Вече почти две десетилетия Ася Демирева е сертифицирана и обичана консултантка по кърмене (IBCLC), което неусетно я е превърнало в гуру в една доста нишова сфера.
Това е най-хубавата работа, по-добра дори от дегустатор на сладолед.
Често жените идват при нея с новопокълнало чувство за вина или боязън, че нямат майчински инстинкт: не се справих, не ми се получава да кърмя, а искам.
Телата ни са съвършени, а ние, с нашите мозъци и незрелите си разбирания, им пречим да си свършат работата. Ние сме програмирани да знаем кое е правилно, но на съвременните поколения е вменено, че за да направим нещо добре, трябва да бъдем научени. Не виждаме живота в абсолютния му, природен покой. Моята прабаба, която е била неграмотна, е знаела какво е пермакултурен дизайн, без разбира се, да го нарича така. Но е знаела къде коя култура да посади и че на тази почва след две години ще се чувства добре друго растение, защото вече е обогатена от предишните с конкретни вещества. Ние обаче сме загубили това знание, което се е предавало от поколение на поколение. Загубили сме и вкоренения си инстинкт да отглеждаме други хора. Само преди около 150 години хората са виждали всичко – съвкупяването на животните, раждането. Вместо да се радваме на живота, ние никога не сме посрещали живот. Затова не знаем какво да правим. Хората преди нас са имали имплантирани модели за грижа, биологични модели, които при това са визуализирани стотици пъти. Днес пречим на телата си да действат свободно, спънати от недоверие и противоречива информация.
Ася Демирева е наясно със сблъсъка на младите майки с общия информационен шум, с непомерните изисквания за правилност, които обществото налага. Затова и напоследък в мрежата се появяват групи за споделяне – на майките, които не се справят, които се чувстват уплашени или просто искат да говорят за трудностите и „тегавините“ в този етап от живота си.
Мисията на Ася е не просто да говори за ползите от кърменето – ползи и за майката, и за бебето, но и да подпомогне процеса на засукване, обяснявайки рефлекторната му природа и разчитайки на инстинктите, заложени в телата ни. Тя е и сред създателките на възглавницата „Матеа“, която облекчава позицията на майките и осигурява комфорт при кърмене.
Стотици пъти съм присъствала на момента, в който един човек засуква от майка си и как тази жена емоционално го преживява, как цялото ѝ тяло се разтреперва, много често тя се разплаква. Аз имам късмета да съм свидетел на този първи контакт.
Първата детска мечта на Ася Демирева е да учи медицина; майка ѝ обаче я убеждава, че трудно би се справила емоционално с подобна професия. И така, Ася завършва Френската гимназия в Бургас и след това журналистика в Софийския университет. Това са точно годините на приватизацията и начеваща политическа журналистика и тя осъзнава, че ще завърши, без да иска да работи това. Създава семейство и през 2006 г. се обучава за консултантка по кърмене. Малко по-късно, вече майка на едно дете, започва да работи за сп. „Моето дете“. И понеже житейското колело се върти неумолимо, но и с подобаващ усет за историческа ирония, по времето, по което се развежда, Ася става главен редактор на списанието.
Когато години по-късно заради работата си следва за лекарски асистент и изучава обща медицина, установява, че майка ѝ е била права и трудно би оцеляла в болница.
Ако бях станала лекар, щях да работя предимно с болни бебета. Сега работя със здрави и много щастливи родители, после те си тръгват с нахранени и доволно заспиващи бебета.
Разбира се, истината е, че понякога родителите се изплашени и напрегнати, друг път идват на консултация в комплект с две баби.
Преди години обяснявах на бабите със страхопочитание и желание да насоча начина им на мислене в различна посока, но сега, от „пиедестала“ на двайсетгодишния ми опит, говоря по-авторитетно, а и с повече разбиране. Истината е, че бабите, които вече консултирам, са първите ползвателки на форума „БГ мама“.
Хората, ангажирани с медицински професии, често са изправени пред необходимостта да се сблъскват с различни начини на мислене, методи за справяне със стреса, а и с възприемане на биологичните ни параметри. Когато става въпрос за деца обаче, цялото ни общество сякаш се държи нелогично.
Живеем в кански парадокс – считаме, че на четири месеца бебето ни трябва да заспива самостоятелно, което е смешно, но на осем години вземаме детето за ръка от ръката на учителката. То не знае как да се прибере до вкъщи, откъде се купува хлябът и че той струва пари. А във все още съществуващите племенни култури това е възрастта, в която момчетата получават оръжие – собствено копие например. Те вече имат правото да убият животно и да приготвят храна. Тоест могат да се защитят и да се нахранят.
Ася всъщност помага на младите родители да не страхуват. Но и да си припомнят, че човек заспива в абсолютна безопасност. А за бебетата това е в прегръдката на друг човек.
Ние знаем за зоната за терморегулация при майката – тя се намира около гърдите. Когато бебето е хладно, тази зона се затопля, и обратното – ако кожата на майката фиксира, че има нужда от охлаждане, го прави. Това е велик способ за регулация. Майката е първата инстанция в адаптацията на този нов човек в новия за него свят. Имаме всички механизми да го посрещнем извън тялото си. Затова „кожа в кожа“ е и метафора – точно така започва животът.
За хора като Ася Демирева, които работят с наука, но виждат началата на живия живот, границата между биологично и трансцедентно е проницаема. Тя познава механизмите на телесното, а работата ѝ изисква и да го обясни на майките.
Ние създаваме тела от тялото си, храним ги от себе си, трансформирайки нашата храна в нещо жизненоважно за оцеляването на бебетата – всъщност ние имаме божествени функции.
Дългогодишната ѝ практика с бебета я е убедила, че дори новороденото не е табула раза, не е бяло платно, върху което се пише отначало.
Но за този живот, в това тяло, всяко конкретно бебе започва да се учи сега. И нашата работа като родители е първо да го приведем във физическата норма за конкретното общество – без значение дали ще е високотехнологично, или не, дали ще е бедно дете в богата държава, или обратното.
А това е невъзможно без майката да се събере и да се задейства спрямо собствените си представи за правилно. Иначе,
всяка жена има собствено дъно на тема майчинство, което копае системно,
твърди Ася и се надява все повече жени да избират подкрепата на психолог, за да се справят.
Всяка майка има своите страхове и форми на несигурност, но преди години сякаш беше по-просто. Днес имаме свръхсоциален елемент на социалните мрежи.
В момента количеството на информацията е ужасяващо. А вече съществува и понятието mommy shaming, което отразява съвсем реалния процес не просто на засрамване, а на тотално отричане: ако не правиш нещата по съответния начин, каква майка си изобщо?! Поредната стигма у нас пък е свързана с възрастта, на която кърменето трябва да престане. Само преди десетилетие общуването между майките е било по-скоро обмяна на опит, сочат наблюденията на Ася Демирева. От друга страна, тя смята, че социалните мрежи и миниобществата, които те поддържат, имат голямо и качествено значение за съвременния родител.
Самата тя е възпитана от майка, която е фиксирала модела, че ако едно решение е взето след претегляне на плюсове и минуси, значи то е правилно. Към онзи момент и онези обстоятелства то е било най-доброто. Тоест „не връщаме времето и не се самообвиняваме“. Това се оказва нейната лична работеща стратегия по отношение на майчинството, а Ася има две деца и със сигурност е преминала през обичайните изпитания. С първото си дете излиза ежедневно навън, защото по това време има паник атаки:
Най-големият ми страх беше, че мога да получа инфаркт и да минат часове, преди някой да дойде и да спаси бебето ми. Така че започнах да тренирам екстравертността си. Виждах се непрекъснато с жени с бебета. Винаги съм чела много и обичам да препредавам информация, затова се чувствах изключително добре да разказвам всичко, което съм научила. Всъщност съм тренирала за консултант.
Ася Демирева е различна по рождение – с вродена липса на кост, т.нар. малък пищял, фибулата. Затова десният ѝ крак е по-къс.
Това е източникът на всичките ми детски травми и върху него работя все още с психолога си. Но то е и в основата на избора ми на професия, която е свързана с оказване на помощ.
Ася е израснала по времето на социализма, когато в детските болници децата са оставяни сами. Да, дори и четиригодишните. Но е имала късмета майка ѝ да бъде до нея само защото е била медицинска сестра.
Това не ме спаси от манипулации без упойки и без нива на физическа болка, които не са окей за малко дете. Някъде там у мен се роди убедеността, че нито едно дете повече не бива да преживее това. Аз исках да стана лекар, за да спася децата.
Глобално Ася смята, че разбиранията ѝ са доста стереотипни. Тя уважава йерархията, приема, че обществото ни вменява роли и ролевите модели трябва да бъдат спазвани. И че малкият човек трябва да постигне конкретни нива, за да бъде равен на големите. Но не може да се съгласи да се отнасяме с малките деца като с незначителни.
У нас малките са нищожни. А това не е вярно. Ние имаме нужда от техния подход, от тяхното любопитство и интерес към всичко и ако си позволим да бъдем като тях, ще живеем в по-добро общество. Вместо това ние ги омаловажаваме.
Хората, които тихо и кротко променят средата, формират общности и задават посоки, в които има смисъл да тръгнем заедно. Тук ви срещаме с тях. Това са „Тези хора“.
В навечерието на един от най-хубавите български празници – 24 май, Деня на българската просвета и култура – разговорът ни със Зорница Христова естествено тръгна от литературата, но много бързо стигна до паметта, езика, детството, общественото доверие и въпроса какво всъщност остава след думите. Коментирахме, че формалното празнично говорене за езика понякога рискува да се превърне в ритуал без съдържание, а в същото време именно словото някога е било истинско „оръжие“, променяло общества и съдби.
Говорихме за книгите и четенето като възможност за бавно размишление в свят на непрекъснат шум, за липсващата критика, за маркетинга, който често подменя разговора за литература, за нуждата някой все пак да пази пространствата за смисъл…
Зорница разказа и за рубриката си „По буквите“, в която книгите не стоят една до друга като заглавия в каталог, а разговарят помежду си – през паметта, през настоящето, през личния опит на читателя. За Зорница литературата не е самотен предмет, а жива среда, в която различни светове непрекъснато си общуват.
Особено място в разговора ни зае детската литература като едно от най-трудните и най-важни изкуства. Говорихме за свободата през играта, за правото на детето да чува сложни думи, да се страхува, да си въобразява, да мисли различно. И за онези книги, които остават като емоционална памет за цял живот.
Накрая стигнахме и до езика като удоволствие, а не като назидание, и до онова усещане, че думите имат значение не когато ги пазим под стъклен похлупак, а когато успяват да провокират размисли и да създават близост и доверие.
Гледайте целия разговор в нашия YouTube канал:
Може да го чуете и като аудиозапис в SoundCloud:
На живо зададох на Зорница въпроси от публиката, но нямаше как да обхванем всички. Затова я помолих да отговори тук на още един ваш въпрос:
Как намирате баланса между комерсиалния успех на едно издателство и поддържането на безкомпромисен литературен стандарт?
Ха-ха-ха, този въпрос е много мило зададен! Можеше да бъде: „Кое е по-лошо: да правите книги, от които Ви е срам, или да правите книги, които не се продават?“ Така зададен, въпросът е лесен. Но все пак искам и да се продават, разбира се – продажбите ти показват, че книгата е била нужна.
Така и си задавам въпроса: От какви книги има нужда? И защо? Много от нашите научнопопулярни книги – „Витоша“, книгите от поредицата „Философски закуски“, „Книга за смъртта“, „Един ден в музея“, „Бедността. Пътеводител за деца“, „Сладоледена реторика“ – са издадени по тази причина. Смятам, че има нужда от тях. Това са и тиражите, които свършват първи.
Други излизат просто защото страшно много ми харесват, без дълбок пазарен замисъл. Не може всичко да е по схема. Нали литературата трябва да изненадва, да доставя удоволствие, да „отваря приказка“ с разни части от теб, които иначе не са особено разговорливи. Понякога сред тези книги, издадени „защото така“, дадено заглавие се разграбва за миг.
Не е ли по-сладко хубавата книга сама да си пробие път, отколкото да правиш книги според проправените вече пътеки? За мен поне е. „Когато искам да мълча“ е бестселър не само у нас, но и в Италия. А смятах, че я правим за двайсетина наши приятели…
Преди срещата ви помолихме да отговорите на кратката ни анкета. Ето и резултатите от нея:
Книгата е най-добрият офлайн режим за ума.
Зорница Христова е писателка, преводачка, редакторка и издателка. Тя е съоснователка на „Точица“ – издателство, специализирано в съвременни детски книги с висок литературен и визуален стандарт. Авторка е на книги за деца и възрастни. Работи активно и като преводачка от английски език. Сред преведените от нея автори са Джулиан Барнс, Джон Ървинг, Тони Джуд, Джумпа Лахири, Джеръм К. Джеръм, Том Улф, Йосиф Бродски и много други. В текстовете и публичните си изяви често защитава ролята на преводача като съавтор и литературен посредник.
Зорница Христова е и дългогодишна литературна журналистка и есеистка. В „Тоест“ води рубриката „По буквите“ – пренесената от Марин Бодаков легендарна колонка „Ходене по буквите“ във вестник „Култура“, която по-късно Зорница продължи в негова памет. В своите текстове тя съчетава литературна критика, културен анализ и личен есеистичен подход, като особено внимание отделя на паметта, превода, детската литература и връзката между книгите и обществената среда.
Така протече десетият епизод на „Тоест разговаряме“, който беше и последният в рамките на инициативата, подкрепена от Институт „Отворено общество – София“ и проекта Media Resilience на Европейския съюз. Искрено се надяваме, че тези разговори са ви били интересни и полезни. Ако искате да ги продължим, подкрепете ни!
В десетте епизода на „Тоест разговаряме“ всеки месец ви срещахме с автори, които познавате добре от анализите или от рубриките им в „Тоест“, но този път ги видяхте и чухте в по-личен и непосредствен формат. Във видеоразговорите, предавани на живо, активно участие имахте и вие, нашата публика – със своите въпроси, коментари и включване в тематичната анкета. Водещ на поредицата беше Владислав Севов, дългогодишен телевизионен журналист и съосновател на „Тоест“.
„Тоест разговаряме“ е поредица от 10 епизода, подкрепена от Институт „Отворено общество – София“ и съфинансирана от Европейския съюз в рамките на проекта Media Resilience. Изразените възгледи и мнения са само и изцяло на техните автори и не отразяват непременно възгледите и мненията на Европейския съюз, на Европейската изпълнителна агенция за образование и култура (EACEA) или на Институт „Отворено общество – София“ (ИООС). Нито Европейският съюз, нито EACEA, нито ИООС могат да бъдат държани отговорни за тях.
Тия дни изчетох доста от написаното за Баба Алино. Твърденията на кмета на Варна, на предишния кмет, на Радевките, на ДНСК, на инвеститора и купилите имоти. Хареса ми как Красен Николов и Димитър Николов са подредили хронологията в Медиапул, но знам, че повечето няма да си направят труда да прочетат извън лозунгите на купувачи и политици.
В понеделник говорих по Дарик за темата за незаконното строителство, нарушенията, прозрачността на документите и контрола. Също за риска за пореден път единният регистър по устройството на територията да не се случи и да не позволи прозрачността, която служебния кабинет заложи в проекта. Най-вече, че липсата на отворени данни и прозрачност пречи на комуникацията между институциите, което всъщност стои в голяма степен в корена на проблема с ония 100 декара Баба Алино. Че злоупотреби и чадър е имало – имало е, че полицията не е съдействала също е вярно, но е вярно и че измамата е успяла, защото отговорните институции не си говорят.
Говорих също, че е грешно да се смята, че банките правят някакви реални проверки и щом са дали ипотека значи, че всичко било наред. Отдавна говоря как имотния (не)пазар поставя под огромен риск банковата ни система и управлението на този риск е под всяка критика гледайки данните за заемите на БНБ. Тук липсата на прозрачност – особено за сградите без акт 16 и фалиралите фирми-бушони на инвеститори – пречи да се осъзнае колко рискови всъщност са инвестициите в имот.
Тук обаче се чудя за съвсем друго
Купувачите на тези жилища в комбина с инвеститора изглежда искат да съдят общината и държавата, че ще им бутат сградите. Учудва ме, защото вместо това следва да съдят точно инвеститора за измама, на каквото всъщност сме свидетели в момента. Мисленето обаче е, че „то незаконно, ама нали минаваше номер до сега, защо изведнъж стана проблем“ по същия начин както някой си хвърля боклука през прозореца години наред и става агресивен като му направят забележка. Щом са си платили на някого там, значи имат право независимо, че всичко е незаконно и са засегнали защитена местност.
При това доста други хора ги защитават, а в същото време крещят за скоростно събаряне на единственото жилище – макар и незаконно – на семейства в ромски махали. Единствената разлика, която виждам е, че в случая в Баба Алино става въпрос за милиони и чадъри много години назад във всякакви институции, а във втория – за социален, образователен и в немалка степен плод на ефективната сегрегация в обществото ни.
Та затова говоря, че трябва да внимаваме за червените флагове и хората със схема. На теб може да не ти пука, че някой заобикаля закон и наредби и укрива данъци за няколко процента печалба отгоре. Могъл – откраднал, нали? Какво обаче те кара да мислиш, че по същия начин няма прецака и теб? Дори толкова повече следва да си сигурен. Затова е добре да прилагаме здрав разум.
А за случая във Варна тепърва следва да разбираме фактите. По паниката на предходния кмет ми става ясно накъде ще излязат нещата, ако не се заметат под килима в премиерския кабинет. С тази прокуратура в този вид обаче не очаквам шанс за реални мерки дори да се подмени главния прокурор.
Полезно стълпновение
За само няколко дни по темата за незаконните имоти се изказа половината администрация. Хареса ми интервюто на бившия служебен министър Найденов. През час излизат отрязани снимки на разрешения и решения – дали са за строеж, дали за търпимост, дали за ПУП или изготвянето на такъв. Неизменно са придружени не само от твърдения на собственици, но и сносни обяснения на архитекти, юристи и чиновници какво значат.
Замислих се, че този поток на документи може да е искрено полезен. Липсва основно разбиране как протича процесът и какво значат отделните документи. След толкова години дълбане в темата аз също едва виждам повърхността. Според архитекти много в самата гилдия не разбират дори половината. Затова ми хрумна, че този скандал е възможност не само да се осветлят механизмите за подобни измами, пропуските в регулацията и оперативната работа на администрацията, но и да служи като средство за повишаване на общата култура поне на онези, които следят случая. И отново – разбирането не значи да приемаме проблемите, сложността и ограниченията на самата администрация, а да задаваме по-добри въпроси и да искаме промени с конкретика.
Netflix’s TimeSeries Abstraction is a scalable system for ingesting and querying petabytes of temporal event data with millisecond latency. We use Apache Cassandra 4.x as the underlying storage for these main reasons:
Throughput, latency, and cost: Cassandra can handle millions of low‑latency reads and writes in a cost-effective manner.
Operational maturity: Our data platform team has deep operational expertise running large Cassandra clusters in production.
However, using Cassandra at this scale introduces trade‑offs for TimeSeries workloads. A key challenge is wide partitions, as TimeSeries dataset partitions can grow quite large with events accumulating over time.
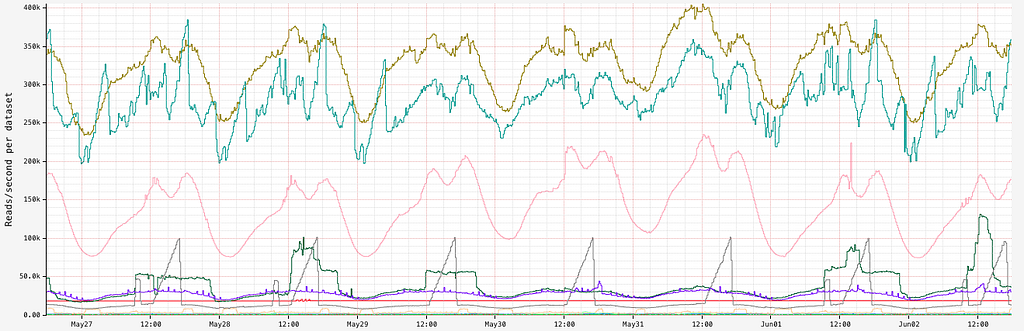
This problem is further compounded by the fact that TimeSeries servers routinely deal with a very high read throughput:
Reads/second for different datasets
This post walks through our journey to reduce the impact of wide partitions in our TimeSeries datasets, the solutions we built, and the lessons we learned.
Impact of Wide Partitions
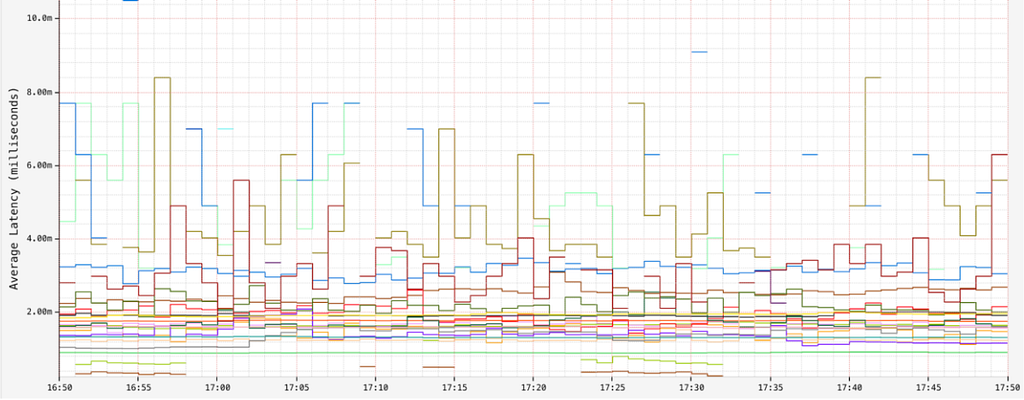
For most of our datasets, we observe an average read latency in the order of single-digit milliseconds:
Ideal Latency for Reads (ms)
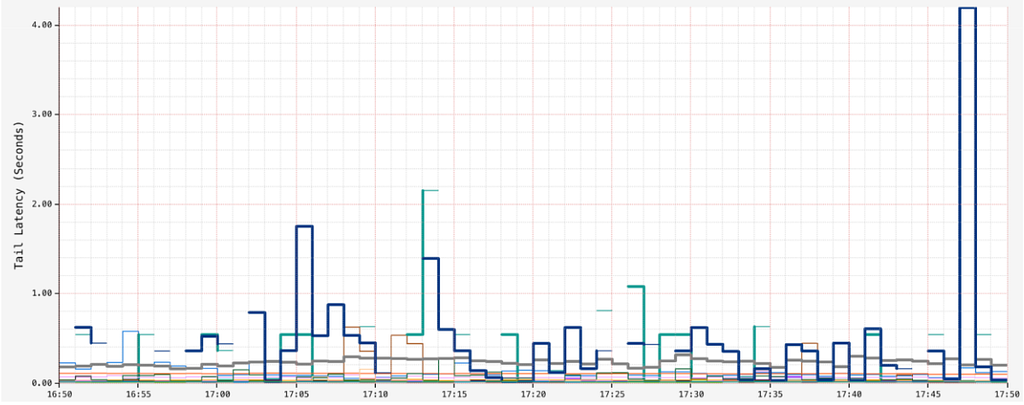
However, in some datasets, as partitions grow too wide, we observe high read latencies in the order of seconds, especially towards the tail end:
High Tail Latency for Reads (seconds)
This can result in timeouts:
Read timeouts / second
In extreme cases, if most of the reads target wide partitions, we can see Garbage Collection pauses, high CPU utilization and thread queueing.
High CPU utilization and thread-queueing in Cassandra clusters
Scaling up the underlying Cassandra cluster is always an option, but we need smarter alternatives than just throwing more money at the problem.
TimeSeries Partitioning Strategy
The TimeSeries Abstraction was designed to solve the problem of wide partitions by dividing the data into discrete time chunks. For more in-depth information, refer to our previous blog.
To summarize, here is an illustration of how TimeSeries partitioning strategy helps us break up wide partitions into manageable chunks.
Time Series partitioning breaking up a dataset into Time slices, time buckets and event buckets
This strategy further allows us to efficiently query and drop data based on time, without having to deal with tombstones.
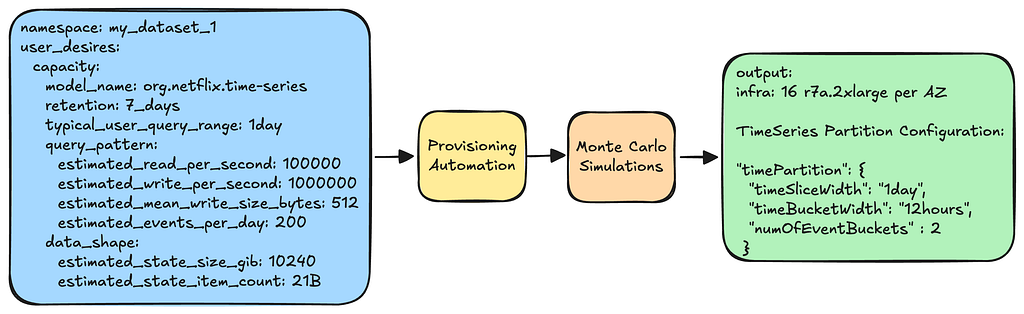
Picking the Partitioning Strategy
When a namespace (a.k.a. dataset) is created, users must specify their anticipated workload characteristics. This specification is then fed into our provisioning pipeline. The pipeline processes these inputs, runs Monte Carlo simulations, and produces an optimal infrastructure and partition configuration.
Provisioning picks optimal infra and configuration based on user inputs
You can learn more about our methodology of capacity planning in this insightful AWS re:Invent talk given by one of our stunning colleagues.
The Problem with the Current Approach
Although this method of provisioning is effective in many situations, it proves insufficient for TimeSeries workloads under these conditions:
Workload is unknown or inaccurately estimated: Early on in a project, users can lack a reliable picture of production traffic or simply misestimate key parameters.
Workload evolves over time: Traffic patterns, client behavior, and product requirements change. A “good” partitioning strategy on day one can become inefficient months later.
Data outliers exist: Not all TimeSeries IDs behave the same. A small percentage of IDs can receive a vastly higher volume of events than the rest.
Fortunately, our design with discrete Time Slices gives us a natural escape hatch for the first two scenarios; each new Time Slice can use a different partitioning strategy.
Each Time Slice can have a unique partition strategy
However, manually adjusting these configurations in a fleet that has thousands of TimeSeries datasets is not sustainable. We need automation.
Solution 1: Time Slice Re-Partitioning
Cassandra exposes useful introspection APIs for understanding data usage and access patterns. For example, nodetool tablehistograms provide percentile distributions for partition sizes in a table. Using these tools, we can detect cases of both over and under partitioning.
Below is an example of over‑partitioning, where the TimeSeries provisioning pipeline selected very small time_bucket intervals based on user provided inputs:
Provisioning selected 60s time buckets based on user inputs
causing partitions to have less than 10 KB of data, leading to high read amplification and thread queueing:
Histogram of the given Cassandra table showing partition size percentiles
In order to tune partition strategies efficiently, we added a background worker, which monitors partition histograms of Time Slices attached to a given application, and exposes it via a Cassandra virtual table:
Histograms exposed through a Cassandra Virtual table
It then computes an adjustment factor when it detects partition sizes not meeting a configured density. This configured density is often set between 2 MiB to 10 MiB depending on the workload.
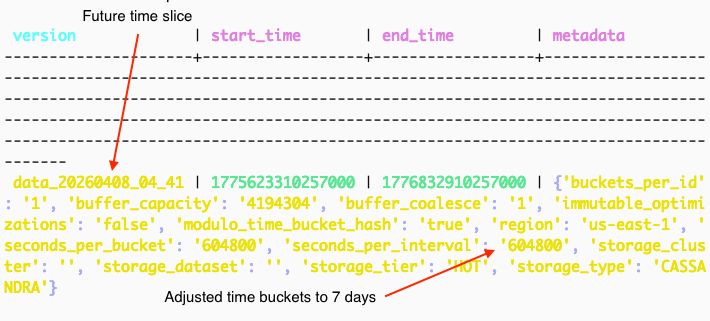
DynamicTimeSliceConfigWorker: namespace: my_dataset_1 Observed: TimeSlices have p99 partitions below configured target of 10MB. Proposed: time_bucket interval: 60s -> 604800s
The worker can then update future Time Slices with the new partition strategy:
Partitioning adjusted for future Time Slice(s)
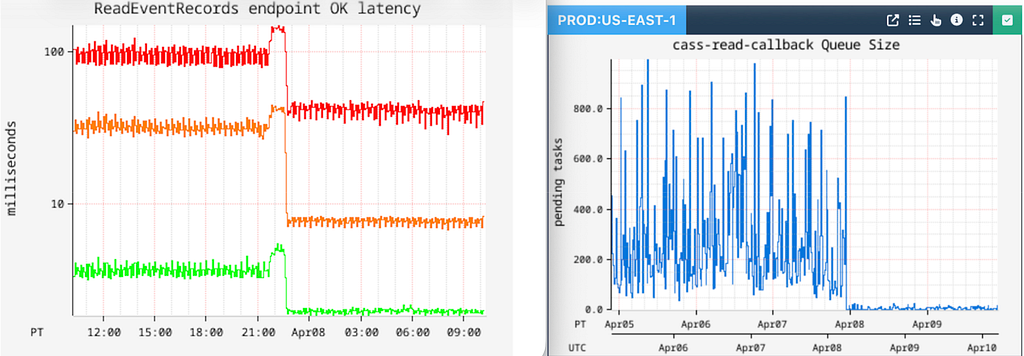
This strategy has yielded real results in reducing our read latencies, as well as reducing the number of timeouts caused by thread queueing.
Reduction in tail latency and thread queueing for
However, this strategy only works if most of the data exhibits such behavior that warrants re-partitioning of the entire table. It does not work in cases where only a percentage of IDs within the table are wide.
We have a couple of options here:
Do Nothing: This is sometimes the right approach if there is no observed impact to the application’s top-level metrics.
Partial Returns: We implemented a ‘Partial Return’ feature, which aborts an inflight request if it has breached a configured latency SLO, while returning whatever data it has collected up until that point. This is a great option for clients who care more about latency than fetching all the data.
Tail latency drops around the SLO cutoff as Partial Returns are enabled
Block IDs: This is an extreme step but worth mentioning, because we do deal with bad data that occasionally seeps into the system e.g. test or spam IDs that can make the system unstable.
Ultimately, we encounter scenarios where valid and important TimeSeries IDs accumulate a high enough volume of events, with callers needing to process all the related data. Simply tolerating elevated latencies or timeouts when querying these IDs is not a desirable outcome.
This is where dynamic partitioning comes into play.
Solution 2: Dynamic Partitioning per ID
Dynamic partitioning is an asynchronous pipeline that auto-detects and splits wide partitions on a TimeSeries ID level rather than at the table level.
It has three main stages:
Detection: Detects wide partitions for a given TimeSeries ID during the read path.
Planning & Splitting: Plans and executes splits of those partitions into optimal sizes asynchronously.
Serving Reads: Re-routes the read queries transparently to read data from the split partitions when ready.
This is how it works at a high level; we will dive into details after:
Dynamic Wide Partition Split Async Pipeline
Here are the different stages of the pipeline:
Detection
Every TimeSeries read operation tracks how many bytes are read for a given partition. If the bytes read exceed a configured threshold, the server emits a detection event to Kafka:
{ "time_slice": "data_20260328", // the Cassandra table this event was detected in "time_series_id": "profileId:123", // the ID detected as wide "time_bucket": 7, // the existing time_bucket partition "event_bucket": 2, // the existing event_bucket partition "immutable": true, // TimeSeries servers can compute if this partition is no longer receiving writes "version": "0" // reserved for future use e.g. invalidate if partition is no longer immutable }
Our decision to detect wide partitions on reads, as opposed to writes, is based on our observation that the majority of the data in the wild doesn’t need this treatment. The slight downside is that some reads on these large partitions may suffer sub-optimal performance for a very short duration (typically seconds) until this process catches up.
Immutability
Although splitting mutable partitions is possible, it is inherently more complex. As a first step towards solving this problem, we chose to reduce the surface area of this change by focusing on immutable partitions, while still meaningfully reducing caller timeouts.
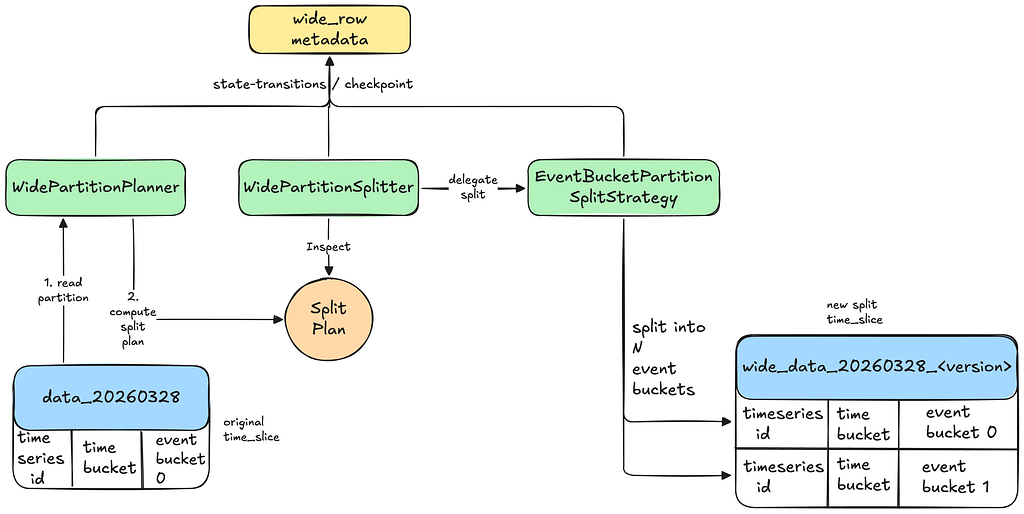
Planning
Detection may occur based on a partial read, so the planner must still read the entire partition once to compute an accurate split plan. The checkpointing becomes crucial here. For planning reads that fail to process the entire partition, the process can always continue from the last saved checkpoint.
Checkpointing
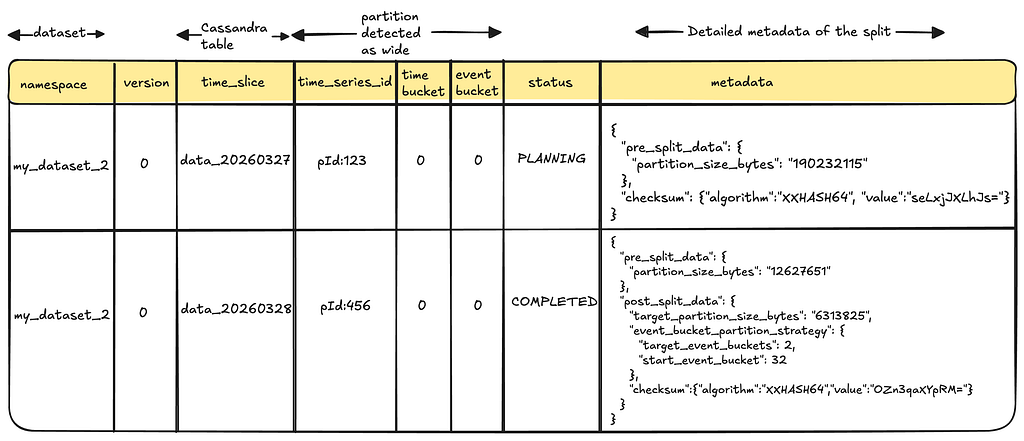
The wide_row metadata table serves as the backbone for state transitions and checkpointing of partition splits. It also stores information that is used later by TimeSeries servers to properly route Read queries.
wide_row metadata for storing split states and checkpoints
Splitting
The Planner delegates the splitting of data to an appropriate split-strategy. For example, if EventBucketPartitionSplitStrategy is selected, we split the partition by assigning more event buckets to the same time bucket. If the partition is ultra-wide, we cap the number of event buckets we split into, in order to control the resultant read amplification. Spreading into multiple partitions in such cases is still beneficial in order to spread the read workload to multiple Cassandra replicas.
Split by assigning more event buckets for a given time bucket
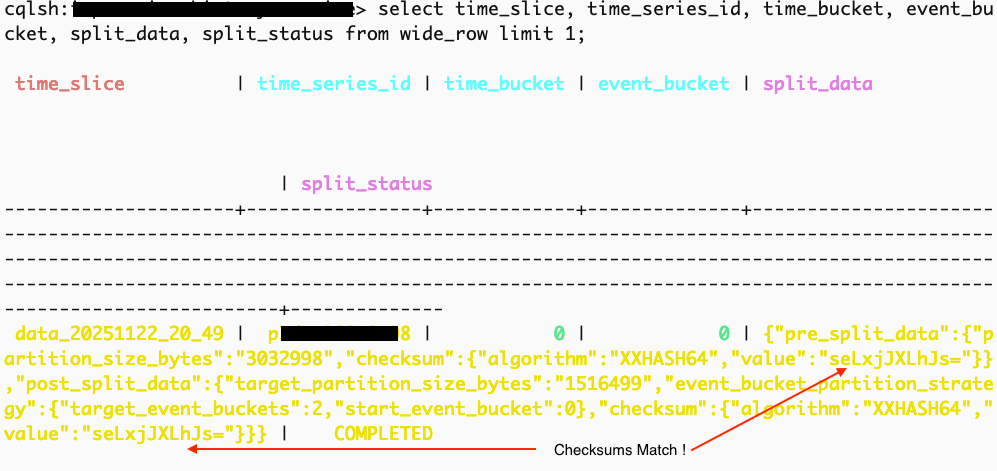
Validating Splits
The Planner stores a pre-split checksum of a given partition during the planning phase, while the Splitter computes and stores the post-split checksum. The split status is marked as completed only if the two checksums match.
Ensure checksums match pre- and post-split before marking a split as COMPLETED
Tracking Splits
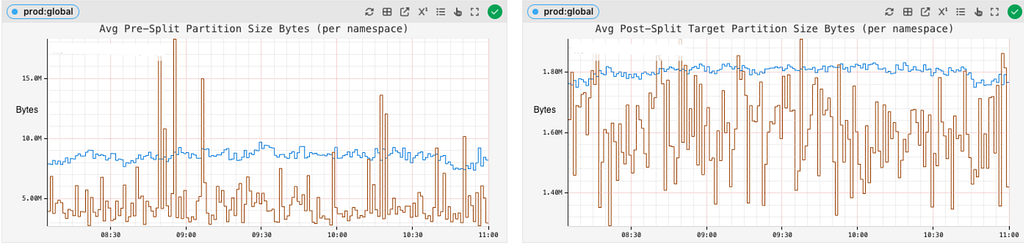
The pre- and post-split partition sizes across different datasets are tracked to see how effectively the partition splits are being planned and executed:
Track pre- and post-split partition sizes to ensure we are splitting optimally
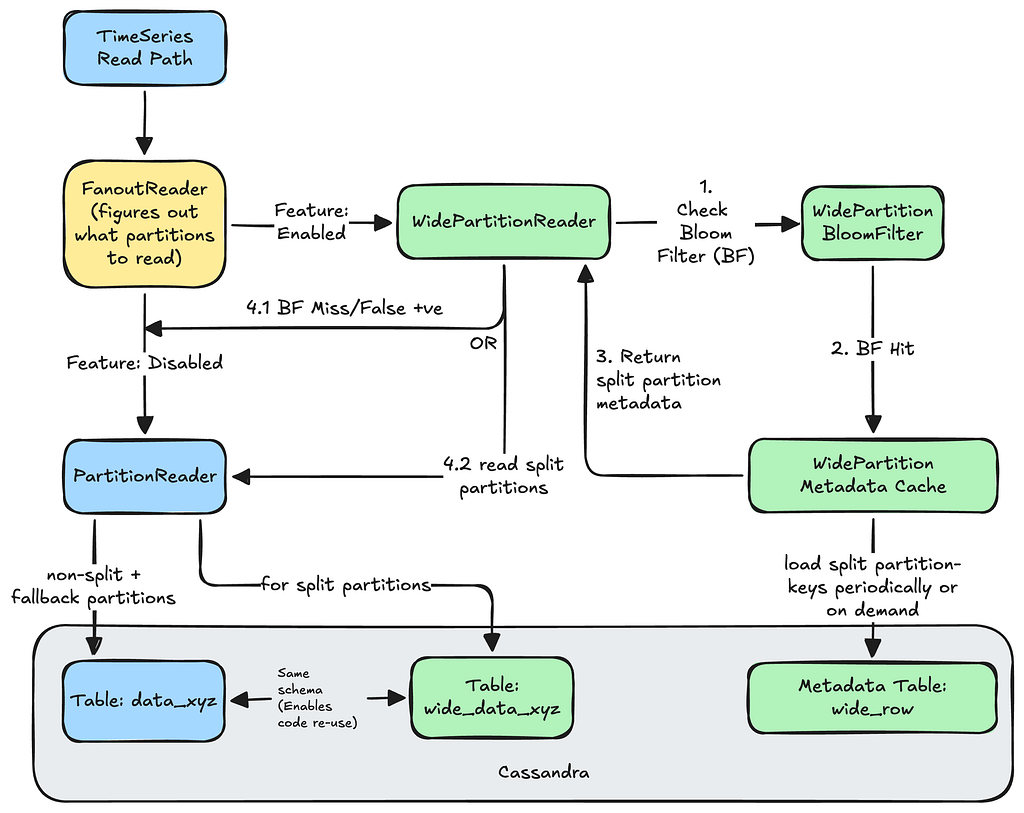
Serving Reads
The TimeSeries servers load the partition-keys of completed splits periodically into in-memory Bloom filters. Every read operation checks the Bloom filter to see whether a query can be diverted to the split partitions.
Here is what the Read path looks like:
Read path for diverting reads to existing or split partitions
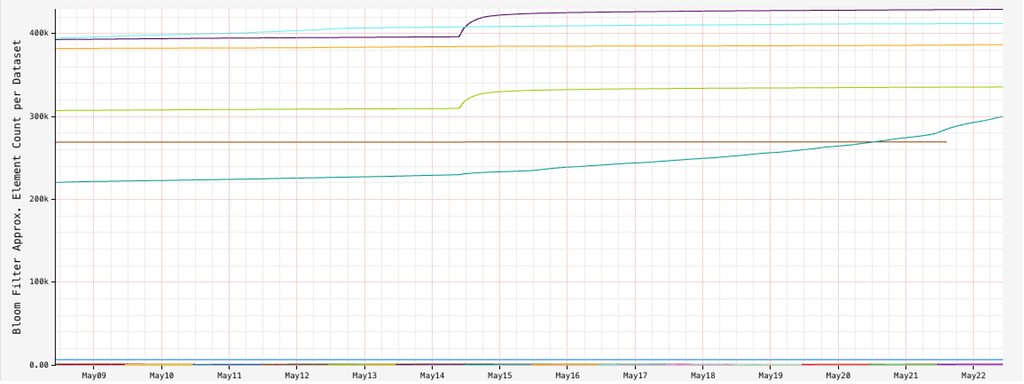
The size of the Bloom filters is monitored to ensure we have enough memory per server. Due to the compactness of partition keys, and ratio of wide partitions in a given dataset, the filters fit comfortably in each server instance.
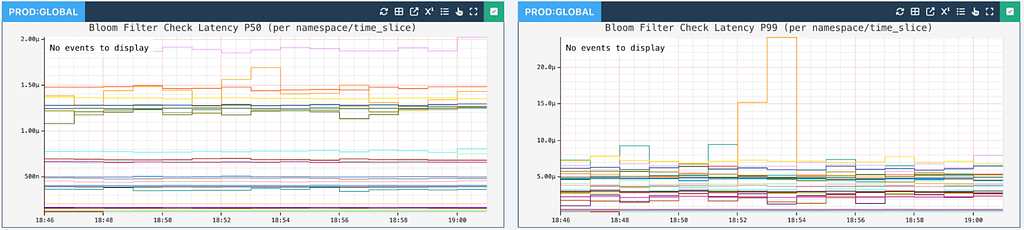
Bloom filter approximate element count per namespace and time slice
The Bloom filter latency to check whether a given partition key is wide for every read request is typically in single-digit microseconds or better, making this diversion practically invisible to the callers.
Latency for checking Bloom filters is extremely small for callers to notice the diversion
For the cases that do end up with a Bloom filter hit, the TimeSeries servers lookup the wide_row metadata to see how to read a specific wide partition:
{ "pre_split_data": { "time_slice": "data_20260328", "time_series_id": "6313825", → What to read "time_bucket": 0, "event_bucket": 2 … }, "post_split_data": { "time_slice": "wide_data_20260328_0", → Where to read it from "event_bucket_partition_strategy": { → Strategy to delegate to for reading "target_event_buckets": 2, "start_event_bucket": 32 → How should the strategy read it } … }
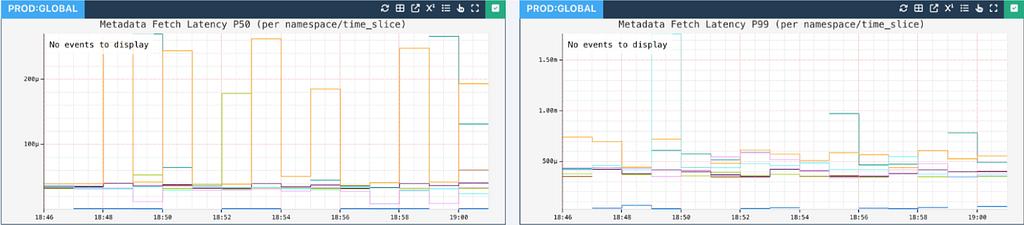
This metadata read is backed by a read-through cache, making it quite performant:
Metadata fetch latency is quite low to affect read operations
Finally, the reads for the split partitions are delegated to our existing PartitionReader. Having the same schema for the split table allows us to reuse code and minimize changes.
Fallbacks
The existing wide partition from the original time slice is never deleted. This helps us in creating safe fallbacks in many different scenarios of partial failures and eventual consistency. The slightly larger storage space we use as a result is worth the operational safety we gain.
Building Additional Confidence
Serving incorrect reads would be disastrous. To establish trust beyond checksums, we leveraged additional mechanisms such as:
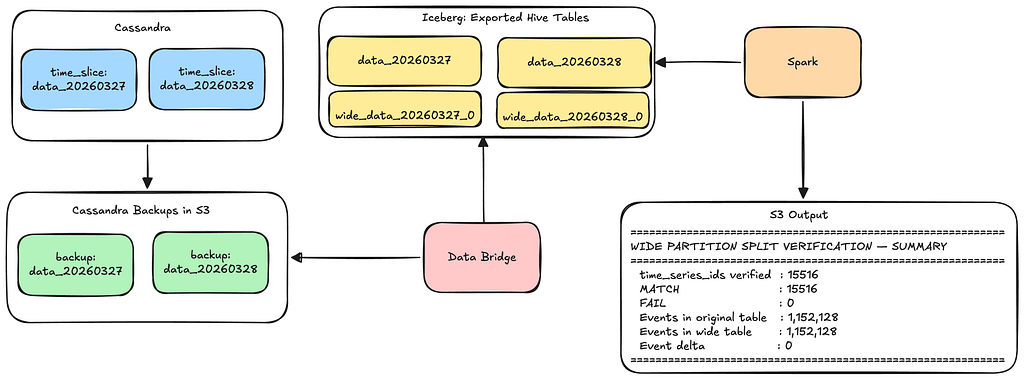
Using our existing Data Bridge pipelines to verify splits offline:
Spark job to ensure that the split data is an exact match to the original data
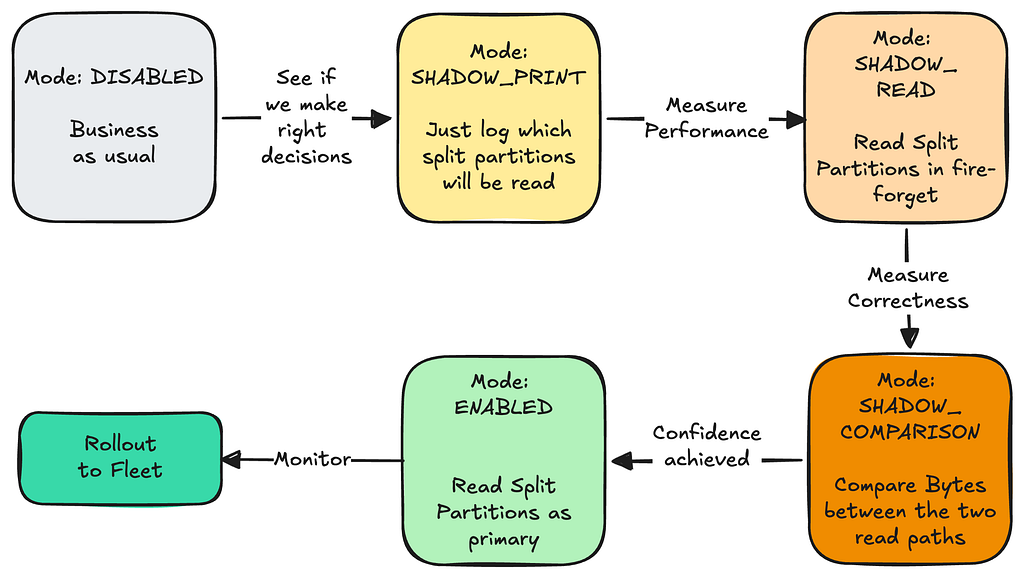
Implementing a phased rollout strategy to safely advance through stages as our confidence in the system grew:
Advance through Read modes once previous mode passes checks
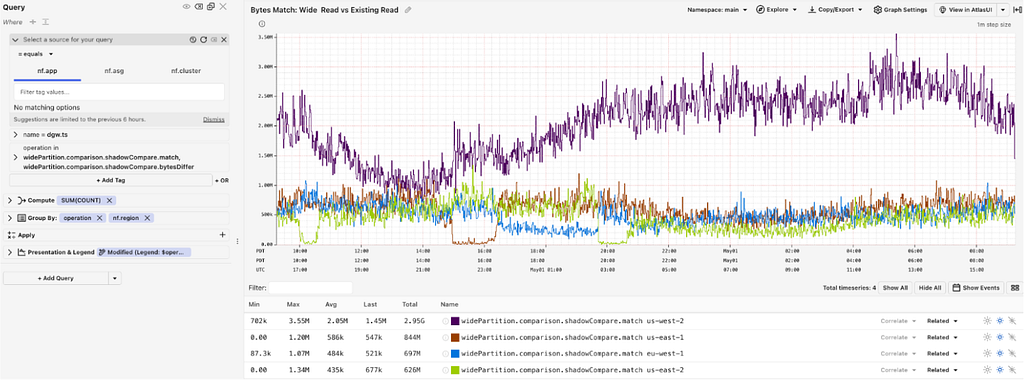
A critical part of this phased rollout was the Comparison phase, which compared bytes served by old read path and the new read path while in shadow mode:
A chart of bytes match vs bytes differ in a given shadow period
Results
As a result of these dynamic splits, we see a huge improvement in the average read latency of most wide partitions, bringing it down from seconds:
Existing average latency for reading wide partitions
to low double-digit milliseconds!
Average latency for reading dynamically split partitions
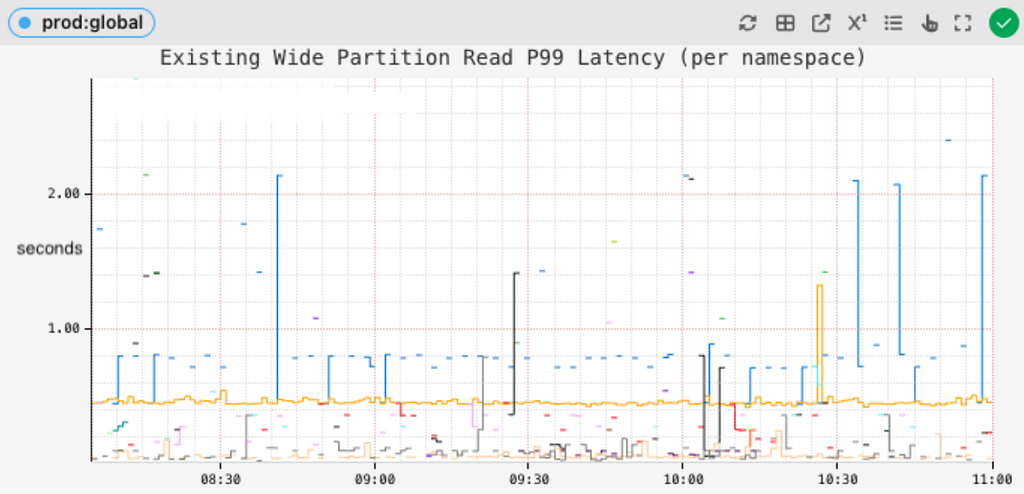
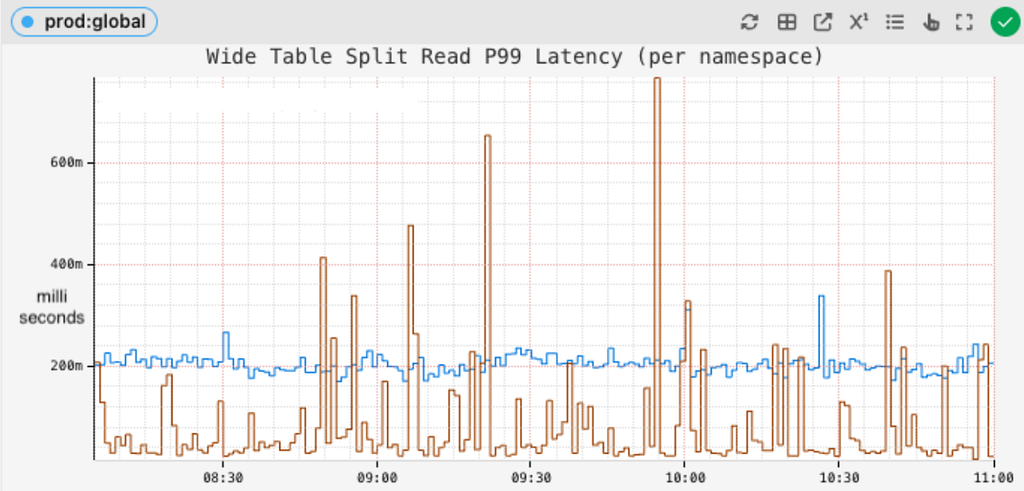
Tail latencies of reading wide partitions dropped from several seconds:
Existing tail latency for reading wide partitions
to around 200 ms or better:
Tail latency for reading dynamically split partitions
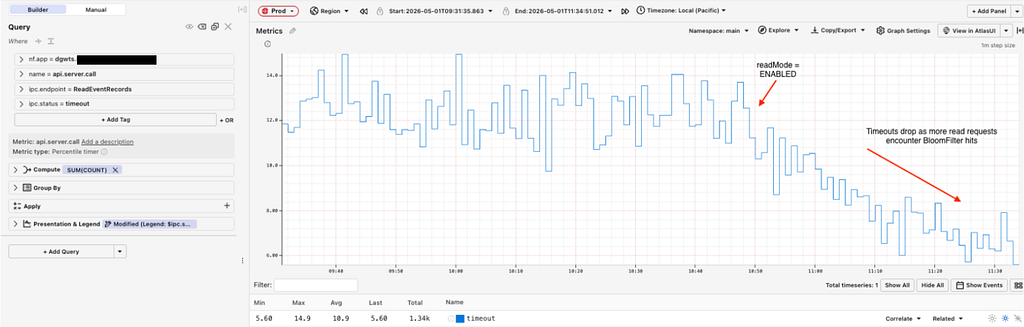
resulting in a drop in read timeouts:
Further, for extreme wide rows, where a dataset would face constant timeouts and unavailability blips, the service was able to paginate and query 500MB+ partitions while remaining available:
There is more work planned around this feature, like splitting mutable wide partitions, or re-processing previously failed splits, but this has been a successful start in improving service performance and reducing our support burden.
Further, we would like to highlight some key lessons that we learned at different points in this journey.
Reducing Surface Area: As a first step, explore simpler solutions that can still deliver meaningful impact. Also, reducing the surface area of a complex change and deploying incrementally pays off operationally.
Building Confidence: Invest time and resources to build confidence in new features, especially when justified by the feature complexity, deployment blast radius, and/or potential impact.
Let’s Encrypt is committed to a post-quantum-safe Web PKI. The path we’re planning to take is Merkle Tree Certificates (“MTCs”), a new approach that adds post-quantum authentication to the web without sacrificing the speed and reliability that have made TLS universal.
This post is about these plans and why we believe MTCs are worth pursuing as a key to a post-quantum future.
An increasingly urgent problem
For much of the last several years, the conversation about post-quantum cryptography has been a conversation about encryption. The reasoning was straightforward: an attacker who records encrypted traffic today might be able to decrypt it years from now once quantum computers can break the underlying math. Authentication, the part of TLS that indicates a server is who it says it is, has been a less urgent problem. A quantum computer needs to forge a signature in real time, not retroactively, so threats to authentication hinge on the existence of a cryptographically relevant quantum computer (CRQC).
That comfort has been eroding for a while. In the United States, the NSA’s CNSA 2.0 suite has directed national security systems toward post-quantum algorithms on a 2030-to-2035 schedule since 2022, and NIST’s draft transition guidance would deprecate RSA-2048 and P-256 after 2030 and disallow them after 2035. The European Union’s roadmap targets high-risk systems by the end of 2030 and broad migration by 2035. These mandates don’t bind the public Web PKI directly, but they set the end-of-decade timeline that the vendors, libraries, and standards bodies it relies on are already working toward.
This year, the timeline shortened further. Google announced that it would migrate its services by 2029, citing tightening estimates for the potential arrival of a CRQC. Cloudflare followed with a parallel commitment. In addition, Go 1.27 adds ML-DSA, a NIST-standardized post-quantum signature scheme, to the standard library, a sign that post-quantum signatures are becoming practical infrastructure.
Post-quantum authentication is no longer a problem the Web PKI ecosystem should defer. Long-lived keys (root certificate authorities, code-signing keys, identity systems) are particularly valuable targets, and new technology takes years to gain broad adoption, so the work has to start early.
The Web PKI’s unique circumstances
The Web PKI is one of the trickiest places to deploy post-quantum signatures. The reason is size.
ML-DSA-44, one of the smaller NIST standardized post-quantum signature schemes, has a signature roughly 2,420 bytes long. The algorithms used in the Web PKI today are much smaller. RSA-2048 signatures are 256 bytes and ECDSA-P256 signatures are 64 bytes. Public keys are bigger as well: 1,312 bytes for ML-DSA-44, 256 bytes for RSA-2048, and 64 bytes for ECDSA-P256. A typical Web PKI handshake today carries five signatures and two public keys. Replacing those with ML-DSA equivalents would push a single TLS handshake well past 10 kilobytes. Cloudflare’s research has shown that, at that scale, a meaningful share of TLS connections fail on real-world networks, and the rest get slower.
Larger handshakes would affect every TLS connection, not just those that would fail. They would mean constrained bandwidth, slower connections, and a worse experience for users, all in exchange for security against a threat that hasn’t materialized yet. That’s a steep cost to enable by default, and defaults are what actually move security at web scale.
Merkle Tree Certificates
A different design called Merkle Tree Certificates (“MTCs”) has been emerging over the past year, and we believe it is a strong path forward for the post-quantum Web PKI.
Instead of issuing certificates one at a time and signing each one individually, an MTC certificate authority issues certificates in batches, with a single signature covering the entire batch. Browsers stay up to date on those batch signatures (called “landmarks”) separately from the TLS handshake.
In the common case, the entire authentication path in an MTC handshake is one signature, one public key, and one inclusion proof. That’s smaller than today’s Web PKI handshake, even though MTCs use post-quantum algorithms. The other case is the “standalone” form. It uses slightly larger handshakes as a fallback when a client’s landmark is out of date.
There is more to MTCs than size optimization. Because every certificate is part of a published Merkle tree, transparency becomes a property of issuance itself. Today’s Certificate Transparency ecosystem is bolted on after the fact: certificates are issued by CAs, then logged separately, with extra signatures riding along in the TLS handshake to attest to that logging. With MTCs, a certificate cannot exist outside the Merkle tree. Certificate Transparency is built in.
This is not entirely new ground for us. Let’s Encrypt has operated Certificate Transparency logs since 2019. Those logs are append-only Merkle trees, the same core data structure MTCs are built on, and ones we have run in production, at scale, for years.
Cloudflare and Chrome are already running a feasibility experiment with MTCs against real internet traffic. The IETF’s PLANTS working group is working on standardizing the design. Chrome has announced that MTCs are its preferred path for adding post-quantum certificates to the public web.
Our plans
We are planning to support Merkle Tree Certificates as the path forward for the post-quantum Web PKI. We are targeting late 2026 for a staging environment that issues MTCs, and 2027 for a production-ready environment.
This is not a small endeavor. Issuing MTCs at the scale of Let’s Encrypt requires meaningful changes throughout our stack: in our issuance infrastructure, in the ACME protocol our subscribers use to obtain certificates, in revocation and operational tooling, and in the transparency-log infrastructure that MTCs subsume. We have been participating in the IETF PLANTS and ACME working groups as the standards take shape.
Alongside the MTC work, we are tracking the standards for ML-DSA signatures in X.509 (RFC 9881) and TLS (draft-ietf-tls-mldsa), and the ecosystem work this depends on, like the addition of ML-DSA to the Go standard library. The Web PKI’s transition to post-quantum security needs all of this to land in browsers, libraries, and ACME clients, whether the certificates ultimately delivered are MTCs or ML-DSA signed X.509.
What this means if you use Let’s Encrypt
Nothing changes today. Your current Let’s Encrypt certificates will continue to be issued and renewed exactly as they always have been. When post-quantum certificates become available from Let’s Encrypt, they will arrive the way our service always has: free, automated, and available to anyone with an ACME client.
The transition will take time. There are standards still being finalized, root programs still defining their requirements, and engineering work that has to land in the broader ecosystem (browsers, libraries, ACME clients) before any of this matters at scale. We will keep the community informed as the work progresses and as the timelines firm up.
If you maintain an ACME client or run an ACME-driven certificate pipeline, this is a good moment to start tracking the work in the PLANTS working group and the discussions on the [email protected] mailing list. Some of the changes coming will require client-side support, and the ecosystem will benefit from clients that are ready when the issuance side is.
A note on the wider post-quantum transition
For the broader internet community: post-quantum encryption is the more urgent problem, because any TLS connection without post-quantum key exchange is potentially harvestable for later decryption. If you operate servers, please ensure they support hybrid post-quantum key exchange (X25519MLKEM768). Major browsers and operating systems already do, and turning it on at the server is one of the highest-leverage things you can do this year.
In closing
We have been building infrastructure for the public web since 2013 on the principle that security should be available to everyone, automatically, at no cost. The quantum transition is a generational change in how that security works under the hood.
As you scale your use of Amazon Web Services (AWS), managing KMS keys becomes increasingly important. Whether you manage a handful of keys or thousands across multiple AWS accounts and AWS Regions, there’s often a need to audit key usage to help you meet compliance requirements, evaluate your risk posture, and optimize key management costs. However, determining which keys are actively in use and which have been sitting idle can be a time consuming and complex task.
To help with this, AWS Key Management Service (AWS KMS) has launched the GetKeyLastUsage API, a new feature that you can use to quickly determine when each key was last used for a cryptographic operation, significantly enhancing your audit capabilities and key lifecycle management. For more information, see Determine past usage of a KMS key.
Before this launch, the primary way to audit key usage was through AWS CloudTrail logs. CloudTrail captures every cryptographic operation by default, so the data is available. The difficulty is turning that data into actionable insight. You need to identify which keys to examine, query the right logs, and repeat that process frequently enough to maintain an accurate view. For the most recent 90 days, CloudTrail event history makes this manageable. Beyond that, you need to create a dedicated trail to deliver logs to Amazon Simple Storage Service (Amazon S3) for long-term retention, then query those logs using tools such as Amazon Athena to determine when a key was last used.
Determine when a key was last used
AWS KMS now provides a direct way to see when a key was last used for cryptographic operations. You can also see this information using the AWS Management Console for AWS KMS and the AWS Command Line Interface (AWS CLI).
The GetKeyLastUsage API returns the date and time of the most recent cryptographic operation performed with a KMS key, without requiring you to search through CloudTrail logs. The API returns the date and time of the last key operation, the type of operation performed, CloudTrail event ID, and KMS request ID. You can access this information for all customer-managed keys and AWS managed keys irrespective of key spec, key origin, key store, or key usage type.
In addition, you can restrict a key from being disabled or scheduled for deletion if it was recently used, by incorporating this usage information as a condition within the KMS key policy. See the Preventing accidental key deletion with policy controls section for implementation details.
About the tracking period
One of the important concepts you must understand before relying on the last usage information reported on a KMS key is the tracking period. The tracking period is the date from which AWS KMS began tracking cryptographic activity for the key. Tracking began on April 23, 2026, for most AWS Regions. Understanding the tracking period is critical because it determines whether the absence of usage information means a key has never been used or only hasn’t been used since tracking started.
For example, if you have a key created on January 1, 2026, and you check its usage, any cryptographic operations that occurred between January 1 and April 22 wouldn’t be captured in the usage information. Thus, you can’t conclude that it’s never been used, because it might have been used in the months before tracking began.
Getting started
There’s nothing to enable or additional configuration required to view usage information on last cryptographic operation performed on your KMS keys.
To view KMS key usage:
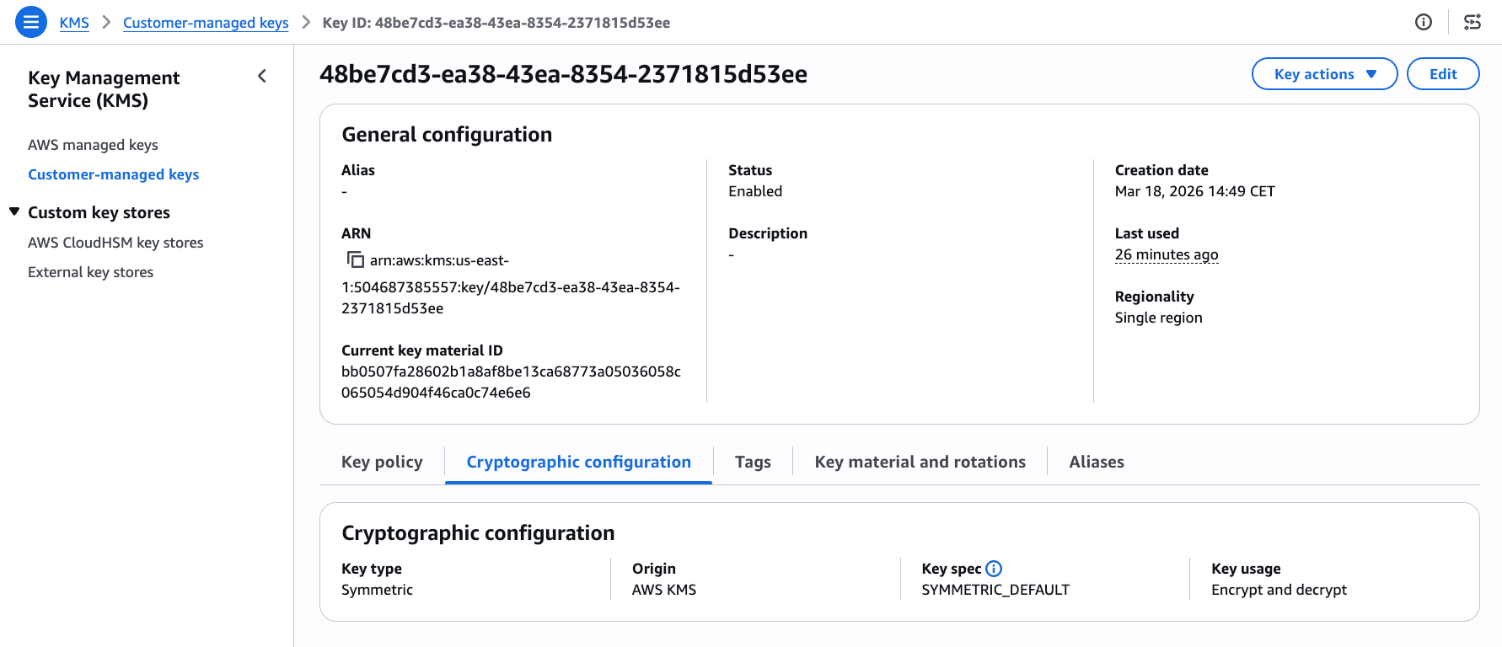
Go to the AWS KMS console and choose Customer-managed keys in the navigation pane and select a key. Look for Last used on the general configuration.
Figure 1: KMS key general configuration page
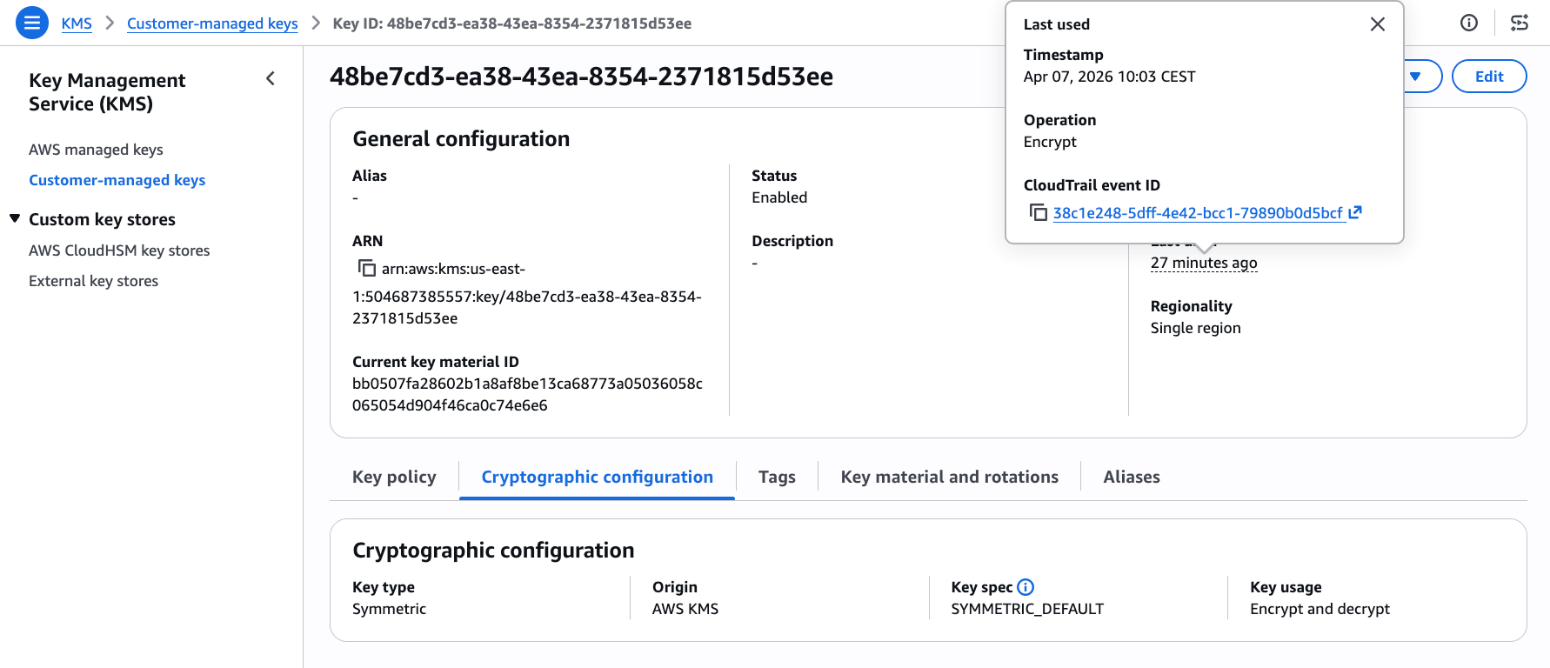
Choose the link under Last used to see additional details such as Timestamp, Operation, and the CloudTrail event ID.
Figure 2: View last used details including timestamp, operation, and event ID
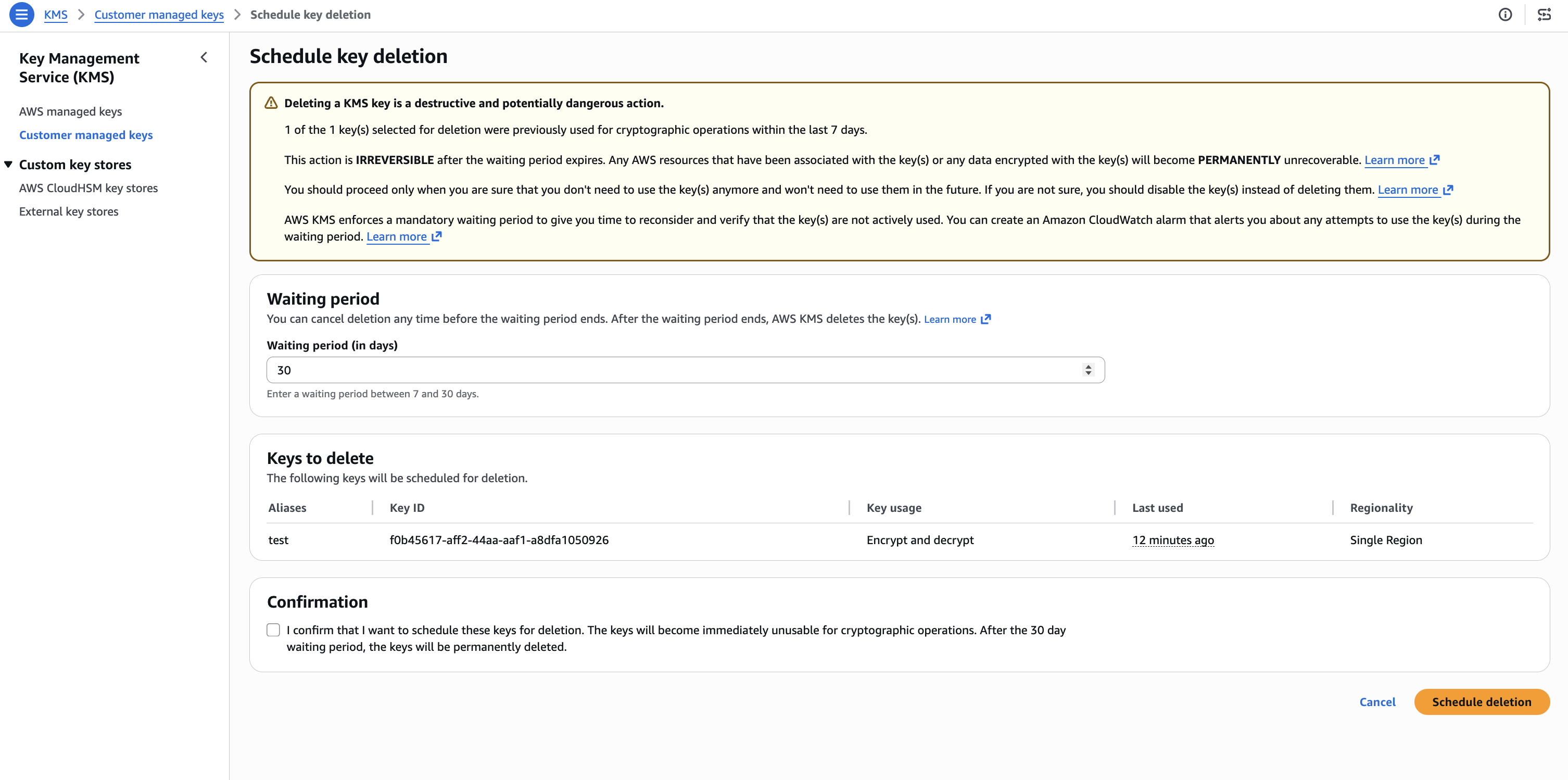
The Last used column is also shown when you attempt to schedule key deletion, so that you can make informed decisions.
Figure 3: Scheduled key deletion warning
API reference
See the following examples for ideas on how to use the GetKeyLastUsage API to better understand KMS key usage.
Use case 1: Cost optimization through unused key cleanup
If you manage thousands of AWS KMS keys distributed across multiple AWS accounts, you might have keys that have remained unused since creation or keys that are no longer needed. By cleaning up these keys, you can reduce operational costs and minimize your security footprint. However, without visibility into which keys are actively performing cryptographic operations, it can be difficult to distinguish between keys protecting critical workloads and those that can be safely decommissioned.
Note that there are some precautions that you should take before scheduling key deletion. While the last usage information can help identify unused keys, it shouldn’t be the only factor in deciding whether to delete or disable a key. The last usage information tells you when a key was last used, not whether it will be needed in the future. A key might be unused for months but still required to decrypt files, for compliance scenarios or disaster recovery as shown in figure 4.
When you identify a potentially unused key, first disable it using DisableKey and monitor your applications and services for any encryption or decryption failures.
Figure 4: A use case where GetKeyLastUsage doesn’t accurately reflect whether a KMS key is still required
As an example, Amazon EBS volumes only interact with KMS keys during specific lifecycle events like volume creation, attachment, and detachment. After a volume is attached to an Amazon Elastic Compute Cloud (Amazon EC2) instance, the plaintext data encryption key is cached in the Nitro Card hardware, and all subsequent read/write operations use this cached key without any further AWS KMS API calls. This means a production volume running continuously for months or years will show no KMS activity during that entire period. However, the volume remains completely dependent on that KMS key for any future operations like instance restarts, volume reattachments, or disaster recovery scenarios. If someone deletes the KMS key, the encrypted data key stored with the volume can never be decrypted again, making the volume’s data permanently and irreversibly inaccessible. Before deleting any KMS key, you must verify it has no associated EBS volumes or snapshots, regardless of how long ago the last KMS API call occurred.
AWS provides a mechanism where you can create a CloudWatch alarm that notifies you if a key pending deletion is being accessed, giving you an opportunity to cancel the deletion before data becomes inaccessible.
Solution with GetKeyLastUsage API
Here’s a sample script that scans all customer-managed keys in an account and retrieves each key’s last usage date through the GetKeyLastUsage API. It accepts two optional inputs: a threshold in days and an AWS Region. The script filters and displays only keys that haven’t been used within the specified period, presenting results in a table with the key name, AWS account ID, AWS Region, and last usage date. This can help you identify unused encryption keys.
The following is an example to scan all keys that haven’t been used in the last 180 days in the us-east-1 Region:
./script.sh 180 us-east-1
#!/bin/bash
DAYS=${1:-90}
REGION=${2:-$(aws configure get region)}
CUTOFF=$(date -v-${DAYS}d +%s 2>/dev/null || date -d "-${DAYS} days" +%s)
ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
printf "Showing keys not used in the last %s days (Region: %s)\n\n" "$DAYS" "$REGION"
printf "%-50s %-15s %-20s %-15s\n" "Key Name" "Account ID" "Region" "Last Usage Date"
printf "%.0s-" {1..100}
printf "\n"
for key_id in $(aws kms list-keys --region $REGION --query 'Keys[*].KeyId' --output text); do
key_manager=$(aws kms describe-key --region $REGION --key-id $key_id --query 'KeyMetadata.KeyManager' --output text)
if [ "$key_manager" = "CUSTOMER" ]; then
last_usage=$(aws kms get-key-last-usage --region $REGION --key-id $key_id)
timestamp=$(echo $last_usage | jq -r '.KeyLastUsage.TimeStamp // empty')
if [ -z "$timestamp" ]; then
last_epoch=0
else
last_epoch=$(date -jf "%Y-%m-%dT%H:%M:%S" "$(echo $timestamp | cut -d. -f1)" +%s 2>/dev/null || date -d "$timestamp" +%s)
fi
if [ "$last_epoch" -lt "$CUTOFF" ]; then
key_alias=$(aws kms list-aliases --region $REGION --key-id $key_id --query 'Aliases[0].AliasName' --output text)
key_name=${key_alias:-$key_id}
[ "$key_name" = "None" ] && key_name=$key_id
if [ -z "$timestamp" ]; then
tracking_date=$(echo $last_usage | jq -r '.TrackingStartDate' | cut -d'T' -f1)
last_used="${tracking_date}*"
else
last_used=$(echo $timestamp | cut -d'T' -f1)
fi
printf "%-50s %-15s %-20s %-15s\n" "$key_name" "$ACCOUNT_ID" "$REGION" "$last_used"
fi
fi
done
printf "\n* = No operations performed since tracking started\n"
Use case 2: Preventing accidental key deletion with policy controls
Organizations frequently face the risk of accidental key deletions, which can have severe operational consequences. Despite precautions and safety measures, accidents can happen. A key might be deleted because someone believes it’s no longer in use, only to discover that critical applications or workloads depend on it. This results in data access failures, application downtime, and emergency recovery procedures. Without visibility into recent key usage, teams lack the information needed to make safe disable decisions or implement effective safeguards.
Solution with policy based controls
To prevent KMS keys from being accidentally Disabled or Deleted use the kms:TrailingDaysWithoutKeyUsage condition key in key policies to automatically block deletion or disabling of recently used keys:
Open the AWS KMS console and choose Customer managed keys in the navigation pane.
Select the key you want to protect.
In the Key policy tab, choose Edit.
In the policy editor, add the following statement:
The policy prevents deletion or disabling a key if it was used within the past 365 days. You can adjust the threshold to match your organization’s requirements. For more information about the condition key, see kms:TrailingDaysWithoutKeyUsage.
Important considerations
When reviewing key usage for possible deletion, consider the following:
Key deletion is irreversible and makes encrypted data unrecoverable. AWS enforces a 7–30 day waiting period. During this time, monitor usage attempts and cancel the deletion if necessary. Delete a key only if you’re certain that no data has been encrypted or will be encrypted with it. Consider disabling the key first to test the impact of unavailable keys.
CloudTrail remains authoritative because it provides the full audit trail. GetKeyLastUsage quickly tells you when and what operations occurred, but CloudTrail shows you who made the request and with what parameters. Learn more about logging KMS API calls with CloudTrail.
Conclusion
The GetKeyLastUsage API enhances your KMS key management capabilities by providing immediate access to usage data that was previously only present in CloudTrail logs. Start by opening the AWS KMS console and checking the Last used field for any customer-managed keys and AWS managed keys to see this information in action. For broader key auditing, integrate the API into your existing automation scripts using the AWS CLI examples provided.
If you have feedback about this post, submit comments in the Comments section below.
Extended
attributes (xattrs) provide a way to attach key/value metadata to
inodes—files, directories, and the like—in a filesystem. As with many
Linux filesystems, the FUSE filesystem
supports xattrs. In a filesystem-track session at the 2026 Linux Storage,
Filesystem, Memory Management, and BPF Summit, FUSE maintainer Miklos
Szeredi led a discussion about caching xattrs in kernel memory; he would
like to create some common infrastructure that could be used by FUSE and
shared with other filesystems.
Software as a service (SaaS) providers building AI-powered applications on Amazon Bedrock AgentCore often need to serve multiple tenants with distinct security requirements from a shared infrastructure. Some tenants require cross-account access from their own Amazon Web Services (AWS) accounts, while others mandate that traffic stay within a private virtual private cloud (VPC) for regulatory compliance. Without centralized resource-level control, managing these diverse requirements can be complex.
AgentCore supports resource-based policies, giving you centralized, resource-level control over who can access your AgentCore Runtime and AgentCore Runtime endpoint resources and under what conditions.
In this post, you walk through a multi-tenant AI customer service platform where two tenants need different levels of access to the same agent. You learn how to use resource-based policies on AgentCore to grant cross-account access for one tenant while restricting another to VPC-only traffic—all while sharing the same underlying AgentCore Runtime and AgentCore Runtime endpoint.
The multi-tenant scenario
Imagine you’re an SaaS provider who builds and operates an AI-powered customer service platform. You use AgentCore to deploy intelligent agents that handle customer inquiries, answering product questions, processing returns, and escalating complex issues to human agents.
You serve multiple enterprise clients (tenants), each with their own AWS account and unique security requirements:
Tenant A: Example Corp is a large retailer operating in AWS account 111122223333. Their development teamis building a customer-facing chat agent that calls your AI agent to answer product questions in real time, and their admin team needs access to test agent behavior and monitor responses. Both roles must invoke the agent directly from Example Corp’s own AWS account without you having to share credentials or create AWS Identity and Access Management (IAM) users on their behalf. Example Corp has no network restriction requirements—their teams can invoke the agent from any network path as long as they have valid AWS credentials.
Tenant B: AnyCompany is a healthcare company operating in AWS account 444455556666. Because of regulatory (HIPAA) requirements, AI agent traffic must originate only from their private VPC (vpc-health1234). Their internal support staff uses the AI agent to assist with patient billing inquiries, which might involve protected health information (PHI). Their compliance team mandates that no API call to the agent can be made from developer laptops, public endpoints, or any network outside the controlled VPC boundary.
Your platform (SaaS provider) runs in account 555555555555 in the us-west-2 AWS Region. You operate an AgentCore Runtime (support-agent-runtime) that handles the core customer service logic, and an AgentCore Runtime endpoint (DEFAULT) that routes requests to the latest version of the support agent. Both tenants share this same agent infrastructure.
You can use resource-based policies to define who can access your AgentCore Runtime and AgentCore Runtime endpoint directly on the resources themselves—centralizing access control on the resource side. For cross-account scenarios like Example Corp, both a resource-based policy on your resources and an identity-based policy in the tenant’s account are required. For VPC-restricted scenarios like AnyCompany, you can use specific IAM conditions to enforce that requests originate only from an approved VPC, adding a network-level security boundary on top of identity-based controls.
Solution architecture
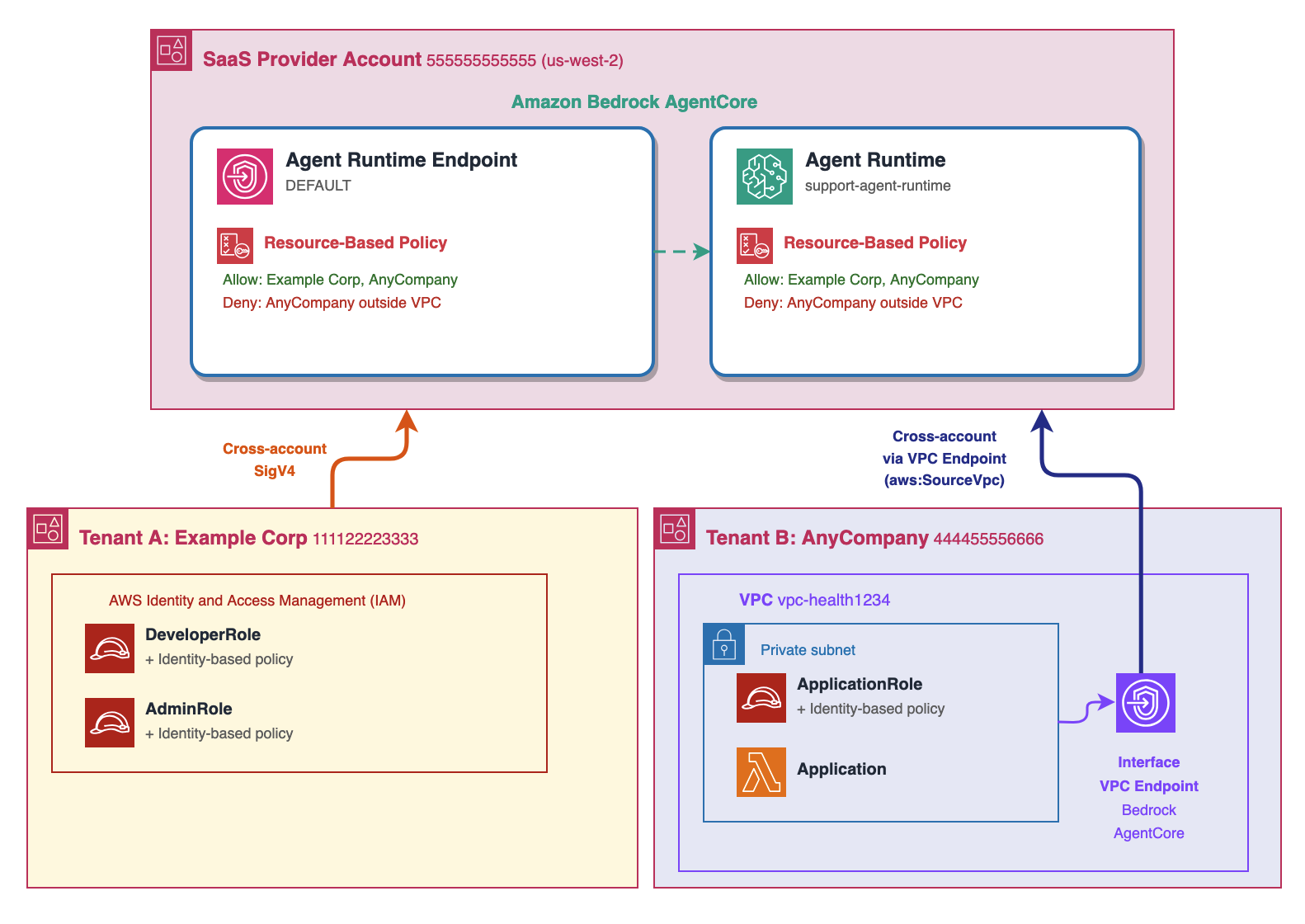
The following diagram shows the architecture for the multi-tenant AI customer service platform with both access patterns.
Figure 1: Architecture for the multi-tenant AI customer service platform with both access patterns
Your account (555555555555) with AgentCore Runtime and AgentCore Runtime endpoint
Example Corp’s account (111122223333) with DeveloperRole and AdminRole
AnyCompany’s account (444455556666) with VPC boundary and ApplicationRole
Policy enforcement points on both resources
VPC endpoint in AnyCompany’s VPC connecting to AgentCore
The SaaS provider account (555555555555) hosts the AgentCore Runtime and AgentCore Runtime endpoint that both tenants share. Example Corp (111122223333) accesses the agent cross-account using IAM roles—DeveloperRole and AdminRole—authenticated with Signature Version 4 (SigV4), the standard AWS request signing protocol. AWS evaluates both the resource-based policy on your resources and the identity-based policy in Example Corp’s account before granting access.
AnyCompany (444455556666) also accesses the agent cross-account, but with an additional constraint: all requests must originate from within their private VPC (vpc-health1234) through a VPC endpoint for AgentCore. The resource-based policy on your resources includes an explicit Deny statement that blocks any request from AnyCompany’s ApplicationRole when it doesn’t originate from the approved VPC.
In both cases, resource-based policies must be applied to both the AgentCore Runtime and AgentCore Runtime endpoint. AWS evaluates policies on both resources for InvokeAgentRuntime operations—if either resource denies access or lacks an explicit Allow, the request is denied.
Prerequisites
Before you begin, ensure you have the following:
An AWS account with AgentCore access and permissions to call PutResourcePolicy, GetResourcePolicy, and DeleteResourcePolicy on AgentCore resources
An AgentCore Runtime with SigV4 authentication and a DEFAULT AgentCore Runtime endpoint pointing to the latest runtime version
For the VPC-restricted scenario, the tenant must have a VPC endpoint for AgentCore configured in their VPC. An interface VPC endpoint creates a private connection between the tenant’s VPC and the AgentCore service without requiring traffic to traverse the public internet. For more information, see Interface VPC endpoints for Amazon Bedrock AgentCore.
Implementation
Both Example Corp and AnyCompanyoperate in separate AWS accounts from your platform. For cross-account access to AgentCore Runtime, AWS requires that both of the following allow the action:
A resource-based policyin your platform account applied to both the AgentCore Runtime and its AgentCore Runtime endpoint. InvokeAgentRuntime operations require an explicit Allow on both resources—if either lacks one, the request is denied.
An identity-based policy attached to the caller’s IAM role in the tenant’s account.
If either side is missing or denies the action, the request is denied.
Step 1: Configure cross-account access for Example Corp (Tenant A)
Example Corp’s DeveloperRole and AdminRole in account 111122223333 need to invoke your AI customer service agent. Without resource-based policies, enabling this cross-account access would typically require Example Corp’s roles to assume a role in your platform account through IAM role chaining—adding operational complexity, introducing temporary credential management, and creating additional IAM roles that must be maintained in your account for each tenant. With resource-based policies, you grant Example Corp’s roles direct access to your AgentCore Runtime and AgentCore Runtime endpoint without role chaining. Example Corp’s roles can invoke the agent directly from their own account using their own credentials, while you maintain centralized control over access on the resource side.
AgentCore Runtime resource-based policy
The following policy grants Example Corp’s DeveloperRole and AdminRole permission to invoke the agent runtime. This is the first of two resource-based policies required—it controls access to the runtime resource itself. Save this as runtime-policy.json:
The following policy grants the same roles permission to invoke the AgentCore Runtime endpoint. Without this second policy, requests are allowed at the runtime level but denied at the endpoint level, and the invocation fails. Save this as endpoint-policy.json:
Configure an identity-based policy (Example Corp’s account)
Resource-based policies alone aren’t sufficient for cross-account access. Example Corp must also attach an identity-based policy to DeveloperRole and AdminRole in their account (111122223333) that allows the same action on your resources. Without this policy on the tenant side, IAM denies the cross-account request even though your resource-based policies allow it.
Example Corp attaches the following policy to both DeveloperRole and AdminRole:
Attach this policy to both DeveloperRole and AdminRole in Example Corp’s account.
Step 2: Configure cross-account with VPC-restricted access for AnyCompany (Tenant B)
AnyCompany operates under HIPAA compliance requirements and mandates that all traffic to your agent stays within a private network path. Like Example Corp, AnyCompany needs cross-account access from account 444455556666—but with an additional constraint, requests must originate from their VPC vpc-health1234 through an interface VPC endpoint. Any request from outside this VPC is denied, even if it comes from AnyCompany’s ApplicationRole.
Resource-based policies (your platform account): To enforce this, you update the resource-based policies on both the AgentCore Runtime and AgentCore Runtime endpoint. Each policy includes an Allow statement that grants ApplicationRole permission to invoke the agent, paired with a Deny statement that blocks any request not originating from vpc-health1234. In the following policy, the Deny statement uses StringNotEquals on aws:SourceVpc . When a request arrives through an interface VPC endpoint, AWS populates this key with the VPC ID. If it doesn’t match vpc-health1234, or if the key is absent because no VPC endpoint was used, the Deny takes effect. Because an explicit Deny overrides any Allow from any policy, this pattern helps ensure that no other identity-based or resource-based policy can inadvertently grant AnyCompany access from outside the VPC. Add the following statements to runtime-policy-v2.json alongside the Example Corp statement from Step 1:
Because put-resource-policy replaces the entire policy on a resource, your updated policy files must include both the preceding AnyCompany statments and the Example Corp statements from Step 1.
AnyCompany must attach an identity-based policy to ApplicationRole in their account 444455556666 that allows the same InvokeAgentRuntime on your resources in account 555555555555. Without this policy on the tenant side, IAM denies the cross-account request even though your resource-based policies allow it.
AnyCompany attaches the following policy to ApplicationRole:
The VPC restriction is enforced entirely on resource account through the resource-based policy condition, AnyCompany’s identity-based policy doesn’t need VPC conditions. This keeps the tenant-side configuration straightforward while you maintain centralized network-level control.
OAuth authentication considerations
The policies in this post use SigV4 authentication with specific IAM role principals. If your AgentCore Runtime or AgentCore Gateway is configured with OAuth authentication instead, the principal structure changes. OAuth-authenticated resources require a wildcard principal (“Principal": "*") because the caller identity comes from a JSON Web Token (JWT) validated before policy evaluation. Anonymous or unauthenticated requests are rejected before the policy is evaluated, so the wildcard principal doesn’t grant open access. To restrict OAuth-authenticated requests to a specific VPC, combine the wildcard principal with a VPC condition in the resource-based policy. IAM principal-based condition keys such as aws:PrincipalAccount and aws:PrincipalOrgID aren’t populated in the OAuth authentication context—only supported network-level condition keys (such as aws:SourceVpc, aws:SourceVpce, aws:SourceIp) are available for use in resource-based policies with OAuth. For more details, see Resource-based policies for Amazon Bedrock AgentCore.
Understanding policy evaluation
To understand how AWS evaluates these policies when a request arrives, consider the following scenarios:
Caller or principal
Network
Identity-based policy (tenant side)
Runtime resource-based policy
Runtime endpoint resource-based policy
Final policy evaluation result
Example Corp
Any network
Allows
Allows
Allows
Allowed
Example Corp
Any network
Allows
Allows
Allows
Allowed
AnyCompany
From
Allows
Allows ( does not match)
Allows ( does not match)
Allowed
AnyCompany
Outside VPC
Allows
matches
matches
Denied
Any other cross-account role
Any network
Allows
No matching
No matching
Denied
Any other cross-account role
Any network
No policy
Allows
Allows
Denied
Conclusion and next steps
In this post, you learned how to use resource-based policies on AgentCore to secure a multi-tenant AI platform with distinct access patterns for each tenant:
Example Corp gets seamless cross-account integration, their development and admin teams can invoke your AI agent directly from their own AWS account without credential management.
AnyCompany gets the strict network-level isolation their compliance team requires, the AI agent is accessible only from within their private VPC, ensuring that interactions involving potential PHI — stay within the controlled network boundary
Both tenants share the same underlying AgentCore Runtime and AgentCore Runtime endpoint, yet each has tailored security controls enforced at the resource level. his approach avoids per-tenant infrastructure duplication while satisfying each tenant’s security posture, a challenge you likely face when onboarding tenants with different compliance postures. Resource-based policies complement identity-based IAM policies, giving you layered control over which principals can invoke which agents, and from which network paths.
Extracting actionable insights from thousands of contracts and legal documents remains a challenge. For organizations, critical business information is locked in unstructured documents such as contracts, legal agreements, provider arrangements, and vendor invoices. Extracting and operationalizing this information has traditionally been a manual, error-prone, and resource-intensive process. This leads to missed savings opportunities, costly delays, and significant inefficiencies across the enterprise.
AArete, a global management and technology consulting firm specializing in healthcare, recognized this challenge and developed Doczy.ai, an intelligent contract interpretation solution powered by generative AI on Amazon Web Services (AWS).
In this post, we show you how Doczy.ai uses generative AI on AWS to automate contract intelligence at scale, transforming unstructured documents into structured, actionable insights, so organizations can automate critical business processes and unlock the full value of their data.
The challenge: Data trapped in documents
For healthcare organizations, managing and interpreting contracts and documents represents a major operational bottleneck. Manual review processes require deploying teams to extract data from thousands of documents. This is an approach that is neither scalable nor sustainable, highly prone to error, and costly. Organizations relying on institutional knowledge face additional risks: critical information resides with a few key individuals, creating knowledge silos and succession planning challenges. Existing Contract Lifecycle Management (CLM) systems often prove inadequate for capturing the nuanced and complex terms unique to each agreement. These legacy systems can only configure predefined fields, missing the rich detail and contextual information that distinguishes contracts. The downstream impact is substantial: in healthcare, reimbursement terms must be manually translated into claims systems—a slow, error-prone process. Similarly, verifying vendor invoices against contract terms often requires manual effort, leading to payment processing delays and missed contractual savings opportunities. These inefficiencies ultimately leave significant value on the table.
This is where Doczy.ai provides significant value.
Doczy.ai: An intelligent contract interpretation solution
Doczy.ai directly addresses these challenges using advanced AI and scalability on AWS. Developed by AArete, Doczy.ai pushes the boundaries of document intelligence. The solution automatically interprets complex documents and converts them into a structured, queryable information repository that allows organizations to unlock the full value of their data and drive smarter decisions.The evolution of Doczy.ai reflects rapid AI advancement. Prior to 2020, document processing required manual effort, with individuals processing approximately 100 documents per week. Between 2020–2023, the firm implemented rules-based contract processing, achieving approximately 55% accuracy. The breakthrough came in 2024 with an AI-based processing built on AWS achieved 99% accuracy—a dramatic improvement over the 55% accuracy of traditional rules-based systems.
Doczy.ai architecture
Doczy.ai is built on a comprehensive AWS architecture designed to handle the entire document processing lifecycle: from the moment a file enters the system to the moment it generates actionable business intelligence.
Architecture of Doczy.ai
External users access the platform through a secure Next.js frontend, with Amazon Cognito managing authentication and authorization behind the scenes. After authentication, users upload documents directly to Amazon Simple Storage Service (Amazon S3), where durable, scalable object storage ensures nothing is lost and everything is accessible at scale. From there, the real intelligence begins.
An AWS Lambda function triggers Amazon Textract to extract text and metadata from documents in various formats. What sets Doczy.ai apart at this stage is its patented “smart chunking” algorithm, a proprietary approach that goes far beyond pulling words off a page. Rather than treating a document as a flat sequence of text, smart chunking preserves hierarchical structure and one-to-many relationships within documents. It uses a combination of semantic and keyword search to decompose text into meaningful, context-aware chunks, applying dynamic parameters to maintain logical relationships throughout. Sequential identifiers and metadata-driven grouping organize these chunks into field groups, detecting overlaps and removing duplications while keeping the document’s natural flow intact.
After chunking, the document enters the dual clustering engine of Doczy.ai. This two-lens methodology analyzes every contract simultaneously from both a semantic and a structural perspective. On the semantic side, extracted text is converted into embeddings, numerical representations of meaning, and similar ideas are grouped together even when they’re expressed in different words. On the structural side, pattern-recognition algorithms identify clause types, formatting conventions, table layouts, and hierarchical organization, understanding. For example, that a three-nested-level exhibit carries fundamentally different implications than a straightforward attached schedule.These two analyses don’t operate in isolation. Projection algorithms compare the semantic and structural clusters side by side, synthesizing them into a unified, enriched document model that captures both meaning and context. It’s this convergence that drives the 99% accuracy rate of Doczy.ai. The system doesn’t just read the words, it understands the contract. Advanced large language models (LLMs) then generate structured output grounded in this dual-clustered intelligence.Before output is finalized, the system determines each document’s file class and generates prompts tailored to the extracted text, cluster classification, and domain context. Through few-shot and multi-shot prompting, the platform continuously edits the prompt on domain-specific examples and based on real outputs, creating a feedback loop that compounds accuracy improvements over time.
The resulting structured data flows into Snowflake, forming a centralized repository that powers intelligent dashboards with actionable insights and visualizations. Throughout the entire pipeline, Amazon CloudWatch monitors performance in real time and proactively surfaces issues before they escalate, while AWS Secrets Manager safeguards sensitive information, ensuring that security is not an afterthought, but a foundational layer woven into every stage of the system.
The transformative impact of Doczy.ai
The results of this AI-powered approach are transformative and measurable. By automating contract interpretation and document processing, Doczy.ai has demonstrated significant impact at scale for multiple organizations across healthcare and financial services. The scale of operations over the last 22 months demonstrates the maturity and production readiness of Doczy.ai. This solution has processed 2.5 million contract documents (50 million pages) with 137 million API calls to Amazon Bedrock and 442 billion tokens—a level of automation and accuracy previously unattainable through manual or traditional document processing approaches. Over this same period, Doczy.ai has helped clients achieve approximately 330 million dollars in cumulative direct and indirect savings.The 99% accuracy rate represents significant improvement over the approximately 55% accuracy of rules-based systems and far exceeds manual processing, which is typically affected by fatigue and human error. The 97% reduction in manual processing time translates directly to cost savings and enables organizations to reallocate human resources to higher-value activities that require judgment and strategic thinking.
A use case in action: Business process automation for health plans
For health plans, Doczy.ai provides a powerful solution to automate and improve contract management across the entire lifecycle. It ingests existing contracts in both paper and digital formats, integrates with contract management systems such as Coupa and Icertis, and processes new contracts and amendments as they’re executed. It then creates a centralized metadata repository that feeds directly into downstream systems, enabling end-to-end business process automation.This automation unlocks critical capabilities: Organizations can continuously analyze and improve contract terms, identifying opportunities to improve financial performance and operational efficiency. The architecture feeds accurate, up-to-date contract data directly into claims systems, automating the configuration process that previously required manual translation of reimbursement terms and removing manual data entry, configuration errors, and delays. Additionally, the platform helps maintain claim payment accuracy by assessing payments against contract terms, identifying discrepancies, and flagging potential overpayments or underpayments before they occur.By automating manual processes, health plans can adapt quickly to new contract terms and regulatory requirements. The intelligent dashboards and actionable insights provided by Doczy.ai enable decision-makers to understand contract performance, identify trends, and take proactive action to optimize financial outcomes.
Getting started with Doczy.ai
Organizations interested in using Doczy.ai to transform document processing and contract management can engage with AArete to discuss their specific use cases and requirements. AArete offers the platform as a Software as a Service (SaaS) solution, enabling rapid deployment without significant infrastructure investment. AArete’s team of experts will configure this solution for your specific document types, domain terminology, and business processes, supporting maximum value from day one.
Conclusion
The challenge of unlocking data from unstructured documents is a major hurdle for many businesses, particularly in healthcare and financial services where contracts and agreements govern critical operational and financial relationships. By embracing intelligent document intelligence on AWS, organizations can solve this long-standing operational challenge and unlock a new frontier of strategic advantage, turning their data into their most valuable asset.
Built on a sophisticated architecture that orchestrates Amazon Cognito, Amazon S3, AWS Lambda, Amazon Textract, Amazon Elastic Container Service (Amazon ECS), Amazon Bedrock, Amazon CloudWatch, and AWS Secrets Manager, Doczy.ai demonstrates how modern cloud services can solve complex document-heavy business problems. Its advanced hybrid smart chunking, dual clustering, and prompt optimization techniques form the core of a patented contract intelligence engine.
Doczy.ai delivers tangible impact, processing up to 250,000 contract documents per week with 99% accuracy, reducing manual processing time by 97%, and helping clients unlock roughly 330 million dollars in cumulative savings over 22 months. By embracing this intelligent document processing, organizations can turn contracts into a strategic data asset, improving efficiency, accuracy, and profitability while freeing teams to focus on higher-value work.
To learn more about how AArete and Doczy.ai can help your organization transform document processing and unlock the value of your unstructured data, visit the AArete website.
Package managers for operating systems and programming languages have been
around for decades. Each package manager, and its accompanying packaging format,
has been shaped by the needs of its respective ecosystem, but there is a growing
need to make use of package metadata for more than software management: for
example, in vulnerability scans, software bills of materials (SBOMs), and more. On
May 19, Damián Vicino spoke at the Open Source Summit North America 2026
about his experiences in the past year trying to make sense of the varied
metadata provided by more than 20 package managers.
Version
8.3 of Vim Classic has been
released. This is the first release of the Vim fork since the project
was announced
in March.
This release is based on Vim 8.2.0148, with a number of bug fixes
and patches conservatively backported from future versions of Vim
upstream. We elected to clean up this version of Vim, prepare it for a
release, and imagine an alternate history where Vim 8.3 was released
without Vim9 script. The result is Vim Classic 8.3. We chose to take
this approach in order to reduce the long-term maintenance burden of
Vim Classic, acknowledging that our fork lacks the resources and
institutional knowledge available to Vim upstream. However, a
consequence is that there are some Vim plugins which are not
compatible with Vim Classic.
We have made a special effort to assess patches from Vim upstream
which mitigate some of the many CVEs affecting Vim which were
discovered and fixed between versions 8.2 and modern-day Vim, but we
can’t be sure we’ve got all of the security patches which are
applicable to Vim Classic (and practically exploitable). This version
of Vim Classic is therefore recommended for early adopters who are
comfortable adopting a security posture which accounts for the fact
that we may have overlooked some bugs.
LWN covered Vim
Classic and another Vim fork, EVi, in April.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.