Post Syndicated from Eliad Maimon original https://aws.amazon.com/blogs/big-data/enable-business-users-to-analyze-large-datasets-in-your-data-lake-with-amazon-quicksight/
This blog post is co-written with Ori Nakar from Imperva.
Imperva Cloud WAF protects hundreds of thousands of websites and blocks billions of security events every day. Events and many other security data types are stored in Imperva’s Threat Research Multi-Region data lake.
Imperva harnesses data to improve their business outcomes. To enable this transformation to a data-driven organization, Imperva brings together data from structured, semi-structured, and unstructured sources into a data lake. As part of their solution, they are using Amazon QuickSight to unlock insights from their data.
Imperva’s data lake is based on Amazon Simple Storage Service (Amazon S3), where data is continually loaded. Imperva’s data lake has a few dozen different datasets, in the scale of petabytes. Each day, TBs of new data is added to the data lake, which is then transformed, aggregated, partitioned, and compressed.
In this post, we explain how Imperva’s solution enables users across the organization to explore, visualize, and analyze data using Amazon Redshift Serverless, Amazon Athena, and QuickSight.
Challenges and needs
A modern data strategy gives you a comprehensive plan to manage, access, analyze, and act on data. AWS provides the most complete set of services for the entire end-to-end data journey for all workloads, all types of data, and all desired business outcomes. In turn, this makes AWS the best place to unlock value from your data and turn it into insight.
Redshift Serverless is a serverless option of Amazon Redshift that allows you to run and scale analytics without having to provision and manage data warehouse clusters. Redshift Serverless automatically provisions and intelligently scales data warehouse capacity to deliver high performance for all your analytics. You just need to load and query your data, and you only pay for the compute used for the duration of the workloads on a per-second basis. Redshift Serverless is ideal when it’s difficult to predict compute needs such as variable workloads, periodic workloads with idle time, and steady-state workloads with spikes.
Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, straightforward to use, and makes it simple for anyone with SQL skills to quickly analyze large-scale datasets in multiple Regions.
QuickSight is a cloud-native business intelligence (BI) service that you can use to visually analyze data and share interactive dashboards with all users in the organization. QuickSight is fully managed and serverless, requires no client downloads for dashboard creation, and has a pay-per-session pricing model that allows you to pay for dashboard consumption. Imperva uses QuickSight to enable users with no technical expertise, from different teams such as marketing, product, sales, and others, to extract insight from the data without the help of data or research teams.
QuickSight offers SPICE, an in-memory, cloud-native data store that allows end-users to interactively explore data. SPICE provides consistently fast query performance and automatically scales for high concurrency. With SPICE, you save time and cost because you don’t need to retrieve data from the data source (whether a database or data warehouse) every time you change an analysis or update a visual, and you remove the load of concurrent access or analytical complexity off the underlying data source with the data.
In order for QuickSight to consume data from the data lake, some of the data undergoes additional transformations, filters, joins, and aggregations. Imperva cleans their data by filtering incomplete records, reducing the number of records by aggregations, and applying internal logic to curate millions of security incidents out of hundreds of millions of records.
Imperva had the following requirements for their solution:
- High performance with low query latency to enable interactive dashboards
- Continuously update and append data to queryable sources from the data lake
- Data freshness of up to 1 day
- Low cost
- Engineering efficiency
The challenge faced by Imperva and many other companies is how to create a big data extract, transform, and load (ETL) pipeline solution that fits these requirements.
In this post, we review two approaches Imperva implemented to address their challenges and meet their requirements. The solutions can be easily implemented while maintaining engineering efficiency, especially with the introduction of Redshift Serverless.
Imperva’s solutions
Imperva needed to have the data lake’s data available through QuickSight continuously. The following solutions were chosen to connect the data lake to QuickSight:
- QuickSight caching layer, SPICE – Use Athena to query the data into a QuickSight SPICE dataset
- Redshift Serverless – Copy the data to Redshift Serverless and use it as a data source
Our recommendation is to use a solution based on the use case. Each solution has its own advantages and challenges, which we discuss as part of this post.
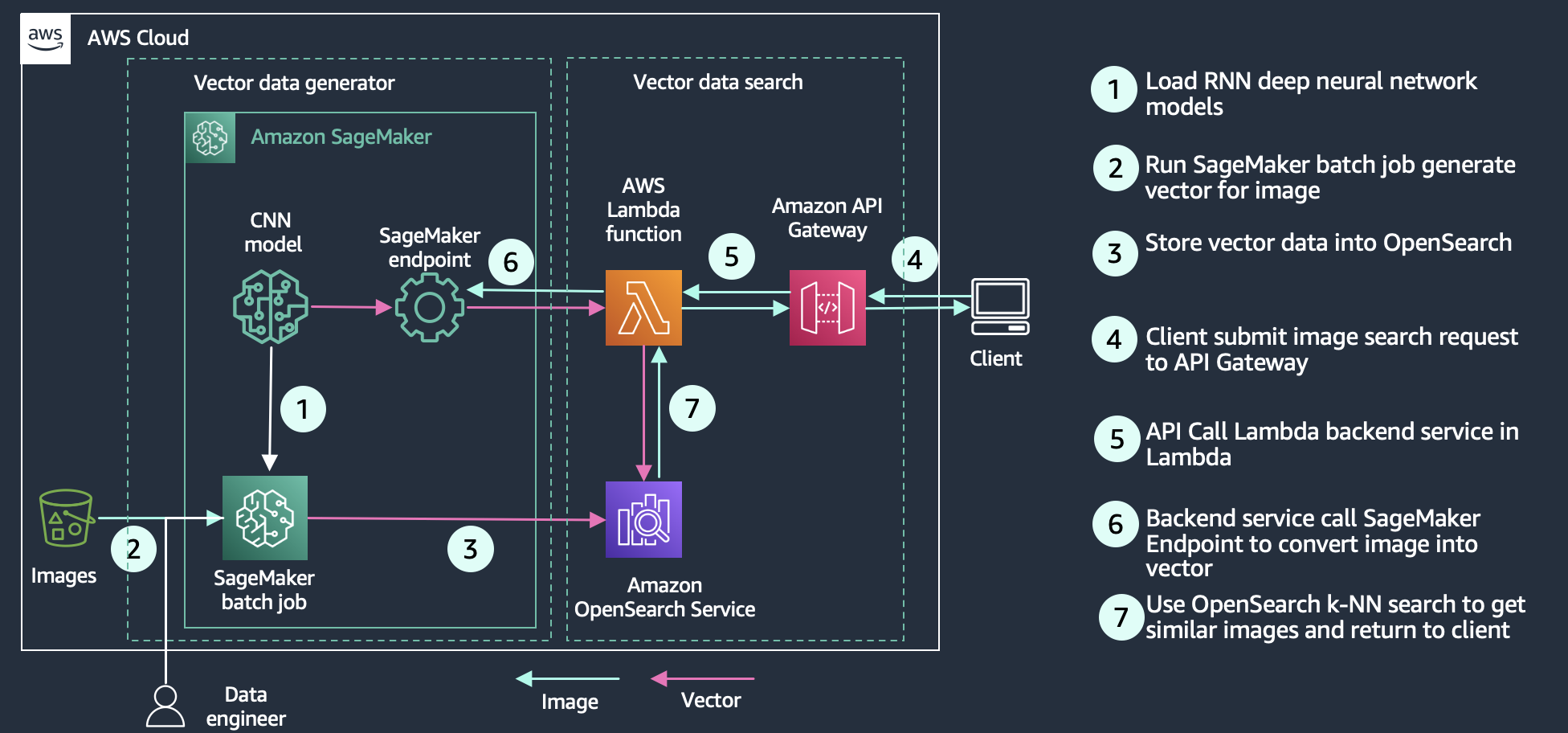
The high-level flow is the following:
- Data is continuously updated from the data lake into either Redshift Serverless or the QuickSight caching layer, SPICE
- An internal user can create an analysis and publish it as a dashboard for other internal or external users
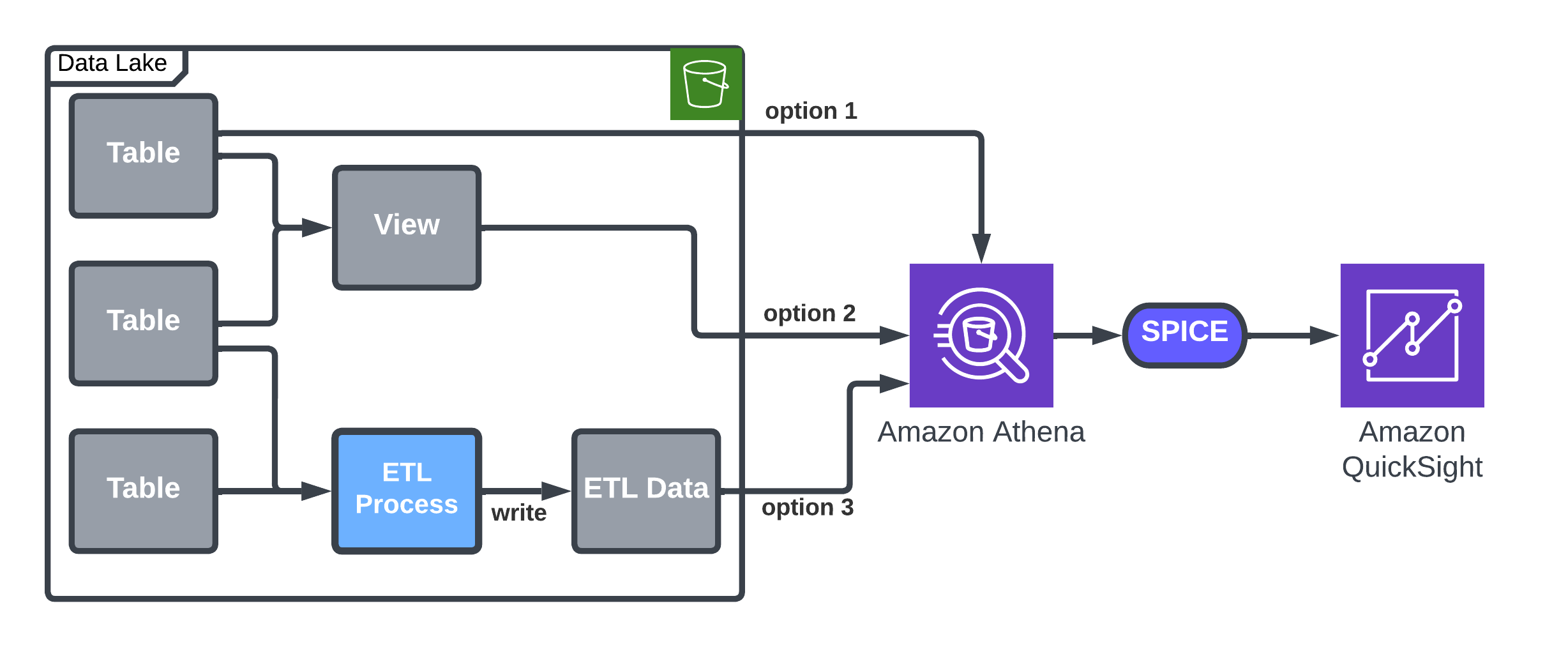
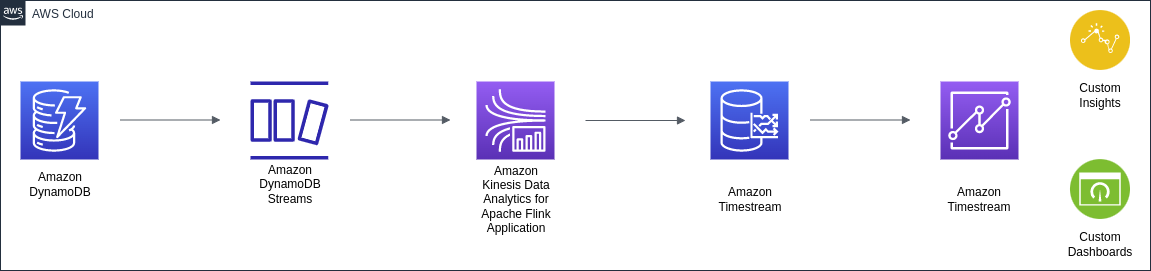
The following architecture diagram shows the high-level flow.

In the following sections, we discuss the details about the flow and the different solutions, including a comparison between them, which can help you choose the right solution for you.
Solution 1: Query with Athena and import to SPICE
QuickSight provides inherent capabilities to upload data using Athena into SPICE, which is a straightforward approach that meets Imperva’s requirements regarding simple data management. For example, it suits stable data flows without frequent exceptions, which may result in SPICE full refresh.
You can use Athena to load data into a QuickSight SPICE dataset, and then use the SPICE incremental upload option to load new data to the dataset. A QuickSight dataset will be connected to a table or a view accessible by Athena. A time column (like day or hour) is used for incremental updates. The following table summarizes the options and details.
| Option | Description | Pros/Cons |
| Existing table | Use the built-in option by QuickSight. | Not flexible—the table is imported as is in the data lake. |
| Dedicated view |
A view will let you better control the data in your dataset. It allows joining data, aggregation, or choosing a filter like the date you want to start importing data from. Note that QuickSight allows building a dataset based on custom SQL, but this option doesn’t allow incremental updates. |
Large Athena resource consumption on a full refresh. |
| Dedicated ETL |
Create a dedicated ETL process, which is similar to a view, but unlike the view, it allows reuse of the results in case of a full refresh. In case your ETL or view contains grouping or other complex operations, you know that these operations will be done only by the ETL process, according to the schedule you define. |
Most flexible, but requires ETL development and implementation and additional Amazon S3 storage. |
The following architecture diagram details the options for loading data by Athena into SPICE.
The following code provides a SQL example for a view creation. We assume the existence of two tables, customers and events, with one join column called customer_id. The view is used to do the following:
- Aggregate the data from daily to weekly, and reduce the number of rows
- Control the start date of the dataset (in this case, 30 weeks back)
- Join the data to add more columns (
customer_type) and filter it
Solution 2: Load data into Redshift Serverless
Redshift Serverless provides full visibility to the data, which can be viewed or edited at any time. For example, if there is a delay in adding data to the data lake or the data isn’t properly added, with Redshift Serverless, you can edit data using SQL statements or retry data loading. Redshift Serverless is a scalable solution that doesn’t have a dataset size limitation.
Redshift Serverless is used as a serving layer for the datasets that are to be used in QuickSight. The pricing model for Redshift Serverless is based on storage utilization and the run of queries; idle compute resources have no associated cost. Setting up a cluster is simple and doesn’t require you to choose node types or amount of storage. You simply load the data to tables you create and start working.
To create a new dataset, you need to create an Amazon Redshift table and run the following process every time data is added:
- Transform the data using an ETL process (optional):
- Read data from the tables.
- Transform to the QuickSight dataset schema.
- Write the data to an S3 bucket and load it to Amazon Redshift.
- Delete old data if it exists to avoid duplicate data.
- Load the data using the COPY command.
The following architecture diagram details the options to load data into Redshift Serverless with or without an ETL process.

The Amazon Redshift COPY command is simple and fast. For example, to copy daily partition Parquet data, use the following code:
Use the following COPY command to load the output file of the ETL process. Values will be truncated according to Amazon Redshift column size. The column truncation is important because, unlike in the data lake, in Amazon Redshift, the column size must be set. This option prevents COPY failures:
The Amazon Redshift COPY operation provides many benefits and options. It supports multiple formats as well as column mapping, escaping, and more. It also allows more control over data format, object size, and options to tune the COPY operation for improved performance. Unlike data in the data lake, Amazon Redshift has column length specifications. We use TRUNCATECOLUMNS to truncates the data in columns to the appropriate number of characters so that it fits the column specification.
Using this method provides full control over the data. In case of a problem, we can repair parts of the table by deleting old data and loading the data again. It’s also possible to use the QuickSight dataset JOIN option, which is not available in SPICE when using incremental update.
Additional benefit of this approach is that the data is available for other clients and services looking to use the same data, such as SQL clients or notebooks servers such as Apache Zeppelin.
Conclusion
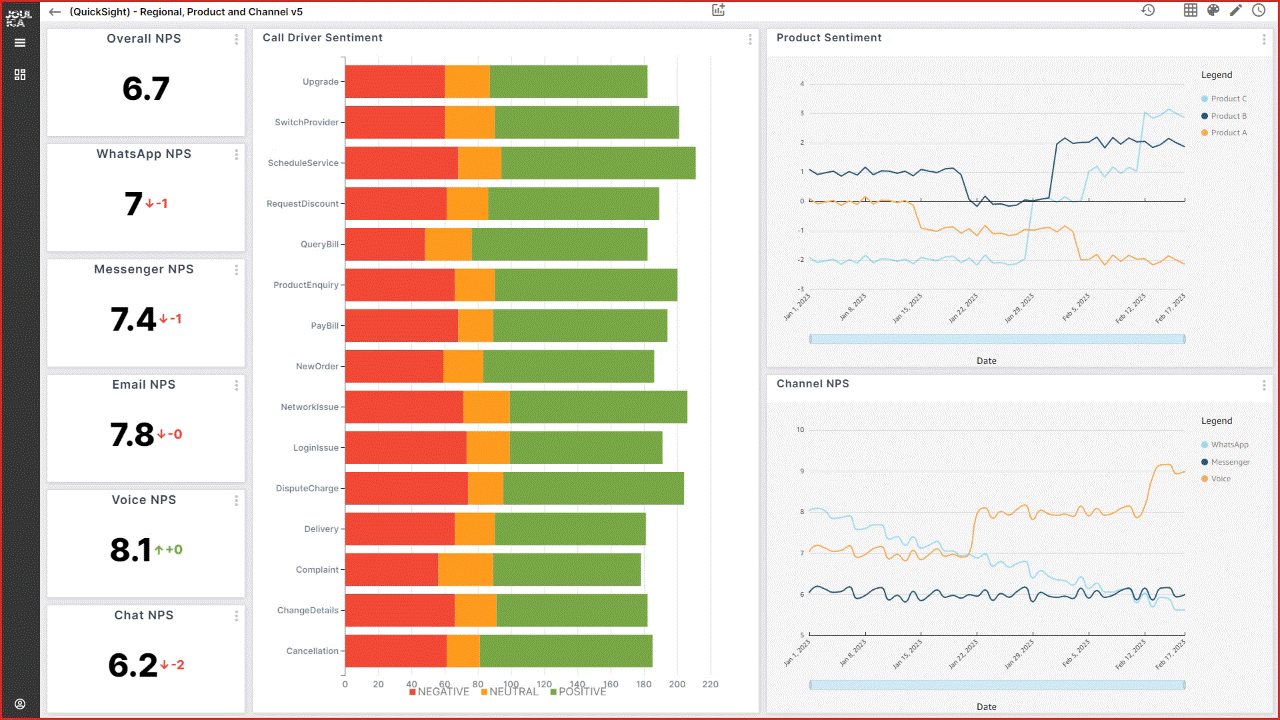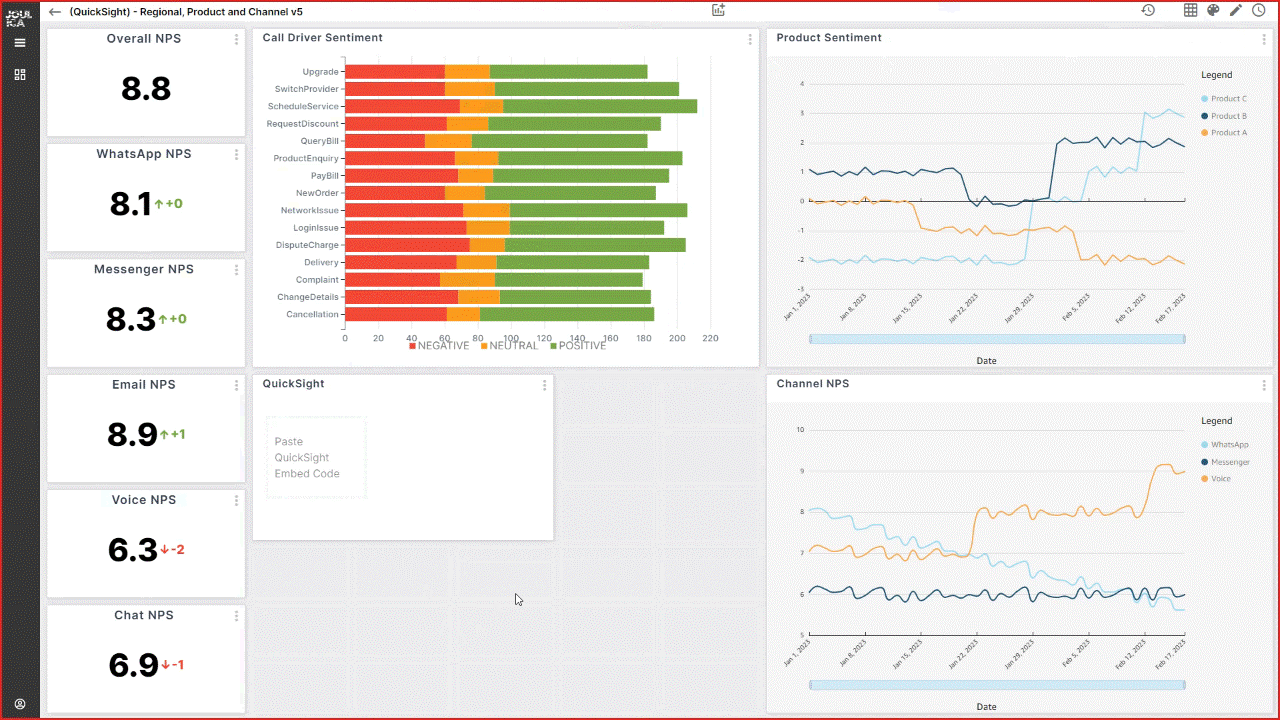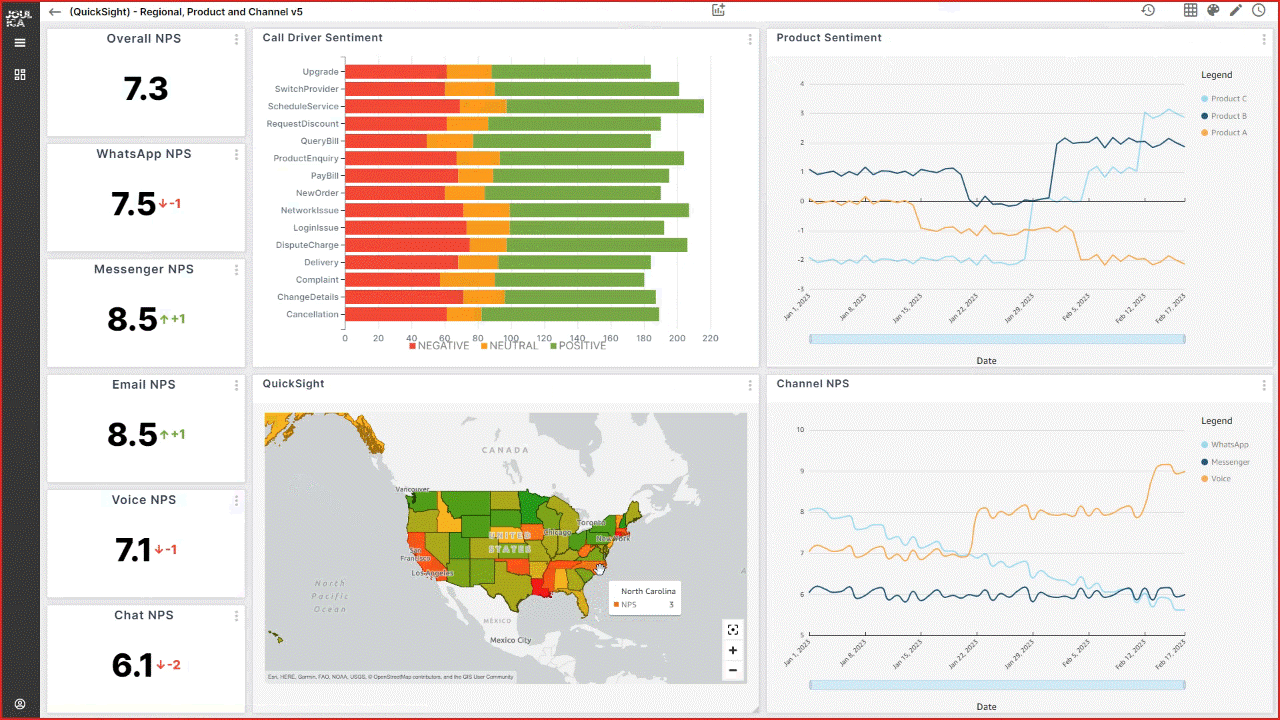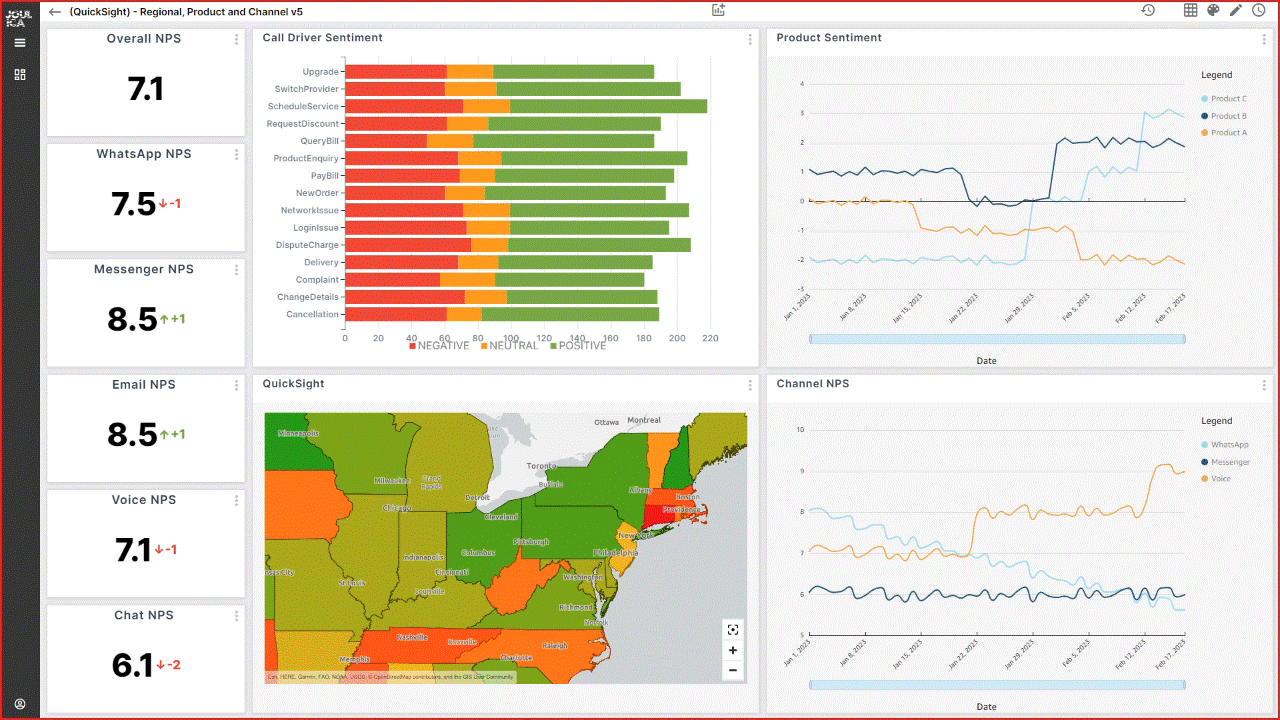
QuickSight allows Imperva to expose business data to various departments within an organization. In the post, we explored approaches for importing data from a data lake to QuickSight, whether continuously or incrementally.
However, it’s important to note that there is no one-size-fits-all solution; the optimal approach will depend on the specific use case. Both options—continuous and incremental updates—are scalable and flexible, with no significant cost differences observed for our dataset and access patterns.
Imperva found incremental refresh to be very useful and uses it for simple data management. For more complex datasets, Imperva has benefitted from the greater scalability and flexibility provided by Redshift Serverless.
In cases where a higher degree of control over the datasets was required, Imperva chose Redshift Serverless so that data issues could be addressed promptly by deleting, updating, or inserting new records as necessary.
With the integration of dashboards, individuals can now access data that was previously inaccessible to them. Moreover, QuickSight has played a crucial role in streamlining our data distribution processes, enabling data accessibility across all departments within the organization.
To learn more, visit Amazon QuickSight.
About the Authors

Eliad Maimon is a Senior Startups Solutions Architect at AWS in Tel-Aviv with over 20 years of experience in architecting, building, and maintaining software products. He creates architectural best practices and collaborates with customers to leverage cloud and innovation, transforming businesses and disrupting markets. Eliad is specializing in machine learning on AWS, with a focus in areas such as generative AI, MLOps, and Amazon SageMaker.

Ori Nakar is a principal cyber-security researcher, a data engineer, and a data scientist at Imperva Threat Research group. Ori has many years of experience as a software engineer and engineering manager, focused on cloud technologies and big data infrastructure.
 Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a Ph. D. in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a Ph. D. in Computer Science and Artificial Intelligence from Northwestern University. Jianwei Li is a Principal Analytics Specialist TAM at Amazon Web Services. Jianwei provides consultant service for customers to help customer design and build modern data platform. Jianwei has been working in big data domain as software developer, consultant and tech leader.
Jianwei Li is a Principal Analytics Specialist TAM at Amazon Web Services. Jianwei provides consultant service for customers to help customer design and build modern data platform. Jianwei has been working in big data domain as software developer, consultant and tech leader. Dylan Tong is a Senior Product Manager at AWS. He works with customers to help drive their success on the AWS platform through thought leadership and guidance on designing well architected solutions. He has spent most of his career building on his expertise in data management and analytics by working for leaders and innovators in the space.
Dylan Tong is a Senior Product Manager at AWS. He works with customers to help drive their success on the AWS platform through thought leadership and guidance on designing well architected solutions. He has spent most of his career building on his expertise in data management and analytics by working for leaders and innovators in the space. Vamshi Vijay Nakkirtha is a Software Engineering Manager working on the OpenSearch Project and Amazon OpenSearch Service. His primary interests include distributed systems. He is an active contributor to various plugins, like k-NN, GeoSpatial, and dashboard-maps.
Vamshi Vijay Nakkirtha is a Software Engineering Manager working on the OpenSearch Project and Amazon OpenSearch Service. His primary interests include distributed systems. He is an active contributor to various plugins, like k-NN, GeoSpatial, and dashboard-maps.















 Ameya Agavekar is a results-driven, highly skilled data strategist. Ameya leads the data engineering and data science function for AWS Professional Services World-Wide Business Insights & Analytics team. Outside of work, Ameya is a professional pilot. He enjoys serving community by applying his unique flying skills with the US Airforce auxiliary Civil Air Patrol.
Ameya Agavekar is a results-driven, highly skilled data strategist. Ameya leads the data engineering and data science function for AWS Professional Services World-Wide Business Insights & Analytics team. Outside of work, Ameya is a professional pilot. He enjoys serving community by applying his unique flying skills with the US Airforce auxiliary Civil Air Patrol. Tucker Shouse leads the AWS Professional Services World-Wide Business Insights & Analytics team. Prior to AWS, Tucker worked with financial services, retail, healthcare, and non-profit clients to develop digital and data products and strategies as a Manager at Alvarez & Marsal Corporate Performance Improvement. Outside of work, Tucker enjoys spending time with his wife and daughter enjoying the outdoors and music.
Tucker Shouse leads the AWS Professional Services World-Wide Business Insights & Analytics team. Prior to AWS, Tucker worked with financial services, retail, healthcare, and non-profit clients to develop digital and data products and strategies as a Manager at Alvarez & Marsal Corporate Performance Improvement. Outside of work, Tucker enjoys spending time with his wife and daughter enjoying the outdoors and music.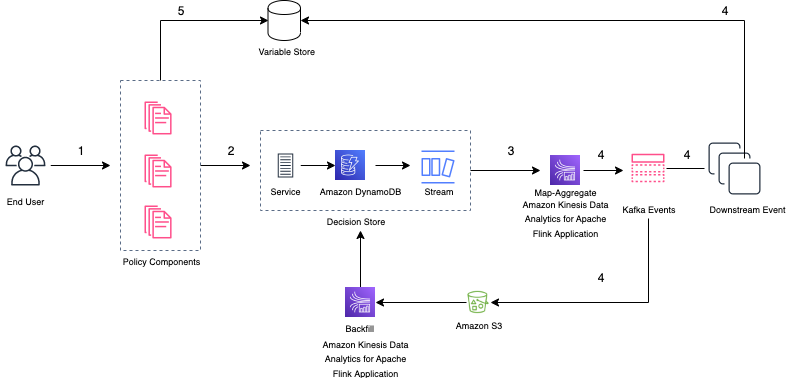
 Nir Tsruya is a Lead Engineer in Klarna. He leads 2 engineering teams focusing mainly on real time data processing and analytics at large scale.
Nir Tsruya is a Lead Engineer in Klarna. He leads 2 engineering teams focusing mainly on real time data processing and analytics at large scale. Ankit Gupta is a Senior Solutions Architect at Amazon Web Serves based in Stockholm, Sweden, where we helps customers across the Nordics succeed in Cloud. He’s particularly passionate about building strong Networking foundation in Cloud.
Ankit Gupta is a Senior Solutions Architect at Amazon Web Serves based in Stockholm, Sweden, where we helps customers across the Nordics succeed in Cloud. He’s particularly passionate about building strong Networking foundation in Cloud. Daniel Arenhage is a Solutions Architect at Amazon Web Services based in Gothenburg, Sweden.
Daniel Arenhage is a Solutions Architect at Amazon Web Services based in Gothenburg, Sweden.
 Tony McCormack is the CEO and Co-founder of Joulica. Based in Galway, Ireland, he is focused on providing enterprise-grade reporting and analytics for Amazon Connect, Salesforce Service Cloud, and other platforms in the customer experience market. He has extensive experience in the contact center domain, with a passion for real-time analytics and their integration into end-user applications.
Tony McCormack is the CEO and Co-founder of Joulica. Based in Galway, Ireland, he is focused on providing enterprise-grade reporting and analytics for Amazon Connect, Salesforce Service Cloud, and other platforms in the customer experience market. He has extensive experience in the contact center domain, with a passion for real-time analytics and their integration into end-user applications.
 Sumesh M R is a Full Stack Machine Learning Architect at Cargotec. He has several years of software engineering and ML background. Sumesh is an expert in Sagemaker and other AWS ML/Analytics services. He is passionate about data science and loves to explore the latest ML libraries and techniques. Before joining Cargotec, he worked as a Solution Architect at TCS. In his spare time, he loves to play cricket and badminton.
Sumesh M R is a Full Stack Machine Learning Architect at Cargotec. He has several years of software engineering and ML background. Sumesh is an expert in Sagemaker and other AWS ML/Analytics services. He is passionate about data science and loves to explore the latest ML libraries and techniques. Before joining Cargotec, he worked as a Solution Architect at TCS. In his spare time, he loves to play cricket and badminton. Tero Karttunen is a Senior Cloud Architect at Knowit Finland. He advises clients on architecting and adopting Data Architectures that best serve their Data Analytics and Machine Learning needs. He has helped Cargotec in their data journey for more than two years. Outside of work, he enjoys running, winter sports, and role-playing games.
Tero Karttunen is a Senior Cloud Architect at Knowit Finland. He advises clients on architecting and adopting Data Architectures that best serve their Data Analytics and Machine Learning needs. He has helped Cargotec in their data journey for more than two years. Outside of work, he enjoys running, winter sports, and role-playing games. Arun A K is a Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on AWS Glue, AWS Lake Formation, Amazon Athena, and Amazon EMR. In his free time, he likes to spend time with his friends and family.
Arun A K is a Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on AWS Glue, AWS Lake Formation, Amazon Athena, and Amazon EMR. In his free time, he likes to spend time with his friends and family.
 Mira Daniels (Data Engineer in Data Platform team), recently moved from Data Analytics to Data Engineering to make quality data more easily accessible for data consumers. She has been focusing on Digital Analytics and marketing data in the past.
Mira Daniels (Data Engineer in Data Platform team), recently moved from Data Analytics to Data Engineering to make quality data more easily accessible for data consumers. She has been focusing on Digital Analytics and marketing data in the past. Sean Whitfield (Senior Data Engineer in Data Platform team), a data enthusiast with a life science background who pursued his passion for data analysis into the realm of IT. His expertise lies in building robust data engineering and self-service tools. He also has a fervor for sharing his knowledge with others and mentoring aspiring data professionals.
Sean Whitfield (Senior Data Engineer in Data Platform team), a data enthusiast with a life science background who pursued his passion for data analysis into the realm of IT. His expertise lies in building robust data engineering and self-service tools. He also has a fervor for sharing his knowledge with others and mentoring aspiring data professionals.
 Joseph W. Landucci serves as Director of Technology Management at BWH Hotels where he has spent over eight years building and evolving their data management strategy. In this role he is responsible for the management and strategic direction of six product teams: Database, Revenue Management Systems, Data Services, Loyalty Applications, Loyalty Automation and Enterprise Analytics.
Joseph W. Landucci serves as Director of Technology Management at BWH Hotels where he has spent over eight years building and evolving their data management strategy. In this role he is responsible for the management and strategic direction of six product teams: Database, Revenue Management Systems, Data Services, Loyalty Applications, Loyalty Automation and Enterprise Analytics.
 Brian Kasen is the Director, Business Intelligence at Mitratech. He is passionate about helping HR leaders be more data-driven in their efforts to hire, retain, and engage their employees. Prior to Mitratech, Brian spent much of his career building analytic solutions across a range of industries, including higher education, restaurant, and software.
Brian Kasen is the Director, Business Intelligence at Mitratech. He is passionate about helping HR leaders be more data-driven in their efforts to hire, retain, and engage their employees. Prior to Mitratech, Brian spent much of his career building analytic solutions across a range of industries, including higher education, restaurant, and software. Rebecca McAlpine is the Senior Product Manager for Trakstar Insights at Mitratech. Her experience in HR tech experience has allowed her to work in various areas, including data analytics, business systems optimization, candidate experience, job application management, talent engagement strategy, training, and performance management.
Rebecca McAlpine is the Senior Product Manager for Trakstar Insights at Mitratech. Her experience in HR tech experience has allowed her to work in various areas, including data analytics, business systems optimization, candidate experience, job application management, talent engagement strategy, training, and performance management.





 Michael Hamilton is a Sr Analytics Solutions Architect focusing on helping enterprise customers in the south east modernize and simplify their analytics workloads on AWS. He enjoys mountain biking and spending time with his wife and three children when not working.
Michael Hamilton is a Sr Analytics Solutions Architect focusing on helping enterprise customers in the south east modernize and simplify their analytics workloads on AWS. He enjoys mountain biking and spending time with his wife and three children when not working. Angus Ferguson is a Solutions Architect at AWS who is passionate about meeting customers across the world, helping them solve their technical challenges. Angus specializes in Data & Analytics with a focus on customers in the financial services industry.
Angus Ferguson is a Solutions Architect at AWS who is passionate about meeting customers across the world, helping them solve their technical challenges. Angus specializes in Data & Analytics with a focus on customers in the financial services industry.

 Cynthia Valeriano is a Business Intelligence Developer of at Defontana, with skills focused on data analysis and visualization. With 3 years of experience in administrative areas and 2 years of experience in business intelligence projects, she has been in charge of implementing data migration and transformation tasks with various AWS tools, such as AWS DMS and AWS Glue, in addition to generating multiple dashboards in Amazon QuickSight.
Cynthia Valeriano is a Business Intelligence Developer of at Defontana, with skills focused on data analysis and visualization. With 3 years of experience in administrative areas and 2 years of experience in business intelligence projects, she has been in charge of implementing data migration and transformation tasks with various AWS tools, such as AWS DMS and AWS Glue, in addition to generating multiple dashboards in Amazon QuickSight. Jaime Olivares is a Senior software developer at Defontana, with 6 years of experience in the development of various technologies focused on the analysis of solutions and customer requirements. Experience with AWS in various services, including product development through QuickSight for the analysis of business and accounting data.
Jaime Olivares is a Senior software developer at Defontana, with 6 years of experience in the development of various technologies focused on the analysis of solutions and customer requirements. Experience with AWS in various services, including product development through QuickSight for the analysis of business and accounting data. Guillermo Puelles is a Technical Manager of the “Appia” Integrations team at Defontana, with 9 years of experience in software development and 5 years working with AWS tools. Responsible for planning and managing various projects for the implementation of BI solutions through QuickSight and other AWS services.
Guillermo Puelles is a Technical Manager of the “Appia” Integrations team at Defontana, with 9 years of experience in software development and 5 years working with AWS tools. Responsible for planning and managing various projects for the implementation of BI solutions through QuickSight and other AWS services.











 Kenta Oda is the Chief Technology Officer at SOFTBRAIN Co., Ltd. He is in responsible of new product development with keen insight on better customer experience and go-to-market strategy.
Kenta Oda is the Chief Technology Officer at SOFTBRAIN Co., Ltd. He is in responsible of new product development with keen insight on better customer experience and go-to-market strategy.



 Phil Goldstein is a copywriter and editor with AWS product marketing. He has 15 years of technology writing experience, and prior to joining AWS was a senior editor at a content marketing agency and a business journalist covering the wireless industry.
Phil Goldstein is a copywriter and editor with AWS product marketing. He has 15 years of technology writing experience, and prior to joining AWS was a senior editor at a content marketing agency and a business journalist covering the wireless industry.
 Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects focused on underprivileged Children’s education.
Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects focused on underprivileged Children’s education. Chandra Dhandapani is a Senior Solutions Architect at AWS, where he specializes in creating solutions for customers in Analytics, AI/ML, and Databases. He has a lot of experience in building and scaling applications across different industries including Healthcare and Fintech. Outside of work, he is an avid traveler and enjoys sports, reading, and entertainment.
Chandra Dhandapani is a Senior Solutions Architect at AWS, where he specializes in creating solutions for customers in Analytics, AI/ML, and Databases. He has a lot of experience in building and scaling applications across different industries including Healthcare and Fintech. Outside of work, he is an avid traveler and enjoys sports, reading, and entertainment. Amit Kumar Agrawal is a Senior Solutions Architect at AWS, based out of San Francisco Bay Area. He works with large strategic ISV customers to architect cloud solutions that address their business challenges. During his free time he enjoys exploring the outdoors with his family.
Amit Kumar Agrawal is a Senior Solutions Architect at AWS, based out of San Francisco Bay Area. He works with large strategic ISV customers to architect cloud solutions that address their business challenges. During his free time he enjoys exploring the outdoors with his family. Viral Shah is a Analytics Sales Specialist working with AWS for 5 years helping customers to be successful in their data journey. He has over 20+ years of experience working with enterprise customers and startups, primarily in the data and database space. He loves to travel and spend quality time with his family.
Viral Shah is a Analytics Sales Specialist working with AWS for 5 years helping customers to be successful in their data journey. He has over 20+ years of experience working with enterprise customers and startups, primarily in the data and database space. He loves to travel and spend quality time with his family.