Post Syndicated from Nikos Tragaras, Raphaël Afanyan original https://aws.amazon.com/blogs/big-data/how-nexthink-built-real-time-alerts-with-amazon-managed-service-for-apache-flink/
This post is cowritten with Nikos Tragaras and Raphaël Afanyan from Nexthink.
In this post, we describe Nexthink’s journey as they implemented a new real-time alerting system using Amazon Managed Service for Apache Flink. We explore the architecture, the rationale behind key technology choices, and the Amazon Web Services (AWS) services that enabled a scalable and efficient solution.
Nexthink is a pioneering leader in digital employee experience (DEX). With a mission to empower IT teams and elevate workplace productivity, Nexthink’s Infinity platform offers real-time visibility into end user environments, actionable insights, and robust automation capabilities. By combining real-time analytics, proactive monitoring, and intelligent automation, Infinity enables organizations to deliver an optimal digital workspace.
In the past 5 years, Nexthink completed its transformation into a fully-fledged cloud platform that processes trillions of events per day, reaching over 5 GB per second of aggregated throughput. Internally, Infinity comprises more than 300 microservices that use the power of Apache Kafka through Amazon Managed Service for Apache Kafka (Amazon MSK) for data ingestion and intra-service communication. The Nexthink ecosystem includes several hundreds of Micronaut-based Java microservices deployed in Amazon Elastic Kubernetes Service (Amazon EKS). The vast majority of microservices interact with Kafka through the Kafka Streams framework.
Nexthink alerting system
To help you understand Nexthink’s journey toward a new real-time alerting solution, we begin by examining the existing system and the evolving requirements that led them to seek a new solution.
Nexthink’s existing alerting system provides near real-time notifications, helping users detect and respond to critical events quickly. While effective, this system has limitations in scalability, flexibility, and real-time processing capabilities.
Nexthink gathers telemetry data from thousands of customers’ laptops covering CPU usage, memory, software versions, network performance, and more. Amazon MSK and ClickHouse serve as the backbone for this data pipeline. All endpoint data is ingested in Kafka multi-tenant topics, which are processed and finally stored in a ClickHouse database.
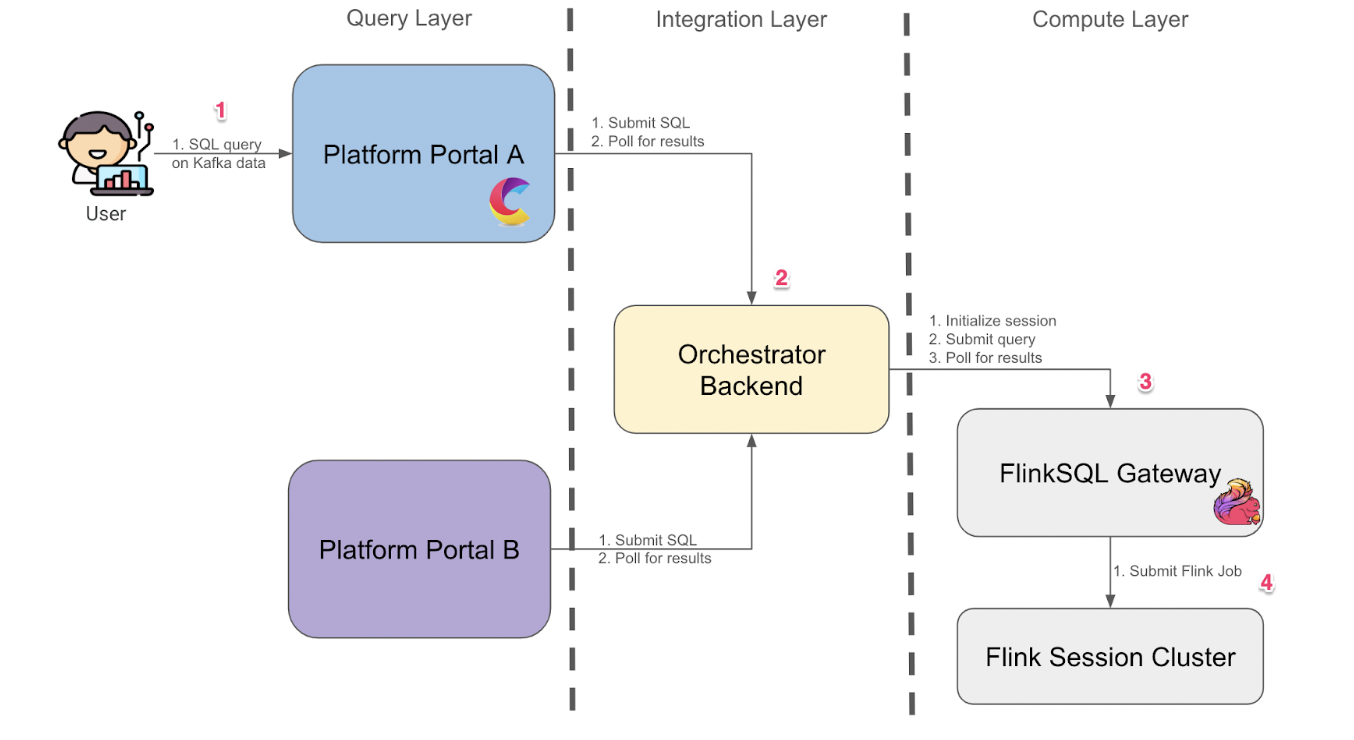
Using the current alerting system, clients can define monitoring rules in Nexthink Query Language (NQL), which are evaluated in near real time by polling the database every 15 minutes. Alerts are triggered when anomalies are detected against client-defined thresholds or long-term baselines. This process is illustrated in the following architecture diagram.

Originally, database-polling allowed great flexibility in the evaluation of complex alerts. However, this approach placed heavy stress on the database. As the company grew and supported larger customers with more endpoints and monitors, the database experienced increasingly heavy loads.
Evolution to a new use-case: Real-time alerts
As Nexthink expanded its data collection to include virtual desktop infrastructure (VDI), the need for real-time alerting became even more critical. Unlike traditional endpoints, such as laptops, where events are gathered every 5 minutes, VDI data is ingested every 30 seconds—significantly increasing the volume and frequency of data. The existing architecture relied on database polling to evaluate alerts, running at a 15-minute interval. This approach was inadequate for the new VDI use case, where alerts needed to be evaluated in near real time on messages arriving every 30 seconds. Merely increasing the polling frequency wasn’t a viable option because it would place excessive load on the database, leading to performance bottlenecks and scalability challenges. To meet these new demands efficiently, we shifted to real-time alert evaluation directly on Kafka topics.
Technology options
As we evaluated solutions for our real-time alerting system, we analyzed two main technology options: Apache Kafka Streams and Apache Flink. Each option had benefits and limitations that needed to be considered.
All Nexthink microservices up to that point integrated with Kafka using Apache Kafka Streams. We’ve observed in practice multiple benefits:
- Lightweight and seamless integration. No need for additional infrastructure.
- Low latency using RocksDB as a local key-value store.
- Team expertise. Nexthink teams have been writing microservices with Kafka-streams for a long time and feel very comfortable using it.
In some use cases however, we found that there were important limitations:
- Scalability – Scalability was constrained by the tight coupling between parallelism of microservices and the number of partitions in Kafka topics. Many microservices had already scaled out to match the partition count of the topics they consumed, limiting their ability to scale further. One potential solution was increasing the partition count. However, this approach introduced significant operational overhead, especially with microservices consuming topics owned by other domains. It required rebalancing the entire Kafka cluster and needed coordination across multiple teams. Additionally, such modifications impacted downstream services, requiring careful reconfiguration of stateful processing. The alternative approach would be to introduce intermediate topics to redistribute workload, but this would add complexity to the data pipeline and increase resource consumption on Kafka. These challenges made it clear that a more flexible and scalable approach was needed.
- State management – Services that needed to create large K-tables in memory had an increased startup time. Also, in cases where the internal state was large in volume, we found that it applied significant load to the Kafka cluster during the creation of the internal state.
- Late event processing – In windowing operations, late events had to be managed manually with techniques that complexified the codebase.
Seeking an alternative that could help us overcome the challenges posed by our current system, we decided to evaluate Flink. Its robust streaming capabilities, scalability, and flexibility made it an excellent choice for building real-time alerting systems based on Kafka topics. Several advantages made Flink particularly appealing:
- Native integration with Kafka – Flink offers native connectors for Kafka, which is a central component in the Nexthink ecosystem.
- Event-time processing and support for late events – Flink allows messages to be processed based on the event time (that is, when the event actually occurred) even if they arrive out of order. This feature is crucial for real-time alerts because it guarantees their accuracy.
- Scalability – Flink’s distributed architecture allows it to scale horizontally independently from the number of partitions in the Kafka topics. This feature weighed a lot in our decision-making because the dependence on the number of partitions was a strong limitation in our platform up to this point.
- Fault tolerance – Flink supports checkpoints, allowing managed state to be persisted and ensuring consistent recovery in case of failures. Unlike Kafka Streams, which relies on Kafka itself for long-term state persistence (adding extra load to the cluster), Flink’s checkpointing mechanism operates independently and runs out-of-band, minimizing the impact on Kafka while providing efficient state management.
- Amazon Managed Service for Apache Flink – Amazon Managed Service for Apache Flink is a fully managed service that simplifies the deployment, scaling, and management of Flink applications for real-time data processing. By eliminating the operational complexities of managing Flink clusters, AWS enables organizations to focus on building and running real-time analytics and event-driven applications efficiently. Amazon Managed Service for Apache Flink provided us with significant flexibility. It streamlined our evaluation process, which meant we could quickly set up a proof-of-concept environment without getting into the complexities of managing an internal Flink cluster. Moreover, by reducing the overhead of cluster management, it made Flink a viable technology choice and accelerated our delivery timeline.
Solution
After careful evaluation of both options, we chose Apache Flink as our solution due to its superior scalability, robust event-time processing, and efficient state management capabilities. Here’s how we implemented our new real-time alerting system.
The following diagram is the solution architecture.

The first use case was to detect issues with VDI. However, our intention was to build a generic solution that would give us the option to onboard in the future existing use cases currently implemented through polling. We wanted to maintain a common way of configuring monitoring conditions and allow alert evaluation both with polling as well as in real time, depending on the type of device being monitored.
This solution comprises multiple parts:
- Monitor configuration – Using Nexthink Query Language (NQL), the alerts administrator defines a monitor that specifies, for example:
- Data source – VDI events
- Time window – Every 30 seconds
- Metric – Average network latency, grouped by desktop pool
- Trigger condition(s) – Latency exceeding 300 ms for a continual period of 5 minutes
This monitor configuration is then stored in an internally developed document store and propagated downstream in a Kafka topic.
- Data processing using Generic Stream Services– The Nexthink Collector, an agent installed on endpoints, captures and reports various kinds of activities from the VDI endpoints where it’s installed. These events are forwarded to Amazon MSK in one of Nexthink’s production virtual private clouds (VPCs) and are consumed by Java microservices running on Amazon EKS belonging to several domains within Nexthink
One of them is Generic Stream Services, a system that processes the collected events and aggregates them in buckets of 30 seconds. This component works as self-service for all the feature teams in Nexthink and can query and aggregate data from an NQL query. This way, we were able to keep a unified user experience on monitor configuration using NQL, regardless of how alerts were evaluated. This component is broken down into two services:
-
- GS processor – Consumes raw VDI session events and applies initial processing
- GS aggregator – Groups and aggregates the data according to the monitor configuration
- Real-time monitoring using Flink – Static threshold alerting and seasonal change detection, which identifies variations in data that follow a recurring pattern over time, are the two types of detection that we offer for VDI issues. The system splits the processing between two applications:
- Baseline application – Calculates statistical baselines with seasonality using time-of-day anomaly algorithm. For example, the latency by VDI client location or the CPU queue length of a desktop pool.
- Alert application – Generates alerts based on user-defined thresholds when the unexpected values don’t change over time or dynamic thresholds based on baselines, which trigger when a metric deviates from an expected pattern.
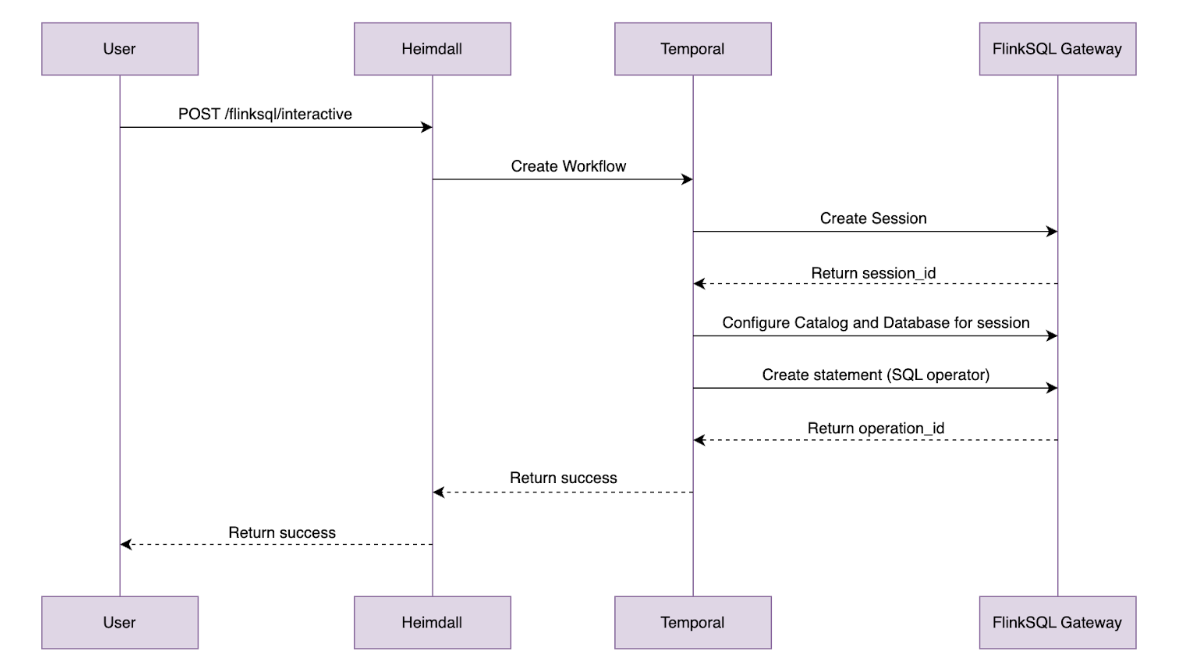
The following diagram illustrates how we join VDI metrics with monitor configurations, aggregate data using sliding time windows, and evaluate threshold rules, all within Apache Flink. From this process, alerts are generated and are then grouped and filtered before being processed further by the consumers of alerts.

- Alert processing and notifications – After an alert is triggered (when a threshold is exceeded) or recovered (when a metric returns to normal levels), the system will assess their impact to prioritize response through the impact processing module. Alerts are then consumed by notification services that deliver messages through emails or webhooks. The alert and impact data are then ingested into a time series database.
Benefits of the new architecture
One of the key advantages of adopting a streaming-based approach over polling was its ease of configuration and management, especially for a small team of three engineers. There was no need for cluster management, so all we needed to do was to provision the service and start coding.
Given our prior experience with Kafka and Kafka Streams and combined with the simplicity of a managed service, we were able to quickly develop and deploy a new alerting system without the overhead of complex infrastructure setup. We used Amazon Managed Service for Apache Flink to spin up a proof of concept within a few hours, which meant the team could focus on defining the business logic without having concerns related to cluster management.
Initially, we were concerned about the challenges of joining multiple Kafka topics. With our previous Kafka Streams implementation, joined topics required identical partition keys, a constraint known as co-partitioning. This created an inflexible architecture, particularly when integrating topics across different business domains. Each domain naturally had its own optimal partitioning strategy, forcing difficult compromises.
Amazon Managed Service for Apache Flink solved this problem through its internal data partitioning capabilities. Although Flink still incurs some network traffic when redistributing data across the cluster during joins, the overhead is practically negligible. The resulting architecture is both more scalable (because topics can be scaled independently based on their specific throughput requirements) and easier to maintain without complex partition alignment concerns.
This significantly improved our ability to detect and respond to VDI performance degradations in real time while keeping our architecture clean and efficient.
Lessons learnt
As with any new technology, adopting Flink for real-time processing came with its own set of challenges and insights.
One of the primary difficulties we encountered was observing Flink’s internal state. Unlike Kafka Streams, where the internal state is by default backed by a Kafka topic from which its content can be visualized, Flink’s architecture makes it inherently difficult to inspect what is happening inside a running job. This required us to invest in robust logging and monitoring strategies to better understand what is happening during the execution and debug issues effectively.
Another critical insight emerged around late event handling—specifically, managing events with timestamps that fall within a time-window’s boundaries but arrive after that window has closed. Amazon Managed Service for Apache Flink addresses this challenge through its built-in watermarking mechanism. A watermark is a timestamp-based threshold that indicates when Flink should consider all events before a specific time to have arrived. This allows the system to make informed decisions about when to process time-based operations like window aggregations. Watermarks flow through the streaming pipeline, enabling Flink to track the progress of event time processing even with out-of-order events.
Although watermarks provide a mechanism to manage late data, they introduce challenges when dealing with multiple input streams operating at different speeds. Watermarks work well when processing events from a single source but can become problematic when joining streams with varying velocities. This is because they can lead to unintended delays or premature data discards. For example, a slow stream can hold back processing across the entire pipeline, and an idle stream might cause premature window closing. Our implementation required careful tuning of watermark strategies and allowable lateness parameters to balance processing timeliness with data completeness.
Our transition from Kafka Streams to Apache Flink proved smoother than initially anticipated. Teams with Java backgrounds and prior experience with Kafka Streams found Flink’s programming model intuitive and easy to use. The DataStream API offers familiar concepts and patterns, and Flink’s more advanced features could be adopted incrementally as needed. This gradual learning curve gave our developers the flexibility to become productive quickly, focusing first on core stream processing tasks before moving on to more advanced concepts like state management and late event processing.
The future of Flink in Nexthink
Real-time alerting is now deployed to production and available to our clients. A major success of this project was the fact that we successfully introduced a technology as an alternative to Kafka streams, with very little management requirements, guaranteed scalability, data-management flexibility, and comparable cost.
The impact on the Nexthink alerting system was significant because we no longer have a single evaluating alert through database polling. Therefore, we’re already assessing the timeframe for onboarding other alerting use cases to real-time evaluation with Flink. This will alleviate database load and will also provide more accuracy on the alert triggering.
Yet the impact of Flink isn’t limited to the Nexthink alerting system. We now have a proven production-ready alternative for services that are limited in terms of scalability due to the number of partitions of the topics they are consuming. Thus, we’re actively evaluating the option to convert more services to Flink to allow them to scale out more flexibly.
Conclusion
Amazon Managed Service for Apache Flink has been transformative for our real-time alerting system at Nexthink. By handling the complex infrastructure management, AWS enabled our team to deploy a sophisticated streaming solution in less than a month, keeping our focus on delivering business value rather than managing Flink clusters.
The capabilities of Flink have proven it to be more than an alternative to Kafka Streams. It’s become a compelling first choice for both new projects and existing feature refactoring. Windowed processing, late event management, and stateful streaming operations have made complex use cases remarkably straightforward to implement. As our development teams continue to explore Flink’s potential, we’re increasingly confident that it will play a central role in Nexthink’s real-time data processing architecture moving forward.
To get started with Amazon Managed Service for Apache Flink, explore the getting started resources and the hands-on workshop. To learn more about Nexthink’s broader journey with AWS, visit the blog post on Nexthink’s MSK-based architecture.
About the authors
 Nikos Tragaras is a Principal Software Architect at Nexthink with around two decades of experience in building distributed systems, from traditional architectures to modern cloud-native platforms. He has worked extensively with streaming technologies, focusing on reliability and performance at scale. Passionate about programming, he enjoys building clean solutions to complex engineering problems
Nikos Tragaras is a Principal Software Architect at Nexthink with around two decades of experience in building distributed systems, from traditional architectures to modern cloud-native platforms. He has worked extensively with streaming technologies, focusing on reliability and performance at scale. Passionate about programming, he enjoys building clean solutions to complex engineering problems
Raphaël Afanyan is a Software Engineer and Tech Lead of the Alerts team at Nexthink. Over the years, he has worked on designing and scaling data processing systems and played a key role in building Nexthink’s alerting platform. He now collaborates across teams to bring innovative product ideas to life, from backend architecture to polished user interfaces.
 Simone Pomata is a Senior Solutions Architect at AWS. He has worked enthusiastically in the tech industry for more than 10 years. At AWS, he helps customers succeed in building new technologies every day.
Simone Pomata is a Senior Solutions Architect at AWS. He has worked enthusiastically in the tech industry for more than 10 years. At AWS, he helps customers succeed in building new technologies every day.
 Subham Rakshit is a Senior Streaming Solutions Architect for Analytics at AWS based in the UK. He works with customers to design and build streaming architectures so they can get value from analyzing their streaming data. His two little daughters keep him occupied most of the time outside work, and he loves solving jigsaw puzzles with them. Connect with him on LinkedIn.
Subham Rakshit is a Senior Streaming Solutions Architect for Analytics at AWS based in the UK. He works with customers to design and build streaming architectures so they can get value from analyzing their streaming data. His two little daughters keep him occupied most of the time outside work, and he loves solving jigsaw puzzles with them. Connect with him on LinkedIn.
 Lorenzo Nicora works as a Senior Streaming Solutions Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open source technologies extensively and contributed to several projects, including Apache Flink.
Lorenzo Nicora works as a Senior Streaming Solutions Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open source technologies extensively and contributed to several projects, including Apache Flink.





 Nikos Tragaras is a Principal Software Architect at Nexthink with around two decades of experience in building distributed systems, from traditional architectures to modern cloud-native platforms. He has worked extensively with streaming technologies, focusing on reliability and performance at scale. Passionate about programming, he enjoys building clean solutions to complex engineering problems
Nikos Tragaras is a Principal Software Architect at Nexthink with around two decades of experience in building distributed systems, from traditional architectures to modern cloud-native platforms. He has worked extensively with streaming technologies, focusing on reliability and performance at scale. Passionate about programming, he enjoys building clean solutions to complex engineering problems Raphaël Afanyan is a Software Engineer and Tech Lead of the Alerts team at Nexthink. Over the years, he has worked on designing and scaling data processing systems and played a key role in building Nexthink’s alerting platform. He now collaborates across teams to bring innovative product ideas to life, from backend architecture to polished user interfaces.
Raphaël Afanyan is a Software Engineer and Tech Lead of the Alerts team at Nexthink. Over the years, he has worked on designing and scaling data processing systems and played a key role in building Nexthink’s alerting platform. He now collaborates across teams to bring innovative product ideas to life, from backend architecture to polished user interfaces. Simone Pomata is a Senior Solutions Architect at AWS. He has worked enthusiastically in the tech industry for more than 10 years. At AWS, he helps customers succeed in building new technologies every day.
Simone Pomata is a Senior Solutions Architect at AWS. He has worked enthusiastically in the tech industry for more than 10 years. At AWS, he helps customers succeed in building new technologies every day. Subham Rakshit is a Senior Streaming Solutions Architect for Analytics at AWS based in the UK. He works with customers to design and build streaming architectures so they can get value from analyzing their streaming data. His two little daughters keep him occupied most of the time outside work, and he loves solving jigsaw puzzles with them. Connect with him on
Subham Rakshit is a Senior Streaming Solutions Architect for Analytics at AWS based in the UK. He works with customers to design and build streaming architectures so they can get value from analyzing their streaming data. His two little daughters keep him occupied most of the time outside work, and he loves solving jigsaw puzzles with them. Connect with him on  Lorenzo Nicora works as a Senior Streaming Solutions Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open source technologies extensively and contributed to several projects, including Apache Flink.
Lorenzo Nicora works as a Senior Streaming Solutions Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open source technologies extensively and contributed to several projects, including Apache Flink.