Mitre’s CVE’s program—which provides common naming and other informational resources about cybersecurity vulnerabilities—was about to be cancelled, as the US Department of Homeland Security failed to renew the contact. It was funded for eleven more months at the last minute.
This is a big deal. The CVE program is one of those pieces of common infrastructure that everyone benefits from. Losing it will bring us back to a world where there’s no single way to talk about vulnerabilities. It’s kind of crazy to think that the US government might damage its own security in this way—but I suppose no crazier than any of the other ways the US is working against its own interests right now.
Sasha Romanosky, senior policy researcher at the Rand Corporation, branded the end to the CVE program as “tragic,” a sentiment echoed by many cybersecurity and CVE experts reached for comment.
“CVE naming and assignment to software packages and versions are the foundation upon which the software vulnerability ecosystem is based,” Romanosky said. “Without it, we can’t track newly discovered vulnerabilities. We can’t score their severity or predict their exploitation. And we certainly wouldn’t be able to make the best decisions regarding patching them.”
Ben Edwards, principal research scientist at Bitsight, told CSO, “My reaction is sadness and disappointment. This is a valuable resource that should absolutely be funded, and not renewing the contract is a mistake.”
He added “I am hopeful any interruption is brief and that if the contract fails to be renewed, other stakeholders within the ecosystem can pick up where MITRE left off. The federated framework and openness of the system make this possible, but it’ll be a rocky road if operations do need to shift to another entity.”
More similar quotes in the article.
My guess is that we will somehow figure out how to transition this program to continue without the US government. It’s too important to be at risk.
Microsoft discovered eleven vulnerabilities in GRUB2, including integer and buffer overflows in filesystem parsers, command flaws, and a side-channel in cryptographic comparison.
Additionally, 9 buffer overflows in parsing SquashFS, EXT4, CramFS, JFFS2, and symlinks were discovered in U-Boot and Barebox, which require physical access to exploit.
The newly discovered flaws impact devices relying on UEFI Secure Boot, and if the right conditions are met, attackers can bypass security protections to execute arbitrary code on the device.
Nothing major here. These aren’t exploitable out of the box. But that an AI system can do this at all is impressive, and I expect their capabilities to continue to improve.
US National Security Advisor Mike Waltz, who started the now-infamous group chat coordinating a US attack against the Yemen-based Houthis on March 15, is seemingly now suggesting that the secure messaging service Signal has security vulnerabilities.
"I didn’t see this loser in the group," Waltz told Fox News about Atlantic editor in chief Jeffrey Goldberg, whom Waltz invited to the chat. "Whether he did it deliberately or it happened in some other technical mean, is something we’re trying to figure out."
Waltz’s implication that Goldberg may have hacked his way in was followed by a report from CBS News that the US National Security Agency (NSA) had sent out a bulletin to its employees last month warning them about a security "vulnerability" identified in Signal.
The truth, however, is much more interesting. If Signal has vulnerabilities, then China, Russia, and other US adversaries suddenly have a new incentive to discover them. At the same time, the NSA urgently needs to find and fix any vulnerabilities quickly as it can—and similarly, ensure that commercial smartphones are free of backdoors—access points that allow people other than a smartphone’s user to bypass the usual security authentication methods to access the device’s contents.
That is essential for anyone who wants to keep their communications private, which should be all of us.
It’s common knowledge that the NSA’s mission is breaking into and eavesdropping on other countries’ networks. (During President George W. Bush’s administration, the NSA conducted warrantless taps into domestic communications as well—surveillance that several district courts ruled to be illegal before those decisions were later overturned by appeals courts. To this day, many legal experts maintain that the program violated federal privacy protections.) But the organization has a secondary, complementary responsibility: to protect US communications from others who want to spy on them. That is to say: While one part of the NSA is listening into foreign communications, another part is stopping foreigners from doing the same to Americans.
Those missions never contradicted during the Cold War, when allied and enemy communications were wholly separate. Today, though, everyone uses the same computers, the same software, and the same networks. That creates a tension.
When the NSA discovers a technological vulnerability in a service such as Signal (or buys one on the thriving clandestine vulnerability market), does it exploit it in secret, or reveal it so that it can be fixed? Since at least 2014, a US government interagency "equities" process has been used to decide whether it is in the national interest to take advantage of a particular security flaw, or to fix it. The trade-offs are often complicated and hard.
Waltz—along with Vice President J.D. Vance, Defense Secretary Pete Hegseth, and the other officials in the Signal group—have just made the trade-offs much tougher to resolve. Signal is both widely available and widely used. Smaller governments that can’t afford their own military-grade encryption use it. Journalists, human rights workers, persecuted minorities, dissidents, corporate executives, and criminals around the world use it. Many of these populations are of great interest to the NSA.
At the same time, as we have now discovered, the app is being used for operational US military traffic. So, what does the NSA do if it finds a security flaw in Signal?
Previously, it might have preferred to keep the flaw quiet and use it to listen to adversaries. Now, if the agency does that, it risks someone else finding the same vulnerability and using it against the US government. And if it was later disclosed that the NSA could have fixed the problem and didn’t, then the results might be catastrophic for the agency.
Smartphones present a similar trade-off. The biggest risk of eavesdropping on a Signal conversation comes from the individual phones that the app is running on. While it’s largely unclear whether the US officials involved had downloaded the app onto personal or government-issued phones—although Witkoff suggested on X that the program was on his "personal devices"—smartphones are consumer devices, not at all suitable for classified US government conversations. An entire industry of spyware companies sells capabilities to remotely hack smartphones for any country willing to pay. More capable countries have more sophisticated operations. Just last year, attacks that were later attributed to China attempted to access both President Donald Trump and Vance’s smartphones. Previously, the FBI—as well as law enforcement agencies in other countries—have pressured both Apple and Google to add "backdoors" in their phones to more easily facilitate court-authorized eavesdropping.
These backdoors would create, of course, another vulnerability to be exploited. A separate attack from China last year accessed a similar capability built into US telecommunications networks.
The vulnerabilities equities have swung against weakened smartphone security and toward protecting the devices that senior government officials now use to discuss military secrets. That also means that they have swung against the US government hoarding Signal vulnerabilities—and toward full disclosure.
This is plausibly good news for Americans who want to talk among themselves without having anyone, government or otherwise, listen in. We don’t know what pressure the Trump administration is using to make intelligence services fall into line, but it isn’t crazy to worry that the NSA might again start monitoring domestic communications.
Because of the Signal chat leak, it’s less likely that they’ll use vulnerabilities in Signal to do that. Equally, bad actors such as drug cartels may also feel safer using Signal. Their security against the US government lies in the fact that the US government shares their vulnerabilities. No one wants their secrets exposed.
I have long advocated for a "defense dominant" cybersecurity strategy. As long as smartphones are in the pocket of every government official, police officer, judge, CEO, and nuclear power plant operator—and now that they are being used for what the White House now calls calls "sensitive," if not outright classified conversations among cabinet members—we need them to be as secure as possible. And that means no government-mandated backdoors.
We may find out more about how officials—including the vice president of the United States—came to be using Signal on what seem to be consumer-grade smartphones, in a apparent breach of the laws on government records. It’s unlikely that they really thought through the consequences of their actions.
Nonetheless, those consequences are real. Other governments, possibly including US allies, will now have much more incentive to break Signal’s security than they did in the past, and more incentive to hack US government smartphones than they did before March 24.
For just the same reason, the US government has urgent incentives to protect them.
On January 23, 2025, Cloudflare was notified via its Bug Bounty Program of a vulnerability in Cloudflare’s Mutual TLS (mTLS) implementation.
The vulnerability affected customers who were using mTLS and involved a flaw in our session resumption handling. Cloudflare’s investigation revealed no evidence that the vulnerability was being actively exploited. And tracked asCVE-2025-23419, Cloudflare mitigated the vulnerability within 32 hours after being notified. Customers who were using Cloudflare’s API shield in conjunction with WAF custom rules that validated the issuer’s Subject Key Identifier (SKI) were not vulnerable. Access policies such as identity verification, IP address restrictions, and device posture assessments were also not vulnerable.
Background
The bug bounty report detailed that a client with a valid mTLS certificate for one Cloudflare zone could use the same certificate to resume a TLS session with another Cloudflare zone using mTLS, without having to authenticate the certificate with the second zone.
Cloudflare customers can implement mTLS through Cloudflare API Shield with Custom Firewall Rules and the Cloudflare Zero Trust product suite. Cloudflare establishes the TLS session with the client and forwards the client certificate to Cloudflare’s Firewall or Zero Trust products, where customer policies are enforced.
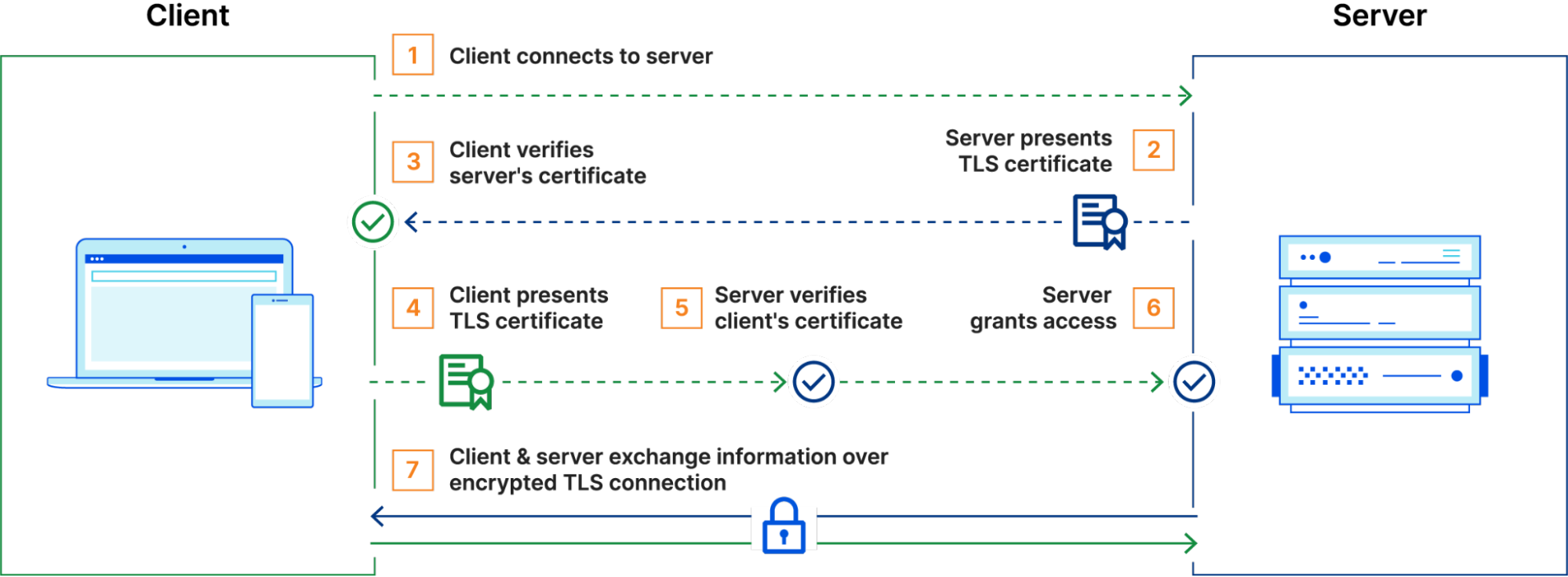
mTLS operates by extending the standard TLS handshake to require authentication from both sides of a connection – the client and the server. In a typical TLS session, a client connects to a server, which presents its TLS certificate. The client verifies the certificate, and upon successful validation, an encrypted session is established. However, with mTLS, the client also presents its own TLS certificate, which the server verifies before the connection is fully established. Only if both certificates are validated does the session proceed, ensuring bidirectional trust.
mTLS is useful for securing API communications, as it ensures that only legitimate and authenticated clients can interact with backend services. Unlike traditional authentication mechanisms that rely on credentials or tokens, mTLS requires possession of a valid certificate and its corresponding private key.
To improve TLS connection performance, Cloudflare employs session resumption. Session resumption speeds up the handshake process, reducing both latency and resource consumption. The core idea is that once a client and server have successfully completed a TLS handshake, future handshakes should be streamlined — assuming that fundamental parameters such as the cipher suite or TLS version remain unchanged.
There are two primary mechanisms for session resumption: session IDs and session tickets. With session IDs, the server stores the session context and associates it with a unique session ID. When a client reconnects and presents this session ID in its ClientHello message, the server checks its cache. If the session is still valid, the handshake is resumed using the cached state.
Session tickets function in a stateless manner. Instead of storing session data, the server encrypts the session context and sends it to the client as a session ticket. In future connections, the client includes this ticket in its ClientHello, which the server can then decrypt to restore the session, eliminating the need for the server to maintain session state.
A resumed mTLS session leverages previously established trust, allowing clients to reconnect to a protected application without needing to re-initiate an mTLS handshake.
The mTLS resumption vulnerability
In Cloudflare’s mTLS implementation, however, session resumption introduced an unintended behavior. BoringSSL, the TLS library that Cloudflare uses, will store the client certificate from the originating, full TLS handshake in the session. Upon resuming that session, the client certificate is not revalidated against the full chain of trust, and the original handshake’s verification status is respected. To avoid this situation, BoringSSL provides an API to partition session caches/tickets between different “contexts” defined by the application. Unfortunately, Cloudflare’s use of this API was not correct, which allowed TLS sessions to be resumed when they shouldn’t have been.
To exploit this vulnerability, the security researcher first set up two zones on Cloudflare and configured them behind Cloudflare’s proxy with mTLS enabled. Once their domains were configured, the researcher authenticated to the first zone using a valid client certificate, allowing Cloudflare to issue a TLS session ticket against that zone.
The researcher then changed the TLS Server Name Indication (SNI) and HTTP Host header from the first zone (which they had authenticated with) to target the second zone (which they had not authenticated with). The researcher then presented the session ticket when handshaking with the second Cloudflare-protected mTLS zone. This resulted in Cloudflare resuming the session with the second zone and reporting verification status for the cached client certificate as successful,bypassing the mTLS authentication that would normally be required to initiate a session.
If you were using additional validation methods in your API Shield or Access policies – for example, checking the issuers SKI, identity verification, IP address restrictions, or device posture assessments – these controls continued to function as intended. However, due to the issue with TLS session resumption, the mTLS checks mistakenly returned a passing result without re-evaluating the full certificate chain.
Remediation and next steps
We have disabled TLS session resumption for all customers that have mTLS enabled. As a result, Cloudflare will no longer allow resuming sessions that cache client certificates and their verification status.
We are exploring ways to bring back the performance improvements from TLS session resumption for mTLS customers.
Further hardening
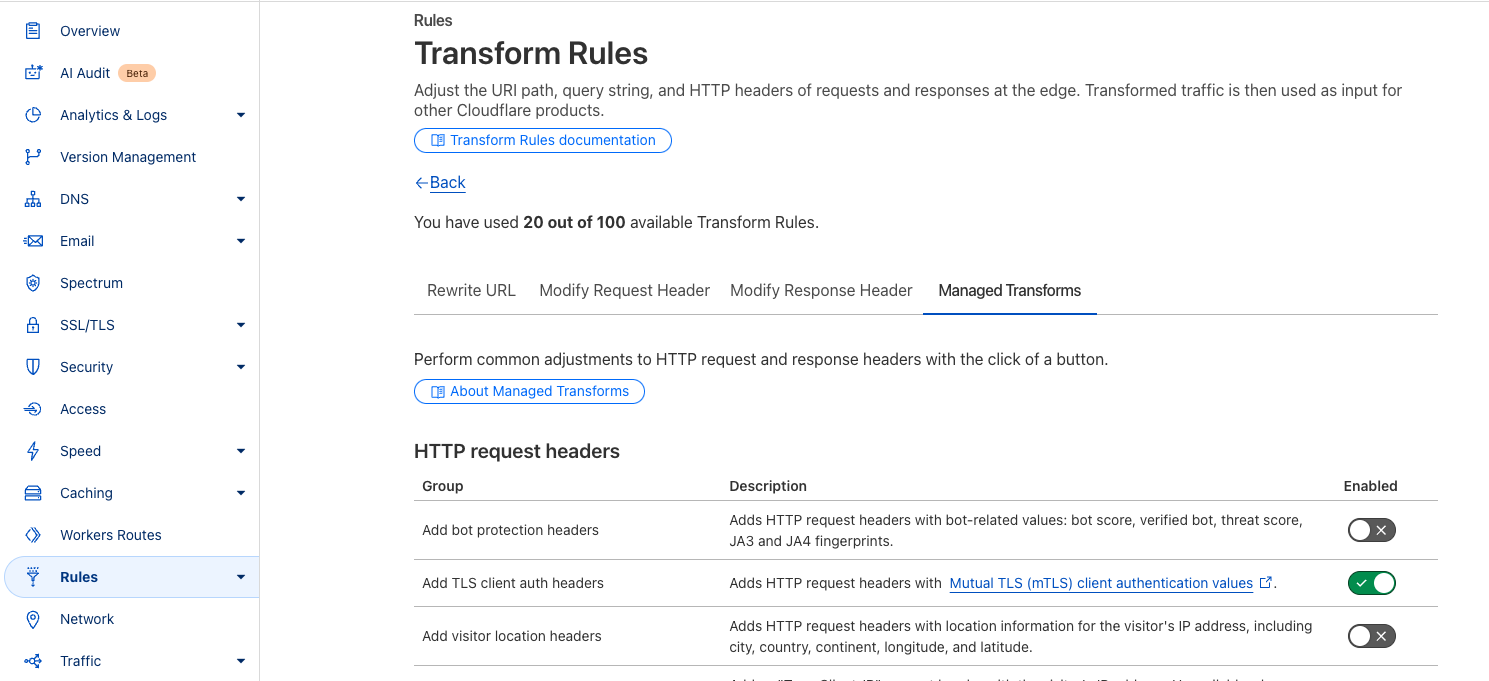
Customers can further harden their mTLS configuration and add enhanced logging to detect future issues by using Cloudflare’s Transform Rules, logging, and firewall features.
While Cloudflare has mitigated the issue by disabling session resumption for mTLS connections, customers may want to implement additional monitoring at their origin to enforce stricter authentication policies. All customers using mTLS can also enable additional request headers using our Managed Transforms product. Enabling this feature allows us to pass additional metadata to your origin with the details of the client certificate that was used for the connection.
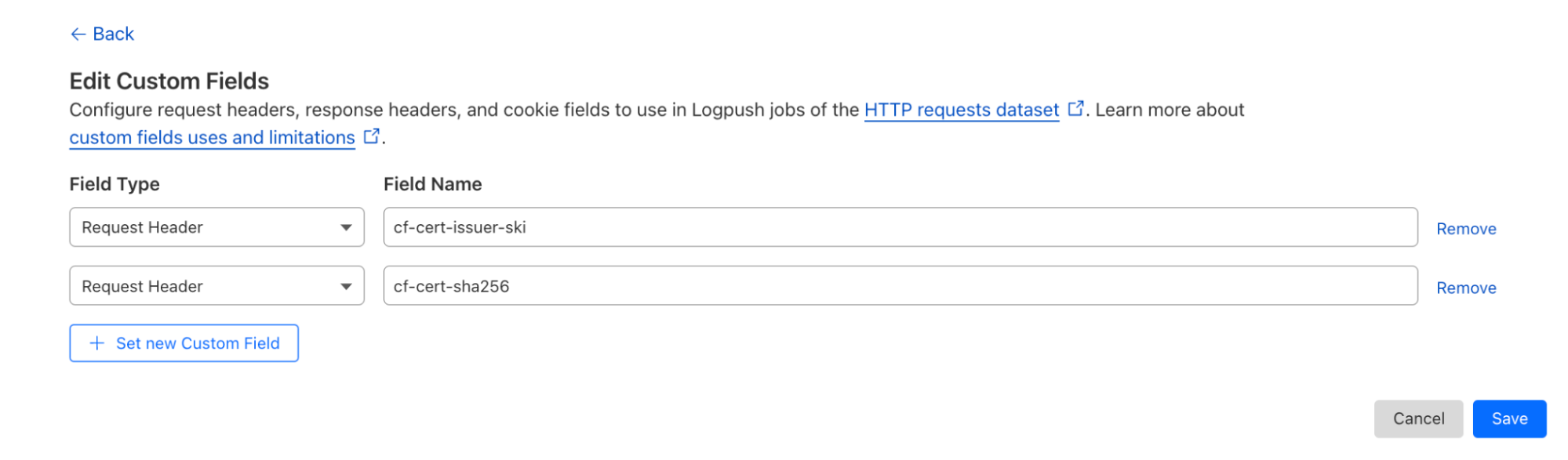
Enabling this feature allows you to see the following headers where mTLS is being utilized on a request.
Customers already logging this information — either at their origin or via Cloudflare Logs — can retroactively check for unexpected certificate hashes or issuers that did not trigger any security policy.
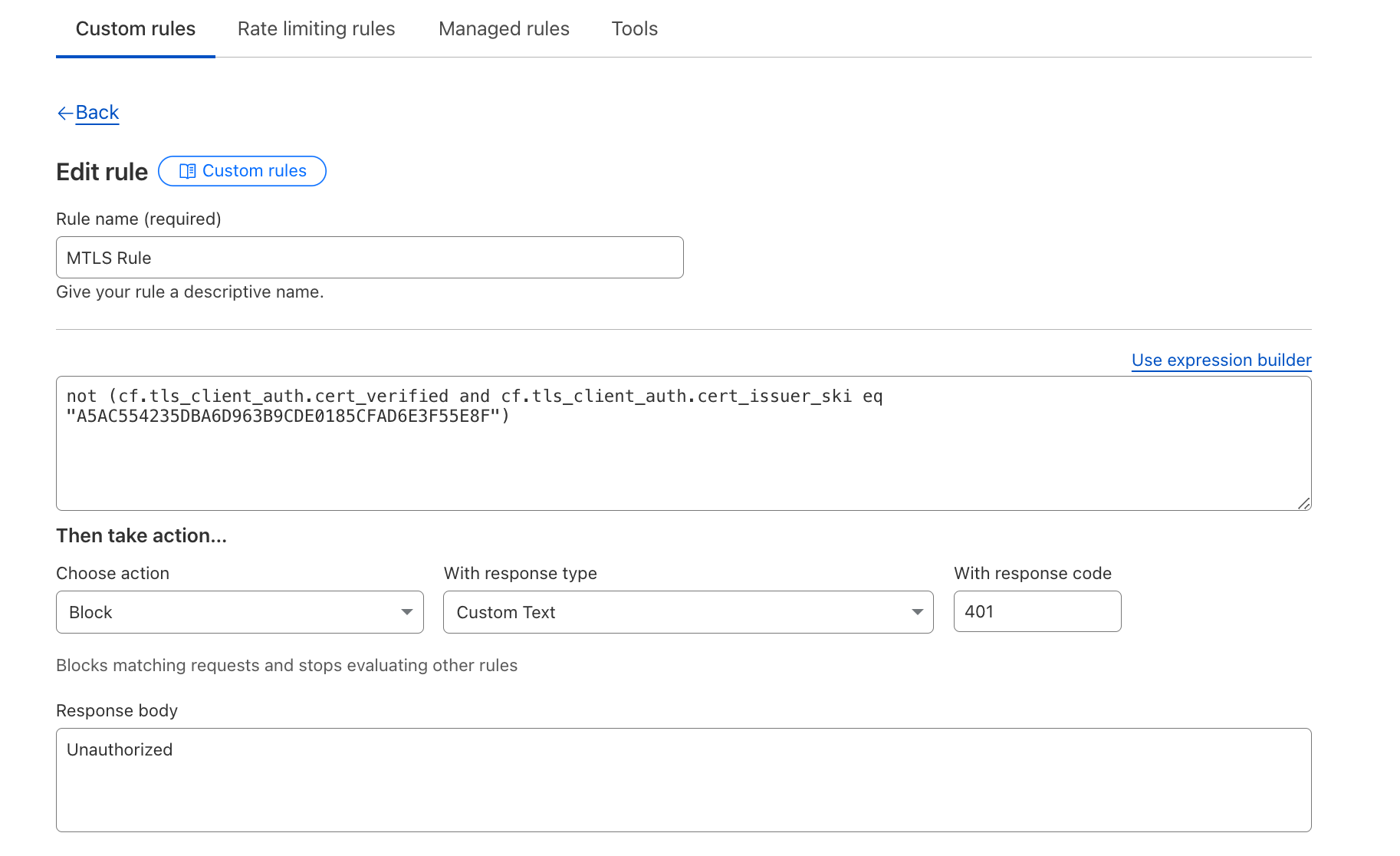
Users are also able to use this information within their WAF custom rules to conduct additional checks. For example, checking the Issuer’s SKI can provide an extra layer of security.
Customers who enabled this additional check were not vulnerable.
Conclusion
We sincerely thank the security researcher who responsibly disclosed this issue via our HackerOne Bug Bounty Program, allowing us to identify and mitigate the vulnerability. We welcome further submissions from our community of researchers to continually improve our products’ security.
Finally, we want to apologize to our mTLS customers. Security is at the core of everything we do at Cloudflare, and we deeply regret any concerns this issue may have caused. We have taken immediate steps to resolve the vulnerability and have implemented additional safeguards to prevent similar issues in the future.
Timeline
All timestamps are in UTC
2025-01-23 15:40 – Cloudflare is notified of a vulnerability in Mutual TLS and the use of session resumption.
2025-01-23 16:02 to 21:06 – Cloudflare validates Mutual TLS vulnerability and prepares a release to disable session resumption for Mutual TLS.
2025-01-23 21:26 – Cloudflare begins rollout of remediation.
2025-01-24 20:15 – Rollout completed. Vulnerability is remediated.
Not everything needs to be digital and “smart.” License plates, for example:
Josep Rodriguez, a researcher at security firm IOActive, has revealed a technique to “jailbreak” digital license plates sold by Reviver, the leading vendor of those plates in the US with 65,000 plates already sold. By removing a sticker on the back of the plate and attaching a cable to its internal connectors, he’s able to rewrite a Reviver plate’s firmware in a matter of minutes. Then, with that custom firmware installed, the jailbroken license plate can receive commands via Bluetooth from a smartphone app to instantly change its display to show any characters or image.
[…]
Because the vulnerability that allowed him to rewrite the plates’ firmware exists at the hardware level—in Reviver’s chips themselves—Rodriguez says there’s no way for Reviver to patch the issue with a mere software update. Instead, it would have to replace those chips in each display.
The whole point of a license plate is that it can’t be modified. Why in the world would anyone think that a digital version is a good idea?
Zero-day vulnerabilities are more commonly used, according to the Five Eyes:
Key Findings
In 2023, malicious cyber actors exploited more zero-day vulnerabilities to compromise enterprise networks compared to 2022, allowing them to conduct cyber operations against higher-priority targets. In 2023, the majority of the most frequently exploited vulnerabilities were initially exploited as a zero-day, which is an increase from 2022, when less than half of the top exploited vulnerabilities were exploited as a zero-day.
Malicious cyber actors continue to have the most success exploiting vulnerabilities within two years after public disclosure of the vulnerability. The utility of these vulnerabilities declines over time as more systems are patched or replaced. Malicious cyber actors find less utility from zero-day exploits when international cybersecurity efforts reduce the lifespan of zero-day vulnerabilities.
I’ve been writing about the possibility of AIs automatically discovering code vulnerabilities since at least 2018. This is an ongoing area of research: AIs doing source code scanning, AIs finding zero-days in the wild, and everything in between. The AIs aren’t very good at it yet, but they’re getting better.
Since July 2024, ZeroPath is taking a novel approach combining deep program analysis with adversarial AI agents for validation. Our methodology has uncovered numerous critical vulnerabilities in production systems, including several that traditional Static Application Security Testing (SAST) tools were ill-equipped to find. This post provides a technical deep-dive into our research methodology and a living summary of the bugs found in popular open-source tools.
Expect lots of developments in this area over the next few years.
Let’s stick with software. Imagine that we have an AI that finds software vulnerabilities. Yes, the attackers can use those AIs to break into systems. But the defenders can use the same AIs to find software vulnerabilities and then patch them. This capability, once it exists, will probably be built into the standard suite of software development tools. We can imagine a future where all the easily findable vulnerabilities (not all the vulnerabilities; there are lots of theoretical results about that) are removed in software before shipping.
When that day comes, all legacy code would be vulnerable. But all new code would be secure. And, eventually, those software vulnerabilities will be a thing of the past. In my head, some future programmer shakes their head and says, “Remember the early decades of this century when software was full of vulnerabilities? That’s before the AIs found them all. Wow, that was a crazy time.” We’re not there yet. We’re not even remotely there yet. But it’s a reasonable extrapolation.
EDITED TO ADD: And Google’s LLM just discovered an exploitable zero-day.
This vulnerability hacks a feature that allows ChatGPT to have long-term memory, where it uses information from past conversations to inform future conversations with that same user. A researcher found that he could use that feature to plant “false memories” into that context window that could subvert the model.
A month later, the researcher submitted a new disclosure statement. This time, he included a PoC that caused the ChatGPT app for macOS to send a verbatim copy of all user input and ChatGPT output to a server of his choice. All a target needed to do was instruct the LLM to view a web link that hosted a malicious image. From then on, all input and output to and from ChatGPT was sent to the attacker’s website.
The press is reporting a critical Windows vulnerability affecting IPv6.
As Microsoft explained in its Tuesday advisory, unauthenticated attackers can exploit the flaw remotely in low-complexity attacks by repeatedly sending IPv6 packets that include specially crafted packets.
Microsoft also shared its exploitability assessment for this critical vulnerability, tagging it with an “exploitation more likely” label, which means that threat actors could create exploit code to “consistently exploit the flaw in attacks.”
Details are being withheld at the moment. Microsoft strongly recommends patching now.
Cloudflare reports on the state of applications security. It claims that 6.8% of Internet traffic is malicious. And that CVEs are exploited as quickly as 22 minutes after proof-of-concepts are published.
On Thursday, researchers from security firm Binarly revealed that Secure Boot is completely compromised on more than 200 device models sold by Acer, Dell, Gigabyte, Intel, and Supermicro. The cause: a cryptographic key underpinning Secure Boot on those models that was compromised in 2022. In a public GitHub repository committed in December of that year, someone working for multiple US-based device manufacturers published what’s known as a platform key, the cryptographic key that forms the root-of-trust anchor between the hardware device and the firmware that runs on it. The repository was located at https://github.com/raywu-aaeon/Ryzen2000_4000.git, and it’s not clear when it was taken down.
The repository included the private portion of the platform key in encrypted form. The encrypted file, however, was protected by a four-character password, a decision that made it trivial for Binarly, and anyone else with even a passing curiosity, to crack the passcode and retrieve the corresponding plain text. The disclosure of the key went largely unnoticed until January 2023, when Binarly researchers found it while investigating a supply-chain incident. Now that the leak has come to light, security experts say it effectively torpedoes the security assurances offered by Secure Boot.
[…]
These keys were created by AMI, one of the three main providers of software developer kits that device makers use to customize their UEFI firmware so it will run on their specific hardware configurations. As the strings suggest, the keys were never intended to be used in production systems. Instead, AMI provided them to customers or prospective customers for testing. For reasons that aren’t clear, the test keys made their way into devices from a nearly inexhaustive roster of makers. In addition to the five makers mentioned earlier, they include Aopen, Foremelife, Fujitsu, HP, Lenovo, and Supermicro.
New attack against the RADIUS authentication protocol:
The Blast-RADIUS attack allows a man-in-the-middle attacker between the RADIUS client and server to forge a valid protocol accept message in response to a failed authentication request. This forgery could give the attacker access to network devices and services without the attacker guessing or brute forcing passwords or shared secrets. The attacker does not learn user credentials.
This is one of those vulnerabilities that comes with a cool name, its own website, and a logo.
The MD5 cryptographic hash function was first broken in 2004, when researchers demonstrated the first MD5 collision, namely two different messages X1 and X2 where MD5(X1) = MD5 (X2). Over the years, attacks on MD5 have only continued to improve, getting faster and more effective againstrealprotocols. But despite continuous advancements in cryptography, MD5 has lurked in network protocols for years, and is still playing a critical role in some protocols even today.
One such protocol is RADIUS (Remote Authentication Dial-In User Service). RADIUS was first designed in 1991 – during the era of dial-up Internet – but it remains an important authentication protocol used for remote access to routers, switches, and other networking gear by users and administrators. In addition to being used in networking environments, RADIUS is sometimes also used in industrial control systems. RADIUS traffic is still commonly transported over UDP in the clear, protected only by outdated cryptographic constructions based on MD5.
In this post, we present an improved attack against MD5 and use it to exploit all authentication modes of RADIUS/UDP apart from those that use EAP (Extensible Authentication Protocol). The attack allows a Monster-in-the-Middle (MitM) with access to RADIUS traffic to gain unauthorized administrative access to devices using RADIUS for authentication, without needing to brute force or steal passwords or shared secrets. This post discusses the attack and provides an overview of mitigations that network operators can use to improve the security of their RADIUS deployments.
RADIUS/UDP in Password Authentication Protocol (PAP) mode. Our attack also applies to RADIUS/UDP CHAP and RADIUS/UDP MS-CHAP authentication modes as well.
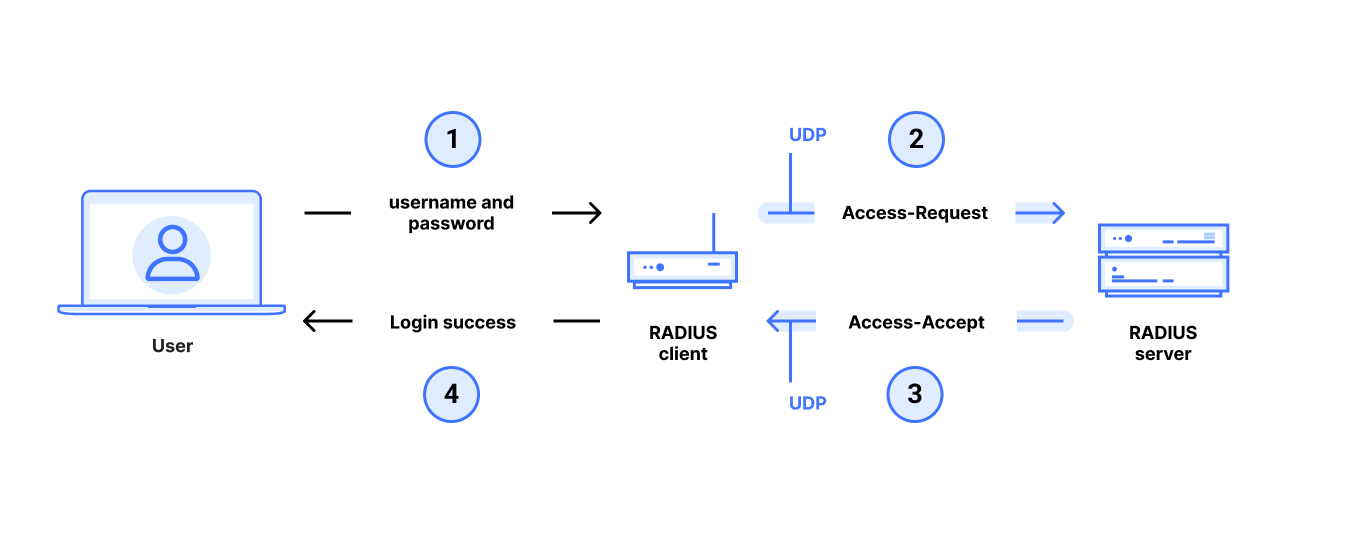
In a typical RADIUS use case, an end user gets administrative access to a router, switch, or other networked device by entering a username and password with administrator privileges at a login prompt. The target device runs a RADIUS client which queries a remote RADIUS server to determine whether the username and password are valid for login. This communication between the RADIUS client and RADIUS server is very sensitive: if an attacker can violate the integrity of this communication, it can control who can gain administrative access to the device, even if the connection between user and device is secure. An attacker that gains administrative access to a router or switch can redirect traffic, drop or add routes, and generally control the flow of network traffic. This makes RADIUS an important protocol for the security of modern networks.
Our understanding of cryptography and protocol design was fairly unrefined when RADIUS was first introduced in the 1990s. Despite this, the protocol hasn’t changed much, likely because updating RADIUS deployments can be tricky due to its use in legacy devices (e.g. routers) that are harder to upgrade.
Prior to our work, there was no publicly-known attack exploiting MD5 to violate the integrity of the RADIUS/UDP traffic. However, attacks continue to get faster, cheaper, become more widely available, and become more practical against real protocols. Protocols that we thought might be “secure enough”, in spite of their reliance on outdated cryptography, tend to crack as attacks continue to improve over time.
In our attack, a MitM gains unauthorized access to a networked device by violating the integrity of communications between the device’s RADIUS client and its RADIUS server. In other words, our MitM attacker has access to RADIUS traffic and uses it to pivot into unauthorized access to the devices hosting the RADIUS clients that generated this RADIUS traffic. From there, the attacker can gain administrative access to the networking device and thus control the Internet traffic that flows through the network.
Overview of the Blast-RADIUS attack on RADIUS/UDP in PAP mode
RADIUS/UDP has many modes, and our attacks work on all authentication modes except for those using EAP (Extensible Authentication Protocol). To simplify exposition, we start by focusing on the RADIUS/UDP PAP (Password Authentication Protocol) authentication mode.
With RADIUS/UDP PAP authentication, the RADIUS client sends a username and password in an Access-Request packet to the RADIUS server over UDP. The server drops the packet if its source IP address does not match a known client, but otherwise the Access-Request is entirely unauthenticated. This makes it vulnerable to modifications by a MitM.
The RADIUS server responds with either an Access-Reject, Access-Accept (or possibly also an Access-Challenge)packet sent to the RADIUS client over UDP. These response packets are “authenticated” with an ad hoc “message authentication code (MAC)” to prevent modifications by an MitM. This “MAC” is based on MD5 and is called the Response Authenticator.
This ad hoc construction in the Response Authenticator attribute has been part of the RADIUS protocol since 1994. It was not changed in 1997, when HMAC was standardized in order to construct a provably-secure cryptographic MAC using a cryptographic hash function. It was not changed in 2004, when the first collisions in MD5 were found. And it is still part of the protocol today.
In this post, we’ll describe our improved attack on MD5 as it is used in the RADIUS Response Authenticator.
The RADIUS Response Authenticator
The Response Authenticator “authenticates” RADIUS responses via an ad hoc MD5 construction that involves concatenating several fields in the RADIUS request and response packets, appending a Secret shared between RADIUS client and RADIUS server, and then hashing the result with MD5. Specifically, the Response Authenticator is computed as
MD5( Code || ID || Len || Request Authenticator || Attributes || Secret )
where the Code, ID, Length, and Attributes are copied directly from the response packet, and Request Authenticator is a 16-byte random nonce and included in the corresponding request packet.
First, let’s simplify the construction in the Response Authenticator as: the “MAC” on message X1 is computed as MD5 (X1 || Secret) where X1 is a message and Secret is the secret key for the “MAC”.
Next, we note that MD5 is vulnerable to length extension attacks. Namely, given MD5(X) for an unknown X, along with the length of X, then anyone who knows Y can compute MD5(X || Y).
Length extension attacks are possible because of how MD5 processes inputs in consecutive blocks, and are the primary reason why HMAC was standardized in 1997.
This block-wise processing is also an issue for the Response Authenticator of RADIUS. If someone finds an MD5 collision, namely two different messages X1 and X2 such that MD5(X1) = MD5(x2), then it follows that MD5 (X1 || Secret) = MD5 (X2 || Secret).
This breaks the security of the “MAC”. Here’s how: consider an attacker that finds two messages X1 and X2 that are an MD5 collision. The attacker then learns the “MAC” on X1, which is
MD5 (X1 || Secret). Now the attacker can forge the “MAC” on X2 without ever needing to know the Secret, simply by reusing the “MAC” on X1. This attack violates the security definition of a message authentication code.
This attack is especially concerning since finding MD5 collisions has been possible since 2004.
The first attacks on MD5 in 2004 produced so-called “identical prefix collisions” of the form
MD5 (P || G1 || S) = MD5 (P || G2 || S), where P is a meaningful message, S is a meaningful message, and G1 and G2 are meaningless gibberish. This attack has since been made very fast and can now run on a regular consumer laptop in seconds. While this attack is a devastating blow for any cryptographic hash function, it’s still pretty difficult to use gibberish messages (with identical prefixes) to create practical attacks on real protocols like RADIUS.
In 2007, a more powerful attack was presented, the “chosen-prefix collision attack”. This attack is slower and more costly, but allows the prefixes in the collision to be different, making it valuable for practical attacks on real protocols. In other words, the collision is of the form
MD5 (P1 || G1 || S) = MD5 (P2 || G2 || S), where P1 and P2 are different freely-chosen meaningful messages, G1 and G2 are meaningless gibberish and S is a meaningful message. We will use an improved version of this attack to break the security of the RADIUS/UDP Response Authenticator.
Roughly speaking, in our attack, P1 will correspond to a RADIUS Access-Reject, and P2 will correspond to a RADIUS Access-Accept, thus allowing us to break the security of the protocol by letting an unauthorized user log into a networking device running a RADIUS client.
Before we move on, note that in 2000, RFC2869 added support for HMAC-MD5 to RADIUS/UDP, using a new attribute called Message-Authenticator. HMAC thwarts attacks that use hash function collisions to break the security of a MAC, and HMAC is a secure MAC as long as the underlying hash function is a pseudorandom function. As of this writing, we have not seen a public attack demonstrating that HMAC-MD5 is not a good MAC.
Nevertheless, the RADIUS specifications state that Message-Authenticator is optional for all modes of RADIUS/UDP apart from those that use EAP (Extensible Authentication Protocol). Our attack is for non-EAP authentication modes of RADIUS/UDP using default setups that do not use Message-Authenticator. We further discuss Message-Authenticator and EAP later in this post.
Blast-RADIUS attack
Given that the ad hoc MD5 construction in the Response Authenticator is usually the only thing protecting the integrity of the RADIUS/UDP message, can we exploit it to break the security of the RADIUS/UDP protocol? Yes, we can.
But it wasn’t that easy. We needed to optimize and improve existing chosen-prefix collision attacks on MD5 to (a) make them fast enough to work on packets in flight, (b) respect the limitations imposed by the RADIUS protocol and (c) the RADIUS/UDP packet format.
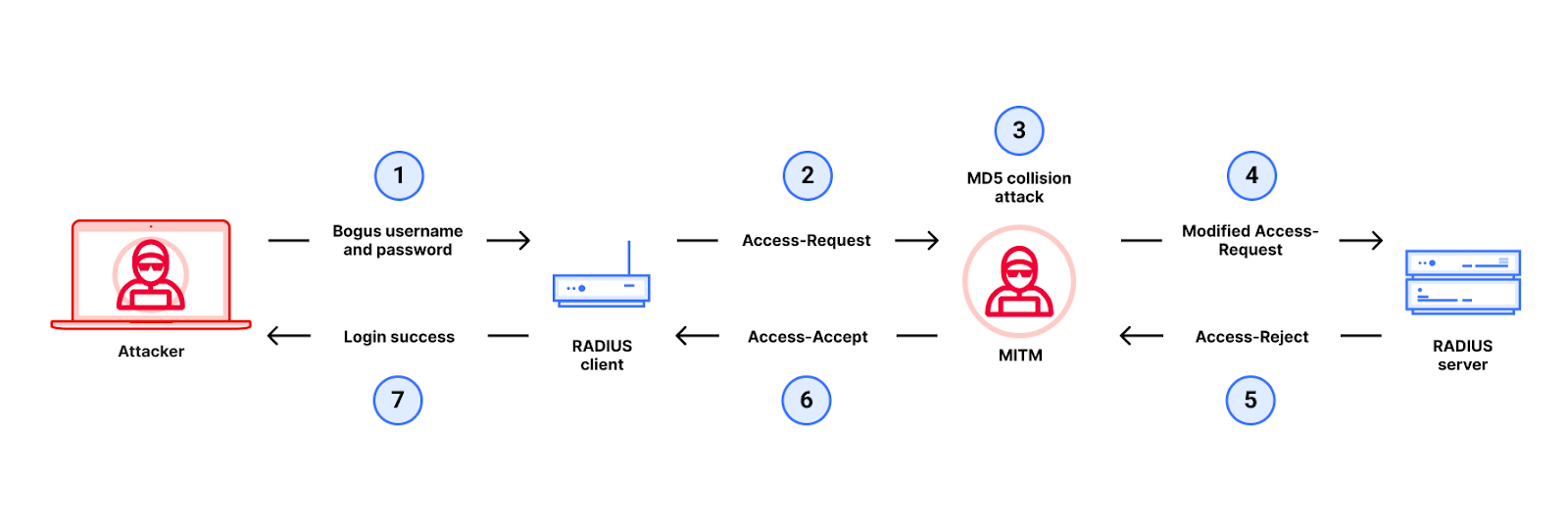
Here is how we did it. The attacker uses a MitM between a RADIUS client (e.g. a router) and RADIUS server to change an Access-Reject packet into an Access-Accept packet by exploiting weaknesses in MD5, thus gaining unauthorized access (to the router). The detailed flow of the attack is in the diagram below.
Details of the Blast-RADIUS attack
Let’s walk through each step of the attack.
1. First, the attacker tries to log in to the device running to the RADIUS client using a bogus username and password.
2. The RADIUS client sends an Access-Request packet that is intercepted by the MitM.
3. Next, the MitM then executes an MD5 chosen-prefix collision attack as follows:
Prefix P1 corresponds to attributes hashed with MD5 to produce the Response Authenticator of an Access-Reject packet. Prefix P2 corresponds to the attributes for an Access-Accept packet. The MitM can predict P1 and P2 simply by looking at the Access-Request packet that it intercepted.
Next, the attacker then runs the MD5 chosen-prefix collision attack to find the two gibberish blocks, G1 (the RejectGib shown in the figure above) and G2 (the AcceptGib) to obtain an MD5 collision between P1 || RejectGib and P2 || AcceptGib.
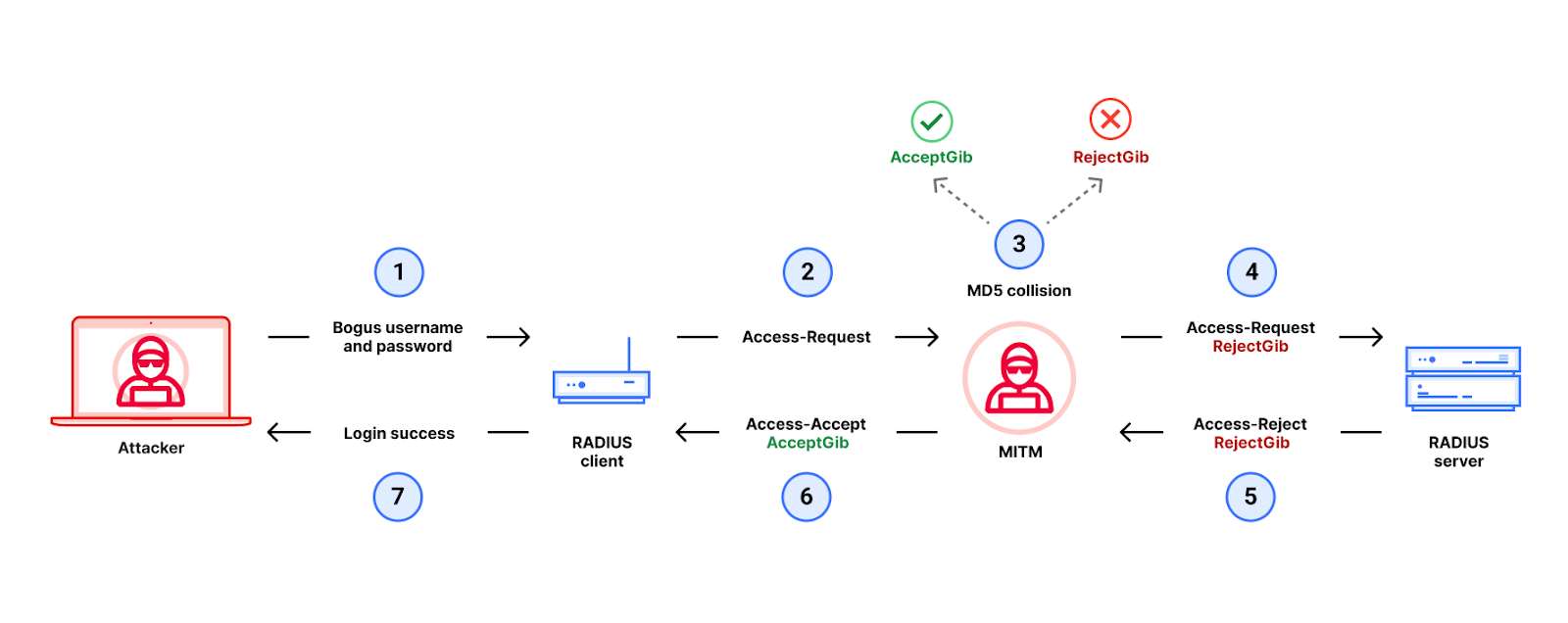
Now we need to get the collision gibberish into the RADIUS packets somehow.
4. To do this, we are going to use an optional RADIUS/UDP attribute called the Proxy-State. The Proxy-State is an ideal place to stuff this gibberish because a RADIUS server must echo back any information it receives in a Proxy-State attribute from the RADIUS client. Even better for our attacker, the Proxy-State must also be hashed by MD5 in the corresponding response’s Response Authenticator.
Our MitM takes the gibberish RejectGib and adds it into the Access-Request packet that the MitM intercepted as multiple Proxy-State attributes. For this to work, we had to ensure that our collision gibberish (RejectGib and AcceptGib) is properly formatted as multiple Proxy-State attributes. This is one novel cryptographic aspect of our attack that you read more about here.
Next, we are going to exploit the fact that the RADIUS server will echo back the gibberish in its response.
5. The RADIUS server receives the modified Access-Request and responds with an Access-Reject packet. This Access-Reject packet includes (a) the Proxy-State attributes containing the RejectGib and (b) a Response Authenticator computed as MD5 (P1 || RejectGib || Secret).
Note that we have successfully changed the input to the Response Authenticator to be one of the MD5 collisions found by the MitM!
6. Finally, the MitM intercepts the Access-Reject packet, and extracts the Response-Authenticator from the intercepted packet, and uses it to forge an Access-Accept packet using our MD5 collision.
The forged packet is (a) formatted as an Access-Accept packet that (b) has the AcceptGib in Proxy-State and (c) copies the Response Authenticator from the Access-Reject packet that the MitM intercepted from the server.
We have now used our MD5 collision to replace an Access-Reject with an Access-Accept.
7. The forged Access-Accept packet arrives at the RADIUS client, which accepts it because
the input to the Response Authenticator is P2 || AcceptGib
the Response-Authenticator is MD5 (P1 || RejectGib || Secret)
P1 || RejectGib is an MD5 collision with P2 || AcceptGib, which implies that
MD5 (P1 || RejectGib || Secret) = MD5 (P2 || AcceptGib || Secret)In other words, the Response-Authenticator on the forged Access-Accept packet is valid.
The attacker has successfully logged into the device.
But, the attack has to be fast.
For all of this to work, our MD5 collision attack had to be fast! If finding the collision takes too long, the client could time out while waiting for a response packet and the attack would fail.
Importantly, the attack cannot be precomputed. One of the inputs to the Response Authenticator is the Request Authenticator attribute, a 16-byte random nonce included in the request packet. Because the Request Authenticator is freshly chosen for every request, the MitM cannot predict the Request Authenticator without intercepting the request packet in flight.
Existing collision attacks on MD5 were too slow for realistic client timeouts; when we started our work, reported attacks took hours (or even up to a day) to find MD5 chosen-prefix collisions. So, we had to devise a new, faster attack on MD5.
To do this, our team improved existing chosen-prefix collision attacks on MD5 and optimized them for speed and space (in addition to figuring out how to make our collision gibberish fit into RADIUS Proxy-State attributes). We demonstrated an improved attack that can run in minutes on an aging cluster of about 2000 CPU cores ranging from 7 to 10 years old, plus four newer low-end GPUs at UCSD. Less than two months after we started this project, we could execute the attack in under five minutes, and validate (in a lab setting) that it works on popular commercial RADIUS implementations.
While many RADIUS devices (like the ones we tested in the lab) tolerate timeouts of five minutes, the default timeouts on most devices are closer to 30 or 60 seconds. Nevertheless, at this point, we had proved our attack. The attack is highly parallelizable. A sophisticated adversary would have easy access to better computing resources than we did, or could further optimize the attack using low-cost cloud compute resources, GPUs or hardware. In other words, a motivated attacker could use better computing resources to get our attack working against RADIUS devices with timeouts shorter than 5 minutes.
It was late January 2024. We had an attack that allows an attacker with MitM access to RADIUS/UDP traffic in PAP mode to gain unauthorized access to devices that use RADIUS to decide who should have administrative access to the device. We stopped our work, wrote up a paper, and got in touch with CERT to coordinate disclosure. In response, CERT has assigned CVE-2024-3596 and VU#456537 to this vulnerability, which affects all authentication modes of RADIUS/UDP apart from those that use EAP.
What’s next?
It’s never easy to update network protocols, especially protocols like RADIUS that have been widely used since the 1990s and enjoy multi-vendor support. Nevertheless, we hope this research will provide an opportunity for network operators to review the security of their RADIUS deployments, and to take advantage of patches released by many RADIUS vendors in response to our work.
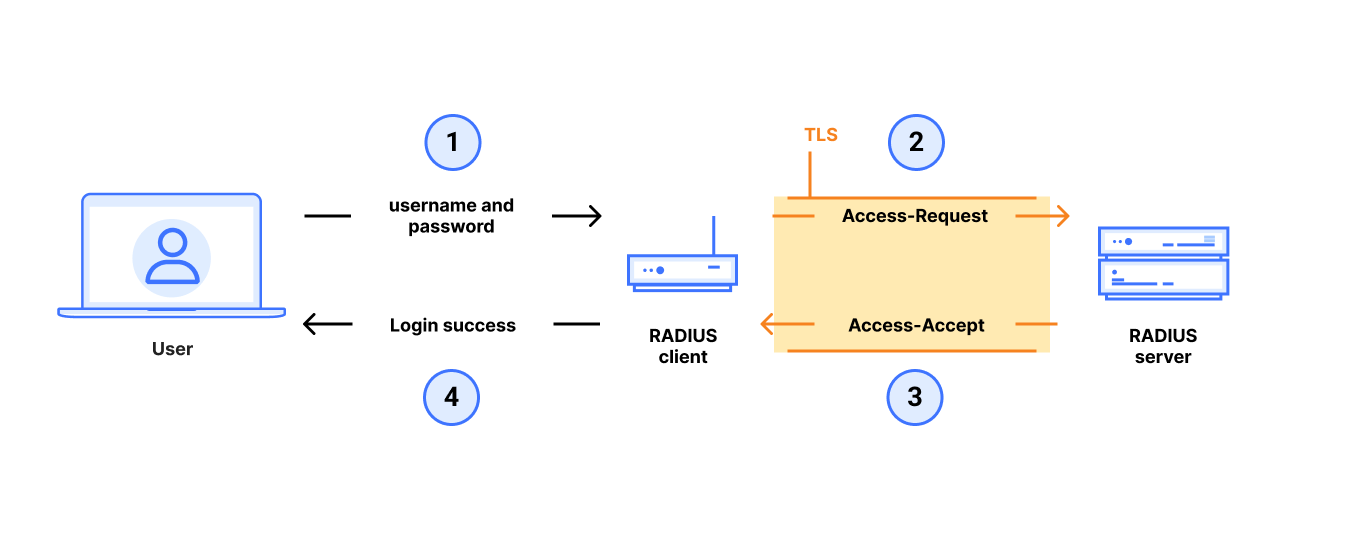
Transitioning to RADIUS over TLS: Following our work, many more vendors now offer RADIUS over TLS (sometimes known as RADSEC), which wraps the entire RADIUS packet payload into a TLS stream sent from RADIUS client to RADIUS server. This is the best mitigation against our attack and any new MD5 attacks that might emerge.
Before implementing this mitigation, network operators should verify that they can upgrade both their RADIUS clients and their RADIUS servers to support RADIUS over TLS. There is a risk that legacy clients that cannot be upgraded or patched would still need to speak RADIUS/UDP.
Patches for RADIUS/UDP. There is also a new short-term mitigation for RADIUS/UDP. In this post, we only cover mitigations for client-server deployments; see this new whitepaper by Alan DeKok for mitigations for more complex “multihop” RADIUS deployment that involve more parties than just a client and a server.
Earlier, we mentioned that the RADIUS specifications have a Message-Authenticator attribute that uses HMAC-MD5 and is optional for RADIUS/UDP modes that do not use EAP. The new mitigation involves making the Message-Authenticator a requirement for both request and response packets for all modes of RADIUS/UDP. The mitigation works because Message-Authenticator uses HMAC-MD5, which is not susceptible to our MD5 chosen-prefix collision attack.
Specifically:
The recipient of any RADIUS/UDP packet must always require the packet to contain a Message-Authenticator, and must validate the HMAC-MD5 in the Message-Authenticator.
RADIUS servers should send the Message-Authenticator as the first attribute in every Access-Accept or Access-Reject response sent by the RADIUS server.
There are a few things to watch out for when applying this patch in practice. Because RADIUS is a client-server protocol, we need to consider (a) the efficacy of the patch if it is not uniformly applied to all RADIUS clients and servers and (b) the risk of the patch breaking client-server compatibility.
Let’s first look at (a) efficacy. Patching only the client does not stop our attacks. Why? Because the mitigation requires the sender to include a Message-Authenticator in the packet, AND the recipient to require a Message-Authenticator to be present in the packet and to validate it. (In other words, both client and server have to change their behaviors.) If the recipient does not require the Message-Authenticator to be present in the packet, the MitM could do a downgrade attack where it strips the Message-Authenticator from the packet and our attack would still work. Meanwhile, there is some evidence (see this whitepaper by Alan DeKok) that patching only the server might be more effective, due to mitigation #2, sending the Message-Authenticator as the first attribute in the response packet.
Now let’s consider (b) the risk of breaking client-server compatibility.
Deploying the patch on clients is unlikely to break compatibility, because the RADIUS specifications have long required that RADIUS servers MUST be able to process any Message-Authenticator attribute sent by a RADIUS client. That said, we cannot rule out the existence of RADIUS servers that do not comply with this long-standing aspect of the specification, so we suggest testing against the RADIUS servers before patching clients.
On the other side, patching the server without breaking compatibility with legacy clients could be trickier. Commercial RADIUS servers are mostly built on one of a tiny number of implementations (like FreeRADIUS), and actively-maintained implementations should be up-to-date on mitigations. However, there is a wider set of RADIUS client implementations, some of which are legacy and difficult to patch. If an unpatched legacy client does not know how to send a Message Authenticator attribute, then the server cannot require it from that client without breaking backwards compatibility.
The bottom line is that for all of this to work, it is important to patch servers AND patch clients.
You can find more discussion on RADIUS/UDP mitigations in a new whitepaper by Alan DeKok, which also contains guidance on how to apply these mitigations to more complex “multihop” RADIUS deployments.
Isolating RADIUS traffic. It has long been a best practice to avoid sending RADIUS/UDP or RADIUS/TCP traffic in the clear over the public Internet. On internal networks, a best practice is to isolate RADIUS traffic in a restricted-access management VLAN or to tunnel it over TLS or IPsec. This is helpful because it makes RADIUS traffic more difficult for attackers to access, so that it’s harder to execute our attack. That said, an attacker may still be able to execute our attack to accomplish a privilege escalation if a network misconfiguration or compromise allows a MitM to access RADIUS traffic. Thus, the other mitigations we mention above are valuable even if RADIUS traffic is isolated.
Non-mitigations. While it is possible to use TCP as transport for RADIUS, RADIUS/TCP is experimental, and offers no benefit over RADIUS/UDP or RADIUS/TLS. (Confusingly, RADIUS/TCP is sometimes also called RADSEC; but in this post we only use RADSEC to describe RADIUS/TLS.) We discuss other non-mitigations in our paper.
A side note about EAP-TLS
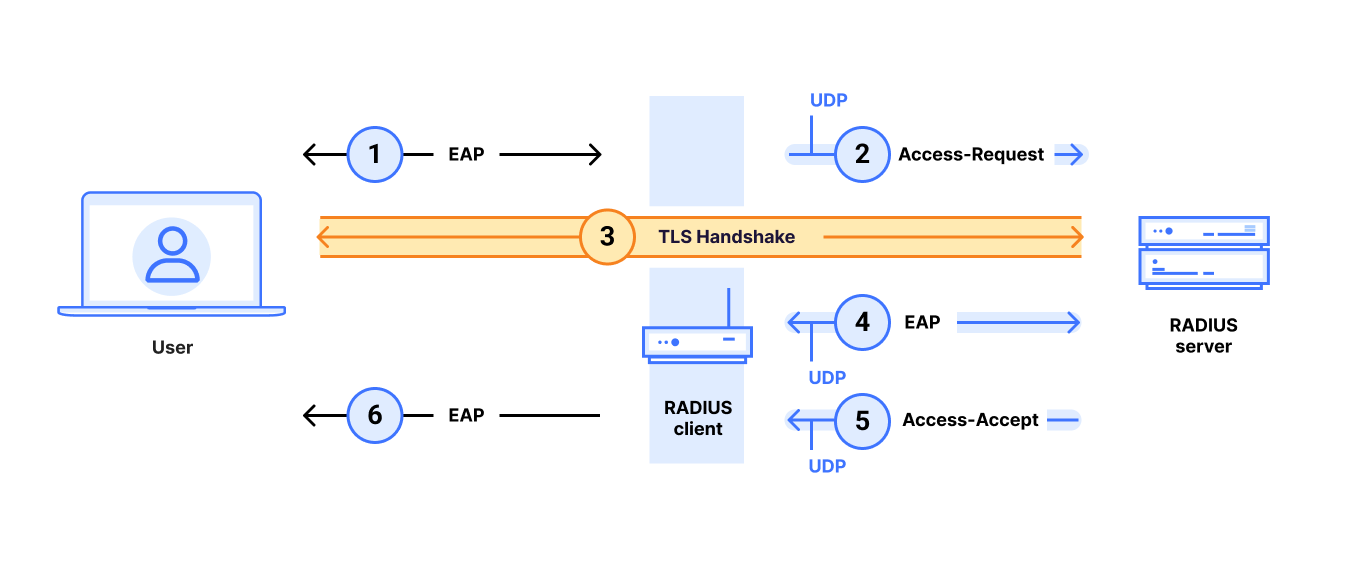
When we were checking inside Cloudflare for internal exposure to the Blast-RADIUS attack, we found EAP-TLS used in certain office routers in our internal Wi-Fi networks. We ultimately concluded that these routers were not vulnerable to the attack. Nevertheless, we share our experience here to provide more exposition about the use of EAP (Extensible Authentication Protocol) and its implications for security. RADIUS uses EAP in several different modes which can be very complicated and are not the focus of this post. Still, we provide a limited sketch of EAP-TLS to show how it is different from RADIUS/TLS.
First, it is important to note that even though EAP-TLS and RADIUS/TLS have similar names, the two protocols are very different. RADIUS/TLS encapsulates RADIUS traffic in TLS (as described above). But EAP-TLS does not; in fact, EAP-TLS sends RADIUS traffic over UDP!
EAP-TLS only uses the TLS handshake to authenticate the user; the TLS handshake is executed between the user and the RADIUS server. However, TLS is not used to encrypt or authenticate the RADIUS packets; the RADIUS client and RADIUS still communicate in the clear over UDP.
The user initiates EAP authentication with the RADIUS client.
The RADIUS client sends a RADIUS/UDP Access Request to the RADIUS server over UDP.
The user and the Authentication Server engage in a TLS handshake. This TLS handshake may or may not be encapsulated inside RADIUS/UDP packets.
The parties may communicate further.
The RADIUS server sends the RADIUS client a RADIUS/UDP Access-Accept (or Access-Reject) packet over UDP.
The RADIUS client indicates to the user that the EAP login was successful (or not).
As shown in the figure, with EAP-TLS the Access-Request and Access-Accept/Access-Reject are RADIUS/UDP messages. Therefore, there is a question as to whether a Blast-RADIUS attack can be executed against these RADIUS/UDP messages.
We have not demonstrated any attack against an implementation of EAP-TLS in RADIUS.
However, we cannot rule out the possibility that some EAP-TLS implementations could be vulnerable to a variant of our attack. This is due to ambiguities in the RADIUS specifications. At a high level, the issue is that:
The RADIUS specifications require that any RADIUS/UDP packet with EAP attributes includes the HMAC-MD5 Message-Authenticator attribute, which would stop our attack.
However, what happens if a MitM attacker strips the EAP attributes from the RADIUS/UDP response packet? If the MitM could get away with stripping out the EAP attribute, it could also get away with stripping out the Message-Authenticator (which is optional for non-EAP modes of RADIUS/UDP), and a variant of the Blast-RADIUS attack might work. The ambiguity follows because the specifications are unclear on what the RADIUS client should do if it sent a request with an EAP attribute but got back a response without an EAP attribute and without a Message-Authenticator. See more details and specific quotes from the specifications in our paper.
Therefore, we emphasize that the recommended mitigation is RADIUS/TLS (also called RADSEC), which is different from EAP-TLS.
As a final note, we mentioned that the Cloudflare’s office routers that were using EAP-TLS were not vulnerable to the Blast-RADIUS attack. This is because these routers were set to run with local authentication, where both the RADIUS client and the RADIUS server are confined inside the router (thus preventing a MitM from gaining access to the traffic sent between RADIUS client and RADIUS server, preventing our attack). Nevertheless, we should note that this vendor’s routers have many settings, some of which involve using an external RADIUS server. Fortunately, this vendor is one of many that have recently released support for RADIUS/TLS (also called RADSEC).
Work in the IETF
The IETF is an important venue for standardizing network protocols like RADIUS. The IETF’s radext working group is currently considering an initiative to deprecate RADIUS/UDP and create a “standards track” specification of RADIUS over TLS or DTLS, that should help accelerate the deployment of RADIUS/TLS in the field. We hope that our work will accelerate the community’s ongoing efforts to secure RADIUS and reduce its reliance on MD5.
The vulnerability, which is a signal handler race condition in OpenSSH’s server (sshd), allows unauthenticated remote code execution (RCE) as root on glibc-based Linux systems; that presents a significant security risk. This race condition affects sshd in its default configuration.
[…]
This vulnerability, if exploited, could lead to full system compromise where an attacker can execute arbitrary code with the highest privileges, resulting in a complete system takeover, installation of malware, data manipulation, and the creation of backdoors for persistent access. It could facilitate network propagation, allowing attackers to use a compromised system as a foothold to traverse and exploit other vulnerable systems within the organization.
Moreover, gaining root access would enable attackers to bypass critical security mechanisms such as firewalls, intrusion detection systems, and logging mechanisms, further obscuring their activities. This could also result in significant data breaches and leakage, giving attackers access to all data stored on the system, including sensitive or proprietary information that could be stolen or publicly disclosed.
This vulnerability is challenging to exploit due to its remote race condition nature, requiring multiple attempts for a successful attack. This can cause memory corruption and necessitate overcoming Address Space Layout Randomization (ASLR). Advancements in deep learning may significantly increase the exploitation rate, potentially providing attackers with a substantial advantage in leveraging such security flaws.
polyfill.io, a popular JavaScript library service, can no longer be trusted and should be removed from websites.
Multiple reports, corroborated with data seen by our own client-side security system, Page Shield, have shown that the polyfill service was being used, and could be used again, to inject malicious JavaScript code into users’ browsers. This is a real threat to the Internet at large given the popularity of this library.
We have, over the last 24 hours, released an automatic JavaScript URL rewriting service that will rewrite any link to polyfill.io found in a website proxied by Cloudflare to a link to our mirror under cdnjs. This will avoid breaking site functionality while mitigating the risk of a supply chain attack.
Any website on the free plan has this feature automatically activated now. Websites on any paid plan can turn on this feature with a single click.
You can find this new feature under Security ⇒ Settings on any zone using Cloudflare.
Contrary to what is stated on the polyfill.io website, Cloudflare has never recommended the polyfill.io service or authorized their use of Cloudflare’s name on their website. We have asked them to remove the false statement and they have, so far, ignored our requests. This is yet another warning sign that they cannot be trusted.
If you are not using Cloudflare today, we still highly recommend that you remove any use of polyfill.io and/or find an alternative solution. And, while the automatic replacement function will handle most cases, the best practice is to remove polyfill.io from your projects and replace it with a secure alternative mirror like Cloudflare’s even if you are a customer.
You can do this by searching your code repositories for instances of polyfill.io and replacing it with cdnjs.cloudflare.com/polyfill/ (Cloudflare’s mirror). This is a non-breaking change as the two URLs will serve the same polyfill content. All website owners, regardless of the website using Cloudflare, should do this now.
How we came to this decision
Back in February, the domain polyfill.io, which hosts a popular JavaScript library, was sold to a new owner: Funnull, a relatively unknown company. At the time, we were concerned that this created a supply chain risk. This led us to spin up our own mirror of the polyfill.io code hosted under cdnjs, a JavaScript library repository sponsored by Cloudflare.
The new owner was unknown in the industry and did not have a track record of trust to administer a project such as polyfill.io. The concern, highlighted even by the original author, was that if they were to abuse polyfill.io by injecting additional code to the library, it could cause far reaching security problems on the Internet affecting several hundreds of thousands websites. Or it could be used to perform a targeted supply-chain attack against specific websites.
Unfortunately, that worry came true on June 25, 2024 as the polyfill.io service was being used to inject nefarious code that, under certain circumstances, redirected users to other websites.
We have taken the exceptional step of using our ability to modify HTML on the fly to replace references to the polyfill.io CDN in our customers’ websites with links to our own, safe, mirror created back in February.
In the meantime, additional threat feed providers have also taken the decision to flag the domain as malicious. We have not outright blocked the domain through any of the mechanisms we have because we are concerned it could cause widespread web outages given how broadly polyfill.io is used with some estimates indicating usage on nearly 4% of all websites.
Corroborating data with Page Shield
The original report indicates that malicious code was injected that, under certain circumstances, would redirect users to betting sites. It was doing this by loading additional JavaScript that would perform the redirect, under a set of additional domains which can be considered Indicators of Compromise (IoCs):
(note the intentional misspelling of Google Analytics)
Page Shield, our client side security solution, is available on all paid plans. When turned on, it collects information about JavaScript files loaded by end user browsers accessing your website.
By looking at the database of detected JavaScript files, we immediately found matches with the IoCs provided above starting as far back as 2024-06-08 15:23:51 (first seen timestamp on Page Shield detected JavaScript file). This was a clear indication that malicious activity was active and associated with polyfill.io.
Replacing insecure JavaScript links to polyfill.io
To achieve performant HTML rewriting, we need to make blazing-fast HTML alterations as responses stream through Cloudflare’s network. This has been made possible by leveraging ROFL (Response Overseer for FL). ROFL powers various Cloudflare products that need to alter HTML as it streams, such as Cloudflare Fonts,Email Obfuscation and Rocket Loader
ROFL is developed entirely in Rust. The memory-safety features of Rust are indispensable for ensuring protection against memory leaks while processing a staggering volume of requests, measuring in the millions per second. Rust’s compiled nature allows us to finely optimize our code for specific hardware configurations, delivering performance gains compared to interpreted languages.
The performance of ROFL allows us to rewrite HTML on-the-fly and modify the polyfill.io links quickly, safely, and efficiently. This speed helps us reduce any additional latency added by processing the HTML file.
If the feature is turned on, for any HTTP response with an HTML Content-Type, we parse all JavaScript script tag source attributes. If any are found linking to polyfill.io, we rewrite the src attribute to link to our mirror instead. We map to the correct version of the polyfill service while the query string is left untouched.
The logic will not activate if a Content Security Policy (CSP) header is found in the response. This ensures we don’t replace the link while breaking the CSP policy and therefore potentially breaking the website.
Default on for free customers, optional for everyone else
Cloudflare proxies millions of websites, and a large portion of these sites are on our free plan. Free plan customers tend to have simpler applications while not having the resources to update and react quickly to security concerns. We therefore decided to turn on the feature by default for sites on our free plan, as the likelihood of causing issues is reduced while also helping keep safe a very large portion of applications using polyfill.io.
Paid plan customers, on the other hand, have more complex applications and react quicker to security notices. We are confident that most paid customers using polyfill.io and Cloudflare will appreciate the ability to virtually patch the issue with a single click, while controlling when to do so.
All customers can turn off the feature at any time.
This isn’t the first time we’ve decided a security problem was so widespread and serious that we’d enable protection for all customers regardless of whether they were a paying customer or not. Back in 2014, we enabled Shellshock protection for everyone. In 2021, when the log4j vulnerability was disclosed we rolled out protection for all customers.
Do not use polyfill.io
If you are using Cloudflare, you can remove polyfill.io with a single click on the Cloudflare dashboard by heading over to your zone ⇒ Security ⇒ Settings. If you are a free customer, the rewrite is automatically active. This feature, we hope, will help you quickly patch the issue.
Nonetheless, you should ultimately search your code repositories for instances of polyfill.io and replace them with an alternative provider, such as Cloudflare’s secure mirror under cdnjs (https://cdnjs.cloudflare.com/polyfill/). Website owners who are not using Cloudflare should also perform these steps.
Abstract: LLM agents have become increasingly sophisticated, especially in the realm of cybersecurity. Researchers have shown that LLM agents can exploit real-world vulnerabilities when given a description of the vulnerability and toy capture-the-flag problems. However, these agents still perform poorly on real-world vulnerabilities that are unknown to the agent ahead of time (zero-day vulnerabilities).
In this work, we show that teams of LLM agents can exploit real-world, zero-day vulnerabilities. Prior agents struggle with exploring many different vulnerabilities and long-range planning when used alone. To resolve this, we introduce HPTSA, a system of agents with a planning agent that can launch subagents. The planning agent explores the system and determines which subagents to call, resolving long-term planning issues when trying different vulnerabilities. We construct a benchmark of 15 real-world vulnerabilities and show that our team of agents improve over prior work by up to 4.5×.
The LLMs aren’t finding new vulnerabilities. They’re exploiting zero-days—which means they are not trained on them—in new ways. So think about this sort of thing combined with another AI that finds new vulnerabilities in code.
These kinds of developments are important to follow, as they are part of the puzzle of a fully autonomous AI cyberattack agent. I talk about this sort of thing more here.
Cloudforce One is publishing the results of our investigation and real-time effort to detect, deny, degrade, disrupt, and delay threat activity by the Russia-aligned threat actor FlyingYeti during their latest phishing campaign targeting Ukraine. At the onset of Russia’s invasion of Ukraine on February 24, 2022, Ukraine introduced a moratorium on evictions and termination of utility services for unpaid debt. The moratorium ended in January 2024, resulting in significant debt liability and increased financial stress for Ukrainian citizens. The FlyingYeti campaign capitalized on anxiety over the potential loss of access to housing and utilities by enticing targets to open malicious files via debt-themed lures. If opened, the files would result in infection with the PowerShell malware known as COOKBOX, allowing FlyingYeti to support follow-on objectives, such as installation of additional payloads and control over the victim’s system.
Since April 26, 2024, Cloudforce One has taken measures to prevent FlyingYeti from launching their phishing campaign – a campaign involving the use of Cloudflare Workers and GitHub, as well as exploitation of the WinRAR vulnerability CVE-2023-38831. Our countermeasures included internal actions, such as detections and code takedowns, as well as external collaboration with third parties to remove the actor’s cloud-hosted malware. Our effectiveness against this actor prolonged their operational timeline from days to weeks. For example, in a single instance, FlyingYeti spent almost eight hours debugging their code as a result of our mitigations. By employing proactive defense measures, we successfully stopped this determined threat actor from achieving their objectives.
Executive Summary
On April 18, 2024, Cloudforce One detected the Russia-aligned threat actor FlyingYeti preparing to launch a phishing espionage campaign targeting individuals in Ukraine.
From mid-April to mid-May, we observed FlyingYeti conduct reconnaissance activity, create lure content for use in their phishing campaign, and develop various iterations of their malware. We assessed that the threat actor intended to launch their campaign in early May, likely following Orthodox Easter.
After several weeks of monitoring actor reconnaissance and weaponization activity (Cyber Kill Chain Stages 1 and 2), we successfully disrupted FlyingYeti’s operation moments after the final COOKBOX payload was built.
The payload included an exploit for the WinRAR vulnerability CVE-2023-38831, which FlyingYeti will likely continue to use in their phishing campaigns to infect targets with malware.
We offer steps users can take to defend themselves against FlyingYeti phishing operations, and also provide recommendations, detections, and indicators of compromise.
Who is FlyingYeti?
FlyingYeti is the cryptonym given by Cloudforce One to the threat group behind this phishing campaign, which overlaps with UAC-0149 activity tracked by CERT-UA in February and April 2024. The threat actor uses dynamic DNS (DDNS) for their infrastructure and leverages cloud-based platforms for hosting malicious content and for malware command and control (C2). Our investigation of FlyingYeti TTPs suggests this is likely a Russia-aligned threat group. The actor appears to primarily focus on targeting Ukrainian military entities. Additionally, we observed Russian-language comments in FlyingYeti’s code, and the actor’s operational hours falling within the UTC+3 time zone.
Campaign background
In the days leading up to the start of the campaign, Cloudforce One observed FlyingYeti conducting reconnaissance on payment processes for Ukrainian communal housing and utility services:
April 22, 2024 – research into changes made in 2016 that introduced the use of QR codes in payment notices
April 22, 2024 – research on current developments concerning housing and utility debt in Ukraine
April 25, 2024 – research on the legal basis for restructuring housing debt in Ukraine as well as debt involving utilities, such as gas and electricity
Cloudforce One judges that the observed reconnaissance is likely due to the Ukrainian government’s payment moratorium introduced at the start of the full-fledged invasion in February 2022. Under this moratorium, outstanding debt would not lead to evictions or termination of provision of utility services. However, on January 9, 2024, the government lifted this ban, resulting in increased pressure on Ukrainian citizens with outstanding debt. FlyingYeti sought to capitalize on that pressure, leveraging debt restructuring and payment-related lures in an attempt to increase their chances of successfully targeting Ukrainian individuals.
Analysis of the Komunalka-themed phishing site
The disrupted phishing campaign would have directed FlyingYeti targets to an actor-controlled GitHub page at hxxps[:]//komunalka[.]github[.]io, which is a spoofed version of the Kyiv Komunalka communal housing site https://www.komunalka.ua. Komunalka functions as a payment processor for residents in the Kyiv region and allows for payment of utilities, such as gas, electricity, telephone, and Internet. Additionally, users can pay other fees and fines, and even donate to Ukraine’s defense forces.
Based on past FlyingYeti operations, targets may be directed to the actor’s Github page via a link in a phishing email or an encrypted Signal message. If a target accesses the spoofed Komunalka platform at hxxps[:]//komunalka[.]github[.]io, the page displays a large green button with a prompt to download the document “Рахунок.docx” (“Invoice.docx”), as shown in Figure 1. This button masquerades as a link to an overdue payment invoice but actually results in the download of the malicious archive “Заборгованість по ЖКП.rar” (“Debt for housing and utility services.rar”).
Figure 1: Prompt to download malicious archive “Заборгованість по ЖКП.rar”
A series of steps must take place for the download to successfully occur:
The target clicks the green button on the actor’s GitHub page hxxps[:]//komunalka.github[.]io
The target’s device sends an HTTP POST request to the Cloudflare Worker worker-polished-union-f396[.]vqu89698[.]workers[.]dev with the HTTP request body set to “user=Iahhdr”
The Cloudflare Worker processes the request and evaluates the HTTP request body
If the request conditions are met, the Worker fetches the RAR file from hxxps[:]//raw[.]githubusercontent[.]com/kudoc8989/project/main/Заборгованість по ЖКП.rar, which is then downloaded on the target’s device
Cloudforce One identified the infrastructure responsible for facilitating the download of the malicious RAR file and remediated the actor-associated Worker, preventing FlyingYeti from delivering its malicious tooling. In an effort to circumvent Cloudforce One’s mitigation measures, FlyingYeti later changed their malware delivery method. Instead of the Workers domain fetching the malicious RAR file, it was loaded directly from GitHub.
Analysis of the malicious RAR file
During remediation, Cloudforce One recovered the RAR file “Заборгованість по ЖКП.rar” and performed analysis of the malicious payload. The downloaded RAR archive contains multiple files, including a file with a name that contains the unicode character “U+201F”. This character appears as whitespace on Windows devices and can be used to “hide” file extensions by adding excessive whitespace between the filename and the file extension. As highlighted in blue in Figure 2, this cleverly named file within the RAR archive appears to be a PDF document but is actually a malicious CMD file (“Рахунок на оплату.pdf[unicode character U+201F].cmd”).
Figure 2: Files contained in the malicious RAR archive “Заборгованість по ЖКП.rar” (“Housing Debt.rar”)
FlyingYeti included a benign PDF in the archive with the same name as the CMD file but without the unicode character, “Рахунок на оплату.pdf” (“Invoice for payment.pdf”). Additionally, the directory name for the archive once decompressed also contained the name “Рахунок на оплату.pdf”. This overlap in names of the benign PDF and the directory allows the actor to exploit the WinRAR vulnerability CVE-2023-38831. More specifically, when an archive includes a benign file with the same name as the directory, the entire contents of the directory are opened by the WinRAR application, resulting in the execution of the malicious CMD. In other words, when the target believes they are opening the benign PDF “Рахунок на оплату.pdf”, the malicious CMD file is executed.
The CMD file contains the FlyingYeti PowerShell malware known as COOKBOX. The malware is designed to persist on a host, serving as a foothold in the infected device. Once installed, this variant of COOKBOX will make requests to the DDNS domain postdock[.]serveftp[.]com for C2, awaiting PowerShell cmdlets that the malware will subsequently run.
Alongside COOKBOX, several decoy documents are opened, which contain hidden tracking links using the Canary Tokens service. The first document, shown in Figure 3 below, poses as an agreement under which debt for housing and utility services will be restructured.
Figure 3: Decoy document Реструктуризація боргу за житлово комунальні послуги.docx
The second document (Figure 4) is a user agreement outlining the terms and conditions for the usage of the payment platform komunalka[.]ua.
The use of relevant decoy documents as part of the phishing and delivery activity are likely an effort by FlyingYeti operators to increase the appearance of legitimacy of their activities.
The phishing theme we identified in this campaign is likely one of many themes leveraged by this actor in a larger operation to target Ukrainian entities, in particular their defense forces. In fact, the threat activity we detailed in this blog uses many of the same techniques outlined in a recent FlyingYeti campaign disclosed by CERT-UA in mid-April 2024, where the actor leveraged United Nations-themed lures involving Peace Support Operations to target Ukraine’s military. Due to Cloudforce One’s defensive actions covered in the next section, this latest FlyingYeti campaign was prevented as of the time of publication.
Mitigating FlyingYeti activity
Cloudforce One mitigated FlyingYeti’s campaign through a series of actions. Each action was taken to increase the actor’s cost of continuing their operations. When assessing which action to take and why, we carefully weighed the pros and cons in order to provide an effective active defense strategy against this actor. Our general goal was to increase the amount of time the threat actor spent trying to develop and weaponize their campaign.
We were able to successfully extend the timeline of the threat actor’s operations from hours to weeks. At each interdiction point, we assessed the impact of our mitigation to ensure the actor would spend more time attempting to launch their campaign. Our mitigation measures disrupted the actor’s activity, in one instance resulting in eight additional hours spent on debugging code.
Due to our proactive defense efforts, FlyingYeti operators adapted their tactics multiple times in their attempts to launch the campaign. The actor originally intended to have the Cloudflare Worker fetch the malicious RAR file from GitHub. After Cloudforce One interdiction of the Worker, the actor attempted to create additional Workers via a new account. In response, we disabled all Workers, leading the actor to load the RAR file directly from GitHub. Cloudforce One notified GitHub, resulting in the takedown of the RAR file, the GitHub project, and suspension of the account used to host the RAR file. In return, FlyingYeti began testing the option to host the RAR file on the file sharing sites pixeldrain and Filemail, where we observed the actor alternating the link on the Komunalka phishing site between the following:
We notified GitHub of the actor’s evolving tactics, and in response GitHub removed the Komunalka phishing site. After analyzing the files hosted on pixeldrain and Filemail, we determined the actor uploaded dummy payloads, likely to monitor access to their phishing infrastructure (FileMail logs IP addresses, and both file hosting sites provide view and download counts). At the time of publication, we did not observe FlyingYeti upload the malicious RAR file to either file hosting site, nor did we identify the use of alternative phishing or malware delivery methods.
A timeline of FlyingYeti’s activity and our corresponding mitigations can be found below.
Event timeline
Date
Event Description
2024-04-18 12:18
Threat Actor (TA) creates a Worker to handle requests from a phishing site
2024-04-18 14:16
TA creates phishing site komunalka[.]github[.]io on GitHub
2024-04-25 12:25
TA creates a GitHub repo to host a RAR file
2024-04-26 07:46
TA updates the first Worker to handle requests from users visiting komunalka[.]github[.]io
2024-04-26 08:24
TA uploads a benign test RAR to the GitHub repo
2024-04-26 13:38
Cloudforce One identifies a Worker receiving requests from users visiting komunalka[.]github[.]io, observes its use as a phishing page
2024-04-26 13:46
Cloudforce One identifies that the Worker fetches a RAR file from GitHub (the malicious RAR payload is not yet hosted on the site)
2024-04-26 19:22
Cloudforce One creates a detection to identify the Worker that fetches the RAR
2024-04-26 21:13
Cloudforce One deploys real-time monitoring of the RAR file on GitHub
2024-05-02 06:35
TA deploys a weaponized RAR (CVE-2023-38831) to GitHub with their COOKBOX malware packaged in the archive
2024-05-06 10:03
TA attempts to update the Worker with link to weaponized RAR, the Worker is immediately blocked
2024-05-06 10:38
TA creates a new Worker, the Worker is immediately blocked
2024-05-06 11:04
TA creates a new account (#2) on Cloudflare
2024-05-06 11:06
TA creates a new Worker on account #2 (blocked)
2024-05-06 11:50
TA creates a new Worker on account #2 (blocked)
2024-05-06 12:22
TA creates a new modified Worker on account #2
2024-05-06 16:05
Cloudforce One disables the running Worker on account #2
2024-05-07 22:16
TA notices the Worker is blocked, ceases all operations
2024-05-07 22:18
TA deletes original Worker first created to fetch the RAR file from the GitHub phishing page
2024-05-09 19:28
Cloudforce One adds phishing page komunalka[.]github[.]io to real-time monitoring
2024-05-13 07:36
TA updates the github.io phishing site to point directly to the GitHub RAR link
2024-05-13 17:47
Cloudforce One adds COOKBOX C2 postdock[.]serveftp[.]com to real-time monitoring for DNS resolution
2024-05-14 00:04
Cloudforce One notifies GitHub to take down the RAR file
2024-05-15 09:00
GitHub user, project, and link for RAR are no longer accessible
2024-05-21 08:23
TA updates Komunalka phishing site on github.io to link to pixeldrain URL for dummy payload (pixeldrain only tracks view and download counts)
2024-05-21 08:25
TA updates Komunalka phishing site to link to FileMail URL for dummy payload (FileMail tracks not only view and download counts, but also IP addresses)
2024-05-21 12:21
Cloudforce One downloads PixelDrain document to evaluate payload
2024-05-21 12:47
Cloudforce One downloads FileMail document to evaluate payload
2024-05-29 23:59
GitHub takes down Komunalka phishing site
2024-05-30 13:00
Cloudforce One publishes the results of this investigation
Coordinating our FlyingYeti response
Cloudforce One leveraged industry relationships to provide advanced warning and to mitigate the actor’s activity. To further protect the intended targets from this phishing threat, Cloudforce One notified and collaborated closely with GitHub’s Threat Intelligence and Trust and Safety Teams. We also notified CERT-UA and Cloudflare industry partners such as CrowdStrike, Mandiant/Google Threat Intelligence, and Microsoft Threat Intelligence.
Hunting FlyingYeti operations
There are several ways to hunt FlyingYeti in your environment. These include using PowerShell to hunt for WinRAR files, deploying Microsoft Sentinel analytics rules, and running Splunk scripts as detailed below. Note that these detections may identify activity related to this threat, but may also trigger unrelated threat activity.
PowerShell hunting
Consider running a PowerShell script such as this one in your environment to identify exploitation of CVE-2023-38831. This script will interrogate WinRAR files for evidence of the exploit.
CVE-2023-38831
Description:winrar exploit detection
open suspios (.tar / .zip / .rar) and run this script to check it
function winrar-exploit-detect(){
$targetExtensions = @(".cmd" , ".ps1" , ".bat")
$tempDir = [System.Environment]::GetEnvironmentVariable("TEMP")
$dirsToCheck = Get-ChildItem -Path $tempDir -Directory -Filter "Rar*"
foreach ($dir in $dirsToCheck) {
$files = Get-ChildItem -Path $dir.FullName -File
foreach ($file in $files) {
$fileName = $file.Name
$fileExtension = [System.IO.Path]::GetExtension($fileName)
if ($targetExtensions -contains $fileExtension) {
$fileWithoutExtension = [System.IO.Path]::GetFileNameWithoutExtension($fileName); $filename.TrimEnd() -replace '\.$'
$cmdFileName = "$fileWithoutExtension"
$secondFile = Join-Path -Path $dir.FullName -ChildPath $cmdFileName
if (Test-Path $secondFile -PathType Leaf) {
Write-Host "[!] Suspicious pair detected "
Write-Host "[*] Original File:$($secondFile)" -ForegroundColor Green
Write-Host "[*] Suspicious File:$($file.FullName)" -ForegroundColor Red
# Read and display the content of the command file
$cmdFileContent = Get-Content -Path $($file.FullName)
Write-Host "[+] Command File Content:$cmdFileContent"
}
}
}
}
}
winrar-exploit-detect
Microsoft Sentinel
In Microsoft Sentinel, consider deploying the rule provided below, which identifies WinRAR execution via cmd.exe. Results generated by this rule may be indicative of attack activity on the endpoint and should be analyzed.
DeviceProcessEvents
| where InitiatingProcessParentFileName has @"winrar.exe"
| where InitiatingProcessFileName has @"cmd.exe"
| project Timestamp, DeviceName, FileName, FolderPath, ProcessCommandLine, AccountName
| sort by Timestamp desc
Splunk
Consider using this script in your Splunk environment to look for WinRAR CVE-2023-38831 execution on your Microsoft endpoints. Results generated by this script may be indicative of attack activity on the endpoint and should be analyzed.
| tstats `security_content_summariesonly` count min(_time) as firstTime max(_time) as lastTime from datamodel=Endpoint.Processes where Processes.parent_process_name=winrar.exe `windows_shells` OR Processes.process_name IN ("certutil.exe","mshta.exe","bitsadmin.exe") by Processes.dest Processes.user Processes.parent_process_name Processes.parent_process Processes.process_name Processes.process Processes.process_id Processes.parent_process_id
| `drop_dm_object_name(Processes)`
| `security_content_ctime(firstTime)`
| `security_content_ctime(lastTime)`
| `winrar_spawning_shell_application_filter`
Cloudflare product detections
Cloudflare Email Security
Cloudflare Email Security (CES) customers can identify FlyingYeti threat activity with the following detections.
CVE-2023-38831
FLYINGYETI.COOKBOX
FLYINGYETI.COOKBOX.Launcher
FLYINGYETI.Rar
Recommendations
Cloudflare recommends taking the following steps to mitigate this type of activity:
Implement Zero Trust architecture foundations:
Deploy Cloud Email Security to ensure that email services are protected against phishing, BEC and other threats
Leverage browser isolation to separate messaging applications like LinkedIn, email, and Signal from your main network
Scan, monitor and/or enforce controls on specific or sensitive data moving through your network environment with data loss prevention policies
Ensure your systems have the latest WinRAR and Microsoft security updates installed
Consider preventing WinRAR files from entering your environment, both at your Cloud Email Security solution and your Internet Traffic Gateway
Run an Endpoint Detection and Response (EDR) tool such as CrowdStrike or Microsoft Defender for Endpoint to get visibility into binary execution on hosts
Search your environment for the FlyingYeti indicators of compromise (IOCs) shown below to identify potential actor activity within your network.
If you’re looking to uncover additional Threat Intelligence insights for your organization or need bespoke Threat Intelligence information for an incident, consider engaging with Cloudforce One by contacting your Customer Success manager or filling out this form.
On Thursday, Google said an anonymous source notified it of the vulnerability. The vulnerability carries a severity rating of 8.8 out of 10. In response, Google said, it would be releasing versions 124.0.6367.201/.202 for macOS and Windows and 124.0.6367.201 for Linux in subsequent days.
“Google is aware that an exploit for CVE-2024-4671 exists in the wild,” the company said.
Google didn’t provide any other details about the exploit, such as what platforms were targeted, who was behind the exploit, or what they were using it for.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.