Post Syndicated from Eric Johnson original https://aws.amazon.com/blogs/compute/accelerating-serverless-development-with-aws-sam-accelerate/
Building a serverless application changes the way developers think about testing their code. Previously, developers would emulate the complete infrastructure locally and only commit code ready for testing. However, with serverless, local emulation can be more complex.
In this post, I show you how to bypass most local emulation by testing serverless applications in the cloud against production services using AWS SAM Accelerate. AWS SAM Accelerate aims to increase infrastructure accuracy for testing with sam sync, incremental builds, and aggregated feedback for developers. AWS SAM Accelerate brings the developer to the cloud and not the cloud to the developer.
AWS SAM Accelerate
The AWS SAM team has listened to developers wanting a better way to emulate the cloud on their local machine and we believe that testing against the cloud is the best path forward. With that in mind, I am happy to announce the beta release of AWS SAM Accelerate!
Previously, the latency of deploying after each change has caused developers to seek other options. AWS SAM Accelerate is a set of features to reduce that latency and enable developers to test their code quickly against production AWS services in the cloud.
To demonstrate the different options, this post uses an example application called “Blog”. To follow along, create your version of the application by downloading the demo project. Note, you need the latest version of AWS SAM and Python 3.9 installed. AWS SAM Accelerate works with other runtimes, but this example uses Python 3.9.
After installing the pre-requisites, set up the demo project with the following commands:
- Create a folder for the project called blog
mkdir blog && cd blog - Initialize a new AWS SAM project:
sam init - Chose option 2 for Custom Template Location.
- Enter https://github.com/aws-samples/aws-sam-accelerate-demo as the location.
AWS SAM downloads the sample project into the current folder. With the blog application in place, you can now try out AWS SAM Accelerate.
AWS SAM sync
The first feature of AWS SAM Accelerate is a new command called sam sync. This command synchronizes your project declared in an AWS SAM template to the AWS Cloud. However, sam sync differentiates between code and configuration.
AWS SAM defines code as the following:
- AWS Lambda function code.
- AWS Lambda layer resources.
- AWS Step Functions templates in Amazon States Language form.
- Amazon API Gateway OpenAPI documents identified in the CodeUri parameter.
Anything else is considered configuration. The following description of the sam sync options explains how sam sync differentiates between configuration synchronization and code synchronization. The resulting patterns are the fastest way to test code in the cloud with AWS SAM.
Using sam sync (no options)
The sam sync command with no options deploys or updates all infrastructure and code like the sam deploy command. However, unlike sam deploy, sam sync bypasses the AWS CloudFormation changeset process. To see this, run:
sam sync --stack-name blog
AWS SAM sync with no options
First, sam sync builds the code using the sam build command and then the application is synchronized to the cloud.

Successful sync
Using SAM sync code, resource, resource-id flags
The sam sync command can also synchronize code changes to the cloud without updating the infrastructure. This code synchronization uses the service APIs and bypasses CloudFormation, allowing AWS SAM to update the code in seconds instead of minutes.
To synchronize code, use the --code flag, which instructs AWS SAM to sync all the code resources in the stack:
sam sync --stack-name blog --code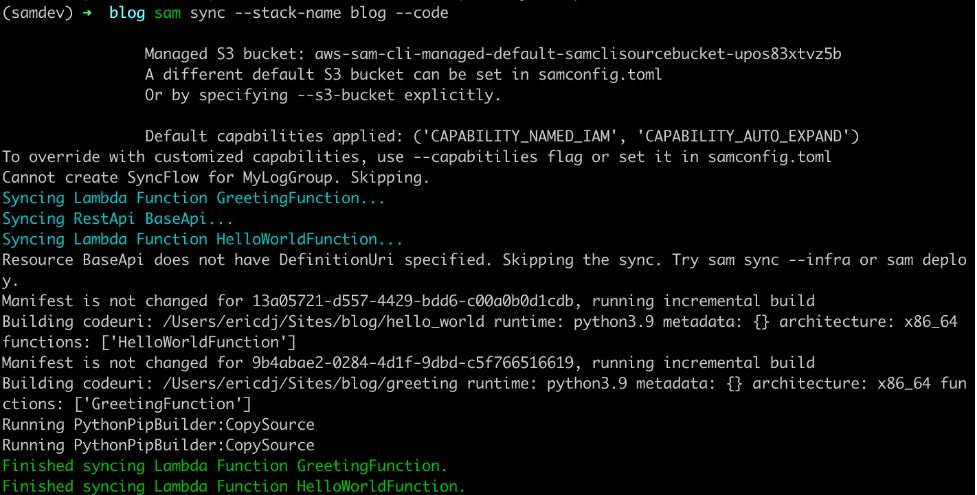
AWS SAM sync with the code flag
The sam sync command verifies each of the code types present and synchronizes the sources to the cloud. This example uses an API Gateway REST API and two Lambda functions. AWS SAM skips the REST API because there is no external OpenAPI file for this project. However, the Lambda functions and their dependencies are synchronized.
You can limit the synchronized resources by using the --resource flag with the --code flag:
sam sync --stack-name blog --code --resource AWS::Serverless::Function
SAM sync specific resource types
This command limits the synchronization to Lambda functions. Other available resources are AWS::Serverless::Api, AWS::Serverless::HttpApi, and AWS::Serverless::StateMachine.
You can target one specific resource with the --resource-id flag to get more granular:
sam sync --stack-name blog --code --resource-id HelloWorldFunction
SAM sync specific resource
This time sam sync ignores the GreetingFunction and only updates the HelloWorldFunction declared with the command’s --resource-id flag.
Using the SAM sync watch flag
The sam sync --watch option tells AWS SAM to monitor for file changes and automatically synchronize when changes are detected. If the changes include configuration changes, AWS SAM performs a standard synchronization equivalent to the sam sync command. If the changes are code only, then AWS SAM synchronizes the code with the equivalent of the sam sync --code command.
The first time you run the sam sync command with the --watch flag, AWS SAM ensures that the latest code and infrastructure are in the cloud. It then monitors for file changes until you quit the command:
sam sync --stack-name blog --watch
Initial sync
To see a change, modify the code in the HelloWorldFunction (hello_world/app.py) by updating the response to the following:
return {
"statusCode": 200,
"body": json.dumps({
"message": "hello world, how are you",
# "location": ip.text.replace("\n", "")
}),
}Once you save the file, sam sync detects the change and syncs the code for the HelloWorldFunction to the cloud.

AWS SAM detects changes
Auto dependency layer nested stack
During the initial sync, there is a logical resource name called AwsSamAutoDependencyLayerNestedStack. This feature helps to synchronize code more efficiently.
When working with Lambda functions, developers manage the code for the Lambda function and any dependencies required for the Lambda function. Before AWS SAM Accelerate, if a developer does not create a Lambda layer for dependencies, then the dependencies are re-uploaded with the function code on every update. However, with sam sync, the dependencies are automatically moved to a temporary layer to reduce latency.

Auto dependency layer in change set
During the first synchronization, sam sync creates a single nested stack that maintains a Lambda layer for each Lambda function in the stack.
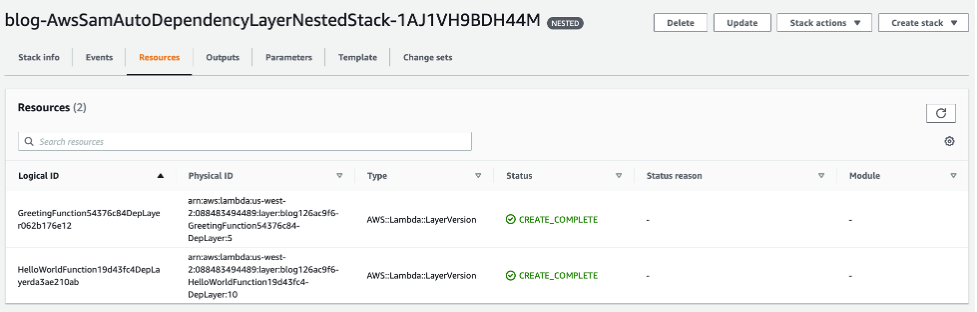
Auto dependency layer in console
These layers are only updated when the dependencies for one of the Lambda functions are updated. To demonstrate, change the requirements.txt (greeting/requirements.txt) file for the GreetingFunction to the following:
Requests
boto3AWS SAM detects the change, and the GreetingFunction and its temporary layer are updated:

Auto dependency layer synchronized
The Lambda function changes because the Lambda layer version must be updated.
Incremental builds with sam build
The second feature of AWS SAM Accelerate is an update to the SAM build command. This change separates the cache for dependencies from the cache for the code. The build command now evaluates these separately and only builds artifacts that have changed.
To try this out, build the project with the cached flag:
sam build --cached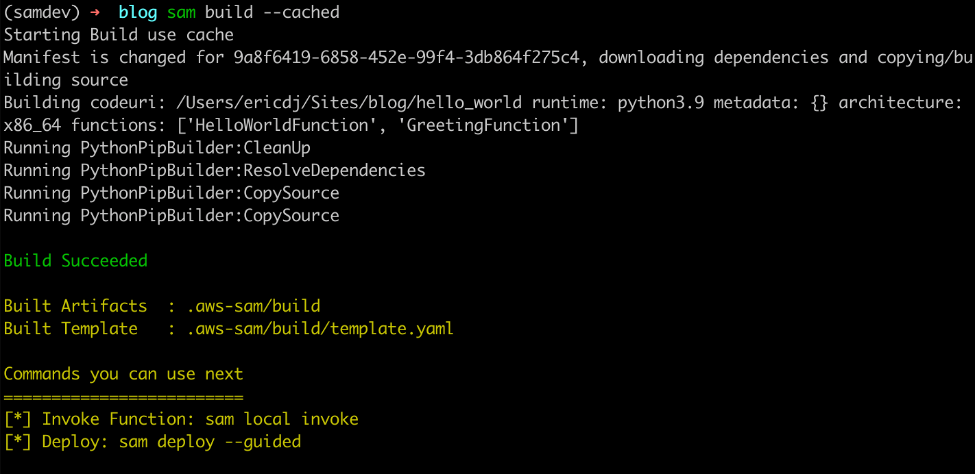
The first build establishes cache
The first build recognizes that there is no cache and downloads the dependencies and builds the code. However, when you rerun the command:

The second build uses existing cached artifacts
The sam build command verifies that the dependencies have not changed. There is no need to download them again so it builds only the application code.
Finally, update the requirements file for the HelloWorldFunction (hello_w0rld/requirements.txt) to:
Requests
boto3Now rerun the build command:

AWS SAM build detects dependency changes
The sam build command detects a change in the dependency requirements and rebuilds the dependencies and the code.
Aggregated feedback for developers
The final part of AWS SAM Accelerate’s beta feature set is aggregating logs for developer feedback. This feature is an enhancement to the already existing sam logs command. In addition to pulling Amazon CloudWatch Logs or the Lambda function, it is now possible to retrieve logs for API Gateway and traces from AWS X-Ray.
To test this, start the sam logs:
sam logs --stack-name blog --include-traces --tailInvoke the HelloWorldApi endpoint returned in the outputs on syncing:
curl https://112233445566.execute-api.us-west-2.amazonaws.com/Prod/helloThe sam logs command returns logs for the AWS Lambda function, Amazon API Gateway REST execution logs, and AWS X-Ray traces.

AWS Lambda logs from Amazon CloudWatch

Amazon API Gateway execution logs from Amazon CloudWatch
Traces from AWS X-Ray
The full picture

Development diagram for AWS SAM Accelerate
With AWS SAM Accelerate, creating and testing an application is easier and faster. To get started:
- Start a new project:
sam init - Synchronize the initial project with a development environment:
sam sync --stack-name <project name> --watch - Start monitoring for logs:
sam logs --stack-name <project name> --include-traces --tail - Test using response data or logs.
- Iterate.
- Rinse and repeat!
Some caveats
AWS SAM Accelerate is in beta as of today. The team has worked hard to implement a solid minimum viable product (MVP) to get feedback from our community. However, there are a few caveats.
- Amazon State Language (ASL) code updates for Step Functions does not currently support DefinitionSubstitutions.
- API Gateway OpenAPI template must be defined in the DefiitionUri parameter and does not currently support pseudo parameters and intrinsic functions at this time
- The
sam logscommand only supports execution logs on REST APIs and access logs on HTTP APIs. - Function code cannot be inline and must be defined as a separate file in the CodeUri parameter.
Conclusion
When testing serverless applications, developers must get to the cloud as soon as possible. AWS SAM Accelerate helps developers escape from emulating the cloud locally and move to the fidelity of testing in the cloud.
In this post, I walk through the philosophy of why the AWS SAM team built AWS SAM Accelerate. I provide an example application and demonstrate the different features designed to remove barriers from testing in the cloud.
We invite the serverless community to help improve AWS SAM for building serverless applications. As with AWS SAM and the AWS SAM CLI (which includes AWS SAM Accelerate), this project is open source and you can contribute to the repository.
For more serverless content, visit Serverless Land.