Post Syndicated from Darren Roback original https://aws.amazon.com/blogs/security/building-sensitive-data-remediation-workflows-in-multi-account-aws-environments/
The rapid growth of data has empowered organizations to develop better products, more personalized services, and deliver transformational outcomes for their customers. As organizations use Amazon Web Services (AWS) to modernize their data capabilities, they can sometimes find themselves with data spread across several AWS accounts, each aligned to distinct use cases and business units. This can present a challenge for security professionals, who need not only a mechanism to identify sensitive data types—such as protected health information (PHI), payment card industry (PCI), and personally identifiable information (PII), or organizational intellectual property—stored on AWS, but also the ability to automatically act upon these findings through custom logic that supports organizational policies and regulatory requirements.
In this blog post, we present a solution that provides you with visibility into sensitive data residing across a fleet of AWS accounts through a ChatOps-style notification mechanism using Microsoft Teams, which also provides contextual information needed to conduct security investigations. This solution also incorporates a decision logic mechanism to automatically quarantine sensitive data assets while they’re pending review, which can be tailored to meet unique organizational, industry, or regulatory environment requirements.
Prerequisites
Before you proceed, ensure that you have the following within your environment:
- Access to a set of AWS accounts that have been joined to an organization with all features enabled.
- Logically grouped AWS Organizations member accounts into organizational units (OUs).
- Enabled AWS CloudFormation trusted access within AWS Organizations.
- Enabled tag policies within AWS Organizations.
- A designated security tooling account within AWS Organizations that’s dedicated to operating security services, monitoring AWS accounts, and automating security alerting and response, and whose access is restricted through AWS Identity and Access Management (IAM) to security professionals.
- Permissions to create the resources listed below using CloudFormation.
- A Microsoft Teams account with permissions to add apps and webhooks in your desired team and channel.
Assumptions
Things to know about the solution in this blog post:
- This solution assumes that Amazon Simple Storage Service (Amazon S3) buckets in scope for sensitive data discovery and remediation are not enabled for S3 versioning. Amazon Macie supports sensitive data discovery of current object versions, and the solution presented here automatically quarantines current object versions determined to contain sensitive data. Additional customization of this solution might be required to allow or deny access to previous object versions and delete markers.
- This solution assumes that you’ve set up your AWS accounts for IAM authentication, and the notifications presented to you in Microsoft Teams will reflect an IAM user authentication experience. If you’re using AWS IAM Identity Center with federated authentication, additional customization of this solution might be required.
Solution overview
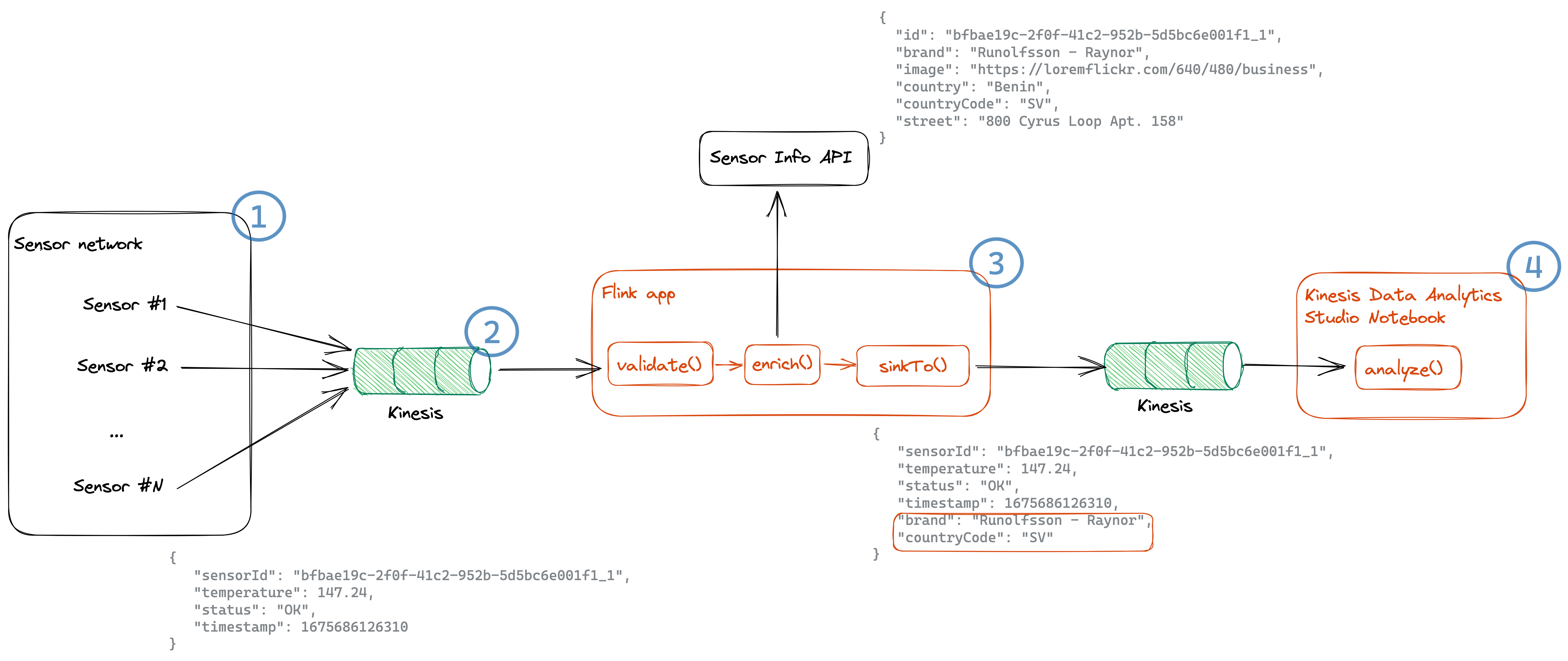
The solution architecture and overall workflow are detailed in Figure 1 that follows.
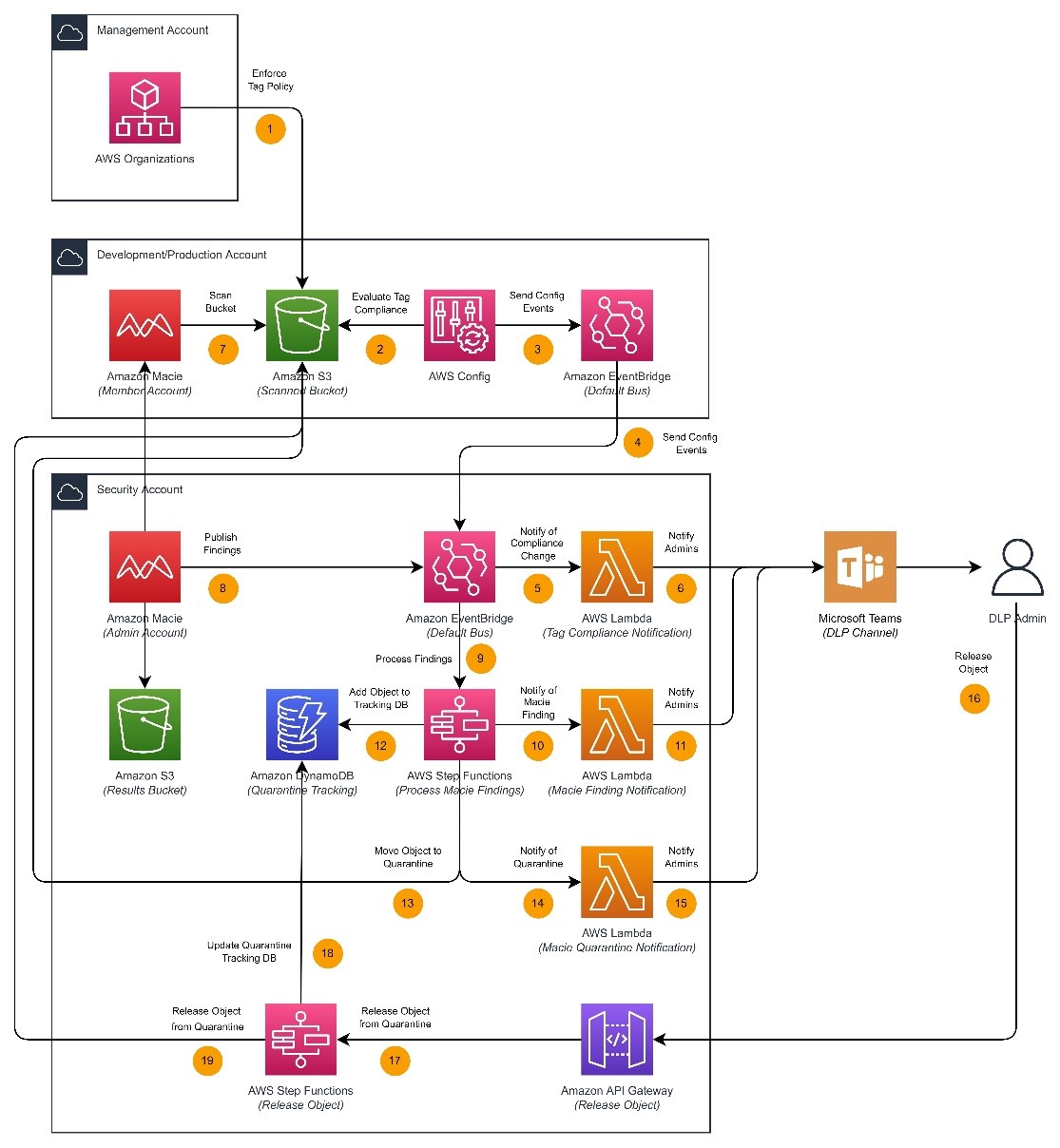
Figure 1: Solution overview
Upon discovering sensitive data in member accounts, this solution selectively quarantines objects based on their finding severity and public status. This logic can be customized to evaluate additional details such as the finding type or number of sensitive data occurrences detected. The ability to adjust this workflow logic can provide a custom-tailored solution to meet a variety of industry use cases, helping you adhere to industry-specific security regulations and frameworks.
Figure 1 provides an overview of the components used in this solution, and for illustrative purposes we step through them here.
Automated scanning of buckets
Macie supports various scope options for sensitive data discovery jobs, including the use of bucket tags to determine in-scope buckets for scanning. Setting up automated scanning includes the use of an AWS Organizations tag policy to verify that the S3 buckets deployed in your chosen OUs conform to tagging requirements, an AWS Config job to automatically check that tags have been applied correctly, an Amazon EventBridge rule and bus to receive compliance events from a fleet of member accounts, and an AWS Lambda function to notify administrators of compliance change events.
- An AWS Organizations tag policy verifies that the S3 buckets created in the in-scope AWS accounts have a tag structure that facilitates automated scanning and identification of the bucket owner. Specific tags enforced with this tag policy include RequireMacieScan : True|False and BucketOwner : <variable>. The tag policy is enforced at the OU level.
- A custom AWS Config rule evaluates whether these tags have been applied to all in-scope S3 buckets, and marks resources as compliant or not compliant.
- After every evaluation of S3 bucket tag compliance, AWS Config will send compliance events to an EventBridge event bus in the same AWS member account.
- An EventBridge rule is used to send compliance messages from member accounts to a centralized security account, which is used for operational administration of the solution.
- An EventBridge rule in the centralized security account is used to send all tag compliance events to a Lambda serverless function, which is used for notification.
- The tag compliance notification function receives the tag compliance events from EventBridge, parses the information, and posts it to a Microsoft Teams webhook. This provides you with details such as the affected bucket, compliance status, and bucket owner, along with a link to investigate the compliance event in AWS Config.
Detecting sensitive data
Macie is a key component of this solution and facilitates sensitive data discovery across a fleet of AWS accounts based on the RequireMacieScan tag value configured at the time of bucket creation. Setting up sensitive data detection includes using Macie for sensitive data discovery, an EventBridge rule and bus to receive these finding events from the Macie delegated administrator account, an AWS Step Functions state machine to process these findings, and a Lambda function to notify administrators of new findings.
- Macie is used to detect sensitive data in member account S3 buckets with job definitions based on bucket tags, and central reporting of findings through a Macie delegated administrator account (that is, the central security account).
- When new findings are detected, Macie will send finding events to an EventBridge event bus in the security account.
- An EventBridge rule is used to send all finding events to AWS Step Functions, which runs custom business logic to evaluate each finding and determine the next action to take on the affected object.
- In the default configuration, for findings that are of low or medium severity and in objects that are not publicly accessible, Step Functions sends finding event information to a Lambda serverless function, which is used for notification. You can alter this event processing logic in Step Functions to change which finding types initiate an automated quarantine of the object.
- The Macie finding notification function receives the finding events from Step Functions, parses this information, and posts it to a Microsoft Teams webhook. This presents you with details such as the affected bucket and AWS account, finding ID and severity, public status, and bucket owner, along with a link to investigate the finding in Macie.
Automated quarantine
As outlined in the previous section, this solution uses event processing decision logic in Step Functions to determine whether to quarantine a sensitive object in place. Setting up automated quarantine includes a Step Functions state machine for Macie finding processing logic, an Amazon DynamoDB table to track items moved to quarantine, a Lambda function to notify administrators of quarantine, and an Amazon API Gateway and second Step Functions state machine to facilitate remediation or removal of objects from quarantine.
- In the default configuration for findings that are of high severity, or in objects that are publicly accessible, Step Functions adds the affected object’s metadata to an Amazon DynamoDB table, which is used to track quarantine and remediation status at scale.
- Step Functions then quarantines the affected object, moving it to an automatically configured and secured prefix in the same S3 bucket while the finding is being investigated. Only select personnel (that is, cybersecurity) has access to the object.
- Step Functions then sends finding event information to a Lambda serverless function, which is used for notification.
- The Macie quarantine notification function receives the finding events from Step Functions, parses this information, and posts it to a Microsoft Teams webhook. This presents you with similar details to the Macie finding notification function, but also notes the object has been moved to quarantine, and provides a one-click option to release the object from quarantine.
- In the Microsoft Teams channel, which should only be accessible to qualified security professionals, DLP administrators select the option to release the object from quarantine. This invokes a REST API deployed on API Gateway.
- API Gateway invokes a release object workflow in Step Functions, which begins to process releasing the affected object from quarantine.
- Step Functions inspects the affected object ID received through API Gateway, and first retrieves details about this object from DynamoDB. Upon receiving these details, the object is removed from the quarantine tracking database.
- Step Functions then moves the affected object to its original location in Amazon S3, thereby making the object accessible again under the original bucket policy and IAM permissions.
Organization structure
As mentioned in the prerequisites, the solution uses a set of AWS accounts that have been joined to an organization, which is shown in Figure 2. While the logical structure of your AWS Organizations deployment can differ from what’s shown, for illustration purposes, we’re looking for sensitive data in the Development and Production AWS accounts, and the examples shown throughout the remainder of this blog post reflect that.
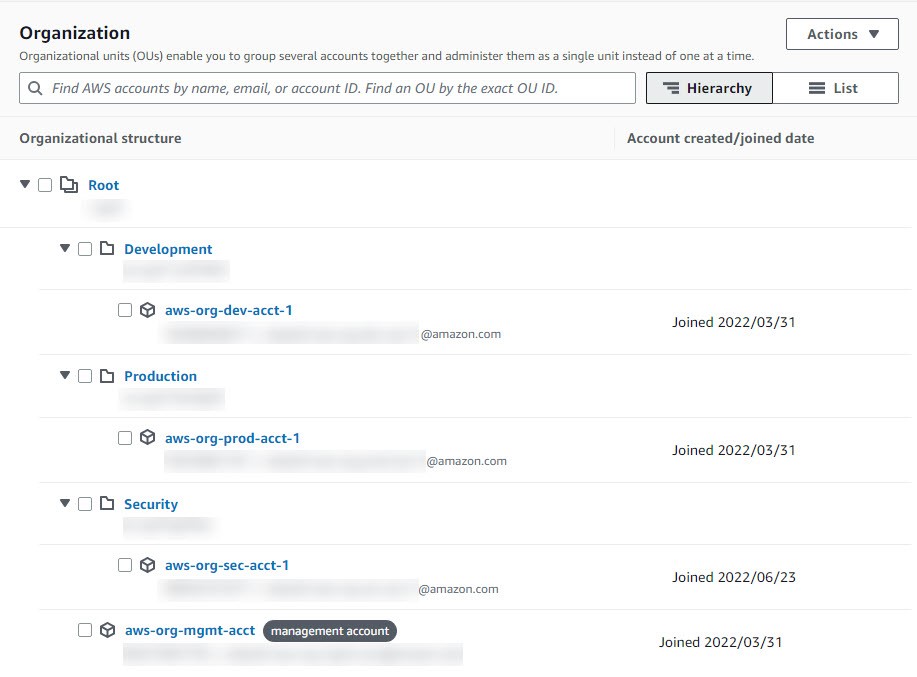
Figure 2: Organization structure
Deploy the solution
The overall deployment process of this solution has been decomposed into three AWS CloudFormation templates to be deployed to your management, security, and member accounts as CloudFormation stacks and StackSets, respectively. Performing the deployment in this manner not only verifies that the solution is extended to other member accounts created after the initial solution deployment, but also serves as an illustrative aid of the components deployed in each portion of the solution. An overview of the deployment process is as follows:
- Set up of Microsoft Teams webhooks to receive information from this solution.
- Deployment of a CloudFormation stack to the management account to configure the tag policy for this solution.
- Deployment of a CloudFormation stack set to member accounts to enable monitoring of S3 bucket tags and forwarding of tag compliance events to the security account.
- Deployment of a CloudFormation stack to the security account to configure the remainder of the solution that will facilitate sensitive data discovery, finding event processing, administrator notification, and release from quarantine functionality.
- Remaining manual configuration of quarantine remediation API authorization, enabling Macie, and specifying a Macie results location.
Set up Microsoft Teams
Before deploying the solution, you must create two incoming webhooks in a Microsoft Teams channel of your choice. Due to the sensitivity of the event information provided and the ability to release objects from quarantine, we recommend that this channel only be accessible to information security professionals. In addition, we recommend creating two distinct webhooks to distinguish tag compliance events from finding events and have named the webhooks in the examples S3-Tag-Compliance-Notification and Macie-Finding-Notification, respectively. A complete walkthrough of creating an incoming webhook is out of scope for this blog post, but you can access Microsoft’s documentation on creating incoming webhooks for an overview. After the webhooks have been created, save the URLs, to use in the solution deployment process.
Configure the management account
The first step of the deployment process is to deploy a CloudFormation stack in your management account that creates an AWS Organizations tag policy and applies it to the OUs of your choice. Before performing this step, note the two OU IDs you will apply the policy to, as these will be captured as input parameters for the CloudFormation stack.
- Choose the following Launch Stack button to open the CloudFormation console pre-loaded with the template for this step:

Note: The stack will launch in the N. Virginia (us-east-1) Region. To deploy this solution into other AWS Regions, change your regional selection in the CloudFormation console, and deploy it to the selected Region.
- For Stack name, enter ConfigureManagementAccount.
- For First AWS Organizations Unit ID, enter your first OU ID.
- For Second AWS Organizations Unit ID, enter your second OU ID.
- Choose Next.

Figure 3: Management account stack details

After you’ve entered all details, launch the stack and wait until the stack has reached CREATE_COMPLETE status before proceeding. The deployment process will take 1–2 minutes.
Configure the member accounts
The next step of the deployment process is to deploy a CloudFormation Stack, which will initiate a StackSet deployment from your management account that’s scoped to the OUs of your choice. This stack set will enable AWS Config along with an AWS Config rule to evaluate Amazon S3 tag compliance and will deploy an EventBridge rule to send compliance events from AWS Config in your member accounts to a centralized event bus in your security account. If AWS Config has previously been enabled, select True for the AWS Config Status parameter to help prevent an overwrite of your existing settings. Prior to performing this setup, note the two AWS Organizations OU IDs you will deploy the stack set to. You will also be prompted to enter the AWS account ID and Region of your security account.
- Choose the following Launch Stack button to open the CloudFormation console pre-loaded with the template for this step:
Note: The stack will launch in the N. Virginia (us-east-1) Region. To deploy this solution into other AWS Regions, change your regional selection in the CloudFormation console, and deploy it to the selected Region.
- For Stack name, enter DeployToMemberAccounts.
- For First AWS Organizations Unit ID, enter your first OU ID.
- For Second AWS Organizations Unit ID, enter your second OU ID.
- For Deployment Region, enter the Region you want to deploy the Stack set to.
- For AWS Config Status, accept the default value of false if you have not previously enabled AWS Config in your accounts.
- For Support all resource types, accept the default value of false.
- For Include global resource types, accept the default value of false.
- For List of resource types if not all supported, accept the default value of AWS::S3::Bucket.
- For Configuration delivery channel name, accept the default value of <Generated>.
- For Snapshot delivery frequency, accept the default value of 1 hour.
- For Security account ID, enter your security account ID.
- For Security account region, select the Region of your security account.
- Choose Next.

Figure 4: Member account Stack details

After you’ve entered all details, launch the stack and wait until the stack has reached CREATE_COMPLETE status before proceeding. The deployment process will take 3–5 minutes.
Configure the security account
The next step of the deployment process involves deploying a CloudFormation stack in your security account that creates all the resources needed for at-scale sensitive data detection, automated quarantine, and security professional notification and response. This stack configures the following:
- An S3 bucket and AWS Key Management Service (AWS KMS) keys for storage and encryption of discovery results in Macie.
- Two rules in EventBridge for routing tag compliance and Macie finding events.
- Two Step Functions state machines whose logic will be used for automated object quarantine and release.
- Three Lambda functions for tag compliance, Macie findings, and quarantine notification.
- A DynamoDB table for quarantine status tracking.
- An API Gateway REST endpoint to facilitate the release of objects from quarantine.
Before performing this setup, note your AWS Organizations ID and two Microsoft Teams webhook URLs previously configured.
- Choose the following Launch Stack button to open the CloudFormation console pre-loaded with the template for this step:
Note: The stack will launch in the N. Virginia (us-east-1) Region. To deploy this solution into other AWS Regions, change your regional selection in the CloudFormation console, and deploy it to the selected Region.
- For Stack name, enter ConfigureSecurityAccount.
- For AWS Org ID, enter your AWS Organizations ID.
- For Webhook URI for S3 tag compliance notifications, enter the first webhook URL you created in Microsoft Teams.
- For Webhook URI for Macie finding and quarantine notifications, enter the second webhook URL you created in Microsoft Teams.
- Choose Next.
Figure 5: Security account stack details

After you’ve entered all details, launch the stack and wait until the stack has reached CREATE_COMPLETE status before proceeding. The deployment process will take 3–5 minutes.
Remaining configuration
While most of the solution is deployed automatically using CloudFormation, there are a few items that you must configure manually.
Configure Lambda API key environment variable
When the CloudFormation stack was deployed to the security account, CloudFormation created a new REST API for security professionals to release objects from quarantine. This API was configured with an API key to be used for authorization, and you must retrieve the value of this API key and set it as an environment variable in your MacieQuarantineNotification function, which also deployed in the security account. To retrieve the value of this API key, navigate to the REST API created in the security account, select API Keys, and retrieve the value of APIKey1. Next, navigate to the MacieQuarantineNotification function in the Lambda console, and set the ReleaseObjectApiKey environment variable to the value of your API key.
Enable Macie
Next, you must enable Macie to facilitate sensitive data discovery in selected accounts in your organization, and this process begins with the selection of a delegated administrator account (that is, the security account), followed by onboarding the member accounts you want to test with. See Integrating and configuring an organization in Amazon Macie for detailed instructions on enabling Macie in your organization.
Configure the Macie results bucket and KMS key
Macie creates an analysis record for each Amazon S3 object that it analyzes. This includes objects where Macie has detected sensitive data as well as objects where sensitive data was not detected or that Macie could not analyze. The CloudFormation stack deployed in the security account created an S3 bucket and KMS key for this, and they are noted as MacieResultsS3BucketName and MacieResultsKmsKeyAlias in the CloudFormation stack output. Use these resources to configure the Macie results bucket and KMS key in the security account according to Storing and retaining sensitive data discovery results with Amazon Macie. Customization of the S3 bucket policy or KMS key policy has already been done for you as part of the ConfigureSecurityAccount CloudFormation template deployed earlier.
Validate the solution
With the solution fully deployed, you now need to deploy an S3 bucket with sample data to test the solution and review the findings.
Create a member account S3 bucket
In any of the member accounts onboarded into this solution as part of the Configure the member accounts step, deploy a new S3 bucket and the KMS key used to encrypt the bucket using the CloudFormation template that follows. Before performing this step, note the InvestigateMacieFindingsRole, StepFunctionsProcessFindingsRole, and StepFunctionsReleaseObjectRole outputs from the CloudFormation template deployed to the security account, as these will be captured as input parameters for the CloudFormation stack.
- Choose the following Launch Stack button to open the CloudFormation console pre-loaded with the template for this step:
Note: The stack will launch in the N. Virginia (us-east-1) Region. To deploy this solution into other AWS Regions, change your regional selection in the CloudFormation console, and deploy it to the selected Region.
- For Stack name, enter DeployS3BucketKmsKey.
- For IAM Role used by Step Functions to process Macie findings, enter the ARN that was provided to you as the StepFunctionsProcessFindingsRole output from the Configure security account step.
- For IAM Role used by Step Functions to release objects from quarantine, enter the ARN that was provided to you as the StepFunctionsReleaseObjectRole output from the Configure security account step.
- For IAM Role used by security professionals to investigate Macie findings, enter the ARN that was provided to you as the InvestigateMacieFindingsRole output from the Configure security account step.
- For Department name of the bucket owner, enter any department or team name you want to designate as having ownership responsibility over the S3 bucket.
- Choose Next.
Figure 6: Deploy S3 bucket and KMS key stack details

After you’ve entered all details, launch the stack and wait until the stack has reached CREATE_COMPLETE status before proceeding. The deployment process will take 3–5 minutes.
Monitor S3 bucket tag compliance
Shortly after the deployment of the new S3 bucket, you should see a message in your Microsoft Teams channel notifying you of the tag compliance status of the new bucket. This AWS Config rule is evaluated automatically any time an S3 resource event takes place, and the tag compliance event is sent to the centralized security account for notification purposes. While the notification shown in Figure 7 depicts a compliant S3 bucket, a bucket deployed without the required tags will be marked as NON_COMPLIANT, and security professionals can check the AWS Config compliance status directly in the AWS console for the member account.
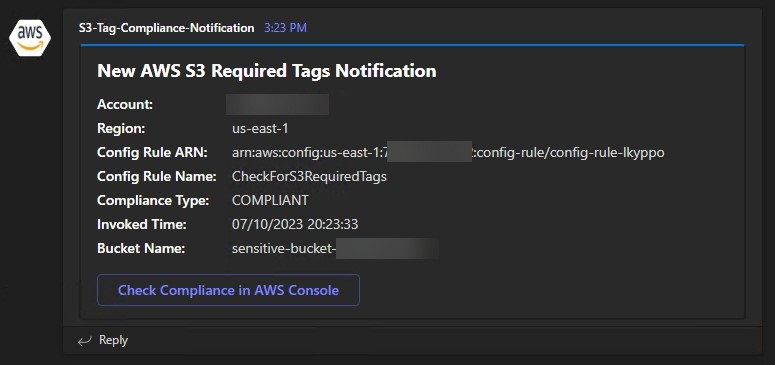
Figure 7: S3 tag compliance notification
Upload sample data
Download this .zip file of sample data and upload the expanded files into the newly created S3 bucket. The sample files include fictitious PII, including credit card information and social security numbers, and so will invoke various Macie findings.
Note: All data in this blog post has been artificially created by AWS for demonstration purposes and has not been collected from any individual person. Similarly, such data does not, nor is it intended, to relate back to any individual person.
Configure a Macie discovery job
Configure a sensitive data discovery job in the Amazon Macie delegated administrator account (that is, the security account) according to Creating a sensitive data discovery job. When creating the job, specify tag-based bucket criteria instructing Macie to scan any bucket with a tag key of RequireMacieScan and a tag value of True. This instructs Macie to scan buckets matching this criterion across the accounts that have been onboarded into Macie.
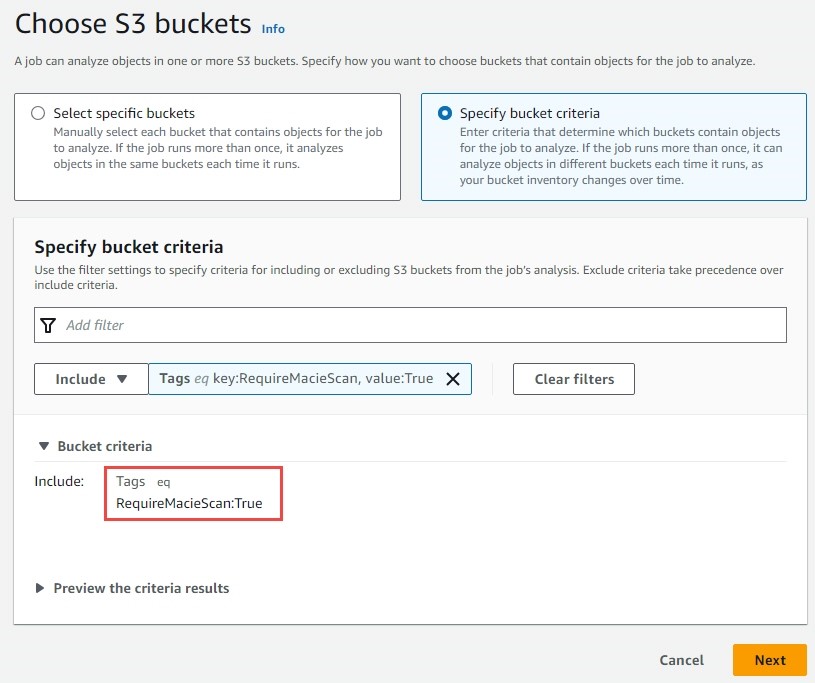
Figure 8: Macie bucket criteria
On the discovery options page, specify a one-time job with a sampling depth of 100 percent. Further refine the job scope by adding the quarantine prefix to the exclusion criteria of the sensitive data discovery job.
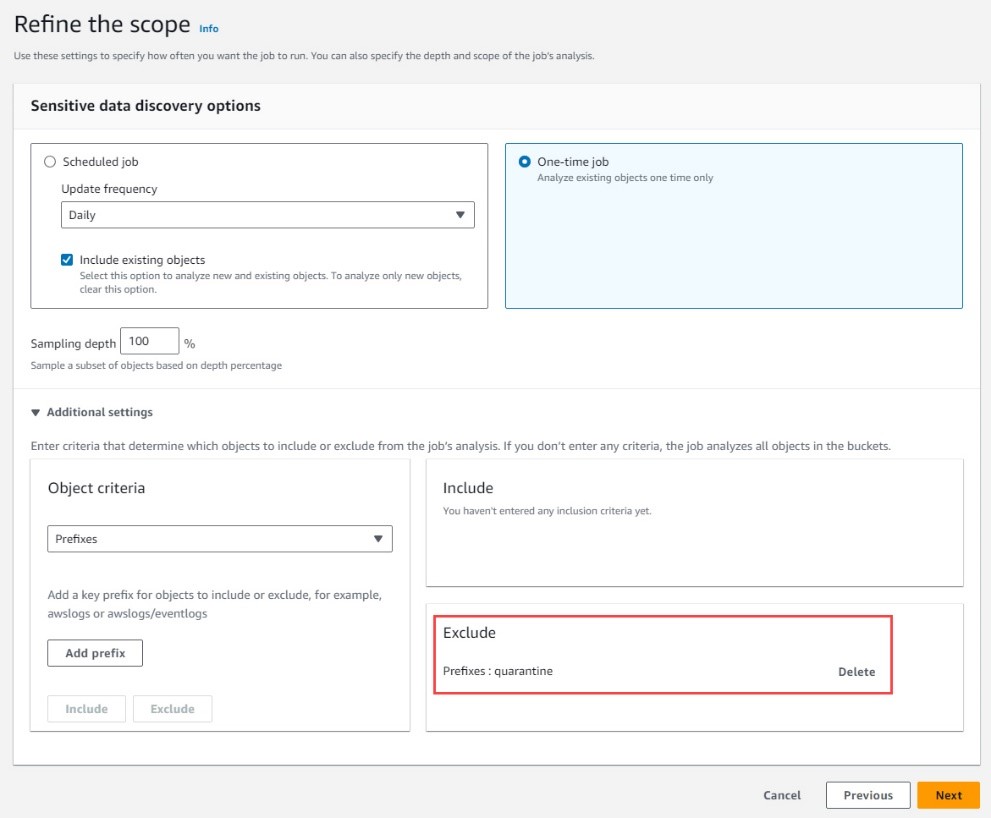
Figure 9: Macie scan scope
Select the AWS_CREDENTIALS, CREDIT_CARD_NUMBER, CREDIT_CARD_SECURITY_CODE, and DATE_OF_BIRTH managed data identifiers and proceed to the review screen. On the review screen, ensure that the bucket name you created is listed under bucket matches, and launch the discovery job.
Note: This solution also works with the Automated Sensitive Data Discovery feature in Amazon Macie. I recommend you investigate this feature further for broad visibility into where sensitive data might reside within your Amazon S3 data estate. Regardless of the method you choose, you will be able to integrate the appropriate notification and quarantine solution.
Review and investigate findings
After a few minutes, the discovery job will complete and soon you should see four messages in your Microsoft teams channel notifying you of the finding events created by Macie. One of these findings will be marked as medium severity, while the other three will be marked as high.
Review the medium severity finding, and recall the flow of event information from the solution overview section. Macie scanned a bucket in the member account and presented this finding in the Macie delegated administrator account. Macie then sent this finding event to EventBridge, which initiated a workflow run in Step Functions. Step Functions invoked customer-specified logic to evaluate the finding and determined that because the object isn’t publicly accessible, and because the finding isn’t high severity, it should only notify security professionals rather than quarantine the object in question. Several key pieces of information necessary for investigation are presented to the security team, along with a link to directly investigate the finding in the AWS console of the central security account.
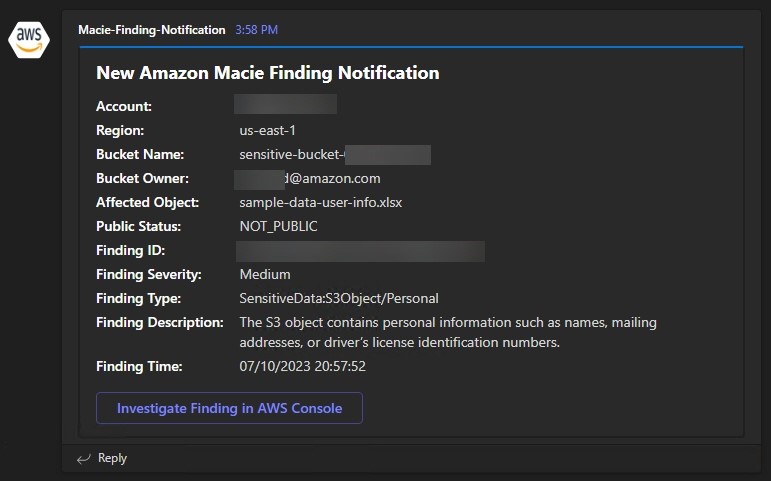
Figure 10: Macie medium severity finding notification
Now review the high severity finding. The flow of event information in this scenario is identical to the medium severity finding, but in this case, Step Functions quarantined the object because the severity is high. The security team is again presented with an option to use the console to investigate further. The process to investigate this finding is a bit different due to the object being moved to a quarantine prefix. If security professionals want to view the original object in its entirety, they would assume the InvestigateMacieFindingsRole in the security account, which has cross-account access to the S3 bucket quarantine prefix in the in-scope member accounts. S3 buckets deployed in member accounts using the CloudFormation template listed above will have a special bucket policy that denies access to the quarantine prefix for any role other than the InvestigateMacieFindingsRole, StepFunctionsProcessFindingsRole, and StepFunctionsReleaseObjectRole. This makes sure that objects are truly quarantined and inaccessible while being investigated by security professionals.
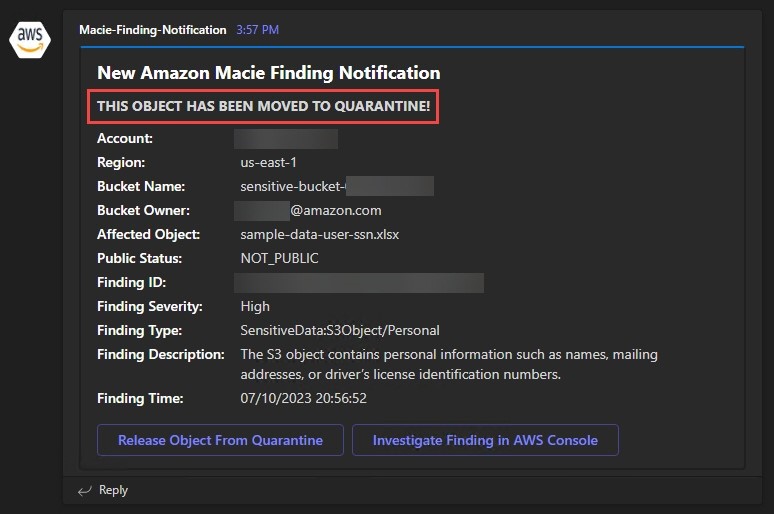
Figure 11: Macie high severity finding notification
Unlike the previous example, the security team is also notified that an affected object was moved to quarantine, and is presented with a separate option to release the object from quarantine. Choosing Release Object from Quarantine runs an HTTP POST to the REST API transparently in the background, and the API responds with a SUCCEEDED or FAILED message indicating the result of the operation.
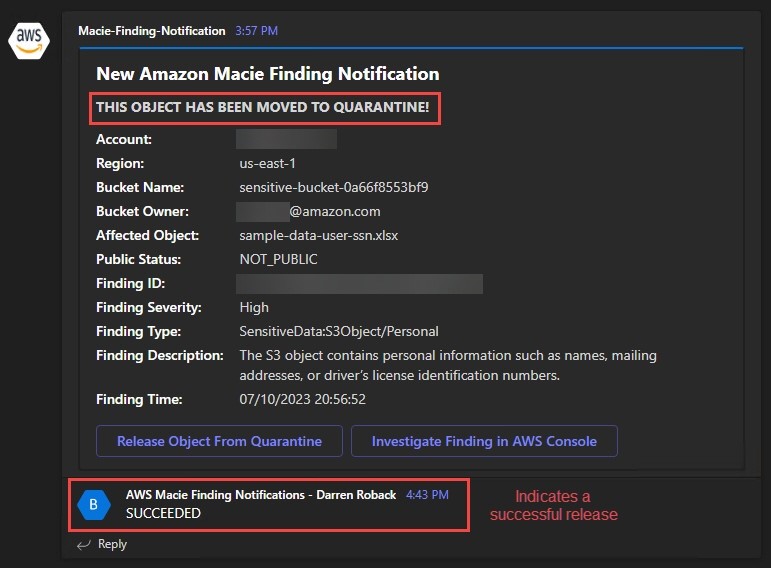
Figure 12: Release object from quarantine
The state machine uses decision logic based on the affected object’s public status and the severity of the finding. Customers deploying this solution can choose to alter this logic or add additional customization by altering the Step Functions state machine definition either directly in the CloudFormation template or through the Step Functions Workflow Studio low-code interface available in the Step Functions console. For reference, the full event schema used by Macie can be found in the Eventbridge event schema for Macie findings.
The logic of the Step Functions state machine used to process Macie finding events follows and is shown in Figure 13.
- An EventBridge rule invokes the Step Functions state machine as Macie findings are received.
- Step Functions parses Macie event data to determine the finding severity.
- If the finding is high severity or determined to be public, the affected object is then added to the quarantine tracking database in DynamoDB.
- After adding the object to quarantine tracking, the object is copied into the quarantine prefix within its S3 bucket.
- After being copied, the object is deleted from its original S3 location.
- After the object is deleted, the MacieQuarantineNotification function is invoked to alert you of the finding and quarantine status.
- If the finding is not high severity and not determined to be public, the MacieFindingNotification function is invoked to alert you of the finding.
Figure 13: Process Macie findings workflow

Solution cleanup
To remove the solution and avoid incurring additional charges for the AWS resources used in this solution, perform the following steps.
Note: If you want to only suspend Macie, which will preserve your settings, resources, and findings, see Suspending or disabling Amazon Macie.
- Open the Macie console in your security account. Under Settings, choose Accounts. Select the checkboxes next to the member accounts onboarded previously, select the Actions dropdown, and select Disassociate Account. When that has completed, select the same accounts again, and choose Delete.
- Open the Macie console in your management account. Click on Get started, and remove your security account as the Macie delegated administrator.
- Open the Macie console in your security account, choose Settings, then choose Disable Macie.
- Open the S3 console in your security account. Remove all objects from the Macie results S3 bucket.
- Open the CloudFormation console in your security account. Select the ConfigureSecurityAccount stack and choose Delete.
- Open the Macie console in your member accounts. Under Settings, choose Disable Macie.
- Open the Amazon S3 console in your member accounts. Remove all sample data objects from the S3 bucket.
- Open the CloudFormation console in your member accounts. Select the DeployS3BucketKmsKey stack and choose Delete.
- Open the CloudFormation console in your management account. Select the DeployToMemberAccounts stack and choose Delete.
- Still in the CloudFormation console in your management account, select the ConfigureManagementAccount stack and choose Delete.
Summary
In this blog post, we demonstrated a solution to process—and act upon—sensitive data discovery findings surfaced by Macie through the incorporation of decision logic implemented in Step Functions. This logic provides granularity on quarantine decisions and extensibility you can use to customize automated finding response to suit your business and regulatory needs.
In addition, we demonstrated a mechanism to notify you of finding event information as it’s discovered, while providing you with the contextual details necessary for investigative purposes. Additional customization of the information presented in Microsoft Teams can be accomplished through parsing of the event payload. You can also customize the Lambda functions to interface with Slack, as demonstrated in this sample solution for Macie.
Finally, we demonstrated a solution that can operate at-scale, and will automatically be deployed to new member accounts in your organization. By using an in-place quarantine strategy instead of one that is centralized, you can more easily manage this solution across potentially hundreds of AWS accounts and thousands of S3 buckets. By incorporating a global tracking database in DynamoDB, this solution can also be enhanced through a visual dashboard depicting quarantine insights.
If you have feedback about this post, let us know in the comments section. If you have questions about this post, start a new thread on AWS Security, Identity, & Compliance re:Post or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
 Luis Morales works as Senior Solutions Architect with digital-native businesses to support them in constantly reinventing themselves in the cloud. He is passionate about software engineering, cloud-native distributed systems, test-driven development, and all things code and security.
Luis Morales works as Senior Solutions Architect with digital-native businesses to support them in constantly reinventing themselves in the cloud. He is passionate about software engineering, cloud-native distributed systems, test-driven development, and all things code and security. Lorenzo Nicora works as Senior Streaming Solution Architect helping customers across EMEA. He has been building cloud-native, data-intensive systems for several years, working in the finance industry both through consultancies and for fin-tech product companies. He leveraged open source technologies extensively and contributed to several projects, including Apache Flink.
Lorenzo Nicora works as Senior Streaming Solution Architect helping customers across EMEA. He has been building cloud-native, data-intensive systems for several years, working in the finance industry both through consultancies and for fin-tech product companies. He leveraged open source technologies extensively and contributed to several projects, including Apache Flink.
































 Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. Ismail focuses on architecting solutions for organizations across their end-to-end data analytics estate, including batch and real-time streaming, big data, data warehousing, and data lake workloads. He primarily works with direct-to-consumer platform companies in the ecommerce, FinTech, PropTech, and HealthTech space to achieve their business objectives with well-architected data platforms.
Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. Ismail focuses on architecting solutions for organizations across their end-to-end data analytics estate, including batch and real-time streaming, big data, data warehousing, and data lake workloads. He primarily works with direct-to-consumer platform companies in the ecommerce, FinTech, PropTech, and HealthTech space to achieve their business objectives with well-architected data platforms.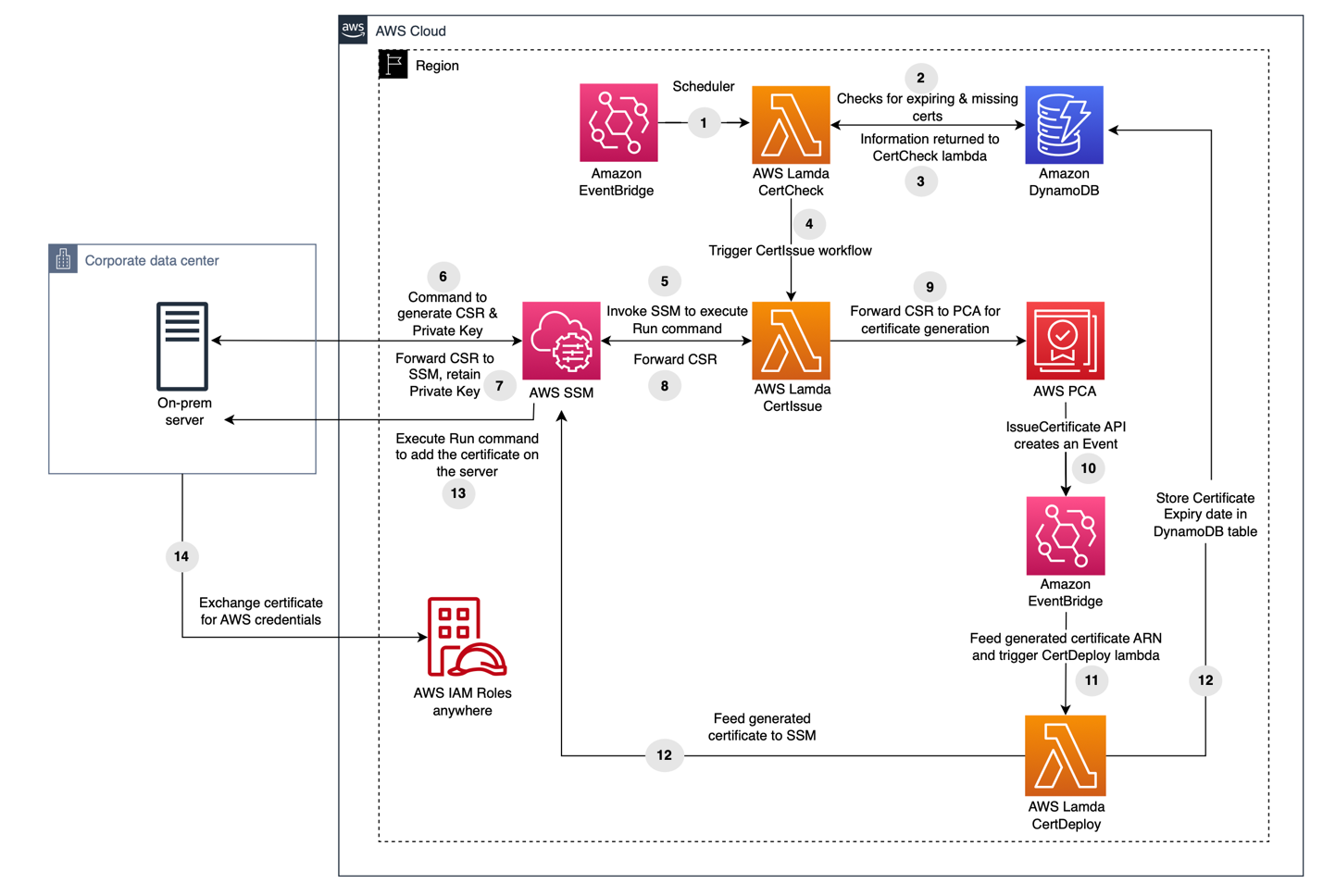






















 Ashley Zhou is a Software Development Engineer at AWS. She is interested in data analytics and distributed systems.
Ashley Zhou is a Software Development Engineer at AWS. She is interested in data analytics and distributed systems. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.



















 Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse.
Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse.























 John Cherian is Senior Solutions Architect(SA) at Amazon Web Services helps customers with strategy and architecture for building solutions on AWS.
John Cherian is Senior Solutions Architect(SA) at Amazon Web Services helps customers with strategy and architecture for building solutions on AWS. Emerson Antony is Senior Cloud Architect at Amazon Web Services helps customers with implementing AWS solutions.
Emerson Antony is Senior Cloud Architect at Amazon Web Services helps customers with implementing AWS solutions. Kiran Anand is Principal AWS Data Lab Architect at Amazon Web Services helps customers with Big data & Analytics architecture.
Kiran Anand is Principal AWS Data Lab Architect at Amazon Web Services helps customers with Big data & Analytics architecture.
























 This will start a new session with the updated parameters.
This will start a new session with the updated parameters.



 Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services. Raj Devnath is a Product Manager at AWS on Amazon Athena. He is passionate about building products customers love and helping customers extract value from their data. His background is in delivering solutions for multiple end markets, such as finance, retail, smart buildings, home automation, and data communication systems.
Raj Devnath is a Product Manager at AWS on Amazon Athena. He is passionate about building products customers love and helping customers extract value from their data. His background is in delivering solutions for multiple end markets, such as finance, retail, smart buildings, home automation, and data communication systems.

























 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.







 Amit Maindola is a Senior Data Architect focused on big data and analytics at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
Amit Maindola is a Senior Data Architect focused on big data and analytics at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.

 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat. Hendy Wijaya is a Senior OpenSearch Specialist Solutions Architect at Amazon Web Services. Hendy enables customers to leverage AWS services to achieve their business objectives and gain competitive advantages. He is passionate in collaborating with customers in getting the best out of OpenSearch and Amazon OpenSearch
Hendy Wijaya is a Senior OpenSearch Specialist Solutions Architect at Amazon Web Services. Hendy enables customers to leverage AWS services to achieve their business objectives and gain competitive advantages. He is passionate in collaborating with customers in getting the best out of OpenSearch and Amazon OpenSearch Utkarsh Agarwal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available and secure solutions in AWS Cloud. In his free time, he enjoys watching movies, TV series and of course cricket! Lately, he his also attempting to master the art of cooking in his free time – The taste buds are excited, but the kitchen might disagree.
Utkarsh Agarwal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available and secure solutions in AWS Cloud. In his free time, he enjoys watching movies, TV series and of course cricket! Lately, he his also attempting to master the art of cooking in his free time – The taste buds are excited, but the kitchen might disagree.