Post Syndicated from Steve Roberts original https://aws.amazon.com/blogs/aws/new-aws-systems-manager-fleet-manager/
Organizations, and their systems administrators, routinely face challenges in managing increasingly diverse portfolios of IT infrastructure across cloud and on-premises environments. Different tools, consoles, services, operating systems, procedures, and vendors all contribute to complicate relatively common, and related, management tasks. As workloads are modernized to adopt Linux and open-source software, those same systems administrators, who may be more familiar with GUI-based management tools from a Windows background, have to continually adapt and quickly learn new tools, approaches, and skill sets.
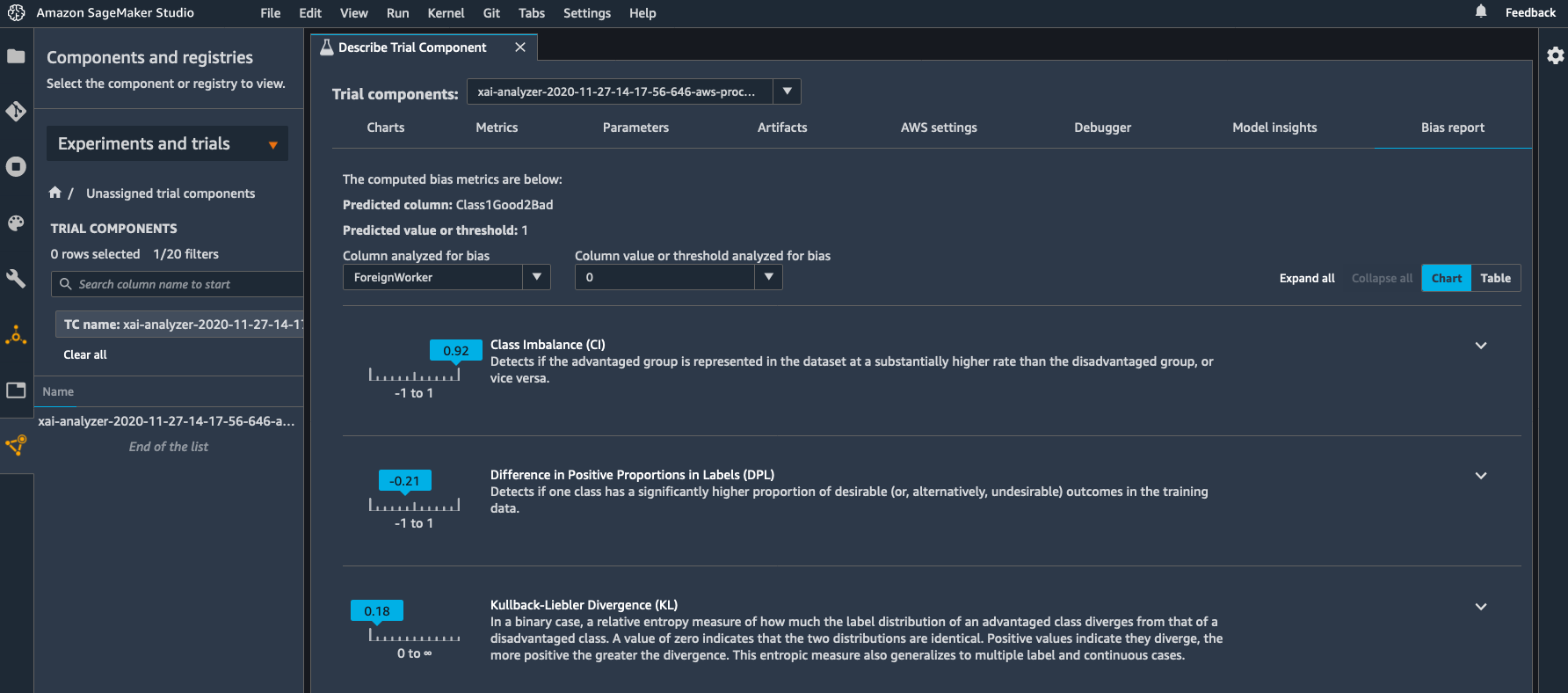
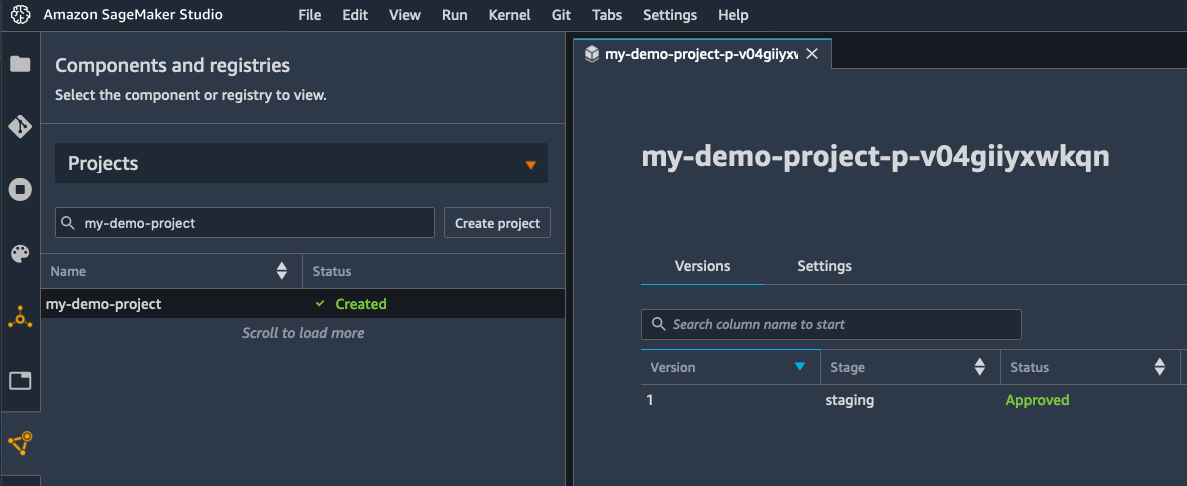
AWS Systems Manager is an operational hub enabling you to manage resources on AWS and on-premises. Available today, Fleet Manager is a new console based experience in Systems Manager that enables systems administrators to view and administer their fleets of managed instances from a single location, in an operating-system-agnostic manner, without needing to resort to remote connections with SSH or RDP. As described in the documentation, managed instances includes those running Windows, Linux, and macOS operating systems, in both the AWS Cloud and on-premises. Fleet Manager gives you an aggregated view of your compute instances regardless of where they exist.
All that’s needed, whether for cloud or on-premises servers, is the Systems Manager agent installed on each server to be managed, some AWS Identity and Access Management (IAM) permissions, and AWS Key Management Service (KMS) enabled for Systems Manager‘s Session Manager. This makes it an easy and cost-effective approach for remote management of servers running in multiple environments without needing to pay the licensing cost of expensive management tools you may be using today. As noted earlier, it also works with instances running macOS. With the agent software and permissions set up, Fleet Manager enables you to explore and manage your servers from a single console environment. For example, you can navigate file systems, work with the registry on Windows servers, manage users, and troubleshoot logs (including viewing Windows event logs) and monitor common performance counters without needing the Amazon CloudWatch agent to be installed.
Exploring an Instance With Fleet Manager
To get started exploring my instances using Fleet Manager, I first head to the Systems Manager console. There, I select the new Fleet Manager entry on the navigation toolbar. I can also select the Managed Instances option – Fleet Manager replaces Managed Instances going forward, but the original navigation toolbar entry will be kept for backwards compatibility for a short while. But, before we go on to explore my instances, I need to take you on a brief detour.
When you select Fleet Manager, as with some other views in Systems Manager, a check is performed to verify that a role, named AmazonSSMRoleForInstancesQuickSetup, exists in your account. If you’ve used other components of Systems Manager in the past, it’s quite possible that it does. The role is used to permit Systems Manager to access your instances on your behalf and if the role exists, then you’re directed to the requested view. If however the role doesn’t exist, you’ll first be taken to the Quick Setup view. This in itself will trigger creation of the role, but you might want to explore the capabilities of Quick Setup, which you can also access any time from the navigation toolbar.
Quick Setup is a feature of Systems Manager that you can use to set up specific configuration items, such as the Systems Manager and CloudWatch agents on your instances (and keep them up-to-date), and also IAM roles permitting access to your resources for Systems Manager components. For this post, all the instances I’m going to use already have the required agent set up, including the role permissions, so I’m not going to discuss this view further but I encourage you to check it out. I also want to remind you that to take full advantage of Fleet Manager‘s capabilities you first need to have KMS encryption enabled for your instances and secondly, the role attached to your Amazon Elastic Compute Cloud (EC2) instances must have the kms:Decrypt role permission included, referencing the key you selected when you enabled KMS encryption. You can enable encryption, and select the KMS key, using the Preferences section of the Session Manager console, and of course you can set up the role permission in the IAM console.
That’s it for the diversion; if you have the role already, as I do, you’ll now be at the Managed instances list view. If you’re at Quick Setup instead, simply click the Fleet Manager navigation button once more.
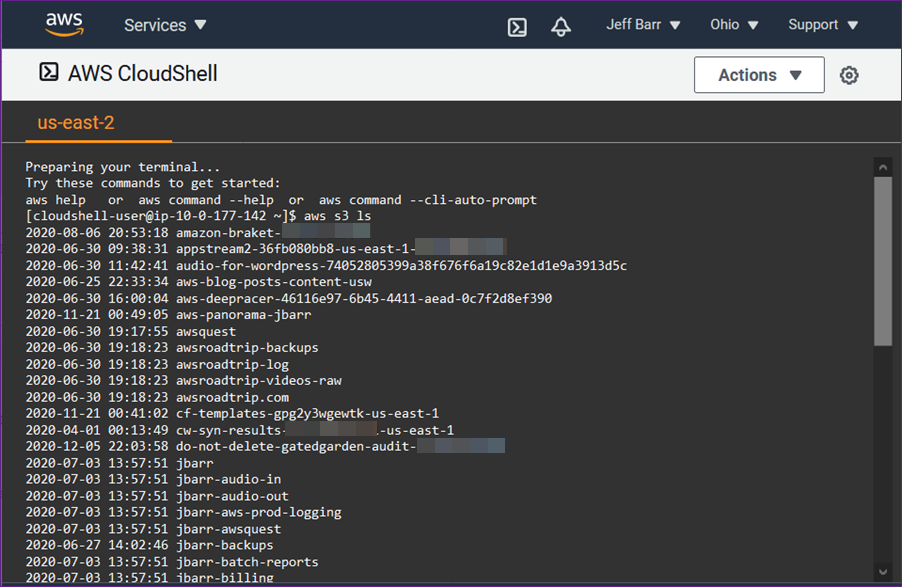
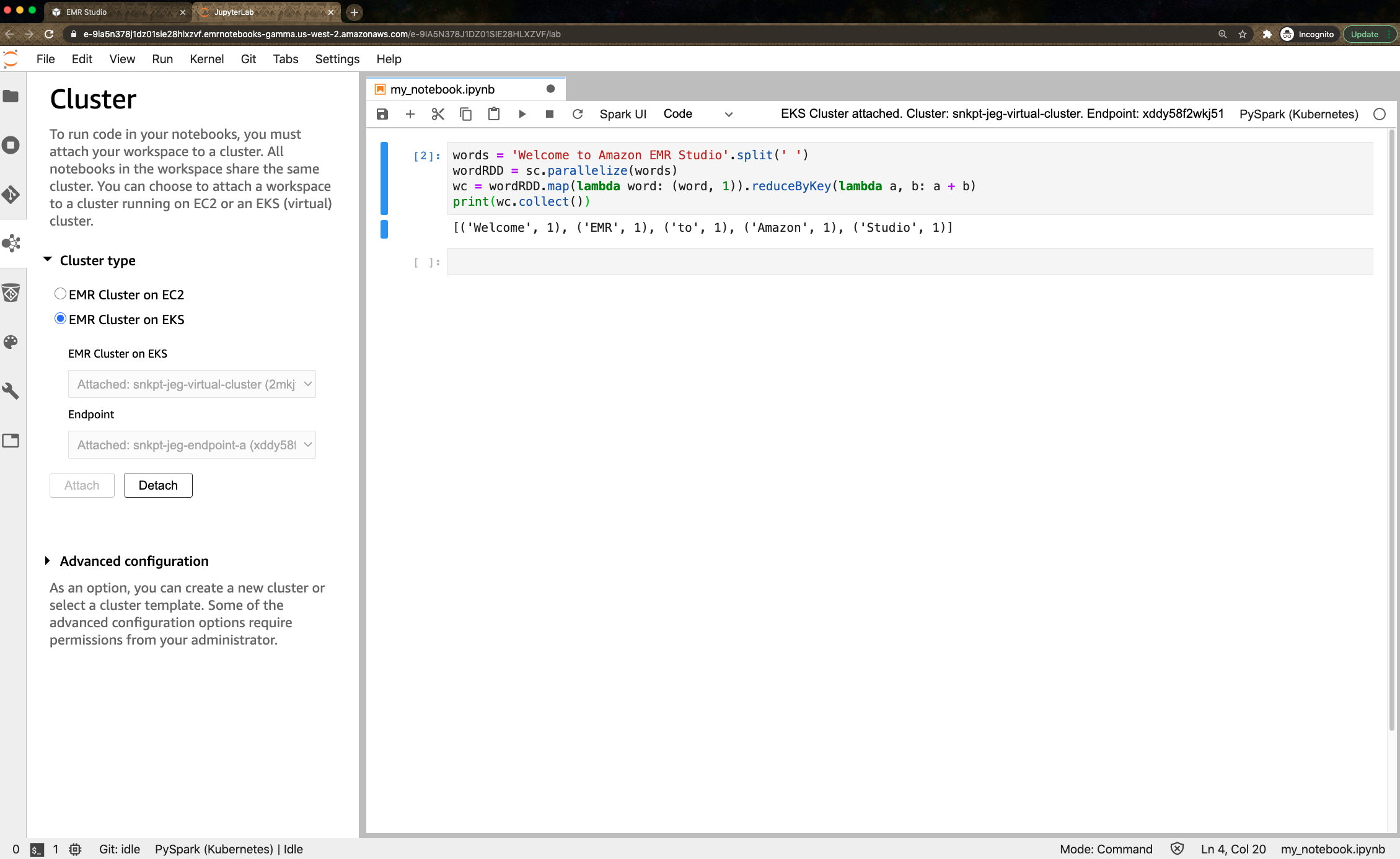
The Managed instances view shows me all of my instances, in the cloud or on-premises, that I can access. Selecting an instance, in this case an EC2 Windows instance launched using AWS Elastic Beanstalk, and clicking Instance actions presents me with a menu of options. The options (less those specific to Windows) are available for my Amazon Linux instance too, and for instances running macOS I can use the View file system option.
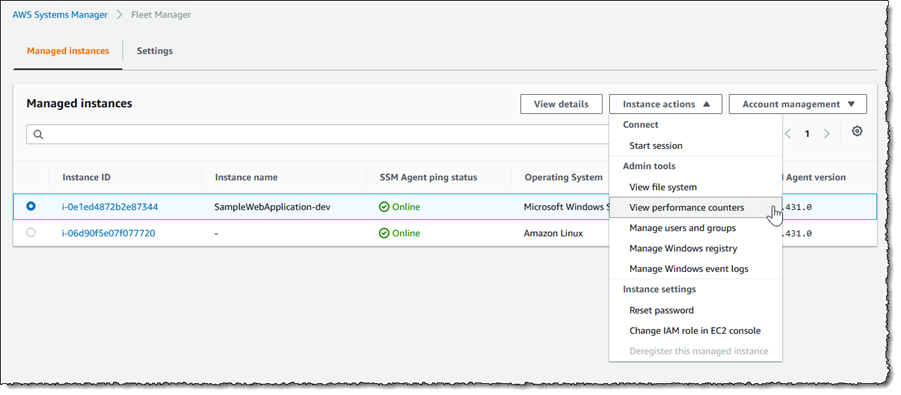
The File system view displays a read-only view onto the file system of the selected instance. This can be particularly useful for viewing text-based log files, for example, where I can preview up to 10,000 lines of a log file and even tail it to view changes as the log updates. I used this to open and tail an IIS web server log on my Windows Server instance. Having selected the instance, I next select View file system from the Instance actions dropdown (or I can click the Instance ID to open a view onto that instance and select File system from the menu displayed on the instance view).
Having opened the file system view for my instance, I navigate to the folder on the instance containing the IIS web server logs.
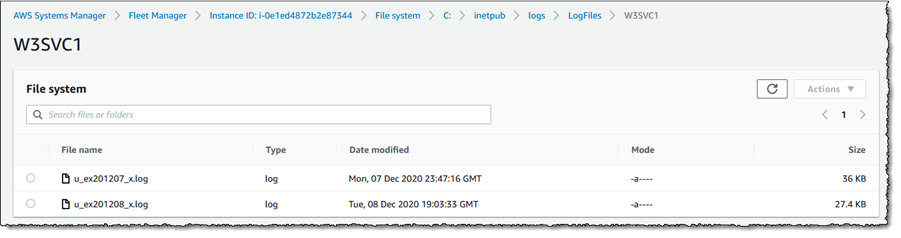
Selecting a log file, I then click Actions and select Tail file. This opens a view onto the log file contents, which updates automatically as new content is written.
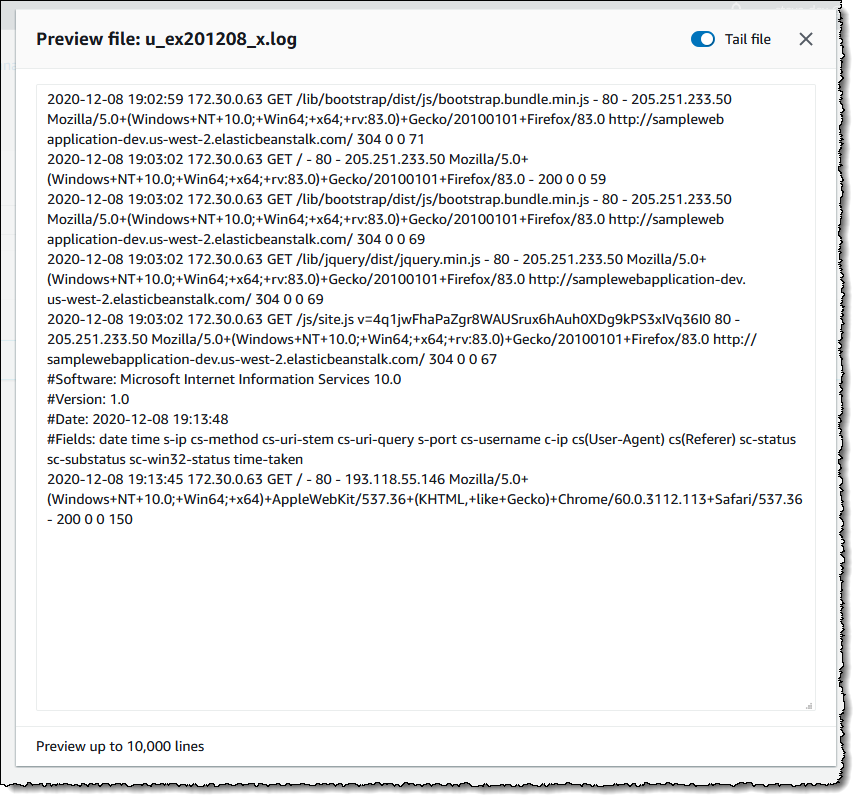
As I mentioned, the File system view is also accessible for macOS-based instances. For example, here is a screenshot of viewing the Applications folder on an EC2 macOS instance.
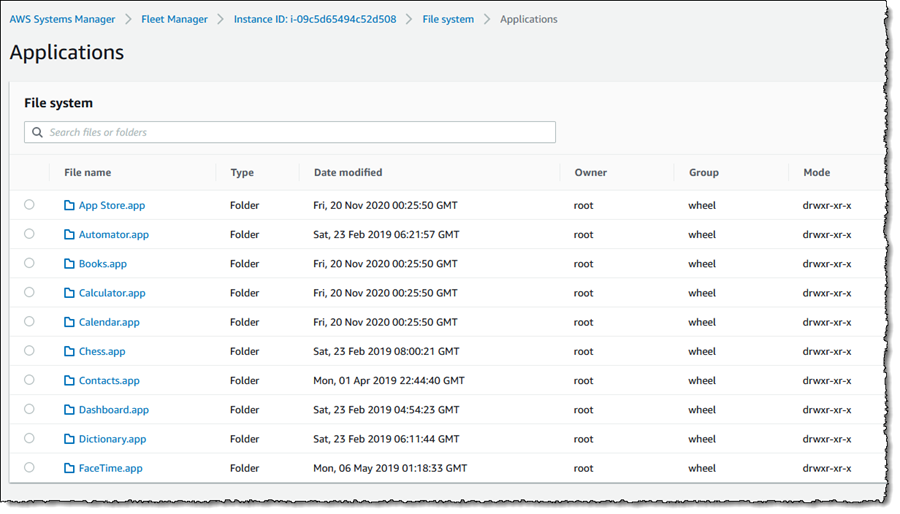
Next, let’s examine the Performance counters view, which is available for both Windows and Linux instances. This view displays CPU, memory, network traffic, and disk I/O and will be familiar to Windows users from Task Manager. The metrics shown reflect the guest OS metrics, whereas EC2 instance metrics you may be used to relate to the hypervisor. On this particular instance I’ve deployed an ASP.NET Core 5 application, which generates a varying length collection of Fibonacci numbers on page refresh. Below is a snapshot of the counters, after I’ve put the instance under a small amount of load. The view updates automatically every 5 seconds.
There are more views available than I have space for in this post. Using the Windows Registry view, I can view and edit the registry on the selected Windows instance. Windows event logs gives me access to the Application and Service logs, and common Windows logs such as System, Setup, Security, etc. With Users and groups I can manage users or groups, including assignment of users to groups (again for both Windows and Linux instances). For all views, Fleet Manager enables me to use a single and convenient console.
Getting Started
AWS Systems Manager Fleet Manager is available today for use with managed instances running Windows, Linux, and macOS. Information on pricing, for this and other Systems Manager features, can be found at this page.
Learn more, and get started with Fleet Manager today, at AWS Systems Manager.









































 Traditionally, organizations rely on manual audits of large amounts of data, which is not scalable and is prone to human error. Others use rule-based methods based on arbitrary ranges, which are often static, do not easily adapt to seasonality changes, and lead to too many false detections.
Traditionally, organizations rely on manual audits of large amounts of data, which is not scalable and is prone to human error. Others use rule-based methods based on arbitrary ranges, which are often static, do not easily adapt to seasonality changes, and lead to too many false detections.