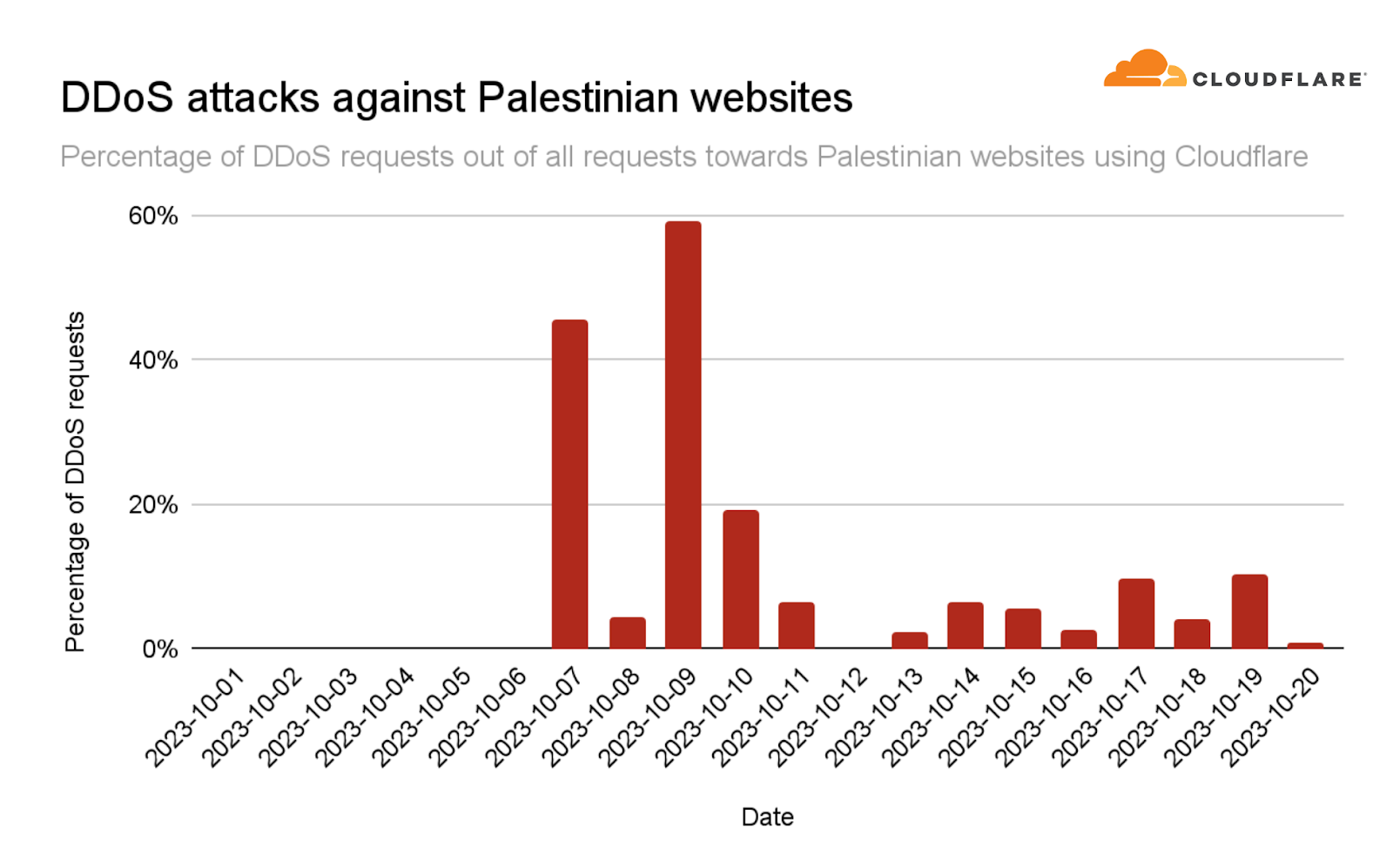
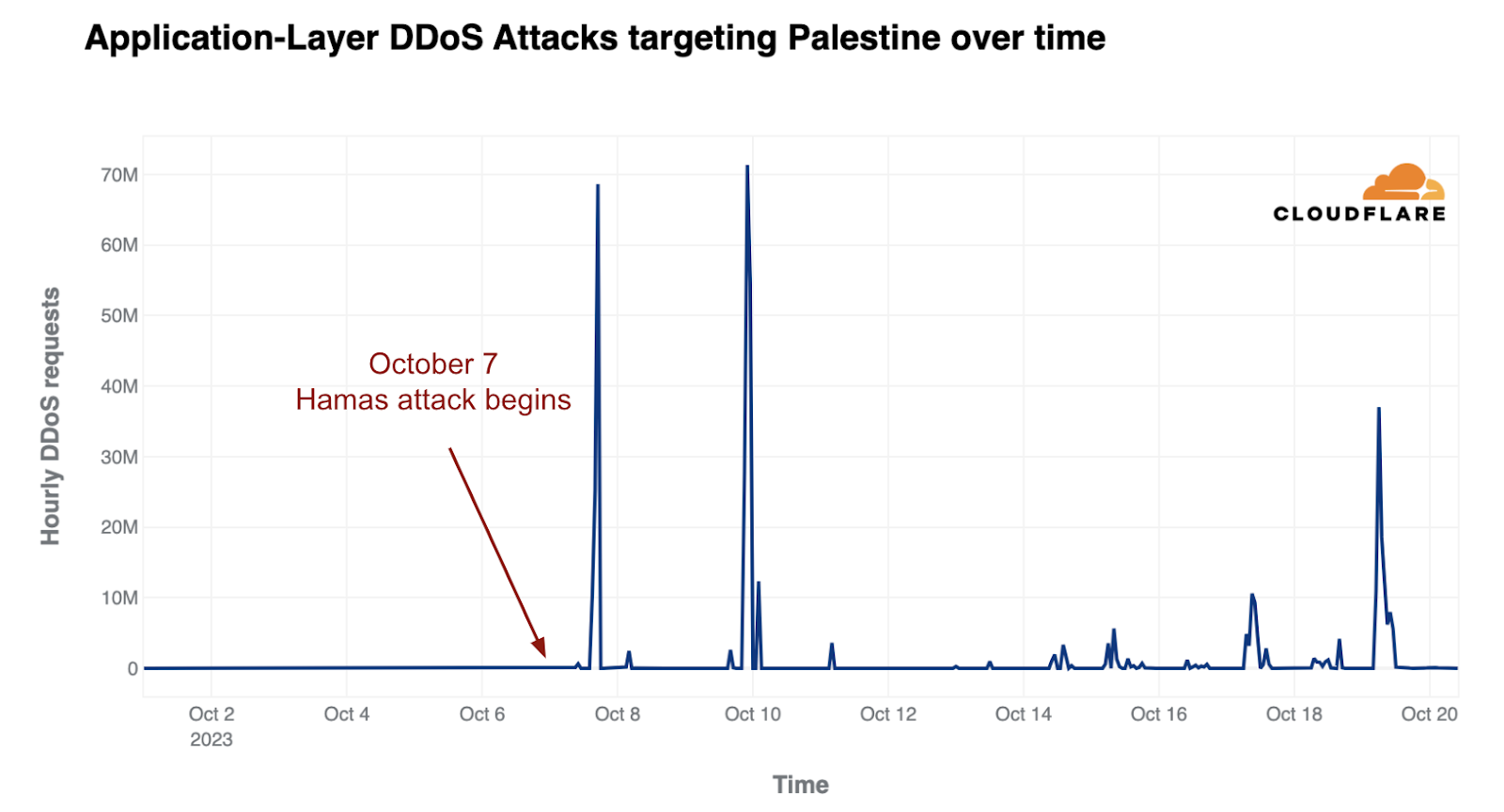
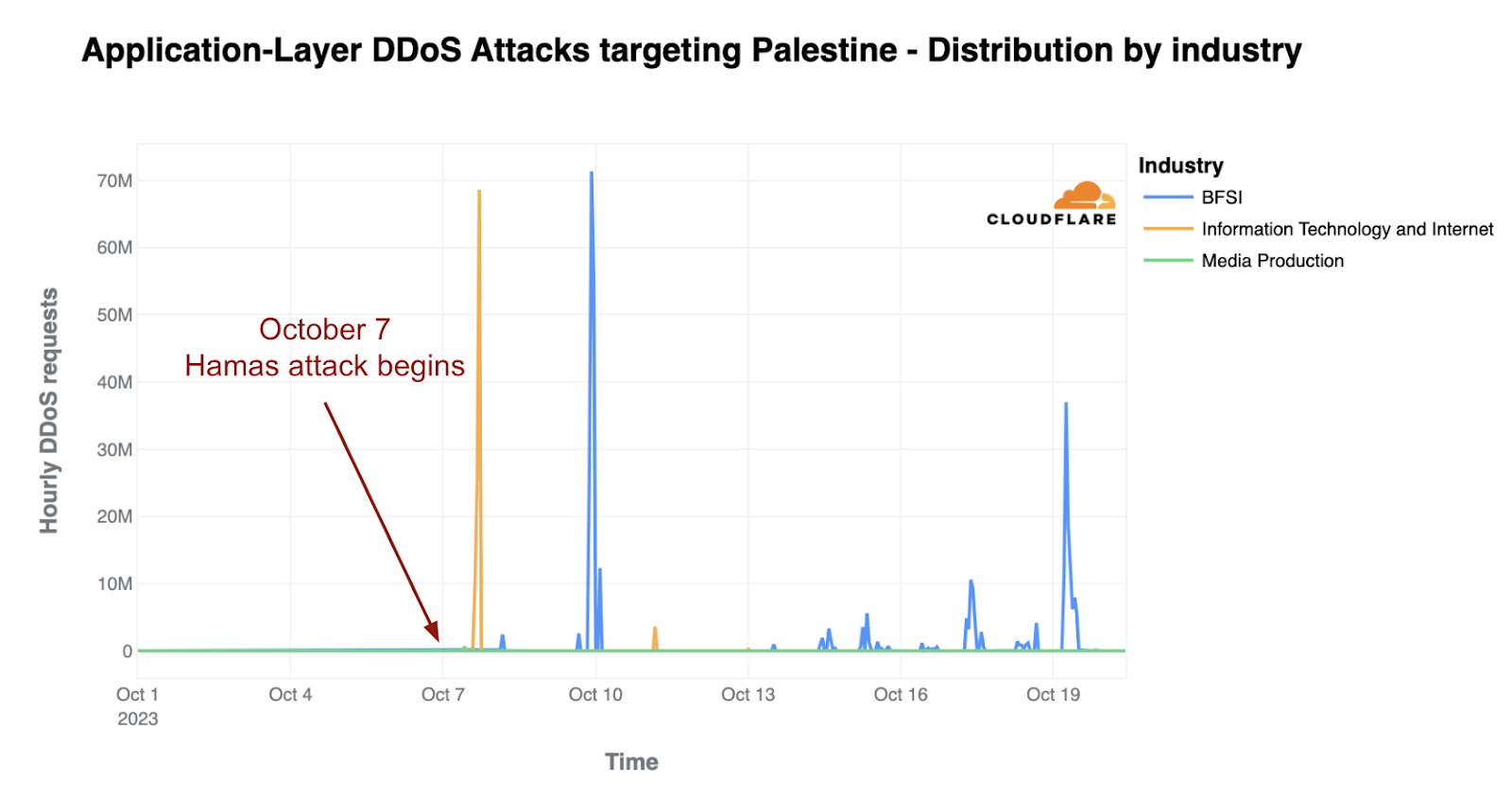
Post Syndicated from Pathik Shah original https://aws.amazon.com/blogs/big-data/run-spark-sql-on-amazon-athena-spark/
At AWS re:Invent 2022, Amazon Athena launched support for Apache Spark. With this launch, Amazon Athena supports two open-source query engines: Apache Spark and Trino. Athena Spark allows you to build Apache Spark applications using a simplified notebook experience on the Athena console or through Athena APIs. Athena Spark notebooks support PySpark and notebook magics to allow you to work with Spark SQL. For interactive applications, Athena Spark allows you to spend less time waiting and be more productive, with application startup time in under a second. And because Athena is serverless and fully managed, you can run your workloads without worrying about the underlying infrastructure.
Modern applications store massive amounts of data on Amazon Simple Storage Service (Amazon S3) data lakes, providing cost-effective and highly durable storage, and allowing you to run analytics and machine learning (ML) from your data lake to generate insights on your data. Before you run these workloads, most customers run SQL queries to interactively extract, filter, join, and aggregate data into a shape that can be used for decision-making, model training, or inference. Running SQL on data lakes is fast, and Athena provides an optimized, Trino- and Presto-compatible API that includes a powerful optimizer. In addition, organizations across multiple industries such as financial services, healthcare, and retail are adopting Apache Spark, a popular open-source, distributed processing system that is optimized for fast analytics and advanced transformations against data of any size. With support in Athena for Apache Spark, you can use both Spark SQL and PySpark in a single notebook to generate application insights or build models. Start with Spark SQL to extract, filter, and project attributes that you want to work with. Then to perform more complex data analysis such as regression tests and time series forecasting, you can use Apache Spark with Python, which allows you to take advantage of a rich ecosystem of libraries, including data visualization in Matplot, Seaborn, and Plotly.
In this first post of a three-part series, we show you how to get started using Spark SQL in Athena notebooks. We demonstrate querying databases and tables in the Amazon S3 and the AWS Glue Data Catalog using Spark SQL in Athena. We cover some common and advanced SQL commands used in Spark SQL, and show you how to use Python to extend your functionality with user-defined functions (UDFs) as well as to visualize queried data. In the next post, we’ll show you how to use Athena Spark with open-source transactional table formats. In the third post, we’ll cover analyzing data sources other than Amazon S3 using Athena Spark.
Prerequisites
To get started, you will need the following:
Provide Athena Spark access to your data through an IAM role
As you proceed through this walkthrough, we create new databases and tables. By default, Athena Spark doesn’t have permission to do this. To provide this access, you can add the following inline policy to the AWS Identity and Access Management (IAM) role attached to the workgroup, providing the region and your account number. For more information, refer to the section To embed an inline policy for a user or role (console) in Adding IAM identity permissions (console).
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ReadfromPublicS3",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::athena-examples-us-east-1/*",
"arn:aws:s3:::athena-examples-us-east-1"
]
},
{
"Sid": "GlueReadDatabases",
"Effect": "Allow",
"Action": [
"glue:GetDatabases"
],
"Resource": "arn:aws:glue:<region>:<account-id>:*"
},
{
"Sid": "GlueReadDatabase",
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetTable",
"glue:GetTables",
"glue:GetPartition",
"glue:GetPartitions"
],
"Resource": [
"arn:aws:glue:<region>:<account-id>:catalog",
"arn:aws:glue:<region>:<account-id>:database/sparkblogdb",
"arn:aws:glue:<region>:<account-id>:table/sparkblogdb/*",
"arn:aws:glue:<region>:<account-id>:database/default"
]
},
{
"Sid": "GlueCreateDatabase",
"Effect": "Allow",
"Action": [
"glue:CreateDatabase"
],
"Resource": [
"arn:aws:glue:<region>:<account-id>:catalog",
"arn:aws:glue:<region>:<account-id>:database/sparkblogdb"
]
},
{
"Sid": "GlueDeleteDatabase",
"Effect": "Allow",
"Action": "glue:DeleteDatabase",
"Resource": [
"arn:aws:glue:<region>:<account-id>:catalog",
"arn:aws:glue:<region>:<account-id>:database/sparkblogdb",
"arn:aws:glue:<region>:<account-id>:table/sparkblogdb/*" ]
},
{
"Sid": "GlueCreateDeleteTablePartitions",
"Effect": "Allow",
"Action": [
"glue:CreateTable",
"glue:UpdateTable",
"glue:DeleteTable",
"glue:BatchCreatePartition",
"glue:CreatePartition",
"glue:DeletePartition",
"glue:BatchDeletePartition",
"glue:UpdatePartition",
"glue:GetPartition",
"glue:GetPartitions",
"glue:BatchGetPartition"
],
"Resource": [
"arn:aws:glue:<region>:<account-id>:catalog",
"arn:aws:glue:<region>:<account-id>:database/sparkblogdb",
"arn:aws:glue:<region>:<account-id>:table/sparkblogdb/*"
]
}
]
}
Run SQL queries directly in notebook without using Python
When using Athena Spark notebooks, we can run SQL queries directly without having to use PySpark. We do this by using cell magics, which are special headers in a notebook that change the cells’ behavior. For SQL, we can add the %%sql magic, which will interpret the entire cell contents as a SQL statement to be run on Athena Spark.
Now that we have our workgroup and notebook created, let’s start exploring the NOAA Global Surface Summary of Day dataset, which provides environmental measures from various locations all over the earth. The datasets used in this post are public datasets hosted in the following Amazon S3 locations:
- Parquet data for year 2020 –
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/2020/
- Parquet data for year 2021 –
s3://athena-examples-us-east-1/athenasparksqlblog/noaa_pq/year=2021/
- Parquet data from year 2022 –
s3://athena-examples-us-east-1/athenasparksqlblog/noaa_pq/year=2022/
To use this data, we need an AWS Glue Data Catalog database that acts as the metastore for Athena, allowing us to create external tables that point to the location of datasets in Amazon S3. First, we create a database in the Data Catalog using Athena and Spark.
Create a database
Run following SQL in your notebook using %%sql magic:
%%sql
CREATE DATABASE sparkblogdb
You get the following output:

Create a table
Now that we have created a database in the Data Catalog, we can create a partitioned table that points to our dataset stored in Amazon S3:
%%sql
CREATE EXTERNAL TABLE sparkblogdb.noaa_pq(
station string,
date string,
latitude string,
longitude string,
elevation string,
name string,
temp string,
temp_attributes string,
dewp string,
dewp_attributes string,
slp string,
slp_attributes string,
stp string,
stp_attributes string,
visib string,
visib_attributes string,
wdsp string,
wdsp_attributes string,
mxspd string,
gust string,
max string,
max_attributes string,
min string,
min_attributes string,
prcp string,
prcp_attributes string,
sndp string,
frshtt string)
PARTITIONED BY (year string)
STORED AS PARQUET
LOCATION 's3://athena-examples-us-east-1/athenasparksqlblog/noaa_pq/'
This dataset is partitioned by year, meaning that we store data files for each year separately, which simplifies management and improves performance because we can target the specific S3 locations in a query. The Data Catalog knows about the table, and now we’ll let it work out how many partitions we have automatically by using the MSCK utility:
%%sql
MSCK REPAIR TABLE sparkblogdb.noaa_pq
When the preceding statement is complete, you can run the following command to list the yearly partitions that were found in the table:
%%sql
SHOW PARTITIONS sparkblogdb.noaa_pq

Now that we have the table created and partitions added, let’s run a query to find the minimum recorded temperature for the 'SEATTLE TACOMA AIRPORT, WA US' location:
%%sql
select year, min(MIN) as minimum_temperature
from sparkblogdb.noaa_pq
where name = 'SEATTLE TACOMA AIRPORT, WA US'
group by 1
You get the following output:

Query a cross-account Data Catalog from Athena Spark
Athena supports accessing cross-account AWS Glue Data Catalogs, which enables you to use Spark SQL in Athena Spark to query a Data Catalog in an authorized AWS account.
The cross-account Data Catalog access pattern is often used in a data mesh architecture, when a data producer wants to share a catalog and data with consumer accounts. The consumer accounts can then perform data analysis and explorations on the shared data. This is a simplified model where we don’t need to use AWS Lake Formation data sharing. The following diagram gives an overview of how the setup works between one producer and one consumer account, which can be extended to multiple producer and consumer accounts.

You need to set up the right access policies on the Data Catalog of the producer account to enable cross-account access. Specifically, you must make sure the consumer account’s IAM role used to run Spark calculations on Athena has access to the cross-account Data Catalog and data in Amazon S3. For setup instructions, refer to Configuring cross-account AWS Glue access in Athena for Spark.
There are two ways the consumer account can access the cross-account Data Catalog from Athena Spark, depending on whether you are querying from one producer account or multiple.
Query a single producer table
If you are just querying data from a single producer’s AWS account, you can tell Athena Spark to only use that account’s catalog to resolve database objects. When using this option, you don’t have to modify the SQL because you’re configuring the AWS account ID at session level. To enable this method, edit the session and set the property "spark.hadoop.hive.metastore.glue.catalogid": "999999999999" using the following steps:
- In the notebook editor, on the Session menu, choose Edit session.

- Choose Edit in JSON.
- Add the following property and choose Save:
{"spark.hadoop.hive.metastore.glue.catalogid": "999999999999"} This will start a new session with the updated parameters.
This will start a new session with the updated parameters.
- Run the following SQL statement in Spark to query tables from the producer account’s catalog:
%%sql
SELECT *
FROM <central-catalog-db>.<table>
LIMIT 10
Query multiple producer tables
Alternatively, you can add the producer AWS account ID in each database name, which is helpful if you’re going to query Data Catalogs from different owners. To enable this method, set the property {"spark.hadoop.aws.glue.catalog.separator": "/"} when invoking or editing the session (using the same steps as the previous section). Then, you add the AWS account ID for the source Data Catalog as part of the database name:
%%sql
SELECT *
FROM `<producer-account1-id>/database1`.table1 t1
join `<producer-account2-id>/database2`.table2 t2
ON t1.id = t2.id
limit 10
If the S3 bucket belonging to the producer AWS account is configured with Requester Pays enabled, the consumer is charged instead of the bucket owner for requests and downloads. In this case, you can add the following property when invoking or editing an Athena Spark session to read data from these buckets:
{"spark.hadoop.fs.s3.useRequesterPaysHeader": "true"}
Infer the schema of your data in Amazon S3 and join with tables crawled in the Data Catalog
Rather than only being able to go through the Data Catalog to understand the table structure, Spark can infer schema and read data directly from storage. This feature allows data analysts and data scientists to perform a quick exploration of the data without needing to create a database or table, but which can also be used with other existing tables stored in the Data Catalog in the same or across different accounts. To do this, we use a Spark temp view, which is an in-memory data structure that stores the schema of data stored in a data frame.
Using the NOAA dataset partition for 2020, we create a temporary view by reading S3 data into a data frame:
year_20_pq = spark.read.parquet(f"s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/2020/")
year_20_pq.createOrReplaceTempView("y20view")
Now you can query the y20view using Spark SQL as if it were a Data Catalog database:
%%sql
select count(*)
from y20view

You can query data from both temporary views and Data Catalog tables in the same query in Spark. For example, now that we have a table containing data for years 2021 and 2022, and a temporary view with 2020’s data, we can find the dates in each year when the maximum temperature was recorded for 'SEATTLE TACOMA AIRPORT, WA US'.
To do this, we can use the window function and UNION:
%%sql
SELECT date,
max as maximum_temperature
FROM (
SELECT date,
max,
RANK() OVER (
PARTITION BY year
ORDER BY max DESC
) rnk
FROM sparkblogdb.noaa_pq
WHERE name = 'SEATTLE TACOMA AIRPORT, WA US'
AND year IN ('2021', '2022')
UNION ALL
SELECT date,
max,
RANK() OVER (
ORDER BY max DESC
) rnk
FROM y20view
WHERE name = 'SEATTLE TACOMA AIRPORT, WA US'
) t
WHERE rnk = 1
ORDER by 1
You get the following output:

Extend your SQL with a UDF in Spark SQL
You can extend your SQL functionality by registering and using a custom user-defined function in Athena Spark. These UDFs are used in addition to the common predefined functions available in Spark SQL, and once created, can be reused many times within a given session.
In this section, we walk through a straightforward UDF that converts a numeric month value into the full month name. You have the option to write the UDF in either Java or Python.
Java-based UDF
The Java code for the UDF can be found in the GitHub repository. For this post, we have uploaded a prebuilt JAR of the UDF to s3://athena-examples-us-east-1/athenasparksqlblog/udf/month_number_to_name.jar.
To register the UDF, we use Spark SQL to create a temporary function:
%%sql
CREATE OR REPLACE TEMPORARY FUNCTION
month_number_to_name as 'com.example.MonthNumbertoNameUDF'
using jar "s3a://athena-examples-us-east-1/athenasparksqlblog/udf/month_number_to_name.jar";
Now that the UDF is registered, we can call it in a query to find the minimum recorded temperature for each month of 2022:
%%sql
select month_number_to_name(month(to_date(date,'yyyy-MM-dd'))) as month_yr_21,
min(min) as min_temp
from sparkblogdb.noaa_pq
where NAME == 'SEATTLE TACOMA AIRPORT, WA US'
group by 1
order by 2
You get the following output:

Python-based UDF
Now let’s see how to add a Python UDF to the existing Spark session. The Python code for the UDF can be found in the GitHub repository. For this post, the code has been uploaded to s3://athena-examples-us-east-1/athenasparksqlblog/udf/month_number_to_name.py.
Python UDFs can’t be registered in Spark SQL, so instead we use a small bit of PySpark code to add the Python file, import the function, and then register it as a UDF:
sc.addPyFile('s3://athena-examples-us-east-1/athenasparksqlblog/udf/month_number_to_name.py')
from month_number_to_name import month_number_to_name
spark.udf.register("month_number_to_name_py",month_number_to_name)
Now that the Python-based UDF is registered, we can use the same query from earlier to find the minimum recorded temperature for each month of 2022. The fact that it’s Python rather than Java doesn’t matter now:
%%sql
select month_number_to_name_py(month(to_date(date,'yyyy-MM-dd'))) as month_yr_21,
min(min) as min_temp
from sparkblogdb.noaa_pq
where NAME == 'SEATTLE TACOMA AIRPORT, WA US'
group by 1
order by 2
The output should be similar to that in the preceding section.
Plot visuals from the SQL queries
It’s straightforward to use Spark SQL, including across AWS accounts for data exploration, and not complicated to extend Athena Spark with UDFs. Now let’s see how we can go beyond SQL using Python to visualize data within the same Spark session to look for patterns in the data. We use the table and temporary views created previously to generate a pie chart that shows percentage of readings taken in each year for the station 'SEATTLE TACOMA AIRPORT, WA US'.
Let’s start by creating a Spark data frame from a SQL query and converting it to a pandas data frame:
#we will use spark.sql instead of %%sql magic to enclose the query string
#this will allow us to read the results of the query into a dataframe to use with our plot command
sqlDF = spark.sql("select year, count(*) as cnt from sparkblogdb.noaa_pq where name = 'SEATTLE TACOMA AIRPORT, WA US' group by 1 \
union all \
select 2020 as year, count(*) as cnt from y20view where name = 'SEATTLE TACOMA AIRPORT, WA US'")
#convert to pandas data frame
seatac_year_counts=sqlDF.toPandas()
Next, the following code uses the pandas data frame and Matplot library to plot a pie chart:
import matplotlib.pyplot as plt
# clear the state of the visualization figure
plt.clf()
# create a pie chart with values from the 'cnt' field, and yearly labels
plt.pie(seatac_year_counts.cnt, labels=seatac_year_counts.year, autopct='%1.1f%%')
%matplot plt
The following figure shows our output.

Clean up
To clean up the resources created for this post, complete the following steps:
- Run the following SQL statements in the notebook’s cell to delete the database and tables from the Data Catalog:
%%sql
DROP TABLE sparkblogdb.noaa_pq
%%sql
DROP DATABASE sparkblogdb
- Delete the workgroup created for this post. This will also delete saved notebooks that are part of the workgroup.
- Delete the S3 bucket that you created as part of the workgroup.
Conclusion
Athena Spark makes it easier than ever to query databases and tables in the AWS Glue Data Catalog directly through Spark SQL in Athena, and to query data directly from Amazon S3 without needing a metastore for quick data exploration. It also makes it straightforward to use common and advanced SQL commands used in Spark SQL, including registering UDFs for custom functionality. Additionally, Athena Spark makes it effortless to use Python in a fast start notebook environment to visualize and analyze data queried via Spark SQL.
Overall, Spark SQL unlocks the ability to go beyond standard SQL in Athena, providing advanced users more flexibility and power through both SQL and Python in a single integrated notebook, and providing fast, complex analysis of data in Amazon S3 without infrastructure setup. To learn more about Athena Spark, refer to Amazon Athena for Apache Spark.
About the Authors
 Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
Raj Devnath is a Product Manager at AWS on Amazon Athena. He is passionate about building products customers love and helping customers extract value from their data. His background is in delivering solutions for multiple end markets, such as finance, retail, smart buildings, home automation, and data communication systems.





 This will start a new session with the updated parameters.
This will start a new session with the updated parameters.



 Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services. Raj Devnath is a Product Manager at AWS on Amazon Athena. He is passionate about building products customers love and helping customers extract value from their data. His background is in delivering solutions for multiple end markets, such as finance, retail, smart buildings, home automation, and data communication systems.
Raj Devnath is a Product Manager at AWS on Amazon Athena. He is passionate about building products customers love and helping customers extract value from their data. His background is in delivering solutions for multiple end markets, such as finance, retail, smart buildings, home automation, and data communication systems.