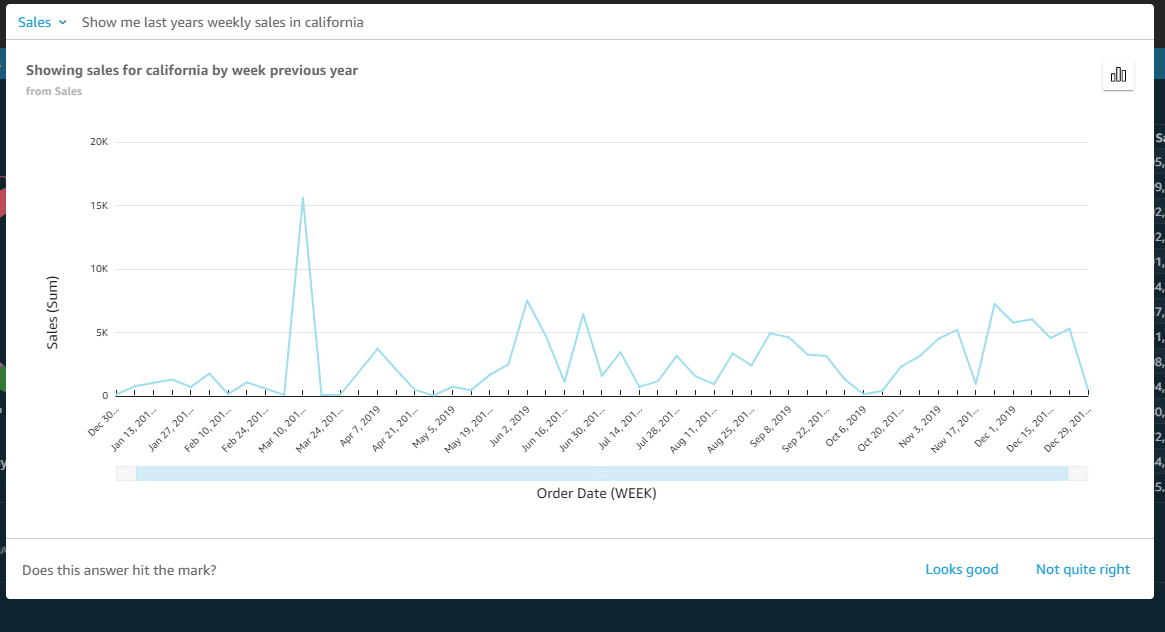
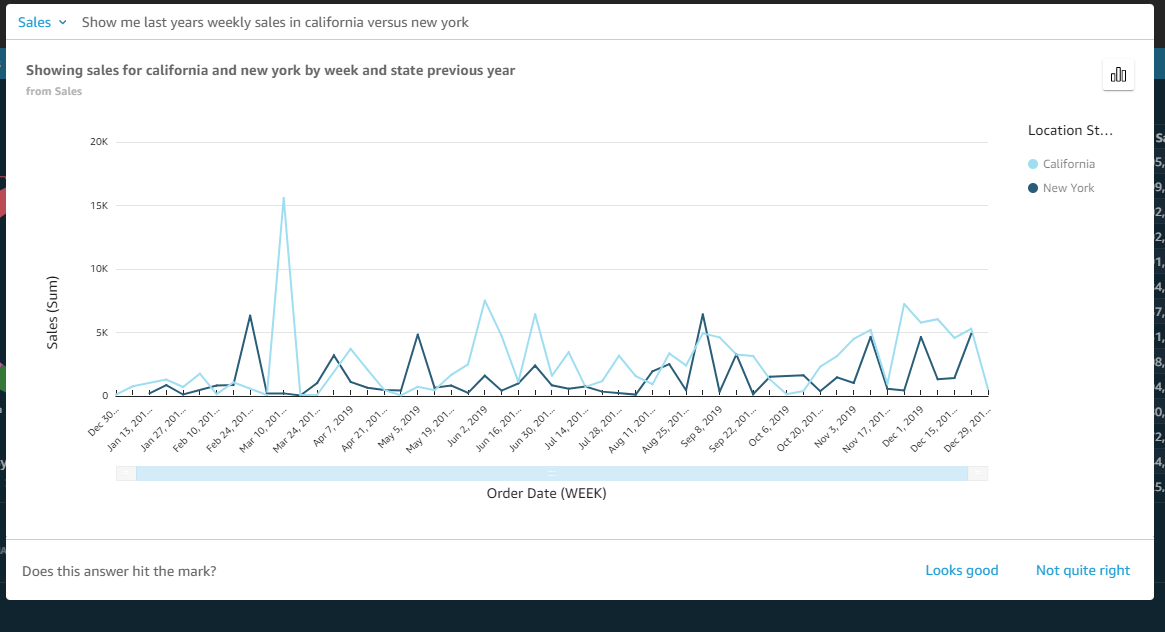
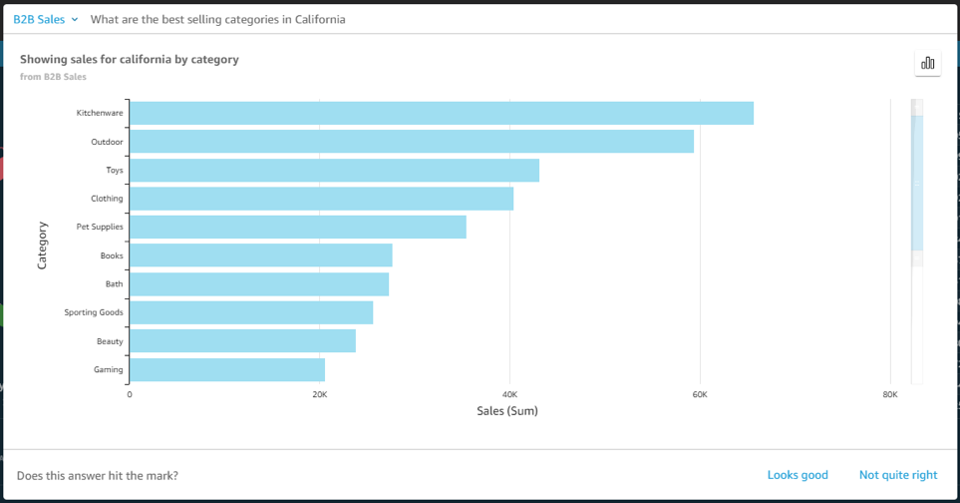
Post Syndicated from Julien Simon original https://aws.amazon.com/blogs/aws/amazon-sagemaker-simplifies-training-deep-learning-models-with-billions-of-parameters/
Today, I’m extremely happy to announce that Amazon SageMaker simplifies the training of very large deep learning models that were previously difficult to train due to hardware limitations.
In the last 10 years, a subset of machine learning named deep learning (DL) has taken the world by storm. Based on neural networks, DL algorithms have an extraordinary ability to extract information patterns hidden in vast amounts of unstructured data, such as images, videos, speech, or text. Indeed, DL has quickly achieved impressive results on a variety of complex human-like tasks, especially on computer vision and natural language processing. In fact, innovation has never been faster, as DL keeps improving its results on reference tasks like the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), the General Language Understanding Evaluation (GLUE), or the Stanford Question Answering Dataset (SQUAD).
In order to tackle ever more complex tasks, DL researchers are designing increasingly sophisticated models, adding more neuron layers and more connections to improve pattern extraction and prediction accuracy, with a direct impact on model size. For example, you would get very good results on image classification with a 100-megabyte ResNet-50 model. For more difficult tasks such as object detection or instance segmentation, you would have to use larger models such as Mask R-CNN or YOLO v4, weighing in at about 250 megabytes.
As you can guess, model growth also impacts the amount of time and hardware resources required for model training, which is why Graphical Processing Units (GPU) have long been the preferred option to train and fine-tune large DL models. Thanks to their massively parallel architecture and their large on-board memory, they make it possible to use a technique called mini-batch training. By sending several data samples at once to the GPU, instead of sending them one by one, communication overhead is reduced, and training jobs are greatly accelerated. For example, the NVIDIA A100 available on the Amazon Elastic Compute Cloud (EC2) p4 family has over 7,000 compute cores and 40 gigabytes of fast onboard memory. Surely, that should be enough to train large batches of data on very large models, shouldn’t it?
Well, it’s not. Natural language processing behemoths such as OpenAI GPT-2 (1.5 billion parameters), T5-3B (3 billion parameters) and GPT-3 (175 billion parameters) consume tens or even hundreds of gigabytes of GPU memory. Likewise, state-of-the-art models working on high-resolution 3D images can be too large to fit in GPU memory, even with a batch size of 1…
Trying to square the circle, DL researchers use a combination of techniques, such as the following:
- Buy more powerful GPUs, although we just saw that this is simply not an option for some models.
- Work with less powerful models, and sacrifice accuracy.
- Implement gradient checkpointing, a technique that relies on saving intermediate training results to disk instead of keeping everything in memory, at the expense of a 20-30% training slowdown.
- Implement model parallelism, that is to say split the model manually, and train its (smaller) pieces on different GPUs. Needless to say, this is an extremely difficult, time-consuming, and uncertain task, even for expert practitioners.
Customers have told us that none of the above was a satisfactory solution to working with very large models. They asked us for a simpler and more cost-effective solution, and we got to work.
Introducing Model Parallelism in Amazon SageMaker
Model parallelism in SageMaker automatically and efficiently partitions models across several GPUs, eliminating the need for accuracy compromises or for complex manual work. In addition, thanks to this scale-out approach to model training, not only can you work with very large models without any memory bottleneck, you can also leverage a large number of smaller and more cost-effective GPUs.
At launch, this is supported for TensorFlow and PyTorch, and it only requires minimal changes in your code. When you launch a training job, you can specify whether your model should be optimized for speed or for memory usage. Then, Amazon SageMaker runs an initial profiling job on your behalf in order to analyze the compute and memory requirements of your model. This information is then fed to a partitioning algorithm which decides how to split the model and how to map model partitions to GPUs, while minimizing communication. The outcome of the partitioning decision is saved to a file, which is passed as input to the actual training job.
As you can see, SageMaker takes care of everything. If you’d like, you could also manually profile and partition the model, then train on SageMaker.
Before we look at the code, I’d like to give you a quick overview of the internals.
Training with Model Partitions and Microbatches
As model partitions running on different GPUs expect forward pass inputs from each other (activation values), processing training mini-batches across a sequence of partitions would only keep one partition busy at all times, while stalling the other ones.
To avoid this inefficient behavior, mini-batches are split into microbatches that are processed in parallel on the different GPUs. For example, GPU #1 could be forward propagating microbatch n, while GPU #2 could do the same for microbatch n+1. Activation values can be stored, and passed to the next partition whenever it’s ready to accept them.
For back propagation, partitions also expect input values from each other (gradients). As a partition can’t simultaneously run forward and backward propagation, we could wait for all GPUs to complete the forward pass on their own microbatch, before letting them run the corresponding backward pass. This simple mode is available in Amazon SageMaker.
There’s an even more efficient option, called interleaved mode. Here, SageMaker replicates partitions according to the number of microbatches. For example, working with 2 microbatches, each GPU would run two copies of the partition it has received. Each copy would collaborate with partitions running on other GPUs, either for forward or backpropagation.
Here’s how things could look like, with 4 different microbatches being processed by 2 duplicated partitions.

To sum things up, interleaving the forward and backward passes of different microbatches is how SageMaker maximimes GPU utilization.
Now, let’s see how we can put this to work with TensorFlow.
Implementing Model Parallelism in Amazon SageMaker
Thanks to the SageMaker Model Parallelism (SMP) library, you can easily implement model parallelism in your own TensorFlow code (the process is similar for PyTorch). Here’s what you need to do:
- Define and initialize the partitioning configuration.
- Make your model a subclass of the
DistributedModelclass, using standard Keras subclassing. - Write and decorate with
@smp.stepa training function that represents a forward and backward step for the model. This function will be pipelined according to the architecture described in the previous section. - Optionally, do the same for an evaluation function that will also be pipelined.
Let’s apply this to a simple convolution network training on the MNIST dataset, using an ml.p3.8xlarge instance equipped with 4 NVIDIA V100 GPUs.
First, I initialize the SMP API.
import smdistributed.modelparallel.tensorflow as smp
smp.init()Then, I subclass DistributedModel and build my model.
class MyModel(smp.DistributedModel):
def __init__(self):
super(MyModel, self).__init__()
self.conv = Conv2D(32, 3, activation="relu")
self.flatten = Flatten()
self.dense1 = Dense(128)
self.dense2 = Dense(10)
. . .This is what the training function looks like.
@smp.step
def forward_backward(images, labels):
predictions = model(images, training=True)
loss = loss_obj(labels, predictions)
grads = optimizer.get_gradients(loss, model.trainable_variables)
return grads, lossThen, I can train as usual with the TensorFlow estimator available in the SageMaker SDK. I only need to add the model parallelism configuration: 2 partitions (hence training on 2 GPUs), and 2 microbatches (hence 2 copies of each partition) with interleaving.
smd_mp_estimator = TensorFlow(
entry_point="tf2.py",
role=role,
framework_version='2.3.1',
pv_version='py3',
instance_count=1,
instance_type='ml.p3.16xlarge',
distribution={
"smdistributed": {
"modelparallel": {
"enabled":True,
"parameters": {
"microbatches": 2,
"partitions": 2,
"pipeline": "interleaved",
"optimize": "memory",
"horovod": True,
}
}
},
"mpi": {
"enabled": True,
"processes_per_host": 2, # Pick your processes_per_host
"custom_mpi_options": mpioptions
},
}
)Getting Started
As you can see, model parallelism makes it easier to train very large state-of-the-art deep learning models. It’s available today in all regions where Amazon SageMaker is available, at no additional cost.
Examples are available to get you started right away. Give them a try, and let us know what you think. We’re always looking forward to your feedback, either through your usual AWS support contacts, or on the AWS Forum for SageMaker.
 Today I am happy to announce that the
Today I am happy to announce that the 





 Neela Sawant is a Senior Applied Scientist in the Amazon CodeGuru team. Her background is building AI-powered solutions to customer problems in a variety of domains such as software, multimedia, and retail. When she isn’t working, you’ll find her exploring the world anew with her toddler and hacking away at AI for social good.
Neela Sawant is a Senior Applied Scientist in the Amazon CodeGuru team. Her background is building AI-powered solutions to customer problems in a variety of domains such as software, multimedia, and retail. When she isn’t working, you’ll find her exploring the world anew with her toddler and hacking away at AI for social good. Pierre Marieu is a Software Development Engineer in the Amazon CodeGuru Profiler team in London. He loves building tools that help the day-to-day life of other software engineers. Previously, he worked at Amadeus IT, building software for the travel industry.
Pierre Marieu is a Software Development Engineer in the Amazon CodeGuru Profiler team in London. He loves building tools that help the day-to-day life of other software engineers. Previously, he worked at Amadeus IT, building software for the travel industry.