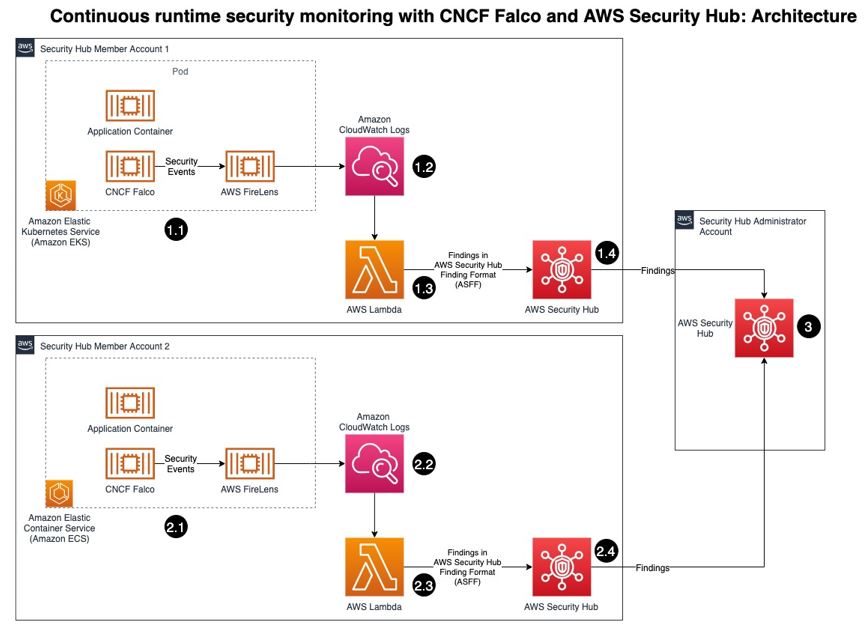
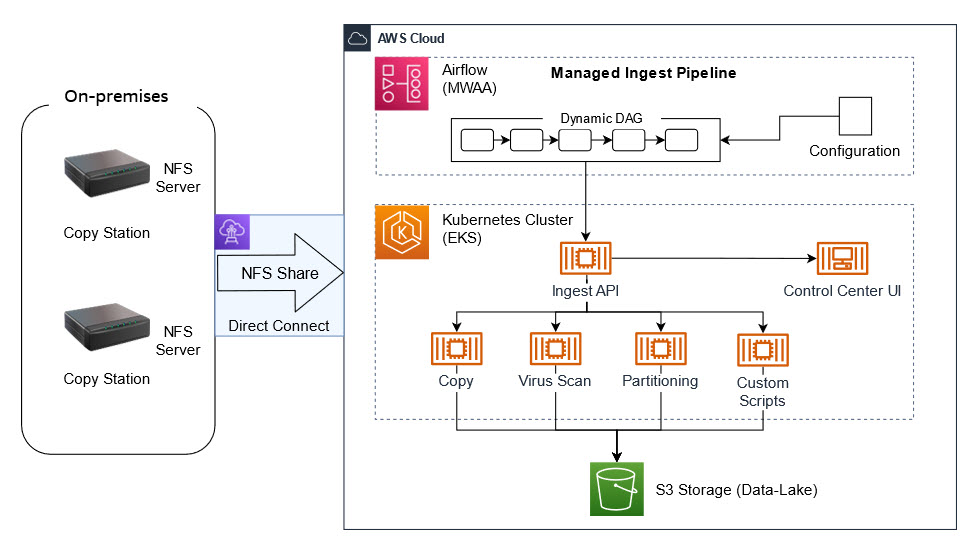
Post Syndicated from Зорница Латева original https://toest.bg/covid-19-za-politicheska-upotreba/
Използването на темата за COVID-19 за извличане на политически дивиденти не е български патент. В последните месеци обаче една по същество националистическа крайнодясна партия превърна говоренето за вируса и мерките срещу разпространението му в свое основно предизборно оръжие. На вота на 14 ноември предвожданата от Костадин Костадинов партия „Възраждане“ успя да събере над 127 500 гласа – с близо 50 000 повече спрямо изборите през април. Това ѝ осигури 13 места в 47-мото Народно събрание.
Риториката на Костадинов на тема COVID-19, ваксини и зелени сертификати не е единствената причина за този електорален резултат. Но със сигурност има съществена роля за постигането му.
„Гласът на здравомислещите“
През последните години Костадинов се превърна от местен в национален фактор на политическата сцена. Неговият възход съвпадна със залеза на други националистически формации, като „Атака“, ВМРО и НФСБ. Костадинов създава „Възраждане“ през 2014 г., след като вече е минал през няколко партии със същия профил. По това време той е директор на Историческия музей в Добрич и общински съветник във Варна (от 2011 г. до влизането му като депутат в настоящото Народно събрание). На предсрочните парламентарни избори през 2017 г. партията му става единствената извънпарламентарна формация със субсидия, след като печели 1,11% подкрепа. През 2019 г. стига до балотаж в надпреварата за кмет на Варна, но губи от Портних.
Костадинов беше и е сред противниците на Истанбулската конвенция и Стратегията за детето. Обявявал се е срещу промени в учебниците, издал е и собствен „учебник по родинознание“, който не е одобрен от МОН. Доскоро любимите му теми бяха против Европейския съюз, еврозоната, САЩ, „джендърите“. В официалната му страница във Facebook от септември насам те са изместени от тезите му срещу ваксинацията срещу COVID-19 и налагането на мерки срещу разпространението на коронавируса, като зелените сертификати, маските, пълното или частичното спиране на дейности от обществения живот. Откакто е в парламента, не пропуска тази тема, а на консултациите за съставяне на правителство при президента, на които отиде без маска, обяви, че първият приоритет на „Възраждане“ е връщането на нормалността с отпадането на мерките срещу вируса. Говорене, което би се харесало на всеки човек, който иска отново да живее спокойно и без ограничения.
Костадинов обаче удобно премълчава цената на връщането към нормалността – препълнени болници, срината здравна система и стотици починали всеки ден. Самият той се определя като глас на здравомислещите хора.
„Това е грип. Ваксините не са ефективни“
В публичните си изяви и постовете в социалните мрежи Костадинов нарича COVID-19 „грип“. Той не отрича, че има тежки случаи и починали, но смята, че информацията за това се преекспонира. Твърди, че болниците са препълнени именно заради страха на хората от усложнения и летален изход от заболяването. Костадинов не предлага мерки срещу COVID-19, а популистки пропагандира пълното отпадане на вече наложените. Неколкократно определя зеления сертификат като „античовешки“, а мерките, основани на него, като „концлагерни“.
Лидерът на „Възраждане“ заявява, че е „за“ ваксините, но не и за тези срещу коронавируса, които определя като „експериментални продукти“. Според него ваксините срещу коронавируса са разработени прекалено бързо, не са ефективни, а кампанията за масовото им прилагане е рекламна.
„Както всеки един човек знае, и без да има медицинско образование, ваксините предпазват на 100% от заболяване. Именно заради това ние от „Възраждане“ подкрепяме ваксинацията с утвърдените и доказани във времето ваксини срещу сериозните болести. […] Ваксините, които са доказали своята ефикасност, са разработвани десетилетия. Повече от 20 години е разработвана ваксината срещу детски паралич. Повече от 30 години е разработвана ваксината срещу малария. Ваксините срещу дифтерит, срещу коклюш и всички тези болести, които са били бичове за човешката цивилизация, са разработвани десетилетия от най-добрите учени на човечеството“, казва лидерът на „Възраждане“.
Той добавя, че ваксинацията срещу COVID-19 трябва да е доброволна и от нея не бива да произтичат ограничения или привилегии.
Това не е грип
Грипът и COVID-19 си приличат по начина на разпространение и по симптомите. Част от усложненията и при двете заболявания са подобни. Една от основните разлики между тях е, че при грип от години се прилагат ефективни противовирусни препарати, които могат да съкратят времето на протичане на болестта. До момента лекарство срещу коронавируса, което да се прилага масово, няма. Използват се медикаменти за други болести, и то основно в болнични условия.
Освен това смъртността от COVID-19 е по-висока от тази от грип. Колко точно по-висока, все още не е установено, но според публикация на Института „Джонс Хопкинс“ разликата може и да е над 10 пъти в полза на коронавируса. Според данните на Световната здравна организация годишно от свързани с грип усложнения умират между 290 000 и 650 000 души по целия свят. За последните две години от COVID-19 са починали над 5,34 млн. души. Дори ако се вземе предвид горната граница от смъртни случаи от грип – 650 000 на година, за две години починалите от усложнения, свързани с вируса на инфлуенцата, са около 1,3 млн. души, или над 4 пъти по-малко, отколкото при коронавируса.
Данните за България показват, че общата смъртност от 5 януари 2020 г. до момента е с 25% по-висока от очакваната смъртност на базата на данни от годините преди разпространението на коронавируса.
Колко ефективни са ваксините
Въпреки твърденията на Костадин Костадинов, че познатите и използвани от десетилетия ваксини са 100% ефективни, такива препарати почти не съществуват. В листовката на задължителната ваксина срещу полиомиелит (детски паралич) е записано, че тя е ефективна 99–100% (при прилагане на всички дози). Тази за дифтерия е с ефективност 97%. Ваксината срещу малария, която Костадинов споменава, действително се разработва от 30 години. Към момента обаче ефективността ѝ е 40%. Противогрипните ваксини, които Костадинов посочва като доказани, предпазват между 30 и 60% срещу различните щамове. Но и те, както и ваксините срещу COVID-19 намаляват риска от усложнения при евентуално заразяване.
Ефективността на антиковид ваксините продължава да се изследва, а данните се променят и според изменението на самия вирус. При Алфа варианта ефективността на иРНК ваксините се измерваше на над 90%. При Делта варианта, който доминира в момента, това число намалява, но се смята, че различните препарати (включително векторните) предпазват между 60 и 90% от заболяване.
В България няма точна статистика колко от всички установени случаи на COVID-19 до момента са при ваксинирани хора, както и колко от тях са стигнали до болница или са починали. Подобна статистика се дава на дневна база от последните няколко месеца. Информацията ден за ден показва, че обикновено над 80% от новозаразените не са били имунизирани. Делът на неваксинираните сред хоспитализираните с ковид е 85–90%, а сред починалите – 90–95%. И това на фона на новините за случаи с издаване на фалшиви сертификати за ваксинация.
Години работа
Ваксините срещу COVID-19 действително се появиха бързо. Масовото им прилагане започна в рамките на около година. Първи бяха иРНК препаратите. Този вид ваксини до момента не бяха прилагани по света, което допълнително предизвика съмнения и недоверие, но те всъщност се разработват от десетилетия. По данни на СЗО и национални здравни организации, като Центровете за контрол и превенция на заболяванията в САЩ, иРНК ваксините са проучвани за превенция на грип, бяс, зика, цитомегаловирус. Очаква се, че този тип ваксини ще бъдат все по-разпространени, тъй като може да се произвеждат в големи количества за кратко време.
Нарушени ли са човешките права
По света от десетилетия се прилагат задължителни ваксини. България не прави изключение. А липсата на имунизации води до ограничения – децата, на които не са поставени всички препарати и дози, не могат да посещават ясли, детски градини и училище.
Според решение на Европейския съд за правата на човека от април т.г. задължителната ваксинация не нарушава човешките права. Съдът се произнесе по жалба на родители от Чехия, чиято имунизационна политика е доста сходна с българската. ЕСПЧ постанови, че задължителната ваксинация е необходима мярка в демократичните общества, и подчерта, че никой не бива принудително да се ваксинира, а се оспорват последиците от отказа от имунизация. В решението се казва, че наистина за децата това да не посещават детска градина е загуба на важна възможност да развият личността си и да започнат да придобиват важни социални и учебни умения. „Това обаче е пряка последица от избора на техните родителите да откажат да изпълнят законово задължение, чиято цел е опазването на здравето конкретно на децата в тази възрастова група“, пише в решението.
Освен това възможността деца, които не могат да бъдат ваксинирани по медицински причини, да посещават детска градина зависи от високия процент на ваксинация сред другите деца. „Съдът смята, че не може да се счита за непропорционално държавата да изисква от тези, за които ваксинацията представлява малък риск за здравето, да приемат тази универсално практикувана защитна мярка като законово задължение в името на социалната солидарност и на по-малкия брой уязвими деца, които не могат да се възползват от ваксинацията“, пише още в решението.
Някои страни задължиха определени групи, като медици, полицаи, пожарникари, да се ваксинират срещу ковид. В държави като Италия и Австрия са въведени и изисквания за наличие на здравен сертификат за всички работещи. ЕСПЧ вече отхвърли жалбите на френски пожарникари и на гръцки медици срещу задължителното изискване да се имунизират.
В България ваксината срещу COVID-19 не е задължителна за никого. Със зеления сертификат, който се издава и на ваксинирани, и на преболедували, и на хора с отрицателен тест за коронавирус или положителен за антитела, се налагат ограничения, като забрана за посещения на някои обществени места на закрито за тези, които не разполагат с документа. Въвеждането му доведе до съдебни жалби, за каквито призоваха и от „Възраждане“. До момента десетки са отхвърлени.
Зеленият сертификат вкара „Възраждане“ в парламента
„Говоренето срещу ваксините и зеленият сертификат вкараха „Възраждане“ в парламента“, коментира Първан Симеонов, политолог и изпълнителен директор на „Галъп интернешънъл болкан“. Той допълва, че в предходните два вота за парламент партията леко е повишила резултата си и въпреки че предварителните социологически проучвания не ѝ отреждаха място в Народното събрание след 14 ноември, е направила „силен финален спринт“.
Според него говоренето на крайнодесния Костадин Костадинов срещу правилата, наложени заради COVID-19, е част от подобна тенденция и в Западна Европа. „Получава се парадокс – радикалната десница пропагандира за човешките права, а прогресивната левица, която не съществува у нас, пропагандира за спазване на правилата“, обясни Симеонов. По думите му, на местна почва посланията на Костадинов в предизборната кампания са се отличили толкова ярко, тъй като е липсвало „обратното говорене“ за налагане на ограничения и в полза на ваксините. „Никоя друга партия не зае твърда позиция“, коментира политологът.
Доколко антиковид говоренето е помогнало за изборния резултат на „Възраждане“, косвено се разглежда в доклада на Центъра за изследване на демокрацията отпреди изборите на тема „Пропаганда и дезинформация в предизборната кампания: основни послания и канали за разпространение“. Проучването обхваща информацията в публично достъпни Facebook страници и групи, които са били наблюдавани в периода между 14 октомври и 8 ноември 2021 г.
Изследването показва, че партия „Възраждане“ и нейният лидер са абсолютни шампиони по бързо увеличаване на броя на последователите в социалната мрежа. Костадинов е привлякъл най-много нови последователи от всички кандидат-президенти (над 22 000 само за 3 седмици) и като основна причина ярко се откроява въвеждането на задължителния зелен сертификат на 19 октомври. От петте изследвани националистически и проруски партии („Възраждане“, АБВ, ВМРО, „Атака“ и „Воля“) „Възраждане“ е привлякла най-много внимание на публиката във Facebook – с 95% от всички взаимодействия и 98% от всички нови последователи.
Анализ на страницата на Костадинов с инструмента BuzzSumo също показва, че ангажираността, която публикациите на страницата създават сред потребителите (харесвания, коментари, споделяния), нараства лавинообразно. През септември общата ангажираност с постовете е била над 401 000 реакции, през октомври, когато се въвежда и сертификатът, тя рязко нараства на близо 900 000 реакции, а през ноември вече е почти 1,2 млн. реакции. Най-активните публикации са именно тези с възгледите му за пандемията, зеления сертификат и ваксините. От септември до момента средната ангажираност на постовете на страницата на Костадинов се е увеличила от около 2500 на 7685 реакции средно на публикация.



Влизането на „Възраждане“ в парламента дава все по-голяма трибуна на Костадинов да пропагандира тезите си против антиковид ваксините и срещу мерките за ограничаването на разпространението на коронавируса. Като депутат неговите изказвания се появяват все по-често в националните медии и достигат до още повече хора. И със сигурност ще намерят благоприятна почва сред част от обществото, уморено от ограничения и страх от COVID-19. А това е опасно не само за съмишлениците на Костадинов, които не желаят да се ваксинират, да носят маски и да спазват ограничения, а и за останалите. Тъй като коронавирусът не избира приемниците си според това дали искат и спазват правилата, или не.
Увеличаващата се гласност на политици като Костадинов ще прави все по-трудно налагането на допълнителни ограничения във времена на поредната ковид вълна. И подкопава и без това не особено ефективните усилия на властите за увеличаване на дела на ваксинираните българи. А с това се отдалечава моментът за връщане към що-годе нормален живот, в който разпространението на вируса може да се контролира.
Заглавна илюстрация: © Пеню Кирацов
Източник