Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Севда Семер, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.
превод от английски Стоян Гяуров, изд. „Колибри“, 2021
Има различни видове есета. Има ясни и целеустремени, последователни като валяк. Има и такива като полет на птица или пеперуда. Те са неочаквани, будещи любопитство и задаващи въпроси, доставящи неусетно удоволствие, а и знание. Те не създават впечатление, че нещата са окончателно изяснени, не – карат те да търсиш още повече. Сборникът на Уайнбъргър е от втория забележителен и рядък вид. Книга, която спокойно поставям до „Приказка без край“ на Михаел Енде – заради богатството ѝ.
Елиът Уайнбъргър е отказал се от поезията поет, но е личен приятел и преводач на Нобеловия лауреат Октавио Пас, също така неслучайно е и преводач на Борхес и Бей Дао – за щастие, все познати на български автори. В тази книга той ни разкрива обширна територия от красота и ерудиция, умело смесвайки проза и поезия. В 34 на брой текста, които за удобство могат да се нарекат и достъпни авангардни есета, авторът отвежда нищо неподозиращия читател, включително и пишещия настоящия отзив, под повърхността на уж познати неща.
От самото начало текстовете тъкат, плетат и хвърлят мрежа, която улавя и извежда на повърхността нещо уж познато, като например сезоните, вятъра или мушитрънчетата. („Че малкото мушитрънче идва от дълбините на миналото, е очевидно от разказите за него. Мушитрънчето е предател на християнството. Когато св. Стефан се опитва да избяга от затвора, едно мушитрънче каца на лицето на пазача и го събужда, което довежда до мъченичеството на светеца.“)
Но мрежата не се задоволява единствено с това. Тя е фина и умна. Стигнала е до дълбочини, които (да, потвърдено е вече) съществуват. Тя слага на масата изрази, предмети, странни левитиращи личности, чудни детайли, явления, празници, континенти и култури, за които малко хора отвъд тесните специалисти са чували. Лошото на такива експерти е, че често пишат и говорят сухо, неразбираемо и отвлечено. Хубавото на Уайнбъргър е, че всичко, което пише, съдържа заразителна свежест и желание за споделяне на нещо, което го е учудило и му е важно. А, да – и притежава чувство за хумор.
Темите елегантно се преплитат, всеки текст се закача към предишните и следващите по деликатен начин, без ненужно подчертаване или шумно щракване. Концептуалното нюансиране е забележително. Неусетно, страница след страница, усещаш, че си във вихър. В него се въртят многото светове, които световната култура предлага, а съвременните ценности и контекст с лекота пренебрегват или зачеркват.
В един момент се запитах кое е „истинското нещо“ от заглавието? Това е може би разговорът, щафетата, обменът на истории, римуваната симетрия на човешкото въображение. Шеметният вихър може да те отведе от земята до небето по главозамайващо концентриран начин. Отдавна не ми се беше случвало толкова интересно и целенасочено скитане из безкрайния свят на колективната фантазия.
Научих за магаре, пишещо любовна поезия, и за италианец, който сравнява носорог с Лаура на Петрарка по красота. Разбрах, че някога на китайски идеалната комбинация и баланс между пиктограмите за вятър и кокал е била птицата, метафора за идеалното стихотворение. Също така в Китай е имало едно време и Министерство на литературните добродетели, а на езика босави думата за „утре“ е същата като за „вчера“.
Учудих се, че представителите на древната перуанска култура моче „са писали върху боб, от който са се запазили много малко зърна, и така писмото им се е изличило“, а „подобно на питагорейците Емпедокъл забранявал на учениците си да ядат боб. „Боб бил вулгарен израз за тестис или пък бобът бил вятърничава работа и преливащ от житейска сила, или бобът приличал на Вратата към Хадес, или пък бобът съдържал душите на мъртвите, или бобът имал несвързани помежду си стъбла, през които душите на мъртвите изпълзявали изпод земята, или пък бобът, заровен в земята, приемал формата на човешка или детска глава.“ Внимавайте с боба.
Според Лидия Дейвис Уайнбъргър ни напомня, че „има повече – и много повече – от това, което виждаме в културата на нашето време“. В свитъците на мандейците се разказва историята на едно странно същество на име Динанукхт – „получовек, полукнига, който седи край водите между световете и чете себе си“. Уайнбъргър и Динанукхт със сигурност са роднини, но слава богу, единият е и писател и споделя какво е прочел. Чрез това споделяне поне аз разбирам колко едностранчиво мисля понякога и как разсъжденията ми са изпълнени с предразсъдъците на времето и средата, в които съм роден и израснал. Такива книги те хващат за раменете, разтърсват те и ти казват, че май нищо не знаеш. Това е здравословно и приятно.
Бих искал да споделя още много истории и любопитни неща. Ще се задоволя само с началото на едни от най-хубавите шест страници от литературата – литературата въобще, – на които съм попадал. Посветени са на звездите:
Какво са звездите? Те са парчета от лед, в които се отразява слънцето; те са светлини, плуващи върху водите отвъд прозрачния купол; те са гвоздеи, забити в небето; те са дупки в голямата завеса между нас и морето от светлина; те са дупки в твърдата черупка, която ни пази от отвъдния ад; те са дъщерите на слънцето; те са пратениците на боговете; те имат формата на колела и са кондензиран въздух, с пламъци, които фучат в пространствата между спиците; те седят на малки столчета; те са разпилени из небето; те са пратеници на влюбените; те се състоят от атоми, които се носят из вакуума и се съединяват помежду си; те са душите на умрели бебета, които се превръщат в цветя на небето; те са птици с горящи пера; те оплождат майките на великите хора; те са блестящи концентрати на дъха-дух, направени от излишните останки при сътворението на слънцето и луната; те са вестители на война, смърт, глад, чума, добри и лоши реколти, раждането на крале; те регулират цените на солта и рибата; те са семената на всички същества на земята; те са стадото на луната, разпръснато по небето като овце на ливадата, които тя води на паша; те са кристални сфери, чието движение произвежда музика в небето; те са неподвижни, а ние се движим; ние сме неподвижни, а те се движат; те са изгубили се ловци на тюлени…
И още, и още. Щедра книга, която, щеш – не щеш, ще те обогати и ще те направи по-грижовен и разбран (а това май е повече от нужно днес), ако я прочетеш. Даже и с голям риск да не гледаш на света по същия начин.
Заглавно изображение: Колаж от корицата на книгата (худ. Иво Рафаилов, изд. „Колибри“) и снимка на Giancarlo Duarte / Unsplash
Активните дарители на „Тоест“ получават постоянна отстъпка в размер на 20% от коричната цена на всички заглавия от каталога на „Колибри“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Севда Семер, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.
превод от английски Стоян Гяуров, изд. „Колибри“, 2021
Има различни видове есета. Има ясни и целеустремени, последователни като валяк. Има и такива като полет на птица или пеперуда. Те са неочаквани, будещи любопитство и задаващи въпроси, доставящи неусетно удоволствие, а и знание. Те не създават впечатление, че нещата са окончателно изяснени, не – карат те да търсиш още повече. Сборникът на Уайнбъргър е от втория забележителен и рядък вид. Книга, която спокойно поставям до „Приказка без край“ на Михаел Енде – заради богатството ѝ.
Елиът Уайнбъргър е отказал се от поезията поет, но е личен приятел и преводач на Нобеловия лауреат Октавио Пас, също така неслучайно е и преводач на Борхес и Бей Дао – за щастие, все познати на български автори. В тази книга той ни разкрива обширна територия от красота и ерудиция, умело смесвайки проза и поезия. В 34 на брой текста, които за удобство могат да се нарекат и достъпни авангардни есета, авторът отвежда нищо неподозиращия читател, включително и пишещия настоящия отзив, под повърхността на уж познати неща.
От самото начало текстовете тъкат, плетат и хвърлят мрежа, която улавя и извежда на повърхността нещо уж познато, като например сезоните, вятъра или мушитрънчетата. („Че малкото мушитрънче идва от дълбините на миналото, е очевидно от разказите за него. Мушитрънчето е предател на християнството. Когато св. Стефан се опитва да избяга от затвора, едно мушитрънче каца на лицето на пазача и го събужда, което довежда до мъченичеството на светеца.“)
Но мрежата не се задоволява единствено с това. Тя е фина и умна. Стигнала е до дълбочини, които (да, потвърдено е вече) съществуват. Тя слага на масата изрази, предмети, странни левитиращи личности, чудни детайли, явления, празници, континенти и култури, за които малко хора отвъд тесните специалисти са чували. Лошото на такива експерти е, че често пишат и говорят сухо, неразбираемо и отвлечено. Хубавото на Уайнбъргър е, че всичко, което пише, съдържа заразителна свежест и желание за споделяне на нещо, което го е учудило и му е важно. А, да – и притежава чувство за хумор.
Темите елегантно се преплитат, всеки текст се закача към предишните и следващите по деликатен начин, без ненужно подчертаване или шумно щракване. Концептуалното нюансиране е забележително. Неусетно, страница след страница, усещаш, че си във вихър. В него се въртят многото светове, които световната култура предлага, а съвременните ценности и контекст с лекота пренебрегват или зачеркват.
В един момент се запитах кое е „истинското нещо“ от заглавието? Това е може би разговорът, щафетата, обменът на истории, римуваната симетрия на човешкото въображение. Шеметният вихър може да те отведе от земята до небето по главозамайващо концентриран начин. Отдавна не ми се беше случвало толкова интересно и целенасочено скитане из безкрайния свят на колективната фантазия.
Научих за магаре, пишещо любовна поезия, и за италианец, който сравнява носорог с Лаура на Петрарка по красота. Разбрах, че някога на китайски идеалната комбинация и баланс между пиктограмите за вятър и кокал е била птицата, метафора за идеалното стихотворение. Също така в Китай е имало едно време и Министерство на литературните добродетели, а на езика босави думата за „утре“ е същата като за „вчера“.
Учудих се, че представителите на древната перуанска култура моче „са писали върху боб, от който са се запазили много малко зърна, и така писмото им се е изличило“, а „подобно на питагорейците Емпедокъл забранявал на учениците си да ядат боб. „Боб бил вулгарен израз за тестис или пък бобът бил вятърничава работа и преливащ от житейска сила, или бобът приличал на Вратата към Хадес, или пък бобът съдържал душите на мъртвите, или бобът имал несвързани помежду си стъбла, през които душите на мъртвите изпълзявали изпод земята, или пък бобът, заровен в земята, приемал формата на човешка или детска глава.“ Внимавайте с боба.
Според Лидия Дейвис Уайнбъргър ни напомня, че „има повече – и много повече – от това, което виждаме в културата на нашето време“. В свитъците на мандейците се разказва историята на едно странно същество на име Динанукхт – „получовек, полукнига, който седи край водите между световете и чете себе си“. Уайнбъргър и Динанукхт със сигурност са роднини, но слава богу, единият е и писател и споделя какво е прочел. Чрез това споделяне поне аз разбирам колко едностранчиво мисля понякога и как разсъжденията ми са изпълнени с предразсъдъците на времето и средата, в които съм роден и израснал. Такива книги те хващат за раменете, разтърсват те и ти казват, че май нищо не знаеш. Това е здравословно и приятно.
Бих искал да споделя още много истории и любопитни неща. Ще се задоволя само с началото на едни от най-хубавите шест страници от литературата – литературата въобще, – на които съм попадал. Посветени са на звездите:
Какво са звездите? Те са парчета от лед, в които се отразява слънцето; те са светлини, плуващи върху водите отвъд прозрачния купол; те са гвоздеи, забити в небето; те са дупки в голямата завеса между нас и морето от светлина; те са дупки в твърдата черупка, която ни пази от отвъдния ад; те са дъщерите на слънцето; те са пратениците на боговете; те имат формата на колела и са кондензиран въздух, с пламъци, които фучат в пространствата между спиците; те седят на малки столчета; те са разпилени из небето; те са пратеници на влюбените; те се състоят от атоми, които се носят из вакуума и се съединяват помежду си; те са душите на умрели бебета, които се превръщат в цветя на небето; те са птици с горящи пера; те оплождат майките на великите хора; те са блестящи концентрати на дъха-дух, направени от излишните останки при сътворението на слънцето и луната; те са вестители на война, смърт, глад, чума, добри и лоши реколти, раждането на крале; те регулират цените на солта и рибата; те са семената на всички същества на земята; те са стадото на луната, разпръснато по небето като овце на ливадата, които тя води на паша; те са кристални сфери, чието движение произвежда музика в небето; те са неподвижни, а ние се движим; ние сме неподвижни, а те се движат; те са изгубили се ловци на тюлени…
И още, и още. Щедра книга, която, щеш – не щеш, ще те обогати и ще те направи по-грижовен и разбран (а това май е повече от нужно днес), ако я прочетеш. Даже и с голям риск да не гледаш на света по същия начин.
Активните дарители на „Тоест“ получават постоянна отстъпка в размер на 20% от коричната цена на всички заглавия от каталога на „Колибри“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
“The more you practice the art of thankfulness, the more you have to be thankful for.”
— Norman Vincent Peale, American author
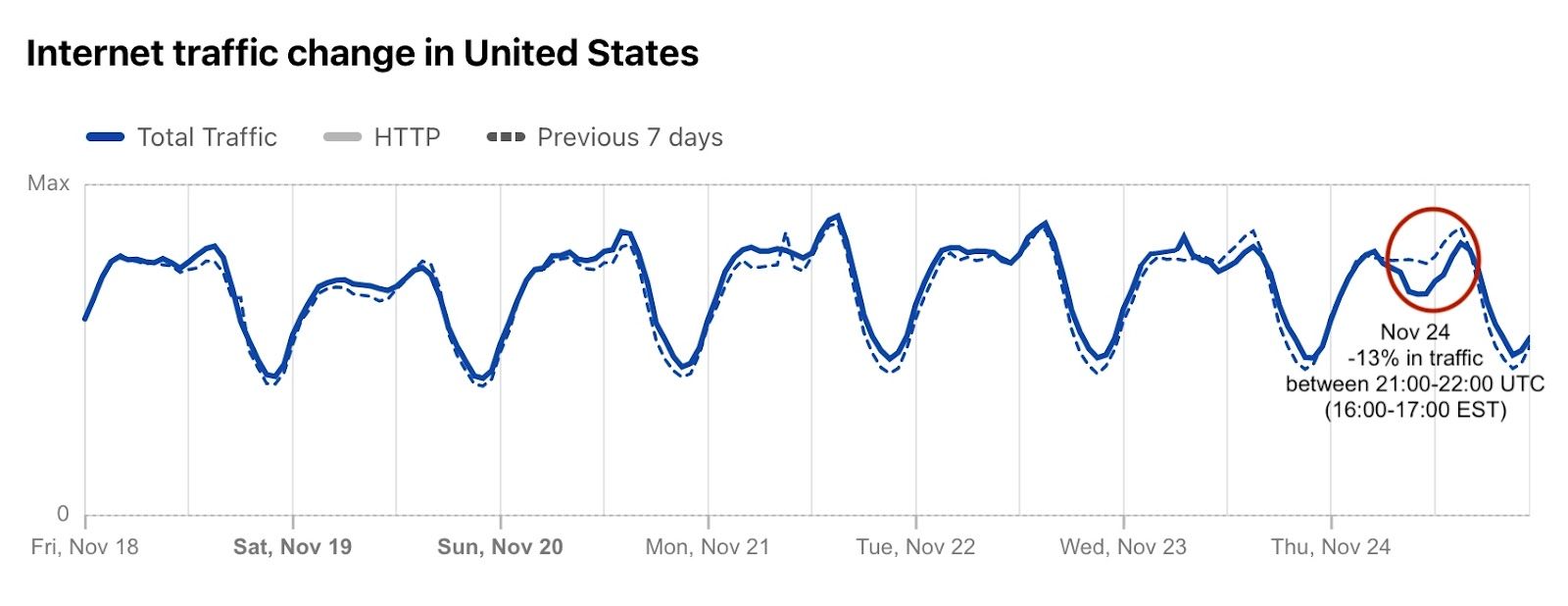
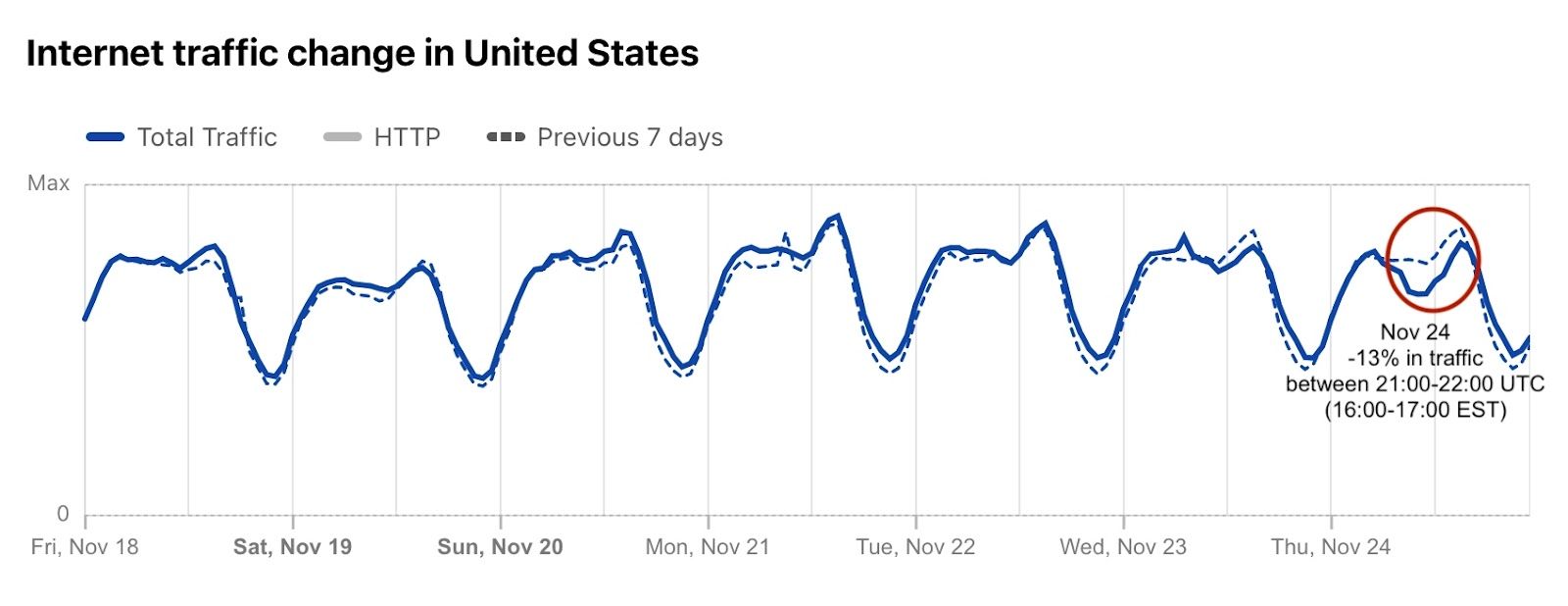
The turkey. The sweet potatoes. The stuffing. The pumpkin pie. Yesterday, November 24, 2022, was Thanksgiving Day in the US. A time for families and loved ones to be together and thankful, according to the tradition. Last year, we saw how the US paused shopping (and browsing) for Thanksgiving. So, how was it this year? Not only did we see Internet traffic go down (by 13%) during Thanksgiving dinner, but it was much higher than usual the day before and the day after (the Black Friday effect… so far). There was also a clear, but short, Thanksgiving day effect on e-commerce DNS trends.
We’ll have to wait to see what Black Friday looks like.
Let’s start with Internet traffic at the time of Thanksgiving dinner. Although every family is different, a 2018 survey of US consumers showed that for 42% early afternoon (between 13:00 and 15:00 is the preferred time to sit at the table and start to dig in). But 16:00 seems to be the “correct time” — The Atlantic explains why.
That said, Cloudflare Radar shows that between 21:00 and 01:00 UTC (we use that as the standard timezone in Radar) there was a clear drop in Internet traffic, mostly between 21:00 and 22:00 UTC, when traffic dropped 13%, compared with the week before. That time period is “translated” for the East Coast to between 16:00 and 20:00 EST and for the West Coast the time between 13:00 to 17:00 PST. Similar to what we saw last year.
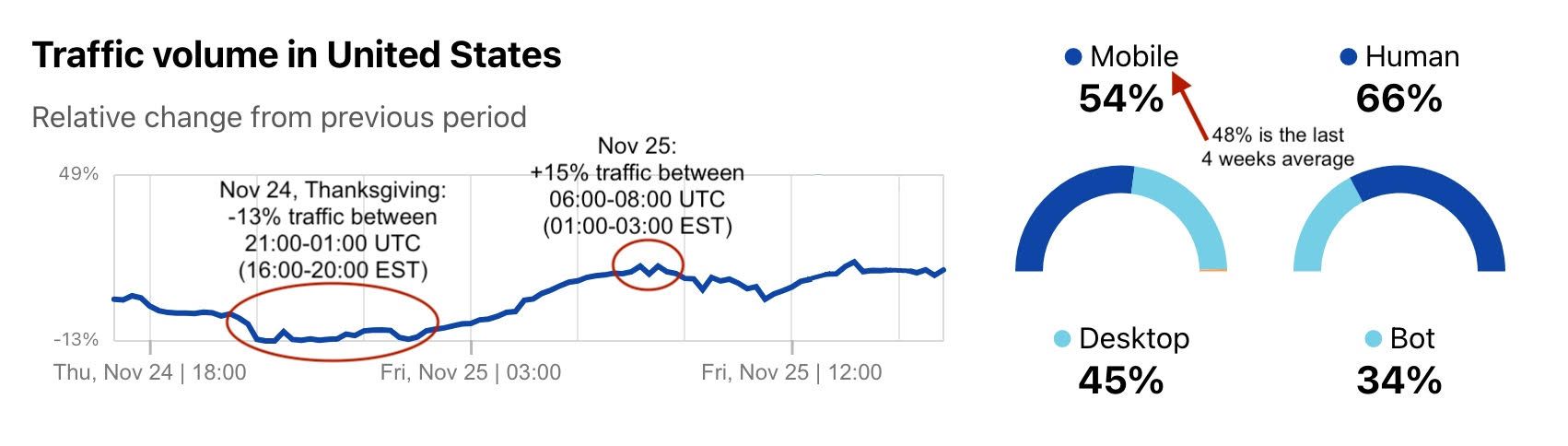
Radar also allows anyone to focus on the last 24 hours and check the traffic volume change compared with the previous period. The more granular view in the next graph shows not only the 13% drop during Thanksgiving dinner, but also the clear increase after. At around 01:00 EST (22:00 PST), traffic was 15% higher than the day before, and today, November 25, Black Friday morning (08:00 EST, 05:00 PST), was growing ~16% more in traffic at 09:00 EST (06:00 PST).
It’s a similar perspective when we look at the last seven days, a filter that also shows the night before Thanksgiving in the US, traffic was 15% higher than the week before at around 01:00-03:00 EST (22:00-00:00 PST). And there’s a general increase in traffic this week, probably related to the fact it is also “Black Friday Week” (more on e-commerce trends at the end).
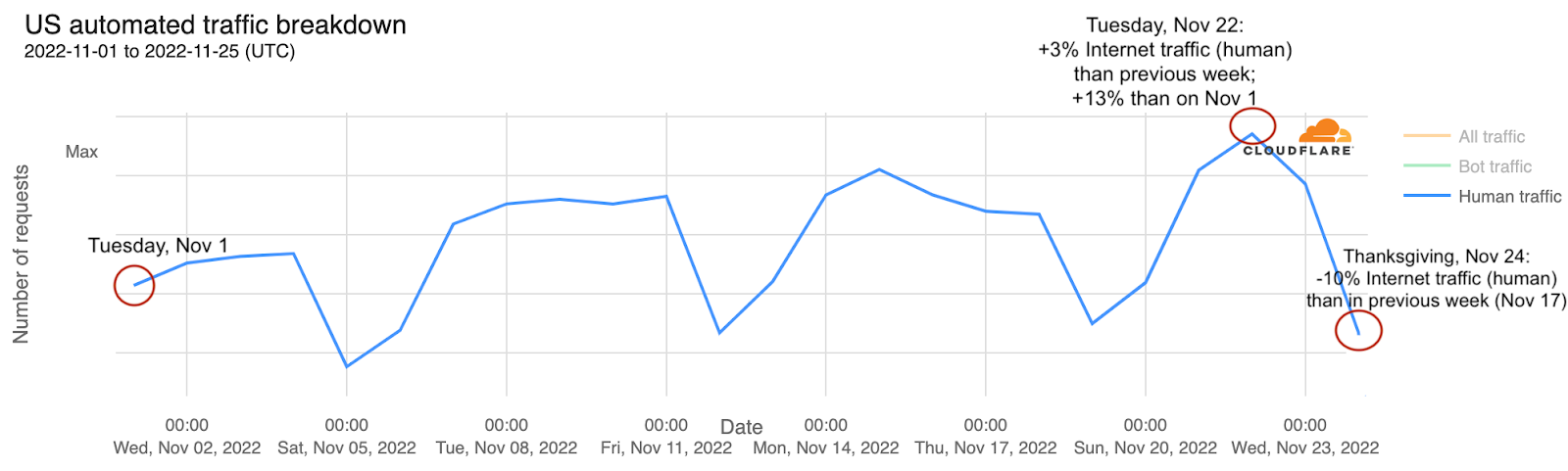
In terms of Internet traffic growth (made by humans, not bots) in November, there’s a clear increase throughout the month, but mostly this week. The next chart aggregates traffic by day. So far, Tuesday, November 22, 2022, was the day of the month with most traffic in the US — +13% than what we saw on Tuesday, November 1.
It’s also clear in the previous graph that weekends in the US have less traffic, especially Saturdays, but that Thanksgiving Day was the one with less traffic of the past two weeks — 10% less traffic than the same day the week before.
We’ve been focused on human Internet traffic. Bots, on the other hand, are not that interested in the Thanksgiving and Black Friday, and there was actually more bot traffic in the US last week than in this one. So far.
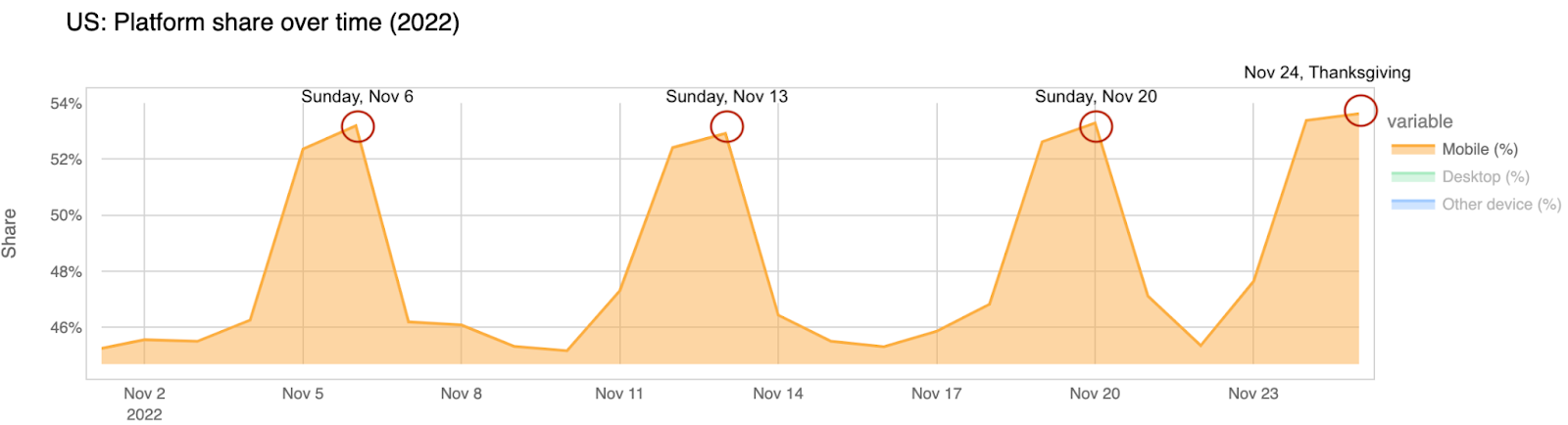
To wrap up this Internet traffic section, let’s look at mobile device trends. In the last four weeks, we saw an average of 48% of Internet traffic in the US coming from mobile devices. But on Thanksgiving Day that average was 55%. That was actually the day in November when people in the US were most online using their mobile devices.
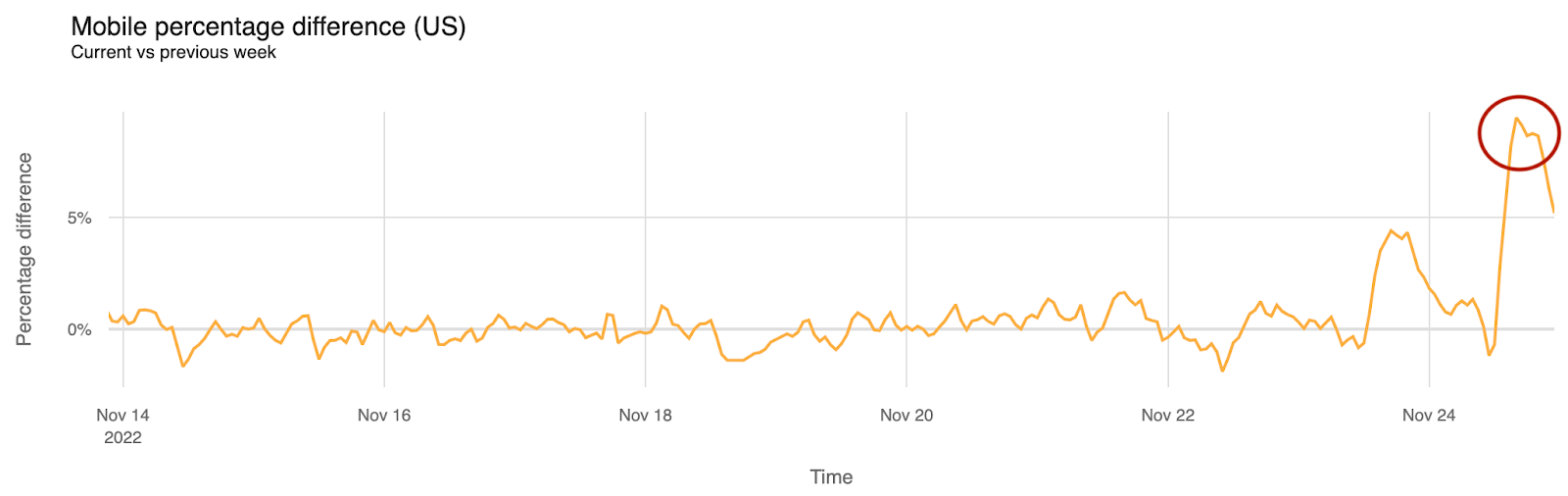
Here’s the view that shows the mobile percentage difference from the past two weeks, with an up to 9% increase (compared with the previous week) in mobile devices’ predominance in Internet traffic, between 10:00 and 16:00 EST (07:00-13:00 PST).
E-commerce interest: growing (but with a Thanksgiving dip)
Now, let’s look at DNS query trends (from our globally used 1.1.1.1 DNS resolver) to e-commerce websites in the US. First, the Thanksgiving Day effect.
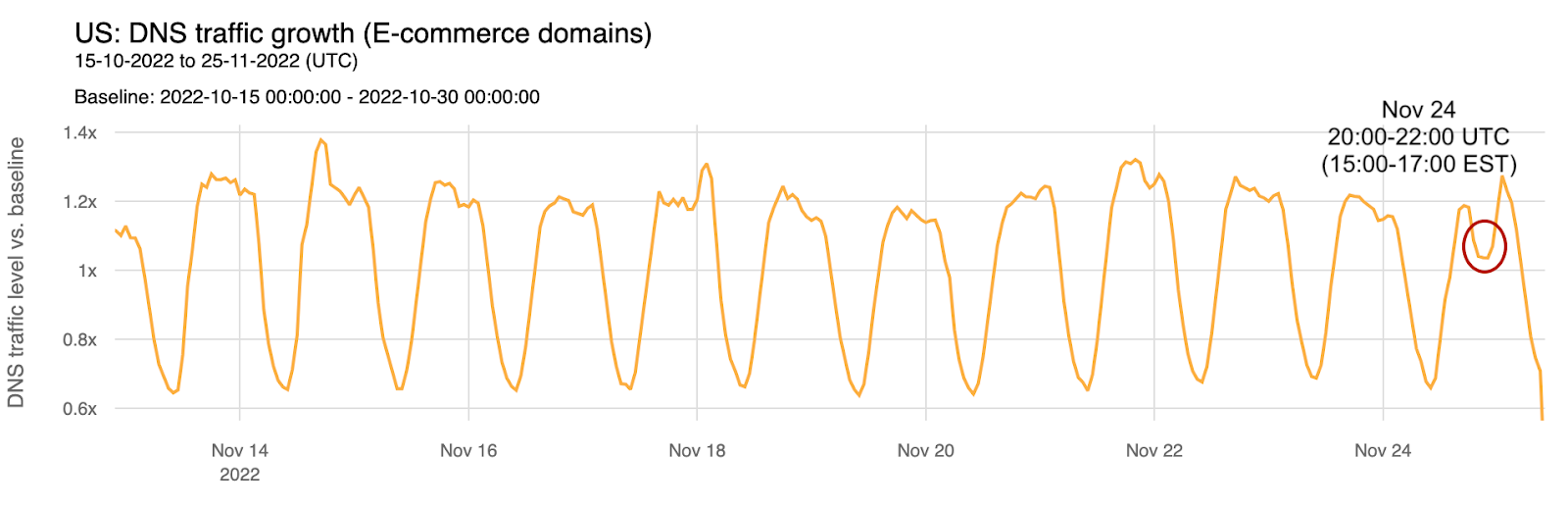
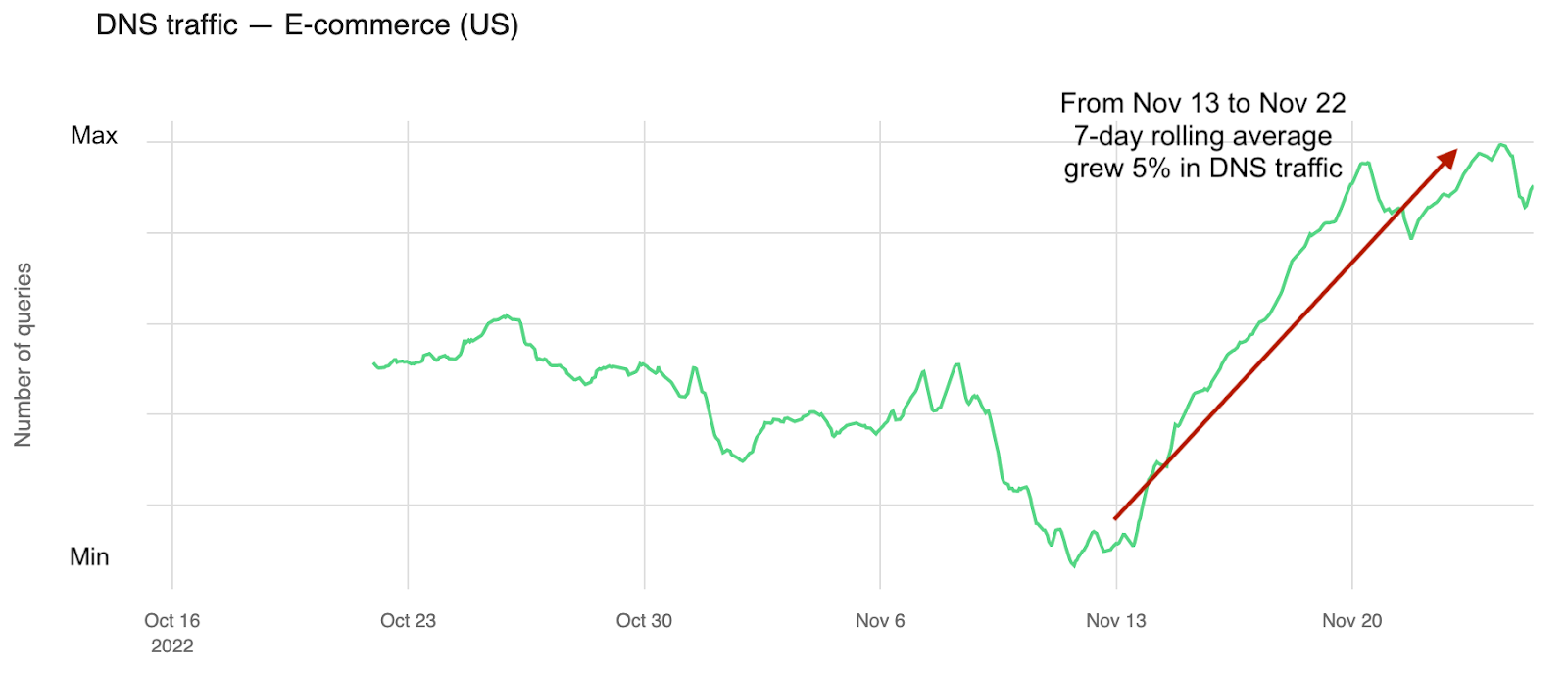
Aggregating several e-commerce domains, we can see not only that there are several spikes in the last two weeks, but that during Thanksgiving, there was a clear dip in DNS traffic between 15:00 and 17:00 EST (12:00-14:00 PST). How much? At 17:00 EST, Thanksgiving Day, there was 13% less DNS traffic than in the previous week.
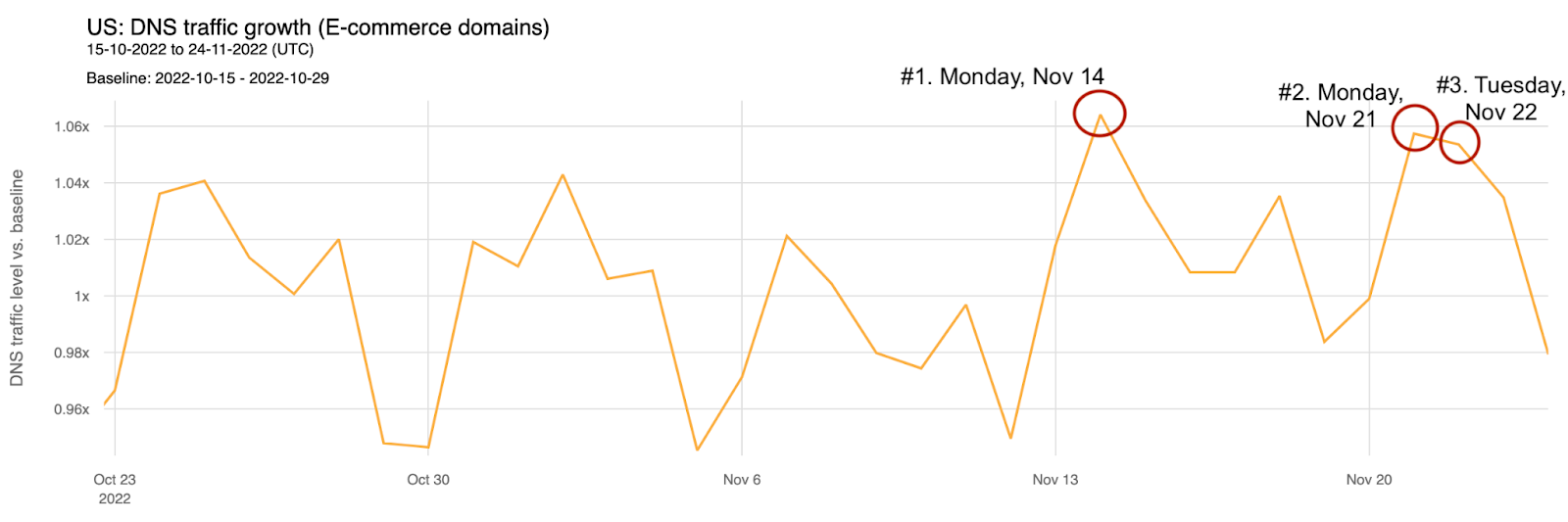
Using a smoothed seven day rolling average to those e-commerce domains (only in the US), the growth trend for the past 30 days is even more clear in the past two weeks (after a clear dip in early November). From November 13 to November 22, the rolling average grew ~5%.
Last year, Cyber Monday was the biggest day for online shopping, in terms of DNS queries that we saw. Next week, we’ll see how it was this year.
Japan: A different kind of Thanksgiving
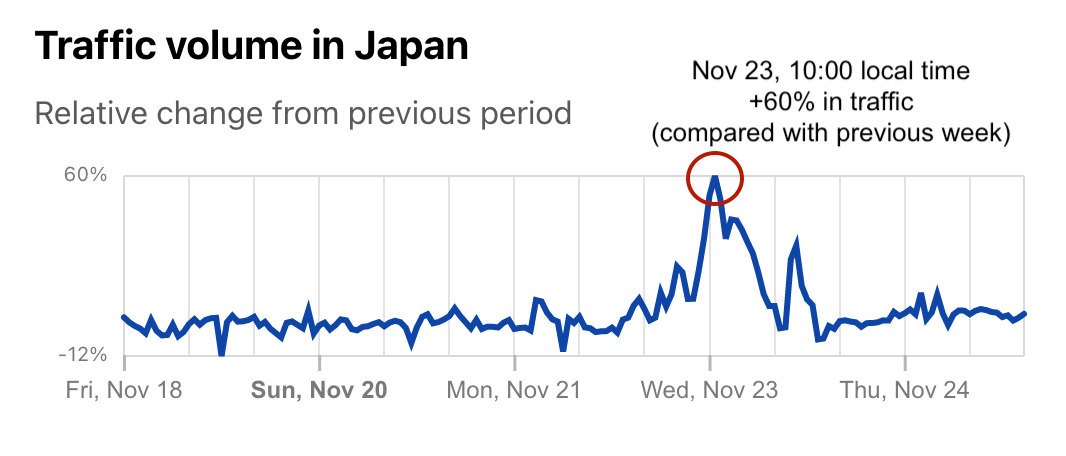
Also this week, Japan had its Labor Thanksgiving, an annual public holiday that was celebrated on Wednesday, November 23, 2022. And there was also a clear impact, but because, in Japan, this is a day full of events held throughout the country, there was an increase in traffic during the day. How much?
The peak was at around 01:00 UTC (10:00 in local time), when Internet traffic was 60% higher than in the previous week (and it continued to remain high during Labor Thanksgiving Day).
You can check Cloudflare Radar, but also our Twitter account where we continue to see country patterns related to the FIFA World Cup in Qatar (Internet traffic does shift, depending on the country, when national teams are playing), but also e-commerce DNS trends.
These discoveries were made by our very own Ron Bowes, who developed an exploit module for authenticated RCE against F5 devices running in appliance mode to achieve a Meterpreter session as the root user.
Ron Bowes has also developed an F5 Metasploit module exploiting CVE-2022-41622, a CSRF vulnerability in F5 Big-IP versions 17.0.0.1 and below – which leads to an arbitrary file overwrite as root. With this module, a user can choose to overwrite various system files to achieve a Meterpreter session as the root user.
For more information, see Rapid7’s blog post which detail the vulnerabilities.
DuckyScript support
Community contributor h00die contributed an enhancement to msfvenom. This adds the ducky-script-psh format to msfvenom:
F5 BIG-IP iControl CSRF File Write SOAP API by Ron Bowes, which exploits CVE-2022-41622 – This module exploits a CSRF vulnerability in F5 Big-IP versions 17.0.0.1 and below which leads to an arbitrary file overwrite as root. With this module, a user can choose to overwrite various system files to achieve a Meterpreter session as the root user.
ChurchInfo 1.2.13-1.3.0 Authenticated RCE by m4lwhere, which exploits CVE-2021-43258 – A new module has been added for CVE-2021-43258 which exploits a flaw whereby, when emailing users in the ChurchInfo database with attachments, the uploaded file is hosted in a web accessible location under the ChurchInfo web root before the email is sent. An authenticated attacker can abuse this to gain RCE as the www-user user.
Enhancements and features (6)
#17145 from k0pak4 – This PR adds the ability to authenticate via hash and improves the error reporting when authentication fails.
#17279 from h00die – This adds the ducky-script-psh format to msfvenom so it can create payloads that are compatible with Bad USB devices such as the Flipper Zero.
#17283 from bcoles – Improves the linux/gather/enum_psk module, and adds documentation
#17284 from bcoles – Updates modules/post/linux/gather/enum_network and modules/post/linux/gather/tor_hiddenservices to extract hostname details in a similar fashion to other modules
#17285 from bcoles – Improves validation in linux/gather/tor_hiddenservices to ensure that the locate command is present before running the module
#17296 from jmartin-r7 – Adds clarification to the module documentation that links to external resources are not controlled by project maintainers. These external resources may no longer exist and are subject to malicious takeover in the future. These links should be reviewed accordingly.
Bugs fixed (1)
#17277 from adfoster-r7 – Fixes a crash within the python reverse http stager.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the binary installers (which also include the commercial edition).
Can you create fairy tales with Zabbix? Of course, you can! By day, I am a monitoring technical lead in a global cyber security company. By night, I monitor my home with Zabbix & Grafana and do some weird experiments with them. Welcome to my blog about this project.
We all know how Zabbix has a never-ending list of integrations for just about everything — need to integrate it with OpsGenie, PagerDuty, Teams, Slack, or something else? No problem, there’s probably a ready-made integration for that already.
But, based on questions I’ve received over the years at work, not everyone realizes how utterly powerful the alert message templating engine is for you to create custom messages with the help of built-in macros and of course the user macros you can define. The default Zabbix HTML e-mail message template is very compact in its format, and for me easy to read, but years ago someone at work told me that the alerts were not easy for him to follow.
What I did back then was that I created an alert template of my own, which tells about the events in a bit different format, here’s a short snippet from those alerts.
Fairy tale time!
Now that at home we have our almost-three-months-old-baby, I’m using her as the perfect excuse to make Zabbix alerts to be like fairy tales. You know the drill. Your kiddo wants to hear yet another story before he or she falls asleep, and you have already run out of fresh stories to read.
What if your Zabbix would generate fairy tales for you? Well, not really, but at least the following would make the stories a bit more amusing to you and very confusing to your kid.
Let’s first create a new media type via Zabbix Administration –> Media types. For this, I just cloned the default HTML e-mail media type and gave it a name.
And then, my fantastic story template looks like this:
Add the template to user media type
Next, to actually receive these alerts, you need to configure your user profile and in its media types add the new media type.
Using the template
Getting the new template into use is easy; just go to Zabbix Configuration –> Actions and create a new trigger action with whatever conditions you like.
And then on Operations tab make Zabbix send the alerts via your new fairy tale media type.
The alert e-mail
So this is how the e-mail looks like.
Now go and add some CSS, pictures, whatever you like to your stories. And, perhaps, unlike me, go and change the {ITEM.DESCRIPTION} macro to contain also some instructions what to do with the alert, like at our custom alerts at work I have a tendency to add some hints about how to resolve the issue.
I have been working at Forcepoint since 2014 and I would have many stories to tell you about all these years. — Janne Pikkarainen
This post was originally published on the author’s LinkedIn account.
Security updates have been issued by Fedora (firefox), Mageia (dropbear, freerdp, java, libx11, and tumbler), Slackware (ruby), SUSE (erlang, grub2, libdb-4_8, and tomcat), and Ubuntu (exim4, jbigkit, and tiff).
However, we have rarely talked about the second part of our networking setup — how our servers fetch the content from the Internet. In this blog we’re going to cover this gap. We’ll discuss how we manage Cloudflare IP addresses used to retrieve the data from the Internet, how our egress network design has evolved and how we optimized it for best use of available IP space.
Brace yourself. We have a lot to cover.
Terminology first!
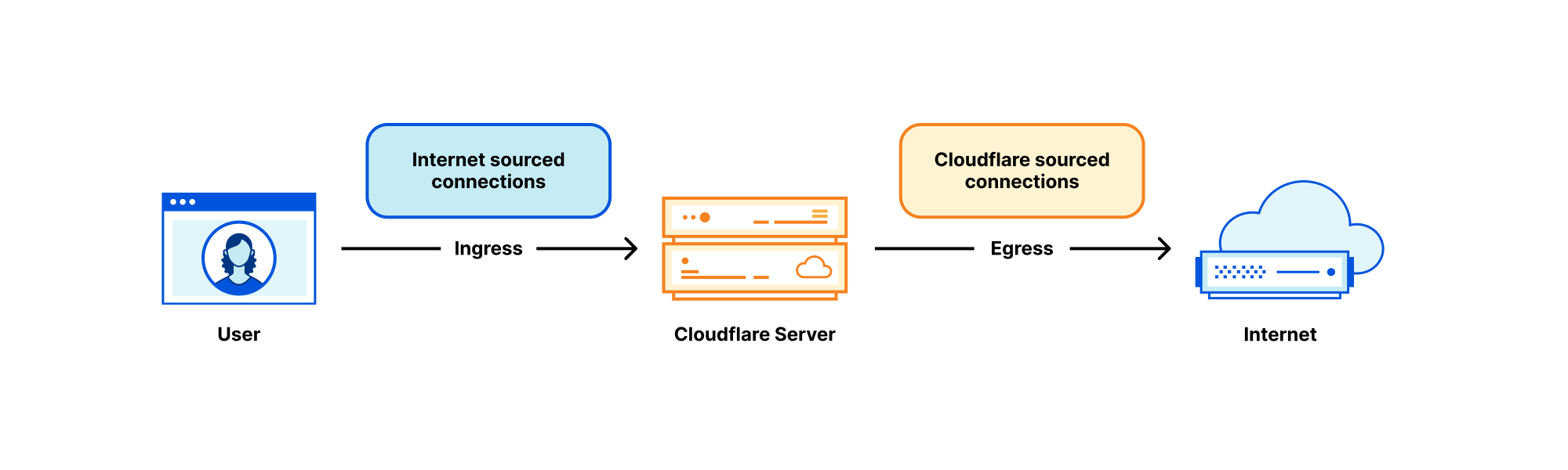
Each Cloudflare server deals with many kinds of networking traffic, but two rough categories stand out:
Internet sourced traffic – Inbound connections initiated by eyeball to our servers. In the context of this blog post we’ll call these “ingress connections”.
Cloudflare sourced traffic – Outgoing connections initiated by our servers to other hosts on the Internet. For brevity, we’ll call these “egress connections”.
The egress part, while rarely discussed on this blog, is critical for our operation. Our servers must initiate outgoing connections to get their jobs done! Like:
For the Spectrum product, each ingress TCP connection results in one egress connection.
Workers often run multiple subrequests to construct an HTTP response. Some of them might be querying servers to the Internet.
We also operate client-facing forward proxy products – like WARP and Teams. These proxies deal with eyeball connections destined to the Internet. Our servers need to establish connections to the Internet on behalf of our users.
And so on.
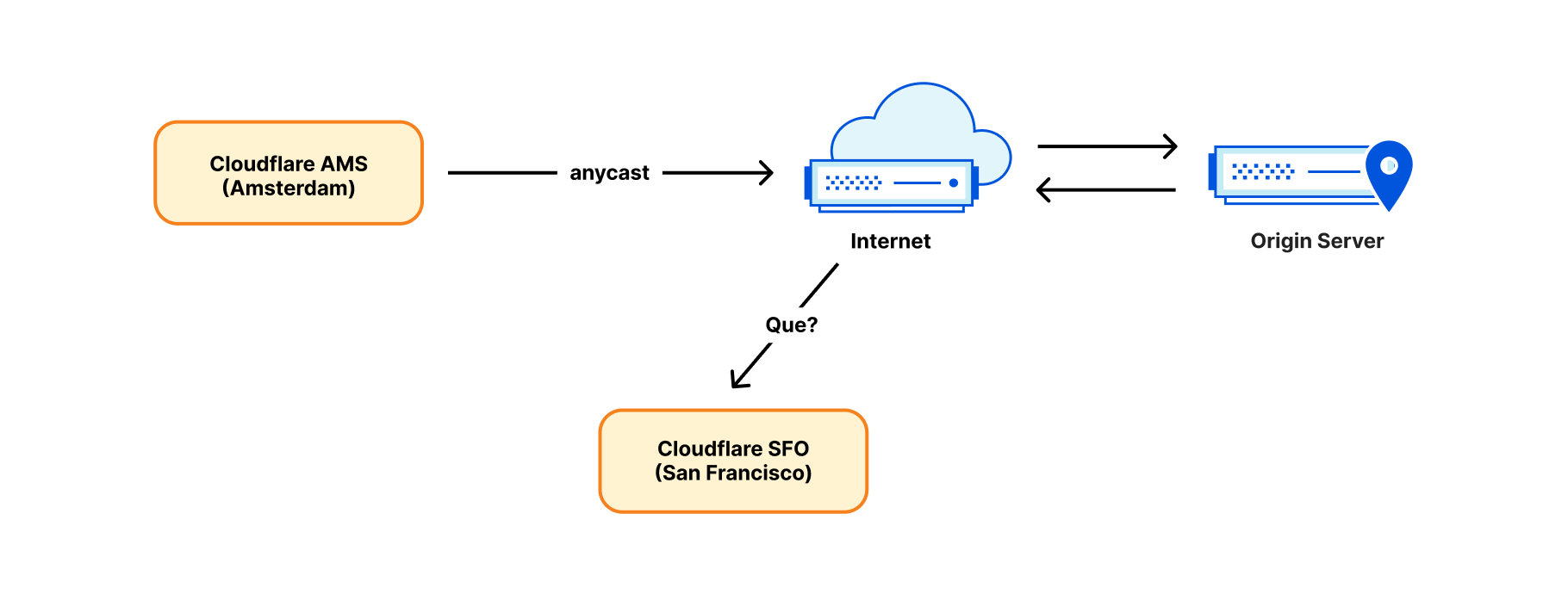
Anycast on ingress, unicast on egress
Our ingress network architecture is very different from the egress one. On ingress, the connections sourced from the Internet are handled exclusively by our anycast IP ranges. Anycast is a technology where each of our data centers “announces” and can handle the same IP ranges. With many destinations possible, how does the Internet know where to route the packets? Well, the eyeball packets are routed towards the closest data center based on Internet BGP metrics, often it’s also geographically the closest one. Usually, the BGP routes don’t change much, and each eyeball IP can be expected to be routed to a single data center.
However, while anycast works well in the ingress direction, it can’t operate on egress. Establishing an outgoing connection from an anycast IP won’t work. Consider the response packet. It’s likely to be routed back to a wrong place – a data center geographically closest to the sender, not necessarily the source data center!
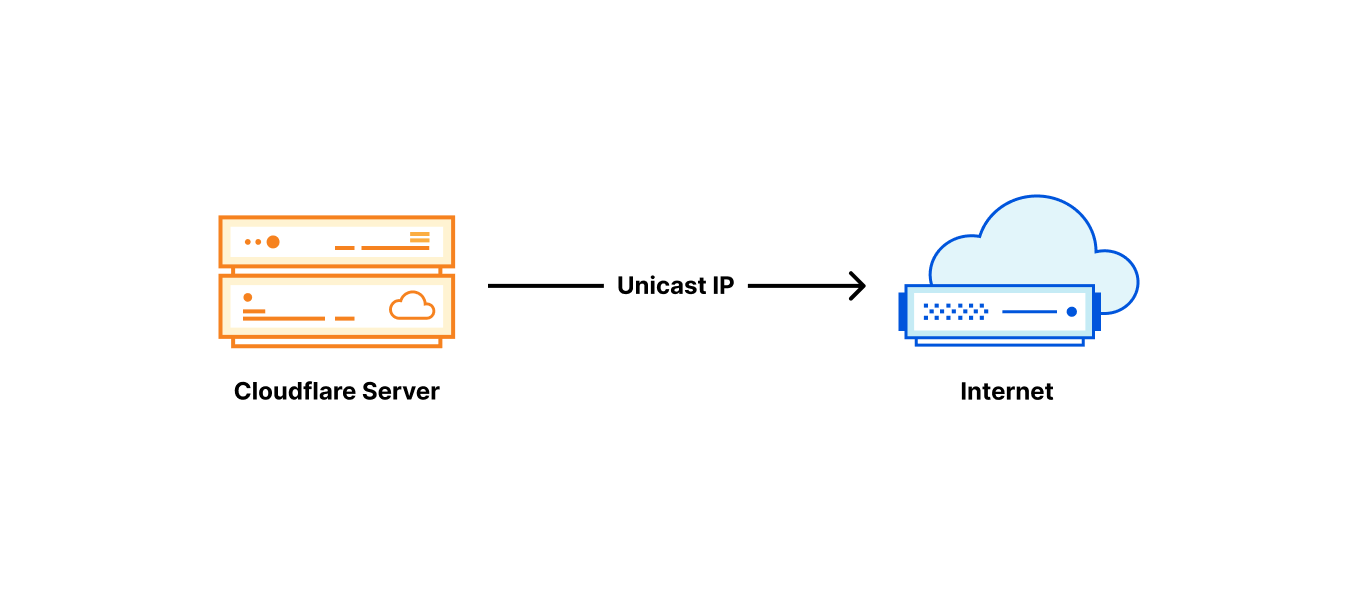
For this reason, until recently, we established outgoing connections in a straightforward and conventional way: each server was given its own unicast IP address. “Unicast IP” means there is only one server using that address in the world. Return packets will work just fine and get back exactly to the right server identified by the unicast IP.
Segmenting traffic based on egress IP
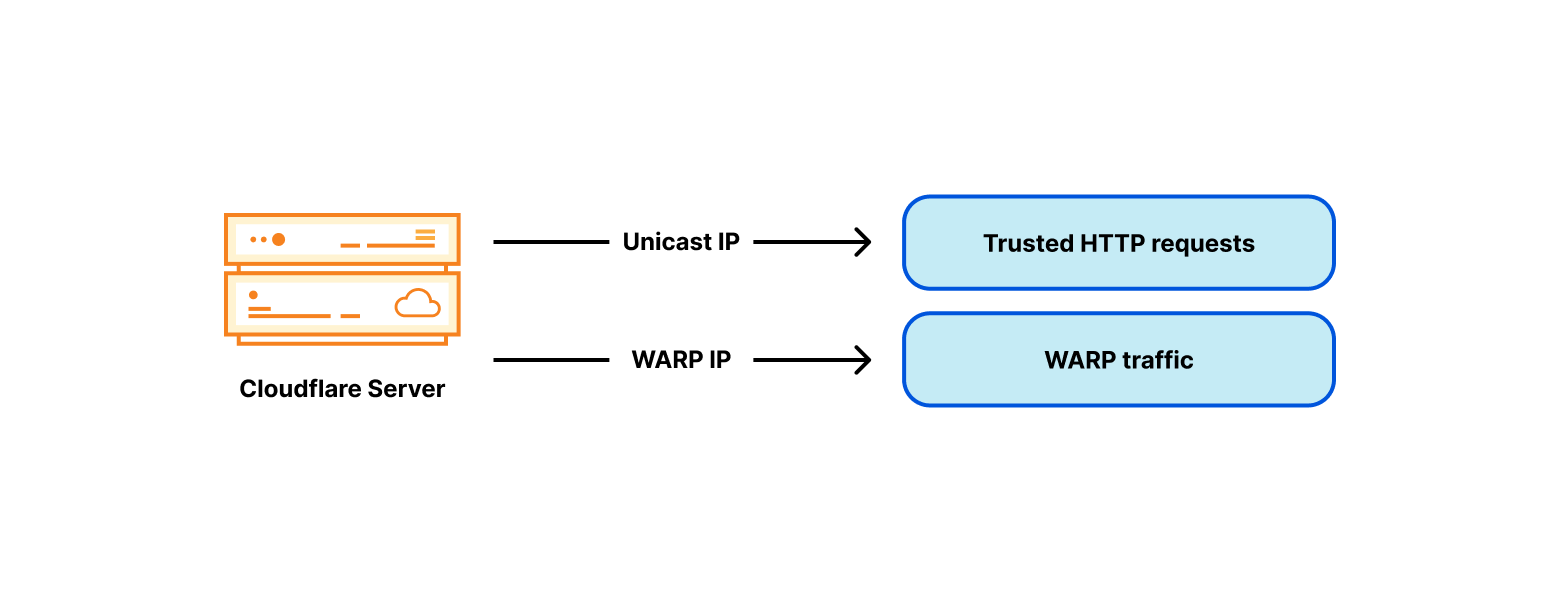
Originally connections sourced by Cloudflare were mostly HTTP fetches going to origin servers on the Internet. As our product line grew, so did the variety of traffic. The most notable example is our WARP app. For WARP, our servers operate a forward proxy, and handle the traffic sourced by end-user devices. It’s done without the same degree of intermediation as in our CDN product. This creates a problem. Third party servers on the Internet — like the origin servers — must be able to distinguish between connections coming from Cloudflare services and our WARP users. Such traffic segmentation is traditionally done by using different IP ranges for different traffic types (although recently we introduced more robust techniques like Authenticated Origin Pulls).
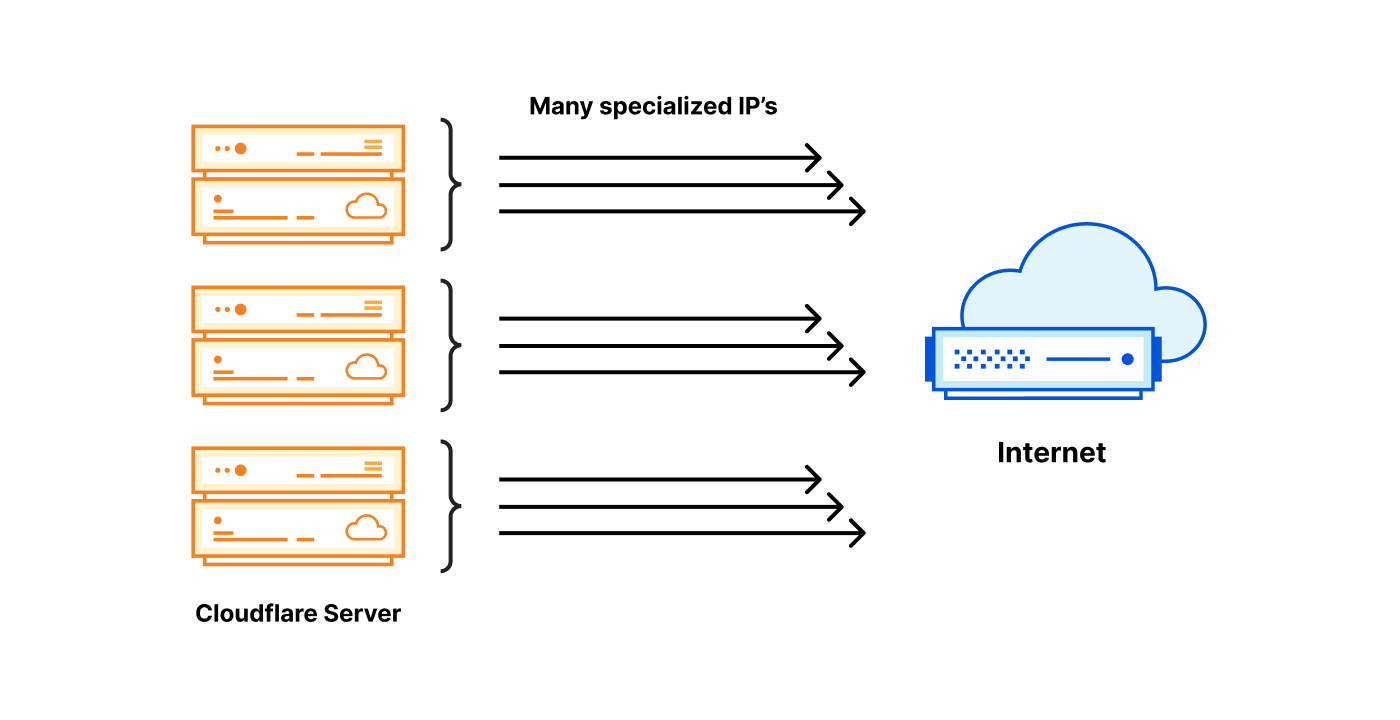
To work around the trusted vs untrusted traffic pool differentiation problem, we added an untrusted WARP IP address to each of our servers:
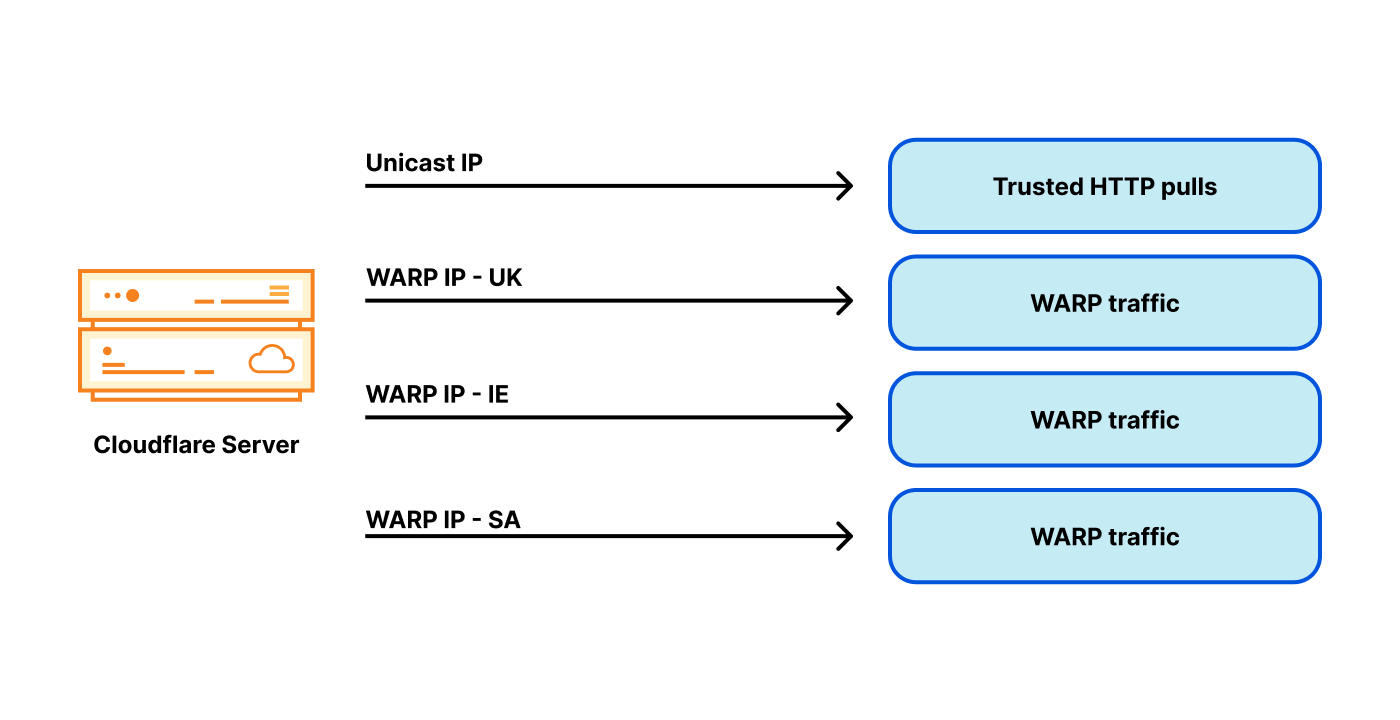
Country tagged egress IP addresses
It quickly became apparent that trusted vs untrusted weren’t the only tags needed. For WARP service we also need country tags. For example, United Kingdom based WARP users expect the bbc.com website to just work. However, the BBC restricts many of its services to people just in the UK.
It does this by geofencing — using a database mapping public IP addresses to countries, and allowing only the UK ones. Geofencing is widespread on today’s Internet. To avoid geofencing issues, we need to choose specific egress addresses tagged with an appropriate country, depending on WARP user location. Like many other parties on the Internet, we tag our egress IP space with country codes and publish it as a geofeed (like this one). Notice, the published geofeed is just data. The fact that an IP is tagged as say UK does not mean it is served from the UK, it just means the operator wants it to be geolocated to the UK. Like many things on the Internet, it is based on trust.
Notice, at this point we have three independent geographical tags:
the country tag of the WARP user – the eyeball connecting IP
the location of the data center the eyeball connected to
the country tag of the egressing IP
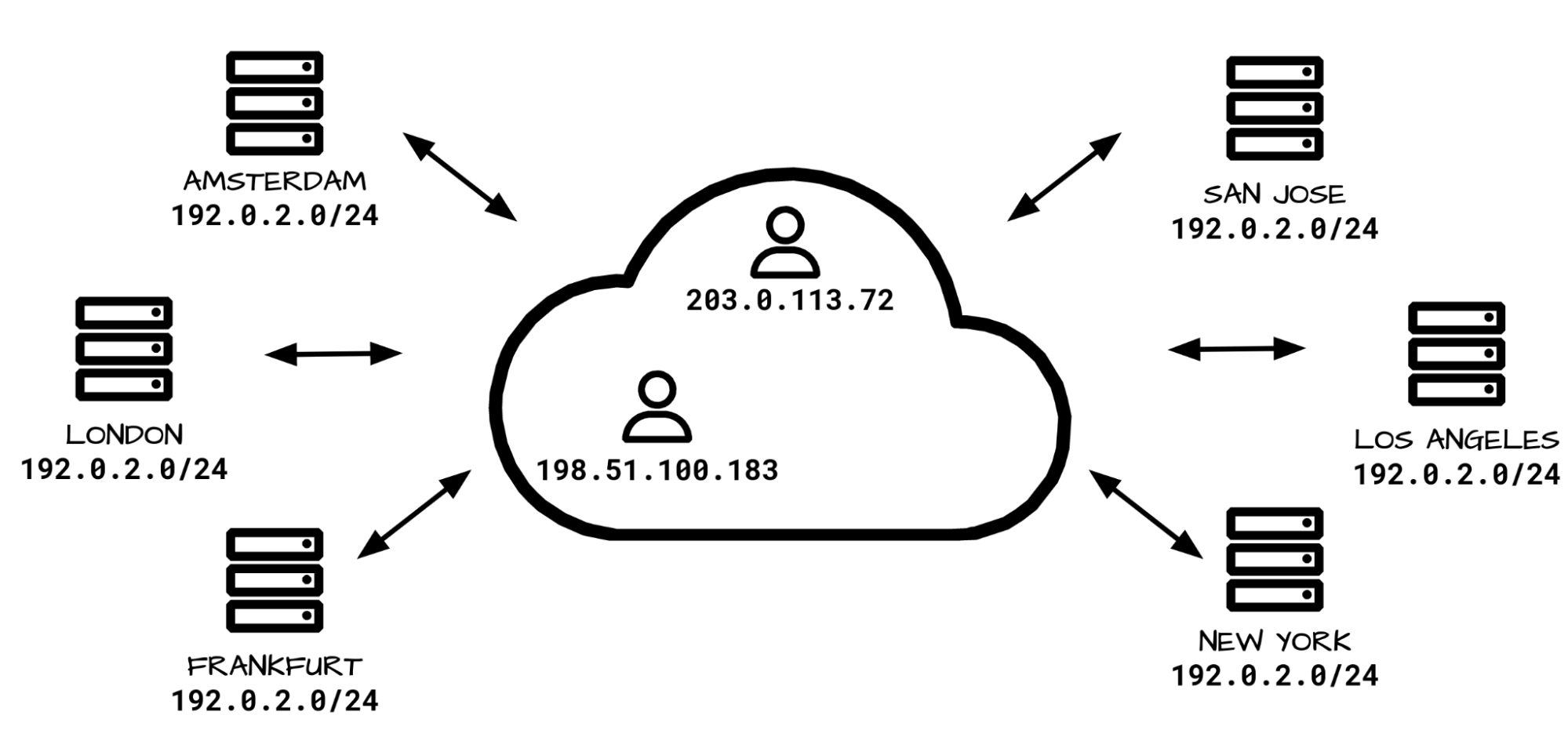
For best service, we want to choose the egressing IP so that its country tag matches the country from the eyeball IP. But egressing from a specific country tagged IP is challenging: our data centers serve users from all over the world, potentially from many countries! Remember: due to anycast we don’t directly control the ingress routing. Internet geography doesn’t always match physical geography. For example our London data center receives traffic not only from users in the United Kingdom, but also from Ireland, and Saudi Arabia. As a result, our servers in London need many WARP egress addresses associated with many countries:
Can you see where this is going? The problem space just explodes! Instead of having one or two egress IP addresses for each server, now we require dozens, and IPv4 addresses aren’t cheap. With this design, we need many addresses per server, and we operate thousands of servers. This architecture becomes very expensive.
Is anycast a problem?
Let me recap: with anycast ingress we don’t control which data center the user is routed to. Therefore, each of our data centers must be able to egress from an address with any conceivable tag. Inside the data center we also don’t control which server the connection is routed to. There are potentially many tags, many data centers, and many servers inside a data center.
Maybe the problem is the ingress architecture? Perhaps it’s better to use a traditional networking design where a specific eyeball is routed with DNS to a specific data center, or even a server?
That’s one way of thinking, but we decided against it. We like our anycast on ingress. It brings us many advantages:
Performance: with anycast, by definition, the eyeball is routed to the closest (by BGP metrics) data center. This is usually the fastest data center for a given user.
Automatic failover: if one of our data centers becomes unavailable, the traffic will be instantly, automatically re-routed to the next best place.
DDoS resilience: during a denial of service attack or a traffic spike, the load is automatically balanced across many data centers, significantly reducing the impact.
Uniform software: The functionality of every data center and of every server inside a data center is identical. We use the same software stack on all the servers around the world. Each machine can perform any action, for any product. This enables easy debugging and good scalability.
For these reasons we’d like to keep the anycast on ingress. We decided to solve the issue of egress address cardinality in some other way.
Solving a million dollar problem
Out of the thousands of servers we operate, every single one should be able to use an egress IP with any of the possible tags. It’s easiest to explain our solution by first showing two extreme designs.
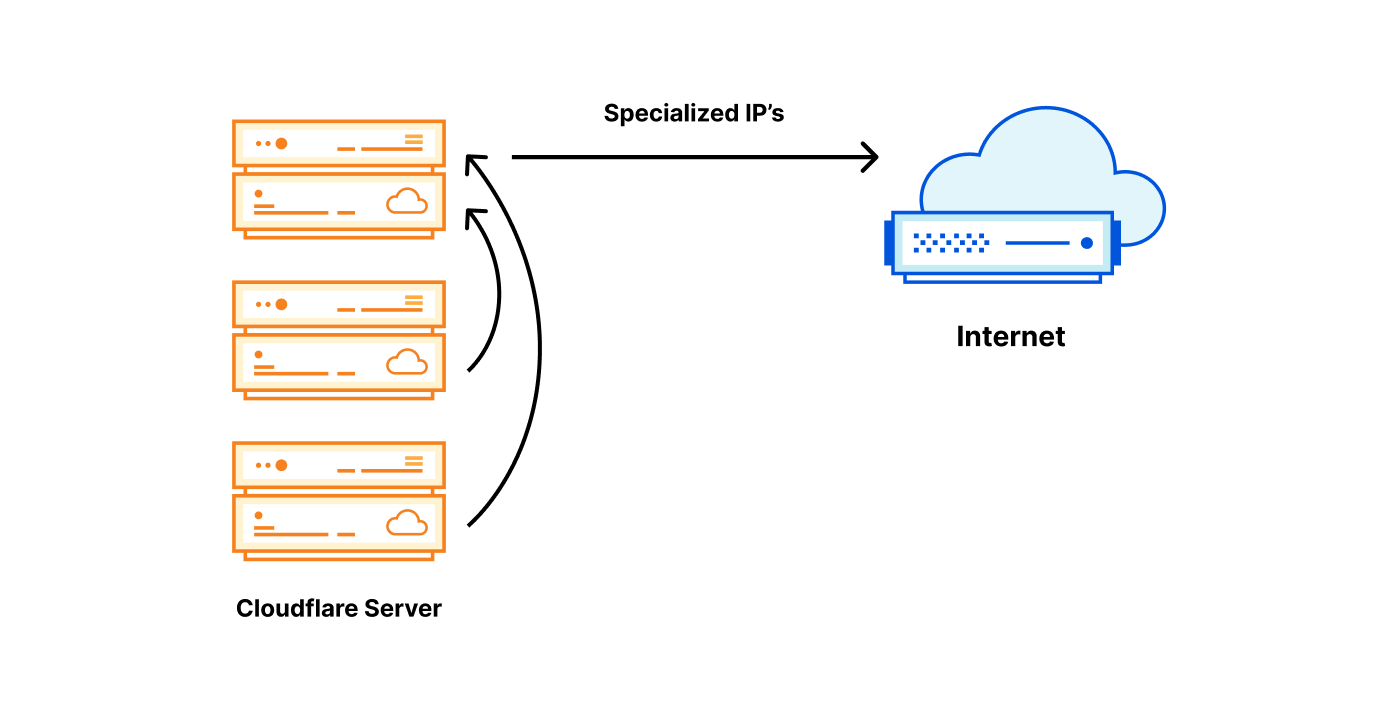
Each server owns all the needed IPs: each server has all the specialized egress IPs with the needed tags.
One server owns the needed IP: a specialized egress IP with a specific tag lives in one place, other servers forward traffic to it.
Both options have pros and cons:
Specialized IP on every server
Specialized IP on one server
Super expensive $$$, every server needs many IP addresses.
Cheap $, only one specialized IP needed for a tag.
Egress always local – fast
Egress almost always forwarded – slow
Excellent reliability – every server is independent
Poor reliability – introduced chokepoints
There’s a third way
We’ve been thinking hard about this problem. Frankly, the first extreme option of having every needed IP available locally on every Cloudflare server is not totally unworkable. This is, roughly, what we were able to pull off for IPv6. With IPv6, access to the large needed IP space is not a problem.
However, in IPv4 neither option is acceptable. The first offers fast and reliable egress, but requires great cost — the IPv4 addresses needed are expensive. The second option uses the smallest possible IP space, so it’s cheap, but compromises on performance and reliability.
The solution we devised is a compromise between the extremes. The rough idea is to change the assignment unit. Instead of assigning one /32 IPv4 address for each server, we devised a method of assigning a /32 IP per data center, and then sharing it among physical servers.
Specialized IP on every server
Specialized IP per data center
Specialized IP on one server
Super expensive $$$
Reasonably priced $$
Cheap $
Egress always local – fast
Egress always local – fast
Egress almost always forwarded – slow
Excellent reliability – every server is independent
Excellent reliability – every server is independent
Poor reliability – many choke points
Sharing an IP inside data center
The idea of sharing an IP among servers is not new. Traditionally this can be achieved by Source-NAT on a router. Sadly, the sheer number of egress IP’s we need and the size of our operation, prevents us from relying on stateful firewall / NAT at the router level. We also dislike shared state, so we’re not fans of distributed NAT installations.
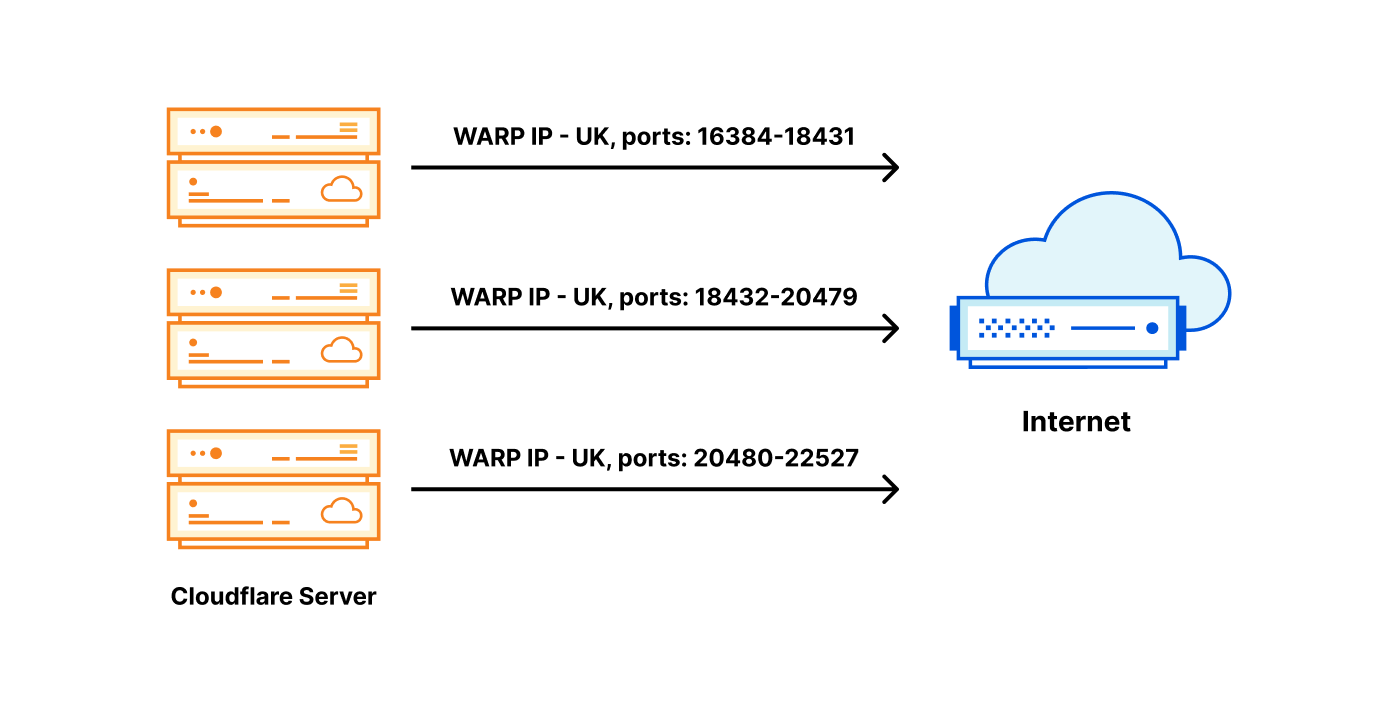
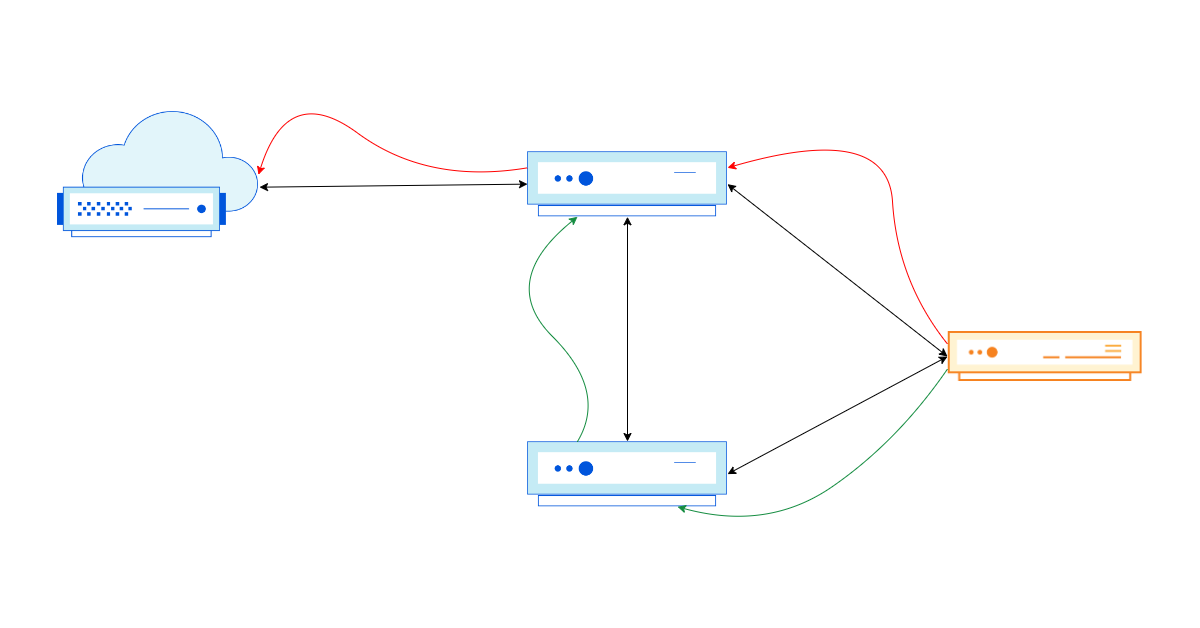
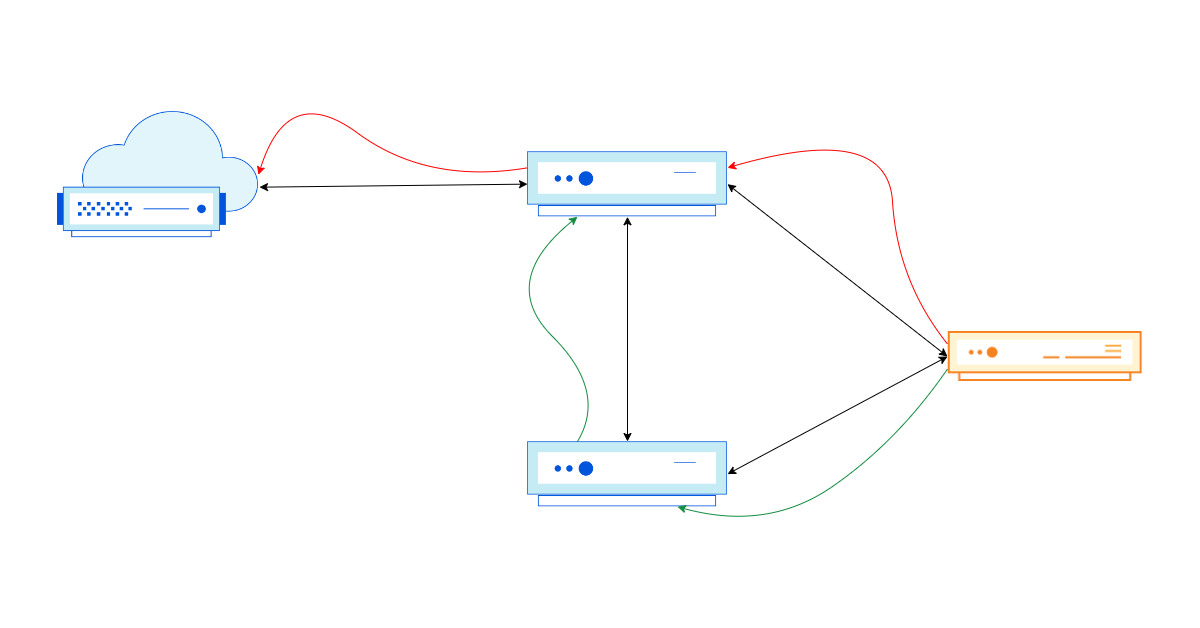
What we chose instead, is splitting an egress IP across servers by a port range. For a given egress IP, each server owns a small portion of available source ports – a port slice.
When return packets arrive from the Internet, we have to route them back to the correct machine. For this task we’ve customized “Unimog” – our L4 XDP-based load balancer – (“Unimog, Cloudflare’s load balancer (2020)“) and it’s working flawlessly.
This is pretty much it. Each server is aware which IP addresses and port slices it owns. For inbound routing Unimog inspects the ports and dispatches the packets to appropriate machines.
Sharing a subnet between data centers
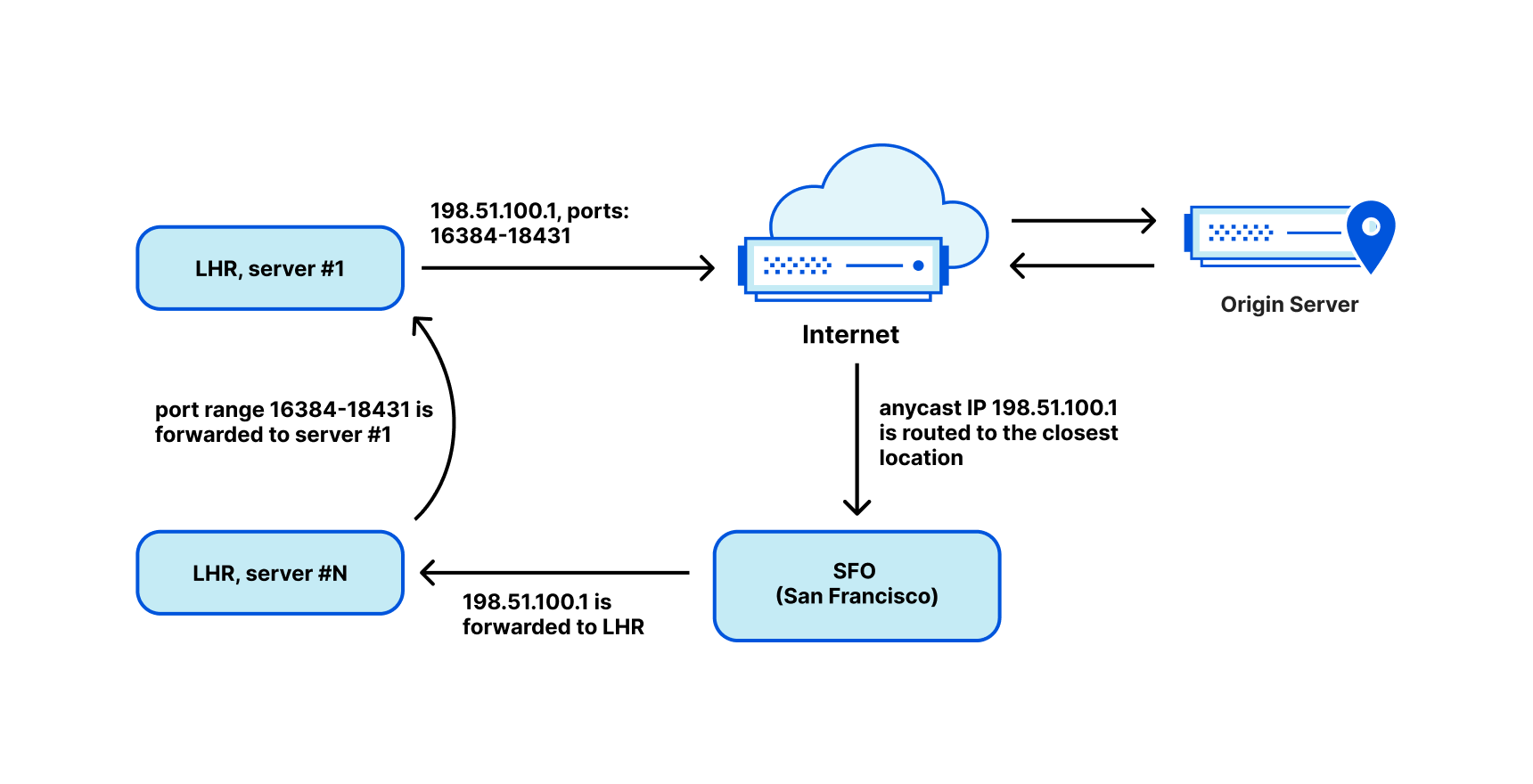
This is not the end of the story though, we haven’t discussed how we can route a single /32 address into a datacenter. Traditionally, in the public Internet, it’s only possible to route subnets with granularity of /24 or 256 IP addresses. In our case this would lead to great waste of IP space.
To solve this problem and improve the utilization of our IP space, we deployed our egress ranges as… anycast! With that in place, we customized Unimog and taught it to forward the packets over our backbone network to the right data center. Unimog maintains a database like this:
198.51.100.1 - forward to LHR
198.51.100.2 - forward to CDG
198.51.100.3 - forward to MAN
...
With this design, it doesn’t matter to which data center return packets are delivered. Unimog can always fix it and forward the data to the right place. Basically, while at the BGP layer we are using anycast, due to our design, semantically an IP identifies a datacenter and an IP and port range identify a specific machine. It behaves almost like a unicast.
We call this technology stack “soft-unicast” and it feels magical. It’s like we did unicast in software over anycast in the BGP layer.
Soft-unicast is indistinguishable from magic
With this setup we can achieve significant benefits:
We are able to share a /32 egress IP amongst many servers.
We can spread a single subnet across many data centers, and change it easily on the fly. This allows us to fully use our egress IPv4 ranges.
We can group similar IP addresses together. For example, all the IP addresses tagged with the “UK” tag might form a single continuous range. This reduces the size of the published geofeed.
It’s easy for us to onboard new egress IP ranges, like customer IP’s. This is useful for some of our products, like Cloudflare Zero Trust.
All this is done at sensible cost, at no loss to performance and reliability:
Typically, the user is able to egress directly from the closest datacenter, providing the best possible performance.
Depending on the actual needs we can allocate or release the IP addresses. This gives us flexibility with the IP cost management, we don’t need to overspend upfront.
Since we operate multiple egress IP addresses in different locations, the reliability is not compromised.
The true location of our IP addresses is: “the cloud”
While soft-unicast allows us to gain great efficiency, we’ve hit some issues. Sometimes we get a question “Where does this IP physically exist?”. But it doesn’t have an answer! Our egress IPs don’t exist physically anywhere. From a BGP standpoint our egress ranges are anycast, so they live everywhere. Logically each address is used in one data center at a time, but we can move it around on demand.
Content Delivery Networks misdirect users
As another example of problems, here’s one issue we’ve hit with third party CDNs. As we mentioned before, there are three country tags in our pipeline:
The country tag of the IP eyeball is connecting from.
The location of our data center.
The country tag of the IP addresses we chose for the egress connections.
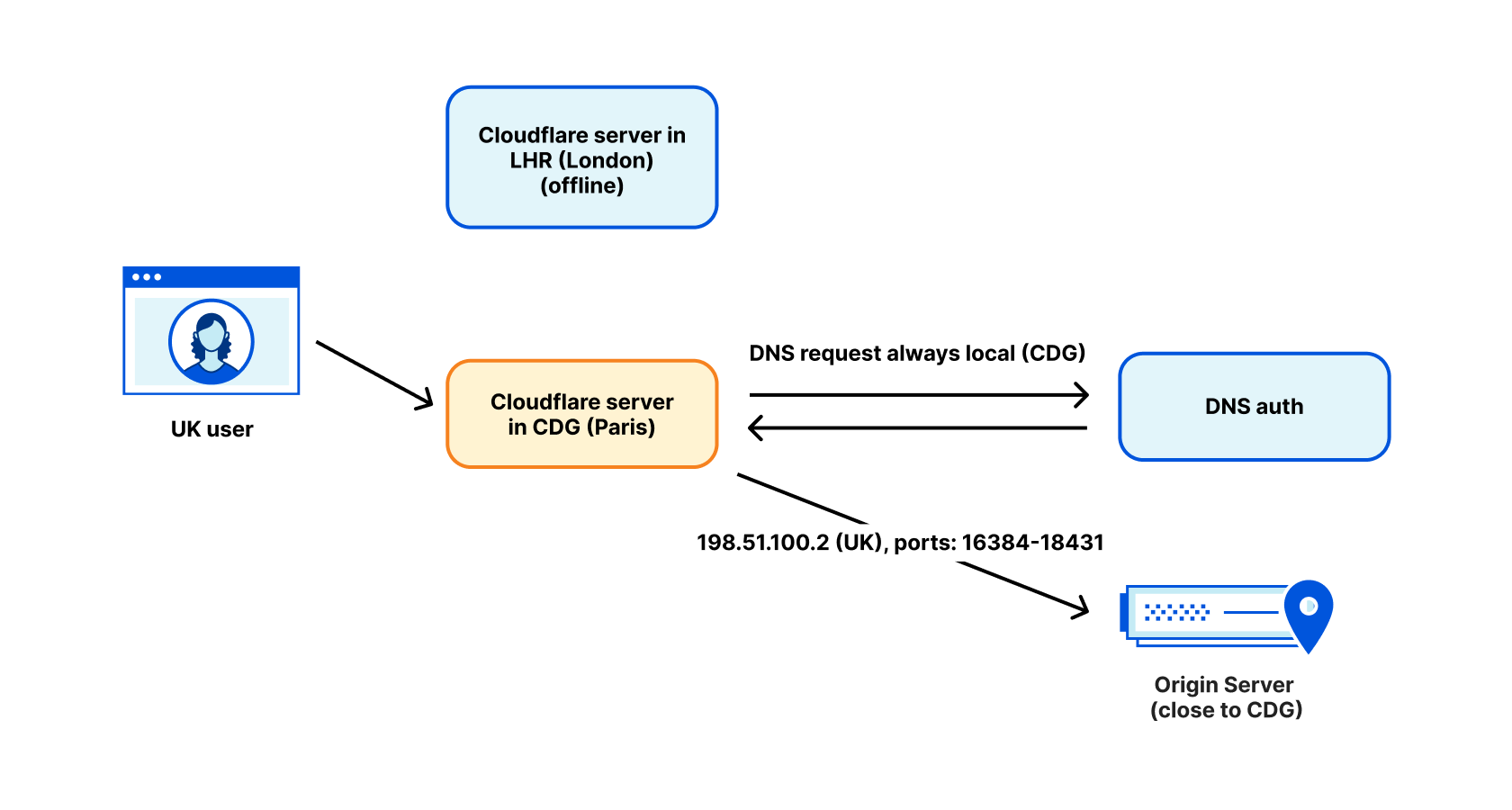
The fact that our egress address is tagged as “UK” doesn’t always mean it actually is being used in the UK. We’ve had cases when a UK-tagged WARP user, due to the maintenance of our LHR data center, was routed to Paris. A popular CDN performed a reverse-lookup of our egress IP, found it tagged as “UK”, and directed the user to a London CDN server. This is generally OK… but we actually egressed from Paris at the time. This user ended up routing packets from their home in the UK, to Paris, and back to the UK. This is bad for performance.
We address this issue by performing DNS requests in the egressing data center. For DNS we use IP addresses tagged with the location of the data center, not the intended geolocation for the user. This generally fixes the problem, but sadly, there are still some exceptions.
The future is here
Our 2021 experiments with Addressing Agility proved we have plenty of opportunity to innovate with the addressing of the ingress. Soft-unicast shows us we can achieve great flexibility and density on the egress side.
With each new product, the number of tags we need on the egress grows – from traffic trustworthiness, product category to geolocation. As the pool of usable IPv4 addresses shrinks, we can be sure there will be more innovation in the space. Soft-unicast is our solution, but for sure it’s not our last development.
For now though, it seems like we’re moving away from traditional unicast. Our egress IP’s really don’t exist in a fixed place anymore, and some of our servers don’t even own a true unicast IP nowadays.
In the first part of this blog series, Optimize your modern data architecture for sustainability: Part 1 – data ingestion and data lake, we focused on the 1) data ingestion, and 2) data lake pillars of the modern data architecture. In this blog post, we will provide guidance and best practices to optimize the components within the 3) unified data governance, 4) data movement, and 5) purpose-built analytics pillars. Figure 1 shows the different pillars of the modern data architecture. It includes data ingestion, data lake, unified data governance, data movement, and purpose-built analytics pillars.
Figure 1. Modern Data Analytics Reference Architecture on AWS
3. Unified data governance
A centralized Data Catalog is responsible for storing business and technical metadata about datasets in the storage layer. Administrators apply permissions in this layer and track events for security audits.
Data discovery
To increase data sharing and reduce data movement and duplication, enable data discovery and well-defined access controls for different user personas. This reduces redundant data processing activities. Separate teams within an organization can rely on this central catalog. It provides first-party data (such as sales data) or third-party data (such as stock prices, climate change datasets). You’ll only need access data once, rather than having to pull from source repeatedly.
AWS Glue Data Catalog can simplify the process for adding and searching metadata. Use AWS Glue crawlers to update the existing schemas and discover new datasets. Carefully plan schedules to reduce unnecessary crawling.
Data sharing
Establish well-defined access control mechanisms for different data consumers using services such as AWS Lake Formation. This will enable datasets to be shared between organizational units with fine-grained access control, which reduces redundant copying and movement. Use Amazon Redshift data sharing to avoid copying the data across data warehouses.
Well-defined datasets
Create well-defined datasets and associated metadata to avoid unnecessary data wrangling and manipulation. This will reduce resource usage that might result from additional data manipulation.
4. Data movement
AWS Glue provides serverless, pay-per-use data movement capability, without having to stand up and manage servers or clusters. Set up ETL pipelines that can process tens of terabytes of data.
You can create and share AWS Glue workflows for similar use cases by using AWS Glue blueprints, rather than creating an AWS Glue workflow for each use case. AWS Glue job bookmark can track previously processed data.
Consider using Glue Flex Jobs for non-urgent or non-time sensitive data integration workloads such as pre-production jobs, testing, and one-time data loads. With Flex, AWS Glue jobs run on spare compute capacity instead of dedicated hardware.
Joins between several dataframes is a common operation in Spark jobs. To reduce shuffling of data between nodes, use broadcast joins when one of the merged dataframes is small enough to be duplicated on all the executing nodes.
The latest AWS Glue version provides more new and efficient features for your workload.
5. Purpose-built analytics
Data Processing modes
Real-time data processing options need continuous computing resources and require more energy consumption. For the most favorable sustainability impact, evaluate trade-offs and choose the optimal batch data processing option.
Identify the batch and interactive workload requirements and design transient clusters in Amazon EMR. Using Spot Instances and configuring instance fleets can maximize utilization.
To improve energy efficiency, Amazon EMR Serverless can help you avoid over- or under-provisioning resources for your data processing jobs. Amazon EMR Serverless automatically determines the resources that the application needs, gathers these resources to process your jobs, and releases the resources when the jobs finish.
Amazon Redshift RA3 nodes can improve compute efficiency. With RA3 nodes, you can scale compute up and down without having to scale storage. You can choose Amazon Redshift Serverless to intelligently scale data warehouse capacity. This will deliver faster performance for the most demanding and unpredictable workloads.
Energy efficient transformation and data model design
Data processing and data modeling best practices can reduce your organization’s environmental impact.
The Amazon Redshift Advisor provides specific, tailored recommendations to optimize the data warehouse based on performance statistics and operations data.
Consider migrating Amazon EMR or Amazon OpenSearch Service to a more power-efficient processor such as AWS Graviton. AWS Graviton 3 delivers 2.5–3 times better performance over other CPUs. Graviton 3-based instances use up to 60% less energy for the same performance than comparable EC2 instances.
Consider querying the data in place with Amazon Athena or Amazon Redshift Spectrum for one-off analysis, rather than copying the data to Amazon Redshift.
Track and assess improvement for environmental sustainability
The optimal way to evaluate success in optimizing your workloads for sustainability is to use proxy measures and unit of work KPI. This can be GB per transaction for storage, or vCPU minutes per transaction for compute.
In Table 1, we list certain metrics you could collect on analytics services as proxies to measure improvement. These fall under each pillar of the modern data architecture covered in this post.
Table 1. Metrics for the Modern data architecture pillars
Conclusion
In this blog post, we provided best practices to optimize processes under the unified data governance, data movement, and purpose-built analytics pillars of modern architecture.
If you are looking for more architecture content, refer to the AWS Architecture Center for reference architecture diagrams, vetted architecture solutions, Well-Architected best practices, patterns, icons, and more.
We are excited to announce our next free online seminars, running monthly from January 2023 and focusing on primary school (K–5) teaching and learning of computing.
Our seminars, having covered various topics in computing education over the last three years, will now offer you a close look at current questions and research in primary computing education. Through this series we want to connect research and teaching practice, and further primary computing education across the globe.
Are these seminars for me?
Our upcoming seminars are for everyone interested in computing education, not just for primary school teachers — you are all cordially invited to join us. Previous seminars have been attended by a valuable mix of teachers, volunteers, tech industry professionals, and researchers, all keen to explore how computing education research can be put into practice.
Whether you teach in a classroom, or support learners in a coding club, you will find out how our youngest learners develop their computing knowledge. You’ll also explore with us what this means for your learning context in practical terms.
What you can expect from the online seminars
Each seminar starts with a presenter explaining, in easy-to-understand terms, some recent research they have done. The presentation is followed by a discussion in smaller groups. We then regroup for a Q&A session with the presenter.
Attendees of our previous seminars have said:
“The seminar will be useful in my practice when our coding club starts.”
“I love this initiative, your choice of speakers has been fantastic. You are creating a very valuable CPD resource for Computer Science teachers and educators all over the world. Thank you. 🙏”
“Just wanted to say a huge thank you for organising this. It was brilliant to hear the presentation but also the input from other educators in the breakout room. I currently teach in a department of one, which can be quite lonely, so to join other educators was brilliant and a real encouragement.”
Learn from specialists to benefit your own learners
Computer science has been taught in universities for many years, and only more recently has the subject been introduced in schools. That means there isn’t a lot of research about computing education for school-aged learners yet, and even less research about how young children of primary school age learn about computing.
That’s why we are excited to invite you to learn with us as we hear from international primary computing research teams who share their knowledge in our online seminars:
Tuesday 10 January 2023: Kicking off our series are Dr Katie Rich and Carla Strickland from Chicago with a seminar on how they developed new instructional materials for teaching variables in primary school. They will specifically focus on how they combined research with classroom realities, and share experiences of using their new materials in class.
Tuesday 7 February 2023: Dr Jean Salac from the University of Washington is particularly interested in identifying and addressing inequities in the computing classroom, and will speak about a new learning strategy that has been found to improve students’ understanding of computing concepts and to increase equal access to computing.
Tuesday 7 March 2023: Our own Dr Bobby Whyte from the Raspberry Pi Foundation will share practical examples of how primary computing can be integrated into literacy education. He will specifically look at storytelling elements within computing education and discuss the benefits of combining competency areas.
May 2023: Information coming soon
Tuesday 6 June 2023: In a collaborative seminar, Aim Unahalekhaka from Tufts University in Massachusetts will first present her research into how children learn coding through ScratchJr. Participants are encouraged to bring a tablet or device with ScratchJr to then look at practical project evaluations and teaching strategies that can help young learners create purposefully.
Tuesday 12 September 2023: Joining us from the University of Passau in Germany, Luisa Greifenstein will speak about how to give children appropriate feedback that encourages positive attitudes towards computing education. In particular, she will be looking at the effects of different feedback strategies and present a new Scratch tool that offers automated feedback.
October 2023: Information coming soon
Tuesday 7 November 2023: We are delighted to be joined by Dr Aman Yadav from Michigan State University who will focus on computational thinking and its value for primary schooling. In his seminar, he will not only discuss the unique opportunities for computational thinking in primary school but also discuss findings from a recent project that focused on teachers’ perspectives.
Sign up now to attend the seminars
All our seminars start at 17:00 UK time (18:00 CET / 12:00 noon ET / 9:00 PT) and take place in an online format. Sign up now to receive a calendar invitation and the link to join on the day of each seminar.
The Internet, in its purest form, is a loosely connected graph of independent networks (also called Autonomous Systems (AS for short)). These networks use a signaling protocol called BGP (Border Gateway Protocol) to inform their neighbors (also known as peers) about the reachability of IP prefixes (a group of IP addresses) in and through their network. Part of this exchange contains useful metadata about the IP prefix that are used to inform network routing decisions. One example of the metadata is the full AS-path, which consists of the different autonomous systems an IP packet needs to pass through to reach its destination.
As we all want our packets to get to their destination as fast as possible, selecting the shortest AS-path for a given prefix is a good idea. This is where something called prepending comes into play.
Routing on the Internet, a primer
Let’s briefly talk about how the Internet works at its most fundamental level, before we dive into some nitty-gritty details.
The Internet is, at its core, a massively interconnected network of thousands of networks. Each network owns two things that are critical:
1. An Autonomous System Number (ASN): a 32-bit integer that uniquely identifies a network. For example, one of the Cloudflare ASNs (we have multiple) is 13335.
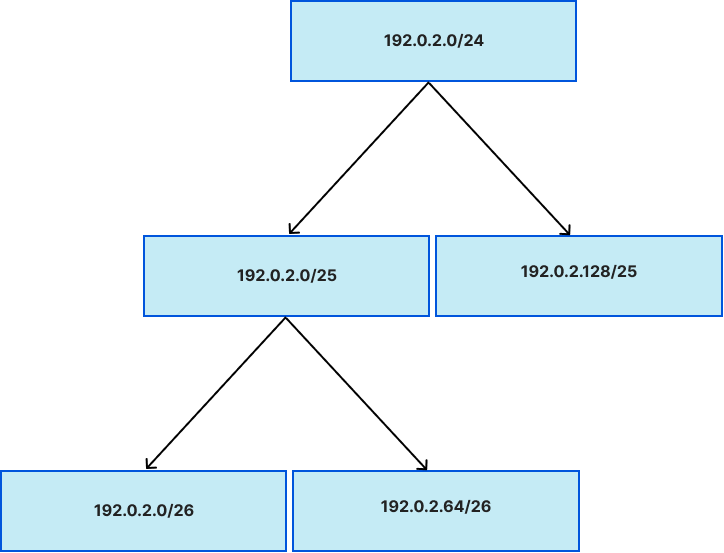
2. IP prefixes: An IP prefix is a range of IP addresses, bundled together in powers of two: In the IPv4 space, two addresses form a /31 prefix, four form a /30, and so on, all the way up to /0, which is shorthand for “all IPv4 prefixes”. The same applies for IPv6 but instead of aggregating 32 bits at most, you can aggregate up to 128 bits. The figure below shows this relationship between IP prefixes, in reverse — a /24 contains two /25s that contains two /26s, and so on.
To communicate on the Internet, you must be able to reach your destination, and that’s where routing protocols come into play. They enable each node on the Internet to know where to send your message (and for the receiver to send a message back).
As mentioned earlier, these destinations are identified by IP addresses, and contiguous ranges of IP addresses are expressed as IP prefixes. We use IP prefixes for routing as an efficiency optimization: Keeping track of where to go for four billion (232) IP addresses in IPv4 would be incredibly complex, and require a lot of resources. Sticking to prefixes reduces that number down to about one million instead.
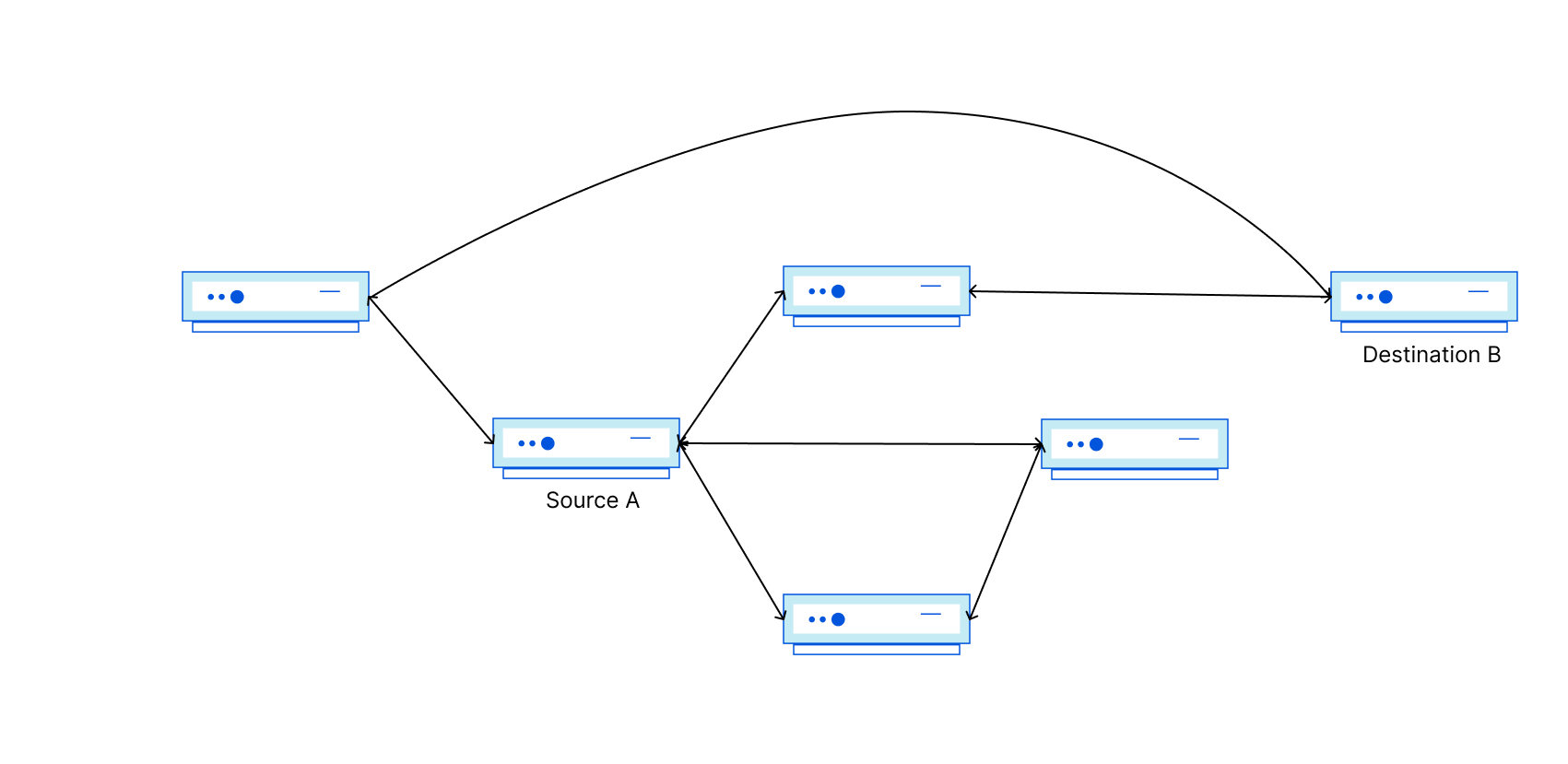
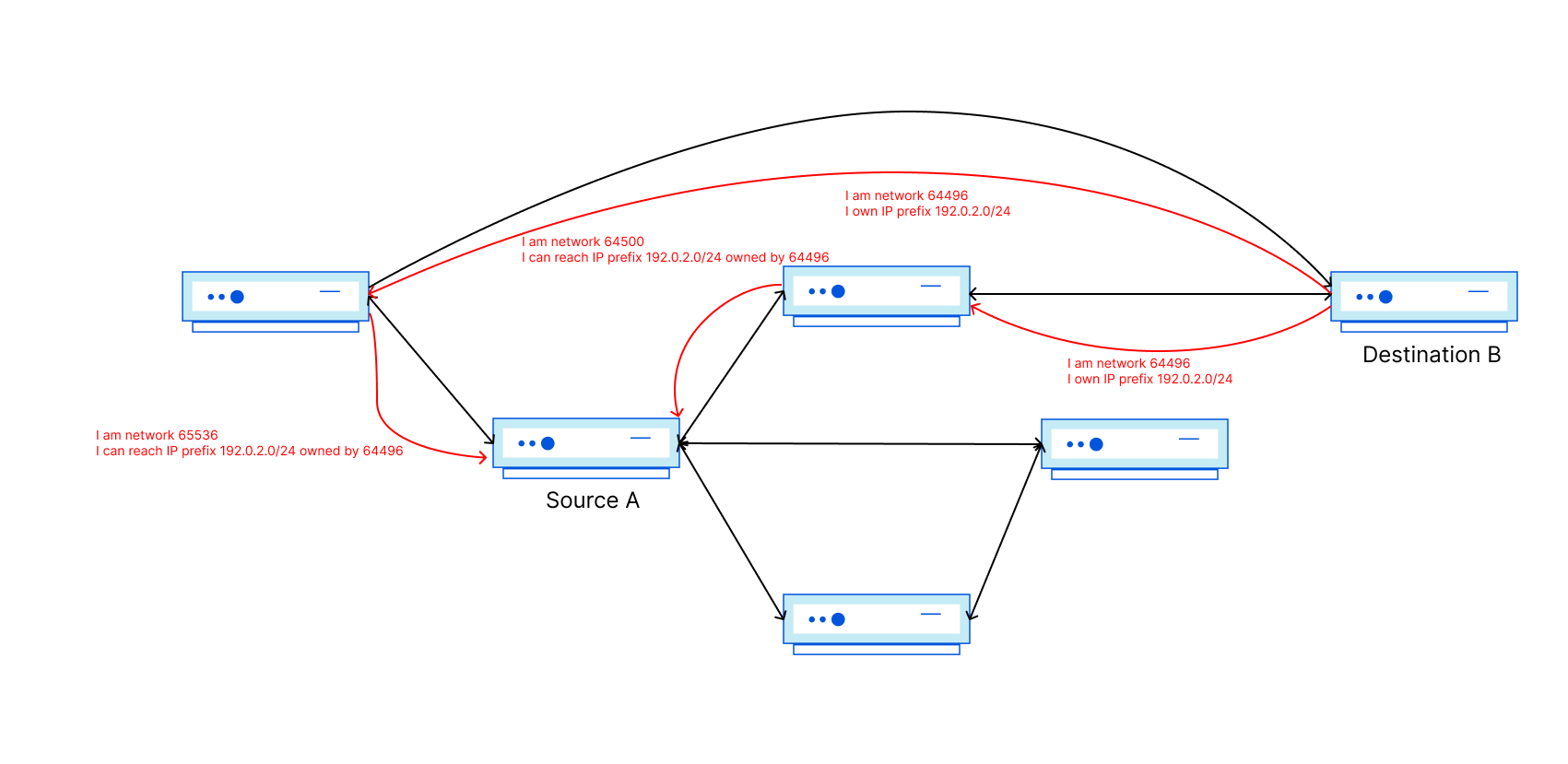
Now recall that Autonomous Systems are independently operated and controlled. In the Internet’s network of networks, how do I tell Source A in some other network that there is an available path to get to Destination B in (or through) my network? In comes BGP! BGP is the Border Gateway Protocol, and it is used to signal reachability information. Signal messages generated by the source ASN are referred to as ‘announcements’ because they declare to the Internet that IP addresses in the prefix are online and reachable.
Have a look at the figure above. Source A should now know how to get to Destination B through 2 different networks!
This is what an actual BGP message would look like:
As you can see, BGP messages contain more than just the IP prefix (the NLRI bit) and the path, but also a bunch of other metadata that provides additional information about the path. Other fields include communities (more on that later), as well as MED, or origin code. MED is a suggestion to other directly connected networks on which path should be taken if multiple options are available, and the lowest value wins. The origin code can be one of three values: IGP, EGP or Incomplete. IGP will be set if you originate the prefix through BGP, EGP is no longer used (it’s an ancient routing protocol), and Incomplete is set when you distribute a prefix into BGP from another routing protocol (like IS-IS or OSPF).
Now that source A knows how to get to Destination B through two different networks, let’s talk about traffic engineering!
Traffic engineering
Traffic engineering is a critical part of the day to day management of any network. Just like in the physical world, detours can be put in place by operators to optimize the traffic flows into (inbound) and out of (outbound) their network. Outbound traffic engineering is significantly easier than inbound traffic engineering because operators can choose from neighboring networks, even prioritize some traffic over others. In contrast, inbound traffic engineering requires influencing a network that is operated by someone else entirely. The autonomy and self-governance of a network is paramount, so operators use available tools to inform or shape inbound packet flows from other networks. The understanding and use of those tools is complex, and can be a challenge.
The available set of traffic engineering tools, both in- and outbound, rely on manipulating attributes (metadata) of a given route. As we’re talking about traffic engineering between independent networks, we’ll be manipulating the attributes of an EBGP-learned route. BGP can be split into two categories:
EBGP: BGP communication between two different ASNs
IBGP: BGP communication within the same ASN.
While the protocol is the same, certain attributes can be exchanged on an IBGP session that aren’t exchanged on an EBGP session. One of those is local-preference. More on that in a moment.
BGP best path selection
When a network is connected to multiple other networks and service providers, it can receive path information to the same IP prefix from many of those networks, each with slightly different attributes. It is then up to the receiving network of that information to use a BGP best path selection algorithm to pick the “best” prefix (and route), and use this to forward IP traffic. I’ve put “best” in quotation marks, as best is a subjective requirement. “Best” is frequently the shortest, but what can be best for my network might not be the best outcome for another network.
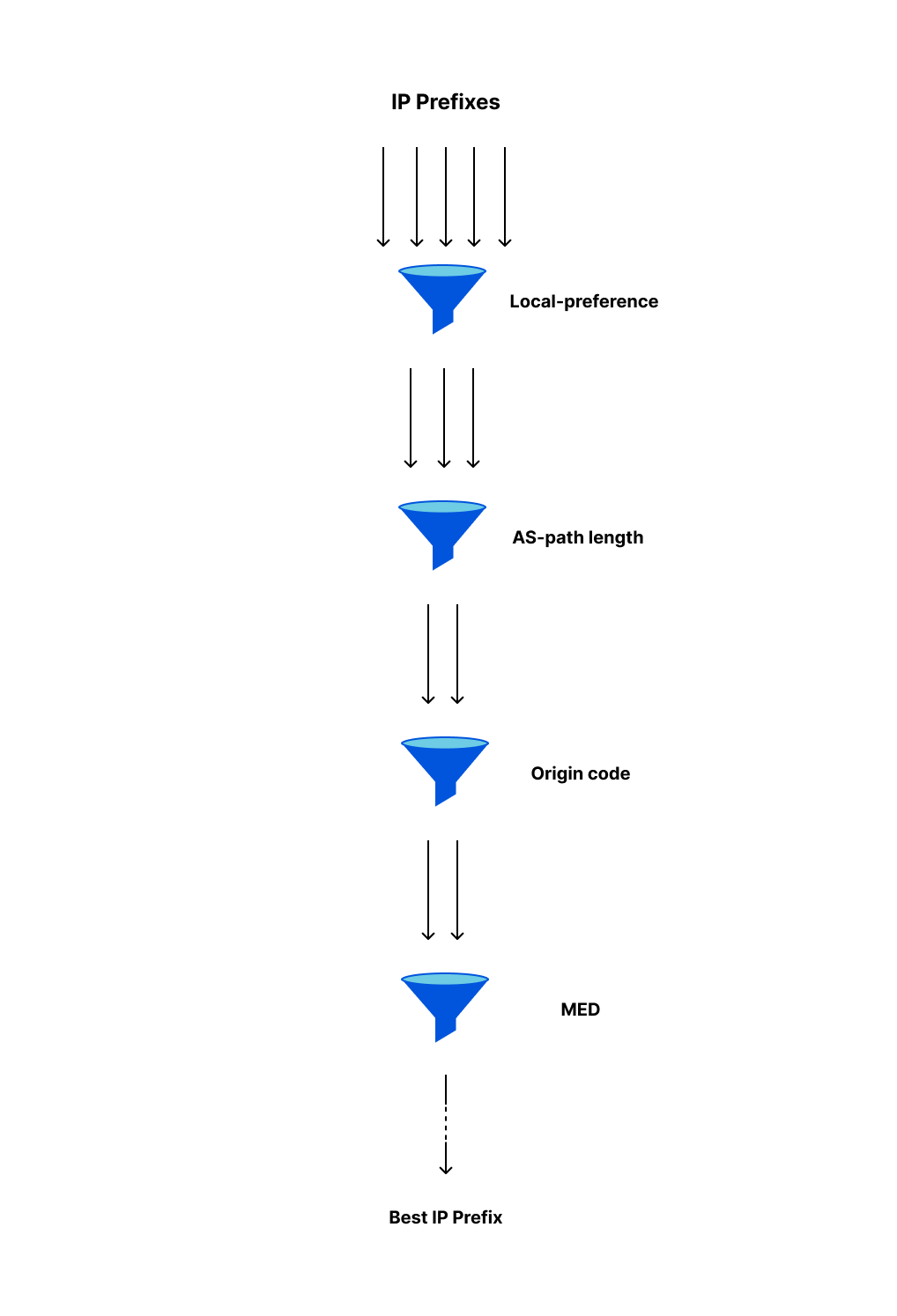
BGP will consider multiple prefix attributes when filtering through the received options. However, rather than combine all those attributes into a single selection criteria, BGP best path selection uses the attributes in tiers — at any tier, if the available attributes are sufficient to choose the best path, then the algorithm terminates with that choice.
The BGP best path selection algorithm is extensive, containing 15 discrete steps to select the best available path for a given prefix. Given the numerous steps, it’s in the interest of the network to decide the best path as early as possible. The first four steps are most used and influential, and are depicted in the figure below as sieves.
Picking the shortest path possible is usually a good idea, which is why “AS-path length” is a step executed early on in the algorithm. However, looking at the figure above, “AS-path length” appears second, despite being the attribute to find the shortest path. So let’s talk about the first step: local preference.
Local preference Local preference is an operator favorite because it allows them to handpick a route+path combination of their choice. It’s the first attribute in the algorithm because it is unique for any given route+neighbor+AS-path combination.
A network sets the local preference on import of a route (having learned about the route from a neighbor network). Being a non-transitive property, meaning that it’s an attribute that is never sent in an EBGP message to other networks. This intrinsically means, for example, that the operator of AS 64496 can’t set the local preference of routes to their own (or transiting) IP prefixes inside neighboring AS 64511. The inability to do so is partially why inbound traffic engineering through EBGP is so difficult.
Prepending artificially increases AS-path length Since no network is able to directly set the local preference for a prefix inside another network, the first opportunity to influence other networks’ choices is modifying the AS-path. If the next hops are valid, and the local preference for all the different paths for a given route are the same, modifying the AS-path is an obvious option to change the path traffic will take towards your network. In a BGP message, prepending looks like this:
Specifically, operators can do AS-path prepending. When doing AS-path prepending, an operator adds additional autonomous systems to the path (usually the operator uses their own AS, but that’s not enforced in the protocol). This way, an AS-path can go from a length of 1 to a length of 255. As the length has now increased dramatically, that specific path for the route will not be chosen. By changing the AS-path advertised to different peers, an operator can control the traffic flows coming into their network.
Unfortunately, prepending has a catch: To be the deciding factor, all the other attributes need to be equal. This is rarely true, especially in large networks that are able to choose from many possible routes to a destination.
Business Policy Engine
BGP is colloquially also referred to as a Business Policy Engine: it does not select the best path from a performance point of view; instead, and more often than not, it will select the best path from a business point of view. The business criteria could be anything from investment (port) efficiency to increased revenue, and more. This may sound strange but, believe it or not, this is what BGP is designed to do! The power (and complexity) of BGP is that it enables a network operator to make choices according to the operator’s needs, contracts, and policies, many of which cannot be reflected by conventional notions of engineering performance.
Different local preferences
A lot of networks (including Cloudflare) assign a local preference depending on the type of connection used to send us the routes. A higher value is a higher preference. For example, routes learned from transit network connections will get a lower local preference of 100 because they are the most costly to use; backbone-learned routes will be 150, Internet exchange (IX) routes get 200, and lastly private interconnect (PNI) routes get 250. This means that for egress (outbound) traffic, the Cloudflare network, by default, will prefer a PNI-learned route, even if a shorter AS-path is available through an IX or transit neighbor.
Part of the reason a PNI is preferred over an IX is reliability, because there is no third-party switching platform involved that is out of our control, which is important because we operate on the assumption that all hardware can and will eventually break. Another part of the reason is for port efficiency reasons. Here, efficiency is defined by cost per megabit transferred on each port. Roughly speaking, the cost is calculated by:
which is combined with the cross-connect cost (might be monthly recurring (MRC), or a one-time fee). PNI is preferable because it helps to optimize value by reducing the overall cost per megabit transferred, because the unit price decreases with higher utilization of the port.
This reasoning is similar for a lot of other networks, and is very prevalent in transit networks. BGP is at least as much about cost and business policy, as it is about performance.
Transit local preference
For simplicity, when referring to transits, I mean the traditional tier-1 transit networks. Due to the nature of these networks, they have two distinct sets of network peers:
In normal circumstances, transit customers will get a higher local preference assigned than the local preference used for their settlement-free peers. This means that, no matter how much you prepend a prefix, if traffic enters that transit network, traffic will always land on your interconnection with that transit network, it will not be offloaded to another peer.
A prepend can still be used if you want to switch/offload traffic from a single link with one transit if you have multiple distinguished links with them, or if the source of traffic is multihomed behind multiple transits (and they don’t have their own local preference playbook preferring one transit over another). But inbound traffic engineering traffic away from one transit port to another through AS-path prepending has significant diminishing returns: once you’re past three prepends, it’s unlikely to change much, if anything, at that point.
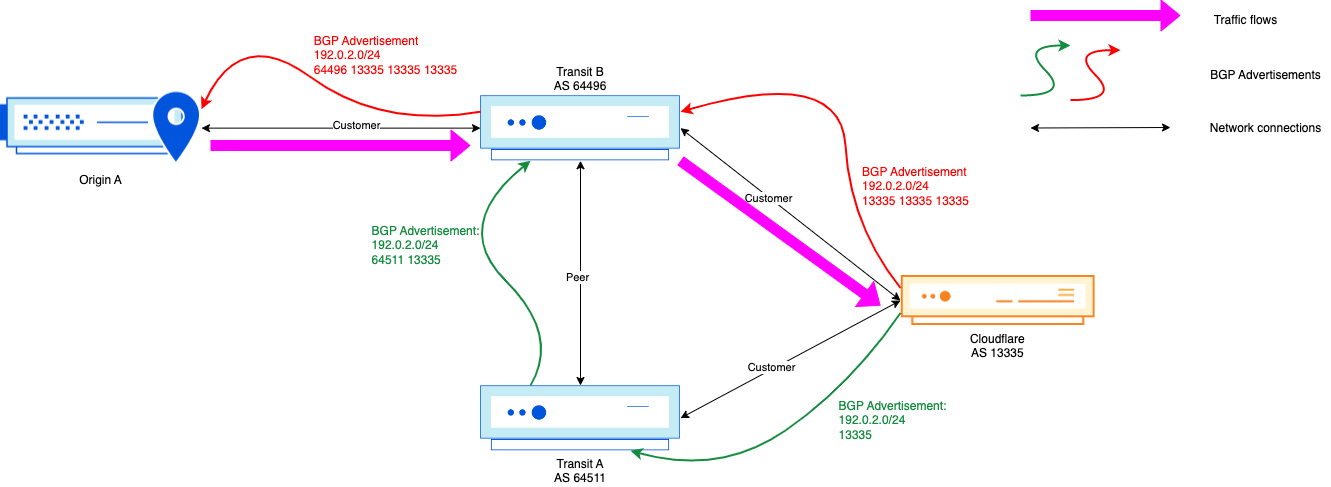
Example
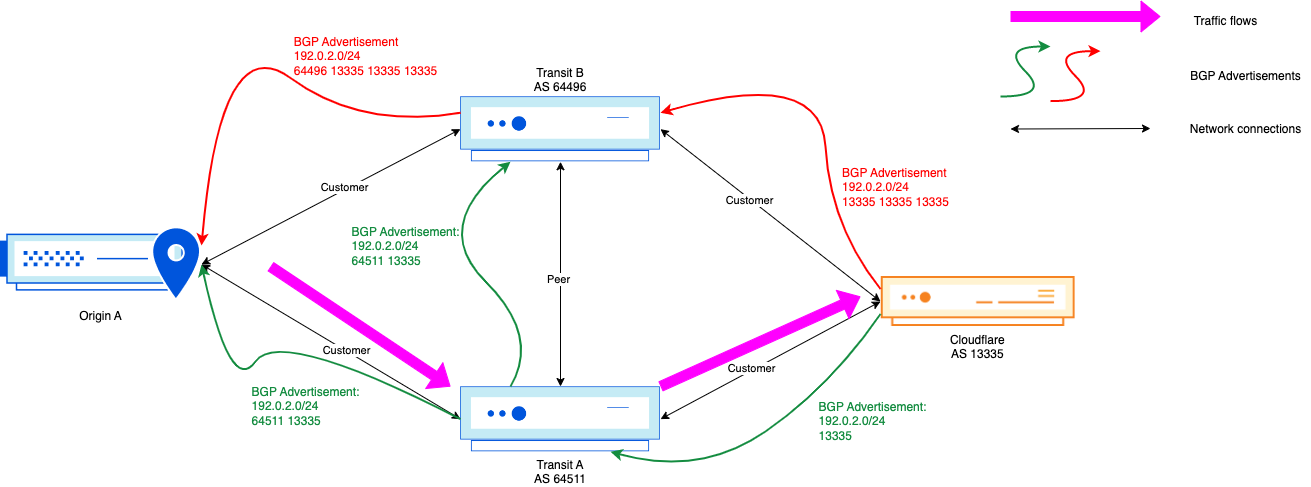
In the above scenario, no matter the adjustment Cloudflare makes in its AS-path towards AS 64496, the traffic will keep flowing through the Transit B <> Cloudflare interconnection, even though the path Origin A → Transit B → Transit A → Cloudflare is shorter from an AS-path point of view.
In this scenario, not a lot has changed, but Origin A is now multi-homed behind the two transit providers. In this case, the AS-path prepending was effective, as the paths seen on the Origin A side are both the prepended and non-prepended path. As long as Origin A is not doing any egress traffic engineering, and is treating both transit networks equally, then the path chosen will be Origin A → Transit A → Cloudflare.
Community-based traffic engineering
So we have now identified a pretty critical problem within the Internet ecosystem for operators: with the tools mentioned above, it’s not always (some might even say outright impossible) possible to accurately dictate paths traffic can ingress your own network, reducing the control an autonomous system has over its own network. Fortunately, there is a solution for this problem: community-based local preference.
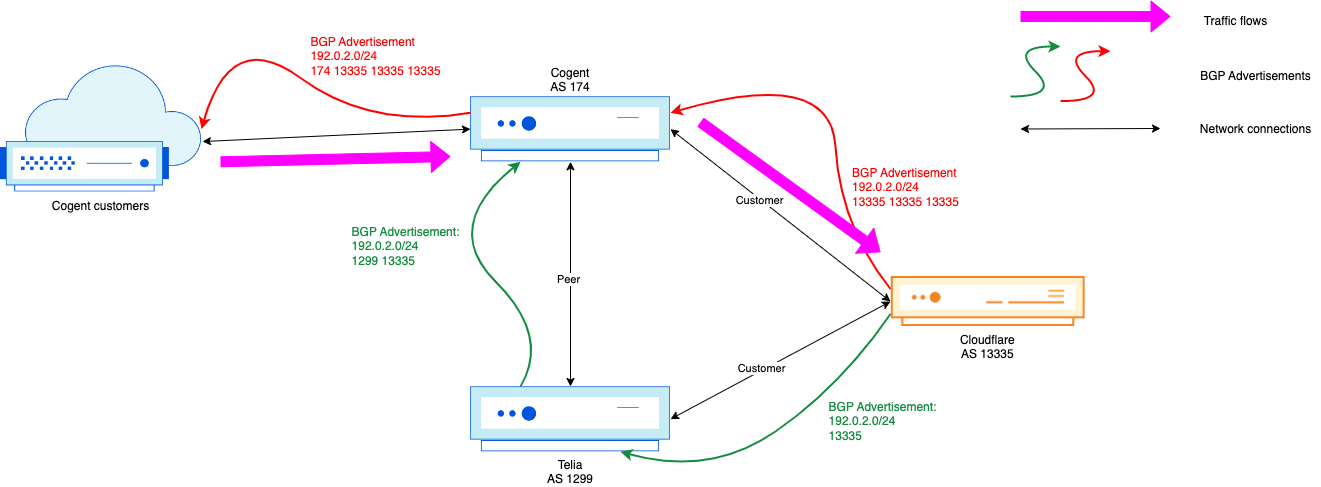
Some transit providers allow their customers to influence the local preference in the transit network through the use of BGP communities. BGP communities are an optional transitive attribute for a route advertisement. The communities can be informative (“I learned this prefix in Rome”), but they can also be used to trigger actions on the receiving side. For example, Cogent publishes the following action communities:
Community
Local preference
174:10
10
174:70
70
174:120
120
174:125
125
174:135
135
174:140
140
When you know that Cogent uses the following default local preferences in their network:
Peers → Local preference 100 Customers → Local preference 130
It’s easy to see how we could use the communities provided to change the route used. It’s important to note though that, as we can’t set the local preference of a route to 100 (or 130), AS-path prepending remains largely irrelevant, as the local preference won’t ever be the same.
Take for example the following configuration:
term ADV-SITELOCAL {
from {
prefix-list SITE-LOCAL;
route-type internal;
}
then {
as-path-prepend "13335 13335";
accept;
}
}
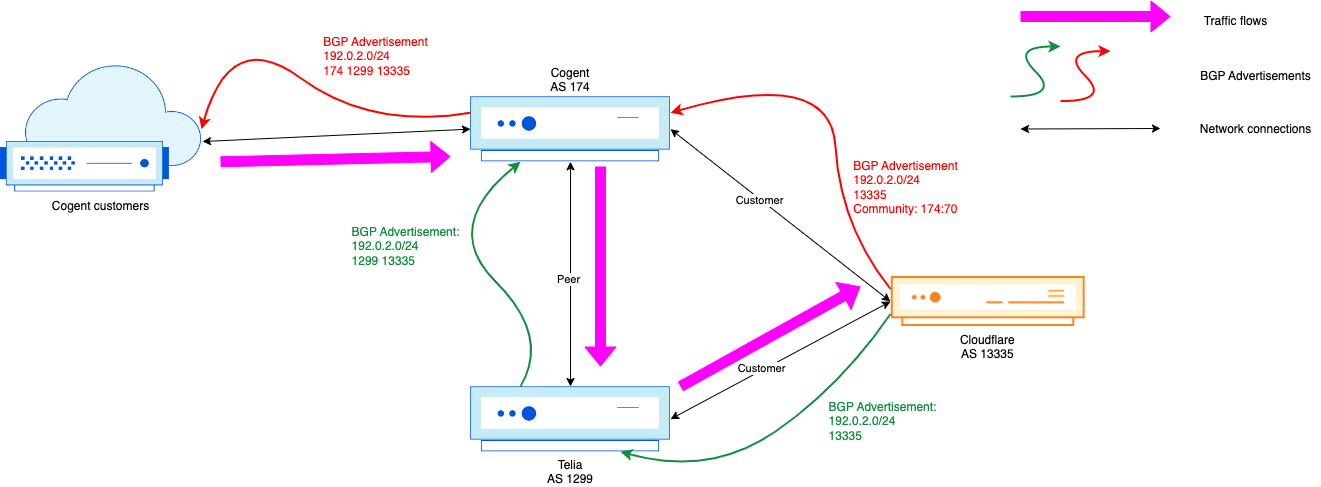
We’re prepending the Cloudflare ASN two times, resulting in a total AS-path of three, yet we were still seeing a lot (too much) traffic coming in on our Cogent link. At that point, an engineer could add another prepend, but for a well-connected network as Cloudflare, if two prepends didn’t do much, or three, then four or five isn’t going to do much either. Instead, we can leverage the Cogent communities documented above to change the routing within Cogent:
term ADV-SITELOCAL {
from {
prefix-list SITE-LOCAL;
route-type internal;
}
then {
community add COGENT_LPREF70;
accept;
}
}
The above configuration changes the traffic flow to this:
Which is exactly what we wanted!
Conclusion
AS-path prepending is still useful, and has its use as part of the toolchain for operators to do traffic engineering, but should be used sparingly. Excessive prepending opens a network up to wider spread route hijacks, which should be avoided at all costs. As such, using community-based ingress traffic engineering is highly preferred (and recommended). In cases where communities aren’t available (or not available to steer customer traffic), prepends can be applied, but I encourage operators to actively monitor their effects, and roll them back if ineffective.
To all of our readers: Happy Thanksgiving from all of us here at Backblaze! We’re taking some time to be with our families and friends, and we hope you are, too.
If your people are anything like ours, we imagine you might be getting asked to fix grandma’s antique desktop computer or explain what the deal is with TikTok to that one bookish friend. Maybe you’re one of those blended families who are still trying to figure out how to share your iPhone pictures with the Android users or vice-versa.
Never fear—we’ve compiled a list of posts that might come in handy when you’re called upon to be an unofficial IT admin to family or friends. Consider this your guide to being your family’s IT superhero. (Caution: If you do too good a job, they may will definitely keep coming to you).
Fortunately, unofficial IT admin is not a thankless job—prepare to have thanks showered upon you for making the internet work and quite possibly saving Thanksgiving. Don’t forget to set yourself up well for the future by referring them all to Backblaze Personal Backup. (Or, just gift it to them and then set it up, since you’re already helping.) Just make sure you get an extra serving of pumpkin pie out of the deal.
The Russian federation has found a way to legalise its capture of Europe’s biggest nuclear power plant. Russia’s armed forces stormed the Zaporizhzhia plant in South-Eastern Ukraine in March 2022.…
We are so excited to share another story from the community! Our series of community stories takes you across the world to hear from young people and educators who are engaging with creating digital technologies in their own personal ways.
Selin and her robot guide dog IC4U.
In this story we introduce you to Selin, a digital maker from Istanbul, Turkey, who is passionate about robotics and AI. Watch the video to hear how Selin’s childhood pet inspired her to build tech projects that aim to help others live well.
Meet Selin
Selin (16) started her digital making journey because she wanted to solve a problem: after her family’s beloved dog Korsan passed away, she wanted to bring him back to life. Selin thought a robotic dog could be the answer, and so she started to design her project on paper. When she found out that learning to code would mean she could actually make a robotic dog, Selin began to teach herself about coding and digital making. Selin has since built seven robots, and her enthusiasm for creating digital technologies shows no sign of stopping.
Selin and her robot guide dog IC4U.
One of Selin’s big motivations to explore digital making was having an event to work towards. When she discovered Coolest Projects, our global technology showcase for young people, Selin set herself the task of making a robot that she could present at the Coolest Projects event in 2018.
When thinking about ideas for what to make for Coolest Projects, Selin remembered how it felt to lose her dog. She wondered what it must be like when a blind person’s guide dog passes away, as that person loses their friend as well as their support. So Selin decided to make a robotic guide dog called IC4U. She contacted several guide dog organisations to find out how guide dogs are trained and what they need to be able to do so she could replicate their behaviour in her robot. The robot is voice-controlled so that people with impaired sight can interact with it easily.
Selin at Coolest Projects International in 2018.
Selin and her parents travelled to Coolest Projects International in Dublin with Selin’s robotic guide dog, and Selin and IC4U became a judges’ favourite in the Hardware category. Selin enjoyed participating in Coolest Projects so much that she started designing her project for next year’s event straight away:
“When I returned back I immediately started working for next year’s Coolest Projects.”
Selin
Many of Selin’s tech projects share a theme: to help make the world a better place. For example, another robot made by Selin is the BB4All — a school assistant robot to tackle bullying. And last year, while she attended the Stanford AI4ALL summer camp, Selin worked with a group of young people to design a tech project to increase the speed and accuracy of lung cancer diagnoses.
Through her digital making projects, Selin wants to show how people can use robotics and AI technology to support people and their well-being. In 2021, Selin’s commitment to making these projects was recognised when she was awarded the Aspiring Teen Award by Women in Tech.
Listening to Selin, it is inspiring to hear how a person can use technology to express themselves as well as create projects that have the potential to do so much good. Selin acknowledges that sometimes the first steps can be the hardest, especially for girls interested in tech: “I know it’s hard to start at first, but interests are gender-free.”
“Be curious and courageous, and never let setbacks stop you so you can actually accomplish your dream.”
Selin
We have loved seeing all the wonderful projects that Selin has made in the years since she first designed a robot dog on paper. And it’s especially cool to see that Selin has also continued to work on her robot IC4U, the original project that led her to coding, Coolest Projects, and more. Selin’s robot has developed with its maker, and we can’t wait to see what they both go on to do next.
Help us celebrate Selin and inspire other young people to discover coding and digital making as a passion, by sharing her story on Twitter, LinkedIn, and Facebook.
Руската федерация документално узакони рейдърското завземане от въоръжените й сили на най-голямата ядрена централа в Европа – АЕЦ Запорожие в Югоизтозточна Украйна, извършено през март 2022 г. Регистрирането на две…
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
 Има различни видове есета. Има ясни и целеустремени, последователни като валяк. Има и такива като полет на птица или пеперуда. Те са неочаквани, будещи любопитство и задаващи въпроси, доставящи неусетно удоволствие, а и знание. Те не създават впечатление, че нещата са окончателно изяснени, не – карат те да търсиш още повече. Сборникът на Уайнбъргър е от втория забележителен и рядък вид. Книга, която спокойно поставям до „Приказка без край“ на Михаел Енде – заради богатството ѝ.
Има различни видове есета. Има ясни и целеустремени, последователни като валяк. Има и такива като полет на птица или пеперуда. Те са неочаквани, будещи любопитство и задаващи въпроси, доставящи неусетно удоволствие, а и знание. Те не създават впечатление, че нещата са окончателно изяснени, не – карат те да търсиш още повече. Сборникът на Уайнбъргър е от втория забележителен и рядък вид. Книга, която спокойно поставям до „Приказка без край“ на Михаел Енде – заради богатството ѝ.