Post Syndicated from Lotfi Mouhib original https://aws.amazon.com/blogs/big-data/accelerate-your-data-exploration-and-experimentation-with-the-aws-analytics-reference-architecture-library/
Organizations use their data to solve complex problems by starting small, running iterative experiments, and refining the solution. Although the power of experiments can’t be ignored, organizations have to be cautious about the cost-effectiveness of such experiments. If time is spent creating the underlying infrastructure for enabling experiments, it further adds to the cost.
Developers need an integrated development environment (IDE) for data exploration and debugging of workflows, and different compute profiles for running these workflows. If you choose Amazon EMR for such use cases, you can use an IDE called Amazon EMR Studio for data exploration, transformation, version control, and debugging, and run Spark jobs to process large volume of data. Deploying Amazon EMR on Amazon EKS simplifies management, reduces costs, and improves performance. However, a data engineer or IT administrator needs to spend time creating the underlying infrastructure, configuring security, and creating a managed endpoint for users to connect to. This means such projects have to wait until these experts create the infrastructure.
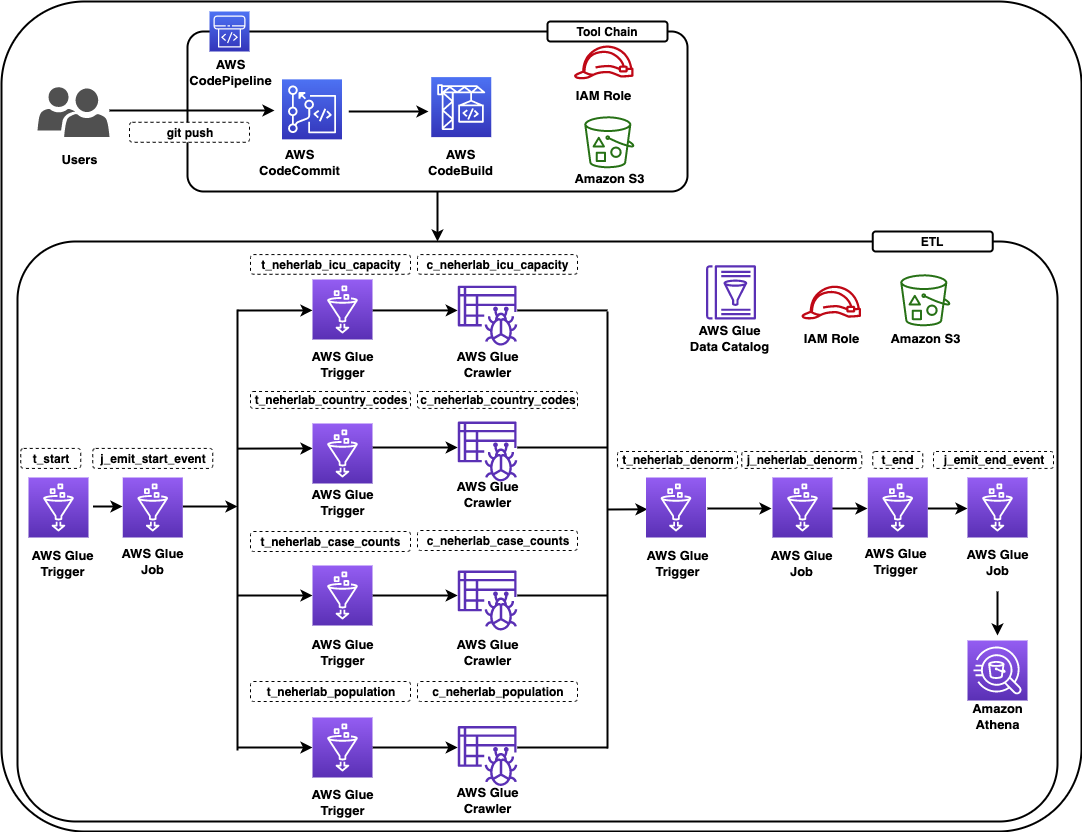
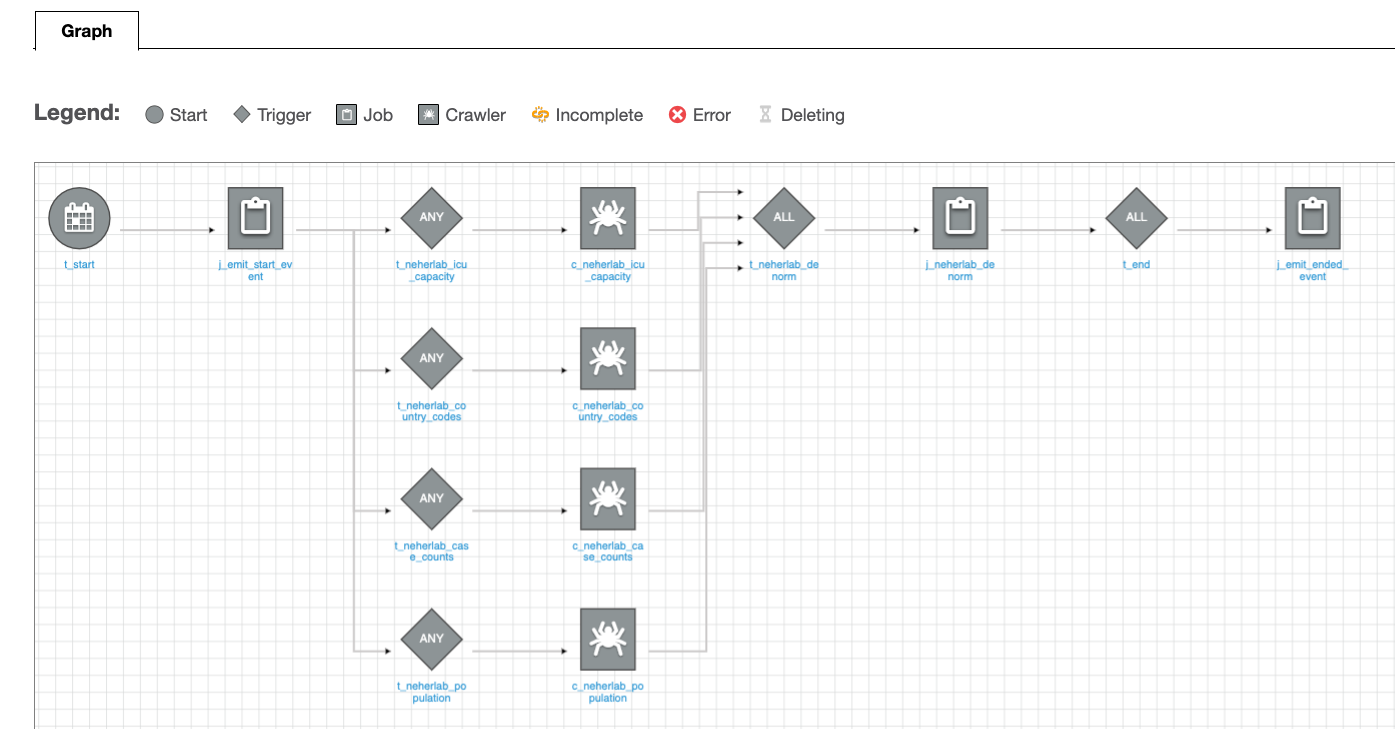
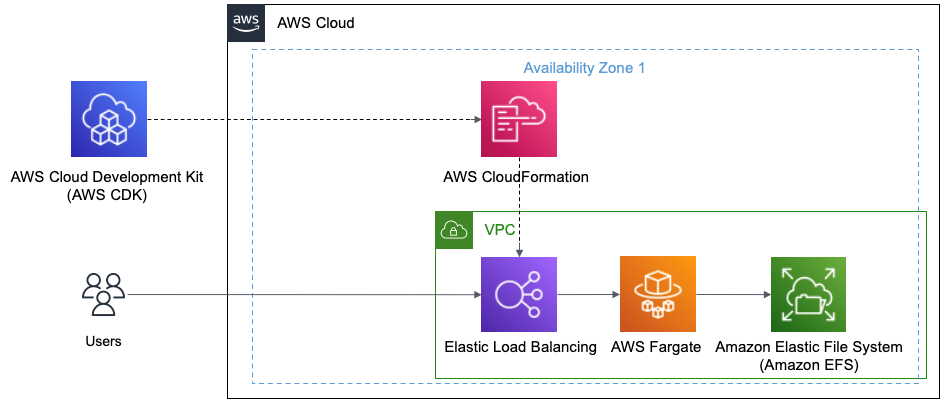
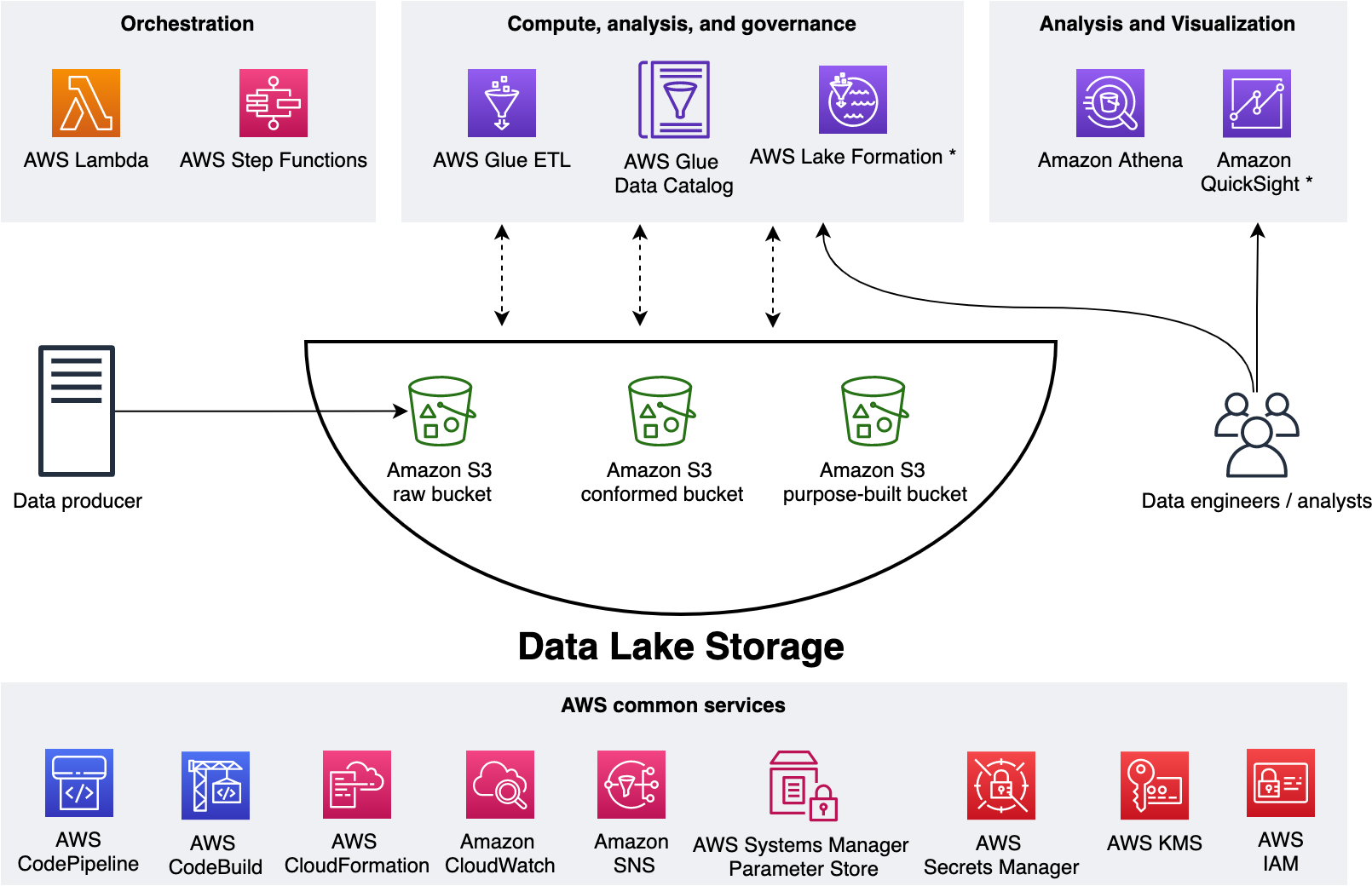
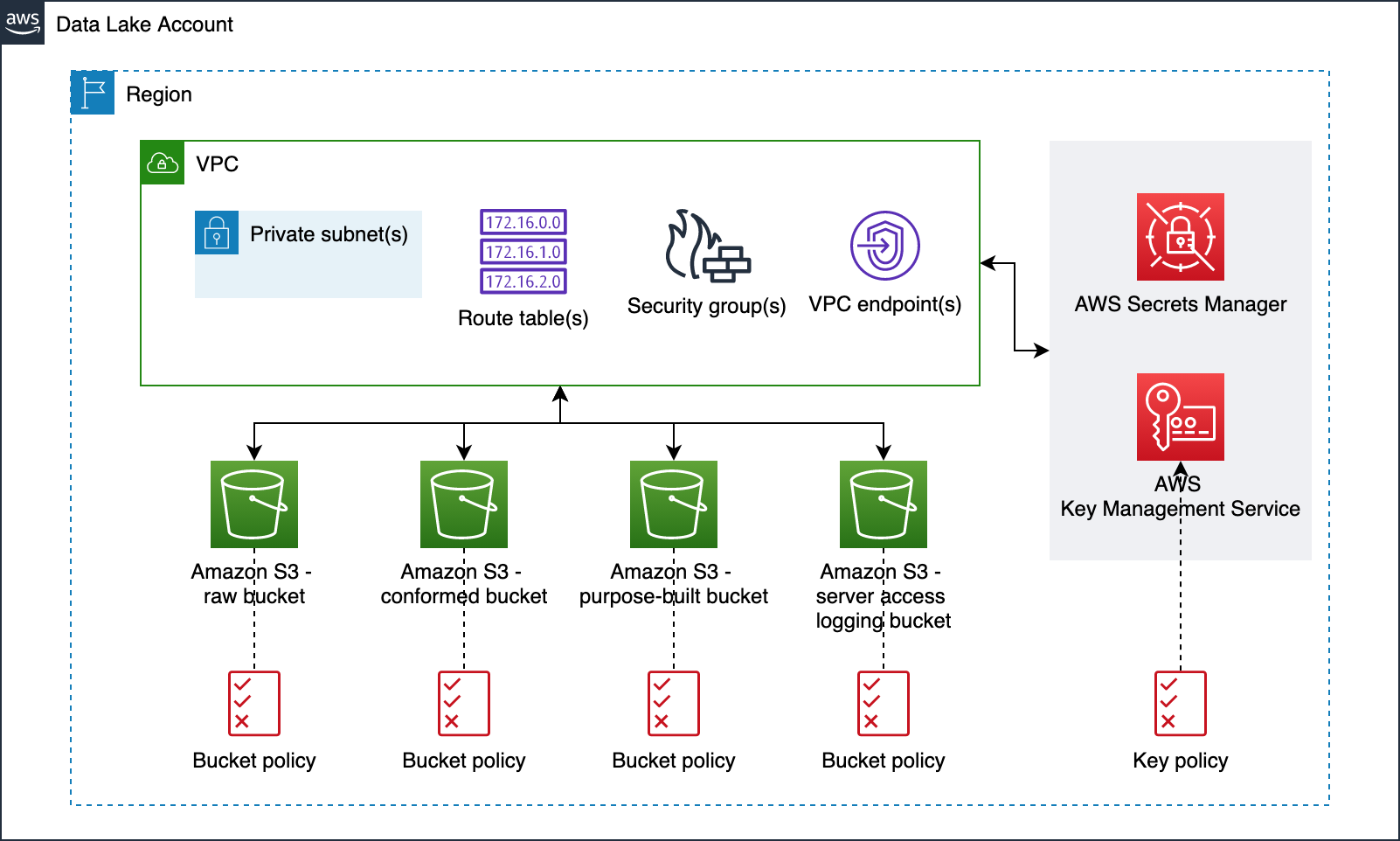
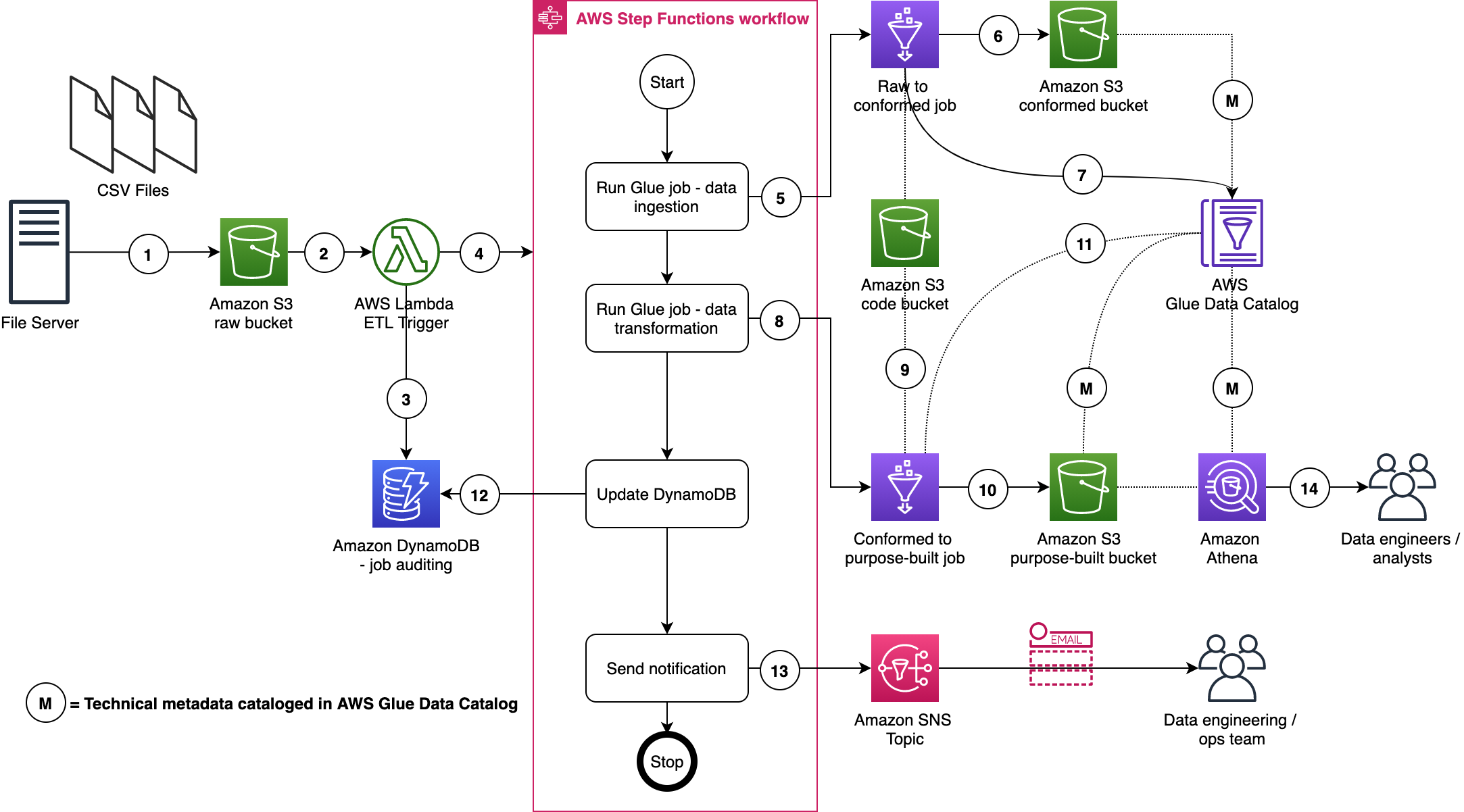
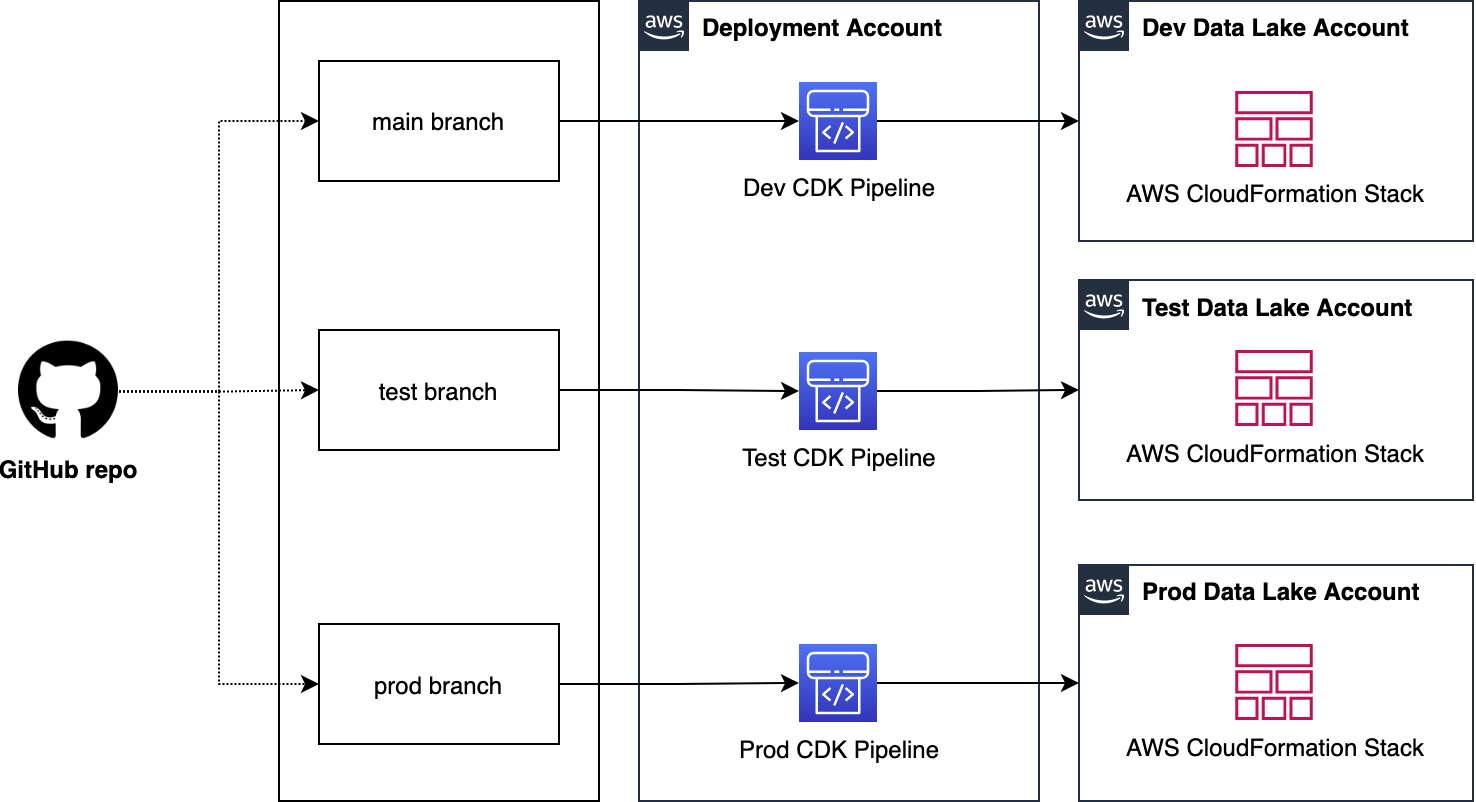
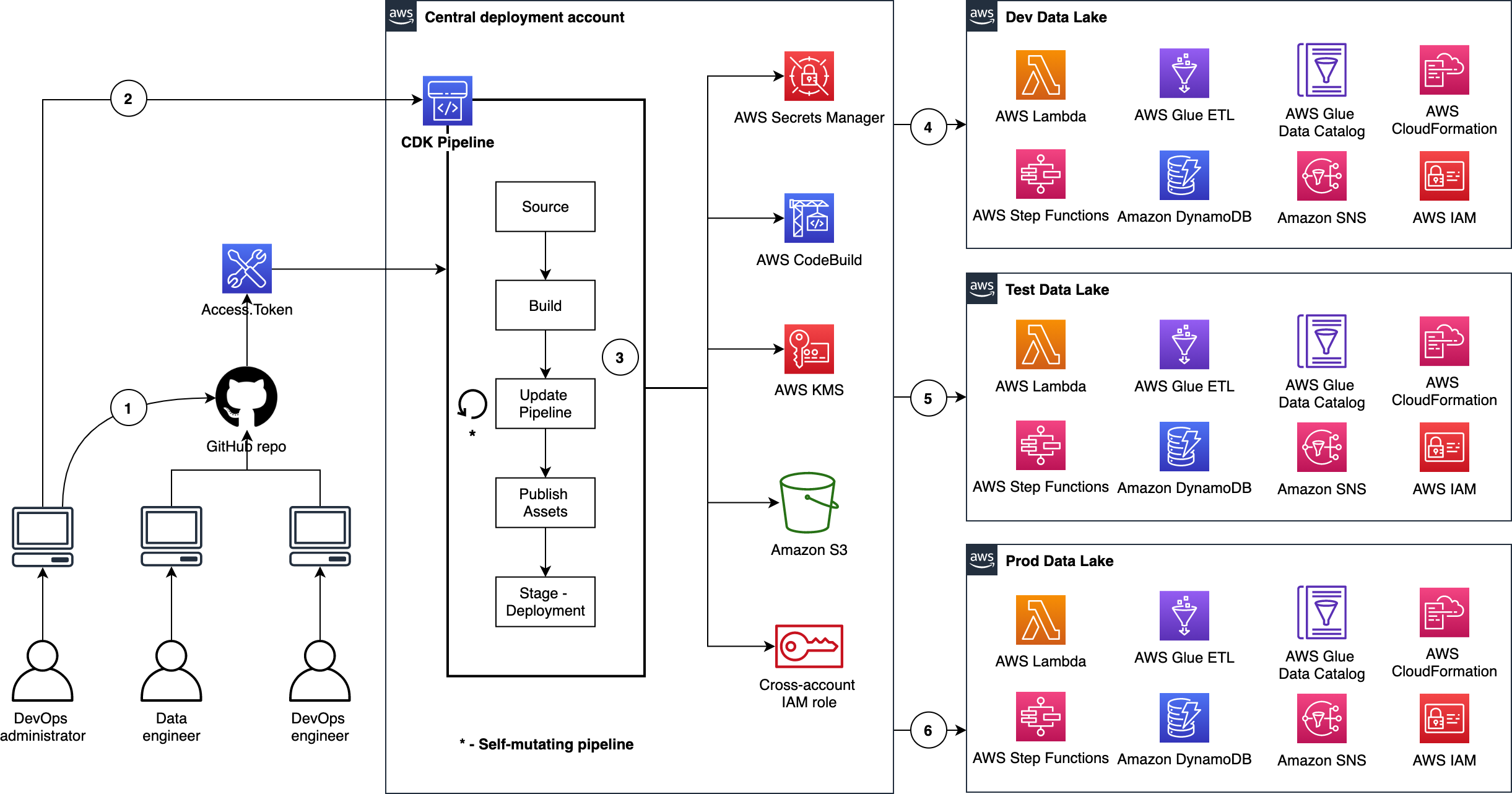
In this post, we show how a data engineer or IT administrator can use the AWS Analytics Reference Architecture (ARA) to accelerate infrastructure deployment, saving your organization both time and money spent on these data analytics experiments. We use the library to deploy an Amazon Elastic Kubernetes (Amazon EKS) cluster, configure it to use Amazon EMR on EKS, and deploy a virtual cluster and managed endpoints and EMR Studio. You can then either run jobs on the virtual cluster or run exploratory data analysis with Jupyter notebooks on Amazon EMR Studio and Amazon EMR on EKS. The architecture below represent the infrastructure you will deploy with the AWS Analytics Reference Architecture.

Prerequisites
To follow along, you need to have an AWS account that is bootstrapped with the AWS Cloud Development Kit (AWS CDK). For instructions, refer to Bootstrapping. The following tutorial uses TypeScript, and requires version 2 or later of the AWS CDK. If you don’t have the AWS CDK installed, refer to Install the AWS CDK.
Set up an AWS CDK project
To deploy resources using the ARA, you first need to set up an AWS CDK project and install the ARA library. Complete the following steps:
- Create a folder named emr-eks-app:
- Initialize an AWS CDK project in an empty directory and run the following command:
- Install the ARA library:
- In lib/emr-eks-app.ts, import the ARA library as follows. The first line calls the ARA library, the second one defines AWS Identity and Access Management (IAM) policies:
Create and define an EKS cluster and compute capacity
To create an EMR on EKS virtual cluster, you first need to deploy an EKS cluster. The ARA library defines a construct called EmrEksCluster. The construct provisions an EKS cluster, enables IAM roles for service accounts, and deploys a set of supporting controllers like certificate manager controller (needed by the managed endpoint that is used by Amazon EMR Studio) as well as a cluster auto scaler to have an elastic cluster and save on cost when no job is submitted to the cluster.
In lib/emr-eks-app.ts, add the following line:
To learn more about the properties you can customize, refer to EmrEksClusterProps. There are two mandatory parameters in EmrEksCluster construct: The first is eksAdminRoleArn role is mandatory and is the role you use to interact with the Kubernetes control plane. This role must have administrative permissions to create or update the cluster. The second parameter is autoscaling, this parameter allows you to select the autoscaling mechanism, either Karpenter or native Kubernetes Cluster Autoscaler. In this blog we will use Karpenter and we recommend its use due to faster autoscaling, simplified node management and provisioning. Now you’re ready to define the compute capacity.
One way to define worker nodes in Amazon EKS is to use managed node groups. We use one node group called tooling, which hosts the coredns, ingress controller, certificate manager, Karpenter and any other pod that is necessary for the running EMR on EKS jobs or ManagedEndpoint. We also define default Karpenter Provisioners that define capacity to be used for jobs submitted by EMR on EKS. These Provisioners are optimized for different Spark use cases (critical jobs, non-critical job, experimentation and interactive sessions). The construct also allows you to submit your own provisioner defined by a Kubernetes manifest through a method called addKarpenterProvisioner. Let’s discuss the predefined Provisioners.
Default Provisioners configurations
The default provisioners are set for rapid experimentation and are always created by default. However, if you don’t want to use them, you can set the defaultNodeGroups parameter to false in the EmrEksCluster properties at creation time. The Provisioners are defined as follows and are created in each of the subnets that are used by Amazon EKS:
- Critical provisioner – It is dedicated to supporting jobs with aggressive SLAs and are time sensitive. The provisioner uses On-Demand Instances, which aren’t stopped, unlike Spot Instances, and their lifecycle follows through one of the jobs. The nodes use instance stores, which are NVMe disks physically attached to the host, which offer a high I/O throughput that allow better Spark performance, because it’s used as temporary storage for disk spill and shuffle. The instance types used in the node are of the m6gd family. The instances use the AWS Graviton processor, which offers better price/performance than x86 processors. To use this provisioner in your jobs, you can use the following sample configuration, which is referenced in the configuration override of the EMR on EKS job submission.
- Non-critical provisioner – This Provisioner leverage Spot Instances to save costs for jobs that aren’t time sensitive or jobs that are used for experiments. This node use Spot Instances because the jobs aren’t critical and can be interrupted. These instances can be stopped if the instance is reclaimed. The instance types used in the node are of the m6gd family, the driver is On-Demand and executors are on spot instances.
- Notebook provisioner – The Provisioner is for running managed endpoints that are used by Amazon EMR Studio for data exploration using Amazon EMR on EKS. The instances are of t3 family and are On-Demand for driver and Spot Instances for executors to keep the cost low. If the executor instances are stopped, new ones are started by Karpenter. If the executor instances are stopped too often, you can define your own that use On-Demand instances.
The following link provides more details about how each of the provisioner are defined. One import property that is defined in the default Provisioners is there is one for each AZ. This is important because it allows you to reduce inter-AZ network transfer cost when Spark runs a shuffle.
For this post, we use the default Provisioners, so you don’t need to add any lines of code for this section. If you want yo add your own Provisioners you can leverage the method addKarpenterProvisioner to apply your own manifests. You can use helper methods in Utils class like readYamlDocument to read YAML document and loadYaml load YAML files and pass them as arguments to addKarpenterProvisioner method.
Deploy the virtual cluster and an execution role
A virtual cluster is a Kubernetes namespace that Amazon EMR is registered with; when you submit a job, the driver and executor pods are running in the associated namespace. The EmrEksCluster construct offers a method called addEmrVirtualCluster, which creates the virtual cluster for you. The method takes EmrVirtualClusterOptions as a parameter, which has the following attributes:
- name – The name of your virtual cluster.
- createNamespace – An optional field that creates the EKS namespace. This is of type Boolean and by default it doesn’t create a separate EKS namespace, so your virtual cluster is created in the default namespace.
- eksNamespace – The name of the EKS namespace to be linked with the virtual EMR cluster. If no namespace is supplied, the construct uses the default namespace.
- In
lib/emr-eks-app.ts, add the following line to create your virtual cluster:Now we create the execution role, which is an IAM role that is used by the driver and executor to interact with AWS services. Before we can create the execution role for Amazon EMR, we need to first create the
ManagedPolicy. Note that in the following code, we create a policy to allow access to the Amazon Simple Storage Service (Amazon S3) bucket and Amazon CloudWatch logs. - In
lib/emr-eks-app.ts, add the following line to create the policy:If you want to use the AWS Glue Data Catalog, add its permission in the preceding policy.
Now we create the execution role for Amazon EMR on EKS using the policy defined in the previous step using the
createExecutionRoleinstance method. The driver and executor pods can then assume this role to access and process data. The role is scoped in such a way that only pods in the virtual cluster namespace can assume it. To learn more about the condition implemented by this method to restrict access to the role to only pods that are created by Amazon EMR on EKS in the namespace of the virtual cluster, refer to Using job execution roles with Amazon EMR on EKS. - In
lib/emr-eks-app.ts, add the following line to create the execution role:The preceding code produces an IAM role called
execRoleJobwith the IAM policy defined inemrekspolicyand scoped to the namespacedataanalysis. - Lastly, we output parameters that are important for the job run:
Deploy Amazon EMR Studio and provision users
To deploy an EMR Studio for data exploration and job authoring, the ARA library has a construct called NotebookPlatform. This construct allows you to deploy as many EMR Studios as you need (within the account limit) and set them up with the authentication mode that is suitable for you and assign users to them. To learn more about the authentication modes available in Amazon EMR Studio, refer to Choose an authentication mode for Amazon EMR Studio.
The construct creates all the necessary IAM roles and policies needed by Amazon EMR Studio. It also creates an S3 bucket where all the notebooks are stored by Amazon EMR Studio. The bucket is encrypted with a customer managed key (CMK) generated by the AWS CDK stack. The following steps show you how to create your own EMR Studio with the construct.
The notebook platform construct takes NotebookPlatformProps as a property, which allows you to define your EMR Studio, a namespace, the name of the EMR Studio, and its authentication mode.
- In
lib/emr-eks-app.ts, add the following line:For this post, we use IAM users so that you can easily reproduce it in your own account. However, if you have IAM federation or single sign-on (SSO) already in place, you can use them instead of IAM users.To learn more about the parameters of
NotebookPlatformProps, refer to NotebookPlatformProps.Next, we need to create and assign users to the Amazon EMR Studio. For this, the construct has a method called
addUserthat takes a list of users and either assigns them to Amazon EMR Studio in case of SSO or updates the IAM policy to allows access to Amazon EMR Studio for the provided IAM users. The user can also have multiple managed endpoints, and each user can have their Amazon EMR version defined. They can use a different set of Amazon Elastic Compute Cloud (Amazon EC2) instances and different permissions using job execution roles. - In
lib/emr-eks-app.ts, add the following line:In the preceding code, for the sake of brevity, we reuse the same IAM policy that we created in the execution role.
Note that the construct optimizes the number of managed endpoints that are created. If two endpoints have the same name, then only one is created.
- Now that we have defined our deployment, we can deploy it:
You can find a sample project that contains all the steps of the walk through in the following GitHub repository.
When the deployment is complete, the output contains the S3 bucket containing the assets for podTemplate, the link for the EMR Studio, and the EMR Studio virtual cluster ID. The following screenshot shows the output of the AWS CDK after the deployment is complete.

Submit jobs

Because we’re using the default Provisioners, we will use the podTemplate that is defined by the construct available on the ARA GitHub repository. These are uploaded for you by the construct to an S3 bucket called <clustername>-emr-eks-assets; you only need to refer to them in your Spark job. In this job, you also use the job parameters in the output at the end of the AWS CDK deployment. These parameters allow you to use the AWS Glue Data Catalog and implement Spark on Kubernetes best practices like dynamicAllocation and pod collocation. At the end of cdk deploy ARA will output job sample configurations with the best practices listed before that you can use to submit a job. You can submit a job as follows.
A job run is a unit of work such as a Spark JAR file that is submitted to the EMR on EKS cluster. We start a job using the start-job-run command. Note you can use SparkSubmitParameters to specify the Amazon S3 path to the pod template, as shown in the following command:
The code takes the following values:
- <CLUSTER-ID> – The EMR virtual cluster ID
- <SPARK-JOB-NAME> – The name of your Spark job
- <ROLE-ARN> – The execution role you created
- <S3URI-SPARK-JOB> – The Amazon S3 URI of your Spark job
- <S3URI-CRITICAL-DRIVER> – The Amazon S3 URI of the driver pod template, which you get from the AWS CDK output
- <S3URI-CRITICAL-EXECUTOR> – The Amazon S3 URI of the executor pod template
- <Log_Group_Name> – Your CloudWatch log group name
- <Log_Stream_Prefix> – Your CloudWatch log stream prefix
You can go to the Amazon EMR console to check the status of your job and to view logs. You can also check the status by running the describe-job-run command:
Explore data using Amazon EMR Studio
In this section, we show how you can create a workspace in Amazon EMR Studio and connect to the Amazon EKS managed endpoint from the workspace. From the output, use the link to Amazon EMR Studio to navigate to the EMR Studio deployment. You must sign in with the IAM username you provided in the addUser method.
Create a Workspace
To create a Workspace, complete the following steps:
- Log in to the EMR Studio created by the AWS CDK.
- Choose Create Workspace.
- Enter a workspace name and an optional description.
- Select Allow Workspace Collaboration if you want to work with other Studio users in this Workspace in real time.
- Choose Create Workspace.

After you create the Workspace, choose it from the list of Workspaces to open the JupyterLab environment.

The following screenshot shows what the terminal looks like. For more information about the user interface, refer to Understand the Workspace user interface.

Connect to an EMR on EKS managed endpoint
You can easily connect to the EMR on EKS managed endpoint from the Workspace.
- In the navigation pane, on the Clusters menu, select EMR Cluster on EKS for Cluster type.
The virtual clusters appear on the EMR Cluster on EKS drop-down menu, and the endpoint appears on the Endpoint drop-down menu. If there are multiple endpoints, they appear here, and you can easily switch between endpoints from the Workspace. - Select the appropriate endpoint and choose Attach.


Work with a notebook
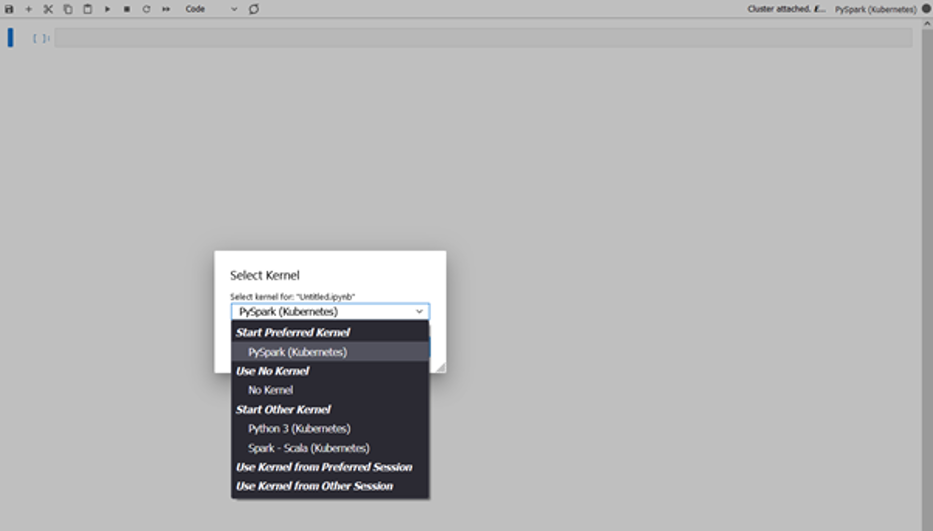
You can now open a notebook and connect to a preferred kernel to do your tasks. For instance, you can select a PySpark kernel, as shown in the following screenshot.
Explore your data
The first step of our data exploration exercise is to create a Spark session and then load the New York taxi dataset from the S3 bucket into a data frame. Use the following code block to load the data into a data frame. Copy the Amazon S3 URI for the location where the dataset resides in Amazon S3.
After we load the data into a data frame, we replace the data of the current_date column with the actual current date, count the number of rows, and save the data into a Parquet file:
The following screenshot shows the result of our notebook running on Amazon EMR Studio and with PySpark running on Amazon EMR on EKS.

Clean up
To clean up after this post, run cdk destroy.
Conclusion
In this post, we showed how you can use the ARA to quickly deploy a data analytics infrastructure and start experimenting with your data. You can find the full example referenced in this post in the GitHub repository. The AWS Analytics Reference Architecture implements common Analytics pattern and AWS best practices to offer you ready to use constructs to for your experiments. One of the patterns is the data mesh, which you can consult how to use in this blog post.
You can also explore other constructs offered in this library to experiment with AWS Analytics services before transitioning your workload for production.
About the Authors
 Lotfi Mouhib is a Senior Solutions Architect working for the Public Sector team with Amazon Web Services. He helps public sector customers across EMEA realize their ideas, build new services, and innovate for citizens. In his spare time, Lotfi enjoys cycling and running.
Lotfi Mouhib is a Senior Solutions Architect working for the Public Sector team with Amazon Web Services. He helps public sector customers across EMEA realize their ideas, build new services, and innovate for citizens. In his spare time, Lotfi enjoys cycling and running.
 Sandipan Bhaumik is a Senior Analytics Specialist Solutions Architect based in London. He has worked with customers in different industries like Banking & Financial Services, Healthcare, Power & Utilities, Manufacturing and Retail helping them solve complex challenges with large-scale data platforms. At AWS he focuses on strategic accounts in the UK and Ireland and helps customers to accelerate their journey to the cloud and innovate using AWS analytics and machine learning services. He loves playing badminton, and reading books.
Sandipan Bhaumik is a Senior Analytics Specialist Solutions Architect based in London. He has worked with customers in different industries like Banking & Financial Services, Healthcare, Power & Utilities, Manufacturing and Retail helping them solve complex challenges with large-scale data platforms. At AWS he focuses on strategic accounts in the UK and Ireland and helps customers to accelerate their journey to the cloud and innovate using AWS analytics and machine learning services. He loves playing badminton, and reading books.