Post Syndicated from Jeremy Ber original https://aws.amazon.com/blogs/big-data/build-highly-available-streams-with-amazon-kinesis-data-streams/
Many use cases are moving towards a real-time data strategy due to demand for real-time insights, low-latency response times, and the ability to adapt to the changing needs of end-users. For this type of workload, you can use Amazon Kinesis Data Streams to seamlessly provision, store, write, and read data in a streaming fashion. With Kinesis Data Streams, there are no servers to manage, and you can scale your stream to handle any additional throughput as it comes in.
Kinesis Data Streams offers 99.9% availability in a single AWS Region. For even higher availability, there are several strategies to explore within the streaming layer. This post compares and contrasts different strategies for creating a highly available Kinesis data stream in case of service interruptions, delays, or outages in the primary Region of operation.
Considerations for high availability
Before we dive into our example use case, there are several considerations to keep in mind when designing a highly available Kinesis Data Streams workload that relate to the business need for a particular pipeline:
- Recovery Time Objective (RTO) is defined by the organization. RTO is the maximum acceptable delay between the interruption of service and restoration of service. This determines what is considered an acceptable time window when service is unavailable.
- Recovery Point Objective (RPO) is defined by the organization. RPO is the maximum acceptable amount of time since the last data recovery point. This determines what is considered an acceptable loss of data between the last recovery point and the interruption of service.
In a general sense, the lower your values for RPO and RTO, the more expensive the overall solution becomes. This is because the solution needs to account for minimizing both data loss and service unavailability by having multiple instances of the service up and running in multiple Regions. This is why a big piece of high availability is the replication of data flowing through a workload. In our case, the data is replicated across Regions of Kinesis Data Streams. Conversely, the higher the RPO and RTO values are, the more complexity you introduce into your failover mechanism. This is due to the fact that the cost savings you realize by not standing up multiple instances across multiple Regions are offset by the orchestration needed to spin up these instances in the event of an outage.
In this post, we are only covering failover of a Kinesis data stream. In use cases where higher availability is required across the entire data pipeline, having failover architectures for every component (Amazon API Gateway, AWS Lambda, Amazon DynamoDB) is strongly encouraged.
The simplest approach to high availability is to start a new instance of producers, consumers, and data streams in a new Region upon service unavailability detection. The benefit here is primarily cost, but your RPO and RTO values will be higher as a result.
We cover the following strategies for highly available Kinesis Data Streams:
- Warm standy – An architecture in which there is active replication of data from the Kinesis data stream in Region A to Region B. Consumers of the data stream are running in both Regions at all times. Recommended for use cases that can’t withstand extended downtime past their replication lag.
- Cold standby – Active replication of data from the data stream in Region A to Region B, but consumers of the data stream in Region B are spun up when an outage in Region A is detected. Recommended for use cases that can afford some downtime as infrastructure is spun up in secondary Region. In this scenario, RPO will be similar to the warm standby strategy; however, RTO will increase.
For high availability purposes, these use cases need to replicate the data across Regions in a way that allows consumers and producers of the data stream to fail over quickly upon detection of a service unavailability and utilize the secondary Region’s stream. Let’s take an example architecture to further explain these DR strategies. We use API Gateway and Lambda to publish stock ticker information to a Kinesis data stream. The data is then retrieved by another Lambda consumer to save durably into DynamoDB for querying, alerting, and reporting. The following diagram illustrates this architecture.

We use this architecture with an example use case requiring the streaming workload to be highly available in the event of a Region outage. The customer can withstand an RTO of 15 minutes during an outage, because they refresh end-users’ dashboards on a 15-minute interval. The customer is sensitive to downtime and data loss, because their data will be used for historical auditing purposes, operational metrics, and dashboards for end-users. Downtime for this customer means that data isn’t able to be persisted in their database from their streaming layer, and therefore unavailable to any consuming application. For this use case, data can be retried up to 5 minutes from our Lambda function before failing over to the new Region. Consumers are considered unavailable when the stream is unavailable, and can scale up in the secondary Region to account for any backlog of events.
How might we approach making a Kinesis data stream highly available for this use case?
Warm standby pattern
The following architecture diagram illustrates the warm standby high availability pattern for Kinesis Data Streams.

The warm standby architectural pattern involves running a Kinesis data stream both in the primary and secondary Region, along with consumers and downstream destinations of the primary Region’s streaming layer being replicated as well. Sources are configured to automatically fail over to the secondary Region in the case of service unavailability in the first Region. We dive into details of how to achieve this in the client failover section of this post. Data is replicated across Regions from the data stream in the primary Region to the secondary Region. This is done instead of having the sources publish to both Regions to avoid any consistency issues between the streams in the two Regions.
Although this architectural pattern gives very high availability, it’s also the most expensive option because we’re duplicating virtually the entire streaming layer across two Regions. For business use cases that can’t withstand extended data loss or withstand downtime, this may be the best option for them. From an RTO perspective, this architectural pattern ensures there will be no downtime. There is some nuance in the RPO metric in that it depends heavily on the replication lag. In the event of the primary stream becoming unavailable, whatever data hasn’t yet been replicated may be unavailable in the secondary Region. This data won’t be considered lost, but may be unavailable for consumption until the primary stream becomes available again. This method also can result in events being out of order.
For business needs that can’t tolerate this level of record unavailability, consider retaining data on the producer for the purposes of publishing to an available stream when available, or rewinding against the source for the producer if possible so that data stuck in the primary Region can be resent to the secondary stream upon failover. We cover this consideration in the client failover section of this post.
Cold standby pattern
The following architecture diagram illustrates the cold standby high availability pattern for Kinesis Data Streams.
The cold standby architectural pattern involves running a data stream both in the primary and secondary Region, and spinning up the downstream resources like a stream consumer and destination for streams when a service interruption is detected—passive mode. Just like the warm standby pattern, sources are configured to automatically fail over to the secondary Region in the case of service unavailability in the first Region. Likewise, data is replicated across Regions from the data stream in the primary Region to the secondary Region.
The primary benefit this architectural pattern provides is cost efficiency. By not running consumers at all times, this effectively reduces your costs significantly compared to the warm standby pattern. However, this pattern may introduce some data unavailability for downstream systems while the secondary Region infrastructure is provisioned. Additionally, depending on replication lag, some records may be unavailable, as discussed in the warm standby pattern. It should be noted that depending on how long it takes to spin up resources, it may take some time for consumers to reprocess the data in the secondary Region, and latency can be introduced when failing over. Our implementation assumes a minimal replication lag and that downstream systems have the ability to reprocess a configurable amount of data to catch up to the tip of the stream. We discuss approaches to spinning these resources up in the client failover section, but one possible approach to this would be using an AWS CloudFormation template that spins these resources up on service unavailability detection.
For business needs that can tolerate some level of data unavailability and can accept interruptions while the new infrastructure in the secondary Region is spun up, this is an option to consider both from a cost perspective and an RPO/RTO perspective. The complexity of spinning up resources upon detecting service unavailability is offset by the lower cost of the overall solution.
Which pattern makes sense for our use case?
Let’s revisit the use case described earlier to identify which of the strategies best meets our needs. We can extract the pieces of information from the customer’s problem statement to identify that they need a high availability architecture that:
- Can’t withstand extended amounts of data loss
- Must resume operations within 15 minutes of service interruption identification
This criterion tells us that their RPO is close to zero, and their RTO is 15 minutes. From here, we can determine that the cold standby architecture with data replication provides us limited data loss, and the maximum downtime will be determined by the time it takes to provision consumers and downstream destinations in the secondary Region.
Let’s dive deeper into the implementation details of each of the core phases of high availability, including an implementation guide for our use case.
Launch AWS CloudFormation resources
If you want to follow along with our code samples, you can launch the following CloudFormation stack and follow the instructions in order to simulate the cold standby architecture referenced in this post.

For purposes of the Kinesis Data Streams high availability setup demo, we use us-west-2 as the primary Region and us-east-2 as the failover Region. While deploying this solution in your own account, you can choose your own primary and failover Regions.
- Deploy the supplied CloudFormation template in failover Region
us-east-2.
Make sure you specify us-east-2 as the value for the FailoverRegion parameter in the CloudFormation template.
- Deploy the supplied CloudFormation template in primary Region
us-west-2.
Make sure you specify us-east-2 as the value for the FailoverRegion parameter in the CloudFormation template.
In steps 1 and 2, we deployed the following resources in the primary and failover Regions:
- KDS-HA-Stream – AWS::Kinesis::Stream (primary and failover Region)
- KDS-HA-ProducerLambda – AWS::Lambda::Function (primary Region)
- KDS-HA-ConsumerLambda – AWS::Lambda::Function (primary and failover Region)
- KDS-HA-ReplicationAgentLambda – AWS::Lambda::Function (primary Region)
- KDS-HA-FailoverLambda – AWS::Lambda::Function (primary Region)
- ticker-prices – AWS::DynamoDB::GlobalTable (primary and failover Region)
The KDS-HA-Stream Kinesis data stream is deployed in both Regions. An enhanced fan-out consumer of the KDS-HA-Stream stream KDS-HA-ReplicationAgentLambda in the primary Region is responsible for replicating messages to the data stream in the failover Region.
KDS-HA-ConsumerLambda is a Lambda function consuming messages out of the KDS-HA-Stream stream and persisting data into a DynamoDB table after preprocessing.
You can inspect the content of the ticker-prices DynamoDB table in the primary and failover Region. Note that last_updated_region attribute shows us-west-2 as its value because it’s the primary Region.
Replication
When deciding how to replicate data from a data stream in Region A to a data stream in Region B, there are several strategies that involve a consumer reading data off of the primary stream and sending that data cross-Region to the secondary data stream. This would act as a replicator service, responsible for copying the data between the two streams, maintaining a relatively low latency to replicate and ensuring data isn’t lost during this replication.
Because replication off of a shared throughput data stream could impact the flow of data in a production workload, we recommend using the enhanced fan-out feature of Kinesis Data Streams consumers to ensure replication doesn’t have an impact on consumption latency.
The replication strategy implemented in this post features asynchronous replication, meaning that the replication process doesn’t block any standard data flow in the primary stream. Synchronous replication would be a safer approach to guarantee replication and avoid data loss; however, this isn’t possible without a service-side implementation.
The following image shows a timeline of data flow for the cold standby architecture, with data being replicated as soon as it’s published.

Lambda replication
Lambda can treat a Kinesis data stream as an event source, which will funnel events from your data stream into a Lambda function. This Lambda function then receives and forwards these events across Regions to your data stream in a secondary Region. Lambda functions allow you to utilize best streaming practices such as retries of records that encounter errors, bisect on error functionality, and using the Lambda parallelization factor; using more instances of your Lambda function than you have available shards can help process records faster.
This Lambda function is at the crux of the architecture for high availability; it’s responsible solely for sending data across Regions, and it also has the best capability to monitor the replication progress. Important metrics to monitor for Lambda replication include IteratorAge, which indicates how old the last record in the batch was when it finished processing. A high IteratorAge value indicates that the Lambda function is falling behind and therefore is not keeping up with data ingestion for replication purposes. A high IteratorAge can lead to a higher RPO and the higher likelihood of data unavailability when a passive failover happens.
We use the following sample Lambda function in our CloudFormation template to replicate data across Regions:
import json
import boto3
import random
import os
import base64
def lambda_handler(event, context):
client = boto3.client("kinesis", region_name=os.environ["FAILOVER_REGION"])
records = []
for record in event["Records"]:
records.append(
{
"PartitionKey": record["kinesis"]["partitionKey"],
"Data": base64.b64decode(record["kinesis"]["data"]).decode("utf-8"),
}
)
response = client.put_records(Records=records, StreamName="KDS-HA-Stream")
if response["FailedRecordCount"] > 0:
print("Failed replicating data: " + json.dumps(response))
raise Exception("Failed replicating data!")
The Lambda replicator in the CloudFormation template is configured to read from the data stream in the primary Region.
The following code contains the necessary AWS Identity and Access Management (IAM) permissions for Lambda, giving access for the Lambda function to assume this role. All actions are permitted on data streams and DynamoDB. In the principal of least privilege, it’s recommended to restrict this to the necessary streams in a production environment.
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- 'sts:AssumeRole'
Path: /
Policies:
- PolicyName: root
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- 'kinesis:DescribeStream'
- 'kinesis:DescribeStreamSummary'
- 'kinesis:GetRecords'
- 'kinesis:GetShardIterator'
- 'kinesis:ListShards'
- 'kinesis:ListStreams'
- 'kinesis:SubscribeToShard'
- 'kinesis:PutRecords'
Resource:
- 'arn:aws:kinesis:*:*:stream/KDS-HA-Stream'
- 'arn:aws:kinesis:*:*:stream/KDS-HA-Stream/consumer/KDS-HA-Stream-EFO-Consumer:*'
ManagedPolicyArns:
- 'arn:aws:iam::aws:policy/CloudWatchLogsFullAccess'
Health check
A generalized strategy for determining when to consider our data stream unavailable involves the use of Amazon CloudWatch metrics. We use the metrics coming off of our Lambda producer and consumer in order to assess the availability of our data stream. While producing to a data stream, an error might appear as one of the following responses back from the data stream: PutRecord or PutRecords returns an AmazonKinesisException 500 or AmazonKinesisException 503 error. When consuming from a data stream, an error might appear as one of the following responses back from the data stream: SubscribeToShard.Success or GetRecords returns an AmazonKinesisException 500 or AmazonKinesisException 503.
We can calculate our effective error rate based on PutRecord.Success and GetRecord.Success. An average error rate of 1% or higher over a time window of 5 minutes, for example, could indicate that there is an issue with the data stream, and we may want to fail over. In our CloudFormation template, this error rate threshold as well as time window are configurable, but by default we check for an error rate of 1% in the last 5 minutes to trigger a failover of our clients.
Client failover
When a data stream is deemed to be unreachable, we must now take action to keep our system available and reachable for clients on both ends of the interaction. This means for producers following the cold standby high availability architecture, we change the destination stream where the producer was writing. If high availability and failover of data producers and consumers isn’t a requirement of a given use case, a different architecture would be a better fit.
Prior to failover, the producer may have been delivering data to a stream in Region A, but we now automatically update the destination to be the stream in Region B. For different clients, the methodology of updating the producer will be different, but for ours, we store the active destination for producers in the Lambda environment variables from AWS CloudFormation and update our Lambda functions dynamically on health check failure scenarios.
For our use case, we use the maximum consumer lag time (iteratorAge) plus some buffer to influence the starting position of the failover consumer. This allows us to ensure that the consumer in the secondary Region doesn’t skip records that haven’t been processed in the originating Region, but some data overlap may occur. Note that some duplicates in the downstream system may be introduced, and having an idempotent sink or some method of handling duplicates must be implemented in order to avoid duplicate-related isssues.
In the case where data is successfully written to a data stream but is unable to be consumed from the stream, the data will not be replicated and therefore be unavailable in the second Region. The data will be durably stored in the primary data stream until it comes back online and can be read from. Note that if the stream is unavailable for a longer period of time than your total data retention period on the data stream, this data will be lost. Data retention for Kinesis Data Streams can be retrospectively increased up to 1 year.
For consumers in a cold standby architecture, upon failure detection, the consumer will be disabled or shut down, and the same consumer instance will be spun up in the secondary Region to consume from the secondary data stream. On the consumer side, we assume that the consumer application is stateless in our provided solution. If your application requires state, you can migrate or preload the application state via Amazon Simple Storage Service (Amazon S3) or a database. For a stateless application, the most important aspect of failover is the starting position.
In the following timeline, we can see that at some point, the stream in Region A was deemed unreachable.


The consumer application in Region A was reading data at time t10, and when it fails over to the secondary Region (B), it reads starting at t5 (5 minutes before the current iteratorAgeMilliseconds). This ensures that data isn’t skipped by the consumer application. Keep in mind that there may be some overlap in records in the downstream destinations.
In the provided cold standby AWS CloudFormation example, we can manually trigger a failover with the AWS Command Line Interface (AWS CLI). In the following code, we manually fail over to us-east-2:
aws lambda invoke --function-name KDS-HA-FailoverLambda --cli-binary-format raw-in-base64-out --payload '{}' response.json --region us-west-2
After a few minutes, you can inspect the content of the ticker-prices DynamoDB table in the primary and failover Region. Note that the last_updated_region attribute shows us-east-2 as its value because it’s failed over to the us-east-2 Region.
Failback
After an outage or service unavailability is deemed to be resolved, the next logical step is to reorient your clients back to their original operating Regions. Although it may be tempting to automate this procedure, a manual failback approach during off-business hours when minimal production disruption will take place makes more sense.
In the following images, we can visualize the timeline with which consumer applications are failed back to the original Region.


The producer switches back to the original Region, and we wait for the consumer in Region B to reach 0 lag. At this point, the consumer application in Region B is disabled, and replication to Region B is resumed. We have now returned to our normal state of processing messages as shown in the replication section of this post.
In our AWS CloudFormation setup, we perform a failback with the following steps:
- Re-enable the event source mapping and start consuming messages from the primary Region at the latest position:
aws lambda create-event-source-mapping --function-name KDS-HA-ConsumerLambda --batch-size 100 --event-source-arn arn:aws:kinesis:us-west-2:{{accountId}}:stream/KDS-HA-Stream --starting-position LATEST --region us-west-2
- Switch the producer back to the primary Region:
aws lambda update-function-configuration --function-name KDS-HA-ProducerLambda --environment "Variables={INPUT_STREAM=KDS-HA-Stream,PRODUCING_TO_REGION=us-west-2}" --region us-west-2
- In the failover Region (
us-east-2), wait for your data stream’s GetRecords max iterator age (in milliseconds) CloudWatch metric to report 0 as a value. We’re waiting for the consumer Lambda function to catch up with all produced messages.
- Stop consuming messages from the failover Region.
- Run the following AWS CLI command and grab the UUID from the response, which we use to delete the existing event source mapping. Make sure you’re picking event source mapping for the Lambda function
KDS-HA-ConsumerLambda.
aws lambda list-event-source-mappings --region us-east-2
aws lambda delete-event-source-mapping --uuid {{UUID}} --region us-east-2
- Restart the replication agent in the primary Region.
- Run following AWS CLI command, and capture ConsumerARN from the response:
aws kinesis list-stream-consumers --stream-arn arn:aws:kinesis:us-west-2:{{accountId}}:stream/KDS-HA-Stream --region us-west-2
aws lambda create-event-source-mapping --function-name KDS-HA-ReplicationAgentLambda --batch-size 100 --event-source-arn {{ConsumerARN}} --starting-position LATEST --region us-west-2
When this is complete, you can observe the same data stream metrics—the number of records in and out per second, consumer lag metrics, and number of errors as described in the health check section of this post—to ensure that each of the components has resumed processing data in the original Region. We can also take note of the data landing in DynamoDB, which displays which Region data is being updated from in order to determine the success of our failback procedure.
We recommend for any streaming workload that can’t withstand extended data loss or downtime to implement some form of cross-Region high availability in the unlikely event of service unavailability. These recommendations can help you determine which pattern is right for your use case.
Clean up
To avoid incurring future charges, complete the following steps:
- Delete the CloudFormation stack from primary Region
us-west-2.
- Delete the CloudFormation stack from failover Region
us-east-2.
- List all event source mappings in primary Region
us-west-2 using the aws lambda list-event-source-mappings --region us-west-2 command and note the UUIDs of the event source mappings tied to the KDS-HA-ConsumerLambda and KDS-HA-ReplicationAgentLambda Lambda functions.
- Delete event source mappings in primary Region us-west-2 tied to the KDS-HA-ConsumerLambda and KDS-HA-ReplicationAgentLambda Lambda functions using the
aws lambda delete-event-source-mapping --uuid {{UUID}} --region us-west-2 command and UUIDs noted in the previous step.
Conclusion
Building highly available Kinesis data streams across multiple Regions is multi-faceted, and all aspects of your RPO, RTO, and operational costs need to be carefully considered. The code and architecture discussed in this post is one of many different architectural patterns you can choose for your workloads, so make sure to choose the appropriate architecture based on the criteria for your specific requirements.
To learn more about Kinesis Data Streams, we have a getting started guide as well as a workshop to walk through all the integrations with Kinesis Data Streams. You can also contact your AWS Solutions Architects, who can be of assistance alongside your high availability journey.
About the Authors
 Jeremy Ber has been working in the telemetry data space for the past 7 years as a Software Engineer, Machine Learning Engineer, and most recently a Data Engineer. In the past, Jeremy has supported and built systems that stream in terabytes of data per day, and process complex machine learning algorithms in real time. At AWS, he is a Senior Streaming Specialist Solutions Architect supporting both Amazon MSK and Amazon Kinesis.
Jeremy Ber has been working in the telemetry data space for the past 7 years as a Software Engineer, Machine Learning Engineer, and most recently a Data Engineer. In the past, Jeremy has supported and built systems that stream in terabytes of data per day, and process complex machine learning algorithms in real time. At AWS, he is a Senior Streaming Specialist Solutions Architect supporting both Amazon MSK and Amazon Kinesis.
Pratik Patel is a Sr Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices, and proactively helps keep customer’s AWS environments operationally healthy.

 Avinash Kolluri is a Senior Solutions Architect at AWS. He works across Amazon Alexa and Devices to architect and design modern distributed solutions. His passion is to build cost-effective and highly scalable solutions on AWS. In his spare time, he enjoys cooking fusion recipes and traveling.
Avinash Kolluri is a Senior Solutions Architect at AWS. He works across Amazon Alexa and Devices to architect and design modern distributed solutions. His passion is to build cost-effective and highly scalable solutions on AWS. In his spare time, he enjoys cooking fusion recipes and traveling. Vipul Verma is a Sr.Software Engineer at Amazon.com. He has been with Amazon since 2015,solving real-world challenges through technology that directly impact and improve the life of Amazon customers. In his spare time, he enjoys hiking.
Vipul Verma is a Sr.Software Engineer at Amazon.com. He has been with Amazon since 2015,solving real-world challenges through technology that directly impact and improve the life of Amazon customers. In his spare time, he enjoys hiking.
 Al MS is a product manager for Amazon EMR at Amazon Web Services.
Al MS is a product manager for Amazon EMR at Amazon Web Services.
 Yuzhou Sun is a software development engineer for EMR at Amazon Web Services.
Yuzhou Sun is a software development engineer for EMR at Amazon Web Services. Steve Koonce is an Engineering Manager for EMR at Amazon Web Services.
Steve Koonce is an Engineering Manager for EMR at Amazon Web Services.
 Jason Berkowitz is a Senior Product Manager with AWS Lake Formation. He comes from a background in machine learning and data lake architectures. He helps customers become data-driven.
Jason Berkowitz is a Senior Product Manager with AWS Lake Formation. He comes from a background in machine learning and data lake architectures. He helps customers become data-driven. Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She enjoys building data lake solutions for AWS customers and partners. When not on the keyboard, she explores the latest science and technology trends and spends time with her family.
Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She enjoys building data lake solutions for AWS customers and partners. When not on the keyboard, she explores the latest science and technology trends and spends time with her family.








 Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product.
Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product.
 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat. Jon Handler (@_searchgeek) is a Sr. Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with the CloudSearch and Elasticsearch teams, providing help and guidance to a broad range of customers who have search workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine.
Jon Handler (@_searchgeek) is a Sr. Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with the CloudSearch and Elasticsearch teams, providing help and guidance to a broad range of customers who have search workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine.






 Usama Naseem is a Senior Product Manager for Amazon MSK and focuses on MSK Serverless. Previously, he held product management roles for AWS Lambda and Amazon Fresh. He is passionate about giving customers the tools to build real-time applications in the cloud. Outside of work, he continues to be under the delusion that he will be the best squash player in the world one day.
Usama Naseem is a Senior Product Manager for Amazon MSK and focuses on MSK Serverless. Previously, he held product management roles for AWS Lambda and Amazon Fresh. He is passionate about giving customers the tools to build real-time applications in the cloud. Outside of work, he continues to be under the delusion that he will be the best squash player in the world one day.


 Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects, especially those focused on underprivileged Children’s education.
Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects, especially those focused on underprivileged Children’s education. Prabu Ravichandran is a Senior Data Architect with Amazon Web Services, focussed on Analytics, data Lake architecture and implementation. He helps customers architect and build scalable and robust solutions using AWS services. In his free time, Prabu enjoys traveling and spending time with family.
Prabu Ravichandran is a Senior Data Architect with Amazon Web Services, focussed on Analytics, data Lake architecture and implementation. He helps customers architect and build scalable and robust solutions using AWS services. In his free time, Prabu enjoys traveling and spending time with family.

























 Mehmet Demir is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada. He helps customers in building well-architected solutions that support business innovation.
Mehmet Demir is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada. He helps customers in building well-architected solutions that support business innovation. Ankur Taunk is a Senior Specialist Solutions Architect at AWS. He helps customer achieve their desired business outcomes in the Contact Center space leveraging Amazon Connect.
Ankur Taunk is a Senior Specialist Solutions Architect at AWS. He helps customer achieve their desired business outcomes in the Contact Center space leveraging Amazon Connect.












 Akira Ajisaka is a Senior Software Development Engineer on the AWS Glue team. He likes open-source software and distributed systems. In his spare time, he enjoys playing both arcade and console games.
Akira Ajisaka is a Senior Software Development Engineer on the AWS Glue team. He likes open-source software and distributed systems. In his spare time, he enjoys playing both arcade and console games. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike. Savio Dsouza is a Software Development Manager on the AWS Glue team. His teams work on building and innovating in distributed compute systems and frameworks, namely on Apache Spark.
Savio Dsouza is a Software Development Manager on the AWS Glue team. His teams work on building and innovating in distributed compute systems and frameworks, namely on Apache Spark.


 Igal Mizrahi is a Senior Software Engineer for AWS QuickSight Charting team. He has been part of the team for the past 3 years, and previously worked on Amazon’s mobile shopping application for 4 years.
Igal Mizrahi is a Senior Software Engineer for AWS QuickSight Charting team. He has been part of the team for the past 3 years, and previously worked on Amazon’s mobile shopping application for 4 years.

 Pavani Baddepudi is a senior product manager working in search services at AWS. Her interests include distributed systems, networking, and security.
Pavani Baddepudi is a senior product manager working in search services at AWS. Her interests include distributed systems, networking, and security.


 Vivek Shrivastava is a Principal Data Architect, Data Lake in AWS Professional Services. He is a Bigdata enthusiast and holds 13 AWS Certifications. He is passionate about helping customers build scalable and high-performance data analytics solutions in the cloud. In his spare time, he loves reading and finds areas for home automation
Vivek Shrivastava is a Principal Data Architect, Data Lake in AWS Professional Services. He is a Bigdata enthusiast and holds 13 AWS Certifications. He is passionate about helping customers build scalable and high-performance data analytics solutions in the cloud. In his spare time, he loves reading and finds areas for home automation



 Manan Goel is a Product Go-To-Market Leader for AWS Analytics Services including Amazon Redshift at AWS. He has more than 25 years of experience and is well versed with databases, data warehousing, business intelligence, and analytics. Manan holds a MBA from Duke University and a BS in Electronics & Communications engineering.
Manan Goel is a Product Go-To-Market Leader for AWS Analytics Services including Amazon Redshift at AWS. He has more than 25 years of experience and is well versed with databases, data warehousing, business intelligence, and analytics. Manan holds a MBA from Duke University and a BS in Electronics & Communications engineering.

























 Babu Srinivasan is a Senior Partner Solutions Architect at MongoDB. In his current role, he is working with AWS to build the technical integrations and reference architectures for the AWS and MongoDB solutions. He has more than two decades of experience in Database and Cloud technologies . He is passionate about providing technical solutions to customers working with multiple Global System Integrators(GSIs) across multiple geographies.
Babu Srinivasan is a Senior Partner Solutions Architect at MongoDB. In his current role, he is working with AWS to build the technical integrations and reference architectures for the AWS and MongoDB solutions. He has more than two decades of experience in Database and Cloud technologies . He is passionate about providing technical solutions to customers working with multiple Global System Integrators(GSIs) across multiple geographies. Robert Walters is currently a Senior Product Manager at MongoDB. Previous to MongoDB, Rob spent 17 years at Microsoft working in various roles, including program management on the SQL Server team, consulting, and technical pre-sales. Rob has co-authored three patents for technologies used within SQL Server and was the lead author of several technical books on SQL Server. Rob is currently an active blogger on MongoDB Blogs.
Robert Walters is currently a Senior Product Manager at MongoDB. Previous to MongoDB, Rob spent 17 years at Microsoft working in various roles, including program management on the SQL Server team, consulting, and technical pre-sales. Rob has co-authored three patents for technologies used within SQL Server and was the lead author of several technical books on SQL Server. Rob is currently an active blogger on MongoDB Blogs.














 Jeremy Ber has been working in the telemetry data space for the past 7 years as a Software Engineer, Machine Learning Engineer, and most recently a Data Engineer. In the past, Jeremy has supported and built systems that stream in terabytes of data per day, and process complex machine learning algorithms in real time. At AWS, he is a Senior Streaming Specialist Solutions Architect supporting both Amazon MSK and Amazon Kinesis.
Jeremy Ber has been working in the telemetry data space for the past 7 years as a Software Engineer, Machine Learning Engineer, and most recently a Data Engineer. In the past, Jeremy has supported and built systems that stream in terabytes of data per day, and process complex machine learning algorithms in real time. At AWS, he is a Senior Streaming Specialist Solutions Architect supporting both Amazon MSK and Amazon Kinesis. Pratik Patel is a Sr Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices, and proactively helps keep customer’s AWS environments operationally healthy.
Pratik Patel is a Sr Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices, and proactively helps keep customer’s AWS environments operationally healthy.











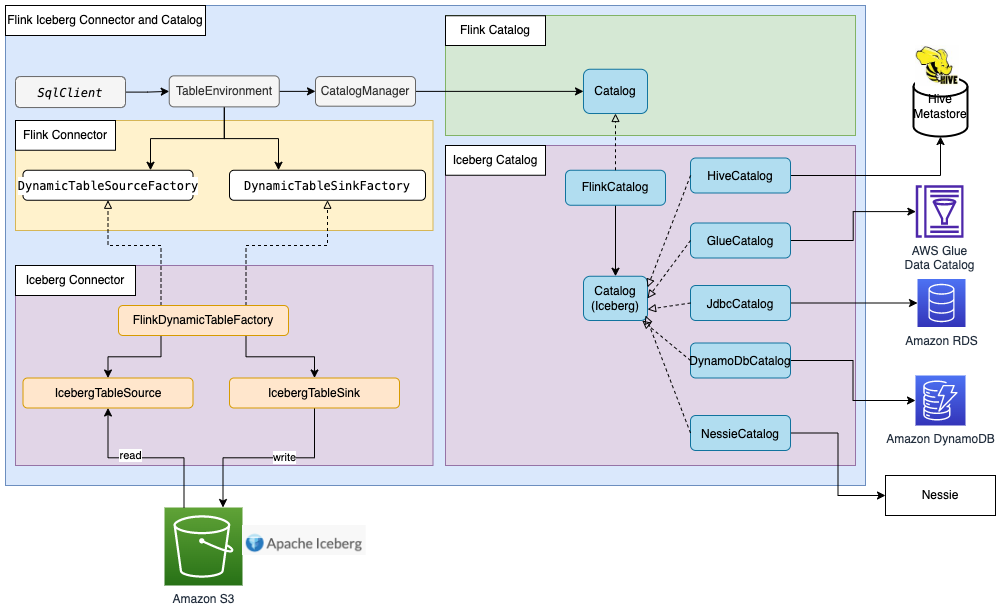
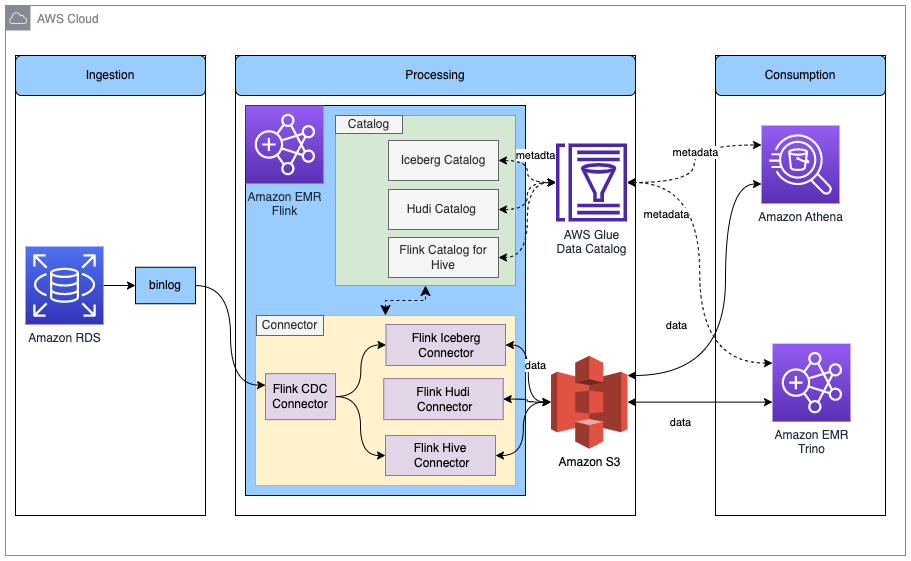
 Rajarshi Sarkar is a Software Development Engineer at Amazon EMR. He works on cutting-edge features of Amazon EMR and is also involved in open-source projects such as Apache Iceberg and Trino. In his spare time, he likes to travel, watch movies and hang out with friends.
Rajarshi Sarkar is a Software Development Engineer at Amazon EMR. He works on cutting-edge features of Amazon EMR and is also involved in open-source projects such as Apache Iceberg and Trino. In his spare time, he likes to travel, watch movies and hang out with friends.