Post Syndicated from Purna Sanyal original https://aws.amazon.com/blogs/devops/journey-to-adopt-cloud-native-devops-platform-series-2-progressive-delivery-on-amazon-eks-with-flagger-and-gloo-edge-ingress-controller/
In the last post, OfferUp modernized its DevOps platform with Amazon EKS and Flagger to accelerate time to market, we talked about hypergrowth and the technical challenges encountered by OfferUp in its existing DevOps platform. As a reminder, we presented how OfferUp modernized its DevOps platform with Amazon Elastic Kubernetes Service (Amazon EKS) and Flagger to gain developer’s velocity, automate faster deployment, and achieve lower cost of ownership.
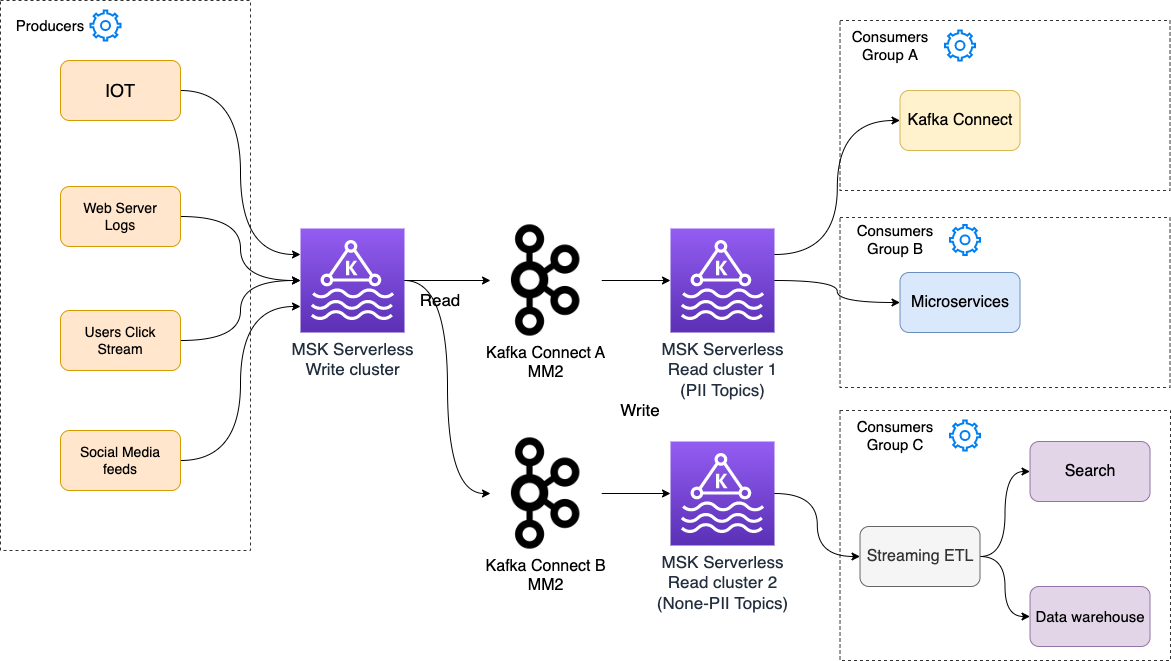
In this post, we discuss the technical steps to build a DevOps platform that enables the progressive deployment of microservices on Amazon Managed Amazon EKS. Progressive delivery exposes a new version of the software incrementally to ingress traffic and continuously measures the success rate of the metrics before allowing all of the new traffics to a newer version of the software. Flagger is the Graduate project of Cloud Native Computing Foundations (CNCF) that enables progressive canary delivery, along with bule/green and A/B Testing, while measuring metrics like HTTP/gRPC request success rate and latency. Flagger shifts and routes traffic between app versions using a service mesh or an Ingress controller
We leverage Gloo Ingress Controller for traffic routing, Prometheus, Datadog, and Amazon CloudWatch for application metrics analysis and Slack to send notification. Flagger will post messages to slack when a deployment has been initialized, when a new revision has been detected, and if the canary analysis failed or succeeded.
Prerequisite steps to build the modern DevOps platform
You need an AWS Account and AWS Identity and Access Management (IAM) user to build the DevOps platform. If you don’t have an AWS account with Administrator access, then create one now by clicking here. Create an IAM user and assign admin role. You can build this platform in any AWS region however, I will you us-west-1 region throughout this post. You can use a laptop (Mac or Windows) or an Amazon Elastic Compute Cloud (AmazonEC2) instance as a client machine to install all of the necessary software to build the GitOps platform. For this post, I launched an Amazon EC2 instance (with Amazon Linux2 AMI) as the client and install all of the prerequisite software. You need the awscli, git, eksctl, kubectl, and helm applications to build the GitOps platform. Here are the prerequisite steps,
- Create a named profile(eks-devops) with the config and credentials file:
aws configure --profile eks-devops
AWS Access Key ID [None]: xxxxxxxxxxxxxxxxxxxxxx
AWS Secret Access Key [None]: xxxxxxxxxxxxxxxxxx
Default region name [None]: us-west-1
Default output format [None]:
View and verify your current IAM profile:
export AWS_PROFILE=eks-devops
aws sts get-caller-identity
- If the Amazon EC2 instance doesn’t have git preinstalled, then install git in your Amazon EC2 instance:
sudo yum update -y
sudo yum install git -y
Check git version
git version
Git clone the repo and download all of the prerequisite software in the home directory.
git clone https://github.com/aws-samples/aws-gloo-flux.git
- Download all of the prerequisite software from
install.shwhich includes awscli, eksctl, kubectl, helm, and docker:
cd aws-gloo-flux/eks-flagger/
ls -lt
chmod 700 install.sh ecr-setup.sh
. install.sh
Check the version of the software installed:
aws --version
eksctl version
kubectl version -o json
helm version
docker --version
docker info
If the docker info shows an error like “permission denied”, then reboot the Amazon EC2 instance or re-log in to the instance again.
- Create an Amazon Elastic Container Repository (Amazon ECR) and push application images.
Amazon ECR is a fully-managed container registry that makes it easy for developers to share and deploy container images and artifacts. ecr setup.sh script will create a new Amazon ECR repository and also push the podinfo images (6.0.0, 6.0.1, 6.0.2, 6.1.0, 6.1.5 and 6.1.6) to the Amazon ECR. Run ecr-setup.sh script with the parameter, “ECR repository name” (e.g. ps-flagger-repository) and region (e.g. us-west-1)
./ecr-setup.sh <ps-flagger-repository> <us-west-1>
You’ll see output like the following (truncated).
###########################################################
Successfully created ECR repository and pushed podinfo images to ECR #
Please note down the ECR repository URI
xxxxxx.dkr.ecr.us-west-1.amazonaws.com/ps-flagger-repository
Technical steps to build the modern DevOps platform
This post shows you how to use the Gloo Edge ingress controller and Flagger to automate canary releases for progressive deployment on the Amazon EKS cluster. Flagger requires a Kubernetes cluster v1.16 or newer and Gloo Edge ingress 1.6.0 or newer. This post will provide a step-by-step approach to install the Amazon EKS cluster with managed node group, Gloo Edge ingress controller, and Flagger for Gloo in the Amazon EKS cluster. Now that the cluster, metrics infrastructure, and Flagger are installed, we can install the sample application itself. We’ll use the standard Podinfo application used in the Flagger project and the accompanying loadtester tool. The Flagger “podinfo” backend service will be called by Gloo’s “VirtualService”, which is the root routing object for the Gloo Gateway. A virtual service describes the set of routes to match for a set of domains. We’ll automate the canary promotion, with the new image of the “podinfo” service, from version 6.0.0 to version 6.0.1. We’ll also create a scenario by injecting an error for automated canary rollback while deploying version 6.0.2.
- Use myeks-cluster.yaml to create your Amazon EKS cluster with managed nodegroup. myeks-cluster.yaml deployment file has “cluster name” value as ps-eks-66, region value as us-west-1, availabilityZones as [us-west-1a, us-west-1b], Kubernetes version as 1.24, and nodegroup Amazon EC2 instance type as m5.2xlarge. You can change this value if you want to build the cluster in a separate region or availability zone.
eksctl create cluster -f myeks-cluster.yaml
Check the Amazon EKS Cluster details:
kubectl cluster-info
kubectl version -o json
kubectl get nodes -o wide
kubectl get pods -A -o wide
Deploy the Metrics Server:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
kubectl get deployment metrics-server -n kube-system
Update the kubeconfig file to interact with you cluster:
# aws eks update-kubeconfig --name <ekscluster-name> --region <AWS_REGION>
kubectl config view
cat $HOME/.kube/config
- Create a namespace “gloo-system” and Install Gloo with Helm Chart. Gloo Edge is an Envoy-based Kubernetes-native ingress controller to facilitate and secure application traffic.
helm repo add gloo https://storage.googleapis.com/solo-public-helm
kubectl create ns gloo-system
helm upgrade -i gloo gloo/gloo --namespace gloo-system
- Install Flagger and the Prometheus add-on in the same gloo-system namespace. Flagger is a Cloud Native Computing Foundation project and part of Flux family of GitOps tools.
helm repo add flagger https://flagger.app
helm upgrade -i flagger flagger/flagger \
--namespace gloo-system \
--set prometheus.install=true \
--set meshProvider=gloo
- [Optional] If you’re using Datadog as a monitoring tool, then deploy Datadog agents as a DaemonSet using the Datadog Helm chart. Replace RELEASE_NAME and DATADOG_API_KEY accordingly. If you aren’t using Datadog, then skip this step. For this post, we leverage the Prometheus open-source monitoring tool.
helm repo add datadog https://helm.datadoghq.com
helm repo update
helm install <RELEASE_NAME> \
--set datadog.apiKey=<DATADOG_API_KEY> datadog/datadog
Integrate Amazon EKS/ K8s Cluster with the Datadog Dashboard – go to the Datadog Console and add the Kubernetes integration.
- [Optional] If you’re using Slack communication tool and have admin access, then Flagger can be configured to send alerts to the Slack chat platform by integrating the Slack alerting system with Flagger. If you don’t have admin access in Slack, then skip this step.
helm upgrade -i flagger flagger/flagger \
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
--set slack.channel=general \
--set slack.user=flagger \
--set clusterName=<my-cluster>
- Create a namespace “apps”, and applications and load testing service will be deployed into this namespace.
kubectl create ns apps
Create a deployment and a horizontal pod autoscaler for your custom application or service for which canary deployment will be done.
kubectl -n apps apply -k app
kubectl get deployment -A
kubectl get hpa -n apps
Deploy the load testing service to generate traffic during the canary analysis.
kubectl -n apps apply -k tester
kubectl get deployment -A
kubectl get svc -n apps
- Use apps-vs.yaml to create a Gloo virtual service definition that references a route table that will be generated by Flagger.
kubectl apply -f ./apps-vs.yaml
kubectl get vs -n apps
[Optional] If you have your own domain name, then open apps-vs.yaml in vi editor and replace podinfo.example.com with your own domain name to run the app in that domain.
- Use canary.yaml to create a canary custom resource. Review the service, analysis, and metrics sections of the canary.yaml file.
kubectl apply -f ./canary.yaml
After a couple of seconds, Flagger will create the canary objects. When the bootstrap finishes, Flagger will set the canary status to “Initialized”.
kubectl -n apps get canary podinfo
NAME STATUS WEIGHT LASTTRANSITIONTIME
podinfo Initialized 0 2023-xx-xxTxx:xx:xxZ
Gloo automatically creates an ELB. Once the load balancer is provisioned and health checks pass, we can find the sample application at the load balancer’s public address. Note down the ELB’s Public address:
kubectl get svc -n gloo-system --field-selector 'metadata.name==gateway-proxy' -o=jsonpath='{.items[0].status.loadBalancer.ingress[0].hostname}{"\n"}'
Validate if your application is running, and you’ll see an output with version 6.0.0.
curl <load balancer’s public address> -H "Host:podinfo.example.com"
Trigger progressive deployments and monitor the status
You can Trigger a canary deployment by updating the application container image from 6.0.0 to 6.01.
kubectl -n apps set image deployment/podinfo podinfod=<ECR URI>:6.0.1
Flagger detects that the deployment revision changed and starts a new rollout.
kubectl -n apps describe canary/podinfo
Monitor all canaries, as the promoted status condition can have one of the following statuses: initialized, Waiting, Progressing, Promoting, Finalizing, Succeeded, and Failed.
watch kubectl get canaries --all-namespaces
curl < load balancer’s public address> -H "Host:podinfo.example.com"
Once canary is completed, validate your application. You can see that the version of the application is changed from 6.0.0 to 6.0.1.
{
"hostname": "podinfo-primary-658c9f9695-4pqbl",
"version": "6.0.1",
"revision": "",
"color": "#34577c",
"logo": "https://raw.githubusercontent.com/stefanprodan/podinfo/gh-pages/cuddle_clap.gif",
"message": "greetings from podinfo v6.0.1",
}
[Optional] Open podinfo application from the laptop browser
Find out both of the IP addresses associated with load balancer.
dig < load balancer’s public address >
Open /etc/hosts file in the laptop and add both of the IPs of load balancer in the host file.
sudo vi /etc/hosts
<Public IP address of LB Target node> podinfo.example.com
e.g.
xx.xx.xxx.xxx podinfo.example.com
xx.xx.xxx.xxx podinfo.example.com
Type “podinfo.example.com” in your browser and you’ll find the application in form similar to this:

Figure 1: Greetings from podinfo v6.0.1
Automated rollback
While doing the canary analysis, you’ll generate HTTP 500 errors and high latency to check if Flagger pauses and rolls back the faulted version. Flagger performs automatic Rollback in the case of failure.
Introduce another canary deployment with podinfo image version 6.0.2 and monitor the status of the canary.
kubectl -n apps set image deployment/podinfo podinfod=<ECR URI>:6.0.2
Run HTTP 500 errors or a high-latency error from a separate terminal window.
Generate HTTP 500 errors:
watch curl -H 'Host:podinfo.example.com' <load balancer’s public address>/status/500
Generate high latency:
watch curl -H 'Host:podinfo.example.com' < load balancer’s public address >/delay/2
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero, and the rollout is marked as failed.
kubectl get canaries --all-namespaces
kubectl -n apps describe canary/podinfo
Cleanup
When you’re done experimenting, you can delete all of the resources created during this series to avoid any additional charges. Let’s walk through deleting all of the resources used.
Delete Flagger resources and apps namespace
kubectl delete canary podinfo -n apps
kubectl delete HorizontalPodAutoscaler podinfo -n apps
kubectl delete deployment podinfo -n apps
helm -n gloo-system delete flagger
helm -n gloo-system delete gloo
kubectl delete namespace apps
Delete Amazon EKS Cluster
After you’ve finished with the cluster and nodes that you created for this tutorial, you should clean up by deleting the cluster and nodes with the following command:
eksctl delete cluster --name <cluster name> --region <region code>
Delete Amazon ECR
aws ecr delete-repository --repository-name ps-flagger-repository --force
Conclusion
This post explained the process for setting up Amazon EKS cluster and how to leverage Flagger for progressive deployments along with Prometheus and Gloo Ingress Controller. You can enhance the deployments by integrating Flagger with Slack, Datadog, and webhook notifications for progressive deployments. Amazon EKS removes the undifferentiated heavy lifting of managing and updating the Kubernetes cluster. Managed node groups automate the provisioning and lifecycle management of worker nodes in an Amazon EKS cluster, which greatly simplifies operational activities such as new Kubernetes version deployments.
We encourage you to look into modernizing your DevOps platform from monolithic architecture to microservice-based architecture with Amazon EKS, and leverage Flagger with the right Ingress controller for secured and automated service releases.
Further Reading
Journey to adopt Cloud-Native DevOps platform Series #1: OfferUp modernized DevOps platform with Amazon EKS and Flagger to accelerate time to market
About the authors: