Post Syndicated from Armando Faz-Hernández original https://blog.cloudflare.com/circl-pairings-update/


In 2019, we announced the release of CIRCL, an open-source cryptographic library written in Go that provides optimized implementations of several primitives for key exchange and digital signatures. We are pleased to announce a major update of our library: we have included more packages for elliptic curve-based cryptography (ECC), pairing-based cryptography, and quantum-resistant algorithms.
All of these packages are the foundation of work we’re doing on bringing the benefits of cutting edge research to Cloudflare. In the past we’ve experimented with post-quantum algorithms, used pairings to keep keys safe around the world, and implemented advanced elliptic curves. Now we’re continuing that work, and sharing the foundation with everyone.
In this blog post we’re going to focus on pairing-based cryptography and give you a brief overview of some properties that make this topic so pleasant. If you are not so familiar with elliptic curves, we recommend this primer on ECC.
Otherwise, let’s get ready, pairings have arrived!
What are pairings?
Elliptic curve cryptography enables an efficient instantiation of several cryptographic applications: public-key encryption, signatures, zero-knowledge proofs, and many other more exotic applications like oblivious transfer and OPRFs. With all of those applications you might wonder what is the additional value that pairings offer? To see that, we need first to understand the basic properties of an elliptic curve system, and from that we can highlight the big gap that pairings have.
Conventional elliptic curve systems work with a single group $\mathbb{G}$: the points of an elliptic curve $E$. In this group, usually denoted additively, we can add the points $P$ and $Q$ and get another point on the curve $R=P+Q$; also, we can multiply a point $P$ by an integer scalar $k$ and by repeatedly doing
$$ kP = \underbrace{P+P+\dots+P}_{k \text{ terms}} $$
This operation is known as scalar multiplication, which resembles exponentiation, and there are efficient algorithms for this operation. But given the point $Q=kP$, and $P$, it is very hard for an adversary that doesn’t know $k$ to find it. This is the Elliptic Curve Discrete Logarithm problem (ECDLP).
Now we show a property of scalar multiplication that can help us to understand the properties of pairings.
Scalar Multiplication is a Linear Map
Note the following equivalences:
$ (a+b)P = aP + bP $
$ b (aP) = a (bP) $.
These are very useful properties for many protocols: for example, the last identity allows Alice and Bob to arrive at the same value when following the Diffie-Hellman key-agreement protocol.
But while point addition and scalar multiplication are nice, it’s also useful to be able to multiply points: if we had a point $P$ and $aP$ and $bP$, getting $abP$ out would be very cool and let us do all sorts of things. Unfortunately Diffie-Hellman would immediately be insecure, so we can’t get what we want.
Guess what? Pairings provide an efficient, useful sort of intermediary point multiplication.
It’s intermediate multiplication because although the operation takes two points as operands, the result of a pairing is not a point, but an element of a different group; thus, in a pairing there are more groups involved and all of them must contain the same number of elements.
Pairing is denoted as $$ e \colon\; \mathbb{G}_1 \times \mathbb{G}_2 \rightarrow \mathbb{G}_T $$
Groups $\mathbb{G}_1$ and $\mathbb{G}_2$ contain points of an elliptic curve $E$. More specifically, they are the $r$-torsion points, for a fixed prime $r$. Some pairing instances fix $\mathbb{G}_1=\mathbb{G}_2$, but it is common to use disjoint sets for efficiency reasons. The third group $\mathbb{G}_T$ has notable differences. First, it is written multiplicatively, unlike the other two groups. $\mathbb{G}_T$ is not the set of points on an elliptic curve. It’s instead a subgroup of the multiplicative group over some larger finite field. It contains the elements that satisfy $x^r=1$, better known as the $r$-roots of unity.
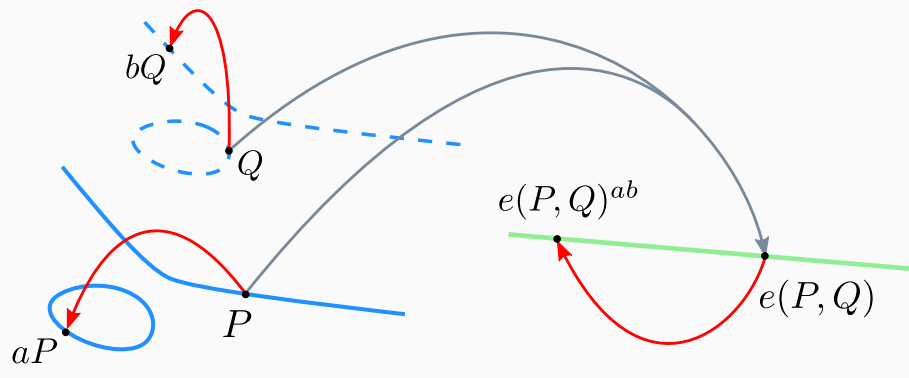
While every elliptic curve has a pairing, very few have ones that are efficiently computable. Those that do, we call them pairing-friendly curves.
The Pairing Operation is a Bilinear Map
What makes pairings special is that \(e\) is a bilinear map. Yes, the linear property of the scalar multiplication is present twice, one per group. Let’s see the first linear map.
For points $P, Q, R$ and scalars $a$ and $b$ we have:
$ e(P+Q, R) = e(P, R) * e(Q, R) $
$ e(aP, Q) = e(P, Q)^a $
So, a scalar $a$ acting in the first operand as $aP$, finds its way out and escapes from the input of the pairing and appears in the output of the pairing as an exponent in $\mathbb{G}_T$. The same linear map is observed for the second group:
$ e(P, Q+R) = e(P, Q) * e(P, R) $
$ e(P, bQ) = e(P, Q)^b $
Hence, the pairing is bilinear. We will see below how this property becomes useful.
Can bilinear pairings help solving ECDLP?
The MOV (by Menezes, Okamoto, and Vanstone) attack reduces the discrete logarithm problem on elliptic curves to finite fields. An attacker with knowledge of $kP$ and public points $P$ and $Q$ can recover $k$ by computing:
$ g_k = e(kP, Q) = e(P, Q)^k $,
$ g = e(P, Q) $
$ k = \log_g(g_k) $
Note that the discrete logarithm to be solved was moved from $\mathbb{G}_1$ to $\mathbb{G}_T$. So an attacker must ensure that the discrete logarithm is easier to solve in $\mathbb{G}_T$, and surprisingly, for some curves this is the case.
Fortunately, pairings do not present a threat for standard curves (such as the NIST curves or Curve25519) because these curves are constructed in such a way that $\mathbb{G}_T$ gets very large, which makes the pairing operation not efficient anymore.
This attacking strategy was one of the first applications of pairings in cryptanalysis as a tool to solve the discrete logarithm. Later, more people noticed that the properties of pairings are so useful, and can be used constructively to do cryptography. One of the fascinating truisms of cryptography is that one person’s sledgehammer is another person’s brick: while pairings yield a generic attack strategy for the ECDLP problem, it can also be used as a building block in a ton of useful applications.
Applications of Pairings
In the 2000s decade, a large wave of research works were developed aimed at applying pairings to many practical problems. An iconic pairing-based system was created by Antoine Joux, who constructed a one-round Diffie-Hellman key exchange for three parties.
Let’s see first how a three-party Diffie-Hellman is done without pairings. Alice, Bob and Charlie want to agree on a shared key, so they compute, respectively, $aP$, $bP$ and $cP$ for a public point P. Then, they send to each other the points they computed. So Alice receives $cP$ from Charlie and sends $aP$ to Bob, who can then send $baP$ to Charlie and get $acP$ from Alice and so on. After all this is done, they can all compute $k=abcP$. Can this be performed in a single round trip?
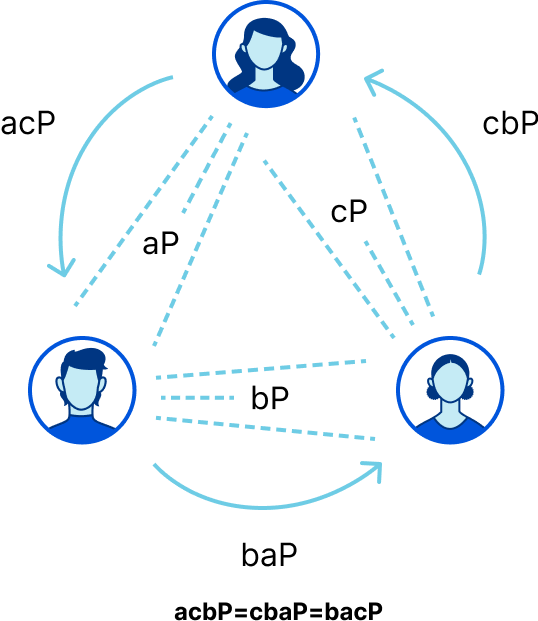

The 3-party Diffie-Hellman protocol needs two communication rounds (on the top), but with the use of pairings a one-round trip protocol is possible.
Affirmative! Antoine Joux showed how to agree on a shared secret in a single round of communication. Alice announces $aP$, gets $bP$ and $cP$ from Bob and Charlie respectively, and then computes $k= (bP, cP)^a$. Likewise Bob computes $e(aP,cP)^b$ and Charlie does $e(aP,bP)^c$. It’s not difficult to convince yourself that all these values are equivalent, just by looking at the bilinear property.
$e(bP,cP)^a = e(aP,cP)^b = e(aP,bP)^c = e(P,P)^{abc}$
With pairings we’ve done in one round what would otherwise take two.
Another application in cryptography addresses a problem posed by Shamir in 1984: does there exist an encryption scheme in which the public key is an arbitrary string? Imagine if your public key was your email address. It would be easy to remember and certificate authorities and certificate management would be unnecessary.
A solution to this problem came some years later, in 2001, and is the Identity-based Encryption (IBE) scheme proposed by Boneh and Franklin, which uses bilinear pairings as the main tool.
Nowadays, pairings are used for the zk-SNARKS that make Zcash an anonymous currency, and are also used in drand to generate public-verifiable randomness. Pairings and the compact, aggregatable BLS signatures are used in Ethereum. We have used pairings to build Geo Key Manager: pairings let us implement a compact broadcast and negative broadcast scheme that together make Geo Key Manager work.
In order to make these schemes, we have to implement pairings, and to do that we need to understand the mathematics behind them.
Where do pairings come from?
In order to deeply understand pairings we must understand the interplay of geometry and arithmetic, and the origins of the group’s law. The starting point is the concept of a divisor, a formal combination of points on the curve.
$D = \sum n_i P_i$
The sum of all the coefficients $n_i$ is the degree of the divisor. If we have a function on the curve that has poles and zeros, we can count them with multiplicity to get a principal divisor. Poles are counted as negative, while zeros as positive. For example if we take the projective line, the function $x$ has the divisor $(0)-(\infty)$.
The degree of a divisor is the sum of its coefficients. All principal divisors have degree $0$. The group of degree zero divisors modulo the principal divisors is the Jacobian. This means that we take all the degree zero divisors, and freely add or subtract principle divisors, constructing an abelian variety called the Jacobian.
Until now our constructions have worked for any curve. Elliptic curves have a special property: since a line intersects the curve in three points, it’s always possible to turn an element of the Jacobian into one of the form $(P)-(O)$ for a point $P$. This is where the addition law of elliptic curves comes from.

Given a function $f$ we can evaluate it on a divisor $D=\sum n_i P_i$ by taking the product $\prod f(P_i)^{n_i}$. And if two functions $f$ and $g$ have disjoint divisors, we have the Weil duality:
$ f(\text{div}(g)) = g(\text{div}(f)) $,
The existence of Weil duality is what gives us the bilinear map we seek. Given an $r$-torsion point $T$ we have a function $f$ whose divisor is $r(T)-r(O)$. We can write down an auxiliary function $g$ such that $f(rP)=g^r(P)$ for any $P$. We then get a pairing by taking.
$e_r(S,T)=\frac{g(X+S)}{g(X)}$.
The auxiliary point $X$ is any point that makes the numerator and denominator defined.
In practice, the pairing we have defined above, the Weil pairing, is little used. It was historically the first pairing and is extremely important in the mathematics of elliptic curves, but faster alternatives based on more complicated underlying mathematics are used today. These faster pairings have different $\mathbb{G}_1$ and $\mathbb{G}_2$, while the Weil pairing made them the same.
Shift in parameters
As we saw earlier, the discrete logarithm problem can be attacked either on the group of elliptic curve points or on the third group (an extension of a prime field) whichever is weaker. This is why the parameters that define a pairing must balance the security of the three groups.
Before 2015 a good balance between the extension degree, the size of the prime field, and the security of the scheme was achieved by the family of Barreto-Naehrig (BN) curves. For 128 bits of security, BN curves use an extension of degree 12, and have a prime of size 256 bits; as a result they are an efficient choice for implementation.
A breakthrough for pairings occurred in 2015 when Kim and Barbescu published a result that accelerated the attacks in finite fields. This resulted in increasing the size of fields to comply with standard security levels. Just as short hashes like MD5 got depreciated as they became insecure and $2^{64}$ was no longer enough, and RSA-1024 was replaced with RSA-2048, we regularly change parameters to deal with improved attacks.
For pairings this implied the use of larger primes for all the groups. Roughly speaking, the previous 192-bit security level becomes the new 128-bit level after this attack. Also, this shift in parameters brings the family of Barreto-Lynn-Scott (BLS) curves to the stage because pairings on BLS curves are faster than BN in this new setting. Hence, currently BLS curves using an extension of degree 12, and primes of around 384 bits provide the equivalent to 128 bit security.
The IETF draft (currently in preparation) draft-irtf-cfrg-pairing-friendly-curves specifies secure pairing-friendly elliptic curves. It includes parameters for BN and BLS families of curves. It also targets different security levels to provide crypto agility for some applications relying on pairing-based cryptography.
Implementing Pairings in Go
Historically, notable examples of software libraries implementing pairings include PBC by Ben Lynn, Miracl by Michael Scott, and Relic by Diego Aranha. All of them are written in C/C++ and some ports and wrappers to other languages exist.
In the Go standard library we can find the golang.org/x/crypto/bn256 package by Adam Langley, an implementation of a pairing using a BN curve with 256-bit prime. Our colleague Brendan McMillion built github.com/cloudflare/bn256 that dramatically improves the speed of pairing operations for that curve. See the RWC-2018 talk to see our use case of pairing-based cryptography. This time we want to go one step further, and we started looking for alternative pairing implementations.
Although one can find many libraries that implement pairings, our goal is to rely on one that is efficient, includes protection against side channels, and exposes a flexible API oriented towards applications that permit generality, while avoiding common security pitfalls. This motivated us to include pairings in CIRCL. We followed best practices on secure code development and we want to share with you some details about the implementation.
We started by choosing a pairing-friendly curve. Due to the attack previously mentioned, the BN256 curve does not meet the 128-bit security level. Thus there is a need for using stronger curves. Such a stronger curve is the BLS12-381 curve that is widely used in the zk-SNARK protocols and short signature schemes. Using this curve allows us to make our Go pairing implementation interoperable with other implementations available in other programming languages, so other projects can benefit from using CIRCL too.
This code snippet tests the linearity property of pairings and shows how easy it is to use our library.
import ( "crypto/rand" "fmt" e "github.com/cloudflare/circl/ecc/bls12381" ) func ExamplePairing() { P, Q := e.G1Generator(), e.G2Generator() a, b := new(e.Scalar), new(e.Scalar) aP, bQ := new(e.G1), new(e.G2) ea, eb := new(e.Gt), new(e.Gt) a.Random(rand.Reader) b.Random(rand.Reader) aP.ScalarMult(a, P) bQ.ScalarMult(b, Q) g := e.Pair( P, Q) ga := e.Pair(aP, Q) gb := e.Pair( P,bQ) ea.Exp(g, a) eb.Exp(g, b) linearLeft := ea.IsEqual(ga) // e(P,Q)^a == e(aP,Q) linearRight:= eb.IsEqual(gb) // e(P,Q)^b == e(P,bQ) fmt.Print(linearLeft && linearRight) // Output: true }
We applied several optimizations that allowed us to improve on performance and security of the implementation. In fact, as the parameters of the curve are fixed, some other optimizations become easier to apply; for example, the code for prime field arithmetic and the towering construction for extension fields as we detail next.
Formally-verified arithmetic using fiat-crypto
One of the more difficult parts of a cryptography library to implement correctly is the prime field arithmetic. Typically people specialize it for speed, but there are many tedious constraints on what the inputs to operations can be to ensure correctness. Vulnerabilities have happened when people get it wrong, across many libraries. However, this code is perfect for machines to write and check. One such tool is fiat-crypto.
Using fiat-crypto to generate the prime field arithmetic means that we have a formal verification that the code does what we need. The fiat-crypto tool is invoked in this script, and produces Go code for addition, subtraction, multiplication, and squaring over the 381-bit prime field used in the BLS12-381 curve. Other operations are not covered, but those are much easier to check and analyze by hand.
Another advantage is that it avoids relying on the generic big.Int package, which is slow, frequently spills variables to the heap causing dynamic memory allocations, and most importantly, does not run in constant-time. Instead, the code produced is straight-line code, no branches at all, and relies on the math/bits package for accessing machine-level instructions. Automated code generation also means that it’s easier to apply new techniques to all primitives.
Tower Field Arithmetic
In addition to prime field arithmetic, say integers modulo a prime number p, a pairing also requires high-level arithmetic operations over extension fields.
To better understand what an extension field is, think of the analogous case of going from the reals to the complex numbers: the operations are referred as usual, there exist addition, multiplication and division $(+, -, \times, /)$, however they are computed quite differently.
The complex numbers are a quadratic extension over the reals, so imagine a two-level house. The first floor is where the real numbers live, however, they cannot access the second floor by themselves. On the other hand, the complex numbers can access the entire house through the use of a staircase. The equation $f(x)=x^2+1$ was not solvable over the reals, but is solvable over the complex numbers, since they have the number $i^2=1$. And because they have the number $i$, they also have to have numbers like $3i$ and $5+i$ that solve other equations that weren’t solvable over the reals either. This second story has given the roots of the polynomials a place to live.
Algebraically we can view the complex numbers as $\mathbb{R}[x]/(x^2+1)$, the space of polynomials where we consider $x^2=-1$. Given a polynomial like $x^3+5x+1$, we can turn it into $4x+1$, which is another way of writing $1+4i$. In this new field $x^2+1=0$ holds automatically, and we have added both $x$ as a root of the polynomial we picked. This process of writing down a field extension by adding a root of a polynomial works over any field, including finite fields.
Following this analogy, one can construct not a house but a tower, say a $k=12$ floor building where the ground floor is the prime field $\mathbb{F}_p$. The reason to build such a large tower is because we want to host VIP guests: namely a group called $\mu_r$, the $r$-roots of unity. There are exactly $r$ members and they behave as an (algebraic) group, i.e. for all $x,y \in \mu_r$, it follows $x*y \in \mu_r$ and $x^r = 1$.
One particularity is that making operations on the top-floor can be costly. Assume that whenever an operation is needed in the top-floor, members who live on the main floor are required to provide their assistance. Hence an operation on the top-floor needs to go all the way down to the ground floor. For this reason, our tower needs more than a staircase, it needs an efficient way to move between the levels, something even better than an elevator.
What if we use portals? Imagine anyone on the twelfth floor using a portal to go down immediately to the sixth floor, and then use another one connecting the sixth to the second floor, and finally another portal connecting to the ground floor. Thus, one can get faster to the first floor rather than descending through a long staircase.
The building analogy can be used to understand and construct a tower of finite fields. We use only some extensions to build a twelfth extension from the (ground) prime field $\mathbb{F}_p$.
$\mathbb{F}_{p}$ ⇒ $\mathbb{F}_{p^2}$ ⇒ $\mathbb{F}_{p^4}$ ⇒ $\mathbb{F}_{p^{12}}$
In fact, the extension of finite fields is as follows:
- $\mathbb{F}_{p^2}$ is built as polynomials in $\mathbb{F}_p[u]$ reduced modulo $u^2+1=0$.
- $\mathbb{F}_{p^6}$ is built as polynomials in $\mathbb{F}_{p^2}[v]$ reduced modulo $v^2+u+1=0$.
- $\mathbb{F}_{p^{12}}$ is built as polynomials in $\mathbb{F}_{p^6}[w]$ reduced modulo $w^2+v=0$, or as polynomials in $\mathbb{F}_{p^4}[w]$ reduced modulo $w^3+v=0$.
The portals here are the polynomials used as modulus, as they allow us to move from one extension to the other.
Different constructions for higher extensions have an impact on the number of operations performed. Thus, we implemented the latter tower field for $\mathbb{F}_{p^{12}}$ as it results in a lower number of operations. The arithmetic operations are quite easy to implement and manually verify, so at this level formal verification is not as effective as in the case of prime field arithmetic. However, having an automated tool that generates code for this arithmetic would be useful for developers not familiar with the internals of field towering. The fiat-crypto tool keeps track of this idea [Issue 904, Issue 851].
Now, we describe more details about the main core operations of a bilinear pairing.
The Miller loop and the final exponentiation
The pairing function we implemented is the optimal r-ate pairing, which is defined as:
$ e(P,Q) = f_Q(P)^{\text{exp}} $
That is the construction of a function $f$ based on $Q$, then evaluated on a point $P$, and the result of that is raised to a specific power. The efficient function evaluation is performed using “the Miller loop”, which is an algorithm devised by Victor Miller and has a similar structure to a double-and-add algorithm for scalar multiplication.
After having computed $f_Q(P)$ this value is an element of $\mathbb{F}_{p^{12}}$, however it is not yet an $r$-root of unity; in order to do so, the final exponentiation accomplishes this task. Since the exponent is constant for each curve, special algorithms can be tuned for it.
One interesting acceleration opportunity presents itself: in the Miller loop the elements of $\mathbb{F}_{p^{12}}$ that we have to multiply by are special — as polynomials, they have no linear term and their constant term lives in $\mathbb{F}_{p^{2}}$. We created a specialized multiplication that avoids multiplications where the input has to be zero. This specialization accelerated the pairing computation by 12%.
So far, we have described how the internal operations of a pairing are performed. There are still some other functions floating around regarding the use of pairings in cryptographic protocols. It is also important to optimize these functions and now we will discuss some of them.
Product of Pairings
Often protocols will want to evaluate a product of pairings, rather than a single pairing. This is the case if we’re evaluating multiple signatures, or if the protocol uses cancellation between different equations to ensure security, as in the dual system encoding approach to designing protocols. If each pairing was evaluated individually, this would require multiple evaluations of the final exponentiation. However, we can evaluate the product first, and then evaluate the final exponentiation once. This requires a different interface that can take vectors of points.
Occasionally, there is a sign or an exponent in the factors of the product. It’s very easy to deal with a sign explicitly by negating one of the input points, almost for free. General exponents are more complicated, especially when considering the need for side channel protection. But since we expose the interface, later work on the library will accelerate it without changing applications.
Regarding API exposure, one of the trickiest and most error prone aspects of software engineering is input validation. So we must check that raw binary inputs decode correctly as the points used for a pairing. Part of this verification includes subgroup membership testing which is the topic we discuss next.
Subgroup Membership Testing
Checking that a point is on the curve is easy, but checking that it has the right order is not: the classical way to do this is an entire expensive scalar multiplication. But implementing pairings involves the use of many clever tricks that help to make things run faster.
One example is twisting: the $\mathbb{G}_2$ group are points with coordinates in $\mathbb{F}_{p^{12}}$, however, one can use a smaller field to reduce the number of operations. The trick here is using an associated curve $E’$, which is a twist of the original curve $E$. This allows us to work on the subfield $\mathbb{F}_{p^{2}}$ that has cheaper operations.
Additionally, twisting the curve over $\mathbb{G}_2$ carries some efficiently computable endomorphisms coming from the field structure. For the cost of two field multiplications, we can compute an additional endomorphism, dramatically decreasing the cost of scalar multiplication.
By searching for the smallest combination of scalars that could zero out the $r$-torsion points, Sean Bowe came up with a much more efficient way to do subgroup checks. We implement his trick, with a big reduction in the complexity of some applications.
As can be seen, implementing a pairing is full of subtleties. We just saw that point validation in the pairing setting is a bit more challenging than in the conventional case of elliptic curve cryptography. This kind of reformulation also applies to other operations that require special care on their implementation. One another example is how to encode binary strings as elements of the group $\mathbb{G}_1$ (or $\mathbb{G}_2$). Although this operation might sound simple, implementing it securely needs to take into consideration several aspects; thus we expand more on this topic.
Hash to Curve
An important piece on the Boneh-Franklin Identity-based Encryption scheme is a special hash function that maps an arbitrary string — the identity, e.g., an email address — to a point on an elliptic curve, and that still behaves as a conventional cryptographic hash function (such as SHA-256) that is hard to invert and collision-resistant. This operation is commonly known as hashing to curve.
Boneh and Franklin found a particular way to perform hashing to curve: apply a conventional hash function to the input bitstring, and interpret the result as the $y$-coordinate of a point, then from the curve equation $y^2=x^3+b$, find the $x$-coordinate as $x=\sqrt[3]{y^2-b}$. The cubic root always exists on fields of characteristic $p\equiv 2 \bmod{3}$. But this algorithm does not apply to other fields in general restricting the parameters to be used.
Another popular algorithm, but since now we need to remark it is an insecure way for performing hash to curve is the following. Let the hash of the input be the $x$-coordinate, and from it find the $y$-coordinate by computing a square root $y= \sqrt{x^3+b}$. Note that not all $x$-coordinates lead that the square root exists, which means the algorithm may fail; thus, it’s a probabilistic algorithm. To make sure it works always, a counter can be added to $x$ and increased everytime the square root is not found. Although this algorithm always finds a point on the curve, this also makes the algorithm run in variable time i.e., it’s a non-constant time algorithm. The lack of this property on implementations of cryptographic algorithms makes them susceptible to timing attacks. The DragonBlood attack is an example of how a non-constant time hashing algorithm resulted in a full key recovery of WPA3 Wi-Fi passwords.
Secure hash to curve algorithms must guarantee several properties. It must be ensured that any input passed to the hash produces a point on the targeted group. That is no special inputs must trigger exceptional cases, and the output point must belong to the correct group. We make emphasis on the correct group since in certain applications the target group is the entire set of points of an elliptic curve, but in other cases, such as in the pairing setting, the target group is a subgroup of the entire curve, recall that $\mathbb{G}_1$ and $\mathbb{G}_2$ are $r$-torsion points. Finally, some cryptographic protocols are proven secure provided that the hash to curve function behaves as a random oracle of points. This requirement adds another level of complexity to the hash to curve function.
Fortunately, several researchers have addressed most of these problems and some other researchers have been involved in efforts to define a concrete specification for secure algorithms for hashing to curves, by extending the sort of geometric trick that worked for the Boneh-Franklin curve. We have participated in the Crypto Forum Research Group (CFRG) at IETF on the work-in-progress Internet draft-irtf-cfrg-hash-to-curve. This document specifies secure algorithms for hashing targeting several elliptic curves including the BLS12-381 curve. At Cloudflare, we are actively collaborating in several working groups of IETF, see Jonathan Hoyland’s post to know more about it.
Our implementation complies with the recommendations given in the hash to curve draft and also includes many implementation techniques and tricks derived from a vast number of academic research articles in pairing-based cryptography. A good compilation of most of these tricks is delightfully explained by Craig Costello.
We hope this post helps you to shed some light and guidance on the development of pairing-based cryptography, as it has become much more relevant these days. We will share with you soon an interesting use case in which the application of pairing-based cryptography helps us to harden the security of our infrastructure.
What’s next?
We invite you to use our CIRCL library, now equipped with bilinear pairings. But there is more: look at other primitives already available such as HPKE, VOPRF, and Post-Quantum algorithms. On our side, we will continue improving the performance and security of our library, and let us know if any of your projects uses CIRCL, we would like to know your use case. Reach us at research.cloudflare.com.
You’ll soon hear more about how we’re using CIRCL across Cloudflare.























{kind=link}