If you are reading this blog, there is a high chance you frequently use the AWS Management Console. I taught AWS classes for years. During classes, students’ first hands-on experience with the AWS Cloud happened on the console, and I bet yours did too.
Until today, the home page of the console showed your most recently used services and a set of static links organized in sections, such as Getting Started with AWS, Build a Solution, or Explore AWS with links to training courses. However, we learned from our data that their usage is very different depending on your profile. You also told us it is cumbersome and time-consuming to navigate to different parts of the console to get an overview of important information for you.
We listened to your feedback, and I’m happy to announce a redesigned home page for the AWS Management Console. This new home page experience includes dynamic content, can be customized, and includes data from multiple AWS Regions.
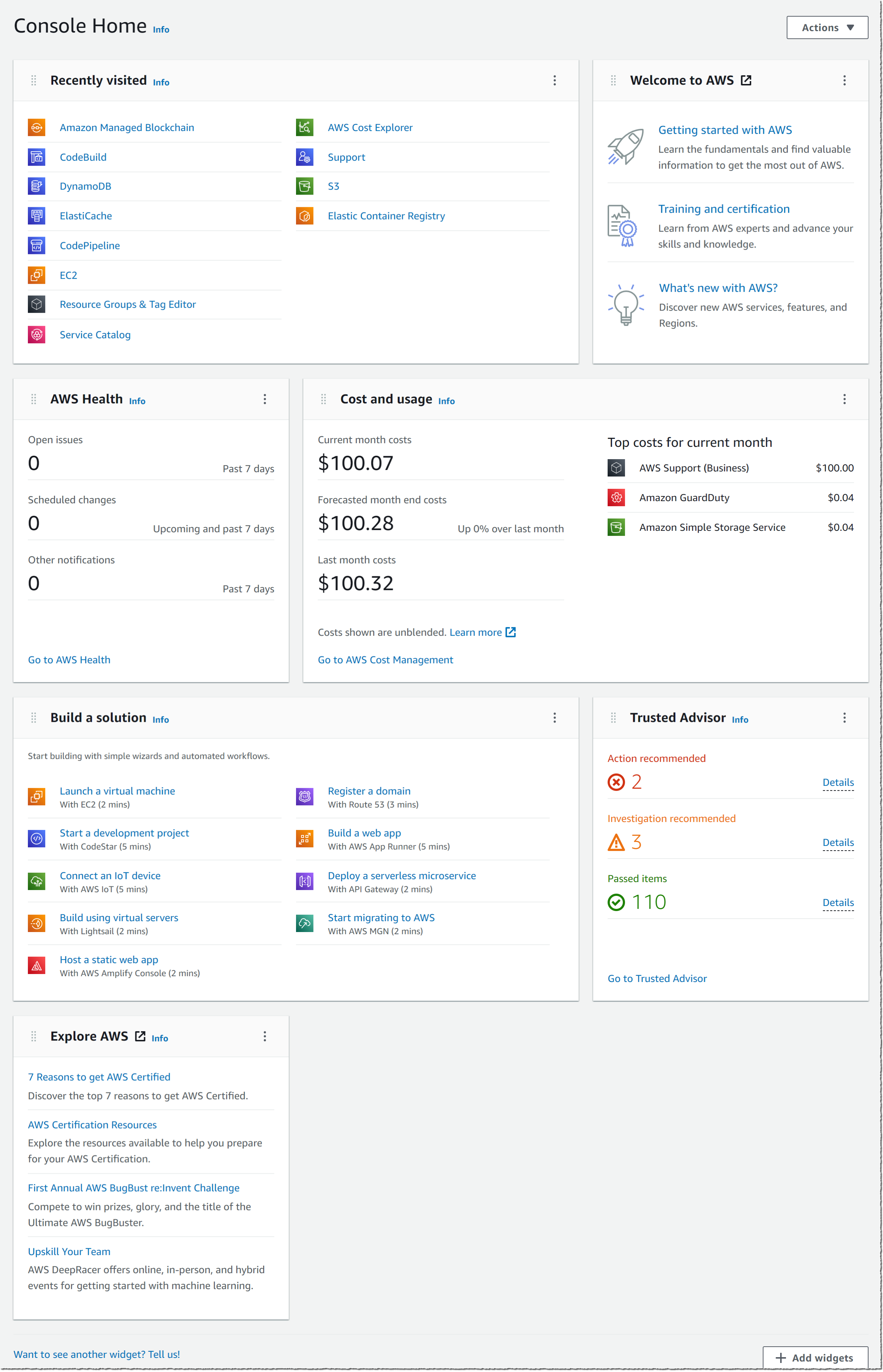
The screenshot below shows the default view of this new console home page:
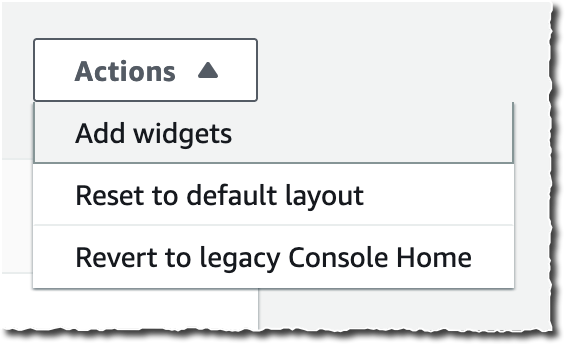
The new Console Home is made of widgets. I may choose which widget to display on the page and where to include it. I may use the actions in the Actions drop down to customize my home page.
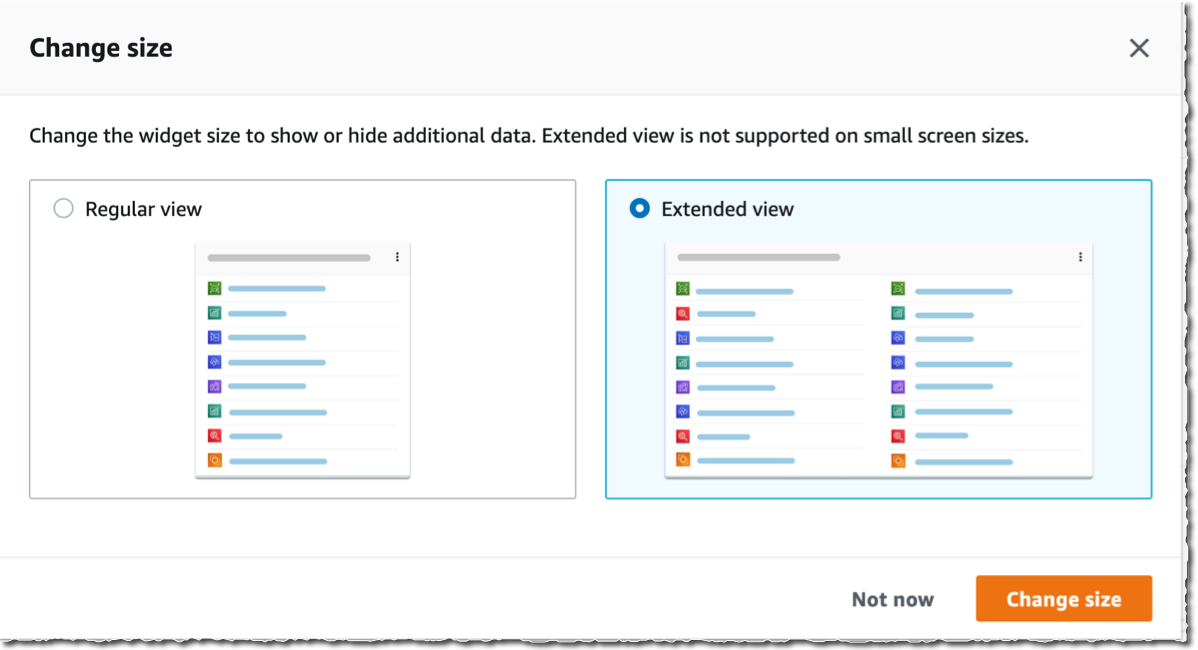
I may move and arrange widgets on the home page to organize the content as I want. When I click on the three little dots on the widget title bar, I may choose to remove the widget or resize it. I have the choice between Regular view and Extended view.
At launch, the console provides eight widgets, and we will add more over time. Three widgets provide me with static links to learn how to build a solution or to explore AWS (Welcome to AWS, Build a Solution and Explore AWS). The other five are dynamic; their content depends on the usage of AWS by my applications and infrastructure:
AWS Health: this widget provides information on important events and changes
Cost and usage: this widget provides an overview of service costs, with a break down per AWS service.
Favorites: this widget shows a list of services that I have bookmarked
Recently visited: this widget provides the list of top recently visited services
Trusted Advisor: this widget provides recommendations to follow AWS best practices
As usual, we pay attention to the importance of not disturbing existing workflows and habits. You can use the new Console Home after opt-in. You can revert back to the old console home with a simple click.
This new Console Home is the first step to bring you more relevant content on this very first page you see every day. Stay tuned for more.
According to the Cloud Native Computing Foundation’s annual survey, Kubernetes use in production has increased 300% since 2016 to 83% of respondents. There’s no doubt that a fundamental shift has taken place over the past few years—applications are being deployed in container environments and those deployments are being managed by Kubernetes.
But customers that are deploying Kubernetes environments need a new tool to protect all of that data. Purpose-built for Kubernetes, Kasten by Veeam is that tool.
Now, through a new partnership, joint Kasten and Backblaze customers will be able to name Backblaze B2 Cloud Storage as a storage destination where they can store and protect copies of their applications affordably.
This partnership enables developers to:
Back up and restore production stateful Kubernetes applications.
Safeguard application data from ransomware encryption with Object Lock for immutability.
Support regulatory compliance and corporate disaster recovery mandates.
“Kubernetes containers are the standard for many organizations building, deploying, and scaling applications with portability and efficiency. Backblaze and Kasten together offer a compelling solution to support these organizations’ business continuity needs with set-and-forget-it ease and cost effectiveness.”
—Nilay Patel, VP of Sales and Partnerships, Backblaze
The joint solution is fully scalable at enterprise grade. What’s more, organizations only pay for storage used, with no data retention penalties for deleting past backups.
About Kasten
Owned by Veeam, Kasten is an award-winning market leader in Kubernetes backup. Their product was built natively for containers, and the software-only solution runs directly on your cluster within its own namespace.
Together, Kasten and Backblaze provide a simple, seamless integration for shared customers, focusing on ease of use.
“Backup and protection are paramount in a world in which data is everything and cyberattacks continue to rise. The Backblaze-Kasten partnership offers the application protection and disaster recovery support companies seek, with flexibility and freedom to choose their preferred storage partner.”
—Gaurav Rishi, VP of Product, Kasten by Veeam
Customers can test the Kasten solution for free with clusters made up of 10 nodes or less. And Backblaze covers the first 10GB stored.
Data Protection That Scales With You
Kubernetes was built to provide scalability, giving businesses the flexibility to manage and optimize resources. Through this partnership, customers now have storage that matches that flexibility in Backblaze B2. With Backblaze, customers are able to scale their application backups as their applications scale.
Interested in learning more? Join us for a webinar on February 2, 2022 at 10 a.m. PST to discover how to add seamless ransomware protection to your Kubernetes environments—stay tuned for more details and a link to register. Or, if you are ready to future-proof your application, click here to get started today.
My colleague Marek Polacek and I implemented a new warning for GCC
12, -Wbidi-chars, for detecting Trojan Source attacks involving
Unicode control characters. Marek implemented the guts of the
warning, but when I tried it out on the examples provided by the
Trojan Source researchers, I found I had trouble understanding the
initial results—precisely because of the obfuscation itself.
So for GCC 12, I’ve added a new flag to GCC diagnostics, indicating
that the diagnostic itself relates to source code encoding. When
any such diagnostic is printed, GCC will now escape non-ASCII
characters in the source code.
Security updates have been issued by Debian (cfrpki, gdal, and lighttpd), Fedora (perl-CPAN and roundcubemail), Mageia (firefox), openSUSE (jawn, kernel, and thunderbird), Oracle (kernel, openssl, and webkitgtk4), Red Hat (cpio, idm:DL1, kernel, kernel-rt, openssl, virt:av and virt-devel:av, webkit2gtk3, and webkitgtk4), Scientific Linux (openssl and webkitgtk4), SUSE (kernel and thunderbird), and Ubuntu (apache-log4j2, ghostscript, and lxml).
In our first post on demystifying the concepts and practices behind extended detection and response (XDR) technology, Forrester analyst Allie Mellen joined Sam Adams, Rapid7’s VP for Detection and Response, to outline the basic framework for XDR and highlight the key outcomes it can help security teams achieve. One of the core components of XDR is that it expands the sources of telemetry available to security operations center (SOC) teams so they have richer, more complete data to help them detect and respond to threats.
That raises the question: How do SOC analysts keep productivity high while sifting through huge volumes of data?
Automation is one of the key ways SOC teams make their processes more efficient as they identify the most relevant threats and initiate the right responses. But automation can’t do everything an analyst can, and finding the right balance between machine learning and human know-how is an essential part of a successful XDR implementation.
Become the bridge
As Sam pointed out in his discussion with Allie, the security analyst acts as a bridge between what the data is saying and what the right course of action is in response to it.
“I got the alert, and you know, that’s not the hard part anymore,” he said. “The hard part is responding to the alert and figuring out what to do with that alert – and really, what the impact is on my company.”
For Allie, XDR helps analysts find a balance between security and productivity, but not by leaning too heavily on automation. In fact, she suggested we’ve had a “misplaced hope” for what machine learning can help us accomplish. Instead, it’s about setting up automation that augments the analysts’ work by helping them ask the right questions up front — and get to the answers faster.
The expert and the end user
In addition, automation can’t always tell us who the expert actually is about a particular security event. Sam gave the example of a suspicious login from Bermuda: After receiving that alert, it’s actually no longer the analyst who’s the expert on that incident, but the end user who was involved. The logical next step is to pick up the phone or send an email and ask that user, “Are you in Bermuda?” — and that takes a human touch rather than an automated action.
“We assume we can get everything we need from the tools,” Allie pointed out, “and they abstract us away from the rest of the enterprise in that way. But it can be just as easy as turning to the person next to you and saying, ‘Hey, did you log into this?'”
Allie went on to note that this is one of the main reasons why it’s so important to foster a security culture throughout the whole business. When you build connections between the security team and individuals from other parts of the organization, and keep that rapport strong over time, SOC analysts can get many of the answers they need from their peers in other departments — and get to the answers much more quickly and accurately than a machine ever could.
Culture is a uniquely human thing, one that machines can never replicate or replace — and security culture is no exception. XDR broadens the data and tools that SOC teams can use to help them protect the organization, but even the best technology is no replacement for an educated team of end users who know how to implement security best practices, not to mention the sharp insights of seasoned SOC analysts. The real magic happens when all these elements, human and automated, work together — and in an XDR model, automation fills the gaps instead of taking center stage.
Researchers have figured how how to intercept and fake an iPhone reboot:
We’ll dissect the iOS system and show how it’s possible to alter a shutdown event, tricking a user that got infected into thinking that the phone has been powered off, but in fact, it’s still running. The “NoReboot” approach simulates a real shutdown. The user cannot feel a difference between a real shutdown and a “fake shutdown.” There is no user-interface or any button feedback until the user turns the phone back “on.”
Historically, when malware infects an iOS device, it can be removed simply by restarting the device, which clears the malware from memory.
However, this technique hooks the shutdown and reboot routines to prevent them from ever happening, allowing malware to achieve persistence as the device is never actually turned off.
I see this as another manifestation of the security problems that stem from all controls becoming software controls. Back when the physical buttons actually did things — like turn the power, the Wi-Fi, or the camera on and off — you could actually know that something was on or off. Now that software controls those functions, you can never be sure.
Годината започна с ръст на отчетените случаи на заразени със SARS-CoV-2 и с констатацията, че вариантът Омикрон вече е в България. Трето поред правителство (технически погледнато – дори четвърто, тъй като служебното реализира два поредни мандата) е изправено пред необходимостта да предприеме някакви действия, с които да намали цената на поредната епидемична вълна, изразена както в човешки жертви или дългосрочни последици за здравето на гражданите, така и в икономически загуби и социални щети.
По време на последната есенна вълна на пандемията в България се открои ясен политически наратив, свързан с ролята на децата. Той беше провокиран от повишеното напрежение както у родителите, така и у голяма част от самите деца, които в последните 20 месеца понесоха несъразмерни ограничения в усилията за контрол над епидемичните пикове. И макар от лятото да се повтаряше като мантра, че присъственото обучение е приоритет, че няма да допуснем отново училищата да са затворени, а заведенията да работят, и че децата са най-важни, през първите три месеца и половина от тази учебна година учениците в началния етап прекараха три, а по-големите – шест седмици у дома с обяснението, че обществото ни няма друг избор. Но дали тази аргументация е поне близо до истината?
Агресивното настояване за отмяна на всякакви мерки е базирано почти изцяло на фалшиви новини и конспиративни вярвания. Обратната теза, която поставя децата на фокус като разпространители на вируса и като потенциално рискова група, по-скоро спекулира с интерпретацията на доказаните от науката факти. И двете групи обаче използват децата като инструмент в опит да постигнат по-силно влияние на тезите си, да емоционализират посланията си и да улеснят възприемането на тези послания от широк кръг възрастни – баби, дядовци, родители, учители и др. Липсата на достатъчно добре комуникирана, базирана на наука официална позиция, която да балансира тези крайности, доведе до силно обществено противопоставяне, а най-добрият интерес на децата остана встрани като една неприпозната, неизговорена и ненужна тема.
У нас през изминалите две години не се формира обществен или дори само политически консенсус по нито един от въпросите за пандемията и управлението ѝ в национален мащаб. Това се отнася и до темите, свързани с децата – какви са рисковете за тях и каква е ролята им в процесите на разпространение и овладяване на заболяването.
Как боледуват децата
Когато в края на зимата на 2020 г. пандемията от COVID-19 удари Европа, в момент на несигурност, повсеместен локдаун, ужасяващи новини за рекордна смъртност и препълнени болници в много страни по света единственият светъл лъч беше ключовото към онзи момент наблюдение на китайските учени – децата боледуват по-рядко, по-леко и загиват от COVID-19 в много редки случаи. Макар някои от първоначалните хипотези за вируса SARS-CoV-2 да се развиха и промениха напълно, две години и хиляди страници научни трудове по-късно този извод в голяма степен се препотвърждава, включително и по отношение на актуалния в момента вариант Омикрон. Поради много силната му заразност обаче – особено сред неваксинирани групи, към които със сигурност се причисляват децата – тревогата у някои експерти остава.
В Съединените щати, където вълната вече е в активната си фаза, точно преди Нова година беше отчетен ръст на хоспитализациите на деца с коронавирусна инфекция. Няколко щата съобщиха за увеличение с около 50% на педиатричните приеми за COVID-19 през декември. Въпреки този ръст предварителните данни показват, че и при варианта Омикрон повечето от заразените деца боледуват леко.
Съвсем скорошно проучване, което все още не е преминало през научна проверка (т.нар. peer-review), обобщава данни от Южна Африка. От близо 6300 регистрирани случая, при 462 е имало нужда от болнично лечение. Изследователите получават подробни данни за 139 хоспитализирани деца под 13 години. От тях 31 са се нуждаели от кислородно лечение, седем – от апаратна вентилация, а четири са починали поради сложни съпътстващи патологии. Всички деца и по-голямата част от родителите, за които има налични данни, са били неваксинирани. Най-честите симптоми, отвеждащи децата в болница, са затруднения при дишането и дехидратация, съпътствани от висока температура, кашлица, повръщане и диария, цитира се в доклада на учените.
Друг въпрос, който буди тревога, засяга постковид синдрома и продължителния ковид. Специалисти от различни държави признават, че данните за отражението на тези състояния върху децата засега са много по-малко, отколкото при възрастните. Проучване в Англия, макар също още непреминало през научна проверка, сочи, че между 16 и 30% от изследваните деца на възраст от 11 до 17 години, прекарали COVID-19 с някаква клинична изява, страдат повече от три месеца от уморяемост, главоболие, задъхване или друг, неопределен дискомфорт. Друго изследване показва много по-малък дял на засегнатите от продължителни симптоми – между 2 и 4%. Както в тези, така и в други изследвания в сферата обаче се подчертава, че изводите са ограничени и е нужна повече и по-активна научна работа.
У нас картината с детската заболеваемост също е неясна. Официалната статистика сочи, че до момента около 42 000 лица под 19 години са регистрирани като боледували от COVID-19. Предполага се обаче, че значителен дял от боледуващите деца не са били тествани в лаборатория и са останали „скрити“ за системата. Начинът, по който у нас се събира и обработва здравна информация, допълнително затруднява проследяването на статистиките за тежко боледуващите и починали вследствие на заболяването. В началото на януари 2021 г. Министерството на здравеопазването подаде информация за пет деца, починали от COVID-19 през 2020 г. Половин година по-късно Националният статистически институт удвои този брой, отчитайки 11 случая на починали от коронавирусно заболяване на възраст от 0 до 19 години. Според портала за отворени данни пък за целия период на качване на информация от юни 2020 г. до момента починалите от COVID-19 под 19-годишна възраст са 24, от които 8 – през 2020 г.
Практиката на педиатрите, лекуващи COVID-19 и други респираторни инфекции у нас, потвърждава напълно научните хипотези за нисък дял на тежко боледуващи деца. „В педиатричните отделения не е имало натоварване от деца с коронавирусна инфекция. Ние знаем какво се случва при грип – години наред сме имали недостиг на легла във всички болници при грипна епидемия. При COVID-19 до момента не сме наблюдавали такова нещо, не очаквам да се случи и с настоящия вариант“, коментира доц. Рада Маркова, педиатър и детски пулмолог. Според нея и при настоящата вълна сред децата ще има много заболели, но те ще могат да се лекуват в домашни условия.
Ролята на децата и училищата в разпространението на COVID-19 – и изборът на България
„Нямаме друг избор.“ Така накратко може да се обобщи аргументацията, с която няколко пъти поред децата бяха изпратени в дистанционно обучение, извънкласните занимания и алтернативните им форми на обучение бяха затворени, а спортът беше достъпен в най-добрия случай само за картотекираните спортисти под 18-годишна възраст.
Този подход противоречеше на всички препоръки за действие, издавани от световни организации в хода на кризата. Още на 15 април 2020 г. Европейската комисия публикува Пътна карта, в която беше посочено, че училищата следва да бъдат последните институции, които се затварят, и първите, които отварят врати за присъствена работа. На 8 юли 2021 г. Европейският център за контрол на заболяванията (ECDC) публикува актуализиран технически доклад относно COVID-19 при децата и ролята на училищата при разпространението на коронавируса. Основна препоръка на Центъра отново бе до решение за затваряне на училища да се прибягва само в краен случай, тъй като вредите от него надвишават ползите. В свое становище, актуализирано през декември 2021 г. и резюмиращо проучвания на работата на училищата в условията на COVID-19, Американските центрове за контрол на заболяванията (CDC) потвърждават, че „когато стратегиите за превенция се комбинират и прилагат правилно, предаването на вируса в училищата може да бъде ограничено“.
По данни на ЮНЕСКО, у нас училищата са били напълно или частично затворени в продължение на 47 седмици в периода от началото на пандемията до края на декември 2021 г. Това означава, че голяма част от учениците над 10-годишна възраст са посещавали присъствено училище по-малко от 1/3 от учебното време в този период, разпростиращ се в общо три учебни години.
България, разбира се, не е единствената държава, която прави компромис с децата. В Европейския съюз в сходно положение са учениците в Чехия (46 седмици), Полша (43) и Латвия (49). На обратния полюс са Хърватия, Испания и Франция, където учениците са били по домовете си съответно 10, 12 и 15 седмици за целия период на пандемията. Разликите в тези периоди, както и разминаването между препоръките и действията на правителствата, показват ясно, че избор за това каква роля да бъде отредена на децата в управлението на пандемията, всъщност има. Той обаче се определя от политическите, обществените и личните приоритети на възрастните.
… характеристиката на вируса е такава, че той до голяма степен щади младите хора, там тежко протичане е по-скоро изключение. Усилията ни са насочени те да пазят по-възрастните си роднини. Но ако тия по-възрастни роднини сами не се пазят, ако хората се събират в затворени помещения, ако не се ползват стриктно лични предпазни средства, целият ефект ще бъде изконсумиран.
Думите са казани още през юли 2020 г. от главния държавен здравен инспектор доц. Ангел Кунчев. Година и половина по-късно към това обобщение може да се добави и готовността (или липсата ѝ) на възрастните у нас да се ваксинират. Доц. Рада Маркова обяснява: „Ваксинацията трябва да бъде поголовен ангажимент на възрастното население, тъй като за нас, възрастните, тази болест е опасна и носи сериозни последици. А у нас ваксинационното покритие сред възрастните е незадоволително. И това ще се види ясно отново в рамките на идните две седмици.“
Децата и ваксините срещу COVID-19
По данни на Министерството на здравеопазването към 29 декември 2021 г., у нас с една доза от ваксините срещу COVID-19 са имунизирани 259 деца на възраст между 5 и 11 години включително, а 20 805 – между 12 и 17 години включително. От втората група със завършен имунизационен цикъл са 17 856 деца.
Твърдението, че ваксините срещу COVID-19 са „експериментални течности“ с несигурни дългосрочни ефекти, е може би най-популярната теза на дезинформацията по темата. Това твърдение отдавна е детайлно опровергано от експертите по безопасност на лекарствата. По отношение на имунизирането на деца от 5 до 11 години обаче педиатрите все още изразяват резерви. Според медиците решението „за“ или „против“ ваксинация трябва да се съобрази и с тежестта на заболяването в дадената възрастова група, а за здравите деца има много малък риск да развият тежък COVID-19.
„Децата трябва да бъдат ваксинирани, ако са със сериозни хронични заболявания или с наднормено тегло“, смята доц. Рада Маркова. Сходна теза споделя и проф. Пенка Переновска, която е главен координатор на Експертния съвет по педиатрия към Министерството на здравеопазването. Тя съветва родителите на собствените си пациенти от рискови групи да ги ваксинират. По думите ѝ, препоръките на Съвета в този дух са подготвени и изпратени в МЗ и се очаква съвсем скоро да бъдат публикувани. Това би трябвало да уеднакви подхода към ваксиниране на децата според тяхната възраст (над 12 или между 5 и 11 години) или според здравословното им състояние (има ли повишен риск от тежък COVID-19, или не). В момента, поради липсата на такава препоръка, практиките се разминават – докато в едни имунизационни пунктове децата се ваксинират само срещу подпис на един родител, в други се изисква писмено становище от личния педиатър, препоръчващо или разрешаващо ваксинацията.
Мнението на Европейската лекарствена агенция е, че предимствата от поставянето на ваксина срещу COVID-19 и при по-малките деца надвишават рисковете, особено при тези, чието здравословно състояние предполага по-висок риск от тежко протичане на коронавирусната инфекция. То се базира на проучването на производителя на единствената засега одобрена ваксина за деца под 11 години сред близо 2000 деца, които не са се срещали с вируса. От 1305 ваксинирани 3 са развили COVID-19 впоследствие след заразяване. За сравнение – в групата, получила плацебо, от 663 деца са се разболели 16. Нежеланите реакции, установени в рамките на изпитването, са същите, които са наблюдавани и във възрастовата група от 16 до 25 години – болка и зачервяване на мястото на убождането, главоболие, мускулни болки и отпадналост. Те обичайно отшумяват до 48 часа.
Очаква се до февруари да се появят допълнителни данни за това как по-малките понасят ваксинирането, тъй като редица държави започнаха да ваксинират децата още през есента и вече има поставени милиони дози при най-ниската разрешена възрастова група.
Избор в бъдещо време
В момента ваксинацията е една от възможностите децата в районите с висок брой заболели от COVID-19 да ходят на училище, наред с доказано преболедуване или ежеседмично тестване с неинвазивен, бърз антигенен тест.
Последните публично обявени данни от Министерството на образованието и науката сочат, че към 14 декември 2021 г. около 20% от учениците в страната продължават да се обучават дистанционно, а след зимната ваканция този дял е намалял на 12%. Въпреки това десетки хиляди деца остават у дома по решение на родителите си: някои – защото се страхуват от COVID-19, други – защото се страхуват от тестовете, ваксините и мерките като цяло.
Междувременно в аналитичен доклад относно образователните пропуски и неравенства, причинени от пандемията, се твърди, че „колкото по-продължителен е периодът на дистанционно обучение, толкова по-големи са очакваните обучителни дефицити“. България е една от държавите с най-остър проблем по отношение на натрупаните дефицити и разширяващите се образователни неравенства. В анализ на МОН, изготвен след края на предходната учебна година, също се акцентира върху този проблем, като се посочва, че обучението от разстояние в електронна среда вече е довело до риск от отпадане от образование на 25% от учениците.
През есента УНИЦЕФ публикува мащабно изследване, с което алармира за влошеното психично здраве на децата в хода на пандемията. Организацията показва и икономическия ефект от този проблем – пропуснатите ползи за икономиката заради психични разстройства сред младите хора се оценяват на почти 390 млрд. долара на година.
Всички тези рискове в момента са предимно проблем на самите деца и на техните родители. Последствията обаче ще се носят от цялото общество в бъдеще с неопределен хоризонт, което придава огромна тежест на избора ни как да говорим и какви решения да вземем за децата и пандемията днес.
„Тоест“ е официален партньор за публикуването на материалите от поредицата „Хроники на инфодемията“, реализирана от АЕЖ-България съвместно с Фондация „Фридрих Науман“.
Остригана детска главица. Куче. Оскъден интериор. Реплики от по две думи. Баир, овце, дядо. Оскъдни диалози. Защо не ме викна? Спеше.
Сушена риба се върти в кадър. Овце. Река. Птица. Пръчка. Разходка по обяд. Изоставена къшла. Паяжини, светлина. Страх. И изотникъде – статуя. На момче с паница храна и орел.
Чакаш действието да се разрази. Не се разразява. Оскъден диалог. Знаеш ли какво видях? Казах ли ти да не ходиш там. Статуята изчезва.
Първата част на „Февруари“ напомня за иранското кино, за децата във филмите на Киаростами и Маджиди. Малкият Лъчезар Димитров играе естествено, приглушено и изразително. Христо Димитров – Хиндо („Мера според мера“) звучи и изглежда като непроницаемите старци по селата, когато са заети с работа. Какво влиза на мястото на почти липсващите реплики? Звуците – удар на пръчка в клон, звук на вода, крясък на птица. Операторският поглед, който е погледът на детето.
Втора част. Служба. Започва със сватбата, през чиито ритуални движения героят минава като през строева подготовка. Като че ли не забелязва разлика между едното и другото. Прави каквото трябва да прави. Не го оставя да ангажира съзнанието му, което е сякаш погълнато от своята сетивност. Оставено на себе си, то иска просто да гледа и да слуша гларусите. Порасналият Петър (Кольо Добрев) не иска да ги изучава, не иска да става биолог, не иска да става и офицер, въпреки че му предлагат, не иска да взема никакви решения да променя живота си. Иска просто да го живее.
В казармената част е второто възможно пропукване на света му – след статуята в къшлата. Негов аскер аркадаш решава да му прочете стихотворение. В сюжетен план това стои леко немотивирано, не става ясно защо точно на него (не е показал никаква склонност), гласът на четящия е от малкото неорганични неща във филма. Стихотворението обаче („Кост от глухарче“ на Борис Христов) е само по себе си толкова силно и органично свързано с темата на филма, че бързо прощаваш. А е свързано, защото четенето му не води до никакъв обрат, също както статуята в първата част – Петър вижда нещо отвъд своя си живот, забелязва го, но не тръгва към него. По средата на стихотворението започва да чува само близкия гларус.
Третата част. Старостта, уязвимостта. Тук за първи път се намесва глас зад кадър, който чете откъс от „Лято“ на Камю и вади на повърхността темата на филма. Може би някой по-ригиден съдник би казал, че не трябва да се обяснява, след като е показано, да не се подценява зрителят и прочее. На мен, честно казано, ми беше приятно да слушам този текст, докато гледам каруцата през замръзналото поле. Иван Налбантов в ролята на остарелия Петър е почти реплика на Христо Димитров като дядото – но реплика омекотена, чувствителна, макар и също тъй мълчалива. Или може би просто все още сме в сетивността на героя, както не сме били в сетивността на дядото. Интересуват ни примерно затоплената на печката тухла и топлината, която тя отдава на премръзналите нозе.
Въпросът за музиката във филм, който разказва за един непропусклив за изкуството свят, е много интересен. Ако в предишния филм на Камен Калев „Източни пиеси“ музиката на Андрония Попова е съзвучна с героите, то тук чудният саундтрак на Петър Дундаков обгръща героя, без да го докосва. Не говори на него, разказва за него: примерно когато той се върти в снежната буря и ѝ се наслаждава, и насладата му напомня на нас и на режисьора за английски барок, за Пърсел, да речем – но не и на самия герой. Самият той предпочита шума от камъче по заледена река.
„Февруари“ е филм, способен да достави удоволствие. То не идва пряко нито от хубавата му направа, нито от майсторството на участниците, нито дори от странджанската природа. Радостта, която носи, е чисто носталгична: типажът на Петър е всъщност добре познат, но малко познаван; почти всеки има в семейните албуми по някоя остригана главица с такова изражение – и обичта, която усещаш на излизане от киното, е обич към конкретни хора. И това е повече от достатъчно.
Enterprise distributions are famous for maintaining the same versions of
software throughout their, normally five-year-plus, support windows. But
many of the projects those distributions are based on have far shorter
support periods; part of what the enterprise distributions sell is patching
over those mismatches. But openSUSE Leap is not exactly an
enterprise distribution, so some users are chafing under the restrictions
that come from Leap being based on SUSE Enterprise Linux (SLE). In
particular, shipping Python 3.6, which reached its end of life at the
end of 2021, is seen as problematic for the upcoming Leap 15.4 release.
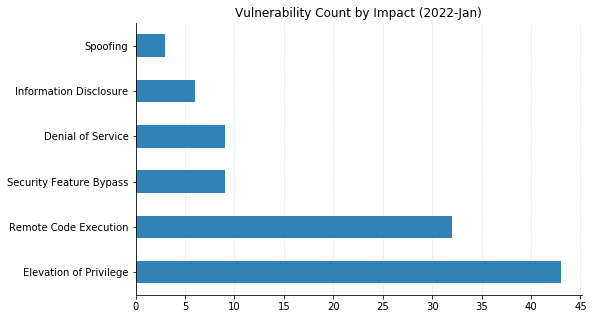
The first Patch Tuesday of 2022 sees Microsoft publishing fixes for over 120 CVEs across the bulk of their product line, including 29 previously patched CVEs affecting their Edge browser via Chromium. None of these have yet been seen exploited in the wild, though six were publicly disclosed prior to today. This includes two Remote Code Execution (RCE) vulnerabilities in open source libraries that are bundled with more recent versions of Windows: CVE-2021-22947, which affects the curl library, and CVE-2021-36976 which affects libarchive.
The majority of this month’s patched vulnerabilities, such as CVE-2022-21857 (affecting Active Directory Domain Services), allow attackers to elevate their privileges on systems or networks they already have a foothold in.
Critical RCEs
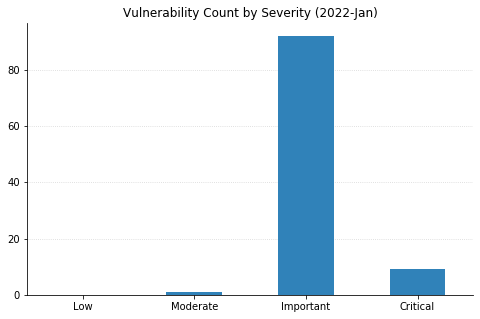
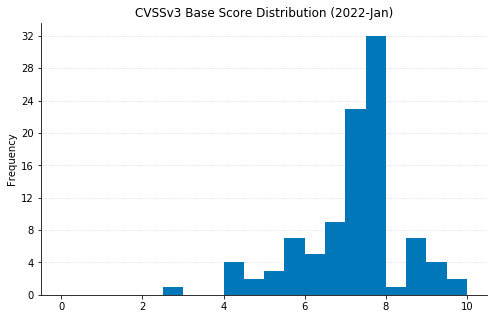
Besides CVE-2021-22947 (libcurl), several other Critical RCE vulnerabilities were also fixed. Most of these have caveats that reduce their scariness to some degree. The worst of these is CVE-2021-21907, affecting the Windows HTTP protocol stack. Although it carries a CVSSv3 base score of 9.8 and is considered potentially “wormable” by Microsoft, similar vulnerabilities have not proven to be rampantly exploited (see the AttackerKB analysis for CVE-2021-31166).
Not quite as bad is CVE-2022-21840, which affects all supported versions of Office, as well as Sharepoint Server. Exploitation would require social engineering to entice a victim to open an attachment or visit a malicious website – thankfully the Windows preview pane is not a vector for this attack.
CVE-2022-21846 affects Exchange Server, but cannot be exploited directly over the public internet (attackers need to be “adjacent” to the target system in terms of network topology). This restriction also applies to CVE-2022-21855 and CVE-2022-21969, two less severe RCEs in Exchange this month.
CVE-2022-21912 and CVE-2022-21898 both affect DirectX Graphics and require local access. CVE-2022-21917 is a vulnerability in the Windows Codecs library. In most cases, systems should automatically get patched; however, some organizations may have the vulnerable codec preinstalled on their gold images and disable Windows Store updates.
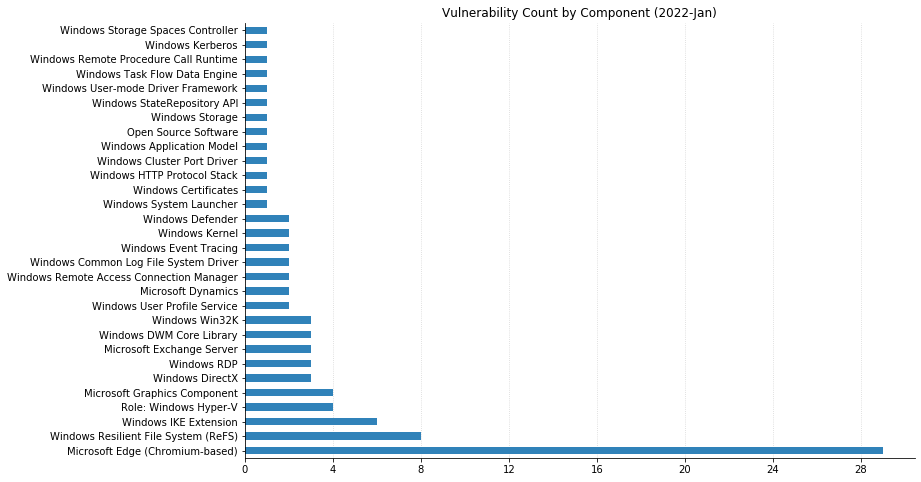
Defenders should prioritize patching servers (Exchange, Sharepoint, Hyper-V, and IIS) followed by web browsers and other client software.
Every year, Amazon Web Services (AWS) looks to help our customers gain more experience and knowledge of our services through hands-on workshops. In 2021, we unfortunately couldn’t connect with you in person as much as we would have liked, so we wanted to create and share new ways to learn and build on AWS. We built and published several security-focused workshops that help you learn how to use or configure new services and features securely. Workshops are hands-on learning modules designed to teach or introduce practical skills, techniques, or concepts you can use to solve business problems.
In this blog post, we highlight the newest AWS security-focused workshops below. There are also several other workshops that were developed before 2021; you can find them on AWS Workshops, AWS Security Workshops, and AWS Samples. Here’s the list:
In this workshop, get familiar with Amazon Macie and learn to scan and classify data in your Amazon Simple Storage Service (Amazon S3) buckets. Work with Macie (data classification) and AWS Security Hub (centralized security view) to see how data in your environment is stored, and to understand any changes in S3 bucket policies that may affect your security posture. Learn to create a custom data identifier and to create and scope data discovery and classification jobs in Macie. Finally, use Macie to filter and investigate the results from the scans you create.
AWS makes it easy to protect your data with encryption. This hands-on workshop provides an opportunity to dive deep into encryption at rest options with AWS. Learn AWS server-side encryption with AWS Key Management Service (AWS KMS) for services such as Amazon S3, Amazon Elastic Block Store (Amazon EBS), and Amazon Relational Database Service (Amazon RDS). Also, learn best practices for using AWS KMS across multiple accounts and Regions and how to scale while optimizing for performance.
In this workshop, learn how to integrate AWS Secrets Manager in your development platform, backed by serverless applications. Work through a sample application, and use Secrets Manager to retrieve credentials as well as work with attribute-based access control using tags. Also, learn how to monitor the compliance of secrets and implement incident response workflows that will rotate the secret, restore the resource policy, alert the SOC, and deny access to the offender.
This workshop covers private certificate management on AWS, employing the concepts of least privilege, separation of duties, monitoring, and automation. Participants learn operational aspects of creating a complete certificate authority (CA) hierarchy, building a simple web application, and issuing private certificates. It also covers how job functions—including CA administrators, application developers, and security administrators—can follow the principle of least privilege to perform various functions associated with certificate management. Finally, learn about IoT certificates, code-signing, and certificate templates to enable all your use cases.
Amazon S3 provides many security and access settings to help you secure your data, controls that ensure that those settings remain in place, and features to help you audit those settings and controls. This workshop walks you through these Amazon S3 capabilities and scenarios, to help you apply them for different security requirements.
Amazon S3 Object Lambda works with your existing applications, and allows you to add your own code using AWS Lambda functions to automatically process and transform data from Amazon S3 before returning it to an application. This enables different views of the same object depending on user identity, such as restricting access to confidential information, or disallowing access to personally identifiable information (PII) data. In this workshop, learn how to use Amazon S3 Object Lambda to modify objects during GET requests, so you no longer need to store multiple views of the same document.
In this hands-on workshop, learn how to use AWS Nitro Enclaves to isolate highly-sensitive data from your users, applications, and third-party libraries on your Amazon Elastic Compute Cloud (Amazon EC2) instances. Explore AWS Nitro Enclaves, discuss common use cases, and build and run your own enclave. During this workshop, learn about enclave isolation, cryptographic attestation, enclave image files, local Vsock communication channels, common debugging scenarios, and the enclave lifecycle.
Learn how to use the protective, detective and monitoring controls in AWS to protect your data in S3 from ransomware threats. Set up Amazon GuardDuty for S3 and AWS Identity and Access Management (IAM) Access Analyzer, and learn to read and respond to findings and create IAM invariants. Create a tiered storage approach to backup and recovery, and learn to use Amazon S3 Object Lock, versioning, and replication to provide immutable storage and protect against accidental or malicious deletion.
Operating multiple AWS accounts under an organization is how many users consume AWS Cloud services. In this workshop, learn how to build foundational security monitoring in multi-account environments. Walk through an initial setup of AWS Security Hub for centralized aggregation of findings across your AWS Organizations organization. Additionally, learn how to centralize Amazon GuardDuty findings, Amazon Detective functions, AWS Identity and Access Management (IAM) Access Analyzer findings (if available), AWS Config rule evaluations, and AWS CloudTrail logs into the central security monitoring account (security tools account). Finally, implement a service control policy (SCP) that denies the ability to disable these security controls.
Automation and simplification are key to managing compliance at scale. Remediation is one of the essential elements of simplifying and managing risk. In this workshop, see how to build a remediation workflow using AWS Config and AWS Systems Manager automation. Learn how this workflow can be deployed at scale and monitored with AWS Security Hub to oversee the entire organization and how to use AWS Audit Manager to easily access evidence of risk management.
Want to analyze Identity and Access Management (IAM) policies at scale? Want to help your developers write secure IAM policies? This workshop provides you the hands-on opportunity to run IAM Access Analyzer policy validation on your AWS CloudFormation templates in a continuous integration/continuous deployment (CI/CD) pipeline.
In this workshop, learn how to create a data perimeter by building controls that allow access to data only from expected network locations and by trusted identities. The workshop consists of five modules, each designed to illustrate a different Identity and Access Management (IAM) or network control. Learn where and how to implement the appropriate controls based on different risk scenarios. Discover how to implement these controls as service control policies, identity- and resource-based policies, and Amazon Virtual Private Cloud (Amazon VPC) endpoint policies.
In this workshop, get hands-on experience implementing a Zero Trust architecture for service-to-service workloads on AWS. Learn how to use services such as Amazon API Gateway and Virtual Private Cloud (Amazon VPC) endpoints to integrate network and identity controls while using Amazon GuardDuty, Lambda, and Amazon DynamoDB to take advantage of native service controls. Learn how these services allow you to authorize specific flows between components to reduce lateral network mobility risk and improve the overall security posture of your workload.
Enterprise users adopting machine learning (ML) on AWS often look for prescriptive guidance on implementing security best practices, establishing governance, securing their ML models, and meeting compliance standards. Building a repeatable solution provides users with standardization and governance over what gets provisioned in their AWS account. In this workshop, learn steps you can take to secure third-party ML model deployments. We provide cloud infrastructure-as-code templates to automate the setup of a hardened Amazon SageMaker environment. These templates include private networking, VPC endpoints, end-to-end encryption, logging and monitoring, and enhanced governance and access controls through AWS Service Catalog.
In this workshop, get hands-on experience with Prowler, AWS Security Hub, and Amazon QuickSight by building a custom security dashboard for the AWS environment. Using a multi-account deployment of Prowler integrated into Security Hub, learn to identify and analyze Prowler findings and integrate QuickSight to visualize the information. Discover how to get the most from QuickSight and Prowler with automatically created datasets.
This workshop is designed to get you familiar with AWS Security Hub, so you can better understand how to use it in your own AWS environment. This workshop has two sections. The first section demonstrates the features and functions of AWS Security Hub. The second section shows you how to use AWS Security Hub to import findings from different data sources, analyze findings so you can prioritize response work, and implement responses to findings to help improve your security posture.
This workshop guides you through building an incident response plan for your AWS environment using Jupyter notebooks. Walk through an easy-to-follow sample incident, using building blocks as a ready-to-use playbook in a Jupyter notebook. Then, follow simple steps to add additional programmatic and documented steps to your incident response plan.
In this hands-on workshop, learn about several AWS services involved in threat detection and response as you walk through real-world threat scenarios. Learn about the threat detection capabilities of Amazon GuardDuty, Amazon Macie, and AWS Security Hub and the available response options. For each hands-on scenario, review methods to detect and respond to threats using the following services: AWS CloudTrail, Virtual Private Cloud (Amazon VPC) Flow Logs, Amazon CloudWatch Events, AWS Lambda, Amazon Inspector, Amazon GuardDuty, and AWS Security Hub.
In this workshop, learn how to develop incident response playbooks. Explore the incident response lifecycle, including preparation, detection and analysis, containment, eradication and recovery, and post-incident activity. To get the most out of this workshop, you should have advanced experience with AWS services and responsibilities aligned with incident response frameworks such as NIST SP 800-61 R2.
This list is representative of the security workshops created in 2021 to help customers on their journey in AWS. If you’d like to find more workshops, please go to AWS Workshops and select Security in the top navigation bar, or you can also check out AWS Security Workshops for a subset of workshops curated by AWS Security Specialists. We hope you enjoy these workshops!
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
Deploying global applications has many challenges, especially when accessing a database to build custom pages for end users. One example is an application using AWS Lambda@Edge. Two main challenges include performance and availability.
This blog explains how you can optimally deploy a global application with fast response times and without application changes.
The Amazon Aurora Global Database enables a single database cluster to span multiple AWS Regions by asynchronously replicating your data within subsecond timing. This provides fast, low-latency local reads in each Region. It also enables disaster recovery from Region-wide outages using multi-Region writer failover. These capabilities minimize the recovery time objective (RTO) of cluster failure, thus reducing data loss during failure. You will then be able to achieve your recovery point objective (RPO).
However, there are some implementation challenges. Most applications are designed to connect to a single hostname with atomic, consistent, isolated, and durable (ACID) consistency. But Global Aurora clusters provide reader hostname endpoints in each Region. In the primary Region, there are two endpoints, one for writes, and one for reads. To achieve strong data consistency, a global application requires the ability to:
Choose the optimal reader endpoints
Change writer endpoints on a database failover
Intelligently select the reader with the most up-to-date, freshest data
These capabilities typically require additional development.
The architecture in Figure 1 shows Aurora Global Databases primary Region in AP-SOUTHEAST-2, and secondary Regions in AP-SOUTH-1 and US-WEST-2. The Heimdall Proxy uses latency-based routing to determine the closest Reader Instance for read traffic, and redirects all write traffic to the Writer Instance. The Heimdall Configuration stores the Amazon Resource Name (ARN) of the global cluster. It automatically detects failover and cross-Region on the cluster, and directs traffic accordingly.
With an Aurora Global Database, there are two approaches to failover:
Managed planned failover. To relocate your primary database cluster to one of the secondary Regions in your Aurora global database, see Managed planned failovers with Amazon Aurora Global Database. With this feature, RPO is 0 (no data loss) and it synchronizes secondary DB clusters with the primary before making any other changes. RTO for this automated process is typically less than that of the manual failover.
Manual unplanned failover. To recover from an unplanned outage, you can manually perform a cross-Region failover to one of the secondaries in your Aurora Global Database. The RTO for this manual process depends on how quickly you can manually recover an Aurora global database from an unplanned outage. The RPO is typically measured in seconds, but this is dependent on the Aurora storage replication lag across the network at the time of the failure.
The Heimdall Proxy automatically detects Amazon Relational Database Service (RDS) / Amazon Aurora configuration changes based on the ARN of the Aurora Global cluster. Therefore, both managed planned and manual unplanned failovers are supported.
Solution benefits for global applications
Implementing the Heimdall Proxy has many benefits for global applications:
An Aurora Global Database has a primary DB cluster in one Region and up to five secondary DB clusters in different Regions. But the Heimdall Proxy deployment does not have this limitation. This allows for a larger number of endpoints to be globally deployed. Combined with Amazon Route 53 latency-based routing, new connections have a shorter establishment time. They can use connection pooling to connect to the database, which reduces overall connection latency.
SQL results are cached to the application for faster response times.
The proxy intelligently routes non-cached queries. When safe to do so, the closest (lowest latency) reader will be used. When not safe to access the reader, the query will be routed to the global writer. Proxy nodes globally synchronize their state to ensure that volatile tables are locked to provide ACID compliance.
Heimdall Data, based in the San Francisco Bay Area, is an AWS Advanced ISV partner. They have AWS Service Ready designations for Amazon RDS and Amazon Redshift. Heimdall Data offers a database proxy that offloads SQL improving database scale. Deployment does not require code changes.
Before you can create visuals and dashboards that convey useful information, you need to transform and prepare the underlying data. With AWS Glue DataBrew, you can now easily transform and prepare datasets from Amazon Simple Storage Service (Amazon S3), an Amazon Redshift data warehouse, Amazon Aurora, and other Amazon Relational Database Service (Amazon RDS) databases and upload them into Amazon S3 to visualize the transformed data in a dashboard using Amazon QuickSight or other business intelligence (BI) tools like Tableau.
DataBrew now also supports writing prepared data into Tableau Hyper format, allowing you to easily take prepared datasets from Amazon S3 and upload them into Tableau for further visualization and analysis. Hyper is Tableau’s in-memory data engine technology optimized for fast data ingest and analytical query processing on large or complex datasets.
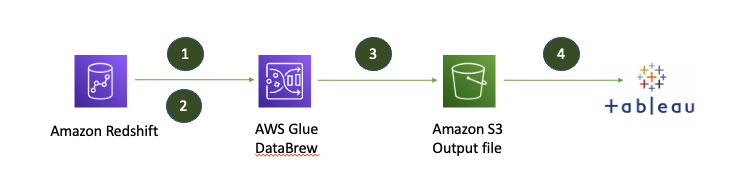
In this post, we use DataBrew to extract data from Amazon Redshift, cleanse and transform data using DataBrew to Tableau Hyper format without any coding, and store it in Amazon S3.
Overview of solution
The following diagram illustrates the architecture of the solution.
The solution workflow includes the following steps:
You create a JDBC connection for Amazon Redshift and a DataBrew project on the DataBrew console.
DataBrew queries data from Amazon Redshift by creating a recipe and performing transformations.
The DataBrew job writes the final output to an S3 bucket in Tableau Hyper format.
You can now upload the file into Tableau for further visualization and analysis.
Prerequisites
For this walkthrough, you should have the following prerequisites:
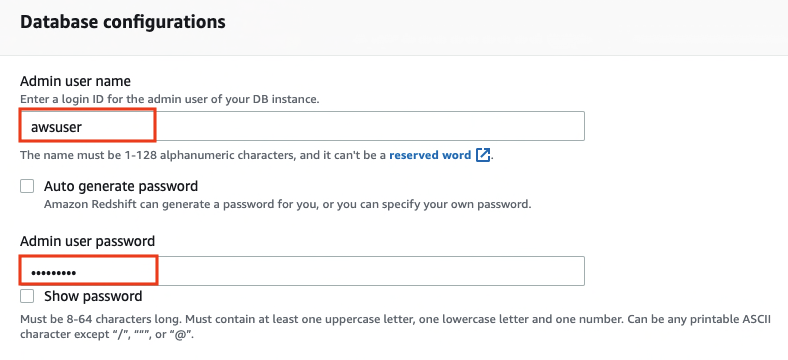
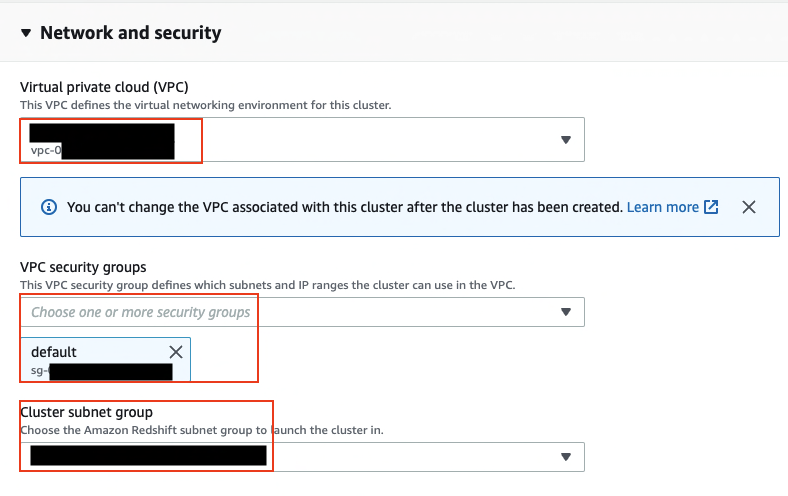
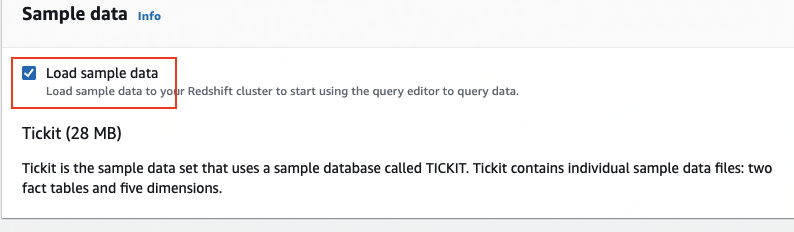
The following screenshots show the configuration for creating an Amazon Redshift cluster using the Amazon Redshift console with demo sales data. For more information about network security for the cluster, see Setting Up a VPC to Connect to JDBC Data Stores.
For this post, we use the sample data that comes with the Amazon Redshift cluster.
In this post, we only demonstrate how to transform your Amazon Redshift data to Hyper format; uploading the file for further analysis is out of scope.
Create an Amazon Redshift connection
In this step, you use the DataBrew console to create an Amazon Redshift connection.
On the DataBrew console, choose Datasets.
On the Connections tab, choose Create connection.
For Connection name, enter a name (for example, ticket-db-connection).
For Connection type, select Amazon Redshift.
In the Connection access section, provide details like cluster name, database name, user name, and password.
Choose Create connection.
Create your dataset
To create a new dataset, complete the following steps:
On the DataBrew console, choose Datasets.
On the Datasets tab, choose Connect new dataset.
For Dataset name, enter sales.
For Connect to new dataset, select Amazon Redshift.
Choose the connection you created (AwsGlueDataBrew-tickit-sales-db-connection).
Select the public schema and sales table
In the Additional configurations section, for Enter S3 destination, enter the S3 bucket you created as a prerequisite.
DataBrew uses this bucket to store the intermediate results.
Choose Create dataset. If your query is taking too much time, then add LIMIT clause in your Select statement.
Create a project using the dataset
To create a new project, complete the following steps:
On the DataBrew console, choose Projects and choose Create project.
For Project name, enter sales-project.
For Attached recipe, choose Create new recipe.
For Recipe name, enter sales-project-recipe.
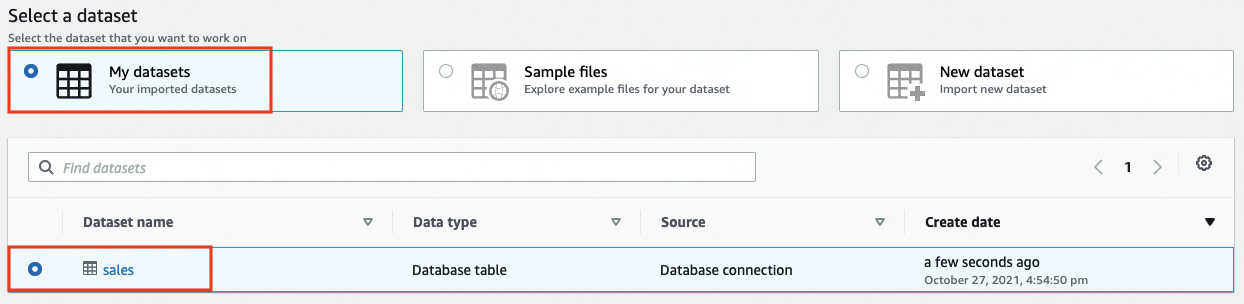
For Select a dataset, select My datasets.
Select the sales dataset.
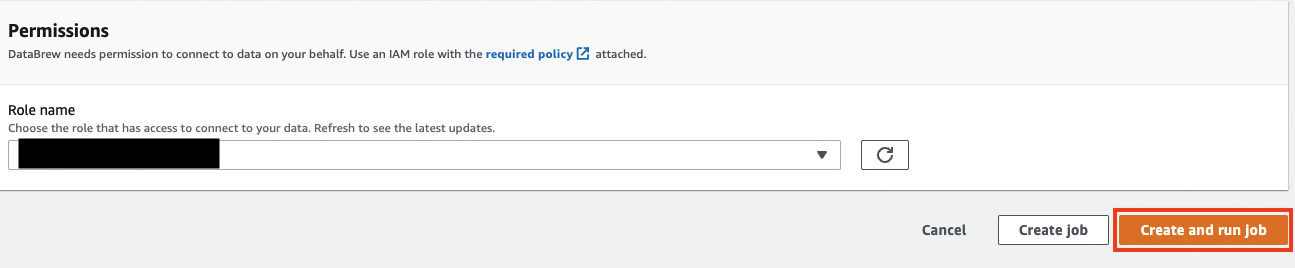
Under Permissions, for Role name, choose an existing IAM role created during the prerequisites or create a new role.
Choose Create project.
When the project is opened, a DataBrew interactive session is created. DataBrew retrieves sample data based on your sampling configuration selection.
When we connect a dataset to an Amazon Redshift cluster in your VPC, DataBrew provisions an elastic network interface in your VPC without a public IPV4 address. Because of this, you need to provision a NAT gateway in your VPC as well as an appropriate subnet route table configured for the subnets associated with the AWS Glue network interfaces. To use DataBrew with a VPC subnet without a NAT, you must have a gateway VPC endpoint to Amazon S3 and a VPC endpoint for the AWS Glue interface in your VPC. For more information, see Create a gateway endpoint and Interface VPC endpoints (AWS PrivateLink).
Build a transformation recipe
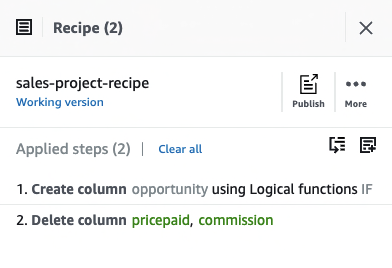
In this step, we perform some feature engineering techniques (transformations) to prepare our dataset and drop the unnecessary columns from our dataset that aren’t required for this exercise.
On the DataBrew console, choose Column.
Choose Delete.
For Source columns, select the columns pricepaid and commissions.
Choose Apply.
Add a logical condition
With DataBrew, you can now use IF, AND, OR, and CASE logical conditions to create transformations based on functions. With this feature, you have the flexibility to use custom values or reference other columns within the expressions, and can create adaptable transformations for their specific use cases.
To add a logical condition to your transformation recipe, complete the following steps:
On the DataBrew console, choose Conditions.
Choose IF.
For Matching conditions, select Match all conditions.
For Source, choose the value qtysold.
For Enter a value, select Enter a custom value and enter 2.
For Destination column, enter opportunity.
Choose Apply.
The following screenshot shows the full recipe that we applied to our dataset.
Create the DataBrew job
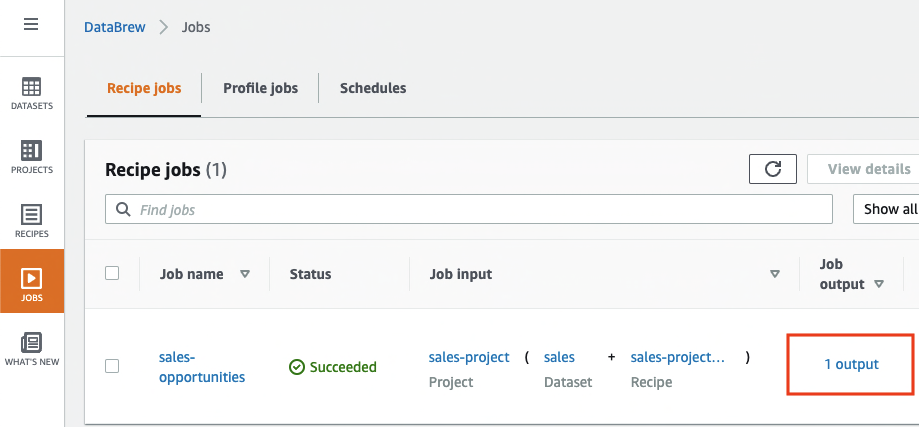
Now that we have built the recipe, we can create and run the DataBrew recipe job.
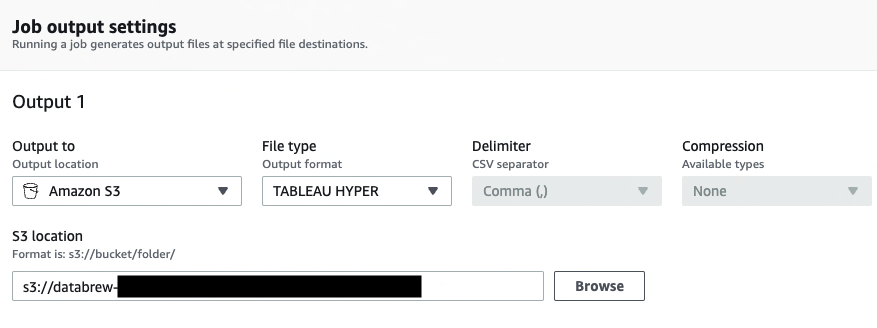
On the project details page, choose Create job.
For Job name, enter sales-opportunities.
We choose TABLEAU HYPER as the output format.
For S3 location, enter the previously created S3 bucket.
For Role name, choose an existing role created during the prerequisites or create a new role.
Choose Create and run job.
Navigate to the Jobs page and wait for the sales-opportunity job to complete.
Choose the output link to navigate to the Amazon S3 console to access the job output.
Clean up
To avoid incurring future charges, delete the resources you created:
Amazon Redshift cluster
Recipe job
Job output stored in the S3 bucket
IAM roles created as part of this exercise
DataBrew project sales-project and its associated recipe sales-project-recipe
DataBrew datasets
Conclusion
In this post, we showed you how to connect to an Amazon Redshift cluster and create a DataBrew dataset.
We saw how easy it is to get data from Amazon Redshift into DataBrew and apply transformations without any coding. We then ran a recipe job to convert this dataset to Tableau Hyper format file and store it in Amazon S3 for visualization using Tableau. Learn more about all the products and service integrations that AWS Glue DataBrew supports.
About the Authors
NipunChagari is a Senior Solutions Architect at AWS, where he helps customers build highly available, scalable, and resilient applications on the AWS Cloud. He is currently focused on helping customers leverage serverless technology to meet their business objectives.
MohitMalik is a Senior Solutions Architect at Amazon Web Services who specializes in compute, networking, and serverless technologies. He enjoys helping customers learn how to operate efficiently and effectively in the cloud. In his spare time, Mohit enjoys spending time with his family, reading books, and watching movies.
If you want to understand how Object Lock immutability works, think of a valuable necklace sitting behind a window. If someone really wants that necklace, they will find a way to break that window. Reinforce the glass, add a silent alarm, none of it will change the fact that thieves can find a way.
With Object Lock immutability, there is no window. Instead, picture a fully realistic holographic representation of the necklace. You can still see your necklace, you can still enjoy its sparkle, but nothing anyone does to that hologram can alter the actual physical necklace.
Object Lock immutability works in a similar fashion, at least metaphorically speaking. (Object Lock doesn’t create a facsimile, per se, but it does protect objects from being manipulated, copied, encrypted, changed, or deleted for as long as the lock is set.) And it protects something far more valuable than some trinket: It protects your data.
In this post, learn about five different ways you can use Object Lock as well as some tips for using Object Lock effectively.
What Is Object Lock Immutability?
In functional programming, immutability is a characteristic of an object whose state cannot be changed after it has been created. Conversely, mutable objects are variable. But what does all that mean when it comes to Object Lock? By creating a model in which an individual object (i.e., a unit of data that contains all of the bytes that constitute what you would typically think of as a “file”) remains static and unchangeable, Object Lock immutability prevents important files from being deleted, corrupted, or otherwise damaged. Your files can, however, be freely accessed, giving you free rein to view important documents. This Write Once, Read Many (WORM) model is the cornerstone of Object Lock immutability.
Those of us above a certain age may recall the days when data was regularly transferred via floppy disc. Back in those dark days of dial-up, there was a simple plastic switch on each floppy disc that marked the disc as read-only or read-and-write. If the switch was flipped, the data on the disc could be read or transferred at will, but it was a one-way street. You were unable to alter the original data stored on the disc.
Object Lock Immutability serves the same function as that plastic switch, only it operates entirely within the code of your storage software. You can view, share, and open files at will. But the contents of that file cannot be changed.
Object Lock Immutability Use Cases
With the right approach, Object Lock immutability can be used to solve a few problems, including:
Aiding recovery from ransomware attacks.
Migrating from an LTO tape system.
Supporting records retention requirements.
Protecting your company during lawsuits.
Enhancing version control during software development.
Aid Recovery From Ransomware Attacks
Ransomware attacks are a major challenge for many businesses. In our research on the true cost of ransomware, we found that the cost of these incidents can exceed $1 million! That’s the bad news.
The good news is advanced planning can make it easier to recover from attacks. Specifically, preserving data backups with Object Lock is a helpful way to speed up your recovery from ransomware attacks. For example, you might decide to make daily backups of your most critical files and retain those backups for three months. In this case, you would have plenty of options for how to recover from an attack.
To achieve consistent security protection, we recommend integrating Object Lock into your IT security policy. For further guidance on how to do this, see our post, “How to Add Object Lock to Your IT Security Policy.”
Migrating From an LTO Tape System
Until recently, the most common way to protect data from being overwritten, corrupted, or deleted was by creating an “air gap” by way of LTO tapes. Under this system, sensitive files would be backed up to a tape and then physically removed from the drive. This created an effective shield of literal, physical air around the data by removing it entirely from your network, but it came at a cost.
Tape systems require an up-front investment and require ongoing maintenance, management, and eventual replacement. With Object Lock immutability as part of your cloud backup solution, the entire process of creating an air gap happens virtually, saving time and money while accomplishing the same goal. You can calculate the savings between cloud storage and tape yourself.
Support Records Retention Requirements
Your company probably has a variety of records retention requirements to fulfill. For example, the finance department likely has to retain records in case you are audited by tax authorities. In addition, your contracts with customers may expect you to retain records for a specific project for a set period. Once you determine which records need to be retained, Object Lock can preserve the records so they cannot be modified or deleted for the required duration. Object Lock means accidental deletion of records is much less likely.
Protect the Company’s Interests During Lawsuits
Lawsuits and disputes are a fact of life in today’s environment, but there are steps you can take to reduce the impact and expense associated with them.
By applying Object Lock, your company will be better able to navigate the challenges of a lawsuit. You can focus on the substance of the dispute rather than spending endless hours answering questions about your data integrity.
Enhance Version Control During Software Development
New versions of files are created on a nearly constant basis during software development projects. Some software projects release new versions every day or every week. With many different software versions on your plate, there is a risk your team might get disorganized. Now, imagine if a new release of your software ends up having a serious security or performance flaw. In that case, rolling back to the previous version may save a tremendous amount of time and energy.
By using Object Lock on previous versions of your software, you can have confidence in your ability to access previous versions. For companies that produce custom software for clients, enhancing version control through Object Lock may be helpful for other reasons. In the event of a problem, a client might ask for access to earlier versions of the software. Preserving earlier versions of your software development with Object Lock makes it easier to respond to such requests.
Tips for Using Object Lock Immutability Effectively
As with any technology, achieving optimal results from Object Lock requires a thoughtful, guided approach. From a technical standpoint, there is no limit to how much data you can protect with Object Lock. However, excessive use of Object Lock may consume a significant amount of your data storage resources, negating any time and cost savings you’ve achieved.
Altering the amount of time an object is placed in Object Lock is just one way to ensure you’re getting the most out of this technology. Others include:
Reviewing Older Object Lock Files: You might find that you rarely need to access Object Lock-protected data that is older than six months. Obviously, this amount of time will vary greatly depending on your needs, but it’s important to make sure you’re not spending resources protecting files that don’t need the extra protection. Depending on what you find, you may want to adjust guidance to employees accordingly.
Ensuring Consistency: To achieve more consistent usage of Object Lock immutability, start by clarifying your expectations in a company policy. This could be as simple as a checklist document explaining when and how to use Object Lock or an appendix to your IT security policy. In addition, ask managers to periodically review (e.g., every six months) how Object Lock is used in their departments and provide feedback to employees as needed.
As a concept, Object Lock immutability is fairly easy to understand and even easier to use in protecting your vital data from incursion, corruption or deletion. Beyond simply protecting valuable data from cyber threats, it can create a clear timeline in case of litigation or simplify complicated development projects. By understanding how this tool works and how best to use it, you can secure your data, increase your efficiency, and improve the operation of your cloud storage.
The new IRAP report includes reassessment of the existing 111 services which are already in scope for IRAP, as well as the 14 additional services listed below, and the new Melbourne region. For the full list of in-scope services, see the AWS Services in Scope page on the IRAP tab. All services in scope are available in the Asia Pacific (Sydney) Region.
We have created the IRAP documentation pack on AWS Artifact, which includes the AWS Consumer Guide and the whitepaper Reference Architectures for ISM PROTECTED Workloads in the AWS Cloud, which was created to help Australian government agencies and their partners plan, architect, and risk assess workloads based on AWS Cloud services.
Please reach out to your AWS representatives to let us know which additional services you would like to see in scope for coming IRAP assessments. We strive to bring more services into the scope of the IRAP PROTECTED level, based on your requirements.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
Earlier posts in this series covered the basics of A/B tests (Part 1 and Part 2 ), core statistical concepts (Part 3 and Part 4), and how to build confidence in decisions based on A/B test results (Part 5). Here we describe the role of Experimentation and A/B testing within the larger Data Science and Engineering organization at Netflix, including how our platform investments support running tests at scale while enabling innovation. The subsequent and final post in this series will discuss the importance of the culture of experimentation within Netflix.
Experimentation and causal inference is one of the primary focus areas within Netflix’s Data Science and Engineering organization. To directly support great decision-making throughout the company, there are a number of data science teams at Netflix that partner directly with Product Managers, engineering teams, and other business units to design, execute, and learn from experiments. To enable scale, we’ve built, and continue to invest in, an internal experimentation platform (XP for short). And we intentionally encourage collaboration between the centralized experimentation platform and the data science teams that partner directly with Netflix business units.
Experimentation and causal inference data scientists who work directly with Netflix business units develop deep domain understanding and intuition about the business areas where they work. Data scientists in these roles apply the scientific method to improve the Netflix experience for current and future members, and are involved in the whole life cycle of experimentation: data exploration and ideation; designing and executing tests; analyzing results to help inform decisions on tests; synthesizing learnings from numerous tests (and other sources) to understand member behavior and identify opportunity areas for innovation. It’s a virtuous, scientifically rigorous cycle of testing specific hypotheses about member behaviors and preferences that are grounded in general principles (deduction), and generalizing learning from experiments to build up our conceptual understanding of our members (induction). In success, this cycle enables us to rapidly innovate on all aspects of the Netflix service, confident that we are delivering more joy to our members as our decisions are backed by empirical evidence.
Success in these roles requires a broad technical skill set, a self-starter attitude, and a deep curiosity about the domain space. Netflix data scientists are relentless in their pursuit of knowledge from data, and constantly look to go the extra distance and ask one more question. “What more can we learn from this test, to inform the next one?” “What information can I synthesize from the last year of tests, to inform opportunity sizing for next year’s learning roadmap?” “What other data and intuition can I bring to the problem?” “Given my own experience with Netflix, where might there be opportunities to test and improve on the current experience?” We look to our data scientists to push the boundaries on both the design and analysis of experiments: what new approaches or methods may yield valuable insights, given the learning agenda in a particular part of the product? These data scientists are also sought after as trusted thought partners by their business partners, as they develop deep domain expertise about our members and the Netflix experience.
Here are quick summaries of a few of the experimentation areas at Netflix and some of the innovative work that’s come out of each. This is not an exhaustive list, and we’ve focused on areas where opportunities to learn and deliver a better member experience through experimentation may be less obvious.
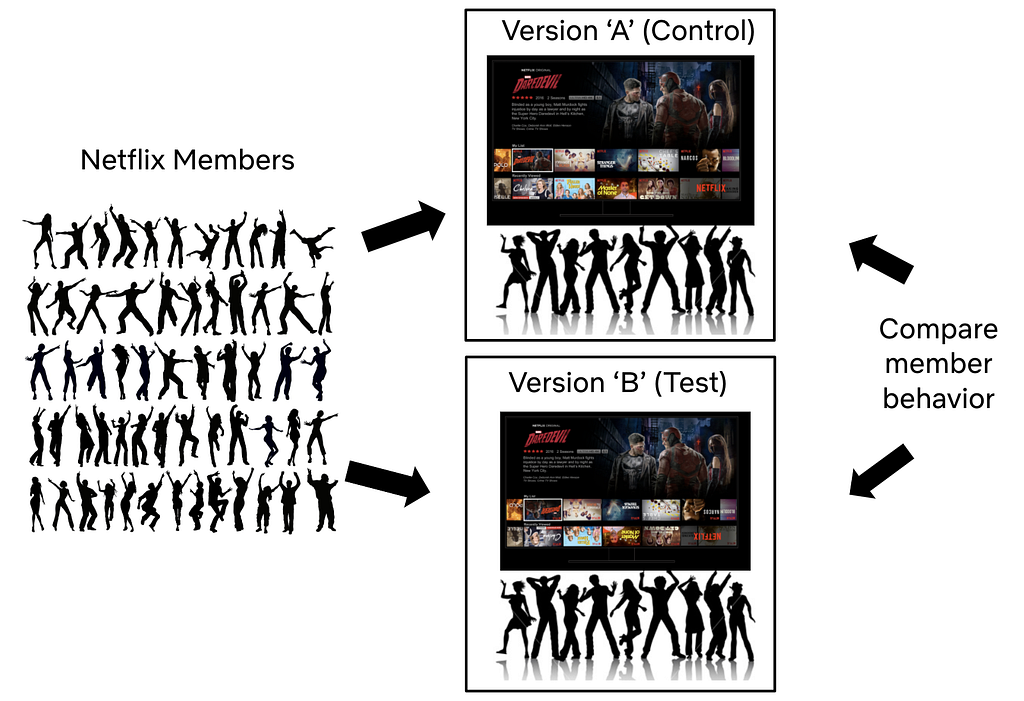
A/B tests are used throughout Netflix to deliver more joy to current and future members.
Growth Advertising
At Netflix, we want to entertain the world! Our growth team advertises on social media platforms and other websites to share news about upcoming titles and new product features, with the ultimate goal of growing the number of Netflix members worldwide. Data Scientists play a vital role in building automated systems that leverage causal inference to decide how we spend our advertising budget.
In advertising, the treatments (the ads that we purchase) have a direct monetary cost to Netflix. As a result, we are risk averse in decision making and actively mitigate the probability of purchasing ads that are not efficiently attracting new members. Abiding by this risk aversion is challenging in our domain because experiments generally have low power (see Part 4). For example we rely on difference-in-differences techniques for unbiased comparisons between the potentially different audiences experiencing each advertising treatment, and these approaches effectively reduce the sample size (more details for the very interested reader). One way to address these power reductions would be to simply run longer experiments — but that would slow down our overall pace of innovation.
Here we highlight two related problems for experimentation in this domain and briefly describe how we address them while maintaining a high cadence of experimentation.
Recall that Part 3 and Part 4 described two types of errors: false positives (or Type-I errors) and false negatives (Type-II errors). Particularly in regimes where experiments are low-powered, two other error types can occur with high probability, so are important to consider when acting upon a statistically significant test result:
A Type-S error occurs when, given that we observe a statistically-significant result, the estimated metric movement has the opposite sign relative to the truth.
A Type-M error occurs when,given that we observe a statistically-significant result, the size of the estimated metric movement is magnified (or exaggerated) relative to the truth.
If we simply declare statistically significant test results (with positive metric movements) to be winners, a Type-S error would imply that we actually selected the wrong treatment to promote to production, and all our future advertising spend would be producing suboptimal results. A Type-M error means that we are over-estimating the impact of the treatment. In the short term, a Type-M error means we would overstate our result, and in the long-term it could lead to overestimating our optimal budget level, or even misprioritizing future research tracks.
To reduce the impact of these errors, we take a Bayesian approach to experimentation in growth advertising. We’ve run many tests in this area and use the distribution of metric movements from past tests as an additional input to the analysis. Intuitively (and mathematically) this approach results in estimated metric movements that are smaller in magnitude and that feature narrower confidence intervals (Part 3). Combined, these two effects reduce the risk of Type-S and Type-M errors.
As the benefits from ending suboptimal treatments early can be substantial, we would also like to be able to make informed, statistically-valid decisions to end experiments as quickly as possible.This is an active research area for the team, and we’ve investigated Group Sequential Testing and Bayesian Inference as methods to allow for optimal stopping (see below for more on both of those). The latter, when combined with decision theoretic concepts like expected loss (or risk) minimization, can be used to formally evaluate the impact of different decisions — including the decision to end the experiment early.
Payments
The payments team believes that the methods of payment (credit card, direct debit, mobile carrier billing, etc) that a future or current member has access to should never be a barrier to signing up for Netflix, or the reason that a member leaves Netflix. There are numerous touchpoints between a member and the payments team: we establish relationships between Netflix and new members, maintain those relationships with renewals, and (sadly!) see the end of those relationships when members elect to cancel.
We innovate on methods of payment, authentication experiences, text copy and UI designs on the Netflix product, and any other place that we may smooth the payment experience for members. In all of these areas, we seek to improve the quality and velocity of our decision-making, guided by the testing principles laid out in this series.
Decision quality doesn’t just mean telling people, “Ship it!” when the p-value (see Part 3) drops below 0.05. It starts with having a good hypothesis and a clear decision framework — especially one that judiciously balances between long-term objectives and getting a read in a pragmatic timeframe. We don’t have unlimited traffic or time, so sometimes we have to make hard choices. Are there metrics that can yield a signal faster? What’s the tradeoff of using those? What’s the expected loss of calling this test, versus the opportunity cost of running something else? These are fun problems to tackle, and we are always looking to improve.
We also actively invest in increasing decision velocity, often in close partnership with the Experimentation Platform team. Over the past year, we’ve piloted models and workflows for three approaches to faster experimentation: Group Sequential Testing (GST), Gaussian Bayesian Inference, and Adaptive Testing. Any one of these techniques would enhance our experiment throughput on their own; together, they promise to alter the trajectory of payments experimentation velocity at Netflix.
Partnerships
We want all of our members to enjoy a high quality experience whenever and however they access Netflix. Our partnerships teams work to ensure that the Netflix app and our latest technologies are integrated on a wide variety of consumer products, and that Netflix is easy to discover and use on all of these devices. We also partner with mobile and PayTV operators to create bundled offerings to bring the value of Netflix to more future members.
In the partnerships space, many experiences that we want to understand, such as partner-driven marketing campaigns, are not amenable to the A/B testing framework that has been the focus of this series. Sometimes, users self-select into the experience, or the new experience is rolled out to a large cluster of users all at once. This lack of randomization precludes the straightforward causal conclusions that follow from A/B tests. In these cases, we use quasi experimentation and observational causal inference techniques to infer the causal impact of the experience we are studying. A key aspect of a data scientist’s role in these analyses is to educate stakeholders on the caveats that come with these studies, while still providing rigorous evaluation and actionable insights, and providing structure to some otherwise ambiguous problems. Here are some of the challenges and opportunities in these analyses:
Treatment selection confounding. When users self-select into the treatment or control experience (versus the random assignment discussed in Part 2), the probability that a user ends up in each experience may depend on their usage habits with Netflix. These baseline metrics are also naturally correlated with outcome metrics, such as member satisfaction, and therefore confound the effect of the observed treatment on our outcome metrics. The problem is exacerbated when the treatment choice or treatment uptake varies with time, which can lead to time varying confounding. To deal with these cases, we use methods such as inverse propensity scores, doubly robust estimators, difference-in-difference, or instrumental variables to extract actionable causal insights, with longitudinal analyses to account for the time dependence.
Synthetic controls and structural models. Adjusting for confounding requires having pre-treatment covariates at the same level of aggregation as the response variable. However, sometimes we do not have access to that information at the level of individual Netflix members. In such cases, we analyze aggregate level data using synthetic controls and structural models.
Sensitivity analysis. In the absence of true A/B testing, our analyses rely on using the available data to adjust away spurious correlations between the treatment and the outcome metrics. But how well we can do so depends on whether the available data is sufficient to account for all such correlations. To understand the validity of our causal claims, we perform sensitivity analyses to evaluate the robustness of our findings.
Messaging
At Netflix, we are always looking for ways to help our members choose content that’s great for them. We do this on the Netflix product through the personalized experience we provide to every member. But what about other ways we can help keep members informed about new or relevant content, so they’ve something great in mind when it’s time to relax at the end of a long day?
Messaging, including emails and push notifications, is one of the key ways we keep our members in the loop. The messaging team at Netflix strives to provide members with joy beyond the time when they are actively watching content. What’s new or coming soon on Netflix? What’s the perfect piece of content that we can tell you about so you can plan “date time movie night” on the go? As a messaging team, we are also mindful of all the digital distractions in our members’ lives, so we work tirelessly to send just the right information to the right members at the right time.
Data scientists in this space work closely with product managers and engineers to develop messaging solutions that maximize long term satisfaction for our members. For example, we are constantly working to deliver a better, more personalized messaging experience to our members. Each day, we predict how each candidate message would meet a members’ needs, given historical data, and the output informs what, if any, message they will receive. And to ensure that innovations on our personalized messaging approach result in a better experience for our members, we use A/B testing to learn and confirm our hypotheses.
An exciting aspect of working as a data scientist on messaging at Netflix is that we are actively building and using sophisticated learning models to help us better serve our members. These models, based on the idea of bandits, continuously balance learning more about member messaging preferences with applying those learnings to deliver more satisfaction to our members. It’s like a continuous A/B test with new treatments deployed all the time. This framework allows us to conduct many exciting and challenging analyses without having to deploy new A/B tests every time.
Evidence Selection
When a member opens the Netflix application, our goal is to help them choose a title that is a great fit for them. One way we do this is through constantly improving the recommendation systems that produce a personalized home page experience for each of our members. And beyond title recommendations, we strive to select and present artwork, imagery and other visual “evidence” that is likewise personalized, and helps each member understand why a particular title is a great choice for them — particularly if the title is new to the service or unfamiliar to that member.
Creative excellence and continuous improvements to evidence selection systems are both crucial in achieving this goal. Data scientists working in the space of evidence selection use online experiments and offline analysis to provide robust causal insights to power product decisions in both the creation of evidence assets, such as the images that appear on the Netflix homepage, and the development of models that pair members with evidence.
Sitting at the intersection of content creation and product development, data scientists in this space face some unique challenges:
Predicting evidence performance. Say we are developing a new way to generate a piece of evidence, such as a trailer. Ideally, we’d like to have some sense of the positive outcomes of the new evidence type prior to making a potentially large investment that will take time to pay off. Data scientists help inform investment decisions like these by developing causally valid predictive models.
Matching members with the best evidence. High quality and properly selected evidence is key to a great Netflix experience for all of our members. While we test and learn about what types of evidence are most effective, and how to match members to the best evidence, we also work to minimize the potential downsides by investing in efficient approaches to A/B tests that allow us to rapidly stop suboptimal treatment experiences.
Providing timely causal feedback on evidence development. Insights from data, including from A/B tests, are used extensively to fuel the creation of better artwork, trailers, and other types of evidence. In addition to A/B tests, we work on developing experimental design and analysis frameworks that provide fine-grained causal inference and can keep up with the scale of our learning agenda. We use contextual bandits that minimize regret in matching members to evidence, and through a collaboration with our Algorithms Engineering team, we’ve built the ability to log counterfactuals: what would a different selection policy have recommended? These data provide us with a platform to run rich offline experiments and derive causal inferences that meet our challenges and answer questions that may be slow to answer with A/B tests.
Streaming
Now that you’ve signed up for Netflix and found something exciting to watch, what happens when you press play? Behind the scenes, Netflix infrastructure has already kicked into gear, finding the fastest way to deliver your chosen content with great audio and video quality.
The numerous engineering teams involved in delivering high quality audio and video use A/B tests to improve the experience we deliver to our members around the world. Innovation areas include the Netflix app itself (across thousands of types of devices), encoding algorithms, and ways to optimize the placement of content on our global Open Connect distribution network.
Data science roles in this business area emphasize experimentation at scale and support for autonomous experimentation for engineering teams: how do we enable these teams to efficiently and confidently execute, analyze, and make decisions based on A/B tests? We’ll touch upon four ways that partnerships between data science and engineering teams have benefited this space.
Automation. As streaming experiments are numerous (thousands per year) and tend to be short lived, we’ve invested in workflow automations. For example, we piggyback on Netflix’s amazing tools for safe deployment of the Netflix client by integrating the experimentation platform’s API directly with Spinnaker deployment pipelines. This allows engineers to set up, allocate, and analyze the effects of changes they’ve made using a single configuration file. Taking this model even further, users can even ‘automate the automation’ by running multiple rounds of an experiment to perform sequential optimizations.
Beyond average treatment effects. As many important streaming video and audio metrics are not well approximated by a normal distribution, we’ve found it critical to look beyond average treatment effects. To surmount these challenges, we partnered with the experimentation platform to develop and integrate high-performance bootstrap methods for compressed data, making it fast to estimate distributions and quantile treatment effects for even the most pathological metrics. Visualizing quantiles leads to novel insights about treatment effects, and these plots, now produced as part of our automated reporting, are often used to directly support high-level product decisions.
Alternatives to A/B testing. The Open Connect engineering team faces numerous measurement challenges. Congestion can cause interactions between treatment and control groups; in other cases we are unable to randomize due to the nature of our traffic steering algorithms. To address these and other challenges, we are investing heavily in quasi-experimentation methods. We use Metaflow to pair existing infrastructure for metric definitions and data collection from our Experimentation Platform with custom analysis methods that are based on a difference-in-difference approach. This workflow has allowed us to quickly deploy self-service tools to measure changes that cannot be measured with traditional A/B testing. Additionally, our modular approach has made it easy to scale quasi-experiments across Open Connect use cases, allowing us to swap out data sources or analysis methods depending on each team’s individual needs.
Support for custom metrics and dimensions. Last, we’ve developed a (relatively) frictionless path that allows all experimenters (not just data scientists) to create custom metrics and dimensions in a snap when they are needed. Anything that can be logged can be quickly passed to the experimentation platform, analyzed, and visualized alongside the long-lived quality of experience metrics that we consider for all tests in this domain. This allows our engineers to use paved paths to ask and answer more precise questions, so they can spend less time head-scratching and more time testing out exciting ideas.
Scaling experimentation and investing in infrastructure
To support the scale and complexity of the experimentation program at Netflix, we’ve invested in building out our own experimentation platform (referred to as “XP” internally). Our XP provides robust and automated (or semi automated) solutions for the full lifecycle of experiments, from experience management through to analysis, and meets the data scale produced by a high throughput of large tests.
XP provides a framework that allows engineering teams to define sets of test treatment experiences in their code, and then use these to configure an experiment. The platform then randomly selects members (or other units we might experiment on, like playback sessions) to assign to experiments, before randomly assigning them to an experience within each experiment (control or one of the treatment experiences). Calls by Netflix services to XP then ensure that the correct experiences are delivered, based on which tests a member is part of, and which variants within those tests. Our data engineering systems collect these test metadata, and then join them with our core data sets: logs on how members and non members interact with the service, logs that track technical metrics on streaming video delivery, and so forth. These data then flow through automated analysis pipelines and are reported in ABlaze, the front end for reporting and configuring experiments at Netflix. Aligned with Netflix culture, results from tests are broadly accessible to everyone in the company, not limited to data scientists and decision makers.
The Netflix XP balances execution of the current experimentation program with a focus on future-looking innovation. It’s a virtuous flywheel, as XP aims to take whatever is pushing the boundaries of our experimentation program this year and turn it into next year’s one-click solution. That may involve developing new solutions for allocating members (or other units) to experiments, new ways of tracking conflicts between tests, or new ways of designing, analyzing, and making decisions based on experiments. For example, XP partners closely with engineering teams on feature flagging and experience delivery. In success, these efforts provide a seamless experience for Netflix developers that fully integrates experimentation into the software development lifecycle.
For analyzing experiments, we’ve built the Netflix XP to be both democratized and modular. By democratized, we mean that data scientists (and other users) can directly contribute metrics, causal inference methods for analyzing tests, and visualizations. Using these three modules, experimenters can compose flexible reports, tailored to their tests, that flow through to both our frontend UI and a notebook environment that supports ad hoc and exploratory analysis.
This model supports rapid prototyping and innovation as we abstract away engineering concerns so that data scientists can contribute code directly to our production experimentation platform — without having to become software engineers themselves. To ensure that platform capabilities are able to support the required scale (number and size of tests) as analysis methods become more complex and computationally intensive, we’ve invested in developing expertise in performant and robust Computational Causal Inference software for test analysis.
It takes a village to build an experimentation platform: software engineers to build and maintain the backend engineering infrastructure; UI engineers to build out the ABlaze front end that is used to manage and analyze experiments; data scientists with expertise in causal inference and numerical computing to develop, implement, scale, and socialize cutting edge methodologies; user experience designers who ensure our products are accessible to our stakeholders; and product managers who keep the platform itself innovating in the right direction. It’s an incredibly multidisciplinary endeavor, and positions on XP provide opportunities to develop broad skill sets that span disciplines. Because experimentation is so pervasive at Netflix, those working on XP are exposed to challenges, and get to collaborate with colleagues, from all corners of Netflix. It’s a great way to learn broadly about ‘how Netflix works’ from a variety of perspectives.
Summary
At Netflix, we’ve invested in data science teams that use A/B tests, other experimentation paradigms, and the scientific method more broadly, to support continuous innovation on our product offerings for current and future members. In tandem, we’ve invested in building out an internal experimentation platform (XP) that supports the scale and complexity of our experimentation and learning program.
In practice, the dividing line between these two investments is blurred and we encourage collaboration between XP and business-oriented data scientists, including through internal events like A/B Experimentation Workshops and Causal Inference Summits. To ensure that experimentation capabilities at Netflix evolve to meet the on-the-ground needs of experimentation practitioners, we are intentional in ensuring that the development of new measurement and experiment management capabilities, and new software systems to both enable and scale research, is a collaborative partnership between XP and experimentation practitioners. In addition, our intentionally collaborative approach provides great opportunities for folks to lead and contribute to high-impact projects that deliver new capabilities, spanning engineering, measurement, and internal product development. And because of the strategic value Netflix places on experimentation, these collaborative efforts receive broad visibility, including from our executives.
So far, this series has covered the why, what and how of A/B testing, all of which are necessary to reap the benefits of an experimentation-based approach to product development. But without a little magic, these basics are still not enough. That magic will be the focus of the next and final post in this series: the learning and experimentation culture that pervades Netflix. Follow the Netflix Tech Blog to stay up to date.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.