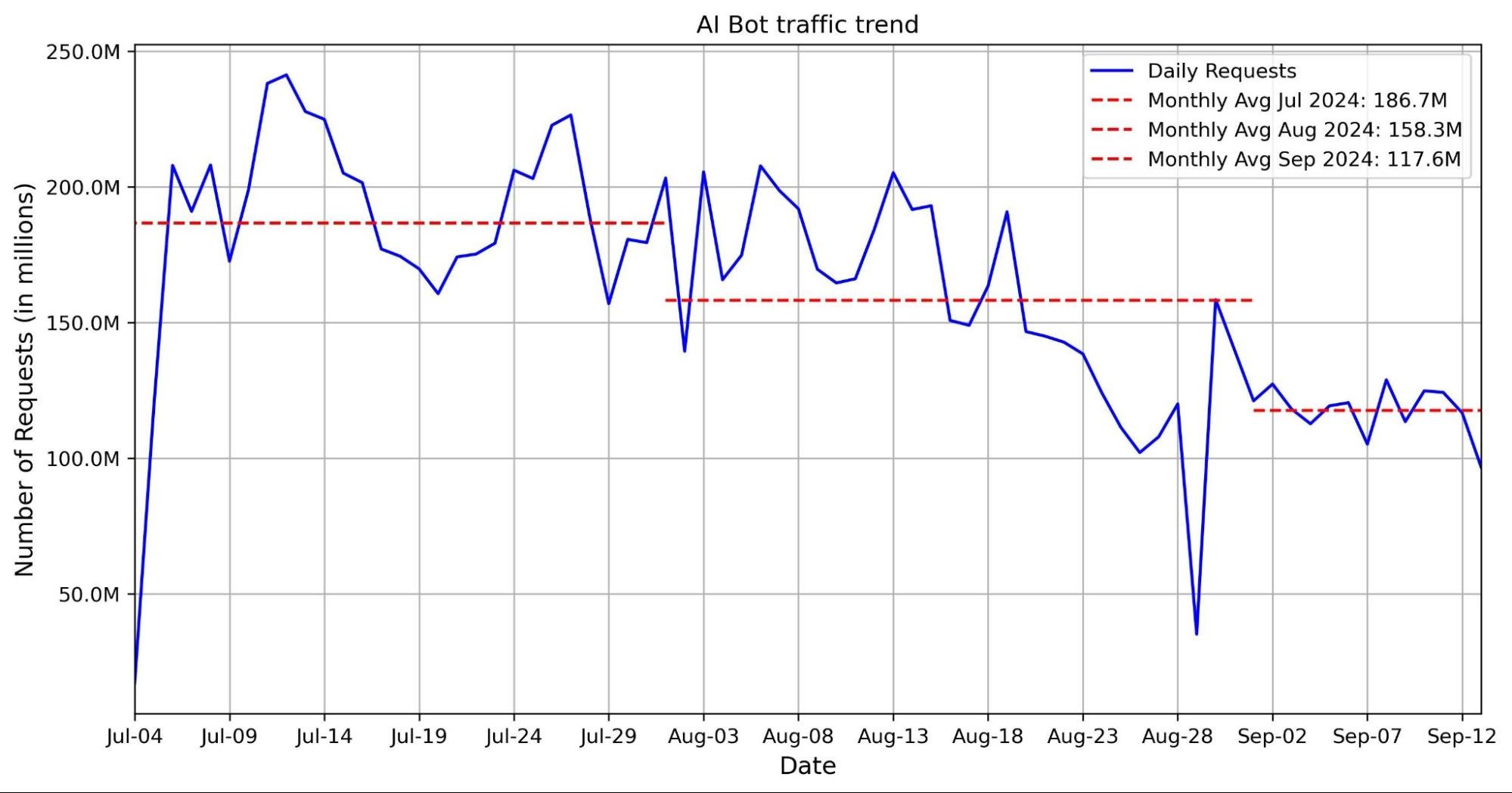
Post Syndicated from Rita Kozlov original https://blog.cloudflare.com/building-ai-agents-with-mcp-authn-authz-and-durable-objects/
It’s not a secret that at Cloudflare we are bullish on the future of agents. We’re excited about a future where AI can not only co-pilot alongside us, but where we can actually start to delegate entire tasks to AI.
While it hasn’t been too long since we first announced our Agents SDK to make it easier for developers to build agents, building towards an agentic future requires continuous delivery towards this goal. Today, we’re making several announcements to help accelerate agentic development, including:
-
New Agents SDK capabilities: Build remote MCP clients, with transport and authentication built-in, to allow AI agents to connect to external services.
-
BYO Auth provider for MCP: Integrations with Stytch, Auth0, and WorkOS to add authentication and authorization to your remote MCP server.
-
Hibernation for McpAgent: Automatically sleep stateful, remote MCP servers when inactive and wake them when needed. This allows you to maintain connections for long-running sessions while ensuring you’re not paying for idle time.
-
Durable Objects free tier: We view Durable Objects as a key component for building agents, and if you’re using our Agents SDK, you need access to it. Until today, Durable Objects was only accessible as part of our paid plans, and today we’re excited to include it in our free tier.
-
Workflows GA: Enables you to ship production-ready, long-running, multi-step actions in agents.
-
AutoRAG: Helps you integrate context-aware AI into your applications, in just a few clicks
-
agents.cloudflare.com: our new landing page for all things agents.
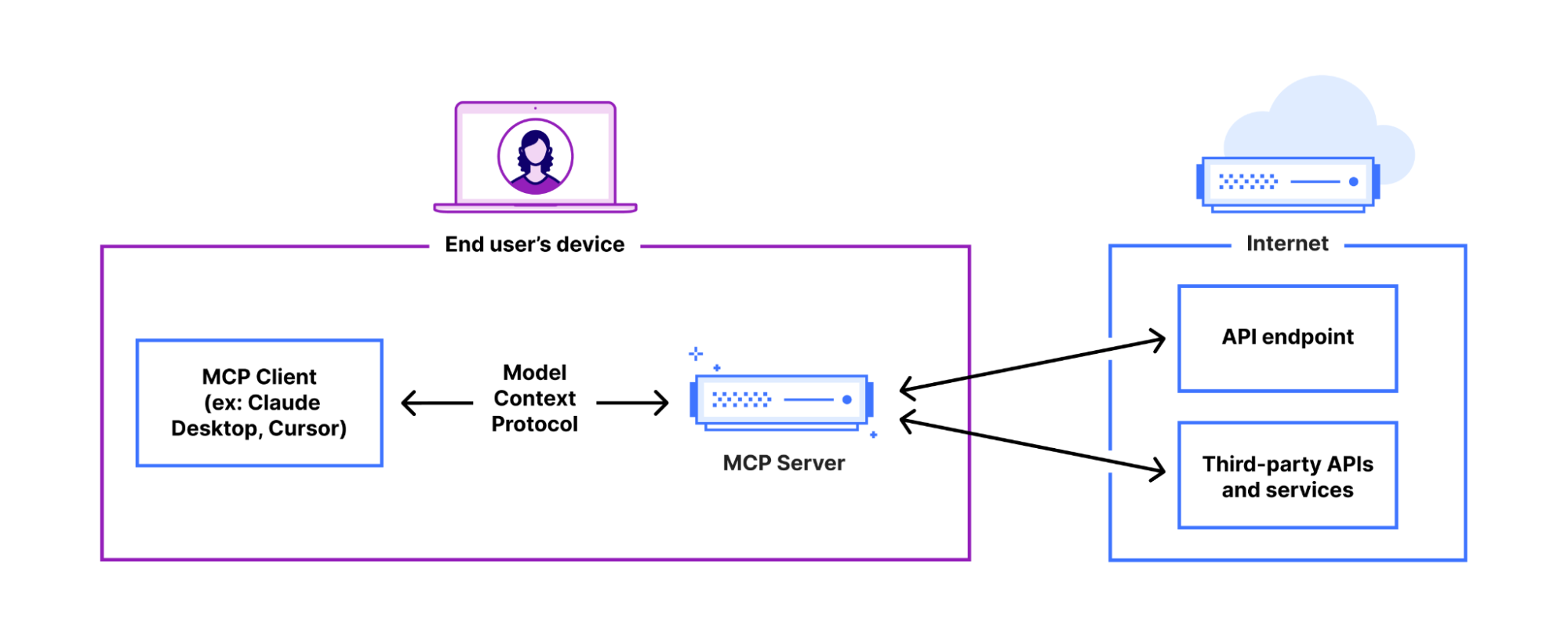
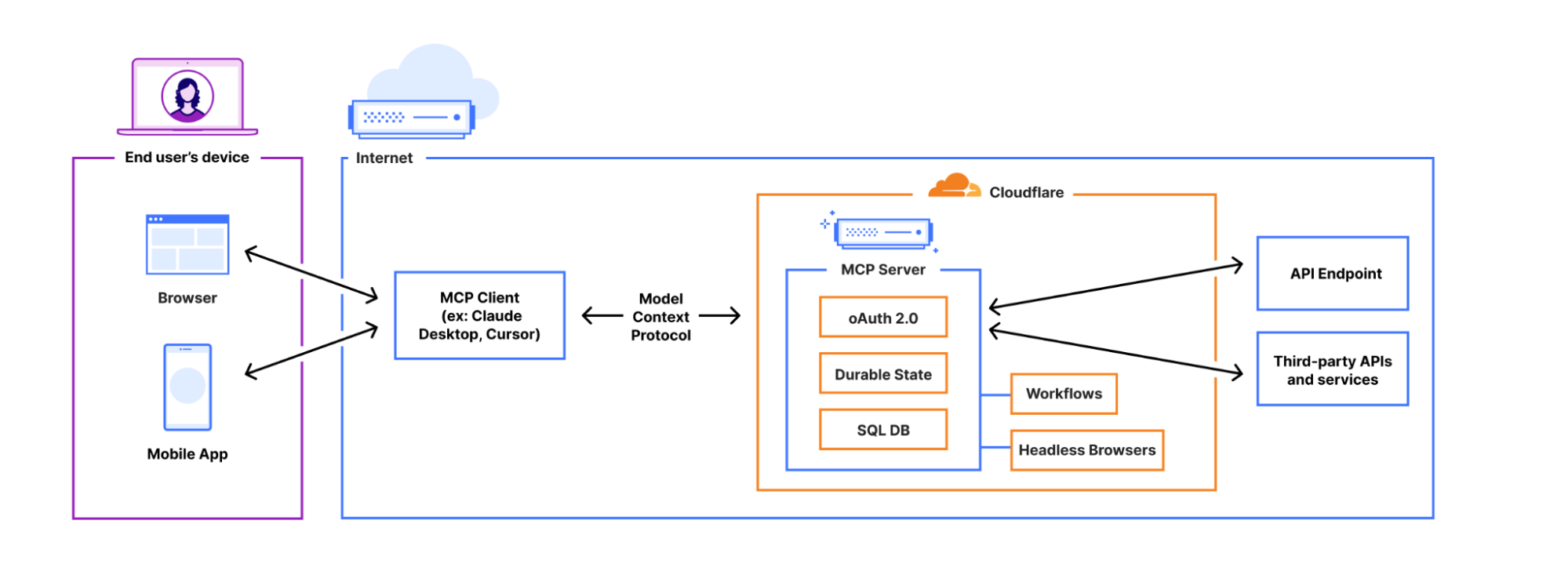
AI agents can now connect to and interact with external services through MCP (Model Context Protocol). We’ve updated the Agents SDK to allow you to build a remote MCP client into your AI agent, with all the components — authentication flows, tool discovery, and connection management — built-in for you.
This allows you to build agents that can:
-
Prompt the end user to grant access to a 3rd party service (MCP server).
-
Use tools from these external services, acting on behalf of the end user.
-
Call MCP servers from Workflows, scheduled tasks, or any part of your agent.
-
Connect to multiple MCP servers and automatically discover new tools or capabilities presented by the 3rd party service.
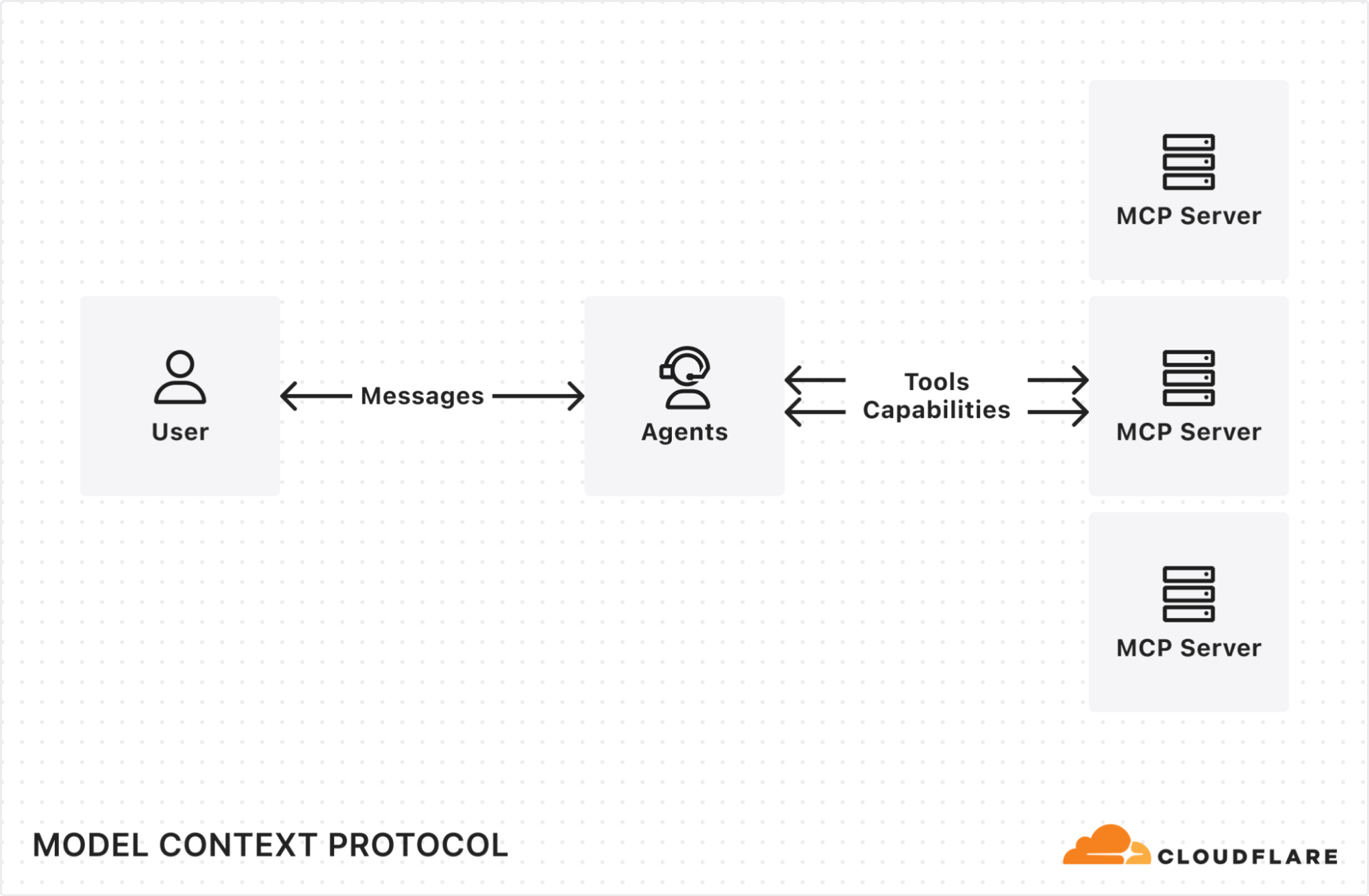
MCP (Model Context Protocol) — first introduced by Anthropic — is quickly becoming the standard way for AI agents to interact with external services, with providers like OpenAI, Cursor, and Copilot adopting the protocol.
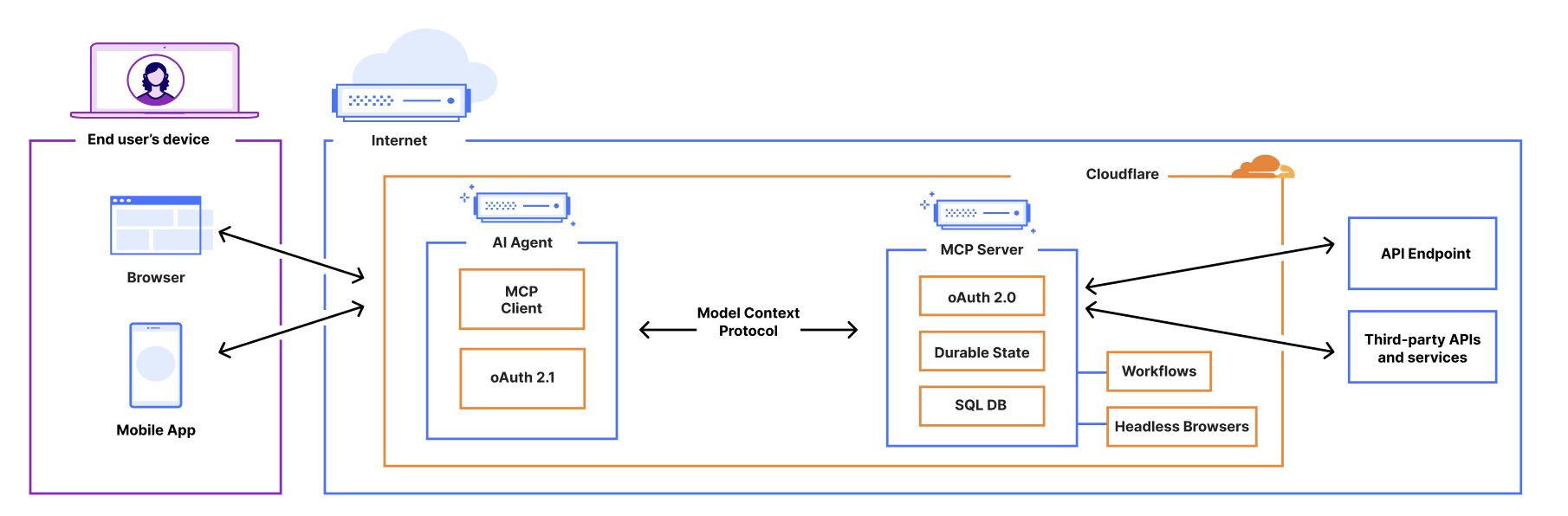
We recently announced support for building remote MCP servers on Cloudflare, and added an McpAgent class to our Agents SDK that automatically handles the remote aspects of MCP: transport and authentication/authorization. Now, we’re excited to extend the same capabilities to agents acting as MCP clients.
Want to see it in action? Use the button below to deploy a fully remote MCP client that can be used to connect to remote MCP servers.

AI agents need to connect to external services to access tools, data, and capabilities beyond their built-in knowledge. That means AI agents need to be able to act as remote MCP clients, so they can connect to remote MCP servers that are hosting these tools and capabilities.
We’ve added a new class, MCPClientManager, into the Agents SDK to give you all the tooling you need to allow your AI agent to make calls to external services via MCP. The MCPClientManager class automatically handles:
-
Transport: Connect to remote MCP servers over SSE and HTTP, with support for Streamable HTTP coming soon.
-
Connection management: The client tracks the state of all connections and automatically reconnects if a connection is lost.
-
Capability discovery: Automatically discovers all capabilities, tools, resources, and prompts presented by the MCP server.
-
Real-time updates: When a server’s tools, resources, or prompts change, the client automatically receives notifications and updates its internal state.
-
Namespacing: When connecting to multiple MCP servers, all tools and resources are automatically namespaced to avoid conflicts.
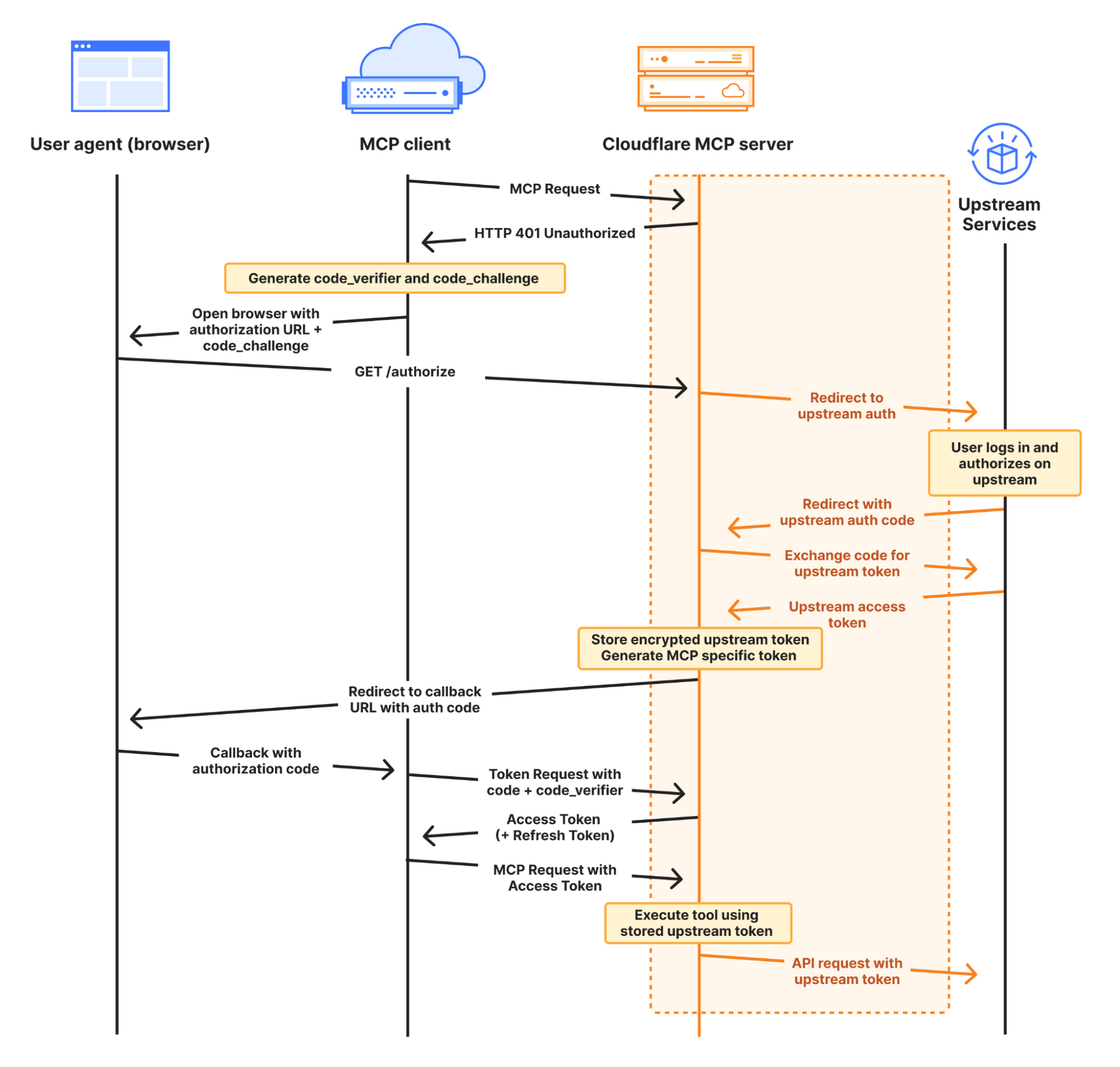
We’ve integrated the complete OAuth authentication flow directly into the Agents SDK, so your AI agents can securely connect and authenticate to any remote MCP server without you having to build authentication flow from scratch.
This allows you to give users a secure way to log in and explicitly grant access to allow the agent to act on their behalf by automatically:
-
Supporting the OAuth 2.1 protocol.
-
Redirecting users to the service’s login page.
-
Generating the code challenge and exchanging an authorization code for an access token.
-
Using the access token to make authenticated requests to the MCP server.
Here is an example of an agent that can securely connect to MCP servers by initializing the client manager, adding the server, and handling the authentication callbacks:
async onStart(): Promise<void> {
// initialize MCPClientManager which manages multiple MCP clients with optional auth
this.mcp = new MCPClientManager("my-agent", "1.0.0", {
baseCallbackUri: `${serverHost}/agents/${agentNamespace}/${this.name}/callback`,
storage: this.ctx.storage,
});
}
async addMcpServer(url: string): Promise<string> {
// Add one MCP client to our MCPClientManager
const { id, authUrl } = await this.mcp.connect(url);
// Return authUrl to redirect the user to if the user is unauthorized
return authUrl
}
async onRequest(req: Request): Promise<void> {
// handle the auth callback after being finishing the MCP server auth flow
if (this.mcp.isCallbackRequest(req)) {
await this.mcp.handleCallbackRequest(req);
return new Response("Authorized")
}
// ...
}Connecting to multiple MCP servers and discovering what capabilities they offer
You can use the Agents SDK to connect an MCP client to multiple MCP servers simultaneously. This is particularly useful when you want your agent to access and interact with tools and resources served by different service providers.
The MCPClientManager class maintains connections to multiple MCP servers through the mcpConnections object, a dictionary that maps unique server names to their respective MCPClientConnection instances.
When you register a new server connection using connect(), the manager:
-
Creates a new connection instance with server-specific authentication.
-
Initializes the connections and registers for server capability notifications.
async onStart(): Promise<void> {
// Connect to an image generation MCP server
await this.mcp.connect("https://image-gen.example.com/mcp/sse");
// Connect to a code analysis MCP server
await this.mcp.connect("https://code-analysis.example.org/sse");
// Now we can access tools with proper namespacing
const allTools = this.mcp.listTools();
console.log(`Total tools available: ${allTools.length}`);
}Each connection manages its own authentication context, allowing one AI agent to authenticate to multiple servers simultaneously. In addition, MCPClientManager automatically handles namespacing to prevent collisions between tools with identical names from different servers.
For example, if both an “Image MCP Server” and “Code MCP Server” have a tool named “analyze”, they will both be independently callable without any naming conflicts.
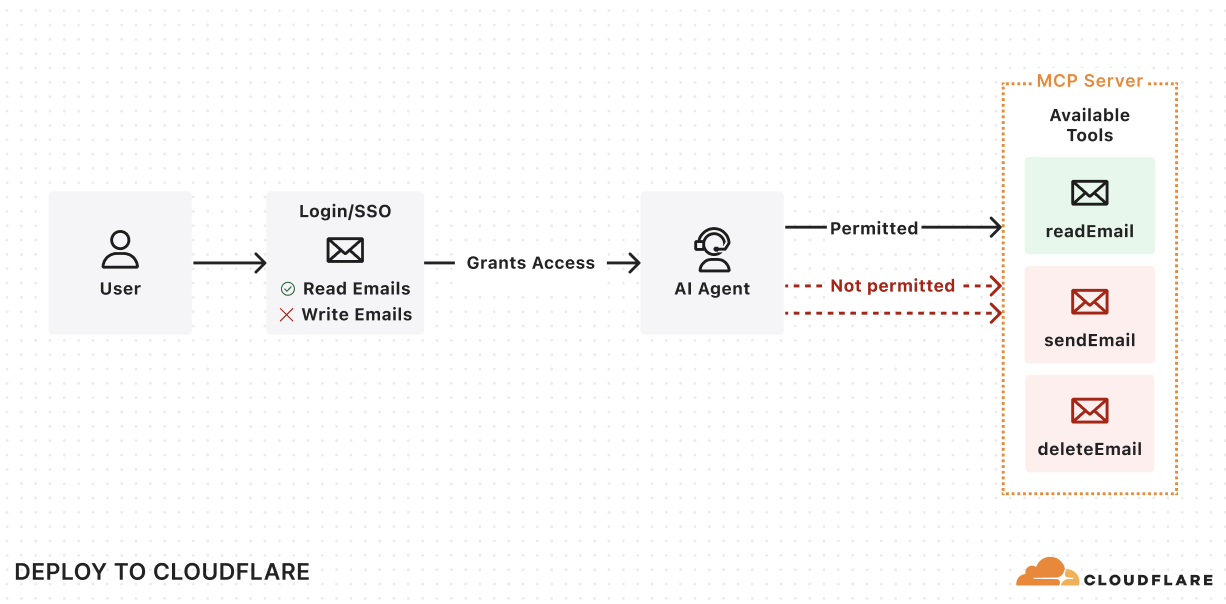
With MCP, users will have a new way of interacting with your application, no longer relying on the dashboard or API as the entrypoint. Instead, the service will now be accessed by AI agents that are acting on a user’s behalf. To ensure users and agents can connect to your service securely, you’ll need to extend your existing authentication and authorization system to support these agentic interactions, implementing login flows, permissions scopes, consent forms, and access enforcement for your MCP server.
We’re adding integrations with Stytch, Auth0, and WorkOS to make it easier for anyone building an MCP server to configure authentication & authorization for their MCP server.
You can leverage our MCP server integration with Stytch, Auth0, and WorkOS to:
-
Allow users to authenticate to your MCP server through email, social logins, SSO (single sign-on), and MFA (multi-factor authentication).
-
Define scopes and permissions that directly map to your MCP tools.
-
Present users with a consent page corresponding with the requested permissions.
Enforce the permissions so that agents can only invoke permitted tools.
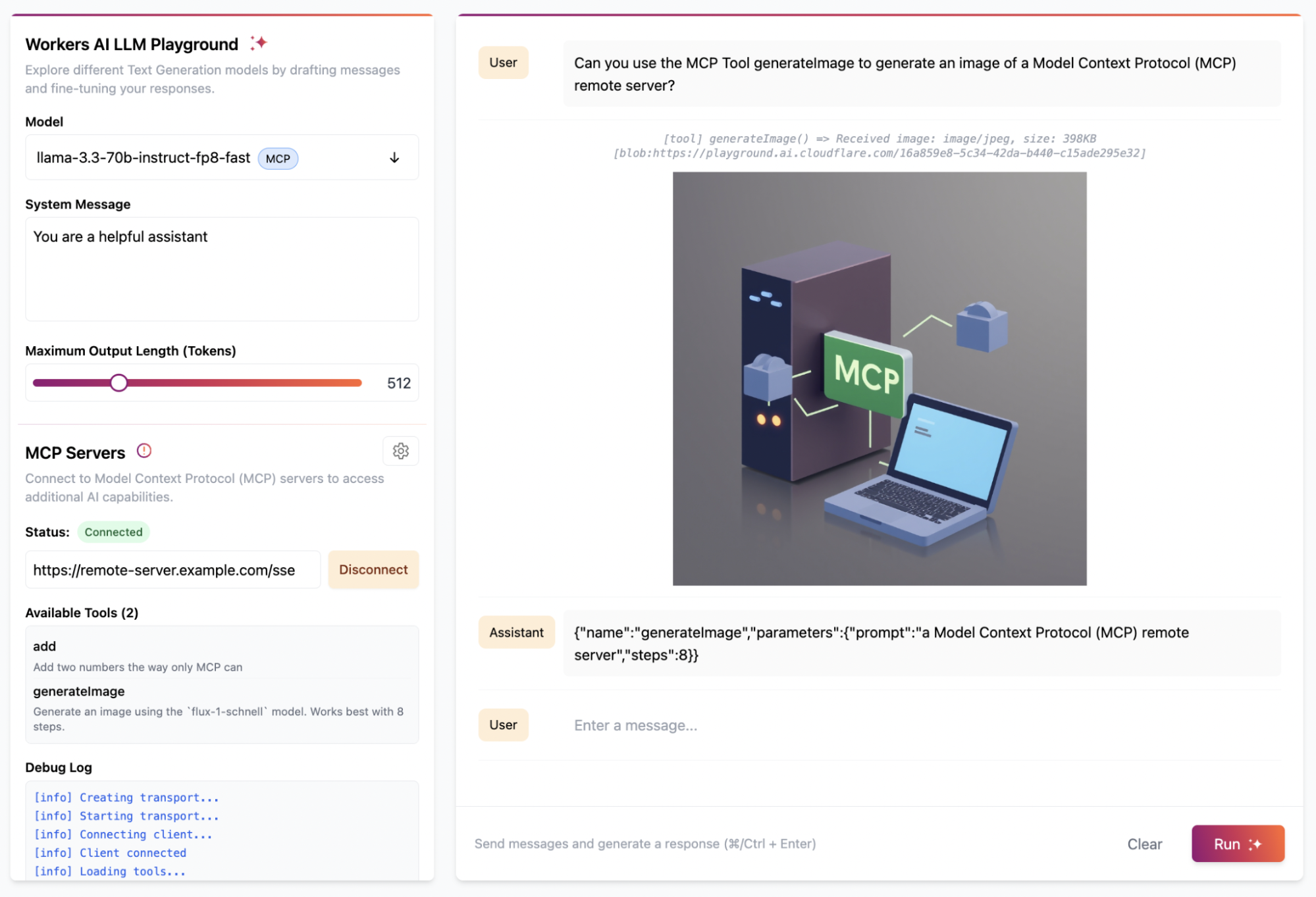
Get started with the examples below by using the “Deploy to Cloudflare” button to deploy the demo MCP servers in your Cloudflare account. These demos include pre-configured authentication endpoints, consent flows, and permission models that you can tailor to fit your needs. Once you deploy the demo MCP servers, you can use the Workers AI playground, a browser-based remote MCP client, to test out the end-to-end user flow.
Get started with a remote MCP server that uses Stytch to allow users to sign in with email, Google login or enterprise SSO and authorize their AI agent to view and manage their company’s OKRs on their behalf. Stytch will handle restricting the scopes granted to the AI agent based on the user’s role and permissions within their organization. When authorizing the MCP Client, each user will see a consent page that outlines the permissions that the agent is requesting that they are able to grant based on their role.
For more consumer use cases, deploy a remote MCP server for a To Do app that uses Stytch for authentication and MCP client authorization. Users can sign in with email and immediately access the To Do lists associated with their account, and grant access to any AI assistant to help them manage their tasks.
Regardless of use case, Stytch allows you to easily turn your application into an OAuth 2.0 identity provider and make your remote MCP server into a Relying Party so that it can easily inherit identity and permissions from your app. To learn more about how Stytch is enabling secure authentication to remote MCP servers, read their blog post.
“One of the challenges of realizing the promise of AI agents is enabling those agents to securely and reliably access data from other platforms. Stytch Connected Apps is purpose-built for these agentic use cases, making it simple to turn your app into an OAuth 2.0 identity provider to enable secure access to remote MCP servers. By combining Cloudflare Workers with Stytch Connected Apps, we’re removing the barriers for developers, enabling them to rapidly transition from AI proofs-of-concept to secure, deployed implementations.” — Julianna Lamb, Co-Founder & CTO, Stytch.
Get started with a remote MCP server that uses Auth0 to authenticate users through email, social logins, or enterprise SSO to interact with their todos and personal data through AI agents. The MCP server securely connects to API endpoints on behalf of users, showing exactly which resources the agent will be able to access once it gets consent from the user. In this implementation, access tokens are automatically refreshed during long running interactions.
To set it up, first deploy the protected API endpoint:
Then, deploy the MCP server that handles authentication through Auth0 and securely connects AI agents to your API endpoint.
“Cloudflare continues to empower developers building AI products with tools like AI Gateway, Vectorize, and Workers AI. The recent addition of Remote MCP servers further demonstrates that Cloudflare Workers and Durable Objects are a leading platform for deploying serverless AI. We’re very proud that Auth0 can help solve the authentication and authorization needs for these cutting-edge workloads.” — Sandrino Di Mattia, Auth0 Sr. Director, Product Architecture.
Get started with a remote MCP server that uses WorkOS’s AuthKit to authenticate users and manage the permissions granted to AI agents. In this example, the MCP server dynamically exposes tools based on the user’s role and access rights. All authenticated users get access to the add tool, but only users who have been assigned the image_generation permission in WorkOS can grant the AI agent access to the image generation tool. This showcases how MCP servers can conditionally expose capabilities to AI agents based on the authenticated user’s role and permission.
“MCP is becoming the standard for AI agent integration, but authentication and authorization are still major gaps for enterprise adoption. WorkOS Connect enables any application to become an OAuth 2.0 authorization server, allowing agents and MCP clients to securely obtain tokens for fine-grained permission authorization and resource access. With Cloudflare Workers, developers can rapidly deploy remote MCP servers with built-in OAuth and enterprise-grade access control. Together, WorkOS and Cloudflare make it easy to ship secure, enterprise-ready agent infrastructure.” — Michael Grinich, CEO of WorkOS.
Starting today, a new improvement is landing in the McpAgent class: support for the WebSockets Hibernation API that allows your MCP server to go to sleep when it’s not receiving requests and instantly wake up when it’s needed. That means that you now only pay for compute when your agent is actually working.
We recently introduced the McpAgent class, which allows developers to build remote MCP servers on Cloudflare by using Durable Objects to maintain stateful connections for every client session. We decided to build McpAgent to be stateful from the start, allowing developers to build servers that can remember context, user preferences, and conversation history. But maintaining client connections means that the session can remain active for a long time, even when it’s not being used.
You don’t need to change your code to take advantage of hibernation. With our latest SDK update, all McpAgent instances automatically include hibernation support, allowing your stateful MCP servers to sleep during inactive periods and wake up with their state preserved when needed.
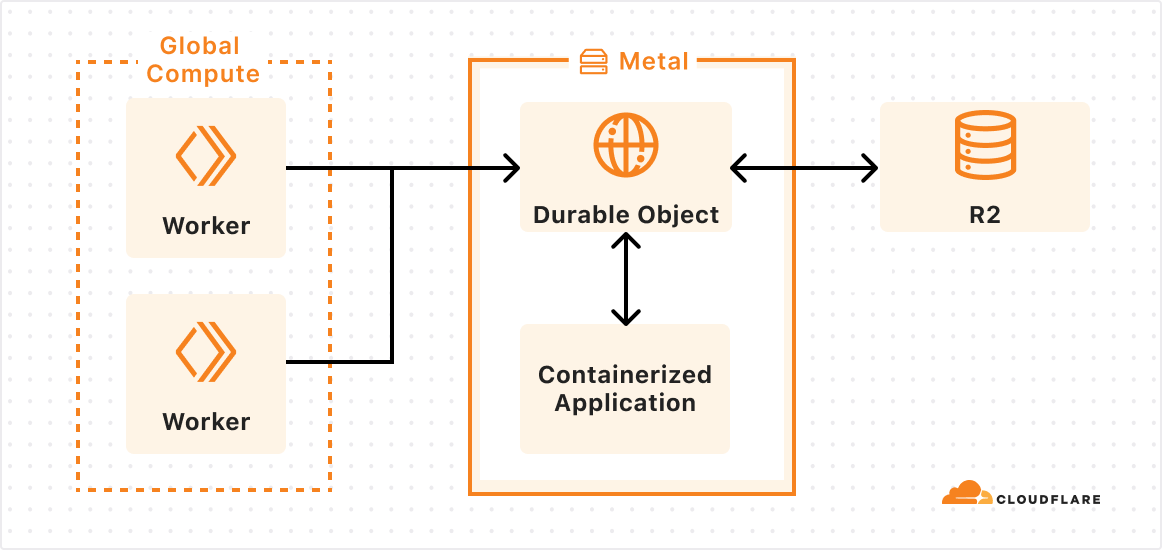
When a request comes in on the Server-Sent Events endpoint, /sse, the Worker initializes a WebSocket connection to the appropriate Durable Object for the session and returns an SSE stream back to the client. All responses flow over this stream.
The implementation leverages the WebSocket Hibernation API within Durable Objects. When periods of inactivity occur, the Durable Object can be evicted from memory while keeping the WebSocket connection open. If the WebSocket later receives a message, the runtime recreates the Durable Object and delivers the message to the appropriate handler.
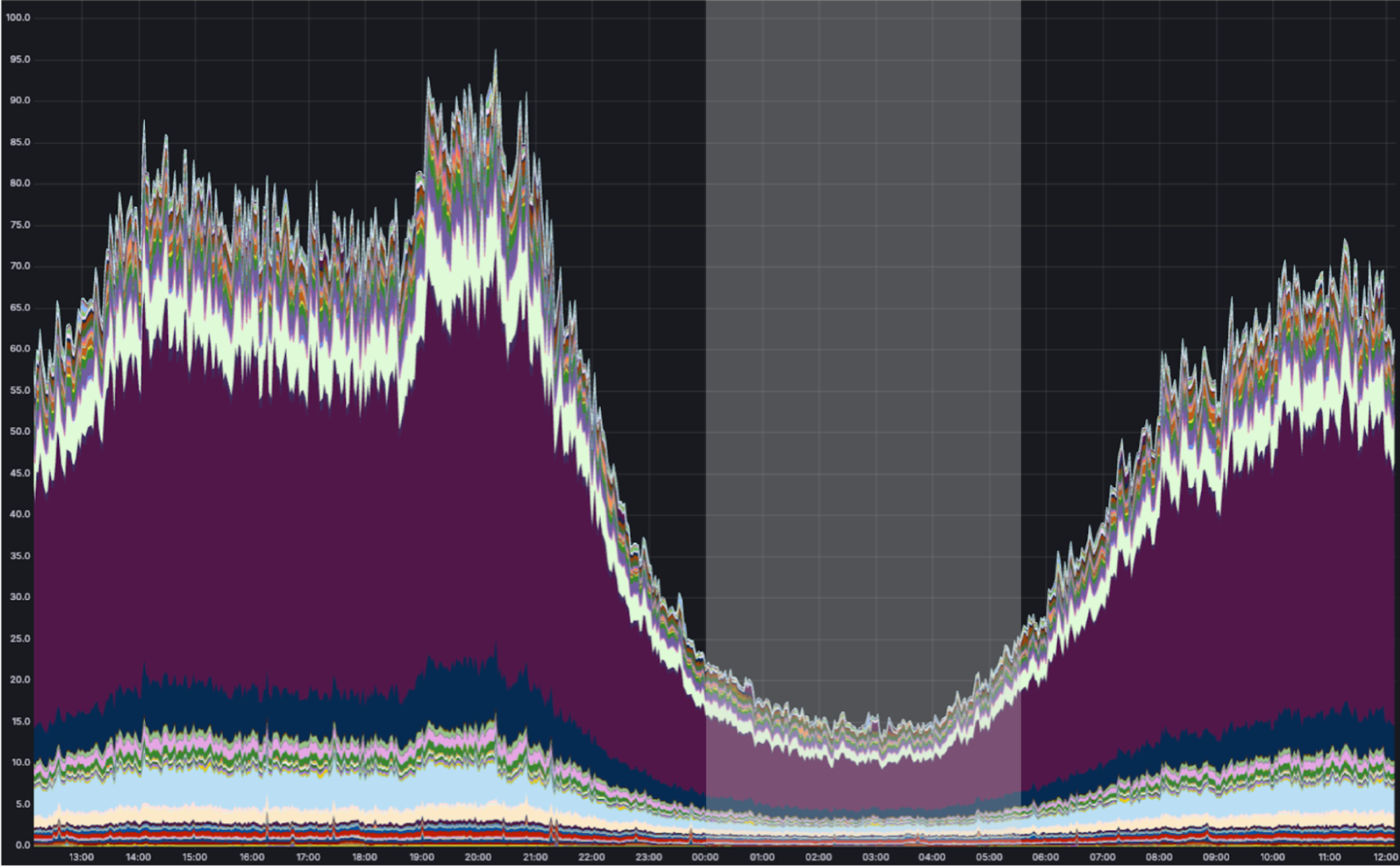
To help you build AI agents on Cloudflare, we’re making Durable Objects available on the free tier, so you can start with zero commitment. With Agents SDK, your AI agents deploy to Cloudflare running on Durable Objects.
Durable Objects offer compute alongside durable storage, that when combined with Workers, unlock stateful, serverless applications. Each Durable Object is a stateful coordinator for handling client real-time interactions, making requests to external services like LLMs, and creating agentic “memory” through state persistence in zero-latency SQLite storage — all tasks required in an AI agent. Durable Objects scale out to millions of agents effortlessly, with each agent created near the user interacting with their agent for fast performance, all managed by Cloudflare.
Zero-latency SQLite storage in Durable Objects was introduced in public beta September 2024 for Birthday Week. Since then, we’ve focused on missing features and robustness compared to pre-existing key-value storage in Durable Objects. We are excited to make SQLite storage generally available, with a 10 GB SQLite database per Durable Object, and recommend SQLite storage for all new Durable Object classes. Durable Objects free tier can only access SQLite storage.
Cloudflare’s free tier allows you to build real-world applications. On the free plan, every Worker request can call a Durable Object. For usage-based pricing, Durable Objects incur compute and storage usage with the following free tier limits.
|
Workers Free |
Workers Paid |
|
|
Compute: Requests |
100,000 / day |
1 million / month included + $0.15 / million |
|
Compute: Duration |
13,000 GB-s / day |
400,000 GB-s / month included + $12.50 / million GB-s |
|
Storage: Rows read |
5 million / day |
25 billion / month included + $0.001 / million |
|
Storage: Rows written |
100,000 / day |
50 million / month included + $1.00 / million |
|
Storage: SQL stored data |
5 GB (total) |
5 GB-month included + $0.20 / GB-month |
We realize this is a lot of information to take in, but don’t worry. Whether you’re new to agents as a whole, or looking to learn more about how Cloudflare can help you build agents, today we launched a new site to help get you started — agents.cloudflare.com.
Let us know what you build!