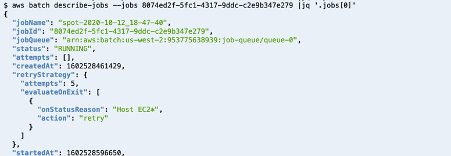
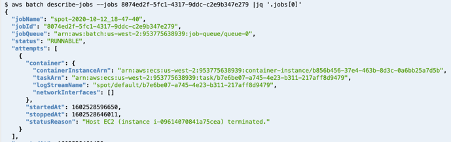
Post Syndicated from Shubha Kumbadakone original https://aws.amazon.com/blogs/compute/integrating-aws-outposts-with-existing-security-zones/
This post is contributed by Santiago Freitas and Matt Lehwess.
AWS Outposts is a fully managed service that extends AWS infrastructure, services, APIs, and tools to your on-premises facility. This blog post explains how the resources created on an Outpost can be integrated with security zones of an existing infrastructure. Integrating Outposts with existing security zones is important for customers that segment their environment into multiple domains based on their security policy.
Background
It’s common for customers to have different security zones within their infrastructure. For example, a customer might have a DMZ security zone where internet facing systems are located, an extra-net security zone where systems used to communicate with business partners are hosted, and an internal security zone where the systems accessible only by employees operate.
As illustrated in the following figure, customers often use firewalls and network ACLs to perform packet inspection and filtering for traffic that flows between security zones. Customers also usually use similar security controls for traffic flowing between different application tiers.

Example of firewall being used for security zone segmentation
Enabling connectivity from an Outposts VPC to your on-premises network
During your Outpost deployment, AWS works with you to establish connectivity to your local network. During this installation process, AWS creates an address pool based on an IP range you assign to the Outpost out of your local network’s IP ranges. This address pool is known as a customer-owned IP address pool or CoIP pool.
When resources running on Outposts (like an EC2 instance) need to communicate with existing on-premises systems, you must assign an Elastic IP address to them. This Elastic IP address comes from the CoIP pool. The resources in your local area network (LAN), including firewalls and network ACLs, see the Elastic IP address as the source IP of the packets sent from the resources running on Outposts. This Elastic IP address is also used as the destination IP for traffic from your on-premises systems to the instance on the Outpost.
How to enable connectivity from an Outposts VPC to your on-premises network
With a typical Outpost deployment, as shown in the following diagram, the following items are required to enable connectivity from the Outpost’s VPC to your on-premises network:
- VPC routing: Routes to your on-premises network in the route table of the VPC’s Outpost subnet.
- CoIP pool: Assigned by you, the customer, and created by AWS at time of install, for example, 192.168.1.0/26 in the diagram. It’s used to allocate Elastic IP addresses that can then be associated with instances or other resources on the Outpost.
- Elastic IP address association: Customer configured, association of Elastic IP addresses from the CoIP pool with EC2 instances and other resources on the Outpost. For example, VPC IP 10.0.3.112 from instance Y has Elastic IP address 192.168.1.15 associated with it.
- Routing advertisement: The Outpost advertises the assigned CoIP range to the local devices within your on-premises network via Border Gateway Protocol (BGP). This is configured by AWS during installation and based on the CoIP pool IP range you provide.

AWS Outposts – typical network topology
Integrating Outposts with existing security zones
CoIP pools, and AWS Resource Access Manager (RAM) are used to facilitate the integration of Outposts with your existing security zones. AWS RAM lets you share your resources with AWS account or through AWS Organizations.
When AWS deploys your Outposts, you can ask AWS to create multiple CoIP pools. Each CoIP pool is configured with an IP range assigned by you during initial installation. If after the initial installation you need AWS to create additional CoIP pools for an existing Outpost, you can open a case with AWS Support and request the creation of additional pools.
CoIP pools are owned initially by the AWS account that owns the Outpost. In a multi-account Outpost deployment, you can share your customer-owned IP pool(s) with other AWS accounts in your AWS Organization using AWS RAM.
VPCs that have subnets on the Outpost must be created in the same account that owns the Outpost. After creation of these subnets within the Outpost account, AWS RAM can then be used to share these subnets with other accounts or organizational units that are in the same organization from AWS Organizations.
After you’ve shared the CoIP pool with the account where you’d like to run your workloads, and you’ve shared an Outpost subnet with that same account, users of that account can deploy resources in the shared Outpost subnet. For the Outposts resources that must communicate with resources in your existing infrastructure, users can assign Elastic IP addresses from one or more of the shared CoIP pools to those Outposts resources.
Multiple CoIP pools and the ability to share them and Outpost subnets with a particular account, gives you granular control over the IP range used by Outpost resources requiring connectivity to your on-premises LAN.
The following figure illustrates the sharing of a subnet and CoIP pool from Account 1, which is the account where the Outpost was initially deployed, with Account 2. As the CoIP pool was shared with Account 2, the users in Account 2 are able to assign an Elastic IP address to the EC2 instance running within Account 2.

AWS Outposts and VPC Sharing
Creating an AWS RAM resource share
The following screenshots demonstrate how to use AWS RAM to share a CoIP pool and a subnet with another account in the same organization from AWS Organizations.
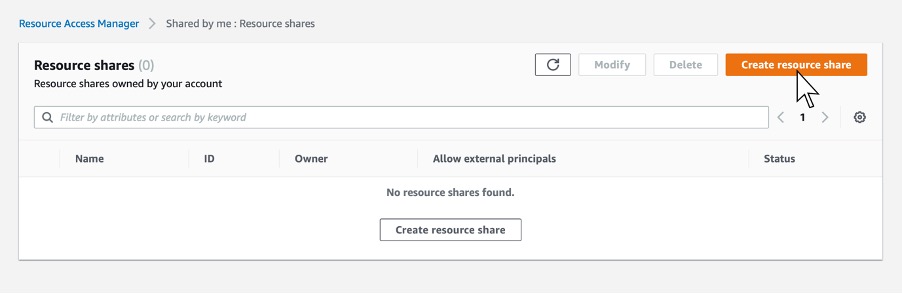
Step 1. Navigate to the AWS RAM service page within the AWS Management Console, and click Create Resource Share. This step is done within the AWS account that owns the Outpost.

Step 2. Next, give the share an appropriate name.

Step 3. Select one or more subnets you’d like to share with your application owner’s account. In this case, select a subnet that exists in your VPC on the Outpost.

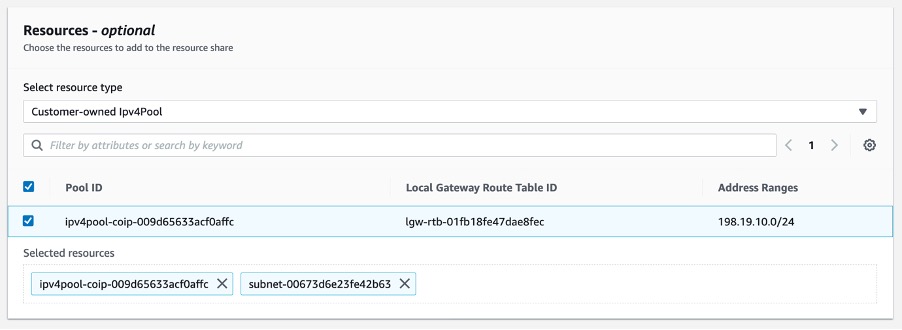
Step 4. In this case, share the CoIP range. You can find that in the resources type list.

Step 5. Select the Customer-owned Ipv4Pool resource type, and then select the CoIP to be shared. Selecting the the CoIP adds it to the list of shared resources along with the subnet selected earlier.

Step 6. Add the account number for the account you’d like to share the Outposts subnet and CoIP pool with.

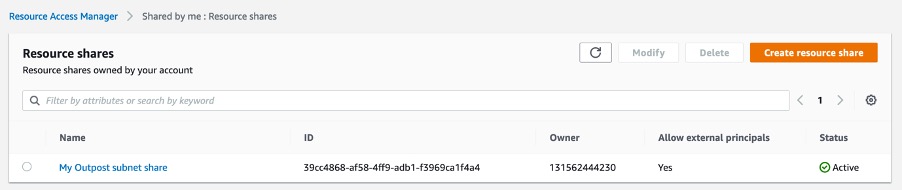
Step 7. Click Create Resource. After clicking the Create Resource share button, you should see the resource share listed and be in the state “active.”

Now that you’ve successfully shared the subnet and CoIP pool with your application account (that’s in the same organization), you can now go in to that account and allocate an Elastic IP address from the CoIP pool. You can then assign the Elastic IP address to an instance launched in the subnet previously shared, which is on the Outpost.
Allocating and associating the Elastic IP address from your CoIP pool
Step 1. From within the application account, allocate an Elastic IP address from the CoIP pool. This is done by navigating to the VPC console, then to Elastic IP addresses, and then click Allocate Elastic IP address.

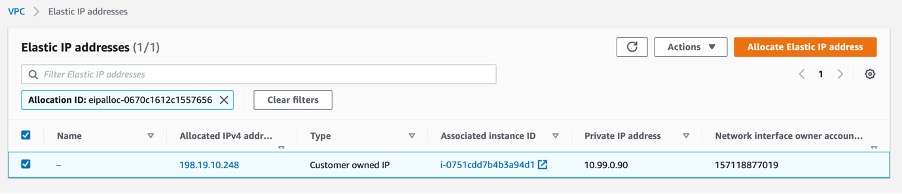
Step 2. Select Customer owned pool of IPv4 addresses, select the CoIP pool that’s been shared with this account previously, then click Allocate. You can see this step in the following image.

Step 3. You can now see the new Elastic IP address that has been allocated from the shared CoIP pool. You can now associate that Elastic IP address with an instance in our shared subnet.

Note: When using the AWS Management Console to allocate an Elastic IP address, the ElasticIP address is automatically allocated from the CoIPpool. If you’re using the AWS CLI, you have the option to select a specific Elastic IP address from the CoIP pool by using the --customer-owned-ipv4-pool <value> option.
Step 4. You can now associate the Elastic IP address of type CoIP with an instance. Click Associate after selecting the instance that is running on your Outpost in the shared subnet. This step is represented in the following image.

Step 5 – Once the operation is complete, you can see the CoIP Elastic IP address in the Elastic IP address console, and that it’s assigned to the instance that’s running in your shared subnet.

The steps preceding demonstrated how to share the Outpost with other accounts through the use of AWS Resource Access Manager, subnet sharing, and CoIP sharing.
Use case
Let’s apply the capabilities described prior into a design. A customer is running a 3-tier web application and would like to host the web and application tiers on Outposts. The database tier is hosted on the existing infrastructure. The application’s user traffic comes from the internet, through an external firewall towards the web tier hosted on the Outpost. Traffic between web and application tiers is secured with security groups and remains within the Outpost. Application servers connect to the database servers via the existing internal firewalls. The customer uses independent external and internal firewalls.
During the Outposts installation, the customer asks AWS to create two CoIP pools. The first CoIP pool, referenced in the following image as CoIP Web, is assigned the IP range 172.0.1.0/24. The second CoIP pool, referenced in the following image as CoIP App, is assigned the IP range 172.0.2.0/24. The customer then creates two additional AWS accounts, one for the web tier and another for the app tier. Within the account that owns the Outpost, the customer creates two VPCs and within each of those VPCs a subnet is created.
The subnet with IP address 10.0.1.0/24 is shared with the web tier account and the subnet with IP address 10.1.2.0/24 is shared with the app tier account. The customer then configures VPC peering between the VPCs to enable communication between the web and app tiers. VPC peering configuration is performed within the account that owns the Outposts.
Note: With VPC peering traffic between the VPCs remains within the Outpost. However, data transfer charges for VPC peering applies. This use-case could also be built with the web tier and app tier using different subnets within the same VPC to save on data transfer costs over VPC peering.
The following image shows initial setup with two CoIP pools, two accounts, and two VPCs.

Initial setup with two CoIP pools, two accounts and two VPCs
After the initial setup the customer then shares each CoIP pool with the appropriate account using AWS RAM. The customer can then create their web and application servers within the respective accounts. As shown in the prior image, the web server is assigned IP address 10.0.1.5 and the application server is assigned IP address 10.1.2.10. Each IP address is part of their respective VPC IP range and are reachable only within the Outpost at this point.
To enable the integration of the web and application servers with the existing infrastructure, the customer assigns an Elastic IP address from the CoIP pool shared with each account to their respective Amazon EC2 instances.
With this configuration, the customer can integrate the web and application servers into the existing security zones. To integrate the web servers, path “A” in the following image, the customer creates a rule in their external firewall that allows communication from any source (internet) to Elastic IP address 172.0.1.5 on port 443 (HTTPS) which has been assigned to the web server.
For the communication between the web and application servers, path “B” in the following image, the customer has configured VPC peering between the two VPCs and created the required security groups.
To integrate the application servers into the Internal Security Zone, path “C” in the following image, the customer has assigned Elastic IP address 172.0.2.10 to the application server and has configured a rule on the Internal Firewall allowing the IP range 172.0.2.0/24 that is assigned to the app CoIP pool to communicate with the database server.

End to end traffic flow from users to web tier and from app tier to database tier
In addition to setting up their Outposts as covered in the preceding details, to enable the communication between the Outposts hosted resources and the existing infrastructure you must create a custom route table and associate it with an Outpost subnet.
Conclusion
AWS Outposts extends AWS infrastructure, services, APIs, and tools to your on-premises facility. During deployment of your Outposts, AWS works with you to establish connectivity to your local network. This blog post builds upon this initial deployment of an Outpost to allow the Outpost’s resources to integrate into your existing security zones. The design is applicable for customers that segment their environment into multiple security zones.

Santiago Freitas is AWS Head of Technology for Central Eastern Europe (CEE), Middle East, North Africa (MENA), Sub Saharan Africa (SSA), Turkey (TUR), and Russia and Commonwealth of Independent States (RUS-CIS). Previously he was an AWS Global Solutions Architect for financial services. Before joining AWS, Santiago was a Distinguished Engineer at Cisco. He is based in Dubai, United Arab Emirates.
Matt is a Principal Developer Advocate for Amazon Web Services where he has spent the last 7 years working with AWS customers and partners, helping them to build best-in-class AWS networking solutions. He is co-author of the AWS Certified Advanced Networking Official Study Guide, as well as an Amazon Re:Invent speaker extraordinaire (5 years and counting!). His primary focus at AWS is to help evangelize AWS networking solutions and more recently, AWS Outposts.
 Nuxt.js scaffolding tool inputs
Nuxt.js scaffolding tool inputs