Post Syndicated from Srividya Parthasarathy original https://aws.amazon.com/blogs/big-data/centrally-manage-access-and-permissions-for-amazon-redshift-data-sharing-with-aws-lake-formation/
Today’s global, data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. Amazon Redshift data sharing allows you to securely share live, transactionally consistent data in one Amazon Redshift data warehouse with another Amazon Redshift data warehouse within the same AWS account, across accounts, and across Regions, without needing to copy or move data from one cluster to another.
Some customers share their data with 50–100 data warehouses in different accounts and do a lot of cross-sharing, making it difficult to track who is accessing what data. They have to navigate to an individual account’s Amazon Redshift console to retrieve the access information. Also, many customers have their data lake on Amazon Simple Storage Service (Amazon S3), which is shared within and across various business units. As the organization grows and democratizes the data, administrators want the ability to manage the datashare centrally for governance and auditing, and to enforce fine-grained access control.
Working backward from customer ask, we are announcing the preview of the following new feature: Amazon Redshift data sharing integration with AWS Lake Formation, which enables Amazon Redshift customers to centrally manage access to their Amazon Redshift datashares using Lake Formation.
Lake Formation has been a popular choice for centrally governing data lakes backed by Amazon S3. Now, with Lake Formation support for Amazon Redshift data sharing, it opens up new design patterns, and broadens governance and security posture across data warehouses. With this integration, you can use Lake Formation to define fine-grained access control on tables and views being shared with Amazon Redshift data sharing for federated AWS Identity and Access Management (IAM) users and IAM roles.
Customers are using the data mesh approach, which provides a mechanism to share data across business units. Customers are also using a modern data architecture to share data from data lake stores and Amazon Redshift purpose-built data stores across business units. Lake Formation provides the ability to enforce data governance within and across business units, which enables secure data access and sharing, easy data discovery, and centralized audit for data access.
United Airlines is in the business of connecting people and uniting the world.
“As a data-driven enterprise, United is trying to create a unified data and analytics experience for our analytics community that will innovate and build modern data-driven applications. We believe we can achieve this by building a purpose-built data mesh architecture using a variety of AWS services like Athena, Aurora, Amazon Redshift, and Lake Formation to simplify management and governance around granular data access and collaboration.”
-Ashok Srinivas, Director of ML Engineering and Sarang Bapat, Director of Data Engineering.
In this post, we show how to centrally manage access and permissions for Amazon Redshift data sharing with Lake Formation.
Solution overview
In this solution, we demonstrate how integration of Amazon Redshift data sharing with Lake Formation for data governance can help you build data domains, and how you can use the data mesh approach to bring data domains together to enable data sharing and federation across business units. The following diagram illustrates our solution architecture.

The data mesh is a decentralized, domain-oriented architecture that emphasizes separating data producers from data consumers via a centralized, federated Data Catalog. Typically, the producers and consumers run within their own account. The details of these data mesh characteristics are as follows:
- Data producers – Data producers own their data products and are responsible for building their data, maintaining its accuracy, and keeping their data product up to date. They determine what datasets can be published for consumption and share their datasets by registering them with the centralized data catalog in a central governance account. You might have a producer steward or administrator persona for managing the data products with the central governance steward or administrators team.
- Central governance account – Lake Formation enables fine-grained access management on the shared dataset. The centralized Data Catalog offers consumers the ability to quickly find shared datasets, allows administrators to centrally manage access permissions on shared datasets, and provides security teams the ability to audit and track data product usage across business units.
- Data consumers – The data consumer obtains access to shared resources from the central governance account. These resources are available inside the consumer’s AWS Glue Data Catalog, allowing fine-grained access on the database and table that can be managed by the consumer’s data stewards and administrators.
The following steps provide an overview of how Amazon Redshift data sharing can be governed and managed by Lake Formation in the central governance pattern of a data mesh architecture:
- In the producer account, data objects are created and maintained in the Amazon Redshift producer cluster. A data warehouse admin creates the Amazon Redshift datashare and adds datasets (tables, views) to the share.
- The data warehouse admin grants and authorizes access on the datashare to the central governance account’s Data Catalog.
- In the central governance account, the data lake admin accepts the datashare and creates the AWS Glue database that points to the Amazon Redshift datashare so that Lake Formation can manage it.
- The data lake admin shares the AWS Glue database and tables to the consumer account using Lake Formation cross-account sharing.
- In the consumer account, the data lake admin accepts the resource share invitation via AWS Resource Access Manager (AWS RAM) and can view the database listed in the account.
- The data lake admin defines the fine-grained access control and grants permissions on databases and tables to IAM users (for this post,
consumer1 and consumer2) in the account.
- In the Amazon Redshift cluster, the data warehouse admin creates an Amazon Redshift database that points to the Glue database and authorizes usage on the created Amazon Redshift database to the IAM users.
- The data analyst as an IAM user can now use their preferred tools like the Amazon Redshift query editor to access the dataset based on the Lake Formation fine-grained permissions.
We use the following account setup for our example in this post:
- Producer account – 123456789012
- Central account – 112233445566
- Consumer account – 665544332211
Prerequisites
Create the Amazon Redshift data share and add datasets
In the data producer account, create an Amazon Redshift cluster using the RA3 node type with encryption enabled. Complete the following steps:
- On the Amazon Redshift console, create a cluster subnet group.
For more information, refer to Managing cluster subnet groups using the console.
- Choose Create cluster.
- For Cluster identifier, provide the cluster name of your choice.
- For Preview track, choose
preview_2022.

- For Node type, choose one of the RA3 node types.
This feature is only supported on the RA3 node type.
- For Number of nodes, enter the number of nodes that you need for your cluster.
- Under Database configurations, choose the admin user name and admin user password.
- Under Cluster permissions, you can select the IAM role and set it as the default.
For more information about the default IAM role, refer to Creating an IAM role as default for Amazon Redshift.

- Turn on the Use defaults option next to Additional configurations to modify the default settings.
- Under Network and security, specify the following:
- For Virtual private cloud (VPC), choose the VPC you would like to deploy the cluster in.
- For VPC security groups, either leave as default or add the security groups of your choice.
- For Cluster subnet group, choose the cluster subnet group you created.

- Under Database configuration, in the Encryption section, select Use AWS Key Management Service (AWS KMS) or Use a hardware security module (HSM).
Encryption is disabled by default.
- For Choose an AWS KMS key, you can either choose an existing AWS Key Management Service (AWS KMS) key, or choose Create an AWS KMS key to create a new key.
For more information, refer to Creating keys.

- Choose Create cluster.
- For this post, create tables and load data into the producer Amazon Redshift cluster using the following script.
Authorize the datashare
Install or update the latest AWS Command Line Interface (AWS CLI) version to run the AWS CLI to authorize the datashare. For instructions, refer to Installing or updating the latest version of the AWS CLI.
Set up Lake Formation permissions
To use the AWS Glue Data Catalog in Lake Formation, complete the following steps in the central governance account to update the Data Catalog settings to use Lake Formation permissions to control catalog resources instead of IAM-based access control:
- Sign in to the Lake Formation console as admin.
- In the navigation pane, under Data catalog, choose Settings.
- Deselect Use only IAM access control for new databases.
- Deselect Use only IAM access control for new tables in new databases.
- Choose Version 2 for Cross account version settings.
- Choose Save.

Set up an IAM user as a data lake administrator
If you’re using an existing data lake administrator user or role add the following managed policies, if not attached and skip the below setup steps:
AWSGlueServiceRole
AmazonRedshiftFullAccess
Otherwise, to set up an IAM user as a data lake administrator, complete the following steps:
- On the IAM console, choose Users in the navigation pane.
- Select the IAM user who you want to designate as the data lake administrator.
- Choose Add an inline policy on the Permissions tab.
- Replace <AccountID> with your own account ID and add the following policy:
{
"Version": "2012-10-17",
"Statement": [ {
"Condition": {"StringEquals": {
"iam:AWSServiceName":"lakeformation.amazonaws.com"}},
"Action":"iam:CreateServiceLinkedRole",
"Resource": "*",
"Effect": "Allow"},
{"Action": ["iam:PutRolePolicy"],
"Resource": "arn:aws:iam::<AccountID>:role/aws-service role/lakeformation.amazonaws.com/AWSServiceRoleForLakeFormationDataAccess",
"Effect": "Allow"
},{
"Effect": "Allow",
"Action": [
"ram:AcceptResourceShareInvitation",
"ram:RejectResourceShareInvitation",
"ec2:DescribeAvailabilityZones",
"ram:EnableSharingWithAwsOrganization"
],
"Resource": "*"
}]
}
- Provide a policy name.
- Review and save your settings.
- Choose Add permissions, and choose Attach existing policies directly.
- Add the following policies:
AWSLakeFormationCrossAccountManagerAWSGlueConsoleFullAccessAWSGlueServiceRoleAWSLakeFormationDataAdminAWSCloudShellFullAccessAmazonRedshiftFullAccess
- Choose Next: Review and add permissions.
Data consumer account setup
In the consumer account, follow the steps mentioned previously in the central governance account to set up Lake Formation and a data lake administrator.
- In the data consumer account, create an Amazon Redshift cluster using the RA3 node type with encryption (refer to the steps demonstrated to create an Amazon Redshift cluster in the producer account).
- Choose Launch stack to deploy an AWS CloudFormation template to create two IAM users with policies.

The stack creates the following users under the data analyst persona:
- After the CloudFormation stack is created, navigate to the Outputs tab of the stack.
- Capture the
ConsoleIAMLoginURL and LFUsersCredentials values.

- Choose the
LFUsersCredentials value to navigate to the AWS Secrets Manager console.
- In the Secret value section, choose Retrieve secret value.

- Capture the secret value for the password.
Both consumer1 and consumer2 need to use this same password to log in to the AWS Management Console.

Configure an Amazon Redshift datashare using Lake Formation
Producer account
Create a datashare using the console
Complete the following steps to create an Amazon Redshift datashare in the data producer account and share it with Lake Formation in the central account:
- On the Amazon Redshift console, choose the cluster to create the datashare.
- On the cluster details page, navigate to the Datashares tab.
- Under Datashares created in my namespace, choose Connect to database.

- Choose Create datashare.

- For Datashare type, choose Datashare.
- For Datashare name, enter the name (for this post,
demotahoeds).
- For Database name, choose the database from where to add datashare objects (for this post,
dev).
- For Publicly accessible, choose Turn off (or choose Turn on to share the datashare with clusters that are publicly accessible).

- Under DataShare objects, choose Add to add the schema to the datashare (in this post, the
public schema).
- Under Tables and views, choose Add to add the tables and views to the datashare (for this post, we add the table
customer and view customer_view).

- Under Data consumers, choose Publish to AWS Data Catalog.
- For Publish to the following accounts, choose Other AWS accounts.
- Provide the AWS account ID of the consumer account. For this post, we provide the AWS account ID of the Lake Formation central governance account.
- To share within the same account, choose Local account.
- Choose Create datashare.

- After the datashare is created, you can verify by going back to the Datashares tab and entering the datashare name in the search bar under Datashares created in my namespace.
- Choose the datashare name to view its details.
- Under Data consumers, you will see the consumer status of the consumer data catalog account as Pending Authorization.

- Choose the checkbox against the consumer data catalog which will enable the Authorize option.

- Click Authorize to authorize the datashare access to the consumer account data catalog, consumer status will change to Authorized.

Create a datashare using a SQL command
Complete the following steps to create a datashare in data producer account 1 and share it with Lake Formation in the central account:
- On the Amazon Redshift console, in the navigation pane, choose Editor, then Query editor V2.
- Choose (right-click) the cluster name and choose Edit connection or Create Connection.
- For Authentication, choose Temporary credentials.
Refer to Connecting to an Amazon Redshift database to learn more about the various authentication methods.
- For Database, enter a database name (for this post, dev).
- For Database user, enter the user authorized to access the database (for this post, awsuser).
- Choose Save to connect to the database.

- Run the following SQL commands to create the datashare and add the data objects to be shared:
create datashare demotahoeds;
ALTER DATASHARE demotahoeds ADD SCHEMA PUBLIC;
ALTER DATASHARE demotahoeds ADD TABLE customer;
ALTER DATASHARE demotahoeds ADD TABLE customer_view;
- Run the following SQL command to share the producer datashare to the central governance account:
GRANT USAGE ON DATASHARE demotahoeds TO ACCOUNT '<central-aws-account-id>' via DATA CATALOG

- You can verify the datashare created and objects shared by running the following SQL command:
DESC DATASHARE demotahoeds

- Run the following command using the AWS CLI to authorize the datashare to the central data catalog so that Lake Formation can manage them:
aws redshift authorize-data-share \
--data-share-arn 'arn:aws:redshift:<producer-region>:<producer-aws-account-id>:datashare:<producer-cluster-namespace>/demotahoeds' \
--consumer-identifier DataCatalog/<central-aws-account-id>
The following is an example output:
{
"DataShareArn": "arn:aws:redshift:us-east-1:XXXXXXXXXX:datashare:cd8d91b5-0c17-4567-a52a-59f1bdda71cd/demotahoeds",
"ProducerArn": "arn:aws:redshift:us-east-1:XXXXXXXXXX:namespace:cd8d91b5-0c17-4567-a52a-59f1bdda71cd",
"AllowPubliclyAccessibleConsumers": false,
"DataShareAssociations": [{
"ConsumerIdentifier": "DataCatalog/XXXXXXXXXXXX",
"Status": "AUTHORIZED",
"CreatedDate": "2022-11-09T21:10:30.507000+00:00",
"StatusChangeDate": "2022-11-09T21:10:50.932000+00:00"
}]
}
You can verify the datashare status on the console by following the steps outlined in the previous section.
Central catalog account
The data lake admin accepts and registers the datashare with Lake Formation in the central governance account and creates a database for the same. Complete the following steps:
- Sign in to the console as the data lake administrator IAM user or role.
- If this is your first time logging in to the Lake Formation console, select Add myself and choose Get started.
- Under Data catalog in the navigation pane, choose Data sharing and view the Amazon Redshift datashare invitations on the Configuration tab.
- Select the datashare and choose Review Invitation.

A window pops up with the details of the invitation.
- Choose Accept to register the Amazon Redshift datashare to the AWS Glue Data Catalog.

- Provide a name for the AWS Glue database and choose Skip to Review and create.

- Review the content and choose Create database.

After the AWS Glue database is created on the Amazon Redshift datashare, you can view them under Shared Databases.

You can also use the AWS CLI to register the datashare and create the database. Use the following commands:
- Describe the Amazon Redshift datashare that is shared with the central account:
aws redshift describe-data-shares
- Accept and associate the Amazon Redshift datashare to Data Catalog:
aws redshift associate-data-share-consumer \
--data-share-arn 'arn:aws:redshift:<producer-region>:<producer-aws-account-id>:datashare:<producer-cluster-namespace>/demotahoeds' \
--consumer-arn arn:aws:glue:us-east-1:<central-aws-account-id>:catalog
The following is an example output:
{
"DataShareArn": "arn:aws:redshift:us-east-1:123456789012:datashare:cd8d91b5-0c17-4567-a52a-59f1bdda71cd/demotahoeds",
"ProducerArn": "arn:aws:redshift:us-east-1:123456789012:namespace:cd8d91b5-0c17-4567-a52a-59f1bdda71cd",
"AllowPubliclyAccessibleConsumers": false,
"DataShareAssociations": [
{
"ConsumerIdentifier": "arn:aws:glue:us-east-1:112233445566:catalog",
"Status": "ACTIVE",
"ConsumerRegion": "us-east-1",
"CreatedDate": "2022-11-09T23:25:22.378000+00:00",
"StatusChangeDate": "2022-11-09T23:25:22.378000+00:00"
}
]
}
- Register the Amazon Redshift datashare in Lake Formation:
aws lakeformation register-resource \
--resource-arn arn:aws:redshift:<producer-region>:<producer-aws-account-id>:datashare:<producer-cluster-namespace>/demotahoeds
- Create the AWS Glue database that points to the accepted Amazon Redshift datashare:
aws glue create-database --region <central-catalog-region> --cli-input-json '{
"CatalogId": "<central-aws-account-id>",
"DatabaseInput": {
"Name": "demotahoedb",
"FederatedDatabase": {
"Identifier": "arn:aws:redshift:<producer-region>:<producer-aws-account-id>:datashare:<producer-cluster-namespace>/demotahoeds",
"ConnectionName": "aws:redshift"
}
}
}'
Now the data lake administrator of the central governance account can view and share access on both the database and tables to the data consumer account using the Lake Formation cross-account sharing feature.
Grant datashare access to the data consumer
To grant the data consumer account permissions on the shared AWS Glue database, complete the following steps:
- On the Lake Formation console, under Permissions in the navigation pane, choose Data Lake permissions.
- Choose Grant.
- Under Principals, select External accounts.
- Provide the data consumer account ID (for this post, 665544332211).
- Under LF_Tags or catalog resources, select Named data catalog resources.
- For Databases, choose the database
demotahoedb.
- Select Describe for both Database permissions and Grantable permissions.
- Choose Grant to apply the permissions.

To grant the data consumer account permissions on tables, complete the following steps:
- On the Lake Formation console, under Permissions in the navigation pane, choose Data Lake permissions.
- Choose Grant.
- Under Principals, select External accounts.
- Provide the consumer account (for this post, we use 665544332211).
- Under LF-Tags or catalog resources, select Named data catalog resources.
- For Databases, choose the database demotahoedb.
- For Tables, choose All tables.
- Select Describe and Select for both Table permissions and Grantable permissions.
- Choose Grant to apply the changes.

Consumer account
The consumer admin will receive the shared resources from the central governance account and delegate access to other users in the consumer account as shown in the following table.
| IAM User |
Object Access |
Object Type |
Access Level |
consumer1 |
public.customer |
Table |
All |
consumer2 |
public.customer_view |
View |
specific columns: c_customer_id, c_birth_country, cd_gender, cd_marital_status, cd_education_status |
In the data consumer account, follow these steps to accept the resources shared with the account:
- Sign in to the console as the data lake administrator IAM user or role.
- If this is your first time logging in to the Lake Formation console, select Add myself and choose Get started.
- Sign in to the AWS RAM console.
- In the navigation pane, under Shared with me, choose Resource shares to view the pending invitations. You will receive 2 invitations.

- Choose the pending invitations and accept the resource share.

- On the Lake formation console, under Data catalog in the navigation pane, choose Databases to view the cross-account shared database.

Grant access to the data analyst and IAM users using Lake Formation
Now the data lake admin in the data consumer account can delegate permissions on the shared database and tables to users in the consumer account.
Grant database permissions to consumer1 and consumer2
To grant the IAM users consumer1 and consumer2 database permissions, follow these steps:
- On the Lake Formation console, under Data catalog in the navigation pane, choose Databases.
- Select the database demotahoedb and on the Actions menu, choose Grant.

- Under Principals, select IAM users and roles.
- Choose the IAM users consumer1 and consumer2.
- Under LF-Tags or catalog resources, demotahoedb is already selected for Databases.
- Select Describe for Database permissions.
- Choose Grant to apply the permissions.

Grant table permissions to consumer1
To grant the IAM user consumer1 permissions on table public.customer, follow these steps:
- Under Data catalog in the navigation pane, choose Databases.
- Select the database
demotahoedb and on the Actions menu, choose Grant.
- Under Principals, select IAM users and roles.
- Choose IAM user
consumer1.
- Under LF-Tags or catalog resources,
demotahoedb is already selected for Databases.
- For Tables, choose
public.customer.
- Select Describe and Select for Table permissions.
- Choose Grant to apply the permissions.

Grant column permissions to consumer2
To grant the IAM user consumer2 permissions on non-sensitive columns in public.customer_view, follow these steps:
- Under Data catalog in the navigation pane, choose Databases.
- Select the database
demotahoedb and on the Actions menu, choose Grant.
- Under Principals, select IAM users and roles.
- Choose the IAM user
consumer2.
- Under LF-Tags or catalog resources,
demotahoedb is already selected for Databases.
- For Tables, choose
public.customer_view.

- Select Select for Table permissions.
- Under Data Permissions, select Column-based access.
- Select Include columns and choose the non-sensitive columns (
c_customer_id, c_birth_country, cd_gender, cd_marital_status, and cd_education_status).
- Choose Grant to apply the permissions.

Consume the datashare from the data consumer account in the Amazon Redshift cluster
In the Amazon Redshift consumer data warehouse, log in as the admin user using Query Editor V2 and complete the following steps:
- Create the Amazon Redshift database from the shared catalog database using the following SQL command:
CREATE DATABASE demotahoedb FROM ARN 'arn:aws:glue:<producer-region>:<producer-aws-account-id>:database/demotahoedb' WITH DATA CATALOG SCHEMA demotahoedb ;
- Run the following SQL commands to create and grant usage on the Amazon Redshift database to the IAM users consumer1 and consumer2:
CREATE USER IAM:consumer1 password disable;
CREATE USER IAM:consumer2 password disable;
GRANT USAGE ON DATABASE demotahoedb TO IAM:consumer1;
GRANT USAGE ON DATABASE demotahoedb TO IAM:consumer2;
In order to use a federated identity to enforce Lake Formation permissions, follow the next steps to configure Query Editor v2.
- Choose the settings icon in the bottom left corner of the Query Editor v2, then choose Account settings.

- Under Connection settings, select Authenticate with IAM credentials.
- Choose Save.

Query the shared datasets as a consumer user
To validate that the IAM user consumer1 has datashare access from Amazon Redshift, perform the following steps:
- Sign in to the console as IAM user
consumer1.
- On the Amazon Redshift console, choose Query Editor V2 in the navigation pane.
- To connect to the consumer cluster, choose the consumer cluster in the tree-view pane.
- When prompted, for Authentication, select Temporary credentials using your IAM identity.
- For Database, enter the database name (for this post,
dev).
- The user name will be mapped to your current IAM identity (for this post,
consumer1).
- Choose Save.

- Once you’re connected to the database, you can validate the current logged-in user with the following SQL command:

- To find the federated databases created on the consumer account, run the following SQL command:
SHOW DATABASES FROM DATA CATALOG [ACCOUNT '<id1>', '<id2>'] [LIKE 'expression'];

- To validate permissions for
consumer1, run the following SQL command:
select * from demotahoedb.public.customer limit 10;
As shown in the following screenshot, consumer1 is able to successfully access the datashare customer object.

Now let’s validate that consumer2 doesn’t have access to the datashare tables “public.customer” on the same consumer cluster.
- Log out of the console and sign in as IAM user consumer2.
- Follow the same steps to connect to the database using the query editor.
- Once connected, run the same query:
select * from demotahoedb.public.customer limit 10;
The user consumer2 should get a permission denied error, as in the following screenshot.

Let’s validate the column-level access permissions of consumer2 on public.customer_view view.
- Connect to Query Editor v2 as
consumer2 and run the following SQL command:
select c_customer_id,c_birth_country,cd_gender,cd_marital_status from demotahoedb.public.customer_view limit 10;
In the following screenshot, you can see consumer2 is only able to access columns as granted by Lake Formation.

Conclusion
A data mesh approach provides a method by which organizations can share data across business units. Each domain is responsible for the ingestion, processing, and serving of their data. They are data owners and domain experts, and are responsible for data quality and accuracy. Using Amazon Redshift data sharing with Lake Formation for data governance helps build the data mesh architecture, enabling data sharing and federation across business units with fine-grained access control.
Special thanks to everyone who contributed to launch Amazon Redshift data sharing with AWS Lake Formation:
Debu Panda, Michael Chess, Vlad Ponomarenko, Ting Yan, Erol Murtezaoglu, Sharda Khubchandani, Rui Bi
References
About the Authors
 Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
 Harshida Patel is a Analytics Specialist Principal Solutions Architect, with AWS.
Harshida Patel is a Analytics Specialist Principal Solutions Architect, with AWS.
 Ranjan Burman is a Analytics Specialist Solutions Architect, with AWS.
Ranjan Burman is a Analytics Specialist Solutions Architect, with AWS.
 Vikram Sahadevan is a Senior Resident Architect on the AWS Data Lab team. He enjoys efforts that focus around providing prescriptive architectural guidance, sharing best practices, and removing technical roadblocks with joint engineering engagements between customers and AWS technical resources that accelerate data, analytics, artificial intelligence, and machine learning initiatives.
Vikram Sahadevan is a Senior Resident Architect on the AWS Data Lab team. He enjoys efforts that focus around providing prescriptive architectural guidance, sharing best practices, and removing technical roadblocks with joint engineering engagements between customers and AWS technical resources that accelerate data, analytics, artificial intelligence, and machine learning initiatives.
 Steve Mitchell is a Senior Solution Architect with a passion for analytics and data mesh. He enjoys working closely with customers as they transition to a modern data architecture.
Steve Mitchell is a Senior Solution Architect with a passion for analytics and data mesh. He enjoys working closely with customers as they transition to a modern data architecture.


















































 Swami Sivasubramanian is the Vice President of AWS Data and Machine Learning.
Swami Sivasubramanian is the Vice President of AWS Data and Machine Learning.

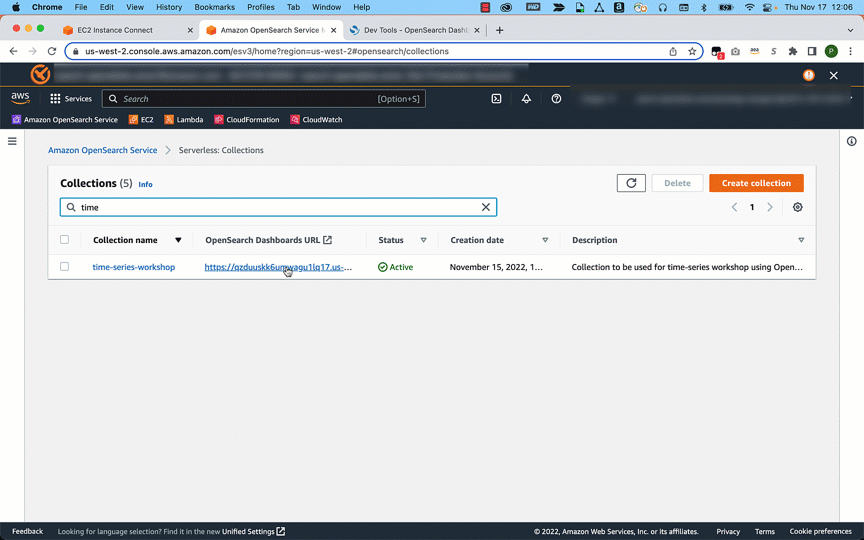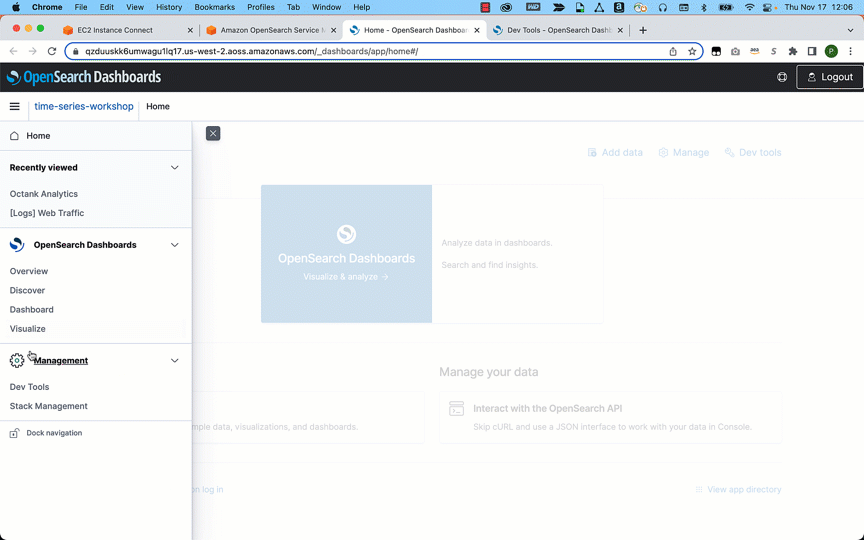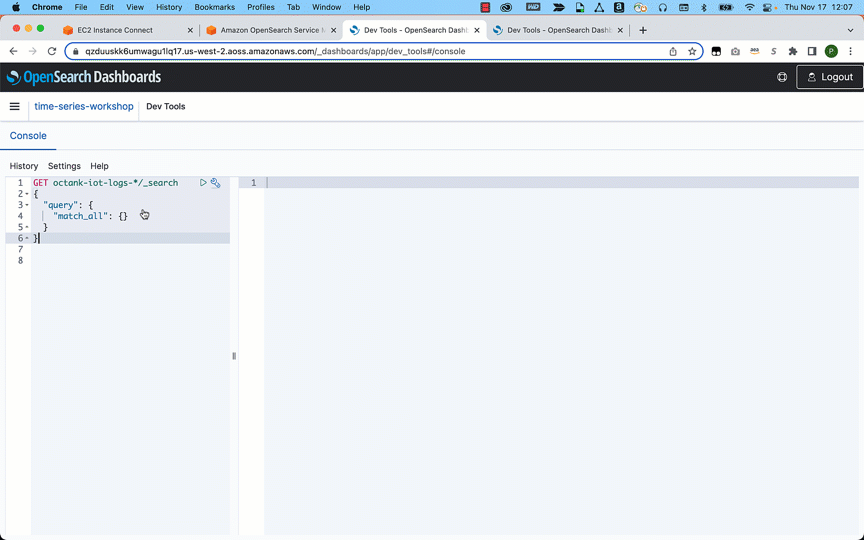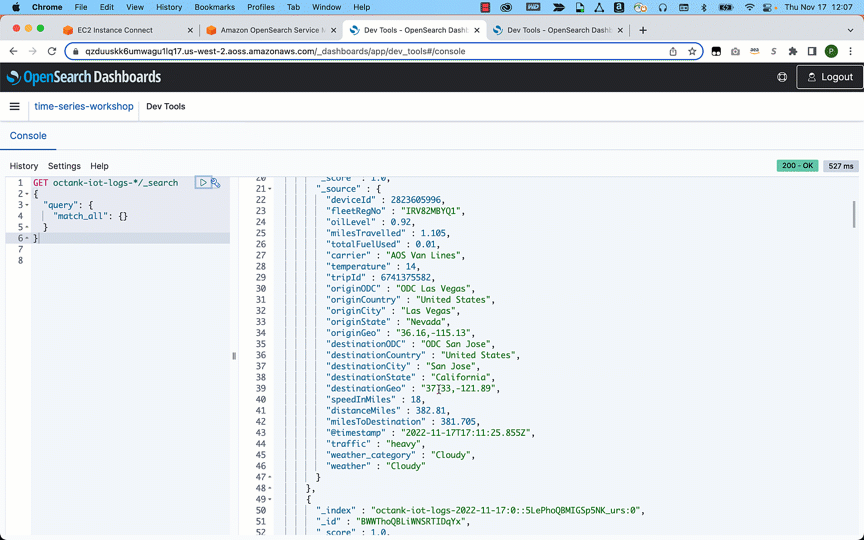
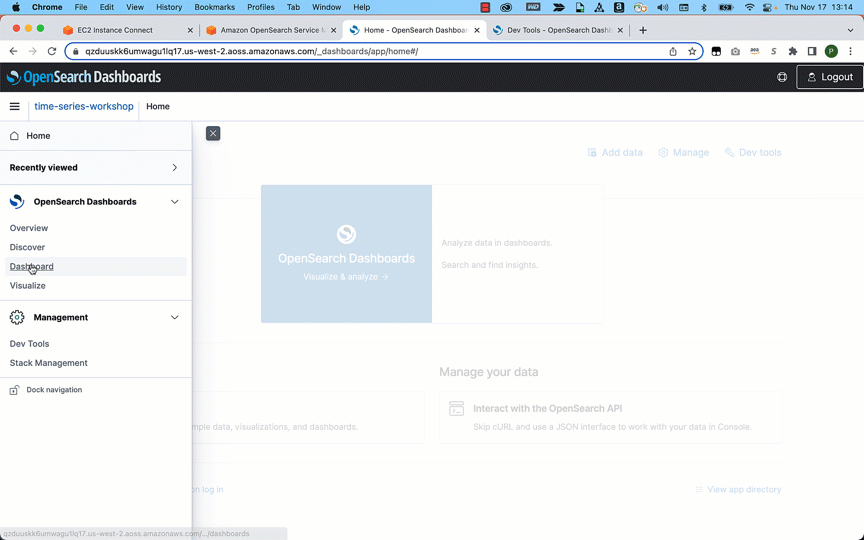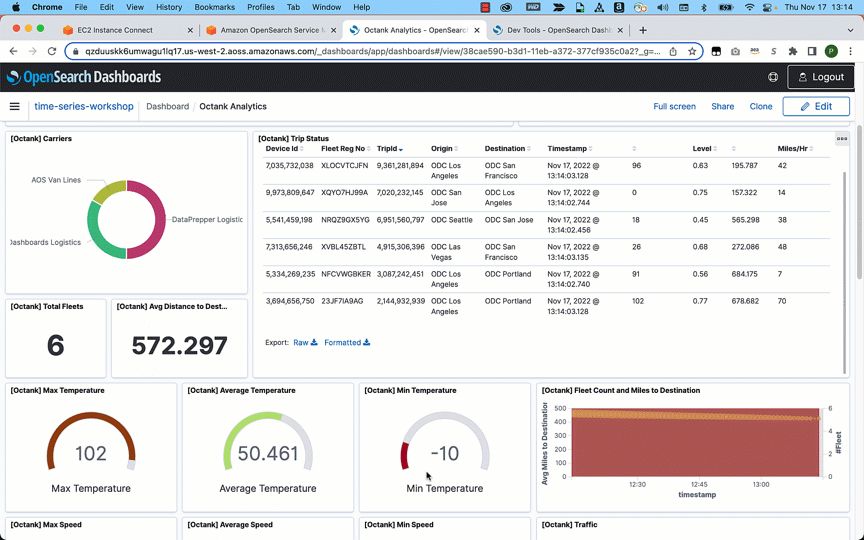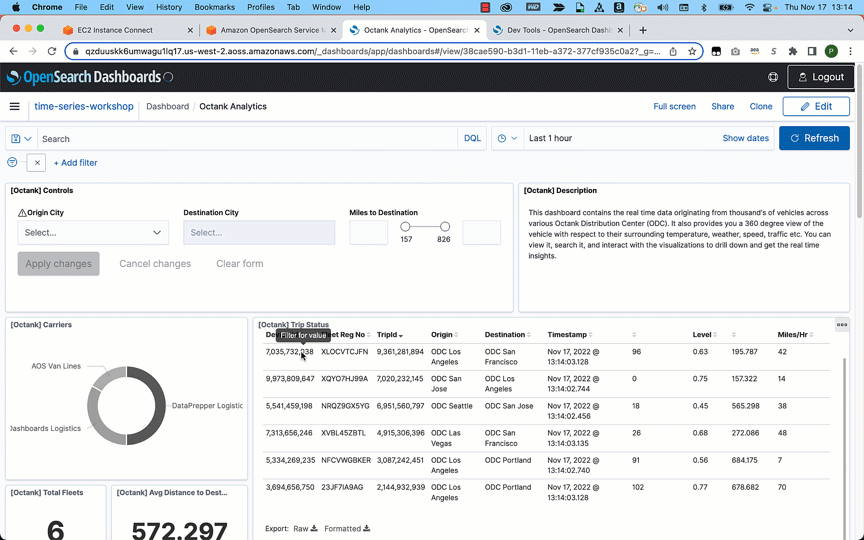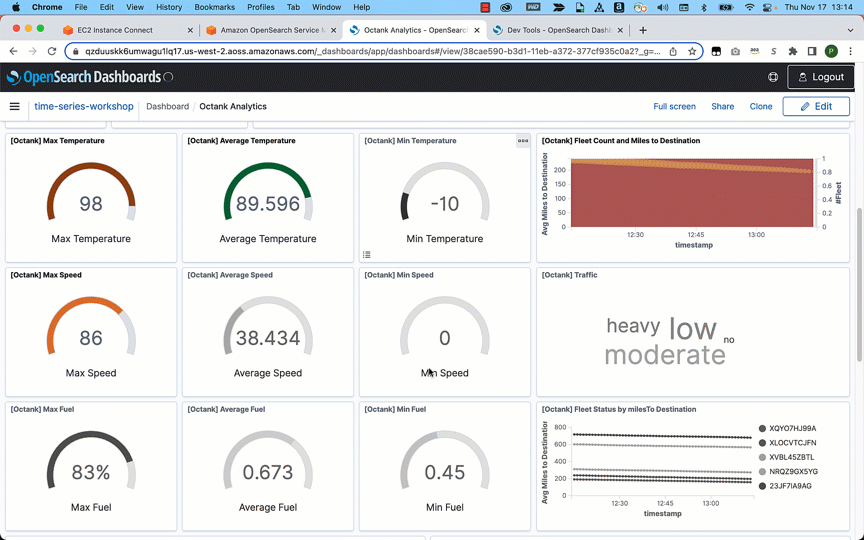









































 You use map apps every day to find your favorite restaurant or travel the fastest route using geospatial data. There are two types of geospatial data: vector data that uses two-dimensional geometries such as a building location (points), roads (lines), or land boundary (polygons), and raster data such as satellite and aerial images.
You use map apps every day to find your favorite restaurant or travel the fastest route using geospatial data. There are two types of geospatial data: vector data that uses two-dimensional geometries such as a building location (points), roads (lines), or land boundary (polygons), and raster data such as satellite and aerial images.