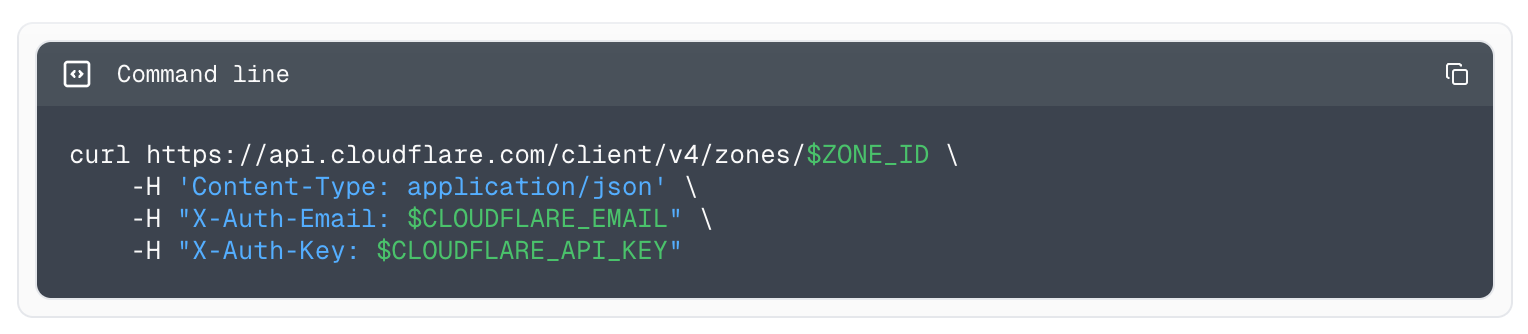
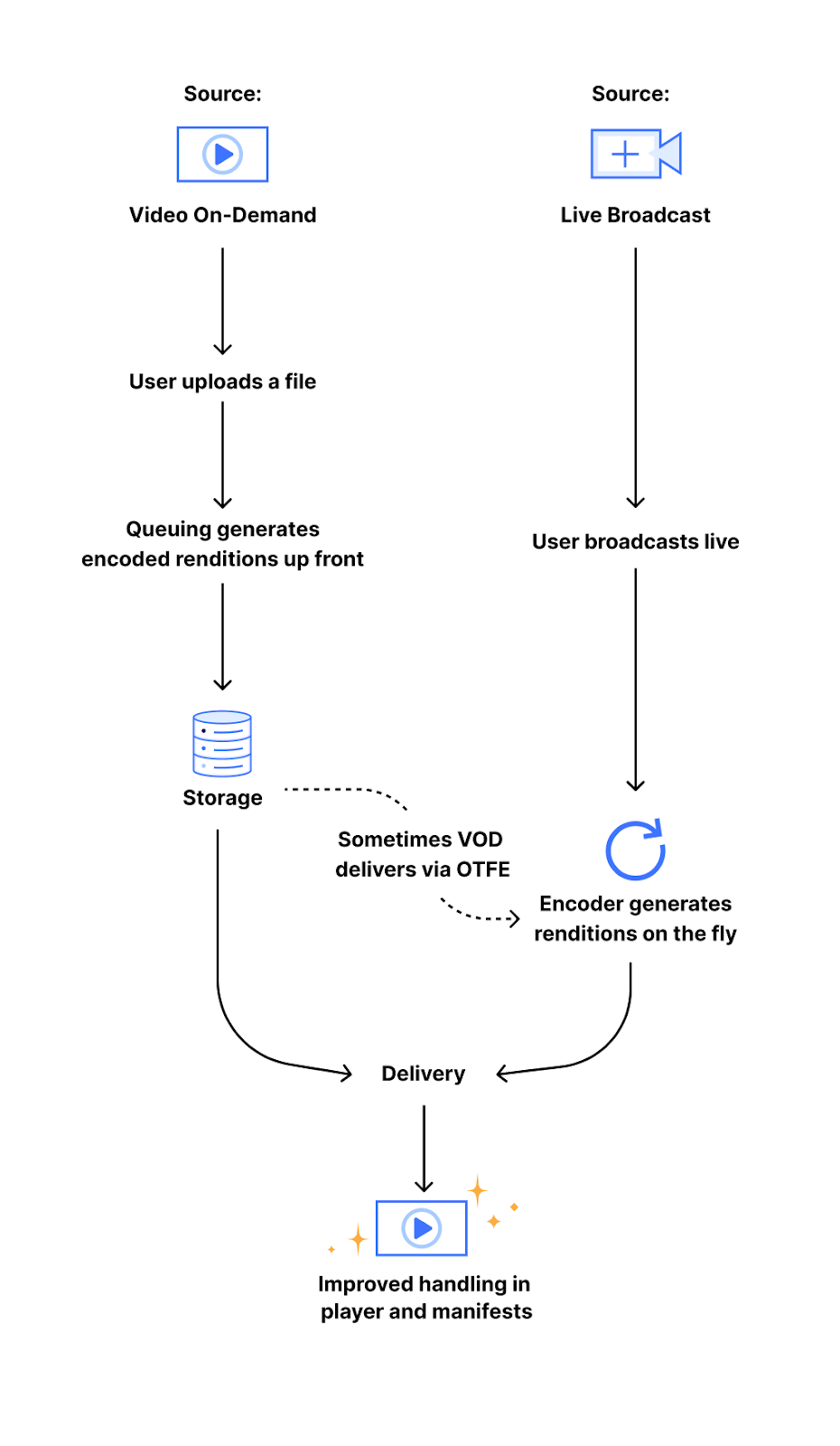
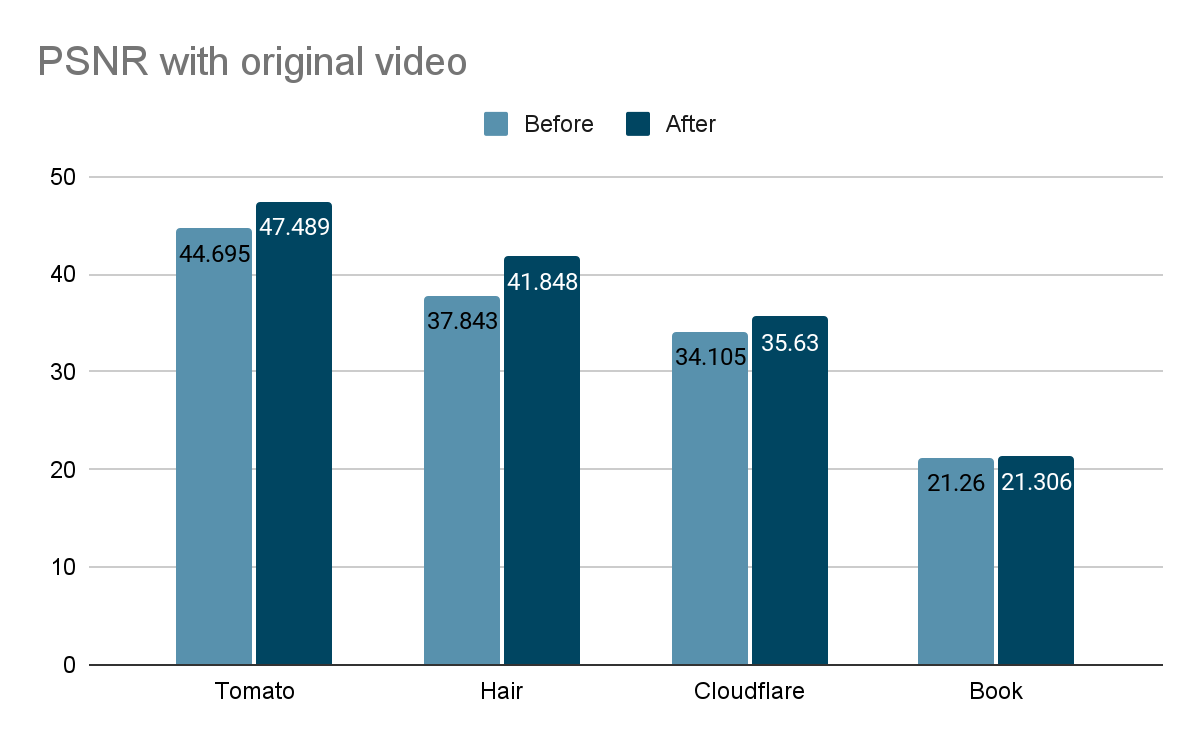
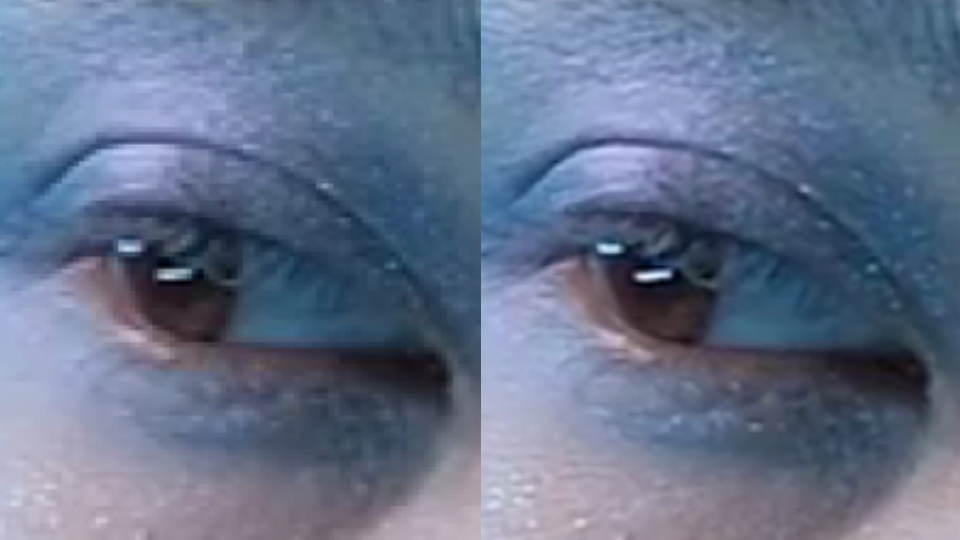
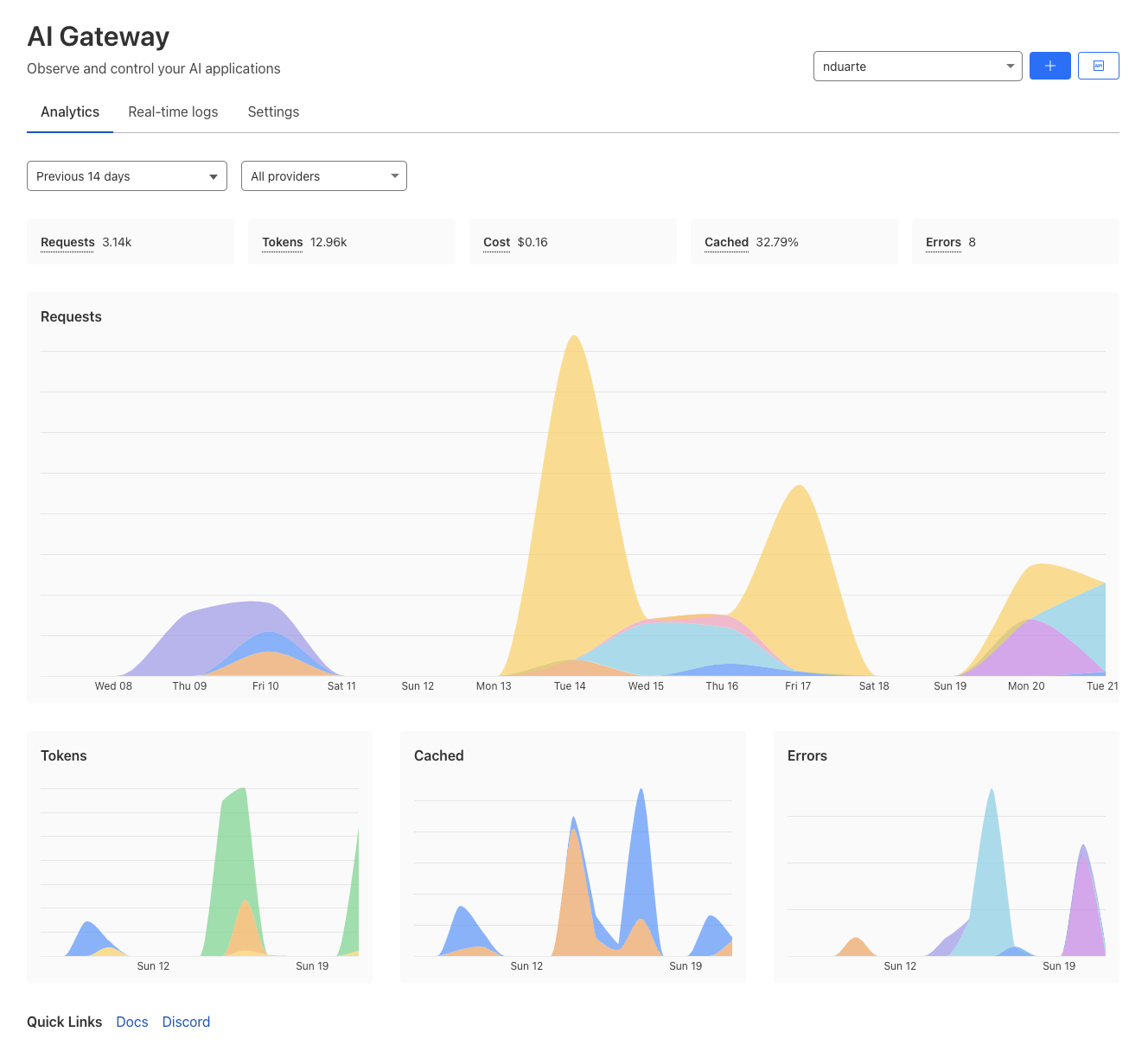
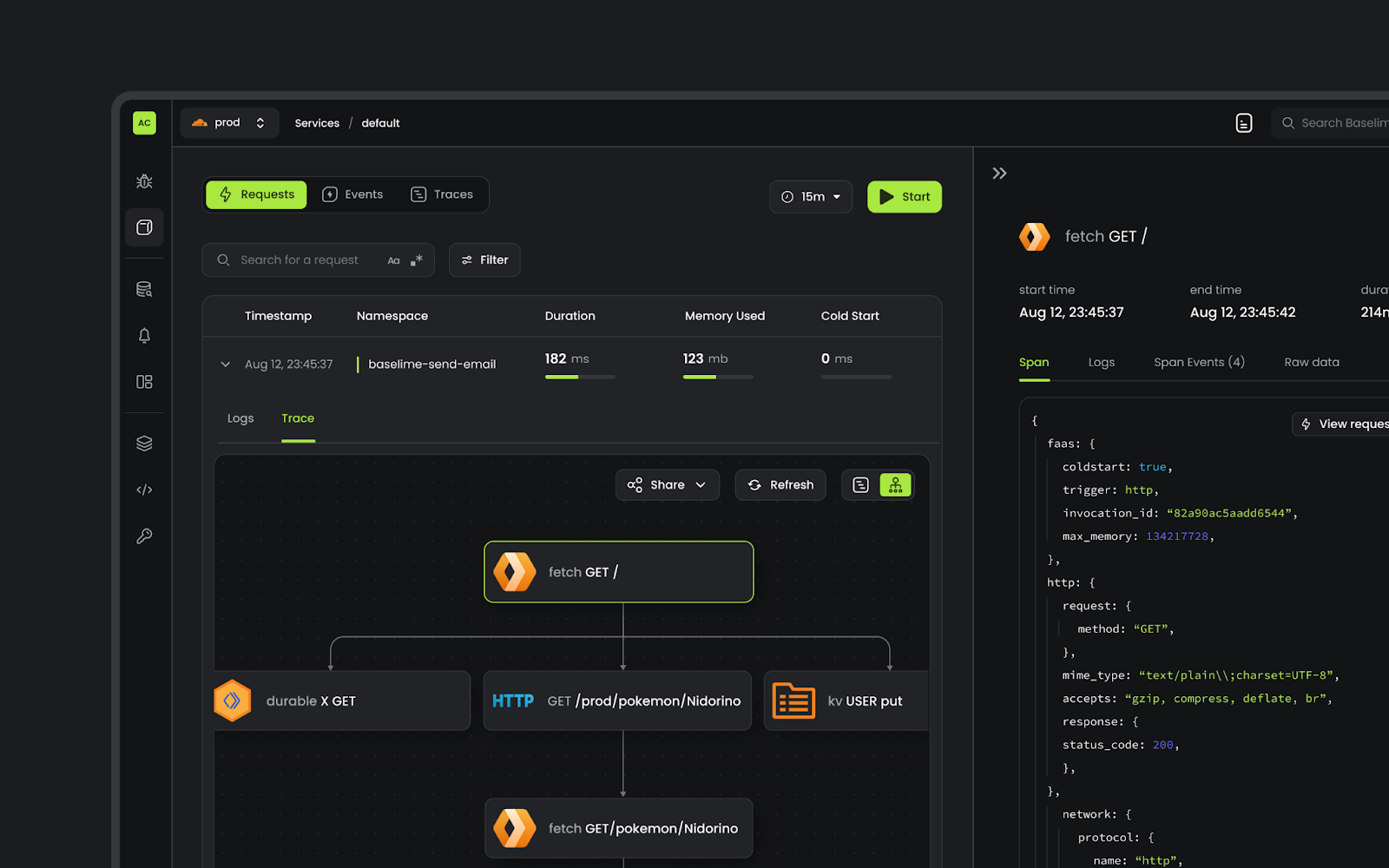
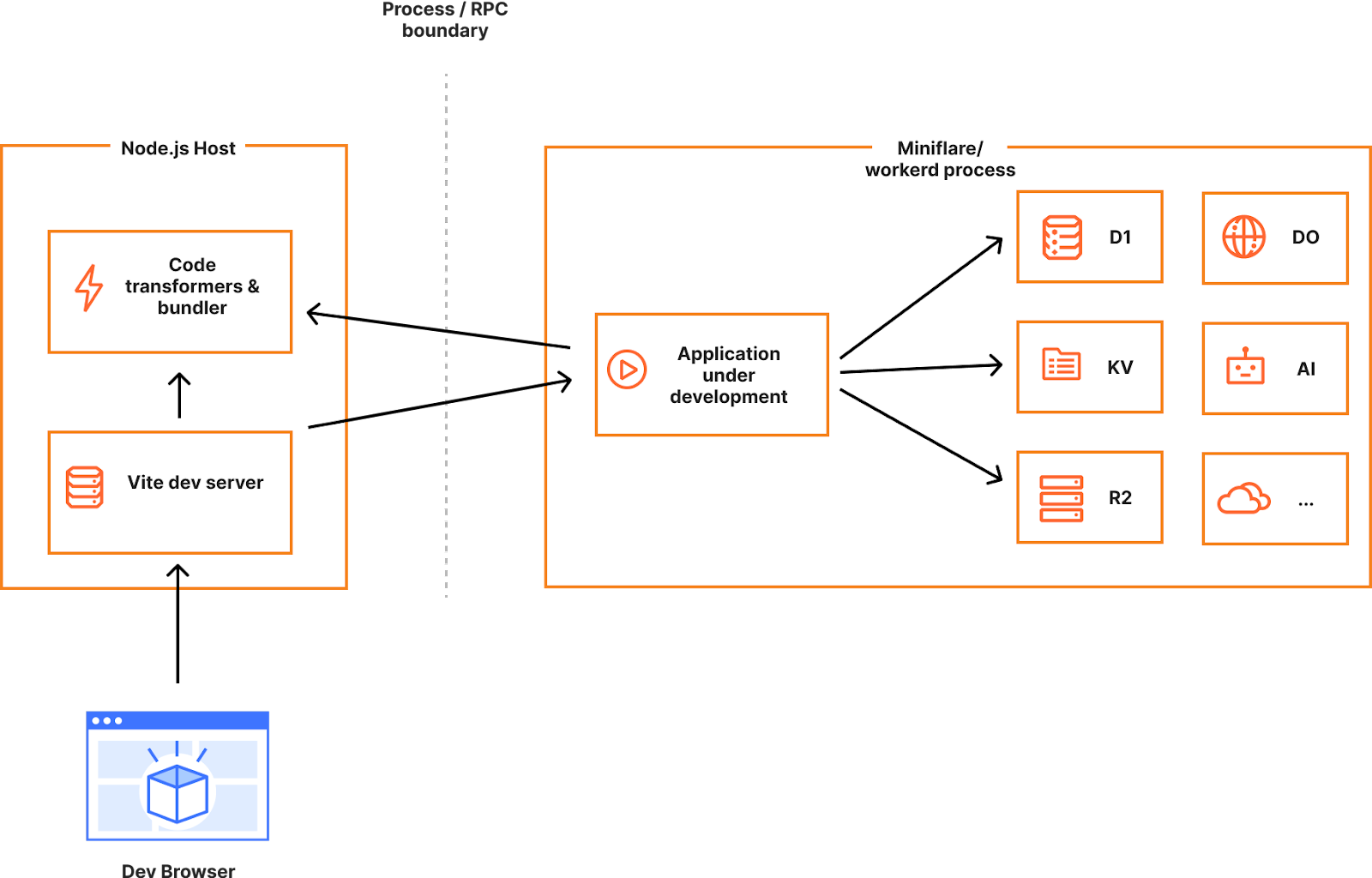
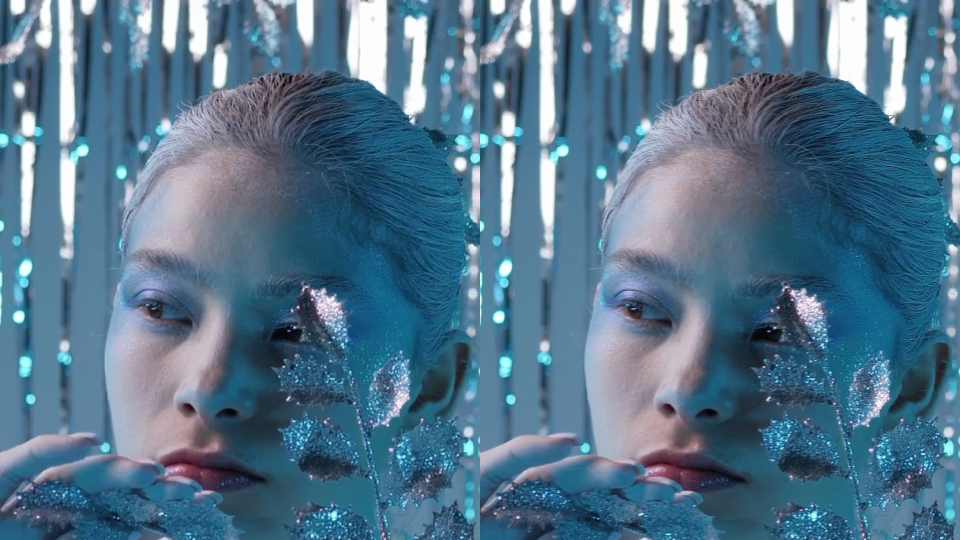Speed is a critical factor that dictates Internet behavior. Every additional millisecond a user spends waiting for your web page to load results in them abandoning your website. The old adage remains as true as ever: faster websites result in higher conversion rates. And with such outcomes tied to Internet speed, we believe a faster Internet is a better Internet.
Customers often use Workers KV to provide Workers with key-value data for configuration, routing, personalization, experimentation, or serving assets. Many of Cloudflare’s own products rely on KV for just this purpose: Pages stores static assets, Access stores authentication credentials, AI Gateway stores routing configuration, and Images stores configuration and assets, among others. So KV’s speed affects the latency of every request to an application, throughout the entire lifecycle of a user session.
Today, we’re announcing up to 3x faster KV hot reads, with all KV operations faster by up to 20ms. And we want to pull back the curtain and show you how we did it.
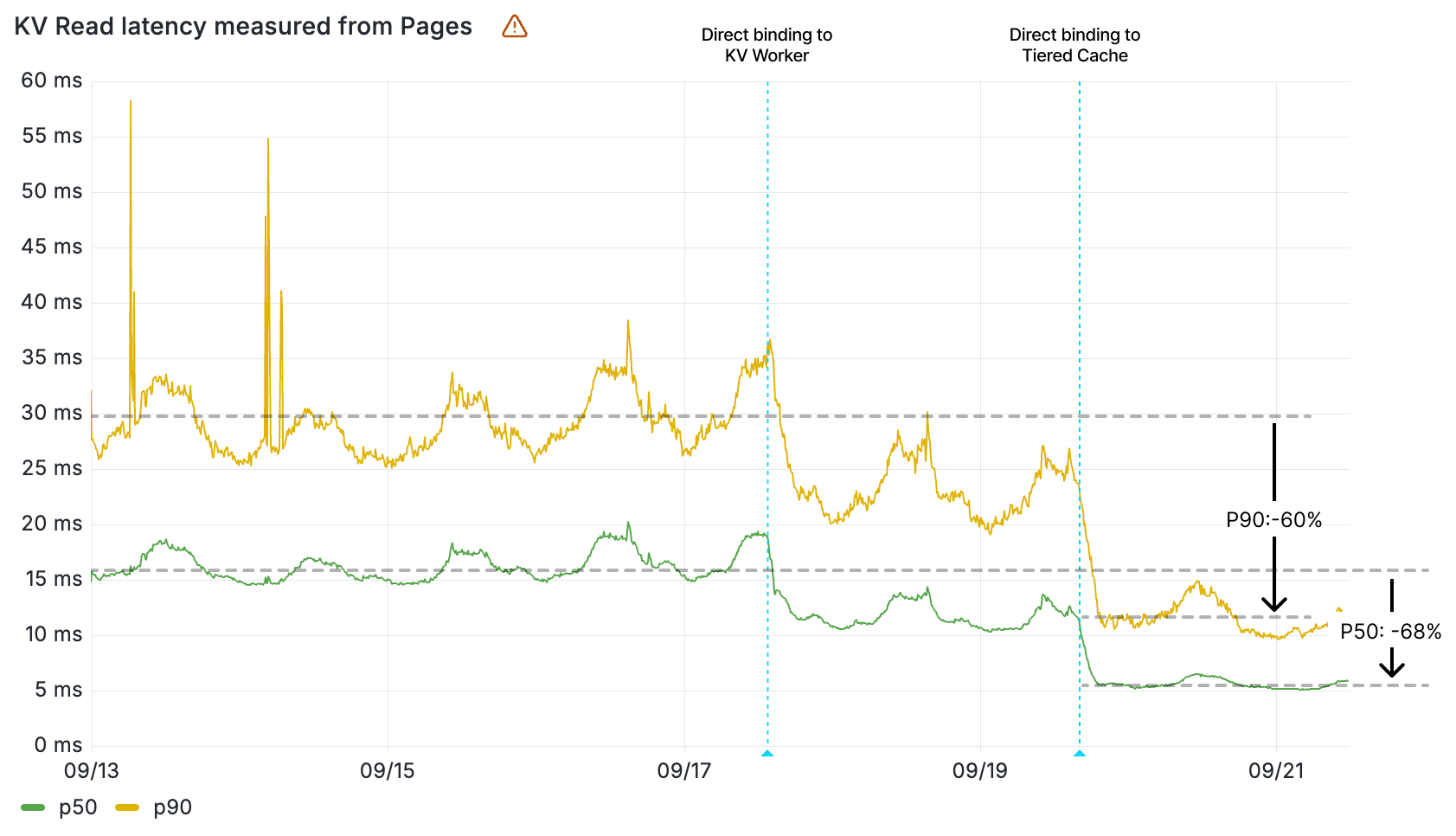
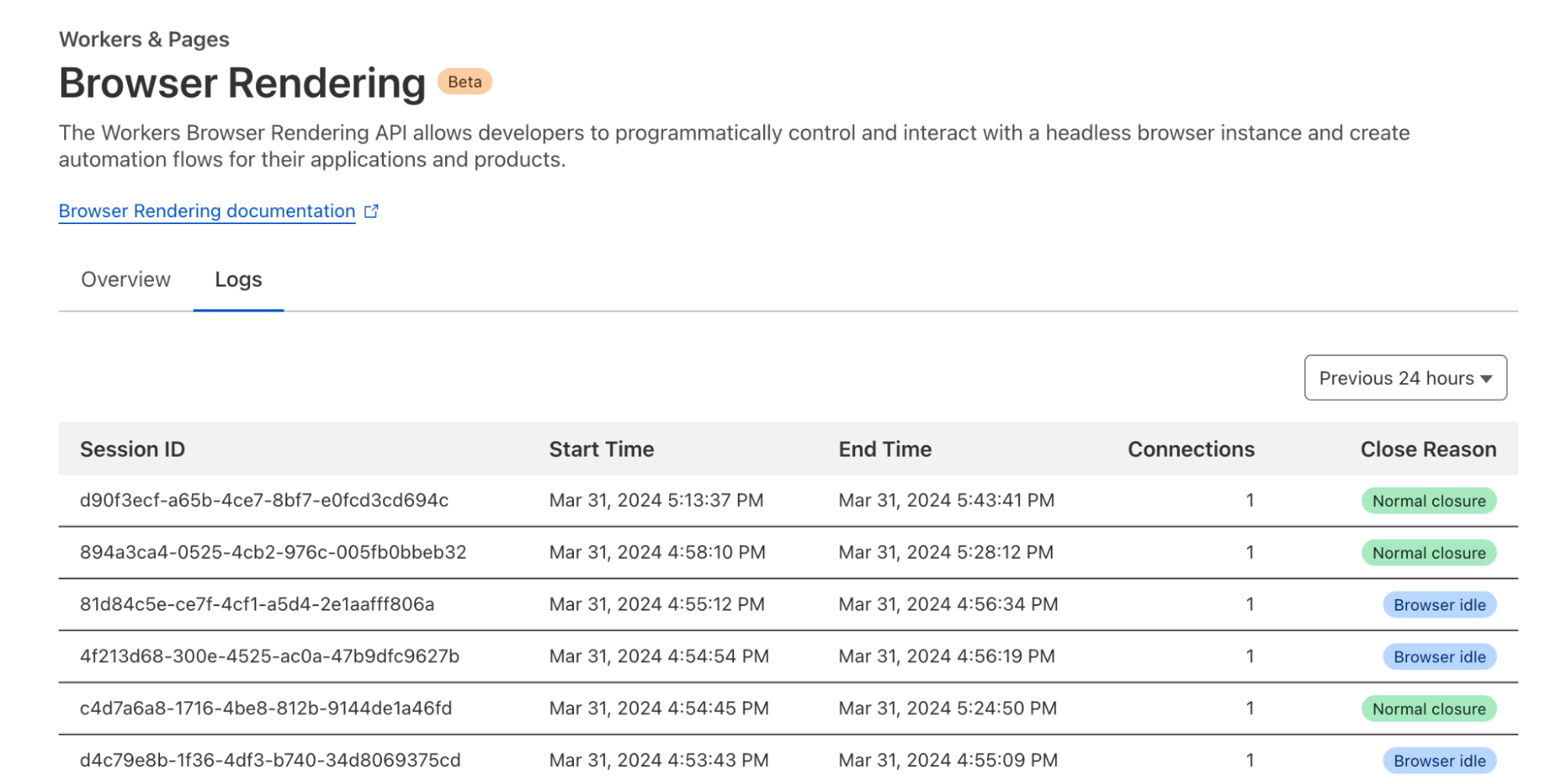
Workers KV read latency (ms) by percentile measured from Pages
Optimizing Workers KV’s architecture to minimize latency
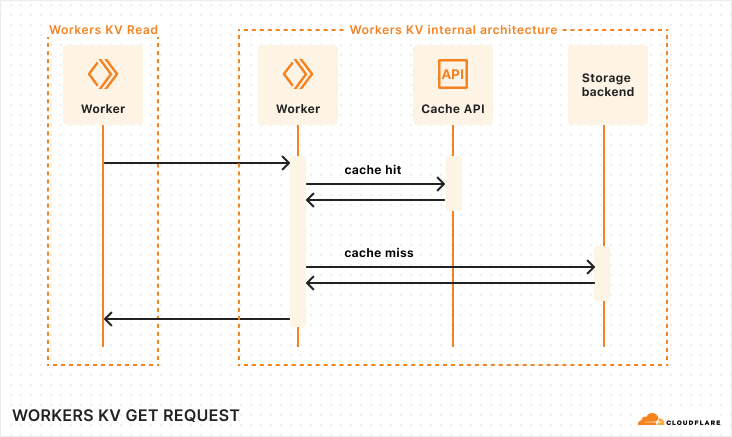
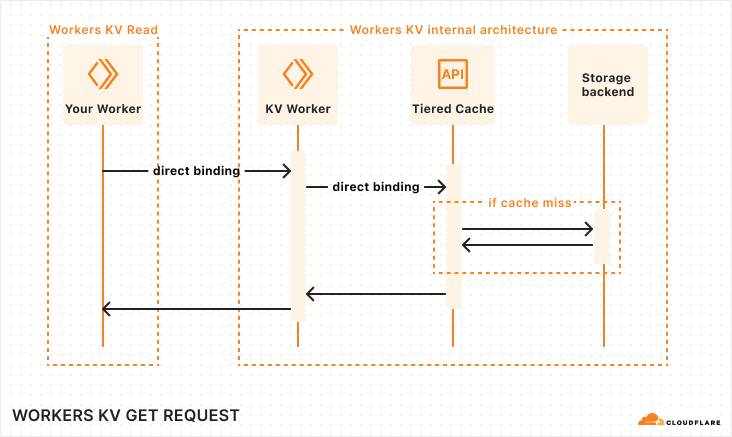
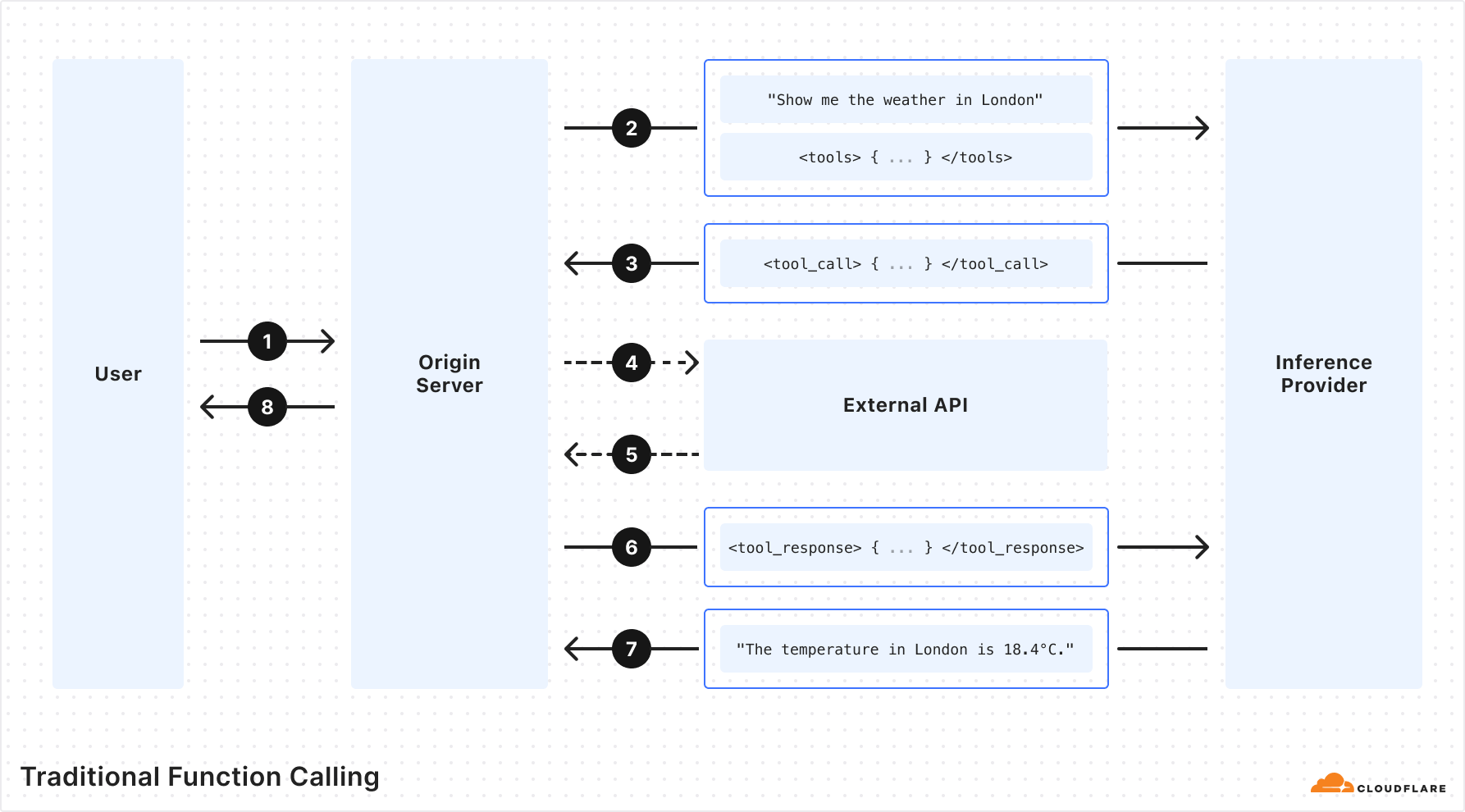
At a high level, Workers KV is itself a Worker that makes requests to central storage backends, with many layers in between to properly cache and route requests across Cloudflare’s network. You can rely on Workers KV to support operations made by your Workers at any scale, and KV’s architecture will seamlessly handle your required throughput.
Sequence diagram of a Workers KV operation
When your Worker makes a read operation to Workers KV, your Worker establishes a network connection within its Cloudflare region to KV’s Worker. The KV Worker then accesses the Cache API, and in the event of a cache miss, retrieves the value from the storage backends.
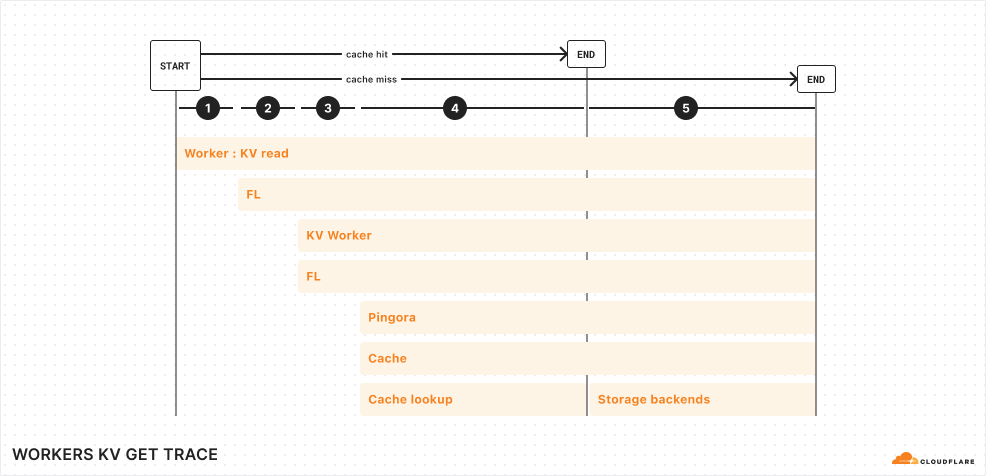
Let’s look one level deeper at a simplified trace:
Simplified trace of a Workers KV operation
From the top, here are the operations completed for a KV read operation from your Worker:
Your Worker makes a connection to Cloudflare’s network in the same data center. This incurs ~5 ms of network latency.
Upon entering Cloudflare’s network, a service called Front Line (FL) is used to process the request. This incurs ~10 ms of operational latency.
FL proxies the request to the KV Worker. The KV Worker does a cache lookup for the key being accessed. This, once again, passes through the Front Line layer, incurring an additional ~10 ms of operational latency.
Cache is stored in various backends within each region of Cloudflare’s network. A service built upon Pingora, our open-sourced Rust framework for proxying HTTP requests, routes the cache lookup to the proper cache backend.
Finally, if the cache lookup is successful, the KV read operation is resolved. Otherwise, the request reaches our storage backends, where it gets its value.
Looking at these flame graphs, it became apparent that a major opportunity presented itself to us: reducing the FL overhead (or eliminating it altogether) and reducing the cache misses across the Cloudflare network would reduce the latency for KV operations.
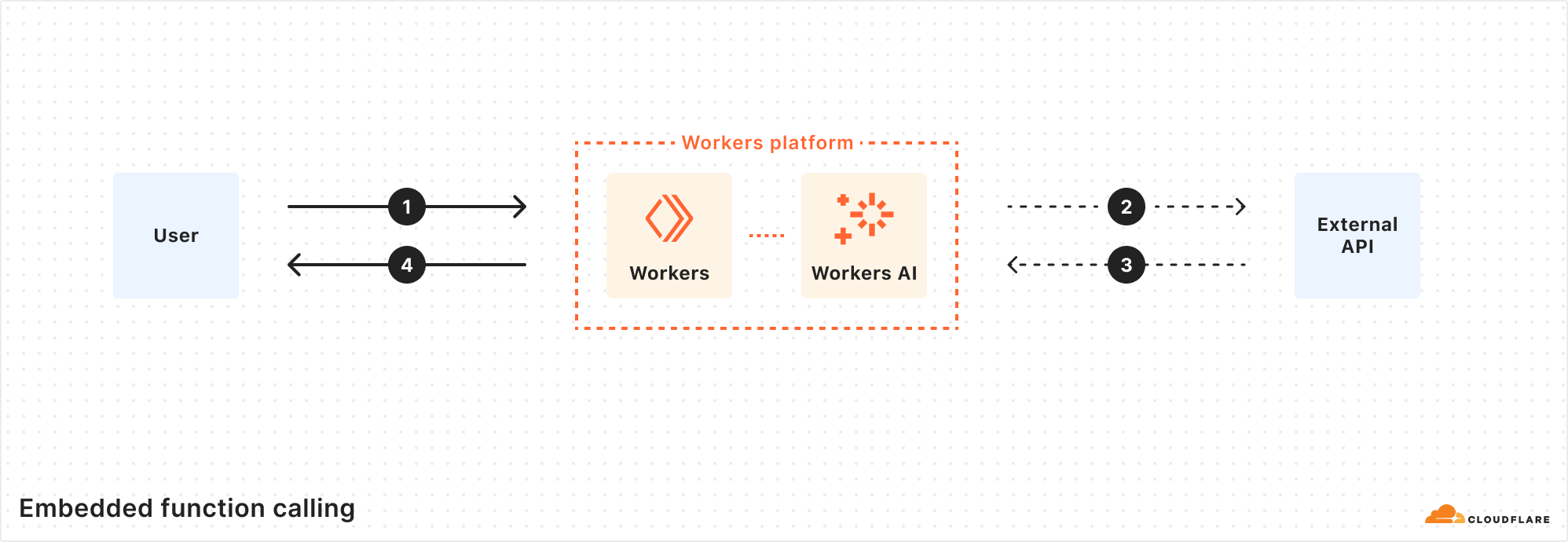
Bypassing FL layers between Workers and services to save ~20ms
A request from your Worker to KV doesn’t need to go through FL. Much of FL’s responsibility is to process and route requests from outside of Cloudflare — that’s more than is needed to handle a request from the KV binding to the KV Worker. So we skipped the Front Line altogether in both layers.
Reducing latency in a Workers KV operation by removing FL layers
To bypass the FL layer from the KV binding in your Worker, we modified the KV binding to connect directly to the KV Worker within the same Cloudflare location. Within the Workers host, we configured a C++ subpipeline to allow code from bindings to establish a direct connection with the proper routing configuration and authorization loaded.
The KV Worker also passes through the FL layer on its way to our internal Pingora service. In this case, we were able to use an internal Worker binding that allows Workers for Cloudflare services to bind directly to non-Worker services within Cloudflare’s network. With this fix, the KV Worker sets the proper cache control headers and establishes its connection to Pingora without leaving the network.
Together, both of these changes reduced latency by ~20 ms for every KV operation.
Implementing tiered cache to minimize requests to storage backends
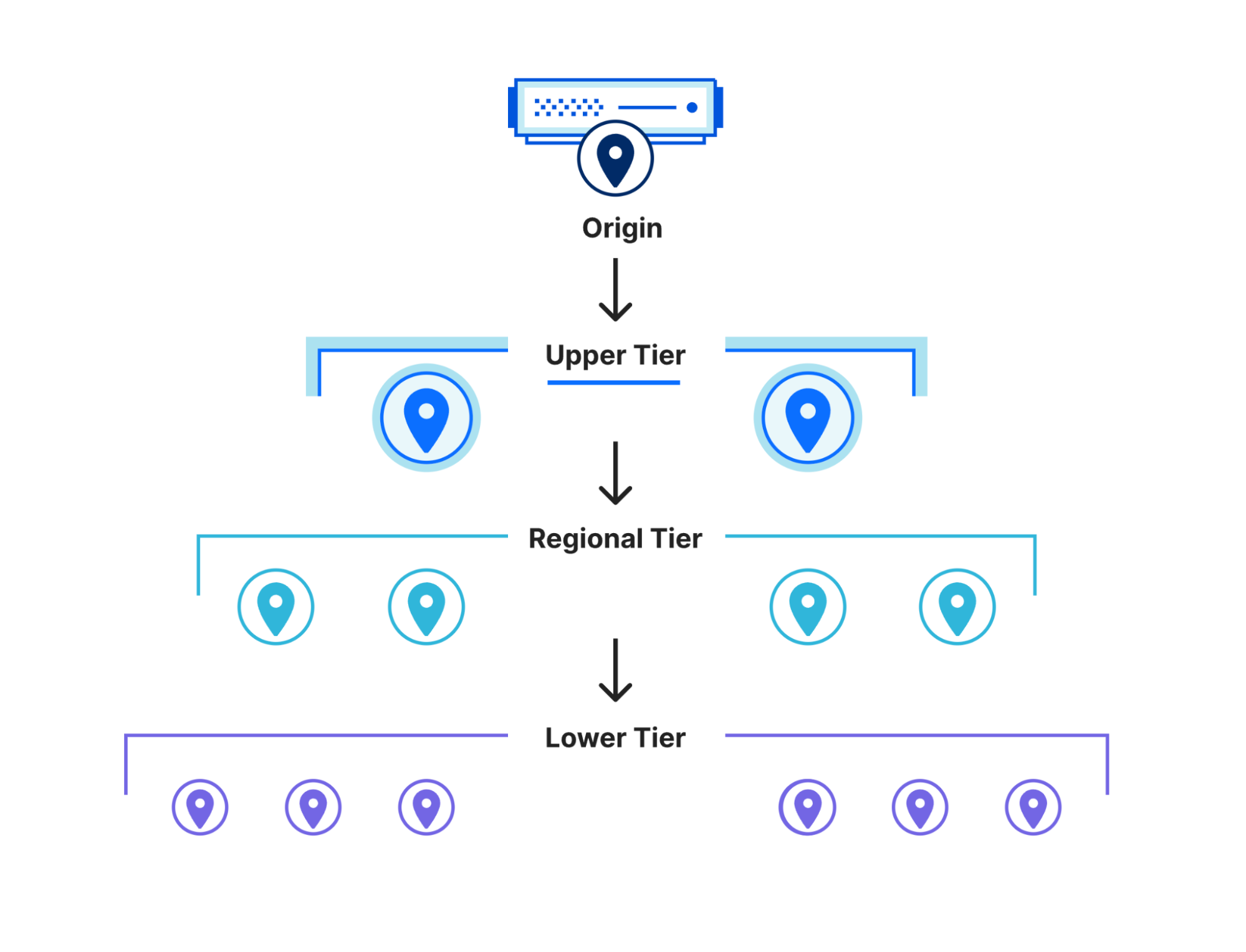
We also optimized KV’s architecture to reduce the amount of requests that need to reach our centralized storage backends. These storage backends are further away and incur network latency, so improving the cache hit rate in regions close to your Workers significantly improves read latency.
Workers KV uses Tiered Cache to resolve operations closer to your users
To accomplish this, we used Tiered Cache, and implemented a cache topology that is fine-tuned to the usage patterns of KV. With a tiered cache, requests to KV’s storage backends are cached in regional tiers in addition to local (lower) tiers. With this architecture, KV operations that may be cache misses locally may be resolved regionally, which is especially significant if you have traffic across an entire region spanning multiple Cloudflare data centers.
This significantly reduced the amount of requests that needed to hit the storage backends, with ~30% of requests resolved in tiered cache instead of storage backends.
KV’s new architecture
As a result of these optimizations, KV operations are now simplified:
When you read from KV in your Worker, the KV binding binds directly to KV’s Worker, saving 10 ms.
The KV Worker binds directly to the Tiered Cache service, saving another 10 ms.
Tiered Cache is used in front of storage backends, to resolve local cache misses regionally, closer to your users.
Sequence diagram of KV operations with new architecture
In aggregate, these changes significantly reduced KV’s latency.
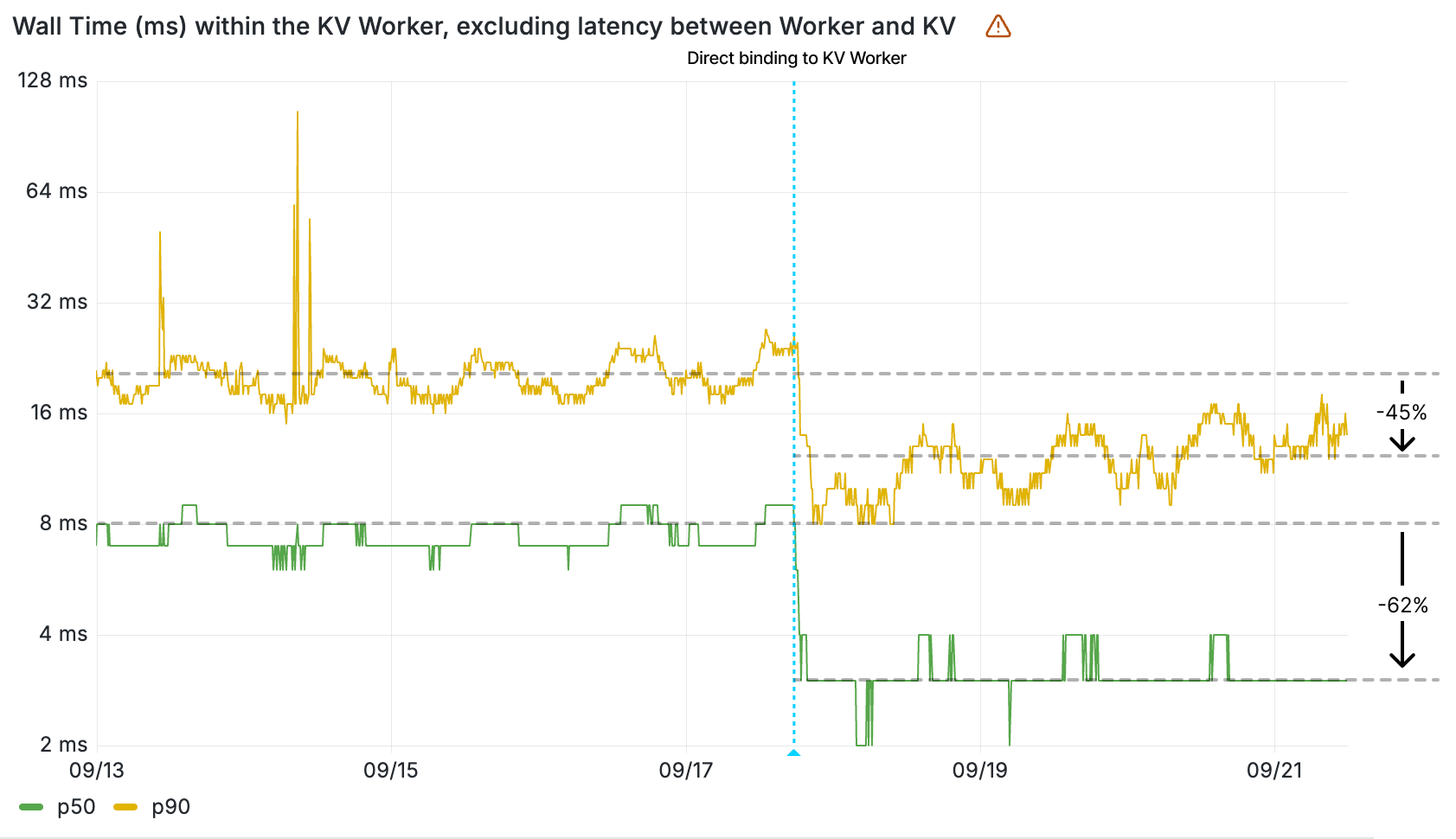
The impact of the direct binding to cache is clearly seen in the wall time of the KV Worker, given this value measures the duration of a retrieval of a key-value pair from cache. The 90th percentile of all KV Worker invocations now resolve in less than 12 ms — before the direct binding to cache, that was 22 ms. That’s a 10 ms decrease in latency.
Wall time (ms) within the KV Worker by percentile
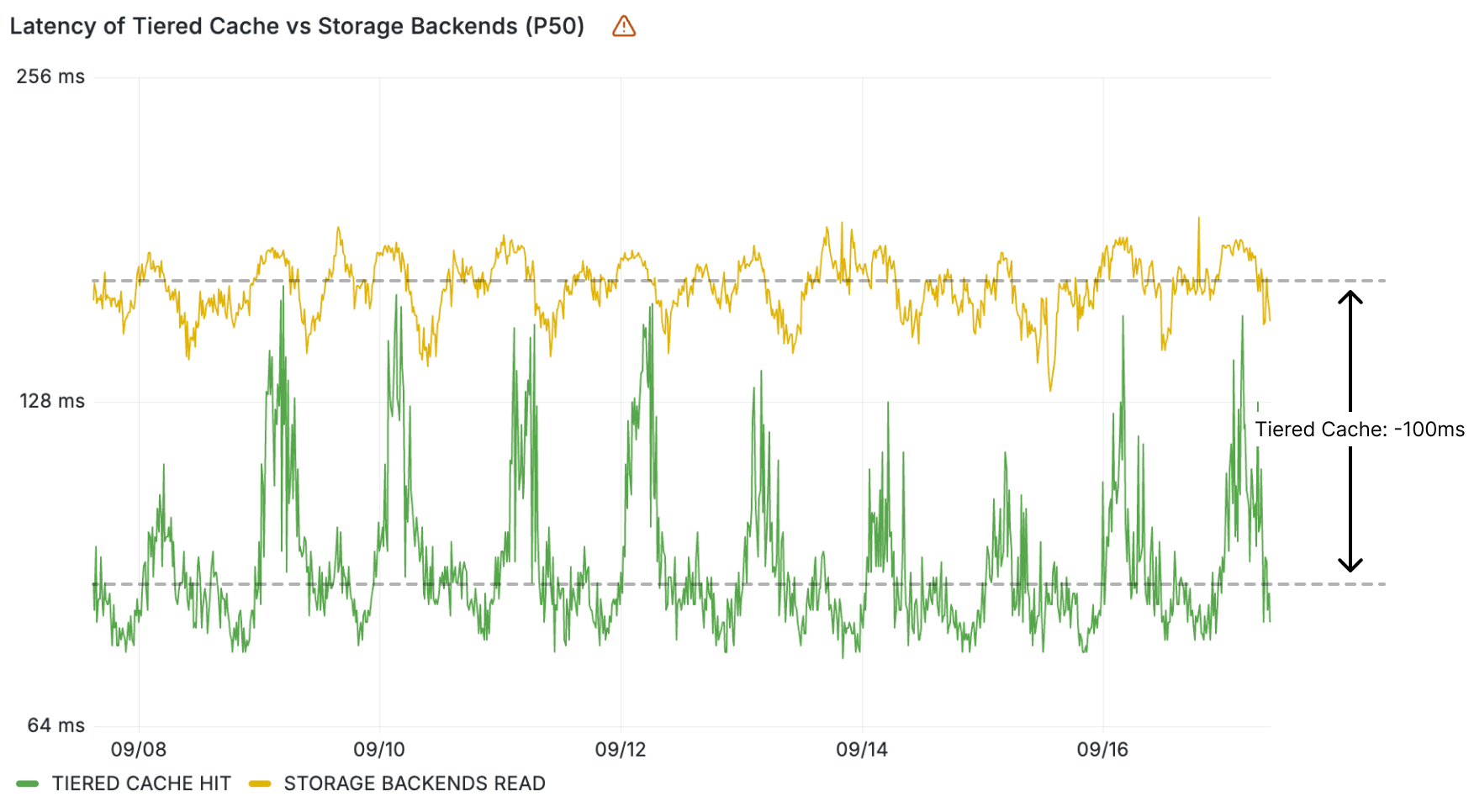
These KV read operations resolve quickly because the data is cached locally in the same Cloudflare location. But what about reads that aren’t resolved locally? ~30% of these resolve regionally within the tiered cache. Reads from tiered cache are up to 100 ms faster than when resolved at central storage backends, once again contributing to making KV reads faster in aggregate.
Wall time (ms) within the KV Worker for tiered cache vs. storage backends reads
These graphs demonstrate the impact of direct binding from the KV binding to cache, and tiered cache. To see the impact of the direct binding from a Worker to the KV Worker, we need to look at the latencies reported by Cloudflare products that use KV.
Cloudflare Pages, which serves static assets like HTML, CSS, and scripts from KV, saw load times for fetching assets improve by up to 68%. Workers asset hosting, which we also announced as part of today’s Builder Day announcements, gets this improved performance from day 1.
Workers KV read operation latency measured within Cloudflare Pages by percentile
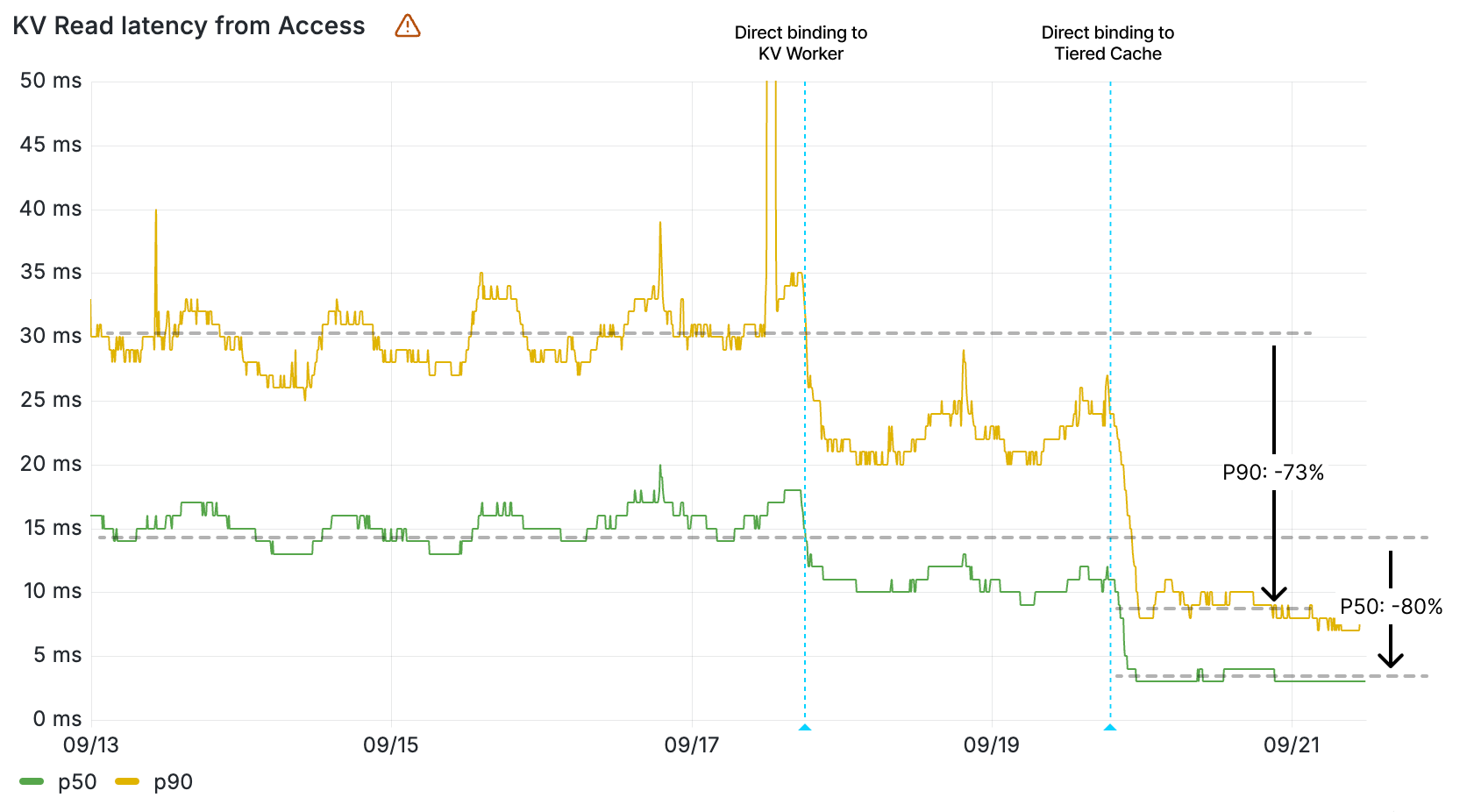
Queues and Access also saw their latencies for KV operations drop, with their KV read operations now 2-5x faster. These services rely on Workers KV data for configuration and routing data, so KV’s performance improvement directly contributes to making them faster on each request.
Workers KV read operation latency measured within Cloudflare Queues by percentile
Workers KV read operation latency measured within Cloudflare Access by percentile
These are just some of the direct effects that a faster KV has had on other services. Across the board, requests are resolving faster thanks to KV’s faster response times.
And we have one more thing to make KV lightning fast.
Optimizing KV’s hottest keys with an in-memory cache
Less than 0.03% of keys account for nearly half of requests to the Workers KV service across all namespaces. These keys are read thousands of times per second, so making these faster has a disproportionate impact. Could these keys be resolved within the KV Worker without needing additional network hops?
Almost all of these keys are under 100 KB. At this size, it becomes possible to use the in-memory cache of the KV Worker — a limited amount of memory within the main runtime process of a Worker sandbox. And that’s exactly what we did. For the highest throughput keys across Workers KV, reads resolve without even needing to leave the Worker runtime process.
Sequence diagram of KV operations with the hottest keys resolved within an in-memory cache
As a result of these changes, KV reads for these keys, which represent over 40% of Workers KV requests globally, resolve in under a millisecond. We’re actively testing these changes internally and expect to roll this out during October to speed up the hottest key-value pairs on Workers KV.
A faster KV for all
Most of these speed gains are already enabled with no additional action needed from customers. Your websites that are using KV are already responding to requests faster for your users, as are the other Cloudflare services using KV under the hood and the countless websites that depend upon them.
And we’re not done: we’ll continue to chase performance throughout our stack to make your websites faster. That’s how we’re going to move the needle towards a faster Internet.
To see Workers KV’s recent speed gains for your own KV namespaces, head over to your dashboard and check out the new KV analytics, with latency and cache status detailed per namespace.
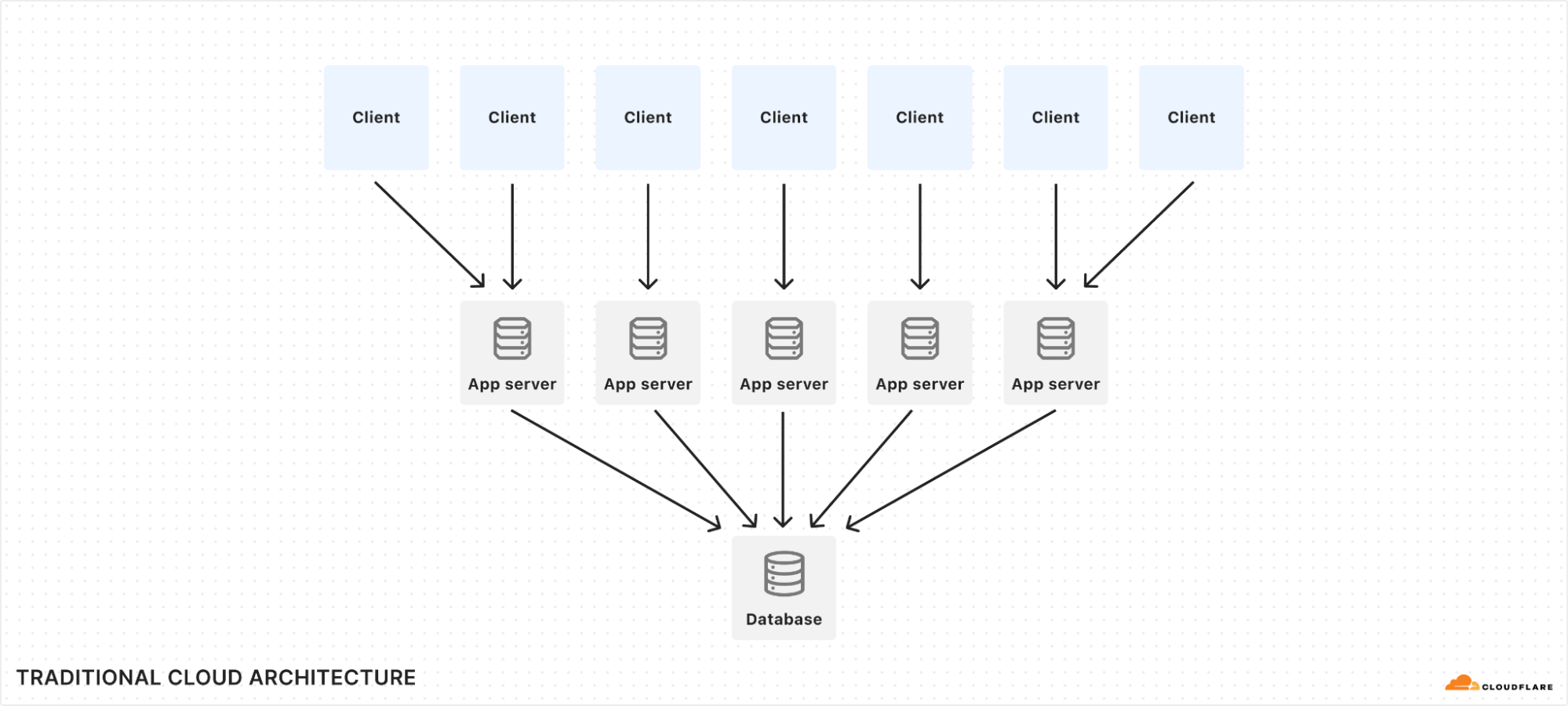
Traditional cloud storage is inherently slow, because it is normally accessed over a network and must carefully synchronize across many clients that could be accessing the same data. But what if we could instead put your application code deep into the storage layer, such that your code runs directly on the machine where the data is stored, and the database itself executes as a local library embedded inside your application?
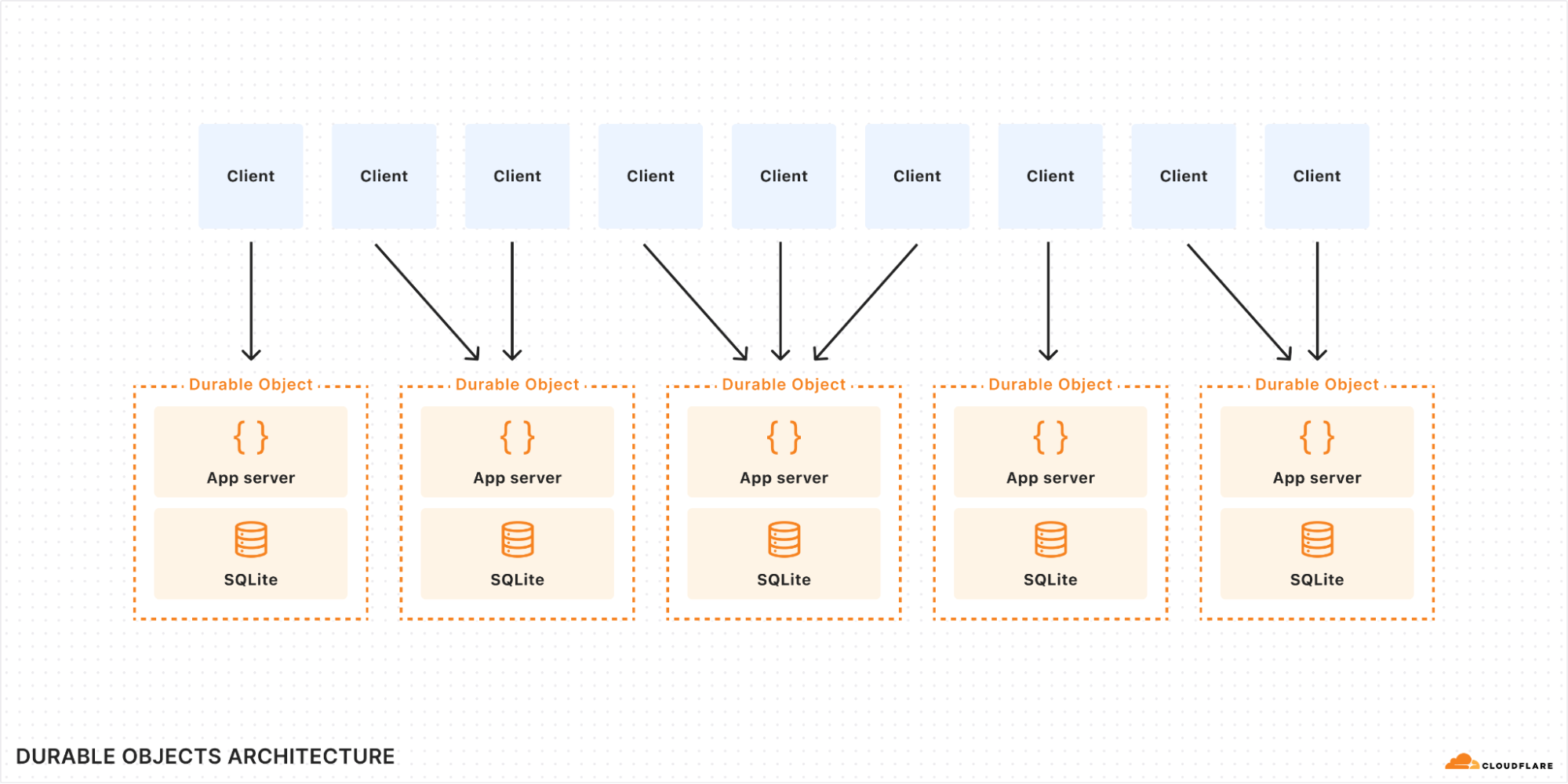
Durable Objects (DO) are a novel approach to cloud computing which accomplishes just that: Your application code runs exactly where the data is stored. Not just on the same machine: your storage lives in the same thread as the application, requiring not even a context switch to access. With proper use of caching, storage latency is essentially zero, while nevertheless being durable and consistent.
Until today, DOs only offered key/value oriented storage. But now, they support a full SQL query interface with tables and indexes, through the power of SQLite.
SQLite is the most-used SQL database implementation in the world, with billions of installations. It’s on practically every phone and desktop computer, and many embedded devices use it as well. It’s known to be blazingly fast and rock solid. But it’s been less common on the server. This is because traditional cloud architecture favors large distributed databases that live separately from application servers, while SQLite is designed to run as an embedded library. In this post, we’ll show you how Durable Objects turn this architecture on its head and unlock the full power of SQLite in the cloud.
Refresher: what are Durable Objects?
Durable Objects (DOs) are a part of the Cloudflare Workers serverless platform. A DO is essentially a small server that can be addressed by a unique name and can keep state both in-memory and on-disk. Workers running anywhere on Cloudflare’s network can send messages to a DO by its name, and all messages addressed to the same name — from anywhere in the world — will find their way to the same DO instance.
DOs are intended to be small and numerous. A single application can create billions of DOs distributed across our global network. Cloudflare automatically decides where a DO should live based on where it is accessed, automatically starts it up as needed when requests arrive, and shuts it down when idle. A DO has in-memory state while running and can also optionally store long-lived durable state. Since there is exactly one DO for each name, a DO can be used to coordinate between operations on the same logical object.
For example, imagine a real-time collaborative document editor application. Many users may be editing the same document at the same time. Each user’s changes must be broadcast to other users in real time, and conflicts must be resolved. An application built on DOs would typically create one DO for each document. The DO would receive edits from users, resolve conflicts, broadcast the changes back out to other users, and keep the document content updated in its local storage.
DOs are especially good at real-time collaboration, but are by no means limited to this use case. They are general-purpose servers that can implement any logic you desire to serve requests. Even more generally, DOs are a basic building block for distributed systems.
When using Durable Objects, it’s important to remember that they are intended to scale out, not up. A single object is inherently limited in throughput since it runs on a single thread of a single machine. To handle more traffic, you create more objects. This is easiest when different objects can handle different logical units of state (like different documents, different users, or different “shards” of a database), where each unit of state has low enough traffic to be handled by a single object. But sometimes, a lot of traffic needs to modify the same state: consider a vote counter with a million users all trying to cast votes at once. To handle such cases with Durable Objects, you would need to create a set of objects that each handle a subset of traffic and then replicate state to each other. Perhaps they use CRDTs in a gossip network, or perhaps they implement a fan-in/fan-out approach to a single primary object. Whatever approach you take, Durable Objects make it fast and easy to create more stateful nodes as needed.
Why is SQLite-in-DO so fast?
In traditional cloud architecture, stateless application servers run business logic and communicate over the network to a database. Even if the network is local, database requests still incur latency, typically measured in milliseconds.
When a Durable Object uses SQLite, SQLite is invoked as a library. This means the database code runs not just on the same machine as the DO, not just in the same process, but in the very same thread. Latency is effectively zero, because there is no communication barrier between the application and SQLite. A query can complete in microseconds.
Reads and writes are synchronous
The SQL query API in DOs does not require you to await results — they are returned synchronously:
// No awaits!
let cursor = sql.exec("SELECT name, email FROM users");
for (let user of cursor) {
console.log(user.name, user.email);
}
This may come as a surprise to some. Querying a database is I/O, right? I/O should always be asynchronous, right? Isn’t this a violation of the natural order of JavaScript?
It’s OK! The database content is probably cached in memory already, and SQLite is being called as a library in the same thread as the application, so the query often actually won’t spend any time at all waiting for I/O. Even if it does have to go to disk, it’s a local SSD. You might as well consider the local disk as just another layer in the memory cache hierarchy: L5 cache, if you will. In any case, it will respond quickly.
Meanwhile, synchronous queries provide some big benefits. First, the logistics of asynchronous event loops have a cost, so in the common case where the data is already in memory, a synchronous query will actually complete faster than an async one.
More importantly, though, synchronous queries help you avoid subtle bugs. Any time your application awaits a promise, it’s possible that some other code executes while you wait. The state of the world may have changed by the time your await completes. Maybe even other SQL queries were executed. This can lead to subtle bugs that are hard to reproduce because they require events to happen at just the wrong time. With a synchronous API, though, none of that can happen. Your code always executes in the order you wrote it, uninterrupted.
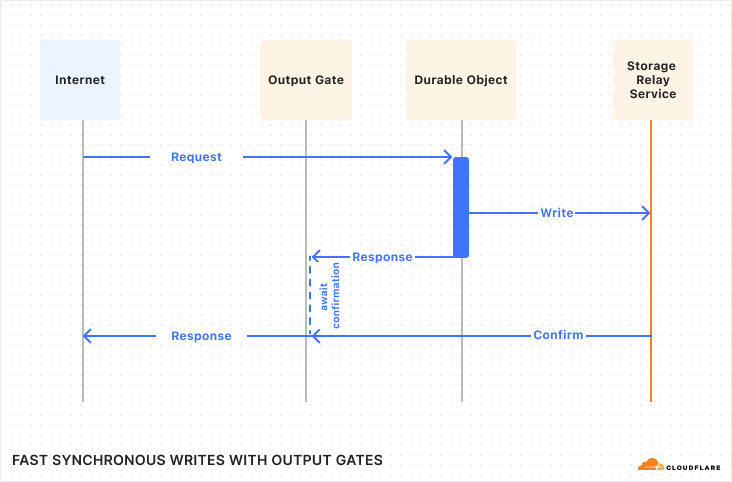
Fast writes with Output Gates
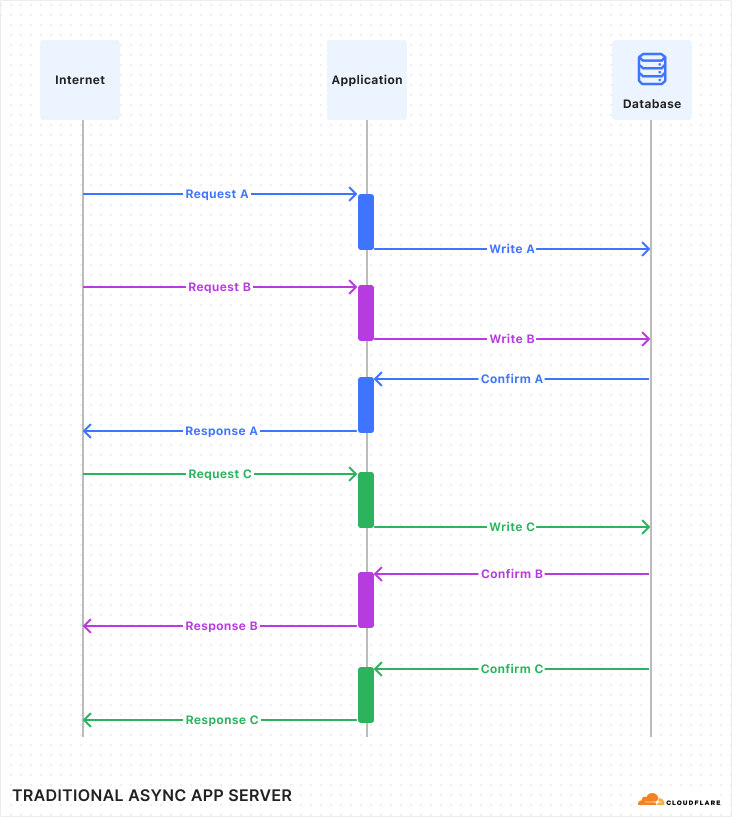
Database experts might have a deeper objection to synchronous queries: Yes, caching may mean we can perform reads and writes very fast. However, in the case of a write, just writing to cache isn’t good enough. Before we return success to our client, we must confirm that the write is actually durable, that is, it has actually made it onto disk or network storage such that it cannot be lost if the power suddenly goes out.
Normally, a database would confirm all writes before returning to the application. So if the query is successful, it is confirmed. But confirming writes can be slow, because it requires waiting for the underlying storage medium to respond. Normally, this is OK because the write is performed asynchronously, so the program can go on and work on other things while it waits for the write to finish. It looks kind of like this:
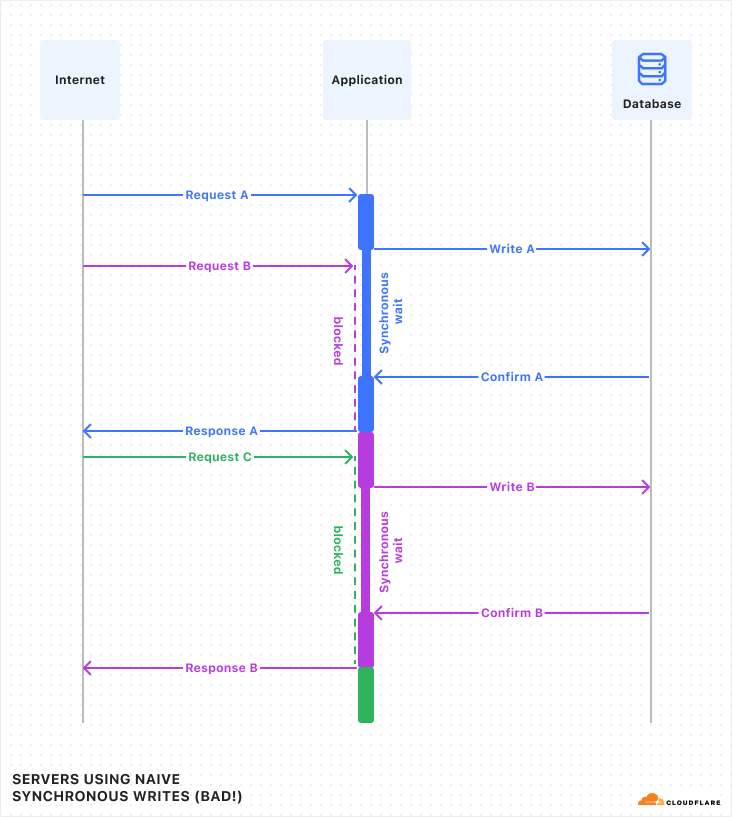
But I just told you that in Durable Objects, writes are synchronous. While a synchronous call is running, no other code in the program can run (because JavaScript does not have threads). This is convenient, as mentioned above, because it means you don’t need to worry that the state of the world may have changed while you were waiting. However, if write queries have to wait a while, and the whole program must pause and wait for them, then throughput will suffer.
Luckily, in Durable Objects, writes do not have to wait, due to a little trick we call “Output Gates”.
In DOs, when the application issues a write, it continues executing without waiting for confirmation. However, when the DO then responds to the client, the response is blocked by the “Output Gate”. This system holds the response until all storage writes relevant to the response have been confirmed, then sends the response on its way. In the rare case that the write fails, the response will be replaced with an error and the Durable Object itself will restart. So, even though the application constructed a “success” response, nobody can ever see that this happened, and thus nobody can be misled into believing that the data was stored.
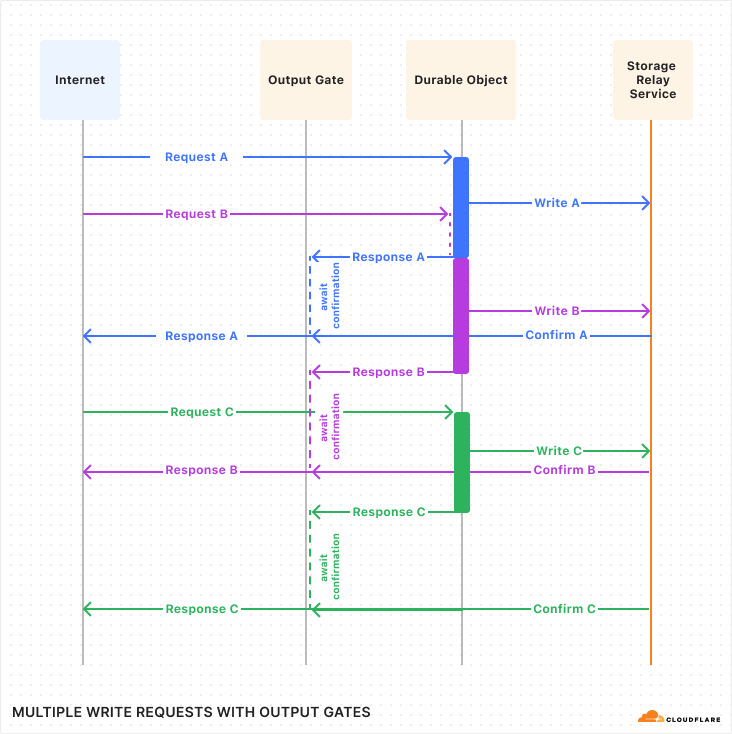
Let’s see what this looks like with multiple requests:
If you compare this against the first diagram above, you should notice a few things:
The timing of requests and confirmations are the same.
But, all responses were sent to the client sooner than in the first diagram. Latency was reduced! This is because the application is able to work on constructing the response in parallel with the storage layer confirming the write.
Request handling is no longer interleaved between the three requests. Instead, each request runs to completion before the next begins. The application does not need to worry, during the handling of one request, that its state might change unexpectedly due to a concurrent request.
With Output Gates, we get the ease-of-use of synchronous writes, while also getting lower latency and no loss of throughput.
N+1 selects? No problem.
Zero-latency queries aren’t just faster, they allow you to structure your code differently, often making it simpler. A classic example is the “N+1 selects” or “N+1 queries” problem. Let’s illustrate this problem with an example:
// N+1 SELECTs example
// Get the 100 most-recently-modified docs.
let docs = sql.exec(`
SELECT title, authorId FROM documents
ORDER BY lastModified DESC
LIMIT 100
`).toArray();
// For each returned document, get the author name from the users table.
for (let doc of docs) {
doc.authorName = sql.exec(
"SELECT name FROM users WHERE id = ?", doc.authorId).one().name;
}
If you are an experienced SQL user, you are probably cringing at this code, and for good reason: this code does 101 queries! If the application is talking to the database across a network with 5ms latency, this will take 505ms to run, which is slow enough for humans to notice.
// Do it all in one query with a join?
let docs = sql.exec(`
SELECT documents.title, users.name
FROM documents JOIN users ON documents.authorId = users.id
ORDER BY documents.lastModified DESC
LIMIT 100
`).toArray();
Here we’ve used SQL features to turn our 101 queries into one query. Great! Except, what does it mean? We used an inner join, which is not to be confused with a left, right, or cross join. What’s the difference? Honestly, I have no idea! I had to look up joins just to write this example and I’m already confused.
Well, good news: You don’t need to figure it out. Because when using SQLite as a library, the first example above works just fine. It’ll perform about the same as the second fancy version.
More generally, when using SQLite as a library, you don’t have to learn how to do fancy things in SQL syntax. Your logic can be in regular old application code in your programming language of choice, orchestrating the most basic SQL queries that are easy to learn. It’s fine. The creators of SQLite have made this point themselves.
Point-in-Time Recovery
While not necessarily related to speed, SQLite-backed Durable Objects offer another feature: any object can be reverted to the state it had at any point in time in the last 30 days. So if you accidentally execute a buggy query that corrupts all your data, don’t worry: you can recover. There’s no need to opt into this feature in advance; it’s on by default for all SQLite-backed DOs. See the docs for details.
How do I use it?
Let’s say we’re an airline, and we are implementing a way for users to choose their seats on a flight. We will create a new Durable Object for each flight. Within that DO, we will use a SQL table to track the assignments of seats to passengers. The code might look something like this:
import {DurableObject} from "cloudflare:workers";
// Manages seat assignment for a flight.
//
// This is an RPC interface. The methods can be called remotely by other Workers
// running anywhere in the world. All Workers that specify same object ID
// (probably based on the flight number and date) will reach the same instance of
// FlightSeating.
export class FlightSeating extends DurableObject {
sql = this.ctx.storage.sql;
// Application calls this when the flight is first created to set up the seat map.
initializeFlight(seatList) {
this.sql.exec(`
CREATE TABLE seats (
seatId TEXT PRIMARY KEY, -- e.g. "3B"
occupant TEXT -- null if available
)
`);
for (let seat of seatList) {
this.sql.exec(`INSERT INTO seats VALUES (?, null)`, seat);
}
}
// Get a list of available seats.
getAvailable() {
let results = [];
// Query returns a cursor.
let cursor = this.sql.exec(`SELECT seatId FROM seats WHERE occupant IS NULL`);
// Cursors are iterable.
for (let row of cursor) {
// Each row is an object with a property for each column.
results.push(row.seatId);
}
return results;
}
// Assign passenger to a seat.
assignSeat(seatId, occupant) {
// Check that seat isn't occupied.
let cursor = this.sql.exec(`SELECT occupant FROM seats WHERE seatId = ?`, seatId);
let result = [...cursor][0]; // Get the first result from the cursor.
if (!result) {
throw new Error("No such seat: " + seatId);
}
if (result.occupant !== null) {
throw new Error("Seat is occupied: " + seatId);
}
// If the occupant is already in a different seat, remove them.
this.sql.exec(`UPDATE seats SET occupant = null WHERE occupant = ?`, occupant);
// Assign the seat. Note: We don't have to worry that a concurrent request may
// have grabbed the seat between the two queries, because the code is synchronous
// (no `await`s) and the database is private to this Durable Object. Nothing else
// could have changed since we checked that the seat was available earlier!
this.sql.exec(`UPDATE seats SET occupant = ? WHERE seatId = ?`, occupant, seatId);
}
}
(With just a little more code, we could extend this example to allow clients to subscribe to seat changes with WebSockets, so that if multiple people are choosing their seats at the same time, they can see in real time as seats become unavailable. But, that’s outside the scope of this blog post, which is just about SQL storage.)
Then in wrangler.toml, define a migration setting up your DO class like usual, but instead of using new_classes, use new_sqlite_classes:
[[migrations]]
tag = "v1"
new_sqlite_classes = ["FlightSeating"]
SQLite-backed objects also support the existing key/value-based storage API: KV data is stored into a hidden table in the SQLite database. So, existing applications built on DOs will work when deployed using SQLite-backed objects.
However, because SQLite-backed objects are based on an all-new storage backend, it is currently not possible to switch an existing deployed DO class to use SQLite. You must ask for SQLite when initially deploying the new DO class; you cannot change it later. We plan to begin migrating existing DOs to the new storage backend in 2025.
Pricing
We’ve kept pricing for SQLite-in-DO similar to D1, Cloudflare’s serverless SQL database, by billing for SQL queries (based on rows) and SQL storage. SQL storage per object is limited to 1 GB during the beta period, and will be increased to 10 GB on general availability. DO requests and duration billing are unchanged and apply to all DOs regardless of storage backend.
During the initial beta, billing is not enabled for SQL queries (rows read and rows written) and SQL storage. SQLite-backed objects will incur charges for requests and duration. We plan to enable SQL billing in the first half of 2025 with advance notice.
Workers Paid
Rows read
First 25 billion / month included + $0.001 / million rows
Rows written
First 50 million / month included + $1.00 / million rows
SQL storage
5 GB-month + $0.20/ GB-month
For more on how to use SQLite-in-Durable Objects, check out the documentation.
What about D1?
Cloudflare Workers already offers another SQLite-backed database product: D1. In fact, D1 is itself built on SQLite-in-DO. So, what’s the difference? Why use one or the other?
In short, you should think of D1 as a more “managed” database product, while SQLite-in-DO is more of a lower-level “compute with storage” building block.
D1 fits into a more traditional cloud architecture, where stateless application servers talk to a separate database over the network. Those application servers are typically Workers, but could also be clients running outside of Cloudflare. D1 also comes with a pre-built HTTP API and managed observability features like query insights. With D1, where your application code and SQL database queries are not colocated like in SQLite-in-DO, Workers has Smart Placement to dynamically run your Worker in the best location to reduce total request latency, considering everything your Worker talks to, including D1. By the end of 2024, D1 will support automatic read replication for scalability and low-latency access around the world. If this managed model appeals to you, use D1.
Durable Objects require a bit more effort, but in return, give you more power. With DO, you have two pieces of code that run in different places: a front-end Worker which routes incoming requests from the Internet to the correct DO, and the DO itself, which runs on the same machine as the SQLite database. You may need to think carefully about which code to run where, and you may need to build some of your own tooling that exists out-of-the-box with D1. But because you are in full control, you can tailor the solution to your application’s needs and potentially achieve more.
Under the hood: Storage Relay Service
When Durable Objects first launched in 2020, it offered only a simple key/value-based interface for durable storage. Under the hood, these keys and values were stored in a well-known off-the-shelf database, with regional instances of this database deployed to locations in our data centers around the world. Durable Objects in each region would store their data to the regional database.
For SQLite-backed Durable Objects, we have completely replaced the persistence layer with a new system built from scratch, called Storage Relay Service, or SRS. SRS has already been powering D1 for over a year, and can now be used more directly by applications through Durable Objects.
SRS is based on a simple idea:
Local disk is fast and randomly-accessible, but expensive and prone to disk failures. Object storage (like R2) is cheap and durable, but much slower than local disk and not designed for database-like access patterns. Can we get the best of both worlds by using a local disk as a cache on top of object storage?
So, how does it work?
The mismatch in functionality between local disk and object storage
A SQLite database on disk tends to undergo many small changes in rapid succession. Any row of the database might be updated by any particular query, but the database is designed to avoid rewriting parts that didn’t change. Read queries may randomly access any part of the database. Assuming the right indexes exist to support the query, they should not require reading parts of the database that aren’t relevant to the results, and should complete in microseconds.
Object storage, on the other hand, is designed for an entirely different usage model: you upload an entire “object” (blob of bytes) at a time, and download an entire blob at a time. Each blob has a different name. For maximum efficiency, blobs should be fairly large, from hundreds of kilobytes to gigabytes in size. Latency is relatively high, measured in tens or hundreds of milliseconds.
So how do we back up our SQLite database to object storage? An obviously naive strategy would be to simply make a copy of the database files from time to time and upload it as a new “object”. But, uploading the database on every change — and making the application wait for the upload to complete — would obviously be way too slow. We could choose to upload the database only occasionally — say, every 10 minutes — but this means in the case of a disk failure, we could lose up to 10 minutes of changes. Data loss is, uh, bad! And even then, for most databases, it’s likely that most of the data doesn’t change every 10 minutes, so we’d be uploading the same data over and over again.
Trick one: Upload a log of changes
Instead of uploading the entire database, SRS records a log of changes, and uploads those.
Conveniently, SQLite itself already has a concept of a change log: the Write-Ahead Log, or WAL. SRS always configures SQLite to use WAL mode. In this mode, any changes made to the database are first written to a separate log file. From time to time, the database is “checkpointed”, merging the changes back into the main database file. The WAL format is well-documented and easy to understand: it’s just a sequence of “frames”, where each frame is an instruction to write some bytes to a particular offset in the database file.
SRS monitors changes to the WAL file (by hooking SQLite’s VFS to intercept file writes) to discover the changes being made to the database, and uploads those to object storage.
Unfortunately, SRS cannot simply upload every single change as a separate “object”, as this would result in too many objects, each of which would be inefficiently small. Instead, SRS batches changes over a period of up to 10 seconds, or up to 16 MB worth, whichever happens first, then uploads the whole batch as a single object.
When reconstructing a database from object storage, we must download the series of change batches and replay them in order. Of course, if the database has undergone many changes over a long period of time, this can get expensive. In order to limit how far back it needs to look, SRS also occasionally uploads a snapshot of the entire content of the database. SRS will decide to upload a snapshot any time that the total size of logs since the last snapshot exceeds the size of the database itself. This heuristic implies that the total amount of data that SRS must download to reconstruct a database is limited to no more than twice the size of the database. Since we can delete data from object storage that is older than the latest snapshot, this also means that our total stored data is capped to 2x the database size.
Credit where credit is due: This idea — uploading WAL batches and snapshots to object storage — was inspired by Litestream, although our implementation is different.
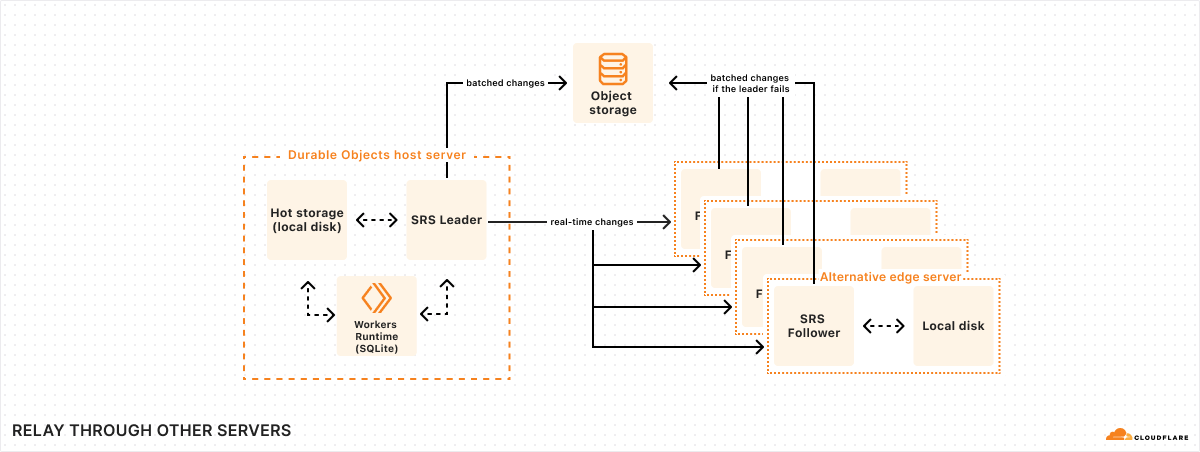
Trick two: Relay through other servers in our global network
Batches are only uploaded to object storage every 10 seconds. But obviously, we cannot make the application wait for 10 whole seconds just to confirm a write. So what happens if the application writes some data, returns a success message to the user, and then the machine fails 9 seconds later, losing the data?
To solve this problem, we take advantage of our global network. Every time SQLite commits a transaction, SRS will immediately forward the change log to five “follower” machines across our network. Once at least three of these followers respond that they have received the change, SRS informs the application that the write is confirmed. (As discussed earlier, the write confirmation opens the Durable Object’s “output gate”, unblocking network communications to the rest of the world.)
When a follower receives a change, it temporarily stores it in a buffer on local disk, and then awaits further instructions. Later on, once SRS has successfully uploaded the change to object storage as part of a batch, it informs each follower that the change has been persisted. At that point, the follower can simply delete the change from its buffer.
However, if the follower never receives the persisted notification, then, after some timeout, the follower itself will upload the change to object storage. Thus, if the machine running the database suddenly fails, as long as at least one follower is still running, it will ensure that all confirmed writes are safely persisted.
Each of a database’s five followers is located in a different physical data center. Cloudflare’s network consists of hundreds of data centers around the world, which means it is always easy for us to find four other data centers nearby any Durable Object (in addition to the one it is running in). In order for a confirmed write to be lost, then, at least four different machines in at least three different physical buildings would have to fail simultaneously (three of the five followers, plus the Durable Object’s host machine). Of course, anything can happen, but this is exceedingly unlikely.
Followers also come in handy when a Durable Object’s host machine is unresponsive. We may not know for sure if the machine has died completely, or if it is still running and responding to some clients but not others. We cannot start up a new instance of the DO until we know for sure that the previous instance is dead – or, at least, that it can no longer confirm writes, since the old and new instances could then confirm contradictory writes. To deal with this situation, if we can’t reach the DO’s host, we can instead try to contact its followers. If we can contact at least three of the five followers, and tell them to stop confirming writes for the unreachable DO instance, then we know that instance is unable to confirm any more writes going forward. We can then safely start up a new instance to replace the unreachable one.
Bonus feature: Point-in-Time Recovery
I mentioned earlier that SQLite-backed Durable Objects can be asked to revert their state to any time in the last 30 days. How does this work?
This was actually an accidental feature that fell out of SRS’s design. Since SRS stores a complete log of changes made to the database, we can restore to any point in time by replaying the change log from the last snapshot. The only thing we have to do is make sure we don’t delete those logs too soon.
Normally, whenever a snapshot is uploaded, all previous logs and snapshots can then be deleted. But instead of deleting them immediately, SRS merely marks them for deletion 30 days later. In the meantime, if a point-in-time recovery is requested, the data is still there to work from.
For a database with a high volume of writes, this may mean we store a lot of data for a lot longer than needed. As it turns out, though, once data has been written at all, keeping it around for an extra month is pretty cheap — typically cheaper, even, than writing it in the first place. It’s a small price to pay for always-on disaster recovery.
Get started with SQLite-in-DO
SQLite-backed DOs are available in beta starting today. You can start building with SQLite-in-DO by visiting developer documentation and provide beta feedback via the #durable-objects channel on our Developer Discord.
Do distributed systems like SRS excite you? Would you like to be part of building them at Cloudflare? We’re hiring!
During Birthday Week 2023, we launched Workers AI. Since then, we have been listening to your feedback, and one thing we’ve heard consistently is that our customers want Workers AI to be faster. In particular, we hear that large language model (LLM) generation needs to be faster. Users want their interactive chat and agents to go faster, developers want faster help, and users do not want to wait for applications and generated website content to load. Today, we’re announcing three upgrades we’ve made to Workers AI to bring faster and more efficient inference to our customers: upgraded hardware, KV cache compression, and speculative decoding.
Thanks to Cloudflare’s 12th generation compute servers, our network now supports a newer generation of GPUs capable of supporting larger models and faster inference. Customers can now use Meta Llama 3.2 11B, Meta’s newly released multi-modal model with vision support, as well as Meta Llama 3.1 70B on Workers AI. Depending on load and time of day, customers can expect to see two to three times the throughput for Llama 3.1 and 3.2 compared to our previous generation Workers AI hardware. More performance information for these models can be found in today’s post: Cloudflare’s Bigger, Better, Faster AI platform.
New KV cache compression methods, now open source
In our effort to deliver low-cost low-latency inference to the world, Workers AI has been developing novel methods to boost efficiency of LLM inference. Today, we’re excited to announce a technique for KV cache compression that can help increase throughput of an inference platform. And we’ve made it open source too, so that everyone can benefit from our research.
It’s all about memory
One of the main bottlenecks when running LLM inference is the amount of vRAM (memory) available. Every word that an LLM processes generates a set of vectors that encode the meaning of that word in the context of any earlier words in the input that are used to generate new tokens in the future. These vectors are stored in the KV cache, causing the memory required for inference to scale linearly with the total number of tokens of all sequences being processed. This makes memory a bottleneck for a lot of transformer-based models. Because of this, the amount of memory an instance has available limits the number of sequences it can generate concurrently, as well as the maximum token length of sequences it can generate.
So what is the KV cache anyway?
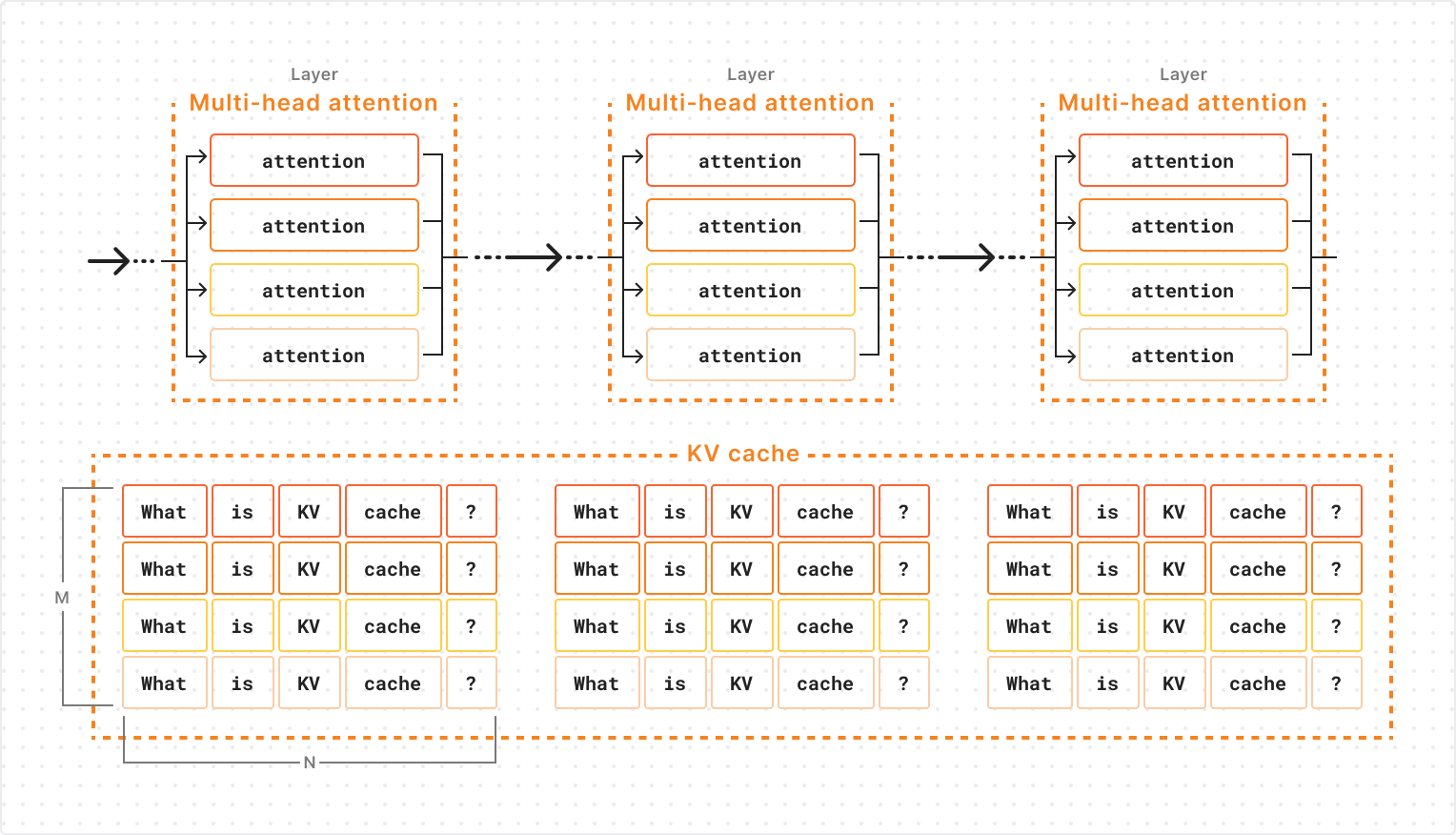
LLMs are made up of layers, with an attention operation occurring in each layer. Within each layer’s attention operation, information is collected from the representations of all previous tokens that are stored in cache. This means that vectors in the KV cache are organized into layers, so that the active layer’s attention operation can only query vectors from the corresponding layer of KV cache. Furthermore, since attention within each layer is parallelized across multiple attention “heads”, the KV cache vectors of a specific layer are further subdivided into groups corresponding to each attention head of that layer.
The diagram below shows the structure of an LLM’s KV cache for a single sequence being generated. Each cell represents a KV and the model’s representation for a token consists of all KV vectors for that token across all attention heads and layers. As you can see, the KV cache for a single layer is allocated as an M x N matrix of KV vectors where M is the number of attention heads and N is the sequence length. This will be important later!
Now that we know what the KV cache looks like, let’s dive into how we can shrink it!
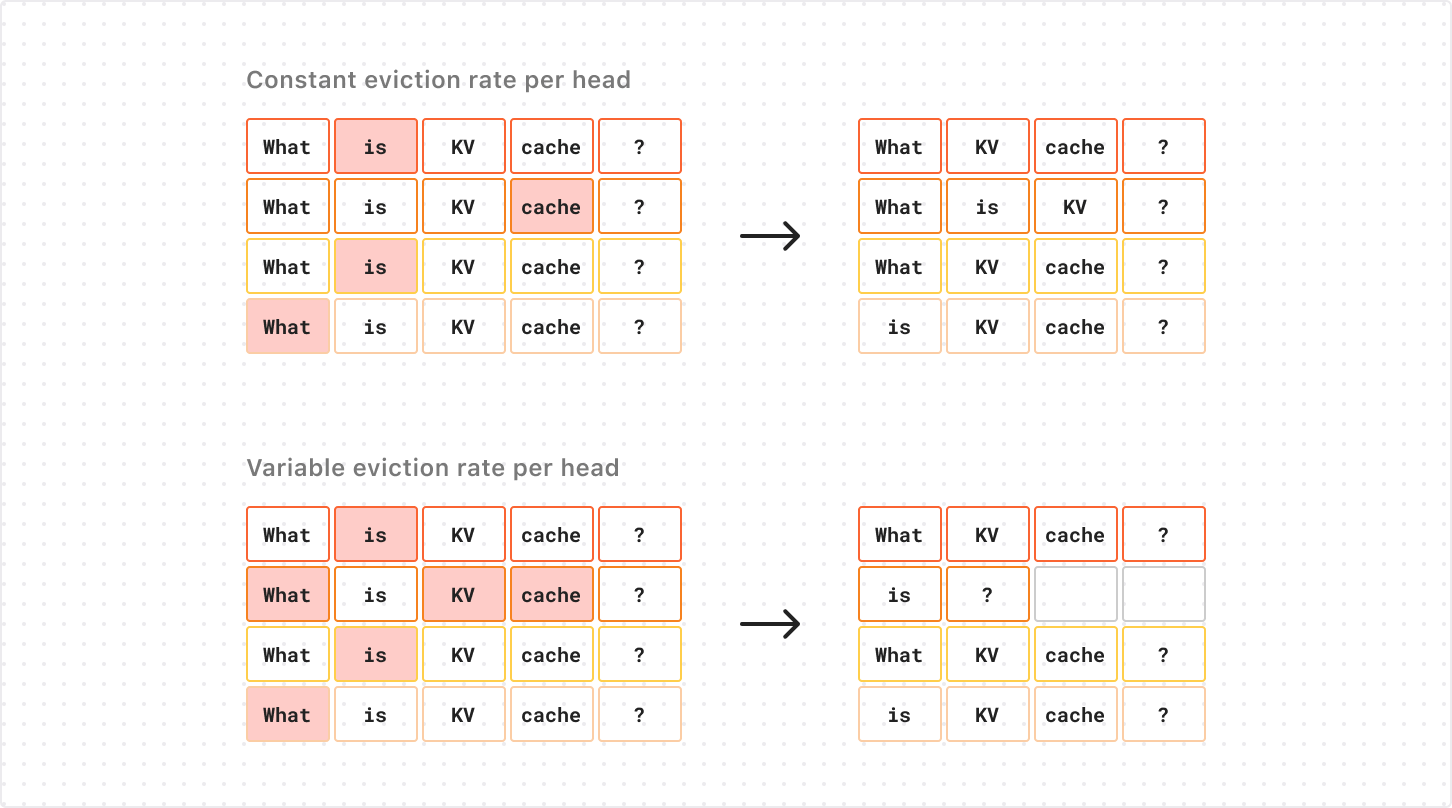
The most common approach to compressing the KV cache involves identifying vectors within it that are unlikely to be queried by future attention operations and can therefore be removed without impacting the model’s outputs. This is commonly done by looking at the past attention weights for each pair of key and value vectors (a measure of the degree with which that KV’s representation has been queried during past attention operations) and selecting the KVs that have received the lowest total attention for eviction. This approach is conceptually similar to a LFU (least frequently used) cache management policy: the less a particular vector is queried, the more likely it is to be evicted in the future.
Different attention heads need different compression rates
As we saw earlier, the KV cache for each sequence in a particular layer is allocated on the GPU as a # attention heads X sequence length tensor. This means that the total memory allocation scales with the maximum sequence length for all attention heads of the KV cache. Usually this is not a problem, since each sequence generates the same number of KVs per attention head.
When we consider the problem of eviction-based KV cache compression, however, this forces us to remove an equal number of KVs from each attention head when doing the compression. If we remove more KVs from one attention head alone, those removed KVs won’t actually contribute to lowering the memory footprint of the KV cache on GPU, but will just add more empty “padding” to the corresponding rows of the tensor. You can see this in the diagram below (note the empty cells in the second row below):
The extra compression along the second head frees slots for two KVs, but the cache’s shape (and memory footprint) remains the same.
This forces us to use a fixed compression rate for all attention heads of KV cache, which is very limiting on the compression rates we can achieve before compromising performance.
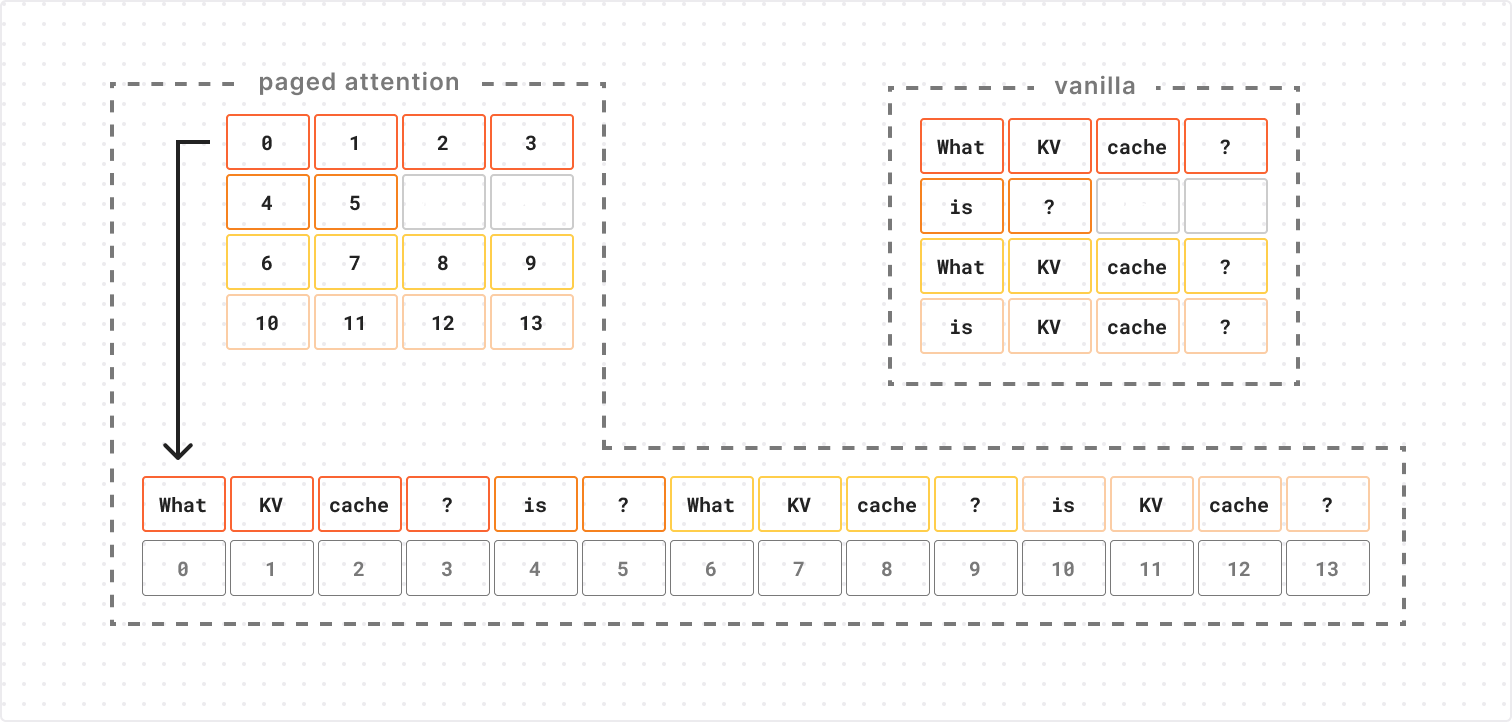
Enter PagedAttention
The solution to this problem is to change how our KV cache is represented in physical memory. PagedAttention can represent N x M tensors with padding efficiently by using an N x M block table to index into a series of “blocks”.
This lets us retrieve the ith element of a row by taking the ith block number from that row in the block table and using the block number to lookup the corresponding block, so we avoid allocating space to padding elements in our physical memory representation. In our case, the elements in physical memory are the KV cache vectors, and the M and N that define the shape of our block table are the number of attention heads and sequence length, respectively. Since the block table is only storing integer indices (rather than high-dimensional KV vectors), its memory footprint is negligible in most cases.
Results
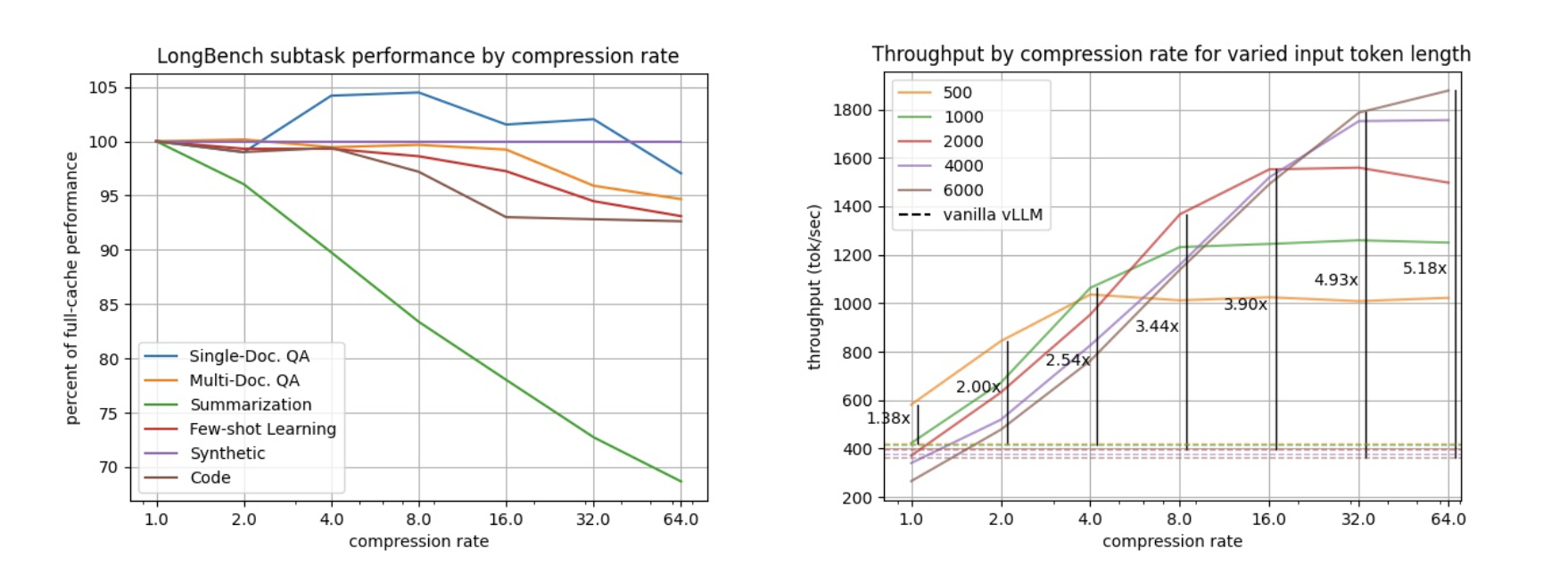
Using paged attention lets us apply different rates of compression to different heads in our KV cache, giving our compression strategy more flexibility than other methods. We tested our compression algorithm on LongBench (a collection of long-context LLM benchmarks) with Llama-3.1-8B and found that for most tasks we can retain over 95% task performance while reducing cache size by up to 8x (left figure below). Over 90% task performance can be retained while further compressing up to 64x. That means you have room in memory for 64 times as many tokens!
This lets us increase the number of requests we can process in parallel, increasing the total throughput (total tokens generated per second) by 3.44x and 5.18x for compression rates of 8x and 64x, respectively (right figure above).
Try it yourself!
If you’re interested in taking a deeper dive check out our vLLM fork and get compressing!!
Speculative decoding for faster throughput
A new inference strategy that we implemented is speculative decoding, which is a very popular way to get faster throughput (measured in tokens per second). LLMs work by predicting the next expected token (a token can be a word, word fragment or single character) in the sequence with each call to the model, based on everything that the model has seen before. For the first token generated, this means just the initial prompt, but after that each subsequent token is generated based on the prompt plus all other tokens that have been generated. Typically, this happens one token at a time, generating a single word, or even a single letter, depending on what comes next.
But what about this prompt:
Knock, knock!
If you are familiar with knock-knock jokes, you could very accurately predict more than one token ahead. For an English language speaker, what comes next is a very specific sequence that is four to five tokens long: “Who’s there?” or “Who is there?” Human language is full of these types of phrases where the next word has only one, or a few, high probability choices. Idioms, common expressions, and even basic grammar are all examples of this. So for each prediction the model makes, we can take it a step further with speculative decoding to predict the next n tokens. This allows us to speed up inference, as we’re not limited to predicting one token at a time.
There are several different implementations of speculative decoding, but each in some way uses a smaller, faster-to-run model to generate more than one token at a time. For Workers AI, we have applied prompt-lookup decoding to some of the LLMs we offer. This simple method matches the last n tokens of generated text against text in the prompt/output and predicts candidate tokens that continue these identified patterns as candidates for continuing the output. In the case of knock-knock jokes, it can predict all the tokens for “Who’s there” at once after seeing “Knock, knock!”, as long as this setup occurs somewhere in the prompt or previous dialogue already. Once these candidate tokens have been predicted, the model can verify them all with a single forward-pass and choose to either accept or reject them. This increases the generation speed of llama-3.1-8b-instruct by up to 40% and the 70B model by up to 70%.
Speculative decoding has tradeoffs, however. Typically, the results of a model using speculative decoding have a lower quality, both when measured using benchmarks like MMLU as well as when compared by humans. More aggressive speculation can speed up sequence generation, but generally comes with a greater impact to the quality of the result. Prompt lookup decoding offers one of the smallest overall quality impacts while still providing performance improvements, and we will be adding it to some language models on Workers AI including @cf/meta/llama-3.1-8b-instruct.
And, by the way, here is one of our favorite knock-knock jokes, can you guess the punchline?
Knock, knock!
Who’s there?
Figs!
Figs who?
Figs the doorbell, it’s broken!
Keep accelerating
As the AI industry continues to evolve, there will be new hardware and software that allows customers to get faster inference responses. Workers AI is committed to researching, implementing, and making upgrades to our services to help you get fast inference. As an Inference-as-a-Service platform, you’ll be able to benefit from all the optimizations we apply, without having to hire your own team of ML researchers and SREs to manage inference software and hardware deployments.
We’re excited for you to try out some of these new releases we have and let us know what you think! Check out our full-suite of AI announcements here and check out the developer docs to get started.
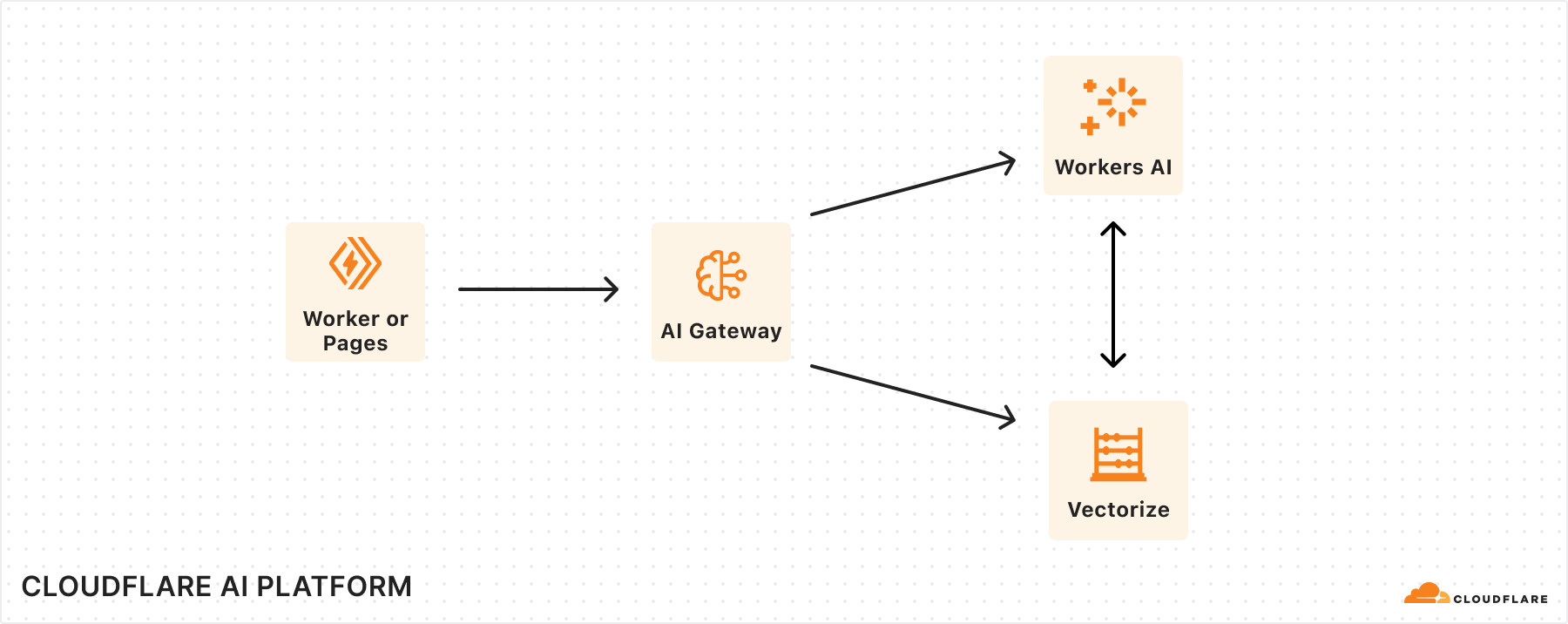
Birthday Week 2024 marks our first anniversary of Cloudflare’s AI developer products — Workers AI, AI Gateway, and Vectorize. For our first birthday this year, we’re excited to announce powerful new features to elevate the way you build with AI on Cloudflare.
Workers AI is getting a big upgrade, with more powerful GPUs that enable faster inference and bigger models. We’re also expanding our model catalog to be able to dynamically support models that you want to run on us. Finally, we’re saying goodbye to neurons and revamping our pricing model to be simpler and cheaper. On AI Gateway, we’re moving forward on our vision of becoming an ML Ops platform by introducing more powerful logs and human evaluations. Lastly, Vectorize is going GA, with expanded index sizes and faster queries.
Whether you want the fastest inference at the edge, optimized AI workflows, or vector database-powered RAG, we’re excited to help you harness the full potential of AI and get started on building with Cloudflare.
The fast, global AI platform
The first thing that you notice about an application is how fast, or in many cases, how slow it is. This is especially true of AI applications, where the standard today is to wait for a response to be generated.
At Cloudflare, we’re obsessed with improving the performance of applications, and have been doubling down on our commitment to make AI fast. To live up to that commitment, we’re excited to announce that we’ve added even more powerful GPUs across our network to accelerate LLM performance.
In addition to more powerful GPUs, we’ve continued to expand our GPU footprint to get as close to the user as possible, reducing latency even further. Today, we have GPUs in over 180 cities, having doubled our capacity in a year.
Bigger, better, faster
With the introduction of our new, more powerful GPUs, you can now run inference on significantly larger models, including Meta Llama 3.1 70B. Previously, our model catalog was limited to 8B parameter LLMs, but we can now support larger models, faster response times, and larger context windows. This means your applications can handle more complex tasks with greater efficiency.
Model
@cf/meta/Llama-3.2-11B-Vision-Instruct
@cf/meta/Llama-3.2-1B-Instruct
@cf/meta/Llama-3.2-3B-Instruct
@cf/meta/Llama-3.1-8B-Instruct
@cf/meta/Llama-3.1-70B-Instruct
@cf/black-forest-labs/flux-1-schnell
The set of models above are available on our new GPUs at faster speeds. If you’re using Llama 3.1, we’ve already upgraded you to the faster inference – so your applications are automatically sped up! In general, you can expect throughput of 80+ Tokens per Second (TPS) for 8b models and a Time To First Token of 300 ms (depending on where you are in the world).
Our model instances now support larger context windows, like the full 128K context window for Llama 3.1 and 3.2. To give you full visibility into performance, we’ll also be publishing metrics like TTFT, TPS, Context Window, and pricing on models in our catalog, so you know exactly what to expect.
We’re committed to bringing the best of open-source models to our platform, and that includes Meta’s release of the new Llama 3.2 collection of models. As a Meta launch partner, we were excited to have Day 0 support for the 11B vision model, as well as the 1B and 3B text-only model on Workers AI.
For more details on how we made Workers AI fast, take a look at our technical blog post, where we share a novel method for KV cache compression (it’s open-source!), as well as details on speculative decoding, our new hardware design, and more.
Greater model flexibility
With our commitment to helping you run more powerful models faster, we are also expanding the breadth of models you can run on Workers AI with our Run Any* Model feature. Until now, we have manually curated and added only the most popular open source models to Workers AI. Now, we are opening up our catalog to the public, giving you the flexibility to choose from a broader selection of models. We will support models that are compatible with our GPUs and inference stack at the start (hence the asterisk on Run Any* Model). We’re launching this feature in closed beta and if you’d like to try it out, please fill out the form, so we can grant you access to this new feature.
The Workers AI model catalog will now be split into two parts: a static catalog and a dynamic catalog. Models in the static catalog will remain curated by Cloudflare and will include the most popular open source models with guarantees on availability and speed (the models listed above). These models will always be kept warm in our network, ensuring you don’t experience cold starts. The usage and pricing model remains serverless, where you will only be charged for the requests to the model and not the cold start times.
Models that are launched via Run Any* Model will make up the dynamic catalog. If the model is public, users can share an instance of that model. In the future, we will allow users to launch private instances of models as well.
This is just the first step towards running your own custom or private models on Workers AI. While we have already been supporting private models for select customers, we are working on making this capacity available to everyone in the near future.
New Workers AI pricing
We launched Workers AI during Birthday Week 2023 with the concept of “neurons” for pricing. Neurons were intended to simplify the unit of measure across various models on our platform, including text, image, audio, and more. However, over the past year, we have listened to your feedback and heard that neurons were difficult to grasp and challenging to compare with other providers. Additionally, the industry has matured, and new pricing standards have materialized. As such, we’re excited to announce that we will be moving towards unit-based pricing and saying goodbye to neurons.
Moving forward, Workers AI will be priced based on model task, size, and units. LLMs will be priced based on the model size (parameters) and input/output tokens. Image generation models will be priced based on the output image resolution and the number of steps. Embeddings models will be priced based on input tokens. Speech-to-text models will be priced on seconds of audio input.
Model Task
Units
Model Size
Pricing
LLMs (incl. Vision models)
Tokens in/out (blended)
<= 3B parameters
$0.10 per Million Tokens
3.1B – 8B
$0.15 per Million Tokens
8.1B – 20B
$0.20 per Million Tokens
20.1B – 40B
$0.50 per Million Tokens
40.1B+
$0.75 per Million Tokens
Embeddings
Tokens in
<= 150M parameters
$0.008 per Million Tokens
151M+ parameters
$0.015 per Million Tokens
Speech-to-text
Audio seconds in
N/A
$0.0039 per minute of audio input
Image Size
Model Type
Steps
Price
<=256×256
Standard
25
$0.00125 per 25 steps
Fast
5
$0.00025 per 5 steps
<=512×512
Standard
25
$0.0025 per 25 steps
Fast
5
$0.0005 per 5 steps
<=1024×1024
Standard
25
$0.005 per 25 steps
Fast
5
$0.001 per 5 steps
<=2048×2048
Standard
25
$0.01 per 25 steps
Fast
5
$0.002 per 5 steps
We paused graduating models and announcing pricing for beta models over the past few months as we prepared for this new pricing change. We’ll be graduating all models to this new pricing, and billing will take effect on October 1, 2024.
Our free tier has been redone to fit these new metrics, and will include a monthly allotment of usage across all the task types.
Model
Free tier size
Text Generation – LLM
10,000 tokens a day across any model size
Embeddings
10,000 tokens a day across any model size
Images
Sum of 250 steps, up to 1024×1024 resolution
Whisper
10 minutes of audio a day
Optimizing AI workflows with AI Gateway
AI Gateway is designed to help developers and organizations building AI applications better monitor, control, and optimize their AI usage, and thanks to our users, AI Gateway has reached an incredible milestone — over 2 billion requests proxied by September 2024, less than a year after its inception. But we are not stopping there.
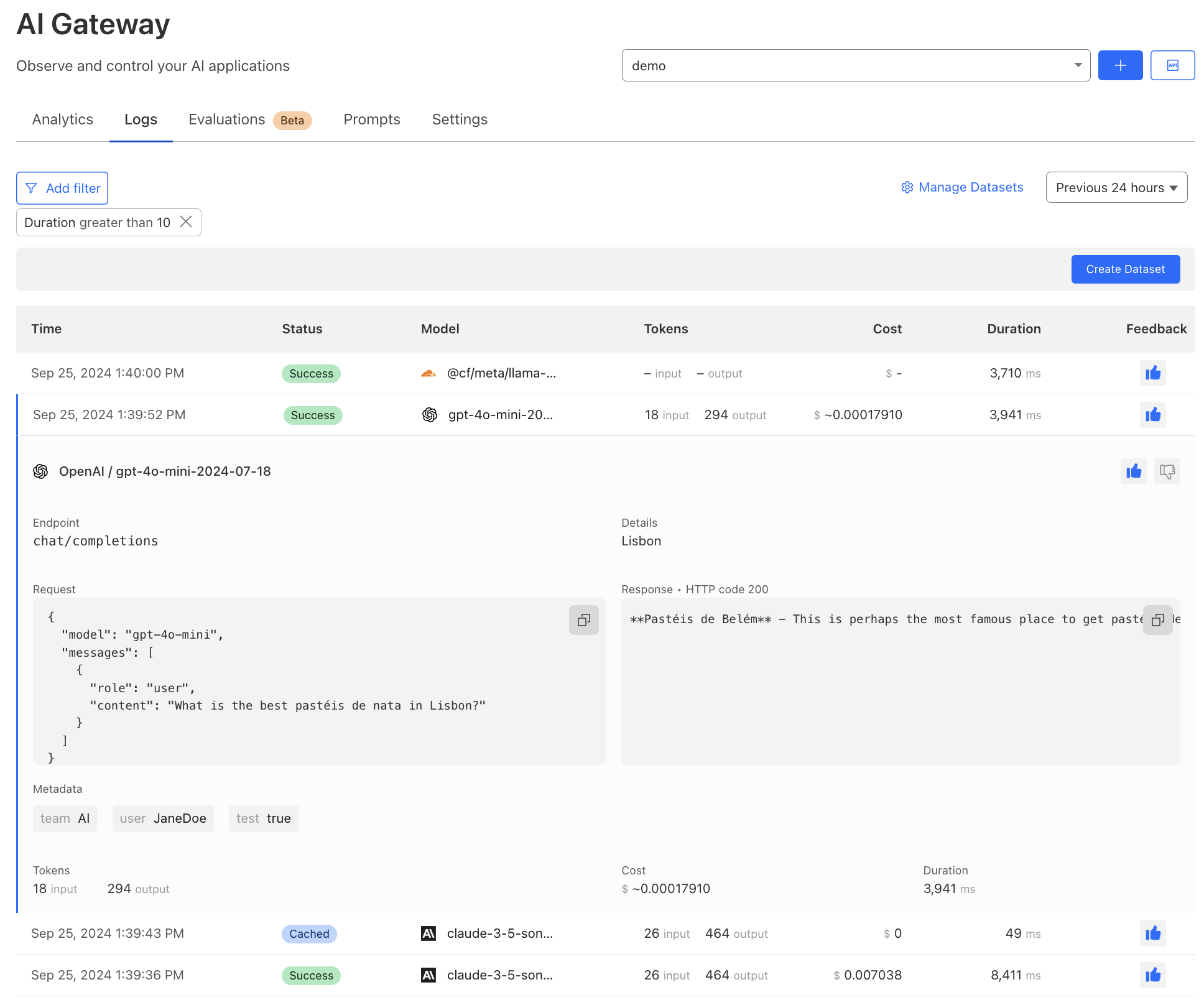
Persistent logs (open beta)
Persistent logs allow developers to store and analyze user prompts and model responses for extended periods, up to 10 million logs per gateway. Each request made through AI Gateway will create a log. With a log, you can see details of a request, including timestamp, request status, model, and provider.
We have revamped our logging interface to offer more detailed insights, including cost and duration. Users can now annotate logs with human feedback using thumbs up and thumbs down. Lastly, you can now filter, search, and tag logs with custom metadata to further streamline analysis directly within AI Gateway.
Persistent logs are available to use on all plans, with a free allocation for both free and paid plans. On the Workers Free plan, users can store up to 100,000 logs total across all gateways at no charge. For those needing more storage, upgrading to the Workers Paid plan will give you a higher free allocation — 200,000 logs stored total. Any additional logs beyond those limits will be available at $8 per 100,000 logs stored per month, giving you the flexibility to store logs for your preferred duration and do more with valuable data. Billing for this feature will be implemented when the feature reaches General Availability, and we’ll provide plenty of advance notice.
Workers Free
Workers Paid
Enterprise
Included Volume
100,000 logs stored (total)
200,000 logs stored (total)
Additional Logs
N/A
$8 per 100,000 logs stored per month
Export logs with Logpush
For users looking to export their logs, AI Gateway now supports log export via Logpush. With Logpush, you can automatically push logs out of AI Gateway into your preferred storage provider, including Cloudflare R2, Amazon S3, Google Cloud Storage, and more. This can be especially useful for compliance or advanced analysis outside the platform. Logpush follows its existing pricing model and will be available to all users on a paid plan.
AI evaluations
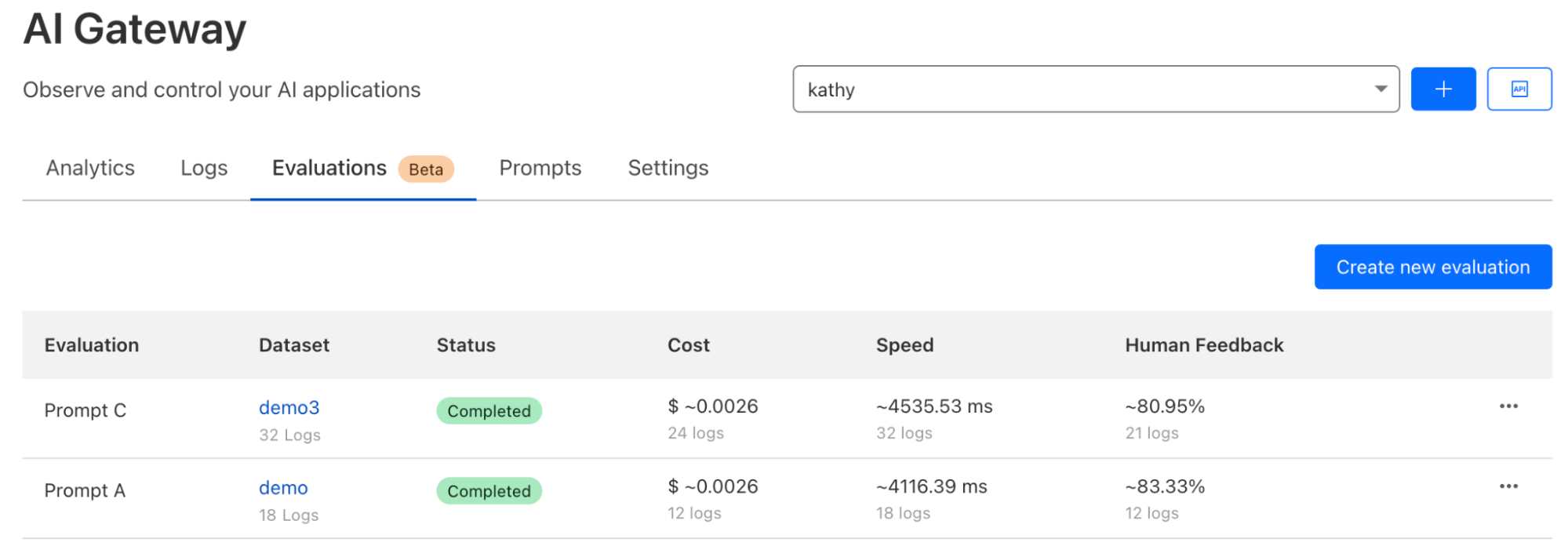
We are also taking our first step towards comprehensive AI evaluations, starting with evaluation using human in the loop feedback (this is now in open beta). Users can create datasets from logs to score and evaluate model performance, speed, and cost, initially focused on LLMs. Evaluations will allow developers to gain a better understanding of how their application is performing, ensuring better accuracy, reliability, and customer satisfaction. We’ve added support for cost analysis across many new models and providers to enable developers to make informed decisions, including the ability to add custom costs. Future enhancements will include automated scoring using LLMs, comparing performance of multiple models, and prompt evaluations, helping developers make decisions on what is best for their use case and ensuring their applications are both efficient and cost-effective.
Vectorize GA
We’ve completely redesigned Vectorize since our initial announcement in 2023 to better serve customer needs. Vectorize (v2) now supports indexes of up to 5 million vectors (up from 200,000), delivers faster queries (median latency is down 95% from 500 ms to 30 ms), and returns up to 100 results per query (increased from 20). These improvements significantly enhance Vectorize’s capacity, speed, and depth of results.
Note: if you got started on Vectorize before GA, to ease the move from v1 to v2, a migration solution will be available in early Q4 — stay tuned!
New Vectorize pricing
Not only have we improved performance and scalability, but we’ve also made Vectorize one of the most cost-effective options on the market. We’ve reduced query prices by 75% and storage costs by 98%.
New Vectorize pricing
Old Vectorize pricing
Price reduction
Writes
Free
Free
n/a
Query
$.01 per 1 million vector dimensions
$0.04 per 1 million vector dimensions
75%
Storage
$0.05 per 100 million vector dimensions
$4.00 per 100 million vector dimensions
98%
You can learn more about our pricing in the Vectorize docs.
Vectorize free tier
There’s more good news: we’re introducing a free tier to Vectorize to make it easy to experiment with our full AI stack.
The free tier includes:
30 million queried vector dimensions / month
5 million stored vector dimensions / month
How fast is Vectorize?
To measure performance, we conducted benchmarking tests by executing a large number of vector similarity queries as quickly as possible. We measured both request latency and result precision. In this context, precision refers to the proportion of query results that match the known true-closest results for all benchmarked queries. This approach allows us to assess both the speed and accuracy of our vector similarity search capabilities. Here are the following datasets we benchmarked on:
Laion-768-5m-ip: 5 million vectors, 768 dimensions, queried with cosine similarity at a top K of 10
We ran this again skipping the result-refinement pass to return approximate results faster
Benchmark dataset
P50 (ms)
P75 (ms)
P90 (ms)
P95 (ms)
Throughput (RPS)
Precision
dbpedia-openai-1M-1536-angular
31
56
159
380
343
95.4%
Laion-768-5m-ip
81.5
91.7
105
123
623
95.5%
Laion-768-5m-ip w/o refinement
14.7
19.3
24.3
27.3
698
78.9%
These benchmarks were conducted using a standard Vectorize v2 index, queried with a concurrency of 300 via a Cloudflare Worker binding. The reported latencies reflect those observed by the Worker binding querying the Vectorize index on warm caches, simulating the performance of an existing application with sustained usage.
Beyond Vectorize’s fast query speeds, we believe the combination of Vectorize and Workers AI offers an unbeatable solution for delivering optimal AI application experiences. By running Vectorize close to the source of inference and user interaction, rather than combining AI and vector database solutions across providers, we can significantly minimize end-to-end latency.
With these improvements, we’re excited to announce the general availability of the new Vectorize, which is more powerful, faster, and more cost-effective than ever before.
Tying it all together: the AI platform for all your inference needs
Over the past year, we’ve been committed to building powerful AI products that enable users to build on us. While we are making advancements on each of these individual products, our larger vision is to provide a seamless, integrated experience across our portfolio.
With Workers AI and AI Gateway, users can easily enable analytics, logging, caching, and rate limiting to their AI application by connecting to AI Gateway directly through a binding in the Workers AI request. We imagine a future where AI Gateway can not only help you create and save datasets to use for fine-tuning your own models with Workers AI, but also seamlessly redeploy them on the same platform. A great AI experience is not just about speed, but also accuracy. While Workers AI ensures fast performance, using it in combination with AI Gateway allows you to evaluate and optimize that performance by monitoring model accuracy and catching issues, like hallucinations or incorrect formats. With AI Gateway, users can test out whether switching to new models in the Workers AI model catalog will deliver more accurate performance and a better user experience.
In the future, we’ll also be working on tighter integrations between Vectorize and Workers AI, where you can automatically supply context or remember past conversations in an inference call. This cuts down on the orchestration needed to run a RAG application, where we can automatically help you make queries to vector databases.
If we put the three products together, we imagine a world where you can build AI apps with full observability (traces with AI Gateway) and see how the retrieval (Vectorize) and generation (Workers AI) components are working together, enabling you to diagnose issues and improve performance.
This Birthday Week, we’ve been focused on making sure our individual products are best-in-class, but we’re continuing to invest in building a holistic AI platform within our AI portfolio, but also with the larger Developer Platform Products. Our goal is to make sure that Cloudflare is the simplest, fastest, more powerful place for you to build full-stack AI experiences with all the batteries included.
We’re excited for you to try out all these new features! Take a look at our updated developer docs on how to get started and the Cloudflare dashboard to interact with your account.
Today, we’re pleased to offer startups up to $250,000 in credits to use on Cloudflare’s Developer Platform. This new credits system will allow you to clearly see usage and associated fees to plan for a predictable future after the $250,000 in credits have been used up or after one year, whichever happens first.
You can see eligibility criteria and apply to the start-up program here.
What can you use the credits for?
Credits can be applied to all Developer Platform products, as well as Argo and Cache Reserve. Moreover, we provide participants with up to three Enterprise-level domains, which includes CDN, DDoS, DNS, WAF, Zero Trust, and other security and performance products that a participant can enable for their website.
Developer tools and building on Cloudflare
You can use credits for Cloudflare Developer Platform products, including those listed in the table below.
Note: credits for the Cloudflare Startup Program apply to Cloudflare products only, this table is illustrative of similar products in the market.
Speed and performance with Cloudflare
We know that founders need all the help they can get when starting their businesses. Beyond the Developer Platform, you can also use the Startup Program for our speed and performance products. Getting customers where they need to go within milliseconds on your website or application is the difference between closing a sale or not. You can test your speed here and learn how to optimize your speed and performance here with solutions like: Images, Argo, and Early Hints.
Security from Cloudflare
But, wait, there’s more: beyond the Developer Platform products and speed tools, you can also use Cloudflare’s many security features through the Startup Program as well. These include Web Application Firewall (WAF), DDoS Alerts, bundled protection plans, and more. The Startup Program also includes Zero Trust solutions. Learn how others are securing their technology and tools with Cloudflare Zero Trust.
For more inspiration, check out our Built with Cloudflare site, which highlights what other startups are building.
Who can use the credits?
Eligibility criteria can be found here and include:
Companies building a software-based product or service
Founded within the last 5 years (2019-2024)
Have between $50,000 - $5,000,000 in funding
Note that for startups who have not yet raised at least $50,000, there may be other opportunities for lower credit amounts. Please apply with the promo code “BOOTSTRAPPED” if you haven’t raised $50,000 yet, but are interested in the Cloudflare Startup Program
Have a LinkedIn profile, valid website, and email address
Bonus criteria that adds to your application: being part of an approved accelerator
What will you build?
We’re excited to see what you will build. Please share what you’re up to with us so that we can help you however it makes sense. If you’re actively using Cloudflare’s Developer Platform, we’d love to hear more about what you’re building and share it on our Built with Cloudflare site.
Are you a startup looking for additional support, resources, or access to funding? Apply for our Workers Launchpad Program! The program runs for a few months, and in addition to the Startup Program, participants get access to hands-on bootcamp sessions, Solutions Architect office hours, introductions to VCs, and the opportunity to present at Demo Day.
Why does Cloudflare support founders and startups?
Founders and developers face enough challenges without having to worry about incurring egregious costs to test technology and start building in the earliest days. You have the world at your fingertips and should be empowered to build and create without limitations. Invest money in your innovation, not in the infrastructure and technology that supports it.
The Startup Program understands this founder experience deeply, as the team is made up of former founders. Cloudflare is committed to programs like this to empower founders building the next big thing. Offering up to $250,000 in credits will allow folks to leverage even more of what we have to offer: a developer experience that removes friction, saves money, and gets applications spun up in hours, not days.
We want to support founders from everywhere on earth.
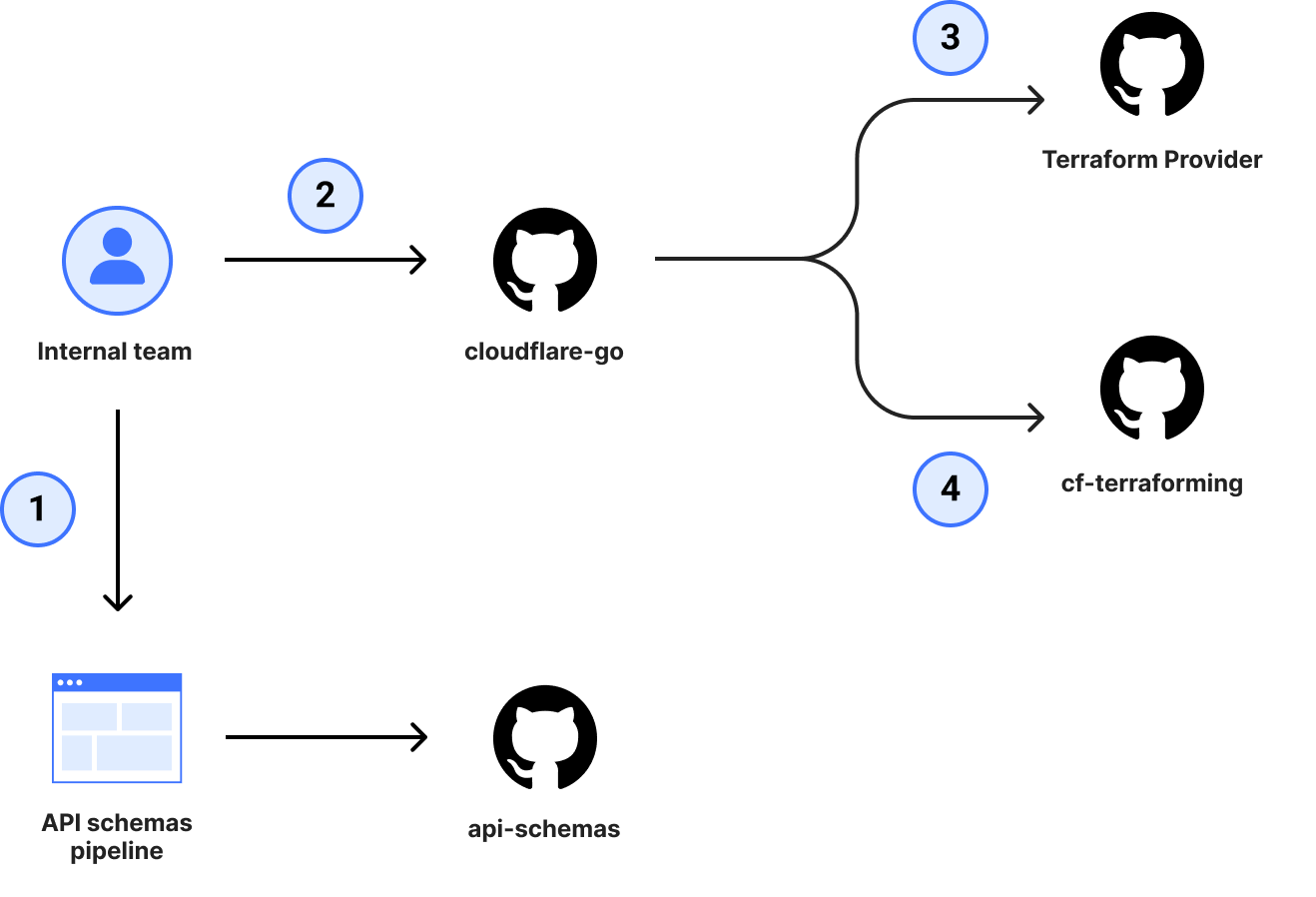
In November 2022, we announced the transition to OpenAPI Schemas for the Cloudflare API. Back then, we had an audacious goal to make the OpenAPI schemas the source of truth for our SDK ecosystem and reference documentation. During 2024’s Developer Week, we backed this up by announcing that our SDK libraries are now automatically generated from these OpenAPI schemas. Today, we’re excited to announce the latest pieces of the ecosystem to now be automatically generated — the Terraform provider and API reference documentation.
This means that the moment a new feature or attribute is added to our products and the team documents it, you’ll be able to see how it’s meant to be used across our SDK ecosystem and make use of it immediately. No more delays. No more lacking coverage of API endpoints.
For anyone who is unfamiliar with Terraform, it is a tool for managing your infrastructure as code, much like you would with your application code. Many of our customers (big and small) rely on Terraform to orchestrate their infrastructure in a technology-agnostic way. Under the hood, it is essentially an HTTP client with lifecycle management built in, which means it makes use of our publicly documented APIs in a way that understands how to create, read, update and delete for the life of the resource.
Keeping Terraform updated — the old way
Historically, Cloudflare has manually maintained a Terraform provider, but since the provider internals require their own unique way of doing things, responsibility for maintenance and support has landed on the shoulders of a handful of individuals. The service teams always had difficulties keeping up with the number of changes, due to the amount of cognitive overhead required to ship a single change in the provider. In order for a team to get a change to the provider, it took a minimum of 3 pull requests (4 if you were adding support to cf-terraforming).
Even with the 4 pull requests completed, it didn’t offer guarantees on coverage of all available attributes, which meant small yet important details could be forgotten and not exposed to customers, causing frustration when trying to configure a resource.
To address this, our Terraform provider needed to be relying on the same OpenAPI schemas that the rest of our SDK ecosystem was already benefiting from.
Updating Terraform automatically
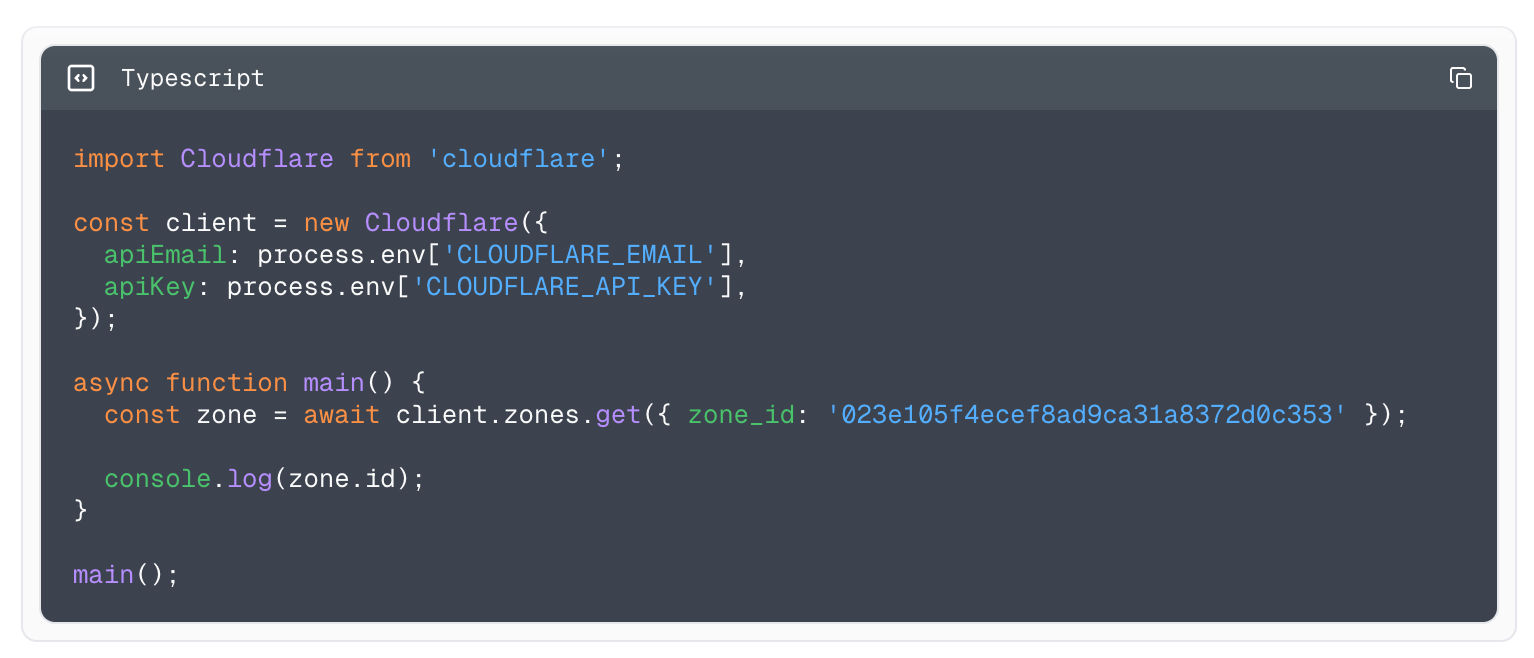
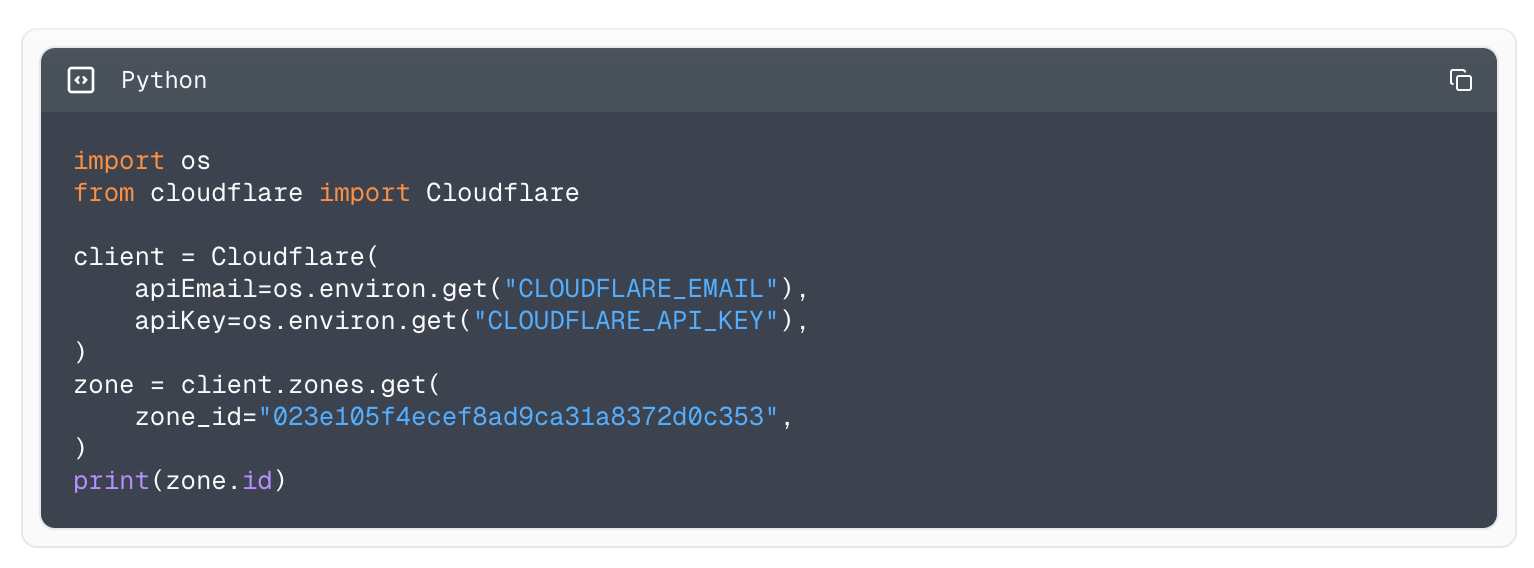
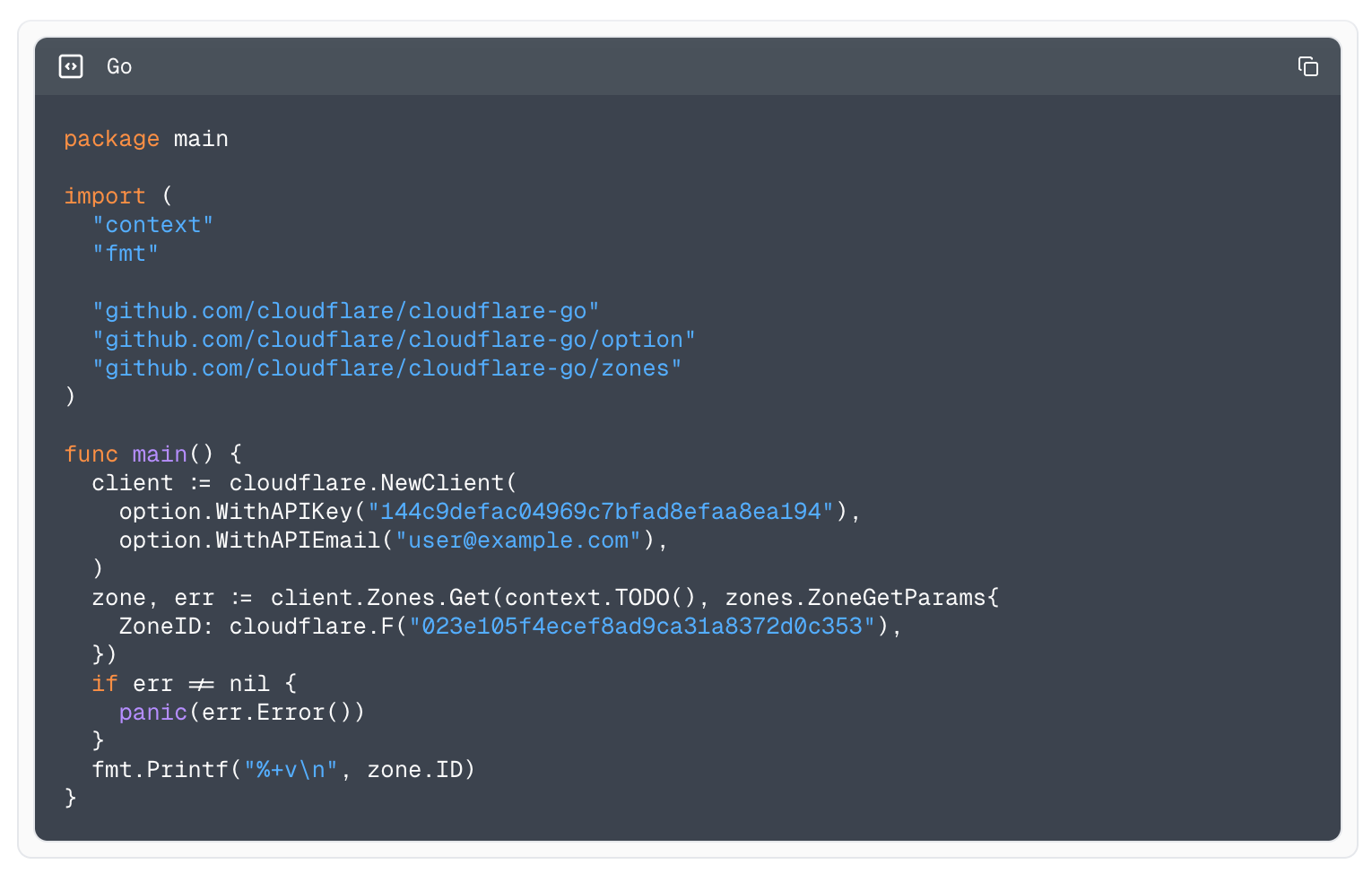
The thing that differentiates Terraform from our SDKs is that it manages the lifecycle of resources. With that comes a new range of problems related to known values and managing differences in the request and response payloads. Let’s compare the two different approaches of creating a new DNS record and fetching it back.
With our Go SDK:
// Create the new record
record, _ := client.DNS.Records.New(context.TODO(), dns.RecordNewParams{
ZoneID: cloudflare.F("023e105f4ecef8ad9ca31a8372d0c353"),
Record: dns.RecordParam{
Name: cloudflare.String("@"),
Type: cloudflare.String("CNAME"),
Content: cloudflare.String("example.com"),
},
})
// Wasteful fetch, but shows the point
client.DNS.Records.Get(
context.Background(),
record.ID,
dns.RecordGetParams{
ZoneID: cloudflare.String("023e105f4ecef8ad9ca31a8372d0c353"),
},
)
And with Terraform:
resource "cloudflare_dns_record" "example" {
zone_id = "023e105f4ecef8ad9ca31a8372d0c353"
name = "@"
content = "example.com"
type = "CNAME"
}
On the surface, it looks like the Terraform approach is simpler, and you would be correct. The complexity of knowing how to create a new resource and maintain changes are handled for you. However, the problem is that for Terraform to offer this abstraction and data guarantee, all values must be known at apply time. That means that even if you’re not using the proxied value, Terraform needs to know what the value needs to be in order to save it in the state file and manage that attribute going forward. The error below is what Terraform operators commonly see from providers when the value isn’t known at apply time.
Error: Provider produced inconsistent result after apply
When applying changes to example_thing.foo, provider "provider[\"registry.terraform.io/example/example\"]"
produced an unexpected new value: .foo: was null, but now cty.StringVal("").
Whereas when using the SDKs, if you don’t need a field, you just omit it and never need to worry about maintaining known values.
Tackling this for our OpenAPI schemas was no small feat. Since introducing Terraform generation support, the quality of our schemas has improved by an order of magnitude. Now we are explicitly calling out all default values that are present, variable response properties based on the request payload, and any server-side computed attributes. All of this means a better experience for anyone that interacts with our APIs.
Making the jump from terraform-plugin-sdk to terraform-plugin-framework
To build a Terraform provider and expose resources or data sources to operators, you need two main things: a provider server and a provider.
The provider server takes care of exposing a gRPC server that Terraform core (via the CLI) uses to communicate when managing resources or reading data sources from the operator provided configuration.
The provider is responsible for wrapping the resources and data sources, communicating with the remote services, and managing the state file. To do this, you either rely on the terraform-plugin-sdk (commonly referred to as SDKv2) or terraform-plugin-framework, which includes all the interfaces and methods provided by Terraform in order to manage the internals correctly. The decision as to which plugin you use depends on the age of your provider. SDKv2 has been around longer and is what most Terraform providers use, but due to the age and complexity, it has many core unresolved issues that must remain in order to facilitate backwards compatibility for those who rely on it. terraform-plugin-framework is the new version that, while lacking the breadth of features SDKv2 has, provides a more Go-like approach to building providers and addresses many of the underlying bugs in SDKv2.
The majority of the Cloudflare Terraform provider is built using SDKv2, but at the beginning of 2023, we took the plunge to multiplex and offer both in our provider. To understand why this was needed, we have to understand a little about SDKv2. The way SDKv2 is structured isn’t really conducive to representing null or “unset” values consistently and reliably. You can use the experimental ResourceData.GetRawConfig to check whether the value is set, null, or unknown in the config, but writing it back as null isn’t really supported.
This caveat first popped up for us when the Edge Rules Engine (Rulesets) started onboarding new services and those services needed to support API responses that contained booleans in an unset (or missing), true, or false state each with their own reasoning and purpose. While this isn’t a conventional API design at Cloudflare, it is a valid way to do things that we should be able to work with. However, as mentioned above, the SDKv2 provider couldn’t. This is because when a value isn’t present in the response or read into state, it gets a Go-compatible zero value for the default. This showed up as the inability to unset values after they had been written to state as false values (and vice versa).
Once we started adding more functionality using terraform-plugin-framework in the old provider, it was clear that it was a better developer experience, so we added a ratchet to prevent SDKv2 usage going forward to get ahead of anyone unknowingly setting themselves up to hit this issue.
When we decided that we would be automatically generating the Terraform provider, it was only fitting that we also brought all the resources over to be based on the terraform-plugin-framework and leave the issues from SDKv2 behind for good. This did complicate the migration as with the improved internals came changes to major components like the schema and CRUD operations that we needed to familiarize ourselves with. However, it has been a worthwhile investment because by doing so, we’ve future-proofed the foundations of the provider and are now making fewer compromises on a great Terraform experience due to buggy, legacy internals.
Iteratively finding bugs
One of the common struggles with code generation pipelines is that unless you have existing tools that implement your new thing, it’s hard to know if it works or is reasonable to use. Sure, you can also generate your tests to exercise the new thing, but if there is a bug in the pipeline, you are very likely to not see it as a bug as you will be generating test assertions that show the bug is expected behavior.
One of the essential feedback loops we have had is the existing acceptance test suite. All resources within the existing provider had a mix of regression and functionality tests. Best of all, as the test suite is creating and managing real resources, it was very easy to know whether the outcome was a working implementation or not by looking at the HTTP traffic to see whether the API calls were accepted by the remote endpoints. Getting the test suite ported over was only a matter of copying over all the existing tests and checking for any type assertion differences (such as list to single nested list) before kicking off a test run to determine whether the resource was working correctly.
While the centralized schema pipeline was a huge quality of life improvement for having schema fixes propagate to the whole ecosystem almost instantly, it couldn’t help us solve the largest hurdle, which was surfacing bugs that hide other bugs. This was time-consuming because when fixing a problem in Terraform, you have three places where you can hit an error:
Before any API calls are made, Terraform implements logical schema validation and when it encounters validation errors, it will immediately halt.
If any API call fails, it will stop at the CRUD operation and return the diagnostics, immediately halting.
After the CRUD operation has run, Terraform then has checks in place to ensure all values are known.
That means that if we hit the bug at step 1 and then fixed the bug, there was no guarantee or way to tell that we didn’t have two more waiting for us. Not to mention that if we found a bug in step 2 and shipped a fix, that it wouldn’t then identify a bug in the first step on the next round of testing.
There is no silver bullet here and our workaround was instead to notice patterns of problems in the schema behaviors and apply CI lint rules within the OpenAPI schemas before it got into the code generation pipeline. Taking this approach incrementally cut down the number of bugs in step 1 and 2 until we were largely only dealing with the type in step 3.
A more reusable approach to model and struct conversion
Within Terraform provider CRUD operations, it is fairly common to see boilerplate like the following:
var plan ThingModel
diags := req.Plan.Get(ctx, &plan)
resp.Diagnostics.Append(diags...)
if resp.Diagnostics.HasError() {
return
}
out, err := r.client.UpdateThingModel(ctx, client.ThingModelRequest{
AttrA: plan.AttrA.ValueString(),
AttrB: plan.AttrB.ValueString(),
AttrC: plan.AttrC.ValueString(),
})
if err != nil {
resp.Diagnostics.AddError(
"Error updating project Thing",
"Could not update Thing, unexpected error: "+err.Error(),
)
return
}
result := convertResponseToThingModel(out)
tflog.Info(ctx, "created thing", map[string]interface{}{
"attr_a": result.AttrA.ValueString(),
"attr_b": result.AttrB.ValueString(),
"attr_c": result.AttrC.ValueString(),
})
diags = resp.State.Set(ctx, result)
resp.Diagnostics.Append(diags...)
if resp.Diagnostics.HasError() {
return
}
At a high level:
We fetch the proposed updates (known as a plan) using req.Plan.Get()
Perform the update API call with the new values
Manipulate the data from a Go type into a Terraform model (convertResponseToThingModel)
Set the state by calling resp.State.Set()
Initially, this doesn’t seem too problematic. However, the third step where we manipulate the Go type into the Terraform model quickly becomes cumbersome, error-prone, and complex because all of your resources need to do this in order to swap between the type and associated Terraform models.
To avoid generating more complex code than needed, one of the improvements featured in our provider is that all CRUD methods use unified apijson.Marshal, apijson.Unmarshal, and apijson.UnmarshalComputed methods that solve this problem by centralizing the conversion and handling logic based on the struct tags.
var data *ThingModel
resp.Diagnostics.Append(req.Plan.Get(ctx, &data)...)
if resp.Diagnostics.HasError() {
return
}
dataBytes, err := apijson.Marshal(data)
if err != nil {
resp.Diagnostics.AddError("failed to serialize http request", err.Error())
return
}
res := new(http.Response)
env := ThingResultEnvelope{*data}
_, err = r.client.Thing.Update(
// ...
)
if err != nil {
resp.Diagnostics.AddError("failed to make http request", err.Error())
return
}
bytes, _ := io.ReadAll(res.Body)
err = apijson.UnmarshalComputed(bytes, &env)
if err != nil {
resp.Diagnostics.AddError("failed to deserialize http request", err.Error())
return
}
data = &env.Result
resp.Diagnostics.Append(resp.State.Set(ctx, &data)...)
Instead of needing to generate hundreds of instances of type-to-model converter methods, we can instead decorate the Terraform model with the correct tags and handle marshaling and unmarshaling of the data consistently. It’s a minor change to the code that in the long run makes the generation more reusable and readable. As an added benefit, this approach is great for bug fixing as once you identify a bug with a particular type of field, fixing that in the unified interface fixes it for other occurrences you may not yet have found.
But wait, there’s more (docs)!
To top off our OpenAPI schema usage, we’re tightening the SDK integration with our new API documentation site. It’s using the same pipeline we’ve invested in for the last two years while addressing some of the common usage issues.
SDK aware
If you’ve used our API documentation site, you know we give you examples of interacting with the API using command line tools like curl. This is a great starting point, but if you’re using one of the SDK libraries, you need to do the mental gymnastics to convert it to the method or type definition you want to use. Now that we’re using the same pipeline to generate the SDKs and the documentation, we’re solving that by providing examples in all the libraries you could use — not just curl.
Example using cURL to fetch all zones.
Example using the Typescript library to fetch all zones.
Example using the Python library to fetch all zones.
Example using the Go library to fetch all zones.
With this improvement, we also remember the language selection so if you’ve selected to view the documentation using our Typescript library and keep clicking around, we keep showing you examples using Typescript until it is swapped out.
Best of all, when we introduce new attributes to existing endpoints or add SDK languages, this documentation site is automatically kept in sync with the pipeline. It is no longer a huge effort to keep it all up to date.
Faster and more efficient rendering
A problem we’ve always struggled with is the sheer number of API endpoints and how to represent them. As of this post, we have 1,330 endpoints, and for each of those endpoints, we have a request payload, a response payload, and multiple types associated with it. When it comes to rendering this much information, the solutions we’ve used in the past have had to make tradeoffs in order to make parts of the representation work.
This next iteration of the API documentation site addresses this is a couple of ways:
It’s implemented as a modern React application that pairs an interactive client-side experience with static pre-rendered content, resulting in a quick initial load and fast navigation. (Yes, it even works without JavaScript enabled!).
It fetches the underlying data incrementally as you navigate.
By solving this foundational issue, we’ve unlocked other planned improvements to the documentation site and SDK ecosystem to improve the user experience without making tradeoffs like we’ve needed to in the past.
Permissions
One of the most requested features to be re-implemented into the documentation site has been minimum required permissions for API endpoints. One of the previous iterations of the documentation site had this available. However, unknown to most who used it, the values were manually maintained and were regularly incorrect, causing support tickets to be raised and frustration for users.
Inside Cloudflare’s identity and access management system, answering the question “what do I need to access this endpoint” isn’t a simple one. The reason for this is that in the normal flow of a request to the control plane, we need two different systems to provide parts of the question, which can then be combined to give you the full answer. As we couldn’t initially automate this as part of the OpenAPI pipeline, we opted to leave it out instead of having it be incorrect with no way of verifying it.
Fast-forward to today, and we’re excited to say endpoint permissions are back! We built some new tooling that abstracts answering this question in a way that we can integrate into our code generation pipeline and have all endpoints automatically get this information. Much like the rest of the code generation platform, it is focused on having service teams own and maintain high quality schemas that can be reused with value adds introduced without any work on their behalf.
Stop waiting for updates
With these announcements, we’re putting an end to waiting for updates to land in the SDK ecosystem. These new improvements allow us to streamline the ability of new attributes and endpoints the moment teams document them. So what are you waiting for? Check out the Terraform provider and API documentation site today.
Cloudflare Stream is an end-to-end solution for video encoding, storage, delivery, and playback. Our focus has always been on simplifying all aspects of video for developers. This goal continues to motivate us as we introduce first-class portrait (vertical) video support today. Newly uploaded or ingested portrait videos will now automatically be processed in full HD quality.
Why portrait video
In the past few years, the popularity of portrait video has exploded, motivated by short-form video content applications such as TikTok or YouTube Shorts. However, Cloudflare customers have been confused as to why their portrait videos appear to be lower quality when viewed on portrait-first devices such as smartphones. This is because our video encoding pipeline previously did not support high-quality portrait videos, leading them to be grainy and lower quality. This pain point has now been addressed with the introduction of high-definition portrait video.
The current stream pipeline
When you upload a video to Stream, it is first encoded into several different “renditions” (sizes or resolutions) before delivery. This is done in order to enable playback in a wide variety of network conditions, as well as to standardize the way a video is experienced. By using these adaptive bitrate renditions, we are able to offer viewers the highest quality streaming experience which fits their network bandwidth, meaning someone watching a video with a slow mobile connection would be served a 240p video (a resolution of 320×240 pixels) and receive the 1080p (a resolution of 1920×1080 pixels) version when they are watching at home on their fiber Internet connection. This encoding pipeline follows one of two different paths:
The first path is our video on-demand (VOD) encoding pipeline, which generates and stores a set of encoded video segments at each of our standard video resolutions. The other path is our on-the-fly encoding (OTFE) pipeline, which uses the same process as Stream Live to generate resolutions upon user request. Both pipelines work with the set of standard resolutions, which are identified through a constrained target (output) height. This means that we encode every rendition to heights of 240 pixels, 360 pixels, etc. up to 1080 pixels.
When originally conceived, this encoding pipeline was not designed with portrait video in mind because portrait video was less common. As a result, portrait videos were encoded with lower quality dimensions that were consistent with landscape video encoding. For example, a portrait HD video would have the dimensions 1920×1080 — scaling that down to the height of a landscape HD video would result in the much smaller output of 1080×606. However, current smartphones all have HD displays, making the discrepancy clear when a portrait video is viewed in portrait mode on a phone. With this new change to our encoding pipeline, all newly uploaded portrait videos will now be automatically encoded with constrained target width, using a new set of standard resolutions for portrait video. These resolutions are the same as the current set of landscape resolutions, but with the dimensions reversed: 240×426 up to 1080×1920.
Technical details
As the Stream intern this summer, I was tasked with this project, as well as the expectation of shipping a long-requested change, by the end of my internship. The first step in implementing this change was to familiarize myself with the complex architecture of Stream’s internal systems. After this, I began brainstorming a few different implementation decisions, like how to consistently track orientation through various stages of the pipeline. Following a group discussion to decide which choices would be the most scalable, least complex, and best for users, it was time to write the technical specification.
Due to the implementation method we chose, making this change involved tracing the life of a video from upload to delivery through both of our encoding pipelines and applying different logic for portrait videos. Previously, all video renditions were identified by their height at each stage of the pipeline, making certain parts of the pipeline completely agnostic to the orientation of a video. With the proposed changes, we would now be using the constraining dimension and orientation to identify a video rendition. Therefore, much of the work involved modifying the different portions of the pipeline to use these new parameters.
The first area of the pipeline to be modified was the Stream API service, which is the process which handles all Stream API calls. The API service enqueues the rendition encoding jobs for a video after it is uploaded, so it was necessary to introduce a new set of renditions designed for portrait videos, and enqueue the corresponding encoding jobs. The queuing system is handled by our in-house queue management system, which handles jobs generically and therefore did not require any changes.
Following this, I tackled the on-the-fly encoding pipeline. The area of interest here was the delivery portion of our pipeline, which generated the set of encoding resolutions to pass on to our on-the-fly encoder. Here I also introduced a new set of portrait renditions and the corresponding logic to encode them for portrait videos. This part of the backend is written and hosted on Cloudflare Workers, which made it very easy and quick to deploy and test changes.
Finally, we wanted to change how we presented these quality levels to users in the Stream built-in player and thought that using the new constrained dimension rather than always showing the height would feel more familiar. For portrait videos, we now display the size of the constraining dimension, which also means quality selection for portrait videos encoded under our old system now more accurately reflects their quality, too. As an example, a 9:16 portrait video would have been encoded to a maximum size of 608×1080 by the previous pipeline. Now, such a rendition will be marked as 608p rather than the full-quality 1080p, which would be a 1080×1920 rendition.
Stream as a whole is built on many of our own Developer Platform products, such as Workers for handling delivery, R2 for rendition storage, Workers AI for automatic captioning, and Durable Objects for bitrate observation, all of which enhance our ability to deploy and ship new updates quickly. Throughout my work on this project, I was able to see all of these pieces in action, as well as gain a new understanding of the powerful tools Cloudflare offers for developers.
Results and findings
After the change, portrait videos are now encoded to higher resolutions and visibly appear to be higher quality. To confirm these differences, I analyzed the effect of the pipeline change on four different sample videos using the peak-signal-to-noise ratio (PSNR, a mathematical representation of image quality). Since the old pipeline produced lower resolution videos, the comparison here is between an upscaled version of the old pipeline rendition and the current pipeline rendition. In the graph below, higher values reflect higher quality relative to the unencoded original video.
According to this metric, we see an increase in quality from the pipeline changes as high as 8%. However, the quality increase is most noticeable to the human eye in videos that feature fine details or a high amount of movement, which is not always captured in the PSNR. For example, compare a side-by-side of a frame from the book sample video encoded both ways:
The difference between the old and new encodings is most clear when zoomed in:
Maximize the Stream player and look at the quality selector (in the gear menu) to see the new quality level labels – select the highest option to compare. Note the improved sharpness of the text in the book sample as well as the improved detail in the hair and eye shadow of the hair and makeup sample.
Implementation challenges
Due to the complex nature of our encoding pipelines, there were several technical challenges to making a large change like this. Aside from simply uploading videos, many of the features we offer, like downloads or clipping, require tweaking to produce the correct video renditions. This involved modifying many parts of the encoding pipeline to ensure that portrait video logic was handled.
There were also some edge cases which were not caught until after release. One release of this feature contained a bug in the on-the-fly encoding logic which caused a subset of new portrait livestream renditions to have negative bitrates, making them unusable. This was due to an internal representation of video renditions’ constraining dimensions being mistakenly used for bitrate observation. We remedied this by increasing the scope of our end-to-end testing to include more portrait video tests and live recording interaction tests.
Another small bug caused downloading very small videos to sometimes fail. This was because for videos under 240p, our smallest encoding resolution, the non-constraining dimension was not being properly scaled to match the aspect ratio of the video, causing some specific combinations of dimensions to be interpreted as portrait when they should have been landscape, and vice versa. This bug was fixed quickly, but was not initially caught after the release since it required a very specific set of conditions to activate. After this experience, I added a few more unit tests involving small videos.
That’s a wrap
As my internship comes to a close, reflecting on the experience makes me grateful for all the team members who have helped me throughout this time. I am very glad to have shipped this project which addresses a long-standing concern and will have real-world customer impact. Support for high-definition portrait video is now available, and we will continue to make improvements to our video solutions suite. You can see the difference yourself by uploading a portrait video to Stream! Or, perhaps you’d like to help build a better Internet, too — our internship and early talent programs are a great way to jumpstart your own journey.
Sample video acknowledgements: The sample video of the book was created by the Stream Product Manager and shows the opening page of The Strange Wonder of Roots by Evan Griffith (HarperCollins). The hair and makeup fashion video was sourced from Mixkit, a great source of free media for video projects.
At Cloudflare, we’re big supporters of the open-source community – and that extends to our approach for Workers AI models as well. Our strategy for our Cloudflare AI products is to provide a top-notch developer experience and toolkit that can help people build applications with open-source models.
We’re excited to be one of Meta’s launch partners to make their newest Llama 3.1 8B model available to all Workers AI users on Day 1. You can run their latest model by simply swapping out your model ID to @cf/meta/llama-3.1-8b-instruct or test out the model on our Workers AI Playground. Llama 3.1 8B is free to use on Workers AI until the model graduates out of beta.
Meta’s Llama collection of models have consistently shown high-quality performance in areas like general knowledge, steerability, math, tool use, and multilingual translation. Workers AI is excited to continue to distribute and serve the Llama collection of models on our serverless inference platform, powered by our globally distributed GPUs.
The Llama 3.1 model is particularly exciting, as it is released in a higher precision (bfloat16), incorporates function calling, and adds support across 8 languages. Having multilingual support built-in means that you can use Llama 3.1 to write prompts and receive responses directly in languages like English, French, German, Hindi, Italian, Portuguese, Spanish, and Thai. Expanding model understanding to more languages means that your applications have a bigger reach across the world, and it’s all possible with just one model.
Llama 3.1 also introduces native function calling (also known as tool calls) which allows LLMs to generate structured JSON outputs which can then be fed into different APIs. This means that function calling is supported out-of-the-box, without the need for a fine-tuned variant of Llama that specializes in tool use. Having this capability built-in means that you can use one model across various tasks.
Workers AI recently announced embedded function calling, which is now usable with Meta Llama 3.1 as well. Our embedded function calling gives developers a way to run their inference tasks far more efficiently than traditional architectures, leveraging Cloudflare Workers to reduce the number of requests that need to be made manually. It also makes use of our open-source ai-utils package, which helps you orchestrate the back-and-forth requests for function calling along with other helper methods that can automatically generate tool schemas. Below is an example function call to Llama 3.1 with embedded function calling that then stores key-values in Workers KV.
const response = await runWithTools(env.AI, "@cf/meta/llama-3.1-8b-instruct", {
messages: [{ role: "user", content: "Greet the user and ask them a question" }],
tools: [{
name: "Store in memory",
description: "Store everything that the user talks about in memory as a key-value pair.",
parameters: {
type: "object",
properties: {
key: {
type: "string",
description: "The key to store the value under.",
},
value: {
type: "string",
description: "The value to store.",
},
},
required: ["key", "value"],
},
function: async ({ key, value }) => {
await env.KV.put(key, value);
return JSON.stringify({
success: true,
});
}
}]
})
We’re excited to see what you build with these new capabilities. As always, use of the new model should be conducted with Meta’s Acceptable Use Policy and License in mind. Take a look at our developer documentation to get started!
Introducing embedded function calling and a new ai-utils package
Today, we’re excited to announce a novel way to do function calling that co-locates LLM inference with function execution, and a new ai-utils package that upgrades the developer experience for function calling.
This is a follow-up to our mid-June announcement for traditional function calling, which allows you to leverage a Large Language Model (LLM) to intelligently generate structured outputs and pass them to an API call. Function calling has been largely adopted and standardized in the industry as a way for AI models to help perform actions on behalf of a user.
Our goal is to make building with AI as easy as possible, which is why we’re introducing a new @cloudflare/ai-utils npm package that allows developers to get started quickly with embedded function calling. These helper tools drastically simplify your workflow by actually executing your function code and dynamically generating tools from OpenAPI specs. We’ve also open-sourced our ai-utils package, which you can find on GitHub. With both embedded function calling and our ai-utils, you’re one step closer to creating intelligent AI agents, and from there, the possibilities are endless.
Why Cloudflare’s AI platform?
OpenAI has been the gold standard when it comes to having performant model inference and a great developer experience. However, they mostly support their closed-source models, while we want to also promote the open-source ecosystem of models. One of our goals with Workers AI is to match the developer experience you might get from OpenAI, but with open-source models.
There are other open-source inference providers out there like Azure or Bedrock, but most of them are focused on serving inference and the underlying infrastructure, rather than being a developer toolkit. While there are external libraries and frameworks like AI SDK that help developers build quickly with simple abstractions, they rely on upstream providers to do the actual inference. With Workers AI, it’s the best of both worlds – we offer open-source model inference and a killer developer experience out of the box.
With the release of embedded function calling and ai-utils today, we’ve advanced how we do inference for function calling and improved the developer experience by making it dead simple for developers to start building AI experiences.
How does traditional function calling work?
Traditional LLM function calling allows customers to specify a set of function names and required arguments along with a prompt when running inference on an LLM. The LLM returns the names and arguments for the functions that the customer can then make to perform actions. These actions give LLMs the ability to do things like fetch fresh data not present in the training dataset and “perform actions” based on user intent.
Traditional function calling requires multiple back-and-forth requests passing through the network in order to get to the final output. This includes requests to your origin server, an inference provider, and external APIs. As a developer, you have to orchestrate all the back-and-forths and handle all the requests and responses. If you were building complex agents with multi-tool calls or recursive tool calls, it gets infinitely harder. Fortunately, this doesn’t have to be the case, and we’ve solved it for you.
Embedded function calling
With Workers AI, our inference runtime is the Workers platform, and the Workers platform can be seen as a global compute network of distributed functions (RPCs). With this model, we can run inference using Workers AI, and supply not only the function names and arguments, but also the runtime function code to be executed. Rather than performing multiple round-trips across networks, the LLM inference and function can run in the same execution environment, cutting out all the unnecessary requests.
Cloudflare is one of the few inference providers that is able to do this because we offer more than just inference – our developer platform has compute, storage, inference, and more, all within the same Workers runtime.
We made it easy for you with a new ai-utils package
And to make it as simple as possible, we created a @cloudflare/ai-utils package that you can use to get started. These powerful abstractions cut down on the logic you have to implement to do function calling – it just works out of the box.
runWithTools
runWithTools is our method that you use to do embedded function calling. You pass in your AI binding (env.AI), model, prompt messages, and tools. The tools array includes the description of the function, similar to traditional function calling, but you also pass in the function code that needs to be executed. This method makes the inference calls and executes the function code in one single step. runWithTools is also able to handle multiple function calls, recursive tool calls, validation for model responses, streaming for the final response, and other features.
Another feature to call out is a helper method called autoTrimTools that automatically selects the relevant tools and trims the tools array based on the names and descriptions. We do this by adding an initial LLM inference call to intelligently trim the tools array before the actual function-calling inference call is made. We found that autoTrimTools helped decrease the number of total tokens used in the entire process (especially when there’s a large number of tools provided) because there’s significantly fewer input tokens used when generating the arguments list. You can choose to use autoTrimTools by setting it as a parameter in the runWithTools method.
const response = await runWithTools(env.AI,"@hf/nousresearch/hermes-2-pro-mistral-7b",
{
messages: [{ role: "user", content: "What's the weather in Austin, Texas?"}],
tools: [
{
name: "getWeather",
description: "Return the weather for a latitude and longitude",
parameters: {
type: "object",
properties: {
latitude: {
type: "string",
description: "The latitude for the given location"
},
longitude: {
type: "string",
description: "The longitude for the given location"
}
},
required: ["latitude", "longitude"]
},
// function code to be executed after tool call
function: async ({ latitude, longitude }) => {
const url = `https://api.weatherapi.com/v1/current.json?key=${env.WEATHERAPI_TOKEN}&q=${latitude},${longitude}`
const res = await fetch(url).then((res) => res.json())
return JSON.stringify(res)
}
}
]
},
{
streamFinalResponse: true,
maxRecursiveToolRuns: 5,
trimFunction: autoTrimTools,
verbose: true,
strictValidation: true
}
)
createToolsFromOpenAPISpec
For many use cases, users will need to make a request to an external API call during function calling to get the output needed. Instead of having to hardcode the exact API endpoints in your tools array, we made a helper function that takes in an OpenAPI spec and dynamically generates the corresponding tool schemas and API endpoints you’ll need for the function call. You call createToolsFromOpenAPISpec from within runWithTools and it’ll dynamically populate everything for you.
const response = await runWithTools(env.AI, "@hf/nousresearch/hermes-2-pro-mistral-7b", {
messages: [{ role: "user",content: "Can you name me 5 repos created by Cloudflare"}],
tools: [
...(await createToolsFromOpenAPISpec( "https://raw.githubusercontent.com/github/rest-api-description/main/descriptions-next/api.github.com/api.github.com.json"
))
]
})
Putting it all together
When you make a function calling inference request with runWithTools and createToolsFromOpenAPISpec, the only thing you need is the prompts – the rest is automatically handled. The LLM will choose the correct tool based on the prompt, the runtime will execute the function needed, and you’ll get a fast, intelligent response from the model. By leveraging our Workers runtime’s bindings and RPC calls along with our global network, we can execute everything from a single location close to the user, enabling developers to easily write complex agentic chains with fewer lines of code.
We’re super excited to help people build intelligent AI systems with our new embedded function calling and powerful tools. Check out our developer docs on how to get started, and let us know what you think on Discord.
With one click, customers can now generate video captions effortlessly using Stream’s newest feature: AI-generated captions for on-demand videos and recordings of live streams. As part of Cloudflare’s mission to help build a better Internet, this feature is available to all Stream customers at no additional cost.
This solution is designed for simplicity, eliminating the need for third-party transcription services and complex workflows. For videos lacking accessibility features like captions, manual transcription can be time-consuming and impractical, especially for large video libraries. Traditionally, it has involved specialized services, sometimes even dedicated teams, to transcribe audio and deliver the text along with video, so it can be displayed during playback. As captions become more widely expected for a variety of reasons, including ethical obligation, legal compliance, and changing audience preferences, we wanted to relieve this burden.
With Stream’s integrated solution, the caption generation process is seamlessly integrated into your existing video management workflow, saving time and resources. Regardless of when you uploaded a video, you can easily add automatic captions to enhance accessibility. Captions can now be generated within the Cloudflare Dashboard or via an API request, all within the familiar and unified Stream platform.
This feature is designed with utmost consideration for privacy and data protection. Unlike other third-party transcription services that may share content with external entities, your data remains securely within Cloudflare’s ecosystem throughout the caption generation process. Cloudflare does not utilize your content for model training purposes. For more information about data protection, review Your Data and Workers AI.
Getting Started
Starting June 20th, 2024, this beta is available for all Stream customers as well as subscribers of the Professional and Business plans, which include 100 minutes of video storage.
To get started, upload a video to Stream (from the Cloudflare Dashboard or via API).
Next, navigate to the “Captions” tab on the video, click “Add Captions,” then select the language and “Generate captions with AI.” Finally, click save and within a few minutes, the new captions will be visible in the captions manager and automatically available in the player, too. Captions can also be generated via the API.
Captions are usually generated in a few minutes. When captions are ready, the Stream player will automatically be updated to offer them to users. The HLS and DASH manifests are also updated so third party players that support text tracks can display them as well.
On-demand videos and recordings of live streams, regardless of when they were created, are supported. While in beta, only English captions can be generated, and videos must be shorter than 2 hours. The quality of the transcription is best on videos with clear speech and minimal background noise.
We’ve been pleased with how well the AI model transcribes different types of content during our tests. That said, there are times when the results aren’t perfect, and another method might work better for some use cases. It’s important to check if the accuracy of the generated captions are right for your needs.
Technical Details
Built using Workers AI
The Stream engineering team built this new feature using Workers AI, allowing us to access the Whisper model – an open source Automatic Speech Recognition model – with a single API call. Using Workers AI radically simplified the AI model deployment, integration, and scaling with an out-of-the-box solution. We eliminated the need for our team to handle infrastructure complexities, enabling us to focus solely on building the automated captions feature.
Writing software that utilizes an AI model can involve several challenges. First, there’s the difficulty of configuring the appropriate hardware infrastructure. AI models require substantial computational resources to run efficiently and require specialized hardware, like GPUs, which can be expensive and complex to manage. There’s also the daunting task of deploying AI models at scale, which involve the complexities of balancing workload distribution, minimizing latency, optimizing throughput, and maintaining high availability. Not only does Workers AI solve the pain of managing underlying infrastructure, it also automatically scales as needed.
Using Workers AI transformed a daunting task into a Worker that transcribes audio files with less than 30 lines of code.
import { Ai } from '@cloudflare/ai'
export interface Env {
AI: any
}
export type AiVTTOutput = {
vtt?: string
}
export default {
async fetch(request: Request, env: Env) {
const blob = await request.arrayBuffer()
const ai = new Ai(env.AI)
const input = {
audio: [...new Uint8Array(blob)],
}
try {
const response: AiVTTOutput = (await ai.run(
'@cf/openai/whisper-tiny-en',
input
)) as any
return Response.json({ vtt: response.vtt })
} catch (e) {
const errMsg =
e instanceof Error
? `${e.name}\n${e.message}\n${e.stack}`
: 'unknown error type'
return new Response(`${errMsg}`, {
status: 500,
statusText: 'Internal error',
})
}
},
}
Quickly captioning videos at scale
The Stream team wanted to ensure this feature is fast and performant at scale, which required engineering work to process a high volume of videos regardless of duration.
First, our team needed to pre-process the audio prior to running AI inference to ensure the input is compatible with Whisper’s input format and requirements.
There is a wide spectrum of variability in video content, from a short grainy video filmed on a phone to a multi-hour high-quality Hollywood-produced movie. Videos may be silent or contain an action-driven cacophony. Also, Stream’s on-demand videos include recordings of live streams which are packaged differently from videos uploaded as whole files. With this variability, the audio inputs are stored in an array of different container formats, with different durations, and different file sizes. We ensured our audio files were properly formatted to be compatible with Whisper’s requirements.
One aspect for pre-processing is ensuring files are a sensible duration for optimized inference. Whisper has an “sweet spot” of 30 seconds for the duration of audio files for transcription. As they note in this Github discussion: “Too short, and you’d lack surrounding context. You’d cut sentences more often. A lot of sentences would cease to make sense. Too long, and you’ll need larger and larger models to contain the complexity of the meaning you want the model to keep track of.” Fortunately, Stream already splits videos into smaller segments to ensure fast delivery during playback on the web. We wrote functionality to concatenate those small segments into 30-second batches prior to sending to Workers AI.
To optimize processing speed, our team parallelized as many operations as possible. By concurrently creating the 30-second audio batches and sending requests to Workers AI, we take full advantage of the scalability of the Workers AI platform. Doing this greatly reduces the time it takes to generate captions, but adds some additional complexity. Because we are sending requests to Workers AI in parallel, transcription responses may arrive out-of-order. For example, if a video is one minute in duration, the request to generate captions for the second 30 seconds of a video may complete before the request for the first 30 seconds of the video. The captions need to be sequential to align with the video, so our team had to maintain an understanding of the audio batch order to ensure our final combined WebVTT caption file is properly synced with the video. We sort the incoming Workers AI responses and re-order timestamps for a final accurate transcript.
The end result is the ability to generate captions for longer videos quickly and efficiently at scale.
Try it now
We are excited to bring this feature to open beta for all of our subscribers as well as Pro and Business plan customers today! Get started by uploading a video to Stream. Review our documentation for tutorials and current beta limitations. Up next, we will be focused on adding more languages and supporting longer videos.
During Developer Week in April 2024, we announced General Availability of Workers AI, and today, we are excited to announce that AI Gateway is Generally Available as well. Since its launch to beta in September 2023 during Birthday Week, we’ve proxied over 500 million requests and are now prepared for you to use it in production.
AI Gateway is an AI ops platform that offers a unified interface for managing and scaling your generative AI workloads. At its core, it acts as a proxy between your service and your inference provider(s), regardless of where your model runs. With a single line of code, you can unlock a set of powerful features focused on performance, security, reliability, and observability – think of it as your control plane for your AI ops. And this is just the beginning – we have a roadmap full of exciting features planned for the near future, making AI Gateway the tool for any organization looking to get more out of their AI workloads.
Why add a proxy and why Cloudflare?
The AI space moves fast, and it seems like every day there is a new model, provider, or framework. Given this high rate of change, it’s hard to keep track, especially if you’re using more than one model or provider. And that’s one of the driving factors behind launching AI Gateway – we want to provide you with a single consistent control plane for all your models and tools, even if they change tomorrow, and then again the day after that.
We’ve talked to a lot of developers and organizations building AI applications, and one thing is clear: they want more observability, control, and tooling around their AI ops. This is something many of the AI providers are lacking as they are deeply focused on model development and less so on platform features.
Why choose Cloudflare for your AI Gateway? Well, in some ways, it feels like a natural fit. We’ve spent the last 10+ years helping build a better Internet by running one of the largest global networks, helping customers around the world with performance, reliability, and security – Cloudflare is used as a reverse proxy by nearly 20% of all websites. With our expertise, it felt like a natural progression – change one line of code, and we can help with observability, reliability, and control for your AI applications – all in one control plane – so that you can get back to building.
Here is that one line code change using the OpenAI JS SDK. And check out our docs to reference other providers, SDKs, and languages.
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: 'my api key', // defaults to process.env["OPENAI_API_KEY"]
baseURL: "https://gateway.ai.cloudflare.com/v1/{account_id}/{gateway_slug}/openai"
});
What’s included today?
After talking to customers, it was clear that we needed to focus on some foundational features before moving onto some of the more advanced ones. While we’re really excited about what’s to come, here are the key features available in GA today:
Analytics: Aggregate metrics from across multiple providers. See traffic patterns and usage including the number of requests, tokens, and costs over time.
Real-time logs: Gain insight into requests and errors as you build.
Caching: Enable custom caching rules and use Cloudflare’s cache for repeat requests instead of hitting the original model provider API, helping you save on cost and latency.
Rate limiting: Control how your application scales by limiting the number of requests your application receives to control costs or prevent abuse.
Support for your favorite providers: AI Gateway now natively supports Workers AI plus 10 of the most popular providers, including Groq and Cohere as of mid-May 2024.
Universal endpoint: In case of errors, improve resilience by defining request fallbacks to another model or inference provider.
We’ve gotten a lot of feedback from developers, and there are some obvious things on the horizon such as persistent logs and custom metadata – foundational features that will help unlock the real magic down the road.
But let’s take a step back for a moment and share our vision. At Cloudflare, we believe our platform is much more powerful as a unified whole than as a collection of individual parts. This mindset applied to our AI products means that they should be easy to use, combine, and run in harmony.
Let’s imagine the following journey. You initially onboard onto Workers AI to run inference with the latest open source models. Next, you enable AI Gateway to gain better visibility and control, and start storing persistent logs. Then you want to start tuning your inference results, so you leverage your persistent logs, our prompt management tools, and our built in eval functionality. Now you’re making analytical decisions to improve your inference results. With each data driven improvement, you want more. So you implement our feedback API which helps annotate inputs/outputs, in essence building a structured data set. At this point, you are one step away from a one-click fine tune that can be deployed instantly to our global network, and it doesn’t stop there. As you continue to collect logs and feedback, you can continuously rebuild your fine tune adapters in order to deliver the best results to your end users.
This is all just an aspirational story at this point, but this is how we envision the future of AI Gateway and our AI suite as a whole. You should be able to start with the most basic setup and gradually progress into more advanced workflows, all without leaving Cloudflare’s AI platform. In the end, it might not look exactly as described above, but you can be sure that we are committed to providing the best AI ops tools to help make Cloudflare the best place for AI.
How do I get started?
AI Gateway is available to use today on all plans. If you haven’t yet used AI Gateway, check out our developer documentation and get started now. AI Gateway’s core features available today are offered for free, and all it takes is a Cloudflare account and one line of code to get started. In the future, more premium features, such as persistent logging and secrets management will be available subject to fees. If you have any questions, reach out on our Discord channel.
Managing consent online can be challenging. After you’ve figured out the necessary regulations, you usually need to configure some Consent Management Platform (CMP) to load all third-party tools and scripts on your website in a way that respects these demands. Cloudflare Zaraz manages the loading of all of these third-party tools, so it was only natural that in April 2023 we announced the Cloudflare Zaraz CMP: the simplest way to manage consent in a way that seamlessly integrates with your third-party tools manager.
As more and more third-party tool vendors are required to handle consent properly, our CMP has evolved to integrate with these new technologies and standardization efforts. Today, we’re happy to announce that the Cloudflare Zaraz CMP is now compatible with the Interactive Advertising Bureau Transparency and Consent Framework (IAB TCF) requirements, and fully supports Google’s Consent Mode v2 signals. Separately, we’ve taken efforts to improve the way Cloudflare Zaraz handles traffic coming from online bots.
IAB TCF Compatibility
Earlier this year, Google announced that websites that would like to use AdSense and other advertising solutions in the European Economic Area (EEA), the UK, and Switzerland, will be required to use a CMP that is approved by IAB Europe, an association for digital marketing and advertising. Their Transparency and Consent Framework sets guidelines for how CMPs should operate. Since March 2024, the Cloudflare Zaraz CMP is compliant with these guidelines, and Zaraz users in Europe can use Google’s advertising products without any restrictions.
Since the IAB TCF requirements can make the consent modal a little complex for users, we have made this compliance mode an opt-in feature. See the official documentation for information on how to enable it.
Google Consent Mode v2
Another new requirement from Google was the need to send “Consent Signals”. These signals are part of what is also known as “Consent Mode”, and later, Consent Mode v2. Together with each event sent to Google Analytics and Google Ads, they tell the Google servers about the consent status of the current visitor – did they agree to have their data used for personalized advertising? Did they accept cookies? These and other questions are answered by Consent Mode v2, telling the Google servers how to treat the data it receives.
Consent Mode v2 usually requires setting two values for each consent category – a default value and an updated one. The default value represents the consent status (granted or denied) a certain category (e.g. using cookies) has before the user has submitted their personal preferences. Usually, and especially within the EU, the default value would be `denied`. Once the user submits their preferences, Consent Mode v2 sends an additional “updated” value that represents the choice the user made.
Implementing Consent Mode v2 is quick and easy with Cloudflare Zaraz, although the specific implementation depends on your CMP. Examples, including integration with the Cloudflare Zaraz CMP, are available in our official documentation.
We believe that better standardization around online consent benefits everyone, and we are glad to be working on tools that respect users’ privacy and improve online user experience.
Bot Management
We also recently integrated better Bot Management support within Cloudflare Zaraz. You often want crawlers to be able to access your website, but you don’t want them to trigger your analytics and conversion pixels. Using the Bot Management feature in the Cloudflare Zaraz Settings page allows you to fine tune which requests will make it to Cloudflare Zaraz and which ones will be skipped. Since Zaraz pricing is based on the total number of Zaraz Events, this can also be useful if you want more control over your Cloudflare Zaraz costs, ensuring you will not be paying for events triggered by bots. Like all other Cloudflare Zaraz features, these new features are also available to users on all plans, including the free plan. For us, it is part of making sure that everyone can benefit from a faster, safer, and more private way to manage third parties online. If you haven’t started using Cloudflare Zaraz already, now is a great time. Go to the Cloudflare dashboard and set it up in just a few clicks.
In April 2020, we blogged about how to get COBOL running on Cloudflare Workers by compiling to WebAssembly. The ecosystem around WebAssembly has grown significantly since then, and it has become a solid foundation for all types of projects, be they client-side or server-side.
As WebAssembly support has grown, more and more languages are able to compile to WebAssembly for execution on servers and in browsers. As Cloudflare Workers uses the V8 engine and supports WebAssembly natively, we’re able to support languages that compile to WebAssembly on the platform.
Recently, work on LLVM has enabled Fortran to compile to WebAssembly. So, today, we’re writing about running Fortran code on Cloudflare Workers.
Before we dive into how to do this, here’s a little demonstration of number recognition in Fortran. Draw a number from 0 to 9 and Fortran code running somewhere on Cloudflare’s network will predict the number you drew.
This is taken from the wonderful Fortran on WebAssembly post but instead of running client-side, the Fortran code is running on Cloudflare Workers. Read on to find out how you can use Fortran on Cloudflare Workers and how that demonstration works.
Wait, Fortran? No one uses that!
Not so fast! Or rather, actually pretty darn fast if you’re doing a lot of numerical programming or have scientific data to work with. Fortran (originally FORmula TRANslator) is very well suited for scientific workloads because of its native functionality for things like arithmetic and handling large arrays and matrices.
If you look at the ranking of the fastest supercomputers in the world you’ll discover that the measurement of “fast” is based on these supercomputers running a piece of software called LINPACK that was originally written in Fortran. LINPACK is designed to help with problems solvable using linear algebra.
The LINPACK benchmarks use LINPACK to solve an n x n system of linear equations using matrix operations and, in doing so, determine how fast supercomputers are. The code is available in Fortran, C and Java.
A related Fortran package, BLAS, also does linear algebra and forms the basis of the number identifying code above. But other Fortran packages are still relevant. Back in 2017, NASA ran a competition to make FUN3D (used to perform calculations of airflow over simulated aircraft). FUN3D is written in Fortran.
So, although Fortran (or at the time FORTRAN) first came to life in 1957, it’s alive and well and being used widely for scientific applications (there’s even Fortran for CUDA). One particular application left Earth 20 years after Fortran was born: Voyager. The Voyager probes use a combination of assembly language and Fortran to keep chugging along.
But back in our solar system, and back on Region: Earth, you can now use Fortran on Cloudflare Workers. Here’s how.
How to get your Fortran code running on Cloudflare Workers
To make it easy to run your Fortran code on Cloudflare Workers, we created a tool called Fortiche (translates to smart in French). It uses Flang and Emscripten under the hood.
Flang is a frontend in LLVM and, if you read the Fortran on WebAssembly blog post, we currently have to patch LLVM to work around a few issues.
Emscripten is used to compile LLVM output and produce code that is compatible with Cloudflare Workers.
This is all packaged in the Fortiche Docker image. Let’s see a simple example.
add.f90:
SUBROUTINE add(a, b, res)
INTEGER, INTENT(IN) :: a, b
INTEGER, INTENT(OUT) :: res
res = a + b
END
Here we defined a subroutine called add that takes a and b, sums them together and places the result in res.
docker run -v $PWD:/input -v $PWD/output:/output xtuc/fortiche --export-func=add add.f90
Passing --export-func=add to Fortiche makes the Fortran add subroutine available to JavaScript.
The output folder contains the compiled WebAssembly module and JavaScript from Emscripten, and a JavaScript endpoint generated by Fortiche:
$ ls -lh ./output
total 84K
-rw-r--r-- 1 root root 392 avril 22 12:00 index.mjs
-rw-r--r-- 1 root root 27K avril 22 12:00 out.mjs
-rwxr-xr-x 1 root root 49K avril 22 12:00 out.wasm
And finally the Cloudflare Worker:
// Import what Fortiche generated
import {load} from "../output/index.mjs"
export default {
async fetch(request: Request): Promise<Response> {
// Load the Fortran program
const program = await load();
// Allocate space in memory for the arguments and result
const aPtr = program.malloc(4);
const bPtr = program.malloc(4);
const outPtr = program.malloc(4);
// Set argument values
program.HEAP32[aPtr / 4] = 123;
program.HEAP32[bPtr / 4] = 321;
// Run the Fortran add subroutine
program.add(aPtr, bPtr, outPtr);
// Read the result
const res = program.HEAP32[outPtr / 4];
// Free everything
program.free(aPtr);
program.free(bPtr);
program.free(outPtr);
return Response.json({ res });
},
};
Interestingly, the values we pass to Fortran are all pointers, therefore we have to allocate space for each argument and result (the Fortran integer type is four bytes wide), and pass the pointers to the `add` subroutine.
Workers AI’s initial launch in beta included support for Llama 2, as it was one of the most requested open source models from the developer community. Since that initial launch, we’ve seen developers build all kinds of innovative applications including knowledge sharing chatbots, creative content generation, and automation for various workflows.
At Cloudflare, we know developers want simplicity and flexibility, with the ability to build with multiple AI models while optimizing for accuracy, performance, and cost, among other factors. Our goal is to make it as easy as possible for developers to use their models of choice without having to worry about the complexities of hosting or deploying models.
As soon as we learned about the development of Llama 3 from our partners at Meta, we knew developers would want to start building with it as quickly as possible. Workers AI’s serverless inference platform makes it extremely easy and cost effective to start using the latest large language models (LLMs). Meta’s commitment to developing and growing an open AI-ecosystem makes it possible for customers of all sizes to use AI at scale in production. All it takes is a few lines of code to run inference to Llama 3:
export interface Env {
// If you set another name in wrangler.toml as the value for 'binding',
// replace "AI" with the variable name you defined.
AI: any;
}
export default {
async fetch(request: Request, env: Env) {
const response = await env.AI.run('@cf/meta/llama-3-8b-instruct', {
messages: [
{role: "user", content: "What is the origin of the phrase Hello, World?"}
]
}
);
return new Response(JSON.stringify(response));
},
};
Built with Meta Llama 3
Llama 3 offers leading performance on a wide range of industry benchmarks. You can learn more about the architecture and improvements on Meta’s blog post. Cloudflare Workers AI supports Llama 3 8B, including the instruction fine-tuned model.
Meta’s testing shows that Llama 3 is the most advanced open LLM today on evaluation benchmarks such as MMLU, GPQA, HumanEval, GSM-8K, and MATH. Llama 3 was trained on an increased number of training tokens (15T), allowing the model to have a better grasp on language intricacies. Larger context windows doubles the capacity of Llama 2, and allows the model to better understand lengthy passages with rich contextual data. Although the model supports a context window of 8k, we currently only support 2.8k but are looking to support 8k context windows through quantized models soon. As well, the new model introduces an efficient new tiktoken-based tokenizer with a vocabulary of 128k tokens, encoding more characters per token, and achieving better performance on English and multilingual benchmarks. This means that there are 4 times as many parameters in the embedding and output layers, making the model larger than the previous Llama 2 generation of models.
Under the hood, Llama 3 uses grouped-query attention (GQA), which improves inference efficiency for longer sequences and also renders their 8B model architecturally equivalent to Mistral-7B. For tokenization, it uses byte-level byte-pair encoding (BPE), similar to OpenAI’s GPT tokenizers. This allows tokens to represent any arbitrary byte sequence — even those without a valid utf-8 encoding. This makes the end-to-end model much more flexible in its representation of language, and leads to improved performance.
Along with the base Llama 3 models, Meta has released a suite of offerings with tools such as Llama Guard 2, Code Shield, and CyberSec Eval 2, which we are hoping to release on our Workers AI platform shortly.
Developer Week 2024 has officially come to a close. Each day last week, we shipped new products and functionality geared towards giving developers the components they need to build full-stack applications on Cloudflare.
Even though Developer Week is now over, we are continuing to innovate with the over two million developers who build on our platform. Building a platform is only as exciting as seeing what developers build on it. Before we dive into a recap of the announcements, to send off the week, we wanted to share how a couple of companies are using Cloudflare to power their applications:
We have been using Workers for image delivery using R2 and have been able to maintain stable operations for a year after implementation. The speed of deployment and the flexibility of detailed configurations have greatly reduced the time and effort required for traditional server management. In particular, we have seen a noticeable cost savings and are deeply appreciative of the support we have received from Cloudflare Workers. – FAN Communications
Milkshake helps creators, influencers, and business owners create engaging web pages directly from their phone, to simply and creatively promote their projects and passions. Cloudflare has helped us migrate data quickly and affordably with R2. We use Workers as a routing layer between our users’ websites and their images and assets, and to build a personalized analytics offering affordably. Cloudflare’s innovations have consistently allowed us to run infrastructure at a fraction of the cost of other developer platforms and we have been eagerly awaiting updates to D1 and Queues to sustainably scale Milkshake as the product continues to grow. – Milkshake
In case you missed anything, here’s a quick recap of the announcements and in-depth technical explorations that went out last week:
A core part of any full-stack application is storing and persisting data! We kicked off the week with announcements that help developers build stateful applications on top of Cloudflare, including making D1, Cloudflare’s SQL database and Hyperdrive, our database accelerating service, generally available.
D1, Cloudflare’s SQL database, is now generally available. With new support for 10GB databases, data export, and enhanced query debugging, we empower developers to build production-ready applications with D1 to meet all their relational SQL needs. To support Workers in global applications, we’re sharing a sneak peek of our design and API for D1 global read replication to demonstrate how developers scale their workloads with D1.
Bindings don’t just reduce boilerplate. They are a core design feature of the Workers platform which simultaneously improve developer experience and application security in several ways. Usually these two goals are in opposition to each other, but bindings elegantly solve for both at the same time.
We made a series of AI-related announcements, including Workers AI, Cloudflare’s inference platform becoming GA, support for fine-tuned models with LoRAs, one-click deploys from HuggingFace, Python support for Cloudflare Workers, and more.
Workers AI now supports fine-tuned models using LoRAs. But what is a LoRA and how does it work? In this post, we dive into fine-tuning, LoRAs and even some math to share the details of how it all works under the hood.
We introduced Python support for Cloudflare Workers, now in open beta. We’ve revamped our systems to support Python, from the Workers runtime itself to the way Workers are deployed to Cloudflare’s network. Learn about a Python Worker’s lifecycle, Pyodide, dynamic linking, and memory snapshots in this post.
We announced three new features for Cloudflare R2: event notifications, support for migrations from Google Cloud Storage, and an infrequent access storage tier.
We’re making it easier to build scalable, reliable, data-driven applications on top of our global network, and so we announced a new Event Notifications framework; our take on durable execution, Workflows; and an upcoming streaming ingestion service, Pipelines.
Together, Cloudflare and Prisma make it easier than ever to deploy globally available apps with a focus on developer experience. To further that goal, Prisma ORM now natively supports Cloudflare Workers and D1 in Preview. With version 5.12.0 of Prisma ORM you can now interact with your data stored in D1 from your Cloudflare Workers with the convenience of the Prisma Client API. Learn more and try it out now.
Picsart, one of the world’s largest digital creation platforms, encountered performance challenges in catering to its global audience. Adopting Cloudflare’s global-by-default Developer Platform emerged as the optimal solution, empowering Picsart to enhance performance and scalability substantially.
We launched four improvements to Pages that bring functionality previously restricted to Workers, with the goal of unifying the development experience between the two. Support for monorepos, wrangler.toml, new additions to Next.js support and database integrations!
Production readiness isn’t just about scale and reliability of the services you build with. We announced five updates that put more power in your hands – Gradual Deployments, Source mapped stack traces in Tail Workers, a new Rate Limiting API, brand-new API SDKs, and updates to Durable Objects – each built with mission-critical production services in mind.
With Cloudflare Calls in open beta, you can build real-time, serverless video and audio applications. Cloudflare Stream lets your viewers instantly clip from ongoing streams. Finally, Cloudflare Images now supports automatic face cropping and has an upload widget that lets you easily integrate into your application.
Cloudflare Calls is a serverless SFU and TURN service running at Cloudflare’s edge. It’s now in open beta and costs $0.05/ real-time GB. It’s 100% anycast WebRTC.
We announced that PartyKit, a trailblazer in enabling developers to craft ambitious real-time, collaborative, multiplayer applications, is now a part of Cloudflare. This acquisition marks a significant milestone in our journey to redefine the boundaries of serverless computing, making it more dynamic, interactive, and, importantly, stateful.
Full-stack web development with Cloudflare is now faster and easier! You can now use your framework’s development server while accessing D1 databases, R2 object stores, AI models, and more. Iterate locally in milliseconds to build sophisticated web apps that run on Cloudflare. Let’s dev together!
Cloudflare Workers now features a built-in RPC (Remote Procedure Call) system for use in Worker-to-Worker and Worker-to-Durable Object communication, with absolutely minimal boilerplate. We’ve designed an RPC system so expressive that calling a remote service can feel like using a library.
We closed out Developer Week by sharing updates on our Workers Launchpad program, our latest Developer Challenge, and the work we’re doing to ensure our community spaces – like our Discord and Community forums – are safe and inclusive for all developers.
Continue the conversation
Thank you for being a part of Developer Week! Want to continue the conversation and share what you’re building? Join us on Discord. To get started building on Workers, check out our developer documentation.
The cloud is changing. Just a few years ago, serverless functions were revolutionary. Today, entire applications are built on serverless architectures, from compute to databases, storage, queues, etc. — with Cloudflare leading the way in making it easier than ever for developers to build, without having to think about their architecture. And while the adoption of serverless has made it simple for developers to run fast, it has also made one of the most difficult problems in software even harder: how the heck do you unravel the behavior of distributed systems?
When I started Baselime 2 years ago, our goal was simple: enable every developer to build, ship, and learn from their serverless applications such that they can resolve issues before they become problems.
Since then, we built an observability platform that enables developers to understand the behaviour of their cloud applications. It’s designed for high cardinality and dimensionality data, from logs to distributed tracing with OpenTelemetry. With this data, we automatically surface insights from your applications, and enable you to quickly detect, troubleshoot, and resolve issues in production.
In parallel, Cloudflare has been busy the past few years building the next frontier of cloud computing: the connectivity cloud. The team is building primitives that enable developers to build applications with a completely new set of paradigms, from Workers to D1, R2, Queues, KV, Durable Objects, AI, and all the other services available on the Cloudflare Developers Platform.
This synergy makes Cloudflare the perfect home for Baselime. Our core mission has always been to simplify and innovate around observability for the future of the cloud, and Cloudflare’s ecosystem offers the ideal ground to further this cause. With Cloudflare, we’re positioned to deeply integrate into a platform that tens of thousands of developers trust and use daily, enabling them to quickly build, ship, and troubleshoot applications. We believe that every Worker, Queue, KV, Durable Object, AI call, etc. should have built-in observability by default.
That’s why we’re incredibly excited about the potential of what we can build together and the impact it will have on developers around the world.
To give you a preview into what’s ahead, I wanted to dive deeper into the 3 core concepts we followed while building Baselime.
High Cardinality and Dimensionality
Cardinality and dimensionality are best described using examples. Imagine you’re playing a board game with a deck of cards. High cardinality is like playing a game where every card is a unique character, making it hard to remember or match them. And high dimensionality is like each card has tons of details like strength, speed, magic, aura, etc., making the game’s strategy complex because there’s so much to consider.
This also applies to the data your application emits. For example, when you log an HTTP request that makes database calls.
High cardinality means that your logs can have a unique userId or requestId (which can take millions of distinct values). Those are high cardinality fields.
High dimensionality means that your logs can have thousands of possible fields. You can record each HTTP header of your request and the details of each database call. Any log can be a key-value object with thousands of individual keys.
The ability to query on high cardinality and dimensionality fields is key to modern observability. You can surface all errors or requests for a specific user, compute the duration of each of those requests, and group by location. You can answer all of those questions with a single tool.
OpenTelemetry
OpenTelemetry provides a common set of tools, APIs, SDKs, and standards for instrumenting applications. It is a game-changer for debugging and understanding cloud applications. You get to see the big picture: how fast your HTTP APIs are, which routes are experiencing the most errors, or which database queries are slowest. You can also get into the details by following the path of a single request or user across your entire application.
Baselime is OpenTelemetry native, and it is built from the ground up to leverage OpenTelemetry data. To support this, we built a set of OpenTelemetry SDKs compatible with several serverless runtimes.
Cloudflare is building the cloud of tomorrow and has developed workerd, a modern JavaScript runtime for Workers. With Cloudflare, we are considering embedding OpenTelemetry directly in the Workers’ runtime. That’s one more reason we’re excited to grow further at Cloudflare, enabling more developers to understand their applications, even in the most unconventional scenarios.
Developer Experience
Observability without action is just storage. I have seen too many developers pay for tools to store logs and metrics they never use, and the key reason is how opaque these tools are.
The crux of the issue in modern observability isn’t the technology itself, but rather the developer experience. Many tools are complex, with a significant learning curve. This friction reduces the speed at which developers can identify and resolve issues, ultimately affecting the reliability of their applications. Improving developer experience is key to unlocking the full potential of observability.
We built Baselime to be an exploratory solution that surfaces insights to you rather than requiring you to dig for them. For example, we notify you in real time when errors are discovered in your application, based on your logs and traces. You can quickly search through all of your data with full-text search, or using our powerful query engine, which makes it easy to correlate logs and traces for increased visibility, or ask our AI debugging assistant for insights on the issue you’re investigating.
It is always possible to go from one insight to another, asking questions about the state of your app iteratively until you get to the root cause of the issue you are troubleshooting.
Cloudflare has always prioritised the developer experience of its developer platform, especially with Wrangler, and we are convinced it’s the right place to solve the developer experience problem of observability.
What’s next?
Over the next few months, we’ll work to bring the core of Baselime into the Cloudflare ecosystem, starting with OpenTelemetry, real-time error tracking, and all the developer experience capabilities that make a great observability solution. We will keep building and improving observability for applications deployed outside Cloudflare because we understand that observability should work across providers.
But we don’t want to stop there. We want to push the boundaries of what modern observability looks like. For instance, directly connecting to your codebase and correlating insights from your logs and traces to functions and classes in your codebase. We also want to enable more AI capabilities beyond our debugging assistant. We want to deeply integrate with your repositories such that you can go from an error in your logs and traces to a Pull Request in your codebase within minutes.
We also want to enable everyone building on top of Large Language Models to do all your LLM observability directly within Cloudflare, such that you can optimise your prompts, improve latencies and reduce error rates directly within your cloud provider. These are just a handful of capabilities we can now build with the support of the Cloudflare platform.
Thanks
We are incredibly thankful to our community for its continued support, from day 0 to today. With your continuous feedback, you’ve helped us build something we’re incredibly proud of.
To all the developers currently using Baselime, you’ll be able to keep using the product and will receive ongoing support. Also, we are now making all the paid Baselime features completely free.
Baselime products remain available to sign up for while we work on integrating with the Cloudflare platform. We anticipate sunsetting the Baselime products towards the end of 2024 when you will be able to observe all of your applications within the Cloudflare dashboard. If you’re interested in staying up-to-date on our work with Cloudflare, we will release a signup link in the coming weeks!
We are looking forward to continuing to innovate with you.
Hello web developers! Last year we released a slew of improvements that made deploying web applications on Cloudflare much easier, and in response we’ve seen a large growth of Astro, Next.js, Nuxt, Qwik, Remix, SolidStart, SvelteKit, and other web apps hosted on Cloudflare. Today we are announcing major improvements to our integration with these web frameworks that makes it easier to develop sophisticated applications that use our D1 SQL database, R2 object store, AI models, and other powerful features of Cloudflare’s developer platform.
In the past, if you wanted to develop a web framework-powered application with D1 and run it locally, you’d have to build a production build of your application, and then run it locally using `wrangler pages dev`. While this worked, each of your code iterations would take seconds, or tens of seconds for big applications. Iterating using production builds is simply too slow, pulls you out of the flow, and doesn’t allow you to take advantage of all the DX optimizations that framework authors have put a lot of hard work into. This is changing today!
Our goal is to integrate with web frameworks in the most natural way possible, without developers having to learn and adopt significant workflow changes or custom APIs when deploying their app to Cloudflare. Whether you are a Next.js developer, a Nuxt developer, or prefer another framework, you can now keep on using the blazing fast local development workflow familiar to you, and ship your application on Cloudflare.
All full-stack web frameworks come with a local development server (dev server) that is custom tailored to the framework and often provides an excellent development experience, with only one exception — they don’t natively support some important features of Cloudflare’s development platform, especially our storage solutions.
Let’s create a new application using C3 — our create-cloudflare CLI. We could use any npm client of our choice (pnpm anyone?!?), but to keep things simple in this post, we’ll stick with the default npm client. To get started, just run:
$ npm create cloudflare@latest
Provide a name for your app, or stick with the randomly generated one. Then select the “Website or web app” category, and pick a full-stack framework of your choice. We support many: Astro, Next.js, Nuxt, Qwik, Remix, SolidStart, and SvelteKit.
Since C3 delegates the application scaffolding to the latest version of the framework-specific CLI, you will scaffold the application exactly as the framework authors intended without missing out on any of the framework features or options. C3 then adds to your application everything necessary for integrating and deploying to Cloudflare so that you don’t have to configure it yourself.
With our application scaffolded, let’s get it to display a list of products stored in a database with just a few steps. First, we add the configuration for our database to our wrangler.toml config file:
Yes, that’s right! You can now configure your bound resources via the wrangler.toml file, even for full-stack apps deployed to Pages. We’ll share much more about configuration enhancements to Pages in a dedicated announcement.
Now let’s create a simple schema.sql file representing our database schema:
Notice that we used the –local flag of wrangler d1 execute to apply the changes to our local D1 database. This is the database that our dev server will connect to.
Next, if you use TypeScript, let TypeScript know about your database by running:
$ npm run build-cf-types
This command is preconfigured for all full-stack applications created via C3 and executes wrangler types to update the interface of Cloudflare’s environment containing all configured bindings.
We can now start the dev server provided by your framework via a handy shortcut:
$ npm run dev
This shortcut will start your framework’s dev server, whether it’s powered by next dev, nitro, or vite.
Now to access our database and list the products, we can now use a framework specific approach. For example, in a Next.js application that uses the App router, we could update app/api/hello/route.ts with the following:
const db = getRequestContext().env.DB;
const productsResults = await db.prepare('SELECT * FROM products').all();
return Response.json(productsResults.results);
Or in a Nuxt application, we can create a server/api/hello.ts file and populate it with:
Assuming that the framework dev server is running on port 3000, you can test the new API route in either framework by navigating to http://localhost:3000/api/hello. For simplicity, we picked API routes in these examples, but the same applies to any UI-generating routes as well.
Each web framework has its own way to define routes and pass contextual information about the request throughout the application, so how you access your databases, object stores, and other resources will depend on your framework. You can read our updated full-stack framework guides to learn more:
Now that you know how to access Cloudflare’s resources in the framework of your choice, everything else you know about your framework remains the same. You can now develop your application locally, using the development server optimized for your framework, which often includes support for hot module replacement (HMR), custom dev tools, enhanced debugging support and more, all while still benefiting from Cloudflare-specific APIs and features. Win-win!
What has actually changed to enable these development workflows?
To decrease the development latency and preserve the custom framework-specific experiences, we needed to enable web frameworks and their dev servers to integrate with wrangler and miniflare in a seamless, almost invisible way.
Miniflare is a key component in this puzzle. It is our local simulator for Cloudflare-specific resources, which is powered by workerd, our JavaScript (JS) runtime. By relying on workerd, we ensure that Cloudflare’s JavaScript APIs run locally in a way that faithfully simulates our production environment. The trouble is that framework dev servers already rely on Node.js to run the application, so bringing another JS runtime into the mix breaks many assumptions in how these dev servers have been architected.
Our team however came up with an interesting approach to bridging the gap between these two JS runtimes. We call it the getPlatformProxy() API, which is now part of wrangler and is super-powered by miniflare’s magic proxy. This API exposes a JS proxy object that behaves just like the usual Workers env object containing all bound resources. The proxy object enables code from Node.js to transparently invoke JavaScript code running in workerd, as well access Cloudflare-specific runtime APIs.
With this bridge between the Node.js and workerd runtimes, your application can now access Cloudflare simulators for D1, R2, KV and other storage solutions directly while running in a dev server powered by Node.js. Or you could even write an Node.js script to do the same:
import {getPlatformProxy} from 'wrangler';
const {env} = getPlatformProxy();
console.dir(env);
const db = env.DB;
// Now let’s execute a DB query that runs in a local D1 db
// powered by miniflare/workerd and access the result from Node.js
const productsResults = await db.prepare('SELECT * FROM products').all();
console.log(productsResults.results);
With the getPlatformProxy() API available, the remaining work was all about updating all framework adapters, plugins, and in some cases frameworks themselves to make use of this API. We are grateful for the support we received from framework teams on this journey, especially Alex from Astro, pi0 from Nuxt, Pedro from Remix, Ryan from Solid, Ben and Rich from Svelte, and our collaborator on the next-on-pages project, James Anderson.
Future improvements to development workflows with Vite
While the getPlatformProxy() API is a good solution for many scenarios, we can do better. If we could run the entire application in our JS runtime rather than Node.js, we could even more faithfully simulate the production environment and reduce developer friction and production surprises.
In the ideal world, we’d like you to develop against the same runtime that you deploy to in production, and this can only be achieved by integrating workerd directly into the dev servers of all frameworks, which is not a small feat considering the number of frameworks out there and the differences between them.
We however got a bit lucky. As we kicked off this effort, we quickly realized that Vite, a popular dev server used by many full-stack frameworks, was gaining increasingly greater adoption. In fact, Remix switched over to Vite just recently and confirmed the popularity of Vite as the common foundation for web development today.
If Vite had first-class support for running a full-stack application in an alternative JavaScript runtime, we could enable anyone using Vite to develop their applications locally with complete access to the Cloudflare developer platform. No more framework specific custom integrations and workarounds — all the features of a full-stack framework, Vite, and Cloudflare accessible to all developers.
Sounds too good to be true? Maybe. We are very stoked to be working with the Vite team on the Vite environments proposal, which could enable just that. This proposal is still evolving, so stay tuned for updates.
What will you build today?
We aim to make Cloudflare the best development platform for web developers. Making it quick and easy to develop your application with frameworks and tools you are already familiar with is a big part of our story. Start your journey with us by running a single command:
Cloudflare Workers now features a built-in RPC (Remote Procedure Call) system enabling seamless Worker-to-Worker and Worker-to-Durable Object communication, with almost no boilerplate. You just define a class:
export class MyService extends WorkerEntrypoint {
sum(a, b) {
return a + b;
}
}
And then you call it:
let three = await env.MY_SERVICE.sum(1, 2);
No schemas. No routers. Just define methods of a class. Then call them. That’s it.
But that’s not it
This isn’t just any old RPC. We’ve designed an RPC system so expressive that calling a remote service can feel like using a library – without any need to actually import a library! This is important not just for ease of use, but also security: fewer dependencies means fewer critical security updates and less exposure to supply-chain attacks.
To this end, here are some of the features of Workers RPC:
For starters, you can pass Structured Clonable types as the params or return value of an RPC. (That means that, unlike JSON, Dates just work, and you can even have cycles.)
You can additionally pass functions in the params or return value of other functions. When the other side calls the function you passed to it, they make a new RPC back to you.
Similarly, you can pass objects with methods. Method calls become further RPCs.
RPC to another Worker (over a Service Binding) usually does not even cross a network. In fact, the other Worker usually runs in the very same thread as the caller, reducing latency to zero. Performance-wise, it’s almost as fast as an actual function call.
When RPC does cross a network (e.g. to a Durable Object), you can invoke a method and then speculatively invoke further methods on the result in a single network round trip.
You can send a byte stream over RPC, and the system will automatically stream the bytes with proper flow control.
All of this is secure, based on the object-capability model.
Workers RPC is a JavaScript-native RPC system. Under the hood, it is built on Cap’n Proto. However, unlike Cap’n Proto, Workers RPC does not require you to write a schema. (Of course, you can use TypeScript if you like, and we provide tools to help with this.)
In general, Workers RPC is designed to “just work” using idiomatic JavaScript code, so you shouldn’t have to spend too much time looking at docs. We’ll give you an overview in this blog post. But if you want to understand the full feature set, check out the documentation.
Why RPC? (And what is RPC anyway?)
Remote Procedure Calls (RPC) are a way of expressing communications between two programs over a network. Without RPC, you might communicate using a protocol like HTTP. With HTTP, though, you must format and parse your communications as an HTTP request and response, perhaps designed in REST style. RPC systems try to make communications look like a regular function call instead, as if you were calling a library rather than a remote service. The RPC system provides a “stub” object on the client side which stands in for the real server-side object. When a method is called on the stub, the RPC system figures out how to serialize and transmit the parameters to the server, invoke the method on the server, and then transmit the return value back.
The merits of RPC have been subject to a great deal of debate. RPC is often accused of committing many of the fallacies of distributed computing.
But this reputation is outdated. When RPC was first invented some 40 years ago, async programming barely existed. We did not have Promises, much less async and await. Early RPC was synchronous: calls would block the calling thread waiting for a reply. At best, latency made the program slow. At worst, network failures would hang or crash the program. No wonder it was deemed “broken”.
Things are different today. We have Promise and async and await, and we can throw exceptions on network failures. We even understand how RPCs can be pipelined so that a chain of calls takes only one network round trip. Many large distributed systems you likely use every day are built on RPC. It works.
The fact is, RPC fits the programming model we’re used to. Every programmer is trained to think in terms of APIs composed of function calls, not in terms of byte stream protocols nor even REST. Using RPC frees you from the need to constantly translate between mental models, allowing you to move faster.
Example: Authentication Service
Here’s a common scenario: You have one Worker that implements an application, and another Worker that is responsible for authenticating user credentials. The app Worker needs to call the auth Worker on each request to check the user’s cookie.
This example uses a Service Binding, which is a way of configuring one Worker with a private channel to talk to another, without going through a public URL. Here, we have an application Worker that has been configured with a service binding to the Auth worker.
Before RPC, all communications between Workers needed to use HTTP. So, you might write code like this:
// OLD STYLE: HTTP-based service bindings.
export default {
async fetch(req, env, ctx) {
// Call the auth service to authenticate the user's cookie.
// We send it an HTTP request using a service binding.
// Construct a JSON request to the auth service.
let authRequest = {
cookie: req.headers.get("Cookie")
};
// Send it to env.AUTH_SERVICE, which is our service binding
// to the auth worker.
let resp = await env.AUTH_SERVICE.fetch(
"https://auth/check-cookie", {
method: "POST",
headers: {
"Content-Type": "application/json; charset=utf-8",
},
body: JSON.stringify(authRequest)
});
if (!resp.ok) {
return new Response("Internal Server Error", {status: 500});
}
// Parse the JSON result.
let authResult = await resp.json();
// Use the result.
if (!authResult.authorized) {
return new Response("Not authorized", {status: 403});
}
let username = authResult.username;
return new Response(`Hello, ${username}!`);
}
}
Meanwhile, your auth server might look like:
// OLD STYLE: HTTP-based auth server.
export default {
async fetch(req, env, ctx) {
// Parse URL to decide what endpoint is being called.
let url = new URL(req.url);
if (url.pathname == "/check-cookie") {
// Parse the request.
let authRequest = await req.json();
// Look up cookie in Workers KV.
let cookieInfo = await env.COOKIE_MAP.get(
hash(authRequest.cookie), "json");
// Construct the response.
let result;
if (cookieInfo) {
result = {
authorized: true,
username: cookieInfo.username
};
} else {
result = { authorized: false };
}
return Response.json(result);
} else {
return new Response("Not found", {status: 404});
}
}
}
This code has a lot of boilerplate involved in setting up an HTTP request to the auth service. With RPC, we can instead express this as a function call:
// NEW STYLE: RPC-based service bindings
export default {
async fetch(req, env, ctx) {
// Call the auth service to authenticate the user's cookie.
// We invoke it using a service binding.
let authResult = await env.AUTH_SERVICE.checkCookie(
req.headers.get("Cookie"));
// Use the result.
if (!authResult.authorized) {
return new Response("Not authorized", {status: 403});
}
let username = authResult.username;
return new Response(`Hello, ${username}!`);
}
}
And the server side becomes:
// NEW STYLE: RPC-based auth server.
import { WorkerEntrypoint } from "cloudflare:workers";
export class AuthService extends WorkerEntrypoint {
async checkCookie(cookie) {
// Look up cookie in Workers KV.
let cookieInfo = await this.env.COOKIE_MAP.get(
hash(cookie), "json");
// Return result.
if (cookieInfo) {
return {
authorized: true,
username: cookieInfo.username
};
} else {
return { authorized: false };
}
}
}
This is a pretty nice simplification… but we can do much more!
Let’s get fancy! Or should I say… classy?
Let’s say we want our auth service to do a little more. Instead of just checking cookies, it provides a whole API around user accounts. In particular, it should let you:
Get or update the user’s profile info.
Send the user an email notification.
Append to the user’s activity log.
But, these operations should only be allowed after presenting the user’s credentials.
Here’s what the server might look like:
import { WorkerEntrypoint, RpcTarget } from "cloudflare:workers";
// `User` is an RPC interface to perform operations on a particular
// user. This class is NOT exported as an entrypoint; it must be
// received as the result of the checkCookie() RPC.
class User extends RpcTarget {
constructor(uid, env) {
super();
// Note: Instance members like these are NOT exposed over RPC.
// Only class (prototype) methods and properties are exposed.
this.uid = uid;
this.env = env;
}
// Get/set user profile, backed by Worker KV.
async getProfile() {
return await this.env.PROFILES.get(this.uid, "json");
}
async setProfile(profile) {
await this.env.PROFILES.put(this.uid, JSON.stringify(profile));
}
// Send the user a notification email.
async sendNotification(message) {
let addr = await this.env.EMAILS.get(this.uid);
await this.env.EMAIL_SERVICE.send(addr, message);
}
// Append to the user's activity log.
async logActivity(description) {
// (Please excuse this somewhat problematic implementation,
// this is just a dumb example.)
let timestamp = new Date().toISOString();
await this.env.ACTIVITY.put(
`${this.uid}/${timestamp}`, description);
}
}
// Now we define the entrypoint service, which can be used to
// get User instances -- but only by presenting the cookie.
export class AuthService extends WorkerEntrypoint {
async checkCookie(cookie) {
// Look up cookie in Workers KV.
let cookieInfo = await this.env.COOKIE_MAP.get(
hash(cookie), "json");
if (cookieInfo) {
return {
authorized: true,
user: new User(cookieInfo.uid, this.env),
};
} else {
return { authorized: false };
}
}
}
Now we can write a Worker that uses this API while displaying a web page:
export default {
async fetch(req, env, ctx) {
// `using` is a new JavaScript feature. Check out the
// docs for more on this:
// https://developers.cloudflare.com/workers/runtime-apis/rpc/lifecycle/
using authResult = await env.AUTH_SERVICE.checkCookie(
req.headers.get("Cookie"));
if (!authResult.authorized) {
return new Response("Not authorized", {status: 403});
}
let user = authResult.user;
let profile = await user.getProfile();
await user.logActivity("You visited the site!");
await user.sendNotification(
`Thanks for visiting, ${profile.name}!`);
return new Response(`Hello, ${profile.name}!`);
}
}
Finally, this worker needs to be configured with a service binding pointing at the AuthService class. Its wrangler.toml may look like:
name = "app-worker"
main = "./src/app.js"
# Declare a service binding to the auth service.
[[services]]
binding = "AUTH_SERVICE" # name of the binding in `env`
service = "auth-service" # name of the worker in the dashboard
entrypoint = "AuthService" # name of the exported RPC class
Wait, how?
What exactly happened here? The Server created an instance of the class User and returned it to the client. It has methods that the client can then just call? Are we somehow transferring code over the wire?
No, absolutely not! All code runs strictly in the isolate where it was originally loaded. What actually happens is, when the return value is passed over RPC, all class instances are replaced with RPC stubs. The stub, when called, makes a new RPC back to the server, where it calls the method on the original User object that was created there:
But then you might ask: how does the RPC stub know what methods are available? Is a list of methods passed over the wire?
In fact, no. The RPC stub is a special object called a “Proxy“. It implements a “wildcard method”, that is, it appears to have an infinite number of methods of every possible name. When you try to call a method, the name you called is sent to the server. If the original object has no such method, an exception is thrown.
Did you spot the security?
In the above example, we see that RPC is easy to use. We made an object! We called it! It all just felt natural, like calling a local API! Hooray!
But there’s another extremely important property that the AuthService API has which you may have missed: As designed, you cannot perform any operation on a user without first checking the cookie. This is true despite the fact that the individual method calls do not require sending the cookie again, and the User object itself doesn’t store the cookie.
The trick is, the initial checkCookie() RPC is what returns a User object in the first place. The AuthService API does not provide any other way to obtain a User instance. The RPC client cannot create a User object out of thin air, and cannot call methods of an object without first explicitly receiving a reference to it.
This is called capability-based security: we say that the User reference received by the client is a “capability”, because receiving it grants the client the ability to perform operations on the user. The getProfile() method grants this capability only when the client has presented the correct cookie.
Capability-based security is often like this: security can be woven naturally into your APIs, rather than feel like an additional concern bolted on top.
More security: Named entrypoints
Another subtle but important detail to call out: in the above example, the auth service’s RPC API is exported as a named class:
export class AuthService extends WorkerEntrypoint {
And in our wrangler.toml for the calling worker, we had to specify an “entrypoint”, matching the class name:
entrypoint = "AuthService" # name of the exported RPC class
In the past, service bindings would bind to the “default” entrypoint, declared with export default {. But, the default entrypoint is also typically exposed to the Internet, e.g. automatically mapped to a hostname under workers.dev (unless you explicitly turn that off). It can be tricky to safely assume that requests arriving at this entrypoint are in any way trusted.
With named entrypoints, this all changes. A named entrypoint is only accessible to Workers which have explicitly declared a binding to it. By default, only Workers on your own account can declare such bindings. Moreover, the binding must be declared at deploy time; a Worker cannot create new service bindings at runtime.
Thus, you can trust that requests arriving at a named entrypoint can only have come from Workers on your account and for which you explicitly created a service binding. In the future, we plan to extend this pattern further with the ability to lock down entrypoints, audit which Workers have bindings to them, tell the callee information about who is calling at runtime, and so on. With these tools, there is no need to write code in your app itself to authenticate access to internal APIs; the system does it for you.
What about type safety?
Workers RPC works in an entirely dynamically-typed way, just as JavaScript itself does. But just as you can apply TypeScript on top of JavaScript in general, you can apply it to Workers RPC.
The @cloudflare/workers-types package defines the type Service<MyEntrypointType>, which describes the type of a service binding. MyEntrypointType is the type of your server-side interface. Service<MyEntrypointType> applies all the necessary transformations to turn this into a client-side type, such as converting all methods to async, replacing functions and RpcTargets with (properly-typed) stubs, and so on.
It is up to you to share the definition of MyEntrypointType between your server app and its clients. You might do this by defining the interface in a separate shared TypeScript file, or by extracting a .d.ts type declaration file from your server code using tsc --declaration.
With that done, you can apply types to your client:
import { WorkerEntrypoint } from "cloudflare:workers";
// The interface that your server-side entrypoint implements.
// (This would probably be imported from a .d.ts file generated
// from your server code.)
declare class MyEntrypointType extends WorkerEntrypoint {
sum(a: number, b: number): number;
}
// Define an interface Env specifying the bindings your client-side
// worker expects.
interface Env {
MY_SERVICE: Service<MyEntrypointType>;
}
// Define the client worker's fetch handler with typed Env.
export default <ExportedHandler<Env>> {
async fetch(req, env, ctx) {
// Now env.MY_SERVICE is properly typed!
const result = await env.MY_SERVICE.sum(1, 2);
return new Response(result.toString());
}
}
RPC to Durable Objects
Durable Objects allow you to create a “named” worker instance somewhere on the network that multiple other workers can then talk to, in order to coordinate between them. Each Durable Object also has its own private on-disk storage where it can store state long-term.
Previously, communications with a Durable Object had to take the form of HTTP requests and responses. With RPC, you can now just declare methods on your Durable Object class, and call them on the stub. One catch: to opt into RPC, you must declare your Durable Object class with extends DurableObject, like so:
import { DurableObject } from "cloudflare:workers";
export class Counter extends DurableObject {
async increment() {
// Increment our stored value and return it.
let value = await this.ctx.storage.get("value");
value = (value || 0) + 1;
this.ctx.storage.put("value", value);
return value;
}
}
Now we can call it like:
let stub = env.COUNTER_NAMEPSACE.get(id);
let value = await stub.increment();
TypeScript is supported here too, by defining your binding with type DurableObjectNamespace<ServerType>:
When talking to a Durable Object, the object may be somewhere else in the world from the caller. RPCs must cross the network. This takes time: despite our best efforts, we still haven’t figured out how to make information travel faster than the speed of light.
When you have a complex RPC interface where one call returns an object on which you wish to make further method calls, it’s easy to end up with slow code that makes too many round trips over the network.
// Makes three round trips.
let foo = await stub.foo();
let baz = await foo.bar.baz();
let corge = await baz.qux[3].corge();
Workers RPC features a way to avoid this: If you know that a call will return a value containing a stub, and all you want to do with it is invoke a method on that stub, you can skip awaiting it:
// Same thing, only one round trip.
let foo = stub.foo();
let baz = foo.bar.baz();
let corge = await baz.qux[3].corge();
Whoa! How does this work?
RPC methods do not return normal promises. Instead, they return special RPC promises. These objects are “custom thenables“, which means you can use them in all the ways you’d use a regular Promise, like awaiting it or calling .then() on it.
But an RPC promise is more than just a thenable. It is also a proxy. Like an RPC stub, it has a wildcard property. You can use this to express speculative RPC calls on the eventual result, before it has actually resolved. These speculative calls will be sent to the server immediately, so that they can begin executing as soon as the first RPC has finished there, before the result has actually made its way back over the network to the client.
This feature is also known as “Promise Pipelining”. Although it isn’t explicitly a security feature, it is commonly provided by object-capability RPC systems like Cap’n Proto.
The future: Custom Bindings Marketplace?
For now, Service Bindings and Durable Objects only allow communication between Workers running on the same account. So, RPC can only be used to talk between your own Workers.
But we’d like to take it further.
We have previously explained why Workers environments contain live objects, also known as “bindings”. But today, only Cloudflare can add new binding types to the Workers platform – like Queues, KV, or D1. But what if anyone could invent their own binding type, and give it to other people?
Previously, we thought this would require creating a way to automatically load client libraries into the calling Workers. That seemed scary: it meant using someone’s binding would require trusting their code to run inside your isolate. With RPC, there’s no such trust. The binding only sees exactly what you explicitly pass to it. It cannot compromise the rest of your Worker.
Could Workers RPC provide the basis for a “bindings marketplace”, where people can offer rich JavaScript APIs to each other in an easy and secure way? We’re excited to explore and find out.
Try it now
Workers RPC is available today for all Workers users. To get started, check out the docs.
Browser Rendering API is now available to all paid Workers customers with improved session management
In May 2023, we announced the open beta program for the Browser Rendering API. Browser Rendering allows developers to programmatically control and interact with a headless browser instance and create automation flows for their applications and products.
At the same time, we launched a version of the Puppeteer library that works with Browser Rendering. With that, developers can use a familiar API on top of Cloudflare Workers to create all sorts of workflows, such as taking screenshots of pages or automatic software testing.
Today, we take Browser Rendering one step further, taking it out of beta and making it available to all paid Workers’ plans. Furthermore, we are enhancing our API and introducing a new feature that we’ve been discussing for a long time in the open beta community: session management.
Session Management
Session management allows developers to reuse previously opened browsers across Worker’s scripts. Reusing browser sessions has the advantage that you don’t need to instantiate a new browser for every request and every task, drastically increasing performance and lowering costs.
Before, to keep a browser instance alive and reuse it, you’d have to implement complex code using Durable Objects. Now, we’ve simplified that for you by keeping your browsers running in the background and extending the Puppeteer API with new session management methods that give you access to all of your running sessions, activity history, and active limits.
Observability is an essential part of any Cloudflare product. You can find detailed analytics and logs of your Browser Rendering usage in the dashboard under your account’s Worker & Pages section.
Browser Rendering is now available to all customers with a paid Workers plan. Each account is limited to running two new browsers per minute and two concurrent browsers at no cost during this period. Check our developers page to get started.
We are rolling out access to Cloudflare Snippets
Powerful, programmable, and free of charge, Snippets are the best way to perform complex HTTP request and response modifications on Cloudflare. What was once too advanced to achieve using Rules products is now possible with Snippets. Since the initial announcement during Developer Week 2022, the promise of extending out-of-the-box Rules functionality by writing simple JavaScript code is keeping the Cloudflare community excited.
During the first 3 months of 2024 alone, the amount of traffic going through Snippets increased over 7x, from an average of 2,200 requests per second in early January to more than 17,000 in March.
However, instead of opening the floodgates and letting millions of Cloudflare users in to test (and potentially break) Snippets in the most unexpected ways, we are going to pace ourselves and opt for a phased rollout, much like the newly released Gradual Rollouts for Workers.
In the next few weeks, 5% of Cloudflare users will start seeing “Snippets” under the Rules tab of the zone-level menu in their dashboard. If you happen to be part of the first 5%, snip into action and try out how fast and powerful Snippets are even for advanced use cases like dynamically changing the date in headers or A / B testing leveraging the `math.random` function. Whatever you use Snippets for, just keep one thing in mind: this is still an alpha, so please do not use Snippets for production traffic just yet.
Until then, keep your eyes out for the new Snippets tab in the Cloudflare dashboard and learn more how powerful and flexible Snippets are at the developer documentation in the meantime.
Coming soon: asynchronous revalidation with stale-while-revalidate
One of the features most requested by our customers is the asynchronous revalidation with stale-while-revalidate (SWR) cache directive, and we will be bringing this to you in the second half of 2024. This functionality will be available by design as part of our new CDN architecture that is being built using Rust with performance and memory safety at top of mind.
Currently, when a client requests a resource, such as a web page or an image, Cloudflare checks to see if the asset is in cache and provides a cached copy if available. If the file is not in the cache or has expired and become stale, Cloudflare connects to the origin server to check for a fresh version of the file and forwards this fresh version to the end user. This wait time adds latency to these requests and impacts performance.
Stale-while-revalidate is a cache directive that allows the expired or stale version of the asset to be served to the end user while simultaneously allowing Cloudflare to check the origin to see if there’s a fresher version of the resource available. If an updated version exists, the origin forwards it to Cloudflare, updating the cache in the process. This mechanism allows the client to receive a response quickly from the cache while ensuring that it always has access to the most up-to-date content. Stale-while-revalidate strikes a balance between serving content efficiently and ensuring its freshness, resulting in improved performance and a smoother user experience.
Customers who want to be part of our beta testers and “cache” in on the fun can register here, and we will let you know when the feature is ready for testing!
Coming on April 16, 2024: Workers for Platforms for our pay-as-you-go plan
Today, we’re excited to share that on April 16th, Workers for Platforms will be available to all developers through our new $25 pay-as-you-go plan!
Workers for Platforms is changing the way we build software – it gives you the ability to embed personalization and customization directly into your product. With Workers for Platforms, you can deploy custom code on behalf of your users or let your users directly deploy their own code to your platform, without you or your users having to manage any infrastructure. You can use Workers for Platforms with all the exciting announcements that have come out this Developer Week – it supports all the bindings that come with Workers (including Workers AI, D1 and Durable Objects) as well as Python Workers.
Here’s what some of our customers – ranging from enterprises to startups – are building on Workers for Platforms:
Shopify Oxygen is a hosting platform for their Remix-based eCommerce framework Hydrogen, and it’s built on Workers for Platforms! The Hydrogen/Oxygen combination gives Shopify merchants control over their buyer experience without the restrictions of generic storefront templates.
Grafbase is a data platform for developers to create a serverless GraphQL API that unifies data sources across a business under one endpoint. They use Workers for Platforms to give their developers the control and flexibility to deploy their own code written in JavaScript/TypeScript or WASM.
Triplit is an open-source database that syncs data between server and browser in real-time. It allows users to build low latency, real-time applications with features like relational querying, schema management and server-side storage built in. Their query and sync engine is built on top of Durable Objects, and they’re using Workers for Platforms to allow their customers to package custom Javascript alongside their Triplit DB instance.
Tools for observability and platform level controls
Workers for Platforms doesn’t just allow you to deploy Workers to your platform – we also know how important it is to have observability and control over your users’ Workers. We have a few solutions that help with this:
Custom Limits: Set CPU time or subrequest caps on your users’ Workers. Can be used to set limits in order to control your costs on Cloudflare and/or shape your own pricing and packaging model. For example, if you run a freemium model on your platform, you can lower the CPU time limit for customers on your free tier.
Tail Workers: Tail Worker events contain metadata about the Worker, console.log() messages, and capture any unhandled exceptions. They can be used to provide your developers with live logging in order to monitor for errors and troubleshoot in real time.
Outbound Workers: Get visibility into all outgoing requests from your users’ Workers. Outbound Workers sit between user Workers and the fetch() requests they make, so you get full visibility over the request before it’s sent out to the Internet.
Pricing
We wanted to make sure that Workers for Platforms was affordable for hobbyists, solo developers, and indie developers. Workers for Platforms is part of a new $25 pay-as-you-go plan, and it includes the following:
Included Amounts
Requests
20 million requests/month +$0.30 per additional million
CPU time
60 million CPU milliseconds/month +$0.02 per additional million CPU milliseconds
Scripts
1000 scripts +0.02 per additional script/month
Workers for Platforms will be available to purchase on April 16, 2024!
The Workers for Platforms will be available to purchase under the Workers for Platforms tab on the Cloudflare Dashboard on April 16, 2024.
With millions of developers around the world building on Cloudflare, we are constantly inspired by what you all are building with us. Every Developer Week, we’re excited to get your hands on new products and features that can help you be more productive, and creative, with what you’re building. But we know our job doesn’t end when we put new products and features in your hands during Developer Week. We also need to cultivate welcoming community spaces where you can come get help, share what you’re building, and meet other developers building with Cloudflare.
We’re excited to close out Developer Week by sharing updates on our Workers Launchpad program, our latest Developer Challenge, and the work we’re doing to ensure our community spaces – like our Discord and Community forums – are safe and inclusive for all developers.
Helping startups go further with Workers Launchpad
In late 2022, we initiated the $2 billion Workers Launchpad Funding Program aimed at aiding the more than one million developers who use Cloudflare’s Developer Platform. This initiative particularly benefits startups that are investing in building on Cloudflare to propel their business growth.
The Workers Launchpad Program offers a variety of resources to help builders scale faster and reach more customers. The program includes, but is not limited to:
Fostering a community of like-minded founders
Facilitating introductions to the Launchpad’s VC partner network of 40+ leading investors
Company-building support and mentorship through virtual Founders Bootcamp sessions
Organizing technical office hours with our engineers
Access to preview upcoming Cloudflare products and Product Managers
Culminating in a Demo Day, for participants to share their stories globally with investors and prospective customers.
So far, 50 amazing startups from 13 countries have successfully graduated from the Workers Launchpad program. We finished up Cohort #1 in March 2023, and Cohort #2 wrapped up August 2023.
Meet Cohort #3 of the Workers Launchpad!
Since the end of Cohort #2, we have received hundreds of new applications from startups across the globe. Startup applicants showcased incredible tools and software across a variety of industries, including AI, SaaS, Supply Chain, Media, Gaming, Hospitality, and Developer Productivity. While we were encouraged by this wave of applicants’ ability to build amazing technology, there were a few that stood out that are leveraging Cloudflare’s Developer Suite to scale their business.
With that being said, we would like to introduce you to the 29 startups that have been chosen to participate in Cohort #3 of Workers Launchpad:
Below, you will find a brief summary of what problems these startups are looking to solve:
AI-powered marketing agent that leverages Gen AI to optimize businesses’ online presence and drive more traffic.
The Cloudflare team is looking forward to working with Cohort #3 participants and sharing what they are building on Cloudflare. To follow along with Cohort #3 of Workers Launchpad, follow @CloudflareDev and join our Developer Discord server.
Are you a startup and interested in joining Cohort #4? Apply here!
AI developer challenge
Now that Workers AI is GA, we’re excited to see what our community can build. We’ve teamed up with our friends at DEV who will be running an AI Developer challenge, which officially launched on Wednesday, April 3, and runs until Sunday, April 14, 2024, when submissions close.
For this challenge, you will build a Workers AI application that makes use of AI task types from Cloudflare’s growing catalog of Open Models. Apps will be evaluated on innovation, creativity, and demonstration of underlying technology with prizes awarded by DEV for the best overall app, as well as projects leveraging multiple models and tasks. For more information and details on how to participate, including DEV’s rules and requirements, head over to the official challenge page.
Creating an inclusive community
Our community has been growing really fast over the past year, so fast that it’s becoming more difficult to welcome each new member that joins our Discord server every day, and Developer Week has always been one of the main drivers of this growth.
When you come into the Cloudflare developer community, it’s important to us that you’re entering a space that is safe and welcoming. Even though we already have rules for the server and community forums, we needed guidelines for our community programs, so that’s why we’ve created a new Code of Conduct that promotes inclusivity, respect, and will help us create a better community for everyone.
Do you want to be part of this and help us create a more inclusive and helpful community? Then please share your feedback and tell us what you would like to see improved in our community and our Discord server in this thread.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.