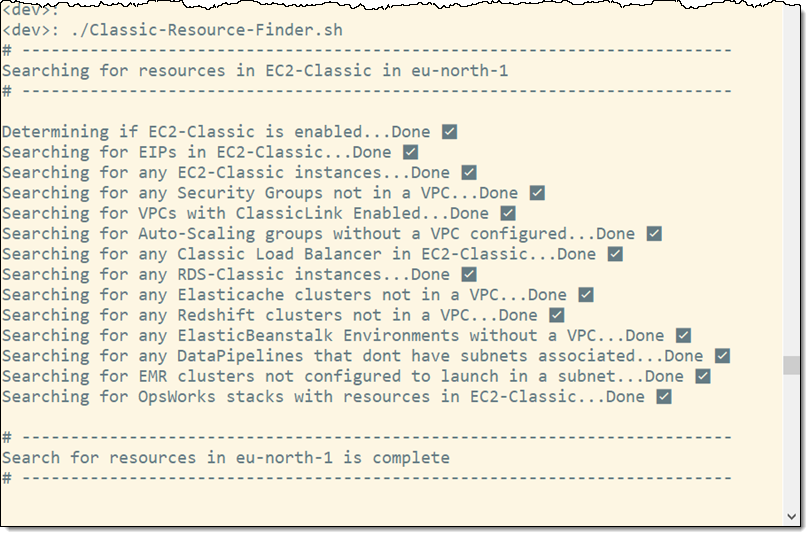
Post Syndicated from Danilo Poccia original https://aws.amazon.com/blogs/aws/new-for-aws-cloudformation-quickly-retry-stack-operations-from-the-point-of-failure/
One of the great advantages of cloud computing is that you have access to programmable infrastructure. This allows you to manage your infrastructure as code and apply the same practices of application code development to infrastructure provisioning.
AWS CloudFormation gives you an easy way to model a collection of related AWS and third-party resources, provision them quickly and consistently, and manage them throughout their lifecycles. A CloudFormation template describes your desired resources and their dependencies so you can launch and configure them together as a stack. You can use a template to create, update, and delete an entire stack as a single unit instead of managing resources individually.
When you create or update a stack, your action might fail for different reasons. For example, there can be errors in the template, in the parameters of the template, or issues outside the template, such as AWS Identity and Access Management (IAM) permission errors. When such an error occurs, CloudFormation rolls back the stack to the previous stable condition. For a stack creation, that means deleting all resources created up to the point of the error. For a stack update, it means restoring the previous configuration.
This rollback to the previous state is great for production environments, but doesn’t make it easy to understand the reason for the error. Depending on the complexity of your template and the number of resources involved, you might spend lots of time waiting for all the resources to roll back before you can update the template with the right configuration and retry the operation.
Today, I am happy to share that now CloudFormation allows you to disable the automatic rollback, keep the resources successfully created or updated before the error occurs, and retry stack operations from the point of failure. In this way, you can quickly iterate to fix and remediate errors and greatly reduce the time required to test a CloudFormation template in a development environment. You can apply this new capability when you create a stack, when you update a stack, and when you execute a change set. Let’s see how this works in practice.
Quickly Iterate to Fix and Remediate a CloudFormation Stack
For one of my applications, I need to set up an Amazon Simple Storage Service (Amazon S3) bucket, an Amazon Simple Queue Service (SQS) queue, and an Amazon DynamoDB table that is streaming item-level changes to an Amazon Kinesis data stream. For this setup, I write down the first version of the CloudFormation template.
AWSTemplateFormatVersion: "2010-09-09"
Description: A sample template to fix & remediate
Parameters:
ShardCountParameter:
Type: Number
Description: The number of shards for the Kinesis stream
Resources:
MyBucket:
Type: AWS::S3::Bucket
MyQueue:
Type: AWS::SQS::Queue
MyStream:
Type: AWS::Kinesis::Stream
Properties:
ShardCount: !Ref ShardCountParameter
MyTable:
Type: AWS::DynamoDB::Table
Properties:
BillingMode: PAY_PER_REQUEST
AttributeDefinitions:
- AttributeName: "ArtistId"
AttributeType: "S"
- AttributeName: "Concert"
AttributeType: "S"
- AttributeName: "TicketSales"
AttributeType: "S"
KeySchema:
- AttributeName: "ArtistId"
KeyType: "HASH"
- AttributeName: "Concert"
KeyType: "RANGE"
KinesisStreamSpecification:
StreamArn: !GetAtt MyStream.Arn
Outputs:
BucketName:
Value: !Ref MyBucket
Description: The name of my S3 bucket
QueueName:
Value: !GetAtt MyQueue.QueueName
Description: The name of my SQS queue
StreamName:
Value: !Ref MyStream
Description: The name of my Kinesis stream
TableName:
Value: !Ref MyTable
Description: The name of my DynamoDB tableNow, I want to create a stack from this template. On the CloudFormation console, I choose Create stack. Then, I upload the template file and choose Next.

I enter a name for the stack. Then, I fill the stack parameters. My template file has one parameter (ShardCountParameter) used to configure the number of shards for the Kinesis data stream. I know that the number of shards should be greater or equal to one, but by mistake, I enter zero and choose Next.
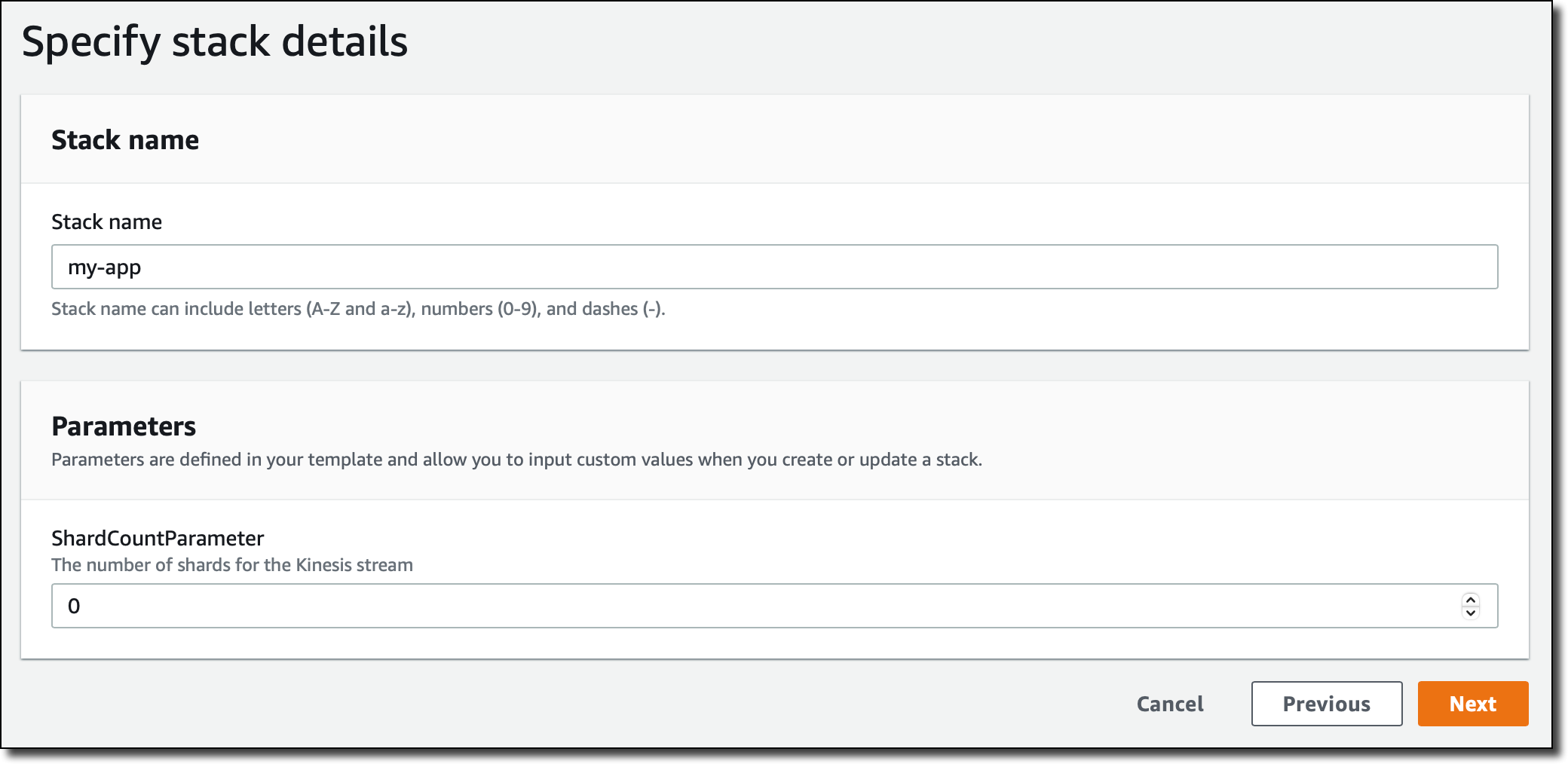
To create, modify, or delete resources in the stack, I use an IAM role. In this way, I have a clear boundary for the permissions that CloudFormation can use for stack operations. Also, I can use the same role to automate the deployment of the stack later in a standardized and reproducible environment.
In Permissions, I select the IAM role to use for the stack operations.

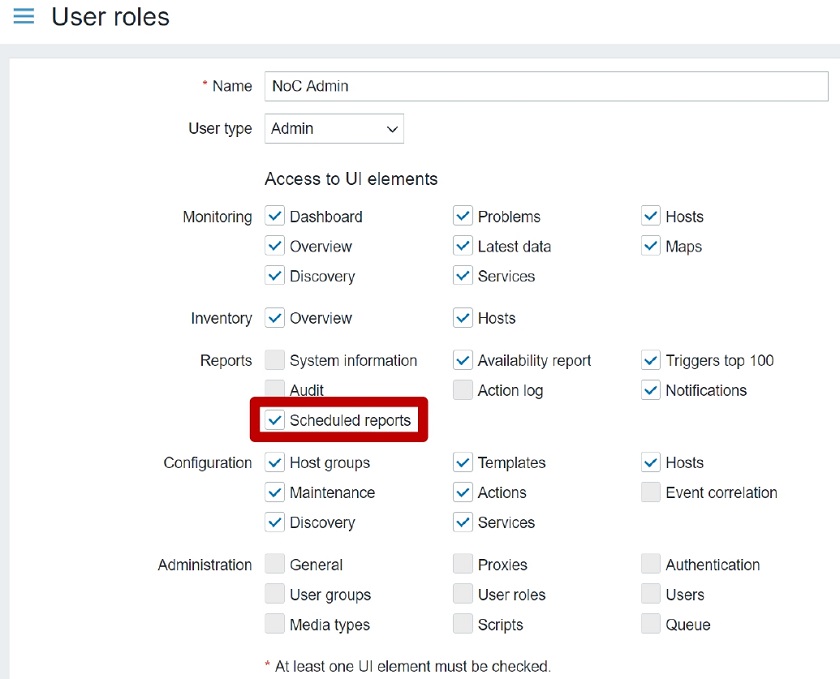
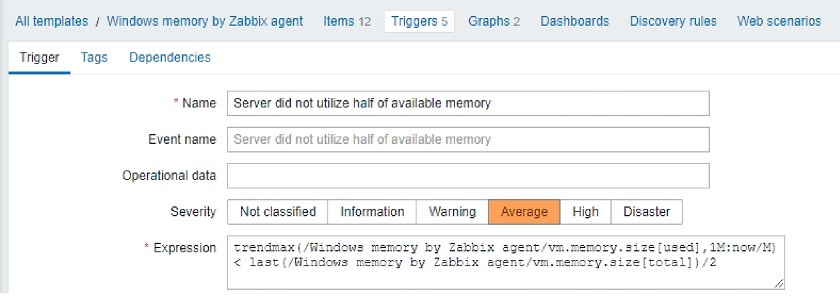
Now it’s time to use the new feature! In the Stack failure options, I select Preserve successfully provisioned resources to keep, in case of errors, the resources that have already been created. Failed resources are always rolled back to the last known stable state.

I leave all other options at their defaults and choose Next. Then, I review my configurations and choose Create stack.
The creation of the stack is in progress for a few seconds, and then it fails because of an error. In the Events tab, I look at the timeline of the events. The start of the creation of the stack is at the bottom. The most recent event is at the top. Properties validation for the stream resource failed because the number of shards (ShardCount) is below the minimum. For this reason, the stack is now in the CREATE_FAILED status.

Because I chose to preserve the provisioned resources, all resources created before the error are still there. In the Resources tab, the S3 bucket and the SQS queue are in the CREATE_COMPLETE status, while the Kinesis data stream is in the CREATE_FAILED status. The creation of the DynamoDB table depends on the Kinesis data stream to be available because the table uses the data stream in one of its properties (KinesisStreamSpecification). As a consequence of that, the table creation has not started yet, and the table is not in the list.

The rollback is now paused, and I have a few new options:
Retry – To retry the stack operation without any change. This option is useful if a resource failed to provision due to an issue outside the template. I can fix the issue and then retry from the point of failure.
Update – To update the template or the parameters before retrying the stack creation. The stack update starts from where the last operation was interrupted by an error.
Rollback – To roll back to the last known stable state. This is similar to default CloudFormation behavior.

Fixing Issues in the Parameters
I quickly realize the mistake I made while entering the parameter for the number of shards, so I choose Update.
I don’t need to change the template to fix this error. In Parameters, I fix the previous error and enter the correct amount for the number of shards: one shard.

I leave all other options at their current values and choose Next.
In Change set preview, I see that the update will try to modify the Kinesis stream (currently in the CREATE_FAILED status) and add the DynamoDB table. I review the other configurations and choose Update stack.
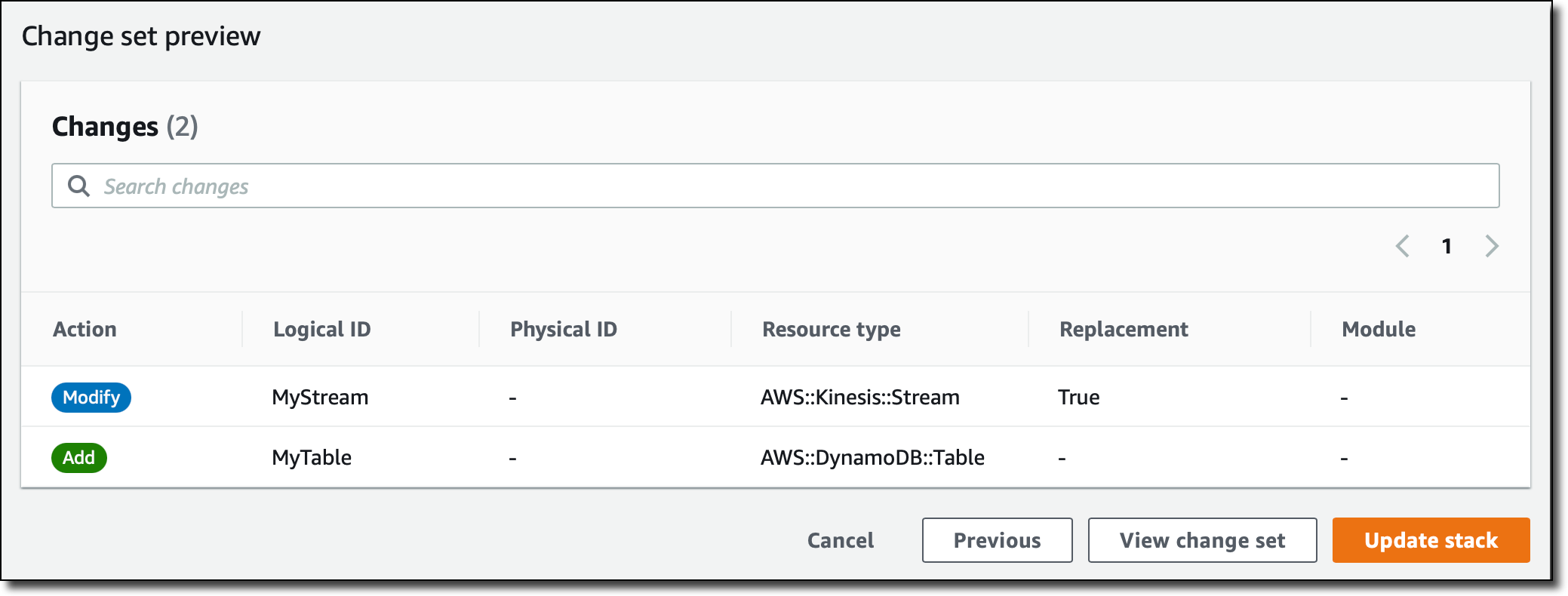
Now the update is in progress. Did I solve all the issues? Not yet. After some time, the update fails.
Fixing Issues Outside the Template
The Kinesis stream has been created, but the IAM role assumed by CloudFormation doesn’t have permissions to create the DynamoDB table.

In the IAM console, I add additional permissions to the role used by the stack operations to be able to create the DynamoDB table.

Back to the CloudFormation console, I choose the Retry option. With the new permissions, the creation of the DynamoDB table starts, but after some time, there is another error.
Fixing Issues in the Template
This time there is an error in my template where I define the DynamoDB table. In the AttributeDefinitions section, there is an attribute (TicketSales) that is not used in the schema.

With DynamoDB, attributes defined in the template should be used either for the primary key or for an index. I update the template and remove the TicketSales attribute definition.
Because I am editing the template, I take the opportunity to also add MinValue and MaxValue properties to the number of shards parameter (ShardCountParameter). In this way, CloudFormation can check that the value is in the correct range before starting the deployment, and I can avoid further mistakes.
I select the Update option. I choose to update the current template, and I upload the new template file. I confirm the current values for the parameters. Then, I leave all other options to their current values and choose Update stack.
This time, the creation of the stack is successful, and the status is UPDATE_COMPLETE. I can see all resources in the Resources tab and their description (based on the Outputs section of the template) in the Outputs tab.

Here’s the final version of the template:
AWSTemplateFormatVersion: "2010-09-09"
Description: A sample template to fix & remediate
Parameters:
ShardCountParameter:
Type: Number
MinValue: 1
MaxValue: 10
Description: The number of shards for the Kinesis stream
Resources:
MyBucket:
Type: AWS::S3::Bucket
MyQueue:
Type: AWS::SQS::Queue
MyStream:
Type: AWS::Kinesis::Stream
Properties:
ShardCount: !Ref ShardCountParameter
MyTable:
Type: AWS::DynamoDB::Table
Properties:
BillingMode: PAY_PER_REQUEST
AttributeDefinitions:
- AttributeName: "ArtistId"
AttributeType: "S"
- AttributeName: "Concert"
AttributeType: "S"
KeySchema:
- AttributeName: "ArtistId"
KeyType: "HASH"
- AttributeName: "Concert"
KeyType: "RANGE"
KinesisStreamSpecification:
StreamArn: !GetAtt MyStream.Arn
Outputs:
BucketName:
Value: !Ref MyBucket
Description: The name of my S3 bucket
QueueName:
Value: !GetAtt MyQueue.QueueName
Description: The name of my SQS queue
StreamName:
Value: !Ref MyStream
Description: The name of my Kinesis stream
TableName:
Value: !Ref MyTable
Description: The name of my DynamoDB tableThis was a simple example, but the new capability to retry stack operations from the point of failure already saved me lots of time. It allowed me to fix and remediate issues quickly, reducing the feedback loop and increasing the number of iterations that I can do in the same amount of time. In addition to using this for debugging, it is also great for incremental interactive development of templates. With more sophisticated applications, the time saved will be huge!
Fix and Remediate a CloudFormation Stack Using the AWS CLI
I can preserve successfully provisioned resources with the AWS Command Line Interface (CLI) by specifying the --disable-rollback option when I create a stack, update a stack, or execute a change set. For example:
For an existing stack, I can see if the DisableRollback property is enabled with the describe stack command:
I can now update stacks in the CREATE_FAILED or UPDATE_FAILED status. To manually roll back a stack that is in the CREATE_FAILED or UPDATE_FAILED status, I can use the new rollback stack command:
Availability and Pricing
The capability for AWS CloudFormation to retry stack operations from the point of failure is available at no additional charge in the following AWS Regions: US East (N. Virginia, Ohio), US West (Oregon, N. California), AWS GovCloud (US-East, US-West), Canada (Central), Europe (Frankfurt, Ireland, London, Milan, Paris, Stockholm), Asia Pacific (Hong Kong, Mumbai, Osaka, Seoul, Singapore, Sydney, Tokyo), Middle East (Bahrain), Africa (Cape Town), and South America (São Paulo).
Do you prefer to define your cloud application resources using familiar programming languages such as JavaScript, TypeScript, Python, Java, C#, and Go? Good news! The AWS Cloud Development Kit (AWS CDK) team is planning to add support for the new capabilities described in this post in the next couple of weeks.
— Danilo












 Fifteen years ago today I wrote the blog post that launched the
Fifteen years ago today I wrote the blog post that launched the 










 Our initial customers saw the value right away and started to put EC2 to use in many different ways. We hosted web sites,
Our initial customers saw the value right away and started to put EC2 to use in many different ways. We hosted web sites,