Post Syndicated from Imtiaz Sayed original https://aws.amazon.com/blogs/big-data/attendee-guide-for-the-aws-analytics-track-at-aws-reinvent-2021/

AWS re:Invent is a learning conference hosted by Amazon Web Services (AWS) for the global cloud computing community. We’re super excited to join you at the 10th annual re:Invent to share the latest from AWS leaders and discover more ways to learn and build. Let’s celebrate this milestone, which will be offered in person in Las Vegas (November 29–December 3) and virtually (November 29–December 10). The health and safety of our customers and partners remains our top priority. You can find additional information on the health measures page. For details about the virtual format, check out the virtual section.
The AWS Analytics track at re:Invent offers sessions in various analytics disciplines delivered by AWS Analytics experts and AWS customers. The sessions vary from intermediate (200) through expert (400) levels, share new AWS innovations, discuss exciting customer experiences, and provide you opportunities to learn how to easily extract more out of your data in the most cost-effective and performant manner.
Keynotes
Adam Selipsky – CEO, Amazon Web Services – Keynote
Adam Selipsky, AWS CEO, takes the stage to share his insights and the latest news about AWS customers, products, and services including Analytics services announcements
Swami Sivasubramanian – Vice President, Amazon Machine Learning – Keynote
Join Swami Sivasubramanian, Vice President, Amazon Machine Learning, on an exploration of what it takes to put data in action with an end to end data strategy including the latest news on databases, analytics, and machine learning.
Leadership session
ANT214-L – Reinvent your business for the future with AWS Analytics
The next wave of digital transformation will be data-driven, and organizations will have to reinvent themselves using data to make decisions quickly and gain faster and deeper insights to serve their customers. In this session, Rahul Pathak, VP of AWS Analytics, addresses the current state of analytics on AWS, focusing on the latest service innovations. Learn how you can put your data to work with the best of both data lakes and purpose-built data stores. Also, discover how AWS can help you build new experiences and reimagine old processes with a modern data architecture on AWS.
Breakout sessions
re:Invent breakout sessions are lecture-style and 1 hour long. These sessions are delivered by AWS experts, customers, and partners, and typically include 10–15 minutes of Q&A at the end. For our virtual attendees, breakout sessions will be made available on-demand in the week after re:Invent.
ANT215 – Introduction to AWS Data Exchange for Amazon Redshift
AWS Data Exchange for Amazon Redshift allows you to combine third-party data found on AWS Data Exchange with your own data from your Amazon Redshift cloud data warehouse, requiring no ETL and accelerating time to value. AWS Data Exchange allows an organization’s line of business to immediately access and analyze a provider’s data once access has been granted, eliminating the need to depend on IT teams to provision the necessary data. Data providers can license access to their Amazon Redshift cloud data warehouses or allow subscribers to download files from Amazon S3 with no heavy lifting.
ANT203 – What’s new in Amazon OpenSearch Service
Amazon OpenSearch Service (successor to Amazon Elasticsearch Service), is a fully managed service that makes it easy for you to deploy, secure, and run OpenSearch and Apache 2.0-licensed Elasticsearch clusters cost-effectively at scale. The OpenSearch project is a community-driven, open-source fork of Elasticsearch and Kibana. This session discusses customer use cases, best practices, and newly launched features. In addition, it discusses how AWS has made the move to OpenSearch seamless and what to expect going forward.
ANT201 – What’s new with Amazon Redshift
Join this session to hear about important new features of Amazon Redshift. Learn about the architectural evolution of Amazon Redshift and how it uses machine learning to create a self-optimizing data warehouse. Additionally, explore how Amazon Redshift integrates with other popular AWS services.
ANT202 – What’s new with Amazon EMR
Amazon EMR simplifies running open-source data processing applications such as Apache Spark, Apache Hive, and Presto on AWS, enabling users to run ETL, ML, real-time processing, data science, and low-latency SQL at petabyte scale. This session covers the latest on Amazon EMR and how Amazon EMR runtimes provide excellent performance to open-source versions of such engines without breaking API compatibility. Discover how Amazon EMR Studio and Amazon SageMaker Studio simplify building applications and pipelines for data scientists and engineers. Learn how to add support for transactions and real-time streams in data lakes with Apache Hudi and Apache Iceberg. See how to enforce fine-grained access control over data in Amazon S3.
ANT318 – Data lakes: Easily build, secure, and share data with AWS Lake Formation
Organizations are breaking down data silos and building petabyte-scale data lakes on AWS to democratize access to thousands of end-users. In this session, learn about recent innovations in AWS Lake Formation that make it easy to build, secure, and manage your data lakes. Hear how an AWS customer built their data mesh architecture using Lake Formation to share data across their lines of business and inform data-driven decisions.
ANT303 – Democratizing data for self-service analytics and ML
Access to all your data for fast analytics at scale is foundational for 360-degree projects involving data engineers, database developers, data analysts, data scientists, BI professionals, and the line of business. In this session, learn how easy-to-use ML can help your organization imagine new products or services, transform your customer experiences, streamline your business operations, and improve your decision-making. A secure, integrated platform that’s easy to use and supports nonproprietary data formats can improve collaboration through data sharing and can also improve customer responsiveness. Learn how AWS developer tools, including the Data API, and native support for semi-structured data using standard SQL commands can improve software time to market.
ANT316 – How Coinbase uses Amazon MSK as an event store for applications
In this session, learn how focusing on security, availability, and customer obsession has translated into operational excellence and product innovations with Amazon MSK, a managed service for Apache Kafka. This session features cryptocurrency exchange company Coinbase’s experience managing streaming events and analyzing billions of daily cryptocurrency transactions with Amazon MSK. Dive into Coinbase’s event streaming architecture to learn how it leverages Amazon MSK as an enterprise event bus to ingest and analyze a huge scale of events from users, applications, databases, and cryptocurrency sources across products.
ANT310 – How VMware uses Amazon Kinesis to keep customers safe from cyberattacks
Streaming data with Amazon Kinesis Data Streams is an easy and cost-effective way to capture data from hundreds of thousands of sources and make it available for analysis in milliseconds. VMware Carbon Black’s cloud-native intelligent threat detection system uses Kinesis Data Streams and other AWS services. Join this session to dive deep into how VMware Carbon Black, a leader in cybersecurity, processes trillions of events per day to uncover concerning behavioral patterns and detect and prevent cybersecurity risks. VMware Carbon Black shares lessons learned while scaling its multi-tenant streaming data infrastructure and best practices for cost-effective data processing in real time.
ANT317 – Serverless data integration with AWS Glue
The first step in an analytics or machine learning project is to prepare your data to obtain quality results. AWS Glue is a serverless data integration service that makes data preparation simpler, faster, and cheaper. In this session, learn about the latest innovations in AWS Glue and hear how an AWS customer uses AWS Glue to enable self-service data preparation across their organization.
ANT307 – What’s new with Amazon Athena
Amazon Athena is a highly scalable analytics service that makes it easy to analyze data in Amazon S3 and other data stores. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. This session offers a deep dive into the service, customer use cases, best practices, newly launched features, and what is next for Athena.
ANT401 – Deep dive: Accelerating Apache Spark with Amazon EMR
Running Apache Spark workloads on Amazon EMR is becoming faster and more cost-effective. In this session, explore the features that Amazon EMR offers to improve performance and reduce the cost of operating big data analytics workloads. In this session, dive deep into the architectures and design patterns that organizations have employed when migrating their open-source analytics applications to Amazon EMR, and explore features such as the performance-optimized Amazon EMR runtime for Apache Spark, Graviton2 instance support, and more.
Chalk talks
Chalk talks are highly interactive sessions with a small audience. Experts lead you through problems and solutions on a digital whiteboard as the discussion unfolds. Each begins with a short lecture (10–15 minutes) delivered by an AWS expert, followed by a Q&A session of 45–50 minutes with the audience.
ANT322 – Amazon EMR on EKS
Is your organization considering a move to Kubernetes and Amazon EKS and wondering how to run Apache Spark applications on Amazon EKS? In this chalk talk, learn how Amazon EMR on EKS simplifies running Spark applications on Amazon EKS. Learn about the benefits of moving to containerization and moving to Amazon EKS. Also, dive into architectures and best practices and learn from customers who are using Spark on Amazon EKS at 3,000 or more nodes.
ANT308 – Building analytics at scale with Amazon Athena
Organizations want analytics solutions that are easy to set up and maintain while delivering the powerful analytics required to succeed with a modern data strategy. This chalk talk covers how you can use Amazon Athena to build powerful capabilities, like real-time fraud detection, and enable data scientists to build and train ML models across all of your data. Learn how Athena offers this capability with no infrastructure for you to manage and offers simple centralized governance and security.
ANT320 – Building data lakes and sharing data with AWS Lake Formation
Building data lakes and sharing data across your organization can be challenging. In this chalk talk, learn how to use AWS Lake Formation to simplify building, securing, and managing your data lakes. Discover best practices for reliably building your data lakes and sharing this data across your lines of business and thousands of users.
ANT301 – Concurrency and scalability strategies with Amazon Redshift
Amazon Redshift provides multiple features to help you deliver consistent performance, even as workloads grow and vary. Learn how to use concurrency scaling, data sharing, and more on their own and together to manage your workloads. In this chalk talk, you have the opportunity to ask Amazon Redshift service team experts about your unique situation.
ANT319 – Data preparation: Building scalable ETL pipelines with AWS Glue
Do you have questions about how AWS Glue works? Join this chalk talk to learn more about the best practices for building data integration pipelines at scale. Learn how to use the different components of AWS Glue to discover, catalog, and prepare your data for machine learning and analytics. Also learn best practices for optimizing your Apache Spark scripts.
ANT306 – Modernize your log analytics solution with Amazon OpenSearch Service
Amazon OpenSearch Service (successor to Amazon Elasticsearch Service) is a fully managed service that makes it easy for you to deploy, secure, and run OpenSearch and Apache 2.0-licensed Elasticsearch clusters cost-effectively at scale. In this chalk talk, learn how to ingest data into Amazon OpenSearch Service from Amazon ECS using FireLens for logging and AWS Distro for OpenTelemetry for distributed tracing. Discover how to leverage OpenSearch Dashboards to analyze your application health and performance.
ANT302 – New use cases for Amazon Redshift
Amazon Redshift continuous innovations provide cloud data warehousing capabilities that deliver price performance leadership and ease of use with scale. Learn how Amazon Redshift features, built on the reliability and performance this service is known for today, can help you empower developers with automated capabilities, reduce time to business insights, or integrate across data types, AWS, and third-party services. Join this chalk talk to explore new features and learn from the experts about ways that you can use them.
ANT314 – Process streaming data using Amazon MSK & Amazon Kinesis Data Analytics
As data streaming architectures evolve, it’s vital to continuously improve your streaming data pipelines and take advantage of new features and updates to streaming services. With fully managed Apache Kafka and Apache Flink services, AWS makes it easy for developers to run streaming applications without managing infrastructure. In this chalk talk, learn how to use Amazon MSK, Amazon Kinesis Data Analytics for Apache Flink, and AWS Lambda to build serverless streaming data pipelines. Discover best practices for application operations and reliability, and see how AWS managed services can help you avoid potential challenges.
ANT321 – Set up capital markets analytics, integrated with your data, using FinSpace
Are you a financial services firm such as a hedge fund, sell side bank, or asset manager with quantitative financial analysts using Jupyter notebooks to perform financial analysis such as time series, portfolio, or risk analytics? Do your analysts require secure access to data across your enterprise? Do your analysts need scalable Apache Spark to process petabytes of data such as trade and quote data? In this chalk talk, learn how Amazon FinSpace provides a managed research notebook environment with the security controls you need and the ability to integrate with data from internal systems and third-party data feeds.
ANT309 – Simplifying Amazon S3 analytics with Amazon Kinesis Data Firehose
Join this chalk talk to learn how Amazon Kinesis Data Firehose enables you to reliably load your streaming data into data lakes, data warehouses, and analytics services built on AWS, with AWS Partners, and using open-source tools. This talk includes a demonstration showcasing how Kinesis Data Firehose easily captures, transforms, and delivers streaming data to a data lake built on Amazon S3. Dive deep into reducing the cost of Amazon S3 analytics queries and simplifying Amazon S3 analytics workflows using Kinesis Data Firehose, Apache Parquet, and dynamic partitioning.
ANT315 – Using Amazon Redshift to directly query third-party data on AWS
In this chalk talk, learn how companies spanning multiple industries are using AWS Data Exchange and Amazon Redshift to find, subscribe to, and immediately access and analyze third-party datasets without having to set up data ingestion pipelines.
ANT405 – Enforcing data access control on Amazon EMR
Organizations often want to enforce fine-grained data access controls across data lakes throughout a company. In this chalk talk, learn about what these controls are and how you can you enforce them when using Apache Spark, Presto, and Hive on Amazon EMR. Discover various ways of authenticating users and how each of these authentication mechanisms impact authorization policies. Lastly, review the use of IAM roles, AWS Lake Formation, and Apache Ranger as tools to enforce fine-grained data access controls, and learn when you should use which. This chalk talk covers the basic tools required to enforce fine-grained authorization and how to use them.
ANT402 – Sizing Amazon OpenSearch Service domains
Whether you’re searching your product catalog or storing your logs for infrastructure monitoring, application performance monitoring, or observability, Amazon OpenSearch Service is the ideal tool. Its distributed search engine scales to support high-volume ingest and query rates. How you scale affects the performance of your workload and your cost running that workload, so it’s important to get it right. How do you find your way through all of the configuration options to create an optimal cluster? Come to this chalk talk with your workload description—source data, velocity, query types, and quantity—and we’ll help you get sized right.
Builders’ sessions
Builders’ sessions are small group sessions led by an AWS expert who demonstrates and builds a solution on AWS. Each builders’ session is an interactive, hour-long engagement. It begins with a short explanation followed by a practical walkthrough of the demonstration. When the demonstration is complete, feel free to use the shared artifacts to build on your own.
ANT311 – Build a data mesh with AWS Lake Formation and AWS Glue
In this builders’ session, learn how to build a data mesh design pattern using AWS Glue and AWS Lake Formation that supports a proliferation of data producers and data consumers with consistent, centralized governance. The design approach facilitates best practices for building scalable data platforms, ubiquitous data sharing, and centralized governance, and enables self-service analytics on AWS.
ANT312 – Building a secure, modern data architecture with AWS analytics
In this builders’ session, learn how to build a secure modern data architecture to combine various disparate data sources using AWS Lake Formation, Amazon AppFlow, AWS Database Migration Service (AWS DMS), and AWS Glue. Gain an understanding of key architecture tenets for ingestion patterns, design factors for securely storing data, how to apply granular security policies, data cataloging, and transformation for consumption.
ANT313 – Security essentials with Amazon MSK
Organizations have unique security and compliance mandates. A well-informed understanding of authentication features is critical to making the right choice for an organization’s security posture. Amazon MSK provides several authentication options to control access to Apache Kafka clusters. In this builders’ session, explore the available Amazon MSK authentication mechanisms, industry best practices, and recommendations for running secure Amazon MSK clusters.
Workshops
Workshops are 2-hour interactive learning sessions where you work in small group teams to solve problems using AWS services. Each workshop starts with a short lecture (10–15 minutes) by the main speaker, and the rest of the time is spent working as a group. Come prepared with your laptop and a willingness to learn!
ANT205- Create and train ML models with ease using Amazon Redshift ML
Amazon Redshift is the most widely deployed data warehouse and is the cornerstone of AWS data lake strategy. Experience how quickly you can build your data warehouse with Amazon Redshift and gain insights using the integrated SQL query editor. In this workshop, data analysts and data scientists can easily train machine learning (ML) models using SQL with Amazon Redshift ML, with zero data movement required. Data engineers can learn how the data API simplifies access and allows you to easily integrate applications with Amazon Redshift and build event-driven applications systems.
ANT204 – Dive into Amazon OpenSearch Service
OpenSearch is an Apache 2.0-licensed tool that provides you with rich, relevant search results for your data. Paired with OpenSearch Dashboards, you can analyze and visualize your log data. In this workshop, discover how Amazon OpenSearch Service enables you to focus on your search or monitoring problem and not worry about managing your infrastructure. Explore the console and deploy an OpenSearch Service domain in Amazon VPC, use OpenSearch search APIs, and work with OpenSearch Dashboards to build out visualizations. Come see how Amazon OpenSearch Service can help you solve your search and analytics needs.
ANT305 – Data science and DataOps workflows with Amazon EMR Studio
Have you ever felt that building data science applications, data engineering pipelines, or machine learning models was hard with Apache Spark on Amazon EMR? Join this workshop to learn how Amazon EMR Studio makes it simple to do these things. The workshop includes a walkthrough of a couple of examples with sample data so you can see how collaboration works with Amazon EMR Studio.
ANT404 – Event detection using Amazon MSK and Amazon Kinesis Data Analytics
In this workshop, you take on the role of an acting technology manager for a Las Vegas casino. Your assignment is to create a stream processing application that identifies customers entering your casino who have gambled heavily in the past and then sends you a text message when big spenders sit down at a gambling table. To do this, use Amazon MSK to capture events, Amazon Kinesis Data Analytics Studio to detect events of interest, and AWS Lambda with Amazon SNS to send you an email for any events.
ANT403 – Powering observability with Amazon OpenSearch Service
Amazon OpenSearch Service’s Trace Analytics functionality allows you to go beyond simple monitoring to understand not just what events are happening, but why they are happening. In this workshop, learn how to instrument, collect, and analyze metrics, traces, and log data all the way from user front ends to service backends and everything in between. Put this together with Amazon OpenSearch Service, AWS Distro for OpenTelemetry, and Data Prepper.
AWS Analytics Kiosk
Join us at the AWS Analytics Kiosk in the AWS Village at the Expo. Dive deep into AWS Analytics with AWS subject matter experts, see the latest demos, ask questions, or just drop by to chat with your peers.
AWS Analytics Meet-and-Greet Cocktail Hour
Date: Tuesday, November 30, 8:00 PM – 9:00 PM PST
Location: Canaletto Ristorante Veneto (The Venetian), Las Vegas, NV
Socialize with the AWS Analytics technical community. Join us and network over hors d’oeuvres and drinks with AWS leaders and specialists.
Looking forward to seeing you there!
About the Authors
 Taz Sayed is the world-wide Analytics Tech Leader at AWS. He enjoys engaging with the wider data analytics community, and designing well-architected solutions for AWS customers.
Taz Sayed is the world-wide Analytics Tech Leader at AWS. He enjoys engaging with the wider data analytics community, and designing well-architected solutions for AWS customers.
 Navnit Shukla is an Analytics Specialist Solution Architect with AWS. He is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions.
Navnit Shukla is an Analytics Specialist Solution Architect with AWS. He is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions.


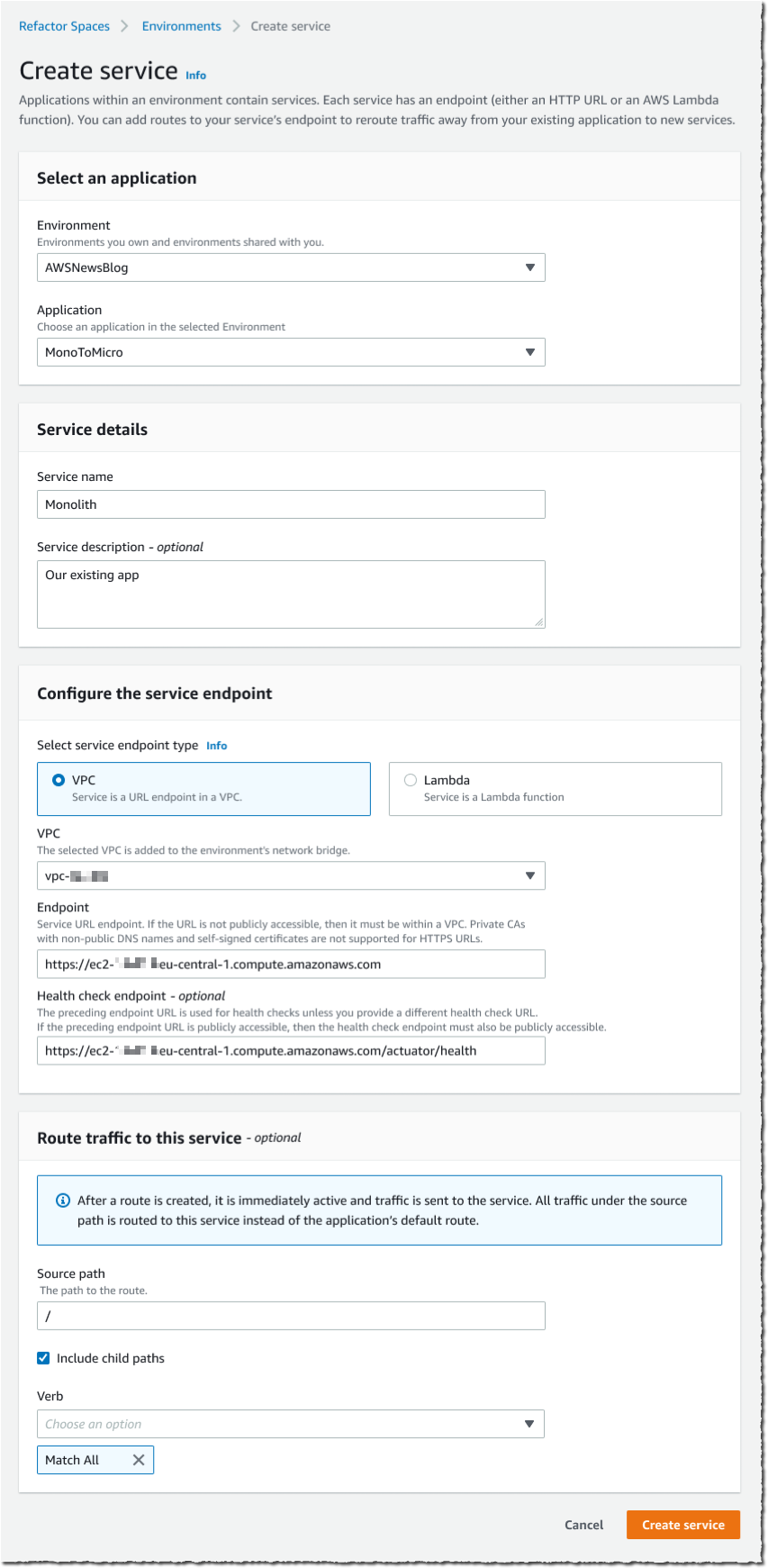
 But now I have two challenges. First, I have to design, code, and deploy a routing mechanism to route API calls made by the front-end application to the correct back-end: either the monolith, or the new microservices. This service will likely be deployed into a distinct AWS account. Then, I have to configure network connectivity between these multiple AWS accounts.
But now I have two challenges. First, I have to design, code, and deploy a routing mechanism to route API calls made by the front-end application to the correct back-end: either the monolith, or the new microservices. This service will likely be deployed into a distinct AWS account. Then, I have to configure network connectivity between these multiple AWS accounts.




 Scaling is a really interesting problem, with challenges around performance, storage, availability, cost, and effectiveness. In addition to handling hundreds of millions of ad requests per second (trillions of ads per day) within a latency budget of 120 ms, the ad server must be able to:
Scaling is a really interesting problem, with challenges around performance, storage, availability, cost, and effectiveness. In addition to handling hundreds of millions of ad requests per second (trillions of ads per day) within a latency budget of 120 ms, the ad server must be able to: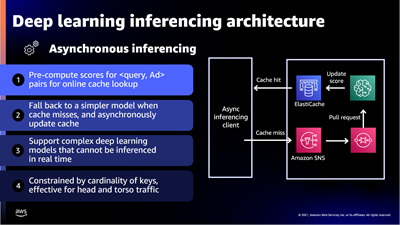 The presentation wraps up by discussing some of the ways that they were able to apply machine learning at scale. For example, to select the right ad for each request, Amazon Ads uses deep learning models to predict relevant ads to show shoppers, predict whether a shopper will click or purchase, and allocate and price an ad. In order to do this, they needed to be able to score thousands of ads per request within a 20 ms window at over 100K transactions per second, all across hundreds of models that each required different hardware and software optimizations.
The presentation wraps up by discussing some of the ways that they were able to apply machine learning at scale. For example, to select the right ad for each request, Amazon Ads uses deep learning models to predict relevant ads to show shoppers, predict whether a shopper will click or purchase, and allocate and price an ad. In order to do this, they needed to be able to score thousands of ads per request within a 20 ms window at over 100K transactions per second, all across hundreds of models that each required different hardware and software optimizations.












 Taz Sayed is the world-wide Analytics Tech Leader at AWS. He enjoys engaging with the wider data analytics community, and designing well-architected solutions for AWS customers.
Taz Sayed is the world-wide Analytics Tech Leader at AWS. He enjoys engaging with the wider data analytics community, and designing well-architected solutions for AWS customers. Navnit Shukla is an Analytics Specialist Solution Architect with AWS. He is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions.
Navnit Shukla is an Analytics Specialist Solution Architect with AWS. He is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions.





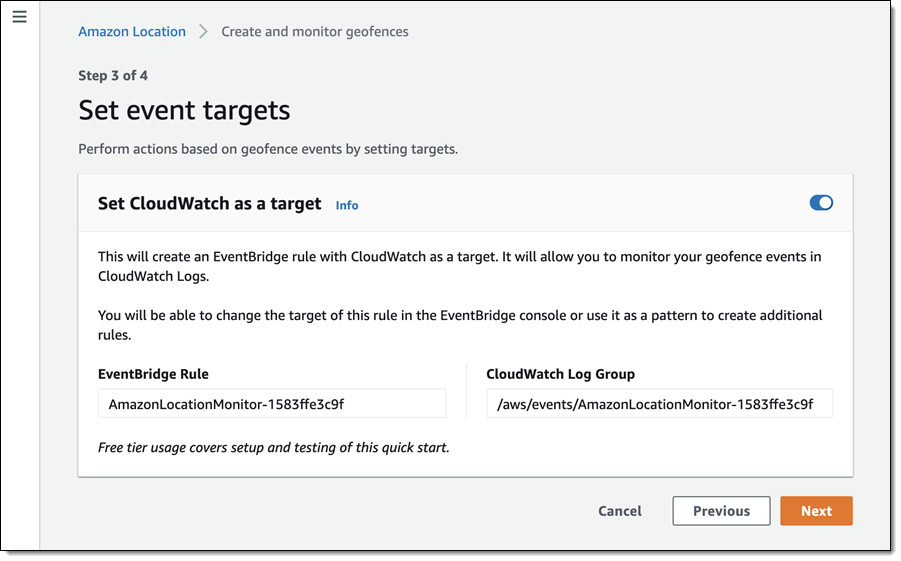
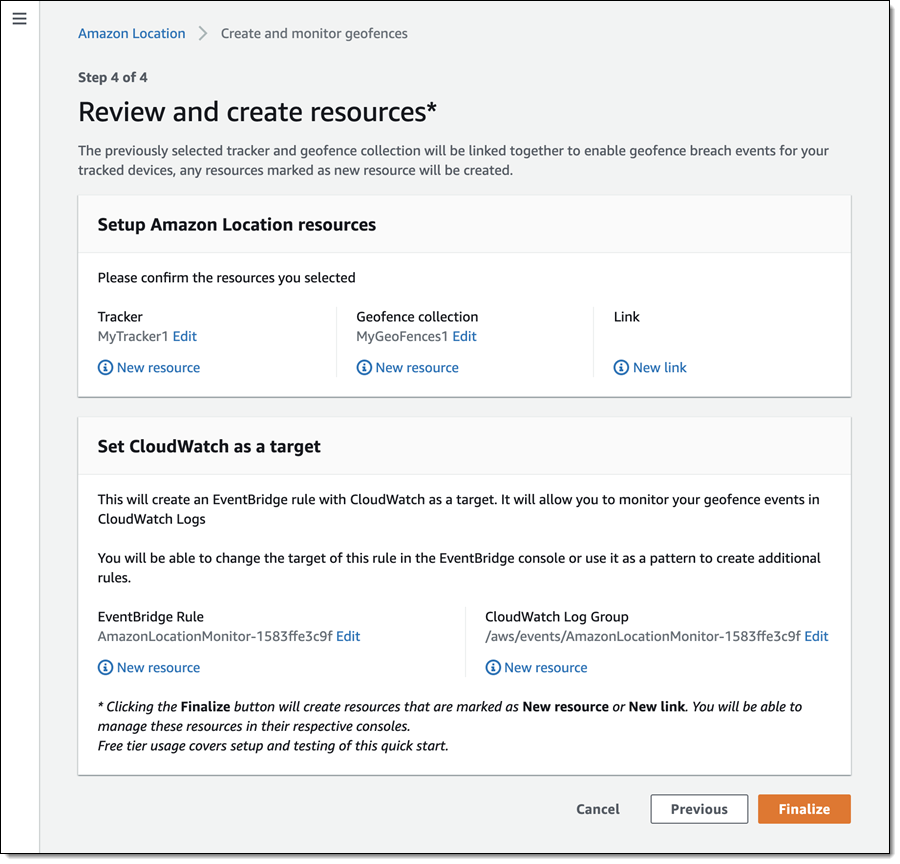
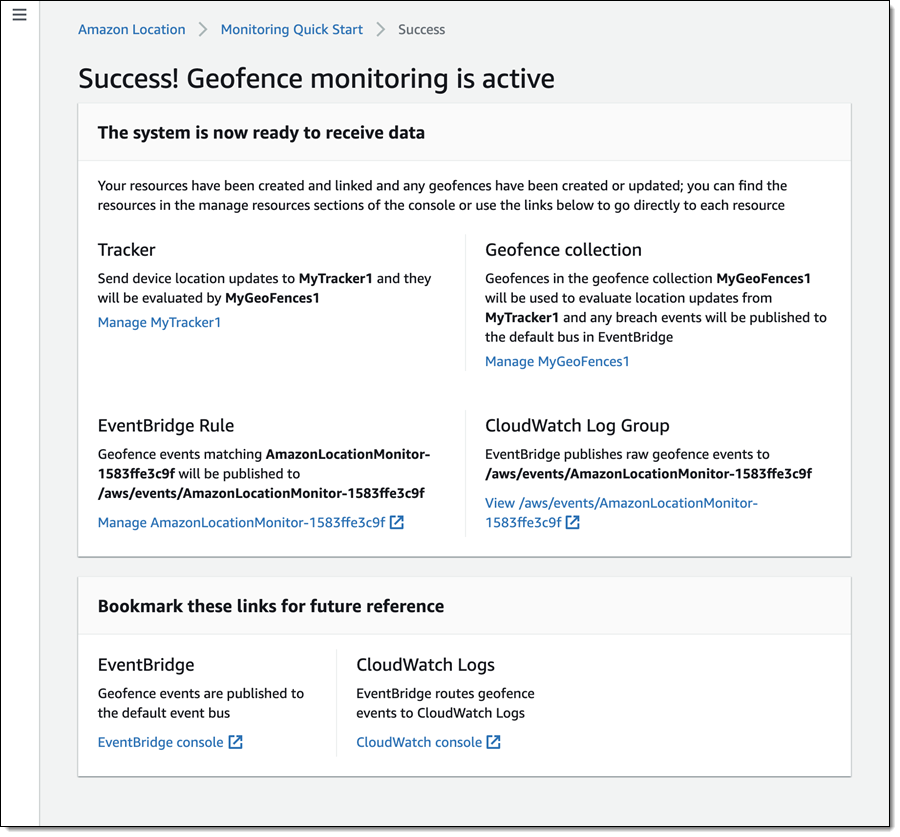
 We want to make it easier and more cost-effective for you to add maps, location awareness, and other location-based features to your web and mobile applications. Until now, doing this has been somewhat complex and expensive, and also tied you to the business and programming models of a single provider.
We want to make it easier and more cost-effective for you to add maps, location awareness, and other location-based features to your web and mobile applications. Until now, doing this has been somewhat complex and expensive, and also tied you to the business and programming models of a single provider.