Post Syndicated from Channy Yun (윤석찬) original https://aws.amazon.com/blogs/aws/deepseek-v3-1-now-available-in-amazon-bedrock/
In March, Amazon Web Services (AWS) became the first cloud service provider to deliver DeepSeek-R1 in a serverless way by launching it as a fully managed, generally available model in Amazon Bedrock. Since then, customers have used DeepSeek-R1’s capabilities through Amazon Bedrock to build generative AI applications, benefiting from the Bedrock’s robust guardrails and comprehensive tooling for safe AI deployment.
Today, I am excited to announce DeepSeek-V3.1 is now available as a fully managed foundation model in Amazon Bedrock. DeepSeek-V3.1 is a hybrid open weight model that switches between thinking mode (chain-of-thought reasoning) for detailed step-by-step analysis and non-thinking mode (direct answers) for faster responses.
According to DeepSeek, the thinking mode of DeepSeek-V3.1 achieves comparable answer quality with better results, stronger multi-step reasoning for complex search tasks, and big gains in thinking efficiency compared with DeepSeek-R1-0528.
| Benchmarks | DeepSeek-V3.1 | DeepSeek-R1-0528 |
|---|---|---|
| Browsecomp | 30.0 | 8.9 |
| Browsecomp_zh | 49.2 | 35.7 |
| HLE | 29.8 | 24.8 |
| xbench-DeepSearch | 71.2 | 55.0 |
| Frames | 83.7 | 82.0 |
| SimpleQA | 93.4 | 92.3 |
| Seal0 | 42.6 | 29.7 |
| SWE-bench Verified | 66.0 | 44.6 |
| SWE-bench Multilingual | 54.5 | 30.5 |
| Terminal-Bench | 31.3 | 5.7 |
DeepSeek-V3.1 model performance in tool usage and agent tasks has significantly improved through post-training optimization compared to previous DeepSeek models. DeepSeek-V3.1 also supports over 100 languages with near-native proficiency, including significantly improved capability in low-resource languages lacking large monolingual or parallel corpora. You can build global applications to deliver enhanced accuracy and reduced hallucinations compared to previous DeepSeek models, while maintaining visibility into its decision-making process.
Here are your key use cases using this model:
- Code generation – DeepSeek-V3.1 excels in coding tasks with improvements in software engineering benchmarks and code agent capabilities, making it ideal for automated code generation, debugging, and software engineering workflows. It performs well on coding benchmarks while delivering high-quality results efficiently.
- Agentic AI tools – The model features enhanced tool calling through post-training optimization, making it strong in tool usage and agentic workflows. It supports structured tool calling, code agents, and search agents, positioning it as a solid choice for building autonomous AI systems.
- Enterprise applications – DeepSeek models are integrated into various chat platforms and productivity tools, enhancing user interactions and supporting customer service workflows. The model’s multilingual capabilities and cultural sensitivity make it suitable for global enterprise applications.
As I mentioned in my previous post, when implementing publicly available models, give careful consideration to data privacy requirements when implementing in your production environments, check for bias in output, and monitor your results in terms of data security, responsible AI, and model evaluation.
You can access the enterprise-grade security features of Amazon Bedrock and implement safeguards customized to your application requirements and responsible AI policies with Amazon Bedrock Guardrails. You can also evaluate and compare models to identify the optimal model for your use cases by using Amazon Bedrock model evaluation tools.
Get started with the DeepSeek-V3.1 model in Amazon Bedrock
If you’re new to using the DeepSeek-V3.1 model, go to the Amazon Bedrock console, choose Model access under Bedrock configurations in the left navigation pane. To access the fully managed DeepSeek-V3.1 model, request access for DeepSeek-V3.1 in the DeepSeek section. You’ll then be granted access to the model in Amazon Bedrock.

Next, to test the DeepSeek-V3.1 model in Amazon Bedrock, choose Chat/Text under Playgrounds in the left menu pane. Then choose Select model in the upper left, and select DeepSeek as the category and DeepSeek-V3.1 as the model. Then choose Apply.
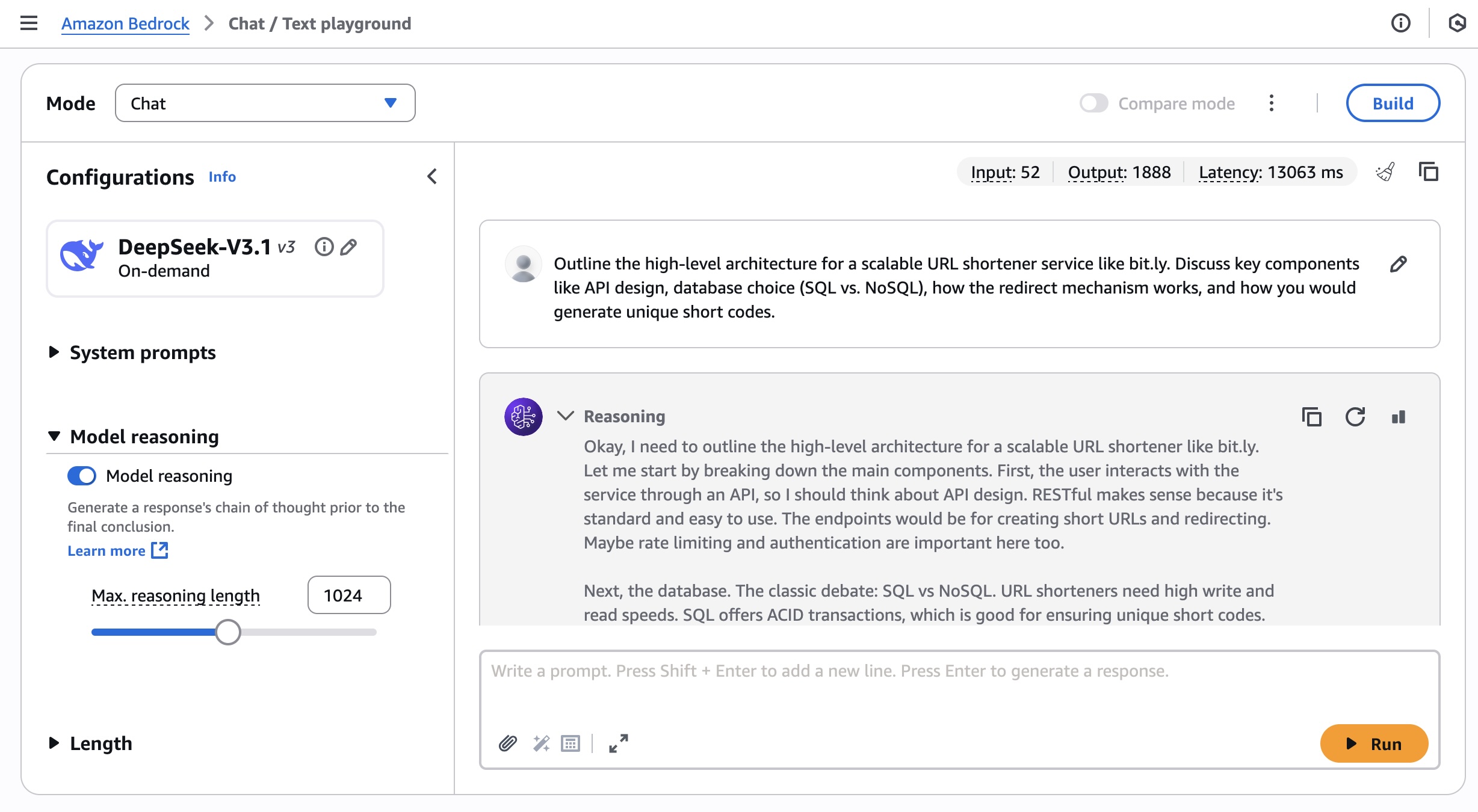
Using the selected DeepSeek-V3.1 model, I run the following prompt example about technical architecture decision.
Outline the high-level architecture for a scalable URL shortener service like bit.ly. Discuss key components like API design, database choice (SQL vs. NoSQL), how the redirect mechanism works, and how you would generate unique short codes.
You can turn the thinking on and off by toggling Model reasoning mode to generate a response’s chain of thought prior to the final conclusion.
You can also access the model using the AWS Command Line Interface (AWS CLI) and AWS SDK. This model supports both the InvokeModel and Converse API. You can check out a broad range of code examples for multiple use cases and a variety of programming languages.
To learn more, visit DeepSeek model inference parameters and responses in the AWS documentation.
Now available
DeepSeek-V3.1 is now available in the US West (Oregon), Asia Pacific (Tokyo), Asia Pacific (Mumbai), Europe (London), and Europe (Stockholm) AWS Regions. Check the full Region list for future updates. To learn more, check out the DeepSeek in Amazon Bedrock product page and the Amazon Bedrock pricing page.
Give the DeepSeek-V3.1 model a try in the Amazon Bedrock console today and send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS Support contacts.
— Channy

 Last week,
Last week, 




















 Speaking of following people, AWS Builder Center makes it really straightforward to connect and engage with others, serving as the central hub for the AWS technical community. It brings together all the different ways that you can connect with fellow builders. For example, the Who to Follow section introduces you to AWS Heroes, Community Builders, and active community members who are sharing their knowledge and expertise in your areas of interest.
Speaking of following people, AWS Builder Center makes it really straightforward to connect and engage with others, serving as the central hub for the AWS technical community. It brings together all the different ways that you can connect with fellow builders. For example, the Who to Follow section introduces you to AWS Heroes, Community Builders, and active community members who are sharing their knowledge and expertise in your areas of interest.



 AWS Builder Center gives you a more personalized and comprehensive way to showcase your AWS journey. Your unique profile comes with a custom URL and shareable QR code, making it straightforward to connect with others and share your presence in the AWS community.
AWS Builder Center gives you a more personalized and comprehensive way to showcase your AWS journey. Your unique profile comes with a custom URL and shareable QR code, making it straightforward to connect with others and share your presence in the AWS community.













 When we introduced the
When we introduced the 











 Willem Visser, VP of EC2 Technology will open with the introduction of the AWS journey since 2006, when
Willem Visser, VP of EC2 Technology will open with the introduction of the AWS journey since 2006, when  Todd Kennedy, Principal Engineer, GoDaddy, will share GoDaddy’s Graviton adoption journey and the benefits it reaped from Graviton. Todd will walk through an example to demonstrate moving Rust workloads to Graviton. Learn how GoDaddy achieved 40 percent compute cost savings and over 20 percent performance gains.
Todd Kennedy, Principal Engineer, GoDaddy, will share GoDaddy’s Graviton adoption journey and the benefits it reaped from Graviton. Todd will walk through an example to demonstrate moving Rust workloads to Graviton. Learn how GoDaddy achieved 40 percent compute cost savings and over 20 percent performance gains.