Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=scpGaFxm3Dc
Friday Squid Blogging: A New Explanation of Squid Camouflage
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/03/friday-squid-blogging-a-new-explanation-of-squid-camouflage.html
New research:
An associate professor of chemistry and chemical biology at Northeastern University, Deravi’s recently published paper in the Journal of Materials Chemistry C sheds new light on how squid use organs that essentially function as organic solar cells to help power their camouflage abilities.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Improving email security with Amazon SES Mail Manager and Hornetsecurity’s Vade Advanced Email Security Add On
Post Syndicated from Zip Zieper original https://aws.amazon.com/blogs/messaging-and-targeting/improving-email-security-with-amazon-ses-mail-manager-and-hornetsecuritys-vade-advanced-email-security-add-on/
Email continues to be a critical communication channel for businesses, powering essential communications across time zones and locations. But as cyber threats grow more sophisticated, how can organizations protect their most vulnerable communication channel? With the increasing complexity of email-based security risks, businesses need robust solutions to safeguard their digital communications. Today, we’re excited to announce the launch of Hornetsecurity’s Vade Advanced Email Security Add On for Amazon Simple Email Service (SES) Mail Manager, a powerful new tool in the fight against email-borne threats.
Amazon SES: Powering email communication at scale
Amazon SES is a cloud-based email service that helps you automate high-volume email communications seamlessly. In May 2024, we launched Mail Manager, introducing email relay and gateway features that help you manage email traffic, ensure compliance and enforce corporate policies. The launch also included an introduction to Mail Manager Email Add Ons which provides optional access to a collection of powerful security tools from certified providers that help you manage and filter incoming emails. Add Ons from our partners deliver advanced email security with flexible, meter-based pricing that is easily activated and integrated into your email workflows directly from the Mail Manager console or Mail Manager APIs.
In this blog, we’ll introduce Hornetsecurity’s Vade Email Add On for Amazon SES Mail Manager, and demonstrate how to enable its advanced email security capabilities to help protect your critical email communications.
Introducing the Vade Email Add On by Hornet Security
Hornetsecurity, a global leader in email security, produces next-generation cloud-based security, compliance, backup, and security awareness solutions that help companies and organizations of all sizes around the world. Its email filters process billions of emails daily, using a vast global email database to power their artificial intelligence (AI) engine. This approach allows the Vade Email Add On to continuously refine and adapt to the latest email threats and filter-bypassing techniques.
The Vade Email Add On brings Vade’s expertise directly to you, providing a seamless and powerful email security solution within the familiar AWS environment:
“Enhance your email service with advanced cybersecurity capabilities by integrating Vade Email Security’s state-of-the-art filtering solution. This Add On empowers users with automated, real-time defense against spam, malware, and phishing—ensuring safer communication. Vade’s AI-powered technology employs a multi-layered approach—combining heuristics, behavioral analysis, and natural language processing—to analyze messages in real time. Strengthen your platform by ensuring ongoing protection against evolving cyber threats.”
Advanced Email Security with the Vade Add On for Mail Manager
Hornetsecurity’s Vade Add On for Mail Manager provides automated, real-time defense against spam, malware, and phishing, which help ensure safer communication, including:
- Advanced Threat Detection: Identifies and blocks sophisticated phishing attempts, malware, and ransomware, providing comprehensive protection against a wide range of cyber threats.
- Behavioral Analysis: Examines the behavior patterns of message senders and content based on over 130 potential data points in each message to detect anomalies and potential threats.
- Patented AI Technology: Leverages proprietary AI algorithms to analyze communication patterns and detect misuse of your service’s digital assets. This technology is powered by our global network of over 1 billion protected mailboxes.
- Real-Time Scanning: Instantly analyze attachments without delaying delivery, thanks to its real time code interpreter.
- Ease of Use: Seamless integration with Mail Manager rules, scanning only messages that meet specific criteria.
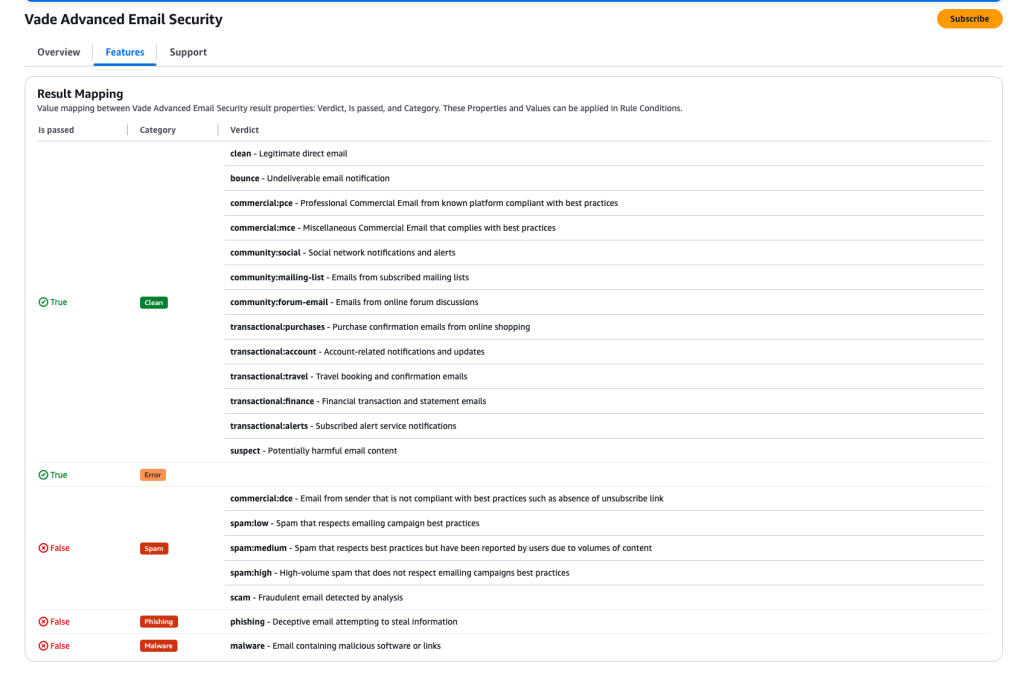
The Vade Email Add-On integrates with Mail Manager’s rules engine. This engine routes messages based on Vade’s scan results and optional detailed verdicts. These verdicts enable precise categorization and handling of incoming emails, improving security and email management.
Configure the Vade Email Add On
In the following example, we’ll walk thru the steps needed to subscribe and configure a rule set with two rules that are processed in priority order:
- Rule 1 –
drop-all-malicious-emailsThis rule has a condition that uses Vade to scan all incoming email and identify messages that are malicious (contain malware or phishing). These messages are then processed by Rule 1’s “Drop action“. Messages that are deemed “safe” are passed to Rule 2 after automatically being inspected and marked as “likely to be spam”, or “not-spam”. - Rule 2 –
forward-to-mailboxMessages passed into Rule 2 are immediately forwarded to the user’s mailbox. In our example, we’re using Amazon WorkMail and Mail Manager’s built-in “Deliver to mailbox” action.- The Vade Add On also distinguishes between spam and clean email, and automatically adds a corresponding header to each message (see below) that can be used to route spam into the user’s “junk” folder.
X-SES-Vade-Advanced-Email-Security-AddonVerdict: spam:high
- Thanks to the seamless integration between Mail Manager Add Ons and WorkMail, messages marked as spam are automatically sent to the user’s Junk folder, enhancing both security and user experience.
- The Vade Add On also distinguishes between spam and clean email, and automatically adds a corresponding header to each message (see below) that can be used to route spam into the user’s “junk” folder.

Follow the steps below to configure the Vade Email Add On using the Amazon SES console for the simple mail flow described above (note – the SES Mail Manager API can be used in lieu of the console).
- Open the Amazon SES console and in the left navigation rail, expand Mail Manager and click Email Add Ons.
- Select the Vade Add On, read the description. Click Subscribe and read the Terms and Conditions. Click Subscribe again to activate the Vade Advanced Email Security Add On in your SES account.
- Pricing is detailed in the Email Add On description page. When this blog was published the price per 1,000 emails processed = $0.415 USD (subject to change, please refer to SES Pricing for the most up to date information).

- In the left navigation rail under Mail Manager, click Rule Sets.
- Create a new Rule set (
process-via-vade) (or modify an existing Rule set).- Create a rule (
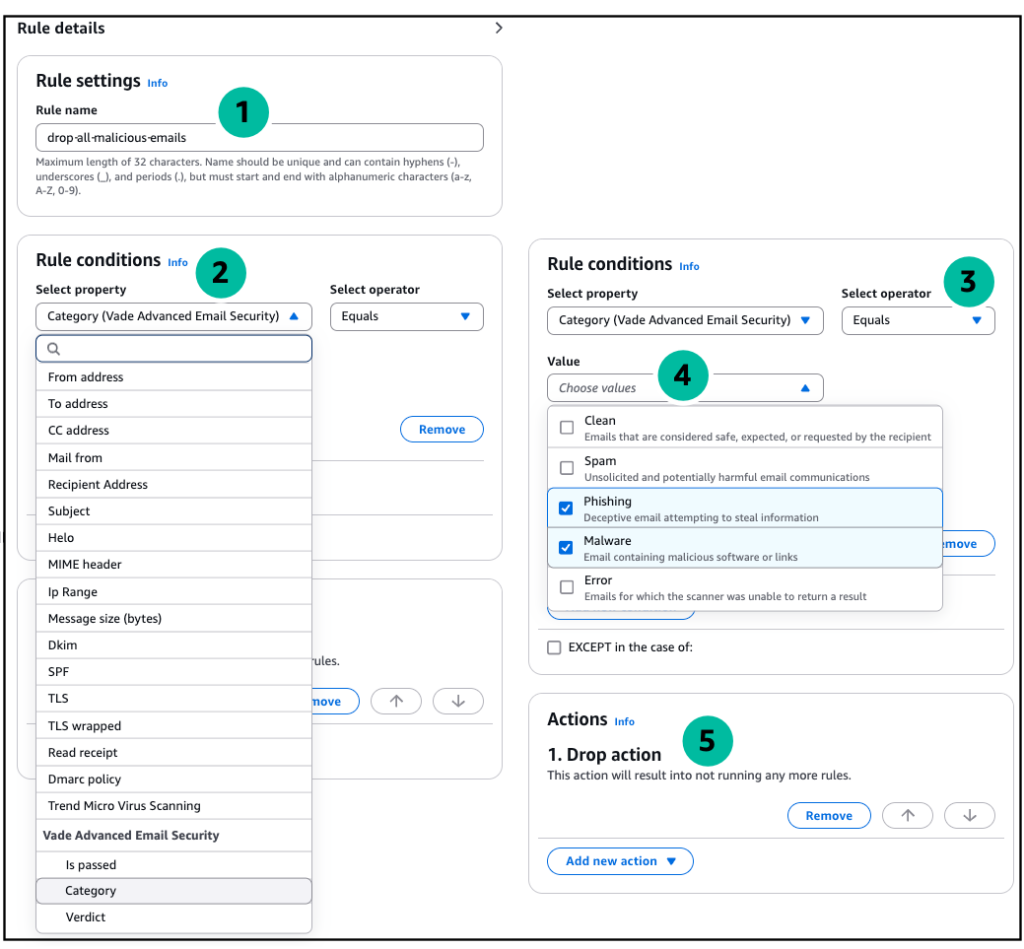
drop-all-malicious-emails) - Under Rule conditions, click select property and select Vade Advanced Email Security Category from the drop-down menu (note the property modifiers allow for increasingly detailed inspection / results for the scan).
- Click the Select operator drop-down and select Equals from the menu.
- Click the Value drop-down and select Phishing and Malware.
- Under Actions, select Drop action to stop processing and discard messages that are found to be malicious.
- Create a rule (
- Create rule (
forward-to-mailbox) to process messages that were passed along by Rule 1. - Under Actions, select Deliver to mailbox (note – if not using Amazon WorkMail, you would select a previously configured SMTPRelay action to send messages to your inbox provider. See this blog for more info).
- Provide your WorkMail ARN
- Select an IAM role that has permission for SES Mail Manager to access to your WorkMail mailbox

- Save the Rule set (it will look like this):

- To use this new Rule set, add it to an active Mail Manager Ingress endpoint. When you click save, the Ingress endpoint will begin using the new Rule set immediately.
The Vade Add-On’s rule conditions (below) enable granular control of email routing. When combined with customizable actions, these rules create an automated email handling system that matches your business needs.
Conclusion
Hornetsecurity’s Vade Email Add On for Amazon SES Mail Manager represents a significant step forward in email security for Amazon SES Mail Manager customers. By combining an advanced artificial intelligence (AI)-driven security engine with the powerful management capabilities of Mail Manager, you can enhance your defense against email-borne threats while maintaining precise control over your email workflows.
Get started today and take your email security to the next level with the Vade Add On for Amazon SES Mail Manager
We encourage you to try the Vade Add On for Amazon SES Mail Manager and experience the benefits of enhanced email security firsthand. To learn more about implementation details and best practices, please visit:
- Amazon SES Mail Manager documentation
- How Amazon SES Mail Manager Elevates Email Security and Efficiency
- Email Archiving with Mail Manager: Why To Archive In Transit vs At The Mailbox
- How to use SES Mail Manager SMTP Relay action to deliver inbound email to Google Workspace and Microsoft 365
- Email Journaling with SES Mail Manager
- How Amazon SES Mail Manager customers can prevent EchoSpoofing
- Modernize email sending with Amazon Simple Email Service and Proofpoint SER
Join the Conversation:
Connect with other administrators and security professionals on the AWS re:Post community to share insights and learn best practices.
Optimizing network footprint in serverless applications
Post Syndicated from Chris McPeek original https://aws.amazon.com/blogs/compute/optimizing-network-footprint-in-serverless-applications/
This post is authored by Anton Aleksandrov, Principal Solution Architect, AWS Serverless and Daniel Abib, Senior Specialist Solutions Architect, AWS
Serverless application developers may commonly encounter scenarios where they need to transport large payloads, especially when building modern cloud applications that need rich data. Examples include analytics services with detailed reports, e-commerce platforms with extensive product catalogs, healthcare applications transmitting patient records, or financial services aggregating transactional data.
Many serverless services have a well-defined maximum payload size. For example, AWS Lambda maximum request/response payload size is 6 MB, and Amazon Simple Queue Service (Amazon SQS) and Amazon EventBridge maximum message size is 256 KB. In this post, you will learn how to use data compression techniques to reduce your network footprint and transport larger payloads under existing constraints.
Overview
Cloud applications evolve continuously and need to be adjusted frequently for new requirements, such as new business features or new Service Level Objectives (SLO) for higher throughput and lower latency. As new use cases and data patterns are added, it is common to see request and response payload sizes increase. At some point, you might hit the maximum service payload size limits, such as 6 MB for synchronous Lambda function invokes, 10 MB for Amazon API Gateway, and 256 KB for Amazon SQS, EventBridge, and asynchronous Lambda invokes.
There are several techniques you can apply when dealing with large payloads. If your payloads are tens of MBs or more, or you need to transport large binary objects with API Gateway, you can store the payload on Amazon Simple Storage Service (Amazon S3) and use pre-signed URLs for clients to directly upload and download from S3.

Figure 1. A sample of architecture for handling large payloads
Lambda function URLs response streaming supports up to 20 MB responses. For handling large messages with services such as SQS or EventBridge, you can store the message in S3 and pass a reference. The downstream consumer will use the reference to download the message directly from S3. One common characteristic of these techniques is that they introduce architectural complexity and may necessitate modifications to your existing solution architecture and data flow patterns.
Furthermore, as your payloads grow in size, you will see increased data transfer costs, especially if your solution is transporting data through Amazon Virtual Private Cloud (VPC) NAT Gateways, VPC endpoints, or sending data across AWS Regions. For example, it is common for VPC-based solutions to have Lambda functions in their architecture. A container running on Amazon Elastic Kubernetes Service (Amazon EKS) might need to invoke a Lambda function, or a VPC-attached Lambda function might need to reach out to the public internet.

Figure 2. Examples of using virtual network appliances with serverless applications
Both NAT Gateway and VPC Endpoint are billed per GB of data processed, which makes data compression a valuable optimization technique. Go to NAT Gateway pricing and VPC Endpoint pricing for details.
The following sections explore data compression techniques and demonstrate how to apply them in your serverless applications. You can learn how to send larger payloads within the existing payload size boundaries and reduce your network footprint without significant architectural changes. This post discusses compression techniques in the context of Lambda and API Gateway, but the same principles can be applied to other services, such as SQS, EventBridge, and AWS AppSync. Understanding compression concepts better equips you to optimize your application’s data-handling capabilities.
What is data compression?
Compression is a widely used approach to reduce data size in order to improve cost-effectiveness and performance for data storage and transmission. Many tools and frameworks incorporate data compression techniques, such as gzip or zstd. It is thoroughly documented in the official IANA specification and IETF RFC 9110. Browsers such as Chrome and Firefox, HTTP toolkits such as curl and Postman, and runtimes such as Node.js and Python natively handle compression, often without user involvement.
Consider HTTP protocol. When a client wants to send a compressed payload, it specifies it in the Content-Type header. To receive a compressed response, the client specifies supported compression methods in the Accept-Encoding request header.

Figure 3. Accept-Encoding request header specifying supported compression methods
The server compresses the response payload using one of the supported methods and uses the Content-Encoding response header to indicate the method to the client.

Figure 4. Content-Encoding response header specifying compression method
This mechanism can accelerate client-server communications by reducing the number of bytes transmitted over the network. Compression efficiency depends on the data type. Text-based formats like JSON, XML, HTML, and YAML compress well, while binary data such as PDF and JPEG generally compress less effectively.
Data compression with API Gateway
API Gateway provides built-in compression support. Use the minimumCompressionSize configuration to set the smallest payload size to compress automatically. The value can be between 0 bytes to 10 MB. Compressing very small payloads might actually increase the final payload size, and you should always test with your real payload patterns to determine the optimal threshold.

Figure 5. Handling data compression in API Gateway
API Gateway enables clients to interact with your API using compressed payloads through supported content encodings. The compression mechanism works bi-directionally. For JSON payloads, API Gateway seamlessly handles compression and decompression, maintaining compatibility with mapping templates. It decompresses incoming payloads before applying request mapping templates and compresses outgoing responses after applying response mapping templates. This automated compression optimizes data transfer:
- When sending compressed data, clients supply the appropriate Content-Encoding header. API Gateway handles the decompression and applies configured mapping templates before forwarding the request to the integration.
- When API Gateway receives an integration response and compression is enabled, it compresses the response payload and returns it to the client, provided that the client has included a matching Accept-Encoding header.
A sample test using the compression technique with API Gateway and JSON payload yielded the following results.
- Compression disabled. Response size = 1 MB, response latency = 660 ms
- Compression enabled. Response size = 220 KB, response latency = 550 ms
Compressing data resulted in 78% network footprint reduction and improved latency by 110 ms.
This configuration-based technique uses the API Gateway native compression. However, payloads are decompressed before being delivered to downstream integrations, thus they still remain subject to Lambda’s 6 MB max payload size. To address this, you can configure binaryMediaTypes in the API Gateway to pass compressed payloads to Lambda directly, enabling the function to handle decompression.
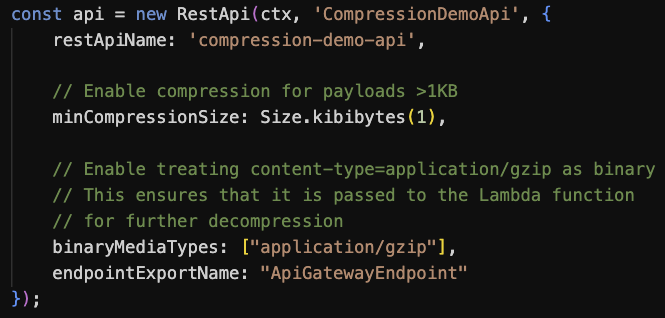
Figure 6. CDK code to configure API Gateway for data compression and binary data passthrough
Handling compressed data in Lambda functions
The Lambda Invoke API supports payloads in plain-text formats, such as JSON. The maximum payload size is 6 MB for synchronous invocations and 256 KB for asynchronous. Although the Invoke API supports uncompressed text-based payloads, you can introduce data compression in your function code and use API Gateway or Function URLs to facilitate content conversion, as illustrated in the following figure.

Figure 7. Transporting compressed payloads in a serverless applications
Handling data compression in your Lambda function code can be done through libraries commonly embedded in the runtime. The following code snippet shows the compressing response payload using Node.js. Similar techniques can be applied to other runtimes.
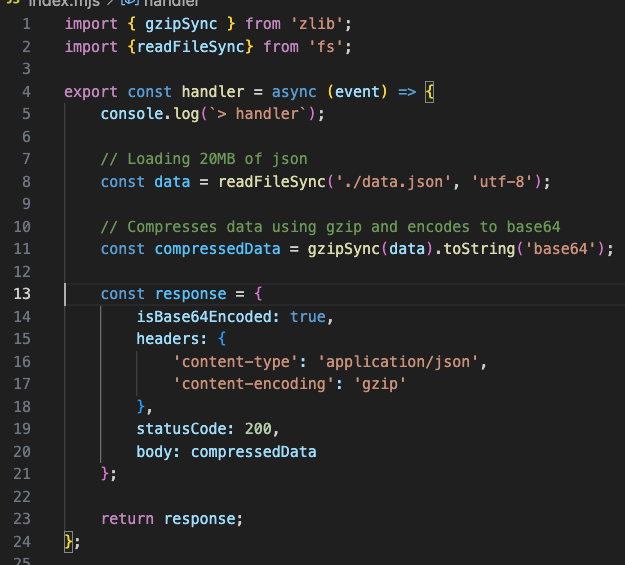
Figure 8. Sample code implementing response payload compression in a Lambda function
- Line 1: Import gzip functionality from the zlib module.
- Lines 11: Compress and Base64-encode data. Gzip compression, similar to many other compression methods, produces a binary stream. Base64 encoding converts it to the text-based format expected by the Lambda service
- Lines 13-21: Response object is created with isBase64Encoded=true and response headers telling the client that the response is a gzip-encoded JSON object.
The following screenshot shows the result: 20 MB uncompressed JSON returned from a Lambda function as a 2.5 MB compressed response body. Network footprint reduced by over 80%.

Figure 9. A screenshot from Postman showing the original and compressed payload size
Using this technique, you can reduce your network footprint and transport payload sizes several times higher than the Lambda maximum payload size.
Using Function URLs with compressed payloads
Transporting compressed payloads through Lambda Function URLs doesn’t necessitate any extra configuration. For handler responses, your code needs to compress and Base64-encode the data as shown in the preceding figure. For invocation requests, the Function URL endpoint recognizes the incoming compressed payload as binary and passes it to your handler as a Base64 encoded string in the event body.

Figure 10. Sample code implementing request payload decompression in a Lambda function
Trade-offs and testing results
Compressing data in function code is a CPU-intensive activity, potentially increasing invocation duration and, as a result, function cost. This, however, can be balanced by the benefits of data compression. As you’ve seen in previous sections, while compressing data adds compute latency, transporting smaller payloads over the network reduces network latency. The following section summarizes a series of tests performed to estimate the impact of data compression on Lambda function invocation duration, Lambda function invocation cost, and data transfer savings with both NAT Gateway and VPC Endpoint. The tests were performed with several assumptions and randomly generated JSON data. You can see full testing results in the sample GitHub.com repo.
Test results demonstrated that the impact on function latency and cost primarily depends on two key factors: payload size and allocated memory (which determines vCPU capacity). Using a Node.js runtime with ARM architecture as an example, compressing a 1 MB JSON object in a function with 1 GB of allocated memory resulted in 124 ms of added processing time on average. For 10 million invocations, this extra processing time adds approximately $16. At the same time, the compression yielded a 70% reduction in payload size. With the same number of invocations, this translates to approximately $300 in savings when using NAT Gateway and $70 in savings when using VPC Endpoints (depending on the number of Availability Zones (AZs)).
AWS Service pricing is updated regularly, you should always consult the respective pricing pages for the latest information. Moreover, you should conduct your own performance and cost estimates using payloads that represent your workloads. Compression effectiveness varies significantly depending on the data type: payloads with low compression rates might not benefit from this technique.
Sample application
Follow the instructions in this GitHub repository to provision the sample in your AWS account. The project creates two Lambda functions to demonstrate receiving and returning compressed JSON using Function URLs and API Gateway.
The sample shows how to GET and POST JSON payloads using gzip compression to reduce the network footprint by over 80%.

Figure 11. A screenshot from Postman showing the original and compressed payload size
Conclusion
Data compression enables larger payload transfers and reduces network footprint. It can help to lower network latencies and optimize data transfer costs. When implementing compression within Lambda functions, it is important to consider its CPU-bound nature, which may increase function duration and costs. You should always evaluate the added compute cost against potential data transfer savings to make sure the technique benefits your use case.
Compression is most effective for handling large text-based payloads and when a slight increase in compute latency balanced by reduced network latency is acceptable.
To learn more about Serverless architectures and asynchronous Lambda invocation patterns, see Serverless Land.
Metasploit Wrap-Up 03/21/2025
Post Syndicated from Simon Janusz original https://blog.rapid7.com/2025/03/21/metasploit-wrap-up-03-21-2025/
SMB to LDAP Relay

This week, the Metasploit team have added an exciting relay module that has been in the works for a long time. This relay module is used to host an SMB server, and execute an SMB to LDAP relay attack against a Domain controller with an LDAP server when NTLMv1 is being used as the SMB authentication method. PetitPotam can be used to coerce authentication on the victim system and relay it to the Domain Controller.
The module automatically takes care of removing the relevant flags to bypass signing.
This module supports the usage of SMBv2 and SMBv3, and captures NTLMv1 and NTLMv2 hashes which can be used for a pass-the-hash attack, or cracked locally to retrieve raw passwords.
When successful, this attack can also open a Metasploit Framework LDAP session. This session can then be leveraged to set up a Resource-Based Constrained Delegation (RBCD) on the Domain Controller to get remote code execution on the victim system.
New module content (1)
Microsoft Windows SMB to LDAP Relay
Authors: Christophe De La Fuente and Spencer McIntyre
Type: Auxiliary
Pull request: #19832 contributed by cdelafuente-r7
Path: server/relay/smb_to_ldap
Description: Adds a module that runs an SMB capture server that relays the credentials to one or more LDAP servers, verifies the credentials, and can establish an LDAP session with the relayed authentication.
Bugs fixed (1)
- #19960 from jheysel-r7 – This fix adds more reliable check method and takes into account the revision number when running the Windows Kernel Time of Check Time of Use LPE (CVE-2024-30038) module.
Documentation
You can find the latest Metasploit documentation on our docsite at docs.metasploit.com.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
commercial edition Metasploit Pro
My Writings Are in the LibGen AI Training Corpus
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/03/my-writings-are-in-the-libgen-ai-training-corpus.html
The Atlantic has a search tool that allows you to search for specific works in the “LibGen” database of copyrighted works that Meta used to train its AI models. (The rest of the article is behind a paywall, but not the search tool.)
It’s impossible to know exactly which parts of LibGen Meta used to train its AI, and which parts it might have decided to exclude; this snapshot was taken in January 2025, after Meta is known to have accessed the database, so some titles here would not have been available to download.
Still…interesting.
Searching my name yields 199 results: all of my books in different versions, plus a bunch of shorter items.
[$] The guaranteed contiguous memory allocator
Post Syndicated from corbet original https://lwn.net/Articles/1015000/
As a system runs and its memory becomes fragmented, allocating large,
physically contiguous regions of memory becomes increasingly difficult.
Much effort over the years has gone into avoiding the need to make such
allocations whenever possible, but there are times when they simply cannot
be avoided. The kernel’s contiguous memory
allocator (CMA) subsystem attempts to make such allocations possible,
but it has never been a perfect solution. Suren Baghdasaryan is is trying
to improve that situation with the guaranteed
contiguous memory allocator patch set, which includes work from Minchan
Kim as well.
Julien Malka proposes method for detecting XZ-like backdoors
Post Syndicated from daroc original https://lwn.net/Articles/1015095/
Julien Malka has
called for the NixOS project to use build-reproducibility to detect when a program has a maintainer-generated tarball that results in a different artifact than building from source. There are good reasons for projects to release maintainer-generated tarballs, but since the materials included in them are usually documentation, extra build scripts, and so on, it makes sense to check that they don’t influence the final build output. While this would not have stopped
last year’s XZ backdoor, it would have made it harder to hide.
People are often convinced that OSS is more trustworthy than closed-source software because the code can be audited by practitioners and security professionals in order to detect vulnerabilities or backdoors. In this instance, this procedure has been made difficult by the fact that part of the code activating the backdoor was not included in the sources available within the git repository but was instead present in the maintainer-provided tarball. While this was used to hide the backdoor out of sight of most investigating eyes, this is also an opportunity for us to improve our software supply chain security processes.
[$] Multiple memory classes for address-space isolation
Post Syndicated from daroc original https://lwn.net/Articles/1014440/
Brendan Jackman has been working to try to get ahead of the next hardware CPU
vulnerability
before it gets discovered. In January, he posted the second version of
a patch set that introduces
address-space isolation (ASI) as a way of
preventing future CPU vulnerabilities from leaking important
information. The core concept is to ensure that data that is not currently
needed is not present in memory, so that speculative execution cannot leak it.
The work is nowhere near ready to be incorporated into the mainline
kernel — not least of all because it has a large performance impact in its
current form — but it is likely to once again be a topic of discussion at the
2025
Linux Filesystem, Memory Management, and BPF Summit.
Samsung 9100 PRO 2TB PCIe Gen5 NVMe SSD Review
Post Syndicated from Will Taillac original https://www.servethehome.com/samsung-9100-pro-2tb-pcie-gen5-nvme-ssd-review/
The Samsung 9100 Pro is a PCIe Gen5 NVMe SSD that brings the performance crown back to Samsung with excellent performance
The post Samsung 9100 PRO 2TB PCIe Gen5 NVMe SSD Review appeared first on ServeTheHome.
Connect, share, and query where your data sits using Amazon SageMaker Unified Studio
Post Syndicated from Lakshmi Nair original https://aws.amazon.com/blogs/big-data/connect-share-and-query-where-your-data-sits-using-amazon-sagemaker-unified-studio/
The ability for organizations to quickly analyze data across multiple sources is crucial for maintaining a competitive advantage. Imagine a scenario where the retail analytics team is trying to answer a simple question: Among customers who purchased summer jackets last season, which customers are likely to be interested in the new spring collection?
While the question is straightforward, getting the answer requires piecing together data across multiple data sources such as customer profiles stored in Amazon Simple Storage Service (Amazon S3) from customer relationship management (CRM) systems, historical purchase transactions in an Amazon Redshift data warehouse, and current product catalog information in Amazon DynamoDB. Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems.
In this blog post, we will demonstrate how business units can use Amazon SageMaker Unified Studio to discover, subscribe to, and analyze these distributed data assets. Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of data silos or the need to copy data between systems.
SageMaker Unified Studio provides a unified experience for using data, analytics, and AI capabilities. You can use familiar AWS services for model development, generative AI, data processing, and analytics—all within a single, governed environment. To strike a fine balance of democratizing data and AI access while maintaining strict compliance and regulatory standards, Amazon SageMaker Data and AI Governance is built into SageMaker Unified Studio. With Amazon SageMaker Catalog, teams can collaborate through projects, discover, and access approved data and models using semantic search with generative AI-created metadata, or you can use natural language to ask Amazon Q to find your data. Within SageMaker Unified Studio, organizations can implement a single, centralized permission model with fine-grained access controls, facilitating seamless data and AI asset sharing through streamlined publishing and subscription workflows. Teams can also query the data directly from sources such as Amazon S3 and Amazon Redshift, through Amazon SageMaker Lakehouse.
SageMaker Lakehouse streamlines connecting to, cataloging, and managing permissions on data from multiple sources. Built on AWS Glue Data Catalog and AWS Lake Formation, it organizes data through catalogs that can be accessed through an open, Apache Iceberg REST API to help ensure secure access to data with consistent, fine-grained access controls. SageMaker Lakehouse organizes data access through two types of catalogs: federated catalogs and managed catalogs (shown in the following figure). A catalog is a logical container that organizes objects from a data store, such as schemas, tables, views, or materialized views such as from Amazon Redshift. You can also create nested catalogs to mirror the hierarchical structure of your data sources within SageMaker Lakehouse.

- Federated catalogs: Through SageMaker Unified Studio, you can create connections to external data sources such as Amazon DynamoDB. See Data connections in Amazon SageMaker Lakehouse for all the supported external data sources. These connections are stored in the AWS Glue Data Catalog (Data Catalog) and registered with Lake Formation, allowing you to create a federated catalog for each available data source.
- Managed catalogs: A managed catalog refers to the data that resides on Amazon S3 or Redshift Managed Storage (RMS).
The existing Data Catalog becomes the Default catalog (identified by the AWS account number) and is readily available in SageMaker Lakehouse.
If the business units don’t have a data warehouse but need the benefits of one—such as a query result cache and query rewrite optimizations—then, they can create an RMS managed catalog in SageMaker Unified Studio. This is a SageMaker Lakehouse managed catalog backed by RMS storage. The table metadata is managed by Data Catalog. When you create an RMS managed catalog, it deploys an Amazon Redshift managed serverless workgroup. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
Functional working model
In SageMaker Unified Studio, the infrastructure team will enable the blueprints and configure the project profiles for tools and technologies to the respective business units to build and monitor their pipelines. They will also onboard the teams to SageMaker Unified Studio, enabling them to build the data products in a single integrated, governed environment. To enforce standardization within the organization, the central governance team can also create hierarchical representations of business units through domain units and dictate certain actions that these teams can perform under a domain unit. Global policies such as data dictionaries (business glossaries), data classification tags, and additional information with metadata forms can be created by the governance team to ensure standardization and consistency within the organization.
Individual business units will use these project profiles based on their needs to process the data using the authorized tool of their choice and create data products. Business units can enjoy the full flexibility to process and consume the data without worrying about the maintenance of the underlying infrastructure. Depending on the nature of the workloads, business units can choose a storage solution that best fits their use case. You can use SageMaker Lakehouse to unify the data across different data sources.
To share the data outside the business unit, the teams will publish the metadata of their data to a SageMaker catalog and make it discoverable and accessible to other business units. Amazon SageMaker Catalog serves as a central repository hub to store both technical and business catalog information of the data product. To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the data quality metrics and data lineage events to track and drive transparency in data pipelines. While sharing the data, data producers of these business units can apply fine grained access control permissions at row and column level to these assets during subscription approval workflows. SageMaker Unified Studio automatically grants subscription access to the subscribed data assets after the subscription request is approved by the data producer. As shown in the following figure, the data sharing capability highlights that the data remains at its origin with the data producer, while consumers from other business units can consume and analyze it using their own compute resources. This approach eliminates any data duplication or data movement.

Solution overview
In this post, we explore two scenarios for sharing data between different teams (retail, marketing, and data analysts). The solution in this post gives you the implementation for a single account use case.
Scenario 1
The retail team needs to create a comprehensive view of customer behavior to optimize their spring collection launch. Their data landscape is diverse:
- Customer profiles stored in Amazon S3 (default Data Catalog)
- Historical purchase transactions stored in RMS (SageMaker Lakehouse managed RMS catalog)
- Inventory information of the product in DynamoDB. (federated catalog)
The team needs to share this unified view with their regional data analysts while maintaining strict data governance protocols. Data analysts discover the data and subscribe to the data. We will also walk through the publishing and subscription workflow as part of the data sharing process. To get a unified view of the customer sales transactions for active products, the data analysts will use Amazon Athena.

Here are the high level steps of the solution implementation as shown in the preceding diagram:
- In this post, we take an example of two teams who participate in the collaboration. The retail team has created a project
retailsales-sql-projectand the data analysts team has created a projectdataanalyst-sql-projectwithin SageMaker Unified Studio. - The retail team creates and stores their data in various sources:
customerdata in Amazon S3 (contains customer data)inventorydata in a DynamoDB table (contains product catalog information)store_sales_lakehousein SageMaker Lakehouse managed RMS (contains purchase history)
- The retail team publishes the assets to the project catalog to make them discoverable to other domain members within the organization.
- The data analysts team discovers the data and subscribes to the data assets.
- An incoming request is sent to the retail team, who then approves the subscription request. After the subscription is approved, data analysts use Athena to create a unified query from all the subscribed data assets to get insights into the data.
In this scenario, we will review how SageMaker Catalog manages the subscription grants to Data Catalog assets (both federated and managed).
For this scenario, we assume that the retail team doesn’t have their own data warehouse and they want to create and manage Amazon Redshift tables using Data Catalog.
Scenario 2
The marketing team needs access to transaction data for campaign optimization. They have campaign performance data stored in an Amazon Redshift data warehouse. However, to have improved campaign ROI and better resource allocation, they need data from the retail team to understand actual customer purchase behavior. To improve the campaign ROI, they need answers to crucial questions such as:
- What is the true conversion rate across different customer segments?
- Which customers should be targeted for upcoming promotions?
- How do seasonal buying patterns affect campaign success?

Here the retail team shares the purchase history data store_sales to the marketing team. In this scenario, shown in the preceding figure, we assume that the retail team has their own data warehouse and uses Amazon Redshift to store the purchase history data.
The high level steps of the solution implementation for this scenario are:
- The marketing team has created the project
marketing-sql-projectwithin SageMaker Unified Studio. - The retail team has
store_salesin Amazon Redshift data warehouse (contains purchase history) - The retail team has published the assets to the project catalog
- The marketing team discovers the data and subscribes to the data assets.
- An incoming request is sent to the retail team, who then approves the subscription request. After the subscription is approved, the marketing team uses Amazon Redshift to consume the purchase history and identify high-value customer segments.
In this scenario, we will review the process of how SageMaker Catalog grants access to managed Amazon Redshift assets.
Prerequisites
To follow the step by step guide, you must complete the following prerequisites:
- Sign up for an AWS account.
- Create a user with administrative access.
- Enable AWS IAM Identity Center in the AWS Region where you want to create your SageMaker Unified Studio domain. Make sure that you are using a Region that SageMaker Unified Studio is available in. Set up your IdP and synchronize identities and groups with IAM Identity Center. For more information, refer to IAM Identity Center Identity source tutorials.
- Create a SageMaker Unified Studio domain and three projects using the SQL analytics project profile. See Create a new project to create a project. For this post, you will create the following projects:
retailsales-sql-project,marketing-sql-projectanddataanalyst-sql-project.
Note that the default SQL analytics project profile provides you with a RedshiftServerless blueprint. However, in this post, we want to showcase the data sharing capabilities of different types of SageMaker Lakehouse catalogs (managed and federated).
For the simplicity, we chose the SQL analytics project profile. However, you can also test this by using the Custom project profile by selecting specific blueprints such as LakehouseCatalog and LakeHouseDatabase for scenarios where the business unit doesn’t have their own data warehouse.
Solution walkthrough (Scenario 1)
The first step focuses on preparing the data for each data source for unified access.
Data preparation
In this section, you will create the following data sets:
customerdata in Amazon S3 (default Data Catalog)inventorydata in a DynamoDB table (federated catalog)store_sales_lakehousein SageMaker Lakehouse managed RMS (managed catalog)
- Sign in to SageMaker Unified Studio as a member of the retail team and select the project
retailsales-sql-project. - On the top menu, choose Build, and under DATA ANALYSIS & INTEGRATION, select Query Editor.

- Select the following options:
- Under CONNECTIONS, select
Athena (Lakehouse). - Under CATALOGS, select
AwsDataCatalog. - Under DATABASES, select
glue_db_<environmentid>or the customer glue database name you provided during project creation. - After the options are selected, choose Choose.
- Under CONNECTIONS, select

When users select a project profile within SageMaker Unified Studio, the system automatically triggers the relevant AWS CloudFormation stack (DataZone-Env-<environmentid>) and deploys the necessary infrastructure resources in the form of environments. Environments are the actual data infrastructure behind a project.
- Run the following SQL:
- After the SQL is executed, you will find that the
customertable has been created in the Lakehouse section under Lakehouse/AwsDataCatalog/glue_db_<environmentid>.

- The product catalog is stored in DynamoDB. You can create a new table named
inventoryin DynamoDB with partition keyprod_idthrough AWS CloudShell with the following command:
- Populate the DynamoDB table using the following commands:
- To use the DynamoDB table in SageMaker Unified Studio, you need to configure a resource-based policy that allows the appropriate actions for the project role.
- To create the resource-based policy, navigate to the DynamoDB console and choose Tables from the navigation pane.
- Select the Permissions table and choose Create table policy.

- The following is an example policy that allows connecting to DynamoDB tables as a federated source. Replace the
<aws_region>with the Region you are working on,<aws_account_id>with the AWS Account ID where DynamoDB is deployed,<dynamodb_table>with the DynamoDB table (in this caseinventory) that you intend to query from Amazon SageMaker Unified Studio and<datazone_usr_role_xxxxxxxxxxxxxx_yyyyyyyyyyyyyy>with the Project role Amazon Resource Name (ARN) in SageMaker Unified Studio portal. You can get the project role ARN by navigating to the project in SageMaker Unified Studio and then to Project overview.


After the policies are incorporated on the DynamoDB table, create an SageMaker Lakehouse connection within SageMaker Unified Studio. As shown in the example, dynamodb-connection-catalogs is created.

- After the connection is successfully established, you will see the DynamoDB table
inventoryunder Lakehouse.

The next step is to create a managed catalog for RMS objects using SageMaker Lakehouse.
- Choose Data in the navigation pane.
- In the data explorer, choose the plus icon to add a data source.
- Select Create Lakehouse catalog.
- Choose Next.

- Enter the name of the catalog. The catalog name provided in the example is
redshift-lakehouse-connection-catalogs. Choose Add data.

- After the connection is created, you will see the catalog under Lakehouse.

- This creates a managed Amazon Redshift Serverless workgroup in your AWS account. You will see a new database
dev@<redshift-catalog-name>in the managed Amazon Redshift Serverless workgroup.- On the top menu, choose Build, and under DATA ANALYSIS & INTEGRATION, select Query Editor.
- Select Redshift (Lakehouse) from CONNECTIONS,
dev@<redshift-catalog-name>from DATABASES and public from SCHEMAS

- Run the following SQL in order. The SQL creates the
store_sales_lakehousetable in thedevdatabase in thepublicschema. The retail team inserts data into thestore_sales_lakehousetable.
- On successful creation of the table, you should now be able to query the data. Select the table
store_sales_lakehouseand select Query with Redshift.

Import assets to the project catalog from various data sources
To share your assets outside your own project to other business units, you must first bring your metadata to SageMaker Catalog. To import the assets into the project’s inventory, you need to create a data source in the project catalog. In this section, we show you how to import the technical metadata from AWS Glue data catalogs. Here, you will import data assets from various sources that you have created as part of your data preparation.
- Sign in to SageMaker Unified Studio as a member of the retail team. Select the project
retailsales-sql-project, under Project catalog. Choose Data sources and import the assets by choosing Run.


- To import the federated catalog, create a new data source and choose Run. This will import the metadata of the inventory data from DynamoDB table.

- After successful run of all the data sources, choose Assets under Project catalog in the navigation plane. You will find all the assets in the Inventory of Project catalog.

Publish the assets
To make the assets discoverable to the data analysts team, the retail team must publish their assets.
- In the project
retailsales-sql-project, choose Project catalog and select Assets. - Select each asset in the INVENTORY tab, enrich the asset with the automated metadata generation and PUBLISH ASSET.

Discover the assets
SageMaker Catalog within SageMaker Unified Studio enables efficient data asset discovery and access management. The data analysts team signs in to SageMaker Unified Studio and selects the project dataanalyst-sql-project. The data analysts team then locates the desired assets in SageMaker Catalog and initiates the subscription request.
In this section, members of dataanalyst-sql-project browse the catalog and find the assets. There are multiple ways to find the desired assets.
- Sign in to SageMaker Unified Studio as a member of the data analysts team. Choose Discover in the top navigation bar and select Catalog. Find the desired asset by browsing or entering the name of the asset into the search bar.
- Search for the asset through a conversational interface using Amazon Q.
- Use the faceted filter search by selecting the desired project in the BROWSE CATALOG.

The data analysts team selects the project retailsales-sql-project.

Subscribe to the assets
The data analysts team submits a subscription request with an appropriate justification for each of these assets.
- For each asset, choose SUBSCRIBE.
- Select
dataanalyst-sql-projectin Project. - Provide the Reason for request as “need this data for analysis”.
Note that during the subscription process, the requester sees a message that the asset access control and fulfillment will be Managed. This means that SageMaker Unified Studio automatically manages subscription access grants and permissions for these assets.

Subscription approval workflow
To approve the subscription request, you must be a member of the retail team and select the project that has published the asset.
- Sign in to SageMaker Unified Studio as a member of the retail team and select the project
retailsales-sql-project. - In the navigation pane, choose Project catalog and then select Subscription requests.
- In INCOMING REQUESTS, choose the REQUESTED tab and select View request for each asset to see detailed information of the subscription request.

- REQUEST DETAILS provides information about the subscribing project, the requestor, and the justification to access the asset.
- RESPONSE DETAILS provides an option to approve the subscription with full access to the data (Full access) or restricted access to the data (Approve with row or column filters). With restricted access to data, the subscription approval workflow process offers granular access control for sensitive data through row-level filtering and column-level filtering. Using row filters, approvers can restrict access to specific records based on defined criteria. Using column filters, approvers can control access to specific columns within the data sets. This allows excluding sensitive fields while sharing the relevant data. Approvers can implement these filters during the approval process, helping to ensure that the data access aligns with the organization’s security requirements and compliance policies. For this post, select Full access in the RESPONSE DETAILS
- (Optional) Decision comment is where you can add a comment about accepting or rejecting the subscription request.
- Choose APPROVE.

- Repeat the subscription approval workflow process for all the requested assets.
- After all the subscription requests are approved, choose the APPROVED tab to view all the approved assets.

Subscription fulfillment methods
After subscription approval, a fulfillment process manages access to the assets. SageMaker Unified Studio provides fulfillment methods for managed assets and unmanaged assets.
- Managed assets: SageMaker Unified Studio automatically manages the fulfillment and permissions for assets such as AWS Glue tables and Amazon Redshift tables and views.
- Unmanaged assets: For unmanaged assets, permissions are handled externally. SageMaker Unified Studio publishes standard events for actions such as approvals through Amazon EventBridge, enabling integration with other AWS services or third-party solutions for custom integrations.
In this scenario 1, because the assets are Data Catalogs, SageMaker Unified Studio grants and manages access to these managed assets on your behalf through Lake Formation. See the SageMaker Unified Studio subscription workflow for updates on sharing options.
Analyze the data
The data analysts team uses the subscribed data assets from varied sources to get unified insights.
- As a data analyst, sign in to SageMaker Unified Studio and select the project
dataanalyst-sql-project. In the navigation pane, choose Project catalog and select Assets. - Choose the SUBSCRIBED tab to find all the subscribed assets from the
retailsales-sql-project. - The status under each asset is
Asset accessible. This indicates that the subscription grants are fulfilled and the data analysts team can now consume the assets with the compute of their choice.

Query using Athena (subscription grants fulfilled using Lake Formation)
As a member of the data analysts team, create a unified view to get purchase history with customer information for active products.
- In the
dataanalyst-sql-projectproject, go to Build and select Query Editor. - Use the following sample query to get the required information. Replace
glue_db_<environmentid>with your subscribed glue database.

Solution walk-through (Scenario 2)
In this scenario, we assume that the retail team stores the purchase history data in their Amazon Redshift data warehouse. Because you’re using the default SQL analytics project profile to create the project, you will use a Redshift Serverless compute (project.redshift). The purchase history data is shared with the marketing team for enhanced campaign performance.
- Sign in to SageMaker Unified Studio as a member of the retail team and select the project
retailsales-sql-project. - On the top menu, choose Build, and under DATA ANALYSIS & INTEGRATION, select Query Editor
- Select the following options:
- Under CONNECTIONS, select
Redshift(Lakehouse). - Under CATALOGS, select
dev. - Under DATABASES, select
public.
- Under CONNECTIONS, select
- Run the following SQL:
5. On successful execution of the query, you will see store_sales under Redshift in the navigation pane.

Import the asset to the project catalog inventory
To share your assets outside your own project to other marketing business units, you must first share your metadata to SageMaker Catalog. To import the assets into the project’s inventory, you need to run the data source in the project catalog.
In the project retailsales-sql-project, under Project catalog, select Data sources and import the asset store-sales. Select the highlighted data source and choose Run as shown in the screenshot.

Publish the asset
To make the assets discoverable to the marketing team, the retail team must publish their asset.
- Go to the navigation pane and choose Project catalog, and then select Assets.
- Select
store-salesin the INVENTORY tab, enrich the asset with the automated metadata generation and PUBLISH ASSET as illustrated in the screenshot.

Discover and subscribe the asset
The marketing team discovers and subscribes to the store-sales asset.
- Sign in to SageMaker Unified Studio as a member of the marketing team and select
marketing-sql-project. - Navigate to the Discover menu in the top navigation bar and choose Catalog. Find the desired asset by browsing or entering the name of the asset into the search bar.
- Select the asset and choose SUBSCRIBE.
- Enter a justification in Reason for request and choose REQUEST.

Subscription approval workflow
The retail team gets an incoming request in their project to approve the subscription request.
- Sign in to the SageMaker Unified Studio and select the project
retailsales-sql-projectas a member of the retail team. Under Project catalog, select Subscription requests. - In the INCOMING REQUESTS, under the REQUESTED tab, select View request for
store-sales.

- You will see detailed information for the subscription request.
- Select Full access in the RESPONSE DETAILS and choose APPROVE.

Analyze the data
Sign in to SageMaker Unified Studio as a member of the marketing team and select marketing-sql-project.
- In the Project catalog, select Assets and choose the SUBSCRIBED tab to find all the subscribed assets from the
retailsales-sql-project. - Notice the status under the asset marked as
Asset accessible. This indicates that the subscription grants are fulfilled and the marketing team can now consume the asset with the compute of their choice.

Query using Amazon Redshift (subscription grants fulfilled using native Amazon Redshift data sharing)
To query the shared data with Amazon Redshift compute, select Build and then Query Editor. Select the following options
- Under CONNECTIONS, select
Redshift(Lakehouse). - Under CATALOGS, select
dev. - Under DATABASES, select
project.

When a subscription to an Amazon Redshift table or view is approved, SageMaker Unified Studio automatically adds the subscribed asset to the consumer’s Amazon Redshift Serverless workgroup for the project. Notice the subscribed asset is shared under the folder project. In the Redshift navigation pane, you can also see the datashare created between the source and the target cluster. In this case, because the data is shared in the same account but between different clusters, SageMaker Unified Studio creates a view in the target database and permissions are granted on the view. See Grant access to managed Amazon Redshift assets in Amazon SageMaker Unified Studio for information about data sharing options within Amazon Redshift.
Clean up
Make sure you remove the SageMaker Unified Studio resources to avoid any unexpected costs. Start by deleting the connections, catalogs, underlying data sources, projects, databases, and domain that you created for this post. For additional details, see the Amazon SageMaker Unified Studio Administrator Guide.
Conclusion
In this post, we explored two distinct approaches to data sharing and analytics.
Business units without an existing data warehouse can use a SageMaker Lakehouse managed RMS catalog. In the first scenario, we showcased subscription fulfillment of AWS Glue Data Catalogs using AWS Lake Formation for federated and managed catalogs. The data analysts team was able to connect and subscribe to the data shared by the retail team that resided in Amazon S3, Amazon Redshift, and other data sources such as DynamoDB through SageMaker Lakehouse.
In the second scenario, we demonstrated the native data-sharing capabilities of Amazon Redshift. In this scenario, we assume that the retail team has sales transactions stored in an Amazon Redshift data warehouse. Using the data sharing feature of Amazon Redshift, the asset was shared to the marketing team using Amazon SageMaker Unified Studio.
Both approaches enable unified querying across varied data sources with teams able to efficiently discover, publish, and subscribe to data assets while maintaining strict access controls through Amazon SageMaker Data and AI Governance. Subscription fulfillment is automated, reducing the administrative overhead. Using the query-in-place approach eliminates data redundancy and maintains data consistency while allowing unified analysis across data sources through a single integrated experience.
To learn more, see the Amazon SageMaker Unified Studio Administrator Guide and the following resources:
- Introducing the next generation of Amazon SageMaker: The center for all your data, analytics, and AI
- Foundational blocks of Amazon SageMaker Unified Studio
- Catalog and govern Amazon Athena federated queries with Amazon SageMaker Lakehouse
- Simplify data access for your enterprise using Amazon SageMaker Lakehouse
- Amazon SageMaker Unified Studio YouTube Playlist
About the authors
 Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance. She can be reached through LinkedIn
Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance. She can be reached through LinkedIn
 Ramkumar Nottath is a Principal Solutions Architect at AWS focusing on Analytics services. He enjoys working with various customers to help them build scalable, reliable big data and analytics solutions. His interests extend to various technologies such as analytics, data warehousing, streaming, data governance, and machine learning. He loves spending time with his family and friends.
Ramkumar Nottath is a Principal Solutions Architect at AWS focusing on Analytics services. He enjoys working with various customers to help them build scalable, reliable big data and analytics solutions. His interests extend to various technologies such as analytics, data warehousing, streaming, data governance, and machine learning. He loves spending time with his family and friends.
Introducing rpi-image-gen for customized Raspberry Pi images
Post Syndicated from jzb original https://lwn.net/Articles/1015059/
Raspberry Pi has
announced rpi-image-gen,
a tool to create custom software images for its devices.
rpi-image-gen is a Bash orientated scripting engine capable of
producing software images with different on-disk partition layouts,
file systems and profiles using collections of metadata and a defined
flow of execution. It provides the means to create a highly customised
software image for your Raspberry Pi device. rpi-image-gen is human
readable, auditable and easy to use.
The Git repository for rpi-image-gen has a number of examples
to help users get started making their own custom images.
An Asahi Linux 6.14 progress report
Post Syndicated from corbet original https://lwn.net/Articles/1015058/
The Asahi Linux project, working to support Linux on Apple hardware, has
published a
progress report to coincide with the 6.14 kernel release.
Now that Rust for Linux abstractions are starting to be merged at a
healthy pace, we are faced with an emerging challenge. It is rare
for any kernel patch to survive the mailing list without at least a
couple of non-trivial changes, and Rust abstractions are no
exception. Every time an abstraction used by our driver is merged,
we must drop our downstream version and rebase the driver atop the
version accepted upstream. This is grueling, menial, and
unpleasant work, and Janne has our deepest gratitude for
volunteering his time to get through it.
Security updates for Friday
Post Syndicated from daroc original https://lwn.net/Articles/1015055/
Security updates have been issued by Debian (chromium), Fedora (fluent-bit, openssh, php, and webkitgtk), Mageia (freerdp), Oracle (libreoffice and webkit2gtk3), Red Hat (kernel-rt), Slackware (libarchive), SUSE (apptainer, gitea-tea, libxml2, tomcat, webkit2gtk3, and wpa_supplicant), and Ubuntu (libxslt and pam-pkcs11).
Rapid7 MDR Supports AWS GuardDuty’s New Attack Sequence Alerts
Post Syndicated from Rapid7 original https://blog.rapid7.com/2025/03/21/rapid7-mdr-supports-aws-guarddutys-new-attack-sequence-alerts/

Co-authored by Yaron Kaplan and Gil Shamgar.
AWS GuardDuty has introduced two powerful new alerts that enhance its threat detection capabilities: “Potential Credential Compromise” and “Potential S3 Data Compromise.” These alerts go beyond traditional threat detection by focusing on attack sequences, providing deeper insights into suspicious activities that may indicate credential misuse or unauthorized data access.
Unlike single-event alerts, these new notifications correlate multiple signals across different timeframes and contexts, helping organizations detect sophisticated attack strategies such as persistence, privilege escalation, and data exfiltration. These advanced alerts represent a significant shift in cloud security, enabling users to take faster, more informed actions against potential threats.
Rapid7’s Managed Threat Complete supports third party cloud security tools, includingAWS GuardDuty alerts, by providing critical capabilities such as alert triage, remediation recommendations, and response actions, helping SOC analysts reduce response time and improve operational efficiency for customers. The Rapid7 SOC has increased their coverage for these new AWS alerts, let’s take a look at each of them and how they work.
AttackSequence:IAM/CompromisedCredentials – Detecting IAM Credential Abuse
The IAM Compromised Credentials alert identifies potential credential theft and abuse within AWS environments by correlating multiple suspicious activities, such as:
- Connection attempts from known malicious IP addresses (e.g., Tor exit nodes)
- High-risk API calls, including attempts to disable security controls
- Actions aligning with multiple MITRE ATT&CK tactics and techniques
- Suspicious privilege escalation attempts
This alert tracks the progression of an attack from initial access attempts to defense evasion techniques like CloudTrail deletions. It provides detailed information about the affected IAM entities, specific API calls made, and geographic origins of suspicious connections, enabling security teams to assess and respond rapidly to potential threats.
AttackSequence:S3/CompromisedData – Protecting Your S3 Data
The S3 Compromised Data alert focuses on detecting potential data breach attempts targeting S3 buckets. This detection mechanism monitors for activity sequences that indicate an attacker attempting to locate, access, or exfiltrate sensitive data. Key aspects of this alert include:
- Identification of suspicious S3 bucket enumeration activities
- Detection of unusual data access patterns
- Monitoring of security control modifications
- Tracking of potential data exfiltration attempts
By correlating various activities such as ListBuckets, GetObject, and DeleteObject operations—especially when performed from suspicious IP addresses or in conjunction with bucket access modifications—this alert helps security teams identify and respond to potential data breaches before significant damage occurs.
Both of these new alert types represent a major advancement in AWS security monitoring, providing teams with more context-aware and actionable insights. Implementing these alerts allows organizations to better protect their AWS environments from sophisticated attack sequences and potential data breaches.
Rapid7 Managed SOC Powered by CDR & ICS
Rapid7’s expert-driven cloud-ready MDR solution offers 24/7 monitoring and continuous tracking and response to cloud threats in real-time. Rapid7 Exposure Command automatically enriches alerts from third-party detection engines, such as AWS GuardDuty and Azure Microsoft Defender for Cloud, to accelerate SOC investigation and response, ensuring threats are contextualized effectively.
With a proactive approach, Rapid7 SOC analysts manage critical incidents to minimize risk and enhance cloud security by reducing response time through enriched insights provided by ICS. InsightCloudSec delivers comprehensive cloud security, helping organizations:
- Stay compliant by enforcing security policies and addressing security gaps
- Reduce attack surface by identifying and fixing risky IAM roles, misconfigurations, and unused resources
- Eliminate risks by identifying issues early to minimize vulnerabilities and strengthen the cloud environment
Contact us to learn more about how Managed Threat Complete and InsightCloudSec brings enhanced cloud detection and response to help customers command their attack surface.
RDP without the risk: Cloudflare’s browser-based solution for secure third-party access
Post Syndicated from Ann Ming Samborski original https://blog.cloudflare.com/browser-based-rdp/
Short-lived SSH access made its debut on Cloudflare’s SASE platform in October 2024. Leveraging the knowledge gained through the BastionZero acquisition, short-lived SSH access enables organizations to apply Zero Trust controls in front of their Linux servers. That was just the beginning, however, as we are thrilled to announce the release of a long-requested feature: clientless, browser-based support for the Remote Desktop Protocol (RDP). Built on top of Cloudflare’s modern proxy architecture, our RDP proxy offers a secure and performant solution that, critically, is also easy to set up, maintain, and use.
Remote Desktop Protocol (RDP) was born in 1998 with Windows NT 4.0 Terminal Server Edition. If you have never heard of that Windows version, it’s because, well, there’s been 16 major Windows releases since then. Regardless, RDP is still used across thousands of organizations to enable remote access to Windows servers. It’s a bit of a strange protocol that relies on a graphical user interface to display screen captures taken in very close succession in order to emulate the interactions on the remote Windows server. (There’s more happening here beyond the screen captures, including drawing commands, bitmap updates, and even video streams. Like we said — it’s a bit strange.) Because of this complexity, RDP can be computationally demanding and poses a challenge for running at high performance over traditional VPNs.
Beyond its quirks, RDP has also had a rather unsavory reputation in the security industry due to early vulnerabilities with the protocol. The two main offenders are weak user sign-in credentials and unrestricted port access. Windows servers are commonly protected by passwords, which often have inadequate security to start, and worse still, may be shared across multiple accounts. This leaves these RDP servers open to brute force or credential stuffing attacks.
Bad actors have abused RDP’s default port, 3389, to carry out on-path attacks. One of the most severe RDP vulnerabilities discovered is called BlueKeep. Officially known as CVE-2019-0708, BlueKeep is a vulnerability that allows remote code execution (RCE) without authentication, as long as the request adheres to a specific format and is sent to a port running RDP. Worse still, it is wormable, meaning that BlueKeep can spread to other machines within the network with no user action. Because bad actors can compromise RDP to gain unauthorized access, attackers can then move laterally within the network, escalating privileges, and installing malware. RDP has also been used to deploy ransomware such as Ryuk, Conti, and DoppelPaymer, earning it the nickname “Ransomware Delivery Protocol.”
This is a subset of vulnerabilities in RDP’s history, but we don’t mean to be discouraging. Thankfully, due to newer versions of Windows, CVE patches, improved password hygiene, and better awareness of privileged access, many organizations have reduced their attack surface. However, for as many secured Windows servers that exist, there are still countless unpatched or poorly configured systems online, making them easy targets for ransomware and botnets.
Despite its security risks, RDP remains essential for many organizations, particularly those with distributed workforces and third-party contractors. It provides value for compute-intensive tasks that require high-powered Windows servers with CPU/GPU resources greater than users’ machines can offer. For security-focused organizations, RDP grants better visibility into who is accessing Windows servers and what actions are taken during those sessions.
Because issuing corporate devices to contractors is costly and cumbersome, many organizations adopt a bring-your-own-device (BYOD) policy. This decision instead requires organizations to provide contractors with a means to RDP to a Windows server with the necessary corporate resources to fulfill their role.
Traditional RDP requires client software on user devices, so this is not an appropriate solution for contractors (or any employees) using personal machines or unmanaged devices. Previously, Cloudflare customers had to rely on self-hosted third-party tools like Apache Guacamole or Devolutions Gateway to enable browser-based RDP access. This created several operational pain points:
-
Infrastructure complexity: Deploying and maintaining RDP gateways increases operational overhead.
-
Maintenance burden: Commercial and open-source tools may require frequent updates and patches, sometimes even necessitating custom forks.
-
Compliance challenges: Third-party software requires additional security audits and risk management assessments, particularly for regulated industries.
-
Redundancy, but not the good kind – Customers come to Cloudflare to reduce the complexity of maintaining their infrastructure, not add to it.
We’ve been listening. Cloudflare has architectured a high-performance RDP proxy that leverages the modern security controls already part of our Zero Trust Network Access (ZTNA) service. We feel that the “security/performance tradeoff” the industry commonly touts is a dated mindset. With the right underlying network architecture, we can help mitigate RDP’s most infamous challenges.
Cloudflare’s browser-based RDP solution is the newest addition to Cloudflare Access alongside existing clientless SSH and VNC offerings, enabling secure, remote Windows server access without VPNs or RDP clients. Built natively within Cloudflare’s global network, it requires no additional infrastructure.
Our browser-based RDP access combines the power of self-hosted Access applications with the additional flexibility of targets, introduced with Access for Infrastructure. Administrators can enforce:
-
Authentication: Control how users authenticate to your internal RDP resources with SSO, MFA, and device posture.
-
Authorization: Use policy-based access control to determine who can access what target and when.
-
Auditing: Provide Access logs to support regulatory compliance and visibility in the event of a security breach.
Users only need a web browser — no native RDP client is necessary! RDP servers are accessed through our app connector, Cloudflare Tunnel, using a common deployment model of existing Access customers. There is no need to provision user devices to access particular RDP servers, making for minimal setup to adopt this new functionality.
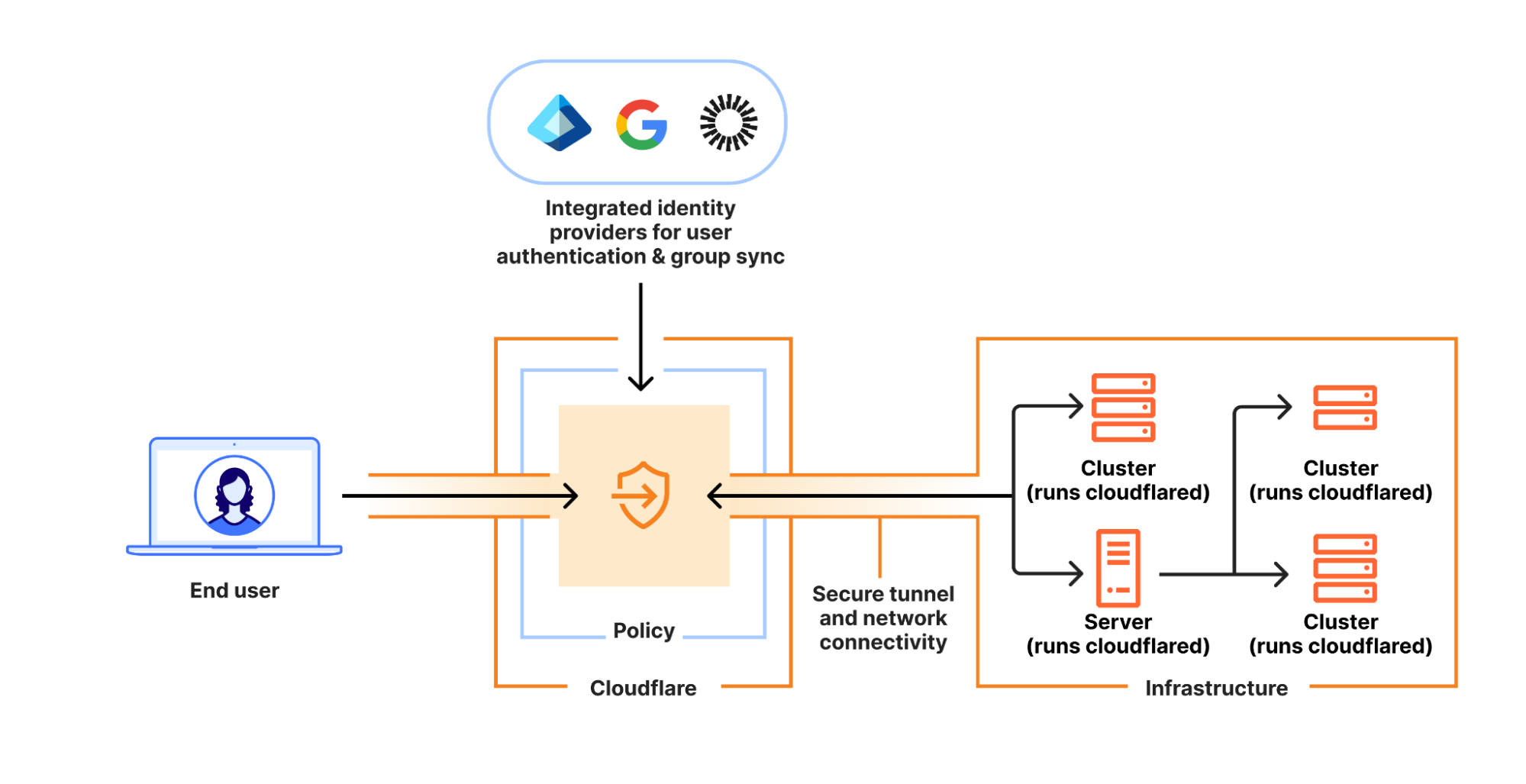
How it works
The client
Cloudflare’s implementation leverages IronRDP, a high-performance RDP client that runs in the browser. It was selected because it is a modern, well-maintained, RDP client implementation that offers an efficient and responsive experience. Unlike Java-based Apache Guacamole, another popular RDP client implementation, IronRDP is built with Rust and integrates very well with Cloudflare’s development ecosystem.
While selecting the right tools can make all the difference, using a browser to facilitate an RDP session faces some challenges. From a practical perspective, browsers just can’t send RDP messages. RDP relies directly on the Layer 4 Transmission Control Protocol (TCP) for communication, and while browsers can use TCP as the underlying protocol, they do not expose APIs that would let apps build protocol support directly on raw TCP sockets.
Another challenge is rooted in a security consideration: the username and password authentication mechanism that is native to RDP leaves a lot to be desired in the modern world of Zero Trust.
In order to tackle both of these challenges, the IronRDP client encapsulates the RDP session in a WebSocket connection. Wrapping the Layer 4 TCP traffic in HTTPS enables the client to use native browser APIs to communicate with Cloudflare’s RDP proxy. Additionally, it enables Cloudflare Access to secure the entire session using identity-aware policies. By attaching a Cloudflare Access authorization JSON Web Token (JWT) via cookie to the WebSocket connection, every inter-service hop of the RDP session is verified to be coming from the authenticated user.
A brief aside into how security and performance is optimized: in conventional client-based RDP traffic, the client and server negotiate a TLS connection to secure and verify the session. However, because the browser WebSocket connection is already secured with TLS to Cloudflare, we employ IronRDP’s RDCleanPath protocol extension to eliminate this second encapsulation of traffic. Removing this redundancy avoids unnecessary performance degradation and increased complexity during session handshakes.
The server
The IronRDP client initiates a WebSocket connection to a dedicated WebSocket proxy, which is responsible for authenticating the client, terminating the WebSocket connection, and proxying tunneled RDP traffic deeper into Cloudflare’s infrastructure to facilitate connectivity. The seemingly simple task of determining how this WebSocket proxy should be built turned out to be the most challenging decision in the development process.
Our initial proposal was to develop a new service that would run on every server within our network. While this was feasible, operating a new service would introduce a non-trivial maintenance burden, which ultimately turned out to be more overhead than value-add in this case. The next proposal was to build it into Front Line (FL), one of Cloudflare’s oldest services that is responsible for handling tens of millions of HTTP requests per second. This approach would have sidestepped the need to expose new IP addresses and benefitted from the existing scaffolding to let the team move quickly. Despite being promising at first, this approach was decided against because FL is undergoing significant investment, and the team didn’t want to build on shifting sands.
Finally, we identified a solution that implements the proxy service using Cloudflare Workers! Fortunately, Workers automatically scales to massive request rates, which eliminates some of the groundwork we’d lay if we had chosen to build a new service. Candidly, this approach was not initially preferred due to some ambiguities around how Workers communicates with internal Cloudflare services, but with support from the Workers team, we found a path forward.
From the WebSocket proxy Worker, the tunneled RDP connection is sent to the Apollo service, which is responsible for routing traffic between on-ramps and off-ramps for Cloudflare Zero Trust. Apollo centralizes and abstracts these complexities to let other services focus on application-specific functionality. Apollo determines which Cloudflare colo is closest to the target Cloudflare Tunnel and establishes a connection to an identical Apollo instance running in that colo. The egressing Apollo instance can then facilitate the final connection to the Cloudflare Tunnel. By using Cloudflare’s global network to traverse the distance between the ingress colo and the target Cloudflare Tunnel, network disruptions and congestion is managed.
Apollo connects to the RDP server and passes the ingress and egress connections to Oxy-teams, the service responsible for inspecting and proxying the RDP traffic. It functions as a pass-through (strictly enabling traffic connectivity) as the web client authenticates to the RDP server. Our initial release makes use of NT Lan Manager (NTLM) authentication, a challenge-response authentication protocol requiring username and password entry. Once the client has authenticated with the server, Oxy-teams is able to proxy all subsequent RDP traffic!
This may sound like a lot of hops, but every server in our network runs every service. So believe it or not, this complex dance takes place on a single server and by using UNIX domain sockets for communication, we also minimize any performance impact. If any of these servers become overloaded, experience a network fault, or have a hardware problem, the load is automatically shifted to a neighboring server with the help of Unimog, Cloudflare’s L4 load balancer.
Putting it all together
-
User initiation: The user selects an RDP server from Cloudflare’s App Launcher (or accesses it via a direct URL). Each RDP server is associated with a public hostname secured by Cloudflare.
-
Ingress: This request is received by the closest data center within Cloudflare’s network.
-
Authentication: Cloudflare Access authenticates the session by validating that the request contains a valid JWT. This token certifies that the user is authorized to access the selected RDP server through the specified domain.
-
Web client delivery: Cloudflare Workers serves the IronRDP web client to the user’s browser.
-
Secure tunneling: The client tunnels RDP traffic from the user’s browser over a TLS-secured WebSocket to another Cloudflare Worker.
-
Traffic routing: The Worker that receives the IronRDP connection terminates the WebSocket and initiates a connection to Apollo. From there, Apollo creates a connection to the RDP server.
-
Authentication relay: With a connection established, Apollo relays RDP authentication messages between the web client and the RDP server.
-
Connection establishment: Upon successful authentication, Cloudflare serves as an RDP proxy between the web browser and the RDP server, connecting the user to the RDP server with free-flowing traffic.
-
Policy enforcement: Cloudflare’s secure web gateway, Oxy-teams, applies Layer 4 policy enforcement and logging of the RDP traffic.
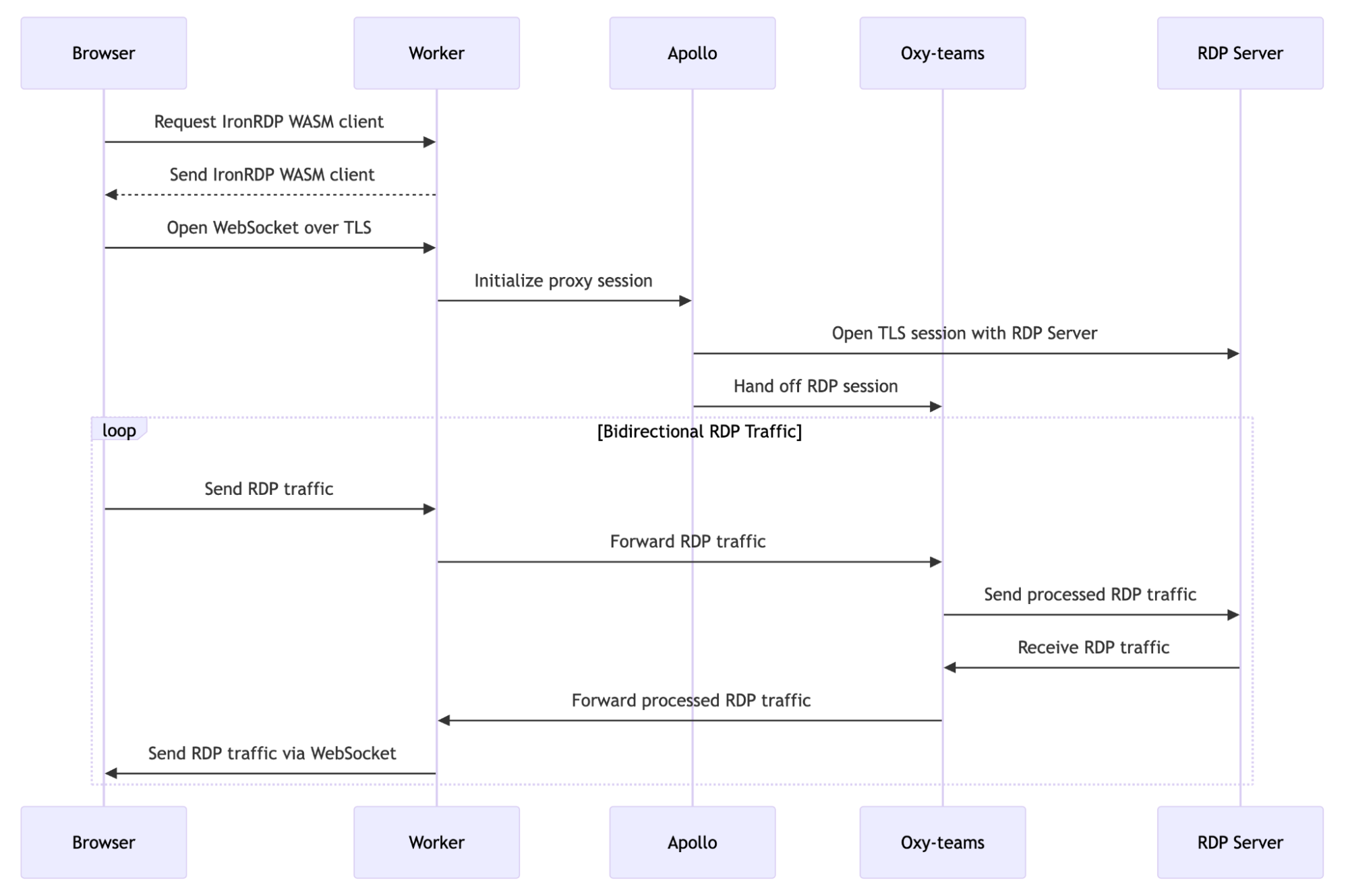
Key benefits of this architecture:
-
No additional software: Access Windows servers directly from a browser.
-
Low latency: Cloudflare’s global network minimizes performance overhead.
-
Enhanced security: RDP access is protected by Access policies, preventing lateral movement.
-
Integrated logging and monitoring: Administrators can observe and control RDP traffic.
To learn more about Cloudflare’s proxy capabilities, take a look at our related blog post explaining our proxy framework.
Cloudflare’s browser-based RDP solution exclusively supports modern RDP authentication mechanisms, enforcing best practices for secure access. Our architecture ensures that RDP traffic using outdated or weak legacy security features from older versions of the RDP standard, such as unsecured password-based authentication or RC4 encryption, are never allowed to reach customer endpoints.
Cloudflare supports secure session negotiation using the following principles:
-
TLS-based WebSocket connection for transport security.
-
Fine-grained policies that enforce single sign on (SSO), multi-factor authentication (MFA), and dynamic authorization.
-
Integration with enterprise identity providers via SAML (Security Assertion Markup Language) and OIDC (OpenID Connect).
Every RDP session that passes through Cloudflare’s network is encrypted and authenticated.
What’s next?
This is only the beginning for our browser-based RDP solution! We have already identified a few areas for continued focus:
-
Enhanced visibility and control for administrators: Because RDP traffic passes through Cloudflare Workers and proxy services, browser-based RDP will expand to include session monitoring. We are also evaluating data loss prevention (DLP) support, such as restricting actions like file transfers and clipboard use, to prevent unauthorized data exfiltration without compromising performance.
-
Advanced authentication: Long-lived credentials are a thing of the past. Future iterations of browser-based RDP will include passwordless functionality, eliminating the need for end users to remember passwords and administrators from having to manage them. To that end, we are evaluating methods such as client certificate authentication, passkeys and smart cards, and integration with third-party authentication providers via Access.
Compliance and FedRAMP High certification
We plan to include browser-based RDP in our FedRAMP High offering for enterprise and government organizations, a high-priority initiative we announced in early February. This certification will validate that our solution meets the highest standards for:
-
Data protection
-
Identity and access management
-
Continuous monitoring
-
Incident response
Seeking FedRAMP High compliance demonstrates Cloudflare’s commitment to securing sensitive environments, such as those in the federal government, healthcare, and financial sectors.
By enforcing a modern, opinionated, and secure implementation of RDP, Cloudflare provides a secure, scalable, and compliant solution tailored to the needs of organizations with critical security and compliance mandates.
At Cloudflare, we are committed to providing the most comprehensive solution for ZTNA, which now also includes privileged access to sensitive infrastructure like Windows servers over browser-based RDP. Cloudflare’s browser-based RDP solution is in closed beta with new customers being onboarded each week. You can request access here to try out this exciting new feature.
In the meantime, check out our Access for Infrastructure documentation to learn more about how Cloudflare protects privileged access to sensitive infrastructure. Access for Infrastructure is currently available free to teams of under 50 users, and at no extra cost to existing pay-as-you-go and Contract plan customers through an Access or Zero Trust subscription. Stay tuned as we continue to natively rebuild BastionZero’s technology into Cloudflare’s Access for Infrastructure service!
Detecting sensitive data and misconfigurations in AWS and GCP with Cloudflare One
Post Syndicated from Alex Dunbrack original https://blog.cloudflare.com/scan-cloud-dlp-with-casb/
Today is the final day of Security Week 2025, and after a great week of blog posts across a variety of topics, we’re excited to share the latest on Cloudflare’s data security products.
This announcement takes us to Cloudflare’s SASE platform, Cloudflare One, used by enterprise security and IT teams to manage the security of their employees, applications, and third-party tools, all in one place.
Starting today, Cloudflare One users can now use the CASB (Cloud Access Security Broker) product to integrate with and scan Amazon Web Services (AWS) S3 and Google Cloud Storage, for posture- and Data Loss Prevention (DLP)-related security issues. Create a free account to check it out.
Scanning both point-in-time and continuously, users can identify misconfigurations in Identity and Access Management (IAM), bucket, and object settings, and detect sensitive information, like Social Security numbers, credit card numbers, or any other pattern using regex, in cloud storage objects.
Over the last few years, our customers — predominantly security and IT teams — have told us about their appreciation for CASB’s simplicity and effectiveness as a SaaS security product. Its number of supported integrations, its ease of setup, and speed in identifying critical issues across popular SaaS platforms, like files shared publicly in Microsoft 365 and exposed sensitive data in Google Workspace, has made it a go-to for many.
However, as we’ve engaged with customers, one thing became clear: the risks of unmonitored or exposed data at-rest go far beyond just SaaS environments. Sensitive information – whether intellectual property, customer data, or personal identifiers – can wreak havoc on an organization’s reputation and its obligations to its customers if it falls into the wrong hands. For many of our customers, the security of data stored in cloud providers like AWS and GCP is even more critical than the security of data in their SaaS tools.
That’s why we’ve extended Cloudflare CASB to include Cloud DLP (Data Loss Prevention) functionality, enabling users to scan objects in Amazon S3 buckets and Google Cloud Storage for sensitive data matches.
With Cloudflare DLP, you can choose from pre-built detection profiles that look for common data types (such as Social Security Numbers or credit card numbers) or create your own custom profiles using regular expressions. As soon as an object matching a DLP profile is detected, you can dive into the details, understanding the file’s context, seeing who owns it, and more. These capabilities provide the insight needed to quickly protect data and prevent exposure in real time.
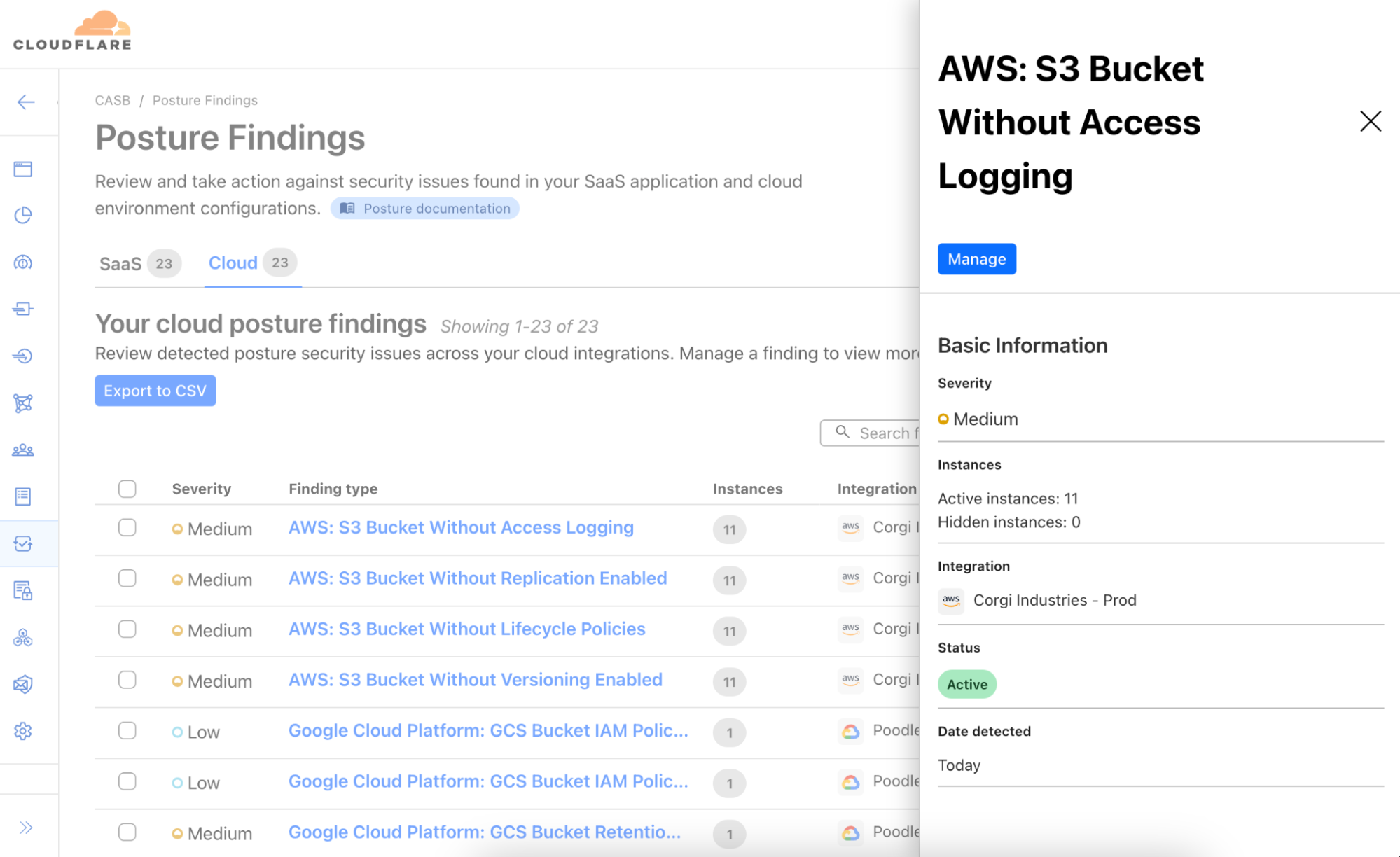
And as with all CASB integrations, this new functionality also comes with posture management features, meaning whether you’re using AWS or GCP, we’ll help you identify misconfigurations and other cloud security issues that could leave your data vulnerable, like buckets that are publicly-accessible or have critical logging settings disabled, access keys needing rotation, or users without multi-factor authentication (MFA). It’s all included.
Cloudflare CASB and DLP are simple to use by default, making it easy to get started right away. But it’s also highly configurable, giving you the flexibility to fine-tune the scanning profiles to suit your specific needs.
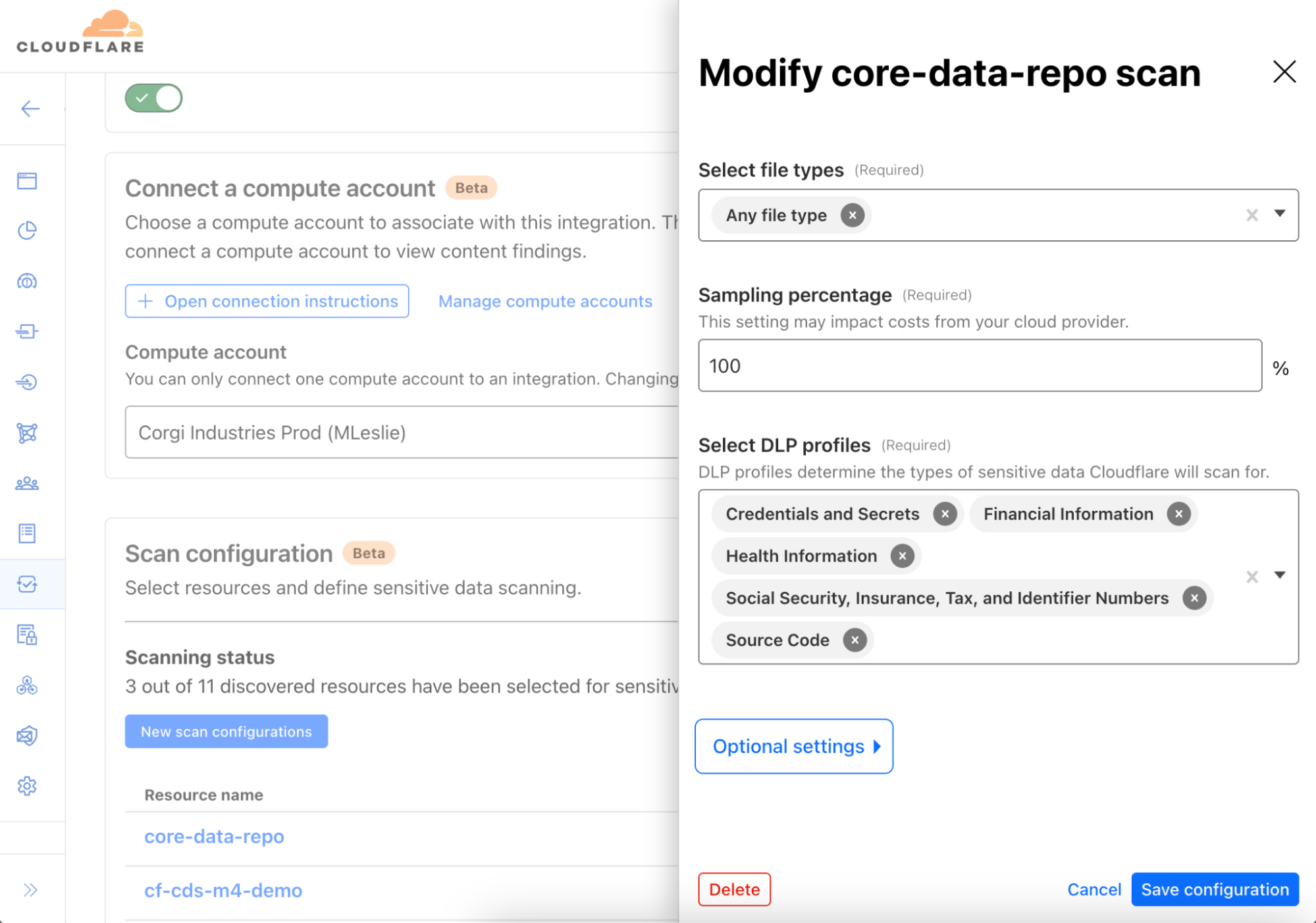
For example, you can adjust which storage buckets or file types to scan, and even sample only a percentage of objects for analysis. The scanning also runs within your own cloud environment, so your data never leaves your infrastructure. This approach keeps your cloud storage secure and your costs managed while allowing you to tailor the solution to your organization’s unique compliance and security requirements.
Looking ahead, our roadmap also includes expanding support to additional cloud storage environments, such as Azure Blob Storage and Cloudflare R2, further extending our comprehensive, multi-cloud security strategy. Stay tuned for more on that!
From the start, we knew that to deliver DLP capabilities across cloud environments, it would require an efficient and scalable design to enable real-time detection of sensitive data exposure.
Serverless architecture for streamlined processing
An early design decision was made to leverage a serverless architecture approach to ensure sensitive data discovery is both efficient and scalable. Here’s how it works:
-
Compute Account: The entire process runs within a cloud account owned by your organization, known as a Compute Account. This design ensures your data remains within your boundaries, avoiding costly cloud egress fees. The Compute Account can be launched in under 15 minutes using a provided Terraform template.
-
Controller function: Every minute, a lightweight, serverless controller function in your cloud environment communicates with Cloudflare’s APIs, fetching the latest DLP configurations and security profiles from your Cloudflare One account.
-
Crawler process: The controller triggers an object discovery task, which is processed by a second serverless function known as the Crawler. The Crawler queries cloud storage accounts, like AWS S3 or Google Cloud Storage, via API to identify new objects. Redis is used within the Compute Account to track which objects have yet to be evaluated.
-
Scanning for sensitive data: Newly discovered objects are sent through a queue to a third serverless function called the Scanner. This function downloads the objects and streams their contents to the DLP engine in the Compute Account, which scans for matches against predefined or custom DLP Profiles.
-
Finding generation and alerts: If a DLP match is found, metadata about the object, such as context and ownership details, is published to a queue. This data is ingested by a Cloudflare-hosted service and presented in the Cloudflare Dashboard as findings, giving security teams the visibility needed to take swift action.
Scalable and secure design
The DLP pipeline ensures that sensitive data never leaves your cloud environment — a privacy-first approach. All communication between the Compute Account and Cloudflare’s APIs are initiated by the controller, also meaning there is no need to perform any extra configuration to allow ingress traffic.
To get started, reach out to your account team to learn more about this new data security functionality and our roadmap. If you want to try this out on your own, you can login to the Cloudflare One dashboard (create a free account here if you don’t have one) and navigate to the CASB page to set up your first integration.
Enhance data protection in Microsoft Outlook with Cloudflare One’s new DLP Assist
Post Syndicated from Ayush Kumar original https://blog.cloudflare.com/enhance-data-protection-in-microsoft-outlook-with-cloudflare-ones-new-dlp/
Cloudflare Email Security customers using Microsoft Outlook can now enhance their data protection using our new DLP Assist capability. This application scans emails in real time as users compose them, identifying potential data loss prevention (DLP) violations, such as Social Security or credit card numbers. Administrators can instantly alert users of violations and take action downstream, whether by blocking or encrypting messages, to prevent sensitive information from leaking. DLP Assist is lightweight, easy to deploy, and helps organizations maintain compliance without disrupting workflow.
After speaking with our customers, we discovered a common challenge: many wanted to implement a data loss prevention policy for Outlook, but found existing solutions either too complex to set up or too costly to adopt.
That’s why we created DLP Assist to be a lightweight application that can be installed in minutes. Unlike other solutions, it doesn’t require changes to outbound email connectors or provide concerns about IP reputation to customers. By fully leveraging the Microsoft ecosystem, DLP Assist makes email DLP accessible to all organizations, whether they have dedicated IT teams or none at all.
We also recognized that traditional DLP solutions often demand significant financial investment in not just software but also in team members to configure and monitor them. DLP Assist aims to eliminate these barriers. Customers can use the application as part of our Email Security product, avoiding the need for additional purchases. Plus, with our DLP engine powered by optical character recognition (OCR), confidence levels, and other detection mechanisms, organizations don’t need a dedicated team to constantly oversee it.
By eliminating the complexities of legacy DLP and email systems, we allow customers to quickly begin preventing the unauthorized egress of sensitive data. With DLP Assist, organizations can be confident in controlling and protecting the information that leaves their environment.
Our DLP Assist is an application that integrates with the Desktop (Mac and Windows) and Web Outlook clients, passively scanning emails as they are composed. Running in the background within Microsoft Outlook, DLP Assist continuously monitors new text and attachments added to emails that users are drafting.
When a customer downloads and installs the application, Cloudflare creates a unique client ID specifically for emails read from the DLP Assist application, which serves as an identifier solely for use by DLP Assist within Cloudflare’s backend. When a user begins drafting a message, the DLP Assist application invokes several Microsoft Outlook APIs to gather information about how the message is changing. These APIs let the Cloudflare application continuously access different parts of the message like subject, body, attachments, etc. While the application is reading the changes within the message, it also establishes a secure, encrypted connection with a Cloudflare Worker.
As raw data about the email and attachments is sent to the Worker, the Worker relays the information to our DLP engine, which is at the heart of our scanning process. It leverages OCR technology to analyze attachments, extract text from images, and detect DLP violations across both email content and embedded data. It also examines raw text to ensure a comprehensive analysis of every part of the email and its attachments. While our engine supports most attachment types, it currently does not process video or audio files.
The DLP engine runs on all of our servers, and we also store the customer DLP profile configuration data on all of our servers. By keeping DLP policy configuration data on all servers alongside our analysis engine, we eliminate the need to reroute requests across our network allowing for low-latency, real-time DLP checks. The customer’s client ID enables us to find and apply their defined DLP profiles and accurately determine policy violations, delivering results directly to the Cloudflare Worker. If a violation is found, the Worker responds to the application to take action within Outlook.
Our architecture ensures real-time scanning with minimal latency, as end users are always near a Cloudflare Worker, regardless of their location. Additionally, this design provides built-in resilience — if a Cloudflare Worker becomes unavailable, another can take over, allowing for uninterrupted DLP enforcement. By scanning in real time, this allows us to provide immediate feedback to the user about any DLP violations that they have within their email, rather than the user having to wait till the message has been sent.
If a violation is detected, the application first displays an insight message — a ribbon notification at the top of the email — alerting the user to the issue. Administrators have full control over this message and can customize it to provide specific guidance or warnings. We find that most of our customers point users to documentation reminding them what is allowed to be sent outside of the organization.

When a DLP violation occurs, DLP Assist also injects a header into the EML file to indicate the violation. If the user removes the content that is in violation, the header is automatically removed as well.
If the violation remains unchanged, DLP Assist invokes a Microsoft Outlook API which prompts the user with a final warning, giving them another opportunity to revise the message before sending.

If the user proceeds without making changes, the email will be sent from the client with headers embedded into the EML showing that message contains a DLP violation. Organizations can configure their outbound mail transfer agent (MTA) to take appropriate action based on these headers. For those with Microsoft as their outbound MTA, Cloudflare’s DLP Assist integrates with Microsoft Purview, enabling organizations to block, encrypt, or require approval before sending.
For example, if an organization configures Purview to block the email, users will receive a notification similar to this one.
Violations detected by the DLP Assist application can also be sent externally through our Logpush feature. Customers have the flexibility to integrate this data with SIEM or SOAR platforms for deeper analysis, or store it in bucket storage solutions like Cloudflare R2. Additionally, customers can enhance their reporting capabilities by viewing block data directly within their outbound gateway.
As we continue to improve our DLP engine, we’re introducing more advanced ways to analyze messages. During Security Week 2025, we’re unveiling new AI methodologies that automatically fine-tune DLP confidence levels using machine learning models. Initially, these enhancements will be rolled out for Gateway violations, but we plan to extend them to email scanning in the near future. For more details, see the associated blog post.
Cloudflare One’s DLP Assist is designed for quick deployment, enabling organizations to implement a data loss prevention solution with minimal effort. It allows customers to immediately begin scanning emails for sensitive data and take action to prevent unauthorized sharing, ensuring compliance and security from day one.
To get started, navigate to the Zero Trust dashboard and click on the Email Security tab. From there, select the Outbound DLP tab.
To install DLP Assist, organizations can download the manifest file, which provides Microsoft with the necessary instructions to install the application within Outlook. Administrators can then upload this manifest file by going to Integrated Apps within the Microsoft 365 Admin Center and selecting Upload Custom Apps:

This application is best suited for use with OWA (Outlook Web Access) and the desktop (Mac and Windows) Outlook client. Due to Microsoft limitations, a stable experience on mobile devices is not yet available.
More information can be found within our developer documentation.
We’re continuously expanding our solutions to help organizations protect their data. Exciting new DLP and Email Security features are on the way throughout 2025, so stay tuned for upcoming announcements.
To learn more about our DLP and Email Security solutions, reach out to your Cloudflare representative. Want to see our detections in action? Run a free Retro Scan to uncover any potentially malicious messages hiding in your inbox.
Prepping for post-quantum: a beginner’s guide to lattice cryptography
Post Syndicated from Christopher Patton original https://blog.cloudflare.com/lattice-crypto-primer/
The cryptography that secures the Internet is evolving, and it’s time to catch up. This post is a tutorial on lattice cryptography, the paradigm at the heart of the post-quantum (PQ) transition.
Twelve years ago (in 2013), the revelation of mass surveillance in the US kicked off the widespread adoption of TLS for encryption and authentication on the web. This transition was buoyed by the standardization and implementation of new, more efficient public-key cryptography based on elliptic curves. Elliptic curve cryptography was both faster and required less communication than its predecessors, including RSA and Diffie-Hellman over finite fields.
Today’s transition to PQ cryptography addresses a looming threat for TLS and beyond: once built, a sufficiently large quantum computer can be used to break all public-key cryptography in use today. And we continue to see advancements in quantum-computer engineering that bring us closer to this threat becoming a reality.
Fortunately, this transition is well underway. The research and standards communities have spent the last several years developing alternatives that resist quantum cryptanalysis. For its part, Cloudflare has contributed to this process and is an early adopter of newly developed schemes. In fact, PQ encryption has been available at our edge since 2022 and is used in over 35% of non-automated HTTPS traffic today (2025). And this year we’re beginning a major push towards PQ authentication for the TLS ecosystem.
Lattice-based cryptography is the first paradigm that will replace elliptic curves. Apart from being PQ secure, lattices are often as fast, and sometimes faster, in terms of CPU time. However, this new paradigm for public key crypto has one major cost: lattices require much more communication than elliptic curves. For example, establishing an encryption key using lattices requires 2272 bytes of communication between the client and the server (ML-KEM-768), compared to just 64 bytes for a key exchange using a modern elliptic-curve-based scheme (X25519). Accommodating such costs requires a significant amount of engineering, from dealing with TCP packet fragmentation, to reworking TLS and its public key infrastructure. Thus, the PQ transition is going to require the participation of a large number of people with a variety of backgrounds, not just cryptographers.
The primary audience for this blog post is those who find themselves involved in the PQ transition and want to better understand what’s going on under the hood. However, more fundamentally, we think it’s important for everyone to understand lattice cryptography on some level, especially if we’re going to trust it for our security and privacy.
We’ll assume you have a software-engineering background and some familiarity with concepts like TLS, encryption, and authentication. We’ll see that the math behind lattice cryptography is, at least at the highest level, not difficult to grasp. Readers with a crypto-engineering background who want to go deeper might want to start with the excellent tutorial by Vadim Lyubashevsky on which this blog post is based. We also recommend Sophie Schmieg’s blog on this subject.
While the transition to lattice cryptography incurs costs, it also creates opportunities. Many things we can build with elliptic curves we can also build with lattices, though not always as efficiently; but there are also things we can do with lattices that we don’t know how to do efficiently with anything else. We’ll touch on some of these applications at the very end.
We’re going to cover a lot of ground in this post. If you stick with it, we hope you’ll come away feeling empowered, not only to tackle the engineering challenges the PQ transition entails, but to solve problems you didn’t know how to solve before.
Strap in — let’s have some fun!
The most pressing problem for the PQ transition is to ensure that tomorrow’s quantum computers don’t break today’s encryption. An attacker today can store the packets exchanged between your laptop and a website you visit, and then, some time in the future, decrypt those packets with the help of a quantum computer. This means that much of the sensitive information transiting the Internet today — everything from API tokens and passwords to database encryption keys — may one day be unlocked by a quantum computer.
In fact, today’s encryption in TLS is mostly PQ secure: what’s at risk is the process by which your browser and a server establish an encryption key. Today this is usually done with elliptic-curve-based schemes, which are not PQ secure; our goal for this section is to understand how to do key exchange with lattices-based schemes, which are.
We will work through and implement a simplified version of ML-KEM, a.k.a. Kyber, the most widely deployed PQ key exchange in use today. Our code will be less efficient and secure than a spec-compliant, production-quality implementation, but will be good enough to grasp the main ideas.
Our starting point is a protocol that looks an awful lot like Diffie-Hellman (DH) key exchange. For those readers unacquainted with DH, the goal is for Alice and Bob to establish a shared secret over an insecure network. To do so, each picks a random secret number, computes the corresponding “key share”, and sends the key share to the other:
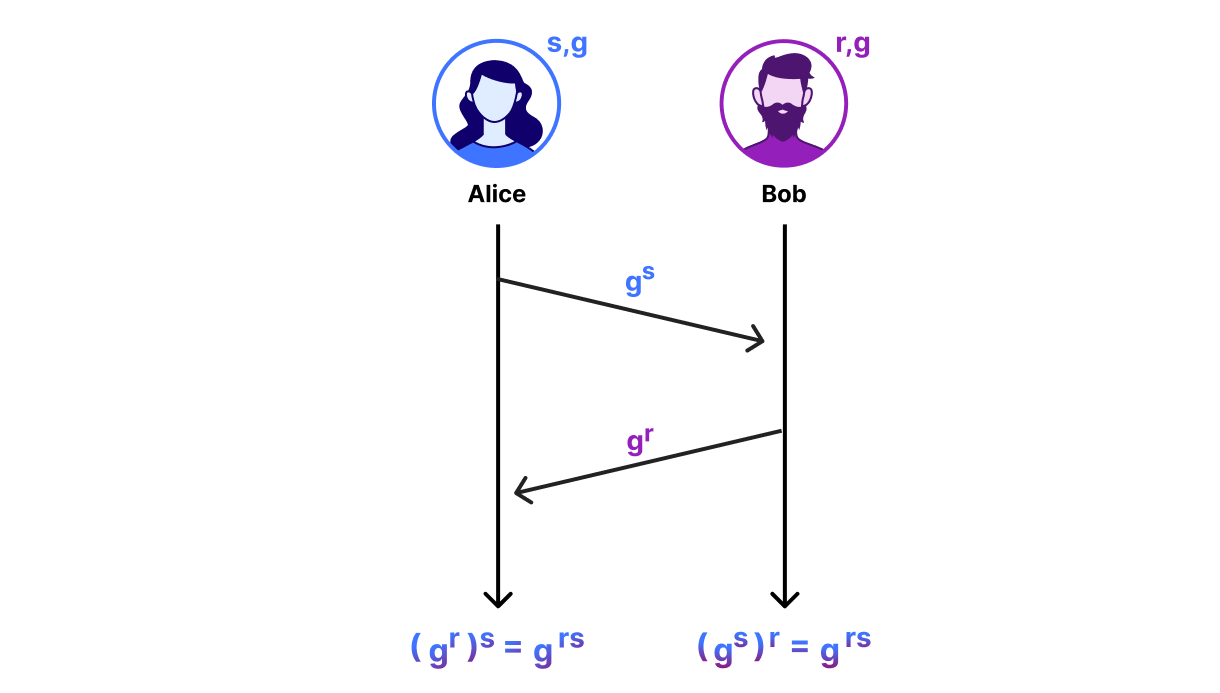
Alice’s secret number is $s$ and her key share is $g^s$; Bob’s secret number is $r$ and his key share is $g^r$. Then given their secret and their peer’s key share, each can compute $g^{rs}$. The security of this protocol comes from how we choose $g$, $s$, and $r$ and how we do arithmetic. The most efficient instantiation of DH uses elliptic curves.
In ML-KEM we replace operations on elliptic curves with matrix operations. It’s not quite a drop-in replacement, so we’ll need a little linear algebra to make sense of it. But don’t worry: we’re going to work with Python so we have running code to play with, and we’ll use NumPy to keep things high level.
All the math we’ll need
A matrix is just a two-dimensional array of numbers. In NumPy, we can create a matrix as follows (importing numpy as np):
A = np.matrix([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])This defines A to be the 3-by-3 matrix with entries A[0,0]==1, A[0,1]==2, A[0,2]==3, A[1,0]==4, and so on.
For the purposes of this post, the entries of our matrices will always be integers. Furthermore, whenever we add, subtract, or multiply two integers, we then reduce the result, just like we do with hours on a clock, so that we end up with a number in range(Q) for some positive number Q, called the modulus. The exact value doesn’t really matter now, but for ML-KEM it’s Q=3329, so let’s go with that for now. (The modulus for a clock would be Q=12.)
In Python, we write multiplication of integers a and b modulo Q as c = a*b % Q. Here we compute a*b, divide the result by Q, then set c to the remainder. For example, 42*1337 % Q is equal to 2890 rather than 56154. Modular addition and subtraction are done analogously. For the rest of this blog, we will sometimes omit “% Q” when it’s clear in context that we mean modular arithmetic.
Next, we’ll need three operations on matrices.
The first is matrix transpose, written A.T in NumPy. This operation flips the matrix along its diagonal so that A.T[j,i] == A[i,j] for all rows i and columns j:
print(A.T)
# [[1 4 7]
# [2 5 8]
# [3 6 9]]To visualize this, imagine writing down a matrix on a translucent piece of paper. Draw a line from the top left corner to the bottom right corner of that paper, then rotate the paper 180° around that line:
The second operation we’ll need is matrix multiplication. Normally, we will multiply a matrix by a column vector, which is just a matrix with one column. For example, the following 3-by-1 matrix is a column vector:
s = np.matrix([[0],
[1],
[0]])We can also write s more concisely as np.matrix([[0,1,0]]).T. To multiply a square matrix A by a column vector s, we compute the dot product of each row of A with s. That is, if t = A*s % Q, then t[i] == (A[i,0]*s[0,0] + A[i,1]*s[1,0] + A[i,2]*s[2,0]) % Q for each row i. The output will always be a column vector:
print(A*s % Q)
# [[2]
# [5]
# [8]]The number of rows of this column vector is equal to the number of rows of the matrix on the left hand side. In particular, if we take our column vector s, transpose it into a 1-by-3 matrix, and multiply it by a 3-by-1 matrix r, then we end up with a 1-by-1 matrix:
r = np.matrix([[1,2,3]]).T
print(s.T*r % Q)
# [[2]]The final matrix operation we’ll need is matrix addition. If A and B are both N-by-M matrices, then C = (A+B) % Q is the N-by-M matrix for which C[i,j] == (A[i,j]+B[i,j]) % Q. Of course, this only works if the matrices we’re adding have the same dimensions.
Warm up
Enough maths — let’s get to exchanging some keys. We start with the DH diagram from before and swap out the computations with matrix operations. Note that this protocol is not secure, but will be the basis of a secure key exchange mechanism we’ll develop in the next section:
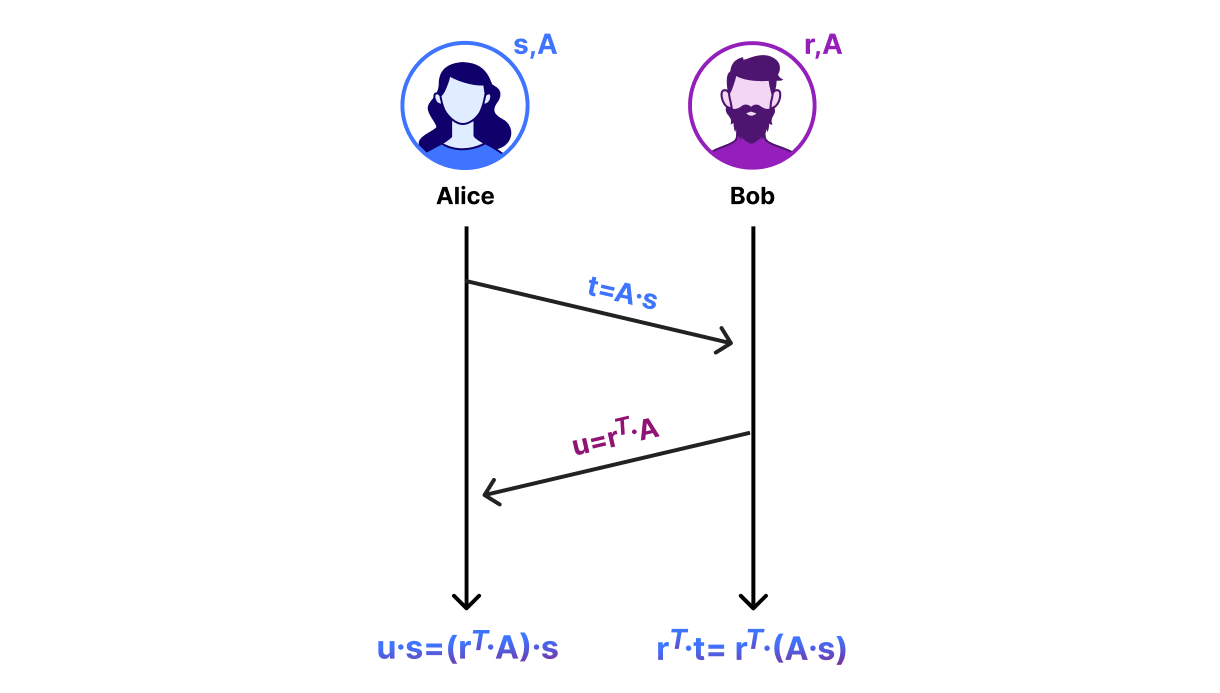
-
Alice and Bob agree on a public,
N-by-NmatrixA. This is analogous to the number $g$ that Alice and Bob agree on in the DH diagram. -
Alice chooses a random length
-Nvectorsand sendst = A*s % Qto Bob. -
Bob chooses a random length
-Nvectorrand sendsu = r.T*A % Qto Alice. You can also compute this as(A.T*r).T % Q.
The vectors t and u are analogous to DH key shares. After the exchange of these key shares, Alice and Bob can compute a shared secret. Alice computes the shared secret as u*s % Q and Bob computes the shared secret as r.T*t % Q. To see why they compute the same key, notice that u*s == (r.T*A)*s == r.T*(A*s) == r.T*t.
In fact, this key exchange is essentially what happens in ML-KEM. However, we don’t use this directly, but rather as part of a public key encryption scheme. Public key encryption involves three algorithms:
-
key_gen():The key generation algorithm that outputs a public encryption keypkand the corresponding secret decryption keysk. -
encrypt(): The encryption algorithm that takes the public key and a plaintext and outputs a ciphertext. -
decrypt(): The decryption algorithm that takes the secret key and a ciphertext and outputs the underlying plaintext. That is,decrypt(sk, encrypt(pk, ptxt)) == ptxtfor any plaintextptxt.
We’ll say the scheme is secure if, given a ciphertext and the public key used to encrypt it, no attacker can discern any information about the underlying plaintext without knowledge of the secret key. Once we have this encryption scheme, we then transform it into a key-encapsulation mechanism (the “KEM” in “ML-KEM”) in the last step. A KEM is very similar to encryption except that the plaintext is always a randomly generated key.
Our encryption scheme is as follows:
-
key_gen(): To generate a key pair, we choose a random, square matrixAand a random column vectors. We set our public key to(A,t=A*s % Q)and our secret key tos. Notice thattis Alice’s key share from the key exchange protocol above. -
encrypt(): Suppose our plaintextptxtis an integer inrange(Q). To encryptptxt, Bob generates his key shareu. He then derives the shared secret and adds it toptxt. The ciphertext has two components:
u = r.T*A % Q
v = (r.T*t + m) % Q
Here m is a 1-by-1 matrix containing the plaintext, i.e., m = np.matrix([[ptxt]]), and r is a random column vector.
-
decrypt(): To decrypt, Alice computes the shared secret and subtracts it fromv:
m = (v - u*s) % Q
Some readers will notice that this looks an awful lot like El Gamal encryption. This isn’t a coincidence. Good cryptographers roll their own crypto; great cryptographers steal from good cryptographers.
Let’s now put this together into code. The last thing we’ll need is a method of generating random matrices and column vectors. We call this function gen_mat() below. Take a crack at implementing this yourself. Our scheme has two parameters: the modulus Q; and the dimension of N of the matrix and column vectors. The choice of N matters for security, but for now feel free to pick whatever value you want.
def key_gen():
# Here `gen_mat()` returns an N-by-N matrix with entries
# randomly chosen from `range(0, Q)`.
A = gen_mat(N, N, 0, Q)
# Like above except the matrix is N-by-1.
s = gen_mat(N, 1, 0, Q)
t = A*s % Q
return ((A, t), s)
def encrypt(pk, ptxt):
(A, t) = pk
m = np.matrix([[ptxt]])
r = gen_mat(N, 1, 0, Q)
u = r.T*A % Q
v = (r.T*t + m) % Q
return (u, v)
def decrypt(sk, ctxt):
s = sk
(u, v) = ctxt
m = (v - u*s) % Q
return m[0,0]
# Test
assert decrypt(sk, encrypt(pk, 1)) == 1Making the scheme secure (or “What is a lattice?”)
By now, you might be wondering what on Earth a lattice even is. We promise we’ll define it, but before we do, it’ll help to understand why our warm-up scheme is insecure and what it’ll take to fix it.
Readers familiar with linear algebra may already see the problem: in order for this scheme to be secure, it should be impossible for the attacker to recover the secret key s; but given the public (A,t), we can immediately solve for s using Gaussian elimination.
In more detail, if A is invertible, we can write the secret key as A-1*t == A-1*(A*s) == (A-1*A)*s == s, where A-1 is the inverse of A. (When you multiply a matrix by its inverse, you get the identity matrix I, which simply takes a column vector to itself, i.e., I*s == s.) We can use Gaussian elimination to compute this matrix. Intuitively, all we’re doing is solving a set of linear equations, where the entries of s are the unknown variables. (Note that this is possible even if A is not invertible.)
In order to make this encryption scheme secure, we need to make it a little… “messier”.
Let’s get messy
For starters, we need to make it hard to recover the secret key from the public key. Let’s try the following: generate another random vector e and add it into A*s. Our key generation algorithm becomes:
def key_gen():
A = gen_mat(N, N, 0, Q)
s = gen_mat(N, 1, 0, Q)
e = gen_mat(N, 1, 0, Q)
t = (A*s + e) % Q
return ((A, t), s)Our formula for the column vector component of the public key, t, now includes an additive term e, which we’ll call the error. Like the secret key, the error is just a random vector.
Notice that the previous attack no longer works: since A-1*t == A-1*(A*s + e) == A-1*(A*s) + A-1*e == s + A-1*e, we need to know e in order to compute s.
Great, but this patch creates another problem. Take a second to plug in this new key generation algorithm into your implementation and test it out. What happens?
You should see that decrypt() now outputs garbage. We can see why using a little algebra:
(v - u*s) == (r.T*t + m) - (r.T*A)*s
== r.T*(A*s + e) + m - (r.T*A)*s
== r.T*(A*s) + r.T*e + m - r.T*(A*s)
== r.T*e + m
The entries of r and e are sampled randomly, so r.T*e is also uniformly random. It’s as if we encrypted m with a one-time pad, then threw away the one-time pad!
Handling decryption errors
What can we do about this? First, it would help if r.T*e were small so that decryption yields something that’s close to the plaintext. Imagine we could generate r and e in such a way that r.T*e were in range(-epsilon, epsilon+1) for some small epsilon. Then decrypt would output a number in range(ptxt-epsilon, ptxt+epsilon+1), which would be pretty close to the actual plaintext.
However, we need to do better than get close. Imagine your browser failing to load your favorite website one-third of the time because of a decryption error. Nobody has time for that.
ML-KEM reduces the probability of decryption errors by being clever about how we encode the plaintext. Suppose all we want to do is encrypt a single bit, i.e., ptxt is either 0 or 1. Consider the numbers in range(Q), and split the number line into four chunks of roughly equal length:
Here we’ve labeled the region around zero (-Q/4 to Q/4 modulo Q) with ptxt=0 and the region far away from zero with ptxt=1. To encode the bit, we set it to the integer corresponding to the middle of its range, i.e., m = np.matrix([[ptxt * Q//2]]). (Note the double “//” — this denotes integer division in Python.) To decode, we choose the ptxt corresponding to whatever range m[0,0] is in. That way if the decryption error is small, then we’re highly likely to end up in the correct range.
Now all that’s left is to ensure the decryption error, r.T*e, is small. We do this by sampling short vectors r and e. By “short” we mean the entries of these vectors are sampled from a range that is much smaller than range(Q). In particular, we’ll pick some small positive integer beta and sample entries range(-beta,beta+1).
How do we choose beta? Well, it should be small enough that decryption succeeds with overwhelming probability, but not so small that r and e are easy to guess and our scheme is broken. Take a minute or two to play with this. The parameters we can vary are:
-
the modulus
Q -
the dimension of the column vectors
N -
the shortness parameter
beta
For what ranges of these parameters is the decryption error low but the secret vectors are hard to guess? For what ranges is our scheme most efficient, in terms of runtime and communication cost (size of the public key plus the ciphertext)? We’ll give a concrete answer at the end of this section, but in the meantime, we encourage you to play with this a bit.
Gauss strikes back
At this point, we have a working encryption scheme that mitigates at least one key-recovery attack. We’ve come pretty far, but we have at least one more problem.
Take another look at our formula for the ciphertext ctxt = (u,v). What would happen if we managed to recover the random vector r? That would be catastrophic, since v == r.T*t + m, and we already know t (part of the public key) and v (part of the ciphertext).
Just as we were able to compute the secret key from the public key in our initial scheme, we can recover the encryption randomness r from the ciphertext component u using Gaussian elimination. Again, this is just because r is the solution to a system of linear equations.
We can mitigate this plaintext-recovery attack just as before, by adding some noise. In particular, we’ll generate a short vector according to gen_mat(N,1,-beta,beta+1) and add it into u. We also need to add noise to v in the same way, for reasons that we’ll discuss in the next section.
Once again, adding noise increases the probability of a decryption error, but this time the magnitude of the error also depends on the secret key s. To see this, recall that during decryption, we multiply u by s (to compute the shared secret), and the error vector is an additive term. We’ll therefore need s to be a short vector as well.
Let’s now put together everything we’ve learned into an updated encryption scheme. Our scheme now has three parameters, Q, N, and beta, and can be used to encrypt a single bit:
def key_gen():
A = gen_mat(N, N, 0, Q)
s = gen_mat(N, 1, -beta, beta+1)
e1 = gen_mat(N, 1, -beta, beta+1)
t = (A*s + e1) % Q
return ((A, t), s)
def encrypt(pk, ptxt):
(A, t) = pk
m = np.matrix([[ptxt*(Q//2) % Q]])
r = gen_mat(N, 1, -beta, beta+1)
e2 = gen_mat(N, 1, -beta, beta+1)
e3 = gen_mat(1, 1, -beta, beta+1)
u = (r.T*A + e2) % Q
v = (r.T*t + e3 + m) % Q
return (u, v)
def decrypt(sk, ctxt):
s = sk
(u, v) = ctxt
m = (v - u*s) % Q
if m[0,0] in range(Q//4, 3*Q//4):
return 1
return 0
# Test
assert decrypt(sk, encrypt(pk, 0)) == 0
assert decrypt(sk, encrypt(pk, 1)) == 1Before moving on, try to find parameters for which the scheme works and for which the secret and error vectors seem hard to guess.
Learning with errors
So far we have a functioning encryption scheme for which we’ve mitigated two attacks, one a key-recovery attack and the other a plaintext-recovery attack. There seems to be no other obvious way of breaking our scheme, unless we choose parameters that are so weak that an attacker can easily guess the secret key s or ciphertext randomness r. Again, these vectors need to be short in order to prevent decryption errors, but not so short that they are easy to guess. (Likewise for the error terms.)
Still, there may be other attacks that require a little more sophistication to pull off. For instance, there might be some mathematical analysis we can do to recover, or at least make a good guess of, a portion of the ciphertext randomness. This raises a more fundamental question: in general, how do we establish that cryptosystems like this are actually secure?
As a first step, cryptographers like to try and reduce the attack surface. Modern cryptosystems are designed so that the problem of attacking the scheme reduces to solving some other problem that is easier to reason about.
Our public key encryption scheme is an excellent illustration of this idea. Think back to the key- and plaintext-recovery attacks from the previous section. What do these attacks have in common?
In both instances, the attacker knows some public vector that allowed it to recover a secret vector:
-
In the key-recovery attack, the attacker knew
tfor whichA*s == t. -
In the plaintext-recovery attack, the attacker knew
ufor whichr.T*A == u(or, equivalently,A.T*r == u.T).
The fix in both cases was to construct the public vector in such a manner that it is hard to solve for the secret, namely, by adding an error term. However, ideally the public vector would reveal no information about the secret whatsoever. This ideal is formalized by the Learning With Errors (LWE) problem.
The LWE problem asks the attacker to distinguish between two distributions. Concretely, imagine we flip a coin, and if it comes up heads, we sample from the first distribution and give the sample to the attacker; and if the coin comes up tails, we sample from the second distribution and give the sample to the attacker. The distributions are as follows:
-
(A,t=A*s + e) whereAis a random matrix generated withgen_mat(N,N,0,Q)andsandeare short vectors generated withgen_mat(N,1,-beta,beta+1). -
(A,t)whereAis a random matrix generated withgen_mat(N,N,0,Q)andtis a random vector generated withgen_mat(N,1,0,Q).
The first distribution corresponds to what we actually do in the encryption scheme; in the second, t is just a random vector, and no longer a secret vector at all. We say that the LWE problem is “hard” if no attacker is able to guess the coin flip with probability significantly better than one-half.
Our encryption is passively secure — meaning the ciphertext doesn’t leak any information about the plaintext — if the LWE problem is hard for the parameters we chose. To see why, notice that both the public key and ciphertext look like LWE instances; if we can replace each instance with an instance of the random distribution, then the ciphertext would be completely independent of the plaintext and therefore leak no information about it at all. Note that, for this argument to go through, we also have to add the error term e3 to the ciphertext component v.
Choosing the parameters
We’ve established that if solving the LWE problem is hard for parameters N, Q, and beta, then so is breaking our public key encryption scheme. What’s left for us to do is tune the parameters so that solving LWE is beyond the reach of any attacker we can think of. This is where lattices come in.
Lattices
A lattice is an infinite grid of points in high-dimensional space. A two-dimensional lattice might look something like this:
The points always follow a clear pattern that resembles “lattice work” you might see in a garden:

(Source: https://picryl.com/media/texture-wood-vintage-backgrounds-textures-8395bb)
For cryptography, we care about a special class of lattices, those defined by a matrix P that “recognizes” points in the lattice. That is, the lattice recognized by P is the set of vectors v for which P*v == 0, where “0” denotes the all-zero vector. The all-zero vector is np.zeros((N,1), dtype=int) in NumPy.
Readers familiar with linear algebra may have a different definition of lattices in mind: in general, a lattice is the set of points obtained by taking linear combinations of some basis. Our lattices can also be formulated in this way, i.e., for a matrix P that recognizes a lattice, we can compute the basis vectors that generate the lattice. However, we don’t much care about this representation here.
The LWE problem boils down to distinguishing a set of points that are “close to” the lattice from a set of points that are “far away from” the lattice. We construct these points from an LWE instance and a random (A,t) respectively. Here we have an LWE sample (left) and a sample from the random distribution (right):
What this shows is that the points of the LWE instance are much closer to the lattice than the random instance. This is indeed the case on average. However, while distinguishing LWE instances from random is easy in two dimensions, it gets harder in higher dimensions.
Let’s take a look at how we construct these points. First, let’s take an LWE instance (A,t=(A*s + e) % Q) and consider the lattice recognized by the matrix P we get by concatenating A with the identity matrix I. This might look something like this (N=3):
A = gen_mat(N, N, 0, Q)
P = np.concatenate((A, np.identity(N, dtype=int)), axis=1)
print(P)
# [[1570 634 161 1 0 0]
# [1522 1215 861 0 1 0]
# [ 344 2651 1889 0 0 1]]Notice that we can compute t by multiplying P by the vector we get by concatenating s and e (beta=2):
s = gen_mat(N, 1, -beta, beta+1)
e = gen_mat(N, 1, -beta, beta+1)
t = (A*s + e) % Q
z = np.concatenate((s, e))
print(z)
# [[-2]
# [ 0]
# [-2]
# [ 0]
# [-1]
# [ 2]]
assert np.array_equal(t, P*z % Q)Let z denote this vector and consider the set of points v for which P*v == t. By definition, we say this set of points is “close to” the lattice because z is a short vector. (Remember: by “short” we mean its entries are bounded around 0 by beta.)
Now consider a random (A,t) and consider the set of points v for which P*v == t. We won’t prove it, but it is a fact that this set of points is likely to be “far away from” the lattice in the sense that there is no short vector z for which P*z == t.
Intuitively, solving LWE gets harder as z gets longer. Indeed, increasing the average length of z (by making beta larger) increases the average distance to the lattice, making it look more like a random instance:

On the other hand, making z too long creates another problem.
Breaking lattice cryptography by finding short vectors
Given a random matrix A, the Short Integer Solution (SIS) problem is to find short vectors (i.e., whose entries are bounded by beta) z1 and z2 for which (A*z1 + z2) % Q is zero. Notice that this is equivalent to finding a short vector z in the lattice recognized by P:
z = np.concatenate((z1, z2))
assert np.array_equal((A*z1 + z2) % Q, P*z % Q)If we had a (quantum) computer program for solving SIS, then we could use this program to solve LWE as well: if (A,t) is an LWE instance, then z1.T*t will be small; otherwise, if (A,t) is random, then z1.T*t will be uniformly random. (You can convince yourself of this using a little algebra.) Therefore, in order for our encryption scheme to be secure, it must be hard to find short vectors in the lattice defined by those parameters.
Intuitively, finding long vectors in the lattice is easier than finding short ones, which means that solving the SIS problem gets easier as beta gets closer to Q. On the other hand, as beta gets closer to 0, it gets easier to distinguish LWE instances from random!
This suggests a kind of Goldilocks zone for LWE-based encryption: if the secret and noise vectors are too short, then LWE is easy; but if the secret and noise vectors are too long, then SIS is easy. The optimal choice is somewhere in the middle.
Enough math, just give me my parameters!
To tune our encryption scheme, we want to choose parameters for which the most efficient known algorithms (quantum or classical) for solving LWE are out of reach for any attacker with as many resources as we can imagine (and then some, in case new algorithms are discovered). But how do we know which attacks to look out for?
Fortunately, the community of expert lattice cryptographers and cryptanalysts maintains a tool called lattice-estimator that estimates the complexity of the best known (quantum) algorithms for lattice problems relevant to cryptography. Here’s what we get when we run this tool for ML-KEM (this requires Sage to run):
sage: from estimator import *
sage: res = LWE.estimate.rough(schemes.Kyber768)
usvp :: rop: ≈2^182.2, red: ≈2^182.2, δ: 1.002902, β: 624, d: 1427, tag: usvp
dual_hybrid :: rop: ≈2^174.3, red: ≈2^174.3, guess: ≈2^162.5, β: 597, p: 4, ζ: 10, t: 60, β': 597, N: ≈2^122.7, m: 768The number that we’re most interested in is “rop“, which estimates the amount of computation the attack would consume. Playing with this tool a bit, we eventually find some parameters for our scheme for which the “usvp” and “dual_hybrid” attacks have comparable complexity. However, lattice-estimator identifies an attack it calls “arora-gb” that applies to our scheme, but not to ML-KEM, that has much lower complexity. (N=600, Q=3329, and beta=4):
sage: res = LWE.estimate.rough(LWE.Parameters(n=600, q=3329, Xs=ND.Uniform(-4,4), Xe=ND.Uniform(-4,4)))
usvp :: rop: ≈2^180.2, red: ≈2^180.2, δ: 1.002926, β: 617, d: 1246, tag: usvp
dual_hybrid :: rop: ≈2^226.2, red: ≈2^225.4, guess: ≈2^224.9, β: 599, p: 3, ζ: 10, t: 0, β': 599, N: ≈2^174.8, m: 600
arora-gb :: rop: ≈2^129.4, dreg: 9, mem: ≈2^129.4, t: 4, m: ≈2^64.7We’d have to bump the parameters even further to the scheme to a regime that has comparable security to ML-KEM.
Finally, a word of warning: when designing lattice cryptography, determining whether our scheme is secure requires a lot more than estimating the cost of generic attacks on our LWE parameters. In the absence of a mathematical proof of security in a realistic adversarial model, we can’t rule out other ways of breaking our scheme. Tread lightly, fair traveler, and bring a friend along for the journey.
Making the scheme efficient
Now that we understand how to encrypt with LWE, let’s take a quick look at how to make our scheme efficient.
The main problem with our scheme is that we can only encrypt a bit at a time. This is because we had to split the range(Q) into two chunks, one that encodes 1 and another that encodes 0. We could improve the bit rate by splitting the range into more chunks, but this would make decryption errors more likely.
Another problem with our scheme is that the runtime depends heavily on our security parameters. Encryption requires O(N2) multiplications (multiplication is the most expensive part of a secure implementation of modular arithmetic), and in order for our scheme to be secure, we need to make N quite large.
ML-KEM solves both of these problems by replacing modular arithmetic with arithmetic over a polynomial ring. This means the entries of our matrices will be polynomials rather than integers. We need to define what it means to add, subtract, and multiply polynomials, but once we’ve done that, everything else about the encryption scheme is the same.
In fact, you probably learned polynomial arithmetic in grade school. The only thing you might not be familiar with is polynomial modular reduction. To multiply two polynomials $f(X)$ and $g(X)$, we start by multiplying $f(X)\cdot g(X)$ as usual. Then we’re going to divide $f(X)\cdot g(X)$ by some special polynomial — ML-KEM uses $X^{256}+1$ — and take the remainder. We won’t try to explain this algorithm, but the takeaway is that the result is a polynomial with $256$ coefficients, each of which is an integer in range(Q).
The main advantage of using a polynomial ring for arithmetic is that we can pack more bits into the ciphertext. Our formula for the ciphertext is exactly the same (u=r.T*A + e2, v=r.T*t + e3 + m), but this time the plaintext m encodes a polynomial. Each coefficient of the polynomial encodes a bit, and we’ll handle decryption errors just as we did before, by splitting range(Q) into two chunks, one that encodes 1 and another that encodes 0. This allows us to reliably encrypt 256 bits (32 bytes) per ciphertext.
Another advantage of using polynomials is that it significantly reduces the dimension of the matrix without impacting security. Concretely, the most widely used variant of ML-KEM, ML-KEM-768, uses a 3-by-3 matrix A, so just 9 polynomials in total. (Note that $256 \cdot 3 = 768$, hence the name “ML-KEM-768”.) However, note that we have to be careful in how we choose the modulus: $X^{256}+1$ is special in that it does not exhibit any algebraic structure that is known to permit attacks.
The choices of Q=3329 for the coefficient modulus and $X^{256}+1$ for the polynomial modulus have one more benefit. They allow polynomial multiplication to be carried out using the NTT algorithm, which massively reduces the number of multiplications and additions we have to perform. In fact, this optimization is a major reason why ML-KEM is sometimes faster in terms of CPU time than key exchange with elliptic curves.
We won’t get into how NTT works here, except to say that the algorithm will look familiar to you if you’ve ever implemented RSA. In both cases we use the Chinese Remainder Theorem to split multiplication up into multiple, cheaper multiplications with smaller moduli.
From public key encryption to ML-KEM
The last step to build ML-KEM is to make the scheme secure against chosen ciphertext attacks (CCA). Currently, it’s only secure against chosen plaintext attacks (CPA), which basically means that the ciphertext leaks no information about the plaintext, regardless of the distribution of plaintexts. CCA security is stronger in that it gives the attacker access to decryptions of ciphertexts of its choosing. (Of course, it’s not allowed to decrypt the target ciphertext itself.) The specific transform used in ML-KEM results in a CCA-secure KEM (“Key-Encapsulation Mechanism”).
Chosen ciphertext attacks might seem a bit abstract, but in fact they formalize a realistic threat model for many applications of KEMs (and public key encryption for that matter). For example, suppose we use the scheme in a protocol in which the server authenticates itself to a client by proving it was able to decrypt a ciphertext generated by the client. In this kind of protocol, the server acts as a sort of “decryption oracle” in which its responses to clients depend on the secret key. Unless the scheme is CCA secure, this oracle can be abused by an attacker to leak information about the secret key over time, allowing it to eventually impersonate the server.
ML-KEM incorporates several more optimizations to make it as fast and as compact as possible. For example, instead of generating a random matrix A, we can derive it from a random, 32-byte string (called a “seed”) using a hash-based primitive called a XOF (“eXtendable Output Function”), in the case of ML-KEM this XOF is SHAKE128. This significantly reduces the size of the public key.
Another interesting optimization is that the polynomial coefficients (integers in range(Q)) in the ciphertext are compressed by rounding off the least significant bits of each coefficient, thereby reducing the overall size of the ciphertext.
All told, for the most widely deployed parameters (ML-KEM-768), the public key is 1184 bytes and the ciphertext is 1088 bytes. There’s no obvious way to reduce this, except by reducing the size of the encapsulated key or the size of the public matrix A. The former would make ML-KEM useful for fewer applications, and the latter would reduce the security margin.
Note that there are other lattice schemes that are smaller, but they are based on different hardness assumptions and are still undergoing analysis.
In the previous section, we learned about ML-KEM, the algorithm already in use to make encryption PQ-secure. However, encryption is only one piece of the puzzle: establishing a secure connection also requires authenticating the server — and sometimes the client, depending on the application.
Authentication is usually provided by a digital signature scheme, which uses a secret key to sign a message and a public key to verify the signature. The signature schemes used today aren’t PQ-secure: a quantum computer can be used to compute the secret key corresponding to a server’s public key, then use this key to impersonate the server.
While this threat is less urgent than the threat to encryption, mitigating it is going to be more complicated. Over the years, we’ve bolted a number of signatures onto the TLS handshake in order to meet the evolving requirements of the web PKI. We have PQ alternatives for these signatures, one of which we’ll study in this section, but so far these signatures and their public keys are too large (i.e., take up too many bytes) to make comfortable replacements for today’s schemes. Barring some breakthrough in NIST’s ongoing standardization effort, we will have to re-engineer TLS and the web PKI to use fewer signatures.
For now, let’s dive into the PQ signature scheme we’re likely to see deployed first: ML-DSA, a.k.a. Dillithium. The design of ML-DSA follows a similar template as ML-KEM. We start by building some intermediate primitive, then we transform that primitive into the primitive we want, in this case a signature scheme.
ML-DSA is quite a bit more involved than ML-KEM, so we’re going to try to boil it down even further and just try to get across the main ideas.
Warm up
Whereas ML-KEM is basically El Gamal encryption with elliptic curves replaced with lattices, ML-DSA is basically the Schnorr identification protocol with elliptic curves replaced with lattices. Schnorr’s protocol is used by a prover to convince a verifier that it knows the secret key associated with its public key without revealing the secret key itself. The protocol has three moves and is executed with four algorithms:
-
initialize(): The prover initializes the protocol and sends a commitment to the verifier -
challenge(): The verifier receives the commitment and sends the prover a challenge -
finish(): The prover receives the challenge and sends the verifier the proof -
verify(): Finally, the verifier uses the proof to decide whether the prover knows the secret key
We get the high-level structure of ML-DSA by making this protocol non-interactive. In particular, the prover derives the challenge itself by hashing the commitment together with the message to be signed. The signature consists of the commitment and proof: to verify the signature, the verifier recomputes the challenge from the commitment and message and runs verify()as usual.
Let’s jump right in to building Schnorr’s identification protocol from lattices. If you’ve never seen this protocol before, then this will look a little like black magic at first. We’ll go through it slowly enough to see how and why it works.
Just like for ML-KEM, our public key is an LWE instance (A,t=A*s1 + s2). However, this time our secret key is the pair of short vectors (s1,s2), i.e., it includes the error term. Otherwise, key generation is exactly the same:
def key_gen():
A = gen_mat(N, N, 0, Q)
s1 = gen_mat(N, 1, -beta, beta+1)
s2 = gen_mat(N, 1, -beta, beta+1)
t = (A*s1 + s2) % Q
return ((A, t), (s1, s2))To initialize the protocol, the prover generates another LWE instance (A,w=A*y1 + y2). You’ll see why in just a moment. The prover sends the hash of w as its commitment:
def initialize(A):
y1 = gen_mat(N, 1, -beta, beta+1)
y2 = gen_mat(N, 1, -beta, beta+1)
w = (A*y1 + y2) % Q
return (H(w), (y1, y2))Here H is some cryptographic hash function, like SHA-3. The prover stores the secret vectors (y1,y2) for use in its next move.
Now it’s time for the verifier’s challenge. The challenge is just an integer, but we need to be careful about how we choose it. For now let’s just pick it at random:
def challenge():
return random.randrange(0, Q)Remember: when we turn this protocol into a digital signature, the challenge is derived from the commitment, H(w), and the message. The range of this hash function must be the same as the set of outputs of challenge().
Now comes the fun part. The proof is a pair of vectors (z1,z2) satisfying A*z1 + z2 == c*t + w. We can easily produce this proof if we know the secret key:
z1 = (c*s1 + y1) % Q
z2 = (c*s2 + y2) % Q
Then A*z1 + z2 == A*(c*s1 + y1) + (c*s2 + y2) == c*(A*s1 + s2) + (A*y1 + y2) == c*t + w. Our goal is to design the protocol such that it’s hard to come up with (z1,z2) without knowing (s1,s2), even after observing many executions of the protocol.
Here are the finish() and verify() algorithms for completeness:
def finish(s1, s2, y1, y2, c):
z1 = (c*s1 + y1) % Q
z2 = (c*s2 + y2) % Q
return (z1, z2)
def verify(A, t, hw, c, z1, z2):
return H((A*z1 + z2 - c*t) % Q) == hw
# Test
((A, t), (s1, s2)) = key_gen()
(hw, (y1, y2)) = initialize(A) # hw: prover -> verifier
c = challenge() # c: verifier -> prover
(z1, z2) = finish(s1, s2, y1, y2, c) # (z1, z2): prover -> verifier
assert verify(A, t, hw, c, z1, z2) # verifierNotice that the verifier doesn’t actually check A*z1 + z2 == c*t + w directly; we have to rearrange the equation so that we can set the commitment to H(w) rather than w. We’ll explain the need for hashing in the next section.
Making this scheme secure
The question of whether this protocol is secure boils down to whether it’s possible to impersonate the prover without knowledge of the secret key. Let’s put our attacker hat on and poke around.
Perhaps there’s a way to compute the secret key, either from the public key directly or by eavesdropping on executions of the protocol with the honest prover. If LWE is hard, then clearly there’s no way we’re going to extract the secret key from the public key t. Likewise, the commitment H(w)doesn’t leak any information that would help us extract the secret key from the proof (z1,z2).
Let’s take a closer look at the proof. Notice that the vectors (y1,y2) “mask” the secret key vectors, sort of how the shared secret masks the plaintext in ML-KEM. However, there’s one big exception: we also scale the secret key vectors by the challenge c.
What’s the effect of scaling these vectors? If we squint at a few proofs, we start to see a pattern emerge. Let’s look at z1 first (N=3, Q=3329, beta=4):
((A, t), (s1, s2)) = key_gen()
print('s1={}'.format(s1.T % Q))
for _ in range(10):
(w, (y1, y2)) = initialize(A)
c = challenge()
(z1, z2) = finish(s1, s2, y1, y2, c)
print('c={}, z1={}'.format(c, z1.T))
# s1=[[ 1 0 3326]]
# c=1123, z1=[[1121 3327 3287]]
# c=1064, z1=[[1060 4 137]]
# c=1885, z1=[[1884 3327 999]]
# c=269, z1=[[ 270 3325 2524]]
# c=1506, z1=[[1510 3325 2141]]
# c=3147, z1=[[3149 4 547]]
# c=703, z1=[[ 700 4 1219]]
# c=1518, z1=[[1518 3327 2104]]
# c=1726, z1=[[1726 0 1478]]
# c=2591, z1=[[2589 4 2217]]Indeed, with enough proof samples, we should be able to make a pretty good guess of the value of s1. In fact, for these parameters, there is a simple statistical analysis we can do to compute s1 exactly. (Hint: Q is a prime number, which means c*pow(c,-1,Q)==1 whenever c>0.) We can also apply this analysis to s2, or compute it directly from t, s1, and A.
The main flaw in our protocol is that, although our secret vectors are short, scaling them makes them so long that they’re not completely masked by (y1,y2). Since c spans the entire range(Q), so do the entries of c*s1. and c*s2, which means in order to mask these entries, we need the entries of (y1,y2) to span range(Q) as well. However, doing this would make solving LWE for (A,w) easy, by solving SIS. We somehow need to strike a balance between the length of the vectors of our LWE instances and the leakage induced by the challenge.
Here’s where things get tricky. Let’s refer to the set of possible outputs of challenge() as the challenge space. We need the challenge space to be fairly large, large enough that the probability of outputting the same challenge twice is negligible.
Why would such a collision be a problem? It’s a little easier to see in the context of digital signatures. Let’s say an attacker knows a valid signature for a message m. The signature includes the commitment H(m), so the attacker also knows the challenge is c == H(H(w),m). Suppose it manages to find a different message m* for which c == H(H(w),m*). Then the signature is also valid for m! And this attack is easy to pull off if the challenge space, that is, the set of possible outputs of H, is too small.
Unfortunately, we can’t make the challenge space larger simply by increasing the size of the modulus Q: the larger the challenge might be, the more information we’d leak about the secret key. We need a new idea.
The best of both worlds
Remember that the hardness of LWE depends on the ratio between beta and Q. This means that y1 and y2 don’t need to be short in absolute terms, but short relative to random vectors.
With that in mind, consider the following idea. Let’s take a larger modulus, say Q=2**31 - 1, and we’ll continue to sample from the same challenge space, range(2**16).
First, notice that z1 is now “relatively” short, since its entries are now in range(-gamma, gamma+1), where gamma = beta*(2**16-1), rather than uniform over range(Q). Let’s also modify initialize() to sample the entries of (y1,y2) from the same range and see what happens:
def initialize(A):
y1 = gen_mat(N, 1, -gamma, gamma+1)
y2 = gen_mat(N, 1, -gamma, gamma+1)
w = (A*y1 + y2) % Q
return (H(w), (y1, y2))
((A, t), (s1, s2)) = key_gen()
print('s1={}'.format(s1.T % Q))
for _ in range(10):
(w, (y1, y2)) = initialize(A)
c = challenge()
(z1, z2) = finish(s1, s2, y1, y2, c)
print('c={}, z1={}'.format(c, z1.T))
# s1=[[3 0 1]]
# c=31476, z1=[[175933 141954 93186]]
# c=27360, z1=[[ 136404 2147438807 283758]]
# c=33536, z1=[[2147430945 2147377022 190671]]
# c=23283, z1=[[186516 73400 4955]]
# c=24756, z1=[[ 328377 2147438906 2147388768]]
# c=12428, z1=[[2147340715 188675 90282]]
# c=24266, z1=[[ 175498 2147261581 2147301553]]
# c=45331, z1=[[357595 185269 177155]]
# c=45641, z1=[[ 21592 2147249191 2147446200]]
# c=57893, z1=[[297750 113335 144894]]This is definitely going in the right direction, since there are no obvious correlations between z1 and s1. (Likewise for z2 and s2.) However, we’re not quite there.
One problem is that the challenge space is still quite small. With only 2**16 challenges to choose from, we’re likely to see a collision even after only a handful of protocol executions. We need the challenge space to be much, much larger, say around 2**256. But then Q has to be an insanely large number in order for the beta to Q ratio to be secure.
ML-DSA is able to side step this problem due to its use of arithmetic over polynomial rings. It uses the same modulus polynomial as ML-KEM, so the challenge is a polynomial with 256 coefficients. The coefficients are chosen carefully so that the challenge space is large, but multiplication by the challenge scales the secret vector by a small amount. Note that we still end up using a slightly larger modulus (Q=8380417) for ML-DSA than for ML-KEM, but only by about twelve bits.
However, there is a more fundamental problem here, which is that we haven’t completely ruled out that signatures may leak information about the secret key.
Cause and effect
Suppose we run the protocol a number of times, and in each run, we happen to choose a relatively small value for some entry of y1. After enough runs, this would eventually allow us to reconstruct the corresponding entry of s1. To rule this out as a possibility, we need to make y1 even longer. (Likewise for y2.) But how long?
Suppose we know that the entries of z1 and z2 are always in range(-beta_loose,beta_loose+1) for some beta_loose > beta. Then we can simulate an honest run of the protocol as follows:
def simulate(A, t):
z1 = gen_mat(N, 1, -beta_loose, beta_loose+1)
z2 = gen_mat(N, 1, -beta_loose, beta_loose+1)
c = challenge()
w = (A*z1 + z2 - c*t) % Q
return (H(w), c, (z1, z2))
# Test
((A, t), (s1, s2)) = key_gen()
(hw, c, (z1, z2)) = simulate(A, t)
assert verify(A, t, hw, c, z1, z2)This procedure perfectly simulates honest runs of the protocol, in the sense that the output of simulate() is indistinguishable from the transcript of a real run of the protocol with the honest prover. To see this, notice that the w, c, z1, and z2 all have the same mathematical relationship (the verification equation still holds) and have the same distribution.
And here’s the punch line: since this procedure doesn’t use the secret key, it follows that the attacker learns nothing from eavesdropping on the honest prover that it can’t compute from the public key itself. Pretty neat!
What’s left to do is arrange for z1 and z2 to fall in this range. First, we modify initialize() by increasing the range of y1 and y2 by beta_loose:
def initialize(A):
y1 = gen_mat(N, 1, -gamma+beta_loose, gamma+beta_loose+1)
y2 = gen_mat(N, 1, -gamma+beta_loose, gamma+beta_loose+1)
w = (A*y1 + y2) % Q
return (H(w), (y1, y2))This ensures the proof vectors z1 and z2 are roughly uniform over range(-beta_loose, beta_loose+1). However, they may fall slightly outside of this range, so need to modify finalize() to abort if not. Correspondingly, verify() should reject proof vectors that are out of range:
def finish(s1, s2, y1, y2, c):
z1 = (c*s1 + y1) % Q
z2 = (c*s2 + y2) % Q
if not in_range(z1, beta_loose) or not in_range(z2, beta_loose):
return (None, None)
return (z1, z2)
def verify(A, t, hw, c, z1, z2):
if not in_range(z1, beta_loose) or not in_range(z2, beta_loose):
return False
return H((A*z1 + z2 - c*t) % Q) == hwIf finish() returns (None,None), then the prover and verifier are meant to abort the protocol and retry until the protocol succeeds:
((A, t), (s1, s2)) = key_gen()
while True:
(hw, (y1, y2)) = initialize(A) # hw: prover -> verifier
c = challenge() # c: verifier -> prover
(z1, z2) = finish(s1, s2, y1, y2, c) # (z1, z2): prover -> verifier
if z1 is not None and z2 is not None:
break
assert verify(A, t, hw, c, z1, z2)Interestingly, we should expect aborts to be quite common. The parameters of ML-DSA are tuned so that the protocol runs five times on average before it succeeds.
Another interesting point is that the security proof requires us to simulate not only successful protocol runs, but aborted protocol runs as well. More specifically, the protocol simulator must abort with the same probability as the real protocol, which implies that the rejection probability is independent of the secret key.
The simulator also needs to be able to produce realistic looking commitments for aborted transcripts. This is exactly why the prover commits to the hash of w rather than w itself: in the security proof, we can easily simulate hashes of random inputs.
Making this scheme efficient
ML-DSA benefits from many of the same optimizations as ML-KEM, including using polynomial rings, NTT for polynomial multiplication, and encoding polynomials with a fixed number of bits. However, ML-DSA has a few more tricks to make things smaller.
First, in ML-DSA, instead of the pair of short vectors z1 and z2, the proof consists of a single vector z=c*s1 + y, where y was committed to in the previous step. In turn, we only end up with a single proof vector z rather than two as before. Getting this to work requires a special encoding of the commitment so that we can’t compute y from it. ML-DSA uses a related trick to reduce the size of the t vector of the public key, but the details are more complicated.
For the parameters we expect to deploy first (ML-DSA-44), the public key is 1312 bytes long and the signature is a whopping 2420 bytes. In contrast to ML-KEM, it is possible to shave off some more bytes. This does not come for free and requires complicating the scheme. An example is HAETAE, which changes the distributions used. Falcon takes it a step further with even smaller signatures, using a completely different approach, which although elegant is also more complex to implement.
Lattice cryptography underpins the first generation of PQ algorithms to get widely deployed on the Internet. ML-KEM is already widely used today to protect encryption from quantum computers, and in the coming years we expect to see ML-DSA deployed to get ahead of the threat of quantum computers to authentication.
Lattices are also the basis of a new frontier for cryptography: computing on encrypted data.
Suppose you wanted to aggregate some metrics submitted by clients without learning the metrics themselves. With LWE-based encryption, you can arrange for each client to encrypt their metrics before submission, aggregate the ciphertexts, then decrypt to get the aggregate.
Suppose instead that a server has a database that it wants to provide clients access to without revealing to the server which rows of the database the client wants to query. LWE-based encryption allows the database to be encoded in a manner that permits encrypted queries.
These applications are special cases of a paradigm known as FHE (“Fully Homomorphic Encryption”), which allows for arbitrary computations on encrypted data. FHE is an extremely powerful primitive, and the only way we know how to build it today is with lattices. However, for most applications, FHE is far less practical than a special-purpose protocol would be (lattice-based or not). Still, over the years we’ve seen FHE get better and better, and for many applications it is already a decent option. Perhaps we’ll dig into this and other lattice schemes in a future blog post.
We hope you enjoyed this whirlwind tour of lattices. Thanks for reading!
Improving Data Loss Prevention accuracy with AI-powered context analysis
Post Syndicated from Warnessa Weaver original https://blog.cloudflare.com/improving-data-loss-prevention-accuracy-with-ai-context-analysis/
We are excited to announce our latest innovation to Cloudflare’s Data Loss Prevention (DLP) solution: a self-improving AI-powered algorithm that adapts to your organization’s unique traffic patterns to reduce false positives.
Many customers are plagued by the shapeshifting task of identifying and protecting their sensitive data as it moves within and even outside of their organization. Detecting this data through deterministic means, such as regular expressions, often fails because they cannot identify details that are categorized as personally identifiable information (PII) nor intellectual property (IP). This can generate a high rate of false positives, which contributes to noisy alerts that subsequently may lead to review fatigue. Even more critically, this less than ideal experience can turn users away from relying on our DLP product and result in a reduction in their overall security posture.
Built into Cloudflare’s DLP Engine, AI enables us to intelligently assess the contents of a document or HTTP request in parallel with a customer’s historical reports to determine context similarity and draw conclusions on data sensitivity with increased accuracy.
In this blog post, we’ll explore DLP AI Context Analysis, its implementation using Workers AI and Vectorize, and future improvements we’re developing.
Data Loss Prevention (DLP) at Cloudflare detects sensitive information by scanning potential sources of data leakage across various channels such as web, cloud, email, and SaaS applications. While we leverage several detection methods, pattern-based methods like regular expressions play a key role in our approach. This method is effective for many types of sensitive data. However, certain information can be challenging to classify solely through patterns. For instance, U.S. Social Security Numbers (SSNs), structured as AAA-GG-SSSS, sometimes with dashes omitted, are often confused with other similarly formatted data, such as U.S. taxpayer identification numbers, bank account numbers, or phone numbers.
Since announcing our DLP product, we have introduced new capabilities like confidence thresholds to reduce the number of false positives users receive. This method involves examining the surrounding context of a pattern match to assess Cloudflare’s confidence in its accuracy. With confidence thresholds, users specify a threshold (low, medium, or high) to signify a preference for how tolerant detections are to false positives. DLP uses the chosen threshold as a minimum, surfacing only those detections with a confidence score that meets or exceeds the specified threshold.
However, implementing context analysis is also not a trivial task. A straightforward approach might involve looking for specific keywords near the matched pattern, such as “SSN” near a potential SSN match, but this method has its limitations. Keyword lists are often incomplete, users may make typographical errors, and many true positives do not have any identifying keywords nearby (e.g., bank accounts near routing numbers or SSNs near names).
To address the limitations of a hardcoded strategy for context analysis, we have developed a dynamic, self-improving algorithm that learns from customer feedback to further improve their future experience. Each time a customer reports a false positive via decrypted payload logs, the system reduces its future confidence for hits in similar contexts. Conversely, reports of true positives increase the system’s confidence for hits in similar contexts.
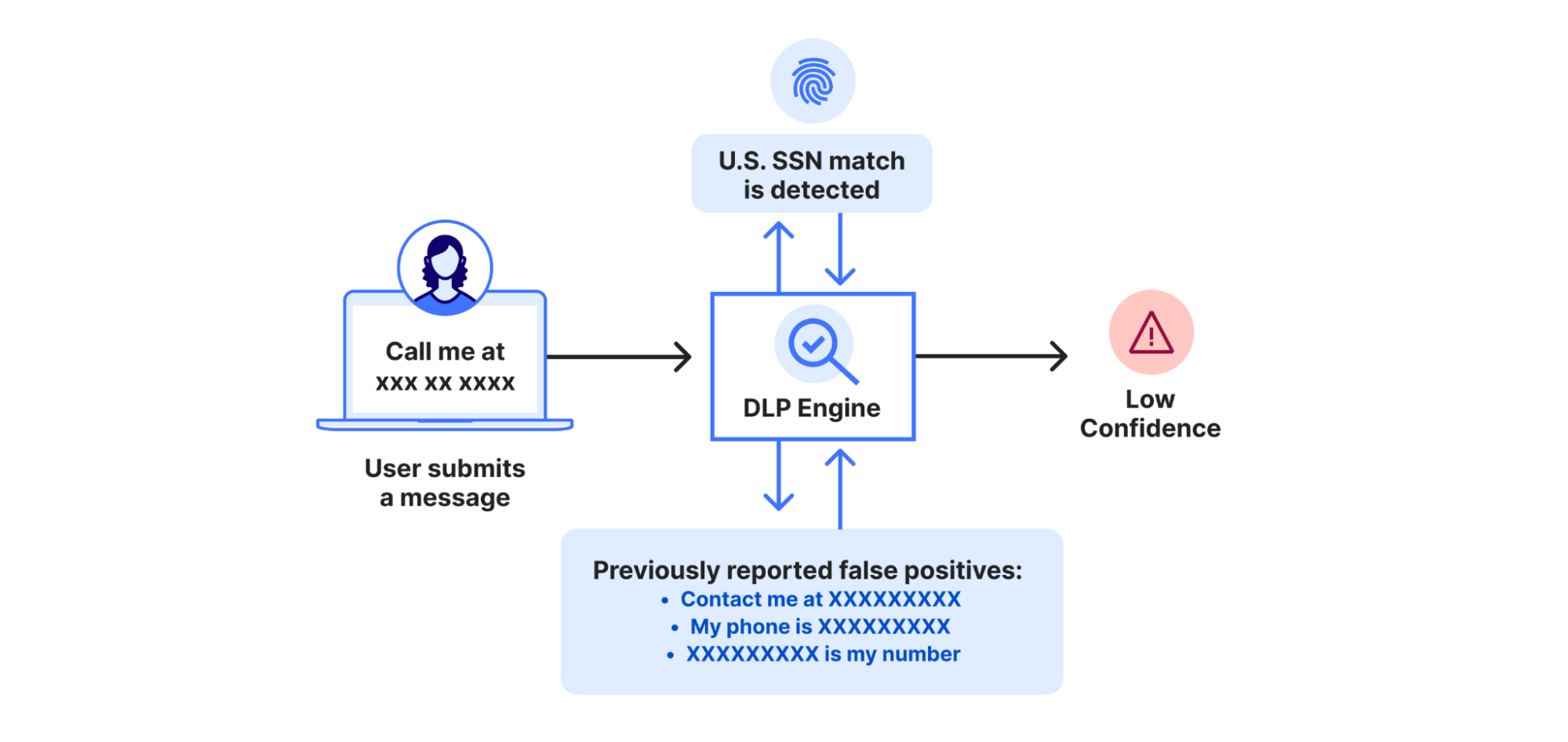
To determine context similarity, we leverage Workers AI. Specifically, a pretrained language model that converts the text into a high-dimensional vector (i.e. text embedding). These embeddings capture the meaning of the text, ensuring that two sentences with the same meaning but different wording map to vectors that are close to each other.
When a pattern match is detected, the system uses the AI model to compute the embedding of the surrounding context. It then performs a nearest neighbor search to find previously logged false or true positives with similar meanings. This allows the system to identify context similarities even if the exact wording differs, but the meaning remains the same.
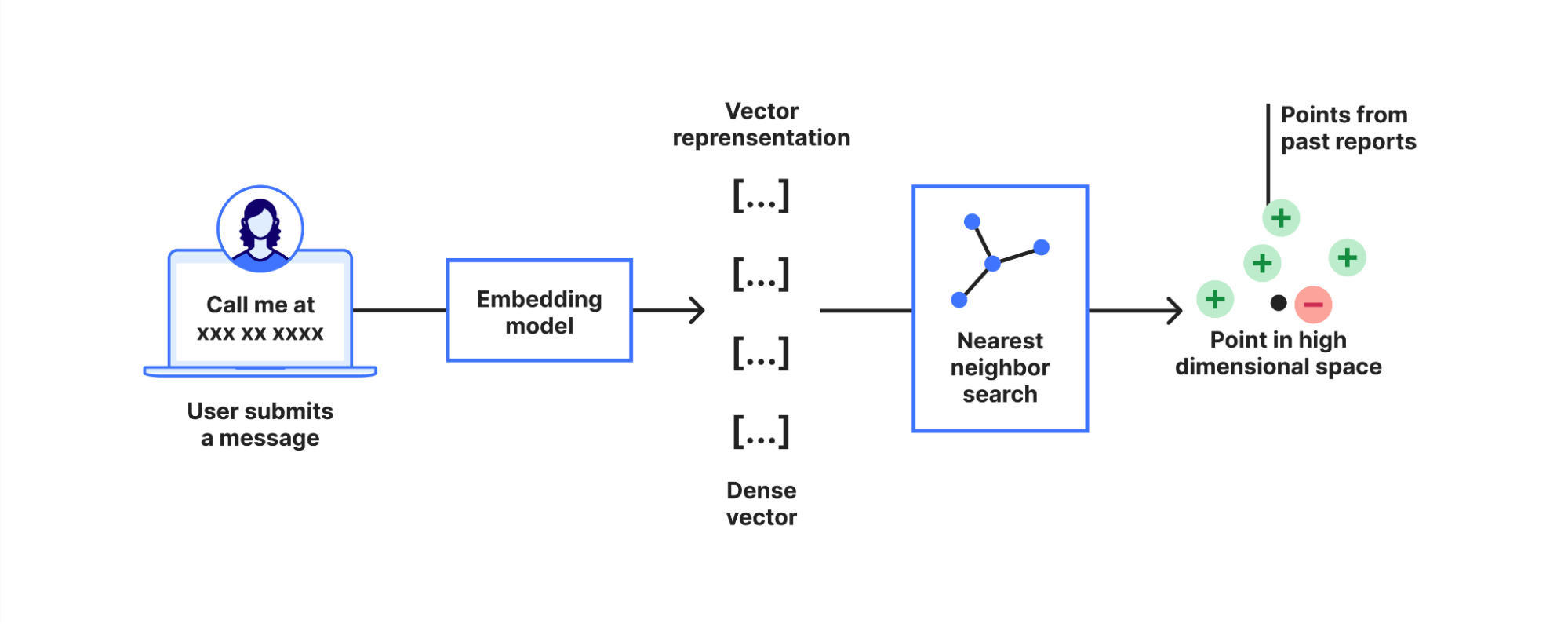
In our experiments using Cloudflare employee traffic, this approach has proven robust, effectively handling new pattern matches it hadn’t encountered before. When the DLP admin reports false and true positives through the Cloudflare dashboard while viewing the payload log of a policy match, it helps DLP continue to improve, leading to a significant reduction in false positives over time.
In developing this new feature, we used components from Cloudflare’s developer platform — Workers AI and Vectorize — which helps simplify our design. Instead of managing the underlying infrastructure ourselves, we leveraged Cloudflare Workers as the foundation, using Workers AI for text embedding, and Vectorize as the vector database. This setup allows us to focus on the algorithm itself without the overhead of provisioning underlying resources.
Thanks to Workers AI, converting text into embeddings couldn’t be easier. With just a single line of code we can transform any text into its corresponding vector representation.
const result = await env.AI.run(model, {text: [text]}).data;This handles everything from tokenization to GPU-powered inference, making the process both simple and scalable.
The nearest neighbor search is equally straightforward. After obtaining the vector from Workers AI, we use Vectorize to quickly find similar contexts from past reports. In the meantime, we store the vector for the current pattern match in Vectorize, allowing us to learn from future feedback.
To optimize resource usage, we’ve incorporated a few more clever techniques. For example, instead of storing every vector from pattern hits, we use online clustering to group vectors into clusters and store only the cluster centroids along with counters for tracking hits and reports. This reduces storage needs and speeds up searches. Additionally, we’ve integrated Cloudflare Queues to separate the indexing process from the DLP scanning hot path, ensuring a robust and responsive system.
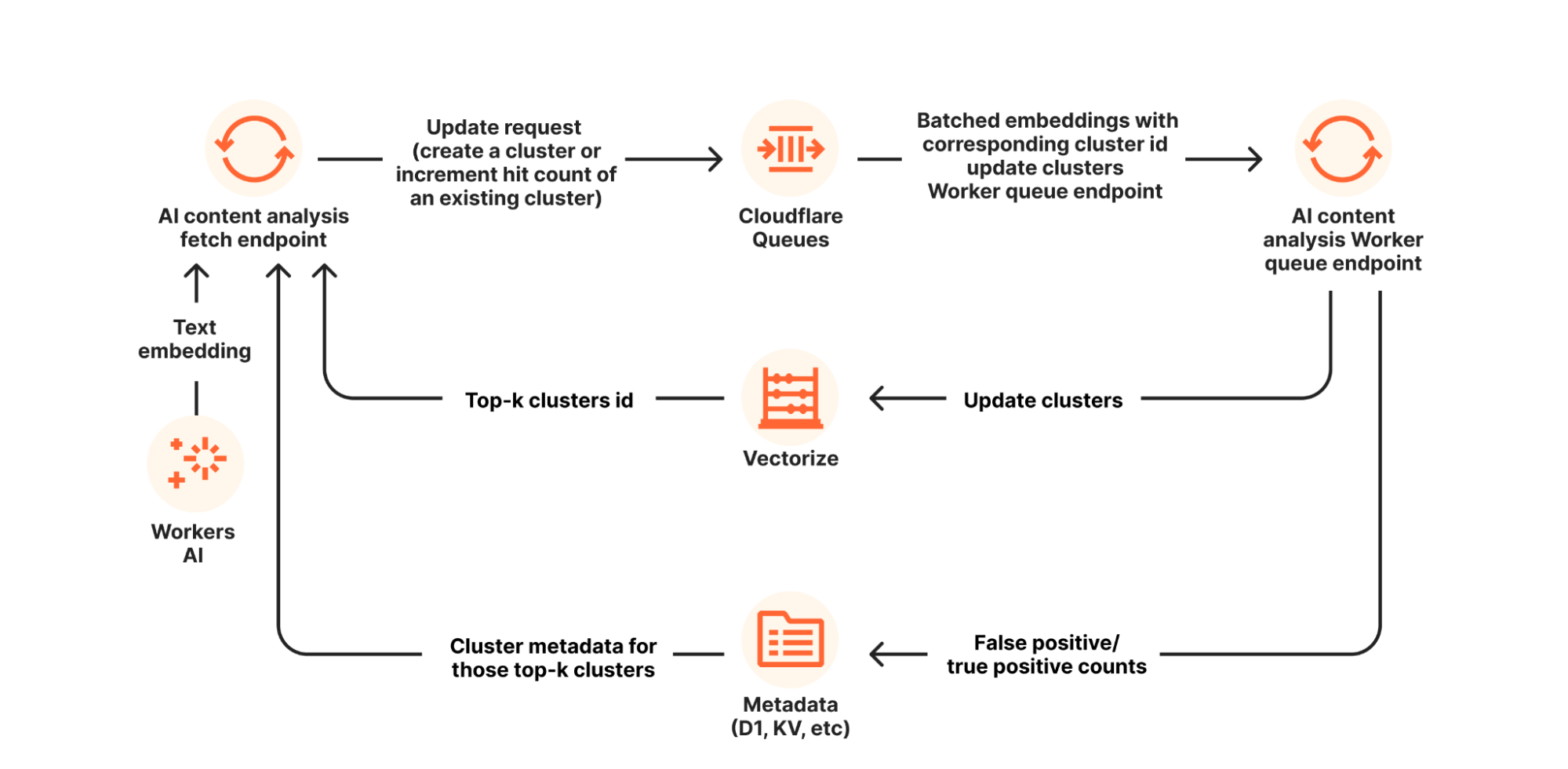
Privacy is a top priority. We redact any matched text before conversion to embeddings, and all vectors and reports are stored in customer-specific private namespaces across Vectorize, D1, and Workers KV. This means each customer’s learning process is independent and secure. In addition, we implement data retention policies so that vectors that have not been accessed or referenced within 60 days are automatically removed from our system.
AI-driven context analysis significantly improves the accuracy of our detections. However, this comes at the cost of some increase in latency for the end user experience. For requests that do not match any enabled DLP entries, there will be no latency increase. However, requests that match an enabled entry in a profile with AI context analysis enabled will typically experience an increase in latency of about 400ms. In rare extreme cases, for example requests that match multiple entries, that latency increase could be as high as 1.5 seconds. We are actively working to drive the latency down, ideally to a typical increase of 250ms or better.
Another limitation is that the current implementation supports English exclusively because of our choice of the language model. However, Workers AI is developing a multilingual model which will enable DLP to increase support across different regions and languages.
Looking ahead, we also aim to enhance the transparency of AI context analysis. Currently, users have no visibility on how the decisions are made based on their past false and true positive reports. We plan to develop tools and interfaces that provide more insight into how confidence scores are calculated, making the system more explainable and user-friendly.
With this launch, AI context analysis is only available for Gateway HTTP traffic. By the end of 2025, AI context analysis will be available in both CASB and Email Security so that customers receive the same AI enhancements across their entire data landscape.
DLP’s AI context analysis is in closed beta. Sign up here for early access to experience immediate improvements to your DLP HTTP traffic matches. More updates are coming soon as we approach general availability!
To get access to DLP via Cloudflare One, contact your account manager.