Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/archiving-and-replaying-events-with-amazon-eventbridge/
Amazon EventBridge is a serverless event bus used to decouple event producers and consumers. Event producers publish events onto an event bus, which then uses rules to determine where to send those events. The rules determine the targets, and EventBridge routes the events accordingly.
In event-driven architectures, it can be useful for services to access past events. This has previously required manual logging and archiving, and creating a mechanism to parse files and put events back on the event bus. This can be complex, since you may not have access to the applications that are publishing the events.
With the announcement of event replay, EventBridge can now record any events processed by any type of event bus. Replay stores these recorded events in archives. You can choose to record all events, or filter events to be archived by using the same event pattern matching logic used in rules.

You can also configure a retention policy for an archive to store data either indefinitely or for a defined number of days. You can now easily configure logging and replay options for events created by AWS services, your own applications, and integrated SaaS partners.
Event replay can be useful for a number of different use-cases:
- Testing code fixes: after fixing bugs in microservices, being able to replay historical events provides a way to test the behavior of the code change.
- Testing new features: using historical production data from event archives, you can measure the performance of new features under load.
- Hydrating development or test environments: you can replay event archives to hydrate the state of test and development environments. This helps provide a more realistic state that approximates production.
This blog post shows you how to create event archives for an event bus, and then how to replay events. I also cover some of the important features and how you can use these in your serverless applications.
Creating event archives
To create an event archive for an event bus:
- Navigate to the EventBridge console and select Archives from the left-hand submenu. Choose the Create Archive button.

- In the Define archive details page:
- Enter ‘my-event-archive’ for Name and provide an optional description.
- Select a source bus from the dropdown (choose default if you want to archive AWS events).
- For retention period, enter ‘30’.
- Choose Next.

- In the Filter events page, you can provide an event pattern to archive a subset of events. For this walkthrough, select No event filtering and choose Create archive.

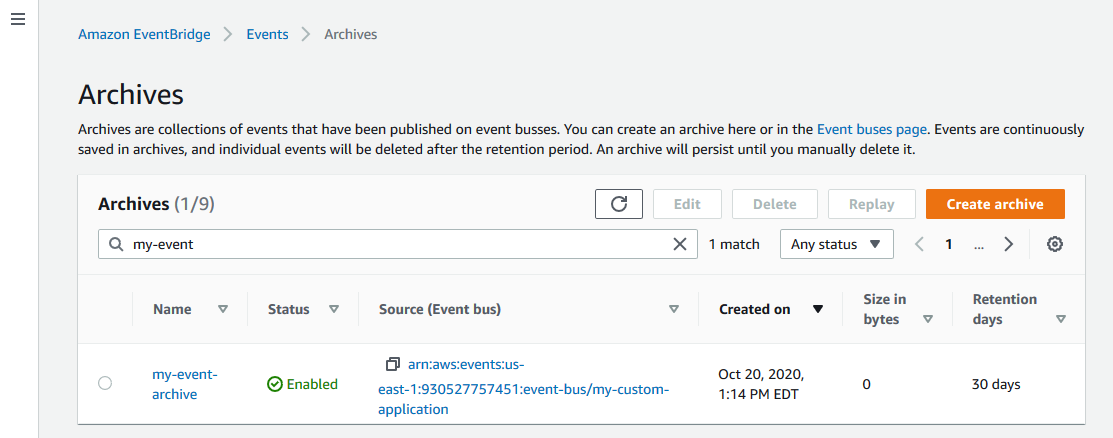
- In the Archives page, you can see the new archive waiting to receive events.

- Choose the archive to open the details page. Over time, as more events are sent to the bus, the archive maintains statistics about the number and size of events stored.



You can also create archives using AWS CloudFormation. The following example creates an archive that filters for a subset of events with a retention period of 30 days:
Type: AWS::Events::Archive
Properties:
Description: My filtered archive.
EventPattern:
source:
- "my-app-worker-service"
RetentionDays: 30
SourceArn: arn:aws:events:us-east-1:123456789012:event-bus/my-custom-application
How this works
Archives are always sourced from a single event bus. Once you have created an archive, it appears on the event bus details page:

You can make changes to an archive definition once it is created. If you shorten the duration, this deletes any events in the archives that are earlier than the new retention period. This deletion process occurs after a period of time and is not immediate. If you extend the duration, this affects event collection from the current point, but does not restore older events.
Each time you create an archive, this automatically generates a rule on the event bus. This is called a managed rule, which is created, updated, and deleted by the EventBridge service automatically. This rule does not count towards the default 300 rules per event bus service quota.

When you open a managed rule, the configuration is read-only.

This configuration shows an event pattern that is applied to all incoming events, including those that may be replayed from archives. The event pattern excludes events containing a replay-name attribute, which prevents replayed events from being archived multiple times.
Replaying archived events
To replay an archive of events:
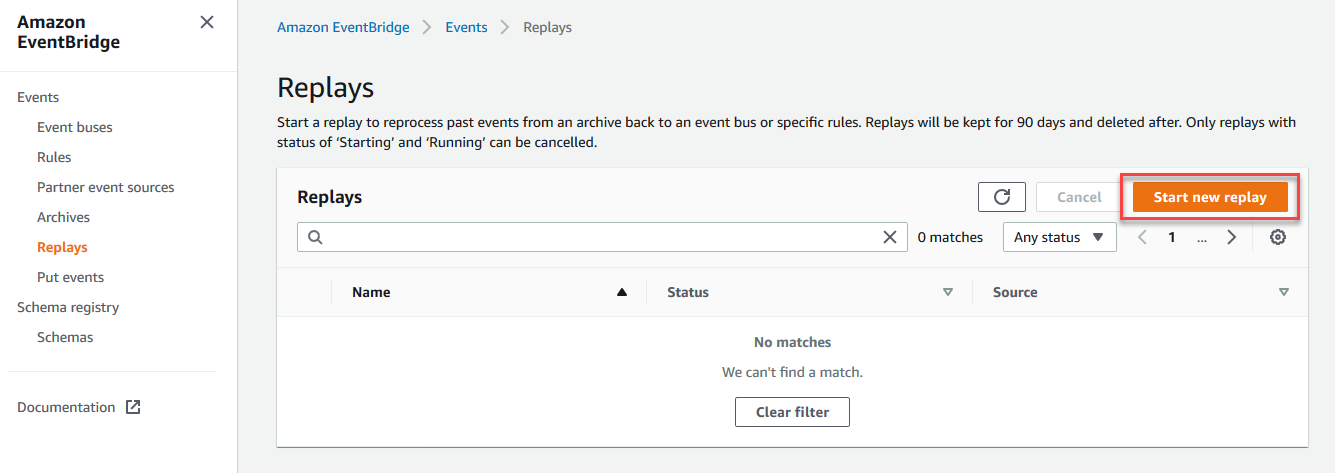
- Navigate to the EventBridge console and select Replays from the left-hand submenu. Choose the Create Archive button.

- In the Start new replay page:
- Enter ‘my-event-replay’ for Name and provide an optional description.
- Select a source bus from the dropdown. This must match the source bus for the event archive.
- For Specify rule(s), select All rules.
- Enter a time frame for the replay. This is the ingestion time for the first and last events in the archive.
- Choose Start Replay.
- The Replays page shows the new replay in Starting status.


How this works
When a replay is started, the service sends the archived event back to the original event bus. It processes these as quickly as possible, with no ordering guarantees. The replay process adds a “replay-name” attribute to the original event. This is the flow of events:
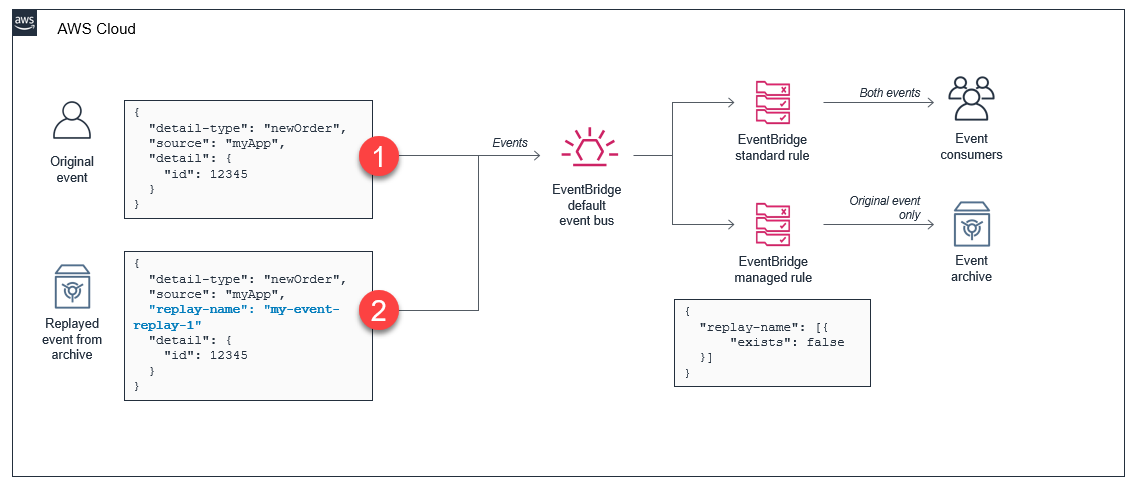
- The original event is sent to the event bus. It is received by any existing rules and the managed rule creating the archive. The event is saved to the event archive.
- When the archived event is replayed, the JSON object includes the replay-name attribute. The existing rules process the event as in the first step. Since the managed rule does not match the replayed event, it is not forwarded to the archive.
Showing additional replay fields
In the Replays console, choose the preferences cog icon to open the Preferences dialog box.

From here, you can add:
- Event start time and end time: Timestamps for the earliest and latest events in the archive that was replayed.
- Replay start time and end time: shows the time filtering parameters set for the listed replay.
- Last replayed: a timestamp of when the final replay event occurred.
You can sort on any of these additional fields.

Advanced routing of replayed events
In this simple example, a replayed archive matches the same rules that the original events triggered. Additionally, replayed events must be sent to the original bus where they were archived from. As a result, a basic replay allows you to duplicate events and copy the rule matching behaviors that occurred originally.
However, you may want to trigger different rules for replayed events or send the events to another bus. You can make use of the replay-name attribute in your own rules to add this advanced routing functionality. By creating a rule that filters for the presence of the “replay-name” event, it ignores all events that are not replays. When you create the replay, instead of targeting all rules on the bus, only target this one rule.

- The original event is put on the event bus. The replay rule is evaluated but does not match.
- The event is played from the archive, targeting only the replay rule. All other rules are excluded automatically by the replay service. The replay rule matches and forwards events onto the rule’s targets.
The target of the replay rule may be typical rule target, including an AWS Lambda function for customized processing, or another event bus.
Conclusion
In event-driven architectures, it can be useful for services to access past events. The new event replay feature in Amazon EventBridge enables you to automatically archive and replay events on an event bus. This can help for testing new features or new code, or hydrating services in development and test to more closely approximate a production environment.
This post shows how to create and replay event archives. It discusses how the archives work, and how you can implement these in your own applications. To learn more about using Amazon EventBridge, visit the learning path for videos, blogs, and other resources.
For more serverless learning resources, visit Serverless Land.