Post Syndicated from Rivlin Pereira original https://aws.amazon.com/blogs/big-data/how-vmware-tanzu-cloudhealth-migrated-from-self-managed-kafka-to-amazon-msk/
This is a post co-written with Rivlin Pereira & Vaibhav Pandey from Tanzu CloudHealth (VMware by Broadcom).
VMware Tanzu CloudHealth is the cloud cost management platform of choice for more than 20,000 organizations worldwide, who rely on it to optimize and govern their largest and most complex multi-cloud environments. In this post, we discuss how the VMware Tanzu CloudHealth DevOps team migrated their self-managed Apache Kafka workloads (running version 2.0) to Amazon Managed Streaming for Apache Kafka (Amazon MSK) running version 2.6.2. We discuss the system architectures, deployment pipelines, topic creation, observability, access control, topic migration, and all the issues we faced with the existing infrastructure, along with how and why we migrated to the new Kafka setup and some lessons learned.
Kafka cluster overview
In the fast-evolving landscape of distributed systems, VMware Tanzu CloudHealth’s next-generation microservices platform relies on Kafka as its messaging backbone. For us, Kafka’s high-performance distributed log system excels in handling massive data streams, making it indispensable for seamless communication. Serving as a distributed log system, Kafka efficiently captures and stores diverse logs, from HTTP server access logs to security event audit logs.
Kafka’s versatility shines in supporting key messaging patterns, treating messages as basic logs or structured key-value stores. Dynamic partitioning and consistent ordering ensure efficient message organization. The unwavering reliability of Kafka aligns with our commitment to data integrity.
The integration of Ruby services with Kafka is streamlined through the Karafka library, acting as a higher-level wrapper. Our other language stack services use similar wrappers. Kafka’s robust debugging features and administrative commands play a pivotal role in ensuring smooth operations and infrastructure health.
Kafka as an architectural pillar
In VMware Tanzu CloudHealth’s next-generation microservices platform, Kafka emerges as a critical architectural pillar. Its ability to handle high data rates, support diverse messaging patterns, and guarantee message delivery aligns seamlessly with our operational needs. As we continue to innovate and scale, Kafka remains a steadfast companion, enabling us to build a resilient and efficient infrastructure.
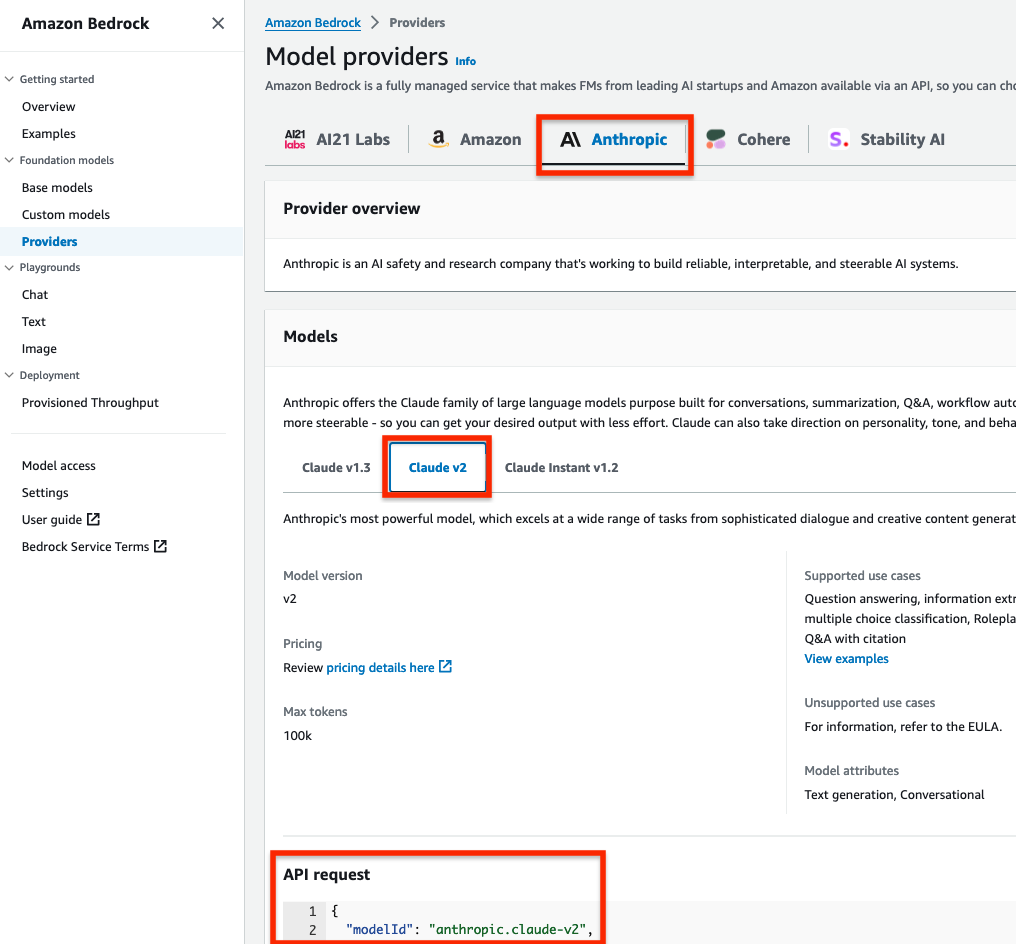
Why we migrated to Amazon MSK
For us, migrating to Amazon MSK came down to three key decision points:
- Simplified technical operations – Running Kafka on a self-managed infrastructure was an operational overhead for us. We hadn’t updated Kafka version 2.0.0 for a while, and Kafka brokers were going down in production, causing issues with topics going offline. We also had to run scripts manually for increasing replication factors and rebalancing leaders, which was additional manual effort.
- Deprecated legacy pipelines and simplified permissions – We were looking to move away from our existing pipelines written in Ansible to create Kafka topics on the cluster. We also had a cumbersome process of giving team members access to Kafka machines in staging and production, and we wanted to simplify this.
- Cost, patching, and support – Because Apache Zookeeper is completely managed and patched by AWS, moving to Amazon MSK was going to save us time and money. In addition, we discovered that running Amazon MSK with the same type of brokers on Amazon Elastic Compute Cloud (Amazon EC2) was cheaper to run on Amazon MSK. Combined with the fact that we get security patches applied on brokers by AWS, migrating to Amazon MSK was an easy decision. This also meant that the team was freed up to work on other important things. Finally, getting enterprise support from AWS was also critical in our final decision to move to a managed solution.
How we migrated to Amazon MSK
With the key drivers identified, we moved ahead with a proposed design to migrate existing self-managed Kafka to Amazon MSK. We conducted the following pre-migration steps before the actual implementation:
- Assessment:
- Conducted a meticulous assessment of the existing EC2 Kafka cluster, understanding its configurations and dependencies
- Verified Kafka version compatibility with Amazon MSK
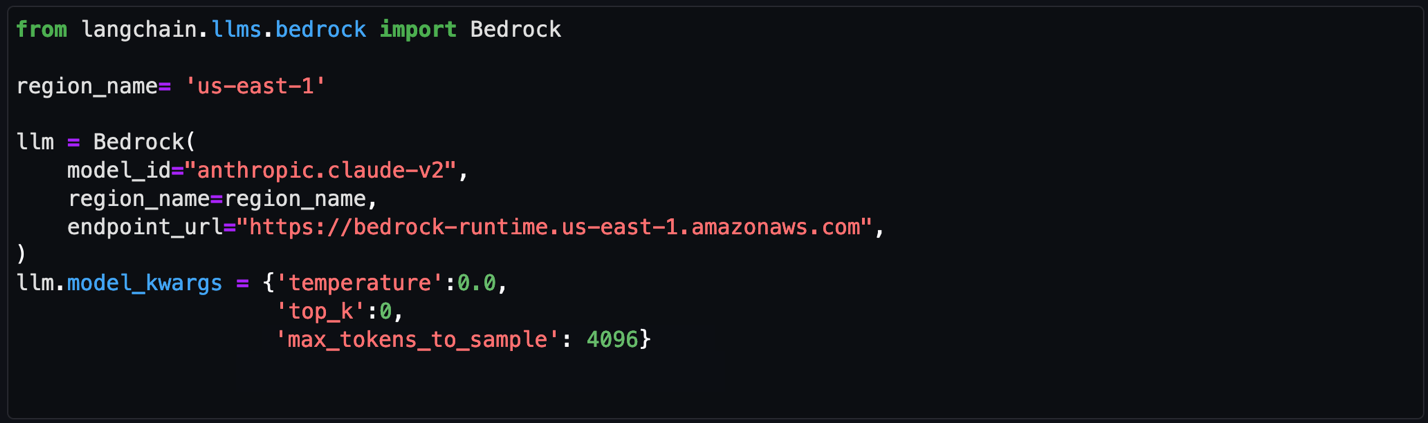
- Amazon MSK setup with Terraform
- Used Terraform to provision an MSK cluster, embracing infrastructure as code (IaC) principles for repeatability and version control
- Configured Amazon Virtual Private Cloud (Amazon VPC) security groups, AWS Identity and Access Management (IAM) roles, and VPC settings through Terraform to establish a robust foundation for Amazon MSK
- Network configuration:
- Ensured seamless network connectivity between the EC2 Kafka and MSK clusters, fine-tuning security groups and firewall settings
After the pre-migration steps, we implemented the following for the new design:
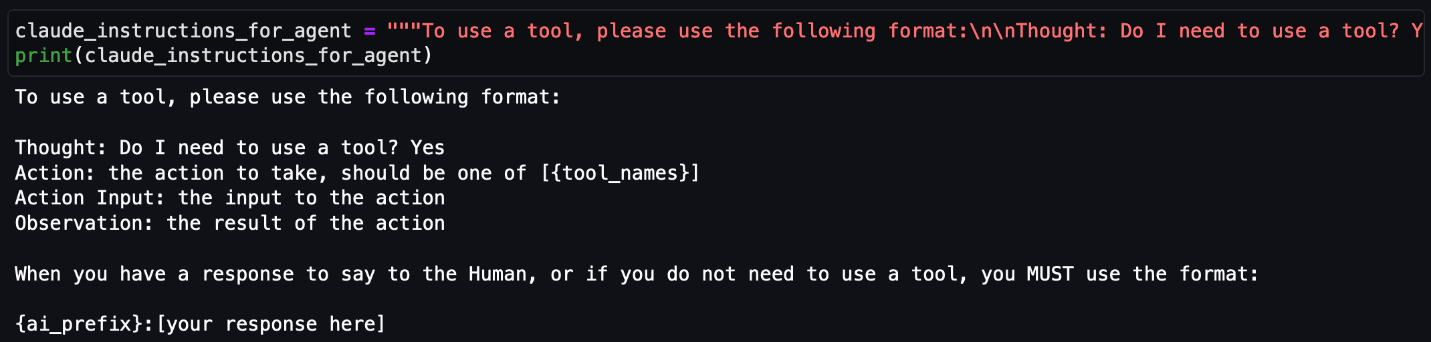
- Automated deployment, upgrade, and topic creation pipelines for MSK clusters:
- In the new setup, we wanted to have automated deployments and upgrades of the MSK clusters in a repeatable fashion using an IaC tool. Therefore, we created custom Terraform modules for MSK cluster deployments as well as upgrades. These modules where called from a Jenkins pipeline for automated deployments and upgrades of the MSK clusters. For Kafka topic creation, we were using an Ansible-based home-grown pipeline, which wasn’t stable and led to a lot of complaints from dev teams. As a result, we evaluated options for deployments to Kubernetes clusters and used the Strimzi Topic Operator to create topics on MSK clusters. Topic creation was automated using Jenkins pipelines, which dev teams could self-service.
- Better observability for clusters:
- The old Kafka clusters didn’t have good observability. We only had alerts on Kafka broker disk size. With Amazon MSK, we took advantage of open monitoring using Prometheus. We stood up a standalone Prometheus server that scraped metrics from MSK clusters and sent them to our internal observability tool. As a result of improved observability, we were able to set up robust alerting for Amazon MSK, which wasn’t possible with our old setup.
- Improved COGS and better compute infrastructure:
- For our old Kafka infrastructure, we had to pay for managing Kafka, Zookeeper instances, plus any additional broker storage costs and data transfer costs. With the move to Amazon MSK, because Zookeeper is completely managed by AWS, we only have to pay for Kafka nodes, broker storage, and data transfer costs. As a result, in final Amazon MSK setup for production, we saved not only on infrastructure costs but also operational costs.
- Simplified operations and enhanced security:
- With the move to Amazon MSK, we didn’t have to manage any Zookeeper instances. Broker security patching was also taken care by AWS for us.
- Cluster upgrades became simpler with the move to Amazon MSK; it’s a straightforward process to initiate from the Amazon MSK console.
- With Amazon MSK, we got broker automatic scaling out of the box. As a result, we didn’t have to worry about brokers running out of disk space, thereby leading to additional stability of the MSK cluster.
- We also got additional security for the cluster because Amazon MSK supports encryption at rest by default, and various options for encryption in transit are also available. For more information, refer to Data protection in Amazon Managed Streaming for Apache Kafka.
During our pre-migration steps, we validated the setup on the staging environment before moving ahead with production.
Kafka topic migration strategy
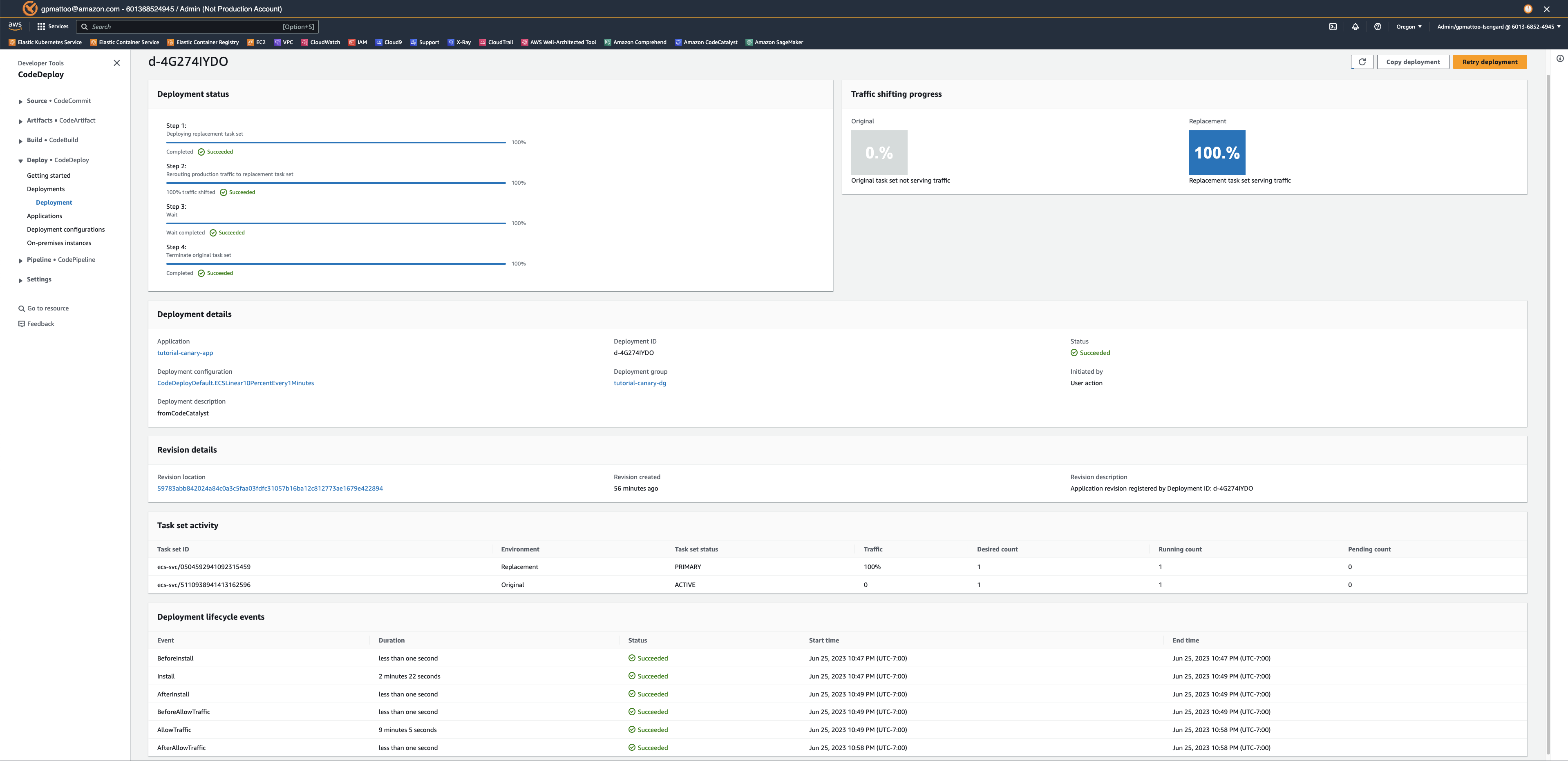
With the MSK cluster setup complete, we performed a data migration of Kafka topics from the old cluster running on Amazon EC2 to the new MSK cluster. To achieve this, we performed the following steps:
- Set up MirrorMaker with Terraform – We used Terraform to orchestrate the deployment of a MirrorMaker cluster consisting of 15 nodes. This demonstrated the scalability and flexibility by adjusting the number of nodes based on the migration’s concurrent replication needs.
- Implement a concurrent replication strategy – We implemented a concurrent replication strategy with 15 MirrorMaker nodes to expedite the migration process. Our Terraform-driven approach contributed to cost optimization by efficiently managing resources during the migration and ensured the reliability and consistency of the MSK and MirrorMaker clusters. It also showcased how the chosen setup accelerates data transfer, optimizing both time and resources.
- Migrate data – We successfully migrated 2 TB of data in a remarkably short timeframe, minimizing downtime and showcasing the efficiency of the concurrent replication strategy.
- Set up post-migration monitoring – We implemented robust monitoring and alerting during the migration, contributing to a smooth process by identifying and addressing issues promptly.
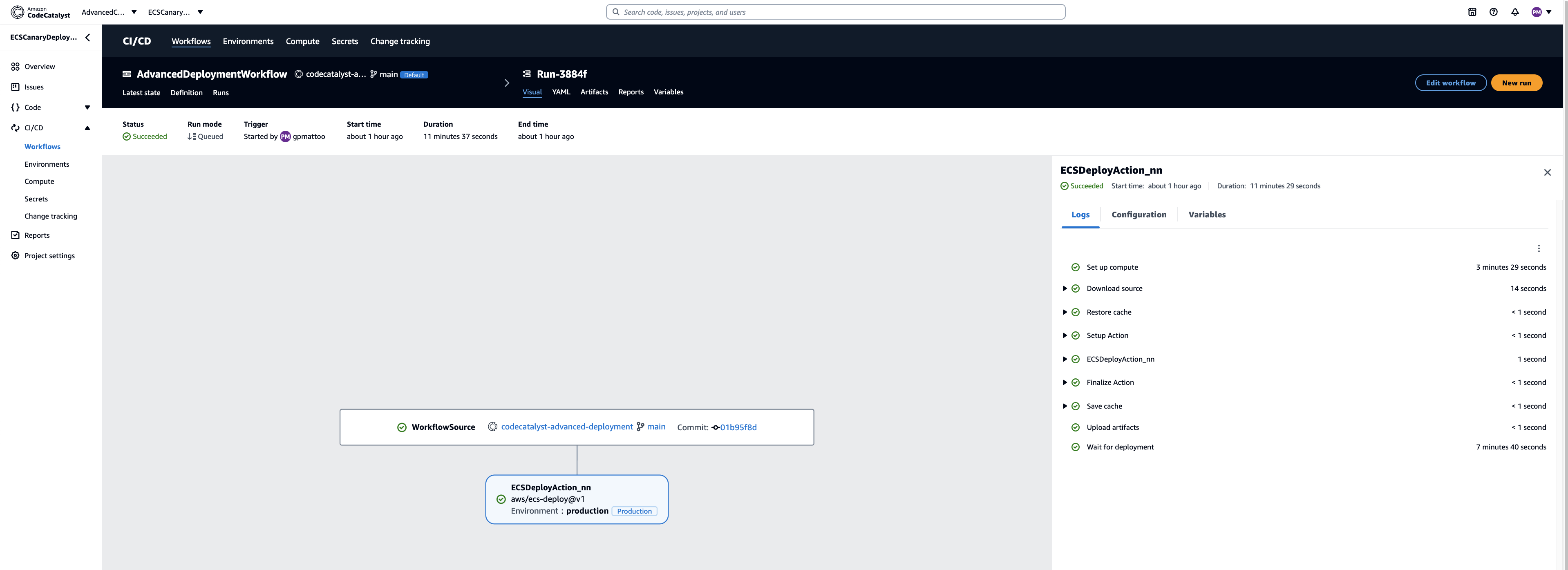
The following diagram illustrates the architecture after the topic migration was complete.

Challenges and lessons learned
Embarking on a migration journey, especially with large datasets, is often accompanied by unforeseen challenges. In this section, we delve into the challenges encountered during the migration of topics from EC2 Kafka to Amazon MSK using MirrorMaker, and share valuable insights and solutions that shaped the success of our migration.
Challenge 1: Offset discrepancies
One of the challenges we encountered was the mismatch in topic offsets between the source and destination clusters, even with offset synchronization enabled in MirrorMaker. The lesson learned here was that offset values don’t necessarily need to be identical, as long as offset sync is enabled, which makes sure the topics have the correct position to read the data from.
We addressed this problem by using a custom tool to run tests on consumer groups, confirming that the translated offsets were either smaller or caught up, indicating synchronization as per MirrorMaker.
Challenge 2: Slow data migration
The migration process faced a bottleneck—data transfer was slower than anticipated, especially with a substantial 2 TB dataset. Despite a 20-node MirrorMaker cluster, the speed was insufficient.
To overcome this, the team strategically grouped MirrorMaker nodes based on unique port numbers. Clusters of five MirrorMaker nodes, each with a distinct port, significantly boosted throughput, allowing us to migrate data within hours instead of days.
Challenge 3: Lack of detailed process documentation
Navigating the uncharted territory of migrating large datasets using MirrorMaker highlighted the absence of detailed documentation for such scenarios.
Through trial and error, the team crafted an IaC module using Terraform. This module streamlined the entire cluster creation process with optimized settings, enabling a seamless start to the migration within minutes.
Final setup and next steps
As a result of the move to Amazon MSK, our final setup after topic migration looked like the following diagram.

We’re considering the following future improvements:
- Move to AWS Graviton based nodes for Amazon MSK for faster performance and cost savings. For more details about Graviton with Amazon MSK, refer to Amazon MSK now supports Graviton3-based M7g instances for new provisioned clusters.
- Use tiered storage to save even more on COGS.
- Create dedicated clusters for certain needs, because we can now create these clusters much faster with automation.
Conclusion.
In this post, we discussed how VMware Tanzu CloudHealth migrated their existing Amazon EC2-based Kafka infrastructure to Amazon MSK. We walked you through the new architecture, deployment and topic creation pipelines, improvements to observability and access control, topic migration challenges, and the issues we faced with the existing infrastructure, along with how and why we migrated to the new Amazon MSK setup. We also talked about all the advantages that Amazon MSK gave us, the final architecture we achieved with this migration, and lessons learned.
For us, the interplay of offset synchronization, strategic node grouping, and IaC proved pivotal in overcoming obstacles and ensuring a successful migration from Amazon EC2 Kafka to Amazon MSK. This post serves as a testament to the power of adaptability and innovation in migration challenges, offering insights for others navigating a similar path.
If you’re running self-managed Kafka on AWS, we encourage you to try the managed Kafka offering, Amazon MSK.
About the Authors
 Rivlin Pereira is Staff DevOps Engineer at VMware Tanzu Division. He is very passionate about Kubernetes and works on CloudHealth Platform building and operating cloud solutions that are scalable, reliable and cost effective.
Rivlin Pereira is Staff DevOps Engineer at VMware Tanzu Division. He is very passionate about Kubernetes and works on CloudHealth Platform building and operating cloud solutions that are scalable, reliable and cost effective.
 Vaibhav Pandey, a Staff Software Engineer at Broadcom, is a key contributor to the development of cloud computing solutions. Specializing in architecting and engineering data storage layers, he is passionate about building and scaling SaaS applications for optimal performance.
Vaibhav Pandey, a Staff Software Engineer at Broadcom, is a key contributor to the development of cloud computing solutions. Specializing in architecting and engineering data storage layers, he is passionate about building and scaling SaaS applications for optimal performance.
 Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
 Todd McGrath is a data streaming specialist at Amazon Web Services where he advises customers on their streaming strategies, integration, architecture, and solutions. On the personal side, he enjoys watching and supporting his 3 teenagers in their preferred activities as well as following his own pursuits such as fishing, pickleball, ice hockey, and happy hour with friends and family on pontoon boats. Connect with him on LinkedIn.
Todd McGrath is a data streaming specialist at Amazon Web Services where he advises customers on their streaming strategies, integration, architecture, and solutions. On the personal side, he enjoys watching and supporting his 3 teenagers in their preferred activities as well as following his own pursuits such as fishing, pickleball, ice hockey, and happy hour with friends and family on pontoon boats. Connect with him on LinkedIn.
 Satya Pattanaik is a Sr. Solutions Architect at AWS. He has been helping ISVs build scalable and resilient applications on AWS Cloud. Prior joining AWS, he played significant role in Enterprise segments with their growth and success. Outside of work, he spends time learning “how to cook a flavorful BBQ” and trying out new recipes.
Satya Pattanaik is a Sr. Solutions Architect at AWS. He has been helping ISVs build scalable and resilient applications on AWS Cloud. Prior joining AWS, he played significant role in Enterprise segments with their growth and success. Outside of work, he spends time learning “how to cook a flavorful BBQ” and trying out new recipes.











 Brandon Abear is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He enjoys all things big data. In his spare time, he enjoys traveling, watching movies, and playing rhythm games.
Brandon Abear is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He enjoys all things big data. In his spare time, he enjoys traveling, watching movies, and playing rhythm games. Dinesh Sharma is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about user experience and developer productivity, always looking for ways to optimize engineering processes and saving cost. In his spare time, he loves reading and is an avid manga fan.
Dinesh Sharma is a Principal Data Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about user experience and developer productivity, always looking for ways to optimize engineering processes and saving cost. In his spare time, he loves reading and is an avid manga fan. John Bush is a Principal Software Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about making it easier for organizations to manage data and use it to drive their businesses forward. In his spare time, he loves hiking, camping, and riding his ebike.
John Bush is a Principal Software Engineer in the Data & Analytics (DnA) organization at GoDaddy. He is passionate about making it easier for organizations to manage data and use it to drive their businesses forward. In his spare time, he loves hiking, camping, and riding his ebike. Ozcan Ilikhan is the Director of Engineering for the Data and ML Platform at GoDaddy. He has over two decades of multidisciplinary leadership experience, spanning startups to global enterprises. He has a passion for leveraging data and AI in creating solutions that delight customers, empower them to achieve more, and boost operational efficiency. Outside of his professional life, he enjoys reading, hiking, gardening, volunteering, and embarking on DIY projects.
Ozcan Ilikhan is the Director of Engineering for the Data and ML Platform at GoDaddy. He has over two decades of multidisciplinary leadership experience, spanning startups to global enterprises. He has a passion for leveraging data and AI in creating solutions that delight customers, empower them to achieve more, and boost operational efficiency. Outside of his professional life, he enjoys reading, hiking, gardening, volunteering, and embarking on DIY projects. Harsh Vardhan is an AWS Solutions Architect, specializing in big data and analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Harsh Vardhan is an AWS Solutions Architect, specializing in big data and analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.



























 Satya Adimula is a Senior Data Architect at AWS based in Boston. With over two decades of experience in data and analytics, Satya helps organizations derive business insights from their data at scale.
Satya Adimula is a Senior Data Architect at AWS based in Boston. With over two decades of experience in data and analytics, Satya helps organizations derive business insights from their data at scale.



















 Amy Tseng is a Managing Director of Data and Analytics(DnA) Integration at BMO. She is one of the AWS Data Hero. She has over 7 years of experiences in Data and Analytics Cloud migrations in AWS. Outside of work, Amy loves traveling and hiking.
Amy Tseng is a Managing Director of Data and Analytics(DnA) Integration at BMO. She is one of the AWS Data Hero. She has over 7 years of experiences in Data and Analytics Cloud migrations in AWS. Outside of work, Amy loves traveling and hiking. Jack Lin is a Director of Engineering on the Data Platform at BMO. He has over 20 years of experience working in platform engineering and software engineering. Outside of work, Jack loves playing soccer, watching football games and traveling.
Jack Lin is a Director of Engineering on the Data Platform at BMO. He has over 20 years of experience working in platform engineering and software engineering. Outside of work, Jack loves playing soccer, watching football games and traveling. Regis Chow is a Director of DnA Integration at BMO. He has over 5 years of experience working in the cloud and enjoys solving problems through innovation in AWS. Outside of work, Regis loves all things outdoors, he is especially passionate about golf and lawn care.
Regis Chow is a Director of DnA Integration at BMO. He has over 5 years of experience working in the cloud and enjoys solving problems through innovation in AWS. Outside of work, Regis loves all things outdoors, he is especially passionate about golf and lawn care. Nishchai JM is an Analytics Specialist Solutions Architect at Amazon Web services. He specializes in building Big-data applications and help customer to modernize their applications on Cloud. He thinks Data is new oil and spends most of his time in deriving insights out of the Data.
Nishchai JM is an Analytics Specialist Solutions Architect at Amazon Web services. He specializes in building Big-data applications and help customer to modernize their applications on Cloud. He thinks Data is new oil and spends most of his time in deriving insights out of the Data. Harshida Patel is a Principal Solutions Architect, Analytics with AWS.
Harshida Patel is a Principal Solutions Architect, Analytics with AWS. Raghu Kuppala is an Analytics Specialist Solutions Architect experienced working in the databases, data warehousing, and analytics space. Outside of work, he enjoys trying different cuisines and spending time with his family and friends.
Raghu Kuppala is an Analytics Specialist Solutions Architect experienced working in the databases, data warehousing, and analytics space. Outside of work, he enjoys trying different cuisines and spending time with his family and friends.


 Toney Thomas is a Data Architect and Data Engineering Lead at Bluestone, renowned for his role in envisioning and coining the company’s pioneering data strategy. With a strategic focus on harnessing the power of advanced technology to tackle intricate business challenges, Toney leads a dynamic team of Data Engineers, Reporting Engineers, Quality Assurance specialists, and Business Analysts at Bluestone. His leadership extends to driving the implementation of robust data governance frameworks across diverse organizational units. Under his guidance, Bluestone has achieved remarkable success, including the deployment of innovative platforms such as a fully governed data mesh business data system with embedded data quality mechanisms, aligning seamlessly with the organization’s commitment to data democratization and excellence.
Toney Thomas is a Data Architect and Data Engineering Lead at Bluestone, renowned for his role in envisioning and coining the company’s pioneering data strategy. With a strategic focus on harnessing the power of advanced technology to tackle intricate business challenges, Toney leads a dynamic team of Data Engineers, Reporting Engineers, Quality Assurance specialists, and Business Analysts at Bluestone. His leadership extends to driving the implementation of robust data governance frameworks across diverse organizational units. Under his guidance, Bluestone has achieved remarkable success, including the deployment of innovative platforms such as a fully governed data mesh business data system with embedded data quality mechanisms, aligning seamlessly with the organization’s commitment to data democratization and excellence. Ben Vengerovsky is a Data Platform Product Manager at Bluestone. He is passionate about using cloud technology to revolutionize the company’s data infrastructure. With a background in mortgage lending and a deep understanding of AWS services, Ben specializes in designing scalable and efficient data solutions that drive business growth and enhance customer experiences. He thrives on collaborating with cross-functional teams to translate business requirements into innovative technical solutions that empower data-driven decision-making.
Ben Vengerovsky is a Data Platform Product Manager at Bluestone. He is passionate about using cloud technology to revolutionize the company’s data infrastructure. With a background in mortgage lending and a deep understanding of AWS services, Ben specializes in designing scalable and efficient data solutions that drive business growth and enhance customer experiences. He thrives on collaborating with cross-functional teams to translate business requirements into innovative technical solutions that empower data-driven decision-making. Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.
Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.
































 Swapna Bandla is a Senior Solutions Architect in the AWS Analytics Specialist SA Team. Swapna has a passion towards understanding customers data and analytics needs and empowering them to develop cloud-based well-architected solutions. Outside of work, she enjoys spending time with her family.
Swapna Bandla is a Senior Solutions Architect in the AWS Analytics Specialist SA Team. Swapna has a passion towards understanding customers data and analytics needs and empowering them to develop cloud-based well-architected solutions. Outside of work, she enjoys spending time with her family. Indira Balakrishnan is a Principal Solutions Architect in the AWS Analytics Specialist SA Team. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems using data-driven decisions. Outside of work, she volunteers at her kids’ activities and spends time with her family.
Indira Balakrishnan is a Principal Solutions Architect in the AWS Analytics Specialist SA Team. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems using data-driven decisions. Outside of work, she volunteers at her kids’ activities and spends time with her family.


 Shabi Abbas Sayed is a Senior Technical Account Manager at AWS. He is passionate about building scalable data warehouses and big data solutions working closely with the customers. He works with large ISVs customers, in helping them build and operate secure, resilient, scalable, and high-performance SaaS applications in the cloud.
Shabi Abbas Sayed is a Senior Technical Account Manager at AWS. He is passionate about building scalable data warehouses and big data solutions working closely with the customers. He works with large ISVs customers, in helping them build and operate secure, resilient, scalable, and high-performance SaaS applications in the cloud. Gaurav Singh is a Senior Solutions Architect at AWS, specializing in AI/ML and Generative AI. Based in Pune, India, he focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. In his spare time, Gaurav loves to explore nature, read, and run.
Gaurav Singh is a Senior Solutions Architect at AWS, specializing in AI/ML and Generative AI. Based in Pune, India, he focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. In his spare time, Gaurav loves to explore nature, read, and run.





 Claudia Chitu is a Data strategist and an influential leader in the Analytics space. Focused on aligning data initiatives with the overall strategic goals of the organization, she employs data as a guiding force for long-term planning and sustainable growth.
Claudia Chitu is a Data strategist and an influential leader in the Analytics space. Focused on aligning data initiatives with the overall strategic goals of the organization, she employs data as a guiding force for long-term planning and sustainable growth. Spyridon Dosis is an Information Security Professional in Acast. Spyridon supports the organization in designing, implementing and operating its services in a secure manner protecting the company and users’ data.
Spyridon Dosis is an Information Security Professional in Acast. Spyridon supports the organization in designing, implementing and operating its services in a secure manner protecting the company and users’ data. Srikant Das is an Acceleration Lab Solutions Architect at Amazon Web Services. He has over 13 years of experience in Big Data analytics and Data Engineering, where he enjoys building reliable, scalable, and efficient solutions. Outside of work, he enjoys traveling and blogging his experiences in social media.
Srikant Das is an Acceleration Lab Solutions Architect at Amazon Web Services. He has over 13 years of experience in Big Data analytics and Data Engineering, where he enjoys building reliable, scalable, and efficient solutions. Outside of work, he enjoys traveling and blogging his experiences in social media.



 repeat → Answer
repeat → Answer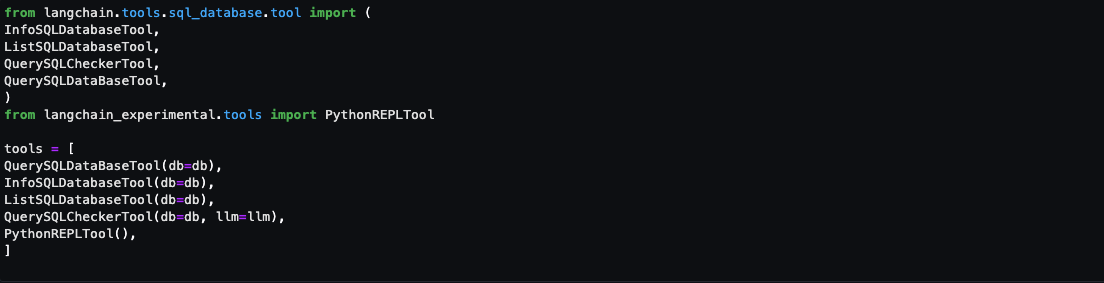







 Alex Naumov is a Principal Data Architect at smava GmbH, and leads the transformation projects at the Data department. Alex previously worked 10 years as a consultant and data/solution architect in a wide variety of domains, such as telecommunications, banking, energy, and finance, using various tech stacks, and in many different countries. He has a great passion for data and transforming organizations to become data-driven and the best in what they do.
Alex Naumov is a Principal Data Architect at smava GmbH, and leads the transformation projects at the Data department. Alex previously worked 10 years as a consultant and data/solution architect in a wide variety of domains, such as telecommunications, banking, energy, and finance, using various tech stacks, and in many different countries. He has a great passion for data and transforming organizations to become data-driven and the best in what they do. Lingli Zheng works as a Business Development Manager in the AWS worldwide specialist organization, supporting customers in the DACH region to get the best value out of Amazon analytics services. With over 12 years of experience in energy, automation, and the software industry with a focus on data analytics, AI, and ML, she is dedicated to helping customers achieve tangible business results through digital transformation.
Lingli Zheng works as a Business Development Manager in the AWS worldwide specialist organization, supporting customers in the DACH region to get the best value out of Amazon analytics services. With over 12 years of experience in energy, automation, and the software industry with a focus on data analytics, AI, and ML, she is dedicated to helping customers achieve tangible business results through digital transformation. Alexander Spivak is a Senior Startup Solutions Architect at AWS, focusing on B2B ISV customers across EMEA North. Prior to AWS, Alexander worked as a consultant in financial services engagements, including various roles in software development and architecture. He is passionate about data analytics, serverless architectures, and creating efficient organizations.
Alexander Spivak is a Senior Startup Solutions Architect at AWS, focusing on B2B ISV customers across EMEA North. Prior to AWS, Alexander worked as a consultant in financial services engagements, including various roles in software development and architecture. He is passionate about data analytics, serverless architectures, and creating efficient organizations.


 Guillaume Saint-Martin leads the Data and Analytics team at Sun King. With 10 years of experience in the data and development sectors, he manages a team of over 30 analysts, data engineers, and data scientists to support Sun King long term modeling and trend analysis.
Guillaume Saint-Martin leads the Data and Analytics team at Sun King. With 10 years of experience in the data and development sectors, he manages a team of over 30 analysts, data engineers, and data scientists to support Sun King long term modeling and trend analysis. Aaber Jah is a Senior Analytics Specialist at AWS based in Chicago, Illinois. He focuses on driving and maintaining AWS Data Analytics business value for customers.
Aaber Jah is a Senior Analytics Specialist at AWS based in Chicago, Illinois. He focuses on driving and maintaining AWS Data Analytics business value for customers. Rohit Vashishtha is a Senior Analytics Specialist Solutions Architect at AWS based in Dallas, Texas. He has over 17 years of experience architecting, building, leading, and maintaining big data platforms. Rohit helps customers modernize their analytic workloads using the breadth of AWS services and ensures that customers get the best price/performance with utmost security and data governance.
Rohit Vashishtha is a Senior Analytics Specialist Solutions Architect at AWS based in Dallas, Texas. He has over 17 years of experience architecting, building, leading, and maintaining big data platforms. Rohit helps customers modernize their analytic workloads using the breadth of AWS services and ensures that customers get the best price/performance with utmost security and data governance.



 Sivaprasad Mahamkali is a Senior Streaming Data Engineer at AWS Professional Services. Siva leads customer engagements related to real-time streaming solutions, data lakes, analytics using opensource and AWS services. Siva enjoys listening to music and loves to spend time with his family.
Sivaprasad Mahamkali is a Senior Streaming Data Engineer at AWS Professional Services. Siva leads customer engagements related to real-time streaming solutions, data lakes, analytics using opensource and AWS services. Siva enjoys listening to music and loves to spend time with his family. Dan Gibbar is a Senior Engagement Manager at AWS Professional Services. Dan leads healthcare and life science engagements collaborating with customers and partners to deliver outcomes. Dan enjoys the outdoors, attempting triathlons, music and spending time with family.
Dan Gibbar is a Senior Engagement Manager at AWS Professional Services. Dan leads healthcare and life science engagements collaborating with customers and partners to deliver outcomes. Dan enjoys the outdoors, attempting triathlons, music and spending time with family. Shrinath Parikh as a Senior Cloud Data Architect with AWS. He works with customers around the globe to assist them with their data analytics, data lake, data lake house, serverless, governance and NoSQL use cases. In Shrinath’s off time, he enjoys traveling, spending time with family and learning/building new tools using cutting edge technologies.
Shrinath Parikh as a Senior Cloud Data Architect with AWS. He works with customers around the globe to assist them with their data analytics, data lake, data lake house, serverless, governance and NoSQL use cases. In Shrinath’s off time, he enjoys traveling, spending time with family and learning/building new tools using cutting edge technologies. Ramesh Daddala is a Associate Director at BMS. Ramesh leads enterprise data engineering engagements related to enterprise data lake services (EDLs) and collaborating with Data partners to deliver and support enterprise data engineering and ML capabilities. Ramesh enjoys the outdoors, traveling and loves to spend time with family.
Ramesh Daddala is a Associate Director at BMS. Ramesh leads enterprise data engineering engagements related to enterprise data lake services (EDLs) and collaborating with Data partners to deliver and support enterprise data engineering and ML capabilities. Ramesh enjoys the outdoors, traveling and loves to spend time with family. Jitendra Kumar Dash is a Senior Cloud Architect at BMS with expertise in hybrid cloud services, Infrastructure Engineering, DevOps, Data Engineering, and Data Analytics solutions. He is passionate about food, sports, and adventure.
Jitendra Kumar Dash is a Senior Cloud Architect at BMS with expertise in hybrid cloud services, Infrastructure Engineering, DevOps, Data Engineering, and Data Analytics solutions. He is passionate about food, sports, and adventure. Pavan Kumar Bijja is a Senior Data Engineer at BMS. Pavan enables data engineering and analytical services to BMS Commercial domain using enterprise capabilities. Pavan leads enterprise metadata capabilities at BMS. Pavan loves to spend time with his family, playing Badminton and Cricket.
Pavan Kumar Bijja is a Senior Data Engineer at BMS. Pavan enables data engineering and analytical services to BMS Commercial domain using enterprise capabilities. Pavan leads enterprise metadata capabilities at BMS. Pavan loves to spend time with his family, playing Badminton and Cricket. Shovan Kanjilal is a Senior Data Lake Architect working with strategic accounts in AWS Professional Services. Shovan works with customers to design data and machine learning solutions on AWS.
Shovan Kanjilal is a Senior Data Lake Architect working with strategic accounts in AWS Professional Services. Shovan works with customers to design data and machine learning solutions on AWS.








 Umesh Chaudhari is a Streaming Solutions Architect at AWS. He works with AWS customers to design and build real time data processing systems. He has 13 years of working experience in software engineering including architecting, designing, and developing data analytics systems.
Umesh Chaudhari is a Streaming Solutions Architect at AWS. He works with AWS customers to design and build real time data processing systems. He has 13 years of working experience in software engineering including architecting, designing, and developing data analytics systems. Vishal Khatri is a Sr. Technical Account Manager and Analytics specialist at AWS. Vishal works with State and Local Government helping educate and share best practices with customers by leading and owning the development and delivery of technical content while designing end-to-end customer solutions.
Vishal Khatri is a Sr. Technical Account Manager and Analytics specialist at AWS. Vishal works with State and Local Government helping educate and share best practices with customers by leading and owning the development and delivery of technical content while designing end-to-end customer solutions.



 Sreenivasa Munagala is a Principal Data Architect at FanDuel Group. He defines their Amazon Redshift optimization strategy and works with the data analytics team to provide solutions to their key business problems.
Sreenivasa Munagala is a Principal Data Architect at FanDuel Group. He defines their Amazon Redshift optimization strategy and works with the data analytics team to provide solutions to their key business problems. Matt Grimm is a Principal Data Architect at FanDuel Group, moving the company to an event-based, data-driven architecture using the integration of both streaming and batch data, while also supporting their Machine Learning Platform and development teams.
Matt Grimm is a Principal Data Architect at FanDuel Group, moving the company to an event-based, data-driven architecture using the integration of both streaming and batch data, while also supporting their Machine Learning Platform and development teams. Luke Shearer is a Cloud Support Engineer at Amazon Web Services for the Data Insight Analytics profile, where he is engaged with AWS customers every day and is always working to identify the best solution for each customer.
Luke Shearer is a Cloud Support Engineer at Amazon Web Services for the Data Insight Analytics profile, where he is engaged with AWS customers every day and is always working to identify the best solution for each customer. Dhaval Shah is Senior Customer Success Engineer at AWS and specializes in bringing the most complex and demanding data analytics workloads to Amazon Redshift. He has more then 20 years of experiences in different databases and data warehousing technologies. He is passionate about efficient and scalable data analytics cloud solutions that drive business value for customers.
Dhaval Shah is Senior Customer Success Engineer at AWS and specializes in bringing the most complex and demanding data analytics workloads to Amazon Redshift. He has more then 20 years of experiences in different databases and data warehousing technologies. He is passionate about efficient and scalable data analytics cloud solutions that drive business value for customers. Ranjan Burman is an Sr. Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 17 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with cloud solutions.
Ranjan Burman is an Sr. Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 17 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with cloud solutions. Sidhanth Muralidhar is a Principal Technical Account Manager at AWS. He works with large enterprise customers who run their workloads on AWS. He is passionate about working with customers and helping them architect workloads for cost, reliability, performance, and operational excellence at scale in their cloud journey. He has a keen interest in data analytics as well.
Sidhanth Muralidhar is a Principal Technical Account Manager at AWS. He works with large enterprise customers who run their workloads on AWS. He is passionate about working with customers and helping them architect workloads for cost, reliability, performance, and operational excellence at scale in their cloud journey. He has a keen interest in data analytics as well.


 Harman Singh Dhodi is an Analyst at HR&A Advisors, Harman combines his passion for data analytics with sustainable infrastructure practices, social inclusion, economic viability, climate resiliency, and building stakeholder capacity. Harman’s work often focuses on translating complex datasets into visual stories and accessible tools that help empower communities to understand the challenges they’re facing and create solutions for a brighter future.
Harman Singh Dhodi is an Analyst at HR&A Advisors, Harman combines his passion for data analytics with sustainable infrastructure practices, social inclusion, economic viability, climate resiliency, and building stakeholder capacity. Harman’s work often focuses on translating complex datasets into visual stories and accessible tools that help empower communities to understand the challenges they’re facing and create solutions for a brighter future. Kiran Kumar Tati is an Analytics Specialist Solutions Architect based out of Omaha, NE. He specializes in building end-to-end analytic solutions. He has more than 13 years of experience with designing and implementing large scale Big Data and Analytics solutions. In his spare time, he enjoys playing cricket and watching sports.
Kiran Kumar Tati is an Analytics Specialist Solutions Architect based out of Omaha, NE. He specializes in building end-to-end analytic solutions. He has more than 13 years of experience with designing and implementing large scale Big Data and Analytics solutions. In his spare time, he enjoys playing cricket and watching sports. Sapna Maheshwari is a Sr. Solutions Architect at Amazon Web Services. She helps customers architect data analytics solutions at scale on AWS. Outside of work she enjoys traveling and trying new cuisines.
Sapna Maheshwari is a Sr. Solutions Architect at Amazon Web Services. She helps customers architect data analytics solutions at scale on AWS. Outside of work she enjoys traveling and trying new cuisines.


 Arun Sudhir is a Staff Software Engineer at Eightfold AI. He has more than 15 years of experience in design and development of backend software systems in companies like Microsoft and AWS, and has a deep knowledge of database engines like Amazon Aurora PostgreSQL and Amazon Redshift.
Arun Sudhir is a Staff Software Engineer at Eightfold AI. He has more than 15 years of experience in design and development of backend software systems in companies like Microsoft and AWS, and has a deep knowledge of database engines like Amazon Aurora PostgreSQL and Amazon Redshift. Rohit Bansal is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build next-generation analytics solutions using AWS Analytics services.
Rohit Bansal is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build next-generation analytics solutions using AWS Analytics services. Anjali Vijayakumar is a Senior Solutions Architect at AWS focusing on EdTech. She is passionate about helping customers build well-architected solutions in the cloud.
Anjali Vijayakumar is a Senior Solutions Architect at AWS focusing on EdTech. She is passionate about helping customers build well-architected solutions in the cloud.