Post Syndicated from Надежда Цекулова original https://www.toest.bg/da-pokazhesh-che-naistina-te-e-grizha/

Срещаме се с д-р Десислава Иванова в дните между Международния ден на анестезиолога – 16 октомври, и Деня на българския лекар – 19 октомври, пред УМБАЛ „Св. Анна“ в София. В момента д-р Иванова е част от анестезиологичния екип на болницата, известна на столичани като „Окръжна“. Всеки ден тя идва на работа от кв. „Надежда“ на колело. В свободното си време обича да „рестартира“ мозъка си с планинско колоездене и скално катерене. Смята, че хората, които искат да променят здравеопазването, трябва да са компетентни и да работят за общото благо.
Представете се.
Вече съм на почти 42. Работя в поредната държавна болница. Не мога да се откъсна от държавите болници.
Защо сменяте болниците?
Според мен е правилно човек да смени, когато отношенията се изчерпят, независимо дали става дума за лични, или професионални отношения. И в двата случая става въпрос за взаимодействие между хората. Даваш, вземаш, когато тези отношения се изчерпят, трябва да освободиш място за някой друг, а ти да намериш ново място, за да продължиш да се развиваш.
Публичният имидж на здравеопазването създава впечатление, че хората си плащат, за да отидат в частна болница и да получат по-любезно отношение, уважение на правата и желанията им. Любопитно е защо през очите Ви на анестезиолог изглежда обратното…
Не знам, може би в държавните болници са се съхранили медицината и отношението към пациента. Работила съм в „Александровска болница“ 6–7 години, в „Пирогов“ още толкова и една година в частна болница. Мисля, че там видях дъното. Дъното на човека в отношението му към човек. В момента работя в УМБАЛ „Св. Анна“, бившата Окръжна болница.
Това, че някъде пациентът получава любезно отношение, не означава, че получава най-добрата медицина. Аз го видях по този начин, не твърдя, че винаги и навсякъде е така. Всички се стараем да бъдем съпричастни към пациентите. На някои колеги им се удава повече, на други по-малко, но това не изчерпва грижата за пациента.
Съпричастността обаче е важна за пациентите. Според Вас дали лекарите биха я изразявали по-добре, ако получават подкрепа за това?
Подкрепа от кого?
Вие от кого бихте искали да получите подкрепа?
Според мен всичко е въпрос на възпитание в семейството. Ако там сте изразявали емоциите си и сте се научили да ги уважавате, това остава за цял живот.
А според Вас няма ли място за отношенията лекар–пациент в медицинското образование? Българското медицинско образование обръща по-малко внимание на този въпрос в сравнение с други системи. Дали трябва да разчитаме само на семейното възпитание, или общуването е инструмент, който един бъдещ лекар трябва да изучи?
Да, и аз съм чувала от колеги, че в други държави се държи много повече на това. При нас общуването е умение, което се добива по-скоро неформално. Аз имах късмета да случа на прекрасни учители. Те ме научиха, че това не го пише в книгите ни, но то е не по-малко важно за пациента и определящо за работата, която можем да свършим. Покрай тях свикнах как да общувам с пациентите, как да стигам до информацията, която ми е нужна, по начин, който да създаде доверие и спокойствие у пациента. Пациентът трябва да усеща твоята подкрепа, да бъде сигурен, че наистина желаеш той да се подобри. И както вербалната, така и невербалната комуникация са пътят да му покажеш това – че наистина те е грижа.
Вие как решихте да станете лекар?
Съседите ни бяха семейство лекари. Може би от тях съм се запалила, но не съм убедена, продължавам понякога да се чудя защо. Майка ми и баща ми са учители – по математика и по руски. Наглед нищо общо! Но всъщност анестезиологията и реанимацията си е чиста физика – ние работим с флуиди, налягане, с електричество, ако щете. А на мен това е голямата ми страст.
Когато едно дете мечтае да се развие в някаква професия, очакванията му понякога катастрофират в реалността. Какво беше за едно момиче от малък град, дете на учители, да стане български лекар?
Преди да стана български лекар, бях български студент по медицина от бедно семейство. В ония години имаше повече кандидати и всеобщото мнение беше, че за да влезеш в Медицинския университет в София, трябва да изкараш едни курсове, които струват хиляди левове. Родителите ми нямаше откъде да ги вземат. Съответно мен ме приеха на третата година без курсове и помня как на първите упражнения ни разпитваха: „Вие при кого ходихте на курсове?“ Като кажех, че идвам от Математическата гимназия в Казанлък, реагираха с огромно учудване: „Е как така влязохте?!“ Все ми се искаше да им кажа: не знам, пуснахте ме, явно ви е писнало да ми гледате почерка.
После трябваше да работя, за да се издържам. Една сутрин след нощна смяна закъснях за упражнения и асистентът ме посрещна с репликата: „Колежке, вие не знаете ли, че медицината не е за бедни хора.“
Така че първите шест години бяха тежка тренировка.
Но попаднах и на много добри учители, които много ме подкрепяха. Помня как д-р Станчев казваше: „Детенце, някой ден пациентът няма да те пита на коя година си приета и с каква диплома си завършила. Ще иска да му помогнеш.“ И то е така.
Как изглежда развитието Ви сега, през прозореца на Окръжна болница? Успявате ли да сте в крак със съвременната анестезиология и интензивно лечение, да настигате амбицията си?
Да. Тук, ако човек иска да работи, му се дава възможност, като се гледа на първо място интересът на пациента. За да си добър в нашата работа – то във всяка професия е така, – трябва да се чете непрекъснато. Нещо, което много ме вдъхновява, са младите колеги в екипа – има млади колеги, специалисти и специализанти, които много четат. Непрекъснато си говорим, обсъждаме статии, случаи. Това е уау!
Та, да се върна на въпроса как изглежда – четеш, прилагаш това, за което ти дава възможност държавата, и хубавото е, че тук ти се отваря поле да работиш.
Това какво означава? Може ли да обясните, защото на мен ми е малко трудно да си представя при недостиг на анестезиолози какво означава да не им се дава да работят.
Стигало се е до такива ситуации, затова и аз съм си тръгвала… Явно има все пак достатъчно колеги, които приемат някой друг да им казва как да си вършат работата. Когато изискванията към теб нарушават принципите ти, просто си тръгваш, това е. И продължаваш да даваш всичко, на което смяташ, че си способен, на друго място.
Мислите ли, че Ви ограничава това, че сте имено български лекар, а не френски или германски, примерно?
Самият факт, че все още съм български лекар, а не френски или германски, означава, че се чувствам удовлетворена. Към момента е така. Не ме мъчи въпросът щастлива ли съм от това, че живея и работя тук – напълно наясно съм.
Вълнувате ли се от здравеопазването като система, от политиките в здравеопазването, от политиката в здравеопазването?
Не. Нямам сили, за съжаление може би. Мисля, че не ми е в компетенциите да се ангажирам.
А аз понякога си мисля, че ако повече редови лекари се вълнуват от политиките в здравеопазването, тези политики може да станат по-качествени и за лекарите, и за пациентите им. Вие явно не мислите така, чудя се защо се разминаваме. Вие как си го обяснявате?
Да се вълнуваш и да имаш идеи не е достатъчно, трябва да можеш и да ги осъществяваш. Според мен хората, които искат да променят средата, завършват „Здравен мениджмънт“, отиват и се борят за общото благо. Аз мисля за себе си, че мога да допринеса за лечебния процес на пациента в болницата. Не мисля, че притежавам качества да променям точно тази система.
Това значи ли, че в други системи се чувствате по-уверена да променяте и да бъдете активист?
Да. Защитата на животните е това, в което съм по-активна – работя с институции, общини, доброволци. Това, което правя всъщност, е да сигнализирам на институциите – най-често общините – да си изпълнят задълженията по Закона за защита на животните. Има програма, която се нарича „Кастрирай и върни“ и нейната цел е по хуманен начин да се намали популацията на бездомни животни – кучета основно, но и котки. Тя обаче не се изпълнява достатъчно добре навсякъде, немалко общини се освобождават от животните по нехуманен начин. Това е нетрайно решение, но на някои общини явно не им пречи. Фактът, че причиняват страдания на гръбначно животно, явно също не им пречи… В случая моята работа е да подавам сигнали, да питам защо така се случва, какво става с парите, които по бюджет са предвидени за кастриране – и така бавно-бавно колелото се завърта.
Явно правите всичко това, без да сте завършили „Мениджмънт на защитата на животни“, примерно.
Добра аналогия, хванахте ме!
Целта не беше да Ви „хващам“. По-скоро да си представим заедно каква е ролята на хилядите редови лекари в това здравеопазването да стане по-хуманно и да причинява по-малко страдание – както на пациентите, така и на всички медици, които се грижат за тях. Защото не можем да разчитаме само на политиците.
Не мога да кажа за всички лекари. Но за себе си мисля, че може би не съм се сблъсквала с толкова остро усещане за несправедливост в работата си, колкото виждам в отношението към животните. Разбира се, че в здравеопазването също има несправедливости. Но като че ли се опитваме да ги компенсираме. Някак въпреки тях да успеем да си свършим работата. Или може би защото все още не съм усетила даден закон, примерно, да ми пречи да си върша работата, или да имам нужда от някакъв закон, за да си я свърша. В нашата професия, ако си чел достатъчно, ако си разбираш от работата и имаш достатъчно опит – професионален и житейски – може да се справиш със ситуацията, така че да се направи нужното за благополучието на пациента.
Казахте „ако имаш достатъчно опит“. Това значи ли, че смятате медицината за изкуство?
Изкуство? Не, това твърдение никога не съм го разбирала. Тази фраза идва много отдалеч във времето, вече сме отишли напред в развитието си. Изкуство ли е?
Министърът на здравеопазването така смята.
Не знаех. Според мен е много повече логика, математика, физика… Наука, отговорност и рационални решения. Протоколи.
Вие по протоколи ли работите?
Да. Имахме такива и в „Пирогов“, имаме и в „Св. Анна“, в клиниките, в които работя. Те са разписани на база международни протоколи и консенсуси, не е нещо, което сме измислили. Просто се адаптира за съответното отделение. В някои държави има национални, но при нас са на ниво болница.
Говорим много за анестезиологията. Някои Ваши колеги казват, че това е най-тежката специалност. На Вас тежка ли ви се струва?
Знаете ли, днес давах една анестезия в Очна клиника. И се замислих как още от университета съществува тоя предразсъдък, че очните болести и дерматологията са елементарни специалности. Но не е така. Ако човек загуби зрението си вследствие на твое неправилно решение, е сериозна отговорност – кое е елементарното? Или например в дерматологията има много заболявания, които са хронични – в момента няма лечение за тях, най-много временно облекчение. Това може да доведе след време до поведенчески и психични промени. И пациентът се надява на теб, а ти трябва да му обясниш, че такова е положението, такова е нивото на науката в момента – това да не би да е лесно? Във всяка специалност има специфики и трудности.
Може би убеждението за леките и тежките специалности идва оттам, че един анестезиолог трудно може да реши, че вече не му се работи в болница, и да стане амбулаторен лекар.
Всичко е въпрос на мотивация! Познавам лекари, които са били анестезиолози и после са станали фармацевтични представители.
Но е много важно да можеш да слагаш граници между професията и личния живот. За да си адекватен лекар, мозъкът ти трябва да е отпочинал. Това важи за всяка професия.
Вие успявате ли да имате личен живот?
Успявам донякъде. Родителството се оказа доста трудна работа. Може би когато синът ми стане на около 30 години, може да го питам как съм се справила, успяла ли съм, или не.
Изглежда като да сменяте една трудна работа с друга трудна работа. Нали казахте, че мозъкът трябва да е отпочинал, как става това?
С хобита. Много ми е любимо скалното катерене, защото само мислиш как да продължиш, без да паднеш. На мен най-големият ми страх не е да не умра, а да не се инвалидизирам. И когато се катеря, умът ми е съсредоточен в това и в нищо друго. Така на другия ден нямам търпение да отида на работа.
Нямате търпение?
Да. Много е хубаво човек да си обича професията! И затова според мен е голям проблем, че хората избират професия по задължение или поне по някакви външни причини, а не защото им е страст. За мен лично лекарската професия е най-важна, защото съм я избрала. Но всъщност всички професии са важни посвоему. Най-важно е да се чувстваш добре с това, което правиш, и да ти е чиста съвестта в края на деня.
В рубриката „Разговори за здравеопазването" Надежда Цекулова кани своите събеседници да поговорят без клишета и празнодумие за проблемите и решенията, болката и оздравяването, медицината и политиката.


























































































































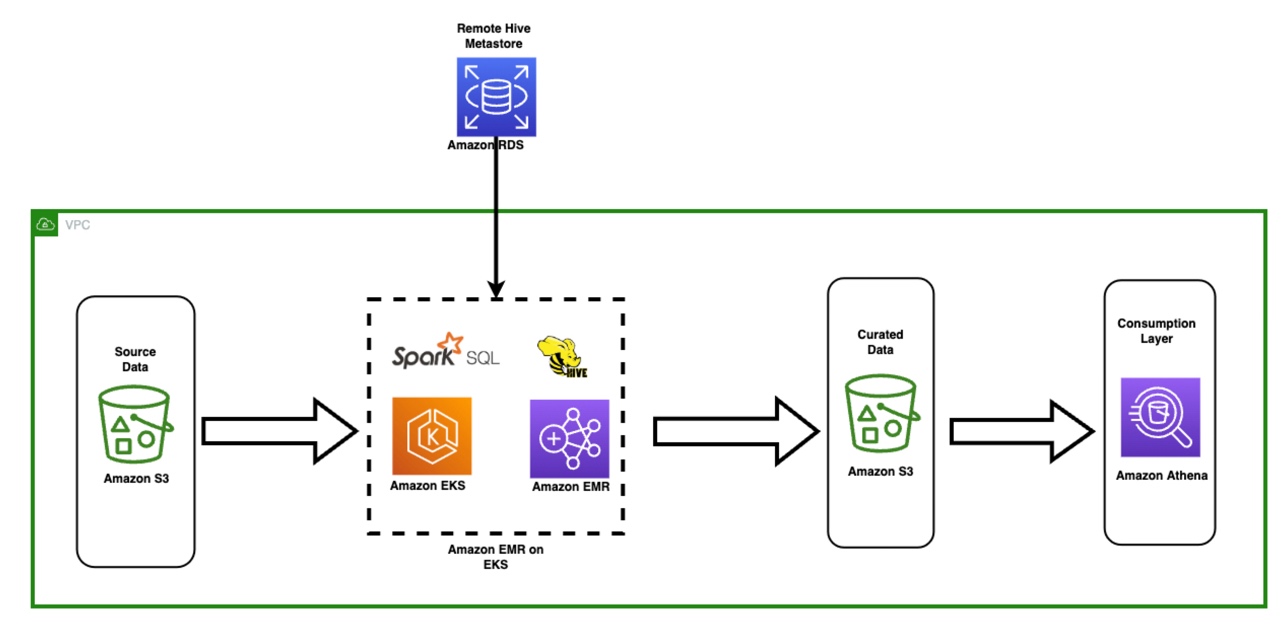







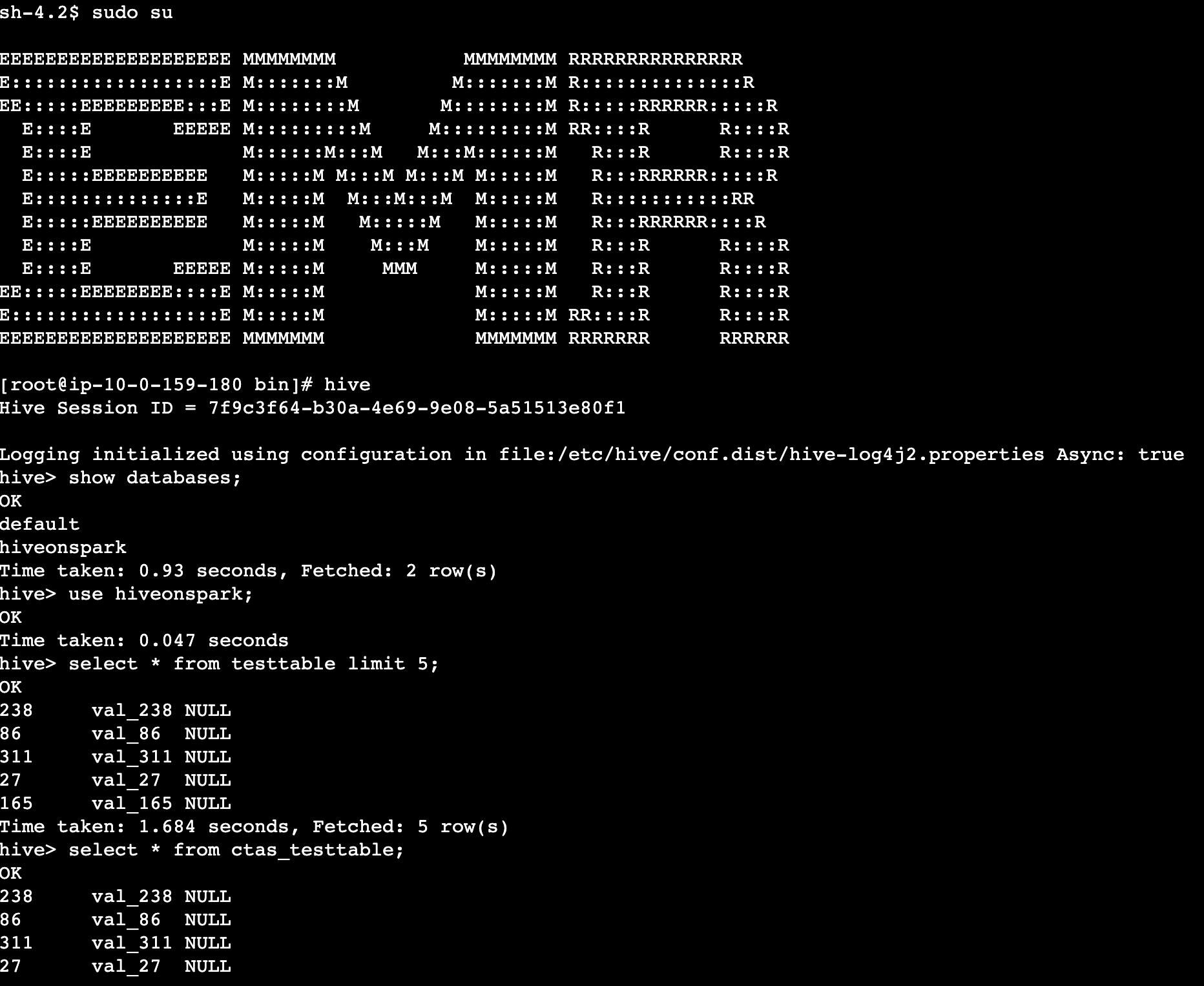
 Amit Maindola is a Senior Data Architect focused on big data and analytics at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
Amit Maindola is a Senior Data Architect focused on big data and analytics at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.

 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat. Hendy Wijaya is a Senior OpenSearch Specialist Solutions Architect at Amazon Web Services. Hendy enables customers to leverage AWS services to achieve their business objectives and gain competitive advantages. He is passionate in collaborating with customers in getting the best out of OpenSearch and Amazon OpenSearch
Hendy Wijaya is a Senior OpenSearch Specialist Solutions Architect at Amazon Web Services. Hendy enables customers to leverage AWS services to achieve their business objectives and gain competitive advantages. He is passionate in collaborating with customers in getting the best out of OpenSearch and Amazon OpenSearch Utkarsh Agarwal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available and secure solutions in AWS Cloud. In his free time, he enjoys watching movies, TV series and of course cricket! Lately, he his also attempting to master the art of cooking in his free time – The taste buds are excited, but the kitchen might disagree.
Utkarsh Agarwal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available and secure solutions in AWS Cloud. In his free time, he enjoys watching movies, TV series and of course cricket! Lately, he his also attempting to master the art of cooking in his free time – The taste buds are excited, but the kitchen might disagree.