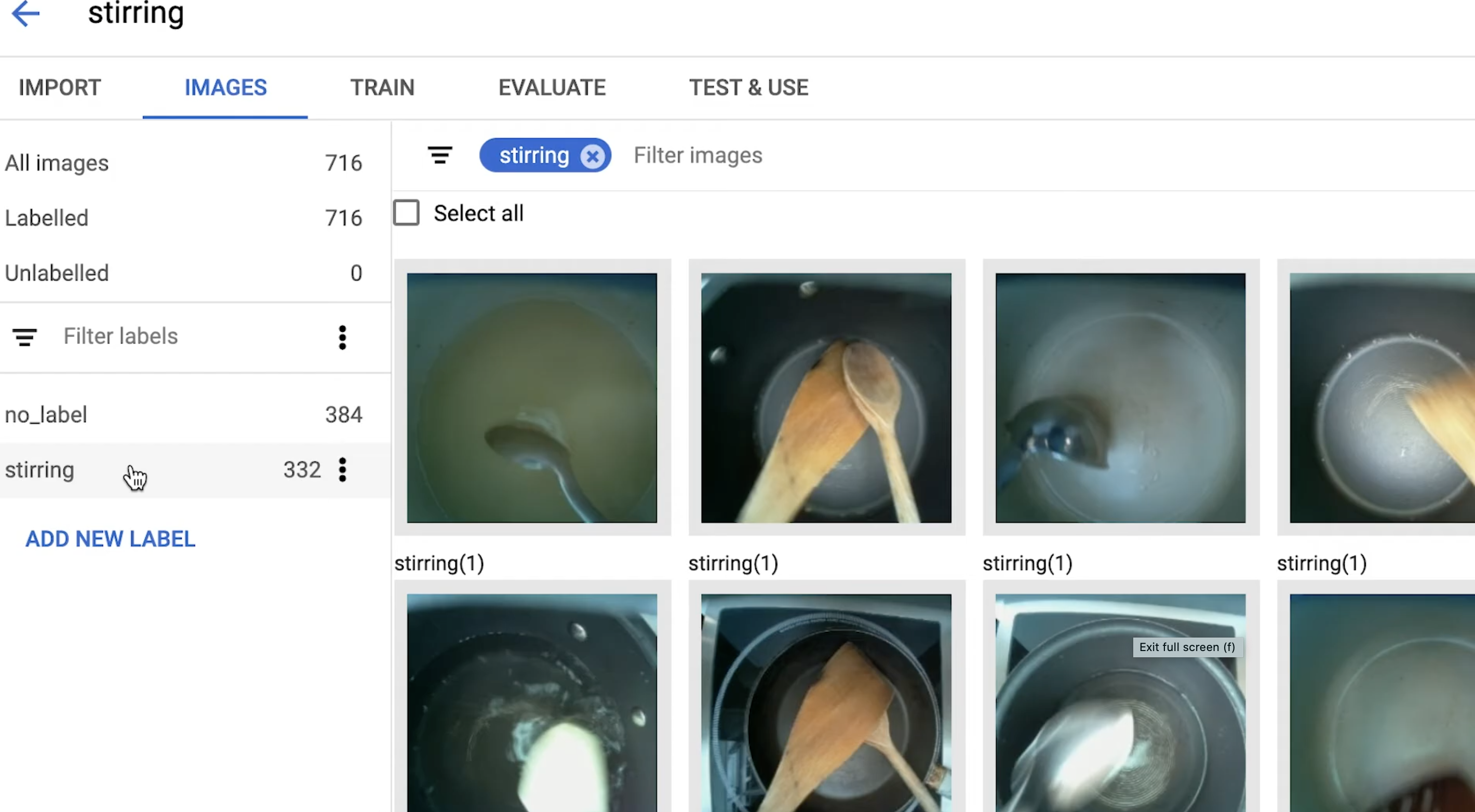
Labelling images to train the image classifier
No machine learning expertise was required to train an image classifier, running on Raspberry Pi, for Ben’s robotic creation; you’ll see in the video that the classifier is a really simple drag-and-drop affair.
Ben has only taught his sous-chef one pasta dish so far, and we admire his dedication to carbs.
Training the image classifier to know when you haven’t stirred the pot in a while
Ben built a control panel for labelling training images in real time and added labels at key recipe milestones while he cooked under the camera’s eye. This process required 500–1000 images per milestone, so Ben made a LOT of pasta while training his robotic sous-chef’s image classifier.
Ben open-sourced this project so you can collaborate to suggest improvements or teach your own robot sous-chef some more dishes. Here’s OnionBot on GitHub.
За кой ли път политическите решения в България могат да бъдат обобщени само с „неведоми са пътищата шизофренични“. Както е модерно да започват, протичат и завършват новините напоследък, „в условията на коронавирус“ депутатите решиха да могат да участват в пленарните заседания и да гласуват дистанционно по електронен път, ако са карантинирани.
И това отрежда волята на същите тези депутати, които съвсем наскоро изсмукаха от пръстите си всевъзможни аргументи, за да се опитат да ни убедят колко несигурно и пагубно ще е електронното гласуване за самите устои на родната демокрация. От девет кладенеца вода извадиха представители на водещи политически сили, за да ни заливат със смехотворни аргументи, а сега излиза, че за едни може интерактивно, а за други не може.
Но, кои сме ние, че да се сравняваме с народните представители? Все пак от нас така или иначе не зависи нищо, а при тях нещата стоят по съвсем различен начин. Ами, я си представете, че трябва да се осигури кворум за приемането на поредния лобистки закон, а КОВИД-а е натръшкал по домовете им прекалено много държавотворци, за да се случи това? Или пък е нужно набързо, без излишни обсъждания и обяснения, набързо да се пробута скандална промяна? Какъв по-лесен начин от това верните другари да се покажат на камерата от къщи, за да се удостовери, че са те и после да си кажат какъв е вотът им. Точно така.
След като приключи вотът в залата, народните представители в коронавирусно изгнание трябва лично и устно да кажат тежката си дума. „За“, „против“ или „въздържал се“. Още един начин да се улесни проверката на лоялността на депутатите към партийните им централи?
Някак неусетно мислите потичат точно в тази посока. Народните представители могат да гласуват дистанционно не заради друго, а защото това по никакъв начин не възпрепятства контрола над поведението им. Каквото каже лидерът, под строй, без излишни разсъждения и колебания. Като „Ало, Ваньо…“.
При обикновените хора съвсем не е така. Дистанцията дава много повече свобода на гласоподавателя да прави както му говори разумът, без да се съобразява с нуждата да постъпи „правилно“. И така до голяма степен се обезсилва армията от стотици хиляди купени гласове, мъртви души и нужна само по избори бюрократщина. А това не бива да се допуска в нито една фасадна демокрация, нали?
Хаосът, несигурността, объркването са най-добрата почва за създаване на подобни изключения от правилото, които се превръщат в норма и си остават и след като най-после истерията отмине. Сега хората са склонни да подминат „интерактивизирането“ на законотворческия процес. Какво пък – току-виж и Делян Пеевски най-после благоволил да упражни правото си на депутатски вот. Да, не е карантиниран с КОВИД, но е в самоизолация за n-ти мандат, та може да се направи изключение.
Важното е да се стегнат редиците, защото мандатът е на финалната права. След изборите, предсрочни или не, някои от сегашните лица на властта няма да попаднат пред обектива никога повече. Освен, ако ги фотографират за семейна снимка или, дай Боже, в карирана затворническа носия. Други пък ще гледат сами да се покрият или да играят твърде изгодната в родната политика роля на „опозиция“. Затова трябва да се побърза да се свърши каквото е нужно сега, в този парламент. Има да се довършва един поток, който си е руски по същина, колкото и по име да е ни риба, ни рак. Има да се усвояват разни милиарди евросредства, да се осъществяват заменки, да се заложат параметри за договори, които ще заробват и внуците ни… Не са едно и две.
В такава ситуация никой послушен депутат не може да си позволи да седи кротко карантиниран вкъщи. Е, той пак ще си седи, но ще гласува каквото трябва. Нали помните? „Работа, работа, работа“.
А, ако по изборите половината държава е парализирана, карантинирана и не може да отиде да упражни вота си на място в избирателните секции, дали ще може негово величество гласоподавателят да се легитимира с камерата на компютъра си и устно да изрази волята си? Не, разбира се. Поне това е за добро. Иначе не се знае кой би могъл да стои зад камерата с насочено в челото му дуло…
***
Поръчайте юбилейната книга на Торлака по случай 10 години Биволъ.
101 текста на Торлака за Биволъ
Поръчайте книгата “101 текста на Торлака за Биволъ”. Специално издание по случай десетата годишнина на сайта Биволъ. Промоционална цена от 12 лв. (6 евро) за 1 екземпляр. Можете да поръчате също 2, 3, 5 или 10 екземпляра за приятели и познати. Доставка до адрес в България или в чужбина след 15 ноември. Цената на доставката в България се заплаща на куриерската компания при получаване на пратката на личен адрес или в нейния офис. За доставка в чужбина ще се свържем с Вас, за да уточним подробностите.
Business leaders know all too well the long list of challenges involved in taking any business to the next level. Cash flow, human resources, infrastructure, growing marketing spend, refining or expanding on processes, and company culture are just a few of the many considerations. One particularly important challenge is choosing the right software and tools early on, to allow your business to provide its products or services efficiently and cost-effectively.
One of the greatest ways to achieve reliable and harmonious business practices is to ensure the technological infrastructure that your business is built upon is carefully planned to not only cater to your immediate business needs but also to be flexible for future growth.
Cloud computing services are more popular than ever before, and even in the face of the COVID-19 pandemic, have continued to grow just as steadily. Below, we’ve outlined 5 common business problems that are solved by migration to AWS cloud. If you’ve been considering the potential advantages of AWS for your business, read on!
Common problem: Convoluted/expensive/unnecessary services within pre-packaged traditional hosting plans.
With traditional hosting services, products tend to be pre-packaged with a selection of commonly required services as well as tiered/set resources. As a business grows larger and requires more heavy-duty online infrastructure, the cost of pre-packaged services can become much more expensive than it needs to be. That is because you may not be using some of the inclusions provided with these services, or require less of one resource or more of another. Pre-packaged service pricing also generally has factored in the cost of software licences needed to deliver all of the inclusions offered. If you’re not using these services, why should you be paying for them?
How AWS cloud computing services solves this: With AWS cloud hosting, each individual service is billed separately, and charges are based on different metrics such as the number of hours or seconds a service is online, or how much data transfer takes place. This allows a business to have very granular control over where they are directing their spend, as well as offering the ability to avoid paying for service inclusions that they are simply not using.
Common problem: Cost creep over time.
Cost creep is a common problem both in traditional hosting services and cloud computing services. As your business grows and evolves, your online infrastructure may need access to more services, features or integrations, as well as more computing resources. Each of these things almost always comes with an additional cost.
How AWS cloud computing services solves this: Between traditional hosting services and cloud computing, cloud is the only one that offers a plethora of ways to prevent, monitor and even reverse cost creep over time. Cost creep is a common occurrence for many businesses, especially in the early deployment stages when traffic is the least predictable and resource requirements are difficult to allocate in advance. This is something that can be greatly improved over time as usage data becomes available, along with traffic and resource usage patterns of your website or application. With proper maintenance and the utilisation of AWS reserved instances (which can provide the same resources at a greatly lower cost), there are many opportunities to minimise, and even reverse cost creep over time with cloud services.
Common problem: Infrastructure that offers a lack of horizontal scaling.
Horizontal scaling can translate to cost efficiencies, by adding or removing computing resources, and only paying for them while you are actually using them. For example, say you were running a food delivery application where you required a lot of computing resources to handle traffic during the lunch and dinner rush. If you were to purchase a computing instance with enough power to handle the rush hour, that might become an expensive waste of resources to still be running when business is quiet at 4 am. This is where horizontal scaling can come in to maximise efficiency through the addition and reduction of additional computing power, as needed.
Traditional hosting services rarely offer horizontal scalability, meaning you will be overpaying for resources or services that you aren’t utilising a lot of the time.
How AWS cloud computing services solves this: AWS offers powerful options when it comes to horizontally scaling computing power on demand. Scaling horizontally means adding additional computing instances to support an application running on an existing instance, as needed.
One of the greatest advantages of cloud computing services such as AWS is that their range of services are billed by the amount of time you are using them. So horizontal scaling can translate to cost efficiencies, by adding or removing computing resources, and only paying for them while you are actually using them.
The 5.10-rc3 kernel prepatch is out for
testing. “Things look normal. rc3 is neither particularly small or
particularly large – it’s pretty much average for an rc3 release for the
last couple of years.”
Преди няколко дни минаха президентските избори в САЩ. Прогнозите са, че ги е спечелил Джо Байдън, но официални крайни резултати още няма.
Из социалните мрежи обаче кипят словесни сражения. Про-тръмписти срещу про-байдънисти. Някои от тях хич не са красиви – както и трябва да се очаква в среда от българи. Нещо друго обаче ми направи силно впечатление.
Из всяка социална мрежа могат да се намерят луди. Вярващи, че кемтрейлсовете ни ръсят с отрови, 5G ни облъчва, ваксините ни чипират, Земята е плоска, съществува световна конспирация (еврейска, банкерска, корпоративна, либерална, глобалистка, рептилска, попълнете каквото ви плаши, ненужното да се зачеркне), и прочее. Списъкът е твърде дълъг, за да може да бъде побран в един скромен запис в блог.
Прави ми впечатление, че към 95% от лудите са поддръжници на Тръмп. Има и поддръжници на Байдън, но са редки. И предостатъчно поддръжници на Тръмп не са луди – но лудите ги притегля той, в съотношение двайсет към едно.
Безспорно Тръмп има заигравки с конспироманите, антиковидистите и някои други видове луди. Но забелязвам, че почти в същото съотношение го поддържат и луди по теми, по които той никога не е вземал отношение – кемтрейлсовете, рептилите, плоската Земя. Предполагам, че по повечето от тези теми той би бил категоричен опонент на съответните луди… Каквото влиза в определението „алтернативно адекватен“, с към 95% вероятност се оказва поддръжник на Тръмп, буквално независимо от темата на лудостта си.
Още по-странно ми е нещо друго. Почти всички поддръжници на Тръмп – включително тези, които категорично ми изглеждат нормални, го подкрепят заради неща, които поне на мен ми изглеждат маловажни или даже вредни. (А някои и просто не са верни.) Заради агресивното му противопоставяне на „леви“ или „либерални“ политики. Заради фанатичната му омраза към мюсюлманите. Заради експлозивния икономически растеж при него. Заради негативното му отношение към екологията. Заради колко повече нелегални мигранти е депортирал от Обама… Един-двама души видях да го подкрепят заради по-категоричната политика срещу Китай – той заслужава признание, че я въведе, въпреки подаръка му към Китай на ден първи от президентството му. Не видях да го подкрепят заради изпълнената съдебна реформа – Америка има крещяща нужда от нея вече 20 години, именно той успя да я наложи. Нито заради опита му (за съжаление неуспешен) да намали цените на лекарствата и медицинските услуги. Нито заради дерегулацията на много бизнес-моменти, които бяха неоправдано свръхрегулирани. Но много се съдират да го хвалят заради премахването на регулации, които са обективно нужни…
(Не че противниците му си нямат залитанията. Вече не броя колко негови противници видях да го плюят заради прическата му, килограмите му и т.н. Но поне откровено лудите са малко. Шепичка го смятат за руски агент – това е най-близкото до вярващата в кемтрейлсове и нефилими маса луди, които го подкрепят.)
Възможно ли е да забелязвам лудостите предимно сред про-тръмпистите, понеже смятам Байдън за по-приемливия от двамата? Това беше първото ми предположение. Малко статистика обаче го отхвърли. Преброих 200 налудни изказвания към двамата кандидати – само 11 бяха в подкрепа на Байдън или срещу Тръмп, останалите бяха в обратната посока. А критериите ми за налудност бяха едни и същи, подбрани преди да започна броенето.
Възможно ли е просто извадката, която ми е попаднала, да е тежко изкривена? Напълно. Не съм правил строго научно проучване, просто отбелязвам какво съм забелязал.
Възможно ли е да има някаква неочаквана (за мен) причина, поради която лудите подкрепят Тръмп? Разбира се. Да приличам на гений, способен да разнищи всеки проблем?
Затова и реших да се допитам до околните, за предположения.
By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.