Post Syndicated from Rick Armstrong original https://aws.amazon.com/blogs/compute/building-arm64-applications-on-aws-graviton2-using-the-aws-cdk-and-self-hosted-runners-for-github-actions/
This post is written by Frank Dallezotte, Sr. Technical Account Manager, and Maxwell Moon, Sr. Solutions Architect
AWS Graviton2 processors are custom built by AWS using the 64-bit Arm Neoverse cores to deliver great price performance for workloads running in Amazon Elastic Compute Cloud (Amazon EC2). These instances are powered by 64 physical core AWS Graviton2 processors utilizing 64-bit Arm Neoverse N1 cores and custom silicon designed by AWS, built using advanced 7-nanometer manufacturing technology.
Customers are migrating their applications to AWS Graviton2 based instance families in order to take advantage of up to 40% better price performance over comparable current generation x86-based instances for a broad spectrum of workloads. This migration includes updating continuous integration and continuous deployment (CI/CD) pipelines in order to build applications for ARM64.
One option for running CI/CD workflows is GitHub Actions, a GitHub product that lets you automate tasks within your software development lifecycle. Customers utilizing GitHub Actions today can host their own runners and customize the environment used to run jobs in GitHub Actions workflows, allowing you to build ARM64 applications. GitHub recommends that you only use self-hosted runners with private repositories.
This post will teach you to set up an AWS Graviton2 instance as a self-hosted runner for GitHub Actions. We will verify the runner is added to the default runner group for a GitHub Organization, which can only be used by private repositories by default. Then, we’ll walk through setting up a continuous integration workflow in GitHub Actions that runs on the self-hosted Graviton2 runner and hosted x86 runners.
Overview
This post will cover the following:
- Network configurations for deploying a self-hosted runner on EC2.
- Generating a GitHub token for a GitHub organization, and then storing the token and organization URL in AWS Systems Manager Parameter Store.
- Configuring a self-hosted GitHub runner on EC2.
- Deploying the network and EC2 resources by using the AWS Cloud Development Kit (AWS CDK).
- Adding Graviton2 self-hosted runners to a workflow for GitHub Actions to an example Python application.
- Running the workflow.
Prerequisites
- An AWS account with permissions to create the necessary resources.
- A GitHub account: This post assumes that you have the required permissions as a GitHub organization admin to configure your GitHub organization, as well as create workflows.
- Familiarity with the AWS Command Line Interface (AWS CLI).
- Access to AWS CloudShell.
- Access to an AWS account with administrator or PowerUser (or equivalent) AWS Identity and Access Management (IAM) role policies attached.
- Account capacity for two Elastic IPs for the NAT gateways.
- An IPv4 CIDR block for a new Virtual Private Cloud (VPC) that is created as part of the AWS CDK stack.
Security
We’ll be adding the self-hosted runner at the GitHub organization level. This makes the runner available for use by the private repositories belonging to the GitHub organization. When new runners are created for an organization, they are automatically assigned to the default self-hosted runner group, which, by default, cannot be utilized by public repositories.
You can verify that your self-hosted runner group is only available to private repositories by navigating to the Actions section of your GitHub Organization’s settings. Select the “Runner Groups” submenu then the Default runner group and confirm that “Allow public repositories” is not checked.
GitHub recommends only utilizing self-hosted runners with private repositories. Allowing self-hosted runners on public repositories and allowing workflows on public forks introduces a significant security risk. More information about the risks can be found in self-hosted runner security with public repositories.
In this post, we verified that for the default runner group, allowing public repositories is not enabled.
AWS CDK
To model and deploy our architecture, we use the AWS CDK. The AWS CDK lets us design components for a self-hosted runner that are customizable and shareable in several popular programming languages.
Our AWS CDK application is defined by two stacks (VPC and EC2) that we’ll use to create the networking resources and our self-hosted runner on EC2.
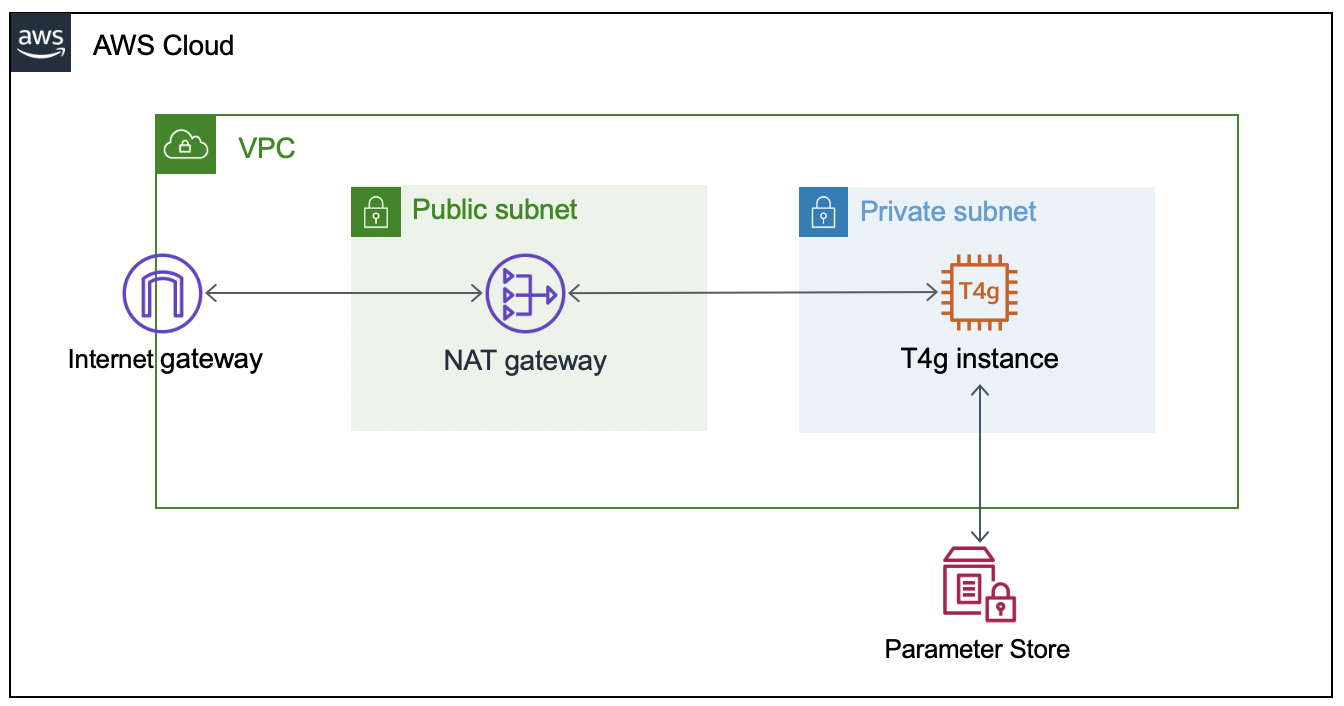
Network Configuration
This section will walk through the networking resources that the CDK stack will create in order to support this architecture. We are deploying our self-hosted runner in a private subnet. A NAT gateway in a public subnet lets the runner make requests to GitHub, but not direct access to the instance from the internet.
- Virtual Private Cloud – Defines a VPC across two Availability Zones with an IPv4 CIDR block that you set.
- Public Subnet – A NAT Gateway will be created in each public subnet for outbound traffic through the VPC’s internet gateway.
- Private Subnet – Contains the EC2 instance for the self-hosted runner that routes internet bound traffic through a NAT gateway in the public subnet.

Configuring the GitHub Runner on EC2
To successfully provision the instance, we must supply the GitHub organization URL and token. To accomplish this, we’ll create two AWS Systems Manager Parameter Store values (gh-url and gh-token), which will be accessed via the EC2 instance user data script when the CDK application deploys the EC2 stack. The EC2 instance will only be accessible through AWS Systems Manager Session Manager.
Get a Token From GitHub
The following steps are based on these instructions for adding self-hosted runners – GitHub Docs.
- Navigate to the private GitHub organization where you’d like to configure a custom GitHub Action Runner.
- Under your repository name, organization, or enterprise, click Settings.
- In the left sidebar, click Actions, then click Runners.
- Under “Runners”, click Add runner.
- Copy the token value under the “Configure” section.
NOTE: this is an automatically generated time-limited token for authenticating the request.
Create the AWS Systems Manager Parameter Store Values
Next, launch an AWS CloudShell environment, and then create the following AWS Systems Manager Parameter Store values in the AWS account where you’ll be deploying the AWS CDK stack.
The names gh-url and gh-token, and types String and SecureString, respectively, are required for this integration:
#!/bin/bash
aws ssm put-parameter --name gh-token --type SecureString --value ABCDEFGHIJKLMNOPQRSTUVWXYZABC
aws ssm put-parameter --name gh-url --type String --value https://github.com/your-url
Self-Hosted Runner Configuration
The EC2 instance user data script will install all required packages, and it will register the GitHub Runner application using the gh-url and gh-token parameters from the AWS Systems Manager Parameter Store. These parameters are stored as variables (TOKEN and REPO) in order to configure the runner.
This script runs automatically when the EC2 instance is launched, and it is included in the GitHub repository. We’ll utilize Amazon Linux 2 for the operating system on the runner instance.
#!/bin/bash
yum update -y
# Download and build a recent version of International Components for Unicode.
# https://github.com/actions/runner/issues/629
# https://github.com/dotnet/core/blob/main/Documentation/linux-prereqs.md
# Install jq for parsing parameter store
yum install -y libicu60 jq
# Get the latest runner version
VERSION_FULL=$(curl -s https://api.github.com/repos/actions/runner/releases/latest | jq -r .tag_name)
RUNNER_VERSION="${VERSION_FULL:1}"
# Create a folder
mkdir /home/ec2-user/actions-runner && cd /home/ec2-user/actions-runner || exit
# Download the latest runner package
curl -o actions-runner-linux-arm64-${RUNNER_VERSION}.tar.gz -L https://GitHub.com/actions/runner/releases/download/v${RUNNER_VERSION}/actions-runner-linux-arm64-${RUNNER_VERSION}.tar.gz
# Extract the installer
tar xzf ./actions-runner-linux-arm64-${RUNNER_VERSION}.tar.gz
chown -R ec2-user /home/ec2-user/actions-runner
REGION=$(curl -s http://169.254.169.254/latest/meta-data/placement/region)
INSTANCE_ID=$(curl -s http://169.254.169.254/latest/meta-data/instance-id)
TOKEN=$(aws ssm get-parameter --region "${REGION}" --name gh-token --with-decryption | jq -r '.Parameter.Value')
REPO=$(aws ssm get-parameter --region "${REGION}" --name gh-url | jq -r '.Parameter.Value')
sudo -i -u ec2-user bash << EOF
/home/ec2-user/actions-runner/config.sh --url "${REPO}" --token "${TOKEN}" --name gh-g2-runner-"${INSTANCE_ID}" --work /home/ec2-user/actions-runner --unattended
EOF
./svc.sh install
./svc.sh start
Deploying the Network Resources and Self-Hosted Runner
In this section, we’ll deploy the network resources and EC2 instance for the self-hosted GitHub runner using the AWS CDK.
From the same CloudShell environment, run the following commands in order to deploy the AWS CDK application:
#!/bin/bash
sudo npm install aws-cdk -g
git clone https://github.com/aws-samples/cdk-graviton2-gh-sh-runner.git
cd cdk-graviton2-gh-sh-runner
python3 -m venv .venv
source .venv/bin/activate
python -m pip install -r requirements.txt
export VPC_CIDR="192.168.0.0/24" # Set your CIDR here.
export AWS_ACCOUNT=`aws sts get-caller-identity | jq -r '.Account'`
cdk bootstrap aws://$AWS_ACCOUNT/$AWS_REGION
cdk deploy --all
# Note: Before the EC2 stack deploys you will be prompted for approval
# The message states 'This deployment will make potentially sensitive changes according to your current security approval level (--require-approval broadening).' and prompts for y/n
These steps will deploy an EC2 instance self-hosted runner that is added to your GitHub organization (as previously specified by the gh-url parameter). Confirm the self-hosted runner has been successfully added to your organization by navigating to the Settings tab for your GitHub organization, selecting the Actions options from the left-hand panel, and then selecting Runners.

Extending a Workflow to use the self-hosted Runner
This section will walk through setting up a GitHub Actions workflow to extend a test pipeline for an example application. We’ll define a workflow that runs a series of static code checks and unit tests on both x86 and ARM.
Our example application is an online bookstore where users can find books, add them to their cart, and create orders. The application is written in Python using the Flask framework, and it uses Amazon DynamoDB for data storage.
Actions expect the workflow to be defined in the folder .github/workflows and the extension of either .yaml or .yml. We’ll create the directory, as well as an empty file inside the directory called main.yml.
#!/bin/bash
mkdir -p .github/workflows
touch .github/workflows/main.yml
First, we must define when our workflow will run. We’ll define the workflow to run when pull requests are created, synchronized (new commits are pushed), or re-opened, and then on push to the main branch.
# main.yml
on:
pull_request:
types: [opened, synchronize, reopened]
push:
branches:
- main
Next, define the workflow by adding jobs. Each job can have one or more steps to run. A step defines a command, set up task, or action that will be run. You can also create custom Actions with user-defined steps and repeatable modules.
Next, we’ll define a single job test to include every step of our workflow, as well as a strategy for the job to run the workflow on both x86 and the Graviton2 self-hosted runner. We’ll specify both ubuntu-latest, a hosted runner, and self-hosted for our Graviton2 runner. This lets our workflow run in parallel on two different CPUs, and it is not disruptive of existing processes.
# main.yml
jobs:
test:
runs-on: ${{ matrix.os }}
strategy:
fail-fast: false
matrix:
os: [ubuntu-latest, self-hosted]
Now we can add steps that each runner will run. We’ll be using custom Actions that we create for each step, as well as the pre-built action checkout for pulling down the latest changes to each runner.
GitHub Actions expects all custom actions to be defined in .github/actions/<name of action>/action.yml. We’ll define four custom Actions – check_system_deps, check_and_install_app_deps, run_static_checks, and run_unit_tests.
#!/bin/bash
for action in check_system_deps check_and_install_app_deps run_static_checks run_unit_tests; do \
mkdir -p .github/actions/${action} && \
touch .github/actions/${action}/action.yml; \
done
We define an Action with a series of steps to ensure that the runner is prepared to run our tests and checks:
- Check that Python3 is installed
- Check that pipenv is installed
Our using statement specifies “composite” to run all steps as a single action.
# .github/actions/check_system_deps/action.yml
name: "Check System Deps"
description: "Check for Python 3.x, list version, Install pipenv if it is not installed"
runs:
using: "composite"
steps:
- name: Check For Python3.x
run: |
which python3
VERSION=$(python3 --version | cut -d ' ' -f 2)
VERSION_PATCH=$(echo ${VERSION} | cut -d '.' -f 2)
[ $VERSION_PATCH -ge 8 ]
shell: bash
- name: Install Pipenv
run: python3 -m pip install pipenv --user
shell: bash
Now that we have the correct version of Python and a package manager installed, we’ll create an action to install our application dependencies:
# .github/actions/check_and_install_app_deps/action.yml
name: "Install deps"
description: "Install application dependencies"
runs:
using: "composite"
steps:
- name: Install deps
run: python3 -m pipenv install --dev
shell: bash
Next, we’ll create an action to run all of our static checks. For our example application, we want to perform the following checks:
- Check for security vulnerabilities using Bandit
- Check the cyclomatic complexity using McCabe
- Check for code that has no references using Vulture
- Perform a static type check using MyPy
- Check for open CVEs in dependencies using Safety
# .github/actions/run_static_checks/action.yml
name: "Run Static Checks"
description: "Run static checks for the python app"
runs:
using: "composite"
steps:
- name: Check common sense security issues
run: python3 -m pipenv run bandit -r graviton2_gh_runner_flask_app/
shell: bash
- name: Check Cyclomatic Complexity
run: python3 -m pipenv run flake8 --max-complexity 10 graviton2_gh_runner_flask_app
shell: bash
- name: Check for dead code
run: python3 -m pipenv run vulture graviton2_gh_runner_flask_app --min-confidence 100
shell: bash
- name: Check static types
run: python3 -m pipenv run mypy graviton2_gh_runner_flask_app
shell: bash
- name: Check for CVEs
run: python3 -m pipenv check
shell: bash
We’ll create an action to run the unit tests using PyTest.
# .github/actions/run_unit_tests/action.yml
name: "Run Unit Tests"
description: "Run unit tests for python app"
runs:
using: "composite"
steps:
- name: Run PyTest
run: python3 -m pipenv run pytest -sv tests
shell: bash
Finally, we’ll bring all of these actions into our steps in main.yml in order to define every step that will be run on each runner any time that our workflow is run.
# main.yml
steps:
- name: Checkout Code
uses: actions/checkout@v2
- name: Check System Deps
uses: ./.github/actions/check_system_deps
- name: Install deps
uses: ./.github/actions/check_and_install_app_deps
- name: Run Static Checks
uses: ./.github/actions/run_static_checks
- name: Run PyTest
uses: ./.github/actions/run_unit_tests
Save the file.
Running the Workflow
The workflow will run on the runners when you commit and push your changes. To demonstrate, we’ll create a PR to update the README of our example app in order to kick off the workflow.
After the change is pushed, see the status of your workflow by navigating to your repository in the browser. Select the Actions tab. Select your workflow run from the list of All Workflows. This opens the Summary page for the workflow run.

As each step defined in the workflow job runs, view their details by clicking the job name on the left-hand panel or on the graph representation. The following images are screenshots of the jobs, and example outputs of each step. First, we have check_system_deps.

We’ve excluded a screenshot of check_and_install_app_deps that shows the output of pipenv install. Next, we can see that our change passes for our run_static_checks Action (first), and unit tests for our run_unit_tests Action (second).


Finally, our workflow completes successfully!

Clean up
To delete the AWS CDK stacks, launch CloudShell and enter the following commands:
#!/bin/bash
cd cdk-graviton2-gh-sh-runner
source .venv/bin/activate
# Re-set the environment variables again if required
# export VPC_CIDR="192.168.0.0/24" # Set your CIDR here.
cdk destroy --all
Conclusion
This post covered the configuring of a self-hosted GitHub Runner on an EC2 instance with a Graviton2 processor, the required network resources, and a workflow that will run on the Runner on each repository push or pull request for the example application. The Runner is configured at the Organization level, which by default only allows access by private repositories. Lastly, we showed an example run of the workflow after creating a pull request for our example app.
Self-hosted runners on Graviton2 for GitHub Actions lets you add ARM64 to your CICD workflows, accelerating migrations to take advantage of the price and performance of Graviton2. In this blog we’ve utilized a strategy to create a build matrix to run jobs on hosted and self-hosted runners.
We could further extend this workflow by automating deployment with AWS CodeDeploy or sending a build status notification to Slack. To reduce the cost of idle resources during periods without builds, you can set up an Amazon CloudWatch Event to schedule a stop and start of the instance during business hours.
Github Actions also supports ephemeral self-hosted runners, which automatically unregister runners from the service. Ephemeral runners are a good choice for self-managed environments where you need each job to run on a clean image.
For more examples of how to create development environments using AWS Graviton2 and AWS CDK, reference Building an ARM64 Rust development environment using AWS Graviton2 and AWS CDK.
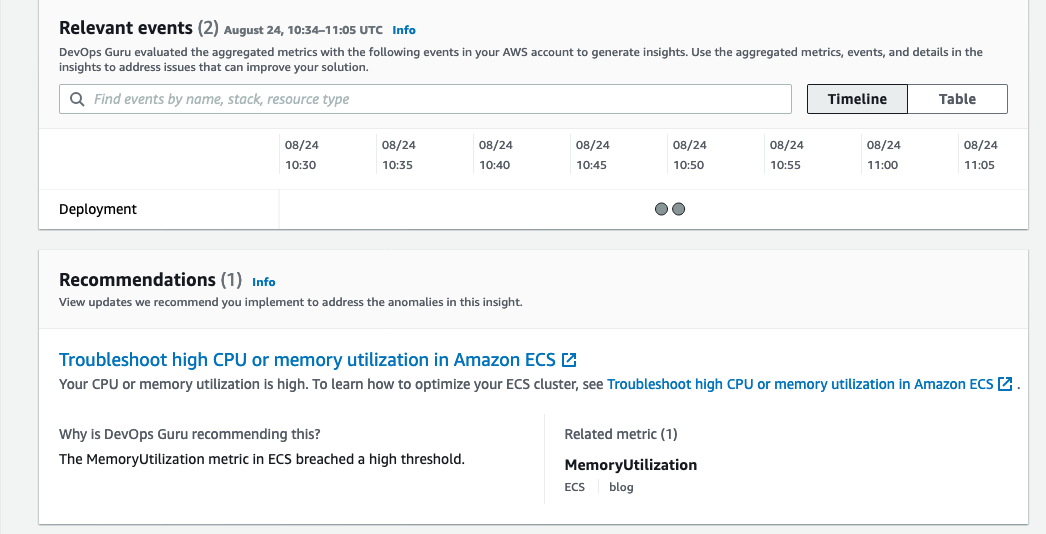
![Architecture Diagram showing the service “Test” using the container “brickwall-maker” with a desired count of two. The two ECS Task’s vended metrics are then processed by CloudWatch Container Insights. Both, CloudWatch Container Insights and CloudTrail, are ingested by Amazon DevOps Guru which then makes detected insights available to the user. [Image: DevOpsGuruBlog1.png]V1: DevOpsGuruBlog1.drawio (https://api.quip-amazon.com/2/blob/fbe9AAT37Ge/LdkTqbmlZ8uNj7A44pZbnw?name=DevOpsGuruBlog1.drawio&s=cVbmAWsXnynz) V2: DevOpsGuruBlog1.drawio (https://api.quip-amazon.com/2/blob/fbe9AAT37Ge/SvsNTJLEJOHHBls_kV7EwA?name=DevOpsGuruBlog1.drawio&s=cVbmAWsXnynz) V3: DevOpsGuruBlog1.drawio (https://api.quip-amazon.com/2/blob/fbe9AAT37Ge/DqKTxtQvmOLrzM3KcF_oTg?name=DevOpsGuruBlog1.drawio&s=cVbmAWsXnynz)](https://d2908q01vomqb2.cloudfront.net/7719a1c782a1ba91c031a682a0a2f8658209adbf/2021/10/29/DevOpsGuruBlog1-1-1.png)