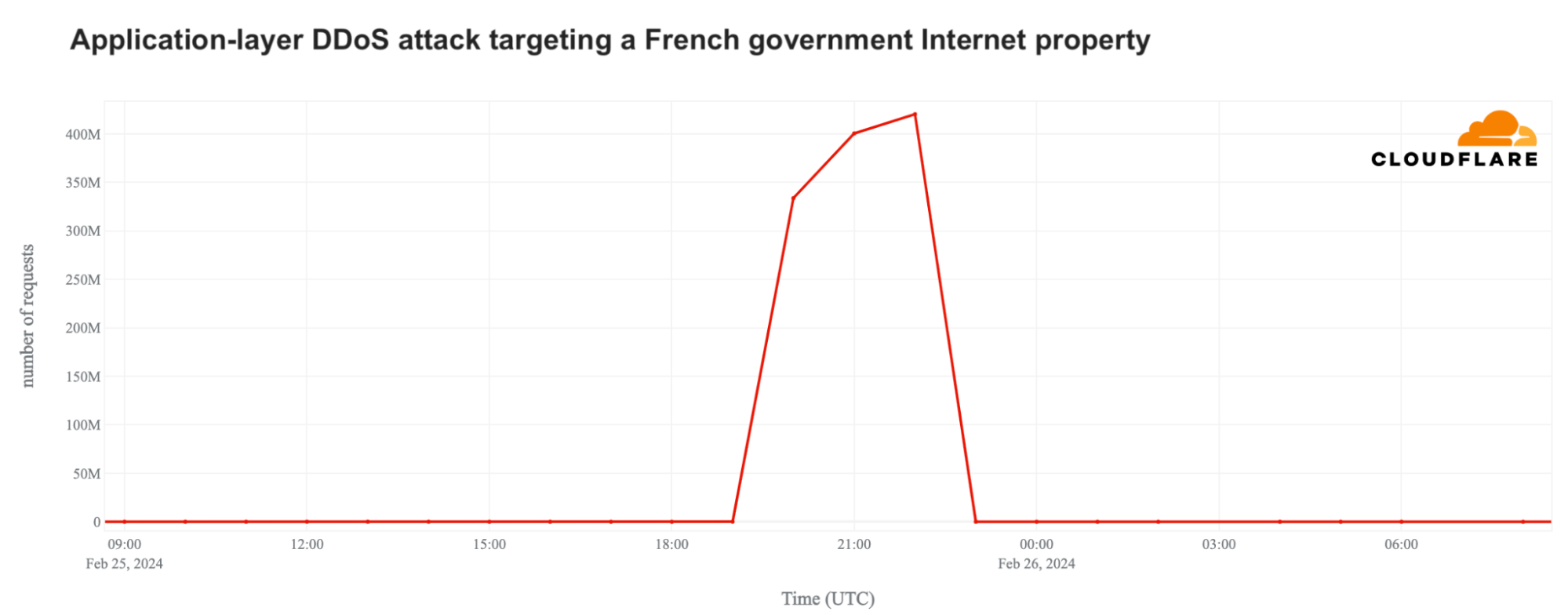
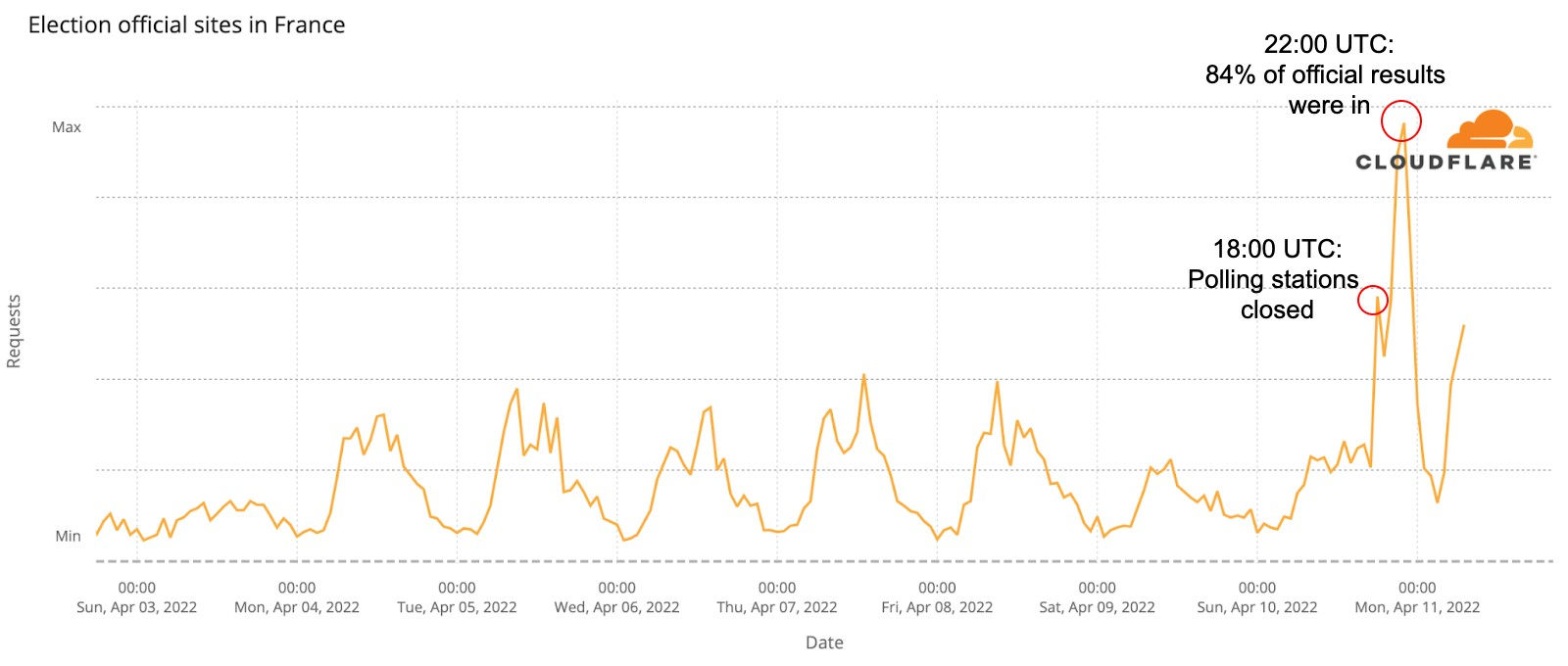
Post Syndicated from original https://www.toest.bg/za-praktikite-na-otkaza-i-izkustvoto-na-zhivota/

Крис Клийв (р. 1973) е английски писател, автор на разкази и на четири романа, всички от които са издадени у нас от издателство ICU – „Възпламеняване“, „Другата ръка“, „На смелите се прощава“, а сега и „Злато“. Възпитаник е на престижния Бейлиол Колидж в Оксфорд, където завършва психология, която също практикува. От 2007 до 2010 г. списва рубрика в „Гардиън“, посветена на децата и родителството. Живее в Лондон със съпругата си и трите им деца.
В първото ни интервю преди няколко години говорихме за предстоящия тогава превод на „Злато“ (последния Ви роман, преведен от Невена Дишлиева и Велин Кръстев). Тогава казахте, че това е Вашата най-позитивна, най-малко изпълнена с трупове книга. Сега в увода към нея добавяте и че е единствената, в която някой наистина печели в живота. Това означава ли, че не сте привърженик на хепиенда? Как гледате на финалите – различават ли се в живота и в литературата?
Страхотен въпрос! Мисля, че литературата започва точно както историите започват в реалния живот: двама души се срещат във влака или някой бяга от затвора – това са естествени и нормални начала. Финалите обаче са толкова различни! Романите трябва все някога да свършат, докато историите в истинския живот никога не приключват. Те се раздвояват ли, раздвояват, подобно на клони на дърво. Това е всъщност повече от липсата на свършек. Историите също така променят и значението си, както когато самите вие станете нечии предци и житейската ви история се превърне в историята на произхода на тези след вас. Така че, действително, да започнеш един роман е много лесно и естествено, но да го завършиш си е истинско изкуство. Много ми е трудно да пиша финали. Не харесвам книги, в които всичко е завършено, приключено, обяснено. Обичам книги, които ме оставят с неясно усещане – нещо като камъче в обувката, нещо, за което да мисля през следващите няколко дни. Така че се опитвам и аз да пиша по този начин – не твърде весело и не прекалено тъжно. Просто да оставя нещо интересно, с което съзнанието на читателя да е ангажирано за известно време.
Писал сте „Злато“ през 2010 г., две години преди Летните олимпийски игри в Лондон. „Възпламеняване“ е написана през 2005 г., когато тероризмът все още беше водеща новина (спомняме си, че публикуването на романа съвпадна с атентатите в Лондон). „На смелите се прощава“ пък е за Втората световна война. Съзнателно ли избирате конкретни, но мащабни събития за сюжетите си и по-лесно ли е да разгръщате обикновените човешки драми на техен фон?
Да, обичам да показвам обикновените животи в рамките на мащабни събития. Намирам художествените романи за интересни, защото ни позволяват да видим несъвършенствата и изключенията в чистите наративи на голямата история. Хората са толкова интересни същества – те правят наистина странни неща, решават дилемата и драмата на съществуването по напълно неочаквани начини. Вярвам, че животът на обикновения човек е значим и очарователен. Като писател използвам големите и силни наративи, които всички познаваме (тероризъм, принудителна миграция, спорт, война), под формата на рамка, съхраняваща по-малките и деликатни човешки истории. По същия начин може да използваме колчета, за да отгледаме грах в градината.
Говорейки за Лондон във въведението към „Злато“, споменавате, че всичките Ви книги са по един или друг начин свързани с града, който противопоставяте на други, доста по user-friendly места. И все пак бихте ли се съгласил, че едно такова огромно, космополитно, изобилно откъм разнообразие, култури и съдби пространство Ви дава по-голямо предимство в прозата, отколкото, да речем, ако като автор работите с едно далеч по-скромно, регионално, непознато място?
Трябва да бъда честен и да кажа, че не знам. Не знам какво би било да напиша книга, чието действие се развива на място, на което не живея. Странно е, нали? Мога да си представя да пиша от гледната точка на най-различни хора, но не мога да си представя история, която не е свързана с родния ми град. Не знам какво говори това за мен като писател. Може би чувствам, че всички истории са наистина за места и времена, и за начина, по който човешкото сърце се проявява в тях. Като писател трябва да усетя мястото буквално в костите си, за да се почувствам уверен, че съм способен да зная как би се чувствало едно или друго човешко сърце на него.
Треньорът Том, един от героите ви в „Злато“, казва: „На моята възраст забележителното събитие не е онова, което те плаши.“ Какво Ви плаши лично Вас днес, на сегашната Ви възраст (може би в сравнение с – да речем – времето, когато написахте книгата)?
Отново страхотен въпрос! Когато написах книгата, не се страхувах много. Бях на около четирийсет, възраст, на която всичко ми изглеждаше възможно. Сега съм на петдесет и много добре осъзнавам, че вече не притежавам това безстрашие. Това, което ме плаши сега, е, че ще се откажем един от друг, че ще разлюбим собствената си човечност. Живеем в епоха на силно емоционално насилие и разединение. Мисля, че сме изтощени един от друг. Мисля, че на хората им е трудно да оценят и да се зарадват на големите, оригиналните, изобретателните сърца, които са ни дадени, защото толкова често тези сърца са ни разочаровали. Всъщност това е причината да уча за психотерапевт и сега да практикувам тази професия, докато същевременно пиша. Интересувам се от проекти, които ни помагат да обикнем отново човека и човешкото – и у себе си, и у другите.
В книгата става дума за два вида успех, пресъздадени през образите и съдбите на двете Ви героини. Ако всичко в този живот минава за някаква форма на постижение или триумф (като това да се излекуваш например), то какво тогава отличава спорта от другите ни житейски победи? Твърде буквален ли е успехът в него?
Спортът е интересен, защото именно абсолютното изискване за абсолютен успех е онова, което прави другите успехи възможни. Добър пример е миналогодишния „Тур дьо Франс“ – имам предвид съперничеството между Йонас Вингегор и Тадей Погакар. Те се отнасяха един към друг безкрайно учтиво и с уважение. Това беше успех на човещината, на който наистина се радвах повече, отколкото на успеха в реалното състезание. Имаше нужда обаче от изискването за спортна победа, защото именно то направи забележителен начина, по който двамата се държаха един с друг. Лесно е да се отнасяш към някого на опашката пред автобуса с любов и уважение – много по-трудно е да направиш същото за най-заклетия си съперник. Ето как спортът ни дава изключителни уроци какви можем да бъдем като човешки същества. Друг чудесен пример са маратоните „Баркли“ – състезание, което е почти невъзможно да бъде завършено. Тази година невероятната Джасмин Парис стана първата жена в историята, постигнала това. Отново подчертавам, че не се интересувам толкова от маратоните сами по себе си, но спортният успех трябва да бъде абсолютно безспорен именно за да направи човешкия успех толкова значим.
Смятате ли, че има момент, в който човек трябва да отстъпи и може би дори да се откаже, имайки предвид, че една от днешните мантри е Never Give Up, Never Give In – никога, нито за миг да не се предаваме?
Абсолютно! Отказването е това, което трябва да практикуваме най-вече. Повечето ни идеи, планове и проекти, оказва се, всъщност не струват и няма смисъл да жертваме живота си на олтара на ината. Изкуството на живота, на това да бъдем хора, е в това да открием малкото неща, от които никога няма да се откажем.
А как може успехът да ни тегли надолу?
Наистина е важно да извоюваме победи и да бележим успехи от време на време. Имаме нужда от доказателства за собствената ни компетентност и умения. В противен случай дори най-смелите сред нас губят кураж и храброст. Но при успеха има два проблема: единият е, че не ни учи на кой знае какво, а другият – че започваме да се страхуваме да не го загубим. Твърде многото успехи ни карат да се боим да рискуваме онова, което вече имаме; твърде многото провали ни карат да губим смелост. Между тези два вида страх ние трябва да преценяваме намеренията и проектите си. Добре е да успяваме и да печелим в около половината от времето, поне така мисля аз.
Една от героините Ви често е на второ място заради своята емпатия и доброта. Възможно ли е любовта да ни прави неспособни да се състезаваме, да ни прави „губещи“?
Не мисля така. Любовта може да ни направи и свирепи, и ожесточени. Вярно е, че спортистите трябва да отнемат победата от съперниците си. Но те също така дават нещо. На спорта, на зрителите, на своите колеги състезатели. Да се състезаваш с цялото си сърце е дар, а този дар може да бъде даден с любов. Вярно е обаче, че има много форми на любов. Мисля, че най-деликатните моменти в спорта са тези, в които любовта към състезанието се балансира с други видове любов.
В предговора разказвате донякъде забавната история за една двойка, която си разпъва сгъваеми столчета на улицата и седи на тях, докато чака да се приближат размирни и опасни улични протестиращи. Какъв е препоръчителният подход в очакване на насилието, на неконтролируемото, на неизбежното?
Любов един към друг – във всяка минута, която ни остава.
Спомняте си лозунга от Втората световна война Keep Calm and Carry On, който споменавате и в „На смелите се прощава“, нали? Възможно ли е забравянето да е част от инстинкта ни да продължим? Или паметта е обратното – необходим пътен знак в процеса на продължаването?
Мисля, че паметта е дълбока форма на любов. Ето защо тоталитарните режими и упражняващите газлайтинг винаги се опитват да я изтрият или контролират. Паметта не е запис на някакви неопровержими факти, подобно на видеозаписа. Тя е непрекъснато променяща се история, която си разказваме, за нещата, имали значение за нас някога. За да продължим, трябва да сме в любяща връзка точно с тези неща – които имат значение за нас. Мисля, че нашата памет и нашата духовност са изключително тясно свързани.
Ще се срещате с читатели в няколко български града. Смятате ли, че публиките ви по света се различават значително една от друга и Ви четат по различен начин, или… романите ви предлагат нещо като есперанто, универсален език?
Мисля, че историите ми са доста универсални и общочовешки, но също така могат и да разделят. Открих, че хората или ги обичат, или ги мразят, така че дори двама души в един и същи град могат да ги прочетат по много различен начин! Изключително съм благодарен за предстоящото ми посещение в България и наистина очаквам с нетърпение да се срещна с читателите. Благодаря ви още веднъж за това, че прочетохте моите книги, и за невероятните въпроси! Това значи страшно много за мен.
Може да видите Крис Клийв на живо в България и да си вземете автограф на следните дати и места:
11 юни, 18.30 ч.
По покана на „Книжарница в куфар“
Стара Загора, РБ „Захарий Княжески“
Крис Клийв заедно с Иво Иванов и Камен Алипиев – Кедъра
12 юни, 19.30 ч.
По покана на „Пловдив чете“
Пловдив, Stage Park, Младежки хълм
Крис Клийв заедно с Иво Иванов и Камен Алипиев – Кедъра
14 юни, 20.00 ч.
По покана на „Литературни срещи“
София, Борисова градина, One More Park Bar
Крис Клийв в разговор с Лора Ненковска









 Joshua Bright is a Senior Product Manager at Amazon Web Services. Joshua leads data lake integration initiatives within the OpenSearch Service team. Outside of work, Joshua enjoys listening to birds while walking in nature.
Joshua Bright is a Senior Product Manager at Amazon Web Services. Joshua leads data lake integration initiatives within the OpenSearch Service team. Outside of work, Joshua enjoys listening to birds while walking in nature.