Post Syndicated from Joerg Woehrle original https://aws.amazon.com/blogs/devops/improve-collaboration-between-teams-by-using-aws-cdk-constructs/
There are different ways to organize teams to deliver great software products. There are companies that give the end-to-end responsibility for a product to a single team, like Amazon’s Two-Pizza teams, and there are companies where multiple teams split the responsibility between infrastructure (or platform) teams and application development teams. This post provides guidance on how collaboration efficiency can be improved in the case of a split-team approach with the help of the AWS Cloud Development Kit (CDK).
The AWS CDK is an open-source software development framework to define your cloud application resources. You do this by using familiar programming languages like TypeScript, Python, Java, C# or Go. It allows you to mix code to define your application’s infrastructure, traditionally expressed through infrastructure as code tools like AWS CloudFormation or HashiCorp Terraform, with code to bundle, compile, and package your application.
This is great for autonomous teams with end-to-end responsibility, as it helps them to keep all code related to that product in a single place and single programming language. There is no need to separate application code into a different repository than infrastructure code with a single team, but what about the split-team model?
Larger enterprises commonly split the responsibility between infrastructure (or platform) teams and application development teams. We’ll see how to use the AWS CDK to ensure team independence and agility even with multiple teams involved. We’ll have a look at the different responsibilities of the participating teams and their produced artifacts, and we’ll also discuss how to make the teams work together in a frictionless way.
This blog post assumes a basic level of knowledge on the AWS CDK and its concepts. Additionally, a very high level understanding of event driven architectures is required.
Team Topologies
Let’s first have a quick look at the different team topologies and each team’s responsibilities.
One-Team Approach
In this blog post we will focus on the split-team approach described below. However, it’s still helpful to understand what we mean by “One-Team” Approach: A single team owns an application from end-to-end. This cross-functional team decides on its own on the features to implement next, which technologies to use and how to build and deploy the resulting infrastructure and application code. The team’s responsibility is infrastructure, application code, its deployment and operations of the developed service.
If you’re interested in how to structure your AWS CDK application in a such an environment have a look at our colleague Alex Pulver’s blog post Recommended AWS CDK project structure for Python applications.
Split-Team Approach
In reality we see many customers who have separate teams for application development and infrastructure development and deployment.
Infrastructure Team
What I call the infrastructure team is also known as the platform or operations team. It configures, deploys, and operates the shared infrastructure which other teams consume to run their applications on. This can be things like an Amazon SQS queue, an Amazon Elastic Container Service (Amazon ECS) cluster as well as the CI/CD pipelines used to bring new versions of the applications into production.
It is the infrastructure team’s responsibility to get the application package developed by the Application Team deployed and running on AWS, as well as provide operational support for the application.
Application Team
Traditionally the application team just provides the application’s package (for example, a JAR file or an npm package) and it’s the infrastructure team’s responsibility to figure out how to deploy, configure, and run it on AWS. However, this traditional setup often leads to bottlenecks, as the infrastructure team will have to support many different applications developed by multiple teams. Additionally, the infrastructure team often has little knowledge of the internals of those applications. This often leads to solutions which are not optimized for the problem at hand: If the infrastructure team only offers a handful of options to run services on, the application team can’t use options optimized for their workload.
This is why we extend the traditional responsibilities of the application team in this blog post. The team provides the application and additionally the description of the infrastructure required to run the application. With “infrastructure required” we mean the AWS services used to run the application. This infrastructure description needs to be written in a format which can be consumed by the infrastructure team.
While we understand that this shift of responsibility adds additional tasks to the application team, we think that in the long term it is worth the effort. This can be the starting point to introduce DevOps concepts into the organization. However, the concepts described in this blog post are still valid even if you decide that you don’t want to add this responsibility to your application teams. The boundary of who is delivering what would then just move more into the direction of the infrastructure team.
To be successful with the given approach, the two teams need to agree on a common format on how to hand over the application, its infrastructure definition, and how to bring it to production. The AWS CDK with its concept of Constructs provides a perfect means for that.
Primer: AWS CDK Constructs
In this section we take a look at the concepts the AWS CDK provides for structuring our code base and how these concepts can be used to fit a CDK project into your team topology.
Constructs
Constructs are the basic building block of an AWS CDK application. An AWS CDK application is composed of multiple constructs which in the end define how and what is deployed by AWS CloudFormation.
The AWS CDK ships with constructs created to deploy AWS services. However, it is important to understand that you are not limited to the out-of-the-box constructs provided by the AWS CDK. The true power of AWS CDK is the possibility to create your own abstractions on top of the default constructs to create solutions for your specific requirement. To achieve this you write, publish, and consume your own, custom constructs. They codify your specific requirements, create an additional level of abstraction and allow other teams to consume and use your construct.
We will use a custom construct to separate the responsibilities between the the application and the infrastructure team. The application team will release a construct which describes the infrastructure along with its configuration required to run the application code. The infrastructure team will consume this construct to deploy and operate the workload on AWS.
How to use the AWS CDK in a Split-Team Setup
Let’s now have a look at how we can use the AWS CDK to split the responsibilities between the application and infrastructure team. I’ll introduce a sample scenario and then illustrate what each team’s responsibility is within this scenario.
Scenario
Our fictitious application development team writes an AWS Lambda function which gets deployed to AWS. Messages in an Amazon SQS queue will invoke the function. Let’s say the function will process orders (whatever this means in detail is irrelevant for the example) and each order is represented by a message in the queue.
The application development team has full flexibility when it comes to creating the AWS Lambda function. They can decide which runtime to use or how much memory to configure. The SQS queue which the function will act upon is created by the infrastructure team. The application team does not have to know how the messages end up in the queue.
With that we can have a look at a sample implementation split between the teams.
Application Team
The application team is responsible for two distinct artifacts: the application code (for example, a Java jar file or an npm module) and the AWS CDK construct used to deploy the required infrastructure on AWS to run the application (an AWS Lambda Function along with its configuration).
The lifecycles of these artifacts differ: the application code changes more frequently than the infrastructure it runs in. That’s why we want to keep the artifacts separate. With that each of the artifacts can be released at its own pace and only if it was changed.
In order to achieve these separate lifecycles, it is important to notice that a release of the application artifact needs to be completely independent from the release of the CDK construct. This fits our approach of separate teams compared to the standard CDK way of building and packaging application code within the CDK construct.
But how will this be done in our example solution? The team will build and publish an application artifact which does not contain anything related to CDK.
When a CDK Stack with this construct is synthesized it will download the pre-built artifact with a given version number from AWS CodeArtifact and use it to create the input zip file for a Lambda function. There is no build of the application package happening during the CDK synth.
With the separation of construct and application code, we need to find a way to tell the CDK construct which specific version of the application code it should fetch from CodeArtifact. We will pass this information to the construct via a property of its constructor.
For dependencies on infrastructure outside of the responsibility of the application team, I follow the pattern of dependency injection. Those dependencies, for example a shared VPC or an Amazon SQS queue, are passed into the construct from the infrastructure team.
Let’s have a look at an example. We pass in the external dependency on an SQS Queue, along with details on the desired appPackageVersion and its CodeArtifact details:
export interface OrderProcessingAppConstructProps {
queue: aws_sqs.Queue,
appPackageVersion: string,
codeArtifactDetails: {
account: string,
repository: string,
domain: string
}
}
export class OrderProcessingAppConstruct extends Construct {
constructor(scope: Construct, id: string, props: OrderProcessingAppConstructProps) {
super(scope, id);
const lambdaFunction = new lambda.Function(this, 'OrderProcessingLambda', {
code: lambda.Code.fromDockerBuild(path.join(__dirname, '..', 'bundling'), {
buildArgs: {
'PACKAGE_VERSION' : props.appPackageVersion,
'CODE_ARTIFACT_ACCOUNT' : props.codeArtifactDetails.account,
'CODE_ARTIFACT_REPOSITORY' : props.codeArtifactDetails.repository,
'CODE_ARTIFACT_DOMAIN' : props.codeArtifactDetails.domain
}
}),
runtime: lambda.Runtime.NODEJS_16_X,
handler: 'node_modules/order-processing-app/dist/index.lambdaHandler'
});
const eventSource = new SqsEventSource(props.queue);
lambdaFunction.addEventSource(eventSource);
}
}
Note the code lambda.Code.fromDockerBuild(...): We use AWS CDK’s functionality to bundle the code of our Lambda function via a Docker build. The only things which happen inside of the provided Dockerfile are:
- the login into the AWS CodeArtifact repository which holds the pre-built application code’s package
- the download and installation of the application code’s artifact from AWS CodeArtifact (in this case via npm)
If you are interested in more details on how you can build, bundle and deploy your AWS CDK assets I highly recommend a blog post by my colleague Cory Hall: Building, bundling, and deploying applications with the AWS CDK. It goes into much more detail than what we are covering here.
Looking at the example Dockerfile we can see the two steps described above:
FROM public.ecr.aws/sam/build-nodejs16.x:latest
ARG PACKAGE_VERSION
ARG CODE_ARTIFACT_AWS_REGION
ARG CODE_ARTIFACT_ACCOUNT
ARG CODE_ARTIFACT_REPOSITORY
RUN aws codeartifact login --tool npm --repository $CODE_ARTIFACT_REPOSITORY --domain $CODE_ARTIFACT_DOMAIN --domain-owner $CODE_ARTIFACT_ACCOUNT --region $CODE_ARTIFACT_AWS_REGION
RUN npm install order-processing-app@$PACKAGE_VERSION --prefix /asset
Please note the following:
- we use
--prefix /asset with our npm install command. This tells npm to install the dependencies into the folder which CDK will mount into the container. All files which should go into the output of the docker build need to be placed here.
- the
aws codeartifact login command requires credentials with the appropriate permissions to proceed. In case you run this on for example AWS CodeBuild or inside of a CDK Pipeline you need to make sure that the used role has the appropriate policies attached.
Infrastructure Team
The infrastructure team consumes the AWS CDK construct published by the application team. They own the AWS CDK Stack which composes the whole application. Possibly this will only be one of several Stacks owned by the Infrastructure team. Other Stacks might create shared infrastructure (like VPCs, networking) and other applications.
Within the stack for our application the infrastructure team consumes and instantiates the application team’s construct, passes any dependencies into it and then deploys the stack by whatever means they see fit (e.g. through AWS CodePipeline, GitHub Actions or any other form of continuous delivery/deployment).
The dependency on the application team’s construct is manifested in the package.json of the infrastructure team’s CDK app:
{
"name": "order-processing-infra-app",
...
"dependencies": {
...
"order-app-construct" : "1.1.0",
...
}
...
}
Within the created CDK Stack we see the dependency version for the application package as well as how the infrastructure team passes in additional information (like e.g. the queue to use):
export class OrderProcessingInfraStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const orderProcessingQueue = new Queue(this, 'order-processing-queue');
new OrderProcessingAppConstruct(this, 'order-processing-app', {
appPackageVersion: "2.0.36",
queue: orderProcessingQueue,
codeArtifactDetails: { ... }
});
}
}
Propagating New Releases
We now have the responsibilities of each team sorted out along with the artifacts owned by each team. But how do we propagate a change done by the application team all the way to production? Or asked differently: how can we invoke the infrastructure team’s CI/CD pipeline with the updated artifact versions of the application team?
We will need to update the infrastructure team’s dependencies on the application teams artifacts whenever a new version of either the application package or the AWS CDK construct is published. With the dependencies updated we can then start the release pipeline.
One approach is to listen and react to events published by AWS CodeArtifact via Amazon EventBridge. On each release AWS CodeArtifact will publish an event to Amazon EventBridge. We can listen to that event, extract the version number of the new release from its payload and start a workflow to update either our dependency on the CDK construct (e.g. in the package.json of our CDK application) or a update the appPackageVersion which the infrastructure team passes into the consumed construct.
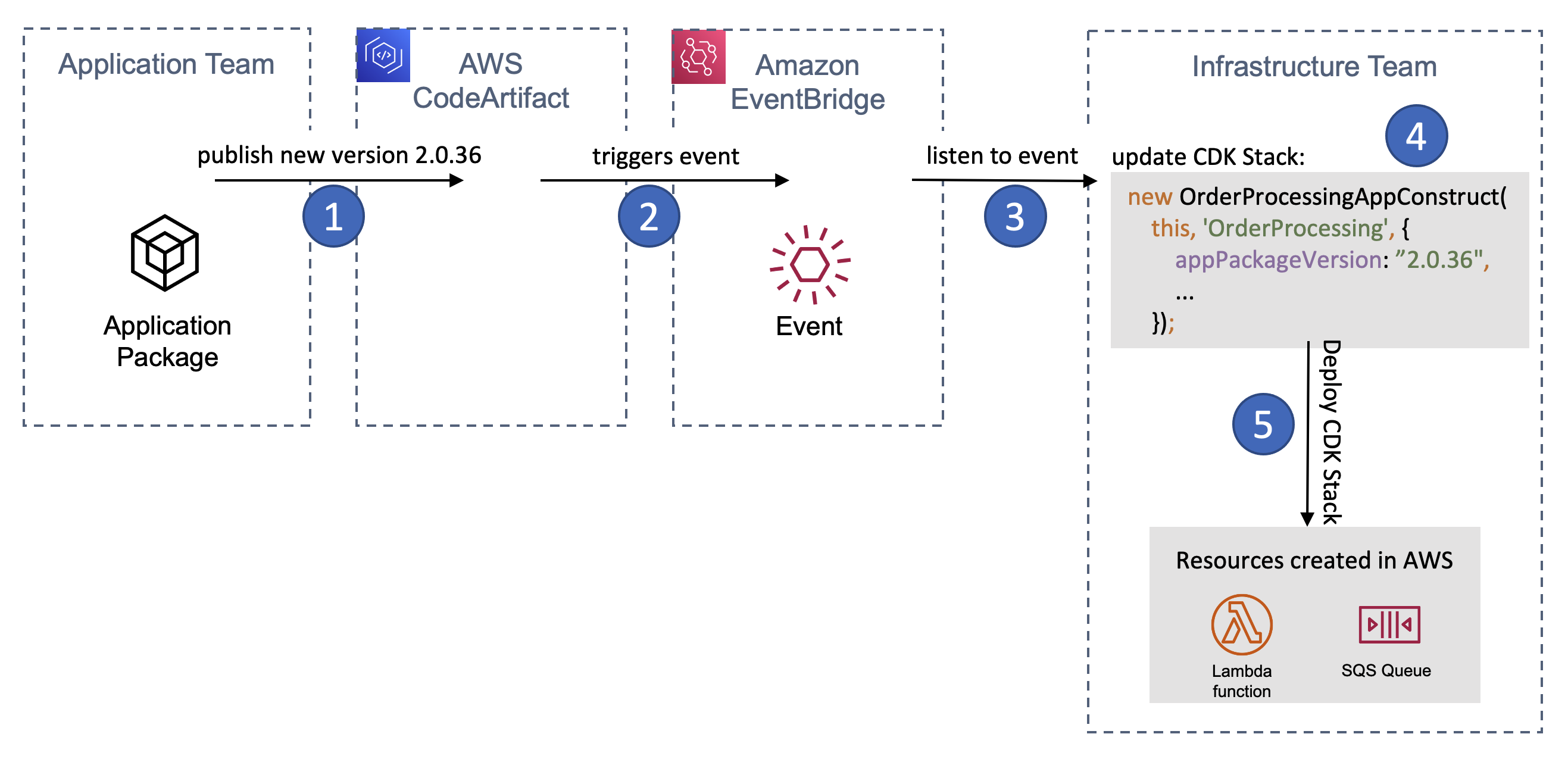
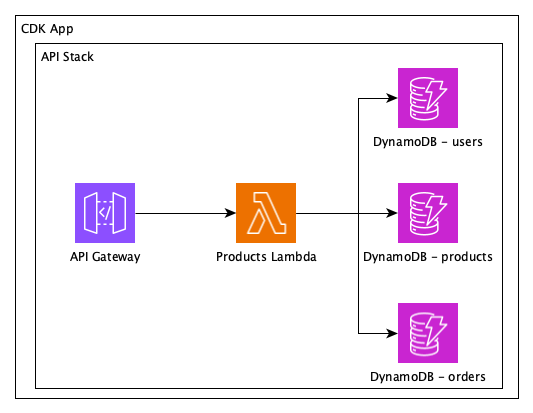
Here’s how a release of a new app version flows through the system:

Figure 1 – A release of the application package triggers a change and deployment of the infrastructure team’s CDK Stack
- The application team publishes a new app version into AWS CodeArtifact
- CodeArtifact triggers an event on Amazon EventBridge
- The infrastructure team listens to this event
- The infrastructure team updates its CDK stack to include the latest
appPackageVersion
- The infrastructure team’s CDK Stack gets deployed
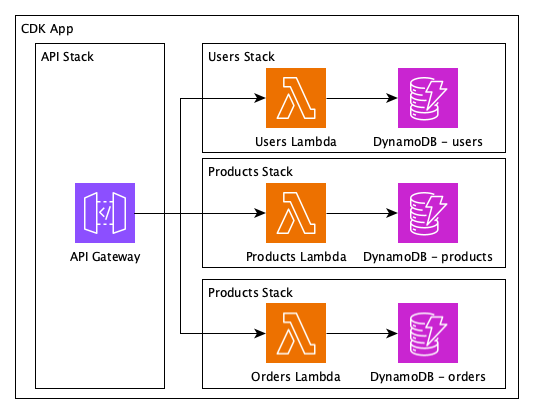
And very similar the release of a new version of the CDK Construct:

Figure 2 – A release of the application team’s CDK construct triggers a change and deployment of the infrastructure team’s CDK Stack
- The application team publishes a new CDK construct version into AWS CodeArtifact
- CodeArtifact triggers an event on Amazon EventBridge
- The infrastructure team listens to this event
- The infrastructure team updates its dependency to the latest CDK construct
- The infrastructure team’s CDK Stack gets deployed
We will not go into the details on how such a workflow could look like, because it’s most likely highly custom for each team (think of different tools used for code repositories, CI/CD). However, here are some ideas on how it can be accomplished:
Updating the CDK Construct dependency
To update the dependency version of the CDK construct the infrastructure team’s package.json (or other files used for dependency tracking like pom.xml) needs to be updated. You can build automation to checkout the source code and issue a command like npm install sample-app-construct@NEW_VERSION (where NEW_VERSION is the value read from the EventBridge event payload). You then automatically create a pull request to incorporate this change into your main branch. For a sample on what this looks like see the blog post Keeping up with your dependencies: building a feedback loop for shared librares.
Updating the appPackageVersion
To update the appPackageVersion used inside of the infrastructure team’s CDK Stack you can either follow the same approach outlined above, or you can use CDK’s capability to read from an AWS Systems Manager (SSM) Parameter Store parameter. With that you wouldn’t put the value for appPackageVersion into source control, but rather read it from SSM Parameter Store. There is a how-to for this in the AWS CDK documentation: Get a value from the Systems Manager Parameter Store. You then start the infrastructure team’s pipeline based on the event of a change in the parameter.
To have a clear understanding of what is deployed at any given time and in order to see the used parameter value in CloudFormation I’d recommend using the option described at Reading Systems Manager values at synthesis time.
Conclusion
You’ve seen how the AWS Cloud Development Kit and its Construct concept can help to ensure team independence and agility even though multiple teams (in our case an application development team and an infrastructure team) work together to bring a new version of an application into production. To do so you have put the application team in charge of not only their application code, but also of the parts of the infrastructure they use to run their application on. This is still in line with the discussed split-team approach as all shared infrastructure as well as the final deployment is in control of the infrastructure team and is only consumed by the application team’s construct.
About the Authors
 |
As a Solutions Architect Jörg works with manufacturing customers in Germany. Before he joined AWS in 2019 he held various roles like Developer, DevOps Engineer and SRE. With that Jörg enjoys building and automating things and fell in love with the AWS Cloud Development Kit. |
|
Mo joined AWS in 2020 as a Technical Account Manager, bringing with him 7 years of hands-on AWS DevOps experience and 6 year as System operation admin. He is a member of two Technical Field Communities in AWS (Cloud Operation and Builder Experience), focusing on supporting customers with CI/CD pipelines and AI for DevOps to ensure they have the right solutions that fit their business needs. |

















 testproject-dev: destroyed
testproject-dev: destroyed