Post Syndicated from Stefano Sandona original https://aws.amazon.com/blogs/big-data/introducing-runtime-roles-for-amazon-emr-steps-use-iam-roles-and-aws-lake-formation-for-access-control-with-amazon-emr/
You can use the Amazon EMR Steps API to submit Apache Hive, Apache Spark, and others types of applications to an EMR cluster. You can invoke the Steps API using Apache Airflow, AWS Steps Functions, the AWS Command Line Interface (AWS CLI), all the AWS SDKs, and the AWS Management Console. Jobs submitted with the Steps API use the Amazon Elastic Compute Cloud (Amazon EC2) instance profile to access AWS resources such as Amazon Simple Storage Service (Amazon S3) buckets, AWS Glue tables, and Amazon DynamoDB tables from the cluster.
Previously, if a step needed access to a specific S3 bucket and another step needed access to a specific DynamoDB table, the AWS Identity and Access Management (IAM) policy attached to the instance profile had to allow access to both the S3 bucket and the DynamoDB table. This meant that the IAM policies you assigned to the instance profile had to contain a union of all the permissions for every step that ran on an EMR cluster.
We’re happy to introduce runtime roles for EMR steps. A runtime role is an IAM role that you associate with an EMR step, and jobs use this role to access AWS resources. With runtime roles for EMR steps, you can now specify different IAM roles for the Spark and the Hive jobs, thereby scoping down access at a job level. This allows you to simplify access controls on a single EMR cluster that is shared between multiple tenants, wherein each tenant can be easily isolated using IAM roles.
The ability to specify an IAM role with a job is also available on Amazon EMR on EKS and Amazon EMR Serverless. You can also use AWS Lake Formation to apply table- and column-level permission for Apache Hive and Apache Spark jobs that are submitted with EMR steps. For more information, refer to Configure runtime roles for Amazon EMR steps.
In this post, we dive deeper into runtime roles for EMR steps, helping you understand how the various pieces work together, and how each step is isolated on an EMR cluster.
Solution overview
In this post, we walk through the following:
- Create an EMR cluster enabled to use the new role-based access control with EMR steps.
- Create two IAM roles with different permissions in terms of the Amazon S3 data and Lake Formation tables they can access.
- Allow the IAM principal submitting the EMR steps to use these two IAM roles.
- See how EMR steps running with the same code and trying to access the same data have different permissions based on the runtime role specified at submission time.
- See how to monitor and control actions using source identity propagation.
Set up EMR cluster security configuration
Amazon EMR security configurations simplify applying consistent security, authorization, and authentication options across your clusters. You can create a security configuration on the Amazon EMR console or via the AWS CLI or AWS SDK. When you attach a security configuration to a cluster, Amazon EMR applies the settings in the security configuration to the cluster. You can attach a security configuration to multiple clusters at creation time, but can’t apply them to a running cluster.
To enable runtime roles for EMR steps, we have to create a security configuration as shown in the following code and enable the runtime roles property (configured via EnableApplicationScopedIAMRole). In addition to the runtime roles, we’re enabling propagation of the source identity (configured via PropagateSourceIdentity) and support for Lake Formation (configured via LakeFormationConfiguration). The source identity is a mechanism to monitor and control actions taken with assumed roles. Enabling Propagate source identity allows you to audit actions performed using the runtime role. Lake Formation is an AWS service to securely manage a data lake, which includes defining and enforcing central access control policies for your data lake.
Create a file called step-runtime-roles-sec-cfg.json with the following content:
{
"AuthorizationConfiguration": {
"IAMConfiguration": {
"EnableApplicationScopedIAMRole": true,
"ApplicationScopedIAMRoleConfiguration":
{
"PropagateSourceIdentity": true
}
},
"LakeFormationConfiguration": {
"AuthorizedSessionTagValue": "Amazon EMR"
}
}
}
Create the Amazon EMR security configuration:
aws emr create-security-configuration \
--name 'iamconfig-with-iam-lf' \
--security-configuration file://step-runtime-roles-sec-cfg.json
You can also do the same via the Amazon console:
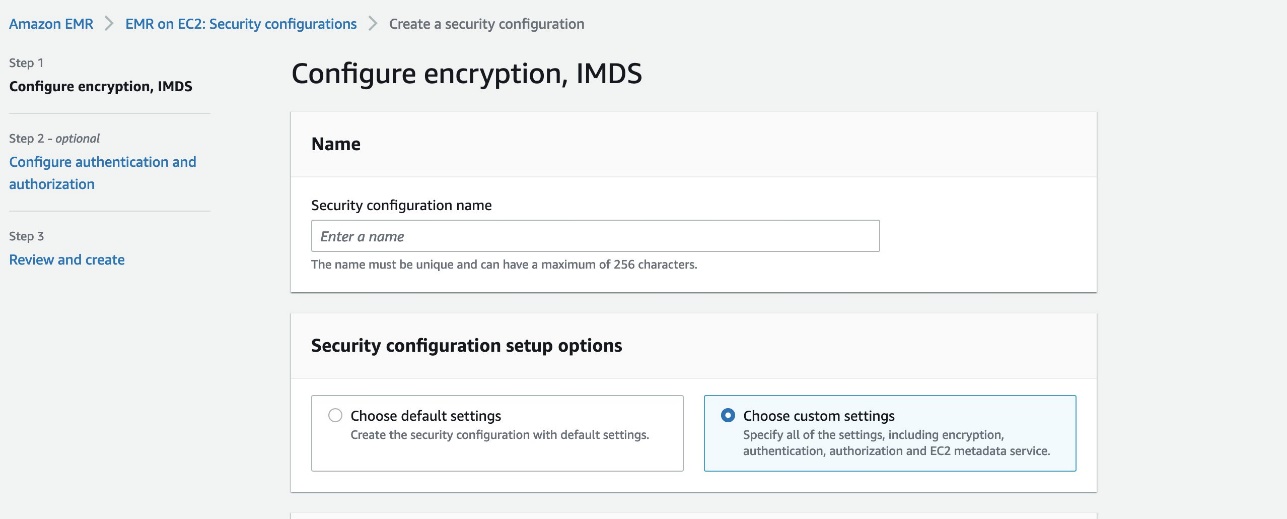
- On the Amazon EMR console, choose Security configurations in the navigation pane.
- Choose Create.

- Choose Create.

- For Security configuration name, enter a name.
- For Security configuration setup options, select Choose custom settings.

- For IAM role for applications, select Runtime role.
- Select Propagate source identity to audit actions performed using the runtime role.
- For Fine-grained access control, select AWS Lake Formation.
- Complete the security configuration.

The security configuration appears in your security configuration list. You can also see that the authorization mechanism listed here is the runtime role instead of the instance profile.

Launch the cluster
Now we launch an EMR cluster and specify the security configuration we created. For more information, refer to Specify a security configuration for a cluster.
The following code provides the AWS CLI command for launching an EMR cluster with the appropriate security configuration. Note that this cluster is launched on the default VPC and public subnet with the default IAM roles. In addition, the cluster is launched with one primary and one core instance of the specified instance type. For more details on how to customize the launch parameters, refer to create-cluster.
If the default EMR roles EMR_EC2_DefaultRole and EMR_DefaultRole don’t exist in IAM in your account (this is the first time you’re launching an EMR cluster with those), before launching the cluster, use the following command to create them:
aws emr create-default-roles
Create the cluster with the following code:
#Change with your Key Pair
KEYPAIR=<MY_KEYPAIR>
INSTANCE_TYPE="r4.4xlarge"
#Change with your Security Configuration Name
SECURITY_CONFIG="iamconfig-with-iam-lf"
#Change with your S3 log URI
LOG_URI="s3://mybucket/logs/"
aws emr create-cluster \
--name "iam-passthrough-cluster" \
--release-label emr-6.7.0 \
--use-default-roles \
--security-configuration $SECURITY_CONFIG \
--ec2-attributes KeyName=$KEYPAIR \
--instance-groups InstanceGroupType=MASTER,InstanceCount=1,InstanceType=$INSTANCE_TYPE InstanceGroupType=CORE,InstanceCount=1,InstanceType=$INSTANCE_TYPE \
--applications Name=Spark Name=Hadoop Name=Hive \
--log-uri $LOG_URI
When the cluster is fully provisioned (Waiting state), let’s try to run a step on it with runtime roles for EMR steps enabled:
#Change with your EMR cluster ID
CLUSTER_ID=j-XXXXXXXXXXXXX
aws emr add-steps \
--cluster-id $CLUSTER_ID \
--steps '[{
"Type": "CUSTOM_JAR",
"ActionOnFailure": "CONTINUE",
"Jar": "command-runner.jar",
"Name": "Spark Example",
"Args": [
"spark-submit",
"--class",
"org.apache.spark.examples.SparkPi",
"/usr/lib/spark/examples/jars/spark-examples.jar",
"5"
]
}]'
After launching the command, we receive the following as output:
An error occurred (ValidationException) when calling the AddJobFlowSteps operation: Runtime roles are required for this cluster. Please specify the role using the ExecutionRoleArn parameter.
The step failed, asking us to provide a runtime role. In the next section, we set up two IAM roles with different permissions and use them as the runtime roles for EMR steps.
Set up IAM roles as runtime roles
Any IAM role that you want to use as a runtime role for EMR steps must have a trust policy that allows the EMR cluster’s EC2 instance profile to assume it. In our setup, we’re using the default IAM role EMR_EC2_DefaultRole as the instance profile role. In addition, we create two IAM roles called test-emr-demo1 and test-emr-demo2 that we use as runtime roles for EMR steps.
The following code is the trust policy for both of the IAM roles, which lets the EMR cluster’s EC2 instance profile role, EMR_EC2_DefaultRole, assume these roles and set the source identity and LakeFormationAuthorizedCaller tag on the role sessions. The TagSession permission is needed so that Amazon EMR can authorize to Lake Formation. The SetSourceIdentity statement is needed for the propagate source identity feature.
Create a file called trust-policy.json with the following content (replace 123456789012 with your AWS account ID):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:role/EMR_EC2_DefaultRole"
},
"Action": "sts:AssumeRole"
},
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:role/EMR_EC2_DefaultRole"
},
"Action": "sts:SetSourceIdentity"
},
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:role/EMR_EC2_DefaultRole"
},
"Action": "sts:TagSession",
"Condition": {
"StringEquals": {
"aws:RequestTag/LakeFormationAuthorizedCaller": "Amazon EMR"
}
}
}
]
}
Use that policy to create the two IAM roles, test-emr-demo1 and test-emr-demo2:
aws iam create-role \
--role-name test-emr-demo1 \
--assume-role-policy-document file://trust-policy.json
aws iam create-role \
--role-name test-emr-demo2 \
--assume-role-policy-document file://trust-policy.json
Set up permissions for the principal submitting the EMR steps with runtime roles
The IAM principal submitting the EMR steps needs to have permissions to invoke the AddJobFlowSteps API. In addition, you can use the Condition key elasticmapreduce:ExecutionRoleArn to control access to specific IAM roles. For example, the following policy allows the IAM principal to only use IAM roles test-emr-demo1 and test-emr-demo2 as the runtime roles for EMR steps.
- Create the
job-submitter-policy.json file with the following content (replace 123456789012 with your AWS account ID):
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AddStepsWithSpecificExecRoleArn",
"Effect": "Allow",
"Action": [
"elasticmapreduce:AddJobFlowSteps"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"elasticmapreduce:ExecutionRoleArn": [
"arn:aws:iam::123456789012:role/test-emr-demo1",
"arn:aws:iam::123456789012:role/test-emr-demo2"
]
}
}
},
{
"Sid": "EMRDescribeCluster",
"Effect": "Allow",
"Action": [
"elasticmapreduce:DescribeCluster"
],
"Resource": "*"
}
]
}
- Create the IAM policy with the following code:
aws iam create-policy \
--policy-name emr-runtime-roles-submitter-policy \
--policy-document file://job-submitter-policy.json
- Assign this policy to the IAM principal (IAM user or IAM role) you’re going to use to submit the EMR steps (replace 123456789012 with your AWS account ID and replace
john with the IAM user you use to submit your EMR steps):
aws iam attach-user-policy \
--user-name john \
--policy-arn "arn:aws:iam::123456789012:policy/emr-runtime-roles-submitter-policy"
IAM user john can now submit steps using arn:aws:iam::123456789012:role/test-emr-demo1 and arn:aws:iam::123456789012:role/test-emr-demo2 as the step runtime roles.
Use runtime roles with EMR steps
We now prepare our setup to show runtime roles for EMR steps in action.
Set up Amazon S3
To prepare your Amazon S3 data, complete the following steps:
- Create a CSV file called
test.csv with the following content:
- Upload the file to Amazon S3 in three different locations:
#Change this with your bucket name
BUCKET_NAME="emr-steps-roles-new-us-east-1"
aws s3 cp test.csv s3://${BUCKET_NAME}/demo1/
aws s3 cp test.csv s3://${BUCKET_NAME}/demo2/
aws s3 cp test.csv s3://${BUCKET_NAME}/nondemo/
For our initial test, we use a PySpark application called test.py with the following contents:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("my app").enableHiveSupport().getOrCreate()
#Change this with your bucket name
BUCKET_NAME="emr-steps-roles-new-us-east-1"
try:
spark.read.csv("s3://" + BUCKET_NAME + "/demo1/test.csv").show()
print("Accessed demo1")
except:
print("Could not access demo1")
try:
spark.read.csv("s3://" + BUCKET_NAME + "/demo2/test.csv").show()
print("Accessed demo2")
except:
print("Could not access demo2")
try:
spark.read.csv("s3://" + BUCKET_NAME + "/nondemo/test.csv").show()
print("Accessed nondemo")
except:
print("Could not access nondemo")
spark.stop()
In the script, we’re trying to access the CSV file present under three different prefixes in the test bucket.
- Upload the Spark application inside the same S3 bucket where we placed the
test.csv file but in a different location:
#Change this with your bucket name
BUCKET_NAME="emr-steps-roles-new-us-east-1"
aws s3 cp test.py s3://${BUCKET_NAME}/scripts/
Set up runtime role permissions
To show how runtime roles for EMR steps works, we assign to the roles we created different IAM permissions to access Amazon S3. The following table summarizes the grants we provide to each role (emr-steps-roles-new-us-east-1 is the bucket you configured in the previous section).
| S3 locations \ IAM Roles |
test-emr-demo1 |
test-emr-demo2 |
| s3://emr-steps-roles-new-us-east-1/* |
No Access |
No Access |
| s3://emr-steps-roles-new-us-east-1/demo1/* |
Full Access |
No Access |
| s3://emr-steps-roles-new-us-east-1/demo2/* |
No Access |
Full Access |
| s3://emr-steps-roles-new-us-east-1/scripts/* |
Read Access |
Read Access |
- Create the file
demo1-policy.json with the following content (substitute emr-steps-roles-new-us-east-1 with your bucket name):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::emr-steps-roles-new-us-east-1/demo1",
"arn:aws:s3:::emr-steps-roles-new-us-east-1/demo1/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:Get*"
],
"Resource": [
"arn:aws:s3:::emr-steps-roles-new-us-east-1/scripts",
"arn:aws:s3:::emr-steps-roles-new-us-east-1/scripts/*"
]
}
]
}
- Create the file
demo2-policy.json with the following content (substitute emr-steps-roles-new-us-east-1 with your bucket name):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::emr-steps-roles-new-us-east-1/demo2",
"arn:aws:s3:::emr-steps-roles-new-us-east-1/demo2/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:Get*"
],
"Resource": [
"arn:aws:s3:::emr-steps-roles-new-us-east-1/scripts",
"arn:aws:s3:::emr-steps-roles-new-us-east-1/scripts/*"
]
}
]
}
- Create our IAM policies:
aws iam create-policy \
--policy-name test-emr-demo1-policy \
--policy-document file://demo1-policy.json
aws iam create-policy \
--policy-name test-emr-demo2-policy \
--policy-document file://demo2-policy.json
- Assign to each role the related policy (replace 123456789012 with your AWS account ID):
aws iam attach-role-policy \
--role-name test-emr-demo1 \
--policy-arn "arn:aws:iam::123456789012:policy/test-emr-demo1-policy"
aws iam attach-role-policy \
--role-name test-emr-demo2 \
--policy-arn "arn:aws:iam::123456789012:policy/test-emr-demo2-policy"
To use runtime roles with Amazon EMR steps, we need to add the following policy to our EMR cluster’s EC2 instance profile (in this example EMR_EC2_DefaultRole). With this policy, the underlying EC2 instances for the EMR cluster can assume the runtime role and apply a tag to that runtime role.
- Create the file
runtime-roles-policy.json with the following content (replace 123456789012 with your AWS account ID):
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "AllowRuntimeRoleUsage",
"Effect": "Allow",
"Action": [
"sts:AssumeRole",
"sts:TagSession",
"sts:SetSourceIdentity"
],
"Resource": [
"arn:aws:iam::123456789012:role/test-emr-demo1",
"arn:aws:iam::123456789012:role/test-emr-demo2"
]
}
]
}
- Create the IAM policy:
aws iam create-policy \
--policy-name emr-runtime-roles-policy \
--policy-document file://runtime-roles-policy.json
- Assign the created policy to the EMR cluster’s EC2 instance profile, in this example
EMR_EC2_DefaultRole:
aws iam attach-role-policy \
--role-name EMR_EC2_DefaultRole \
--policy-arn "arn:aws:iam::123456789012:policy/emr-runtime-roles-policy"
Test permissions with runtime roles
We’re now ready to perform our first test. We run the test.py script, previously uploaded to Amazon S3, two times as Spark steps: first using the test-emr-demo1 role and then using the test-emr-demo2 role as the runtime roles.
To run an EMR step specifying a runtime role, you need the latest version of the AWS CLI. For more details about updating the AWS CLI, refer to Installing or updating the latest version of the AWS CLI.
Let’s submit a step specifying test-emr-demo1 as the runtime role:
#Change with your EMR cluster ID
CLUSTER_ID=j-XXXXXXXXXXXXX
#Change with your AWS Account ID
ACCOUNT_ID=123456789012
#Change with your Bucket name
BUCKET_NAME=emr-steps-roles-new-us-east-1
aws emr add-steps \
--cluster-id $CLUSTER_ID \
--steps '[{
"Type": "CUSTOM_JAR",
"ActionOnFailure": "CONTINUE",
"Jar": "command-runner.jar",
"Name": "Spark Example",
"Args": [
"spark-submit",
"s3://'"${BUCKET_NAME}"'/scripts/test.py"
]
}]' \
--execution-role-arn arn:aws:iam::${ACCOUNT_ID}:role/test-emr-demo1
This command returns an EMR step ID. To check our step output logs, we can proceed two different ways:
- From the Amazon EMR console – On the Steps tab, choose the View logs link related to the specific step ID and select
stdout.
- From Amazon S3 – While launching our cluster, we configured an S3 location for logging. We can find our step logs under
$(LOG_URI)/steps/<stepID>/stdout.gz.
The logs could take a couple of minutes to populate after the step is marked as Completed.
The following is the output of the EMR step with test-emr-demo1 as the runtime role:
+---+---+---+
|_c0|_c1|_c2|
+---+---+---+
| 1| a| 1a|
| 2| b| 2b|
+---+---+---+
Accessed demo1
Could not access demo2
Could not access nondemo
As we can see, only the demo1 folder was accessible by our application.
Diving deeper into the step stderr logs, we can see that the related YARN application application_1656350436159_0017 was launched with the user 6GC64F33KUW4Q2JY6LKR7UAHWETKKXYL. We can confirm this by connecting to the EMR primary instance using SSH and using the YARN CLI:
[hadoop@ip-172-31-63-203]$ yarn application -status application_1656350436159_0017
...
Application-Id : application_1656350436159_0017
Application-Name : my app
Application-Type : SPARK
User : 6GC64F33KUW4Q2JY6LKR7UAHWETKKXYL
Queue : default
Application Priority : 0
...
Please note that in your case, the YARN application ID and the user will be different.
Now we submit the same script again as a new EMR step, but this time with the role test-emr-demo2 as the runtime role:
#Change with your EMR cluster ID
CLUSTER_ID=j-XXXXXXXXXXXXX
#Change with your AWS Account ID
ACCOUNT_ID=123456789012
#Change with your Bucket name
BUCKET_NAME=emr-steps-roles-new-us-east-1
aws emr add-steps \
--cluster-id $CLUSTER_ID \
--steps '[{
"Type": "CUSTOM_JAR",
"ActionOnFailure": "CONTINUE",
"Jar": "command-runner.jar",
"Name": "Spark Example",
"Args": [
"spark-submit",
"s3://'"${BUCKET_NAME}"'/scripts/test.py"
]
}]' \
--execution-role-arn arn:aws:iam::${ACCOUNT_ID}:role/test-emr-demo2
The following is the output of the EMR step with test-emr-demo2 as the runtime role:
Could not access demo1
+---+---+---+
|_c0|_c1|_c2|
+---+---+---+
| 1| a| 1a|
| 2| b| 2b|
+---+---+---+
Accessed demo2
Could not access nondemo
As we can see, only the demo2 folder was accessible by our application.
Diving deeper into the step stderr logs, we can see that the related YARN application application_1656350436159_0018 was launched with a different user 7T2ORHE6Z4Q7PHLN725C2CVWILZWYOLE. We can confirm this by using the YARN CLI:
[hadoop@ip-172-31-63-203]$ yarn application -status application_1656350436159_0018
...
Application-Id : application_1656350436159_0018
Application-Name : my app
Application-Type : SPARK
User : 7T2ORHE6Z4Q7PHLN725C2CVWILZWYOLE
Queue : default
Application Priority : 0
...
Each step was able to only access the CSV file that was allowed by the runtime role, so the first step was able to only access s3://emr-steps-roles-new-us-east-1/demo1/test.csv and the second step was only able to access s3://emr-steps-roles-new-us-east-1/demo2/test.csv. In addition, we observed that Amazon EMR created a unique user for the steps, and used the user to run the jobs. Please note that both roles need at least read access to the S3 location where the step scripts are located (for example, s3://emr-steps-roles-demo-bucket/scripts/test.py).
Now that we have seen how runtime roles for EMR steps work, let’s look at how we can use Lake Formation to apply fine-grained access controls with EMR steps.
Use Lake Formation-based access control with EMR steps
You can use Lake Formation to apply table- and column-level permissions with Apache Spark and Apache Hive jobs submitted as EMR steps. First, the data lake admin in Lake Formation needs to register Amazon EMR as the AuthorizedSessionTagValue to enforce Lake Formation permissions on EMR. Lake Formation uses this session tag to authorize callers and provide access to the data lake. The Amazon EMR value is referenced inside the step-runtime-roles-sec-cfg.json file we used earlier when we created the EMR security configuration, and inside the trust-policy.json file we used to create the two runtime roles test-emr-demo1 and test-emr-demo2.
We can do so on the Lake Formation console in the External data filtering section (replace 123456789012 with your AWS account ID).

On the IAM runtime roles’ trust policy, we already have the sts:TagSession permission with the condition “aws:RequestTag/LakeFormationAuthorizedCaller": "Amazon EMR". So we’re ready to proceed.
To demonstrate how Lake Formation works with EMR steps, we create one database named entities with two tables named users and products, and we assign in Lake Formation the grants summarized in the following table.
| IAM Roles \ Tables |
entities
(DB) |
users
(Table) |
products
(Table) |
| test-emr-demo1 |
Full Read Access |
No Access |
| test-emr-demo2 |
Read Access on Columns: uid, state |
Full Read Access |
Prepare Amazon S3 files
We first prepare our Amazon S3 files.
- Create the
users.csv file with the following content:
00005678,john,pike,england,london,Hidden Road 78
00009039,paolo,rossi,italy,milan,Via degli Alberi 56A
00009057,july,finn,germany,berlin,Green Road 90
- Create the products.csv file with the following content:
P0000789,Bike2000,Sport
P0000567,CoverToCover,Smartphone
P0005677,Whiteboard X786,Home
- Upload these files to Amazon S3 in two different locations:
#Change this with your bucket name
BUCKET_NAME="emr-steps-roles-new-us-east-1"
aws s3 cp users.csv s3://${BUCKET_NAME}/entities-database/users/
aws s3 cp products.csv s3://${BUCKET_NAME}/entities-database/products/
Prepare the database and tables
We can create our entities database by using the AWS Glue APIs.
- Create the
entities-db.json file with the following content (substitute emr-steps-roles-new-us-east-1 with your bucket name):
{
"DatabaseInput": {
"Name": "entities",
"LocationUri": "s3://emr-steps-roles-new-us-east-1/entities-database/",
"CreateTableDefaultPermissions": []
}
}
- With a Lake Formation admin user, run the following command to create our database:
aws glue create-database \
--cli-input-json file://entities-db.json
We also use the AWS Glue APIs to create the tables users and products.
- Create the
users-table.json file with the following content (substitute emr-steps-roles-new-us-east-1 with your bucket name):
{
"TableInput": {
"Name": "users",
"StorageDescriptor": {
"Columns": [{
"Name": "uid",
"Type": "string"
},
{
"Name": "name",
"Type": "string"
},
{
"Name": "surname",
"Type": "string"
},
{
"Name": "state",
"Type": "string"
},
{
"Name": "city",
"Type": "string"
},
{
"Name": "address",
"Type": "string"
}
],
"Location": "s3://emr-steps-roles-new-us-east-1/entities-database/users/",
"InputFormat": "org.apache.hadoop.mapred.TextInputFormat",
"OutputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"Compressed": false,
"SerdeInfo": {
"SerializationLibrary": "org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe",
"Parameters": {
"field.delim": ",",
"serialization.format": ","
}
}
},
"TableType": "EXTERNAL_TABLE",
"Parameters": {
"EXTERNAL": "TRUE"
}
}
}
- Create the
products-table.json file with the following content (substitute emr-steps-roles-new-us-east-1 with your bucket name):
{
"TableInput": {
"Name": "products",
"StorageDescriptor": {
"Columns": [{
"Name": "product_id",
"Type": "string"
},
{
"Name": "name",
"Type": "string"
},
{
"Name": "category",
"Type": "string"
}
],
"Location": "s3://emr-steps-roles-new-us-east-1/entities-database/products/",
"InputFormat": "org.apache.hadoop.mapred.TextInputFormat",
"OutputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"Compressed": false,
"SerdeInfo": {
"SerializationLibrary": "org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe",
"Parameters": {
"field.delim": ",",
"serialization.format": ","
}
}
},
"TableType": "EXTERNAL_TABLE",
"Parameters": {
"EXTERNAL": "TRUE"
}
}
}
- With a Lake Formation admin user, create our tables with the following commands:
aws glue create-table \
--database-name entities \
--cli-input-json file://users-table.json
aws glue create-table \
--database-name entities \
--cli-input-json file://products-table.json
Set up the Lake Formation data lake locations
To access our tables data in Amazon S3, Lake Formation needs read/write access to them. To achieve that, we have to register Amazon S3 locations where our data resides and specify for them which IAM role to obtain credentials from.
Let’s create our IAM role for the data access.
- Create a file called
trust-policy-data-access-role.json with the following content:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": "lakeformation.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
- Use the policy to create the IAM
role emr-demo-lf-data-access-role:
aws iam create-role \
--role-name emr-demo-lf-data-access-role \
--assume-role-policy-document file://trust-policy-data-access-role.json
- Create the file
data-access-role-policy.json with the following content (substitute emr-steps-roles-new-us-east-1 with your bucket name):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::emr-steps-roles-new-us-east-1/entities-database",
"arn:aws:s3:::emr-steps-roles-new-us-east-1/entities-database/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::emr-steps-roles-new-us-east-1"
]
}
]
}
- Create our IAM policy:
aws iam create-policy \
--policy-name data-access-role-policy \
--policy-document file://data-access-role-policy.json
- Assign to our
emr-demo-lf-data-access-role the created policy (replace 123456789012 with your AWS account ID):
aws iam attach-role-policy \
--role-name emr-demo-lf-data-access-role \
--policy-arn "arn:aws:iam::123456789012:policy/data-access-role-policy"
We can now register our data location in Lake Formation.
- On the Lake Formation console, choose Data lake locations in the navigation pane.
- Here we can register our S3 location containing data for our two tables and choose the created
emr-demo-lf-data-access-role IAM role, which has read/write access to that location.

For more details about adding an Amazon S3 location to your data lake and configuring your IAM data access roles, refer to Adding an Amazon S3 location to your data lake.
Enforce Lake Formation permissions
To be sure we’re using Lake Formation permissions, we should confirm that we don’t have any grants set up for the principal IAMAllowedPrincipals. The IAMAllowedPrincipals group includes any IAM users and roles that are allowed access to your Data Catalog resources by your IAM policies, and it’s used to maintain backward compatibility with AWS Glue.
To confirm Lake Formations permissions are enforced, navigate to the Lake Formation console and choose Data lake permissions in the navigation pane. Filter permissions by “Database”:“entities” and remove all the permissions given to the principal IAMAllowedPrincipals.
For more details on IAMAllowedPrincipals and backward compatibility with AWS Glue, refer to Changing the default security settings for your data lake.
Configure AWS Glue and Lake Formation grants for IAM runtime roles
To allow our IAM runtime roles to properly interact with Lake Formation, we should provide them the lakeformation:GetDataAccess and glue:Get* grants.
Lake Formation permissions control access to Data Catalog resources, Amazon S3 locations, and the underlying data at those locations. IAM permissions control access to the Lake Formation and AWS Glue APIs and resources. Therefore, although you might have the Lake Formation permission to access a table in the Data Catalog (SELECT), your operation fails if you don’t have the IAM permission on the glue:Get* API.
For more details about Lake Formation access control, refer to Lake Formation access control overview.
- Create the
emr-runtime-roles-lake-formation-policy.json file with the following content:
{
"Version": "2012-10-17",
"Statement": {
"Sid": "LakeFormationManagedAccess",
"Effect": "Allow",
"Action": [
"lakeformation:GetDataAccess",
"glue:Get*",
"glue:Create*",
"glue:Update*"
],
"Resource": "*"
}
}
- Create the related IAM policy:
aws iam create-policy \
--policy-name emr-runtime-roles-lake-formation-policy \
--policy-document file://emr-runtime-roles-lake-formation-policy.json
- Assign this policy to both IAM runtime roles (replace 123456789012 with your AWS account ID):
aws iam attach-role-policy \
--role-name test-emr-demo1 \
--policy-arn "arn:aws:iam::123456789012:policy/emr-runtime-roles-lake-formation-policy"
aws iam attach-role-policy \
--role-name test-emr-demo2 \
--policy-arn "arn:aws:iam::123456789012:policy/emr-runtime-roles-lake-formation-policy"
Set up Lake Formation permissions
We now set up the permission in Lake Formation for the two runtime roles.
- Create the file
users-grants-test-emr-demo1.json with the following content to grant SELECT access to all columns in the entities.users table to test-emr-demo1:
{
"Principal": {
"DataLakePrincipalIdentifier": "arn:aws:iam::123456789012:role/test-emr-demo1"
},
"Resource": {
"Table": {
"DatabaseName": "entities",
"Name": "users"
}
},
"Permissions": [
"SELECT"
]
}
- Create the file
users-grants-test-emr-demo2.json with the following content to grant SELECT access to the uid and state columns in the entities.users table to test-emr-demo2:
{
"Principal": {
"DataLakePrincipalIdentifier": "arn:aws:iam::123456789012:role/test-emr-demo2"
},
"Resource": {
"TableWithColumns": {
"DatabaseName": "entities",
"Name": "users",
"ColumnNames": ["uid", "state"]
}
},
"Permissions": [
"SELECT"
]
}
- Create the file
products-grants-test-emr-demo2.json with the following content to grant SELECT access to all columns in the entities.products table to test-emr-demo2:
{
"Principal": {
"DataLakePrincipalIdentifier": "arn:aws:iam::123456789012:role/test-emr-demo2"
},
"Resource": {
"Table": {
"DatabaseName": "entities",
"Name": "products"
}
},
"Permissions": [
"SELECT"
]
}
- Let’s set up our permissions in Lake Formation:
aws lakeformation grant-permissions \
--cli-input-json file://users-grants-test-emr-demo1.json
aws lakeformation grant-permissions \
--cli-input-json file://users-grants-test-emr-demo2.json
aws lakeformation grant-permissions \
--cli-input-json file://products-grants-test-emr-demo2.json
- Check the permissions we defined on the Lake Formation console on the Data lake permissions page by filtering by
“Database”:“entities”.

Test Lake Formation permissions with runtime roles
For our test, we use a PySpark application called test-lake-formation.py with the following content:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Pyspark - TEST IAM RBAC with LF").enableHiveSupport().getOrCreate()
try:
print("== select * from entities.users limit 3 ==\n")
spark.sql("select * from entities.users limit 3").show()
except Exception as e:
print(e)
try:
print("== select * from entities.products limit 3 ==\n")
spark.sql("select * from entities.products limit 3").show()
except Exception as e:
print(e)
spark.stop()
In the script, we’re trying to access the tables users and products. Let’s upload our Spark application in the same S3 bucket that we used earlier:
#Change this with your bucket name
BUCKET_NAME="emr-steps-roles-new-us-east-1"
aws s3 cp test-lake-formation.py s3://${BUCKET_NAME}/scripts/
We’re now ready to perform our test. We run the test-lake-formation.py script first using the test-emr-demo1 role and then using the test-emr-demo2 role as the runtime roles.
Let’s submit a step specifying test-emr-demo1 as the runtime role:
#Change with your EMR cluster ID
CLUSTER_ID=j-XXXXXXXXXXXXX
#Change with your AWS Account ID
ACCOUNT_ID=123456789012
#Change with your Bucket name
BUCKET_NAME=emr-steps-roles-new-us-east-1
aws emr add-steps \
--cluster-id $CLUSTER_ID \
--steps '[{
"Type": "CUSTOM_JAR",
"ActionOnFailure": "CONTINUE",
"Jar": "command-runner.jar",
"Name": "Spark Lake Formation Example",
"Args": [
"spark-submit",
"s3://'"${BUCKET_NAME}"'/scripts/test-lake-formation.py"
]
}]' \
--execution-role-arn arn:aws:iam::${ACCOUNT_ID}:role/test-emr-demo1
The following is the output of the EMR step with test-emr-demo1 as the runtime role:
== select * from entities.users limit 3 ==
+--------+-----+-------+-------+------+--------------------+
| uid| name|surname| state| city| address|
+--------+-----+-------+-------+------+--------------------+
|00005678| john| pike|england|london| Hidden Road 78|
|00009039|paolo| rossi| italy| milan|Via degli Alberi 56A|
|00009057| july| finn|germany|berlin| Green Road 90|
+--------+-----+-------+-------+------+--------------------+
== select * from entities.products limit 3 ==
Insufficient Lake Formation permission(s) on products (...)
As we can see, our application was only able to access the users table.
Submit the same script again as a new EMR step, but this time with the role test-emr-demo2 as the runtime role:
#Change with your EMR cluster ID
CLUSTER_ID=j-XXXXXXXXXXXXX
#Change with your AWS Account ID
ACCOUNT_ID=123456789012
#Change with your Bucket name
BUCKET_NAME=emr-steps-roles-new-us-east-1
aws emr add-steps \
--cluster-id $CLUSTER_ID \
--steps '[{
"Type": "CUSTOM_JAR",
"ActionOnFailure": "CONTINUE",
"Jar": "command-runner.jar",
"Name": "Spark Lake Formation Example",
"Args": [
"spark-submit",
"s3://'"${BUCKET_NAME}"'/scripts/test-lake-formation.py"
]
}]' \
--execution-role-arn arn:aws:iam::${ACCOUNT_ID}:role/test-emr-demo2
The following is the output of the EMR step with test-emr-demo2 as the runtime role:
== select * from entities.users limit 3 ==
+--------+-------+
| uid| state|
+--------+-------+
|00005678|england|
|00009039| italy|
|00009057|germany|
+--------+-------+
== select * from entities.products limit 3 ==
+----------+---------------+----------+
|product_id| name| category|
+----------+---------------+----------+
| P0000789| Bike2000| Sport|
| P0000567| CoverToCover|Smartphone|
| P0005677|Whiteboard X786| Home|
+----------+---------------+----------+
As we can see, our application was able to access a subset of columns for the users table and all the columns for the products table.
We can conclude that the permissions while accessing the Data Catalog are being enforced based on the runtime role used with the EMR step.
Audit using the source identity
The source identity is a mechanism to monitor and control actions taken with assumed roles. The Propagate source identity feature similarly allows you to monitor and control actions taken using runtime roles by the jobs submitted with EMR steps.
We already configured EMR_EC2_defaultRole with "sts:SetSourceIdentity" on our two runtime roles. Also, both runtime roles let EMR_EC2_DefaultRole to SetSourceIdentity in their trust policy. So we’re ready to proceed.
We now see the Propagate source identity feature in action with a simple example.
Configure the IAM role that is assumed to submit the EMR steps
We configure the IAM role job-submitter-1, which is assumed specifying the source identity and which is used to submit the EMR steps. In this example, we allow the IAM user paul to assume this role and set the source identity. Please note you can use any IAM principal here.
- Create a file called
trust-policy-2.json with the following content (replace 123456789012 with your AWS account ID):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:user/paul"
},
"Action": "sts:AssumeRole"
},
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:user/paul"
},
"Action": "sts:SetSourceIdentity"
}
]
}
- Use it as the trust policy to create the IAM role
job-submitter-1:
aws iam create-role \
--role-name job-submitter-1 \
--assume-role-policy-document file://trust-policy-2.json
We use now the same emr-runtime-roles-submitter-policy policy we defined before to allow the role to submit EMR steps using the test-emr-demo1 and test-emr-demo2 runtime roles.
- Assign this policy to the IAM role
job-submitter-1 (replace 123456789012 with your AWS account ID):
aws iam attach-role-policy \
--role-name job-submitter-1 \
--policy-arn "arn:aws:iam::123456789012:policy/emr-runtime-roles-submitter-policy"
Test the source identity with AWS CloudTrail
To show how propagation of source identity works with Amazon EMR, we generate a role session with the source identity test-ad-user.
With the IAM user paul (or with the IAM principal you configured), we first perform the impersonation (replace 123456789012 with your AWS account ID):
aws sts assume-role \
--role-arn arn:aws:iam::123456789012:role/job-submitter-1 \
--role-session-name demotest \
--source-identity test-ad-user
The following code is the output received:
{
"Credentials": {
"SecretAccessKey": "<SECRET_ACCESS_KEY>",
"SessionToken": "<SESSION_TOKEN>",
"Expiration": "<EXPIRATION_TIME>",
"AccessKeyId": "<ACCESS_KEY_ID>"
},
"AssumedRoleUser": {
"AssumedRoleId": "AROAUVT2HQ3......:demotest",
"Arn": "arn:aws:sts::123456789012:assumed-role/test-emr-role/demotest"
},
"SourceIdentity": "test-ad-user"
}
We use the temporary AWS security credentials of the role session, to submit an EMR step along with the runtime role test-emr-demo1:
export AWS_ACCESS_KEY_ID="<ACCESS_KEY_ID>"
export AWS_SECRET_ACCESS_KEY="<SECRET_ACCESS_KEY>"
export AWS_SESSION_TOKEN="<SESSION_TOKEN>"
#Change with your EMR cluster ID
CLUSTER_ID=j-XXXXXXXXXXXXX
#Change with your AWS Account ID
ACCOUNT_ID=123456789012
#Change with your Bucket name
BUCKET_NAME=emr-steps-roles-new-us-east-1
aws emr add-steps \
--cluster-id $CLUSTER_ID \
--steps '[{
"Type": "CUSTOM_JAR",
"ActionOnFailure": "CONTINUE",
"Jar": "command-runner.jar",
"Name": "Spark Lake Formation Example",
"Args": [
"spark-submit",
"s3://'"${BUCKET_NAME}"'/scripts/test-lake-formation.py"
]
}]' \
--execution-role-arn arn:aws:iam::${ACCOUNT_ID}:role/test-emr-demo1
In a few minutes, we can see events appearing in the AWS CloudTrail log file. We can see all the AWS APIs that the jobs invoked using the runtime role. In the following snippet, we can see that the step performed the sts:AssumeRole and lakeformation:GetDataAccess actions. It’s worth noting how the source identity test-ad-user has been preserved in the events.

Clean up
You can now delete the EMR cluster you created.
- On the Amazon EMR console, choose Clusters in the navigation pane.
- Select the cluster
iam-passthrough-cluster, then choose Terminate.
- Choose Terminate again to confirm.
Alternatively, you can delete the cluster by using the Amazon EMR CLI with the following command (replace the EMR cluster ID with the one returned by the previously run aws emr create-cluster command):
aws emr terminate-clusters --cluster-ids j-3KVXXXXXXX7UG
Conclusion
In this post, we discussed how you can control data access on Amazon EMR on EC2 clusters by using runtime roles with EMR steps. We discussed how the feature works, how you can use Lake Formation to apply fine-grained access controls, and how to monitor and control actions using a source identity. To learn more about this feature, refer to Configure runtime roles for Amazon EMR steps.
About the authors
 Stefano Sandona is an Analytics Specialist Solution Architect with AWS. He loves data, distributed systems and security. He helps customers around the world architecting their data platforms. He has a strong focus on Amazon EMR and all the security aspects around it.
Stefano Sandona is an Analytics Specialist Solution Architect with AWS. He loves data, distributed systems and security. He helps customers around the world architecting their data platforms. He has a strong focus on Amazon EMR and all the security aspects around it.
Sharad Kala is a senior engineer at AWS working with the EMR team. He focuses on the security aspects of the applications running on EMR. He has a keen interest in working and learning about distributed systems.


























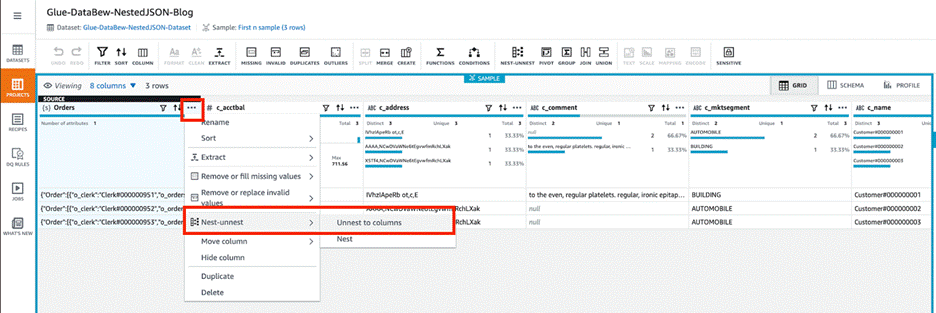
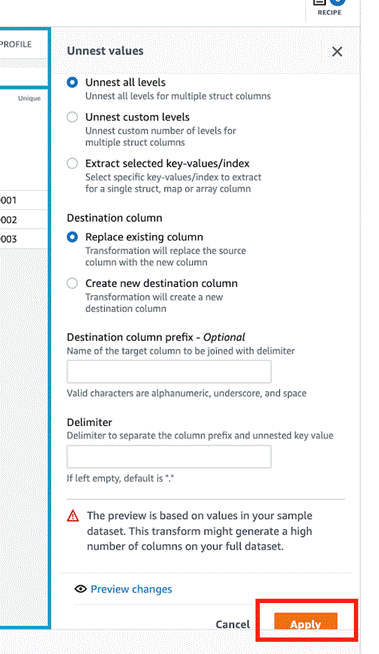
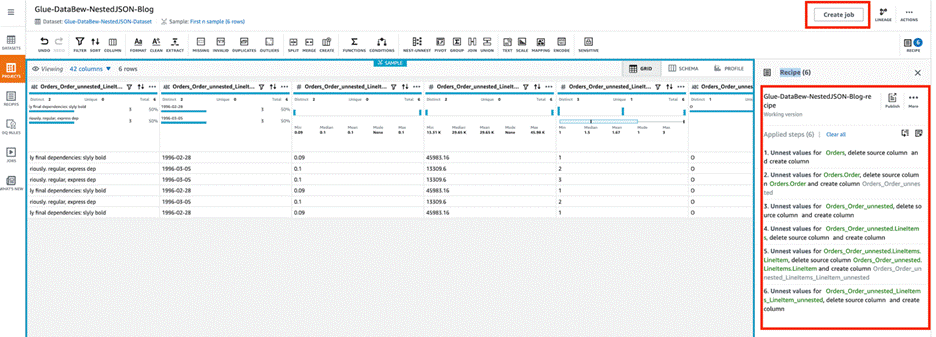
 John Espenhahn is a Software Engineer working on AWS Glue DataBrew service. He has also worked on Amazon Kendra user experience as a part of Database, Analytics & AI AWS consoles. He is passionate about technology and building in the analytics space.
John Espenhahn is a Software Engineer working on AWS Glue DataBrew service. He has also worked on Amazon Kendra user experience as a part of Database, Analytics & AI AWS consoles. He is passionate about technology and building in the analytics space. Nitya Sheth is a Software Engineer working on AWS Glue DataBrew service. He has also worked on AWS Synthetics service as well as on user experience implementations for Database, Analytics & AI AWS consoles. In his free time, he divides his time between exploring new hiking places and new books.
Nitya Sheth is a Software Engineer working on AWS Glue DataBrew service. He has also worked on AWS Synthetics service as well as on user experience implementations for Database, Analytics & AI AWS consoles. In his free time, he divides his time between exploring new hiking places and new books.
























































































































































 Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms. Ranjan Burman is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 15 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with the use of cloud solutions.
Ranjan Burman is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and helps customers build scalable analytical solutions. He has more than 15 years of experience in different database and data warehousing technologies. He is passionate about automating and solving customer problems with the use of cloud solutions.









 Martin Zoellner is an IT Specialist at BMW Group. His role in the project is Subject Matter Expert for DevOps and ETL/SW Architecture.
Martin Zoellner is an IT Specialist at BMW Group. His role in the project is Subject Matter Expert for DevOps and ETL/SW Architecture. Thomas Ehrlich is the functional maintenance manager of Regulatory Reporting application in one of the European BMW market.
Thomas Ehrlich is the functional maintenance manager of Regulatory Reporting application in one of the European BMW market. Veronika Bogusch is an IT Specialist at BMW. She initiated the rebuild of the Financial Services Batch Integration Layer via the Cloud Data Hub. The ingested data assets are the base for the Regulatory Reporting use case described in this article.
Veronika Bogusch is an IT Specialist at BMW. She initiated the rebuild of the Financial Services Batch Integration Layer via the Cloud Data Hub. The ingested data assets are the base for the Regulatory Reporting use case described in this article. George Komninos is a solutions architect for the Amazon Web Services (AWS) Data Lab. He helps customers convert their ideas to a production-ready data product. Before AWS, he spent three years at Alexa Information domain as a data engineer. Outside of work, George is a football fan and supports the greatest team in the world, Olympiacos Piraeus.
George Komninos is a solutions architect for the Amazon Web Services (AWS) Data Lab. He helps customers convert their ideas to a production-ready data product. Before AWS, he spent three years at Alexa Information domain as a data engineer. Outside of work, George is a football fan and supports the greatest team in the world, Olympiacos Piraeus. Rahul Shaurya is a Senior Big Data Architect with AWS Professional Services. He helps and works closely with customers building data platforms and analytical applications on AWS. Outside of work, Rahul loves taking long walks with his dog Barney.
Rahul Shaurya is a Senior Big Data Architect with AWS Professional Services. He helps and works closely with customers building data platforms and analytical applications on AWS. Outside of work, Rahul loves taking long walks with his dog Barney.

































 Jianwei Li is Senior Analytics Specialist TAM. He provides consultant service for AWS enterprise support customers to design and build modern data platform. He has more than 10 years experience in big data and analytics domain. In his spare time, he like running and hiking.
Jianwei Li is Senior Analytics Specialist TAM. He provides consultant service for AWS enterprise support customers to design and build modern data platform. He has more than 10 years experience in big data and analytics domain. In his spare time, he like running and hiking. Narayanan Venkateswaran is an Engineer in the AWS EMR group. He works on developing Hive in EMR. He has over 17 years of work experience in the industry across several companies including Sun Microsystems, Microsoft, Amazon and Oracle. Narayanan also holds a PhD in databases with focus on horizontal scalability in relational stores.
Narayanan Venkateswaran is an Engineer in the AWS EMR group. He works on developing Hive in EMR. He has over 17 years of work experience in the industry across several companies including Sun Microsystems, Microsoft, Amazon and Oracle. Narayanan also holds a PhD in databases with focus on horizontal scalability in relational stores. Partha Sarathi is an Analytics Specialist TAM – at AWS based in Sydney, Australia. He brings 15+ years of technology expertise and helps Enterprise customers optimize Analytics workloads. He has extensively worked on both on-premise and cloud Bigdata workloads along with various ETL platform in his previous roles. He also actively works on conducting proactive operational reviews around the Analytics services like Amazon EMR, Redshift, and OpenSearch.
Partha Sarathi is an Analytics Specialist TAM – at AWS based in Sydney, Australia. He brings 15+ years of technology expertise and helps Enterprise customers optimize Analytics workloads. He has extensively worked on both on-premise and cloud Bigdata workloads along with various ETL platform in his previous roles. He also actively works on conducting proactive operational reviews around the Analytics services like Amazon EMR, Redshift, and OpenSearch. Krish is an Enterprise Support Manager responsible for leading a team of specialists in EMEA focused on BigData & Analytics, Databases, Networking and Security. He is also an expert in helping enterprise customers modernize their data platforms and inspire them to implement operational best practices. In his spare time, he enjoys spending time with his family, travelling, and video games.
Krish is an Enterprise Support Manager responsible for leading a team of specialists in EMEA focused on BigData & Analytics, Databases, Networking and Security. He is also an expert in helping enterprise customers modernize their data platforms and inspire them to implement operational best practices. In his spare time, he enjoys spending time with his family, travelling, and video games.