Cyber Essentials Plus is a UK Government-backed, industry-supported certification scheme intended to help organizations demonstrate organizational cyber security against common cyber attacks. An independent third-party auditor certified by the Information Assurance for Small and Medium Enterprises (IASME) completed the audit. The scope of our Cyber Essentials Plus certificate covers AWS Europe (London), AWS Europe (Ireland), and AWS Europe (Frankfurt) Regions.
The NHS DSPT is a self-assessment that organizations use to measure their performance against data security and information governance requirements. The UK Department of Health and Social Care sets these requirements.
When customers move to the AWS Cloud, AWS is responsible for protecting the global infrastructure that runs our services offered in the AWS Cloud. AWS customers are the data controllers for patient health and care data, and are responsible for anything they put in the cloud or connect to the cloud. For more information, see the AWS Shared Security Responsibility Model.
As always, we value your feedback and questions. Reach out to the AWS Compliance team through the Contact Us page. If you have feedback about this post, submit a comment in the Comments section below. To learn more about our other compliance and security programs, see AWS Compliance Programs.
Want more AWS Security news? Follow us on Twitter.
In this post, we’d like to introduce you to the cryptographic computing feature of AWS Clean Rooms. With AWS Clean Rooms, customers can run collaborative data-query sessions on sensitive data sets that live in different AWS accounts, and can do so without having to share, aggregate, or replicate the data. When customers also use the cryptographic computing feature, their data remains cryptographically protected even while it is being processed by an AWS Clean Rooms collaboration.
Where would AWS Clean Rooms be useful? Consider a scenario where two different insurance companies want to identify duplicate claims so they can identify potential fraud. This would be simple if they could compare their claims with each other, but they might not be able to do so due to privacy constraints.
Alternately, consider an advertising network and a client that want to measure the effectiveness of an advertising campaign. To that end, they would like to know how many of the people who saw the campaign (exposures) went on to make a purchase from the client (purchasers). However, confidentiality concerns might prevent the advertising network from sharing their list of exposures with the client or prevent the client from sharing their list of purchasers with the advertising network.
As these examples show, there can be many situations in which different organizations want to collaborate on a joint analysis of their pooled data, but cannot share their individual datasets directly. One solution to this problem is a data clean room, which is a service trusted by a collaboration’s participants to do the following:
Hold the data of individual parties
Enforce access-control rules that collaborators specify regarding their data
Perform analyses over the pooled data
To serve customers with these needs, AWS recently launched a new data clean-room service called AWS Clean Rooms. This service provides AWS customers with a way to collaboratively analyze data (stored in other AWS services as SQL tables) without having to replicate the data, move the data outside of the AWS Cloud, or allow their collaborators to see the data itself.
Additionally, AWS Clean Rooms provides a feature that gives customers even more control over their data: cryptographic computing. This feature allows AWS Clean Rooms to operate over data that customers encrypt themselves and that the service cannot actually read. Specifically, customers can use this feature to select which portions of their data should be encrypted and to encrypt that data themselves. Collaborators can continue to analyze that data as if it were in the clear, however, even though the data in question remains encrypted while it is being processed in AWS Clean Rooms collaborations. In this way, customers can use AWS Clean Rooms to securely collaborate on data they may not have been able to share due to internal policies or regulations.
Cryptographic computing
Using the cryptographic computing feature of AWS Clean Rooms involves these steps:
Users create AWS Clean Rooms collaborations and set collaboration-wide encryption settings. They then invite collaborators to support the analysis process.
Outside of AWS Clean Rooms, those collaborators agree on a shared secret: a common, secret, cryptographic key.
Collaborators individually encrypt their tables outside of the AWS Cloud (typically on their own premises) using the shared secret, the collaboration ID of the intended collaboration, and the Cryptographic Computing for Clean Rooms (C3R) encryption client (which AWS provides as an open-source package). Collaborators then provide the encrypted tables to AWS Clean Rooms, just as they would have provided plaintext tables.
Collaborators continue to use AWS Clean Rooms for their data analysis. They impose access-control rules on their tables, submit SQL queries over the tables in the collaboration, and retrieve results.
These results might contain encrypted columns, and so collaborators decrypt the results by using the shared secret and the C3R encryption client.
As a result, data that enters AWS Clean Rooms in encrypted format will remain encrypted from input tables to intermediate values to result sets. AWS Clean Rooms will be unable to decrypt or read the data even while performing the queries.
Note: For those interested in the academic aspects of this process, the cryptographic computing feature of AWS Clean Rooms is based on server-aided private set intersection (PSI). Server-aided PSI allows two or more participants to submit sets of values to a server and learn which elements are found in all sets, but without (1) allowing the participants to learn anything about the other (non-shared) elements, or (2) allowing the server to learn anything about the underlying data (aside from the degrees to which the sets overlap). PSI is just one example of the field of cryptographic computing, which provides a variety of new methods by which encrypted data can be processed for various purposes and without decryption. These techniques allow our customers to use the scale and power of AWS systems on data that AWS will not be able to read. See our Cryptographic Computing webpage for more about our work in this area.
Let’s dive deeper into each new step in the process for using cryptographic computing in AWS Clean Rooms.
Key agreement. Each collaboration needs its own shared secret: a secure cryptographic secret (of at least 256 bits). Customers sometimes have a regulatory need to maintain ownership of their encryption keys. Therefore, the cryptographic computing feature supports the case where customers generate, distribute, and store their collaboration’s secret themselves. In this way, customers’ encryption keys are never stored on an AWS system.
Encryption. AWS Clean Rooms allows table owners to control how tables are encrypted on a column-by-column basis. In particular, each column in an encrypted table will be one of three types: cleartext, sealed, or fingerprint. These types map directly to both how columns are used in queries and how they are protected with cryptography, described as follows:
Cleartext columns are not cryptographically processed at all. They are copied to encrypted tables verbatim, and can be used anywhere in a SQL query.
Sealed columns are encrypted. The encryption scheme used (AES-GCM) is randomized, meaning that encrypting the same value multiple times yields different ciphertexts each time. This helps prevent the statistical analysis of these columns, but also means that these columns cannot be used in JOIN clauses. They can be used in SELECT clauses, however, which allows them to appear in query results.
Fingerprint columns are hashed using the Hash-based Message Authentication Code (HMAC) algorithm. There is no way to decrypt these values, and therefore no reason for them to appear in the SELECT clause of a query. They can, however, be used in JOIN clauses: HMAC will map a given value to the same fingerprint every time, meaning that JOINs will be able to unify common values across different fingerprint columns.
Encryption settings. This last point—that fingerprint values will always map a given plaintext value to the same fingerprint—might give pause to some readers. If this is true, won’t the encrypted table be vulnerable to statistical analysis? That is absolutely correct: it will. For this reason, users might wish to set collaboration-wide encryption settings to control these forms of analysis.
To see how statistical analysis might be a concern, imagine a table where one fingerprint column is named US_State. In this case, a simple frequency analysis will reverse-engineer the plaintext values relatively quickly: the most common fingerprint is almost certain to be “California”, followed by “Texas”, “Florida”, and so on. Also, imagine that the same table has another fingerprint column called US_City, and that a given fingerprint appears in both columns. In that case, the fingerprint in question is almost certain to be “New York”. If a row has a fingerprint in the US_City column but a NULL in the US_State column, furthermore, it’s very likely that the fingerprint is for “District of Columbia”. And finally, imagine that the table has a cleartext column called Time_Zone. In this case, values of “HST” (Hawaii standard time) or “AKST” (Alaska standard time) reveal the value in the US_State column regardless of the cryptography.
Not all datasets will be vulnerable to these kinds of statistical analysis, but some will. Only customers can determine which types of analysis may reveal their data and which may not. Because of this, the cryptographic computing feature allows the customer to decide which protections will be needed. At the time of collaboration creation, that is, the creator of the AWS Clean Rooms collaboration can configure the following collaboration-wide encryption settings:
Whether or not fingerprint columns can contain duplicate plaintext values (addressing the “California” example)
Whether or not fingerprint columns with different names should fingerprint values in the same way (addressing the “New York” example)
Whether or not NULL values in the plaintext table should be left as NULL in the encrypted table (addressing the “District of Columbia” example)
Whether or not encrypted tables should be allowed to have cleartext columns at all (addressing the time zone example)
Security is maximized when all of these options are set to “no,” but each “no” will limit the queries that C3R will be able to support. For example, the choice of whether or not encrypted tables should be allowed to have cleartext columns will determine which WHERE clauses will be supported: If cleartext columns are not supported, then the Time_Zone column must be cryptographically processed — meaning that the clause WHERE Time_Zone=”EST” will not act as intended. There might be reasons to set these options to “yes” in order to enable a wider variety of queries, which we discuss in the Query behavior section later in this post.
Decryption. AWS Clean Rooms will write query results to an Amazon Simple Storage Service (Amazon S3) bucket. The recipient copies these results from the bucket to some on-premises storage and then runs the C3R encryption client. The client will find encrypted elements of the output and decrypt them. Note that the client can only decrypt elements from sealed columns. If the output contains elements from a fingerprint column, the client will warn you, but will also leave these elements untouched, as cryptographic fingerprints can’t be decrypted.
Having finished our overview, let’s return to the discussion regarding how encryption can affect the behavior of queries.
Query behavior
Implicit in the discussion so far is something worth calling out explicitly: AWS Clean Rooms runs queries over the data that is provided to it. If the data given to AWS Clean Rooms is encrypted, therefore, queries will be run on the ciphertexts and not the plaintexts. This will not affect the results returned, so long as the columns are used for their intended purposes:
Fingerprint columns are used in JOIN clauses
Sealed columns are used in SELECT clauses
(Cleartext columns can be used anywhere.) Queries might produce unexpected results, however, if the columns are used outside of their intended purposes:
Sometimes queries will fail when they would have succeeded on the plaintext. For example, ciphertexts and fingerprints will be string values, even if the original plaintext values were another type. Therefore, SUM() or AVG() calls on fingerprint or sealed columns will yield errors even if the corresponding plaintext columns were numeric.
Sometimes queries will omit results that would have been found by querying the plaintext. For example, attempting to JOIN on sealed columns will yield empty result sets: no two ciphertexts will be the same, even if they encrypt the same plaintext value. (Also, performing a JOIN on fingerprint columns with different names will exhibit the same behavior, if the collaboration-wide encryption settings specified that fingerprint columns of different names should fingerprint values differently.)
Sometimes results will include rows that would not be found by querying the plaintext. As mentioned, ciphertexts and fingerprints will be string values—base64 encodings of random-looking bytes, specifically. This means that a clause such as WHERE ‘US_State’ CONTAINS ‘CA’ will match some ciphertexts or fingerprints even when they would not match the plaintext.
To avoid these issues, fingerprint and sealed columns should only be used for their intended purposes (JOIN and SELECT clauses, respectively).
Conclusion
In this blog post, you have learned how AWS Clean Rooms can help you harness the power of AWS services to query and analyze your most-sensitive data. By using cryptographic computing, you can work with collaborators to perform joint analyses over pooled data without sharing your “raw” data with each other—or with AWS. If you believe that you can benefit from cryptographic computing (in AWS Clean Rooms or elsewhere), we’d like to hear from you. Please contact us with any questions or feedback. Also, we invite you to learn more about AWS Clean Rooms (including its use of cryptographic computing). Finally, the C3R client is open source, and can be downloaded from its GitHub page.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
AWS Verified Access helps improve your organization’s security posture by using security trust providers to grant access to applications. This service grants access to applications only when the user’s identity and the user’s device meet configured security requirements. In this blog post, we will provide an overview of trust providers and policies, then walk through a Verified Access policy for securing your corporate applications.
Understanding trust data and policies
Verified Access policies enable you to use trust data from trust providers and help protect access to corporate applications that are hosted on Amazon Web Services (AWS). When you create a Verified Access group or a Verified Access endpoint, you create a Verified Access policy, which is applied to the group or both the group and endpoint. Policies are written in Cedar, an AWS policy language. With Verified Access, you can express policies that use the trust data from the trust providers that you configure, such as corporate identity providers and device security state providers.
Verified Access receives trust data or claims from different trust providers. Currently, Verified Access supports two types of trust providers. The first type is an identity trust provider. Identity trust providers manage the identities of digital users, including the user’s email address, groups, and profile information. The second type of trust provider is a device trust provider. Device trust providers manage the device posture for users, including the OS version of the device, risk scores, and other metrics that reflect device posture. When a user makes a request to Verified Access, the request includes claims from the configured trust providers. Verified Access customers permit or forbid access to applications by evaluating the claims in Cedar policies. We will walk through the types of claims that are included from trust providers and the options for custom trust data.
End-to-end Cedar policy use cases
Let’s look at how to use policies with your applications. In general, you use Verified Access to control access to an application for purposes of authentication and initial authorization. This means that you use Verified Access to authenticate the user when they log in and to confirm that the device posture of the end device meets minimum criteria. For authorization logic to control access to actions and resources inside the application, you pass the identity claims to the application. The application uses the information to authorize users within the application after authentication. In other words, not every identity claim needs to be passed or checked in Verified Access to allow traffic to pass to the application. You can and should put additional logic in place to make decisions for users when they gain access to the backend application after initial authentication and authorization by Verified Access. From an identity perspective, this additional criteria might be an email address, a group, and possibly some additional claims. From a device perspective, Verified Access does not at this time pass device trust data to the end application. This means that you should use Verified Access to perform checks involving device posture.
For many applications, you only need a simple policy to provide access to your users. This can include the identity information only. For example, let’s say that you want to write a policy that uses the user’s email address and matches a certain group that the user is part of. Within the Verified Access trust provider configuration, you can include “openid email groups” as the scope, and your OpenID Connect (OIDC) provider will include each claim associated with the scopes that you have configured with the OIDC provider. When the user John in this example uses case logs in to the OIDC provider, he receives the following claims from the OIDC provider. For this provider, the Verified Access Trust Provider is configured for “identity” to be the policy reference name.
With these claims, you can write a policy that matches the email domain and the group, to allow access to the application, as follows.
permit(principal, action, resource)
when {
// Returns true if the email ends in "@example.com"
context.identity.email like "*@example.com" &&
// Returns true if the user is part of the "finance" group
context.identity.groups.contains("finance")
};
Use case 2: Custom claims within a policy
Many times, you are also interested in company-specific or custom claims from the identity provider. The claims that exist with the user endpoint are dependent on how you configure the identity provider. For OIDC providers, this is determined by the scopes that you define when you set up the identity provider. Verified Access uses OIDC scopes to authorize access to details of the user. This includes attributes such as the name, email address, email verification, and custom attributes. Each scope that you configure for the identity provider returns a set of user attributes, which we call claims. Depending on which claims you want to match on in your policy, you configure the scopes and claims in the OIDC provider, which the OIDC provider adds to the user endpoint. For a list of standard claims, including profile, email, name, and others, see the Standard Claims OIDC specification.
In this example use case, as your policy evolves from the basic policy, you decide to add additional company-specific claims to Verified Access. This includes both the business unit and the level of each employee. Within the Verified Access trust provider configuration, you can include “openid email groups profile” as the scope, and your OIDC provider will include each claim associated with the scopes that you have configured with the OIDC provider. Now, when the user John logs in to the OIDC provider, he receives the following claims from the OIDC provider, with both the business unit and role as claims from the “profile” scope in OIDC.
With these claims, the company can write a policy that matches the claims to allow access to the application, as follows.
permit(principal, action, resource)
when {
// Returns true if the email ends in "@example.com"
context.identity.email like "*@example.com" &&
// Returns true if the user is part of the "finance" group
context.identity.groups.contains("finance") &&
// Returns true if the business unit is "corp"
context.identity.business_unit == "corp" &&
// Returns true if the level is greater than 6
context.identity.level >= 6
};
Use case 3: Add a device trust provider to a policy
The other type of trust provider is a device trust provider. Verified Access supports two device trust providers today: CrowdStrike and Jamf. As detailed in the AWS Verified Access Request Verification Flow, for HTTP/HTTPS traffic, the extension in the web browser receives device posture information from the device agent on the user’s device. Each device trust provider determines what risk information and device information to include in the claims and how that information is formatted. Depending on the device trust provider, the claims are static or configurable.
In our example use case, with the evolution of the policy, you now add device trust provider checks to the policy. After you install the Verified Access browser extension on John’s computer, Verified Access receives the following claims from both the identity trust provider and the device trust provider, which uses the policy reference name “crwd”.
With these claims, you can write a policy that matches the claims to allow access to the application, as follows.
permit(principal, action, resource)
when {
// Returns true if the email ends in "@example.com"
context.identity.email like "*@example.com" &&
// Returns true if the user is part of the "finance" group
context.identity.groups.contains("finance") &&
// Returns true if the business unit is "corp"
context.identity.business_unit == "corp" &&
// Returns true if the level is greater than 6
context.identity.level >= 6 &&
// If the CrowdStrike agent is present
( context has "crwd" &&
// The overall device score is greater or equal to 80
context.crwd.assessment.overall >= 80 )
};
The final update to your policy comes in the form of multiple device trust providers. Verified Access provides the ability to match on multiple device trust providers in the same policy. This provides flexibility for your company, which in this example use case has different device trust providers installed on different types of users’ devices. For information about many of the claims that each device trust provider provides to AWS, see Third-party trust providers. However, for this updated policy, John’s claims do not change, but the new policy can match on either CrowdStrike’s or Jamf’s trust data. For Jamf, the policy reference name is “jamf”.
permit(principal, action, resource)
when {
// Returns true if the email ends in "@example.com"
context.identity.email like "*@example.com" &&
// Returns true if the user is part of the "finance" group
context.identity.groups.contains("finance") &&
// Returns true if the business unit is "corp"
context.identity.business_unit == "corp" &&
// Returns true if the level is greater than 6
context.identity.level >= 6 &&
// If the CrowdStrike agent is present
(( context has "crwd" &&
// The overall device score is greater or equal to 80
context.crwd.assessment.overall >= 80 ) ||
// If the Jamf agent is present
( context has "jamf" &&
// The risk level is either LOW or SECURE
["LOW","SECURE"].contains(context.jamf.risk) ))
};
In this blog post, we covered an overview of Cedar policy for AWS Verified Access, discussed the types of trust providers available for Verified Access, and walked through different use cases as you evolve your Cedar policy in Verified Access.
With Amazon Relational Database Service (Amazon RDS), you can set up, operate, and scale a relational database in the AWS Cloud. Amazon RDS provides cost-efficient, resizable capacity for an industry-standard relational database and manages common database administration tasks.
If you use Amazon RDS for your workloads, you can now use Amazon GuardDutyRDS Protection to help detect threats to your data stored in Amazon Aurora databases. GuardDuty is a continuous security monitoring service that can help you identify and prioritize potential threats in your AWS environment. By analyzing and profiling RDS login activity to your Aurora databases, GuardDuty can detect threats, such as high severity brute force events, suspicious logins, access from Tor, and access by known threat actors.
In this post, we will provide an overview of how to get started with RDS Protection, dive into its finding types, and walk you through examples of how to investigate and remediate findings.
Overview of RDS Protection
RDS Protection in GuardDuty analyzes and profiles Amazon RDS login activity to identify potential threats to your data stored in Aurora databases by using a combination of threat intelligence and machine learning. At launch, RDS Protection supports Aurora MySQL versions 2.10.2 and 3.2.1 or later and Aurora PostgreSQL versions 10.17, 11.12, 12.7, 13.3, and 14.3 or later. An updated list of the supported engines and versions is available in the GuardDuty documentation. RDS Protection doesn’t require additional infrastructure, and you don’t need to configure, collect, or store RDS logs in your own account. RDS Protection is also designed to have no impact on the performance of your database instances so that you don’t have to worry about compromising performance to better secure your data stored in Amazon RDS.
When RDS Protection detects a suspicious or anomalous login attempt that indicates a potential threat to your database instance, GuardDuty generates a finding with details to help you quickly identify relevant information to assist in remediation. RDS Protection findings include details on both anomalous and normal login activity in addition to information such as database instance details, database user details, action information, and actor information. These findings are available to you in the GuardDuty console, AWS Command Line Interface (AWS CLI), and API, and all GuardDuty findings are sent to Amazon EventBridge and AWS Security Hub, giving you options to respond by sending alerts to chat or ticketing systems, or by using AWS Lambda and AWS Systems Manager for automatic remediation.
Enable RDS Protection
Getting started with RDS Protection is simple, and you can do it with just a few steps in the console. Both new and existing GuardDuty customers can take advantage of the GuardDuty RDS Protection 30-day free trial. You can turn RDS Protection on or off for each of your accounts in supported AWS Regions. If you already use GuardDuty, you will need to enable RDS Protection either in the console or CLI, or through the API. You will have the option to enable it in the account that you are currently in, or if you are using a GuardDuty delegated administrator account (as shown in Figure 1), you can enable it for all accounts in your AWS Organizations organization. You’ll also have the ability to auto-enable. The auto-enable feature helps ensure that RDS Protection is enabled for each new account added to your organization, without the need for you to configure anything in each member account. If you are turning on GuardDuty for the first time, RDS Protection is enabled by default.
After GuardDuty generates a finding, you will need to analyze the finding so that you understand the potential impact to your environment. We recommend that you familiarize yourself with the GuardDuty finding types. Understanding GuardDuty finding types can help you understand the types of activity that GuardDuty is looking for and help you prepare for how to respond if they occur in your environment.
As adversaries become more sophisticated, it becomes even more important for you to align to a common framework to understand the tactics, techniques, and procedures (TTPs) behind an individual event. GuardDuty aligns findings using the MITRE ATT&CK framework, which is a globally-accessible knowledge base of adversary tactics and techniques based on real-world observations. GuardDuty findings have a specific finding format that helps you understand the details of each finding. You can examine the Threat Purpose section of the GuardDuty finding types to see finding types associated with various MITRE ATT&CK tactics, including CredentialAccess and Discovery. This can help you identify and understand the type of activity associated with a finding.
For example, consider two finding types that seem similar: CredentialAccess:RDS/MaliciousIPCaller.SuccessfulLoginand Discovery:RDS/MaliciousIPCaller. The difference between them is the ThreatPurpose aspect, located at the beginning of the finding type. GuardDuty has determined that both are involved with MaliciousIPCaller, and the difference is the intent of the activity associated with each finding. CredentialAccess SuccessfulLogin indicates that there was a successful login to your RDS database from a known malicious IP address. Discovery indicates that a threat actor opened a connection to the database, but didn’t attempt to authenticate. This indicates scanning behavior, but it might not be targeted at RDS instances. For more information, see GuardDuty RDS Protection finding types.
GuardDuty uses threat intelligence and machine learning to continually monitor and identify potential threats in your environment. To understand how to investigate RDS Protection finding types, you need to understand the details of a finding type that are derived from machine learning. As shown in Figure 2, RDS Protection finding types have two sections: one that shows the unusual behavior and one that shows the normal, historical behavior. To determine this, GuardDuty uses machine learning models to evaluate API requests to your account and identify anomalous events that are associated with tactics used by adversaries. The machine learning model tracks various factors of the API request, such as the user that made the request, the location the request was made from, and the specific API that was requested. It also looks at information such as successfulLoginCount, failedLoginCount, and incompleteConnectionCount for anomalies based on login activity. For more information about anomalous activity in GuardDuty findings, see Anomalous behavior.
With RDS Protection, you now have an additional mechanism to gain insight into your Amazon RDS databases across your accounts to continuously monitor for suspicious activity. RDS Protection can alert you to suspicious activity in Amazon RDS, such as a potentially suspicious or anomalous login attempt, unusual pattern in a series of successful, failed, or incomplete login attempts, and unauthorized access to your database instance from a previously unseen internal or external actor. With this new feature, GuardDuty also extends support for finding types that you might already be familiar with that also apply to RDS databases. These finding types include calls to an RDS database API from a Tor node, or calls to an RDS database from a known malicious IP address, which can indicate that there are interactions with your RDS database from sources that are associated with known malicious activity.
Remediate RDS Protection findings
In this section, we describe two RDS Protection findings and how you can investigate and remediate them. Understanding how to remediate these findings can help you maintain the integrity of your database. We share recommendations that focus specifically on security groups, network access control lists (network ACLs), and firewall rules.
The CredentialAccess:RDS/AnomalousBehavior.SuccessfulLogin finding informs you that an anomalous successful login was observed on an RDS database in your AWS environment. It might indicate that a previous unseen user logged in to an RDS database for the first time. A common scenario involves an internal user logging in to a database that is accessed programmatically by applications and not by individual users. A potential malicious actor might have compromised and accessed the role on your RDS database. The default Severity for this finding varies, depending on the anomalous behavior associated with the finding.
Figure 3 shows an example of this finding.
Figure 3: Finding of an anomalous behavior successful login
How to remediate
If the activity is unexpected for the associated database, AWS recommends that you change the password of the associated database user, and review available audit logs for activity that the user performed. Medium and high severity findings might indicate an overly permissive access policy to the database, and user credentials might have been exposed or compromised. We recommend that you place the database in a private virtual private cloud (VPC), and limit the security group rules to allow traffic only from necessary sources. For more information, see Remediating potentially compromised database with successful login events.
We recommend that you take the following steps to remediate this finding:
Remediation step 1: Identify the affected database and user
Identify the affected database and user and confirm whether the behavior is expected or unexpected by looking through the GuardDuty finding details, which provide the name of the affected database instance and the corresponding user details. Use the findings to confirm if the behavior is expected or not—for example, the findings might help you identify a user who logs in to their database instance after a long time has passed; a user who logs in to their database instance only occasionally, such as a financial analyst who logs in each quarter; or a suspicious actor who is involved in a successful login attempt that isn’t authorized and potentially compromises the database instance. Review the IP address of the finding. Public IP addresses might signify overly permissive access if it’s not a known network associated with your account.
Figure 4: Finding with details showing Amazon RDS database instance and user details
If the behavior is unexpected, complete the following steps:
Restrict database instance access for the suspected accounts and the source of the login activity. For more information, see Remediating potentially compromised credentials and Restrict network access. You can identify the user in the RDS DB user details section within the finding panel in the console, or within the resource.rdsDbUserDetails of the findings JSON. These user details include user name, application used, database accessed, SSL version, and authentication method.
The following CLI command is an example of how to revoke access to a user in a MySQL database. If the behavior is unexpected, you can revoke the privileges while you assess if the user is malicious.
REVOKE CONNECTION_ADMIN ON *.* FROM 'fakeadmin'@'%';
You can revoke privileges from the user, but when taking this action, you should make sure that the user isn’t vital to your system and that revoking permissions won’t break your production or development application. The following CLI command is an example of how to revoke privileges from a user:
REVOKE ALL PRIVILEGES ON *.* FROM 'fakeadmin'@'%';
If you know that the user isn’t necessary for your database or application to function, then you can remove the user from the system. To make sure that your security team can run forensics, check your company’s incident response policy. If you need help getting started with incident response, see AWS sample incident response playbooks. The following CLI command is an example of how to remove a user:
DROP USER 'fakeadmin'@'%';
Let’s say that you find the behavior unexpected, but the user turns out to be the application user, and making a change to the database credential will break your application. You can use AWS Systems Manager to help in this scenario, in which the affected RDS user is the account that is tied to your application. In many cases, a password rotation can break your application, depending on how you connect. If you rotate the password without notifying your application, the application might require additional cascading changes. You could lose connectivity to your application because the credentials that your application is using to connect to your database didn’t change, and now you are experiencing an outage that will remain until you update the credentials. Systems Manager can tie into your application code to automatically update the rotated database credentials in your application. For more information, see Rotate Amazon RDS database credentials automatically with AWS Secrets Manager.
The following figure shows a CLI command to get a secret from Secrets Manager — for this example, we assume the secret is compromised.
Figure 5: Example compromised credentials
The following figures shows that we have a new set of credentials that replace our old credentials, as indicated by “CreatedDate”.
Figure 6: Example remediated credentials
Remediation step 3: Assess the impact and determine what information was accessed
To learn how to restrict IP access on a security group, see Control traffic to resources using security groups. You can identify the user in the RDS DB user details section within the finding panel in the console, or within the resource.rdsDbUserDetails of the findings JSON. These user details include user name, application used, database accessed, SSL version, and authentication method.
Remediation step 5: Perform root-cause analysis and determine the steps that potentially led to this activity
Implementing a lessons-learned framework and methodology can help improve your incident response capabilities and also help prevent the incident from recurring. By learning from each incident, you can help avoid repeating the same mistakes, exposures, or misconfigurations, which can both improve your security posture and reduce the time lost to preventable situations. To learn more about post-incident activity, see AWS Security Incident Response Guide.
The CredentialAccess:RDS/AnomalousBehavior.successfulBruteForce finding informs you that an anomalous login occurred that is indicative of a successful brute force event, as observed on an RDS database in your AWS environment. Before the anomalous successful login, a consistent pattern of unusual failed login attempts was observed. This indicates that the user and password associated with the RDS database in your account might have been compromised, and a potentially malicious actor might have accessed the RDS database. The Severity of this finding is high. Figure 7 shows an example of this finding.
Figure 7: Example of an anomalous successful brute force finding
How to remediate
This activity indicates that database credentials might have been exposed or compromised. We recommend that you change the password of the associated database user, and review available audit logs for activity performed by the potentially compromised user. A consistent pattern of unusual failed login attempts indicates an overly permissive access policy to the database, or that the database might also have been publicly exposed. AWS recommends that you place the database in a private VPC, and limit the security group rules to allow traffic only from necessary sources. For more information, see Remediating potentially compromised database with successful login events.
We recommend that you take the following steps to remediate this finding
Remediation step 1: Identify the affected database and user
The generated GuardDuty finding provides the name of the affected database instance and the corresponding user details. For more information, see Finding details.
Figure 8: Finding details showing Amazon RDS database instance and user details
Remediation step 2: Identify the source of the failed login attempts
In the generated GuardDuty finding, you can find the IP address, and if it was a public connection, the ASN organization in the Actor section of the finding panel. An autonomous system is a group of one or more IP prefixes (lists of IP addresses accessible on a network) run by one or more network operators that maintain a single, clearly-defined routing policy. Network operators need autonomous system numbers (ASNs) to control routing within their networks and to exchange routing information with other internet service providers.
Figure 9: Action and actor details related to GuardDuty brute force finding
Remediation step 3: Confirm that the behavior is unexpected
Examine if this activity represents an attempt to gain additional unauthorized access to the database instance as follows:
If the source is internal to your network, examine if an application is misconfigured and attempting a connection repeatedly.
If this is an external actor, examine whether the corresponding database instance is public facing or is misconfigured and thus allowing potential malicious actors to attempt to log in with common user names.
If the behavior is unexpected, complete the following steps:
As discussed previously for the CredentialAccess:RDS/AnomalousBehavior.SuccessfulLogin finding, you can restrict access to the database through credentials or network access:
Remediation step 5: Perform root-cause analysis and determine the steps that potentially led to this activity
By learning from each incident, you can help avoid repeating the same mistakes, exposures, or misconfigurations, which can both improve your security posture and reduce time lost to preventable situations.
Conclusion
In this post, you learned about the new GuardDuty RDS Protection feature and how to understand, operationalize, and respond to the new findings. You can enable this feature through the GuardDuty console, CLI, or APIs to start monitoring your Amazon RDS workloads today.
If you’ve created EventBridge rules to send findings from GuardDuty to a target, make sure that you’ve configured your rules to deliver the newly added findings. After you enable GuardDuty findings, consider creating IR playbooks, doing tabletops and AWS gamedays, and mapping out what you want to automate. For more information, see the AWS Security Incident Response Guide and AWS Incident Response Playbook resources. To gain hands-on experience with different AWS Security services, see AWS Activation Days. The Activation Days workshops begin with hands-on work with different services in sandbox accounts, and then take you through the steps to deploy them across your organization.
To make it more efficient for you to operate securely on AWS, we are committed to continually improving GuardDuty, and we value your feedback. If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on AWS re:Post or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
AWS is pleased to announce the publication of a checklist to help customers align with the requirements of the European Union’s electronic identification, authentication, and trust services (eIDAS) regulation regarding the use of electronic identities and trust services. The eIDAS regulation covers electronic identification and trust services for electronic transactions in the European single market.
This checklist is intended as a reference and supporting document to help institutions align with the requirements of eIDAS and the European Telecommunications Standards Institute (ETSI). Where applicable, under the AWS Shared Responsibility Model, this checklist provides supporting details and references in relation to AWS to assist institutions when adopting eIDAS and ETSI for their workloads on AWS services.
For the controls that AWS is fully or partially responsible for, the checklist compares the eIDAS and ETSI requirements to the following:
This checklist is valid until the current eIDAS EU regulation 910/2014, published July 23rd, 2014, ceases to be in force. The checklist is available upon request.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
A full conference pass is $1,099. Register today with the code secure150off to receive a limited time $150 discount, while supplies last.
AWS re:Inforce 2023 is fast approaching, and this post can help you plan your agenda with a look at the sessions in the identity and access management track. AWS re:Inforce is a learning conference where you can learn more about cloud security, compliance, identity, and privacy. You have access to hundreds of technical and non-technical sessions, an AWS Partner expo featuring security partners with AWS Security Competencies, and keynote and leadership sessions featuring AWS Security leadership. AWS re:Inforce 2023 will take place in-person in Anaheim, California, on June 13 and 14. re:Inforce 2023 features content in the following six areas:
The identity and access management track will share recommended practices and learnings for identity management and governance in AWS environments. You will hear from other AWS customers about how they are building customer identity and access management (CIAM) patterns for great customer experiences and new approaches for managing standard, elevated, and privileged workforce access. You will also hear from AWS leaders about accelerating the journey to least privilege with access insights and the role of identity within a Zero Trust architecture.
This post highlights some of the identity and access management sessions that you can sign up for, including breakout sessions, chalk talks, code talks, lightning talks, builders’ sessions, and workshops. For the full catalog, see the AWS re:Inforce catalog preview.
Breakout sessions
Lecture-style presentations that cover topics at all levels and delivered by AWS experts, builders, customers, and partners. Breakout sessions typically include 10–15 minutes of Q&A at the end.
IAM201: A first-principles approach: AWS Identity and Access Management (IAM) Learning how to build effectively and securely on AWS starts with a strong working knowledge of AWS Identity and Access Management (IAM). In this session aimed at engineers who build on AWS, explore a no-jargon, first-principles approach to IAM. Learn the fundamental concepts of IAM authentication and authorization policies as well as concrete techniques that you can immediately apply to the workloads you run on AWS.
IAM301: Establishing a data perimeter on AWS, featuring USAA In this session, dive deep into the data perimeter controls that help you manage your trusted identities and their access to trusted resources from expected networks. USAA shares how they use automation to embed security and AWS Identity and Access Management (IAM) baselines to empower a self-service mindset. Learn how they use data perimeters to support decentralization without compromising on security. Also, discover how USAA uses a threat-based approach to prioritize implementation of specific data perimeters.
IAM302: Create enterprise-wide preventive guardrails, featuring Inter & Co. In this session, learn how to establish permissions guardrails within your multi-account environment with AWS Organizations and service control policies (SCPs). Explore how effective use of SCPs can help your builders innovate on AWS while maintaining a high bar on security. Learn about the strategies to incorporate SCPs at different levels within your organization. In addition, Inter & Co. share their strategies for implementing enterprise-wide guardrails at scale within their multi-account environments. Discover how they use code repositories and CI/CD pipelines to manage approvals and deployments of SCPs.
IAM303: Balance least privilege & agile development, feat. Fidelity & Merck Finding a proper balance between securing multiple AWS accounts and enabling agile development to accelerate business innovation has been key to the cloud adoption journey for AWS customers. In this session, learn how Fidelity and Merck empowered their business stakeholders to quickly develop solutions while still conforming to security standards and operating within the guardrails at scale.
IAM304: Migrating to Amazon Cognito, featuring approaches from Fandango Digital transformation of customer-facing applications often involves changes to identity and access management to help improve security and user experience. This process can benefit from fast-growing technologies and open standards and may involve migration to a modern customer identity and access management solution, such as Amazon Cognito, that offers the security and scale your business requires. There are several ways to approach migrating users to Amazon Cognito. In this session, learn about options and best practices, as well as lessons learned from Fandango’s migration to Amazon Cognito.
IAM305: Scaling access with AWS IAM Identity Center, feat. Allegiant Airlines In this session, learn how to scale assignment of permission sets to users and groups by automating federated role-based access to any AWS accounts in your organization. As a highlight of this session, hear Allegiant Airlines’ success story of how this automation has benefited Allegiant by centralizing management of federated access for their organization of more than 5,000 employees. Additionally, explore how to build this automation in your environment using infrastructure as code tools like Terraform and AWS CloudFormation using a CI/CD pipeline.
IAM306: Managing hybrid workloads with IAM Roles Anywhere, featuring Hertz A key element of using AWS Identity and Access Management (IAM) Roles Anywhere is managing how identities are assigned to your workloads. In this session, learn how you can define and manage identities for your workloads, how to use those identities to control access to an AWS resource via attribute-based access control (ABAC), and how to monitor and audit activities performed by those identities. Discover key concepts, best practices, and troubleshooting tips. Hertz describes how they used IAM Roles Anywhere to secure access to AWS services from Salesforce and how it has improved their overall security posture.
IAM307: Steps towards a Zero Trust architecture on AWS Modern workplaces have evolved beyond traditional network boundaries as they have expanded to hybrid and multi-cloud environments. Identity has taken center stage for information security teams. The need for fine-grained, identity-based authorization, flexible identity-aware networks, and the removal of unneeded pathways to data has accelerated the adoption of Zero Trust principles and architecture. In this session, learn about different architecture patterns and security mechanisms available from AWS that you can apply to secure standard, sensitive, and privileged access to your critical data and workloads.
Builders’ sessions
Small-group sessions led by an AWS expert who guides you as you build the service or product on your own laptop. Use your laptop to experiment and build along with the AWS expert.
IAM351: Sharing resources across accounts with least-privilege permissions Are you looking to manage your resource access control permissions? Learn how you can author customer managed permissions to provide least-privilege access to your resources shared using AWS Resource Access Manager (AWS RAM). Explore how to use customer managed permissions with use cases ranging from managing incident response with AWS Systems Manager Incident Manager to enhancing your IP security posture with Amazon VPC IP Address Manager.
IAM352: Cedar policy language in action Cedar is a language for defining permissions as policies that describe who should have access to what. Amazon Verified Permissions and AWS Verified Access use Cedar to define fine-grained permissions for applications and end users. In this builders’ session, come learn by building Cedar policies for access control.
IAM355: Using passwordless authentication with Amazon Cognito and WebAuthn In recent years, passwordless authentication has been on the rise. The FIDO Alliance, a first-mover for enabling passwordless in 2009, is an open industry association whose stated mission is to develop and promote authentication standards that “help reduce the world’s over-reliance on passwords.” This builders’ session allows participants to learn about and follow the steps to implement a passwordless authentication experience on a web or mobile application using Amazon Cognito.
IAM356: AWS Identity and Access Management (IAM) policies troubleshooting In this builders’ session, walk through practical examples that can help you build, test, and troubleshoot AWS Identity and Access Management (IAM) policies. Utilize a workflow that can help you create fine-grained access policies with the help of the IAM API, the AWS Management Console, and AWS CloudTrail. Also review key concepts of IAM policy evaluation logic.
Chalk talks
Highly interactive sessions with a small audience. Experts lead you through problems and solutions on a digital whiteboard as the discussion unfolds.
IAM231: Lessons learned from AWS IAM Identity Center migrations In this chalk talk, discover best practices and tips to migrate your workforce users’ access from IAM users to AWS IAM Identity Center (successor to AWS Single Sign-On). Learn how to create preventive guardrails, gain visibility into the usage of IAM users across an organization, and apply authentication solutions for common use cases.
IAM331: Leaving IAM access keys behind: A modern path forward Static credentials have been used for a long time to secure multiple types of access, including access keys for AWS Identity and Access Management (IAM) users, command line tools, secure shell access, application API keys, and pre-shared keys for VPN access. However, best practice recommends replacing static credentials with short-term credentials. In this chalk talk, learn how to identify static access keys in your environment, quantify the risk, and then apply multiple available methods to replace them with short-term credentials. The talk also covers prescriptive guidance and best practice advice for improving your overall management of IAM access keys.
IAM332: Practical identity and access management: The basics of IAM on AWS Learn from prescriptive guidance on how to build an Identity and Access Management strategy on AWS. We provide guidance on human access versus machine access using services like IAM Identity Center. You will also learn about the different IAM policy types, where each policy type is useful, and how you should incorporate each policy type in your AWS environment. This session will walk you through what you need to know to build an effective identity and access management baseline.
IAM431: A tour of the world of IAM policy evaluation This session takes you beyond the basics of IAM policy evaluation and focuses on how policy evaluation works with advanced AWS features. Hear about how policies are evaluated alongside AWS Key Management Service (AWS KMS) key grants, Amazon Simple Storage Service (Amazon S3) and Amazon Elastic File System (Amazon EFS) access points, Amazon VPC Lattice, and more. You’ll leave this session with prescriptive guidance on what to do and what to avoid when designing authorization schemes.
Code talks
Engaging, code-focused sessions with a small audience. AWS experts lead an interactive discussion featuring live coding and/or code samples as they explain the “why” behind AWS solutions.
IAM341: Cedar: Fast, safe, and fine-grained access for your applications Cedar is a new policy language that helps you write fine-grained permissions in your applications. With Cedar, you can customize authorization and you can define and enforce who can access what. This code talk explains the design of Cedar, how it was built to a high standard of assurance, and its benefits. Learn what makes Cedar ergonomic, fast, and analyzable: simple syntax for expressing common authorization use cases, policy structure that allows for scalable real-time evaluation, and comprehensive auditing based on automated reasoning. Also find out how Cedar’s implementation was made safer through formal verification and differential testing.
IAM441: Enable new Amazon Cognito use cases with OAuth2.0 flows Delegated authorization without user interaction on a consumer device and reinforced passwordless authentication for higher identity assurance are advanced authentication flows achievable with Amazon Cognito. In this code talk, you can discover new OAuth2.0 flow diagrams, code snippets, and long and short demos that offer different approaches to these authentication use cases. Gain confidence using AWS Lambda triggers with Amazon Cognito, native APIs, and OAuth2.0 endpoints to help ensure greater success in customer identity and access management strategy.
Lightning talks
Short and focused theater presentations that are dedicated to either a specific customer story, service demo, or partner offering (sponsored).
IAM221: Accelerate your business with AWS Directory Service In this lightning talk, explore AWS Directory Service for Microsoft Active Directory and discover a number of use cases that provide flexibility, empower agile application development, and integrate securely with other identity stores. Join the talk to discover how you can take advantage of this managed service and focus on what really matters to your customers.
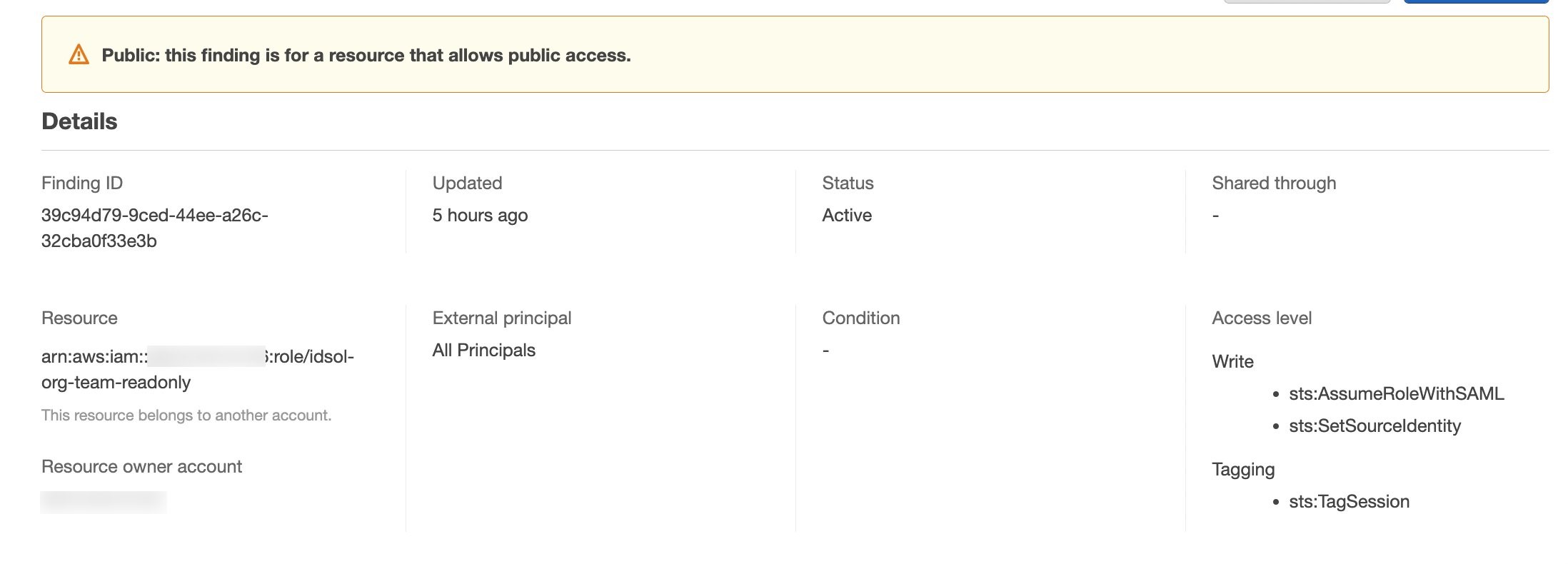
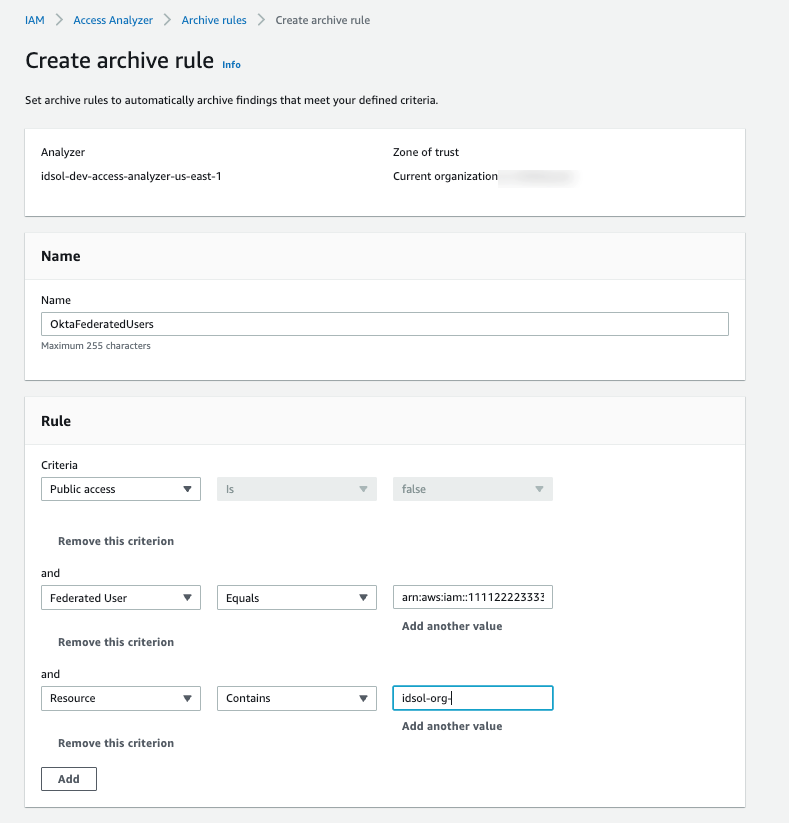
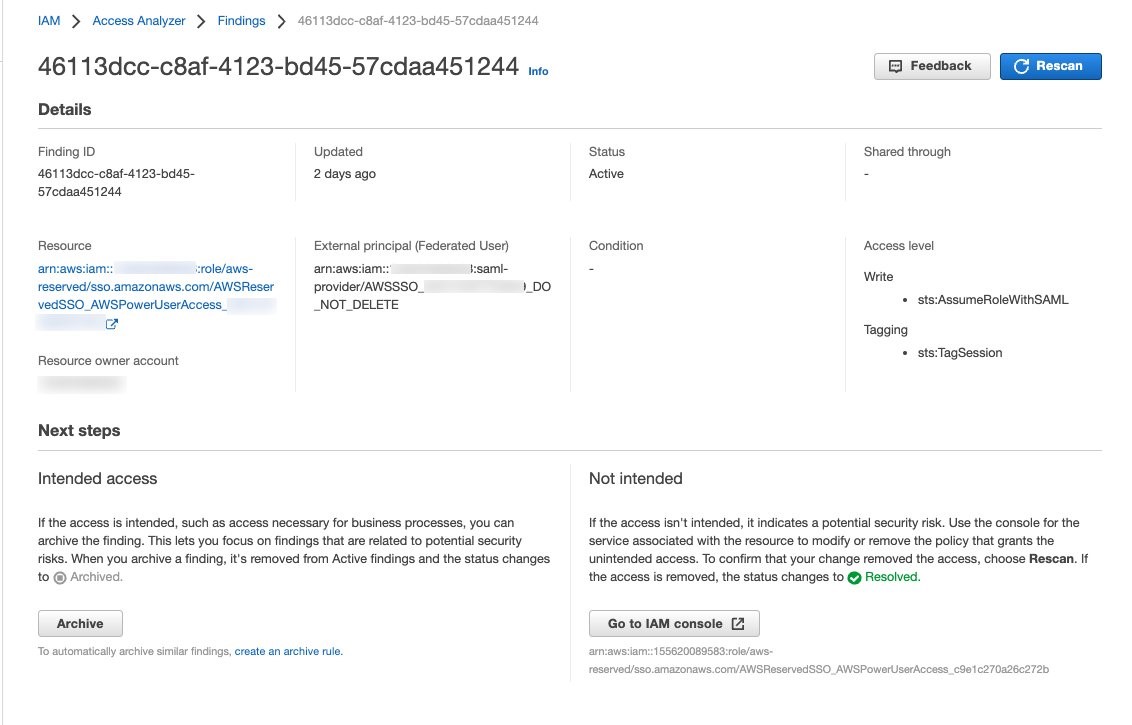
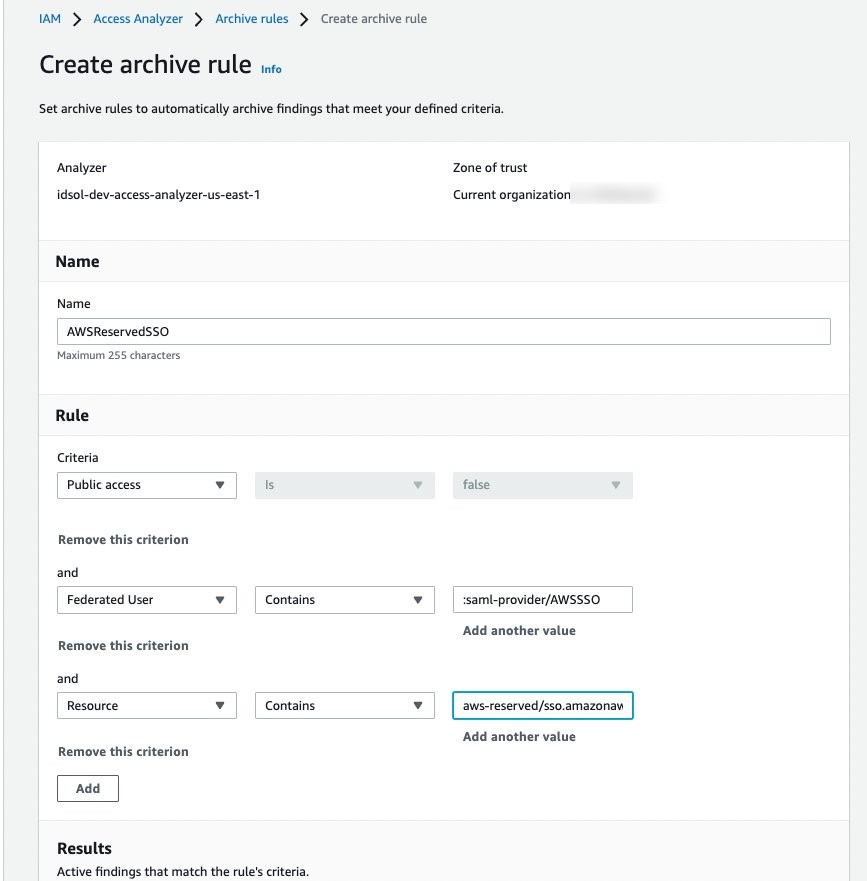
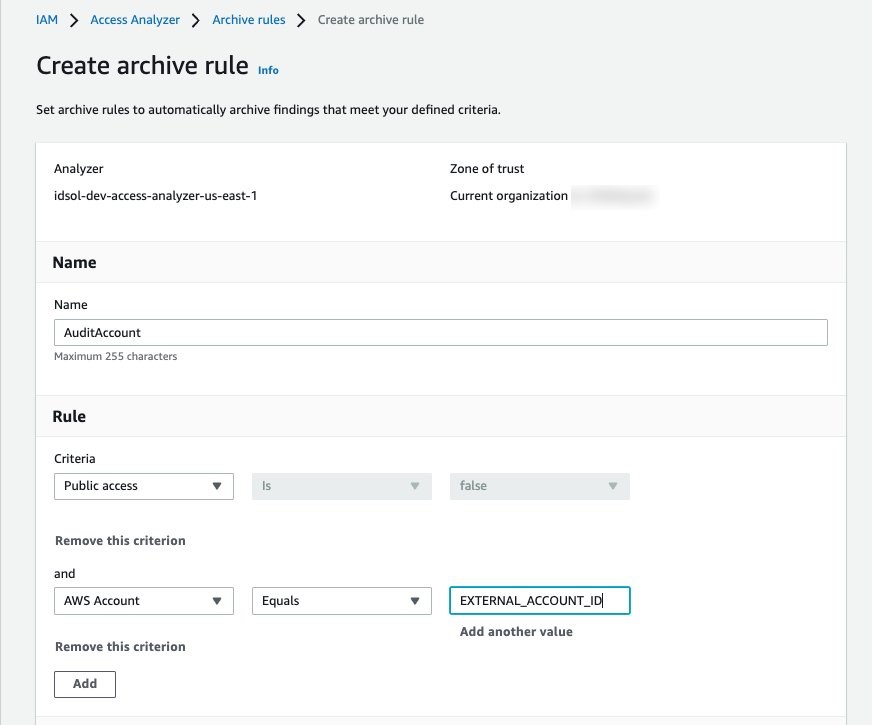
IAM321: Move toward least privilege with IAM Access Analyzer AWS Identity and Access Management (IAM) Access Analyzer provides tools that simplify permissions management by making it easy for organizations to set, verify, and refine permissions. In this lightning talk, dive into how you can detect resources shared with an external entity across one or multiple AWS accounts with IAM Access Analyzer. Find out how you can activate and use this feature and how it integrates with AWS Security Hub.
Workshops
Interactive learning sessions where you work in small teams to solve problems using AWS Cloud security services. Come prepared with your laptop and a willingness to learn!
IAM371: Building a Customer Identity and Access Management (CIAM) solution How do your customers access your application? Get a head start on customer identity and access management (CIAM) by using Amazon Cognito. Join this workshop to learn how to build CIAM solutions on AWS using Amazon Cognito, Amazon Verified Permissions, and several other AWS services. Start from the basic building blocks of CIAM and build up to advanced user identity and access management use cases in customer-facing applications.
IAM372: Consuming AWS Resources from everywhere with IAM Roles Anywhere If your workload already lives on AWS, then there is a high chance that some temporary AWS credentials have been securely distributed to perform needed tasks. But what happens when your workload is on premises? In this workshop, learn how to use AWS Identity and Access Management (IAM) Roles Anywhere. Start from the basics and create the necessary steps to learn how to use your applications outside of AWS in a safe way using IAM Roles Anywhere in practice.
IAM373: Building a data perimeter to allow access to authorized users In this workshop, learn how to create a data perimeter by building controls that allow access to data only from expected network locations and by trusted identities. The workshop consists of five modules, each designed to illustrate a different AWS Identity and Access Management (IAM) principle or network control. Learn where and how to implement the appropriate controls based on different risk scenarios.
If these sessions look interesting to you, join us in Anaheim by registering for AWS re:Inforce 2023. We look forward to seeing you there!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In today’s evolving security threat landscape, security teams increasingly require tools to detect and track security findings to protect their organizations’ assets. One objective of cloud security posture management is to identify and address security findings in a timely and effective manner. AWS Security Hub aggregates, organizes, and prioritizes security alerts and findings from various AWS services and supported security solutions from the AWS Partner Network.
As the volume of findings increases, tracking the changes and actions that have been taken on each finding becomes more difficult, as well as more important to perform timely and effective investigations. In this post, we will show you how to use the new Finding History feature in Security Hub to track and understand the history of a security finding.
Updates to findings occur when finding providers update certain fields, such as resource details, by using the BatchImportFindings API. You, as a user, can update certain fields, such as workflow status, in the AWS Management Console or through the BatchUpdateFindings API. Ticketing, incident management, security information and event management (SIEM), and automatic remediation solutions can also use the BatchUpdateFindings API to update findings. This new capability highlights these various changes and when they occurred so that you don’t need to investigate this yourself.
Finding History
The new Finding History feature in Security Hub helps you understand the state of a finding by providing an immutable history of changes within the finding details. By using this feature, you can track the history of each finding, including the before and after values of the fields that were changed, who or what made the changes, and when the changes were made. This simplifies how you operate on a finding by giving you visibility into the changes made to a finding over time, alongside the rest of the finding details, which removes the need for separate tooling or additional processes. This feature is available at no additional cost in AWS Regions where Security Hub is available, and appears by default for new or updated findings. Finding History is also available through the Security Hub APIs.
To try out this new feature, open the Security Hub console, select a finding, and choose the History tab. There you will see a chronological list of changes that have been made to the finding. The transparency of the finding history helps you quickly assess the status of the finding, understand actions already taken, and take the necessary actions to mitigate risk. For example, upon resolving a finding, you can add a note to the finding to indicate why you resolved it. Both the resolved status and note will appear in the history.
In the following example, the finding was updated and then resolved with an explanatory note left by the person that reviewed the finding. With Finding History, you can see the previous updates and events in the finding’s History tab.
Figure 1: Finding History shows recent updates to the finding
In addition, you can still view the current state of the finding in its Details tab.
Figure 2: Finding Details shows the record of a security check or security-related detection
Conclusion
With the new Finding History feature in Security Hub, you have greater visibility into the activity and updates on each finding, allowing for more efficient investigation and response to potential security risks. Next time that you start work to investigate and respond to a security finding in Security Hub, begin by checking the finding history.
At AWS, earning and maintaining customer trust is the foundation of our business. We understand that protecting customer data is key to achieving this. We also know that trust must continue to be earned through transparency and assurances.
In November 2022, we announced the new AWS Digital Sovereignty Pledge, our commitment to offering all AWS customers the most advanced set of sovereignty controls and features available in the cloud. Two pillars of this are verifiable control over data access, and the ability to encrypt everything everywhere. We already offer a range of data protection features, accreditations, and contractual commitments that give customers control over where they locate their data, who can access it, and how it is used. Today, I’d like to update you on how we are continuing to earn your trust with verifiable control over customer data access and external control of your encryption keys.
AWS Nitro System achieves independent third-party validation
We are committed to helping our customers meet evolving sovereignty requirements and providing greater transparency and assurances to how AWS services are designed and operated. With the AWS Nitro System, which is the foundation of AWS computing service Amazon EC2, we designed and delivered first-of-a-kind innovation by eliminating any mechanism AWS personnel have to access customer data on Nitro. Our removal of an operator access mechanism was unique in 2017 when we first launched the Nitro System.
As we continue to deliver on our digital sovereignty pledge of customer control over data access, I’m excited to share with you an independent report on the security design of the AWS Nitro System. We engaged NCC Group, a global cybersecurity consulting firm, to conduct an architecture review of our security claims of the Nitro System and produce a public report. This report confirms that the AWS Nitro System, by design, has no mechanism for anyone at AWS to access your data on Nitro hosts. The report evaluates the architecture of the Nitro System and our claims about operator access. It concludes that “As a matter of design, NCC Group found no gaps in the Nitro System that would compromise these security claims.” It also goes on to state, “NCC Group finds…there is no indication that a cloud service provider employee can obtain such access…to any host.” Our computing infrastructure, the Nitro System, has no operator access mechanism, and now is supported by a third-party analysis of those data controls. Read more in the NCC Group report.
New AWS Service Term
At AWS, security is our top priority. The NCC report shows the Nitro System is an exceptional computing backbone for AWS, with security at its core. The Nitro controls that prevent operator access are so fundamental to the Nitro System that we’ve added them in our AWS Service Terms, which are applicable to anyone who uses AWS.
Our AWS Service Terms now include the following on the Nitro System:
AWS personnel do not have access to Your Content on AWS Nitro System EC2 instances. There are no technical means or APIs available to AWS personnel to read, copy, extract, modify, or otherwise access Your Content on an AWS Nitro System EC2 instance or encrypted-EBS volume attached to an AWS Nitro System EC2 instance. Access to AWS Nitro System EC2 instance APIs – which enable AWS personnel to operate the system without access to Your Content – is always logged, and always requires authentication and authorization.
External control of your encryption keys with AWS KMS External Key Store
As part of our promise to continue to make the AWS Cloud sovereign-by-design, we pledged to continue to invest in an ambitious roadmap of capabilities, which includes our encryption capabilities. At re:Invent 2022, we took further steps to deliver on this roadmap of encrypt everything everywhere with encryption keys managed inside or outside the AWS Cloud by announcing the availability of AWS Key Management Service (AWS KMS)External Key Store (XKS). This innovation supports our customers who have a regulatory need to store and use their encryption keys outside the AWS Cloud. The open source XKS specification offers customers the flexibility to adapt to different HSM deployment use cases. While AWS KMS also prevents AWS personnel from accessing customer keys, this new capability may help some customers demonstrate compliance with specific regulations or industry expectations requiring storage and use of encryption keys outside of an AWS data center for certain workloads.
In order to accelerate our customers’ ability to adopt XKS for regulatory purposes, we collaborated with external HSM, key management, and integration service providers that our customers trust. To date, Thales, Entrust, Fortanix, DuoKey, and HashiCorp have launched XKS implementations, and Salesforce, Atos, and T-Systems have announced that they are building integrated service offerings around XKS. In addition, many SaaS solutions offer integration with AWS KMS for key management of their encryption offerings. Customers using these solutions, such as the offerings from Databricks, MongoDB, Reltio, Slack, Snowflake, and Zoom, can now utilize keys in external key managers via XKS to secure data. This allows customers to simplify their key management strategies across AWS as well as certain SaaS solutions by providing a centralized place to manage access policies and audit key usage.
We remain committed to helping our customers meet security, privacy, and digital sovereignty requirements. We will continue to innovate sovereignty features, controls, and assurances within the global AWS Cloud and deliver them without compromise to the full power of AWS.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Amazon Inspector is a vulnerability management and application security service that helps improve the security of your workloads. It automatically scans applications for vulnerabilities and provides you with a detailed list of security findings, prioritized by their severity level, as well as remediation instructions. In this blog post, we’ll introduce new features from Amazon Inspector that can help you improve the security posture of your AWS Lambda functions.
At re:Invent 2022, Amazon Inspector announced the ability to perform automated security scans of the application package dependencies and associated layers in your Lambda functions. This adds to the existing ability to scan Amazon Elastic Compute Cloud (Amazon EC2) instances and container images in the Amazon Elastic Container Registry (Amazon ECR). The list of operating systems and programming languages that are supported for scanning is available in the Amazon Inspector documentation. On February 28, 2023, Amazon Inspector also announced a new feature, in public preview, to scan your application code in Lambda functions for vulnerabilities. This new feature uses the Detector Library from Amazon CodeGuru to scan your Lambda code. For more details on how the service scans your code, see the Amazon Inspector documentation.
Security is the top priority at AWS. For Lambda, our serverless compute offering, we released a whitepaper that goes into more detail about the security underpinnings of the service. It is important to highlight some differences in the model between infrastructure services such as Amazon EC2 and serverless options such as Lambda. Given the serverless nature of Lambda, besides the infrastructure, AWS also manages the Firecracker microVM software patches, the execution environment, and runtimes. Meanwhile, customers are responsible for using AWS Identity and Access Management (IAM) to create roles and permissions for their Lambda functions and for securing their code that is used with Lambda.
Activate Amazon Inspector
Let’s go over the steps for activating Amazon Inspector.
First, if you’re an existing Amazon Inspector customer, you can enable the new Lambda features from the Amazon Inspector console.
To enable Lambda scanning from the Amazon Inspector console
In the left navigation pane, expand the Settings section, and choose Account Management.
On the Accounts tab, choose Activate, and then select one of two options:
Lambda standard scanning — With this option enabled, Amazon Inspector only scans for package dependencies in your Lambda functions and associated layers.
Lambda standard scanning and Lambda code scanning — With this option enabled, Amazon Inspector scans for package dependencies and also scans your proprietary application code in Lambda for code vulnerabilities. The code scanning feature is only available in certain AWS Regions.
If you’re a new Amazon Inspector customer, we encourage you to try the service by enabling the 15-day free trial, which includes both Lambda function standard scanning and, if available in your Region, code scanning. Figure 1 shows how the Account Management section of the Amazon Inspector console will look, after you enable both features for Lambda. You also have the ability to exclude Lambda functions from being scanned by using AWS tags, as explained in the Amazon Inspector documentation.
Note: The Export CSV button in Figure 1 will be displayed only when you are logged in as the designated Inspector delegated administrator in the Region.
Figure 1: Amazon Inspector account management area
Let’s see these features in action.
To view security findings in the console
In the Amazon Inspector console, on the Findings menu, choose By Lambda function to display the security scan results that were performed on Lambda functions.
You won’t see Lambda functions in the findings if there are no potential vulnerabilities detected by Amazon Inspector. Amazon Inspector discovers eligible Lambda functions in near real time when it is deployed to Lambda and automatically scans the function code and dependencies. For more details on how Lambda functions are scanned, see the Amazon Inspector documentation.
Package vulnerability findings examples
As an example, we will walk through a simple Node.js 12 application. Figure 2 shows a sample Lambda function for which Amazon Inspector generated findings.
Figure 2: Lambda function finding summary
Amazon Inspector found three findings marked with a severity rating of High or Medium, shown in Figure 3. Amazon Inspector detects software vulnerabilities in Lambda functions and categorizes them as type Package Vulnerability (a vulnerable package in Lambda functions or associated layers) or Code Vulnerability (code vulnerabilities in custom code written by a developer – this does not include third-party dependencies, because these are covered under package vulnerabilities). The three findings in Figure 3 are of type Package Vulnerability, and when you choose the Common Vulnerabilities and Exposures (CVE) title, you can find more details about the vulnerability and its status
Figure 3: Amazon Inspector findings for a sample Lambda function
Each Lambda function can have up to five layers (at the time of this writing). A layer is a .zip file archive that can contain additional code or data. Amazon Inspector will also scan the functions’ available layers, and the findings from these scans will be available on the Layers tab, as shown in Figure 4.
Figure 4: Amazon Inspector findings for Lambda Layers
Amazon Inspector sources the data for its vulnerability intelligence database from more than 50 data feeds to generate its CVE findings. Let’s dive deeper into one finding from the sample application—for instance, the CVE-2021-43138-async package shown in Figure 5. The description of the CVE gives a high-level overview of the vulnerability, along with a CVE score to determine the severity.
Figure 5: CVE-2021-43138 finding details
The Amazon Inspector score assigned to the vulnerability will be affected by details such as whether an exploit is available. Amazon Inspector also uses the network reachability of the function as one of its score parameters. This helps you triage your findings appropriately to focus on the functions that could be most vulnerable.
Amazon Inspector will also provide you with remediation instructions for the vulnerable package, if available. In Figure 6, the recommendation to address this particular finding is to upgrade the async package to 3.2.2 to mitigate the vulnerability.
Figure 6: Remediation instructions for the sample application finding
Code vulnerability findings examples
Now let’s look at the new code scanning feature of Amazon Inspector. With this release, Amazon Inspector reviews the security and quality of the code written in your Lambda functions. To do this, the service uses the Amazon CodeGuru Detector Library, which has trained data across millions of code reviews, to generate findings. Amazon Inspector scans the Lambda function code to detect security flaws like cross-site scripting, injection flaws, data leaks, log injection, OS command injections, and other risk categories in the OWASP Top 10 and CWE Top 25. When you enable code scanning, you can focus on building your application while also following current security recommendations. At the time of this writing, Amazon Inspector supports scanning Java, Node.js, Python, and Go Lambda runtimes. For a full list of supported programming language runtimes, see the Amazon Inspector documentation.
As a demonstration of the Amazon Inspector code scanning feature, let’s take the simple Python Lambda function shown following, which accidentally overrides the Lambda reserved environment variables and also has an open-to-all socket connection.
Overriding reserved environment variables might lead to unexpected behavior or failure of the Lambda function. You can learn more about this vulnerability by reviewing the Detector Library documentation. Similarly, a socket connection without an IP address opens the connection to all entities, allowing the function code to potentially access public IPv4 addresses from within the code. There can be external dependencies in your code, which might reuse the insecure socket connection. To learn more about insecure socket binds, see the Detector Library documentation.
As shown in Figure 7, Amazon Inspector automatically detects these vulnerabilities and tags them as Code Vulnerability, which indicates that the vulnerability is in the code of the function, and not in one of the code-dependent libraries. You can see more details for these new finding types under the By Lambda function section of the Amazon Inspector console. You can filter the results based on the function name to see the active vulnerabilities. For this particular function, Amazon Inspector found two vulnerabilities.
Figure 7: Code Vulnerability sample findings
Similar to other finding types, Amazon Inspector tagged the vulnerability based on its severity level, which can help you to triage findings. Let’s focus on the High severity vulnerability in Figure 8 to learn how you can remediate the issue. Selecting the finding reveals additional details, like the name of the detector, the vulnerability location, and remediation details.
Figure 8: Code Vulnerability finding details
Now let’s see how you can remediate these vulnerabilities according to the suggested remediation. The code is attempting to change the function handler. AWS recommends that you don’t try to override reserved Lambda environment variables, because this can lead to unexpected results. For this case, we recommend that you delete line 8 from the sample code shown here and instead update the Lambda function handler name by using the runtime settings configuration in the Lambda console, as shown in Figure 9.
To change the Lambda function handler
In the Lambda console, search for and then select your Lambda function.
Scroll down to the Runtime settings area and choose Edit.
Under Edit runtime settings, update the handler name, and then choose Save.
Figure 9: Lambda function runtime settings
To address the second finding, we also updated the function by passing an IP address when binding to a socket, according to the recommendations that were included in the finding. Amazon Inspector will automatically detect the changes that are made to fix the issues, and change the status of the finding to closed, as shown in Figure 10. By changing the findings filter to Show all, you can see active and closed findings.
Figure 10: Findings summary after remediation
You can create more complex workflows by using the Amazon Inspector integration with Amazon EventBridge to manually or automatically respond to findings by creating various playbooks to respond to unique events. These findings will also be routed to AWS Security Hub for a centralized view of your Amazon Inspector findings in your AWS accounts and Regions.
Pricing
Pricing for Lambda standard scanning is available on the Amazon Inspector pricing page. During the public preview, the code scanning feature will be available at no additional cost.
Conclusion
In this blog post, we introduced two new Amazon Inspector features that scan your Lambda function application package dependencies, as well as your application code, for security vulnerabilities. With these new features, you can strengthen your security posture by scanning for code security vulnerabilities such as injection flaws, data leaks, and unsanitized input, according to current AWS security recommendations. We encourage you to test Lambda function scanning in your own environment by enabling the free trial for Amazon Inspector and following the steps in the Amazon Inspector documentation.
With Amazon Cognitouser pools, you can configure third-party SAML identity providers (IdPs) so that users can log in by using the IdP credentials. The Amazon Cognito user pool manages the federation and handling of tokens returned by a configured SAML IdP. It uses the public certificate of the SAML IdP to verify the signature in the SAML assertion returned by the IdP. Public certificates have an expiry date, and an expired public certificate will result in a SAML user federation failing because it can no longer be used for signature verification. To avoid user authentication failures, you must monitor and rotate SAML public certificates before expiration.
You can configure SAML IdPs in an Amazon Cognito user pool by using a SAML metadata document or a URL that points to the metadata document. If you use the SAML metadata document option, you must manually upload the SAML metadata. If you use the URL option, Amazon Cognito downloads the metadata from the URL and automatically configures the SAML IdP. In either scenario, if you don’t rotate the SAML certificate before expiration, users can’t log in using that SAML IdP.
In this blog post, I will show you how to monitor SAML certificates that are about to expire or already expired in an Amazon Cognito user pool by using an AWS Lambda function initiated by an Amazon EventBridge rule.
Solution overview
In this section, you will learn how to configure a Lambda function that checks the validity period of the SAML IdP certificates in an Amazon Cognito user pool, logs the findings to AWS Security Hub, and sends out an Amazon Simple Notification Service (Amazon SNS) notification with the list of certificates that are about to expire or have already expired. This Lambda function is invoked by an EventBridge rule that uses a rate or cron expression and runs on a defined schedule. For example, if the rate expression is defined as 1 day, the EventBridge rule initiates the Lambda function once each day. Figure 1 shows an overview of this process.
Figure 1: Lambda function initiated by EventBridge rule
As shown in Figure 1, this process involves the following steps:
Gets the list of SAML IdPs and corresponding X509 certificates.
Verifies if the X509 certificates are about to expire or already expired based on the dates in the certificate.
Based on the results of step 2, the Lambda function logs the findings in AWS Security Hub. Each finding shows the SAML certificate that is about to expire or is already expired.
Based on the results of step 2, the Lambda function publishes a notification to the Amazon SNS topic with the certificate expiration details. For example, if CERT_EXPIRY_DAYS=60, the details of SAML certificates that are going to expire within 60 days or are already expired are published in the SNS notification.
Amazon SNS sends messages to the subscribers of the topic, such as an email address.
Prerequisites
For this setup, you will need to have the following in place:
In this section, we will walk you through how to deploy the Lambda function and configure an EventBridge rule that invokes the Lambda function.
Step 1: Create the Node.js Lambda package
Open a command line terminal or shell.
Create a folder named saml-certificate-expiration-monitoring.
Install the fast-xml-parser module by running the following command:
cd saml-certificate-expiration-monitoring
npm install fast-xml-parser
Create a file named index.js and paste the following content in the file.
const AWS = require('aws-sdk');
const { X509Certificate } = require('crypto');
const { XMLParser} = require("fast-xml-parser");
const https = require('https');
exports.handler = async function(event, context, callback) {
const cognitoUPID = process.env.COGNITO_UPID;
const expiryDays = process.env.CERT_EXPIRY_DAYS;
const snsTopic = process.env.SNS_TOPIC_ARN;
const postToSh = process.env.ENABLE_SH_MONITORING; //Enable security hub monitoring
var securityhub = new AWS.SecurityHub({apiVersion: '2018-10-26'});
var shParams = {
Findings: []
};
AWS.config.apiVersions = {
cognitoidentityserviceprovider: '2016-04-18',
};
// Initialize CognitoIdentityServiceProvider.
const cognitoidentityserviceprovider = new AWS.CognitoIdentityServiceProvider();
let listProvidersParams = {
UserPoolId: cognitoUPID /* required */
};
let hasNext = true;
const providerNames = [];
while (hasNext) {
const listProvidersResp = await cognitoidentityserviceprovider.listIdentityProviders(listProvidersParams).promise();
listProvidersResp['Providers'].forEach(function(provider) {
if(provider.ProviderType == 'SAML') {
providerNames.push(provider.ProviderName);
}
});
listProvidersParams.NextToken = listProvidersResp.NextToken;
hasNext = !!listProvidersResp.NextToken; //Keep iterating if there are more pages
}
let describeIdentityProviderParams = {
UserPoolId: cognitoUPID /* required */
};
//Initialize the options for fast-xml-parser
//Parse KeyDescriptor as an array
const alwaysArray = [
"EntityDescriptor.IDPSSODescriptor.KeyDescriptor"
];
const options = {
removeNSPrefix: true,
isArray: (name, jpath, isLeafNode, isAttribute) => {
if( alwaysArray.indexOf(jpath) !== -1) return true;
},
ignoreDeclaration: true
};
const parser = new XMLParser(options);
let certExpMessage = '';
const today = new Date();
if(providerNames.length == 0) {
console.log("There are no SAML providers in this Cognito user pool. ID : " + cognitoUPID);
}
for (let provider of providerNames) {
describeIdentityProviderParams.ProviderName = provider;
const descProviderResp = await cognitoidentityserviceprovider.describeIdentityProvider(describeIdentityProviderParams).promise();
let xml = '';
//Read SAML metadata from Cognito if the file is available. Else, read the SAML metadata from URL
if('MetadataFile' in descProviderResp.IdentityProvider.ProviderDetails) {
xml = descProviderResp.IdentityProvider.ProviderDetails.MetadataFile;
} else {
let metadata_promise = getMetadata(descProviderResp.IdentityProvider.ProviderDetails.MetadataURL);
xml = await metadata_promise;
}
let jObj = parser.parse(xml);
if('EntityDescriptor' in jObj) {
//SAML metadata can have multiple certificates for signature verification.
for (let cert of jObj['EntityDescriptor']['IDPSSODescriptor']['KeyDescriptor']) {
let certificate = '-----BEGIN CERTIFICATE-----\n'
+ cert['KeyInfo']['X509Data']['X509Certificate']
+ '\n-----END CERTIFICATE-----';
let x509cert = new X509Certificate(certificate);
console.log("------ Provider : " + provider + "-------");
console.log("Cert Expiry: " + x509cert.validTo);
const diffTime = Math.abs(new Date(x509cert.validTo) - today);
const diffDays = Math.ceil(diffTime / (1000 * 60 * 60 * 24));
console.log("Days Remaining: " + diffDays);
if(diffDays <= expiryDays) {
certExpMessage += 'Provider name: ' + provider + ' SAML certificate (serialnumber : '+ x509cert.serialNumber + ') expiring in ' + diffDays + ' days \n';
if(postToSh === 'true') {
//Log finding for security hub
logFindingToSh(context, shParams,
'Provider name: ' + provider + ' SAML certificate is expiring in ' + diffDays + ' days. Please contact the Identity provider to rotate the certificate.',
x509cert.fingerprint, cognitoUPID, provider);
}
}
}
}
}
//Send a SNS message if a certificate is about to expire or already expired
if(certExpMessage) {
console.log("SAML certificates expiring within next " + expiryDays + " days :\n");
console.log(certExpMessage);
certExpMessage = "SAML certificates expiring within next " + expiryDays + " days :\n" + certExpMessage;
// Create publish parameters
let snsParams = {
Message: certExpMessage, /* required */
TopicArn: snsTopic
};
// Create promise and SNS service object
let publishTextPromise = await new AWS.SNS({apiVersion: '2010-03-31'}).publish(snsParams).promise();
console.log(publishTextPromise);
if(postToSh === 'true') {
console.log("Posting the finding to SecurityHub");
let shPromise = await securityhub.batchImportFindings(shParams).promise();
console.log("shPromise : " + JSON.stringify(shPromise));
}
} else {
console.log("No certificates are expiring within " + expiryDays + " days");
}
};
function getMetadata(url) {
return new Promise((resolve, reject) => {
https.get(url, (response) => {
let chunks_of_data = [];
response.on('data', (fragments) => {
chunks_of_data.push(fragments);
});
response.on('end', () => {
let response_body = Buffer.concat(chunks_of_data);
resolve(response_body.toString());
});
response.on('error', (error) => {
reject(error);
});
});
});
}
function logFindingToSh(context, shParams, remediationMsg, certFp, cognitoUPID, provider) {
const accountID = context.invokedFunctionArn.split(':')[4];
const region = process.env.AWS_REGION;
const sh_product_arn = `arn:aws:securityhub:${region}:${accountID}:product/${accountID}/default`;
const today = new Date().toISOString();
shParams.Findings.push(
{
SchemaVersion: "2018-10-08",
AwsAccountId: `${accountID}`, /* required */
CreatedAt: `${today}`, /* required */
UpdatedAt: `${today}`,
Title: 'SAML Certificate expiration',
Description: 'SAML certificate expiry', /* required */
GeneratorId: `${context.invokedFunctionArn}`, /* required */
Id: `${cognitoUPID}:${provider}:${certFp}`, /* required */
ProductArn: `${sh_product_arn}`, /* required */
Severity: {
Original: '89.0',
Label: 'HIGH'
},
Types: [
"Software and Configuration Checks/AWS Config Analysis"
],
Compliance: {Status: 'WARNING'},
Resources: [ /* required */
{
Id: `${cognitoUPID}`, /* required */
Type: 'AWSCognitoUserPool', /* required */
Region: `${region}`,
Details : {
Other: {
"IdPIdentifier" : `${provider}`
}
}
}
],
Remediation: {
Recommendation: {
Text: `${remediationMsg}`,
Url: `https://console.aws.amazon.com/cognito/v2/idp/user-pools/${cognitoUPID}/sign-in/identity-providers/details/${provider}`
}
}
}
);
}
To create the deployment package for a .zip file archive, you can use a built-in .zip file archive utility or other third-party zip file utility. If you are using Linux or Mac OS, run the following command.
zip -r saml-certificate-expiration-monitoring.zip .
Step 2: Create an Amazon SNS topic
Create a standard Amazon SNS topic named saml-certificate-expiration-monitoring-topic for the Lambda function to use to send out notifications, as described in Creating an Amazon SNS topic.
Copy the Amazon Resource Name (ARN) for Amazon SNS. Later in this post, you will use this ARN in the AWS Identity and Access Management (IAM) policy and Lambda environment variable configuration.
After you create the Amazon SNS topic, create email subscribers to this topic.
Step 3: Configure the IAM role and policies and deploy the Lambda function
In the IAM documentation, review the section Creating policies on the JSON tab. Then, using those instructions, use the following template to create an IAM policy named lambda-saml-certificate-expiration-monitoring-function-policy for the Lambda role to use. Replace <REGION> with your Region, <AWS-ACCT-NUMBER> with your AWS account ID, <SNS-ARN> with the Amazon SNS ARN from Step 2: Create an Amazon SNS topic, and <USER_POOL_ID> with your Amazon Cognito user pool ID that you want to monitor.
After the policy is created, create a role for the Lambda function to use the policy, by following the instructions in Creating a role to delegate permissions to an AWS service. Choose Lambda as the service to assume the role and attach the policy lambda-saml-certificate-expiration-monitoring-function-policy that you created in step 1 of this section. Specify a role named lambda-saml-certificate-expiration-monitoring-function-role, and then create the role.
If you make code changes after uploading, deploy the Lambda function.
Step 4: Create an EventBridge rule
Follow the instructions in creating an Amazon EventBridge rule that runs on a schedule to create a rule named saml-certificate-expiration-monitoring-rule. You can use a rate expression of 24 hours to initiate the event. This rule will invoke the Lambda function once per day.
Create an environment variable called CERT_EXPIRY_DAYS. This specifies how much lead time, in days, you want to have before the certificate expiration notification is sent.
Create an environment variable called COGNITO_UPID. This identifies the Amazon Cognito user pool ID that needs to be monitored.
Create an environment variable called ENABLE_SH_MONITORING and set it to true or false. If you set it to true, the Lambda function will log the findings in AWS Security Hub.
Configure a test event for the Lambda function by using the default template and name it TC1, as shown in Figure 2.
Figure 2: Create a Lambda test case
Run the TC1 test case to test the Lambda function. To make sure that the Lambda function ran successfully, check the Amazon CloudWatchlogs. You should see the console log messages from the Lambda function. If ENABLE_SH_MONITORING is set to true in the Lambda environment variables, you will see a list of findings in AWS Security Hub for certificates with an expiry of less than or equal to the value of the CERT_EXPIRY_DAYS environment variable. Also, an email will be sent to each subscriber of the Amazon SNS topic.
Cleanup
To avoid future charges, delete the following resources used in this post (if you don’t need them) and disable AWS Security Hub.
Lambda function
EventBridge rule
CloudWatch logs associated with the Lambda function
Amazon SNS topic
IAM role and policy that you created for the Lambda function
Conclusion
An Amazon Cognito user pool with hundreds of SAML IdPs can be challenging to monitor. If a SAML IdP certificate expires, users can’t log in using that SAML IdP. This post provides the steps to monitor your SAML IdP certificates and send an alert to Amazon Cognito user pool administrators when a certificate is about to expire so that you can proactively work with your SAML IdP administrator to rotate the certificate. Now that you’ve learned the benefits of monitoring your IdP certificates for expiration, I recommend that you implement these, or similar, controls to make sure that you’re notified of these events before they occur.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the Amazon Cognito re:Post or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In the AWS Security Profile series, I interview some of the humans who work in AWS Security and help keep our customers safe and secure. In this profile, I interviewed Tatyana Yatskevich, Principal Solutions Architect for AWS Identity.
How long have you been at AWS and what do you do in your current role?
I’ve been at AWS for about five and a half years now. I’ve had several different roles, but I’m currently part of the Identity Solutions team, which is a team of solutions architects who are embedded into the Identity and Control Service. Our team focuses on staying current with customer use cases and emerging problems in the identity space so that we can facilitate the development of new capabilities and prescriptive guidance from AWS.
To keep up with the demand in certain industries, we work with some enterprise customers that operate large cloud environments on AWS. Knowing what these customers need to do to achieve their business outcomes while operating under stringent regulatory compliance requirements helps us provide valuable input into our service and feature development process and support customers in their cloud journey in the most efficient manner.
How did you get started in security?
At the beginning of my career, I mostly just happened to work on security-related projects. I performed security and vulnerability assessments, facilitated remediation work, and managed traditional on-premises security solutions such as web proxies, firewalls, and VPNs. Through these projects, I developed an interest in the security field because of its wide reach and impact, and because it presents a lot of opportunities for growth and problem solving as new challenges arise almost daily. My roles at AWS have been a logical continuation of my security-focused career. Here, I’ve mostly been motivated by empowering security teams to become business enablers, rather than being perceived as blockers to innovation and agility.
How do you explain your job to non-technical friends and family?
I usually give an example of a service or feature that most of us interact with on a regular basis, such as a banking application. I explain that it takes a lot of engineering work to build that application from the ground up and deliver on the user experience and security. That engineering work involves the use of many different technologies that support the user sign-in process, or storage of your personal information like your social security or credit card numbers. My job is to help companies that provide these services implement the proper security controls so that your personal information is used in accordance with local laws and isn’t disclosed for unauthorized use.
In your opinion, what’s one of the coolest things happening in identity right now?
I think it’s the increased role of identity, authentication, and authorization controls in the overall security model of newly built applications. It spans from helping to ensure secure workforce mobility now that providing access to business applications from anywhere is critical to business competitiveness, to keeping Internet of Things (IoT) infrastructure protected and operated in accordance with zero trust. The realization of the power and the increasing usage of identity-specific controls to manage access to digital assets is the coolest trend in identity right now.
What are you currently working on that you’re excited about?
One of the areas that I’m highly invested in is data perimeters. A data perimeter is a set of capabilities that help customers keep their data within their organizational boundary and mitigate the risks of data exfiltration or unintended access to data. We have customers in a wide variety of industries, such as the financial sector, telecom, media and entertainment, and public sector. There are compliance and regulatory requirements that they operate under. A lot of those requirements emphasize controls that guard sensitive data from unauthorized access and prevent movement of that data to places outside of company’s control.
To help customers meet these requirements in a scalable way, we continuously invest in the development of new capabilities. I talk to some of our largest enterprise customers on a regular basis to understand their challenges in this area, and I work with service teams to introduce new capabilities to meet new requirements. I also lead efforts to extend customer-facing guidance and solutions so that customers can design and implement data perimeters on their own. And I present at AWS events to reach more customers, with the most recent being our presentation with Goldman Sachs at re:Invent 2022.
Tell me about that presentation.
I co-presented a chalk talk with Shubham Shukla, Vice President of Cloud Enablement at Goldman Sachs, called Establishing a Data Perimeter on AWS. The session gave an overview of data perimeter capabilities and showcased Goldman Sachs’ experience implementing data perimeter controls at scale in their multi-account AWS environment. What’s cool about that session, I think, is that it’s always good to present about AWS best practices and our view of how certain things should be done, but it’s extra powerful when we include a customer. This is especially true when a large enterprise customer such as Goldman Sachs shares their experience and talks about how they do certain things in practice, like mapping specific requirements to the actual implementation and talking through lessons learned and their perspective on the problem and solution. A lot of our customers are interested in learning from other customers how to build and operate enterprise security controls at scale. We did a similar presentation with Vanguard at re:Inforce 2022, and I look forward to future opportunities to showcase the awesome work being done by our customers.
What is your favorite Amazon Leadership Principle and why?
Customer Obsession. For me, the core of it is building deeper, longer lasting relationships with our customers and taking their learnings back to our business to work backwards from the actual customer needs. Building better products, helping customers meet their business goals, and having wide-reaching impact is what makes me so excited to come to work every day.
What’s the thing you’re most proud of in your career?
As part of my former role as a security consultant in the AWS Professional Services organization, I led security-related projects to either help customers migrate their workloads to AWS or perform security assessments of their existing AWS environment. Part of that role involved developing mechanisms to better engage with customers on security-related topics and help them develop their own security strategy for running workloads on AWS. That work sometimes involved challenging conversations with customers. I would explain the value of the technology that AWS provides and help customers figure out how to implement AWS services to meet both their business and security needs. I took learnings from these conversations and developed some internal assets that helped newer AWS security consultants conduct those conversations more effectively, and I mentored them throughout the process.
If you had to pick an industry outside of security, what would you want to do?
I would be in the travel industry. I absolutely love visiting new places and exploring nature. I love learning the history and culture of different regions, and trying out different cuisines. It’s something that helps me learn more about myself through new experiences and ultimately be a happier person.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Amazon Web Services (AWS) is pleased to announce that we have achieved an AAA rating from Pinakes. The scope of this qualification covers 166 services in 25 global AWS Regions.
The Spanish banking association Centro de Cooperación Interbancaria (CCI) developed Pinakes, a rating framework intended to manage and monitor the cybersecurity controls of service providers that Spanish financial entities depend on. The requirements arise from the European Banking Authority guidelines (EBA/GL/2019/02).
Pinakes evaluates the cybersecurity levels of service providers through 1,315 requirements across 4 categories (confidentiality, integrity, availability of information, and general) and 14 domains:
Information security management program
Facility security
Third-party management
Normative compliance
Network controls
Access control
Incident management
Encryption
Secure development
Monitoring
Malware protection
Resilience
Systems operation
Staff safety
Each requirement is associated to a rating level (A+, A, B, C, D), ranging from the highest A+ (provider has implemented the most diligent measures and controls for cybersecurity management) to the lowest D (minimum security requirements are met).
An independent third-party auditor has verified the implementation status for each section. As a result, AWS has been qualified with A ratings for Confidentiality, Integrity and Availability, getting an overall rating of AAA.
Our Spanish financial customers can refer to the AWS Pinakes rating to confirm that the AWS control environment is appropriately designed and implemented. By receiving an AAA, AWS demonstrates our commitment to meet the heightened security expectations for cloud service providers set by the CCI. The full evaluation report will be published on AWS Artifact upon request. Pinakes participants who are AWS customers can contact their AWS account manager to request access to it.
As always, we value your feedback and questions. Reach out to the AWS Compliance team through the Contact Us page. To learn more about our other compliance and security programs, see AWS Compliance Programs.
If you have feedback about this post, please submit them in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
Many of our customers use Amazon Cognito user pools to add authentication, authorization, and user management capabilities to their web and mobile applications. You can enable the built-in advanced security in Amazon Cognito to detect and block the use of credentials that have been compromised elsewhere, and to detect unusual sign-in activity and then prompt users for additional verification or block sign-ins. Additionally, you can associate an AWS WAF web access control list (web ACL) with your user pool to allow or block requests to Amazon Cognito user pools, based on security rules.
In this post, we’ll show how you can use AWS WAF with Amazon Cognito user pools and provide a sample set of rate-based rules and advanced AWS WAF rule groups. We’ll also show you how to test and tune the rules to help protect your user pools from common threats.
Rate-based rules for Amazon Cognito user pool endpoints
The following are endpoints exposed publicly by an Amazon Cognito user pool that you can protect with AWS WAF:
Public API operations — These generate a request to Cognito API actions that are either unauthenticated or authenticated with a session string or access token, but not with AWS credentials.
A good way to protect these endpoints is to deploy rate-based AWS WAF rules. These rules will detect and block requests with high rates that could indicate an attempt to exceed your Amazon Cognito API request rate quotas and that could subsequently impact requests from legitimate users.
When you apply rate limits, it helps to group Amazon Cognito API actions into four action categories. You can set specific rate limits per action category giving you traffic visibility for each category.
User Creation — This category includes operations that create new users in Cognito. Setting a rate limit for this category provides visibility for traffic of these operations and threats such as fake users being created in Cognito, which drives up your Monthly Active User (MAU) costs for Cognito.
Sign-in — This category includes operations to initiate a sign-in operation. Setting a rate limit for this category can provide visibility into the abuse of these operations. This could indicate high frequency, automated attempts to guess user credentials, sometimes referred to as credential stuffing.
Account Recovery — This category includes operations to recover accounts, including “forgot password” flows. Setting a rate limit for this category can provide visibility into the abuse of these operations, malicious activity can include: sending fake reset attempts, which might result in emails and SMS messages being sent to users.
Default — This is a catch-all rate limit that applies to an operation that is not in one of the prior categories. Setting a default rate limit can provide visibility and mitigation from request flooding attacks.
Table 1 below shows selected Hosted UI endpoint paths (the equivalent of individual API actions) and the recommended rate-based rule limit category for each.
Additionally, the rate-based rules we provide in this post include the following:
Two IP sets that represent allow lists for IPv4 and IPv6. You can add IPs that represent your trusted source IP addresses to these IP sets so that other AWS WAF rules don’t apply to requests that originate from these IP addresses.
Two IP sets that represent deny lists for IPv4 and IPv6. Add IPs to these IP sets that you want to block in all cases, regardless of the result of other rules.
An AWS managed IP reputation rule group: The AWS managed IP reputation list rule group contains rules that are based on Amazon internal threat intelligence, to identify IP addresses typically associated with bots or other threats. You can limit requests that match rules in this rule group to a specific rate limit.
Deploy rate-based rules
You can deploy the rate-based rules described in the previous section by using the AWS CloudFormation template that we provide here.
To deploy rate-based rules using the template
(Optional but recommended) If you want to enable AWS WAF logging and resources to analyze request rates, create an Amazon Simple Storage Service (Amazon S3) bucket in the same AWS Region as your Amazon Cognito user pool, with a bucket name starting with the prefix aws-waf-logs-. If you previously created an S3 bucket for AWS WAF logs, you can choose to reuse it, or you can create a new bucket to store AWS WAF logs for Amazon Cognito.
Choose the following Launch Stack button to launch a CloudFormation stack in your account.
Note: The stack will launch in the N. Virginia (us-east-1) Region. To deploy this solution into other AWS Regions, download the solution’s CloudFormation template and deploy it to the selected Region.
This template creates the following resources in your AWS account:
A rule group for the rate-based rules, according to the limits shown in Tables 1 and 2.
Four IP sets for an allow list and deny list for IPv4 and IPv6 addresses.
A web ACL that includes the rule group that is created, IP set based rules, and the AWS managed IP reputation rule group.
(Optional) The template enables AWS WAF logging for the web ACL to an S3 bucket that you specify.
(Optional) The template creates resources to help you analyze AWS WAF logs in S3 to calculate peak request rates that you can use to set rate limits for the rate-based rules.
Set the template parameters as needed. The following table shows the default values for the parameters. We recommend that you deploy the template with the default values and with TestMode set to Yes so that all rules are set to Count. This allows all requests but emits Amazon CloudWatch metrics and AWS WAF log events for each rule that matches. You can then follow the guidance in the next section to analyze the logs and tune the rate limits to match the traffic patterns to your user pool. When you are satisfied with the unique rate limits for each parameter, you can update the stack and set TestMode to No to start blocking requests that exceed the rate limits.
The rate limits for AWS WAF rate-based rules are configured as the number of requests per 5-minute period per unique source IP. The value of the rate limit can be between 100 and 2,000,000,000 (2 billion).
Table 3: Default values for template parameters
Parameter name
Description
Default value
Allowed values
Request rate limits by action category
UserCreationRateLimit
Rate limit applied to User Creation actions
2000
100–2,000,000,000
SignInRateLimit
Rate limit applied to Sign-in actions
4000
100–2,000,000,000
AccountRecoveryRateLimit
Rate limit applied to Account Recovery actions
1000
100–2,000,000,000
IPReputationRateLimit
Rate limit applied to requests that match the AWS Managed IP reputation list
1000
100–2,000,000,000
DefaultRateLimit
Default rate limit applied to actions that are not in any of the prior categories
6000
100–2,000,000,000
Test mode
TestMode
Set to Yes to test rules by overriding rule actions to Count. Set to No to apply the default actions for rules after you’ve tested the impact of these rules.
Yes
Yes or No
AWS WAF logging and rate analysis
EnableWAFLogsAndRateAnalysis
Set to Yes to enable logging for the AWS WAF web ACL to an S3 bucket and create resources for request rate analysis. Set to No to disable AWS WAF logging and skip creating resources for rate analysis. If No, the rest of the parameter values in this section are ignored. If Yes, choose values for the rest of the parameters in this section.
Yes
Yes or No
WAFLogsS3Bucket
The name of an existing S3 bucket where AWS WAF logs are delivered. The bucket name must start with aws-waf-logs- and can end with any suffix. Only used if the parameter EnableWAFLogsAndRateAnalysis is set to Yes.
None
Name of an existing S3 bucket that starts with the prefix aws-waf-logs-
DatabaseName
The name of the AWS Glue database to create, which will contain the request rate analysis tables created by this template. (Important: The name cannot contain hyphens.) Only used if the parameter EnableWAFLogsAndRateAnalysis is set to Yes.
rate_analysis
WorkgroupName
The name of the Amazon Athena workgroup to create for rate analysis. Only used if the parameter EnableWAFLogsAndRateAnalysis is set to Yes.
rate_analysis
WAFLogsTableName
The name of the AWS Glue table for AWS WAF logs. Only used if the parameter EnableWAFLogsAndRateAnalysis is set to Yes.
waf_logs
WAFLogsProjectionStartDate
The earliest date to analyze AWS WAF logs, in the format YYYY/MM/DD (example: 2023/02/28). Only used if the parameter EnableWAFLogsAndRateAnalysis is set to Yes.
None
Set this to the current date, in the format YYYY/MM/DD
Wait for the CloudFormation template to be created successfully.
Go to the AWS WAF console and choose the web ACL created by the template. It will have a name ending with CognitoWebACL.
Choose the Associated AWS resources tab, and then choose Add AWS resource.
For Resource type, choose Amazon Cognito user pool, and then select the Amazon Cognito user pools that you want to protect with this web ACL.
Choose Add.
Now that your user pool is being protected by the rate-based rules in the web ACL you created, you can proceed to tune the rate-based rule limits by analyzing AWS WAF logs.
Tune AWS WAF rate-based rule limits
As described in the previous section, the rate-based rules give you the ability to set separate rate limit values for each category of Amazon Cognito API actions.
Although the CloudFormation template has default starting values for these rate limits, it is important that you tune these values to match the traffic patterns for your user pool. To begin the tuning process, deploy the template with default values for all parameters, including Yes for TestMode. This overrides all rule actions to Count, allowing all requests but emitting CloudWatch metrics and AWS WAF log events for each rule that matches.
After you collect AWS WAF logs for a period of time (this period can vary depending on your traffic, from a couple of hours to a couple of days), you can analyze them, as shown in the next section, to get peak request rates to tune the rate limits to match observed traffic patterns for your user pool.
Query AWS WAF logs to calculate peak request rates by request type
You can calculate peak request rates by analyzing information that is present in AWS WAF logs. One way to analyze these is to send AWS WAF logs to S3 and to analyze the logs by using SQL queries in Amazon Athena. If you deploy the template in this post with default values, it creates the resources you need to analyze AWS WAF logs in S3 to calculate peak requests rates by request type.
If you are instead ingesting AWS WAF logs into your security information and event management (SIEM) system or a different analytics environment, you can create equivalent queries by using the query language for your SIEM or analytics environment to get similar results.
To access and edit the queries built by the CloudFormation template for use
Open the Athena console and switch to the Athena workgroup that was created by the template (the default name is rate_analysis).
On the Saved queries tab, choose the query named Peak request rate per 5-minute period by source IP and request category. The following SQL query will be loaded into the edit panel.
-- Gets the top 5 source IPs sending the most requests in a 5-minute period per request category
‐‐ NOTE: change the start and end timestamps to match the duration of interest
SELECT request_category, from_unixtime(time_bin*60*5) AS date_time, client_ip, request_count FROM (
SELECT *, row_number() OVER (PARTITION BY request_category ORDER BY request_count DESC, time_bin DESC) AS row_num FROM (
SELECT
CASE
WHEN ip_reputation_labels.name IN (
'awswaf:managed:aws:amazon-ip-list:AWSManagedIPReputationList',
'awswaf:managed:aws:amazon-ip-list:AWSManagedReconnaissanceList',
'awswaf:managed:aws:amazon-ip-list:AWSManagedIPDDoSList'
) THEN 'IPReputation'
WHEN target.value IN (
'AWSCognitoIdentityProviderService.InitiateAuth',
'AWSCognitoIdentityProviderService.RespondToAuthChallenge'
) THEN 'SignIn'
WHEN target.value IN (
'AWSCognitoIdentityProviderService.ResendConfirmationCode',
'AWSCognitoIdentityProviderService.SignUp',
'AWSCognitoIdentityProviderService.ConfirmSignUp'
) THEN 'UserCreation'
WHEN target.value IN (
'AWSCognitoIdentityProviderService.ForgotPassword',
'AWSCognitoIdentityProviderService.ConfirmForgotPassword'
) THEN 'AccountRecovery'
WHEN httprequest.uri IN (
'/login',
'/oauth2/authorize'
) THEN 'SignIn'
WHEN httprequest.uri IN (
'/signup',
'/confirmUser',
'/resendcode'
) THEN 'UserCreation'
WHEN httprequest.uri IN (
'/forgotPassword',
'/confirmForgotPassword'
) THEN 'AccountRecovery'
ELSE 'Default'
END AS request_category,
httprequest.clientip AS client_ip,
FLOOR("timestamp"/(1000*60*5)) AS time_bin,
COUNT(*) AS request_count
FROM waf_logs
LEFT OUTER JOIN UNNEST(FILTER(httprequest.headers, h -> h.name = 'x-amz-target')) AS t(target) ON TRUE
LEFT OUTER JOIN UNNEST(FILTER(labels, l -> l.name like 'awswaf:managed:aws:amazon-ip-list:%')) AS t(ip_reputation_labels) ON TRUE
WHERE
from_unixtime("timestamp"/1000) BETWEEN TIMESTAMP '2022-01-01 00:00:00' AND TIMESTAMP '2023-01-01 00:00:00'
GROUP BY 1, 2, 3
ORDER BY 1, 4 DESC
)
) WHERE row_num <= 5 ORDER BY request_category ASC, row_num ASC
Scroll down to Line 48 in the Query Editor and edit the timestamps to match the start and end time of the time window of interest.
Run the query to calculate the top 5 peak request rates per 5-minute period by source IP and by action category.
The results show the action category, source IP, time, and count of requests. You can use the request count to tune the rate limits for each action category.
The lowest rate limit you can set for AWS WAF rate-based rules is 100 requests per 5-minute period. If your query results show that the peak request count is less than 100, set the rate limit as 100 or higher.
After you have tuned the rate limits, you can apply the changes to your web ACL by updating the CloudFormation stack.
To update the CloudFormation stack
On the CloudFormation console, choose the stack you created earlier.
Choose Update. For Prepare template, choose Use current template, and then choose Next.
Update the values of the parameters with rate limits to match the tuned values from your analysis.
You can choose to enable blocking of requests by setting TestMode to No. This will set the action to Block for the rate-based rules in the web ACL and start blocking traffic that exceeds the rate limits you have chosen.
Choose Next and then Next again to update the stack.
Now the rate-based rules are updated with your tuned limits, and requests will be blocked if you set TestMode to No.
Protect endpoints with user interaction
Now that we’ve covered the bases with rate-based rules, we’ll show you some more advanced AWS WAF rules that further help protect your user pool. We’ll explore two sample scenarios in detail, and provide AWS WAF rules for each. You can use the rules provided as a guideline to build others that can help with similar use cases.
Rules to verify human activity
The first scenario is protecting endpoints where users have interaction with the page. This will be a browser-based interaction, and a human is expected to be behind the keyboard. This scenario applies to the Hosted UI endpoints such as /login, /signup, and /forgotPassword, where a CAPTCHA can be rendered on the user’s browser for the user to solve. Let’s take the login (sign-in) endpoint as an example, and imagine you want to make sure that only actual human users are attempting to sign in and you want to block bots that might try to guess passwords.
To illustrate how to protect this endpoint with AWS WAF, we’re sharing a sample rule, shown in Figure 1. In this rule, you can take input from prior rules like the Amazon IP reputation list or the Anonymous IP list (which are configured to Count requests and add labels) and combine that with a CAPTCHA action. The logic of the rule says that if the request matches the reputation rules (and has received the corresponding labels) and is going to the /login endpoint, then the AWS WAF action should be to respond with a CAPTCHA challenge. This will present a challenge that increases the confidence that a human is performing the action, and it also adds a custom label so you can efficiently identify and have metrics on how many requests were matched by this rule. The rule is provided in the CloudFormation template and is in JSON format, because it has advanced logic that cannot be displayed by the console. Learn more about labels and CAPTCHA actions in the AWS WAF documentation.
Figure 1: Login sample rule flow
Note that the rate-based rules you created in the previous section are evaluated before the advanced rules. The rate-based rules will block requests to the /login endpoint that exceed the rate limit you have configured, while this advanced rule will match requests that are below the rate limit but match the other conditions in the rule.
Rules for specific activity
The second scenario explores activity on specific application clients within the user pool. You can spot this activity by monitoring the logs provided by AWS WAF, or other traffic logs like Application Load Balancer (ALB) logs. The application client information is provided in the call to the service.
In the Amazon Cognito user pool in this scenario, we have different application clients and they’re constrained by geography. For example, for one of the application clients, requests are expected to come from the United States at or below a certain rate. We can create a rule that combines the rate and geographical criteria to block requests that don’t meet the conditions defined.
The flow of this rule is shown in Figure 2. The logic of the rule will evaluate the application client information provided in the request and the geographic information identified by the service, and apply the selected rate limit. If blocked, the rule will provide a custom response code by using HTTP code 429 Too Many Requests, which can help the sender understand the reason for the block. For requests that you make with the Amazon Cognito API, you could also customize the response body of a request that receives a Block response. Adding a custom response helps provide the sender context and adjust the rate or information that is sent.
Figure 2: AppClientId sample rule flow
AWS WAF can detect geo location with Region accuracy and add specific labels for the location. These can then be used in other rule evaluations. This rule is also provided as a sample in the CloudFormation template.
Advanced protections
To build on the rules we’ve shared so far, you can consider using some of the other intelligent threat mitigation rules that are available as managed rules—namely, bot control for common or targeted bots. These rules offer advanced capabilities to detect bots in sensitive endpoints where automation or non-browser user agents are not expected or allowed. If you receive machine traffic to the endpoint, these rules will result in false positives that would need to be tuned. For more information, see Options for intelligent threat mitigation.
The sample rule flow in Figure 3 shows an example for our Hosted UI, which builds on the first rule we built for specific activity and adds signals coming from the Bot Control common bots managed rule, in this case the non-browser-user-agent label.
Figure 3: Login sample rule with advanced protections
Adding the bot detection label will also add accuracy to the evaluation, because AWS WAF will consider multiple different sources of information when analyzing the request. This can also block attacks that come from a small set of IPs or easily recognizable bots.
We’ve shared this rule in the CloudFormation template sample. The rule requires you to add AWS WAF Bot Control (ABC) before the custom rule evaluation. ABC has additional costs associated with it and should only be used for specific use cases. For more information on ABC and how to enable it, see this blog post.
After adding these protections, we have a complete set of rules for our Hosted UI–specific needs; consider that your traffic and needs might be different. Figure 4 shows you what the rule priority looks like. All rules except the last are included in the provided CloudFormation template. Managed rule evaluations need to have higher priority and be in Count mode; this way, a matching request can get labels that can be evaluated further down the priority list by using the custom rules that were created. For more information, see How labeling works.
Figure 4: Summary of the rules discussed in this post
Conclusion
In this post, we examined the different protections provided by the integration between AWS WAF and Amazon Cognito. This integration makes it simpler for you to view and monitor the activity in the different Amazon Cognito endpoints and APIs, while also adding rate-based rules and IP reputation evaluations. For more specific use cases and advanced protections, we provided sample custom rules that use labels, as well as an advanced rule that uses bot control for common bots. You can use these advanced rules as examples to create similar rules that apply to your use cases.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the re:Post with tag AWS WAF or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Have you ever wanted to initiate change in an Amazon Web Services (AWS) account after you update a GitHub repository, or deploy updates in an AWS application after you merge a commit, without the use of AWS Identity and Access Management (IAM) user access keys? If you configure an OpenID Connect (OIDC) identity provider (IdP) inside an AWS account, you can use IAM roles and short-term credentials, which removes the need for IAM user access keys.
In this blog post, we will walk you through the steps needed to configure a specific GitHub repo to assume an individual role in an AWS account to preform changes. You will learn how to create an OIDC-trusted connection that is scoped to an individual GitHub repository, and how to map the repository to an IAM role in your account. You will create the OIDC connection, IAM role, and trust relationship two ways: with the AWS Management Console and with the AWS Command Line Interface (AWS CLI).
This post focuses on creating an IAM OIDC identity provider for GitHub and demonstrates how to authorize access into an AWS account from a specific branch and repository. You can use OIDC IdPs for workflows that support the OpenID Connect standard, such as Google or Salesforce.
Prerequisites
To follow along with this blog post, you should have the following prerequisites in place:
GitHub is an external provider that is independent from AWS. To use GitHub as an OIDC IdP, you will need to complete four steps to access AWS resources from your GitHub repository. Then, for the fifth and final step, you will use AWS CloudTrail to audit the role that you created and used in steps 1–4.
Create an OIDC provider in your AWS account. This is a trust relationship that allows GitHub to authenticate and be authorized to perform actions in your account.
Create an IAM role in your account. You will then scope the IAM role’s trust relationship to the intended parts of your GitHub organization, repository, and branch for GitHub to assume and perform specific actions.
Assign a minimum level of permissions to the role.
Create a GitHub Actions workflow file in your repository that can invoke actions in your account.
Audit the role’s use with Amazon CloudTrail logs.
Step 1: Create an OIDC provider in your account
The first step in this process is to create an OIDC provider which you will use in the trust policy for the IAM role used in this action.
(Optional) For Add tags, you can add key–value pairs to help you identify and organize your IdPs. To learn more about tagging IAM OIDC IdPs, see Tagging OpenID Connect (OIDC) IdPs.
Verify the information that you entered. Your console should match the screenshot in Figure 1. After verification, choose Add provider.
Note: Each provider is a one-to-one relationship to an external IdP. If you want to add more IdPs to your account, you can repeat this process.
Figure 1: Steps to configure the identity provider
Once you are taken back to the Identity providers page, you will see your new IdP as shown in Figure 2. Select your provider to view its properties, and make note of the Amazon Resource Name (ARN). You will use the ARN later in this post. The ARN will look similar to the following:
You can add GitHub as an IdP in your account with a single AWS CLI command. The following code will perform the previous steps outlined for the console, with the same results. For the value —thumbprint-list, you will use the GitHub OIDC thumbprint 938fd4d98bab03faadb97b34396831e3780aea1.
aws iam create-open-id-connect-provider --url
"https://token.actions.GitHubusercontent.com" --thumbprint-list
"6938fd4d98bab03faadb97b34396831e3780aea1" --client-id-list
'sts.amazonaws.com'
Both of the preceding methods will add an IdP in your account. You can view the provider on the Identity providers page in the IAM console.
Step 2: Create an IAM role and scope the trust policy
You can create an IAM role with either the IAM console or the AWS CLI. If you choose to create the IAM role with the AWS CLI, you will scope the Trust Relationship Policy before you create the role.
In the IAM console, on the Identity providers screen, choose the Assign role button for the newly created IdP.
Figure 3: Assign a role to the identity provider
In the Assign role for box, choose Create a new role, and then choose Next, as shown in the following figure.
Figure 4: Create a role from the Identity provider page
The Create role page presents you with a few options. Web identity is already selected as the trusted entity, and the Identity provider field is populated with your IdP. In the Audience list, select sts.amazonaws.com, and then choose Next.
On the Permissions page, choose Next. For this demo, you won’t add permissions to the role.
(Optional) On the Tags page, add tags to this new role, and then choose Next: Review.
On the Create role page, add a role name. For this demo, enter GitHubAction-AssumeRoleWithAction. Optionally add a description.
To create the role, choose Create role.
Next, you’ll scope the IAM role’s trust policy to a single GitHub organization, repository, and branch.
To scope the trust policy (IAM console)
In the IAM console, open the newly created role and choose Edit trust relationship.
On the Edit trust policy page, modify the trust policy to allow your unique GitHub organization, repository, and branch to assume the role. This example trusts the GitHub organization <aws-samples>, the repository named <EXAMPLEREPO>, and the branch named <ExampleBranch>. Update the Federated ARN with the GitHub IdP ARN that you copied previously.
In the AWS CLI, use the example trust policy shown above for the console. This policy is designed to limit access to a defined GitHub organization, repository, and branch.
Create and save a JSON file with the example policy to your local computer with the file name trustpolicyforGitHubOIDC.json.
Run the following command to create the role.
aws iam create-role --role-name GitHubAction-AssumeRoleWithAction --assume-role-policy-document file://C:\policies\trustpolicyforGitHubOIDC.json
Step 3: Assign a minimum level of permissions to the role
For this example, you won’t add permissions to the IAM role, but will assume the role and call STS GetCallerIdentity to demonstrate a GitHub action that assumes the AWS role.
If you’re interested in performing additional actions in your account, you can add permissions to the role you created, GitHubAction-AssumeRoleWithAction. Common actions for workflows include calling AWS Lambda functions or pushing files to an Amazon Simple Storage Service (Amazon S3) bucket. For more information about using IAM to apply permissions, see Policies and permissions in IAM.
Step 4: Create a GitHub action to invoke the AWS CLI
GitHub actions are defined as methods that you can use to automate, customize, and run your software development workflows in GitHub. The GitHub action that you create will authenticate into your account as the role that was created in Step 2: Create the IAM role and scope the trust policy.
To create a GitHub action to invoke the AWS CLI:
Create a basic workflow file, such as main.yml, in the .github/workflows directory of your repository. This sample workflow will assume the GitHubAction-AssumeRoleWithAction role, to perform the action aws sts get-caller-identity. Your repository can have multiple workflows, each performing different sets of tasks. After GitHub is authenticated to the role with the workflow, you can use AWS CLI commands in your account.
Paste the following example workflow into the file.
# This is a basic workflow to help you get started with Actions
name:Connect to an AWS role from a GitHub repository
# Controls when the action will run. Invokes the workflow on push events but only for the main branch
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
env:
AWS_REGION : <"us-east-1"> #Change to reflect your Region
# Permission can be added at job level or workflow level
permissions:
id-token: write # This is required for requesting the JWT
contents: read # This is required for actions/checkout
jobs:
AssumeRoleAndCallIdentity:
runs-on: ubuntu-latest
steps:
- name: Git clone the repository
uses: actions/checkout@v3
- name: configure aws credentials
uses: aws-actions/[email protected]
with:
role-to-assume: <arn:aws:iam::111122223333:role/GitHubAction-AssumeRoleWithAction> #change to reflect your IAM role’s ARN
role-session-name: GitHub_to_AWS_via_FederatedOIDC
aws-region: ${{ env.AWS_REGION }}
# Hello from AWS: WhoAmI
- name: Sts GetCallerIdentity
run: |
aws sts get-caller-identity
Modify the workflow to reflect your AWS account information:
AWS_REGION: Enter the AWS Region for your AWS resources.
role-to-assume: Replace the ARN with the ARN of the AWS GitHubAction role that you created previously.
In the example workflow, if there is a push or pull on the repository’s “main” branch, the action that you just created will be invoked.
Figure 5 shows the workflow steps in which GitHub does the following:
Authenticates to the IAM role with the OIDC IdP in the Region that was defined in the workflow file in the step configure aws credentials.
Calls aws sts get-caller-identity in the step Hello from AWS. WhoAmI… Run AWS CLI sts GetCallerIdentity.
Figure 5: Results of GitHub action
Step 5: Audit the role usage: Query CloudTrail logs
The final step is to view the AWS CloudTrail logs in your account to audit the use of this role.
To view the event logs for the GitHub action:
In the AWS Management Console, open CloudTrail and choose Event History.
In the Lookup attributes list, choose Event source.
In the search bar, enter sts.amazonaws.com.
Figure 6: Find event history in CloudTrail
You should see the GetCallerIdentity and AssumeRoleWithWebIdentity events, as shown in Figure 6. The GetCallerIdentity event is the Hello from AWS. step in the GitHub workflow file. This event shows the workflow as it calls aws sts get-caller-identity. The AssumeRoleWithWebIdentity event shows GitHub authenticating and assuming your IAM role GitHubAction-AssumeRoleWithAction.
You can also view one event at a time.
To view the AWS CLI GetCallerIdentity event:
In the Lookup attributes list, choose User name.
In the search bar, enter the role-session-name, defined in the workflow file in your repository. This is not the IAM role name, because this role-session-name is defined in line 30 of the workflow example. In the workflow example for this blog post, the role-session-name is GitHub_to_AWS_via_FederatedOIDC.
You can now see the first event in the CloudTrail history.
Figure 7: View the get caller identity in CloudTrail
To view the AssumeRoleWithWebIdentity event
In the Lookup attributes list, choose User name.
In the search bar, enter the GitHub organization, repository, and branch that is defined in the IAM role’s trust policy. In the example outlined earlier, the user name is repo:aws-samples/EXAMPLE:ref:refs/heads/main.
You can now see the individual event in the CloudTrail history.
Figure 8: View the assume role call in CloudTrail
Conclusion
When you use IAM roles with OIDC identity providers, you have a trusted way to provide access to your AWS resources. GitHub and other OIDC providers can generate temporary security credentials to update resources and infrastructure inside your accounts.
In this post, you learned how to use the federated access to assume a role inside AWS directly from a workflow action file in a GitHub repository. With this new IdP in place, you can begin to delete AWS access keys from your IAM users and use short-term credentials.
After you read this post, we recommend that you follow the AWS Well Architected Security Pillar IAM directive to use programmatic access to AWS services using temporary and limited-privilege credentials. If you deploy IAM federated roles instead of AWS user access keys, you follow this guideline and issue tokens by the AWS Security Token Service. If you have feedback on this post, leave a comment below and let us know how you would like to see OIDC workflows expanded to help your IAM needs.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
For the permissions already in place, one of IAM Access Analyzer’s capabilities is that it helps you identify resources in your AWS Organizations organization and AWS accounts that are shared with an external entity.
For each external entity that has access to a resource in your account, IAM Access Analyzer generates a finding. Findings display information about the resource and the policy statement that generated the finding, with details such as the list of actions in the policy granting access, level of access, and conditions that allow the access. You can review the findings to determine if the access is intended or unintended.
As your use of AWS services grows and the number of accounts in your organization increases, the number of findings that you have might also increase. To help reduce noise and allow you to focus on unintended access findings, you can filter findings and create archive rules for intended access.
This blog post provides step-by-step guidance on how to get started with IAM Access Analyzer findings by using different filtering techniques that can help you filter approved use cases that result in access findings. For example, you might see a finding generated for an S3 bucket that hosts images for your website and thus allows public access, as approved by your organization, apply a filter so that you can concentrate on unintended access. IAM Access Analyzer offers a wide range of filters; for a complete list, see the IAM documentation.
In this post, we also share example archive rules for approved use cases that result in access findings. Archive rules automatically archive new findings that meet the criteria you define when you create the rule. You can also apply archive rules retroactively to archive existing findings that meet the archive rule criteria. Finally, we have included an example implementation of archive rules using an AWS CloudFormation template.
IAM Access Analyzer findings overview
To get started, create an analyzer for your entire organization or your account. The organization or account that you choose is known as the zone of trust for the analyzer. The zone of trust determines the type of access that IAM Access Analyzer considers to be trusted. IAM Access Analyzer continuously monitors to identify resource policies, access control lists, and other access controls that grant public or cross-account access from outside the zone of trust, and generates findings. For this blog post, we’ll demonstrate an organization as the zone of trust, showcasing findings from a large-scale, multi-account AWS deployment.
Prerequisites
This blog post assumes that you have the following in place:
IAM Access Analyzer is enabled in your organization or account in the AWS Regions where you operate. For more details on how to enable IAM Access Analyzer, see Enabling IAM Access Analyzer.
Access to the AWS Organizations management account or to a member account in the organization with delegated administrator access for creating and updating IAM Access Analyzer resources.
How to filter the findings
To start filtering your findings and create archive rules, you should complete the following steps:
Review public access findings
Filter by removing permissions errors
Filter for known identity providers
Filter cross-account access from trusted external accounts
We’ll walk you through each step.
1. Review public access findings
Some AWS resources allow public access on the resource by means of a resource-based policy—for example, an Amazon Simple Storage Service (Amazon S3) bucket policy that has the “Principal:*” permission added to its bucket policy. For resources such as Amazon Elastic Block Store (Amazon EBS) snapshots, you can share these by using a flag on the resource permission. IAM Access Analyzer looks for such sharing and reports it in the findings.
From the global report, you can generate a list of resources that allow public access by using the Public access: true query in the IAM console.
If the access is intended, you can archive the findings by creating an archive rule using the AWS Management Console, AWS CLI, or API. When you archive a security finding, IAM Access Analyzer removes it from the Active findings list and changes its status to Archived. For instructions on how to automatically archive expected findings, see How to automatically archive expected IAM Access Analyzer findings.
Example: Known S3 bucket that hosts public website images
If you have resources for which public access is expected, such as an S3 bucket that hosts images for your website, you can add an archive rule with Resource criteria equal to the bucket name, as shown in Figure 1.
Figure 1: Create IAM Access Analyzer archive rule using the console
Is the public access unintended?
If the finding results from policies that were misconfigured to allow unintended public access, you can constrain the access by using AWS global condition context keys or a specific IAM principal ARN. The findings show the account and resource that contain the policy.
For example, if the finding shows a misconfigured S3 bucket, the following policy shows how you can modify the S3 bucket policy to only allow IAM principals from your organization to access the bucket by using the PrincipalOrgID condition key. Replace <DOC-EXAMPLE-BUCKET> with the name of your S3 bucket, and <ORGANIZATION_ID> with your organization ID.
Before you further investigate the IAM Access Analyzer findings, you should make sure that IAM Access Analyzer has enough permissions to access the resources in your accounts to be able to provide the analysis.
IAM Access Analyzer uses an AWS service-linked role to call other AWS services on your behalf. When IAM Access Analyzer analyzes a resource, it reads resource metadata, such as a resource-based policy, access control lists, and other access controls that grant public or cross-account access. If the policies don’t allow an IAM Access Analyzer role to read the resource metadata, it generates an Access Denied error finding, as shown in Figure 2.
Figure 2: IAM Access Analyzer access denied error example
To view these error findings from the IAM Access Analyzer console, filter the findings by using the Error: Access Denied property.
Resolution
To resolve the access issue, make sure that the IAM Access Analyzer service-linked role is not denied access. Review the resource-based policy attached to the resource that IAM Access Analyzer isn’t able to access. For a list of services that support resource-based policies, see the IAM documentation.
For example, if the analyzer can’t access an AWS Key Management Service (AWS KMS) key because of an explicit deny, add an exception for the IAM Access Analyzer service-linked role to the policy statement, similar to the following. Make sure that you change the <ACCOUNT_ID> to your account id.
With SAML 2.0 or Open ID Connect (OIDC)—which are open federation standards that many identity providers (IdPs) use—users can log in to the console or call the AWS API operations without you having to create an IAM user for everyone in your organization.
To set up federation, you must perform a one-time configuration so that your organization’s IdP and your account trust each other. To configure this trust, you must register AWS as a service provider (SP) with the IdP of your organization and set up metadata and key exchange.
The role or roles that you create in IAM define what the federated users from your organization are allowed to use on AWS. When you create the trust policy for the role, you specify the SAML or OIDC provider as the Principal. To only allow users that match certain attributes to access the role, you can scope the trust policy with a Condition.
Example 1: Federation with Okta
Let’s walk through an example that uses Okta as the IdP. Although access to a trusted IdP is intended, IAM Access Analyzer creates a finding for an IAM role that has trust policy granting access to a SAML provider because the trust policy allows access outside of the known zone of trust for the analyzer. You will see findings created for the IAM role granting access to Okta using the IAM trust policy, as shown in Figure 3.
Figure 3: IAM Access Analyzer identity provider finding example
Resolution
Setting access through SAML providers is a privileged operation, so we recommend that you analyze each finding to decide if an exception is acceptable. If you approve of the SAML-provided access setup, you can implement an archive rule to archive such findings with conditions for federation used in combination with your SAML provider. The filter for the Federated User rule depends on the name that you gave to the SAML IdP in your federation setup. For example, if your SAML IdP name is Okta, the rule should have a filter for arn:aws:iam::<ACCOUNT_ID>:saml-provider/Okta, where <ACCOUNT_ID> is your account number, as shown in Figure 4.
Figure 4: Archive rule example for using an IdP-related finding
Note: To include additional values for a multi-account setup, use the Add another value filter.
Example 2: IAM Identity Center
With AWS IAM Identity Center (successor to AWS Single Sign-On), you can manage sign-in security for your workforce. IAM Identity Center provides a central place to define your permission sets, assign them to your users and groups, and give your users a portal where they can access their assigned accounts.
With IAM Identity Center, you manage access to accounts by creating and assigning permission sets. These are IAM role templates that define (among other things) which policies to include in a role. When you create a permission set in IAM Identity Center and associate it to an account, IAM Identity Center creates a role in that account with a trust policy that allows a federated IdP as a principal — in this case, IAM Identity Center.
IAM Access Analyzer generates a finding for this setup because the allowed access is outside of the known zone of trust for the analyzer, as shown in Figure 5.
Figure 5: IAM Access Analyzer finding example for IAM Identity Center
To filter this finding, you need to implement an archive rule.
Resolution
You can implement an archive rule with conditions for federation used in combination with IAM Identity Center as the SAML provider. The roles created by IAM Identity Center in member accounts use a reserved path on AWS: arn:aws:iam::<ACCOUNT_ID>:role/aws-reserved/sso.amazonaws.com/. Hence, you can create an archive rule with a filter that contains :saml-provider/AWSSSO in the Federated User name and aws-reserved/sso.amazonaws.com/ in the Resource, as shown in Figure 6.
Figure 6: Archive rule example for IAM Identity Center generated findings
4. Filter cross-account access findings from trusted external accounts
We recommend that you identify and document accounts and principals that should be allowed access outside of the zone of trust for IAM Access Analyzer.
When a resource-based policy attached to a resource allows cross-account access from outside the zone of trust, IAM Access Analyzer generates cross-account access findings.
Is the cross-account access intended?
When you review cross-account access findings, you need to determine whether the access is intended or not. For example, you might have access provided to your auditor’s account or a partner account for visibility and monitoring of your AWS applications.
For trusted external accounts, you can create an archive rule that includes the AWS account in the criteria for the rule. Figure 7 shows an example of how to create the archive rule for a trusted external account (EXTERNAL_ACCOUNT_ID). In your own rule, replace EXTERNAL_ACCOUNT_ID with the trusted account id.
Figure 7: Archive rule example for trusted account findings
Is the cross-account access unintended?
After you have archived the intended access findings, you can start analyzing the findings initiated from unintended access. When you confirm that the findings show unintended access, you should take steps to remove the access by altering or deleting the policy or access control that granted access. You can expand the solution outlined in the blog post Automate resolution for IAM Access Analyzer cross-account access findings on IAM roles by adding an explicit deny statement.
You can also use AWS CloudTrail to track API calls that could have changed access configuration on your AWS resources.
Deploy IAM Access Analyzer and archive rules with a CloudFormation template
In this section, we demonstrate a sample CloudFormation template that creates an IAM access analyzer and archive rules for findings that are created for identified intended access to resources.
Important: When you create an archive rule using the AWS console, the existing findings and new findings that match criteria mentioned in the rules will be archived. However, archive rules created through CloudFormation or the AWS CLI will only archive the new findings that meet the criteria defined. You need to perform the access-analyzer:ApplyArchiveRule API after you create the archive rule to archive existing findings as well.
The sample CloudFormation template takes the following values as inputs and creates archive rules for findings that are created for identified intended access to resources shared outside of your zone of trust for the specified analyzer:
Analyzer name
Zone of trust
Known public S3 buckets, if you have any (for example, a bucket that hosts public website images).
Note: We use S3 buckets as an example. You can edit the rule to include resource types that are supported by IAM Access Analyzer, if public access is intended.
Trusted accounts — AWS accounts that don’t belong to your organization, but you trust them to have access to resources in your organization
SAML provider — The SAML provider approved to have access to your resources
Note: If you don’t use federation, you can remove the rule SAMLFederatedUsers.
AWSTemplateFormatVersion: 2010-09-09
Description: >+
Sample CloudFormation template creates archive rules for findings
created for resources shared outside of your zone of trust for specified
analyzer.
Metadata:
AWS::CloudFormation::Interface:
ParameterGroups:
- Label:
default: Define Configuration
Parameters:
- AccessAnalyzerName
- ZoneOfTrust
- KnownPublicS3Buckets
- TrustedAccounts
- SAMLProvider
Parameters:
AccessAnalyzerName:
Description: Provide name of the analyzer you would like to create archive rules for.
Type: String
ZoneOfTrust:
Description: Select the zone of trust of AccessAnalyzer
AllowedValues:
- ACCOUNT
- ORGANIZATION
Type: String
KnownPublicS3Buckets:
Description: List of comma-separated known S3 bucket arns, that should allow
public access Example -
arn:aws:s3:::DOC-EXAMPLE-BUCKET,arn:aws:s3:::DOC-EXAMPLE-BUCKET2
Type: CommaDelimitedList
TrustedAccounts:
Description: List of comma-separated account IDs, that do not belong to your
organization but you trust them to have access to resources in your
organization. [Example - Your auditor’s AWS account]
Type: List<Number>
TrustedFederationPrincipals:
Description: List of comma-separated trusted federated principals that are able
to assume roles in your accounts. [Example -
arn:aws:iam::012345678901:saml-provider/Okta,
arn:aws:iam::1111222233334444:saml-provider/Okta]
Type: CommaDelimitedList
Resources:
AccessAnalyzer:
Type: AWS::AccessAnalyzer::Analyzer
Properties:
AnalyzerName: ${AccessAnalyzerName}-${AWS::Region}
Type: ZoneOfTrust
ArchiveRules:
- RuleName: ArchivePublicS3BucketsAccess
Filter:
- Property: resource
Eq: KnownPublicS3Buckets
- RuleName: AccountAccessNecessaryForBusinessProcesses
Filter:
- Property: principal.AWS
Eq: TrustedAccounts
- Property: isPublic
Eq:
- "false"
- RuleName: SAMLFederatedUsers
Filter:
- Property: principal.Federated
Eq: TrustedFederationPrincipals
To download this sample template, download the file IAMAccessAnalyzer.yaml from Amazon S3.
Conclusion
In this blog post, you learned how to start with IAM Access Analyzer findings, filter them based on the level of access given outside of your zone of trust, and create archive rules for intended access findings. By using different filtering techniques to remediate intended access findings, you can concentrate on unintended access.
A full conference pass is $1,099. Register today with the code secure150off to receive a limited time $150 discount, while supplies last.
AWS re:Inforce is fast approaching, and this post can help you plan your agenda. AWS re:Inforce is a security learning conference where you can gain skills and confidence in cloud security, compliance, identity, and privacy. As a re:Inforce attendee, you have access to hundreds of technical and non-technical sessions, an Expo featuring AWS experts and security partners with AWS Security Competencies, and keynote and leadership sessions featuring Security leadership. AWS re:Inforce 2023 will take place in-person in Anaheim, CA, on June 13 and 14. re:Inforce 2023 features content in the following six areas:
Data Protection
Governance, Risk, and Compliance
Identity and Access Management
Network and Infrastructure Security
Threat Detection and Incident Response
Application Security
The data protection track will showcase services and tools that you can use to help achieve your data protection goals in an efficient, cost-effective, and repeatable manner. You will hear from AWS customers and partners about how they protect data in transit, at rest, and in use. Learn how experts approach data management, key management, cryptography, data security, data privacy, and encryption. This post will highlight of some of the data protection offerings that you can add to your agenda. To learn about sessions from across the content tracks, see the AWS re:Inforce catalog preview.
“re:Inforce is a great opportunity for us to hear directly from our customers, understand their unique needs, and use customer input to define solutions that protect sensitive data. We also use this opportunity to deliver content focused on the latest security research and trends, and I am looking forward to seeing you all there. Security is everyone’s job, and at AWS, it is job zero.” — Ritesh Desai, General Manager, AWS Secrets Manager
Breakout sessions, chalk talks, and lightning talks
DAP301: Moody’s database secrets management at scale with AWS Secrets Manager Many organizations must rotate database passwords across fleets of on-premises and cloud databases to meet various regulatory standards and enforce security best practices. One-time solutions such as scripts and runbooks for password rotation can be cumbersome. Moody’s sought a custom solution that satisfies the goal of managing database passwords using well-established DevSecOps processes. In this session, Moody’s discusses how they successfully used AWS Secrets Manager and AWS Lambda, along with open-source CI/CD system Jenkins, to implement database password lifecycle management across their fleet of databases spanning nonproduction and production environments.
DAP401: Security design of the AWS Nitro System The AWS Nitro System is the underlying platform for all modern Amazon EC2 instances. In this session, learn about the inner workings of the Nitro System and discover how it is used to help secure your most sensitive workloads. Explore the unique design of the Nitro System’s purpose-built hardware and software components and how they operate together. Dive into specific elements of the Nitro System design, including eliminating the possibility of operator access and providing a hardware root of trust and cryptographic system integrity protections. Learn important aspects of the Amazon EC2 tenant isolation model that provide strong mitigation against potential side-channel issues.
DAP322: Integrating AWS Private CA with SPIRE and Ottr at Coinbase Coinbase is a secure online platform for buying, selling, transferring, and storing cryptocurrency. This lightning talk provides an overview of how Coinbase uses AWS services, including AWS Private CA, AWS Secrets Manager, and Amazon RDS, to build out a Zero Trust architecture with SPIRE for service-to-service authentication. Learn how short-lived certificates are issued safely at scale for X.509 client authentication (i.e., Amazon MSK) with Ottr.
DAP331: AWS Private CA: Building better resilience and revocation techniques In this chalk talk, explore the concept of PKI resiliency and certificate revocation for AWS Private CA, and discover the reasons behind multi-Region resilient private PKI. Dive deep into different revocation methods like certificate revocation list (CRL) and Online Certificate Status Protocol (OCSP) and compare their advantages and limitations. Leave this talk with the ability to better design resiliency and revocations.
DAP231: Securing your application data with AWS storage services Critical applications that enterprises have relied on for years were designed for the database block storage and unstructured file storage prevalent on premises. Now, organizations are growing with cloud services and want to bring their security best practices along. This chalk talk explores the features for securing application data using Amazon FSx, Amazon Elastic File System (Amazon EFS), and Amazon Elastic Block Store (Amazon EBS). Learn about the fundamentals of securing your data, including encryption, access control, monitoring, and backup and recovery. Dive into use cases for different types of workloads, such as databases, analytics, and content management systems.
Hands-on sessions (builders’ sessions and workshops)
DAP353: Privacy-enhancing data collaboration with AWS Clean Rooms Organizations increasingly want to protect sensitive information and reduce or eliminate raw data sharing. To help companies meet these requirements, AWS has built AWS Clean Rooms. This service allows organizations to query their collective data without needing to expose the underlying datasets. In this builders’ session, get hands-on with AWS Clean Rooms preventative and detective privacy-enhancing controls to mitigate the risk of exposing sensitive data.
DAP371: Post-quantum crypto with AWS KMS TLS endpoints, SDKs, and libraries This hands-on workshop demonstrates post-quantum cryptographic algorithms and compares their performance and size to classical ones. Learn how to use AWS Key Management Service (AWS KMS) with the AWS SDK for Java to establish a quantum-safe tunnel to transfer the most critical digital secrets and protect them from a theoretical computer targeting these communications in the future. Find out how the tunnels use classical and quantum-resistant key exchanges to offer the best of both worlds, and discover the performance implications.
DAP271: Data protection risk assessment for AWS workloads Join this workshop to learn how to simplify the process of selecting the right tools to mitigate your data protection risks while reducing costs. Follow the data protection lifecycle by conducting a risk assessment, selecting the effective controls to mitigate those risks, deploying and configuring AWS services to implement those controls, and performing continuous monitoring for audits. Leave knowing how to apply the right controls to mitigate your business risks using AWS advanced services for encryption, permissions, and multi-party processing.
If these sessions look interesting to you, join us in California by registering for re:Inforce 2023. We look forward to seeing you there!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
A full conference pass is $1,099. Register today with the code secure150off to receive a limited time $150 discount, while supplies last.
AWS re:Inforce is a security learning conference where you can gain skills and confidence in cloud security, compliance, identity, and privacy. As a re:Inforce attendee, you have access to hundreds of technical and non-technical sessions, an Expo featuring AWS experts and security partners with AWS Security Competencies, and keynote and leadership sessions featuring Security leadership. AWS re:Inforce 2023 will take place in-person in Anaheim, CA, on June 13 and 14.
In these sessions, you’ll hear directly from AWS leaders and get hands-on with the tools that help you ship securely. You’ll hear how organization and culture help security accelerate your business, and you’ll dive deep into the technology that helps you more swiftly get features to customers. You might even find some new tools that make it simpler to empower your builders to move quickly and ship securely.
Breakout sessions, chalk talks, and lightning talks
APS221: From code to insight: Amazon Inspector & AWS Lambda in action In this lightning talk, see a demo of Amazon Inspector support for AWS Lambda. Inspect a Java application running on Lambda for security vulnerabilities using Amazon Inspector for an automated and continual vulnerability assessment. In addition, explore how Amazon Inspector can help you identify package and code vulnerabilities in your serverless applications.
APS302: From IDE to code review, increasing quality and security Attend this session to discover how to improve the quality and security of your code early in the development cycle. Explore how you can integrate Amazon Code Whisperer, Amazon CodeGuru reviewer, and Amazon Inspector into your development workflow, which can help you identify potential issues and automate your code review process.
APS201: How AWS and MongoDB raise the security bar with distributed ownership In this session, explore how AWS and MongoDB have approached creating their Security Guardians and Security Champions programs. Learn practical advice on scoping, piloting, measuring, scaling, and managing a program with the goal of accelerating development with a high security bar, and discover tips on how to bridge the gap between your security and development teams. Learn how a guardians or champions program can improve security outside of your dev teams for your company as a whole when applied broadly across your organization.
APS202: AppSec tooling & culture tips from AWS & Toyota Motor North America In this session, AWS and Toyota Motor North America (TMNA) share how they scale AppSec tooling and culture across enterprise organizations. Discover practical advice and lessons learned from the AWS approach to threat modeling across hundreds of service teams. In addition, gain insight on how TMNA has embedded security engineers into business units working on everything from mainframes to serverless. Learn ways to support teams at varying levels of maturity, the importance of differentiating between risks and vulnerabilities, and how to balance the use of cloud-native, third-party, and open-source tools at scale.
APS331: Shift security left with the AWS integrated builder experience As organizations start building their applications on AWS, they use a wide range of highly capable builder services that address specific parts of the development and management of these applications. The AWS integrated builder experience (IBEX) brings those separate pieces together to create innovative solutions for both customers and AWS Partners building on AWS. In this chalk talk, discover how you can use IBEX to shift security left by designing applications with security best practices built in and by unlocking agile software to help prevent security issues and bottlenecks.
Hands-on sessions (builders’ sessions and workshops)
APS271: Threat modeling for builders Attend this facilitated workshop to get hands-on experience creating a threat model for a workload. Learn some of the background and reasoning behind threat modeling, and explore tools and techniques for modeling systems, identifying threats, and selecting mitigations. In addition, explore the process for creating a system model and corresponding threat model for a serverless workload. Learn how AWS performs threat modeling internally, and discover the principles to effectively perform threat modeling on your own workloads.
APS371: Integrating open-source security tools with the AWS code services AWS, open-source, and partner tooling works together to accelerate your software development lifecycle. In this workshop, learn how to use Automated Security Helper (ASH), a source-application security tool, to quickly integrate various security testing tools into your software build and deployment flows. AWS experts guide you through the process of security testing locally on your machines and within the AWS CodeCommit, AWS CodeBuild, and AWS CodePipeline services. In addition, discover how to identify potential security issues in your applications through static analysis, software composition analysis, and infrastructure-as-code testing.
APS352: Practical shift left for builders Providing early feedback in the development lifecycle maximizes developer productivity and enables engineering teams to deliver quality products. In this builders’ session, learn how to use AWS Developer Tools to empower developers to make good security decisions early in the development cycle. Tools such as Amazon CodeGuru, Amazon CodeWhisperer, and Amazon DevOps Guru can provide continuous real-time feedback upon each code commit into a source repository and supplement this with ML capabilities integrated into the code review stage.
APS351: Secure software factory on AWS through the DoD DevSecOps lens Modern information systems within regulated environments are driven by the need to develop software with security at the forefront. Increasingly, organizations are adopting DevSecOps and secure software factory patterns to improve the security of their software delivery lifecycle. In this builder’s session, we will explore the options available on AWS to create a secure software factory aligned with the DoD Enterprise DevSecOps initiative. We will focus on the security of the software supply chain as we deploy code from source to an Amazon Elastic Kubernetes Service (EKS) environment.
If these sessions look interesting to you, join us in California by registering for re:Inforce 2023. We look forward to seeing you there!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
At Amazon Web Services (AWS), we move fast and continually iterate to meet the evolving needs of our customers. We design services that can help our customers meet even the most stringent security and compliance requirements. Additionally, our service teams work closely with our AWS Security Guardians program to coordinate security efforts and to maintain a high quality bar. We also have internal compliance teams that continually monitor security control requirements from all over the world and engage with external auditors to achieve third-party validation of our services against these requirements.
In this post, I’ll cover some key strategies and best practices that we use to scale security and compliance while maintaining a culture of innovation.
Security as the foundation
At AWS, security is our top priority. Although compliance might be challenging, treating security as an integral part of everything we do at AWS makes it possible for us to adhere to a broad range of compliance programs, to document our compliance, and to successfully demonstrate our compliance status to our auditors and customers.
Over time, as the auditors get deeper into what we’re doing, we can also help improve and refine their approach, as well. This increases the depth and quality of the reports that we provide directly to our customers.
The challenge of scaling securely
Many customers struggle with balancing security, compliance, and production. These customers have applications that they want to quickly make available to their own customer base. They might need to audit these applications. The traditional process can include writing the application, putting it into production, and then having the audit team take a look to make sure it meets compliance standards. This approach can cause issues, because retroactively adding compliance requirements can result in rework and churn for the development team.
Enforcing compliance requirements in this way doesn’t scale and eventually causes more complexity and friction between teams. So how do you scale quickly and securely?
Speak their language
The first way to earn trust with development teams is to speak their language. It’s critical to use terms and references that developers use, and to know what tools they are using to develop, deploy, and secure code. It’s not efficient or realistic to ask the engineering teams to do the translation of diverse (and often vague) compliance requirements into engineering specs. The compliance teams must do the hard work of translating what is required into what specifically must be done, using language that engineers are familiar with.
Another strategy to scale is to embed compliance requirements into the way developers do their daily work. It’s important that compliance teams enable developers to do their work just as they normally do, without compliance needing to intervene. If you’re successful at that strategy—and the compliant path becomes the simplest and most natural path—then that approach can lead to a very scalable compliance program that fosters understanding between teams and increased collaboration. This approach has helped break down the barriers between the developer and audit/compliance organizations.
Treat auditors and regulators as partners
I believe that you should treat auditors and regulators as true business partners. An independent auditor or regulator understands how a wide range of customers will use the security assurance artifacts that you are producing, and therefore will have valuable insights into how your reports can best be used. I think people can fall into the trap of treating regulators as adversaries. The best approach is to communicate openly with regulators, helping them understand your business and the value you bring to your customers, and getting them ramped up on your technology and processes.
At AWS, we help auditors and regulators get ramped up in various ways. For example, we have the Digital Audit Symposium, which contains presentations on how we control and operate particular services in terms of security and compliance. We also offer the Cloud Audit Academy, a learning path that provides both cloud-agnostic and AWS-specific training to help existing and prospective auditing, risk, and compliance professionals understand how to audit regulated cloud workloads. We’ve learned that being a partner with auditors and regulators is key in scaling compliance.
Conclusion
Having security as a foundation is essential to driving and scaling compliance efforts. Speaking the language of developers helps them continue to work without disruption, and makes the simple path the compliant path. Although some barriers still exist, especially for organizations in highly regulated industries such as financial services and healthcare, treating auditors like partners is a positive strategic shift in perspective. The more proactive you are in helping them accomplish what they need, the faster you will realize the value they bring to your business.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In the AWS Security Profile — Cryptography Edition series, we interview Amazon Web Services (AWS) thought leaders who help keep our customers safe and secure. This interview features Panos Kampanakis, Principal Security Engineer, AWS Cryptography. Panos shares thoughts on data protection, cloud security, post-quantum cryptography, and more.
What do you do in your current role and how long have you been at AWS?
I have been with AWS for two years. I started as a Technical Program Manager in AWS Cryptography, where I led some AWS Cryptography projects related to cryptographic libraries and FIPS, but I’m currently working as a Principal Security Engineer on a team that focuses on applied cryptography, research, and cryptographic software. I also participate in standardization efforts in the security space, especially in cryptographic applications. It’s a very active space that can consume as much time as you have to offer.
How did you get started in the data protection/ cryptography space? What about it piqued your interest?
I always found cybersecurity fascinating. The idea of proactively focusing on security and enabling engineers to protect their assets against malicious activity was exciting. After working in organizations that deal with network security, application security, vulnerability management, and security information sharing, I found myself going back to what I did in graduate school: applied cryptography.
Cryptography is a constantly evolving, fundamental area of security that requires breadth of technical knowledge and understanding of mathematics. It provides a challenging environment for those that like to constantly learn. Cryptography is so critical to the security and privacy of data and assets that it is top of mind for the private and public sector worldwide.
How do you explain your job to your non-tech friends?
I usually tell them that my work focuses on protecting digital assets, information, and the internet from malicious actors. With cybersecurity incidents constantly in the news, it’s an easy picture to paint. Some of my non-technical friends still joke that I work as a security guard!
What makes cryptography exciting to you?
Cryptography is fundamental to security. It’s critical for the protection of data and many other secure information use cases. It combines deep mathematical topics, data information, practical performance challenges that threaten deployments at scale, compliance with various requirements, and subtle potential security issues. It’s certainly a challenging space that keeps evolving. Post-quantum or privacy preserving cryptography are examples of areas that have gained a lot of attention recently and have been consistently growing.
Given the consistent evolution of security in general, this is an important and impactful space where you can work on challenging topics. Additionally, working in cryptography, you are surrounded by intelligent people who you can learn from.
AWS has invested in the migration to post-quantum cryptography by contributing to post-quantum key agreement and post-quantum signature schemes to protect the confidentiality, integrity, and authenticity of customer data. What should customers do to prepare for post-quantum cryptography?
There are a few things that customers can do while waiting for the ratification of the new quantum-safe algorithms and their deployment. For example, you can inventory the use of asymmetric cryptography in your applications and software. Admittedly, this is not a simple task, but with proper subject matter expertise and instrumentation where necessary, you can identify where you’re using quantum-vulnerable algorithms in order to prioritize the uses. AWS is doing this exercise to have a prioritized plan for the upcoming migration.
You can also study and experiment with the potential impact of these new algorithms in critical use cases. There have been many studies on transport protocols like TLS, virtual private networks (VPNs), Secure Shell (SSH), and QUIC, but organizations might have unique uses that haven’t been accounted for yet. For example, a firm that specializes in document signing might require efficient signature methods with small size constraints, so deploying Dilithium, NIST’s preferred quantum-safe signature, could come at a cost. Evaluating its impact and performance implications would be important. If you write your own crypto software, you can also strive for algorithm agility, which would allow you to swap in new algorithms when they become available.
More importantly, you should push your vendors, your hardware suppliers, the software and open-source community, and cloud providers to adjust and enable their solutions to become quantum-safe in the near future.
What’s been the most dramatic change you’ve seen in the data protection and post-quantum cryptography landscape?
The transition from typical cryptographic algorithms to ones that can operate on encrypted data is an important shift in the last decade. This is a field that’s still seeing great development. It’s interesting how the power of data has brought forward a whole new area of being able to operate on encrypted information so that we can benefit from the analytics. For more information on the work that AWS is doing in this space, see Cryptographic Computing.
In terms of post-quantum cryptography, it’s exciting to see how an important potential risk brought a community from academia, industry, and research together to collaborate and bring new schemes to life. It’s also interesting how existing cryptography has reached optimal efficiency levels that the new cryptographic primitives sometimes cannot meet, which pushes the industry to reconsider some of our uses. Sometimes the industry might overestimate the potential impact of quantum computing to technology, but I don’t believe we should disregard the effect of heavier algorithms on performance, our carbon footprint, energy consumption, and cost. We ought to aim for efficient solutions that don’t undermine security.
Where do you see post-quantum cryptography heading in the future?
Post-quantum cryptography has received a lot of attention, and a transition is about to start ramping up after we have ratified algorithms. Although it’s sometimes considered a Herculian effort, some use cases can transition smoothly.
AWS and other industry peers and researchers have already evaluated some post-quantum migration strategies. With proper prioritization and focus, we can address some of the most important applications and gradually transition the rest. There might be some applications that will have no clear path to a post-quantum future, but most will. At AWS, we are committed to making the transitions necessary to protect our customer data against future threats.
What are you currently working on that you look forward to sharing with customers’?
I’m currently focused on bringing post-quantum algorithms to our customers’ cryptographic use cases. I’m looking into the challenges that this upcoming migration will bring and participating in standards and industry collaborations that will hopefully enable a simpler transition for everyone.
I also engage on various topics with our cryptographic libraries teams (for example, AWS-LC and s2n-tls). We build these libraries with security and performance in mind, and they are used in software across AWS.
Additionally, I work with some AWS service teams to help enable compliance with various cryptographic requirements and regulations.
Is there something you wish customers would ask you about more often?
I wish customers asked more often about provable security and how to integrate such solutions in their software. This is a fascinating field that can prevent serious issues where cryptography can go wrong. It’s a complicated topic. I would like for customers to become more aware of the importance of provable security especially in open-source software before adopting it in their solutions. Using provably secure software that is designed for performance and compliance with crypto requirements is beneficial to everyone.
I also wish customers asked more about why AWS made certain choices when deploying new mechanisms. In areas of active research, it’s often simpler to experimentally build a proof-of-concept of a new mechanism and test and prove its performance in a controlled benchmark scenario. On the other hand, it’s usually not trivial to deploy new solutions at scale (especially given the size and technological breadth of AWS), to help ensure backwards compatibility, commit to supporting these solutions in the long run, and make sure they’re suitable for various uses. I wish I had more opportunities to go over with customers the effort that goes into vetting and deploying new mechanisms at scale.
You have frequently contributed to cybersecurity publications, what is your favorite recent article and why?
I used to play basketball when I was younger, but I no longer have time. I spend most of my time with my family and little toddlers who have infinite amounts of energy. When I find an opportunity, I like reading books and short stories or watching quality films.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In the AWS Security Profile series, I interview some of the humans who work in Amazon Web ServicesSecurity and help keep our customers safe and secure. This interview is with Ryan Dsouza, Principal Solutions Architect for industrial internet of things (IIoT) security.
How long have you been at AWS and what do you do in your current role?
I’ve been with AWS for over five years and have held several positions working with customers, AWS Partner Network partners, and standards organizations on IoT and IIoT solutions. Currently, I’m a Principal Solutions Architect for IIoT security. In this role, I’m the global technical leader and subject matter expert for operational technology (OT) and IIoT security, which means that I lead our OT/IIoT strategy and roadmap, translate customer requirements into technical solutions, and work with industry standards such as ISA/IEC 62443 to support IIoT and cloud technologies. I also work with our strategic OT/IIoT security partners to design and build integrations and solutions on AWS. And I work with some of our strategic customers to help them plan, assess, and manage the risk that comes from OT/IT convergence and to design, build, and operate more secure, scalable, and innovative IIoT solutions by using AWS capabilities to deliver measurable business outcomes.
How did you get started in the world of OT and IIoT security?
I’ve been working with OT for more than 25 years and with IIoT, for the last 10 years. I’ve led digital transformation initiatives for numerous world-class organizations including Accenture, Siemens, General Electric, IBM, and AECOM, serving customers on their digital transformation initiatives across a wide range of industry verticals such as manufacturing, buildings, utilities, smart cities, and more.
Throughout my career, I witnessed devices across critical infrastructure sectors, such as water, manufacturing, electricity, transportation, oil and gas, and buildings, getting digitized and connected to the internet. I quickly realized that this trend of connected assets and digitization will continue to grow and could outstrip the supply of cybersecurity professionals. Each customer that embraces the digital world faces cybersecurity challenges. At AWS, I work with customers to understand these challenges and provide prescriptive and practical guidance on how to secure their OT environments and IIoT solutions to help ensure safe and secure digital transformation.
What makes OT security different from information technology (IT) security?
OT and IT security are two distinct areas of security that are designed to protect different types of systems and assets. OT security is concerned with the protection of industrial control systems and other related operational technology, such as supervisory control and data acquisition (SCADA) systems, which are used to control and monitor physical processes in critical infrastructure industries such as manufacturing, energy, transportation, buildings, and utilities. The main focus of OT security is on the availability, integrity, safety, and reliability of these systems, as well as protection of the physical equipment that is being controlled. OT cybersecurity supports the safe operation of critical infrastructure. IT security, on the other hand, is concerned with the protection of computer systems, networks, and data from cyberthreats such as hacking, malware, and phishing attempts. The main focus of IT security is on the confidentiality, integrity, and availability of information and systems.
As a result of OT/IT convergence, IIoT, and the industrial digital transformation, our customers now must secure an increasing attack surface and overlapping IT and OT environments. They realize that it is business critical to secure OT/IIoT systems to avoid security events that could cause unplanned downtime and pose a safety risk. I refer to this as “securing cyber-physical systems and enabling safe and secure industrial digital transformation.”
How do you explain your job to your non-tech friends?
I explain that OT is used in buildings, manufacturing, utilities, transportation, and more, and when these systems connect to the internet, they’re exposed to risks. The risks are the same as those faced by IoT devices in our own homes and workplaces—but with greater consequences if compromised because these systems deal with critical infrastructure that our society relies on. I often share the Colonial Pipeline example and explain that I help AWS customers understand the risks and the consequences from a compromise, and design cybersecurity solutions to protect these critical infrastructure assets.
What are you currently working on that you’re excited about?
Our customers use lots of security tools from lots of different vendors. Security is a team sport, and I’m really excited to be working with customers, APN partners, and AWS service teams to build security features and product integrations that make it simpler for customers to monitor and secure OT, IIoT, and the cloud. For example, I’m working with our APN security partners to build integrations with AWS Security Hub and Amazon Security Lake, bring zero trust security solutions to OT environments, and improve security at the industrial edge.
Another project that I’m super excited about is bringing OT/IIoT security solutions to our critical infrastructure customers, including small and mid-sized organizations, by simplifying the deployment, management, procurement, and payment process so that customers can get more value from these AWS security solutions faster.
Another area of focus for me is tracking the fast-evolving critical infrastructure cybersecurity regulations, how they impact our customers, and the role that AWS can play to make it simpler for customers to align with these new security and compliance requirements.
Just like how the cloud transformed IT, I think the cloud will continue to revolutionize OT, and I’m super excited and energized to work with customers and APN partners to move OT and IIoT applications to the cloud and build nearly anything they can imagine faster and more cost-effectively on AWS.
What are the biggest challenges in securing critical infrastructure systems?
With critical infrastructure, the biggest challenge is legacy OT systems that may not have been designed with cybersecurity in mind and that use older operating systems and software, which can be difficult to upgrade and patch. These systems were designed to operate in an air-gapped environment, but there is a growing trend to connect them in new ways to IT systems. As IT and OT converge to support expanding business needs, air-gapped devices and perimeter security are no longer sufficient to address and defend against modern threats such as ransomware, data exfiltration, denial of service, and cryptocurrency mining. As OT and IT converge and OT becomes more cloud connected, the biggest challenge is to secure critical infrastructure that uses legacy and aging industrial control systems (ICS) and OT technology. We are seeing a trend to keep ICS/OT systems connected, but in smarter and more secure ways by using network segmentation, edge gateways, and the hybrid cloud so that if a problem occurs, you can still run the most important systems in an isolated and disconnected mode. For example, if your corporate systems are compromised with ransomware, you can disconnect your critical infrastructure systems from the external world and continue the most critical operations. There is a growing need to design innovative and highly distributed solution patterns to keep critical information and hybrid systems safe and secure. This is an area of focus for me at AWS.
What else can enterprises do to manage OT/IT convergence and protect themselves from these security risks?
I’ve done multiple presentations, blog posts, and whitepapers on this topic, and even if the solutions sound simple, they can be challenging to implement in industrial environments. I recommend reading the blog posts Managing Organization Transformation for Successful OT/IT Convergence and Assessing OT and IIoT cybersecurity risk, and implementing the Ten security golden rules for IIoT solutions. AWS offers lots of prescriptive guidance and solutions to help enterprises more safely and securely manage OT/IT convergence and mitigate risk with proper planning and implementation across the various aspects of business—people, processes, and technology. I encourage customers to start by focusing on the security fundamentals of securing identities, assessing their risk from OT/IT convergence, and improving their visibility into devices on the network and across the converged OT and IT environment. I also recommend using standards such as ISA/IEC 62443, which are comprehensive, consensus-based, and form a strong basis for securing critical infrastructure systems.
What skills do professionals need to be successful in critical infrastructure security?
Critical infrastructure security sounds harder than it really is. When I train people, I break it down into bite-sized pieces that are simple to understand and implement. There is some mystery around cybersecurity, but it’s just a lot of small parts. You must learn what all the parts are, what the acronyms are, and how they fit together to form cyber-physical systems. When I describe it in a real-world application, most people pick it up quickly.
Curiosity and a desire to continue learning are important characteristics to have, because cybersecurity is a fast-evolving technology field. Empathy is also important because to secure a system, you must have empathy for the people behind the work and why their goals and needs are important. For example, in the OT world, you have operations folks who just want the thing to work. If an alarm is going off on their computer screen and they must react by clicking a button, they don’t want their screen to lock them out so they can’t click that button, because this could cause the plant to have big problems. So, you need to design a solution that matches user access controls with roles and responsibilities so that a plant operator can take corrective actions in an emergency situation.
Another example is patching critical OT systems that have vulnerabilities. This may not be possible due to the risk of causing unplanned downtime, and it could pose a safety risk or result in additional time and cost for recertification due to compliance requirements. You must have empathy for the people in this situation and their needs, and then, as a security professional, design around that so they can still have those things but in a more secure way. For example, you might need to create mechanisms to identify, network isolate, or replace legacy devices that aren’t capable of receiving updates. If you are detail-oriented and have strong curiosity and empathy, you can succeed in the field of critical infrastructure cybersecurity.
I have two favorite leadership principles: Learn and be Curious; and one that I initially discounted, Frugality. I believe that the best way to predict the future is to invent it, which is why I’m never done learning and seeking new ways to solve problems.
My view on the Frugality leadership principle is that we need to be frugal with each other’s time. There are so many competing demands on everyone’s time, and it’s important in a place like AWS to be mindful of that. Make sure you’ve done your due diligence on something before you broadly ask the question or escalate. Being frugal in my view is about being self-sufficient, learning to use self-service tools, and working with limited time or resources to deliver results.
I wake up every morning with the conviction that the world is always changing, and that, to succeed, I have to change faster by learning new skills and being frugal with time and resources.
What’s the thing you’re most proud of in your career?
I’m really proud of working with critical infrastructure customers across a diverse range of industries over the last 25 years and supporting their digital transformation initiatives. In the early part of my career, I was a design and commissioning engineer of industrial automation systems. In this role, I had the opportunity to design and commission new industrial plants and get them into operation, which was extremely fulfilling. I feel fortunate to have joined a company like AWS that takes cybersecurity seriously in developing its products and cloud services, and I’m proud to bring real-world experience in the design and security of cyber-physical systems to our critical infrastructure customers.
If you had to pick an industry outside of engineering, what would you want to do?
Growing up in India in a family of engineers and doctors, there were only two options: engineer or doctor. Both professions have the ability to change the world. Because my mother and brother worked at Siemens, I pursued a career in engineering. If I had to pick an industry outside of engineering, it would have been in the medical field.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.