Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=osjlUCUCzvQ
Yearly Archives: 2024
Amazon Titan Image Generator v2 is now available in Amazon Bedrock
Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/amazon-titan-image-generator-v2-is-now-available-in-amazon-bedrock/
Today, we are announcing the general availability of the Amazon Titan Image Generator v2 model with new capabilities in Amazon Bedrock. With Amazon Titan Image Generator v2, you can guide image creation using reference images, edit existing visuals, remove backgrounds, generate image variations, and securely customize the model to maintain brand style and subject consistency. This powerful tool streamlines workflows, boosts productivity, and brings creative visions to life.
Amazon Titan Image Generator v2 brings a number of new features in addition to all features of Amazon Titan Image Generator v1, including:
- Image conditioning – Provide a reference image along with a text prompt, resulting in outputs that follow the layout and structure of the user-supplied reference.
- Image guidance with color palette – Control precisely the color palette of generated images by providing a list of hex codes along with the text prompt.
- Background removal – Automatically remove background from images containing multiple objects.
- Subject consistency – Fine-tune the model to preserve a specific subject (for example, a particular dog, shoe, or handbag) in the generated images.
New features in Amazon Titan Image Generator v2
Before getting started, if you are new to using Amazon Titan models, go to the Amazon Bedrock console and choose Model access on the bottom left pane. To access the latest Amazon Titan models from Amazon, request access separately for Amazon Titan Image Generator G1 v2.

Here are details of the Amazon Titan Image Generator v2 in Amazon Bedrock:
Image conditioning
You can use the image conditioning feature to shape your creations with precision and intention. By providing a reference image (that is, a conditioning image), you can instruct the model to focus on specific visual characteristics, such as edges, object outlines, and structural elements, or segmentation maps that define distinct regions and objects within the reference image.
We support two types of image conditioning: Canny edge and segmentation.
- The Canny edge algorithm is used to extract the prominent edges within the reference image, creating a map that the Amazon Titan Image Generator can then use to guide the generation process. You can “draw” the foundations of your desired image, and the model will then fill in the details, textures, and final aesthetic based on your guidance.
- Segmentation provides an even more granular level of control. By supplying the reference image, you can define specific areas or objects within the image and instruct the Amazon Titan Image Generator to generate content that aligns with those defined regions. You can precisely control the placement and rendering of characters, objects, and other key elements.
Here are generation examples that use image conditioning.

To use the image conditioning feature, you can use Amazon Bedrock API, AWS SDK, or AWS Command Line Interface (AWS CLI) and choose CANNY_EDGE or SEGMENTATION for controlMode of textToImageParams with your reference image.
"taskType": "TEXT_IMAGE",
"textToImageParams": {
"text": "a cartoon deer in a fairy world.",
"conditionImage": input_image, # Optional
"controlMode": "CANNY_EDGE" # Optional: CANNY_EDGE | SEGMENTATION
"controlStrength": 0.7 # Optional: weight given to the condition image. Default: 0.7
}The following a Python code example using AWS SDK for Python (Boto3) shows how to invoke Amazon Titan Image Generator v2 on Amazon Bedrock to use image conditioning.
import base64
import io
import json
import logging
import boto3
from PIL import Image
from botocore.exceptions import ClientError
def main():
"""
Entrypoint for Amazon Titan Image Generator V2 example.
"""
try:
logging.basicConfig(level=logging.INFO,
format="%(levelname)s: %(message)s")
model_id = 'amazon.titan-image-generator-v2:0'
# Read image from file and encode it as base64 string.
with open("/path/to/image", "rb") as image_file:
input_image = base64.b64encode(image_file.read()).decode('utf8')
body = json.dumps({
"taskType": "TEXT_IMAGE",
"textToImageParams": {
"text": "a cartoon deer in a fairy world",
"conditionImage": input_image,
"controlMode": "CANNY_EDGE",
"controlStrength": 0.7
},
"imageGenerationConfig": {
"numberOfImages": 1,
"height": 512,
"width": 512,
"cfgScale": 8.0
}
})
image_bytes = generate_image(model_id=model_id,
body=body)
image = Image.open(io.BytesIO(image_bytes))
image.show()
except ClientError as err:
message = err.response["Error"]["Message"]
logger.error("A client error occurred: %s", message)
print("A client error occured: " +
format(message))
except ImageError as err:
logger.error(err.message)
print(err.message)
else:
print(
f"Finished generating image with Amazon Titan Image Generator V2 model {model_id}.")
def generate_image(model_id, body):
"""
Generate an image using Amazon Titan Image Generator V2 model on demand.
Args:
model_id (str): The model ID to use.
body (str) : The request body to use.
Returns:
image_bytes (bytes): The image generated by the model.
"""
logger.info(
"Generating image with Amazon Titan Image Generator V2 model %s", model_id)
bedrock = boto3.client(service_name='bedrock-runtime')
accept = "application/json"
content_type = "application/json"
response = bedrock.invoke_model(
body=body, modelId=model_id, accept=accept, contentType=content_type
)
response_body = json.loads(response.get("body").read())
base64_image = response_body.get("images")[0]
base64_bytes = base64_image.encode('ascii')
image_bytes = base64.b64decode(base64_bytes)
finish_reason = response_body.get("error")
if finish_reason is not None:
raise ImageError(f"Image generation error. Error is {finish_reason}")
logger.info(
"Successfully generated image with Amazon Titan Image Generator V2 model %s", model_id)
return image_bytes
class ImageError(Exception):
"Custom exception for errors returned by Amazon Titan Image Generator V2"
def __init__(self, message):
self.message = message
logger = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
if __name__ == "__main__":
main()Color conditioning
Most designers want to generate images adhering to color branding guidelines so they seek control over color palette in the generated images.
With the Amazon Titan Image Generator v2, you can generate color-conditioned images based on a color palette—a list of hex colors provided as part of the inputs adhering to color branding guidelines. You can also provide a reference image as input (optional) to generate an image with provided hex colors while inheriting style from the reference image.
In this example, the prompt describes:
a jar of salad dressing in a rustic kitchen surrounded by fresh vegetables with studio lighting
The generated image reflects both the content of the text prompt and the specified color scheme to align with the brand’s color guidelines.

To use color conditioning feature, you can set taskType to COLOR_GUIDED_GENERATION with your prompt and hex codes.
"taskType": "COLOR_GUIDED_GENERATION",
"colorGuidedGenerationParam": {
"text": "a jar of salad dressing in a rustic kitchen surrounded by fresh vegetables with studio lighting",
"colors": ['#ff8080', '#ffb280', '#ffe680', '#e5ff80'], # Optional: list of color hex codes
"referenceImage": input_image, #Optional
}Background removal
Whether you’re looking to composite an image onto a solid color backdrop or layer it over another scene, the ability to cleanly and accurately remove the background is an essential tool in the creative workflow. You can instantly remove the background from your images with a single step. Amazon Titan Image Generator v2 can intelligently detect and segment multiple foreground objects, ensuring that even complex scenes with overlapping elements are cleanly isolated.
The example shows an image of an iguana sitting on a tree in a forest. The model was able to identify the iguana as the main object and remove the forest background, replacing it with a transparent background. This lets the iguana stand out clearly without the distracting forest around it.

To use background removal feature, you can set taskType to BACKGROUND_REMOVAL with your input image.
"taskType": "BACKGROUND_REMOVAL",
"backgroundRemovalParams": {
"image": input_image,
}Subject consistency with fine-tuning
You can now seamlessly incorporate specific subjects into visually captivating scenes. Whether it’s a brand’s product, a company logo, or a beloved family pet, you can fine-tune the Amazon Titan model using reference images to learn the unique characteristics of the chosen subject.
Once the model is fine-tuned, you can simply provide a text prompt, and the Amazon Titan Generator will generate images that maintain a consistent depiction of the subject, placing it naturally within diverse, imaginative contexts. This opens up a world of possibilities for marketing, advertising, and visual storytelling.
For example, you could use an image with the caption Ron the dog during fine-tuning, give the prompt as Ron the dog wearing a superhero cape during inference with the fine-tuned model, and get a unique image in response.

To learn, visit model inference parameters and code examples for Amazon Titan Image Generator in the AWS documentation.
Now available
The Amazon Titan Generator v2 model is available today in Amazon Bedrock in the US East (N. Virginia) and US West (Oregon) Regions. Check the full Region list for future updates. To learn more, check out the Amazon Titan product page and the Amazon Bedrock pricing page.
Give Amazon Titan Image Generator v2 a try in Amazon Bedrock today, and send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS Support contacts.
Visit our community.aws site to find deep-dive technical content and to discover how our Builder communities are using Amazon Bedrock in their solutions.
— Channy
Kioxia Optical Interface SSD Demoed at FMS 2024
Post Syndicated from Cliff Robinson original https://www.servethehome.com/kioxia-optical-interface-ssd-demoed-at-fms-2024/
Kioxia has new optical interconnect SSD that uses optics rather than electrical wires to connect SSDs over greater distances
The post Kioxia Optical Interface SSD Demoed at FMS 2024 appeared first on ServeTheHome.
Comic for 2024.08.06 – Line Up 2
Post Syndicated from Explosm.net original https://explosm.net/comics/line-up-2
New Cyanide and Happiness Comic
Clearwater Forest and Panther Lake Booted on Intel 18A
Post Syndicated from Cliff Robinson original https://www.servethehome.com/intel-18a-booted-and-clearwater-forest-up/
Both Panther Lake on the consumer side and Clearwater Forest on the server side are booting on Intel 18A in a big step for Intel Foundry
The post Clearwater Forest and Panther Lake Booted on Intel 18A appeared first on ServeTheHome.
Details Matter: Pentesting a single device to guarantee security
Post Syndicated from Ryan Smith original https://blog.rapid7.com/2024/08/06/details-matter-pentesting-a-single-device-to-guarantee-security/

Rapid7’s penetration testing services regularly assess internal networks of various sizes. For this particular engagement, however, Rapid7 was tasked with performing a penetration test of just one device on an internal network.
The device was being piloted for future deployment and the customer had specific concerns around the security posture of the device. Specifically, the customer tasked Rapid7 with three focus areas: First, ensure the device could not reach any hosts on a separate, segmented network. Second, ensure the standard user provided to Rapid7 could not elevate privileges and gain root access to the device. Third, ensure no unauthorized tools could be downloaded onto the device.
Beginning with segmentation validation, Rapid7 logged on to the device with the provided credentials including the dynamic proxy option. This allowed Rapid7 to run port scans from the deployed Penetration Testing Kit (PTK), but with the traffic going through the device before attempting to reach the segmented network. Rapid7 was only able to interact with hosts on the other network over ICMP and could not log in to or otherwise interact with the hosts. The current configuration of the device appeared to prevent the device from interacting with other hosts, the customer’s first concern.
Moving to privilege escalation, Rapid7 enumerated the device with the provided credentials. One step during this enumeration was to check which commands, if any, the standard user could run as root using the Linux command sudo. Among the available commands were a handful of Bash scripts. Rapid7 reviewed the permissions set on those Bash files and found an installation script was configured to only allow the low privilege user to execute the script and did not allow for reading or writing of the script. However, Rapid7 also observed this restricted file was owned by the low privilege user, which allowed modifying the permissions on the script. Rapid7 created a backup of the script and then modified the script to launch a new Bash shell. Running this modified script with sudo provided Rapid7 with root access to the device.
Enumeration of the device with root access revealed a strong firewall configuration in place which prevented the device from communicating with the segmented network or with the external web sites. Rapid7 disabled the firewall on the device and could connect to hosts on the other network as well as install additional, unauthorized tools.
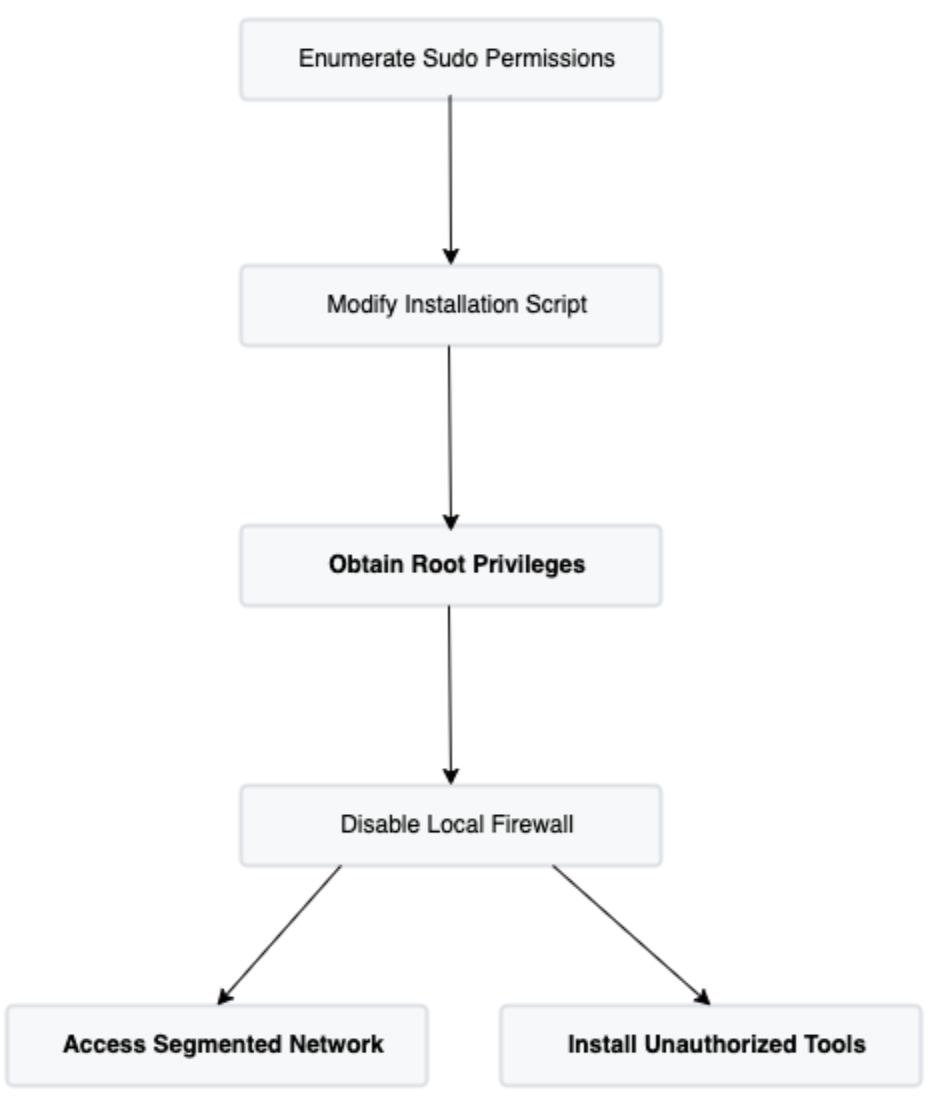
This engagement highlighted the importance of attention to detail when hardening systems. The file ownership misconfiguration on the script enabled Rapid7 to achieve all three of the customer’s concerns around the system’s security posture. The penetration test report provided by Rapid7 to the customer demonstrated the impact of the misconfiguration and outlined recommended remediation steps to secure the device.
Solidigm D7-PS1010 and D7-PS1030 PCIe Gen5 NVMe SSDs Launched
Post Syndicated from Cliff Robinson original https://www.servethehome.com/solidigm-d7-ps1010-and-d7-ps1030-pcie-gen5-nvme-ssds-launched/
The new Solidigm D7-PS1010 and D7-PS1030 are the company’s newest PCIe Gen5 NVMe SSDs for performance storage clusters
The post Solidigm D7-PS1010 and D7-PS1030 PCIe Gen5 NVMe SSDs Launched appeared first on ServeTheHome.
How Amazon GTTS runs large-scale ETL jobs on AWS using Amazon MWAA
Post Syndicated from Louis Hourcade original https://aws.amazon.com/blogs/big-data/how-amazon-gtts-runs-large-scale-etl-jobs-on-aws-using-amazon-mwaa/
The Amazon Global Transportation Technology Services (GTTS) team owns a set of products called INSITE (Insights Into Transportation Everywhere). These products are user-facing applications that solve specific business problems across different transportation domains: network topology management, capacity management, and network monitoring. As of this writing, GTTS serves around 10,000 customers globally on a monthly basis, managing the outbound transportation network.
INSITE applications are in general data intensive. They ingest and transform large volumes of data in different formats and processing patterns (such as batch and near real time) from various sources internal and external to Amazon. Datasets are often shared between applications both within domains and across domains, and are consumed in complex data pipelines that run under tight SLAs. To enable and meet these requirements, GTTS built its own data platform.
A critical component of the data platform is the data pipeline orchestrator. GTTS built its own orchestrator named Langley in 2018, and used it to schedule and monitor extract, transform, and load (ETL) jobs on a variety of compute platforms, such as Amazon EMR, Amazon Redshift, Amazon Relational Database Service (Amazon RDS).
As the Langley user base grew, GTTS engineers faced a couple of challenges on key dimensions, such as maintainability, scalability, multi-tenancy, observability, and interoperability.
Amazon GTTS partnered with AWS Professional Services to modernize their orchestration platform, relying as much as possible on managed services with auto scaling capabilities. After analyzing candidate solutions, the team decided to build a target solution relying on Amazon Managed Workflows for Apache Airflow (Amazon MWAA). This post elaborates on the drivers of the migration and its achieved benefits.
Legacy platform
Amazon GTTS works with diverse and distributed data stores, storing petabytes of data. Data engineers need a tool to define ETL jobs which run on various compute environments, as illustrated in the following diagram.

GTTS built Langley as their custom orchestrator in 2018, and have been operating it ever since. At a high level, the core of Langley’s architecture is based on a set of Amazon Simple Queue Service (Amazon SQS) queues and AWS Lambda functions, and a dedicated RDS database to store ETL job data and metadata. It also uses AWS Data Pipeline to run SQL-based workloads, Amazon Simple Storage Service (Amazon S3) to store configuration files, and Amazon CloudWatch for alarming on failures. Every day, Langley handles the lifecycle of more than 17,000 ETL jobs in Europe and 5,000 ETL jobs in North America.
The following diagram illustrates the Langley architecture.

Business challenges
Langley started as a simple solution to a team-internal problem, but its growth over the years surfaced key issues:
- The maintenance of this custom solution requires considerable time from engineers, which increased over the years with the release of new features, increasing the overall complexity.
- The Langley user base grew continuously and eventually became a key orchestration platform for multiple teams and products across Amazon. However, it wasn’t created with multi-tenancy in mind and therefore it didn’t provide the robustness and the appropriate level of isolation to guard each tenant from impacting others on the shared platform.
- In 2023, AWS announced the upcoming deprecation of Data Pipeline, one of the core services used by Langley.
GTTS partnered with AWS to design and implement a solution to overcome those challenges. AWS used the following evaluation matrix to build a durable solution:
| Maintainability | The level of effort required to maintain the orchestrating system in a functional state, encompassing updates, patches, bug fixes, and routine checks for optimal performance. |
| Costs | The overall expenditure associated with the orchestrator, including infrastructure costs, licensing fees, personnel expenses, and other relevant costs. This criterion particularly assesses the system’s ability to effectively control and reduce costs. |
| Scheduling | The capabilities related to running and scheduling jobs, including the ability to resume an ETL job from a failed step. |
| User experience | The overall satisfaction and usability of a system from the end-users’ perspective, considering factors such as responsiveness, accessibility, interoperability, and ease of use. |
| Security | Mechanisms in place to safeguard data and applications from unauthorized access at all times. |
| Monitoring and alerting | The continuous observation and analysis of system components and performance metrics to detect and address issues, optimize resource usage, and provide overall health and reliability. |
| Scalability | The orchestrator’s capacity to efficiently adapt its resources to handle increased workload or demand, providing sustained performance. |
Among the explored solutions, Amazon MWAA was finally determined as the best overall performer across this matrix.
The next section is a dive deep into the rationales that led GTTS and AWS Professional Services to choose Amazon MWAA as the best performer.
Benefits of migrating to Amazon MWAA
Amazon GTTS and AWS Professional Services worked together to release a Minimum Viable Product (MVP) of the solution described earlier, which showcases the benefits on the agreed decision criteria.
Maintainability
With their legacy system, Amazon GTTS had to manage the orchestrator database, web servers, activity queue, dispatch functions, and worker nodes.
Amazon MWAA eliminates the need for underlying infrastructure management. It takes care of provisioning and maintenance of the Apache Airflow web server, scheduler, worker nodes, and relational database, allowing GTTS teams to focus on building their ETL jobs.
Amazon MWAA offers one-click updates of the infrastructure for minor versions, like moving from Airflow version x.4.z to x.5.z. During the upgrade process, Amazon MWAA captures a snapshot of your environment metadata; upgrades the workers, schedulers, and web server to the new Airflow version; and finally restores the metadata database using the snapshot, backing it with an automated rollback mechanism.
Costs
Amazon MWAA contributes to a more cost-effective solution by automatically scaling workers depending on the workload. This dynamic scaling in and out avoids over-provisioning and allows the organization to pay for the compute they actually use, without the risk of downtime during activity spikes. Because this is an AWS-managed solution, it also reduced GTTS’s Total Cost of Ownership (TCO) by freeing up time from engineers that were managing the legacy system.
Scheduling
Amazon MWAA supports all the trigger mechanisms that the Amazon orchestrator needed:
- Manual trigger – The users can simply invoke a Direct Acyclic Graph (DAG) using the Airflow API or even more simply via the User Interface (UI).
- Scheduler – A scheduler can be defined as code, together with the DAG definition, to make sure it will run at specific rates (from hourly to yearly) or on specific cron schedules.
- Event-driven trigger – Airflow provides native operators that enable invoking a downstream DAG from another DAG or from a dataset update (push approach). It also includes sensors that listen for the completion of a task external to the DAG (pull approach).
- Partial runs on DAG failures – Another key feature for GTTS was the possibility the recover from partial DAG failures without having to rerun the whole DAG. Airflow provides task-level controls that makes this operation straightforward to implement.
User experience
In this section, we discuss three aspects of the user experience: the web UI, the interoperability, and the programming interface.
Web UI
Amazon MWAA comes with a managed web server that hosts the Airflow UI. As a result, and without any maintenance needed, you can use it to quickly run DAGs, check run history, visualize dependencies between DAGs, troubleshoot with a direct access to task logs, manage variables and database connections, and define granular permissions. The following screenshot shows an example of the UI.

Interoperability
One of the most important features evaluated was the ability for the new orchestrator to effortlessly integrate with GTTS multiple data storage services, compute components, and monitoring services.
Amazon MWAA comes with a wide variety of providers preinstalled, such as apache-airflow-providers-amazon, apache-airflow-providers-postgres, and apache-airflow-providers-common-sql. This allowed GTTS to connect with those services using multiple connection methodologies, including AWS IAM Identity Center or AWS Secrets Manager password-based authentications, without having to write a single custom Airflow operator.
Amazon MWAA also makes it straightforward to upgrade providers version and install new ones. By providing a requirements.txt file, GTTS was able to change the major version of apache-airflow-providers-amazon and install the apache-airflow-providers-mysql provider.
Programming interface
Airflow is an orchestrator with a low barrier to entry, especially for those familiar with the Python programming language. Its workflow management is defined in Python scripts, with a well-documented set of native operators and external providers, making it straightforward for Python developers to get started with Airflow and create complex data pipelines.
The following are two key Airflow features:
- TaskFlow API – The TaskFlow API removes a lot of the boilerplate code required by traditional operators by using Python decorators while simplifying the DAG editing process DAG with cleaner and more concise DAG files.
- Dynamic DAG generation – The dynamic DAG generation capability allowed us to generate DAGs from the original legacy orchestrator’s configuration files. This enabled the platform team to build a centralized framework consumed by multiple teams to keep the code DRY (Don’t Repeat Yourself), providing a seamless migration journey from the legacy orchestrator.
The following screenshot shows an example of these features.

Security
The new Amazon MWAA-based architecture improves GTTS’s posture by introducing granular access control. Amazon MWAA integrates with AWS services such as AWS Key Management Service (AWS KMS), Secrets Manager, and IAM Identity Center to keep data safely encrypted at all times, both at rest and in transit using TLS-based communications. Airflow also includes a role-based access control (RBAC) model to determine what users can do on the platform and enforce the principle of least privilege. Amazon MWAA also natively integrates with AWS CloudTrail for auditing purposes.
The Airflow RBAC model enables administrators to define roles with specific privileges to access Airflow system settings and DAGs themselves. This granular access control reduces the risk of data breaches and malicious activities by limiting access to critical DAGs and sensitive Airflow environment variables. Airflow includes five default roles with different sets of permissions (as shown in the following screenshot), but it is possible to create new roles depending on your security requirements.

GTTS used the Airflow RBAC model to restrict permissions of certain teams and consumers of the application. They also used priority weights and Airflow pools to prioritize tasks and control run concurrency. However, if you want to run a multi-tenant orchestration platform, it’s recommended to use a separate environment for each team. You can assume that everything accessible by the Amazon MWAA role is also accessible to users who can write DAGs to the environment.
To ease authentication in Amazon MWAA, GTTS federated their identity provider (IdP) through Amazon Cognito and SAML. With this integration, users log in to the Amazon MWAA UI using the same identity as in other internal systems, which removes the need for new credentials. The user’s group membership is retrieved from the IdP through Amazon Cognito, and a Lambda function redirects the user to Amazon MWAA with the appropriate Airflow role. This process is illustrated in the following architecture, and is abstracted from the user and attached to a public Application Load Balancer that redirects at the end of the process to an Amazon MWAA private cluster, making the authentication workflow seamless and secure. Refer to Accessing a private Amazon MWAA environment using federated identities to implement it using your own IdP.

Monitoring and alerting
Amazon MWAA integrates with CloudWatch, which manages all infrastructure logs for you. When creating an Amazon MWAA environment, you can configure what level of logs should be saved. GTTS enabled CloudWatch logging for all of the five types of components: Airflow task logs, Airflow web server logs, Airflow scheduler logs, Airflow worker logs, and Airflow DAG processing logs.

These logs are all accessible in CloudWatch for continuous monitoring, but Amazon MWAA users can also access task logs directly from the Airflow UI by looking at the DAG run history. The following screenshot shows an example of task-level logs in Airflow 2.5.1.

You can also build CloudWatch monitoring dashboards to keep an eye on the state of your environment and alert administrators when required. Amazon MWAA natively provides Airflow environment metrics and Amazon MWAA infrastructure-related metrics.
Scalability
Each Amazon MWAA environment includes the schedulers, web server, and worker nodes. Scheduler nodes are responsible for the overall orchestration and parsing of DAG files. These tasks happen in worker nodes that Amazon MWAA auto scales up and down according to system load. When creating a new Amazon MWAA environment, you need to specify the type of worker nodes, the minimum and maximum number of worker nodes, and the scheduler count, as shown in the following screenshot.

There are notably two ways GTTS controlled how Amazon MWAA scales to handle the load:
- Minimum and maximum worker count – Amazon MWAA automatically adds or deletes workers within the boundaries you set, depending on the number of tasks that are waiting to be processed. As indicated in the AWS documentation, it is possible to request a quota increase to run up to 50 workers in a single environment.
- Size of the node – Larger worker nodes can run more concurrent tasks. For example, mw1.small instances run 5 concurrent tasks by default, whereas mw1.large instances run 20 concurrent tasks by default. The following figure shows the specification for each instance type.

With Amazon MWAA, GTTS can therefore run up to 4,000 concurrent tasks in a single Amazon MWAA environment (50 worker nodes x 80 tasks per node with mw1.2xlarge). This remains an order of magnitude for the load that can fit into the workers vCPUs and RAM, but it is possible to edit the default configuration to add even more tasks per worker. For more information regarding Amazon MWAA automatic scaling, see Configuring Amazon MWAA automatic scaling.
The Amazon MWAA based orchestration platform
After selecting Amazon MWAA as the core service for their orchestrating system, Amazon GTTS and AWS worked together to develop an end-to-end data platform with automation capabilities, access management, monitoring, and integration with downstream systems. The following diagram illustrates the solution architecture.

The following are notable components of the architecture:
- DAG update – GTTS Developers manage the creation, update, and deletion of Amazon MWAA DAGs through a dedicated code repository. When a developer edits DAG definitions and commits changes to the code repository, a CI/CD pipeline automatically packages the DAG definition and stores it in Amazon S3, which automatically updates DAGs in Amazon MWAA.
- Infrastructure as code – The entire stack is defined as IaC with the AWS CDK, which eases the process of updating components, and makes it repeatable if GTTS wants to extend the solution and redeploy the stack in multiple AWS Regions.
- Authentication, authorizations, and Permissions – Permissions are centrally managed with AWS Identity and Access Management (IAM) together with Airflow roles. GTTS integrated their identity provider with Amazon Cognito and Amazon MWAA, so Amazon employees can connect to the Amazon MWAA UI with the same authentication tool they are used to, and see only the DAGs they are allowed to access.
- UI and DAG runs – Amazon MWAA includes an AWS-managed web server that exposes the Airflow UI. Amazon employees can connect to this UI to list DAGs, run DAGs, and track their status. In addition, GTTS used the native Amazon MWAA scheduler to automatically invoke DAGs at a specific time.
- Airflow workers – The users can use Airflow native providers to run custom Shell or Python code directly on the workers nodes. For compute-intensive jobs, the Amazon MWAA worker can delegate the compute to a more suitable AWS service, such as Apache Spark running on Amazon EMR on Amazon EKS, which will provide compute resources only for the duration of the job, helping in optimizing costs.
- Data stores and external computes services – Amazon MWAA comes also with the AWS provider preloaded, allowing a seamless connectivity with more than 23 AWS compute and data services. GTTS can extend the connectivity to other AWS or external services by using Boto3 with the
PythonOperatoror creating dedicated custom operators. - Logging and alerting – Amazon MWAA is seamlessly integrated with CloudWatch and CloudTrail to publish DAG logs, audit logs, and metrics. This enables GTTS to track completion, troubleshoot, and create an automated alerting and notifications system so DAGs owners can take remediation actions as fast as possible.
Conclusion
Amazon GTTS partnered with AWS Professional Services to overcome the challenges faced by their legacy custom orchestrator against various dimensions such as maintainability, cost efficiency, security, scalability, and observability.
The new Amazon MWAA-based architecture offers significant improvements in the context of the AWS Well-Architected Framework compared to their former system. In terms of operational excellence, the new orchestration platform is built with evolutivity in mind and enables the GTTS team to use the most adapted ETL service to run their jobs. Regarding performance efficiency, GTTS observed up to 70% improvement in end-to-end runtime on their jobs running in Amazon MWAA. In terms of security, the new solution implements best practices such as the deployment in private subnets, authentication of users through Amazon internal federation systems, and data encryption at rest and in transit. Reliability is achieved with Multi-AZ failover and built-in auto scaling to meet the workload demand at all times. Finally, cost is reduced because Amazon MWAA is an AWS-managed service, which decreases the human effort from GTTS to maintain the orchestration platform.
Amazon GTTS is now bringing the MVP into production, where it is planned to handle petabytes of data and host more than 2,000 jobs migrated from the legacy system. Additionally, the migration to Amazon MWAA has empowered GTTS to enhance its operational scalability, paving the way for the integration of new jobs and further expansion with greater efficiency and confidence.
To learn more, refer to the following resources:
- Get started with Amazon Managed Workflows for Apache Airflow
- Amazon MWAA blog posts
- Amazon MWAA for Analytics Workshop
- Amazon Managed Workflows for Apache Airflow at Scale
About the Authors
Béntor Bautista is a Senior Data Engineer at Amazon GTTS
Louis Hourcade is a Solutions Architect at AWS
Raphael Ducay is a Senior DataOps Architect at AWS
Konstantin Zarudaev is a DevOps Consultant at AWS
Dorra Elboukari is a DevOps Architect at AWS
Marcin Zapal is an Engagement Manager at AWS
Grigorios Pikoulas is a Strategic Program Lead at AWS
Antonio Cennamo is a Senior Customer Practice Manager at AWS
Should you wait a bit longer to buy SwitchBot Water Leak sensor?!
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=U2pj_MF7688
Build a real-time analytics solution with Apache Pinot on AWS
Post Syndicated from Raj Ramasubbu original https://aws.amazon.com/blogs/big-data/build-a-real-time-analytics-solution-with-apache-pinot-on-aws/
Online Analytical Processing (OLAP) is crucial in modern data-driven apps, acting as an abstraction layer connecting raw data to users for efficient analysis. It organizes data into user-friendly structures, aligning with shared business definitions, ensuring users can analyze data with ease despite changes. OLAP combines data from various data sources and aggregates and groups them as business terms and KPIs. In essence, it’s the foundation for user-centric data analysis in modern apps, because it’s the layer that translates technical assets into business-friendly terms that enable users to extract actionable insights from data.
Real-time OLAP
Traditionally, OLAP datastores were designed for batch processing to serve internal business reports. The scope of data analytics has grown, and more user personas are now seeking to extract insights themselves. These users often prefer to have direct access to the data and the ability to analyze it independently, without relying solely on scheduled updates or reports provided at fixed intervals. This has led to the emergence of real-time OLAP solutions, which are particularly relevant in the following use cases:
- User-facing analytics – Incorporating analytics into products or applications that consumers use to gain insights, sometimes referred to as data products.
- Business metrics – Providing KPIs, scorecards, and business-relevant benchmarks.
- Anomaly detection – Identifying outliers or unusual behavior patterns.
- Internal dashboards – Providing analytics that are relevant to stakeholders across the organization for internal use.
- Queries – Offering subsets of data to users based on their roles and security levels, allowing them to manipulate data according to their specific requirements.
Overview of Apache Pinot
Building these capabilities in real time means that real-time OLAP solutions have stricter SLAs and larger scalability requirements than traditional OLAP datastores. Accordingly, a purpose-built solution is needed to address these new requirements.
Apache Pinot is an open source real-time distributed OLAP datastore designed to meet these requirements, including low latency (tens of milliseconds), high concurrency (hundreds of thousands of queries per second), near real-time data freshness, and handling petabyte-scale data volumes. It ingests data from both streaming and batch sources and organizes it into logical tables distributed across multiple nodes in a Pinot cluster, ensuring scalability.
Pinot provides functionality similar to other modern big data frameworks, supporting SQL queries, upserts, complex joins, and various indexing options.
Pinot has been tested at very large scale in large enterprises, serving over 70 LinkedIn data products, handling over 120,000 Queries Per Second (QPS), ingesting over 1.5 million events per second, and analyzing over 10,000 business metrics across over 50,000 dimensions. A notable use case is the user-facing Uber Eats Restaurant Manager dashboard, serving over 500,000 users with instant insights into restaurant performance.
Pinot clusters are designed for high availability, horizontal scalability, and live configuration changes without impacting performance. To that end, Pinot is architected as a distributed datastore to enable all of the above requirements, and utilizes similar architectural constructs as Apache Kafka and Apache Hadoop in its design.
Solution overview
In this, we will provide a step-by-step guide showing you how you can build a real-time OLAP datastore on Amazon Web Services (AWS) using Apache Pinot on Amazon Elastic Compute Cloud (Amazon EC2) and do near real-time visualization using Tableau. You can use Apache Pinot for batch processing use cases as well but, in this post, we will focus on a near real-time analytics use case.
You can use Amazon Managed Service for Apache Flink service. The objective in the preceding figure is to ingest streaming data into Pinot, where it can perform.

The objective in the preceding figure is to ingest streaming data into Pinot, where it can perform aggregations, update current data models, and serve OLAP queries in real time to consuming users and applications, which in this case is a user-facing Tableau dashboard.
The data flow as follows:
- Data is ingested from a real-time source, such as clickstream data from a website. For the purposes of this post, we will use the Amazon Kinesis Data Generator to simulate the production of events.
- Events are captured in a streaming storage platform such as or Amazon Managed Streaming for Apache Kafka (MSK) for downstream consumption.
- The events are then ingested into the real-time server within Apache Pinot, which is used to process data coming from streaming sources, such as MSK and KDS. Apache Pinot consists of logical tables, which are partitioned into segments. Due to the time sensitive nature of streaming, events are directly written into memory as consuming segments, which can be thought of as parts of an active table that are continuously ingesting new data. Consuming segments are available for query processing immediately, thereby enabling low latency and high data freshness.
- After the segments reach a threshold in terms of time or number of rows, they are moved into Amazon Simple Storage Service (Amazon S3), which serves as deep storage for the Apache Pinot cluster. Deep storage is the permanent location for segment files. Segments used for batch processing are also stored there.
- In parallel, the Pinot controller tracks the metadata of the cluster and performs actions required to keep the cluster in an ideal state. Its primary function is to orchestrate cluster resources as well as manage connections between resources within the cluster and data sources outside of it. Under the hood, the controller uses Apache Helix to manage cluster state, failover, distribution, and scalability and Apache Zookeeper to handles distributed coordination functions such as leader election, locks, queue management, and state tracking.
- To enable the distributed aspect of the Pinot architecture, the broker accepts queries from the clients and forwards them to servers and collects the results and sends them back. The broker manages and optimizes the queries, distributes them across the servers, combines the results, and returns the result set. The broker sends the request to the right segments on the right servers, optimizes segment pruning, and splits the queries across servers appropriately. The results of each query are then merged and sent back to the requesting client.
- The results of the queries are updated in real time in the Tableau dashboard.
To ensure high availability, the solution deploys application load balancers for the brokers and servers. We can access the Apache Pinot UI using the controller load balancer and use it to run queries and monitor the Apache Pinot cluster
Let’s start to deploy this solution and perform near real-time visualizations using Apache Pinot and Tableau.
Prerequisites
Before you get started, make sure you have the following prerequisites:
- To deploy Apache Pinot
- An AWS account
- A basic understanding of Amazon S3, Amazon EC2, and Kinesis Data Streams
- An AWS Identity and Access Management (IAM) role with permissions to access AWS CloudShell and create a Data Streams instance, EC2 instances, and S3 buckets (see Adding and removing IAM identity permissions)
- Install Git to clone the code repository
- Install Node.js and npm to install packages
- To use Tableau for visualization
- Install Tableau Desktop to visualize data (for this post, 2023.3.0).
- Install Kinesis data generator (KDG) using AWS CloudFormation by following the instructions to stream sample web transactions into the Kinesis data stream. The KDG makes it easy to send data to a Kinesis data stream.
- Download the Apache Pinot drivers from here:
- Copy the drivers to the
C:\Program Files\Tableau\Driversfolder when using Tableau Desktop on Windows. For other operating systems, see the instructions. - Ensure all CloudFormation and AWS Cloud Development Kit (AWS CDK) templates are deployed in the same AWS Region for all resources throughout the following steps.
Deploy the Apache Pinot solution using the AWS CDK
The AWS CDK is an open source project that you can use to define your cloud infrastructure using familiar programming languages. It uses high-level constructs to represent AWS components to simplify the build process. In this post, we use TypeScript and Python to define the cloud infrastructure.
- First, bootstrap the AWS CDK. This sets up the resources required by the AWS CDK to deploy into the AWS account. This step is only required if you haven’t used the AWS CDK in the deployment account and Region. The format for the bootstrap command is
cdk bootstrap aws://<account-id>/<aws-region>.
In the following example, I’m running a bootstrap command for a fictitious AWS account with ID 123456789000 and us-east-1 N.Virginia Region:

- Next, clone the GitHub repository and install all the dependencies from
package.jsonby running the following commands from the root of the cloned repository. - Deploy the AWS CDK stack to create the AWS Cloud infrastructure by running the following command and enter y when prompted. Enter the IP address that you want to use to access the Apache Pinot controller and broker in /32 subnet mask format.
Deployment of the AWS CDK stack takes approximately 10–12 minutes. You should see a stack deployment message that will display the creation of AWS objects, followed by the deployment time, the Stack ARN, and the total time, similar to the following screenshot:

- Now, you can get the Apache Pinot controller Application Load Balancer (ALB) DNS name from the Copy the value for ControllerDNSUrl.
- Launch a browser session and paste the DNS name to see the Apache Pinot controller—it should look like the following screenshot, where you will see:
- Number of controllers, brokers, servers, minions, tenants, and tables
- List of tenants
- List of controllers
- List of brokers

Near real-time visualization using Tableau
Now that we have provisioned all AWS Cloud resources, we will stream some sample web transactions to a Kinesis data stream and visualize the data in near real time from Tableau Desktop.
You can follow these steps to open the Tableau workbook to visualize
- Download the Tableau workbook to your local machine and open the workbook from Tableau Desktop.
- Get the DNS name for Apache Pinot broker’s Application Load Balancer DNS name from the CloudFormation console. Choose Stacks, select the ApachePinotSolutionStack, and then choose Outputs and copy the value for BrokerDNSUrl.
- Choose Edit connection and enter the URL in the following format:
- Enter admin for both the username and password.
- Access the KDG tool by following the instructions. Use the record template that follows to send sample web transactions data to Kinesis Data streams called pinot-stream by choosing Send dataas shown in the following screenshot. Stop sending data after sending a handful of records by choosing Stop sending data to Kinesis.

You should be able to see the web transactions data in Tableau Desktop as shown in the following screenshot.

Clean up
To clean up the AWS resources you created:
- Disable termination protection on the following EC2 instances by going to the Amazon EC2 console and choosing Instance from the navigation pane. Choose Actions, Instance Settings, and then Change termination protection and clear the Termination protection checkbox.
ApachePinotSolutionStack/bastionHostApachePinotSolutionStack/zookeeperNode1ApachePinotSolutionStack/zookeeperNode2ApachePinotSolutionStack/zookeeperNode3
- Run the following command from the cloned GitHub repo and enter
ywhen prompted.
Scaling the solution to production
The example in this post uses minimal resources to demonstrate functionality. Taking this to production requires a higher level of scalability. The solution provides autoscaling policies for independently scaling brokers and servers in and out, allowing the Apache Pinot custer to scale based on CPU requirements.
When autoscaling is initiated, the solution will invoke an AWS Lambda Function, to run the logic needed to add or remove brokers and servers in Apache Pinot.
In Apache Pinot, tables are tagged with an identifier that’s used for routing queries to the appropriate servers. When creating a table, you can specify a table name and optionally tag it. This is useful when you want to route queries to specific servers or build a multi-tenant Apache Pinot cluster. However, tagging adds additional considerations when removing brokers or servers. You need to make sure that neither have any active tables or tags associated with them. And when adding new components, rebalance the segments, so you can use the new brokers and servers.
Therefore, when scaling is needed in the solution, the autoscaling policy will invoke a Lambda function that either rebalances the segments of the tables when you add a new broker or server, or removes any tags associated with the broker or server you remove from the cluster.
Summary
Just like you would commonly use a distributed NoSQL datastore to serve a mobile application that requires low latency, high concurrency, high data freshness, high data volume, and high throughput, a distributed real-time OLAP datastore like Apache Pinot is purpose-built for achieving the same requirements for the analytics workload within your user-facing application. In this post, we walked you through how to deploy a scalable Apache Pinot-based near real-time user facing analytics solution on AWS. If you have any questions or suggestions, write to us in the comments section
About the authors
 Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
 Francisco Morillo is a Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink.
Francisco Morillo is a Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink.
 Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. Ismail focuses on architecting solutions for organizations across their end-to-end data analytics estate, including batch and real-time streaming, big data, data warehousing, and data lake workloads. He primarily partners with airlines, manufacturers, and retail organizations to support them to achieve their business objectives with well-architected data platforms.
Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. Ismail focuses on architecting solutions for organizations across their end-to-end data analytics estate, including batch and real-time streaming, big data, data warehousing, and data lake workloads. He primarily partners with airlines, manufacturers, and retail organizations to support them to achieve their business objectives with well-architected data platforms.
Migrating your on-premises workloads to AWS Outposts rack
Post Syndicated from Macey Neff original https://aws.amazon.com/blogs/compute/migrating-your-on-premises-workloads-to-aws-outposts-rack/
This post is written by Craig Warburton, Senior Solutions Architect, Hybrid. Sedji Gaouaou, Senior Solutions Architect, Hybrid. Brian Daugherty, Principal Solutions Architect, Hybrid.
Migrating workloads to AWS Outposts rack offers you the opportunity to gain the benefits of cloud computing while keeping your data and applications on premises.
For organizations with strict data residency requirements, by deploying AWS infrastructure and services on premises, you can keep sensitive data and mission-critical applications within your own data centers or facilities, helping ensure compliance with data sovereignty laws and regulatory frameworks.
On the other hand, if your organization does not have stringent data residency requirements, you may opt for a hybrid approach, using both Outposts rack and the AWS Regions. With this flexibility, you can process and store data in the most appropriate location based on factors such as latency, cost optimization, and application requirements.
In this post, we cover the best options to migrate your workloads to Outposts rack, taking into account your specific data residency requirements. We explore strategies, tools, and best practices to enable a successful migration tailored to your organization’s needs.
Overview
AWS has a number of services to help you migrate and rehost workloads, including AWS Migration Hub, AWS Application Migration Service, AWS Elastic Disaster Recovery. Alternatively, you can use backup and recovery solutions provided by AWS partners.
At AWS, we use the 7 Rs framework to help organizations evaluate and choose the appropriate migration strategy for moving applications and workloads to the AWS Cloud. The 7 Rs represent:
- Rehosting (rehost or lift and shift)
- Replatforming (lift, tinker, and shift)
- Repurchasing (republish or re-vendor)
- Refactoring (re-architecting)
- Retiring
- Retaining (revisit)
- Relocating (remigrate).
This post focuses on rehosting and the services available to help rehost on-premises applications to Outposts rack.
Before getting started with any migration, AWS recommends a three-phase approach to migrating workloads to the cloud (AWS Region or Outposts rack). The three phases are assess, mobilize, and migrate and modernize.

Figure 1: Diagram showing the three migration phases of assess, mobilize, and migrate and modernize
This post describes the steps that you can take in the migrate and modernize phase. However, the assess and mobilize phases are also critical to allow you to understand what applications will be migrated, the dependencies between them, and the planning associated with how and when migration will occur.
AWS Migration Hub is a cloud migration service provided by AWS that helps organizations accelerate and simplify the process of migrating workloads to AWS. It provides a unified location to track the progress of application migrations across multiple AWS and partner services. This service can be used to help work through all three phases of migration, and we recommend that you start with this service and complete each phase accordingly. The assess phase should help you identify any applications that require consideration when migrating (including any data residency requirements), and the mobilize phase defines the approach to take.
Workload migration to AWS Outposts rack: With staging environment in an AWS Region
After deploying an Outpost rack to your desired on-premises location, you can perform migrations of on-premises systems and virtual machines using either Application Migration Service or third-party backup and recovery services. Both scenarios are described in the following sections.
Scenario 1: Using AWS Application Migration Service
Application Migration Service is able to lift and shift a large number of physical or virtual servers without compatibility issues, performance disruption, or long cutover windows.
In this scenario, at least one Outpost rack is deployed on premises with the following prerequisites:
- At least one Outpost rack installed and activated
- The Outposts rack must be in Direct VPC Routing (DVR) mode
- VPC in Region containing subnet for staging resources
- VPC extended to the Outposts rack containing subnet for target resources
- An AWS Replication Agent installed on each source server
The following diagram shows the solution architecture and includes the on-premises servers that will be migrated from the local network to the Outposts rack. It also includes the staging VPC in Region used to deploy the replication servers, Amazon S3 to store the Amazon EBS snapshots and the target VPC extended to Outposts rack.

Figure 2: Architecture diagram showing migration with Application Migration Service
Step 1: Outposts rack configuration
You can work with AWS specialists to size your Outpost for your workload and application requirements. In this scenario, you don’t need additional Outposts rack capacity for the migration because the staging area will be deployed in the Region (see 1 in Figure 2).
Step 2: Prepare Application Migration service
Set up Application Migration Service from the console in the Region your Outposts rack is anchored to. If this is your first setup, choose Get started on the AWS Application Migration Service console. When creating the replication settings template, make sure your staging area is using subnets in the parent Region (see 2 in Figure 2).
Step 3: Install the AWS Replication Agent to the source servers or machines
For large migrations, source servers may have a wide variety of operating system versions and may be distributed across multiple data centers. AWS Application Migration Service offers the MGN connector, a feature that allows you to automate running commands on your source environment. Finally, ensure that communication is possible between the agent and Application Migration Service (see 3 in Figure 2).
In the following image, there is an example of deploying the AWS Replication Agent providing the required parameters (Region, AWS access key and AWS secret access key).

Once the AWS Replication Agent is installed, the server will be added to the AWS Application Migration Service console. Next, it will undergo the initial sync process, which will be completed when showing the Ready for testing lifecycle state in the Application Migration Service console.
Step 4: Configure launch settings
Prior to testing or cutting over an instance, you must configure the launch settings by creating Amazon Elastic Compute Cloud (Amazon EC2) launch templates, ensuring that you select your extended virtual private cloud (VPC) and subnet deployed on Outposts rack and using an appropriate, available instance type (see 4 in Figure 2).
To identify EC2 instances configured on your Outpost, you can use the following AWS Command Line Interface (AWS CLI):
Outposts get-outpost-instance-types \
--outpost-id op-abcdefgh123456789
The output of this command lists the instance types and sizes configured on your Outpost:
InstanceTypes:
- InstanceType: c5.xlarge
- InstanceType: c5.4xlarge
- InstanceType: r5.2xlarge
- InstanceType: r5.4xlarge
With knowledge of the instance types configured, you can now determine how many of each are available. For example, the following AWS CLI command, which is run on the account that owns the Outpost, lists the number of c5.xlarge instances available for use:
aws cloudwatch get-metric-statistics \
--namespace AWS/Outposts \
--metric-name AvailableInstanceType_Count \
--statistics Average --period 3600 \
--start-time $(date -u -Iminutes -d '-1hour') \
--end-time $(date -u -Iminutes) \
--dimensions \
Name=OutpostId,Value=op-abcdefgh123456789 \
Name=InstanceType,Value=c5.xlarge
This command returns:
Datapoints:
- Average: 10.0
Timestamp: '2024-04-10T10:39:00+00:00'
Unit: Count
Label: AvailableInstanceType_Count
The output indicates that there were (on average) 10 c5.xlarge instances available in the specified time period (1 hour). Using the same command for the other instance types, you discover that there are also 20 c5.4xlarge, 10 r5.2xlarge, and 6 r5.4xlarge available for use in completing the required EC2 launch templates.
Step 5: Install AWS Systems Manager Agent in your on your target instances
Once the launch settings are defined, you must activate the post-launch actions for either a specific server or all the servers. You must leave the Install the Systems Manager agent and allow executing actions on launched servers option toggled on in order for post-launch actions to work. Untoggling the option would disallow Application Migration Service to install the AWS Systems Manager Agent (SSM Agent) on your servers, and post-launch actions would no longer be executed on them (see 5 in Figure 2).

Figure 3: Post-launch actions on the Application Migration Service console
Step 6: Testing and cutover
Once you have configured the launch settings for each source server, you are ready to launch the servers as test instances. Best practice is to test instances before cutover.

Figure 4: Application Migration Service console ready to launch test instances
Finally, after completing the testing of all the source servers, you are ready for cutover (see 6 on Figure 2). Prior to launching cutover instances, check that the source servers are listed as Ready for cutover under Migration lifecycle and Healthy under Data replication status.

Figure 5: Application Migration Console ready for cutover
To launch the cutover instances, select the instances you want to cutover and then select Launch cutover instances under Cutover (see Figure 5).
The AWS Application Migration Service console will indicate Cutover finalized when the cutover has completed successfully, the selected source servers’ Migration lifecycle column will show the Cutover complete status, the Data replication status column will show Disconnected, and the Next step column will show Mark as archived. The source servers have now been successfully migrated into AWS. You can now archive your source servers that have launched cutover instances.
Scenario 2: Using partner backup and replication solutions
You may already be using a third-party or AWS Partner solution to create on-premises backups of bare-metal or virtualized systems. These solutions often use local disk-arrays or object stores to create tiered backups of systems covering restore-points going back years, days, or just a few hours or minutes.
These solutions may also have inherent capabilities to restore from these backups directly to the AWS, enabling migration of on-premises systems to EC2 instances deployed to Outposts rack.
In the scenario illustrated in Figure 6, the partner backup and replication service (BR) creates backups (see 1 in Figure 6) of virtual machines to on-premises disk or object storage repositories. Using the service’s AWS integration, virtual machines can be restored (see 2 in Figure 6) to an EC2 instance deployed on Outposts rack, which is also on premises. The restoration may follow a process that uses helper instances and volumes (see 3 in Figure 6) during intermediate steps to create Amazon Elastic Block Store (Amazon EBS) snapshots (see 4 in Figure 6) and then Amazon Machine Images (AMIs) of the systems being migrated (see 5 in Figure 6), which are ultimately deployed (see 6 in Figure 6) to Outposts rack.

Figure 6: Architecture diagram of the partner backup and replication scenario
When performing this type of migration, there will typically be a stage where you are asked to specify parameters defining the target VPC and subnets. These should be the VPC being extended to the Outpost and a subnet that has been created in that VPC on the Outpost. You will also need to specify an EC2 instance type that is available on the Outpost, which can be discovered using the process described in the previous section.
Workload migration to AWS Outposts rack: With staging environment on an AWS Outpost rack
Data residency can be a critical consideration for organizations that collect and store sensitive information, such as personally identifiable information (PII), financial data or medical records. AWS Elastic Disaster Recovery, supported on Outposts rack, helps enable seamless replication of on-premises data to Outposts rack and addresses data residency concerns by keeping data within your on-premises environment, using Amazon EBS and Amazon S3 on Outposts.
In this scenario, an Outpost rack is deployed on premises with the following prerequisites:
- At least one Outpost rack installed and activated
- The Outposts rack must be in Direct VPC Routing (DVR) mode
- VPC extended to the Outposts rack containing subnets for staging and target resources
- Amazon S3 on Outposts (required for all Elastic Disaster Recovery replication destinations)
- An AWS Replication Agent installed on each source server.
The following diagram shows the solution architecture and includes the on-premises servers that will be migrated from the local network to the Outposts rack. It also includes the staging VPC used to deploy the replication servers on Outposts rack, Amazon S3 on Outposts to store the local Amazon EBS snapshots and the target VPC extended to Outposts rack.

Figure 7: Architecture diagram for workflow migration to AWS Outposts rack
Step 1: Outposts rack configuration
To use Elastic Disaster Recovery on Outposts rack, you need to configure both Amazon EBS and Amazon S3 on Outposts to support nearly continuous replication and point-in-time recovery for your workload needs (see 1 in Figure 7). Specifically, you need to size Amazon EBS and Amazon S3 on Outposts capacity according to your workload capacity requirements and application interdependencies. To do this, you can define dependency groups–each dependency group is a collection of applications and their underlying infrastructure with technical or non-technical dependencies. A 2:1 ratio is recommended for the EBS volumes to be used for near-continuous replication; a 1:1 ratio is recommended for the Amazon S3 on Outposts ratio for EBS snapshots. For example, to migrate 40 terabytes (TB) of workloads, you need to plan for 80TB of EBS volumes and 40TB of S3 on Outposts capacity.
Step 2: Extend VPC to your Outposts rack
Once your Outpost has been provisioned and is available, extend the required Amazon Virtual Private Cloud (Amazon VPC) connection to the Outpost from the Region by creating the desired staging and target subnets (see 2 in Figure 7).
Step 3: Prepare AWS Elastic Disaster Recovery service
Prepare the AWS Elastic Disaster Recovery service from the AWS console to set the default replication and launch settings. When defining these settings, make sure that the Outposts resources available are chosen for staging and target subnets and instance and storage type (see 3 in Figure 7).
Step 4: Install the AWS Replication Agent to the source servers or machines
The next phase will be to install the AWS Replication Agent to the source servers and to ensure that communication is possible between the replication agent and your Outposts replication subnet through the Outposts local gateway to ensure that replication traffic uses the local network (see 4 in Figure 7).
Step 5: Continuous block-level replication
Staging area resources are automatically created and managed by Elastic Disaster Recovery. Once the AWS Replication Agent has been deployed, continuous block-level replication (compressed and encrypted in transit) will occur (see 5 in Figure 7) over the local network.
Step 6: Launch Outposts rack resources
Finally, migrated instances can now be launched using Outposts rack resources based on the launch settings defined previously (see 6 in Figure 7).
Conclusion
In this post, you have learned how to migrate your workloads from your on-premises environment to Outposts rack based on your specific data residency requirements. When you have the flexibility of using Regional services, AWS migration services or partner solutions can be used with infrastructure already in place. If your data must stay on-premises, using AWS Elastic Disaster Recovery allows you to migrate your data without using Regional services, allowing you to migrate to Outposts rack without your data leaving the boundary of a certain geographic location.
To learn more about an end-to-end migration and modernization journey, visit AWS Migration Hub.
[$] CircuitPython: Python for microcontrollers, simplified
Post Syndicated from jake original https://lwn.net/Articles/983870/
CircuitPython is an open-source
implementation of the Python programming language for microcontroller
boards. The project, which is sponsored by Adafruit Industries, is designed with
new programmers in mind, but it also has many features that may be of
interest to more-experienced developers. The recent 9.1.0 release
adds a few minor features, but it follows just a few months after CircuitPython 9.0.0,
which brings some more significant changes, including improved graphics and
USB support.
Firefox 129.0 released
Post Syndicated from corbet original https://lwn.net/Articles/984617/
Version
129.0 of the Firefox browser has been released. Changes include some
improvements to the reader mode, tab previews, and use of HTTPS by default.
The backbone behind Cloudflare’s Connectivity Cloud
Post Syndicated from Shozo Moritz Takaya original https://blog.cloudflare.com/backbone2024
The modern use of “cloud” arguably traces its origins to the cloud icon, omnipresent in network diagrams for decades. A cloud was used to represent the vast and intricate infrastructure components required to deliver network or Internet services without going into depth about the underlying complexities. At Cloudflare, we embody this principle by providing critical infrastructure solutions in a user-friendly and easy-to-use way. Our logo, featuring the cloud symbol, reflects our commitment to simplifying the complexities of Internet infrastructure for all our users.
This blog post provides an update about our infrastructure, focusing on our global backbone in 2024, and highlights its benefits for our customers, our competitive edge in the market, and the impact on our mission of helping build a better Internet. Since the time of our last backbone-related blog post in 2021, we have increased our backbone capacity (Tbps) by more than 500%, unlocking new use cases, as well as reliability and performance benefits for all our customers.
A snapshot of Cloudflare’s infrastructure
As of July 2024, Cloudflare has data centers in 330 cities across more than 120 countries, each running Cloudflare equipment and services. The goal of delivering Cloudflare products and services everywhere remains consistent, although these data centers vary in the number of servers and amount of computational power.
These data centers are strategically positioned around the world to ensure our presence in all major regions and to help our customers comply with local regulations. It is a programmable smart network, where your traffic goes to the best data center possible to be processed. This programmability allows us to keep sensitive data regional, with our Data Localization Suite solutions, and within the constraints that our customers impose. Connecting these sites, exchanging data with customers, public clouds, partners, and the broader Internet, is the role of our network, which is managed by our infrastructure engineering and network strategy teams. This network forms the foundation that makes our products lightning fast, ensuring our global reliability, security for every customer request, and helping customers comply with data sovereignty requirements.
Traffic exchange methods
The Internet is an interconnection of different networks and separate autonomous systems that operate by exchanging data with each other. There are multiple ways to exchange data, but for simplicity, we’ll focus on two key methods on how these networks communicate: Peering and IP Transit. To better understand the benefits of our global backbone, it helps to understand these basic connectivity solutions we use in our network.
-
Peering: The voluntary interconnection of administratively separate Internet networks that allows for traffic exchange between users of each network is known as “peering”. Cloudflare is one of the most peered networks globally. We have peering agreements with ISPs and other networks in 330 cities and across all major
Internet Exchanges (IX’s). Interested parties can register to peer with us anytime, or directly connect to our network with a link through a private network interconnect (PNI).
-
IP transit: A paid service that allows traffic to cross or “transit” somebody else’s network, typically connecting a smaller Internet service provider (ISP) to the larger Internet. Think of it as paying a toll to access a private highway with your car.
The backbone is a dedicated high-capacity optical fiber network that moves traffic between Cloudflare’s global data centers, where we interconnect with other networks using these above-mentioned traffic exchange methods. It enables data transfers that are more reliable than over the public Internet. For the connectivity within a city and long distance connections we manage our own dark fiber or lease wavelengths using Dense Wavelength Division Multiplexing (DWDM). DWDM is a fiber optic technology that enhances network capacity by transmitting multiple data streams simultaneously on different wavelengths of light within the same fiber. It’s like having a highway with multiple lanes, so that more cars can drive on the same highway. We buy and lease these services from our global carrier partners all around the world.
Backbone operations and benefits
Operating a global backbone is challenging, which is why many competitors don’t do it. We take this challenge for two key reasons: traffic routing control and cost-effectiveness.
With IP transit, we rely on our transit partners to carry traffic from Cloudflare to the ultimate destination network, introducing unnecessary third-party reliance. In contrast, our backbone gives us full control over routing of both internal and external traffic, allowing us to manage it more effectively. This control is crucial because it lets us optimize traffic routes, usually resulting in the lowest latency paths, as previously mentioned. Furthermore, the cost of serving large traffic volumes through the backbone is, on average, more cost-effective than IP transit. This is why we are doubling down on backbone capacity in regions such as Frankfurt, London, Amsterdam, and Paris and Marseille, where we see continuous traffic growth and where connectivity solutions are widely available and competitively priced.
Our backbone serves both internal and external traffic. Internal traffic includes customer traffic using our security or performance products and traffic from Cloudflare’s internal systems that shift data between our data centers. Tiered caching, for example, optimizes our caching delivery by dividing our data centers into a hierarchy of lower tiers and upper tiers. If lower-tier data centers don’t have the content, they request it from the upper tiers. If the upper tiers don’t have it either, they then request it from the origin server. This process reduces origin server requests and improves cache efficiency. Using our backbone to transport the cached content between lower and upper-tier data centers and the origin is often the most cost-effective method, considering the scale of our network. Magic Transit is another example where we attract traffic, by means of BGP anycast, to the Cloudflare data center closest to the end user and implement our DDoS solution. Our backbone transports the clean traffic to our customer’s data center, which they connect through a Cloudflare Network Interconnect (CNI).
External traffic that we carry on our backbone can be traffic from other origin providers like AWS, Oracle, Alibaba, Google Cloud Platform, or Azure, to name a few. The origin responses from these cloud providers are transported through peering points and our backbone to the Cloudflare data center closest to our customer. By leveraging our backbone we have more control over how we backhaul this traffic throughout our network, which results in more reliability and better performance and less dependency on the public Internet.
This interconnection between public clouds, offices, and the Internet with a controlled layer of performance, security, programmability, and visibility running on our global backbone is our Connectivity Cloud.
This map is a simplification of our current backbone network and does not show all paths
Expanding our network
As mentioned in the introduction, we have increased our backbone capacity (Tbps) by more than 500% since 2021. With the addition of sub-sea cable capacity to Africa, we achieved a big milestone in 2023 by completing our global backbone ring. It now reaches six continents through terrestrial fiber and subsea cables.
Building out our backbone within regions where Internet infrastructure is less developed compared to markets like Central Europe or the US has been a key strategy for our latest network expansions. We have a shared goal with regional ISP partners to keep our data flow localized and as close as possible to the end user. Traffic often takes inefficient routes outside the region due to the lack of sufficient local peering and regional infrastructure. This phenomenon, known as traffic tromboning, occurs when data is routed through more cost-effective international routes and existing peering agreements.
Our regional backbone investments in countries like India or Turkey aim to reduce the need for such inefficient routing. With our own in-region backbone, traffic can be directly routed between in-country Cloudflare data centers, such as from Mumbai to New Delhi to Chennai, reducing latency, increasing reliability, and helping us to provide the same level of service quality as in more developed markets. We can control that data stays local, supporting our Data Localization Suite (DLS), which helps businesses comply with regional data privacy laws by controlling where their data is stored and processed.
Improved latency and performance
This strategic expansion has not only extended our global reach but has also significantly improved our overall latency. One illustration of this is that since the deployment of our backbone between Lisbon and Johannesburg, we have seen a major performance improvement for users in Johannesburg. Customers benefiting from this improved latency can be, for example, a financial institution running their APIs through us for real-time trading, where milliseconds can impact trades, or our Magic WAN users, where we facilitate site-to-site connectivity between their branch offices.
The table above shows an example where we measured the round-trip time (RTT) for an uncached origin fetch, from an end-user in Johannesburg to various origin locations, comparing our backbone and the public Internet. By carrying the origin request over our backbone, as opposed to IP transit or peering, local users in Johannesburg get their content up to 22% faster. By using our own backbone to long-haul the traffic to its final destination, we are in complete control of the path and performance. This improvement in latency varies by location, but consistently demonstrates the superiority of our backbone infrastructure in delivering high performance connectivity.
Traffic control
Consider a navigation system using 1) GPS to identify the route and 2) a highway toll pass that is valid until your final destination and allows you to drive straight through toll stations without stopping. Our backbone works quite similarly.
Our global backbone is built upon two key pillars. The first is BGP (Border Gateway Protocol), the routing protocol for the Internet, and the second is Segment Routing MPLS (Multiprotocol label switching), a technique for steering traffic across predefined forwarding paths in an IP network. By default, Segment Routing provides end-to-end encapsulation from ingress to egress routers where the intermediate nodes execute no route lookup. Instead, they forward traffic across an end-to-end virtual circuit, or tunnel, called a label-switched path. Once traffic is put on a label-switched path, it cannot detour onto the public Internet and must continue on the predetermined route across Cloudflare’s backbone. This is nothing new, as many networks will even run a “BGP Free Core” where all the route intelligence is carried at the edge of the network, and intermediate nodes only participate in forwarding from ingress to egress.
While leveraging Segment Routing Traffic Engineering (SR-TE) in our backbone, we can automatically select paths between our data centers that are optimized for latency and performance. Sometimes the “shortest path” in terms of routing protocol cost is not the lowest latency or highest performance path.
Supercharged: Argo and the global backbone
Argo Smart Routing is a service that uses Cloudflare’s portfolio of backbone, transit, and peering connectivity to find the most optimal path between the data center where a user’s request lands and your back-end origin server. Argo may forward a request from one Cloudflare data center to another on the way to an origin if the performance would improve by doing so. Orpheus is the counterpart to Argo, and routes around degraded paths for all customer origin requests free of charge. Orpheus is able to analyze network conditions in real-time and actively avoid reachability failures. Customers with Argo enabled get optimal performance for requests from Cloudflare data centers to their origins, while Orpheus provides error self-healing for all customers universally. By mixing our global backbone using Segment Routing as an underlay with Argo Smart Routing and Orpheus as our connectivity overlay, we are able to transport critical customer traffic along the most optimized paths that we have available.
So how exactly does our global backbone fit together with Argo Smart Routing? Argo Transit Selection is an extension of Argo Smart Routing where the lowest latency path between Cloudflare data center hops is explicitly selected and used to forward customer origin requests. The lowest latency path will often be our global backbone, as it is a more dedicated and private means of connectivity, as opposed to third-party transit networks.
Consider a multinational Dutch pharmaceutical company that relies on Cloudflare’s network and services with our SASE solution to connect their global offices, research centers, and remote employees. Their Asian branch offices depend on Cloudflare’s security solutions and network to provide secure access to important data from their central data centers back to their offices in Asia. In case of a cable cut between regions, our network would automatically look for the best alternative route between them so that business impact is limited.
Argo measures every potential combination of the different provider paths, including our own backbone, as an option for reaching origins with smart routing. Because of our vast interconnection with so many networks, and our global private backbone, Argo is able to identify the most performant network path for requests. The backbone is consistently one of the lowest latency paths for Argo to choose from.
In addition to high performance, we care greatly about network reliability for our customers. This means we need to be as resilient as possible from fiber cuts and third-party transit provider issues. During a disruption of the AAE-1 (Asia Africa Europe-1) submarine cable, this is what Argo saw between Singapore and Amsterdam across some of our transit provider paths vs. the backbone.
The large (purple line) spike shows a latency increase on one of our third-party IP transit provider paths due to congestion, which was eventually resolved following likely traffic engineering within the provider’s network. We saw a smaller latency increase (yellow line) over other transit networks, but still one that is noticeable. The bottom (green) line on the graph is our backbone, where round-trip time more or less remains flat throughout the event, due to our diverse backbone connectivity between Asia and Europe. Throughout the fiber cut, we remained stable at around 200ms between Amsterdam and Singapore. There was no noticeable network hiccup as was seen on the transit provider paths, so Argo actively leveraged the backbone for optimal performance.
Call to action
As Argo improves performance in our network, Cloudflare Network Interconnects (CNIs) optimize getting onto it. We encourage our Enterprise customers to use our free CNI’s as on-ramps onto our network whenever practical. In this way, you can fully leverage our network, including our robust backbone, and increase overall performance for every product within your Cloudflare Connectivity Cloud. In the end, our global network is our main product and our backbone plays a critical role in it. This way we continue to help build a better Internet, by improving our services for everybody, everywhere.
If you want to be part of our mission, join us as a Cloudflare network on-ramp partner to offer secure and reliable connectivity to your customers by integrating directly with us. Learn more about our on-ramp partnerships and how they can benefit your business here.
Security updates for Tuesday
Post Syndicated from corbet original https://lwn.net/Articles/984598/
Security updates have been issued by Debian (libreoffice), Gentoo (containerd and firefox), Red Hat (httpd), SUSE (ca-certificates-mozilla, ksh, openssl-3-livepatches, podman, python-Twisted, and skopeo), and Ubuntu (imagemagick).
Hardening the RAG chatbot architecture powered by Amazon Bedrock: Blueprint for secure design and anti-pattern migration
Post Syndicated from Magesh Dhanasekaran original https://aws.amazon.com/blogs/security/hardening-the-rag-chatbot-architecture-powered-by-amazon-bedrock-blueprint-for-secure-design-and-anti-pattern-migration/
This blog post demonstrates how to use Amazon Bedrock with a detailed security plan to deploy a safe and responsible chatbot application. In this post, we identify common security risks and anti-patterns that can arise when exposing a large language model (LLM) in an application. Amazon Bedrock is built with features you can use to mitigate vulnerabilities and incorporate secure design principles. This post highlights architectural considerations and best practice strategies to enhance the reliability of your LLM-based application.
Amazon Bedrock unleashes the fusion of generative artificial intelligence (AI) and LLMs, empowering you to craft impactful chatbot applications. As with technologies handling sensitive data and intellectual property, it’s crucial that you prioritize security and adopt a robust security posture. Without proper measures, these applications can be susceptible to risks such as prompt injection, information disclosure, model exploitation, and regulatory violations. By proactively addressing these security considerations, you can responsibly use Amazon Bedrock foundation models and generative AI capabilities.
The chatbot application use case represents a common pattern in enterprise environments, where businesses want to use the power of generative AI foundation models (FMs) to build their own applications. This falls under the Pre-trained models category of the Generative AI Security Scoping Matrix. In this scope, businesses directly integrate with FMs like Anthropic’s Claude through Amazon Bedrock APIs to create custom applications, such as customer support Retrieval Augmented Generation (RAG) chatbots, content generation tools, and decision support systems.
This post provides a comprehensive security blueprint for deploying chatbot applications that integrate with Amazon Bedrock, enabling the responsible adoption of LLMs and generative AI in enterprise environments. We outline mitigation strategies through secure design principles, architectural considerations, and best practices tailored to the challenges of integrating LLMs and generative AI capabilities.
By following the guidance in this post, you can proactively identify and mitigate risks associated with deploying and operating chatbot applications that integrate with Amazon Bedrock and use generative AI models. The guidance can help you strengthen the security posture, protect sensitive data and intellectual property, maintain regulatory compliance, and responsibly deploy generative AI capabilities within your enterprise environments.
This post contains the following high-level sections:
- Chatbot application architecture overview
- Comprehensive logging and monitoring strategy
- Security anti-patterns and mitigation strategies
- Anti-pattern 1: Lack of secure authentication and access controls
- Anti-pattern 2: Insufficient input sanitization and validation
- Anti-pattern 3: Insecure communication channels
- Anti-pattern 4: Inadequate logging, auditing, and non-repudiation
- Anti-pattern 5: Insecure data storage and access controls
- Anti-pattern 6: Failure to secure FM and generative AI components
- Anti-pattern 7: Lack of responsible AI governance and ethics
- Anti-pattern 8: Lack of comprehensive testing and validation
- Common mitigation strategies for anti-patterns
- Secure and responsible architecture blueprint
Chatbot application architecture overview
The chatbot application architecture described in this post represents an example implementation that uses various AWS services and integrates with Amazon Bedrock and Anthropic’s Claude 3 Sonnet LLM. This baseline architecture serves as a foundation to understand the core components and their interactions. However, it’s important to note that there can be multiple ways for customers to design and implement a chatbot architecture that integrates with Amazon Bedrock, depending on their specific requirements and constraints. Regardless of the implementation approach, it’s crucial to incorporate appropriate security controls and follow best practices for secure design and deployment of generative AI applications.
The chatbot application allows users to interact through a frontend interface and submit prompts or queries. These prompts are processed by integrating with Amazon Bedrock, which uses the Anthropic Claude 3 Sonnet LLM and a knowledge base built from ingested data. The LLM generates relevant responses based on the prompts and retrieved context from the knowledge base. While this baseline implementation outlines the core functionality, it requires incorporating security controls and following best practices to mitigate potential risks associated with deploying generative AI applications. In the subsequent sections, we discuss security anti-patterns that can arise in such applications, along with their corresponding mitigation strategies. Additionally, we present a secure and responsible architecture blueprint for the chatbot application powered by Amazon Bedrock.

Figure 1: Baseline chatbot application architecture using AWS services and Amazon Bedrock
Components in the chatbot application baseline architecture
The chatbot application architecture uses various AWS services and integrates with the Amazon Bedrock service and Anthropic’s Claude 3 Sonnet LLM to deliver an interactive and intelligent chatbot experience. The main components of the architecture (as shown in Figure 1) are:
- User interaction layer:
Users interact with the chatbot application through the Streamlit frontend (3), a Python-based open-source library, used to build the user-friendly and interactive interface. - Amazon Elastic Container Service (Amazon ECS) on AWS Fargate:
A fully managed and scalable container orchestration service that eliminates the need to provision and manage servers, allowing you to run containerized applications without having to manage the underlying compute infrastructure. - Application hosting and deployment:
The Streamlit application (3) components are hosted and deployed on Amazon ECS on AWS Fargate (2), maintaining scalability and high availability. This architecture represents the application and hosting environment in an independent virtual private cloud (VPC) to promote a loosely-coupled architecture. The Streamlit frontend can be replaced with your organization’s specific frontend and quickly integrated with the backend Amazon API Gateway in the VPC. An application load balancer is used to distribute traffic to the Streamlit application instances. - API Gateway driven Lambda Integration:
In this example architecture, instead of directly invoking the Amazon Bedrock service from the frontend, an API Gateway backed by an AWS Lambda function (5) is used as an intermediary layer. This approach promotes better separation of concerns, scalability, and secure access to Amazon Bedrock by limiting direct exposure from the frontend. - Lambda:
Lambda provides highly scalable, short-term serverless compute. Here, the requests from Streamlit are processed. First, the history of the user’s session is retrieved from Amazon DynamoDB (6). Second, the user’s question, history, and the context are formatted into a prompt template and queried against Amazon Bedrock with the knowledge base, employing retrieval augmented generation (RAG). - DynamoDB:
DynamoDB is responsible for storing and retrieving chat history, conversation history, recommendations, and other relevant data using the Lambda function. - Amazon S3:
Amazon Simple Storage Services (Amazon S3) is a data storage service and is used here for storing data artifacts that are ingested into the knowledge base. - Amazon Bedrock:
Amazon Bedrock plays a central role in the architecture. It handles the questions posed by the user using Anthropic Claude 3 Sonnet LLM (9) combined with a previously generated knowledge base (10) of the customer’s organization-specific data. - Anthropic Claude 3 Sonnet:
Anthropic Claude 3 Sonnet is the LLM used to generate tailored recommendations and responses based on user inputs and the context retrieved from the knowledge base. It’s part of the text analysis and generation module in Amazon Bedrock. - Knowledge base and data ingestion:
Relevant documents classified as public are ingested from Amazon S3 (9) into in an Amazon Bedrock knowledge base. Knowledge bases are backed by Amazon OpenSearch Service. Amazon Titan Embeddings (10) are used to generate the vector embeddings database of the documents. Storing the data as vector embeddings allows for semantic similarity searching of the documents to retrieve the context of the question posed by the user (RAG). By providing the LLM with context in addition to the question, there’s a much higher chance of getting a useful answer from the LLM.
Comprehensive logging and monitoring strategy
This section outlines a comprehensive logging and monitoring strategy for the Amazon Bedrock-powered chatbot application, using various AWS services to enable centralized logging, auditing, and proactive monitoring of security events, performance metrics, and potential threats.
- Logging and auditing:
- AWS CloudTrail: Logs API calls made to Amazon Bedrock, including InvokeModel requests, as well as information about the user or service that made the request.
- AWS CloudWatch Logs: Captures and analyzes Amazon Bedrock invocation logs, user prompts, generated responses, and errors or warnings encountered during the invocation process.
- Amazon OpenSearch Service: Logs and indexes data related to the OpenSearch integration, context data retrievals, and knowledge base operations.
- AWS Config: Monitors and audits the configuration of resources related to the chatbot application and Amazon Bedrock service, including IAM policies, VPC settings, encryption key management, and other resource configurations.
- Monitoring and alerting:
- AWS CloudWatch: Monitors metrics specific to Amazon Bedrock, such as the number of model invocations, latency of invocations, and error metrics (client-side errors, server-side errors, and throttling). Configures targeted CloudWatch alarms to proactively detect and respond to anomalies or issues related to Bedrock invocations and performance.
- AWS GuardDuty: Continuously monitors CloudTrail logs for potential threats and unauthorized activity within the AWS environment.
- AWS Security Hub: Provides centralized security posture management and compliance checks.
- Amazon Security Lake: Provides a centralized data lake for log analysis; is integrated with CloudTrail and SecurityHub.
- Security information and event management integration:
- Integrate with security information and event management (SIEM) solutions for centralized log management, real-time monitoring of security events, and correlation of logging data from multiple sources (CloudTrail, CloudWatch Logs, OpenSearch Service, and so on).
- Continuous improvement:
- Regularly review and update logging and monitoring configurations, alerting thresholds, and integration with security solutions to address emerging threats, changes in application requirements, or evolving best practices.
Security anti-patterns and mitigation strategies
This section identifies and explores common security anti-patterns associated with the Amazon Bedrock chatbot application architecture. By recognizing these anti-patterns early in the development and deployment phases, you can implement effective mitigation strategies and fortify your security posture.
Addressing security anti-patterns in the Amazon Bedrock chatbot application architecture is crucial for several reasons:
- Data protection and privacy: The chatbot application processes and generates sensitive data, including personal information, intellectual property, and confidential business data. Failing to address security anti-patterns can lead to data breaches, unauthorized access, and potential regulatory violations.
- Model integrity and reliability: Vulnerabilities in the chatbot application can enable bad actors to manipulate or exploit the underlying generative AI models, compromising the integrity and reliability of the generated outputs. This can have severe consequences, particularly in decision-support or critical applications.
- Responsible AI deployment: As the adoption of generative AI models continues to grow, it’s essential to maintain responsible and ethical deployment practices. Addressing security anti-patterns is crucial for maintaining trust, transparency, and accountability in the chatbot application powered by AI models.
- Compliance and regulatory requirements: Many industries and regions have specific regulations and guidelines governing the use of AI technologies, data privacy, and information security. Addressing security anti-patterns is a critical step towards adhering to and maintaining compliance for the chatbot application.
The security anti-patterns that are covered in this post include:
- Lack of secure authentication and access controls
- Insufficient input validation and sanitization
- Insecure communication channels
- Inadequate prompt and response logging, auditing, and non-repudiation
- Insecure data storage and access controls
- Failure to secure FMs and generative AI components
- Lack of responsible AI governance and ethics
- Lack of comprehensive testing and validation
Anti-pattern 1: Lack of secure authentication and access controls
In a generative AI chatbot application using Amazon Bedrock, a lack of secure authentication and access controls poses significant risks to the confidentiality, integrity, and availability of the system. Identity spoofing and unauthorized access can enable threat actors to impersonate legitimate users or systems, gain unauthorized access to sensitive data processed by the chatbot application, and potentially compromise the integrity and confidentiality of the customer’s data and intellectual property used by the application.
Identity spoofing and unauthorized access are important areas to address in this architecture, as the chatbot application handles user prompts and responses, which may contain sensitive information or intellectual property. If a threat actor can impersonate a legitimate user or system, they can potentially inject malicious prompts, retrieve confidential data from the knowledge base, or even manipulate the responses generated by the Anthropic Claude 3 LLM integrated with Amazon Bedrock.
Anti-pattern examples
- Exposing the Streamlit frontend interface or the API Gateway endpoint without proper authentication mechanisms, potentially allowing unauthenticated users to interact with the chatbot application and inject malicious prompts.
- Storing or hardcoding AWS access keys or API credentials in the application code or configuration files, increasing the risk of credential exposure and unauthorized access to AWS services like Amazon Bedrock or DynamoDB.
- Implementing weak or easily guessable passwords for administrative or service accounts with elevated privileges to access the Amazon Bedrock service or other critical components.
- Lacking multi-factor authentication (MFA) for AWS Identity and Access Management (IAM) users or roles with privileged access, increasing the risk of unauthorized access to AWS resources, including the Amazon Bedrock service, if credentials are compromised.
Mitigation strategies
To mitigate the risks associated with a lack of secure authentication and access controls, implement robust IAM controls, as well as continuous logging, monitoring, and threat detection mechanisms.
IAM controls:
- Use industry-standard protocols like OAuth 2.0 or OpenID Connect, and integrate with AWS IAM Identity Center or other identity providers for centralized authentication and authorization for the Streamlit frontend interface and AWS API Gateway endpoints.
- Implement fine-grained access controls using AWS IAM policies and resource-based policies to restrict access to only the necessary Amazon Bedrock resources, Lambda functions, and other components required for the chatbot application.
- Enforce the use of MFA for all IAM users, roles, and service accounts with access to critical components like Amazon Bedrock, DynamoDB, or the Streamlit application.
Continuous logging and monitoring and threat detection:
- See the Comprehensive logging and monitoring strategy section for guidance on implementing centralized logging and monitoring solutions to track and audit authentication events, access attempts, and potential unauthorized access or credential misuse across the chatbot application components and Amazon Bedrock service, as well as using CloudWatch, Lambda, and GuardDuty to detect and respond to anomalous behavior and potential threats.
Anti-pattern 2: Insufficient input sanitization and validation
Insufficient input validation and sanitization in a generative AI chatbot application can expose the system to various threats, including injection events, data tampering, adversarial events, and data poisoning events. These vulnerabilities can lead to unauthorized access, data manipulation, and compromised model outputs.
Injection events: If user prompts or inputs aren’t properly sanitized and validated, a threat actor can potentially inject malicious code, such as SQL code, leading to unauthorized access or manipulation of the DynamoDB chat history data. Additionally, if the chatbot application or components process user input without proper validation, a threat actor can potentially inject and run arbitrary code on the backend systems, compromising the entire application.
Data tampering: A threat actor can potentially modify user prompts or payloads in transit between the chatbot interface and Amazon Bedrock service, leading to unintended model responses or actions. Lack of data integrity checks can allow a threat actor to tamper with the context data exchanged between Amazon Bedrock and OpenSearch, potentially leading to incorrect or malicious search results influencing the LLM responses.
Data poisoning events: If the training data or context data used by the LLM or chatbot application isn’t properly validated and sanitized, bad actors can potentially introduce malicious or misleading data, leading to biased or compromised model outputs.
Anti-pattern examples
- Failure to validate and sanitize user prompts before sending them to Amazon Bedrock, potentially leading to injection events or unintended data exposure.
- Lack of input validation and sanitization for context data retrieved from OpenSearch, allowing malformed or malicious data to influence the LLM’s responses.
- Insufficient sanitization of LLM-generated responses before displaying them to users, enabling potential code injection or rendering of harmful content.
- Inadequate sanitization of user input in the Streamlit application or Lambda functions, failing to remove or escape special characters, code snippets, or potentially malicious patterns, enabling code injection events.
- Insufficient validation and sanitization of training data or other data sources used by the LLM or chatbot application, allowing data poisoning events that can introduce malicious or misleading data, leading to biased or compromised model outputs.
- Allowing unrestricted character sets, input lengths, or special characters in user prompts or data inputs, enabling adversaries to craft inputs that bypass input validation and sanitization mechanisms, potentially causing undesirable or malicious outputs.
- Relying solely on deny lists for input validation, which can be quickly bypassed by adversaries, potentially leading to injection events, data tampering, or other exploit scenarios.
Mitigation strategies
To mitigate the risks associated with insufficient input validation and sanitization, implement robust input validation and sanitization mechanisms throughout the chatbot application and its components.
Input validation and sanitization:
- Implement strict input validation rules for user prompts at the chatbot interface and Amazon Bedrock service boundaries, defining allowed character sets, maximum input lengths, and disallowing special characters or code snippets. Use Amazon Bedrock’s Guardrails feature, which allows defining denied topics and content filters to remove undesirable and harmful content from user interactions with your applications.
- Use allow lists instead of deny lists for input validation to maintain a more robust and comprehensive approach.
- Sanitize user input by removing or escaping special characters, code snippets, or potentially malicious patterns.
Data flow validation:
- Validate and sanitize data flows between components, including:
- User prompts sent to the FM and responses generated by the FM and returned to the chatbot interface.
- Training data, context data, and other data sources used by the FM or chatbot application.
Protective controls:
- Use AWS Web Application Firewall (WAF) for input validation and protection against common web exploits.
- Use AWS Shield for protection against distributed denial of service (DDoS) events.
- Use CloudTrail to monitor API calls to Amazon Bedrock, including InvokeModel requests.
- See the Comprehensive logging and monitoring strategy section for guidance on implementing Lambda functions, Amazon EventBridge rules, and CloudWatch Logs to analyze CloudTrail logs, ingest application logs, user prompts, and responses, and integrate with incident response and SIEM solutions for detecting, investigating, and mitigating security incidents related to input validation and sanitization, including jailbreaking attempts and anomalous behavior.
Anti-pattern 3: Insecure communication channels
Insecure communication channels between chatbot application components can expose sensitive data to interception, tampering, and unauthorized access risks. Unsecured channels enable man-in-the-middle events where threat actors intercept, modify data in transit such as user prompts, responses, and context data, leading to data tampering, malicious payload injection, and unauthorized information access.
Anti-pattern examples
- Failure to use AWS PrivateLink for secure service-to-service communication within the VPC, exposing communications between Amazon Bedrock and other AWS services to potential risks over the public internet, even when using HTTPS.
- Absence of data integrity checks or mechanisms to detect and prevent data tampering during transmission between components.
- Failure to regularly review and update communication channel configurations, protocols, and encryption mechanisms to address emerging threats and ensure compliance with security best practices.
Mitigation strategies
To mitigate the risks associated with insecure communication channels, implement secure communication mechanisms and enforce data integrity throughout the chatbot application’s components and their interactions. Proper encryption, authentication, and integrity checks should be employed to protect sensitive data in transit and help prevent unauthorized access, data tampering, and man-in-the-middle events.
Secure communication channels:
- Use PrivateLink for secure service-to-service communication between Amazon Bedrock and other AWS services used in the chatbot application architecture. PrivateLink provides a private, isolated communication channel within the Amazon VPC, eliminating the need to traverse the public internet. This mitigates the risk of potential interception, tampering, or unauthorized access to sensitive data transmitted between services, even when using HTTPS.
- Use AWS Certificate Manager (ACM) to manage and automate the deployment of SSL/TLS certificates used for secure communication between the chatbot frontend interface (the Streamlit application) and the API Gateway endpoint. ACM simplifies the provisioning, renewal, and deployment of SSL/TLS certificates, making sure that communication channels between the user-facing components and the backend API are securely encrypted using industry-standard protocols and up-to-date certificates.
Continuous logging and monitoring:
- See the Comprehensive Logging and Monitoring Strategy section for guidance on implementing centralized logging and monitoring mechanisms to detect and respond to potential communication channel anomalies or security incidents, including monitoring communication channel metrics, API call patterns, request payloads, and response data, using AWS services like CloudWatch, CloudTrail, and AWS WAF.
Network segmentation and isolation controls
- Implement network segmentation by deploying the Amazon ECS cluster within a dedicated VPC and subnets, isolating it from other components and restricting communication based on the principle of least privilege.
- Create separate subnets within the VPC for the public-facing frontend tier and the backend application tier, further isolating the components.
- Use AWS security groups and network access control lists (NACLs) to control inbound and outbound traffic at the instance and subnet levels, respectively, for the ECS cluster and the frontend instances.
Anti-pattern 4: Inadequate logging, auditing, and non-repudiation
Inadequate logging, auditing, and non-repudiation mechanisms in a generative AI chatbot application can lead to several risks, including a lack of accountability, challenges in forensic analysis, and compliance concerns. Without proper logging and auditing, it’s challenging to track user activities, diagnose issues, perform forensic analysis in case of security incidents, and demonstrate compliance with regulations or internal policies.
Anti-pattern examples
- Lack of logging for data flows between components, such as user prompts sent to Amazon Bedrock, context data exchanged with OpenSearch, and responses from the LLM, hindering investigative efforts in case of security incidents or data breaches.
- Insufficient logging of user activities within the chatbot application—such as sign in attempts, session duration, and actions performed—limiting the ability to track and attribute actions to specific users.
- Absence of mechanisms to ensure the integrity and authenticity of logged data, allowing potential tampering or repudiation of logged events.
- Failure to securely store and protect log data from unauthorized access or modification, compromising the reliability and confidentiality of log information.
Mitigation strategies
To mitigate the risks associated with inadequate logging, auditing, and non-repudiation, implement comprehensive logging and auditing mechanisms to capture critical events, user activities, and data flows across the chatbot application components. Additionally, measures must be taken to maintain the integrity and authenticity of log data, help prevent tampering or repudiation, and securely store and protect log information from unauthorized access.
Comprehensive logging and auditing:
- See the Comprehensive logging and monitoring strategy section for detailed guidance on implementing logging mechanisms using CloudTrail, CloudWatch Logs, and OpenSearch Service, as well as using CloudTrail for logging and monitoring API calls, especially Amazon Bedrock API calls and other API activities within the AWS environment, using CloudWatch for monitoring Amazon Bedrock-specific metrics, and ensuring log data integrity and non-repudiation through the CloudTrail log file integrity validation feature and implementing S3 Object Lock and S3 Versioning for log data stored in Amazon S3.
- Make sure that log data is securely stored and protected from unauthorized access by using AWS Key Management Service (AWS KMS) for encryption at rest and implementing restrictive IAM policies and resource-based policies to control access to log data.
- Retain log data for an appropriate period based on compliance requirements, using CloudTrail log file integrity validation and CloudWatch Logs retention periods and data archiving capabilities.
User activity monitoring and tracking:
- Use CloudTrail for logging and monitoring API calls, especially Amazon Bedrock API calls and other API activities within the AWS environment, such as API Gateway, Lambda, and DynamoDB. Additionally, use CloudWatch for monitoring metrics specific to Amazon Bedrock, including the number of model invocations, latency, and error metrics (client-side errors, server-side errors, and throttling).
- Integrate with security information and event management (SIEM) solutions for centralized log management and real-time monitoring of security events.
Data integrity and non-repudiation:
- Implement digital signatures or non-repudiation mechanisms to verify the integrity and authenticity of logged data, minimizing tampering or repudiation of logged events. Use the CloudTrail log file integrity validation feature, which uses industry-standard algorithms (SHA-256 for hashing and SHA-256 with RSA for digital signing) to provide non-repudiation and verify log data integrity. For log data stored in Amazon S3, enable S3 Object Lock and S3 Versioning to provide an immutable, write once, read many (WORM) data storage model, helping to prevent object deletions or modifications, and maintaining data integrity and non-repudiation. Additionally, implement S3 bucket policies and IAM policies to restrict access to log data stored in S3, further enhancing the security and non-repudiation of logged events.
Anti-pattern 5: Insecure data storage and access controls
Insecure data storage and access controls in a generative AI chatbot application can lead to significant risks, including information disclosure, data tampering, and unauthorized access. Storing sensitive data, such as chat history, in an unencrypted or insecure manner can result in information disclosure if the data store is compromised or accessed by unauthorized entities. Additionally, a lack of proper access controls can allow unauthorized parties to access, modify, or delete data, leading to data tampering or unauthorized access.
Anti-pattern examples
- Storing chat history data in DynamoDB without encryption at rest using AWS KMS customer-managed keys (CMKs).
- Lack of encryption at rest using CMKs from AWS KMS for data in OpenSearch, Amazon S3, or other components that handle sensitive data.
- Overly permissive access controls or lack of fine-grained access control mechanisms for the DynamoDB chat history, OpenSearch, Amazon S3, or other data stores, increasing the risk of unauthorized access or data breaches.
- Storing sensitive data in clear text, or using insecure encryption algorithms or key management practices.
- Failure to regularly review and rotate encryption keys or update access control policies to address potential security vulnerabilities or changes in access requirements.
Mitigation strategies
To mitigate the risks associated with insecure data storage and access controls, implement robust encryption mechanisms, secure key management practices, and fine-grained access control policies. Encrypting sensitive data at rest and in transit, using customer-managed encryption keys from AWS KMS, and implementing least- privilege access controls based on IAM policies and resource-based policies can significantly enhance the security and protection of data within the chatbot application architecture.
Key management and encryption at rest:
- Implement AWS KMS to manage and control access to CMKs for data encryption across components like DynamoDB, OpenSearch, and Amazon S3.
- Use CMKs to configure DynamoDB to automatically encrypt chat history data at rest.
- Configure OpenSearch and Amazon S3 to use encryption at rest with AWS KMS CMKs for data stored in these services.
- CMKs provide enhanced security and control, allowing you to create, rotate, disable, and revoke encryption keys, enabling better key isolation and separation of duties.
- CMKs enable you to enforce key policies, audit key usage, and adhere to regulatory requirements or organizational policies that mandate customer-managed encryption keys.
- CMKs offer portability and independence from specific services, allowing you to migrate or integrate data across multiple services while maintaining control over the encryption keys.
- AWS KMS provides a centralized and secure key management solution, simplifying the management and auditing of encryption keys across various components and services.
- Implement secure key management practices, including:
- Regular key rotation to maintain the security of your encrypted data.
- Separation of duties to make sure that no single individual has complete control over key management operations.
- Strict access controls for key management operations, using IAM policies and roles to enforce the principle of least privilege.
Fine-grained access controls:
- Implement fine-grained access controls for the DynamoDB chat history data store, OpenSearch, Amazon S3, and other data stores using IAM policies and roles.
- Implement fine-grained access controls and define least-privilege access policies for all resources handling sensitive data, such as the DynamoDB chat history data store, OpenSearch, Amazon S3, and other data stores or services. For example, use IAM policies and resource-based policies to restrict access to specific DynamoDB tables, OpenSearch domains, and S3 buckets, limiting access to only the necessary actions (for example, read, write, and list) based on the principle of least privilege. Extend this approach to all resources handling sensitive data within the chatbot application architecture, making sure that access is granted only to the minimum required resources and actions necessary for each component or user role.
Continuous improvement:
- Regularly review and update encryption configurations, access control policies, and key management practices to address potential security vulnerabilities or changes in access requirements.
Anti-pattern 6: Failure to secure FM and generative AI components
Inadequate security measures for FMs and generative AI components in a chatbot application can lead to severe risks, including model tampering, unintended information disclosure, and denial of service. Threat actors can manipulate unsecured FMs and generative AI models to generate biased, harmful, or malicious responses, potentially causing significant harm or reputational damage.
Lack of proper access controls or input validation can result in unintended information disclosure, where sensitive data is inadvertently included in model responses. Additionally, insecure FM or generative AI components can be vulnerable to denial-of-service events, disrupting the availability of the chatbot application and impacting its functionality.
Anti-pattern examples
- Insecure model fine tuning practices, such as using untrusted or compromised data sources, can lead to biased or malicious models.
- Lack of continuous monitoring for FM and generative AI components, leaving them vulnerable to emerging threats or known vulnerabilities.
- Lack of guardrails or safety measures to control and filter the outputs of FMs and generative AI components, potentially leading to the generation of harmful, biased, or undesirable content.
- Inadequate access controls or input validation for prompts and context data sent to the FM components, increasing the risk of injection events or unintended information disclosure.
- Failure to implement secure deployment practices for FM and generative AI components, including secure communication channels, encryption of model artifacts, and access controls.
Mitigation strategies
To mitigate the risks associated with inadequately secured foundational models (FMs) and generative AI components, implement secure integration mechanisms, robust model fine-tuning and deployment practices, continuous monitoring, and effective guardrails and safety measures. These mitigation strategies help prevent model tampering, unintended information disclosure, denial-of-service events, and the generation of harmful or undesirable content, while ensuring the security, reliability, and ethical alignment of the chatbot application’s generative AI capabilities.
Secure integration with LLMs and knowledge bases:
- Implement secure communication channels (for example HTTPS or PrivateLink) between Amazon Bedrock, OpenSearch, and the FM components to help prevent unauthorized access or data tampering.
- Implement strict input validation and sanitization for prompts and context data sent to the FM components to help prevent injection events or unintended information disclosure.
- Implement access controls and least-privilege principles for the OpenSearch integration to limit the data accessible to the LLM components.
Secure model fine tuning, deployment, and monitoring:
- Establish secure and auditable fine-tuning pipelines, using trusted and vetted data sources, to help prevent tampering or the introduction of biases.
- Implement secure deployment practices for FM and generative AI components, including access controls, secure communication channels, and encryption of model artifacts.
- Continuously monitor FM and generative AI components for security vulnerabilities, performance issues, and unintended behavior.
- Implement rate-limiting, throttling, and load-balancing mechanisms to help prevent denial-of-service events on FM and generative AI components.
- Regularly review and audit FM and generative AI components for compliance with security policies, industry best practices, and regulatory requirements.
Guardrails and safety measures
- Implement guardrails, which are safety measures designed to reduce harmful outputs and align the behavior of FMs and generative AI components with human values.
- Use keyword-based filtering, metric-based thresholds, human oversight, and customized guardrails tailored to the specific risks and cultural and ethical norms of each application domain.
- Monitor the effectiveness of guardrails through performance benchmarking and adversarial testing.
Jailbreak robustness testing
- Conduct jailbreak robustness testing by prompting the FMs and generative AI components with a diverse set of jailbreak attempts across different prohibited scenarios to identify weaknesses and improve model robustness.
Anti-pattern 7: Lack of responsible AI governance and ethics
While the previous anti-patterns focused on technical security aspects, it is equally important to address the ethical and responsible governance of generative AI systems. Without strong governance frameworks, ethical guidelines, and accountability measures, chatbot applications can result in unintended consequences, biased outcomes, and a lack of transparency and trust.
Anti-pattern examples
- Lack of an established ethical AI governance framework, including principles, policies, and processes to guide the responsible development and deployment of the generative AI chatbot application.
- Insufficient measures to ensure transparency, explainability, and interpretability of the LLM and generative AI components, making it difficult to understand and audit their decision-making processes.
- Absence of mechanisms for stakeholder engagement, public consultation, and consideration of societal impacts, potentially leading to a lack of trust and acceptance of the chatbot application.
- Failure to address potential biases, discrimination, or unfairness in the training data, models, or outputs of the generative AI system.
- Inadequate processes for testing, validation, and ongoing monitoring of the chatbot application’s ethical behavior and alignment with organizational values and societal norms.
Mitigation strategies
To minimize a lack of responsible AI governance and ethics, establish a comprehensive ethical AI governance framework, promote transparency and interpretability, engage stakeholders and consider societal impacts, address potential biases and fairness issues, implement continuous improvement and monitoring processes, and use guardrails and safety measures. These mitigation strategies help to foster trust, accountability, and ethical alignment in the development and deployment of the generative AI chatbot application, mitigating the risks of unintended consequences, biased outcomes, and a lack of transparency.
Ethical AI governance framework:
- Establish an ethical AI governance framework, including principles, policies, and processes to guide the responsible development and deployment of the generative AI chatbot application.
- Define clear ethical guidelines and decision-making frameworks to address potential ethical dilemmas, biases, or unintended consequences.
- Implement accountability measures, such as designated ethics boards, ethics officers, or external advisory committees, to oversee the ethical development and deployment of the chatbot application.
Transparency and interpretability:
- Implement measures to promote transparency and interpretability of the LLM and generative AI components, allowing for auditing and understanding of their decision-making processes.
- Provide clear and accessible information to stakeholders and users about the chatbot application’s capabilities, limitations, and potential biases or ethical considerations.
Stakeholder engagement and societal impact:
- Establish mechanisms for stakeholder engagement, public consultation, and consideration of societal impacts, fostering trust and acceptance of the chatbot application.
- Conduct impact assessments to identify and mitigate potential negative consequences or risks to individuals, communities, or society.
Bias and fairness:
- Address potential biases, discrimination, or unfairness in the training data, models, or outputs of the generative AI system through rigorous testing, bias mitigation techniques, and ongoing monitoring.
- Promote diverse and inclusive representation in the development, testing, and governance processes to reduce potential biases and blind spots.
Continuous improvement and monitoring:
- Implement processes for ongoing testing, validation, and monitoring of the chatbot application’s behavior and alignment with organizational values and societal norms.
- Regularly review and update the AI governance framework, policies, and processes to address emerging ethical challenges, societal expectations, and regulatory developments.
Guardrails and safety measures:
- Implement guardrails, such as Guardrails for Amazon Bedrock, which are safety measures designed to reduce harmful outputs and align the behavior of LLMs and generative AI components with human values and responsible AI policies.
- Use Guardrails for Amazon Bedrock to define denied topics and content filters to remove undesirable and harmful content from interactions between users and your applications.
- Define denied topics using natural language descriptions to specify topics or subject areas that are undesirable in the context of your application.
- Configure content filters to set thresholds for filtering harmful content across categories such as hate, insults, sexuality, and violence based on your use cases and responsible AI policies.
- Use the personally identifiable information (PII) redaction feature to redact information such as names, email addresses, and phone numbers from LLM-generated responses or block user inputs that contain PII.
- Integrate Guardrails for Amazon Bedrock with CloudWatch to monitor and analyze user inputs and LLM responses that violate defined policies, enabling proactive detection and response to potential issues.
- Monitor the effectiveness of guardrails through performance benchmarking and adversarial testing, continuously refining and updating the guardrails based on real-world usage and emerging ethical considerations.
Jailbreak robustness testing:
- Conduct jailbreak robustness testing by prompting the LLMs and generative AI components with a diverse set of jailbreak attempts across different prohibited scenarios to identify weaknesses and improve model robustness.
Anti-pattern 8: Lack of comprehensive testing and validation
Inadequate testing and validation processes for the LLM system and the generative AI chatbot application can lead to unidentified vulnerabilities, performance bottlenecks, and availability issues. Without comprehensive testing and validation, organizations might fail to detect potential security risks, functionality gaps, or scalability and performance limitations before deploying the application in a production environment.
Anti-pattern examples
- Lack of functional testing to validate the correctness and completeness of the LLM’s responses and the chatbot application’s features and functionalities.
- Insufficient performance testing to identify bottlenecks, resource constraints, or scalability limitations under various load conditions.
- Absence of security testing, such as penetration testing, vulnerability scanning, and adversarial testing to uncover potential security vulnerabilities or model exploits.
- Failure to incorporate automated testing and validation processes into a continuous integration and continuous deployment (CI/CD) pipeline, leading to manual and one-time testing efforts that might overlook critical issues.
- Inadequate testing of the chatbot application’s integration with external services and components, such as Amazon Bedrock, OpenSearch, and DynamoDB, potentially leading to compatibility issues or data integrity problems.
Mitigation strategies
To address the lack of comprehensive testing and validation, implement a robust testing strategy encompassing functional, performance, security, and integration testing. Integrate automated testing into a CI/CD pipeline, conduct security testing like threat modeling and penetration testing, and use adversarial validation techniques. Continuously improve testing processes to verify the reliability, security, and scalability of the generative AI chatbot application.
Comprehensive testing strategy:
- Establish a comprehensive testing strategy that includes functional testing, performance testing, load testing, security testing, and integration testing for the LLM system and the overall chatbot application.
- Define clear testing requirements, test cases, and acceptance criteria based on the application’s functional and non-functional requirements, as well as security and compliance standards.
Automated testing and CI/CD integration:
- Incorporate automated testing and validation processes into a CI/CD pipeline, enabling continuous monitoring and assessment of the LLM’s performance, security, and reliability throughout its lifecycle.
- Use automated testing tools and frameworks to streamline the testing process, improve test coverage, and facilitate regression testing.
Security testing and adversarial validation:
- Conduct threat modeling exercises early in the design process and as soon as the design is finalized for the chatbot application architecture to proactively identify potential security risks and vulnerabilities. Subsequently, conduct regular security testing—including penetration testing, vulnerability scanning, and adversarial testing—to uncover and validate identified security vulnerabilities or model exploits.
- Implement adversarial validation techniques, such as prompting the LLM with carefully crafted inputs designed to expose weaknesses or vulnerabilities, to improve the model’s robustness and security.
Performance and load testing:
- Perform comprehensive performance and load testing to identify potential bottlenecks, resource constraints, or scalability limitations under various load conditions.
- Use tools and techniques for load generation, stress testing, and capacity planning to ensure the chatbot application can handle anticipated user traffic and workloads.
Integration testing:
- Conduct thorough integration testing to validate the chatbot application’s integration with external services and components, such as Amazon Bedrock, OpenSearch, and DynamoDB, maintaining seamless communication and data integrity.
Continuous improvement:
- Regularly review and update the testing and validation processes to address emerging threats, new vulnerabilities, or changes in application requirements.
- Use testing insights and results to continuously improve the LLM system, the chatbot application, and the overall security posture.
Common mitigation strategies for all anti-patterns
- Regularly review and update security measures, access controls, monitoring mechanisms, and guardrails for LLM and generative AI components to address emerging threats, vulnerabilities, and evolving responsible AI best practices.
- Conduct regular security assessments, penetration testing, and code reviews to identify and remediate vulnerabilities or misconfigurations related to logging, auditing, and non-repudiation mechanisms.
- Stay current with security best practices, guidance, and updates from AWS and industry organizations regarding logging, auditing, and non-repudiation for generative AI applications.
Secure and responsible architecture blueprint
After discussing the baseline chatbot application architecture and identifying critical security anti-patterns associated with generative AI applications built using Amazon Bedrock, we now present the secure and responsible architecture blueprint. This blueprint (Figure 2) incorporates the recommended mitigation strategies and security controls discussed throughout the anti-pattern analysis.

Figure 2: Secure and responsible generative AI chatbot architecture blueprint
In this target state architecture, unauthenticated users interact with the chatbot application through the frontend interface (1), where it’s crucial to mitigate the anti-pattern of insufficient input validation and sanitization by implementing secure coding practices and input validation. The user inputs are then processed through AWS Shield, AWS WAF, and CloudFront (2), which provide DDoS protection, web application firewall capabilities, and a content delivery network, respectively. These services help mitigate insufficient input validation, web exploits, and lack of comprehensive testing by using AWS WAF for input validation and conducting regular security testing.
The user requests are then routed through API Gateway (3), which acts as the entry point for the chatbot application, facilitating API connections to the Streamlit frontend. To address anti-patterns related to authentication, insecure communication, and LLM security, it’s essential to implement secure authentication protocols, HTTPS/TLS, access controls, and input validation within API Gateway. Communication between the VPC resources and API Gateway is secured through VPC endpoints (4), using PrivateLink for secure private communication and attaching endpoint policies to control which AWS principals can access the API Gateway service (8), mitigating the insecure communication channels anti-pattern.
The Streamlit application (5) is hosted on Amazon ECS in a private subnet within the VPC. It hosts the frontend interface and must implement secure coding practices and input validation to mitigate insufficient input validation and sanitization. User inputs are then processed by Lambda (6), a serverless compute service hosted within the VPC, which connects to Amazon Bedrock, OpenSearch, and DynamoDB through VPC endpoints (7). These VPC endpoints have endpoint policies attached to control access, enabling secure private communication between the Lambda function and the services, mitigating the insecure communication channels anti-pattern. Within Lambda, strict input validation rules, allow-lists, and user input sanitization are implemented to address the input validation anti-pattern.
User requests from the chatbot application are sent to Amazon Bedrock (12), a generative AI solution that powers the LLM capabilities. To mitigate the failure to secure FM and generative AI components anti-pattern, secure communication channels, input validation, and sanitization for prompts and context data must be implemented when interacting with Amazon Bedrock.
Amazon Bedrock interacts with OpenSearch Service (9) using Amazon Bedrock knowledge bases to retrieve relevant context data for the user’s question. The knowledge base is created by ingesting public documents from Amazon S3 (10). To mitigate the anti-pattern of insecure data storage and access controls, implement encryption at rest using AWS KMS and fine-grained IAM policies and roles for access control within OpenSearch Service. Titan Embeddings (11) are the format of the vector embeddings, which represent the documents stored in Amazon S3. The vector format enables similarity calculation and retrieval of relevant information (12). To address the failure to secure FM and generative AI components anti-pattern, secure integration with Titan Embeddings and input data validation should be implemented.
The knowledge base data, user prompts, and context data are processed by Amazon Bedrock (13) with the Claude 3 LLM (14). To address the anti-patterns of failure to secure FM and generative AI components, as well as lack of responsible AI governance and ethics, secure communication channels, input validation, ethical AI governance frameworks, transparency and interpretability measures, stakeholder engagement, bias mitigation, and guardrails like Guardrails for Amazon Bedrock should be implemented.
The generated responses and recommendations are then stored and retrieved in Amazon DynamoDB (15) by the Lambda function. To mitigate insecure data storage and access, encrypting data at rest with AWS KMS (16) and implement fine-grained access controls through IAM policies and roles.
Comprehensive logging, auditing, and monitoring mechanisms are provided by CloudTrail (17), CloudWatch (18), and AWS Config (19) to address the inadequate logging, auditing, and non-repudiation anti-pattern. See the Comprehensive logging and monitoring strategy section for detailed guidance on implementing comprehensive logging, auditing, and monitoring mechanisms using CloudTrail, CloudWatch, CloudWatch Logs, and AWS Config to address the inadequate logging, auditing, and non-repudiation anti-pattern; including logging API calls made to Amazon Bedrock service, monitoring Amazon Bedrock-specific metrics, capturing and analyzing Bedrock invocation logs, and monitoring and auditing the configuration of resources related to the chatbot application and Amazon Bedrock service.
IAM (20) plays a crucial role in the overall architecture and in mitigating anti-patterns related to authentication and insecure data storage and access. IAM roles and permissions are critical in enforcing secure authentication mechanisms, least privilege access, multi-factor authentication, and robust credential management across the various components of the chatbot application. Additionally, service control policies (SCPs) can be configured to restrict access to specific models or knowledge bases within Amazon Bedrock, preventing unauthorized access or use of sensitive intellectual property.
Finally, GuardDuty (21), Amazon Inspector (22), Security Hub (23), and Security Lake (24) have been included as additional recommended services to further enhance the security posture of the chatbot application. GuardDuty (21) provides threat detection across the control and data planes, Amazon Inspector (22) enables vulnerability assessments and continuous monitoring of Amazon ECS and Lambda workloads. Security Hub (23) offers centralized security posture management and compliance checks, while Security Lake (24) acts as a centralized data lake for log analysis, integrated with CloudTrail and SecurityHub.
Conclusion
By identifying critical anti-patterns and providing comprehensive mitigation strategies, you now have a solid foundation for a secure and responsible deployment of generative AI technologies in enterprise environments.
The secure and responsible architecture blueprint presented in this post serves as a comprehensive guide for organizations that want to use the power of generative AI while ensuring robust security, data protection, and ethical governance. By incorporating industry-leading security controls—such as secure authentication mechanisms, encrypted data storage, fine-grained access controls, secure communication channels, input validation and sanitization, comprehensive logging and auditing, secure FM integration and monitoring, and responsible AI guardrails—this blueprint addresses the unique challenges and vulnerabilities associated with generative AI applications.
Moreover, the emphasis on comprehensive testing and validation processes, as well as the incorporation of ethical AI governance principles, makes sure that you can not only mitigate potential risks, but also promote transparency, explainability, and interpretability of the LLM components, while addressing potential biases and ensuring alignment with organizational values and societal norms.
By following the guidance outlined in this post and depicted in the architectural blueprint, you can proactively identify and mitigate potential risks, enhance the security posture of your generative AI-based chatbot solutions, protect sensitive data and intellectual property, maintain regulatory compliance, and responsibly deploy LLMs and generative AI technologies in your enterprise environments.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
The backbone behind Cloudflare’s Connectivity Cloud
Post Syndicated from Shozo Moritz Takaya original https://blog.cloudflare.com/backbone2024
The modern use of “cloud” arguably traces its origins to the cloud icon, omnipresent in network diagrams for decades. A cloud was used to represent the vast and intricate infrastructure components required to deliver network or Internet services without going into depth about the underlying complexities. At Cloudflare, we embody this principle by providing critical infrastructure solutions in a user-friendly and easy-to-use way. Our logo, featuring the cloud symbol, reflects our commitment to simplifying the complexities of Internet infrastructure for all our users.
This blog post provides an update about our infrastructure, focusing on our global backbone in 2024, and highlights its benefits for our customers, our competitive edge in the market, and the impact on our mission of helping build a better Internet. Since the time of our last backbone-related blog post in 2021, we have increased our backbone capacity (Tbps) by more than 500%, unlocking new use cases, as well as reliability and performance benefits for all our customers.
A snapshot of Cloudflare’s infrastructure
As of July 2024, Cloudflare has data centers in 330 cities across more than 120 countries, each running Cloudflare equipment and services. The goal of delivering Cloudflare products and services everywhere remains consistent, although these data centers vary in the number of servers and amount of computational power.
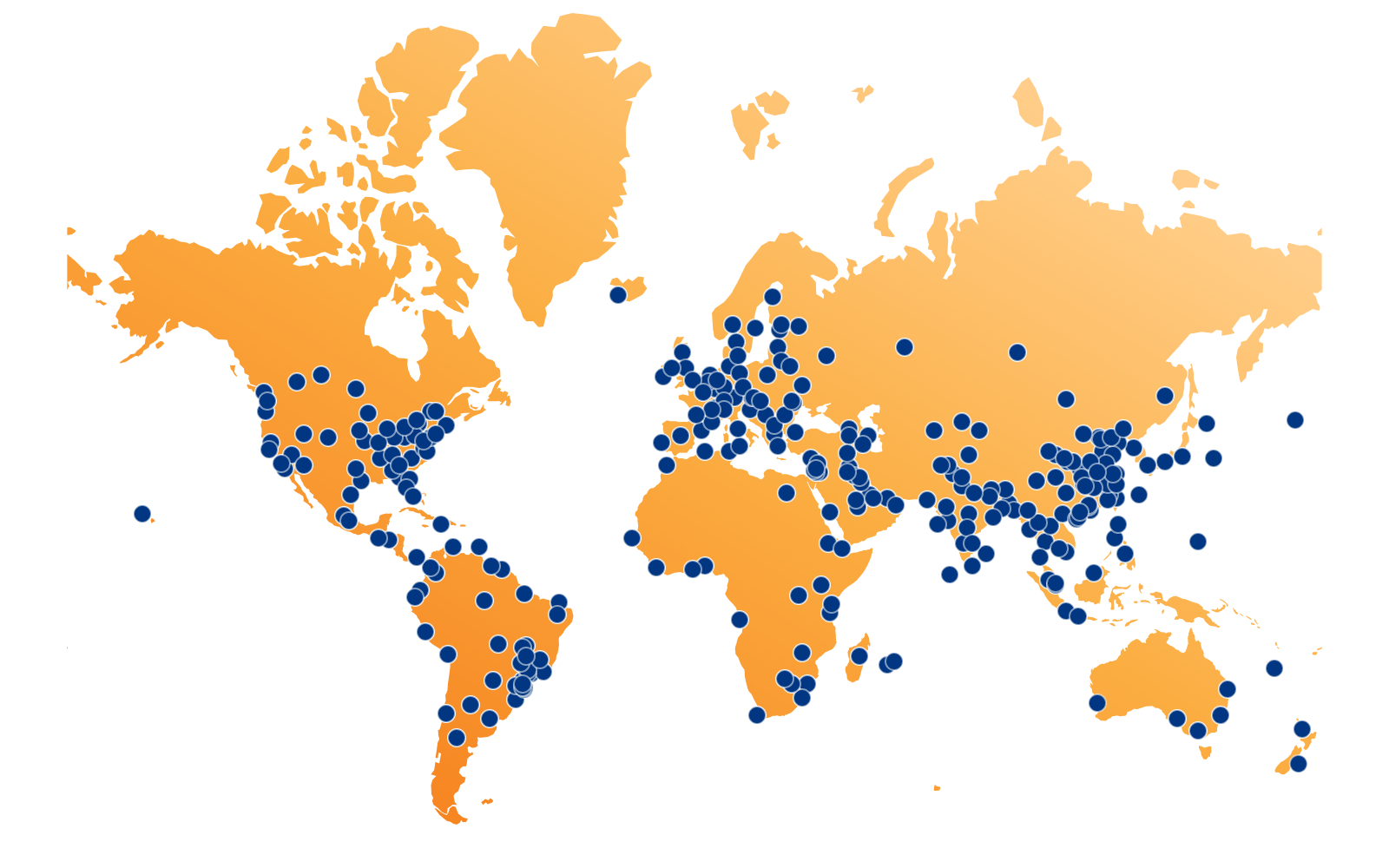
These data centers are strategically positioned around the world to ensure our presence in all major regions and to help our customers comply with local regulations. It is a programmable smart network, where your traffic goes to the best data center possible to be processed. This programmability allows us to keep sensitive data regional, with our Data Localization Suite solutions, and within the constraints that our customers impose. Connecting these sites, exchanging data with customers, public clouds, partners, and the broader Internet, is the role of our network, which is managed by our infrastructure engineering and network strategy teams. This network forms the foundation that makes our products lightning fast, ensuring our global reliability, security for every customer request, and helping customers comply with data sovereignty requirements.
Traffic exchange methods
The Internet is an interconnection of different networks and separate autonomous systems that operate by exchanging data with each other. There are multiple ways to exchange data, but for simplicity, we’ll focus on two key methods on how these networks communicate: Peering and IP Transit. To better understand the benefits of our global backbone, it helps to understand these basic connectivity solutions we use in our network.
- Peering: The voluntary interconnection of administratively separate Internet networks that allows for traffic exchange between users of each network is known as “peering”. Cloudflare is one of the most peered networks globally. We have peering agreements with ISPs and other networks in 330 cities and across all major Internet Exchanges (IX’s). Interested parties can register to peer with us anytime, or directly connect to our network with a link through a private network interconnect (PNI).
- IP transit: A paid service that allows traffic to cross or “transit” somebody else’s network, typically connecting a smaller Internet service provider (ISP) to the larger Internet. Think of it as paying a toll to access a private highway with your car.
The backbone is a dedicated high-capacity optical fiber network that moves traffic between Cloudflare’s global data centers, where we interconnect with other networks using these above-mentioned traffic exchange methods. It enables data transfers that are more reliable than over the public Internet. For the connectivity within a city and long distance connections we manage our own dark fiber or lease wavelengths using Dense Wavelength Division Multiplexing (DWDM). DWDM is a fiber optic technology that enhances network capacity by transmitting multiple data streams simultaneously on different wavelengths of light within the same fiber. It’s like having a highway with multiple lanes, so that more cars can drive on the same highway. We buy and lease these services from our global carrier partners all around the world.
Backbone operations and benefits
Operating a global backbone is challenging, which is why many competitors don’t do it. We take this challenge for two key reasons: traffic routing control and cost-effectiveness.
With IP transit, we rely on our transit partners to carry traffic from Cloudflare to the ultimate destination network, introducing unnecessary third-party reliance. In contrast, our backbone gives us full control over routing of both internal and external traffic, allowing us to manage it more effectively. This control is crucial because it lets us optimize traffic routes, usually resulting in the lowest latency paths, as previously mentioned. Furthermore, the cost of serving large traffic volumes through the backbone is, on average, more cost-effective than IP transit. This is why we are doubling down on backbone capacity in regions such as Frankfurt, London, Amsterdam, and Paris and Marseille, where we see continuous traffic growth and where connectivity solutions are widely available and competitively priced.
Our backbone serves both internal and external traffic. Internal traffic includes customer traffic using our security or performance products and traffic from Cloudflare’s internal systems that shift data between our data centers. Tiered caching, for example, optimizes our caching delivery by dividing our data centers into a hierarchy of lower tiers and upper tiers. If lower-tier data centers don’t have the content, they request it from the upper tiers. If the upper tiers don’t have it either, they then request it from the origin server. This process reduces origin server requests and improves cache efficiency. Using our backbone to transport the cached content between lower and upper-tier data centers and the origin is often the most cost-effective method, considering the scale of our network. Magic Transit is another example where we attract traffic, by means of BGP anycast, to the Cloudflare data center closest to the end user and implement our DDoS solution. Our backbone transports the clean traffic to our customer’s data center, which they connect through a Cloudflare Network Interconnect (CNI).
External traffic that we carry on our backbone can be traffic from other origin providers like AWS, Oracle, Alibaba, Google Cloud Platform, or Azure, to name a few. The origin responses from these cloud providers are transported through peering points and our backbone to the Cloudflare data center closest to our customer. By leveraging our backbone we have more control over how we backhaul this traffic throughout our network, which results in more reliability and better performance and less dependency on the public Internet.
This interconnection between public clouds, offices, and the Internet with a controlled layer of performance, security, programmability, and visibility running on our global backbone is our Connectivity Cloud.
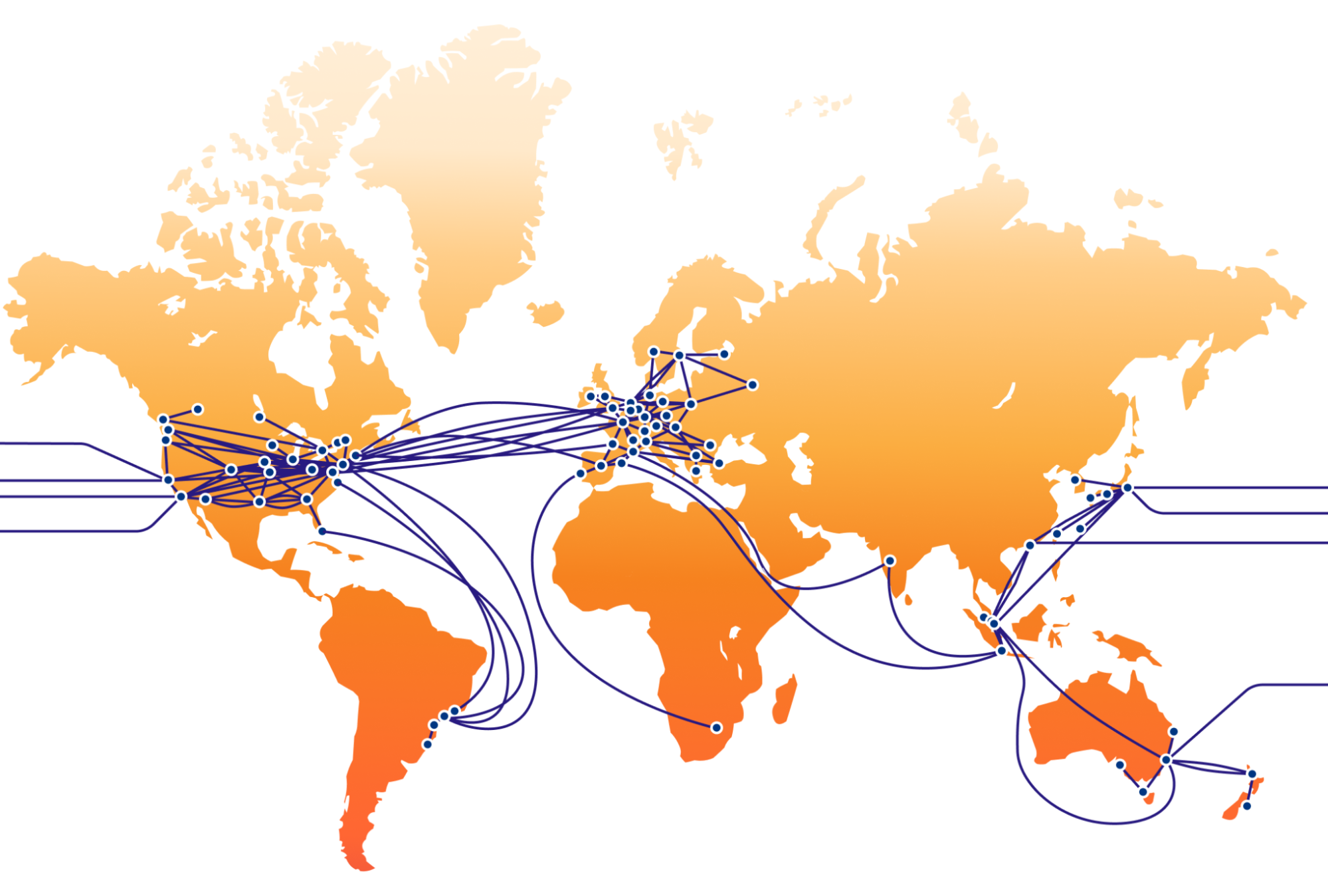
Expanding our network
As mentioned in the introduction, we have increased our backbone capacity (Tbps) by more than 500% since 2021. With the addition of sub-sea cable capacity to Africa, we achieved a big milestone in 2023 by completing our global backbone ring. It now reaches six continents through terrestrial fiber and subsea cables.
Building out our backbone within regions where Internet infrastructure is less developed compared to markets like Central Europe or the US has been a key strategy for our latest network expansions. We have a shared goal with regional ISP partners to keep our data flow localized and as close as possible to the end user. Traffic often takes inefficient routes outside the region due to the lack of sufficient local peering and regional infrastructure. This phenomenon, known as traffic tromboning, occurs when data is routed through more cost-effective international routes and existing peering agreements.
Our regional backbone investments in countries like India or Turkey aim to reduce the need for such inefficient routing. With our own in-region backbone, traffic can be directly routed between in-country Cloudflare data centers, such as from Mumbai to New Delhi to Chennai, reducing latency, increasing reliability, and helping us to provide the same level of service quality as in more developed markets. We can control that data stays local, supporting our Data Localization Suite (DLS), which helps businesses comply with regional data privacy laws by controlling where their data is stored and processed.
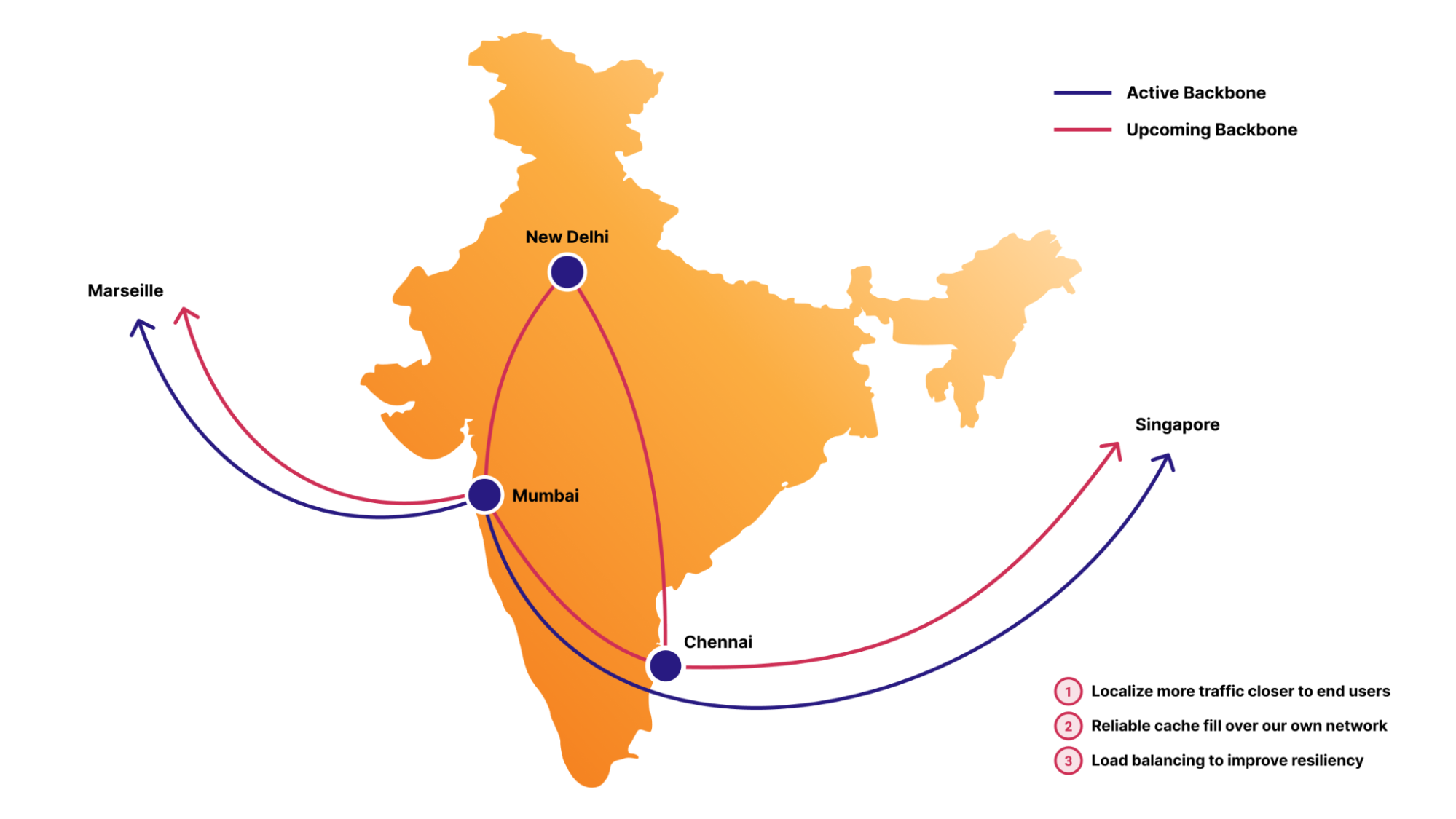
Improved latency and performance
This strategic expansion has not only extended our global reach but has also significantly improved our overall latency. One illustration of this is that since the deployment of our backbone between Lisbon and Johannesburg, we have seen a major performance improvement for users in Johannesburg. Customers benefiting from this improved latency can be, for example, a financial institution running their APIs through us for real-time trading, where milliseconds can impact trades, or our Magic WAN users, where we facilitate site-to-site connectivity between their branch offices.
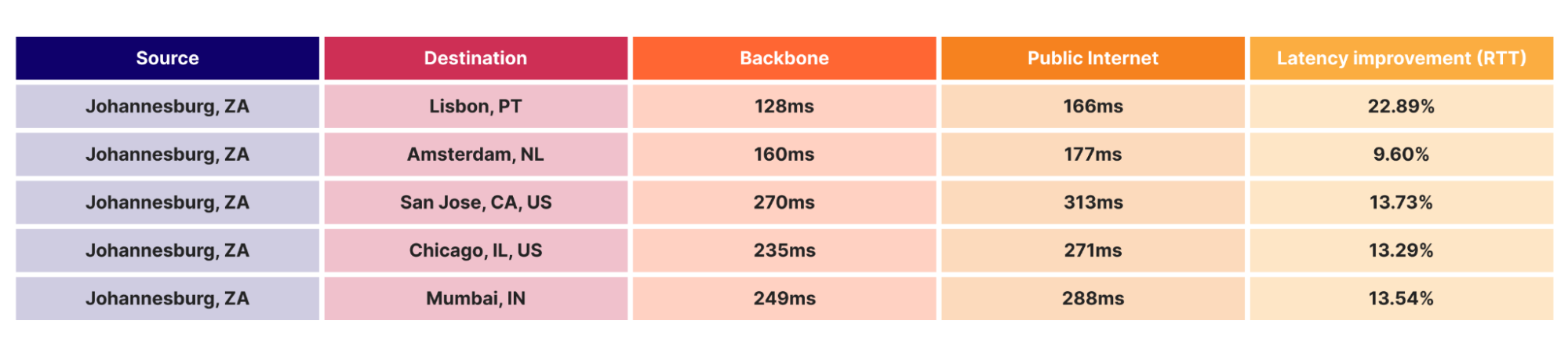
The table above shows an example where we measured the round-trip time (RTT) for an uncached origin fetch, from an end-user in Johannesburg to various origin locations, comparing our backbone and the public Internet. By carrying the origin request over our backbone, as opposed to IP transit or peering, local users in Johannesburg get their content up to 22% faster. By using our own backbone to long-haul the traffic to its final destination, we are in complete control of the path and performance. This improvement in latency varies by location, but consistently demonstrates the superiority of our backbone infrastructure in delivering high performance connectivity.

Traffic control
Consider a navigation system using 1) GPS to identify the route and 2) a highway toll pass that is valid until your final destination and allows you to drive straight through toll stations without stopping. Our backbone works quite similarly.
Our global backbone is built upon two key pillars. The first is BGP (Border Gateway Protocol), the routing protocol for the Internet, and the second is Segment Routing MPLS (Multiprotocol label switching), a technique for steering traffic across predefined forwarding paths in an IP network. By default, Segment Routing provides end-to-end encapsulation from ingress to egress routers where the intermediate nodes execute no route lookup. Instead, they forward traffic across an end-to-end virtual circuit, or tunnel, called a label-switched path. Once traffic is put on a label-switched path, it cannot detour onto the public Internet and must continue on the predetermined route across Cloudflare’s backbone. This is nothing new, as many networks will even run a “BGP Free Core” where all the route intelligence is carried at the edge of the network, and intermediate nodes only participate in forwarding from ingress to egress.
While leveraging Segment Routing Traffic Engineering (SR-TE) in our backbone, we can automatically select paths between our data centers that are optimized for latency and performance. Sometimes the “shortest path” in terms of routing protocol cost is not the lowest latency or highest performance path.
Supercharged: Argo and the global backbone
Argo Smart Routing is a service that uses Cloudflare’s portfolio of backbone, transit, and peering connectivity to find the most optimal path between the data center where a user’s request lands and your back-end origin server. Argo may forward a request from one Cloudflare data center to another on the way to an origin if the performance would improve by doing so. Orpheus is the counterpart to Argo, and routes around degraded paths for all customer origin requests free of charge. Orpheus is able to analyze network conditions in real-time and actively avoid reachability failures. Customers with Argo enabled get optimal performance for requests from Cloudflare data centers to their origins, while Orpheus provides error self-healing for all customers universally. By mixing our global backbone using Segment Routing as an underlay with Argo Smart Routing and Orpheus as our connectivity overlay, we are able to transport critical customer traffic along the most optimized paths that we have available.
So how exactly does our global backbone fit together with Argo Smart Routing? Argo Transit Selection is an extension of Argo Smart Routing where the lowest latency path between Cloudflare data center hops is explicitly selected and used to forward customer origin requests. The lowest latency path will often be our global backbone, as it is a more dedicated and private means of connectivity, as opposed to third-party transit networks.
Consider a multinational Dutch pharmaceutical company that relies on Cloudflare’s network and services with our SASE solution to connect their global offices, research centers, and remote employees. Their Asian branch offices depend on Cloudflare’s security solutions and network to provide secure access to important data from their central data centers back to their offices in Asia. In case of a cable cut between regions, our network would automatically look for the best alternative route between them so that business impact is limited.
Argo measures every potential combination of the different provider paths, including our own backbone, as an option for reaching origins with smart routing. Because of our vast interconnection with so many networks, and our global private backbone, Argo is able to identify the most performant network path for requests. The backbone is consistently one of the lowest latency paths for Argo to choose from.
In addition to high performance, we care greatly about network reliability for our customers. This means we need to be as resilient as possible from fiber cuts and third-party transit provider issues. During a disruption of the AAE-1 (Asia Africa Europe-1) submarine cable, this is what Argo saw between Singapore and Amsterdam across some of our transit provider paths vs. the backbone.
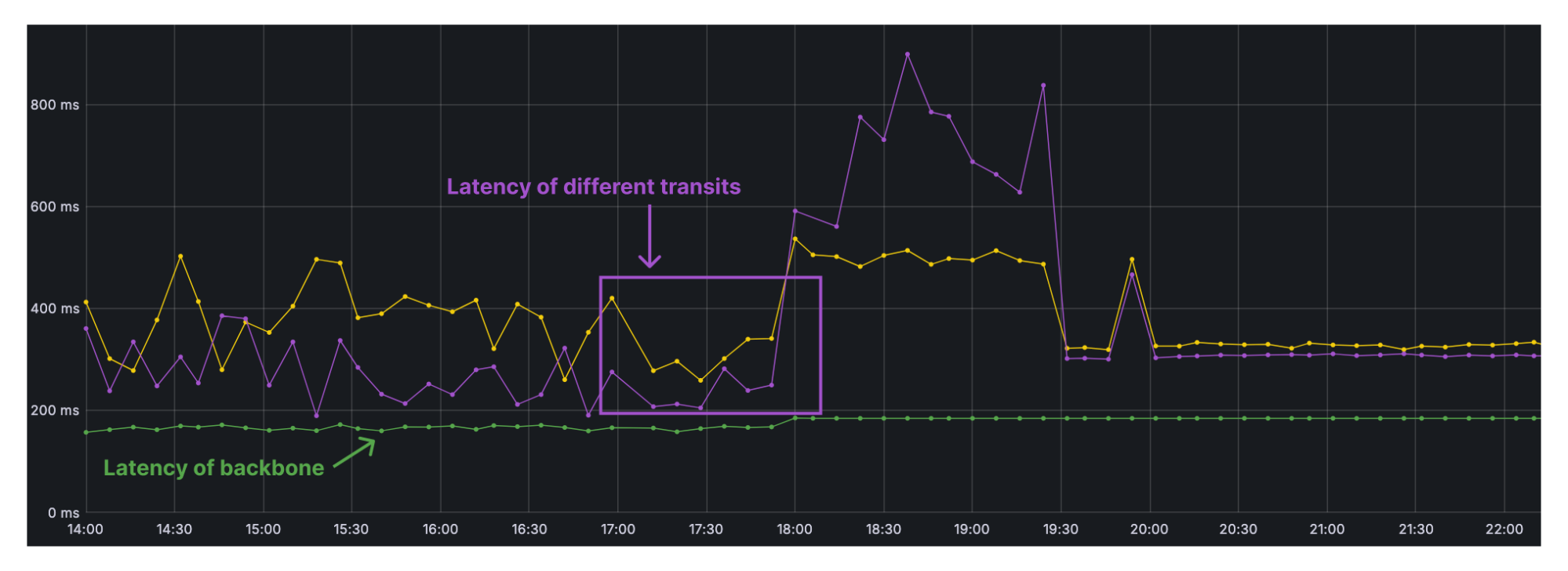
The large (purple line) spike shows a latency increase on one of our third-party IP transit provider paths due to congestion, which was eventually resolved following likely traffic engineering within the provider’s network. We saw a smaller latency increase (yellow line) over other transit networks, but still one that is noticeable. The bottom (green) line on the graph is our backbone, where round-trip time more or less remains flat throughout the event, due to our diverse backbone connectivity between Asia and Europe. Throughout the fiber cut, we remained stable at around 200ms between Amsterdam and Singapore. There was no noticeable network hiccup as was seen on the transit provider paths, so Argo actively leveraged the backbone for optimal performance.

Call to action
As Argo improves performance in our network, Cloudflare Network Interconnects (CNIs) optimize getting onto it. We encourage our Enterprise customers to use our free CNI’s as on-ramps onto our network whenever practical. In this way, you can fully leverage our network, including our robust backbone, and increase overall performance for every product within your Cloudflare Connectivity Cloud. In the end, our global network is our main product and our backbone plays a critical role in it. This way we continue to help build a better Internet, by improving our services for everybody, everywhere.
If you want to be part of our mission, join us as a Cloudflare network on-ramp partner to offer secure and reliable connectivity to your customers by integrating directly with us. Learn more about our on-ramp partnerships and how they can benefit your business here.
Rapid7’s Ransomware Radar Report Shows Threat Actors are Evolving …Fast.
Post Syndicated from Tom Caiazza original https://blog.rapid7.com/2024/08/06/rapid7s-ransomware-radar-report-shows-threat-actors-are-evolving-fast/

Few issues keep cybersecurity professionals up at night more than the threat of ransomware. The ubiquity of targets, the relative organization of threat actors, and their multiple paths of entry make combating ransomware particularly formidable.
But there is one more facet to this threat that makes ransomware a vexing problem across all organizations: it’s evolving, constantly.
In a new report released today by Rapid7 Labs, researchers, threat intelligence experts, and detection & response teams have put together the latest state-of-play in the ransomware space. The Ransomware Radar Report offers some startling insights into who ransomware threat actors are and how they’ve been operating in the first half of 2024.
The fact of the matter is, ransomware as a business is booming. Over the first half of 2024, Rapid7 researchers found an increase of 23% in the number of posts ransomware groups were making to their leak sites. This correlates with the amount of extortion attempts these groups are attempting as they are rarely quiet about who they infiltrate. Surprisingly, one of the newest groups, RansomHub, made the second-most number of posts among the groups studied, with 181 over that six-month period. But, to put that into perspective, the leader, well-established LockBit, made 474 posts over the same time period.
This leads us to another intriguing finding: the number of new (or revamped) ransomware groups. We found that among a total of 68 unique groups posting extortion attempts, some 21 were either net new or rebranded from previous groups. The rebranded groups may indicate a bit of a silver lining as they are potentially due to the success of some recent law enforcement actions against ransomware threat actors.
However, threat actors are only half of the equation. The report also notes that the ransomware ecosystem may be moving away from the attacks on “big fish” we had seen in the past and toward smaller organizations as juicier targets. For instance, organizations with $5 million in annual revenue were five times more likely to be targeted than their larger counterparts. This could be for a lot of reasons, not the least of which is that these smaller organizations contain many of the same data threat actors are after, but they often have less mature security precautions in place.
Ransomware actors are also getting more sophisticated as businesses. They have their own marketplaces, sell their own products, and in some cases have 24/7 support. They also seem to be creating an ecosystem of collaboration and consolidation in the kinds of ransomware they deploy. Rapid7 researchers looked at different ransomware variants and found three distinct clusters of similarities. Essentially, many of these ransomware strains resemble one another. This could indicate collaboration among groups, reuse of source code, or the use of common builders. Other research avenues indicated that the number of ransomware families is going down — potentially showing that threat actors are focusing their efforts on more effective or specialized approaches.
The takeaways in this blog post are only the tip of the iceberg. The Ransomware Radar Report goes deep into the kinds of encryption algorithms that are trending at the moment and why, details on prevailing coding languages, and the varied tactics threat actors use to infiltrate organizations. To get the latest on ransomware and ensure your organization is well-informed and prepared for the fight against these threat actors, download the report here.
Backblaze Drive Stats for Q2 2024
Post Syndicated from Andy Klein original https://www.backblaze.com/blog/backblaze-drive-stats-for-q2-2024/

As of the end of Q2 2024, Backblaze was monitoring 288,665 hard drives (HDDs) and solid state drives (SSDs) in our cloud storage servers located in our data centers around the world. We removed from this analysis 3,789 boot drives, consisting of 2,923 SSDs and 866 hard drives. This leaves us with 284,876 hard drives under management to review for this report. We’ll review the annualized failure rates (AFRs) for Q2 2024 and the lifetime AFRs of the qualifying drive models, and we’ll also check out drive age versus failure rates over time. Along the way, we’ll share our observations and insights on the data presented and, as always, we look forward to you doing the same in the comments section at the end of the post.
Hard drive failure rates for Q2 2024
For our Q2 2024 quarterly analysis, we remove from consideration: drive models which did have at least 100 drives in service at the end of the quarter, drive models which did not accumulate 10,000 or more drive days during the quarter, and individual drives which exceeded their manufacturer’s temperature specification during their lifetime. The removed pool totalled 490 drives, leaving us with 284,386 drives grouped into 29 drive models for our Q2 2024 analysis.
The table below lists the AFRs and related data for these drive models. The table is sorted large to small by drive size then by AFR within drive size.



Notes and observations on the Q2 2024 Drive Stats
- Upward AFR: The AFR for Q2 2024 was 1.71%. That’s up from Q1 2024 at 1.41%, but down from one year ago (Q2 2023) at 2.28%. While the quarter over quarter increase was a bit surprising, quarterly fluctuations in AFR are expected. Sixteen drive models had an AFR of 1.71% or below while 13 drive models had an AFR above.
- Two good zeroes: In Q2 2024, two drive models had zero failures, a 14TB Seagate (model: ST14000NM000J) and a 16TB Seagate (model: ST16000NM002J). Both have a relatively small number of drives and drive days for the quarter, so their success is somewhat muted, but the 16TB Seagate drive model has a very respectable 0.57% lifetime failure rate.
- Another GOAT is gone: In Q1, we migrated the last of our 4TB Toshiba drives. In Q2, we migrated the last of our 6TB drives, including all of the Seagate 6TB drives which had reached an average age of nine years (108 months). This Seagate drive model closed out its career at Backblaze with an impressive 0.86% lifetime AFR.
Currently the 4TB Seagate (model: ST4000DM000) is our oldest data drive model in production at an average age of 99.5 months. The data on these drives is scheduled to be migrated over the next quarter or two using CVT, our in-house drive migration system. They’ll never reach nine years of service.
- The 10-Year Club: With the 6TB Seagate drives being migrated as they hit 10 years of service, we wondered: What is the oldest data drive in service? The answer, a 4TB HGST drive (model: HMS5C4040ALE640) with 9 years, 11 months and 23 days service as of the end of Q2. Alas, the Backblaze Vault in which this drive resides is now being migrated as are many other drives with over nine years of service. We’ll see next quarter to see if any of them made it to the 10-Year Club before they are retired.
While there are no data drives with 10 years of service, there are 11 HDD boot drives that exceed the mark. In fact one, a 500GB WD drive (model: WD5000BPKT) has over 11 years of service. (Psst, don’t tell the CVT team.)
- An HGST surprise: Over the years, the HGST drive models we have used performed very well. So, when the 12TB HGST (model: HUH721212ALN604) drive showed up with a 7.17% AFR for Q2, it’s news. Such uncharacteristic quarterly failure rates for this model actually go back about a year, although the 7.17% AFR is the largest quarterly value to date. As a result, the lifetime AFR has risen from 0.99% to 1.57% over the last year. While the lifetime AFR is not alarming, we are paying attention to this trend.
Lifetime hard drive failure rates
As of the end of Q2 2024, we were tracking 284,876 operational hard drives. To be considered for the lifetime review, a drive model was required to have 500 or more drives as of the end of Q2 2024 and have over 100,000 accumulated drive days during their lifetime. When we removed those drive models which did not meet the lifetime criteria, we had 283,065 drives grouped into 25 models remaining for analysis as shown in the table below.

Age, AFR, and snakes
One of the truisms in our business is that different drive models fail at different rates. Our goal is to develop a failure profile for a given drive model over time. Such a profile can help optimize our drive replacement and migration strategies, and ultimately maintains the durability of our cloud storage service.
For our cohort of data drives, we’ll look at the changes in the lifetime AFR over time for drive models with at least one million drive days as of the end of Q2 2024. This gives us 23 drive models to review. We’ll divide the drive models into two groups: those whose average age is five years (60 months) or less, and those whose average age is above 60 months. Why that cutoff? That’s the typical warranty period for enterprise class hard drives.
Let’s start by plotting the current lifetime AFR for the 14 drives models that have an average age of 60 months or less as shown in the chart below.

Let’s review the drive models by characterizing the four quadrants as follows:
- Quadrant I: Drive models in this quadrant are performing well, and have a respectable AFR of less than 1.5%. Drive models to the right in this quadrant might require a little more attention over the coming months than those to the left.
- Quadrant II: These drive models have failure rates above 1.5%, but are still reasonable at around 2% lifetime AFR. What is important is that AFR does not increase significantly over time.
- Quadrant III: There are no drives currently in this quadrant, but if there were it would not be a cause for alarm. Why? Some drive models experience higher rates of failure early on, and then following the bathtub curve, their AFR drops as they get older.
- Quadrant IV: These drive models are just starting out and are just beginning to establish their failure profile, which at the moment is good.
At a glance, the chart tells us that everything seems fine. The drives in Quadrant I are performing well, the two drives in Quadrant II could be better, but are still acceptable, and there are no surprises in the newer drive models to this point. Let’s see how things fair for the drive models which have an average age of over 60 months as in the chart below.

There are nine drive models which fit the average age criteria, including the Seagate 6TB drive (in yellow) whose drives were removed from service in Q2. As you can see the drive models are spread out across all four quadrants. As before, Quadrant I contains good drives, Quadrants II and III are drives we need to worry about, and Quadrant IV models look good so far.
If we were to stop here we could decide for example that the 4TB Seagate drives are first in line for the CVT migration process, but not so fast. All of these drive models have been around for at least five years and we have their failure rates over time. So, rather than rely on just a point in time, let’s look at their change in failure rates over time in the chart below.

The snake chart, as we’re calling it, shows the lifetime failure rate of each drive model over time. We started at 24 months to make the chart less messy. Regardless, the drive models sort themselves out into either Quadrant I or II once their average age passes 60 months. Let’s take a look at the drives in each of those quadrants.
- Quadrant I: Five of the nine drive models are in Quadrant I as of Q2 2024. The two 4TB HGST drives (brown and purple lines) as well as the 6TB Seagate (red line) have nearly vertical lines indicating their failure rates have been consistent over time, especially after 60 months of service. Such demonstrated consistency over time is a failure profile we like to see.
The failure profile of the 8TB Seagate (blue line) and the 8TB HGST (gray line) are less consistent, with each increasing their failure rates as they have aged. In the case of the HGST drive, the lifetime AFR rose from about 0.5% to 1.0% over an 18 month period starting at 48 months before leveling out. The Seagate drive took about two years starting at 60 months to go from 1.0% to nearly 1.5% before leveling out.
- Quadrant II: The remaining 4 drive models ended in this quadrant. Three of the models, the 8TB Seagate (yellow line), the 10TB Seagate (green line), and the 12TB HGST (teal line) have similar failure profiles. All three got to some point in their lifetime and their curve began bending to the right. In other words, their failure rates over time accelerated. While the 8TB Seagate (yellow) shows some signs of leveling off, all three models will be closely watched and replaced if this trend continues.
Also in Quadrant II is the 4TB Seagate drive (black line). This drive model is aggressively being migrated and is being replaced by 16TB and larger drives via the CVT process. As such, it is hard to tell if the nearly vertical failure profile is a function of the replacement process or the drive model failure rate leveling out over time. Either way, the migration of this drive model is expected to be complete in the next quarter or two.
A normal failure profile
If we had to pick one of the drive models to represent a normal failure profile, it would be the 8TB Seagate (blue line, model: ST800DM002). Why? The failure rate for the first 60 months was consistently around 1.0%, Seagate’s predicted AFR. After 60 months, the AFR increased as the drive aged as one would expect. You might have thought we’d choose the failure profile of one of the two 4TB HGST drive models (brown and purple lines). The “trouble” is their failure rates are well below any published AFR by any drive manufacturer. While that’s great for us, their annualized failure rates over time are sadly not normal.
Can AI help?
The idea of using AI/ML techniques to predict drive failure has been around for several years, but as a first step let’s see if predicting drive failure is even an AI-worthy problem. We recently conducted a webinar “Leveraging Your Cloud Storage Data in AL/ML Apps and Services” in which we outlined general criteria to be used in evaluating if AI/ML is needed to solve a given problem, in this case predicting drive failure. The most salient criteria which applies here is that AI is best used for a problem for which you can not consistently apply a set of rules to solve the problem.
A model is trained by taking the source data and applying an algorithm to iteratively combine and weigh multiple factors. The output is a model which can be used to answer questions about the model’s subject matter, in this case drive failure. For example, we train a model using the Drive Stats data for a given drive model for the last year. Then, we ask the model a question using drive Z’s daily SMART stats and related information. We use this data as input to the model, and while there is no exact match, the model will use inference to develop a response of the probability of drive failure for drive Z over time. As such, it would seem that drive failure prediction would be a good candidate for using AI.
What’s not clear is whether what is learned about one drive model can be applied to another drive model. One look at the snake chart above visualizes the issue as the failure profile for each drive model is different, sometimes radically different. For example, do you think you could train a model on the 4TB Seagate drives (black line) and use it to predict drive failures for either of the 4TB HGST drive models (purple and brown lines)? The answer may be yes, but it certainly doesn’t seem likely.
All that said, several research papers and studies have been published over the years attempting to determine whether or not AI/ML can be used to make drive failure predictions. We’ll be doing a review of these publications in the next couple of months and hopefully shed some light on the ability to use AI to accurately make drive failure predictions in a timely manner.
The Hard Drive Stats data
It has now been over 11 years since we began recording, storing, and reporting the operational statistics of the hard drives and SSDs we use to store data in the Backblaze data storage cloud. We look at the telemetry data of the drives, including their SMART stats and other health related attributes. We do not read or otherwise examine the actual customer data stored.
Over the years, we have analyzed the data we have gathered and published our findings and insights from our analyses. For transparency, we also publish the data itself, known as the Drive Stats dataset. This dataset is open source and can be downloaded from our Drive Stats webpage.
The post Backblaze Drive Stats for Q2 2024 appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
Why we’re taking a problem-first approach to the development of AI systems
Post Syndicated from Ben Garside original https://www.raspberrypi.org/blog/why-were-taking-a-problem-first-approach-to-the-development-of-ai-systems/
If you are into tech, keeping up with the latest updates can be tough, particularly when it comes to artificial intelligence (AI) and generative AI (GenAI). Sometimes I admit to feeling this way myself, however, there was one update recently that really caught my attention. OpenAI launched their latest iteration of ChatGPT, this time adding a female-sounding voice. Their launch video demonstrated the model supporting the presenters with a maths problem and giving advice around presentation techniques, sounding friendly and jovial along the way.

Adding a voice to these AI models was perhaps inevitable as big tech companies try to compete for market share in this space, but it got me thinking, why would they add a voice? Why does the model have to flirt with the presenter?
Working in the field of AI, I’ve always seen AI as a really powerful problem-solving tool. But with GenAI, I often wonder what problems the creators are trying to solve and how we can help young people understand the tech.
What problem are we trying to solve with GenAI?
The fact is that I’m really not sure. That’s not to suggest that I think that GenAI hasn’t got its benefits — it does. I’ve seen so many great examples in education alone: teachers using large language models (LLMs) to generate ideas for lessons, to help differentiate work for students with additional needs, to create example answers to exam questions for their students to assess against the mark scheme. Educators are creative people and whilst it is cool to see so many good uses of these tools, I wonder if the developers had solving specific problems in mind while creating them, or did they simply hope that society would find a good use somewhere down the line?

Whilst there are good uses of GenAI, you don’t need to dig very deeply before you start unearthing some major problems.
Anthropomorphism
Anthropomorphism relates to assigning human characteristics to things that aren’t human. This is something that we all do, all of the time, without it having consequences. The problem with doing this with GenAI is that, unlike an inanimate object you’ve named (I call my vacuum cleaner Henry, for example), chatbots are designed to be human-like in their responses, so it’s easy for people to forget they’re not speaking to a human.

As feared, since my last blog post on the topic, evidence has started to emerge that some young people are showing a desire to befriend these chatbots, going to them for advice and emotional support. It’s easy to see why. Here is an extract from an exchange between the presenters at the ChatGPT-4o launch and the model:
| ChatGPT (presented with a live image of the presenter): “It looks like you’re feeling pretty happy and cheerful with a big smile and even maybe a touch of excitement. Whatever is going on? It seems like you’re in a great mood. Care to share the source of those good vibes?” Presenter: “The reason I’m in a good mood is we are doing a presentation showcasing how useful and amazing you are.” ChatGPT: “Oh stop it, you’re making me blush.” |
The Family Online Safety Institute (FOSI) conducted a study looking at the emerging hopes and fears that parents and teenages have around GenAI.
One quote from a teenager said:
“Some people just want to talk to somebody. Just because it’s not a real person, doesn’t mean it can’t make a person feel — because words are powerful. At the end of the day, it can always help in an emotional and mental way.”
The prospect of teenagers seeking solace and emotional support from a generative AI tool is a concerning development. While these AI tools can mimic human-like conversations, their outputs are based on patterns and data, not genuine empathy or understanding. The ultimate concern is that this exposes vulnerable young people to be manipulated in ways we can’t predict. Relying on AI for emotional support could lead to a sense of isolation and detachment, hindering the development of healthy coping mechanisms and interpersonal relationships.

Arguably worse is the recent news of the world’s first AI beauty pageant. The very thought of this probably elicits some kind of emotional response depending on your view of beauty pageants. There are valid concerns around misogyny and reinforcing misguided views on body norms, but it’s also important to note that the winner of “Miss AI” is being described as a lifestyle influencer. The questions we should be asking are, who are the creators trying to have influence over? What influence are they trying to gain that they couldn’t get before they created a virtual woman?
DeepFake tools
Another use of GenAI is the ability to create DeepFakes. If you’ve watched the most recent Indiana Jones movie, you’ll have seen the technology in play, making Harrison Ford appear as a younger version of himself. This is not in itself a bad use of GenAI technology, but the application of DeepFake technology can easily become problematic. For example, recently a teacher was arrested for creating a DeepFake audio clip of the school principal making racist remarks. The recording went viral before anyone realised that AI had been used to generate the audio clip.
Easy-to-use DeepFake tools are freely available and, as with many tools, they can be used inappropriately to cause damage or even break the law. One such instance is the rise in using the technology for pornography. This is particularly dangerous for young women, who are the more likely victims, and can cause severe and long-lasting emotional distress and harm to the individuals depicted, as well as reinforce harmful stereotypes and the objectification of women.
Why we should focus on using AI as a problem-solving tool
Technological developments causing unforeseen negative consequences is nothing new. A lot of our job as educators is about helping young people navigate the changing world and preparing them for their futures and education has an essential role in helping people understand AI technologies to avoid the dangers.
Our approach at the Raspberry Pi Foundation is not to focus purely on the threats and dangers, but to teach young people to be critical users of technologies and not passive consumers. Having an understanding of how these technologies work goes a long way towards achieving sufficient AI literacy skills to make informed choices and this is where our Experience AI program comes in.

Experience AI is a set of lessons developed in collaboration with Google DeepMind and, before we wrote any lessons, our team thought long and hard about what we believe are the important principles that should underpin teaching and learning about artificial intelligence. One such principle is taking a problem-first approach and emphasising that computers are tools that help us solve problems. In the Experience AI fundamentals unit, we teach students to think about the problem they want to solve before thinking about whether or not AI is the appropriate tool to use to solve it.
Taking a problem-first approach doesn’t by default avoid an AI system causing harm — there’s still the chance it will increase bias and societal inequities — but it does focus the development on the end user and the data needed to train the models. I worry that focusing on market share and opportunity rather than the problem to be solved is more likely to lead to harm.
Another set of principles that underpins our resources is teaching about fairness, accountability, transparency, privacy, and security (Fairness, Accountability, Transparency, and Ethics (FATE) in Artificial Intelligence (AI) and higher education, Understanding Artificial Intelligence Ethics and Safety) in relation to the development of AI systems. These principles are aimed at making sure that creators of AI models develop models ethically and responsibly. The principles also apply to consumers, as we need to get to a place in society where we expect these principles to be adhered to and consumer power means that any models that don’t, simply won’t succeed.
Furthermore, once students have created their models in the Experience AI fundamentals unit, we teach them about model cards, an approach that promotes transparency about their models. Much like how nutritional information on food labels allows the consumer to make an informed choice about whether or not to buy the food, model cards give information about an AI model such as the purpose of the model, its accuracy, and known limitations such as what bias might be in the data. Students write their own model cards based on the AI solutions they have created.
What else can we do?
At the Raspberry Pi Foundation, we have set up an AI literacy team with the aim to embed principles around AI safety, security, and responsibility into our resources and align them with the Foundations’ mission to help young people to:
- Be critical consumers of AI technology
- Understand the limitations of AI
- Expect fairness, accountability, transparency, privacy, and security and work toward reducing inequities caused by technology
- See AI as a problem-solving tool that can augment human capabilities, but not replace or narrow their futures
Our call to action to educators, carers, and parents is to have conversations with your young people about GenAI. Get to know their opinions on GenAI and how they view its role in their lives, and help them to become critical thinkers when interacting with technology.
The post Why we’re taking a problem-first approach to the development of AI systems appeared first on Raspberry Pi Foundation.