Amazon SageMaker Catalog now supports custom metadata forms and rich text descriptions at the column level, extending existing curation capabilities for business names, descriptions, and glossary term classifications.
With these new features, data stewards can define and capture business-specific metadata directly in individual columns, and authors can use markdown-enabled rich text to provide detailed documentation and business context. Both form fields and formatted descriptions are indexed in real time, making them immediately discoverable through catalog search.
Column-level context is essential for understanding and trusting data. This release helps organizations improve data discoverability, collaboration, and governance by letting metadata stewards document columns using structured and formatted information that aligns with internal standards.
In this post, we show how to enhance data discovery in SageMaker Catalog with custom metadata forms and rich text documentation at the schema level.
Key capabilities
SageMaker Catalog now offers the following key capabilities:
Custom metadata forms – Data stewards can now use custom metadata forms to capture organization-specific metadata fields for columns such as Business Owner, Regulatory Classification, Units of Measure, or Approved Use Case. Each field is stored as a key-value pair and indexed for search, enabling business-level queries like “find columns where sensitivity = confidential.”
Rich text (markdown) descriptions – Each column supports a markdown-enabled description field. Authors can format text with headings, bullet lists, and hyperlinks to add deeper business or operational context—for example, logic definitions, sample values, or data lineage references.
Real-time indexing for search – Custom form values and rich text content are indexed as soon as they are saved. Users can search using a metadata value, keyword, or glossary term across columns.
Solution overview
For this post, we explore a financial services use case. Our example financial services organization defines a column metadata form that includes several fields, as illustrated in the following table.
Field
Example Value
Approved Use Case
Financial revenue modeling
Business Owner
Finance Office
Domain
RF
For a dataset column named revenue, the author adds the following markdown description:
# Business Revenue
- Use for Financial Modeling
- Use only for batch use cases
When analysts search for Domain = RF, this column appears in results with complete business context.
In the following sections, we demonstrate how to use to use metadata forms for columns and add rich text descriptions that is searchable.
Prerequisites
To test this solution, you should have an Amazon SageMaker Unified Studio domain set up with a domain owner or domain unit owner privileges. You should also have an existing project to publish assets and catalog assets. For instructions to create these assets, see the Getting started guide.
Complete the following steps to create a new metadata form:
In SageMaker Unified Studio, go to your project.
Under Project catalog in the navigation pane, choose Metadata entities.
Choose Create metadata form.
Provide an optional display name, a technical name, and an optional description, then choose Create metadata form.
Define the form fields. In this example, we add the fields Domain, Business Owner, and Approved Use Case.
For Requirement Options, select the configuration for each field. For our use case, we select Always required.
Choose Create field.
Turn on Enabled so the form is visible and can be used for assets.
Attach metadata form to column
Complete the following steps to attach the metadata form to a column:
Under Project catalog in the navigation pane, choose Assets.
Search for and select your asset (for this example, we use the asset business_finance).
On the Schema tab, choose View/Edit next to the revenue field.
Choose Add metadata form.
Choose the form you created and choose Add.
Add details for the metadata form fields
Add additional context as formatted text
Next, we enter a rich text description for each column using the markdown editor, including headings, bullet lists, links, and sample values. Complete the following steps:
Choose Edit next to README for the revenue field where you added the metadata form.
Enter details and choose Save.
Choose Preview to view the formatted README at the column level.
Publish and verify search
Now you’re ready to publish the asset. The metadata form values and markdown descriptions become part of the catalog record and are indexed for search. You can also see the history of revisions on the History tab. Other project users can see the metadata form and rich text description for the published assets and subscribe to the data asset. You can create more data products with these assets, and they will also have the column metadata form and README.
In the catalog search UI, data users can now filter on custom form fields (for example, “Domain = RF”) or search in natural language for text that matches the column description.
Best practices
Consider the following best practices when using this feature:
Define metadata forms aligned with your business vocabulary (domains, owners, sensitivity levels) proactively before publishing assets at scale.
Make column descriptions actionable—include business definitions, value ranges, logic, update cadence, and dependencies.
Verify the catalog indexing is timely; publish changes proactively so search results reflect new metadata.
Use governance controls. You can combine column-level metadata with existing asset-level templates and approval workflows to enforce publishing standards.
Monitor search usage and metadata completeness; target high-value datasets for complete column-level documentation first.
Do not store confidential or sensitive information in your metadata forms.
Conclusion
With column-level metadata forms and rich text descriptions, SageMaker Catalog helps organizations deliver higher-quality metadata, stronger governance, and better data discovery. These features make it straightforward for teams to capture complete business context and for analysts to quickly locate and understand the data they need.
Custom metadata forms and rich text descriptions at the column level are now available in AWS Regions where SageMaker is supported.
Today, AWS announced a new tenant isolation mode for AWS Lambda, that allows you to process function invocations in separate execution environments for each application end-user or tenant invoking your Lambda function. This capability simplifies building secure multi-tenant SaaS applications by managing tenant-level compute environment isolation and request routing for you. As a result, you can focus on your core business logic rather than implementing your own tenant-aware compute environment isolation.
Overview
Lambda runs your function code in secure execution environments that leverage Firecracker virtualization to provide isolation. These execution environments never share or reuse virtual resources (such as vCPU, disk, or memory) across functions, or even across different versions of the same function. However, Lambda can reuse execution environments for multiple invocations of the same function version, as these execution environments are fully set-up and can therefore deliver faster request processing for your functions.
Figure 1. Incoming invocations processed by a collection of execution environments that belong to a single function.
Multi-tenant SaaS applications that handle sensitive tenant-specific data or execute code supplied dynamically by tenants may need a higher degree of isolation—at the individual application tenant level rather than at the function level—for secure code execution and to reduce the risk of cross-tenant data access.
Prior to today’s launch, developers would implement custom solutions, such as SDKs or application logic to manage isolation within function code. This approach was bug-prone, required more work from application development teams, and didn’t ensure isolation at the compute environment level.
Alternatively, developers adopted the approach of creating separate functions per application tenant, replicating the same code across hundreds or thousands of tenants. This approach provided stronger compute environment isolation than sharing compute environments across multiple tenants of the same function, but increased implementation overhead and operational complexity as workloads grew to support a larger number of tenants over time.
Figure 2. Using function-per-tenant model, each tenant’s requests are processed by a separate function.
Starting today, AWS Lambda offers a new tenant isolation mode that lets you isolate execution environments used across different tenants of your multi-tenant SaaS applications, even when all of the tenants invoke the same function. When you enable the new tenant isolation mode, you include a tenant identifier with each function invocation. Lambda uses this identifier to route the request to the correct execution environment. As a result, each execution environment is reused only for invocations from the same tenant. This means you still get the performance benefits of warm execution environments, while ensuring that each tenant’s workloads remain isolated.
Figure 3. With the new tenant isolation capability, Lambda creates separate execution environments per tenant for a single function.
For organizations handling sensitive tenant-specific data or running untrusted code supplied dynamically by end-users, Lambda’s new tenant isolation mode provides the security benefits of per-tenant compute environment separation without the operational complexity of managing individual functions or infrastructure for each tenant.
Example scenario
Consider building a multi-tenant serverless SaaS application. To optimize performance, your function handler can retrieve tenant-specific configuration and data, cache it in memory, and reuse it for subsequent invocations from the same tenant. For example, you might cache tenant-specific database location, feature flags, or business rules that are frequently accessed during request processing. You may store this information within the application runtime process as global variables or as files in the /tmp directory. However, if the underlying execution environment is used to serve multiple tenants, this approach can potentially expose data across tenants.
With tenant isolation mode you can address this risk with much simpler architecture and configuration. This built-in capability makes Lambda an excellent choice for multi-tenant SaaS applications needing isolated compute environments for individual tenants.
Getting Started with Lambda Tenant Isolation Mode
Use the new tenancy-config parameter to configure tenant isolation mode when you create your function. You can only apply this configuration at function creation time; it cannot be updated for existing functions. The following snippet creates a function with tenancy config using the AWS CLI.
After the function is created, you must provide the tenant ID parameter with each invocation. Lambda uses this identifier to ensure that the execution environment used for a particular tenant is never reused for other tenants. For subsequent invocations from the same tenant, Lambda may reuse the execution environment to optimize performance. Specify this tenant-id parameter as illustrated below:
The new tenant-id parameter is required for functions using the tenant isolation mode. Function invocations omitting this parameter will fail with an invocation error, as shown below:
aws lambda invoke --function-name multitenant-function out.json
An error occurred (InvalidParameterValueException) when calling the Invoke operation:
The invoked function is enabled with tenancy configuration.
Add a valid tenant ID in your request and try again.
Lambda makes the tenant ID parameter available through your function handler’s context object. This allows you to access tenant-specific information in your code, for example if you wish to implement custom logic based on the tenant identity, as shown below:
exports.handler = async function (event, context) {
const tenantId = context.tenantId;
// Process tenant-specific logic
return {
statusCode: 200,
body: `OK for tenantId=${tenantId}`
};
};
The following table outlines differences between Lambda functions with and without tenant isolation mode enabled:
Feature
Without the new tenant isolation mode
With the new tenant isolation mode
Execution environment isolation
Isolated per function version.
Isolated per end-user or tenant invoking a function version.
Execution environment reuse
Can be reused to process all invocations of a function version.
Can only be reused to process invocations from the same tenant invoking a function version.
Data stored on local disk and in-memory
Potentially accessible across all invocations of a function version.
Potentially accessible across invocations from the same tenant. Not accessible for invocations from other tenants.
Cold starts
Occur when there are no warm execution environments available to process incoming invocation.
Occur when there are no tenant-specific warm execution environments available to process incoming invocation. More cold starts expected due to tenant-specific execution environments.
Integrating with Amazon API Gateway
Amazon API Gateway uses Lambda’s Invoke API to invoke Lambda functions. When using the Invoke API, Lambda expects the tenant ID parameter to be passed using the X-Amz-Tenant-Id HTTP header. You can configure API Gateway to inject this HTTP header into the Lambda invocation request with a value obtained from client request properties such as HTTP header, query parameter, or path parameter. When using Lambda Authorizers, you can obtain the value from authorization context information returned by the authorizer, such as principal ID or JWT claim. See API Gateway documentation to learn how you can return authorization information from Lambda authorizers to be used for the X-Amz-Tenant-Id header value.
Figure 4. Obtaining X-Amz-Tenant-Id header value from authentication sources.
The following screenshot illustrates API Gateway Lambda integration configuration, where the incoming request to API Gateway includes an x-tenant-id header that is mapped to the X-Amz-Tenant-Id request header to invoke a Lambda function using tenant isolation mode.
Figure 5. Mapping client request header to Lambda tenant-id header.
The following code snippet illustrates this configuration implemented with the AWS CDK.
const lambdaIntegration = new ApiGw.LambdaIntegration(fn, {
requestParameters: {
// This configures API Gateway to inject X-Amz-Tenant-Id header
// into downstream requests. The header value is obtained from
// x-tenant-id header in the client request.
'integration.request.header.X-Amz-Tenant-Id': 'method.request.header.x-tenant-id'
}
});
resource.addMethod('GET', lambdaIntegration, {
requestParameters: {
// This enables API Gateway to use the x-tenant-id header value
// obtained from the client request. The header name is arbitrary.
// you can use any other header name.
'method.request.header.x-tenant-id': true
}
});
Tenant-aware observability
For functions using tenant isolation, Lambda automatically includes the tenant ID in function logs when you have JSON logging enabled, making it easier to monitor and debug tenant-specific issues. Note that the tenantId property is available during function invocation, rather than during function initialization. The tenantId property is included for both platform events (like platform.start and platform.report) and custom logs you print in your function code, as shown in the following screenshot:
Figure 6. Lambda function logs with tenantId.
Lambda creates a separate CloudWatch log stream for each execution environment. You can use CloudWatch Log Insights to find log streams that belong to a particular tenant by filtering by tenant Id:
fields @logStream, @message
| filter tenantId=='BlueTenant' or record.tenantId=='BlueTenant'
| stats count() as logCount by @logStream
| sort @timestamp desc
You can also retrieve tenant-specific logs across all log streams:
fields @message
| filter tenantId=='BlueTenant' or record.tenantId=='BlueTenant'
| limit 1000
Each log stream starts with function initialization logs followed by the invocation logs. This structure helps you to debug tenant-specific issues and understand the lifecycle of each tenant’s execution environments.
Considerations
When using the new tenant isolation for Lambda functions, consider the following:
Each tenant’s execution environments are isolated from other tenants so that tenant-specific data stored on disk or in memory remain separated from other tenants invoking the same Lambda function.
All tenants share the function’s execution role. For more fine-grained permissions for individual tenants, consider propagating tenant-scoped credentials from the upstream application components invoking your Lambda function.
Your application may experience higher percentage of cold starts, as Lambda processes requests in separate execution environments for each tenant invoking your functions.
You pay a fee for each new tenant-specific execution environment created, depending on the memory configured for your function. See Lambda pricing page for details.
Best practices
When using the new tenant isolation mode for Lambda functions, AWS recommends the following best practices:
Implement robust tenant ID validation at the application layer to prevent unauthorized access through tenant ID manipulation. Consider using a dedicated service or database to maintain valid tenant IDs.
Monitor and audit tenant access patterns regularly to detect potential security anomalies or unauthorized cross-tenant access attempts.
Be aware of Lambda concurrency quotas when building multi-tenant applications. You might need to request quota increases based on your tenant count and usage patterns.
Sample code
Follow the instructions in this GitHub repository to provision a sample project in your own account and see the new Lambda tenant isolation mode in action. The sample project illustrates how to integrate a function using the new tenant isolation mode with Amazon API Gateway and propagate tenant identity from client requests.
Conclusion
The new tenant isolation mode for Lambda simplifies building serverless multi-tenant SaaS applications on AWS. By automatically managing application tenant-level compute environment isolation, this capability eliminates the need for custom isolation logic or separate tenant functions, allowing you to focus on the core business logic while AWS handles the complexities of tenant-aware compute environment isolation.
Combined with the existing security features in Lambda, rapid scaling, and pay-per-use pricing, tenant isolation mode makes Lambda an even more compelling choice for modern SaaS applications, whether you’re building new solutions or enhancing existing ones.
Amazon API Gateway now provides a fully managed portal feature, Amazon API Gateway Portal, that eliminates the need for static websites, open source solutions, or third-party offerings, which often led to fragmented API lifecycle management and increased costs. API Gateway Portal integrates with the API Gateway service and offers features like API products, interactive “Try it” functionality, and documentation for your API portfolio.
This fully managed solution addresses the need for a seamless way to showcase APIs and help developers quickly find, try, and integrate with them. By providing a managed solution that handles infrastructure, security, and scalability, API providers can focus on creating valuable APIs and delivering a great developer experience.
In this post, we will show how you can use the new portal feature to create customizable portals with enhanced security features in minutes, with APIs from multiple accounts, without managing any infrastructure.
Overview
A developer portal is a web page where API providers can share their APIs and API documentation by grouping them into portal products. Each portal product is a logical grouping of REST APIs and contains the documentation that you create and publish for your API consumers. Product pages within a portal contain the custom documentation at the portal product level. Product REST endpoint pages contain the documentation for each of the REST APIs with the details of the path and method of a REST API and the stage it’s deployed to. The combination of Product pages and Product REST endpoint pages provide the complete documentation for our API consumers on how to start using your REST APIs.
This abstraction allows you to organize endpoints from multiple APIs and stages into coherent product offerings for your consumers. For example, if you operate multiple APIs supporting a pet adoption service, you can create an “AdoptAnimals” portal product that groups dog-related endpoints from one API with cat-related endpoints from another API, while organizing user management functions into a separate “AdoptProcess” portal product.
With this flexibility you can present your APIs in a way that matches your business logic rather than your technical architecture and organize your APIs in ways that make the most sense for your consumers. For large enterprises managing extensive API portfolios, API Gateway Portal offers centralized catalogs of APIs across business groups, reducing duplicate work and improving standardization.
The portal feature automatically creates developer portals that display APIs with documentation, interactive testing capabilities, and integrated consumer analytics. The platform uses AWS Resource Access Manager (RAM) for multi-account API sharing, Amazon Cognito for access control, and Amazon CloudWatch for centralized monitoring.
Key features of API Gateway Portal
The API Gateway Portal provides comprehensive functionality for both API providers and consumers.
The following is a list of the key features that were introduced by the service at launch:
Customizable portal experience: You control your portal’s branding through custom logos and color schemes. You can configure custom domain names with SSL certificates managed by AWS Certificate Manager, or use the default domain structure provided by AWS.
Flexible access control: Access to developer portals can be controlled using Amazon Cognito, you can configure portals to be either publicly accessible or require authentication. Integration with Cognito user pools provides secure and scalable identity and access management that is enterprise-grade, cost-effective, and customizable. For organizations using existing identity systems, Cognito supports federation with SAML and OpenID Connect identity providers.
Cross-account API organization: The portal supports sharing portal products across AWS accounts using AWS RAM, so that organizations can create a unified API catalog while maintaining flexibility for API providers to develop and maintain APIs in their own accounts. When you share a portal product with another account, that account cannot modify any properties of your portal product or product endpoint pages, so API providers maintain control over their APIs while still enabling discovery across the organization. The cross-account sharing capabilities provide significant governance benefits for enterprise customers, including centralized discovery, standardization, reduced duplication, clear ownership, and controlled access.
Documentation: Beyond API reference documentation synchronized from your API definitions, you can add supplemental documentation including guides, use cases, and integration examples.
Search, discovery, and interactive API exploration: Consumers can search across your entire catalog. The portal provides intuitive customizable navigation and organization to help users find the right endpoints for their needs. Using the “Try It” functionality consumers can try APIs directly from the portal. Users can input request parameters, headers, and see live responses, reducing time-to-value for API integrations. This environment includes built-in limits for security and cost control.
Access control and governance
Amazon API Gateway Portal provides security and governance capabilities essential for production deployments.
Identity and access management: Integration with Cognito user pools provides secure and scalable identity and access management that is enterprise-grade, cost-effective, and customizable, including multi-factor authentication, password policies, and user lifecycle management.
API authorization: The portal respects existing authorization mechanisms configured on your APIs, including AWS IAM, Lambda authorizers, and Cognito user pools. Portal access doesn’t bypass your established security controls.
Cross-account governance: When sharing portal products across accounts using AWS RAM, the original API owners retain full control over their endpoints, including authorization strategies, integration configurations, and stage settings. Portal owners can use shared portal products but cannot modify the underlying API configurations.
Audit and monitoring: All portal management activities integrate with AWS CloudTrail for comprehensive audit logging. You can use Amazon CloudWatch RUM to perform real user monitoring to collect and view analytics about API consumers in near real time.
Resource limits: The service includes built-in quotas to prevent abuse, including limits on API testing rate limits, payload sizes, and integration timeouts. With these limits the “Try It” functionality cannot impact your production API performance.
Getting Started
Setting up a portal involves three main steps: creating portal products, configuring the portal, and publishing for consumer access. We will walk through those steps in more detail.
Create portal product
The following procedure shows you how to create a portal product:
Navigate to the API Gateway console and select Portal products from the main navigation.
Choose Create portal product and specify your portal product details including name, description, and visibility settings.
Next, select the endpoints you want to include in this portal product. You can choose entire API stages or specific resources and methods, and even rename endpoints with user-friendly names for better discoverability.
The system automatically imports your API documentation. You can improve the documentation with additional context, use cases, and examples later.
Organize product endpoints into custom categories that reflect your business logic rather than technical implementation details.
Configure the developer portal
The following procedure shows how to create a portal.
Select Developer portals in the API Gateway console navigation.
Specify your portal name, description, and domain configuration.
Choose between adding your prefix to the default AWS domain or configuring a custom domain name with your own SSL certificate.
Configure access control by selecting authentication requirements. For internal portals, you might require Amazon Cognito authentication, while public portals can allow anonymous access to documentation.
Upload your logo and select color themes to match your brand identity.
Add your portal products. You can include products from your account or products shared with you from other accounts through AWS RAM. The portal provides search and filtering capabilities for consumers.
Preview and publish
Before making your portal publicly available, use the preview functionality to review the consumer experience. The preview shows exactly how your portal will appear to users, including navigation, documentation, and available API testing capabilities.
When you’re satisfied with the configuration, choose Publish portal to make it accessible to consumers. The publishing process typically completes within a few minutes, and API Gateway provides the final portal URL for distribution to your consumers.
Conclusion and next steps
The new API Gateway Portal eliminates the complexity of building and maintaining custom API documentation sites. Your developers get a professional, feature-rich experience where they can discover and try your APIs immediately. Plus, since everything stays within AWS, you get built-in security, simplified operations, and comprehensive observability through integration with services like CloudWatch and CloudTrail.
Ready to streamline your API discovery experience? Here’s how to get started:
Today, AWS announced support for response streaming in Amazon API Gateway to significantly improve the responsiveness of your REST APIs by progressively streaming response payloads back to the client. With this new capability, you can use streamed responses to enhance user experience when building LLM-driven applications (such as AI agents and chatbots), improve time-to-first-byte (TTFB) performance for web and mobile applications, stream large files, and perform long-running operations while reporting incremental progress using protocols such as server-sent events (SSE).
In this post you will learn about this new capability, the challenges it addresses, and how to use response streaming to improve the responsiveness of your applications.
Overview
Consider this scenario – you’re running an AI-powered agentic application that uses an Amazon Bedrockfoundation model. Your users interact with the application through an API, asking complex questions that require detailed responses. Before response streaming, users would send their prompts and wait to eventually receive the application response, sometimes for tens of seconds. This awkward pause between questions and responses created a disconnected, unnatural experience.
With the new API Gateway response streaming capability, the interaction through the API becomes much more fluid and natural. As soon as your application starts processing the model response, you can stream it back to your users using the API Gateway.
The following animation illustrates this significant user experience improvement. The prompt on the left is processed using a non-streaming response with user having to wait for several seconds to receive the result. The prompt on the right is using the new API Gateway response streaming, significantly reducing TTFB and improving user experience.
Figure 1. Comparing user experience before (left) and after (right) enabling API Gateway response streaming when returning a response from a Bedrock foundational model.
Your users can now see AI responses appear in real-time, word by word, just like watching someone type. This immediate feedback makes your applications feel more responsive and engaging, keeping users connected throughout the interaction. In addition, you don’t have to worry about response size limits or implement complex workarounds – the streaming happens automatically and efficiently, letting you focus on building great user experiences rather than managing infrastructure constraints.
Understanding response steaming
In the traditional request-response model, responses must be fully computed before being sent to the client. This can negatively impact user experience – the client must wait for the complete response to be generated on the server-side and transmitted over-the-wire. This is especially pronounced in interactive, latency-sensitive cloud applications such as AI agents, chatbots, virtual assistants, or music generators.
Figure 2. Response is returned to the client only after it’s been fully generated, increasing time-to-first-byte latency.
Another important scenario is returning larger response payloads, such as images, large documents, or datasets. In some cases, these payloads may exceed the 10 MB response size limit or default integration timeout limit of 29 seconds of API Gateway. Before the launch of response streaming, developers worked around these limitations by using pre-signedAmazon S3 URLs to download large responses or accepting lower RPS for an increase in timeout. While functional, these workarounds introduced additional latency and architectural complexity.
With response streaming support you can address these challenges. You can now update your REST APIs to return streamed responses, significantly enhancing user experience, improving TTFB performance, supporting response payload sizes to exceed 10 MB, and serving requests that can take up to 15 minutes.
Figure 3. Response streaming reduces time-to-first-byte and improves user experience.
The response streaming capability is already delivering significant performance for organizations:
“Working closely with the AWS teams to enable response streaming was instrumental in advancing our roadmap to deliver the most performant storefront experiences for our largest customers at Salesforce Commerce Cloud. Our collaboration exceeded our Core Web Vital goals; we saw our Total Blocking Time metrics drop by over 98%, which will enable our customers to drive higher revenue and conversion rates.”, says Drew Lau, Senior Director of Product Management at Salesforce.
Response streaming is supported for any HTTP-proxy integration, AWS Lambda functions (using proxy integration mode), and private integrations. To get started, configure your API integration to stream the response from your backend, as described in the following sections, and redeploy your API for changes to take effect.
Getting started with response streaming
To enable response streaming for your REST APIs, update your integration configuration to set the response transfer mode to STREAM. This enables API Gateway to start streaming the response to the client as soon as response bytes become available. When using response streaming, you can configure request timeout up to 15 minutes. For best time to first byte user experience, AWS strongly recommends your backend integration also implements response streaming.
You can enable response streaming in several different ways, as illustrated in the following snippets:
Using the API Gateway console, when creating method integrations, select Stream for the Response transfer mode.
Figure 4. Enabling response streaming in API Gateway Console.
Setting response transfer mode using the Open API spec:
Setting response transfer mode using infrastructure-as-code (IaC) frameworks, such as AWS CloudFormation. Note the /response-streaming-invocations Uri fragment, it tells API Gateway to use the Lambda InvokeWithResponseStreaming endpoint:
When using Lambda functions as a downstream integration endpoint, your Lambda functions must be streaming-enabled. The API Gateway uses the InvokeWithResponseStreaming API to invoke functions, as illustrated in the following diagram, and requires Lambda proxy integration. See the API Gateway documentation for additional guidance.
Figure 5. Using API Gateway response streaming with Lambda functions for interactive AI applications.
When you use response streaming with Lambda functions, API Gateway expects the handler response stream to contain the following components (in order):
JSON response metadata – Must be a valid JSON object and can only contain statusCode, headers, multiValueHeaders, and cookies fields (all optional). Metadata cannot be an empty string; at a minimum it must be an empty JSON object.
The 8-null-byte delimiter – Lambda adds this delimiter automatically when you use the built-in awslambda.HttpResponseStream.from() method, as illustrated below. When not using this method, you’re responsible for adding the delimiter yourself.
Response payload – Can be empty.
The following code snippet illustrates how you can return a streamed response from your Lambda functions so it will be compatible with API Gateway response streaming:
Using response streaming with HTTP Proxy integrations
You can stream HTTP responses from your applications used as downstream integration endpoints, for example web servers running on Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS). In this case, you must use HTTP_PROXY integration and specify the response transfer mode as STREAM (using the console, AWS CLI, or IaC). Redeploy your API after modifying it.
Figure 6. Using API Gateway response streaming with HTTP server applications.
Once API Gateway receives a streaming response from your application, it will wait until the HTTP headers block transfer is complete. Then, it will send to the client an HTTP response status code and headers, followed by the content from your application as it gets received by the API Gateway service. It will continue streaming response from your application to the client until the stream ends (up to 15 minutes).
Many popular API and web application development frameworks provide response streaming abstractions. The following code snippet illustrates how you can implement HTTP response streaming using FastAPI:
Adding real-time response streaming to your HTTP clients
Different HTTP clients have different ways to process streamed response fragments as they arrive. The following code snippet illustrates how to process a streamed response with a Node.js application:
When using CURL, you can use the –no-buffer argument to print response fragments as they arrive.
curl --no-buffer {URL}
Sample code
Clone this sample project from GitHub to see API Gateway response streaming in action. Follow instructions in the README.md to provision the sample project in your AWS account.
Considerations
Before you enable response streaming, consider:
Response streaming is available for REST APIs and can be used with HTTP_PROXY integrations, Lambda integrations (in proxy mode), and private integrations.
You can use API Gateway response streaming with any endpoint type, such as Regional, Private, and Edge-optimized, with or without custom domain names.
When using response streaming, you can configure response timeouts up to 15 minutes, according to your scenario requirements.
All streaming responses from Regional or Private endpoints are subject to a 5-minute idle timeout. All streaming responses from edge-optimized endpoints are subject to a 30-second idle timeout.
Within each streaming response, the first 10MB of response payload is not subject to any bandwidth restrictions. Response payload data exceeding 10MB is restricted to 2MB/s.
When processing streamed responses, the following features are not supported: response transformation with VTL, integration response caching, and content encoding.
In addition to the existing access logs variables, the following new variables are available:
$content.integration.responseTransferMode – the response transfer mode of your integration. This can be either BUFFERED or STREAMED.
$context.integration.timeToAllHeaders – the time between when API Gateway establishes the integration connection to when it receives all integration response headers from the client.
$context.integration.timeToFirstContent – the time between when API Gateway establishes the integration connection to when it receives the first content bytes.
With this new capability, you continue to pay the same API Invoke rates for streamed responses. Each 10MB of response data, rounded up to the nearest 10MB, is billed as a single request. See API Gateway pricing page for additional details.
Conclusion
The new response streaming capability for Amazon API Gateway enhances how you can build and deliver responsive APIs in the cloud. With immediate streaming of response data as it becomes available, you can significantly improve time-to-first-byte performance and overcome traditional payload size and timeout limitations. This is particularly valuable for AI-powered applications, file transfers, and interactive web experiences that demand real-time responsiveness.
Amazon Web Services has been designated as a critical third-party provider (CTPP) by the European Supervisory Authorities (ESAs) under the European Union’s Digital Operational Resilience Act (DORA).
This designation is a key milestone in the EU’s implementation of DORA, which took effect in January 2025 and aims to strengthen the operational resilience of the EU financial sector. Under this regulation, certain third-party information and communications technology (ICT) service providers identified as playing a critical role for financial entities in the EU are subject to direct joint oversight by the European Banking Authority (EBA), the European Securities and Markets Authority (ESMA), and the European Insurance and Occupational Pensions Authority (EIOPA).
AWS recognizes the significance of this oversight for our financial services customers as they advance their digital transformation and modernization efforts, which remain essential to their long-term resilience and competitiveness.
What the CTPP designation means for customers
Financial institutions that use AWS services should note that AWS is engaged in an active oversight relationship with the ESAs.
AWS will maintain its commitment to operational resilience as part of the oversight activities associated with the designation.
Customers can use AWS security, resilience, and compliance features while maintaining control over their own cloud environments and compliance journeys.
Proven readiness for DORA oversight
AWS has been engaging with EU institutions, national competent authorities, and the broader financial regulatory community for years, helping to build a more resilient and secure financial system.
Our readiness for this oversight process builds on our demonstrated experience in meeting rigorous operational and regulatory standards. AWS has made, and will continue to make, investments in compliance, risk management, operational resilience, and transparency, which are critical pillars of DORA.
Being designated as a CTPP means AWS will now participate in a formal oversight process. We expect that this process will promote a deeper understanding of how AWS and other cloud technologies help enhance the resilience of the financial services industry.
Supporting customers through DORA implementation
Although AWS is now subject to direct oversight under DORA, we remain equally focused on supporting our financial services customers that are subject to the regulation.
Operational resilience is both a compliance requirement for DORA and a business necessity. Our services are designed to help financial institutions achieve high availability, durability, and scalability, while maintaining robust controls and visibility into their operations.
Our dedicated team of security and compliance specialists is ready to assist financial organizations in understanding how AWS security and compliance features can help them fulfill their obligations under DORA and how AWS services help to support their compliance strategies. We offer detailed documentation, whitepapers, and compliance guides tailored to DORA’s key requirements, such as the AWS User Guide to DORA and Amazon Web Services’ Approach to Operational Resilience in the Financial Sector & Beyond. To learn more about our security and compliance resources, visit the AWS Trust Center. Customers can also download our third-party attestations and certifications through AWS Artifact.
If you have feedback about this post, submit comments in the Comments section below.
Multi-tenant applications often require strict isolation when processing tenant-specific code or data. Examples include software-as-a-service (SaaS) platforms for workflow automation or code execution where customers need to ensure that execution environments used for individual tenants or end users remain completely separate from one another. Traditionally, developers have addressed these requirements by deploying separate Lambda functions for each tenant or implementing custom isolation logic within shared functions which increased architectural and operational complexity.
Today, AWS Lambda introduces a new tenant isolation mode that extends the existing isolation capabilities in Lambda. Lambda already provides isolation at the function level, and this new mode extends isolation to the individual tenant or end-user level within a single function. This built-in capability processes function invocations in separate execution environments for each tenant, enabling you to meet strict isolation requirements without additional implementation effort to manage tenant-specific resources within function code.
Here’s how you can enable tenant isolation mode in the AWS Lambda console:
When using the new tenant isolation capability, Lambda associates function execution environments with customer-specified tenant identifiers. This means that execution environments for a particular tenant aren’t used to serve invocation requests from other tenants invoking the same Lambda function.
The feature addresses strict security requirements for SaaS providers processing sensitive data or running untrusted tenant code. You maintain the pay-per-use and performance characteristics of AWS Lambda while gaining execution environment isolation. Additionally, this approach delivers the security benefits of per-tenant infrastructure without the operational overhead of managing dedicated Lambda functions for individual tenants, which can quickly grow as customers adopt your application.
Getting started with AWS Lambda tenant isolation Let me walk you through how to configure and use tenant isolation for a multi-tenant application.
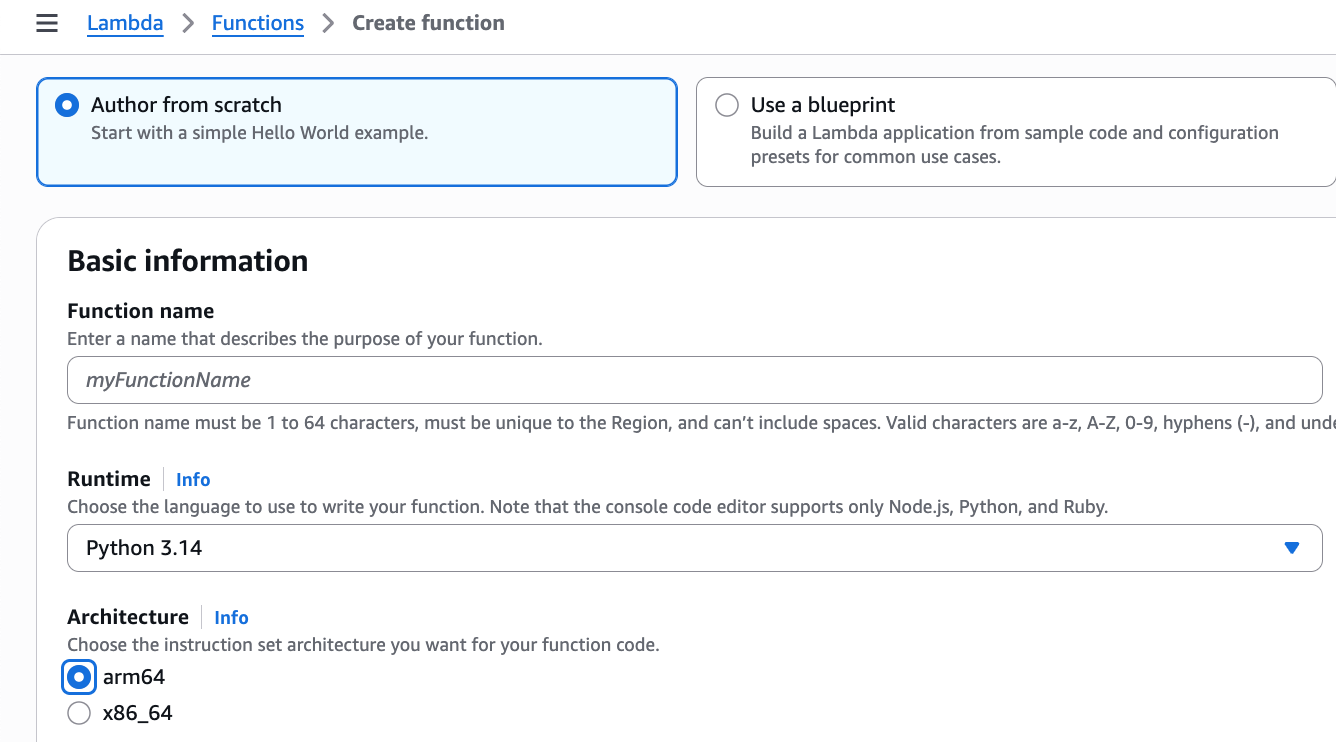
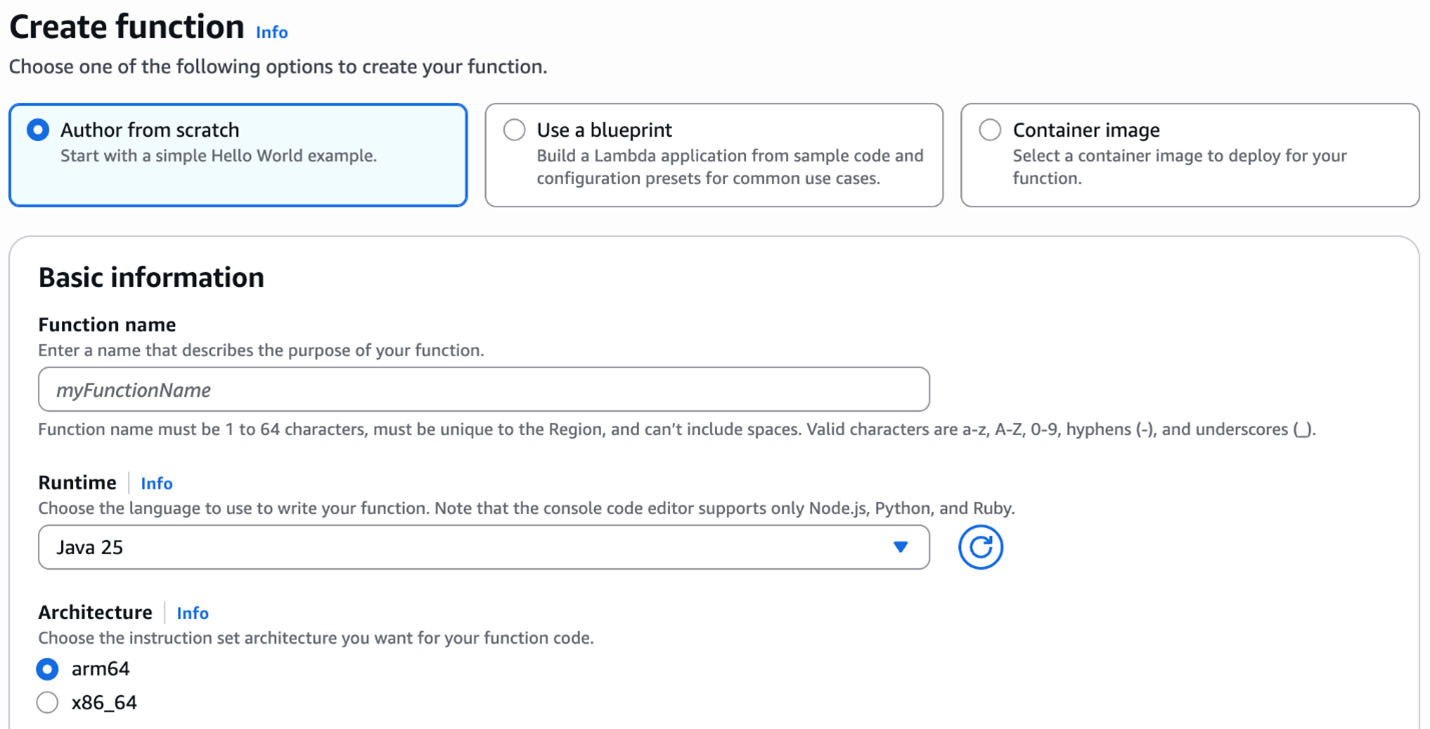
First, on the Create function page in the AWS Lambda console, I choose Author from scratch option.
Then, under Additional configurations, I select Enable under Tenant isolation mode. Note that, tenant isolation mode can only be set during function creation and can’t be modified for existing Lambda functions.
Next, I write Python code to demonstrate this capability. I can access the tenant identifier in my function code through the context object. Here’s the full Python code:
import json
import os
from datetime import datetime
def lambda_handler(event, context):
tenant_id = context.tenant_id
file_path = '/tmp/tenant_data.json'
# Read existing data or initialize
if os.path.exists(file_path):
with open(file_path, 'r') as f:
data = json.load(f)
else:
data = {
'tenant_id': tenant_id,
'request_count': 0,
'first_request': datetime.utcnow().isoformat(),
'requests': []
}
# Increment counter and add request info
data['request_count'] += 1
data['requests'].append({
'request_number': data['request_count'],
'timestamp': datetime.utcnow().isoformat()
})
# Write updated data back to file
with open(file_path, 'w') as f:
json.dump(data, f, indent=2)
# Return file contents to show isolation
return {
'statusCode': 200,
'body': json.dumps({
'message': f'File contents for {tenant_id} (isolated per tenant)',
'file_data': data
})
}
When I’m finished, I choose Deploy. Now, I need to test this capability by choosing Test. I can see on the Create new test event panel that there’s a new setting called Tenant ID.
If I try to invoke this function without a tenant ID, I’ll get the following error “Add a valid tenant ID in your request and try again.”
Let me try to test this function with a tenant ID called tenant-A.
I can see the function ran successfully and returned request_count: 1. I’ll invoke this function again to get request_count: 2.
Now, let me try to test this function with a tenant ID called tenant-B.
The last invocation returned request_count: 1 because I never invoked this function with tenant-B. Each tenant’s invocations will use separate execution environments, isolating the cached data, global variables, and any files stored in /tmp.
This capability transforms how I approach multi-tenant serverless architecture. Instead of wrestling with complex isolation patterns or managing hundreds of tenant-specific Lambda functions, I let AWS Lambda automatically handle the isolation. This keeps tenant data isolated across tenants, giving me confidence in the security and separation of my multi-tenant application.
Additional things to know Here’s a list of additional things you need to know:
Performance — Same-tenant invocations can still benefit from warm execution environment reuse for optimal performance.
Pricing — You’re charged when Lambda creates a new tenant-aware execution environment, with the price depending on the amount of memory you allocate to your function and the CPU architecture you use. For more details, view AWS Lambda pricing.
Availability — Available now in all commercial AWS Regions except Asia Pacific (New Zealand), AWS GovCloud (US), and China Regions.
This launch simplifies building multi-tenant applications on AWS Lambda, such as SaaS platforms for workflow automation or code execution. Learn more about how to configure tenant isolation for your next multi-tenant Lambda function in the AWS Lambda Developer Guide.
Organizations are increasingly expanding their Kubernetes footprint by deploying microservices to incrementally innovate and deliver business value faster. This growth places increased reliance on the network, giving platform teams exponentially complex challenges in monitoring network performance and traffic patterns in EKS. As a result, organizations struggle to maintain operational efficiency as their container environments scale, often delaying application delivery and increasing operational costs.
Today, I’m excited to announce Container Network Observability in Amazon Elastic Kubernetes Service (Amazon EKS), a comprehensive set of network observability features in Amazon EKS that you can use to better measure your network performance in your system and dynamically visualize the landscape and behavior of network traffic in EKS.
Here’s a quick look at Container Network Observability in Amazon EKS:
Container Network Observability in EKS addresses observability challenges by providing enhanced visibility of workload traffic. It offers performance insights into network flows within the cluster and those with cluster-external destinations. This makes your EKS cluster network environment more observable while providing built-in capabilities for more precise troubleshooting and investigative efforts.
Getting started with Container Network Observability in EKS
I can enable this new feature for a new or existing EKS cluster. For a new EKS cluster, during the Configure observability setup, I navigate to the Configure network observability section. Here, I select Edit container network observability. I can see there are three included features: Service map, Flow table, and Performance metric endpoint, which are enabled by Amazon CloudWatch Network Flow Monitor.
On the next page, I need to install the AWS Network Flow Monitor Agent.
After it’s enabled, I can navigate to my EKS cluster and select Monitor cluster.
This will bring me to my cluster observability dashboard. Then, I select the Network tab.
Comprehensive observability features Container Network Observability in EKS provides several key features, including performance metrics, service map, and flow table with three views: AWS service view, cluster view, and external view.
With Performance metrics, you can now scrape network-related system metrics for pods and worker nodes directly from the Network Flow Monitor agent and send them to your preferred monitoring destination. Available metrics include ingress/egress flow counts, packet counts, bytes transferred, and various allowance exceeded counters for bandwidth, packets per second, and connection tracking limits. The following screenshot shows an example of how you can use Amazon Managed Grafana to visualize the performance metrics scraped using Prometheus.
With the Service map feature, you can dynamically visualize intercommunication between workloads in your cluster, making it straightforward to understand your application topology with a quick look. The service map helps you quickly identify performance issues by highlighting key metrics such as retransmissions, retransmission timeouts, and data transferred for network flows between communicating pods.
Let me show you how this works with a sample e-commerce application. The service map provides both high-level and detailed views of your microservices architecture. In this e-commerce example, we can see three core microservices working together: the GraphQL service acts as an API gateway, orchestrating requests between the frontend and backend services.
When a customer browses products or places an order, the GraphQL service coordinates communication with both the products service (for catalog data, pricing, and inventory) and the orders service (for order processing and management). This architecture allows each service to scale independently while maintaining clear separation of concerns.
For deeper troubleshooting, you can expand the view to see individual pod instances and their communication patterns. The detailed view reveals the complexity of microservices communication. Here, you can see multiple pod instances for each service and the network of connections between them.
This granular visibility is crucial for identifying issues like uneven load distribution, pod-to-pod communication bottlenecks, or when specific pod instances are experiencing higher latency. For example, if one GraphQL pod is making disproportionately more calls to a particular products pod, you can quickly spot this pattern and investigate potential causes.
Use the Flow table to monitor the top talkers across Kubernetes workloads in your cluster from three different perspectives, each providing unique insights into your network traffic patterns.
Flow table – Monitor the top talkers across Kubernetes workloads in your cluster from three different perspectives, each providing unique insights into your network traffic patterns:
AWS service view shows which workloads generate the most traffic to Amazon Web Services (AWS) services such as Amazon DynamoDB and Amazon Simple Storage Service (Amazon S3), so you can optimize data access patterns and identify potential cost optimization opportunities.
The Cluster view reveals the heaviest communicators within your cluster (east-west traffic), which means you can spot chatty microservices that might benefit from optimization or colocation strategies
External viewidentifies workloads with the highest traffic to destinations outside AWS (internet or on premises), which is useful for security monitoring and bandwidth management.
The flow table provides detailed metrics and filtering capabilities to analyze network traffic patterns. In this example, we can see the flow table displaying cluster view traffic between our e-commerce services. The table shows that the orders pod is communicating with multiple products pods, transferring amounts of data. This pattern suggests the orders service is making frequent product lookups during order processing.
The filtering capabilities are useful for troubleshooting, for example, to focus on traffic from a specific orders pod. This granular filtering helps you quickly isolate communication patterns when investigating performance issues. For instance, if customers are experiencing slow checkout times, you can filter to see if the orders service is making too many calls to the products service, or if there are network bottlenecks between specific pod instances.
Additional things to know Here are key points to note about Container Network Observability in EKS:
Pricing – For network monitoring, you pay standard Amazon CloudWatch Network Flow Monitor pricing.
Availability – Container Network Observability in EKS is available in all commercial AWS regions where Amazon CloudWatch Network Flow Monitor is available.
Export metrics to your preferred monitoring solution – Metrics are available in OpenMetrics format, compatible with Prometheus and Grafana. For configuration details, refer to Network Flow Monitor documentation.
Code migration is a repository-level transformation process that modernizes entire software projects to run on new platforms, frameworks, or runtime environments while preserving their original functionality and structure. Rather than focusing on isolated files or APIs, it operates across the full repository, spanning source code, dependencies, build systems, and configuration files to ensure consistency and correctness at scale. Typical examples include upgrading Java repositories from legacy versions such as Java 8 to modern Long-Term Support releases like Java 17 or 21, migrating .NET Framework repositories to .NET Core, and upgrading AWS Lambda projects in Python or Node.js to the latest runtime versions.
Code migration is a challenging software engineering (SWE) task that involves runtime upgrade, deprecated API replacement, test framework optimization, and syntax modernization. As we build agentic solutions for code migration, the community needs a standardized benchmark dataset and an evaluation framework to measure how well these systems actually perform. To close this gap, we introduce two benchmark datasets: MigrationBench on Java and Poly-MigrationBench as an extension to other programming languages. These datasets are designed not only to benchmark the effectiveness of Large Language Models (LLMs) in repository-level migration, but also to provide the community with a standardized evaluation framework for reproducible experiments.
Solution Overview
MigrationBench: Repository-Level Java Migration
MigrationBench is a comprehensive repository-level benchmark focused on Java upgrades. Specifically, it evaluates the ability of LLMs and other tools to migrate code from Java 8 to newer Long-Term Support (LTS) versions such as Java 17 and Java 21.
The full dataset includes 5,102 open-source Java 8 Maven repositories collected from GitHub, alongside a representative subset of 300 repositories curated for research requiring fewer compute resources. MigrationBench also provides an evaluation framework for validating Java Maven repository upgrades.
Our data collection process follows a carefully designed pipeline with multiple filtering stages to ensure the quality and relevance of the repositories we include. We begin by collecting Java Maven projects, focusing on repositories written in Java that use Maven as their build tool. Next, we apply a license filter, retaining only repositories under MIT or Apache 2.0 licenses to ensure open and permissible usage. We then apply a quality filter, keeping only repositories with at least three GitHub stars to exclude toy or inactive projects. For each repository, we search for the latest buildable commit that is compatible with Java 8, ensuring a valid starting point for migration. We also remove redundant repositories based on their snapshot hashes. Finally, we further exclude repositories without any unit tests or integration tests, which are essential components to validate migration correctness in a robust way. For more details, checkout our paper MigrationBench: Repository-Level Code Migration Benchmark from Java 8 and the GitHub repository.
Poly-MigrationBench: Extending Beyond Java
While MigrationBench focuses exclusively on Java, the real-world code migration problem spans multiple ecosystems. To address this broader scope, we develop Poly-MigrationBench, an extension that introduces additional languages and platforms. We applied a similar data curation process as MigrationBench to additionally collect
100 .NET Framework repositories. They are to be migrated to .NET core.
74 Node.js repositories with version less than Node.js 22. They are to be migrated to Node.js 22.
83 Python repositories with Python version less than 3.13. They are to be migrated to Python 3.13.
Together, these datasets enable researchers to explore cross-language and cross-platform migration challenges at scale.
Use Case 1: Cross-Platform .NET Migration
One pressing migration challenge lies in moving .NET applications from Windows environments running on the legacy .NET Framework to Linux environments powered by .NET Core. This migration is critical for organizations seeking cross-platform compatibility, improved performance, and modern deployment practices such as containerization.
To support research in this area, we curated a benchmark of 100 open-source .NET Framework repositories from GitHub. These projects were carefully selected for diversity and quality, offering a real world foundation for evaluating migration tools and automated systems. The migration goal is clear: transition .NET Framework repositories to .NET Core on Linux while preserving functional equivalence.
Use Case 2: Node.js Upgrade for AWS Lambda Applications
Another timely migration need involves Lambda functions written in Node.js. Node.js 20, currently supported by Lambda, is scheduled for end-of-support in April 2026 (reference). After this deadline, projects running on Node.js 20 will no longer receive critical security patches or bug fixes.
For increased security and to avoid accumulating technical debt, developers building Lambda applications are proactively upgrading to Node.js 22. To evaluate LLMs’ effectiveness in automating this migration, Poly-MigrationBench provides a dataset of 74 open-source Node.js repositories using Node.js versions no later than 20. The task is to upgrade them to Node.js 22 while ensuring functional correctness is preserved.
Use-case 3: AWS Lambda Python Migrations
We also release benchmarks on Lambda Python repositories to the community to facilitate research and evaluation of automated Lambda function migrations in Python code. According to AWS documentation, Python 3.10 and 3.11 are scheduled to reach end of support for Lambda in June 2026. This approaching deadline highlights the urgency of migrating existing Lambda functions to newer runtimes and underscores the critical need for scalable, reliable, and LLM-driven migration solutions. To facilitate evaluation on this task, we collect 83 Python AWS Lambda repositories with Python version no later than 3.12. The objective is to migrate these repositories to Python 3.13.
Get Started
We’ve open-sourced both the datasets and the evaluation framework on Hugging Face and GitHub to make it easy for the community to explore, reproduce, and extend our work. Alongside them, we also released a baseline solution, SD-Feedback, for MigrationBench, while leaving the development of more sophisticated agentic migration systems as a open challenge for the research community.
MigrationBench
To download the MigrationBench dataset, visit our Hugging Face collection. For evaluation, simply clone our GitHub repository and follow the steps in the README.md.
Poly-MigrationBench
To access the Poly-MigrationBench dataset and evaluation commands, clone our GitHub repository.
For a deeper dive into how the benchmarks were curated and how the evaluation framework was designed, check out our paper:
Code migration is an essential but complex task for maintaining long-term software reliability and security. With MigrationBench and Poly-MigrationBench, we aim to provide the community with systematic, large-scale benchmarks that enable reproducible research and practical evaluation of automated migration approaches.
We are delighted to announce an update to the AWS Well-Architected Generative AI Lens. This update features several new sections of the Well-Architected Generative AI Lens, including new best practices, advanced scenario guidance, and improved preambles on responsible AI, data architecture, and agentic workflows.
The AWS Well-Architected Framework provides architectural best practices for designing and operating generative AI workloads on AWS. The Generative AI Lens uses the Well-Architected Framework to outline the steps for performing a Well-Architected Framework review for your generative AI workloads.
The Generative AI Lens provides a consistent approach for customers to evaluate architectures that use large language models (LLMs) to achieve their business goals. This lens addresses common considerations relevant to model selection, prompt engineering, model customization, workload integration, and continuous improvement. Specifically excluded from the Generative AI Lens are best practices associated with model training and advanced model customization techniques. We identify best practices that help you architect your cloud-based applications and workloads according to AWS Well-Architected design principles gathered from supporting thousands of customer implementations.
What has changed in the updated Generative AI Lens?
The updated Generative AI Lens incorporates several new additions for customers to review. These additions keep the lens on-pace with the rapidly growing area of generative AI, helping customers stay up to date with architectural best practices.
Amazon SageMaker HyperPod guidance
The updated lens features additional guidance for users of Amazon SageMaker HyperPod. SageMaker HyperPod is a highly resilient model training and hosting service that you can use to orchestrate complex, long-running generative AI workflows in the cloud. These workflows could be foundation model pre-training or serving model inference at scale.
We are excited to announce additional guidance for customers using SageMaker HyperPod in the Generative AI Lens. This guidance is built into the existing best practices, expanding the guidance for covered services to include SageMaker capabilities. This guidance joins the existing guidance on Amazon Bedrock, Amazon Q Business, Amazon Q Developer, and Amazon SageMaker AI.
Responsible AI preamble
The updated responsible AI preamble now includes a detailed discussion on the eight core dimensions of responsible AI as described by AWS. Customers can now learn more about the eight dimensions of responsibly developed AI systems directly within the lens. This is required reading for customers in all stages of their generative AI journey.
Data architecture preamble
The updated data architecture preamble reviews strategic considerations associated with a modern data architecture supporting generative AI workloads. This section provides customers with a view into the high-level decisions and considerations needed to architect a data system that services generative AI workloads.
Agentic AI preamble
New to the generative AI lens is the agentic AI preamble. Agentic systems, while technically classified as a subset of distributed computing, play an important role in modern generative AI workloads. This preamble introduces customers to a sampling of architecture paradigms common in agentic systems powered by foundation models.
Scenarios
The Generative AI Lens now includes eight architecture scenarios. These scenarios cover a range of common generative AI powered business applications, including autonomous call centers, knowledge worker co-pilots, and multi-tenant generative AI service systems. The scenario section provides specific guidance for applying generative AI technologies to common business problems. The following image is an example of one of the new scenarios now included in the Generative AI Lens.
Who should use the Generative AI Lens?
The Generative AI Lens is useful to many roles. Business leaders can use this lens to acquire a broader appreciation of the end-to-end implementation and benefits of generative AI. Data scientists and engineers can read this lens to understand how to use, secure, and gain insights from their data at scale. Risk and compliance leaders can understand how generative AI is implemented responsibly by providing compliance with regulatory and governance requirements.
Next steps
The updated Well-Architected Generative AI Lens is available now. Use the lens as a framework to verify that your generative AI workloads are architected with operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability in mind.
If you require support on the implementation or assessment of your generative AI workloads, please contact your AWS Solutions Architect or Account Representative.
Special thanks to everyone across the AWS Solution Architecture, AWS Professional Services, and Machine Learning communities who contributed to the updated Generative AI Lens. These contributions encompassed diverse perspectives, expertise, backgrounds, and experiences in developing the new AWS Well-Architected Generative AI Lens.
We are excited to announce the updated AWS Well-Architected Machine Learning Lens, now enhanced with the latest capabilities and best practices for building machine learning (ML) workloads on AWS.
The AWS Well-Architected Framework provides architectural best practices for designing and operating reliable, secure, efficient, cost-effective, and sustainable workloads in the cloud. The Machine Learning Lens uses the Well-Architected Framework to outline the steps for performing a comprehensive review of your ML architectures.
The updated Machine Learning Lens provides a consistent approach for customers to evaluate architectures across ML workloads, from traditional supervised and unsupervised learning to modern AI applications. This lens addresses common considerations relevant to the complete ML lifecycle, including business goal identification, problem framing, data processing, model development, deployment, and monitoring. The lens incorporates the latest AWS ML services and capabilities introduced since 2023, providing access to current best practices and implementation guidance.
The Machine Learning Lens is part of a collection of Well-Architected lenses published under AWS Well-Architected Lenses.
What is the Machine Learning Lens?
The Well-Architected Machine Learning Lens focuses on the six pillars of the Well-Architected Framework across six phases of the ML lifecycle.
The six phases are:
Business goal identification: Establishing clear business objectives and success criteria for your ML initiative.
ML problem framing: Translating business problems into well-defined ML problems with appropriate metrics.
Data processing: Collecting, preparing, and engineering features from your data sources.
Model development: Building, training, tuning, and evaluating ML models with proper experimentation tracking.
Model deployment: Deploying models into production environments with appropriate infrastructure and monitoring.
Model monitoring: Continuously monitoring model performance and maintaining model quality over time.
Unlike the traditional waterfall approach, an iterative approach is required to achieve a working prototype based on the six phases of the ML lifecycle. The lens provides you with a set of established cloud-agnostic best practices in the form of Well-Architected Framework pillars for each ML lifecycle phase.
You can also use the Well-Architected Machine Learning Lens wherever you are on your cloud journey. You can choose to apply this guidance either during the design of your ML workloads or after your workloads have entered production as a part of the continuous improvement process.
Machine Learning Lens components
The lens includes four focus areas:
Well-Architected ML design principles: Ten design principles that frame the presented best practices, including assign ownership, enable reproducibility, optimize resources, and enable continuous improvement.
The ML lifecycle and the Well-Architected Framework pillars: This considers all aspects of the ML lifecycle and reviews design strategies aligned to the pillars of the overall Well-Architected Framework:
Operational excellence: Ability to support ongoing development, run ML workloads effectively, gain insight into operations, and continuously improve processes.
Security: Ability to protect data, models, and ML infrastructure while taking advantage of cloud technologies to improve security posture.
Reliability: Ability of ML workloads to perform their intended function correctly and consistently, with automatic recovery from failure situations.
Performance efficiency: Ability to use computing resources efficiently for ML workloads and maintain efficiency as demand and technologies evolve.
Cost optimization: Ability to run ML systems to deliver business value at the lowest price point through resource optimization and automation.
Sustainability: Addresses the environmental impact of ML workloads, focusing on energy consumption and resource efficiency.
Cloud-agnostic best practices: 100+ comprehensive best practices covering each ML lifecycle phase across the Well-Architected Framework pillars. Each best practice includes:
Implementation guidance: Detailed AWS implementation plans with references to current AWS ML services and capabilities.
Resources: Curated links to AWS documentation, blogs, videos, and code examples supporting the best practices.
Related ML architecture considerations: Discussions on advanced topics including MLOps patterns, data architecture for ML, model governance strategies, and considerations for responsible AI implementation.
What else is discussed in the Machine Learning Lens?
The Machine Learning Lens also discusses the following key topics:
Responsible AI: Comprehensive guidance on implementing fair, explainable, and unbiased ML systems throughout the development lifecycle.
MLOps and automation: Best practices for implementing continuous integration, continuous deployment, and continuous training for ML workloads.
Data architecture for ML: Guidance on building robust data pipelines, feature stores, and data governance practices that support ML workloads at scale.
Model governance and lineage: Strategies for tracking model versions, maintaining audit trails, and ensuring compliance with regulatory requirements.
What’s new in the updated Machine Learning Lens?
The updated Machine Learning Lens incorporates the latest AWS ML capabilities and best practices introduced since 2023, including:
Enhanced data and AI collaborative workflows: Integrated development through Amazon SageMaker Unified Studio – MLOPS02-BP01, MLOPS01-BP01, MLOPS03-BP01, and MLOPS02-BP04.
AI-assisted development lifecycle: Code generation and productivity enhancement using Kiro and Amazon Q Developer – MLCOST01-BP02, MLOPS01-BP01, MLCOST03-BP02, and MLSUS05-BP02.
Distributed training infrastructure: Large-scale foundation model development and fine-tuning with Amazon SageMaker HyperPod – MLCOST04-BP02, MLCOST04-BP07, MLPERF06-BP05, MLSEC03-BP02, MLCOST04-BP06, MLPERF06-BP07, and MLSUS05-BP02.
Model customization capabilities: Knowledge distillation and fine-tuning for domain-specific applications using Amazon Bedrock with Kiro and Amazon Q Developer integration and model hub with Amazon SageMaker Jumpstart – MLCOST01-BP02, MLCOST01-BP01, MLCOST03-BP02, MLSUS04-BP02, MLCOST05-BP01, and MLSUS05-BP02.
No-code ML development: Natural language support for building models using SageMaker Canvas with Amazon Q Developer integration – MLCOST03-BP02, MLCOST03-BP03, MLOPS01-BP01, and MLSUS05-BP02.
Improved bias detection: Enhanced fairness metrics in SageMaker Clarify with Model Monitor for drift detection – MLREL02-BP01, MLREL03-BP04, MLREL02-BP04, MLREL02-BP05, and MLREL02-BP02.
Modular inference architecture: Flexible deployment with SageMaker Inference Components and Multi-Model Endpoints – MLCOST05-BP01, MLREL01-BP01, MLSUS05-BP01, MLCOST05-BP03, and MLREL01-BP02.
Advanced observability: Improved debugging with SageMaker Debugger, Model Monitor, and CloudWatch across the ML lifecycle – MLOPS06-BP02, MLOPS05-BP02, MLOPS06-BP01, and MLOPS02-BP04.
Enhanced cost optimization: Resource management through SageMaker Training Plans, Savings Plans, and Spot Instance support – MLCOST05-BP03, MLOPS05-BP02, MLCOST06-BP01, MLCOST06-BP02, and MLCOST04-BP06.
Who should use the Machine Learning Lens?
The Machine Learning Lens is valuable for many roles across your organization. Business leaders can use this lens to understand the end-to-end implementation and business value of ML initiatives. Data scientists and ML engineers can leverage the lens to understand how to build, deploy, and maintain ML systems at scale. DevOps and platform engineers can learn how to create reliable, secure infrastructure for ML workloads. Risk and compliance leaders can understand how ML systems are implemented responsibly while adhering to regulatory and governance requirements.
Next steps
If you require support on the implementation or assessment of your ML workloads, please contact your AWS Solutions Architect or Account Representative.
Special thanks to everyone across the AWS Solution Architecture, AWS Professional Services, and Machine Learning communities who contributed to the updated Machine Learning Lens. These contributions encompassed diverse perspectives, expertise, backgrounds, and experiences in developing comprehensive guidance for ML workloads on AWS.
At re:Invent 2025, we introduce one new lens and two significant updates to the AWS Well-Architected Lenses specifically focused on AI workloads: the Responsible AI Lens, the Machine Learning (ML) Lens, and the Generative AI Lens. Together, these lenses provide comprehensive guidance for organizations at different stages of their AI journey, whether you’re just starting to experiment with machine learning or already deploying complex AI applications at scale.
The AWS Well-Architected Framework provides the best architectural practices for designing and operating reliable, secure, performance efficient, cost-optimized, and sustainable workloads in the cloud.
The Responsible AI Lens: Embedding trust in AI systems
The Responsible AI Lens offers a structured approach for developers to assess and track their AI workloads against established best practices, identify potential gaps in their AI implementation and receive actionable guidance to improve their AI systems’ quality and alignment with responsible AI principles. By using the Responsible AI Lens you can make informed decisions that balance business and technical requirements, accelerating your path from AI experimentation to production-ready solutions.
Key takeaways from the Responsible AI Lens:
Every AI system has a Responsible AI consideration: Whether intentionally designed or not, AI systems inherently carry Responsible AI implications that need to be actively managed rather than left to chance.
AI systems can be used beyond original intent and may have unintended impacts: Applications often get utilized in ways developers didn’t anticipate, and due to their probabilistic nature, AI systems can produce unexpected outcomes even within intended use cases, making robust Responsible AI decisions essential from the start.
Responsible AI is an enabler to innovation and trust: Rather than being a constraint, Responsible AI practices can accelerate innovation by proactively building stakeholder and customer trust and reducing downstream risks.
The Responsible AI Lens serves as the foundational guidance for AI development activities, providing critical guidelines that inform both the Machine Learning Lens and the Generative AI Lens implementations.
The Machine Learning Lens: Foundation for ML workloads
The Machine Learning Lens provides you with a set of established cloud-agnostic best practices in the form of Well-Architected Framework pillars for each machine learning (ML) lifecycle phase. The updated Machine Learning Lens provides a consistent approach for designing, building, and operating machine learning workloads on AWS. It addresses the full spectrum of ML workloads, from traditional supervised and unsupervised learning to modern AI applications.
The updated Machine Learning Lens incorporates the latest AWS ML capabilities (evolved since their introduction in 2023). What’s new in the updated ML Lens:
Enhanced data and AI collaborative workflows through Amazon SageMaker Unified Studio.
AI-assisted development for code generation and productivity enhancement.
Distributed training infrastructure for foundation model development and fine-tuning with Amazon SageMaker HyperPod.
Model customization capabilities such as knowledge distillation and fine-tuning domain-specific applications using Amazon Bedrock with Kiro and Amazon Q Developer.
No-code ML development using Amazon SageMaker Canvas with Amazon Q integration.
Improved bias detection with enhanced fairness metrics and Responsible AI capabilities in Amazon SageMaker Clarify.
Automated dashboard creation for business insights through Amazon Quick Sight.
Modular inference architecture for flexible model deployment with Inference Components.
Advanced observability with improved debugging and monitoring capabilities across the ML lifecycle.
Enhanced cost optimization for resource management through Amazon SageMaker Training Plans, Savings Plans, and Spot Instance support.
You can use the ML Lens wherever you are on your cloud journey. You can choose to apply this guidance either during the design of your ML workloads or after your workloads have entered production as part of the continuous improvement process. These improvements are powered by key AWS services including Amazon SageMaker Unified Studio, Amazon Q, Amazon SageMaker HyperPod, and Amazon Bedrock.
The Generative AI Lens: Specialized guidance for foundation models
The Generative AI Lens provides a consistent approach for customers to evaluate architectures that use large language models (LLMs) to achieve their business goals. This lens addresses common considerations relevant to model selection, prompt engineering, model customization, workload integration, and continuous improvement. We identify best practices that help you architect your cloud-based applications and workloads according to AWS Well-Architected design principles gathered from supporting thousands of customer implementations. While the Machine Learning (ML) Lens covers the broad spectrum of ML workloads, the Generative AI Lens focuses specifically on foundation models and generative AI applications. The Generative AI Lens provides the best architectural practices for designing and operating generative AI workloads on AWS.
The updated Generative AI Lens includes several new additions:
Amazon SageMaker HyperPod guidance for orchestrating complex, long-running generative AI workflows that includes additional service capabilities.
Enhanced Responsible AI preamble with detailed discussion on the eight core dimensions of Responsible AI as described by AWS.
Updated data architecture preamble with strategic considerations needed to architect a data system for generative AI workloads.
New agentic AI preamble introducing architecture paradigms for agentic systems.
Eight architecture scenarios covering common generative AI-powered business applications such as autonomous call centers, knowledge worker co-pilots, and multi-tenant generative AI service systems.
The Generative AI Lens builds upon the foundation established by the ML Lens, providing specialized guidance for the unique challenges and opportunities presented by foundation models and generative AI applications.
Implementation strategy for Well-Architected AI/ML guidance: A unified approach
The new lenses – Responsible AI Lens, Machine Learning Lens, and Generative AI Lens – work together to provide comprehensive guidance for AI development. The Responsible AI Lens guides safe, fair, and secure AI development. It helps balance business needs with technical requirements, streamlining the transition from experimentation to production. The Machine Learning Lens guides organizations in evaluating workloads across both modern AI and traditional machine learning approaches. Recent updates focus on key areas including enhanced data and AI collaborative workflows, AI-assisted development capabilities, large-scale infrastructure provisioning, and customizable model deployment. The Generative AI Lens helps customers evaluate large language model (LLM) based architectures and its updates include guidance for Amazon SageMaker HyperPod users, new insights on agentic AI, and updated architectural scenarios.
What are the next steps?
The launch of these new lenses at re:Invent 2025 helps organizations build AI systems that are responsible, trustworthy, powerful, and effective. By providing comprehensive guidance across the full spectrum of AI workloads, AWS supports organizations to accelerate their AI initiatives while maintaining the highest standards of responsible AI and technical excellence.
Learn more about the AWS Well-Architected Framework and implement the best practice guidance provided using the GitHub repository. These lenses are practical tools designed to help you build AI systems that deliver real business value while maintaining the highest standards of ethics, security, and operational excellence.
For additional reading, refer to the AWS Well-Architected Framework and pillar whitepapers, or contact your AWS Solutions Architect or Account Representative for support on implementing these lenses in your organization.
AWS CloudFormation makes it easy to model and provision your cloud application infrastructure as code. CloudFormation templates can be written directly in JSON or YAML, or they can be generated by tools like the AWS Cloud Development Kit (CDK). Resources are created and managed by CloudFormation as units called Stacks. Additionally, change set enable you to preview the stack changes before deployment.
CloudFormation now offers powerful new features that transform how you develop and troubleshoot infrastructure as code, pre-deployment validation that catches errors in seconds, enhanced operation tracking, and simplified failure debugging. These capabilities shift-left infrastructure code validation, helping you prevent infrastructure deployment failures that impacts development velocity.
In this blog post, we’ll explore how these new features accelerate development cycles by catching common errors during change set creation and providing precise troubleshooting through operation tracking and failure filtering. Whether you’re a platform engineer managing complex multi-service deployments or a developer iterating on infrastructure templates, we’ll show you how to:
Validate resource properties and detect naming conflicts before deployment
Prevent deployment failures by checking S3 bucket emptiness before deletion operations
Track operations with unique IDs for focused troubleshooting
Quickly identify root causes using the new describe-events API
This comprehensive guide will walk through real-world scenarios demonstrating how these capabilities can reduce infrastructure deployment failures from hours of debugging to seconds of validation, helping you deliver cloud infrastructure faster and more reliably.
Key Capabilities
Pre-deployment Validation: Catch template errors instantly instead of discovering them after resource provisioning attempts. These include pre-deployment validation for resource property syntax errors, resource naming conflicts for existing resources in your account, and S3 bucket emptiness constraint violations on delete operations.
Operation Tracking: Say goodbye to long debugging sessions. Each stack action now comes with a unique Operation ID, transforming the “needle in haystack” troubleshooting experience into precise, targeted problem-solving.
Streamlined Events API for simplified Debugging: Use the new describe-events API and FailedEvents=true filter to instantly pinpoint issues. One command tells you exactly what went wrong, eliminating the need to scroll through endless logs.
Immediate Feedback: Transform your CI/CD pipeline from a potential bottleneck into a rapid iteration engine. Get immediate feedback on common deployment issues, allowing your team to fix and deploy faster than ever before.
How It works
Pre-deployment Validation
The following scenarios show how you can leverage CloudFormation pre-deployment validation to detect property syntax errors, resource naming conflicts, and constraint violations during change set creation.
Understanding Validation Modes CloudFormation pre-deployment validation operates in two modes that determine how validation failures are handled.
FAIL mode prevents change set execution when validation detects errors, ensuring problematic templates cannot proceed to deployment. This applies to property syntax errors and resource naming conflicts.
WARN mode allows change set creation to succeed despite validation failures, providing warnings that developers can review and address before execution. This applies to constraint violations like S3 bucket emptiness that may be resolvable through manual intervention.
Understanding these modes helps you anticipate whether validation issues will block your deployment workflow or simply require attention before execution.
Let’s walk you through practical scenarios:
Scenario 1: Validate Resource Property Syntax
CloudFormation evaluates each resource property definition or value before provisioning begins. The following example illustrates several common resource property errors:
The “AWS::Lambda::Function” Role property requires an ARN pattern.
The “AWS::Lambda::Function” Timeout property expects an integer instead of a string.
The “AWS::Lambda::Function” TracingConfig.Mode nested property ENUM value is invalid.
The “AWS::Lambda::Alias” Name property is required but not defined.
The “AWS::Lambda::Alias” the extra property Description in a nested path RoutingConfig.AdditionalVersionWeights.0 is not supported.
Prior to this launch, these resource configuration errors would be detected at the resource provisioning time only. However, with the pre-deployment validations feature, these errors can be identified ahead of the deployment phase, streamlining the development-test lifecycle efficiency and minimizing rollbacks during deployments.
You can see the status of the change set is failed with a detailed status reason. You can now proceed to review the change set validation results.
Step 3: Review validation results
Console
With the console, you can review multiple validation errors in a single interface. When you click on a validation, CloudFormation pinpoints the location of the invalid property error in your template.
Figure 3: Pre-deployment validations view
Use Case: Invalid ENUM value for nested property Catching invalid configuration values before deployment. This demonstrates validation of nested properties like TracingConfig.Mode. The tool helpfully shows the supported values “Active” & “Pass through” as well as the provided invalid value “DISABLED”.
Figure 4: Validation of Invalid ENUM value for nested property
Use Case: Lambda Function Timeout property type mismatch Preventing type-related deployment failures. Shows how validation catches string values (“30s”) where integers are required, saving developers from runtime errors.
Figure 5: Validation of Lambda Function Timeout property type mismatch
Use Case: Lambda Function Role property pattern mismatch Validating ARN format requirements. Demonstrates pattern validation ensuring Role properties match required ARN format.
Figure 6: Lambda Function Role property pattern mismatch
Use Case: Undefined required Lambda Alias Name property Catching missing required properties. Shows validation detecting absent mandatory fields, preventing incomplete resource definitions from reaching deployment.
Figure 7: Validation of undefined required Lambda Alias Name property
Notice how the validation Path field (e.g., “/Resources/MyLambdaFunction/Properties/TracingConfig/Mode”) pinpoints the exact template location of each error. This eliminates manual searching through hundreds of lines of infrastructure code – a common time sink that can take minutes in complex templates.
Use case: Unsupported property Shows how CloudFormation validation catches unsupported properties. In this example, the AWS::Lambda::Alias resource had an unsupported extra property Description in a nested path RoutingConfig.AdditionalVersionWeights.0.
Figure 8: CloudFormation validation of unsupported resource property
CLI command You can also use the new describe-events API to review the validation responses.
Scenario 2: Resource Name Conflict Validation Resource name conflict validation makes sure that new resources added to a template are not already present in your AWS account or globally (e.g: Amazon S3, Amazon Route 53 DNS), preventing deployment errors caused due to resource name conflicts
After reviewing the property validation exceptions, let’s assume that you resolved all the issues and successfully deployed the stack. Next, the you have decided to include a S3 bucket resource in the template. You name the bucket “dev-thumbnails” but didn’t verify if the bucket with this name already exists. If a bucket with this name already exists, the CreateChangeSet operation will fail, reporting to the developer that the bucket already exists.
Step 2: Review Deployment Validations Use CloudFormation change set console to review validations response or use the new DescribeEvents API in the CLi.
Scenario 3: S3 bucket not empty Since AWS S3 service does not allow customers to delete S3 Buckets when there are objects in them, the new pre-deployment validations will warn you if you try to delete a bucket that is not empty.
Resuming our journey, let’s assume that you fix the name conflict issue by renaming the bucket to “dev-test-tumbnails”, and then updates the stack. After testing the lambda function’s integration with S3, the dev-cycle generated a few thumbnail objects in the S3 bucket.
Later, you decide to fix the bucket name because you notice a typo: “dev-test-tumbnails” should be “dev-test-thumbnails” (missing “h”). When you update the template to use the corrected name, CloudFormation will need to create the new bucket then delete the old one during the clean-up phase.
{
"OperationEvents": [
{
"EventId": "24920e0f-1941-45a5-9177-786bc805b724",
"StackId": "arn:aws:cloudformation:us-west-2:123456789012:stack/dev-lambda-stack/2d2c3240-bb59-11f0-b080-0613dc96740d",
"OperationId": "8fef2b60-b411-4d0e-920e-7ec7c7aa39f2",
"OperationType": "CREATE_CHANGESET",
"OperationStatus": "SUCCEEDED",
"EventType": "STACK_EVENT",
"Timestamp": "2025-11-06T22:52:26.355000+00:00",
"StartTime": "2025-11-06T22:52:21.071000+00:00",
"EndTime": "2025-11-06T22:52:26.355000+00:00"
},
{
"EventId": "c117e02d-a652-4755-9586-6d4ccb0f6504",
"StackId": "arn:aws:cloudformation:us-west-2:123456789012:stack/dev-lambda-stack/2d2c3240-bb59-11f0-b080-0613dc96740d",
"OperationId": "8fef2b60-b411-4d0e-920e-7ec7c7aa39f2",
"OperationType": "CREATE_CHANGESET",
"EventType": "VALIDATION_ERROR",
"LogicalResourceId": "MyDevThumbnailsBucket",
"PhysicalResourceId": "",
"ResourceType": "AWS::S3::Bucket",
"Timestamp": "2025-11-06T22:52:25.960000+00:00",
"ValidationFailureMode": "WARN", "ValidationName": "BUCKET_EMPTINESS_VALIDATION", "ValidationStatus": "FAILED", "ValidationStatusReason": "The bucket 'dev-tumbnails' is not empty. You must either delete all objects and versions or use the deletion policy to retain it, otherwise the delete operation will fail.", "ValidationPath": "/Resources/MyDevThumbnailsBucket"
},
{
"EventId": "6c66ff53-6751-4b4c-96b8-d1a33fc43b4f",
"StackId": "arn:aws:cloudformation:us-west-2:123456789012:stack/dev-lambda-stack/2d2c3240-bb59-11f0-b080-0613dc96740d",
"OperationId": "8fef2b60-b411-4d0e-920e-7ec7c7aa39f2",
"OperationType": "CREATE_CHANGESET",
"OperationStatus": "IN_PROGRESS",
"EventType": "STACK_EVENT",
"Timestamp": "2025-11-06T22:52:21.071000+00:00",
"StartTime": "2025-11-06T22:52:21.071000+00:00"
}
]
}
Bucket emptiness validation uses WARN mode, which allows change set creation to succeed even when the validation check fails. This gives you time to review and empty the bucket before execution. However, if you execute the change set without emptying the bucket, the delete operation will fail.
Notice in the output above:
ValidationStatus: "FAILED" – The emptiness check detected objects in the bucket
ValidationFailureMode: "WARN" – This is a warning, not a blocking error
OperationStatus: "SUCCEEDED" – Change set creation completed successfully despite the warning
This design allows you to review the warning, take corrective action (such as emptying the bucket), and then proceed with execution.
Beyond catching errors early, these capabilities also transform how you troubleshoot failed deployments with enhanced operation tracking and filtering.
New DescribeEvents API with Operation IDs and root cause filtering
The new DescribeEvents API retrieves CloudFormation events based on flexible query criteria. It groups stack operations by operation ID, enabling you to focus specifically on individual stack operations involved during your stack deployment.
Operation: An operation is any action performed on a stack, including stack lifecycle actions (Create, Update, Delete, Rollback), change set creation, nested stack creation, and automatic rollbacks triggered by failures. Each operation has a unique identifier and represents a discrete change attempt on the stack.
Figure 11: Stack Events grouped by Operation Id
Scenario When an update operation on an existing stack fails and results in a rollback, and you want to understand the reason behind the update stack failure. Using the operation ID obtained from the update stack response or from the describe stacks response, you can call describe events to get details on the failure.
The stack description available via describe-stacks API now includes LastOperations information showing recent operation IDs and their types. This enables you to quickly identify which operations occurred and their current status without parsing through event logs.
Figure 11: CloudFormation Stack Info page showing new operation IDs
Step 3: Review operation status with describe events API and operation id Using the operation ID from the previous step, you can now query specific operation events to understand exactly what happened during that operation. This targeted approach eliminates the need to search through all stack events to find relevant information.
Figure 12: New CloudFormation stack operation page
Step 4: Identify failure root cause(s) with FailedEvents filter The new failure root cause filter instantly surfaces only the events that caused the operation to fail. This eliminates the need to manually scan through progress events to identify the root cause of deployment failures.
The FailedEvents=true filter transforms troubleshooting from parsing dozens of progress events to instantly seeing only what matters. This can make diagnosis of issues during an incident much easier..
Real-World Impact These features improve your Infrastructure development experience with CloudFormation:
Template syntax errors: Previously discovered after minutes of provisioning, now caught in seconds
Resource conflicts: No more failed deployments due to existing resources
Debugging complexity: Transform troubleshooting sessions into faster targeted fixes
CI/CD reliability: Reduce pipeline failures and improve deployment confidence
Getting Started
These capabilities are available today in all AWS Regions where CloudFormation is supported. Pre-deployment validation is automatically enabled for all change set operations, no configuration required.
Try it now:
Create any change set from the CloudFormation console or via SDK or CLI with aws cloudformation create-change-set
Use `aws cloudformation describe-events –change-set-name <your-changeset-arn>` to see validation results
Filter failure root causes instantly: via console or CLI with aws cloudformation describe-events –operation-id <id> –filter FailedEvents=true
Best Practices
Always use change sets: Even for simple updates, change sets now provide validation feedback
Leverage Operation IDs: Use the unique identifiers for focused troubleshooting
Filter events strategically: Use –filters FailedEvents=true to focus on problems
Automate validation: Integrate the describe-events API into your CI/CD pipelines
Use Console: CloudFormation console provides a visual experience with error source mapping to the specific line on your template.
Conclusion
Start using these features today in your development workflow. Whether you’re building new infrastructure or maintaining existing stacks, early validation and enhanced troubleshooting will accelerate your deployment cycles and make it easier to manage infrastructure.
Ready to experience faster CloudFormation development? Create your first change set and see validation in action.
Today, we’re announcing the general availability of Amazon Elastic Compute Cloud (Amazon EC2) P6-B300 instances, our next-generation GPU platform accelerated by NVIDIA Blackwell Ultra GPUs. These instances deliver 2 times more networking bandwidth, and 1.5 times more GPU memory compared to previous generation instances, creating a balanced platform for large-scale AI applications.
With these improvements, P6-B300 instances are ideal for training and serving large-scale AI models, particularly those employing sophisticated techniques such as Mixture of Experts (MoE) and multimodal processing. For organizations working with trillion-parameter models and requiring distributed training across thousands of GPUs, these instances provide the perfect balance of compute, memory, and networking capabilities.
Improvements made compared to predecessors The P6-B300 instances deliver 6.4Tbps Elastic Fabric Adapter (EFA) networking bandwidth, supporting efficient communication across large GPU clusters. These instances feature 2.1TB of GPU memory, allowing large models to reside within a single NVLink domain, which significantly reduces model sharding and communication overhead. When combined with EFA networking and the advanced virtualization and security capabilities of AWS Nitro System, these instances provide unprecedented speed, scale, and security for AI workloads.
The specs for the EC2 P6-B300 instances are as follows.
Instance size
VCPUs
System memory
GPUs
GPU memory
GPU-GPU interconnect
EFA network bandwidth
ENA bandwidth
EBS bandwidth
Local storage
P6-B300.48xlarge
192
4TB
8x B300 GPU
2144GB HBM3e
1800 GB/s
6.4 Tbps
300 Gbps
100 Gbps
8x 3.84TB
Good to know In terms of persistent storage, AI workloads primarily use a combination of high performance persistent storage options such as Amazon FSx for Lustre, Amazon S3 Express One Zone, and Amazon Elastic Block Store (Amazon EBS), depending on price performance considerations. For illustration, the dedicated 300Gbps Elastic Network Adapter (ENA) networking on P6-B300 enables high-throughput hot storage access with S3 Express One Zone, supporting large-scale training workloads. If you’re using FSx for Lustre, you can now use EFA with GPUDirect Storage (GDS) to achieve up to 1.2Tbps of throughput to the Lustre file system on the P6-B300 instances to quickly load your models.
Available now The P6-B300 instances are now available through Amazon EC2 Capacity Blocks for ML and Savings Planin the US West (Oregon) AWS Region. For on-demand reservation of P6-B300 instances, please reach out to your account manager. As usual with Amazon EC2, you pay only for what you use. For more information, refer to Amazon EC2 Pricing. Check out the full collection of accelerated computing instances to help you start migrating your applications.
AWS Lambda now supports Python 3.14 as both a managed runtime and container base image. Python is a popular language for building serverless applications. Developers can now take advantage of new features and enhancements when creating serverless applications on Lambda.
The Python 3.14 runtime supports Powertools for AWS Lambda (Python), a developer toolkit that helps you to implement serverless best practices. Powertools includes observability, batch processing, AWS Systems Manager Parameter Store integration, idempotency, feature flags, Amazon CloudWatch metrics, structured logging, and more.
This blog post highlights notable Python language updates, Python Lambda runtime features and support, and how you can use the new Python 3.14 runtime in your serverless applications.
New Python features
Python 3.14 contains the following notable updates.
Template strings literal
Template strings introduce a new mechanism for custom string processing using the t prefix instead of f for f-strings. Unlike f-strings that return a simple string, t-strings return an object representing both static and interpolated parts.
Evaluation of type annotations
With the implementation of PEP 649, Python 3.14 defers type annotation evaluation until required. This reduces import time overhead and resolves forward reference issues.
Improved Error Messages
The interpreter now provides helpful suggestions when it detects typos in Python keywords. These include incorrect control flow structures, misused conditional expressions, string syntax errors, incompatible type usage in dicts/sets, and context manager protocol mismatches.
whille :
Traceback (most recent call last):
File "<stdin>", line 1
whille :
^^^^^^
SyntaxError: invalid syntax. Did you mean 'while'?
Standard library
The standard library includes a new compression.zstd module that provides native support for zstandard compression, offering better compression ratios and faster decompression compared to existing algorithms.
Python 3.14 also includes improved error messages and enhanced asyncio introspection capabilities.
Lambda runtime changes
The Lambda Python runtime contains the following changes.
Python 3.14 features that are not available
Python 3.14 includes some features that are not enabled for the Lambda managed runtime or base images. These features must be enabled when the Python runtime is compiled and cannot be enabled via an execution-time flag. The just-in-time (JIT) compiler is not available in the Lambda runtime because it’s still in an experimental phase. Free-threaded mode, running Python without the global interpreter lock, is supported in Python 3.14, but it is not enabled in the Lambda runtime due to potential performance impact. To use these features in Lambda, you can deploy your own Python runtime build with these features enabled, using a container image or custom runtime.
Amazon Linux 2023
As with the Python 3.12 and Python 3.13 runtimes, the Python 3.14 runtime is based on the provided.al2023 runtime, which is based on the Amazon Linux 2023 minimal container image. The Amazon Linux 2023 minimal image uses microdnf as a package manager, symlinked as dnf. This replaces the yum package manager used in Python 3.11 and earlier AL2-based images. If you deploy your Lambda functions as container images, you must update your Dockerfiles to use dnf instead of yum when upgrading to the Python 3.14 base image from Python 3.11 or earlier base images.
You can use Python 3.14 for your Lambda functions in the AWS Management Console, an AWS Lambda container image, or the AWS Cloud Development Kit (AWS CDK).
AWS Management Console
To use the Python 3.14 runtime to develop your Lambda functions, specify a runtime parameter value of Python 3.14 when creating or updating a function. On the Create Function page of the AWS Lambda console, Python 3.14 is available in the Runtime dropdown menu.
To update an existing Lambda function to Python 3.14, navigate to the function in the Lambda console and choose Edit in the Runtime settingspanel. The new version of Python is available in the Runtime dropdown menu.
Upgrading a function to Python 3.14
To upgrade a function to Python 3.14, check your code and dependencies for compatibility with Python 3.14, run tests, and update as necessary. Consider using generative AI coding assistants like Amazon Q Developer, Amazon Q Developer for CLI, or Kiro to help with upgrades.
AWS Lambda container image
Change the Python base image version by modifying the FROM statement in your Dockerfile:
FROM public.ecr.aws/lambda/python:3.14
# Copy function code
COPY lambda_handler.py ${LAMBDA_TASK_ROOT}
AWS Serverless Application Model (AWS SAM)
In AWS SAM set the Runtime attribute to python3.14 to use this version.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: Simple Lambda Function
MyFunction:
Type: AWS::Serverless::Function
Properties:
Description: My Python Lambda Function
CodeUri: my_function/
Handler: lambda_function.lambda_handler
Runtime: python3.14
AWS SAM supports generating this template with Python 3.14 for new serverless applications using the sam init command. Refer to the AWS SAM documentation.
AWS Cloud Development Kit
In the AWS CDK, set the runtime attribute to lambda.Runtime.PYTHON_3_14 to use this version.
In Python CDK:
from constructs import Construct
from aws_cdk import ( App, Stack, aws_lambda as _lambda )
class SampleLambdaStack(Stack):
def __init__(self, scope: Construct, id: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
base_lambda = _lambda.Function(self, 'python314LambdaFunction',
handler='lambda_handler.handler',
runtime=_lambda.Runtime.PYTHON_3_14,
code=_lambda.Code.from_asset('lambda'))
In TypeScript CDK:
import * as cdk from 'aws-cdk-lib';
import * as lambda from 'aws-cdk-lib/aws-lambda'
import * as path from 'path';
import { Construct } from 'constructs';
export class SampleLambdaStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// The code that defines your stack goes here
// The python3.14 enabled Lambda Function
const lambdaFunction = new lambda.Function(this, 'python314LambdaFunction', {
runtime: lambda.Runtime.PYTHON_3_14,
memorySize: 512,
code: lambda.Code.fromAsset(path.join(__dirname, '/../lambda')),
handler: 'lambda_handler.handler'
})
}
}
At launch, new Lambda runtimes receive less usage than existing established runtimes. This can result in longer cold start times due to reduced cache residency within internal Lambda sub-systems. Cold start times typically improve in the weeks following launch as usage increases. As a result, AWS recommends not drawing conclusions from side-by-side performance comparisons with other Lambda runtimes until the performance has stabilized. Since performance is highly dependent on workload, customers with performance-sensitive workloads should conduct their own testing instead of relying on generic test benchmarks.
Conclusion
Lambda now supports Python 3.14 as a managed language runtime to help developers build more efficient, powerful, and scalable serverless applications. Python 3.14 language additions include data model improvements, typing changes, and updates to the standard library. The Lambda managed runtime does not include the option to disable the global interpreter lock (GIL) or use the experimental JIT compiler.
You can build and deploy functions using Python 3.14 using the AWS Management Console, AWS CLI, AWS SDK, AWS SAM, AWS CDK, or your choice of infrastructure as code tool. You can also use the Python 3.14 container base image if you prefer to build and deploy your functions using container images.
Try the Python 3.14 runtime in Lambda today and experience the benefits of this updated language version.
Today, AWS announced Amazon Managed Workflows for Apache Airflow (MWAA) Serverless. This is a new deployment option for MWAA that eliminates the operational overhead of managing Apache Airflow environments while optimizing costs through serverless scaling. This new offering addresses key challenges that data engineers and DevOps teams face when orchestrating workflows: operational scalability, cost optimization, and access management.
With MWAA Serverless you can focus on your workflow logic rather than monitoring for provisioned capacity. You can now submit your Airflow workflows for execution on a schedule or on demand, paying only for the actual compute time used during each task’s execution. The service automatically handles all infrastructure scaling so that your workflows run efficiently regardless of load.
Beyond simplified operations, MWAA Serverless introduces an updated security model for granular control through AWS Identity and Access Management (IAM). Each workflow can now have its own IAM permissions, running on a VPC of your choosing so you can implement precise security controls without creating separate Airflow environments. This approach significantly reduces security management overhead while strengthening your security posture.
In this post, we demonstrate how to use MWAA Serverless to build and deploy scalable workflow automation solutions. We walk through practical examples of creating and deploying workflows, setting up observability through Amazon CloudWatch, and converting existing Apache Airflow DAGs (Directed Acyclic Graphs) to the serverless format. We also explore best practices for managing serverless workflows and show you how to implement monitoring and logging.
How does MWAA Serverless work?
MWAA Serverless processes your workflow definitions and executes them efficiently in service-managed Airflow environments, automatically scaling resources based on workflow demands. MWAA Serverless uses the Amazon Elastic Container Service (Amazon ECS) executor to run each individual task on its own ECS Fargate container, on either your VPC or a service-managed VPC. Those containers then communicate back to their assigned Airflow cluster using the Airflow 3 Task API.
Figure 1: Amazon MWAA Architecture
MWAA Serverless uses declarative YAML configuration files based on the popular open source DAG Factory format to enhance security through task isolation. You have two options for creating these workflow definitions:
Write your workflows directly in YAML using AWS managed operators from the Amazon Provider Package
This declarative approach provides two key benefits. First, since MWAA Serverless reads workflow definitions from YAML it can determine task scheduling without running any workflow code. Second, this allows MWAA Serverless to grant execution permissions only when tasks run, rather than requiring broad permissions at the workflow level. The result is a more secure environment where task permissions are precisely scoped and time limited.
Service considerations for MWAA Serverless
MWAA Serverless has the following limitations that you should consider when deciding between serverless and provisioned MWAA deployments:
Operator support
MWAA Serverless only supports operators from the Amazon Provider Package.
To execute custom code or scripts, you’ll need to use AWS services, such as:
Note: Throughout this post, we use example values that you’ll need to replace with your own:
Replace amzn-s3-demo-bucket with your S3 bucket name
Replace 111122223333 with your AWS account number
Replace us-east-2 with your AWS Region. MWAA Serverless is available in multiple AWS Regions. Check the List of AWS Services Available by Region for current availability.
Creating your first serverless workflow
Let’s start by defining a simple workflow that gets a list of S3 objects and writes that list to a file in the same bucket. Create a new file called simple_s3_test.yaml with the following content:
For this workflow to run, you must create an Execution role that has permissions to list and write to the above bucket. The role also needs to be assumable from MWAA Serverless. The following CLI commands create this role and its associated policy:
AWS has published a conversion tool that uses the open-source Airflow DAG processor to serialize Python DAGs into YAML DAG factory format. To install, you run the following:
Note that, because the YAML conversion is done after the DAG parsing, the loop that creates the tasks is run first and the resulting static list of tasks is written to the YAML document with their dependencies.
Migrating an MWAA environment’s DAGs to MWAA Serverless
You can take advantage of a provisioned MWAA environment to develop and test your workflows and then move them to serverless to run efficiently at scale. Further, if your MWAA environment is using compatible MWAA Serverless operators, then you can convert all of the environment’s DAGs at once. The first step is to allow MWAA Serverless to assume the MWAA Execution role via a trust relationship. This is a one-time operation for each MWAA Execution role, and can be performed manually in the IAM console or using an AWS CLI command as follows:
MWAA Serverless workflow execution status is returned via the GetWorkflowRun function. The results from that will return details for that particular run. If there are errors in the workflow definition, they are returned under RunDetail in the ErrorMessage field as in the following example:
MWAA Serverless task logs are stored in the CloudWatch log group /aws/mwaa-serverless/<workflow id>/ (where /<workflow id> is the same string as the unique workflow id in the ARN of the workflow). For specific task log streams, you will need to list the tasks for the workflow run and then get each task’s information. You can combine these operations into a single CLI command.
After completing these steps, verify in the AWS Management Console that all resources have been properly removed. Remember that CloudWatch Logs are retained by default and may need to be deleted separately if you want to remove all traces of your workflow executions.
If you encounter any errors during cleanup, verify you have the necessary permissions and that resources exist before attempting to delete them. Some resources may have dependencies that require them to be deleted in a specific order.
Conclusion
In this post, we explored Amazon MWAA Serverless, a new deployment option that simplifies Apache Airflow workflow management. We demonstrated how to create workflows using YAML definitions, convert existing Python DAGs to the serverless format, and monitor your workflows.
MWAA Serverless offers several key advantages:
No provisioning overhead
Pay-per-use pricing model
Automatic scaling based on workflow demands
Enhanced security through granular IAM permissions
Simplified workflow definitions using YAML
To learn more MWAA Serverless, review the documentation.
The weeks before AWS re:Invent, my team is full steam ahead preparing content for the conference. I can’t wait to meet you at one of my three talks: CMP346 : Supercharge AI/ML on Apple Silicon with EC2 Mac, CMP344: Speed up Apple application builds with CI/CD on EC2 Mac, and DEV416: Develop your AI Agents and MCP Tools in Swift.
Last week, AWS announced three new AWS Heroes. The AWS Heroes program recognizes a vibrant, worldwide group of AWS experts whose enthusiasm for knowledge-sharing has a real impact within the community. Welcome to the community, Dimple, Rola, and Vivek.
We also opened the GenAI Loft in Tel Aviv, Israel. AWS Gen AI Lofts are collaborative spaces and immersive experiences for startups and developers. The Loft content is tailored to address local customer needs – from startups and enterprises to public sector organizations, bringing together developers, investors, and industry experts under one roof.
AWS Network Load Balancer (NLB) now supports QUIC protocol in passthrough mode – This provides ultra-low latency traffic forwarding with session stickiness using QUIC Connection IDs. This capability reduces application latency by 25-30% for mobile-first applications through minimized handshakes and connection resilience. NLB operates in passthrough mode, forwarding QUIC traffic directly to targets while maintaining customer control over TLS certificates and end-to-end encryption. The blog post has the details.
Application Load Balancer (ALB) support client credential flow with JWT verification – This one is important for API developers too. This simplifies the deployment of secure machine-to-machine (M2M) and service-to-service (S2S) communications. This provides ALB with the ability to verify JWTs, reducing architectural complexity and simplifying security implementation.
AWS KMS now supports Edwards-curve Digital Signature Algorithm (EdDSA) – This capability provides 128-bit security equivalent to NIST P-256 with faster signing performance and compact sizes (64-byte signatures, 32-byte public keys). Ed25519 is ideal for IoT devices and blockchain applications requiring small key and signature sizes.
Amazon DCV now supports Amazon EC2 Mac instances – This provides high-performance remote desktop access with 4K resolution and 60 FPS performance. You can connect from Windows, Linux, macOS, or web clients with features including time zone redirection and audio output.
Make your web apps hands-free with Amazon Nova Sonic – Amazon Nova Sonic, a foundation model from AAmazon Bedrock, provides you with the ability to create natural, low-latency, bidirectional speech conversations for applications. This provides users with the ability to collaborate with applications through voice and embedded intelligence, unlocking new interaction patterns and enhancing usability. This blog post demonstrates a reference app, Smart Todo App. It shows how voice can be integrated to provide a hands-free experience for task management.
AWS X-Ray SDKs & Daemon migration to OpenTelemetry – AWS X-Ray is transitioning to OpenTelemetry as its primary instrumentation standard for application tracing. OpenTelemetry-based instrumentation solutions are recommended for producing traces from applications and sending them to AWS X-Ray. X-Ray’s existing console experience and functionality continue to be fully supported and remains unchanged by this transition.
Powering the world’s largest events: How Amazon CloudFront delivers at scale – Amazon CloudFront achieved a record-breaking peak of 268 terabits per second on November 1, 2025, during major game delivery workloads—enough bandwidth to simultaneously stream live sports in HD to approximately 45 million concurrent viewers. This milestone demonstrates the CloudFront massive scale, powered by 750+ edge locations across 440+ cities globally and 1,140+ embedded PoPs within 100+ ISPs, with the latest generation delivering 3x the performance of previous versions.
Upcoming AWS events Check your calendars so that you can sign up for these upcoming events:
AWS Builder Loft – A community tech space in San Francisco where you can learn from expert sessions, join hands-on workshops, explore AI and emerging technologies, and collaborate with other builders to accelerate your ideas. Browse the upcoming sessions and join the events that interest you.
AWS Community Days – Join community-led conferences that feature technical discussions, workshops, and hands-on labs led by experienced AWS users and industry leaders from around the world. I will deliver the opening keynote at the last Community Day of the year in Kinshasa, Democratic Republic of Congo (November 22). The next Community Day will be in Timişoara, România (April 2026). The call for papers is now open.
Today, AWS Lambda is promoting Rust support from Experimental to Generally Available. This means you can now use Rust to build business-critical serverless applications, backed by AWS Support and the Lambda availability SLA.
Rust is a popular programming language due to its combination of high performance, memory safety, and developer experience. It offers speed and memory utilization efficiency comparable with C++, together with the reliability normally associated with higher-level languages.
This post shows you how to build and deploy Rust-based Lambda functions using Cargo Lambda, a third-party open source tool for working with Lambda functions in Rust. We’ll also cover how to deploy your functions using the Cargo Lambda AWS Cloud Development Kit (AWS CDK) construct.
Rust installed on your development machine (version 1.70 or later)
Node.js 20 or later (for AWS CDK deployment)
AWS CDK installed: npm install -g aws-cdk
Solution overview
This post takes you through the following steps:
Install and configure Cargo Lambda.
Create and deploy a basic HTTP Lambda function using Cargo Lambda.
Build a complete serverless API using AWS CDK with Rust Lambda functions.
Install and configure Cargo Lambda
Cargo is the package manager and build system for Rust. Cargo Lambda is a third-party open source extension to the cargo command-line tool that simplifies building and deploying Rust Lambda functions.
To install Cargo Lambda on Linux systems, run:
curl -fsSL https://cargo-lambda.info/install.sh | sh
main.rs – The function entry point where you configure dependencies and shared state
http_handler.rs – The primary function logic
The main.rs file contains the following code:
use lambda_http::{run, service_fn, tracing, Error};
mod http_handler;
use http_handler::function_handler;
#[tokio::main]
async fn main() -> Result<(), Error> {
tracing::init_default_subscriber();
run(service_fn(function_handler)).await
}
The key part of the main.rs file is run(service_fn(function_handler)).await. The run function is part of the http_lambda crate and starts the Lambda Rust runtime interface client (RIC), which actively polls for events from the Lambda Runtime API. The function_handler is the function that is defined in the http_handler.rs file. When the Runtime API returns the invoke event, the RIC calls the function_handler from http_handler.rs:
use lambda_http::{Body, Error, Request, RequestExt, Response};
pub(crate) async fn function_handler(event: Request) -> Result<Response, Error> {
// Extract some useful information from the request
let who = event
.query_string_parameters_ref()
.and_then(|params| params.first("name"))
.unwrap_or("world");
let message = format!("Hello {who}, this is an AWS Lambda HTTP request");
// Return something that implements IntoResponse.
// It will be serialized to the right response event automatically by the runtime
let resp = Response::builder()
.status(200)
.header("content-type", "text/html")
.body(message.into())
.map_err(Box::new)?;
Ok(resp)
}
The function_handler function signature includes a variable event of type Request. The event contents depend on the service triggering the function. For example, it may contain HTTP request information such as path parameters if the request is coming via HTTP, or even an array of Amazon Kinesis stream records.
For non-HTTP functions, events can be strongly typed. Additionally, you can accept any structure as input as long as it implements serde::Serialize and serde::Deserialize.
The example parses query parameters and looks for the first parameter that has the name name.
The lambda_http crate provides an idiomatic way to return a response, using a builder pattern. The function returns a response as a Result with an Ok() which is what the run function in main.rs expects.
Logging
The main.rs file includes the following line by default:
tracing::init_default_subscriber();
The Rust Lambda runtime integrates natively with Tracing libraries for logging and tracing, and supports JSON structured logging. When setting this line and the RUST_LOG environment variable, Lambda sends logs to Amazon CloudWatch. By default, the INFO log level is enabled.
To write logs, use the tracing crate and send events using the following syntax:
tracing::info("This is a log entry");
Building
To build the Lambda function, use cargo lambda build. When compiling the Lambda function, the AWS Lambda Runtime is built into your binary. The compiled binary file is called bootstrap. It is packaged in the function artifact .zip file and visible as a file in the AWS Lambda console.
When Lambda executes this binary, it starts an infinite loop (the Run function). This polls the Lambda Runtime API to receive the invoke request and then calls your handler, the function_handler function.
Your function code runs and then sends the function response back to the Lambda Runtime API, which forwards it onto the caller.
Testing
Before deploying the function, you can debug/test the function locally using cargo lambda.
cargo lambda watch sets up an environment that emulates the Lambda execution environment. This allows you to send requests to the Lambda function and see the results.
To send invocation requests, you can use either cargo lambda or send a curl request to the Lambda emulator.
To use cargo lambda, run the following, replace <lambda-function-name> with hi_api for this example
Once you have built the function using cargo lambda build, you can deploy it to your AWS account.
To deploy your function:
cargo lambda deploy
Once the Lambda function is deployed, you can test it remotely. cargo lambda invoke tests the remote Lambda function using a payload stored in a .json file:
You can create a serverless API in front of this Rust Lambda function using Amazon API Gateway. This example uses the AWS CDK. This example does not have authentication configured for the API Gateway endpoint as it is a sample. The AWS best practice is to implement relevant security controls where necessary.
First, create a new CDK project:
mkdir rusty_cdk
cd rusty_cdk
cdk init --language=typescript
The easiest way to deploy a Rust Lambda function using the AWS CDK is to use the cargo lambdaCDK Construct. This comes with everything required to run Rust Lambda functions on AWS. It is part of the cargo lambda project.
Install the Cargo Lambda CDK construct:
npm i cargo-lambda-cdk
Create a new HTTP Lambda function in your project:
mkdir lambda
cd lambda
cargo lambda new helloRust
When prompted for Is this function an HTTP function?, enter y.
Update your CDK stack lib/rusty_cdk-stack.ts to include both the Lambda function and API Gateway.
import * as cdk from 'aws-cdk-lib';
import { HttpApi } from 'aws-cdk-lib/aws-apigatewayv2';
import { HttpLambdaIntegration } from 'aws-cdk-lib/aws-apigatewayv2-integrations';
import { HttpMethod } from 'aws-cdk-lib/aws-events';
import { RustFunction } from 'cargo-lambda-cdk';
import { Construct } from 'constructs';
export class RustyCdkStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const helloRust = new RustFunction(this, 'helloRust',{
manifestPath: './lambda/helloRust',
runtime: 'provided.al2023',
timeout: cdk.Duration.seconds(30),
});
const api = new HttpApi(this, 'rustyApi');
const helloInteg = new HttpLambdaIntegration('helloInteg', helloRust);
api.addRoutes({
path: '/hello',
methods: [HttpMethod.GET],
integration: helloInteg,
})
new cdk.CfnOutput(this, 'apiUrl',{
description: 'The URL of the API Gateway',
value: `https://${api.apiId}.execute-api.${this.region}.amazonaws.com`,
})
}
}
Bootstrap your AWS account and AWS Region for the AWS CDK:
cdk bootstrap
Deploy your stack:
cdk deploy
Testing the API
To test your deployed API using the URL provided in the AWS CDK output:
curl https://<YOUR_API_URL>/hello
Clean up
To avoid ongoing charges, remove the deployed resources:
cdk destroy
Conclusion
AWS Lambda support for Rust is now Generally Available to build high-performance, memory-efficient serverless applications. Cargo Lambda is a third-party extension to the Rust cargo CLI which simplifies the experience of developing, testing, and deploying Rust applications to Lambda.
To learn more about building serverless applications with Rust:
This blog post highlights notable Java language features, Java Lambda runtime updates, and how you can use the new Java 25 runtime in your serverless applications.
Java 25 language features
Java 25 introduces several language features to enhance developer productivity. There is a new feature that allows statements to appear before an explicit constructor invocation. You can now write code in the constructors without having to invoke super(…) or this(…) as the first statement. In the following example, the Employee class has a constructor which validates the input first and then invokes super(...):
class Person {
int age;
Person(int age) {
if (age < 0)
throw new IllegalArgumentException("Age cannot be negative");
this.age = age;
}
}
class Employee extends Person {
String name;
Employee(String name, int age) {
// This is now allowed - code before super()
if (age < 18 || age > 67)
throw new IllegalArgumentException(...);
super(age);
this.name = name;
}
}
Java 25 supports pattern matching that can handle primitive types in switch and instanceof statements. Previously, pattern matching was limited to reference types (Objects). For example, you can now perform pattern matching with int values, not just Integer objects:
void primitivePatternMatching(Object obj) {
if (obj instanceof int i) {
System.out.println("This is an int: " + i);
}
}
Module import declarations simplifies working with. Instead of writing multiple individual package imports from the same module, you can use the import module syntax to bring publicly exported types into scope. This reduces boilerplate code and makes it easier to work with modular applications. Previously if you used the java.net.http module, you had to import multiple classes with individual import statements:
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
public class HttpClientExample {
public void makeRequest() {
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://api.example.com"))
.build();
// ... rest of implementation
}
}
Now you can import the whole java.net.http module:
import module java.net.http;
public class HttpClientExample {
public void makeRequest() {
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://api.example.com"))
.build();
// Exported types from java.net.http module are now available
}
}
Garbage collection
The generational mode of the Shenandoah garbage collector changes from an experimental feature in Java 24 to an optional product feature. Shenandoah is the low pause time garbage collector that reduces pause times by performing more garbage collection work concurrently with the running Java program. Shenandoah does the bulk of GC work concurrently, including the concurrent compaction, which means its pause times are no longer directly proportional to the size of the heap. The generational mode of Shenandoah improves sustainable throughput, load-spike resilience, and memory utilization.
To use the generational model of Shenandoah in Lambda, set JAVA_TOOL_OPTIONS to -XX:+UseShenandoahGC -XX:ShenandoahGCMode=generational.
Lambda runtime updates
The Java 25 runtime includes several performance optimizations, tuned to optimize cold and warm start performance for a broad range of customer workloads. Cold start refers to the initialization delay that occurs when Lambda prepares a new execution environment for a function that hasn’t been invoked recently, or to process an incoming invoke when all existing execution environments are in use. Warm start refers to invokes that are allocated to a previously initialized execution environment.
Ahead-of-Time (AOT) caches
Starting with Java 25, AWS Lambda replaces the traditional Class Data Sharing (CDS) with ahead-of-time (AOT) caches. This is an advanced optimization feature from Project Leyden that is designed to improve application startup times and reduce memory footprint. Lambda’s benchmarking results show that AOT caches deliver faster cold start performance compared to CDS.
AOT caches are enabled by default to provide performance benefits. Since you cannot use both AOT caches and CDS, if you enable CDS in your Lambda function, then Lambda disables AOT caches. If you use your own custom AOT caches in the Java 25 managed runtime, then the caches may be invalidated when Lambda updates the Java runtime during routine patching. AWS strongly suggests that you don’t use custom AOT caches with managed runtimes.
If you deploy Java 25 functions using container images, you can either implement your own AOT caches or continue using CDS. Since container images are immutable, the issue of AOT caches being invalidated following automatic runtime patching does not arise. To enable AOT caches, pass the flag -XX:AOTCache=/path/to/aot/cache/file via the JAVA_TOOL_OPTIONS environment variable. To enable CDS, pass the flag -Xshare:on -XX:SharedArchiveFile=/var/lang/lib/server/runtime.jsa.
Tiered compilation
Java’s tiered compilation is a just-in-time (JIT) optimization strategy that employs multiple compiler tiers to enhance the performance of frequently executed code progressively using runtime profiling data. Since Java 17, AWS Lambda has modified the default JVM behavior by stopping compilation at the C1 tier (client compiler). This minimizes cold start times for function invocations for most functions, although for compute-intensive functions with a long duration, customers can benefit from tuning tiered compilation to their workload. Starting with Java 25, Lambda no longer stops tiered compilation at C1 for SnapStart and Provisioned Concurrency. This improves performance in these cases without incurring a cold start penalty since tiered compilation occurs outside of the invoke path in these cases.
Priming
Priming is another technique to optimize performance for functions using either SnapStart or Provisioned Concurrency. This involves preloading dependencies, initializing resources, and executing code paths during function initialization. This front-loads work and triggers JIT compilation before taking the SnapStart snapshot, or when Provisioned Concurrency execution environments are pre-provisioned. The result is faster code execution when these execution environments are used for a function warm invoke. For detailed guidance on implementing priming strategies, see the Optimizing cold start performance of AWS Lambda using advanced priming strategies with SnapStart blog post.
Log4j patch for Log4Shell
Log4j is a widely used open source logging library maintained by the Apache Software Foundation. In November 2021, Log4j reported Log4Shell, a zero-day vulnerability involving arbitrary code execution. The Lambda team responded by deploying an emergency patch across all Java runtimes to protect customers from potential exploitation. However, this emergency patch introduced a performance overhead during cold starts. The vulnerability was permanently resolved in Log4j version 2.17.0 in December 2021. Consequently, AWS has removed this patch from the Java 25 runtime to restore optimal performance. You must verify you are using Log4j version 2.17.0 or later.
Lambda runtimes for Java 8, 11, 17, and 21 continue to enable the emergency patch by default. Customers who are using Log4j version 2.17.0 or higher with these runtimes can disable this patch, improving cold start performance. To disable the patch, set the AWS_LAMBDA_DISABLE_CVE_2021_44228_PROTECTION environment variable to true.
Additional performance considerations
At launch, new Lambda runtimes receive less usage than existing, established runtimes. This can result in longer cold start times due to reduced cache residency within internal Lambda sub-systems. Cold start times typically improve in the weeks following launch as usage increases. As a result, AWS recommends not drawing conclusions from side-by-side performance comparisons with other Lambda runtimes until the performance has stabilized.
Since performance is highly dependent on workload, customers with performance-sensitive workloads should conduct their own testing instead of relying on generic test benchmarks. To maximize performance, your workload may benefit from additional workload-specific performance tuning.
Using Java 25 in AWS Lambda
You can use Java 25 for your Lambda functions in the AWS Management Console, an AWS Lambda container image, AWS SAM, or the AWS CDK.
AWS Management Console
To use the Java 25 runtime to develop your Lambda functions, specify a runtime parameter value Java 25 when creating or updating a function. The Java 25 runtime version is now available in the Runtime dropdown menu on the Create function page in the AWS Lambda console:
Creating Java 25 function in AWS Management Console
To update an existing Lambda function to Java 25, navigate to the function in the Lambda console, then choose Java 25 in the Runtime settings section. The new version is available in the Runtime dropdown menu:
Changing a function to Java 25
AWS Lambda container image
Use the Java base image version with the java:25 tag by modifying the FROM statement in your Dockerfile.
Example Dockerfile:
FROM public.ecr.aws/lambda/java:25
# Copy function code and runtime dependencies from Maven layout
COPY target/classes ${LAMBDA_TASK_ROOT}
COPY target/dependency/* ${LAMBDA_TASK_ROOT}/lib/
# Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile)
CMD [ "com.example.myapp.App::handleRequest" ]
AWS SAM supports generating this template with Java 25 for new serverless applications using the sam init command. Refer to the AWS SAM documentation.
AWS Cloud Development Kit (AWS CDK)
In the AWS CDK, set the runtime attribute to Runtime.JAVA_25 to use this version.
import software.amazon.awscdk.core.Construct;
import software.amazon.awscdk.core.Stack;
import software.amazon.awscdk.core.StackProps;
import software.amazon.awscdk.services.lambda.Code;
import software.amazon.awscdk.services.lambda.Function;
import software.amazon.awscdk.services.lambda.Runtime;
public class InfrastructureStack extends Stack {
public InfrastructureStack(final Construct parent, final String id, final StackProps props) {
super(parent, id, props);
Function.Builder.create(this, "HelloWorldFunction")
.runtime(Runtime.JAVA_25)
.code(Code.fromAsset("target/hello-world.jar"))
.handler("helloworld.App::handleRequest")
.memorySize(1024)
.build();
// rest of your CDK code
}
}
Conclusion
Lambda now supports Java 25 as a managed language runtime or with your own custom runtime. This release includes the latest Java 25 language features as well as performance enhancements optimized for Lambda workloads.
You can build and deploy functions using Java 25 using the AWS Management Console, AWS CLI, AWS SDK, AWS SAM, AWS CDK, or your choice of infrastructure as code tool. You can also use the Java container base image with the 25 tag if you prefer to build and deploy your functions using container images.
The Java 25 runtime helps developers build more efficient, powerful, and scalable serverless applications. Read about the Java programming model in the Lambda documentation to learn more about writing functions in Java 25.
AWS re:Invent 2025, the premier cloud computing conference hosted by Amazon Web Services (AWS), returns to Las Vegas, Nevada, December 1–5, 2025. At AWS, security is our top priority, and re:Invent 2025 reflects this commitment with our most comprehensive security track to date. With more than 80 security aligned sessions spanning breakouts, workshops, chalk talks, and hands-on builders’ sessions, we’re bringing together the brightest minds to share insights, best practices, and innovative solutions. For security professionals, developers, and cloud architects, the event offers valuable insights into the latest security innovations at AWS, advanced threat protection capabilities, and defense strategies that scale. While attending re:Invent, you can visit the Security kiosk and AI Security kiosk at the expo hall to engage directly with AWS security experts about your specific needs.
The security track session selection process was driven by our extensive analysis of customer needs and real-world implementation challenges. We specifically focused on security areas where customers seek the most guidance and coalesced the sessions around four major themes: Securing and Leveraging AI, Architecting Security and Identity at scale,Building and scaling a Culture of Security, and Innovations in AWS Security. Our goal with the sessions is to address immediate security challenges and help you achieve broader business outcomes. In the following sections, we highlight a few key sessions in each of the four themes. You can visit the re:Invent catalog for a view of all sessions.
Securing and leveraging AI
Securing and using AI emerges as a dominant theme for the Security and Identity track, reflecting both the opportunities and challenges AI presents. From protecting AI workloads to harnessing AI for enhanced security operations, sessions span multiple AI topics to help organizations navigate this transformative technology safely and effectively. Here are a few key sessions on each of the AI topics.
Securing AI workloads
Breakout SEC410 – Advanced AI Security: Architecting Defense-in-Depth for AI Workloads: Dive deep into advanced security architectures for AI workloads, exploring how to protect your workload against sophisticated attack vectors. Through technical examples, we’ll implement secure architectures for AI workloads, covering identity, fine-grained access policies, and secure foundation model deployment patterns. Learn how to harden generative and agentic AI applications using AWS security capabilities, implementing least-privilege controls, and building secure architectures at scale.
Workshop SEC406 –Red teaming your generative AI and MCP applications at scale: Step into the shoes of an AI-powered red team adversary in the GenAI Red Team Challenge. In this intensive workshop, you’ll deploy an AI security agent to orchestrate sophisticated threat chains against Model Context Protocol (MCP) applications, systematically discovering vulnerabilities. Master countermeasures from prompt templating and guardrails to OAuth-enhanced MCP security configurations that prevent unauthorized access. This hands-on, gamified experience helps you think like a threat actor and equips you with practical skills in automated vulnerability testing and risk mitigation against common MITRE and OWASP vulnerabilities for LLM-based applications. You must bring your laptop to participate.
Security for Agentic AI
ChalkTalk SEC408 –Securing Agentic AI: OWASP, MAESTRO, and Real-World Defense Strategies: Explore the latest in Agentic AI security with OWASP’s updated Threats and Mitigations Guide and Agentic Security Initiative. We will also explore MAESTRO, a specialized threat modeling approach for AI systems, offering a layered methodology to identify and mitigate risks throughout the AI lifecycle. Through a real-world case study, we’ll demonstrate security best practices for agentic AI, including robust governance, continuous monitoring, and least-privilege access. Learn how to confidently deploy autonomous AI agents while minimizing risks. Gain practical insights for building secure, trustworthy, and resilient agentic AI applications that can transform industries safely.
Workshop SEC307 – Design authentication, authorization, and logging logic in Agentic AI apps: This hands-on workshop addresses the critical challenge of managing identities and permissions for generative AI agents. Learn to implement user and machine authentication, along with fine-grained authorization mechanisms, tailored for AI agents, tools, and LLMs. Explore consent management and permission delegation in AI contexts. Participants will gain practical experience using AWS’s latest services, including Strands SDK, Amazon Bedrock AgentCore Identity, Amazon Cognito for identity management, and Amazon Verified Permissions for authorization decisions. By the end, you’ll have the skills to enhance security and compliance in your AI operations using AWS’s cutting-edge identity and access management solutions.
Using AI for security
Builders SEC318– Strengthen your network security with generative AI: Transform how you manage network security using the power of generative AI. See how Amazon Q Developer helps you explore AWS Shield Network Security Director findings through natural language conversations. Learn to quickly identify misconfigured resources, understand security issues, and implement guided fixes across your AWS environment.
Chalktalk SEC304 – Building an AI-Powered security guardian for your Cognito applications: Elevate your application security with an intelligent AI-Powered security guardian to protect your Amazon Cognito-authenticated applications. In this interactive session, we’ll explore identity best practices and building an AI agent using Amazon Bedrock AgentCore to help verify best practices, perform detective analysis, and take automated preventative actions to mitigate risks. We’ll talk through how an AI agent can perform dynamic WAF rule adjustments, modify authentication flows, and perform security operations center (SOC) actions. Bring your questions and scenarios as we deep dive into how to implement AI-driven security controls for your Cognito protected applications.
Building and Scaling Culture of Security
This theme is woven throughout the re:Invent 2025 security track, reflecting the belief that technological solutions alone cannot ensure robust security outcomes. Enterprises with a Culture of Security become security-first organizations, after which they can accelerate secure digital transformations. Some of the sessions that showcase this theme are:
Breakout SEC319 – Climbing the AI Mountain With Your Security Team: Navigate the intersection of AI and security culture in this practical session. Learn how security teams can effectively embrace AI innovation through incremental steps and validation techniques. Using real-world examples, we’ll demonstrate how security practitioners can adapt their skills to AI challenges regardless of their level of specialized expertise and share strategies for building security-aware AI practices. From understanding generative and agentic AI-specific security risks to creating engaging team exercises, discover how to transform security from a potential bottleneck into an enabler of responsible AI innovation. Attendees will leave with actionable insights for building a security-first approach to AI adoption.
Chalktalk SEC343 – Fostering a Resilient Incident Response Culture: Discover how to combine human expertise with intelligent automation in security incident response. Learn how AWS Security Incident Response, auto-triaging capabilities, and generative AI work together to augment—not replace—your team’s decision-making. We’ll explore how integrating AWS Security Incident Response and generative AI into your workflows can reduce alert fatigue, accelerate accurate incident classification, and enable responders to focus on critical analysis. See how leading organizations balance automation with human oversight, creating more efficient and resilient incident response processes while maintaining the crucial elements of human judgment and institutional knowledge. Uncover practical strategies for integrating AI-driven insights with human expertise in your incident response culture.
Chalktalk SEC227 – Translating Security Metrics into Business Outcomes: Today CISOs face the challenge of translating complex security data into business value. This session reveals proven frameworks for transforming security metrics into strategic insights that drive boardroom decisions. Learn how leading organizations leverage AWS Security Hub, OpenSearch and Security Analytics and automation to build real-time risk dashboards that demonstrate security’s business impact. Walk away with practical strategies for evolving your security program from operational metrics to business outcomes, enabling data-driven investment decisions and measurable risk reduction that resonates with executives.
Architecting Security and Identity at scale
This theme explores how you can use the comprehensive toolset and proven patterns provided by AWS to implement enterprise-grade security controls that scale from individual workloads to global organizations. Some key sessions on this theme include:
ChalkTalk SEC333 – From Static to Dynamic: Modernizing AWS Access Management: Building a robust AWS identity foundation requires moving beyond static credentials. This session deep dives into proven patterns for implementing dynamic, temporary access across your AWS organization. We’ll explore real-world challenges of access key dependencies and share practical approaches to transition towards ephemeral credentials using IAM roles and SAML federation. Through practical examples and lessons learned, discover how to implement secure authentication patterns that scale while reducing operational overhead. Walk away with actionable strategies to strengthen your identity perimeter and modernize your access management approach.
Workshop SEC401 – Active defense strategies using AWS Al/ML services: This workshop will help you learn how to develop and deploy active defense strategies, such as deception, using Amazon Bedrock and Amazon SageMaker. Gain hands-on experience developing AI-driven responses for security operations. You will learn how to develop adaptive responses that mimic what an actor may be trying use against you. Discover implementation patterns for prompt engineering, deployment strategies, and monitoring methodologies. You must bring your laptop to participate.
Workshop SEC303 –Advanced AWS Network Security: Building Scalable Production Defenses: In this hands-on workshop, master AWS network security techniques to defend against today’s most critical threats. Learn to implement layer 7 capabilities and deep packet inspection using AWS Network Firewall and Route 53 Resolver DNS Firewall, securing both internet-bound and internal traffic flows. Gain practical experience in configuring scalable, reliable filtering to combat zero-day attacks and ransomware, while also implementing sophisticated east-west traffic controls to prevent lateral movement. Through real-world scenarios, you’ll learn to leverage IDS/IPS filtering, domain-based controls, and principle of least privilege using fully managed AWS services. Leave equipped to build resilient network defenses against modern cyber threats.
Innovations in AWS Security
AWS innovation in security capabilities is designed to help organizations outpace evolving threats. From advanced threat detection powered by machine learning to revolutionary data protection mechanisms, these innovations demonstrate the AWS commitment to keeping customers secure in an evolving landscape. Some of the innovation-focused sessions are:
Breakout SEC203–State of the Art: AWS data protection in 2025 (ft. Vanguard): Join AWS Cryptography leaders for a comprehensive tour of 2025’s groundbreaking security innovations. Discover the latest launches across Cloudfront, KMS, Private CA, and Secrets Manager, showcasing AWS’s implementation of NIST-standardized post quantum cryptography. Learn how we’re revolutionizing cloud security through quantum-resistant algorithms, advanced certificate management, and automated secrets handling. Get an inside look at Vanguards enterprise-wide PQC migration and how they made it a strategic business priority. See firsthand how AWS continues raising the bar on data protection for your most sensitive workloads.
Breakout SEC323 – AWS detection and response innovations that drive security outcomes: Discover how the latest AWS detection and response capabilities can help secure your cloud environment more effectively. Learn practical ways to achieve integrated security outcomes through enhanced threat detection, automated vulnerability management, and streamlined response—all at scale. We’ll show you how to use AWS security services to protect workloads and data, centralize security monitoring, manage security posture continuously, and unify security data, while leveraging generative AI for security operations. Walk away with actionable insights for integrating AWS detection and response services to strengthen and simplify security across your AWS environment.
Breakout SEC310 – Innovations in Infrastructure Protection to strengthen your network: In this session, learn about new capabilities in infrastructure protection services like AWS Network Firewall, Amazon Route 53 DNS Firewall, AWS WAF, and AWS Shield, to simplify your application protection, streamline robust egress protections and gain insight into your network. Dive deep into how new visibility investments can give insight into misconfigurations, possible threats, and proactive identification of network configuration issues.
Conclusion
Don’t miss this opportunity to enhance your cloud security knowledge and connect with AWS security experts and industry peers. For a full view of the Security and Identity sessions, explore the AWS re:invent catalog where you can filter sessions by topic, areas of interest, role, and so on.
When you register, you’ll gain access to the session reservation system where you can reserve your seats. Popular security sessions, especially hands-on sessions, fill up quickly because of limited capacity, so we recommend reserving your preferred sessions as soon as scheduling opens. See you are re:Invent!
If you have feedback about this post, submit comments in the Comments section below.
Are you ready to maximize your Well-Architected and Cloud Optimization learning and networking time at re:Invent 2025? We have put together this comprehensive guide to help you plan your schedule and make the most of the Well-Architected and cloud optimization sessions available this year. These sessions will deliver the practical guidance your teams need to lead strategic cloud initiatives, design next-generation architectures, optimize costs, or secure AI-powered systems.
Key themes at re:Invent for Well-Architected and Cloud Optimization – You can expect to see the following themes at re:Invent 2025
AI-powered architecture and governance
The sessions in this theme showcase how AWS is integrating AI technologies to transform traditional architectural practices. From using AI services for automated Well-Architected reviews to implementing self-evolving systems with agentic AI, these sessions demonstrate how you can use AI to automate architectural decisions, streamline governance processes, and scale best practices across the enterprise.
Well-Architected Framework evolution and implementation
These sessions highlight how the AWS Well-Architected Framework has evolved beyond its original scope to address modern architectural challenges. Attendees will learn how to implement the framework principles across different domains—from IoT security to backup strategies—while focusing on enterprise-scale governance and compliance.
The cost optimization track focuses on innovative approaches to cloud financial management, with a strong emphasis on AI-powered FinOps solutions. Sessions range from hands-on workshops like the Frugal Architect GameDay to chalk talks on establishing effective cost governance models.
This year’s catalog features an exciting mix of content across different formats: from breakout, chalk talks, workshops, builder sessions to code talks.
Breakout sessions – Stay in the know
Sit back and enjoy these presentations to stay current with the latest solution enhancements and practical applications. AWS experts and guest speakers will share valuable insights and real-world examples.
Discover how foundational frameworks like the AWS Well-Architected Framework, AWS Cloud Adoption Framework, and AWS Cloud Operating Model evolved through customer feedback and real-world learnings from thousands of organizations, transforming from structured guidance into dynamic insights for optimizing cloud environments. Learn practical strategies for applying unified best practices to accelerate cloud transformation while managing large-scale architectural changes and maintaining operational excellence.
Move beyond proof-of-concepts to build a production-ready foundation supporting all AI applications across your organization, addressing the critical transition from experimentation to enterprise-scale AI deployment. Navigate model access and management, tool discovery, memory and state handling, and observability at scale while building foundations that seamlessly integrate model access, orchestration workflows, agents, and tools with enterprise-grade governance controls.
Enterprises face a core challenge: translating architectural vision into resilient cloud reality. See how integrating ServiceNow’s Enterprise Architecture Workspace with the AWS Well-Architected Tool transforms traditional design processes. Through elegant “shift-left” methodologies, architects gain contextual insights that seamlessly blend enterprise modeling with cloud best practices. This presentation is brought to you by ServiceNow, an AWS Partner.
Discover how AWS is using generative AI to transform customer support from reactive to proactive. We’ll show how large language models and AI agents are improving customer satisfaction and efficiency. Topics include smart case routing, context-aware support, early problem detection, and responsible AI use. We’ll share real results and discuss balancing AI capabilities with human touch.
As cloud applications grow in complexity, optimizing costs becomes crucial for developers. This session explores AWS native tools and coding practices that reduce expenses without compromising performance or scalability.
Chalk talks
AWS speakers set the stage at the beginning of the talk and then open up for discussion. Bring your questions and dive deep into the topic with AWS experts and other customers.
Learn to architect self-evolving systems using agentic AI that align with AWS Well-Architected principles, exploring cutting-edge patterns for systems that adapt, heal, and optimize themselves autonomously while maintaining architectural integrity. Implement autonomous monitoring and self-healing capabilities with Amazon Bedrock Agents, design AI-driven security controls and automated recovery mechanisms and create systems that continuously adapt to workload patterns while maintaining reliability and performance standards.
ARC317-R/R1 | Chalk talk | December 2, 3:00 PM and December 4, 1:00 PM
Navigate generative AI agent development with robust architectural practices for security and compliance, focusing on proven patterns for building production-ready agentic AI applications that meet enterprise requirements. Design agent architectures with guardrails, monitoring systems, and access controls using the AWS Well-Architected Generative AI Lens while implementing governance patterns that ensure regulatory compliance and enable systems to scale from prototype to enterprise-wide deployment.
Replace time-intensive manual processes with AI-powered systems that generate strategic recommendations, design principles, and best practices at scale while maintaining quality and consistency. Generate organization-specific design principles using AI analysis of architectural patterns, implement AI-driven guidance systems with effective quality control mechanisms, and build knowledge bases that feed AI-powered architectural guidance while maintaining human oversight and addressing ethical considerations.
ARC330-R/R1 | Chalk talk | December 2, 5:30PM and December 4, 2:30 PM
Transform prototypes into production-ready systems by incorporating security, monitoring, and CI/CD through agentic architecting, focusing on practical challenges of moving from experimental AI systems to production-grade architectures. Use AI agents to generate and optimize AWS CDK infrastructure and application code, implement automated security improvements and CI/CD pipeline creation, and maintain AWS Well-Architected principles while enabling teams to focus on business logic as AI handles infrastructure complexity.
ARC318-R/R1 | Chalk talk | December 1, 4:00 PM and December 3, 4:00 PM
Learn how intelligent agents tackle fragmented cost data and optimization processes in complex multi-account environments, moving beyond traditional FinOps approaches to autonomous, intelligent financial optimization. Architect solutions using Amazon OpenSearch Service for data aggregation and Amazon Bedrock for contextual reasoning to design secure, scalable FinOps solutions that continuously optimize costs while delivering measurable business outcomes.
Discover how Koch Industries revolutionized AWS Well-Architected reviews using generative AI, transforming weeks-long manual processes into automated, intelligent systems. Automate architectural assessments using Amazon Bedrock Knowledge Bases and Model Context Protocol (MCP) to scale best practice reviews and optimize workloads in minutes instead of days while achieving more comprehensive, consistent, and actionable recommendations through proven change management and organizational adoption strategies.
ARC323-R/R1 | Chalk talk | December 3, 11:30 AM and December 4, 2:00PM
Discover advanced governance strategies that build upon AWS Control Tower for enterprise-scale environments requiring sophisticated compliance, security, and operational controls. Implement infrastructure across six Well-Architected Foundations capabilities with critical trade-off understanding, build efficient multi-account structures balancing security requirements with innovation needs, and architect automated compliance checks and policy enforcement at scale while enabling self-service capabilities with centralized governance and security controls.
Industrial environments are reaching new levels of connectivity, automation, efficiency, and real-time data insights. However, this increased connectivity also introduces significant security challenges. Unaddressed security concerns can expose vulnerabilities and slow down companies looking to accelerate digital transformation using IoT and cloud. This chalk talk explores relevant techniques, architecture patterns, best practices and AWS security services for securing complex OT/IT environments, IoT devices, edge and cloud using the AWS Well-Architected IoT Lens and AWS Security Reference Architecture (SRA).
COP309-R/R1 | Chalk talk | December 3, 3:00 PM and December 4, 12:30 PM
Generative AI agent development demands robust architectural practices for security and compliance. This chalk talk explores proven patterns for architecting secure, efficient AI agents using the AWS Well-Architected Generative AI Lens. Through collaborative discussion and whiteboarding, examine architectural governance and best practices for production environments. Learn to design agent architectures incorporating guardrails, monitoring systems, access controls, and sustainable deployment practices. Gain actionable insights for building secure, efficient, and cost-effective agentic AI applications that scale.
Join this interactive chalk talk to solve a common challenge where monolithic applications take months to deploy new features, and scaling becomes increasingly difficult. We’ll start with a real scenario, an application running on servers with a shared database. Together, we’ll design the modernization path using Amazon ECS and Well-Architected Framework principles. You’ll explore common architecture patterns, containerization strategies, CI/CD automation, and blue/green deployment approaches for ECS. After this session, you’ll walk away with a practical roadmap to transform your monolithic application into scalable microservices. Bring your curiosity and help us build the architecture live.
Hands-on workshop and Builders’ sessions
AWS speakers will introduce the use-case and tools designed to tackle the challenge. You will follow instructions, complete the tasks, and walk away with better understanding of the capabilities.
ARC302-R | Builders’ session | December 1, 9:00 AM; December 2, 11:30 AM and December 3, 4:00 PM
Build intelligent systems that automate AWS Well-Architected Framework reviews using generative AI, transforming manual architectural assessments into continuous, intelligent governance processes. Evaluate architecture against Well-Architected pillars while incorporating organization-specific requirements, implement continuous analysis of architecture and infrastructure as code templates, and enhance AI understanding of architectural context using Model Context Protocol servers to transform time-intensive reviews into scalable, automated processes with consistent governance.
ARC301-R | Builders’ session | December 1, 8:30 AM; December 2, 3:00 PM and December 3, 10:00 AM
Tackle complex scenarios using AI-powered tools to diagnose and resolve architectural problems, gaining practical experience using AI to transform poorly designed systems into well-architected solutions. Troubleshoot and optimize architectures with scaling bottlenecks and database inefficiencies using Amazon Q, apply Well-Architected principles to enhance performance and security under pressure, and accelerate problem identification and resolution while building AWS optimization expertise and learning to identify architectural anti-patterns before they become critical issues.
Compete to implement cost efficiency improvements across multiple AWS services in this interactive GameDay, applying the Laws of the Frugal Architect to real-world scenarios for practical experience in transforming high-cost infrastructure into efficient, sustainable architectures. Address challenges spanning compute, networking, storage, serverless, and observability domains while learning to reduce cloud unit costs and improve profitability without compromising service quality through gamified scenarios that build rapid cost optimization decision-making skills.
STG313-R | Builders’ session | December 2, 1:30 PM and December 3, 8:30 AM
Enhance AWS Backup implementation using the AWS Backup Evaluator Solution, an AI agent that synthesizes data from multiple sources to provide intelligent backup optimization recommendations. Assess backup environments against the Well-Architected AWS Backup lens using Strands Agents SDK, create unified visibility across backup landscapes to identify optimization opportunities, and implement AI agents that continuously monitor backup efficiency while aligning with AWS best practices to enhance efficiency and cost-effectiveness.
Visit the AWS Cloud Support kiosk in the Venetian
Important notes:
Session dates, times, and locations listed in the post are subject to change as we continue to optimize the schedule on session popularity and venue capacity. Please check this blog post and the re:Invent session catalog regularly for the most up-to-date information about your registered sessions and newly added activities. For a full view of Well-architected content, including sessions with partners, explore the AWS re:Invent catalog and filter on the Well-Architected Framework area of interest.
Remember to reserve your seats early as popular sessions fill up quickly and bring your laptop for hands-on builders’ sessions and workshops. Register today
About the authors
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.

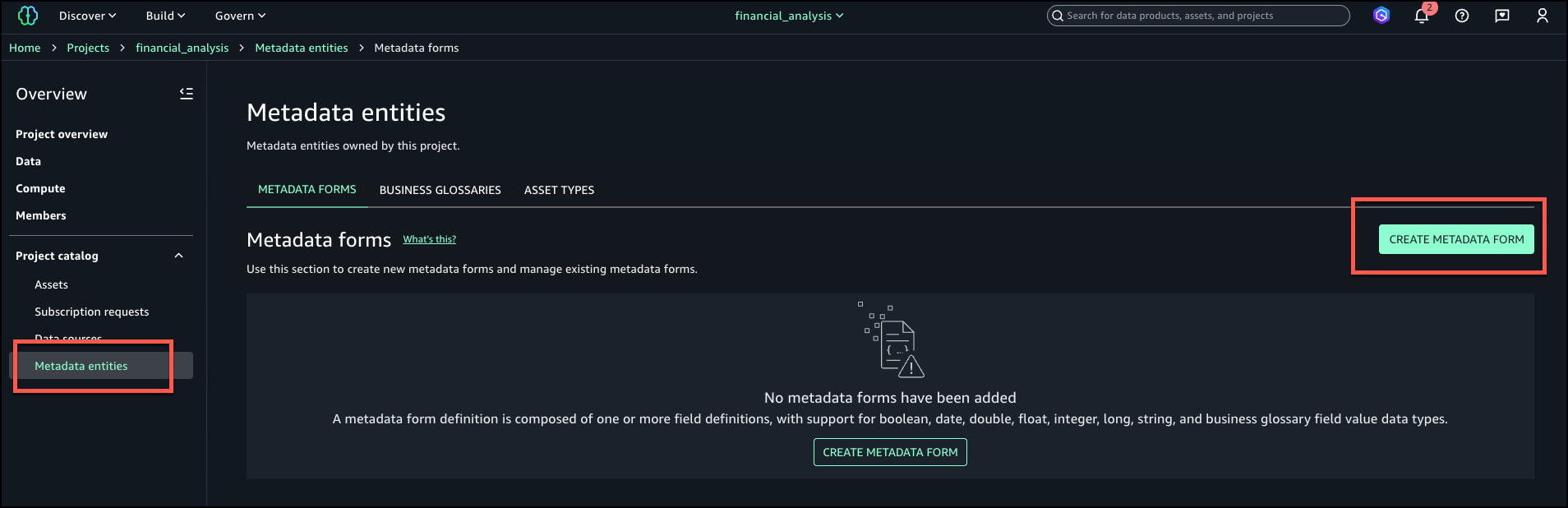
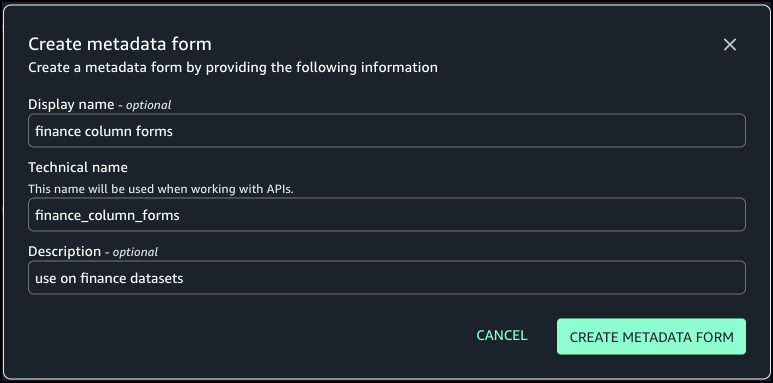
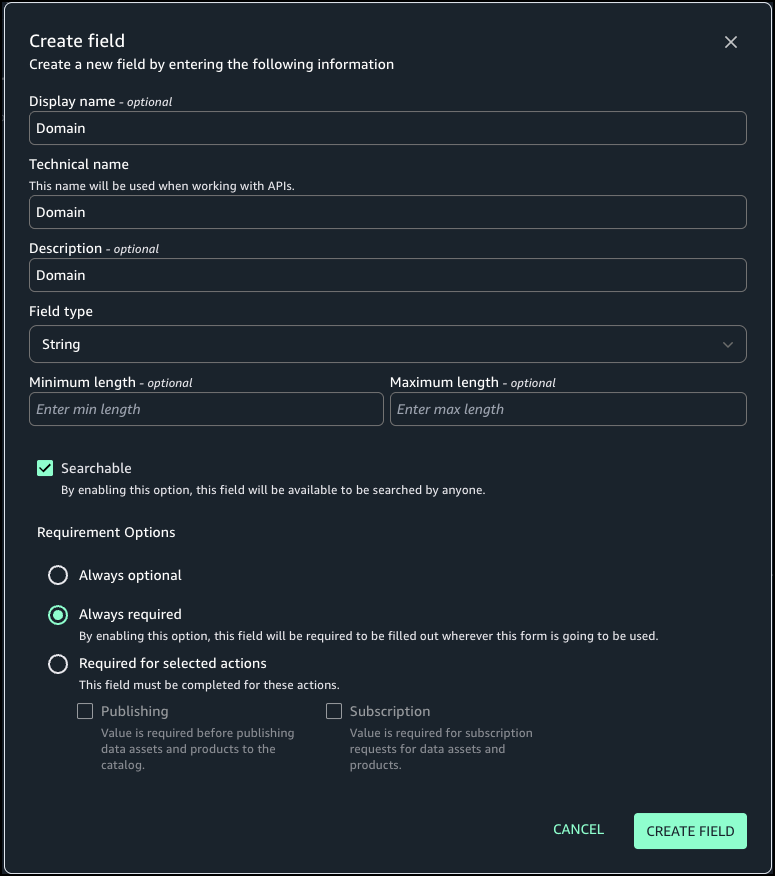

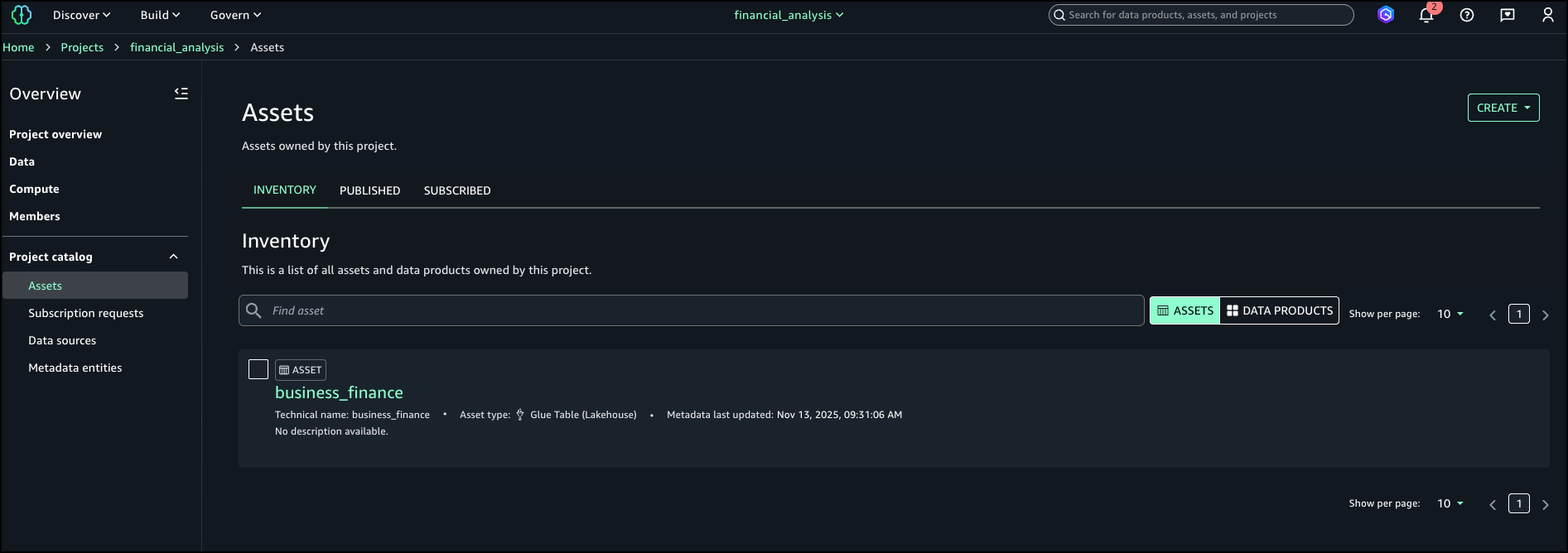
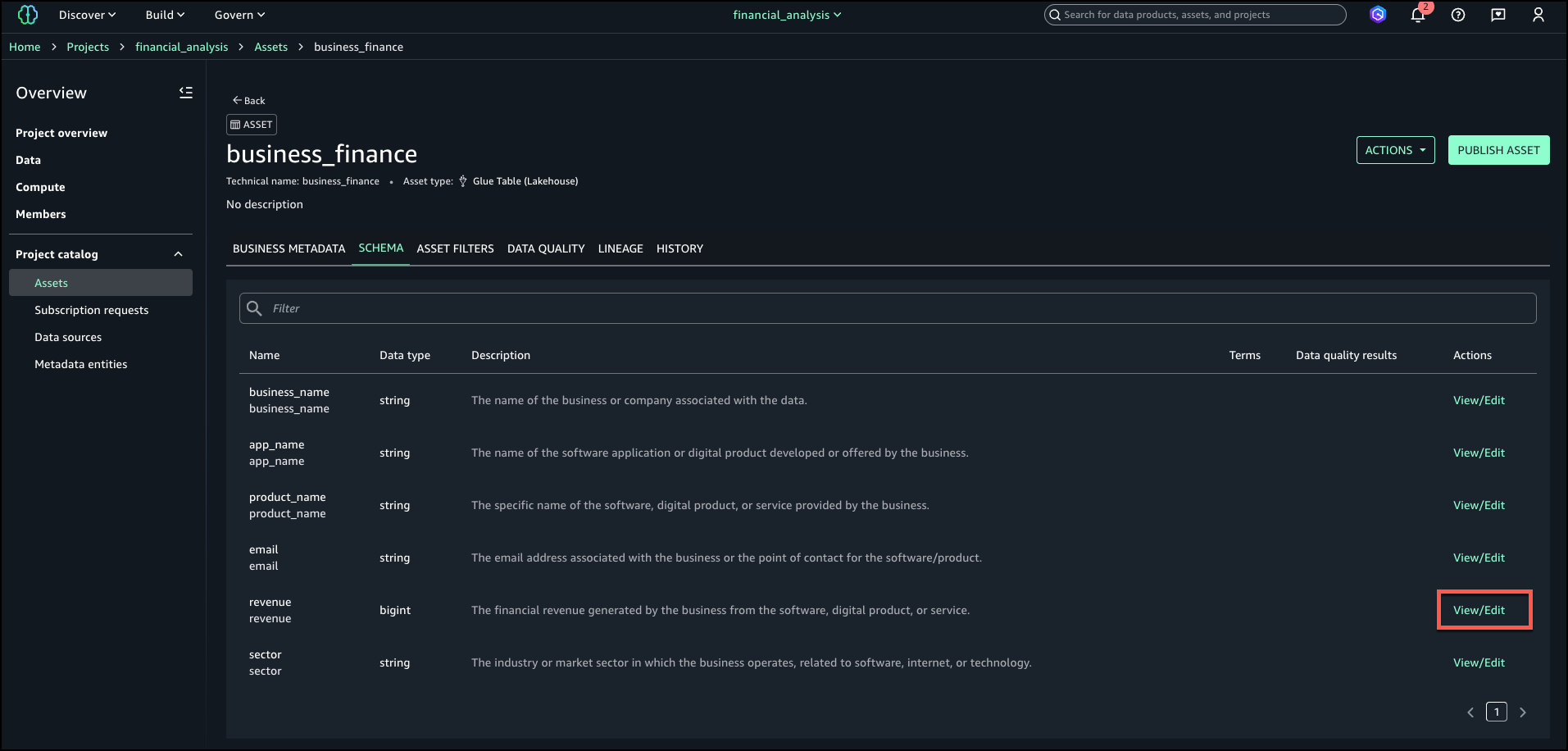
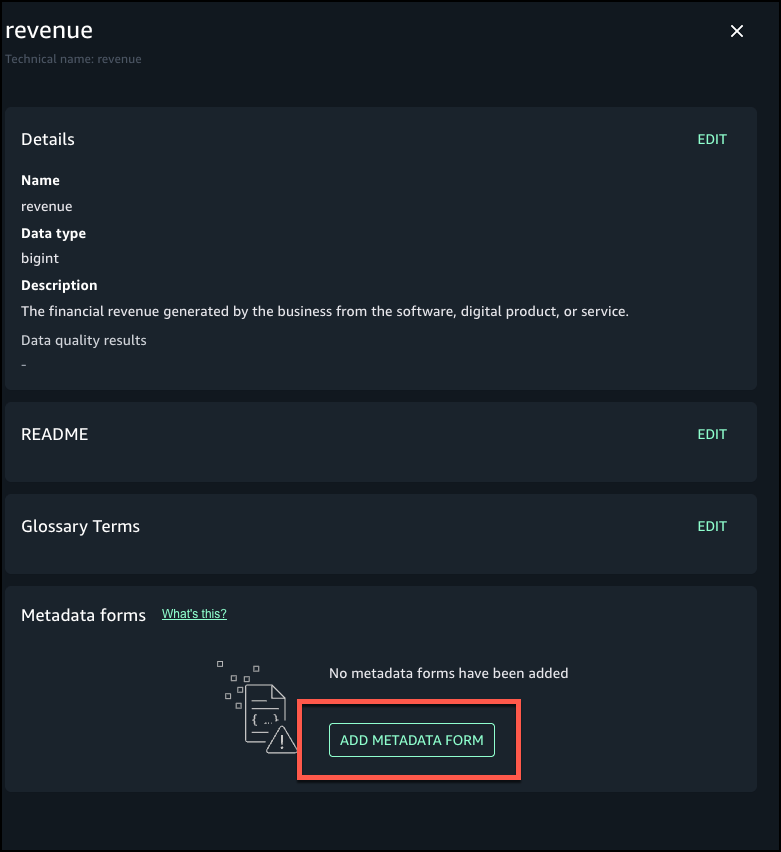

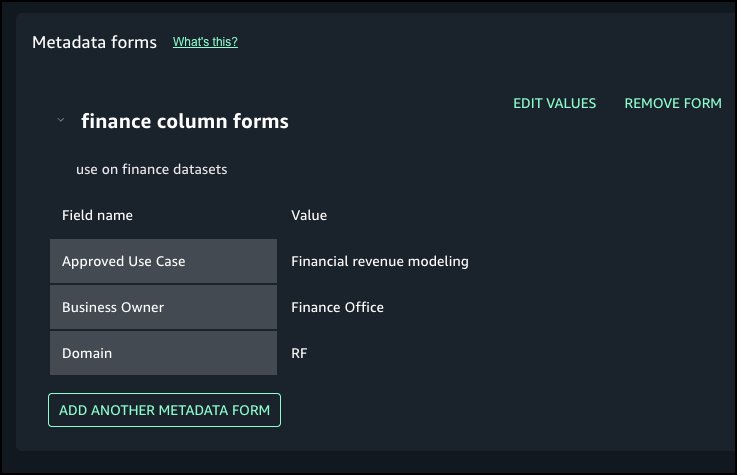
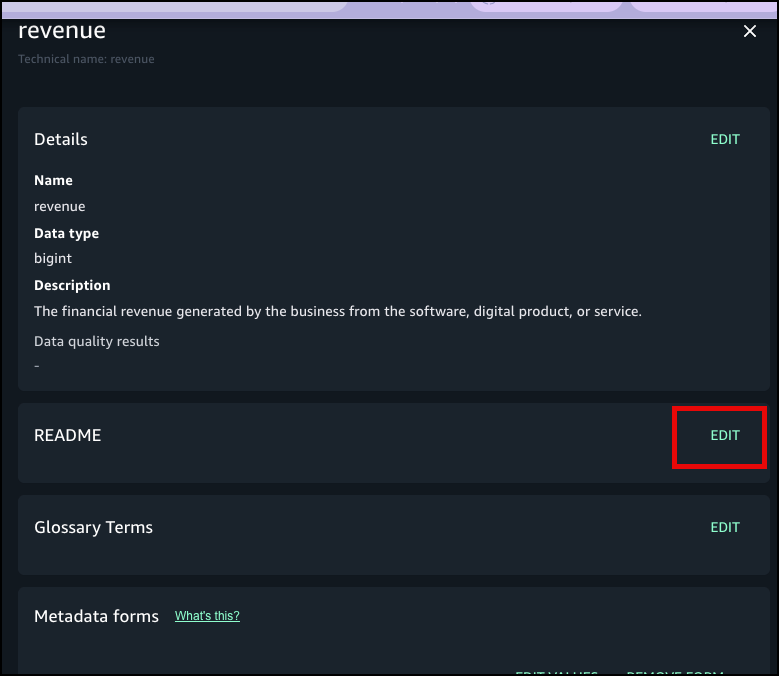
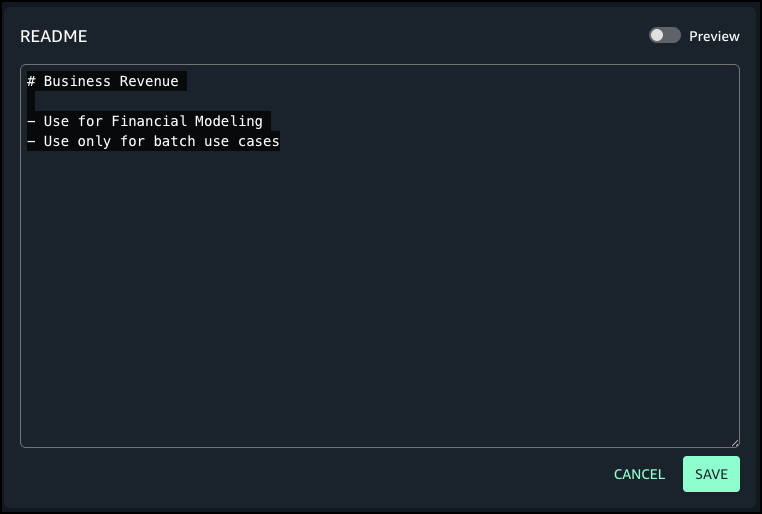
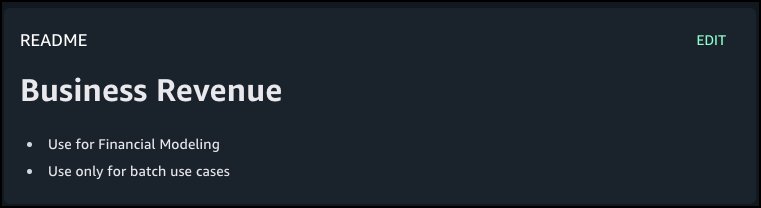
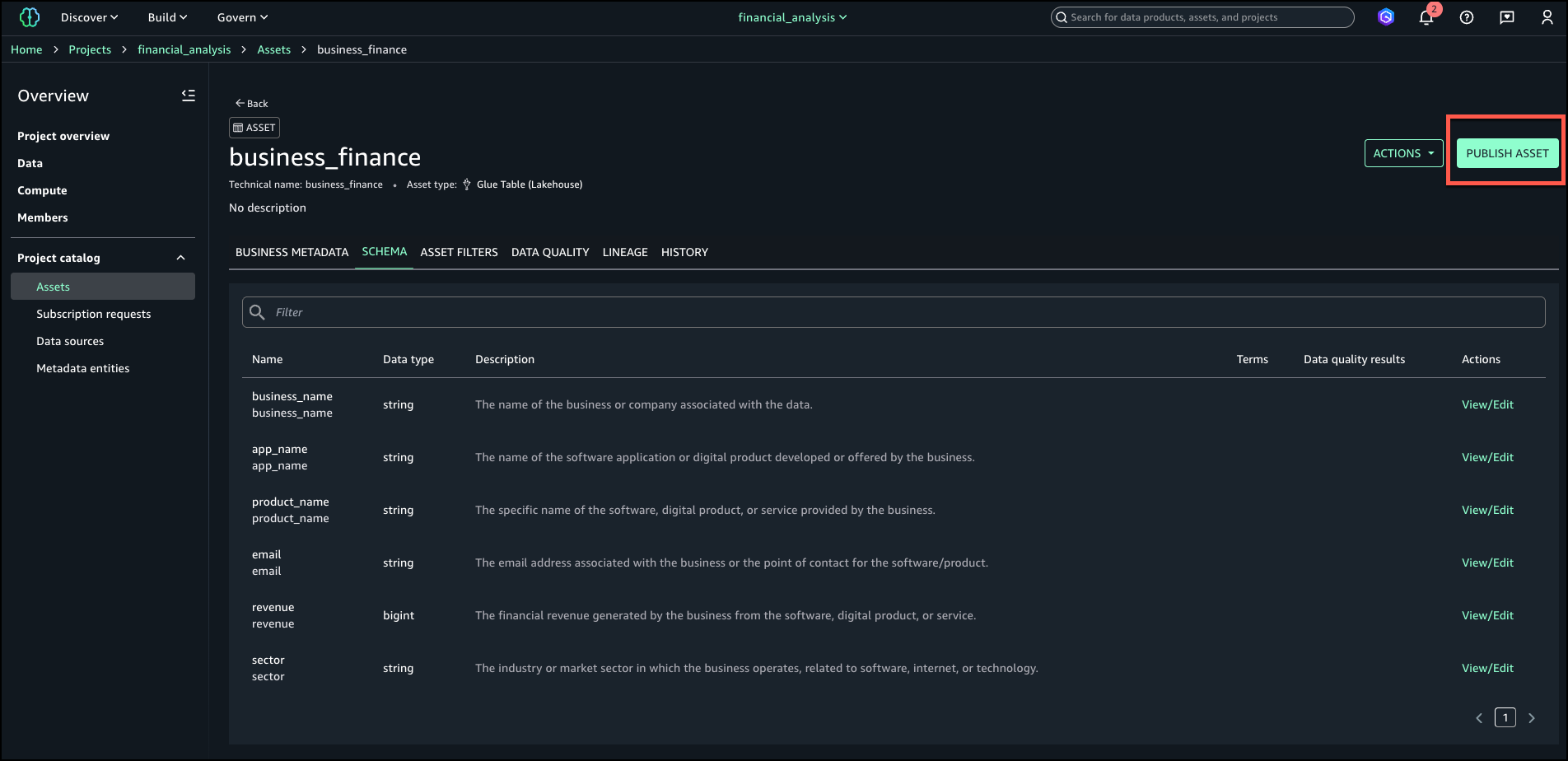
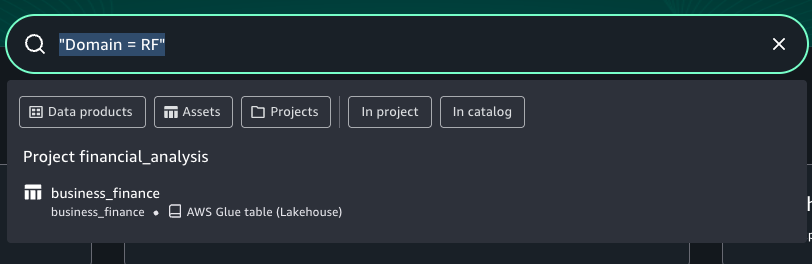

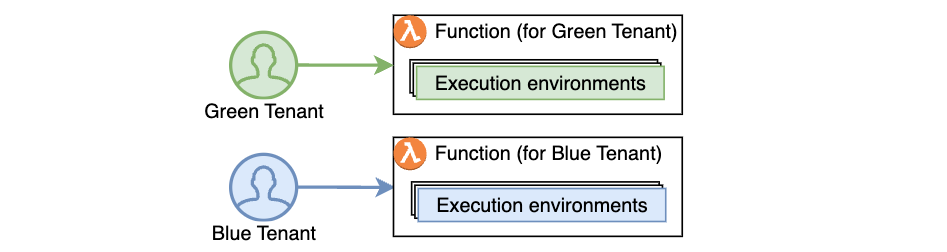
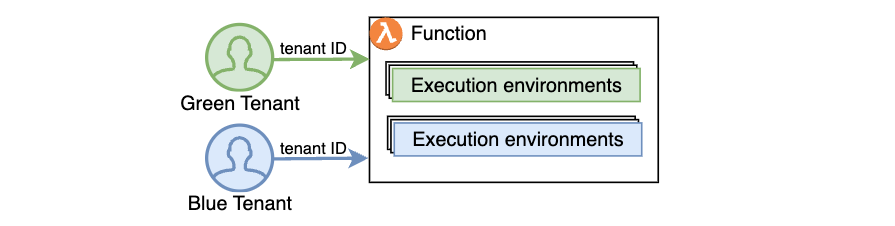
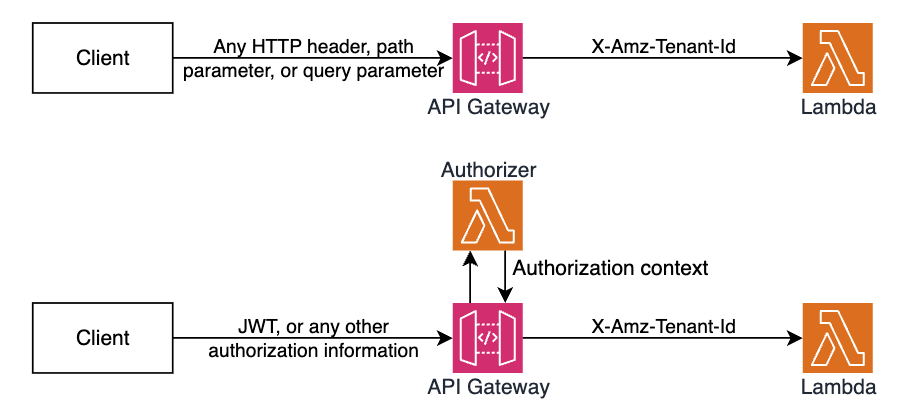
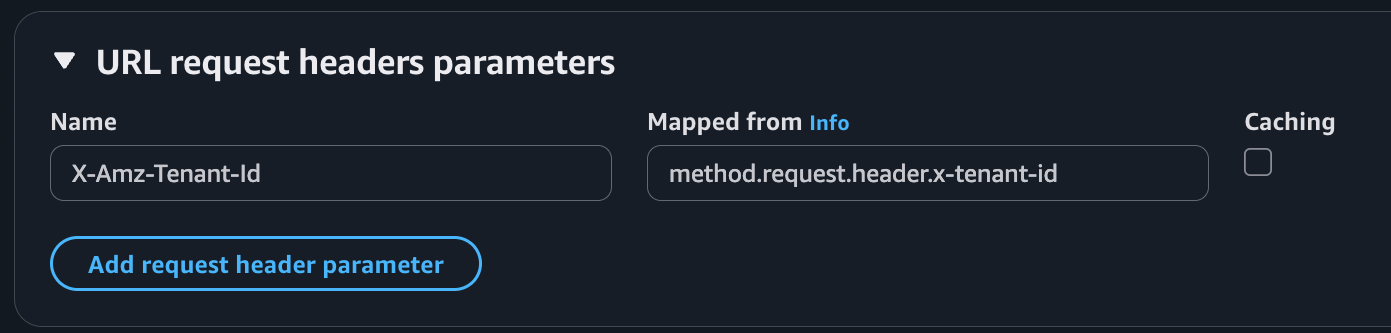
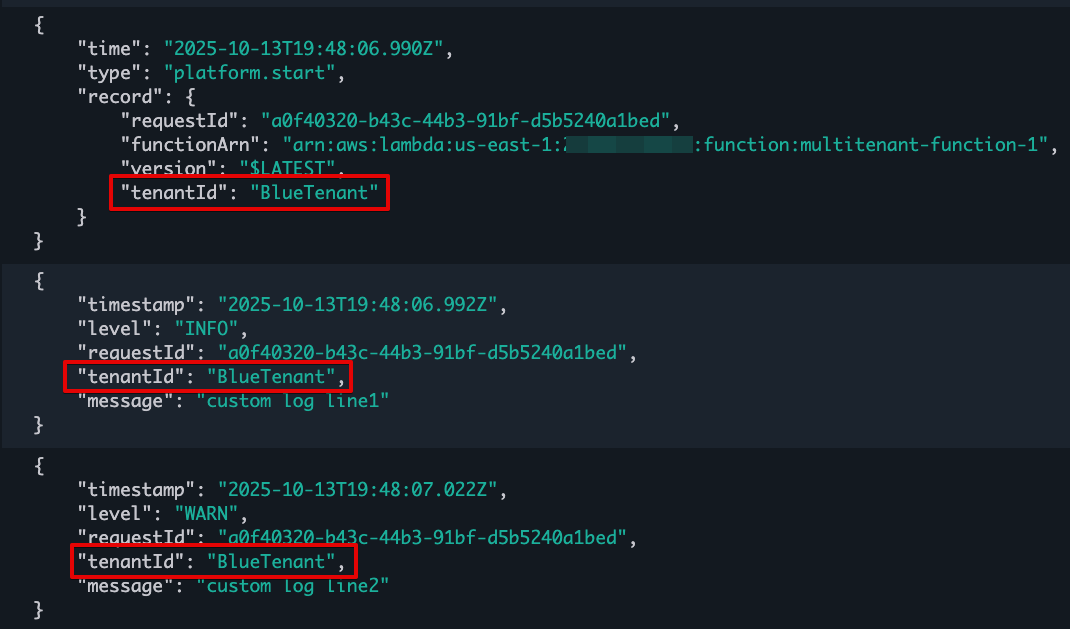
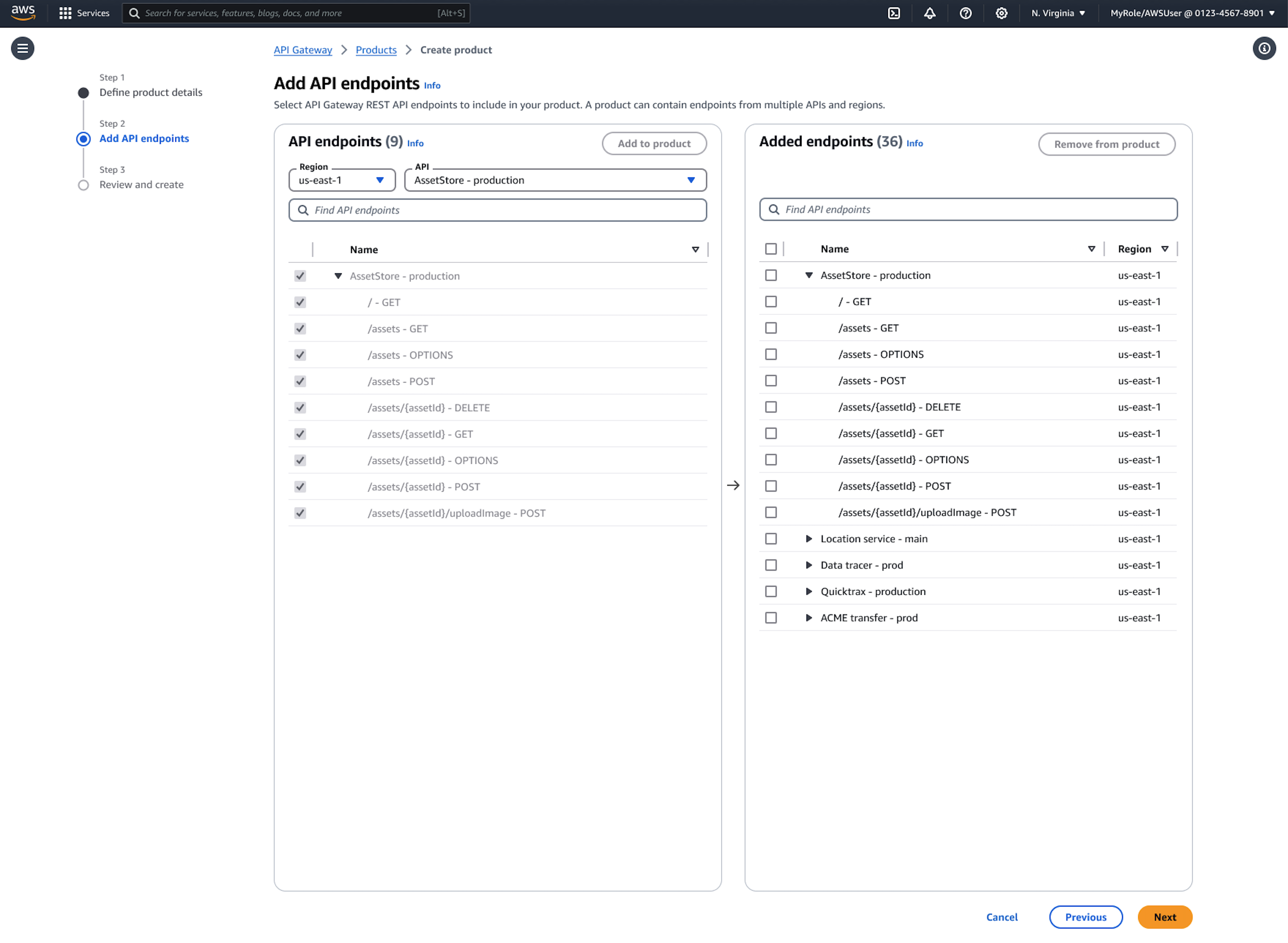
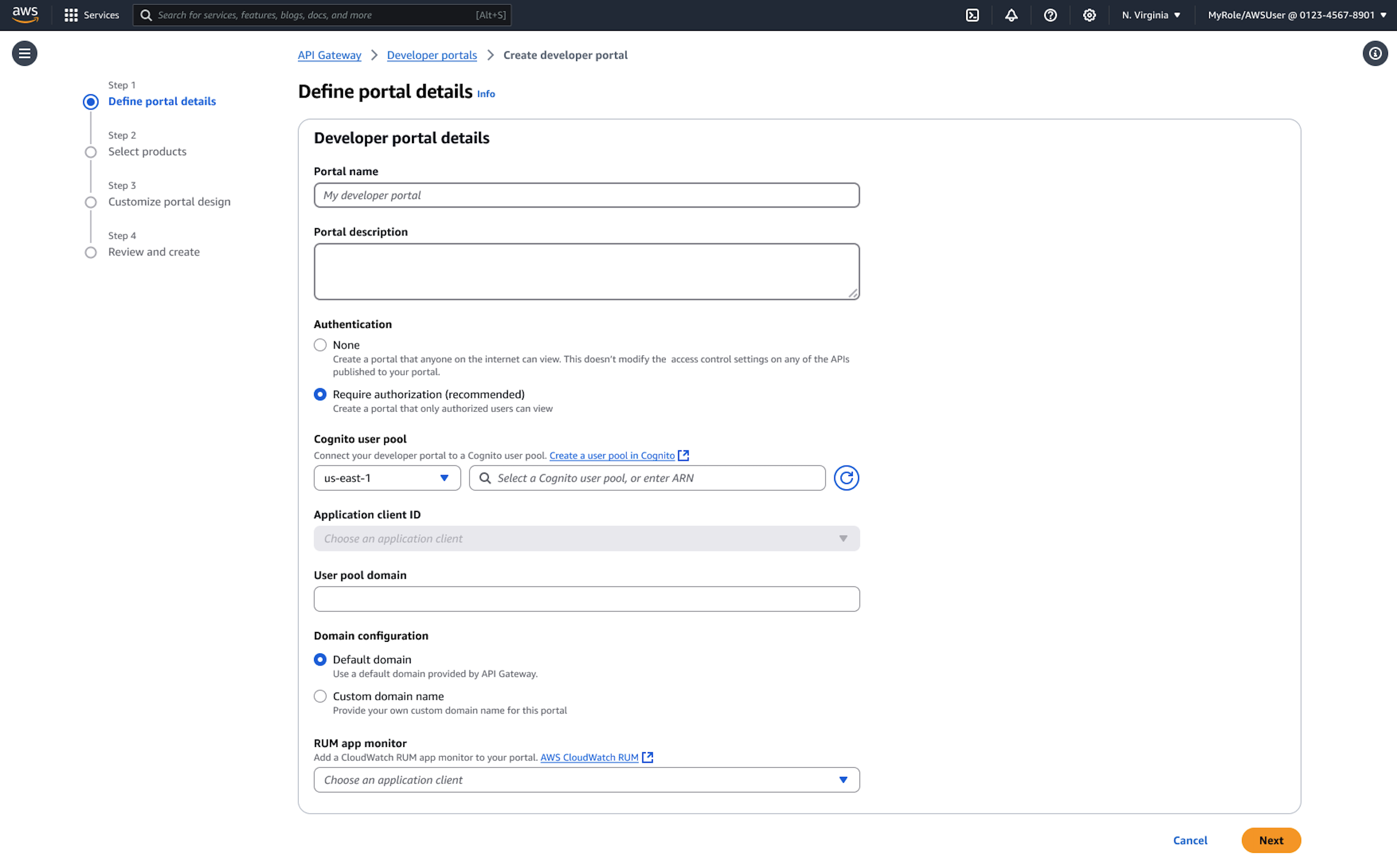
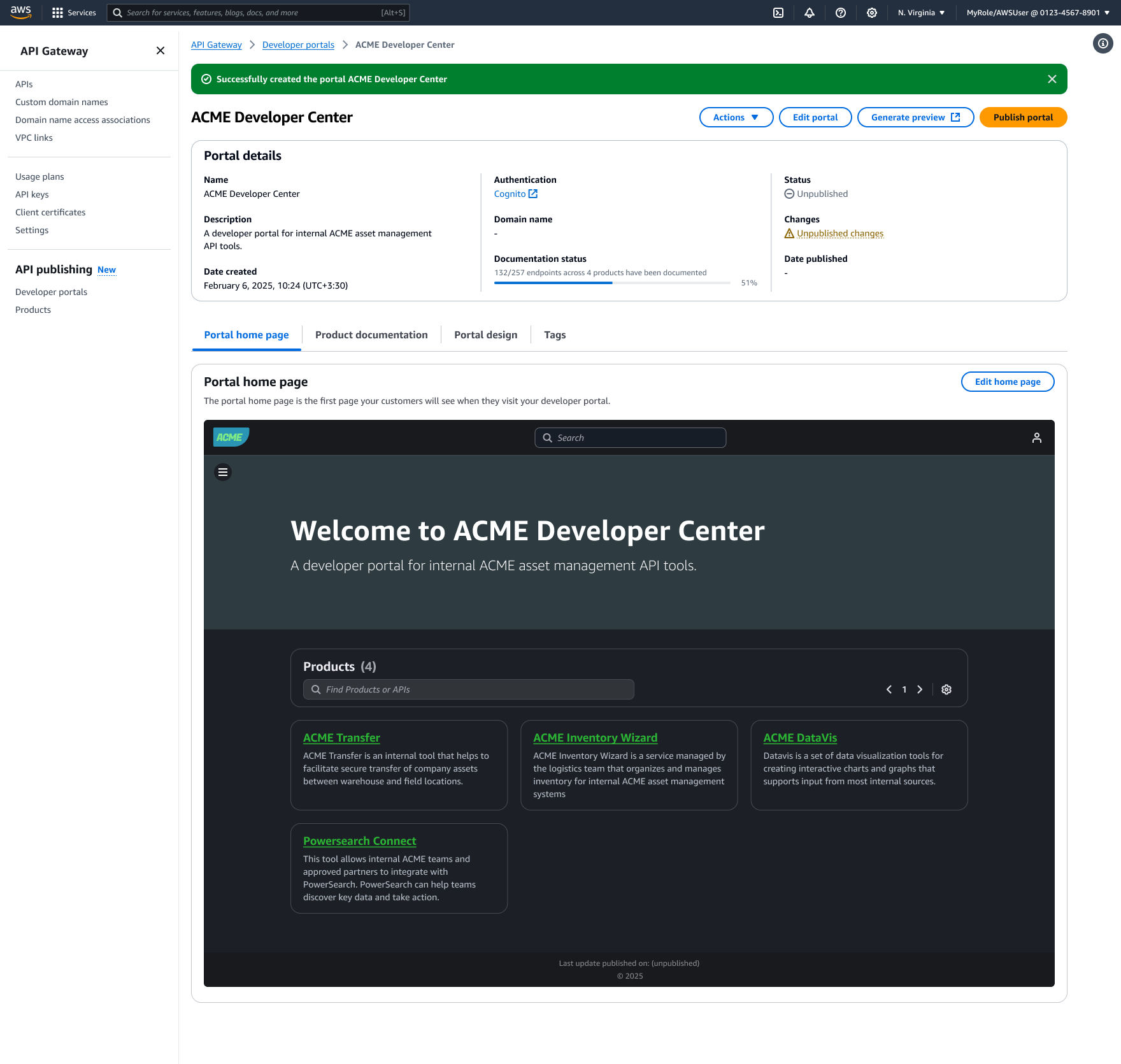
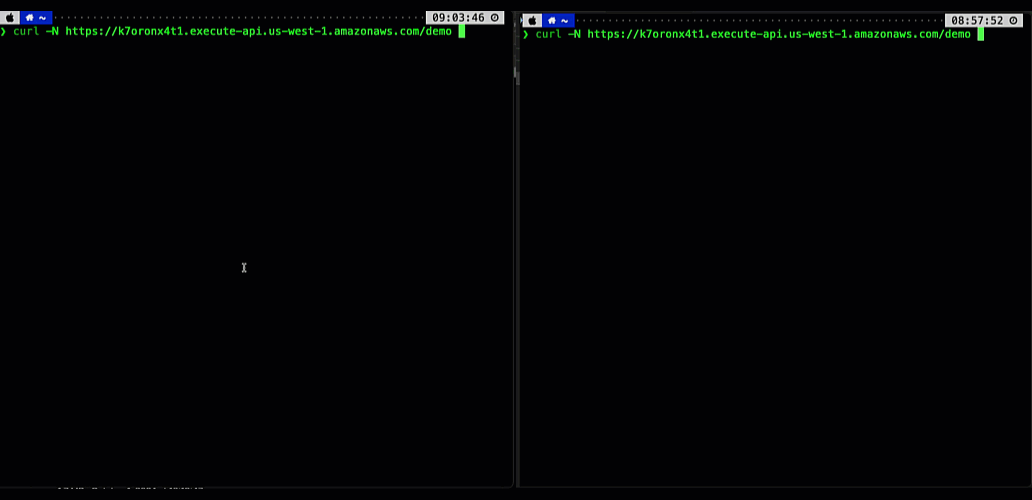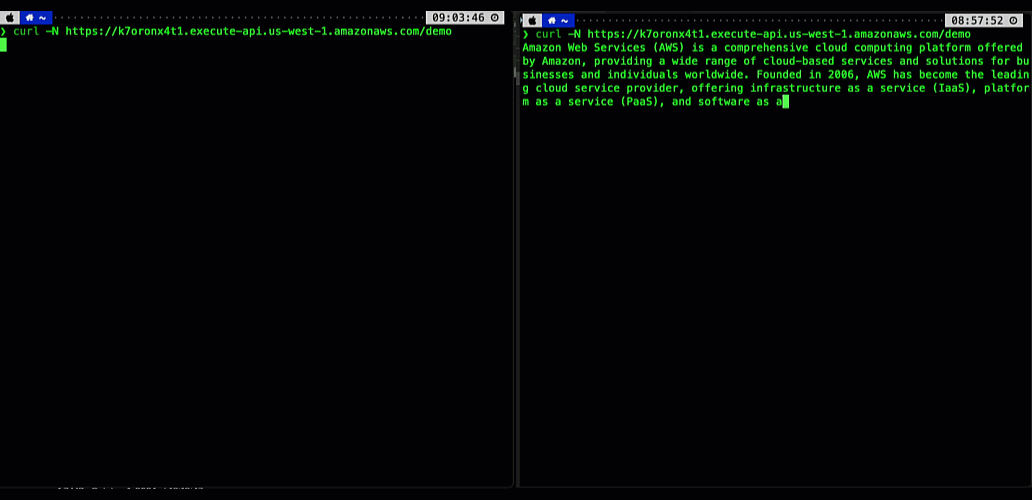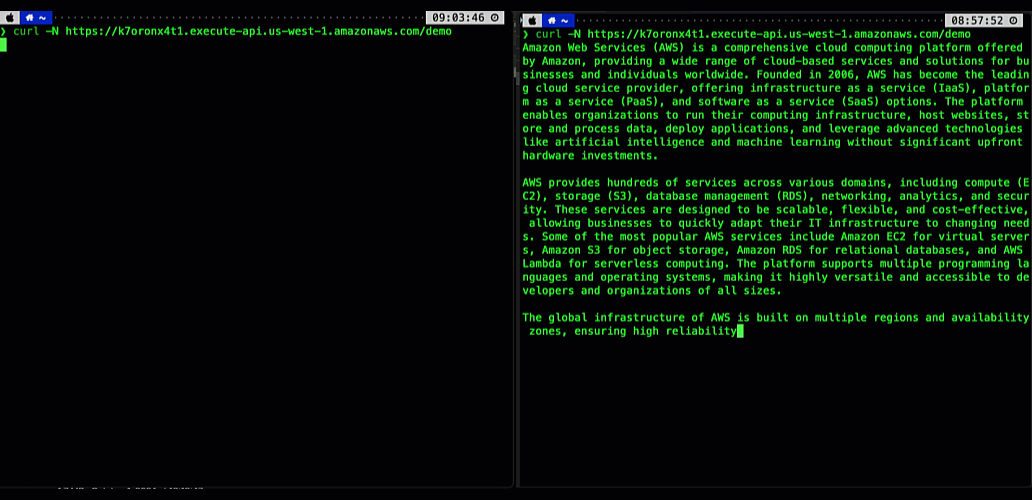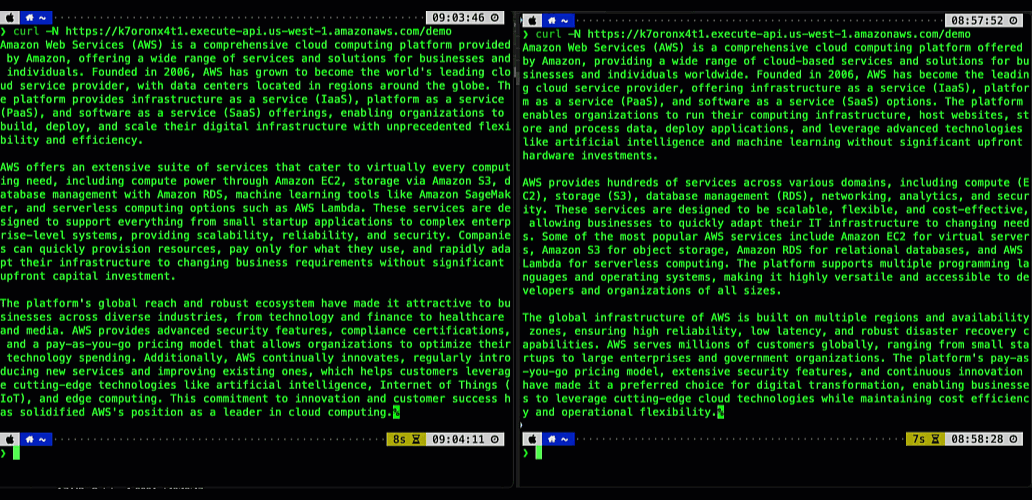
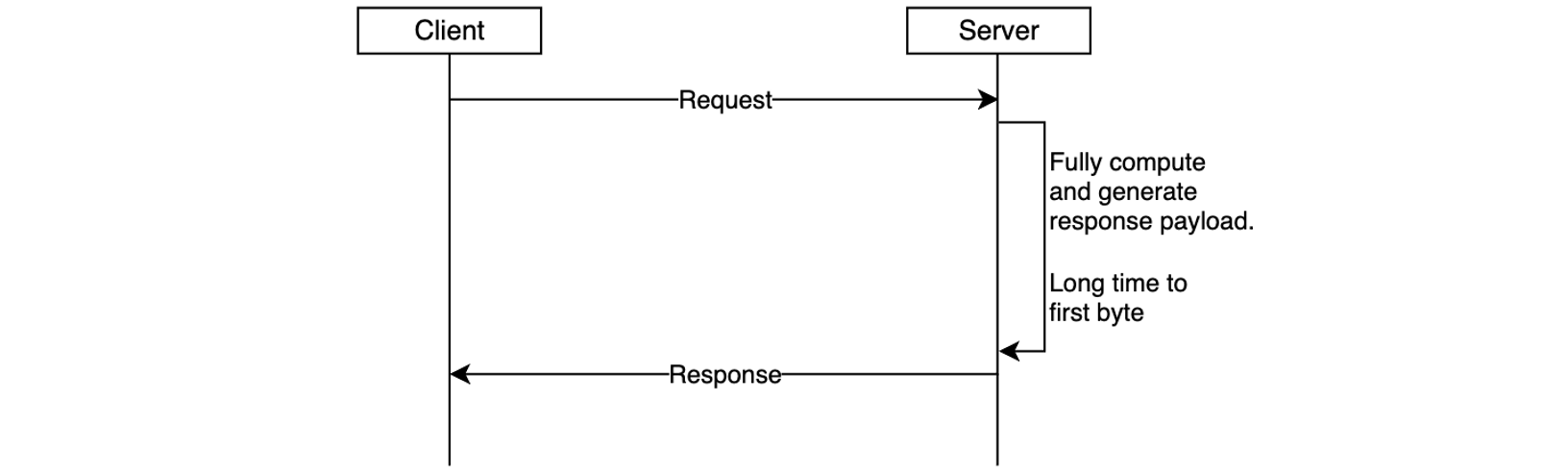
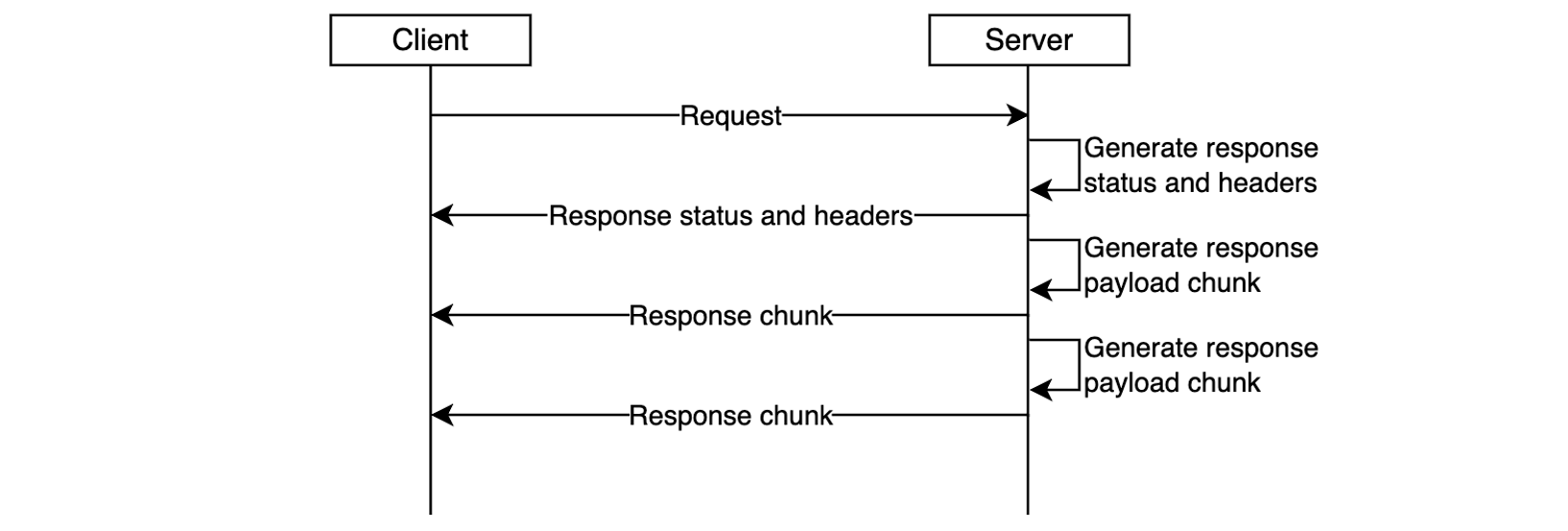
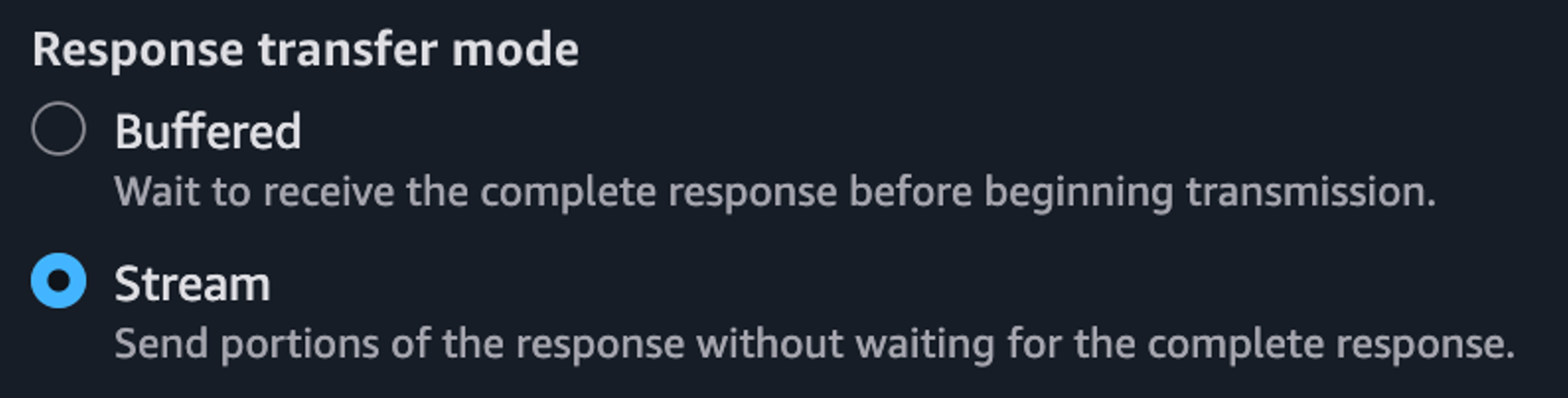


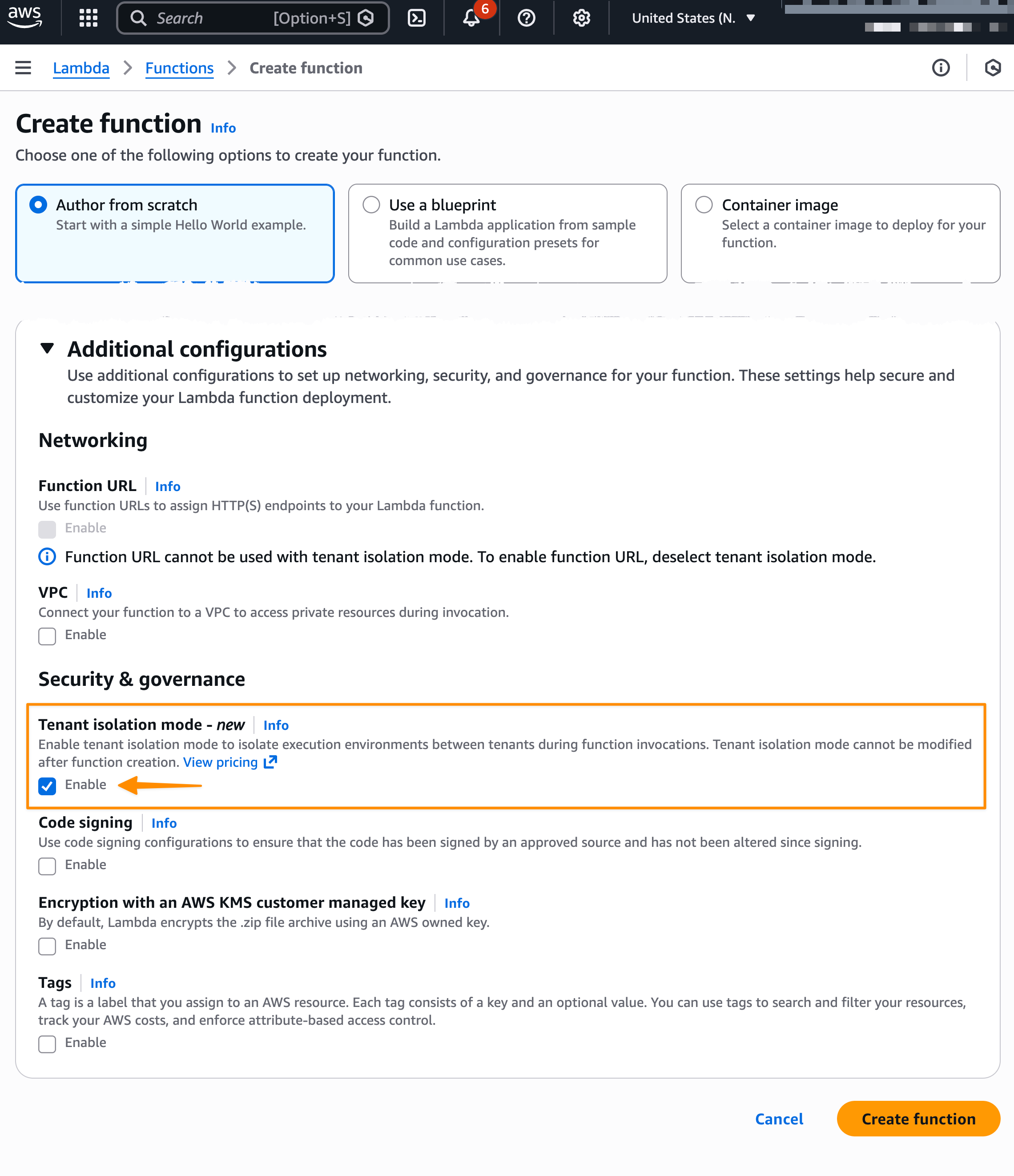
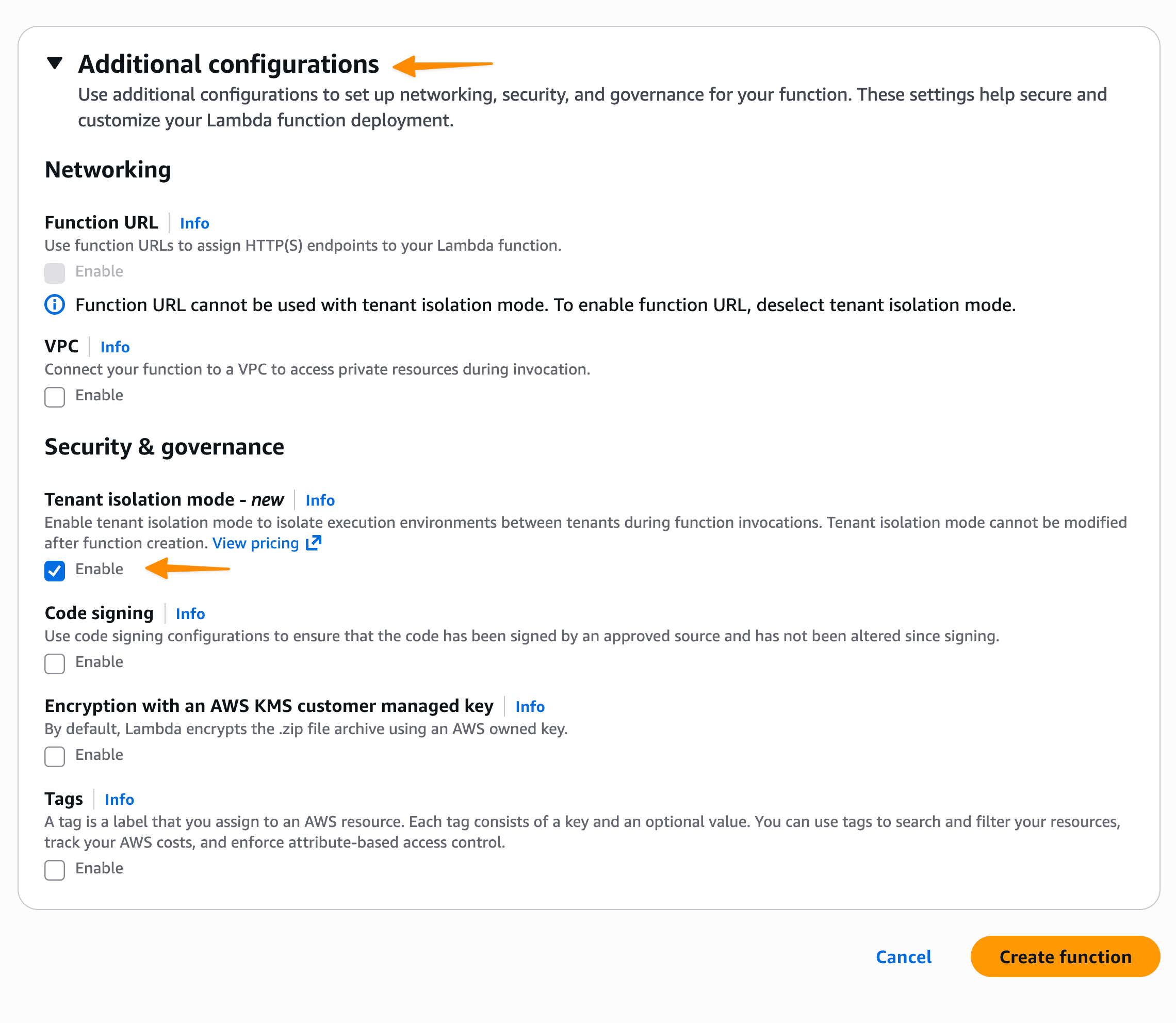
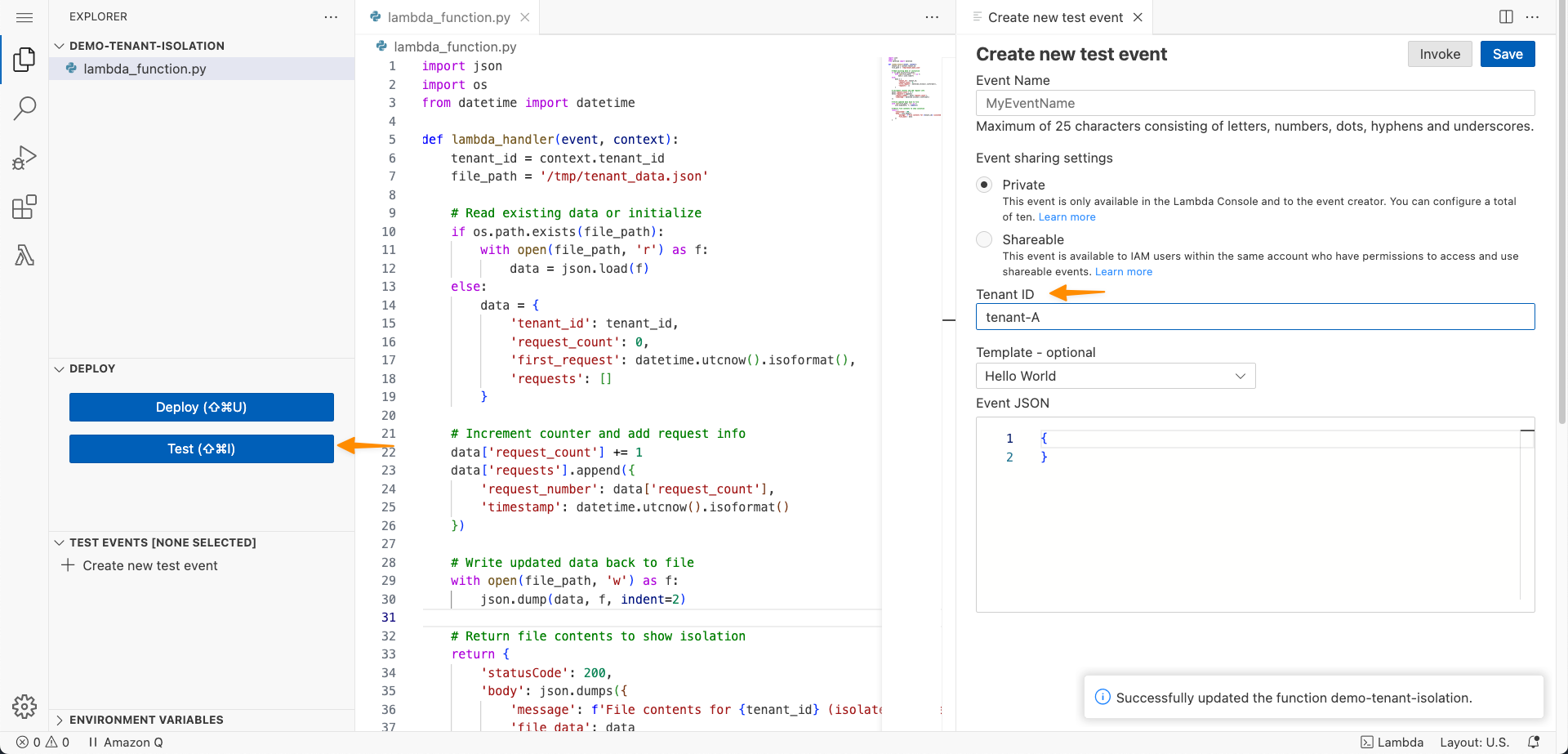
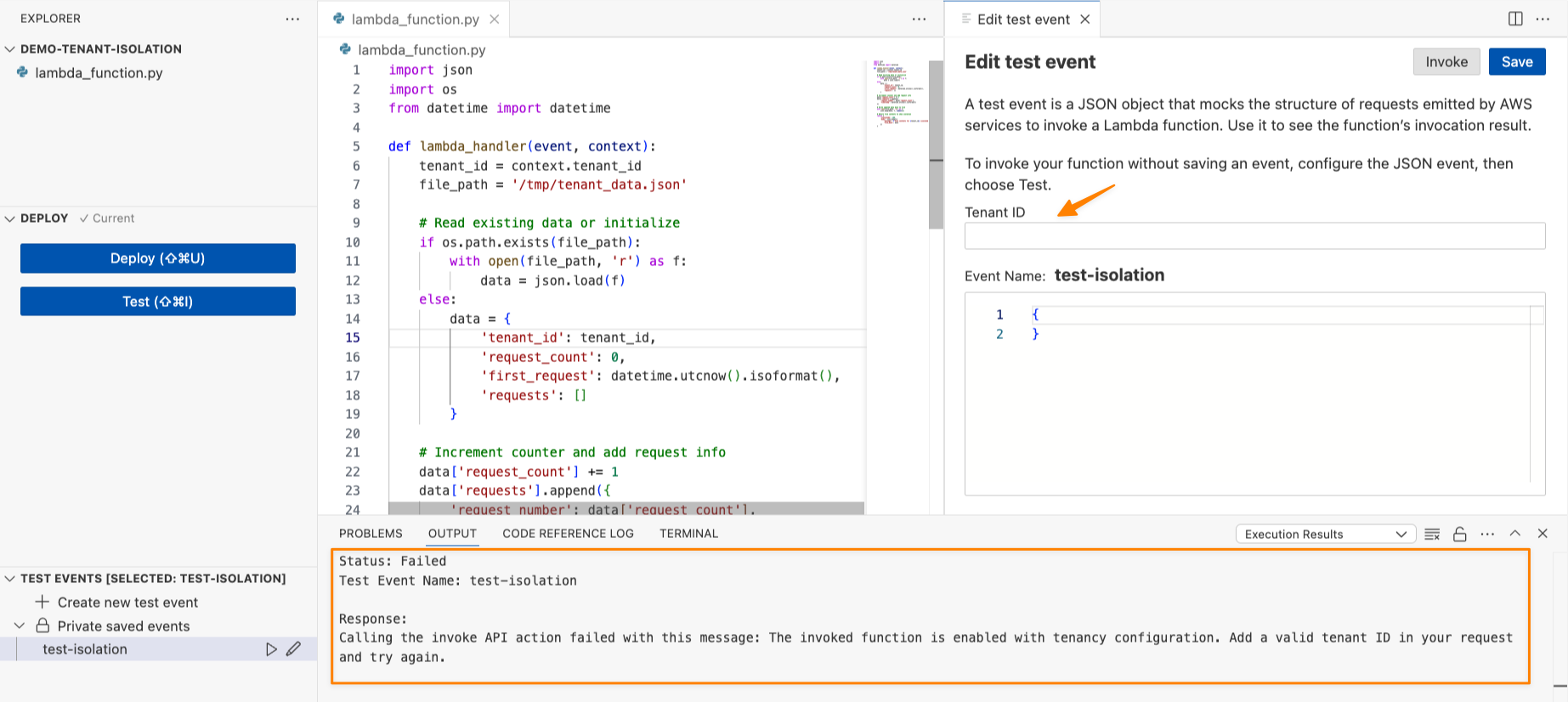
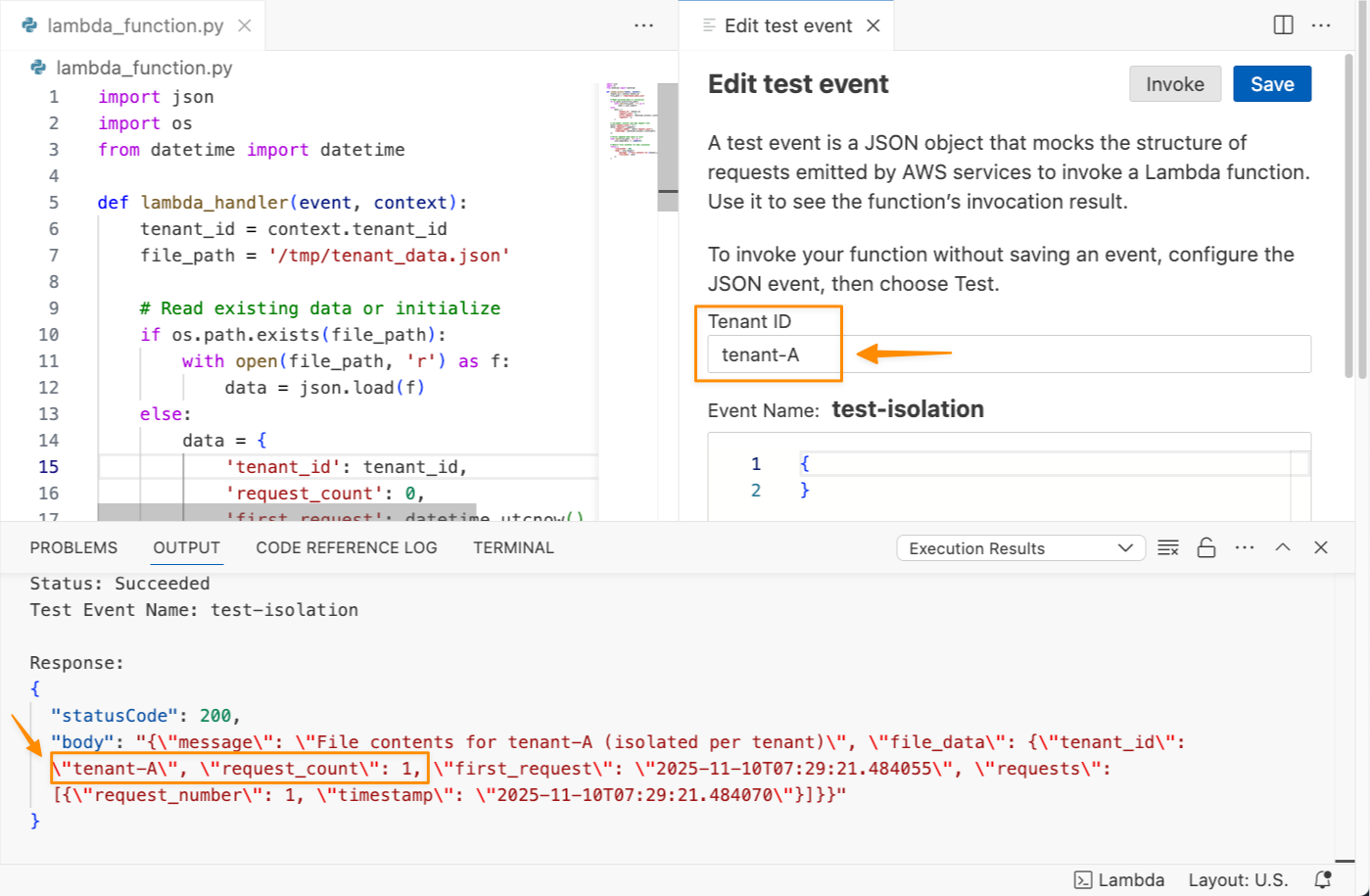
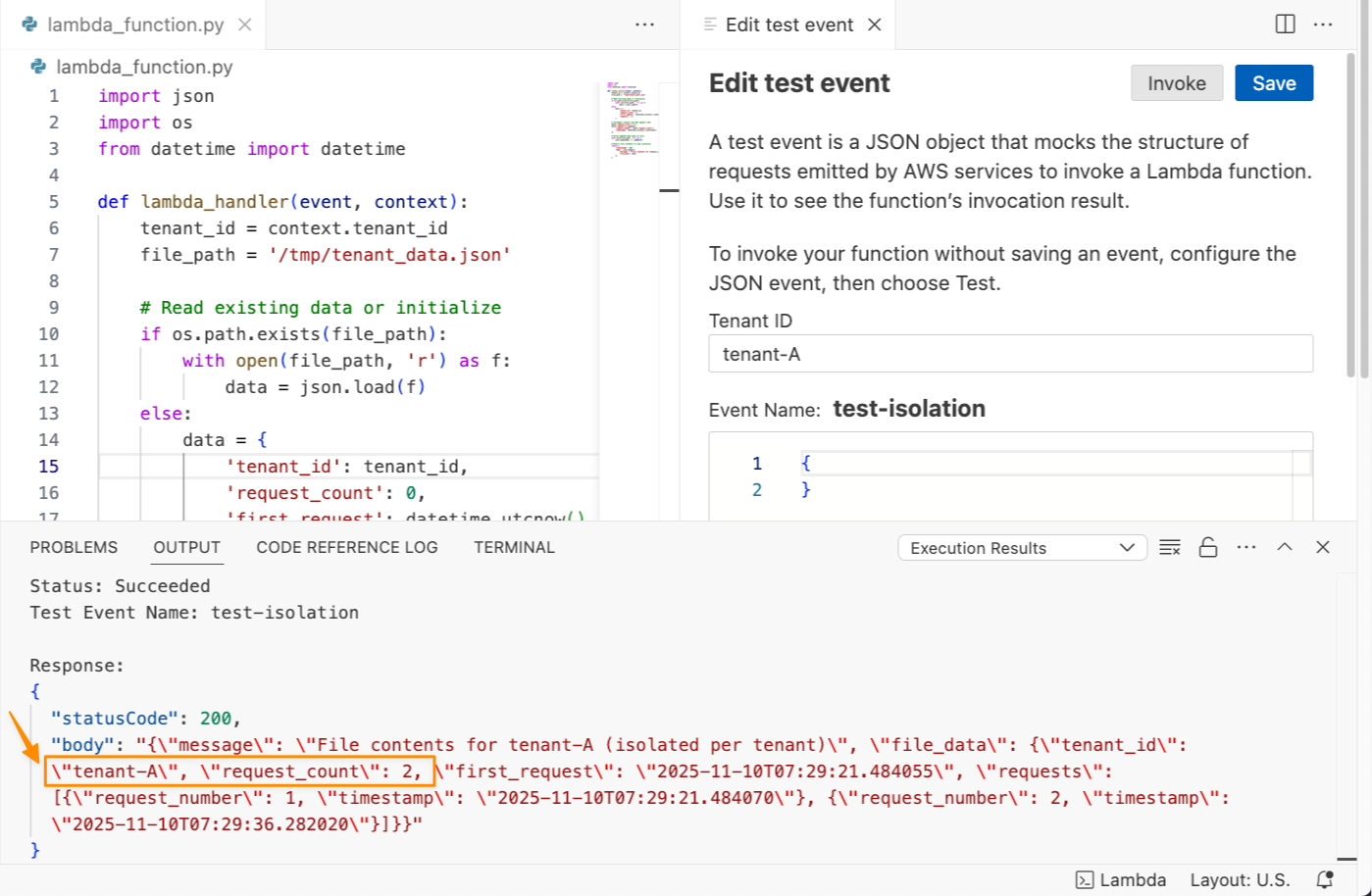
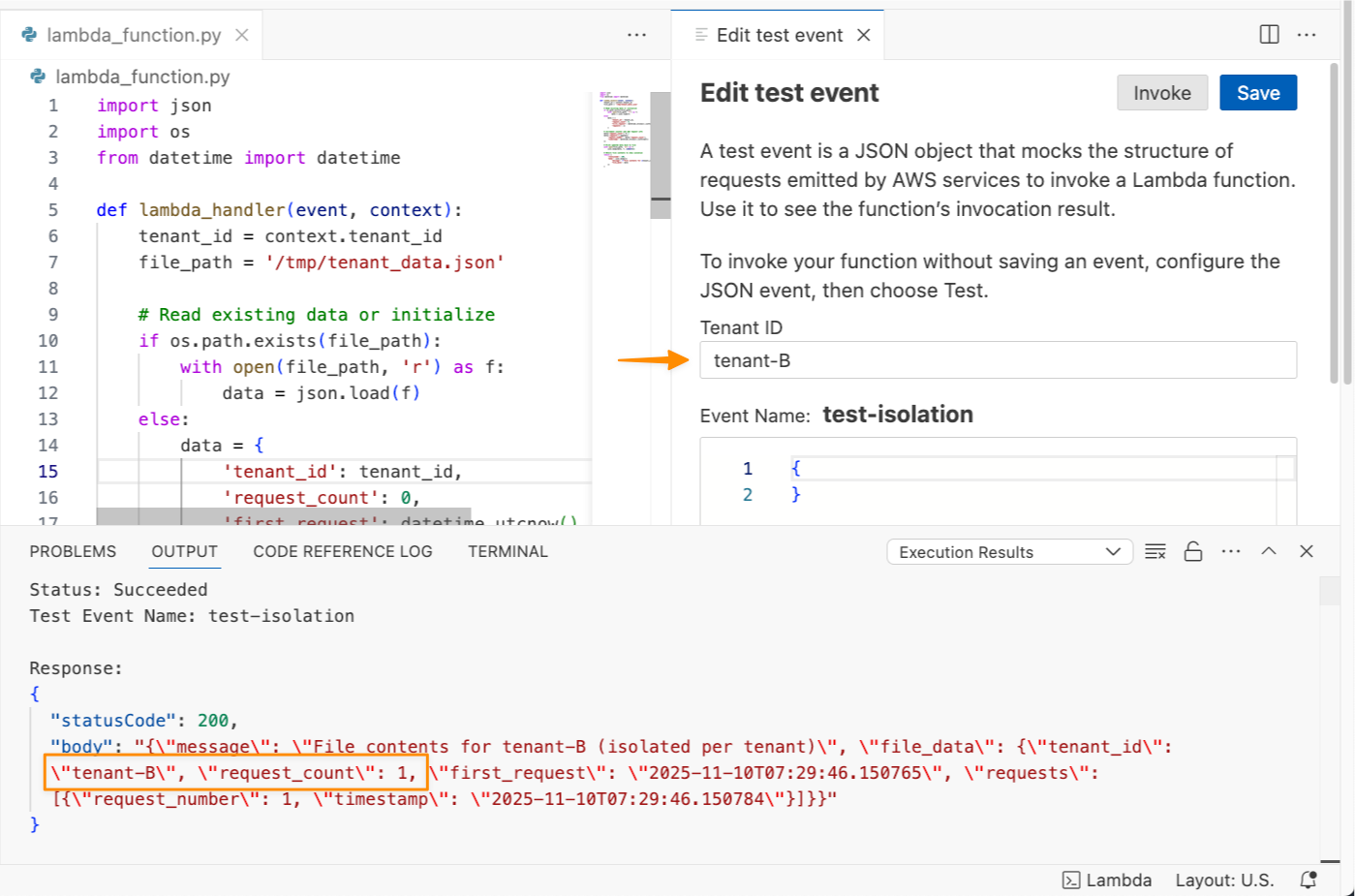
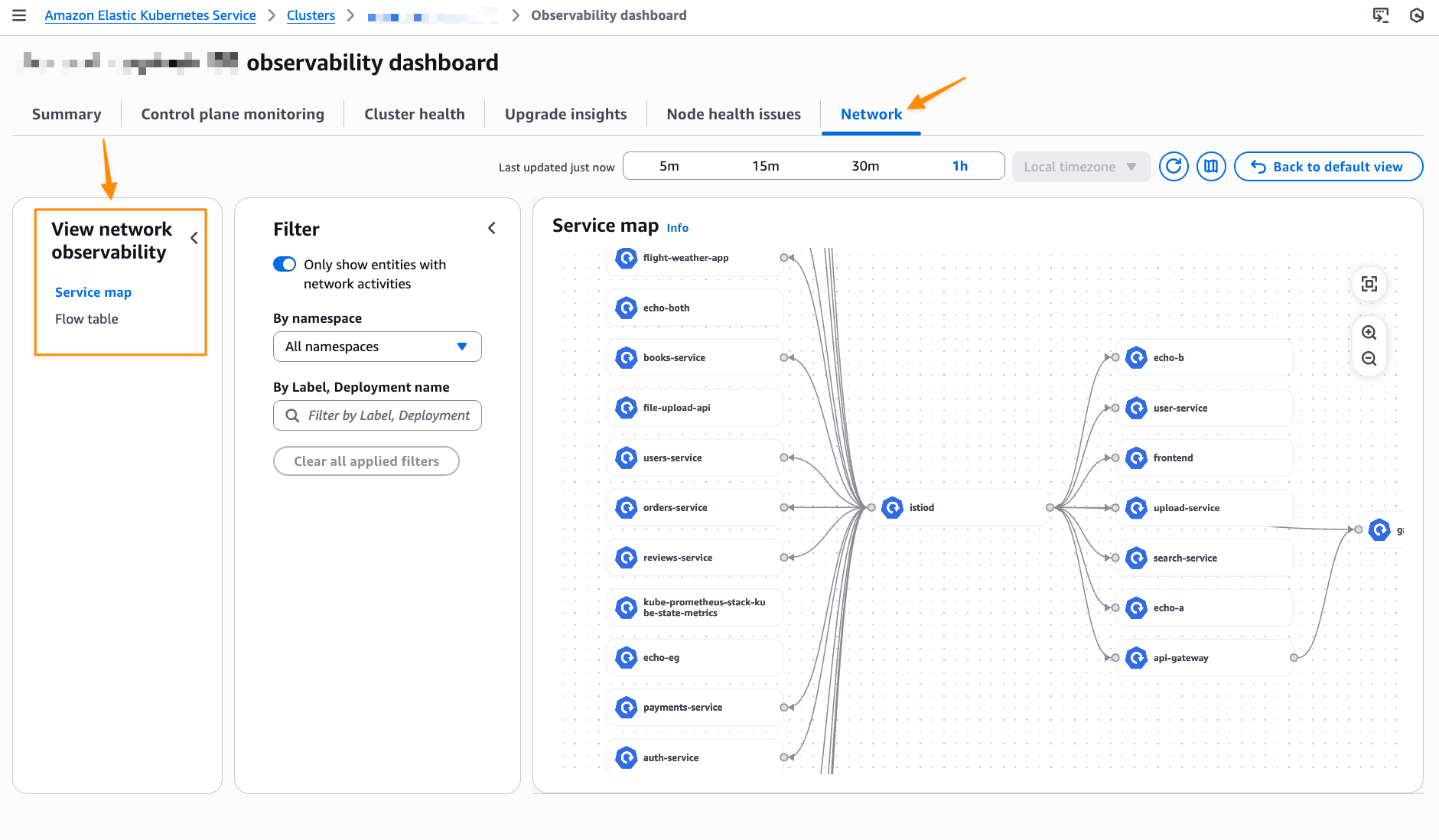
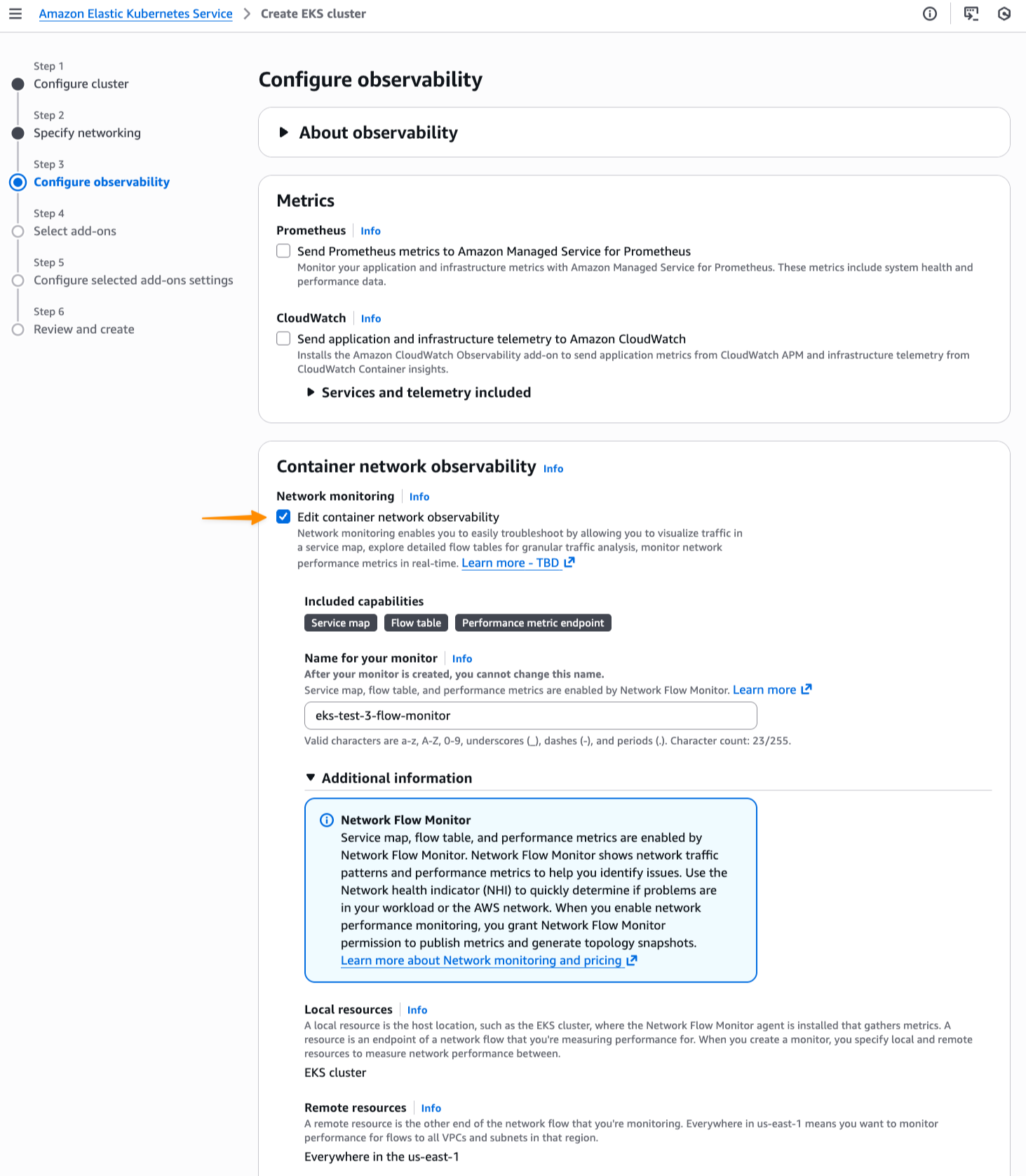
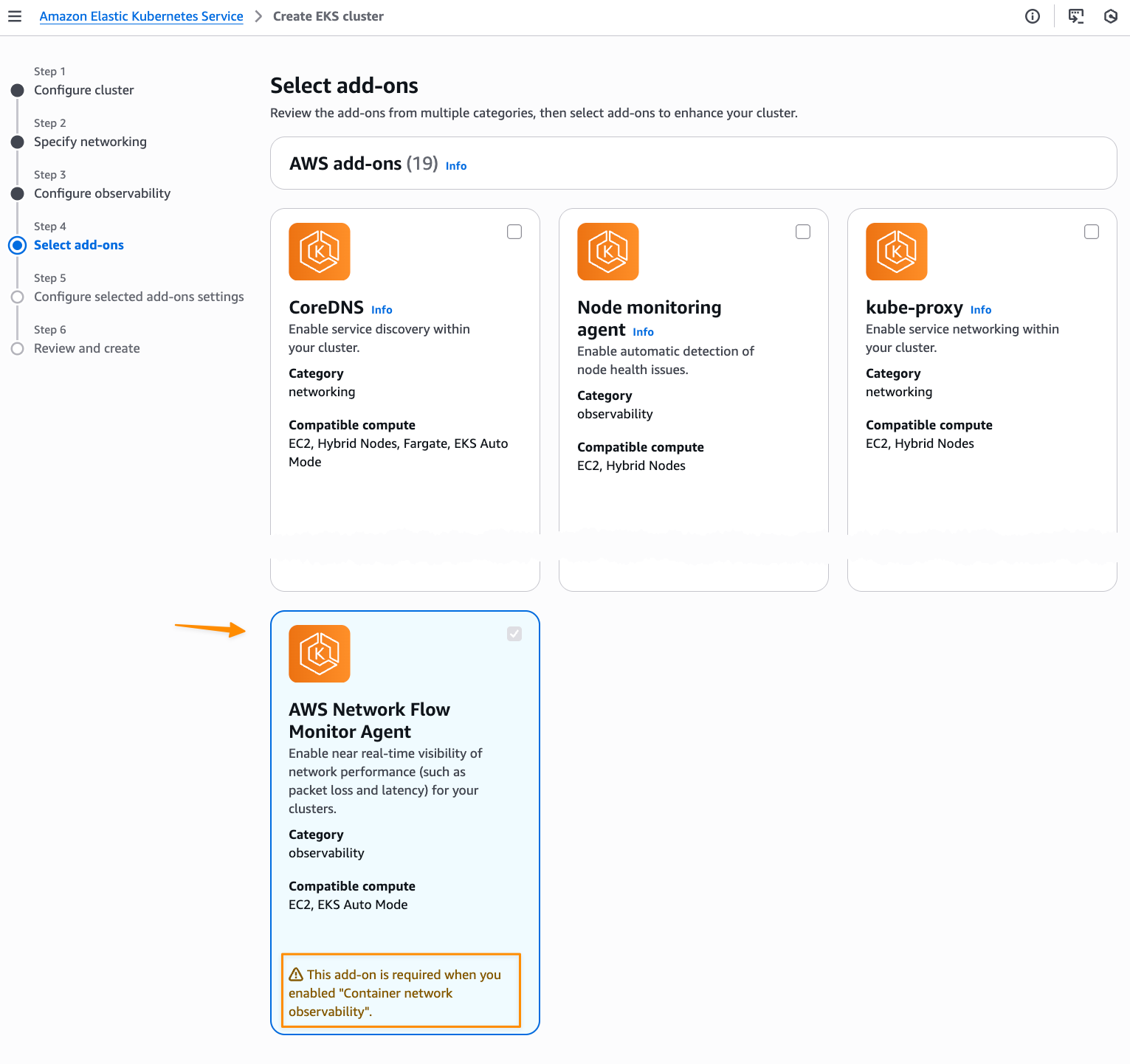
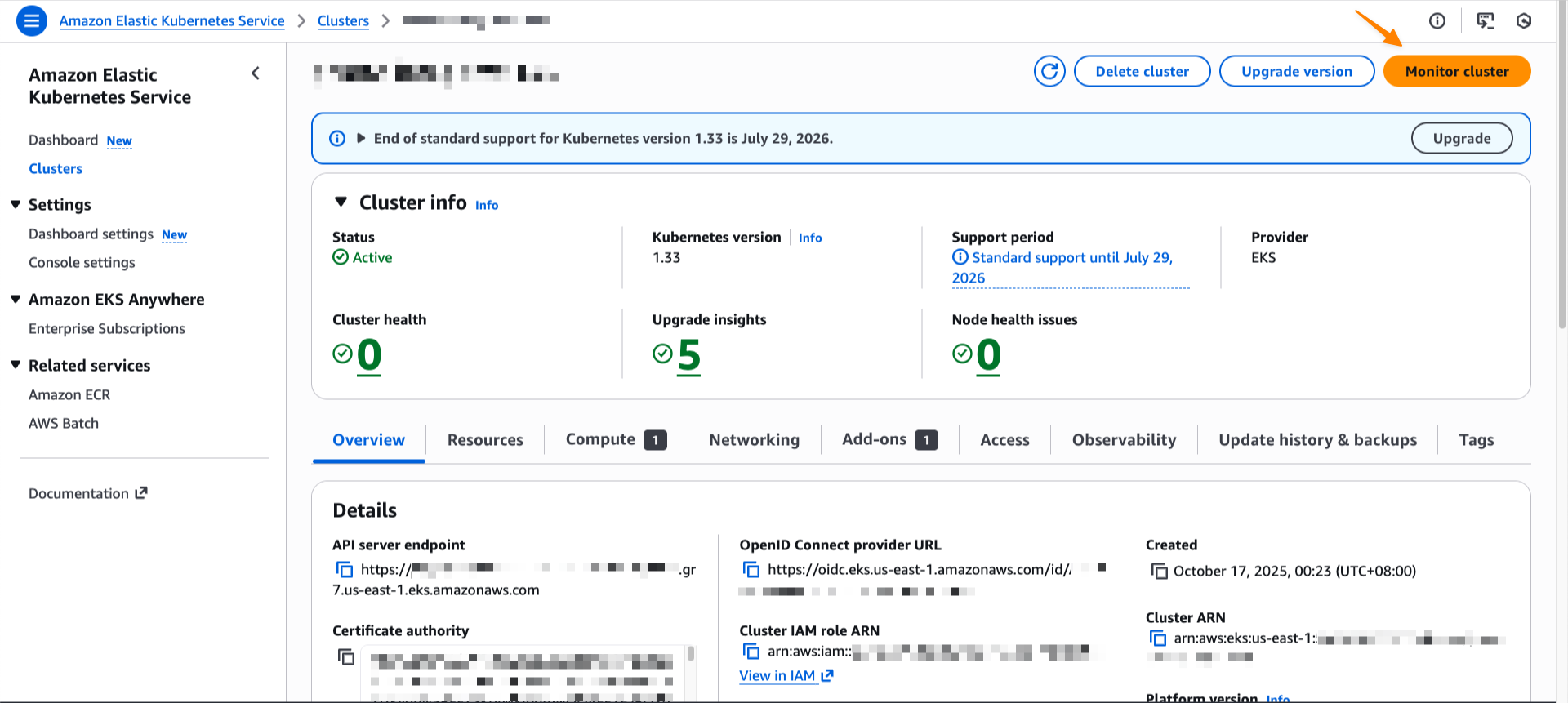
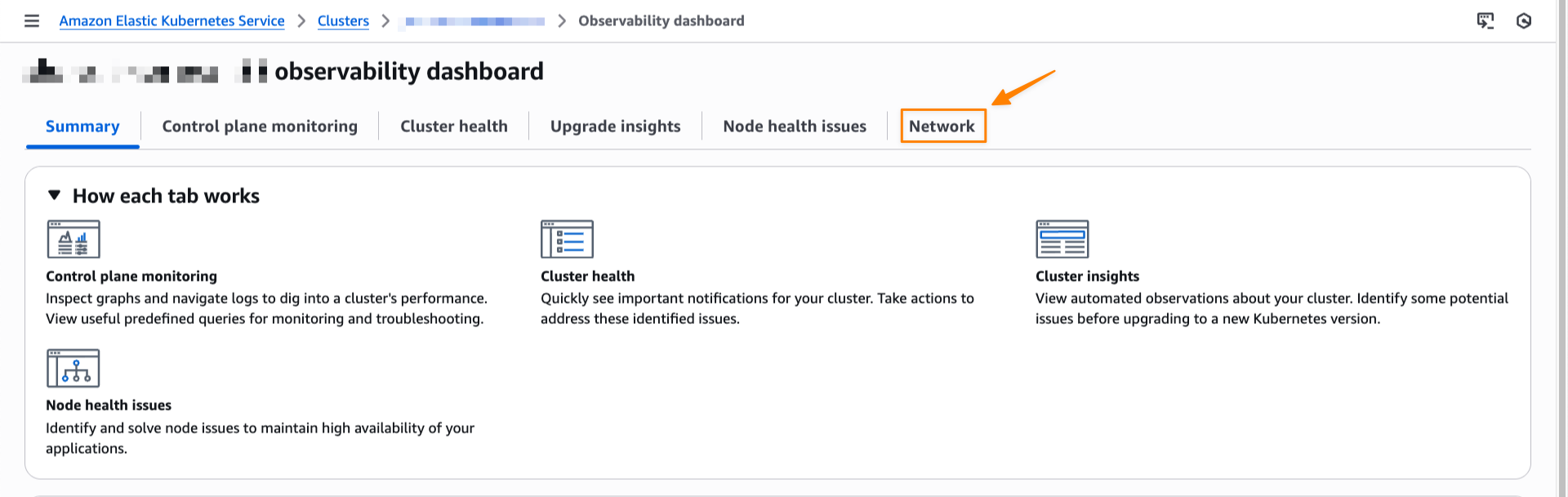
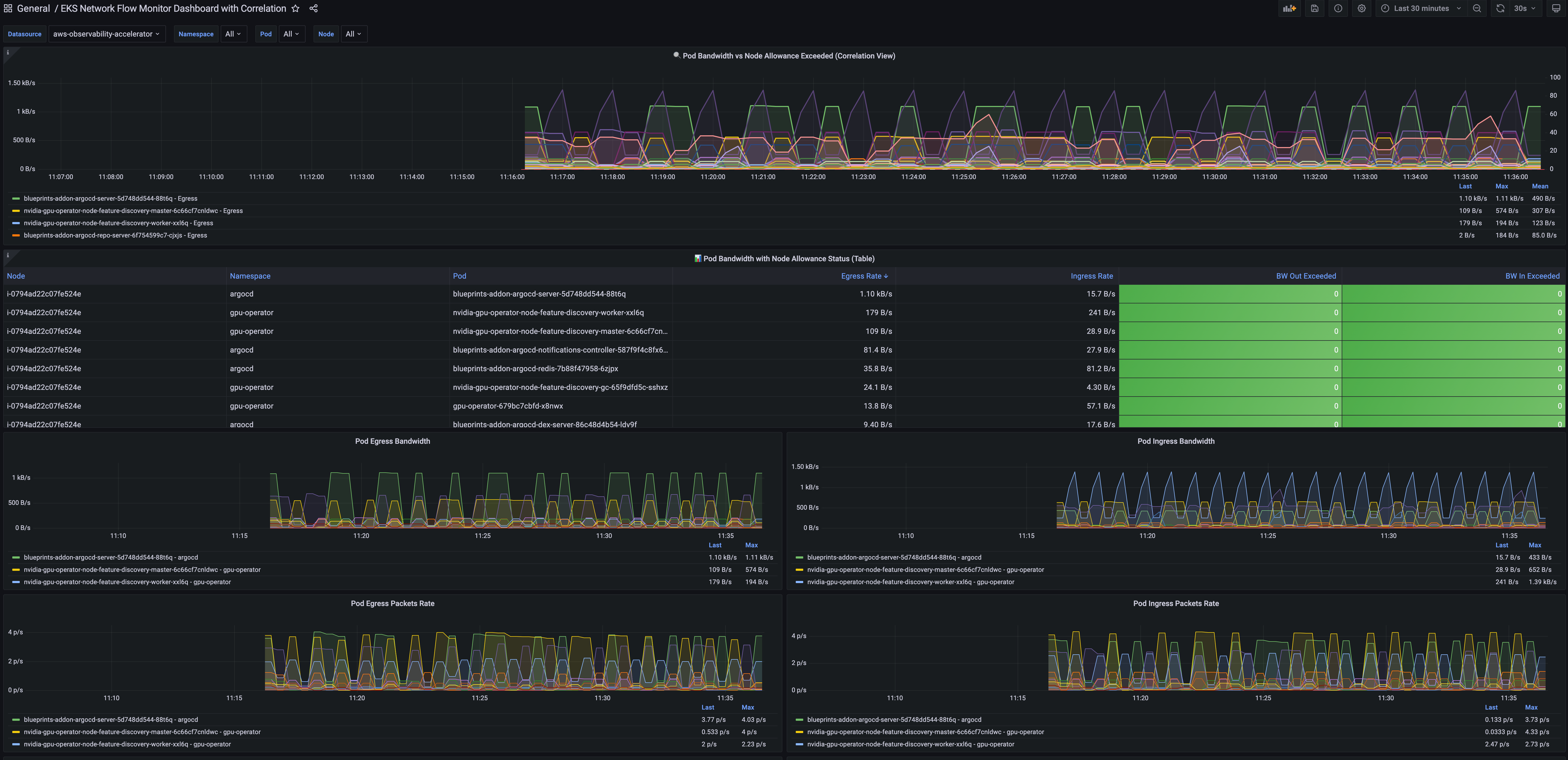
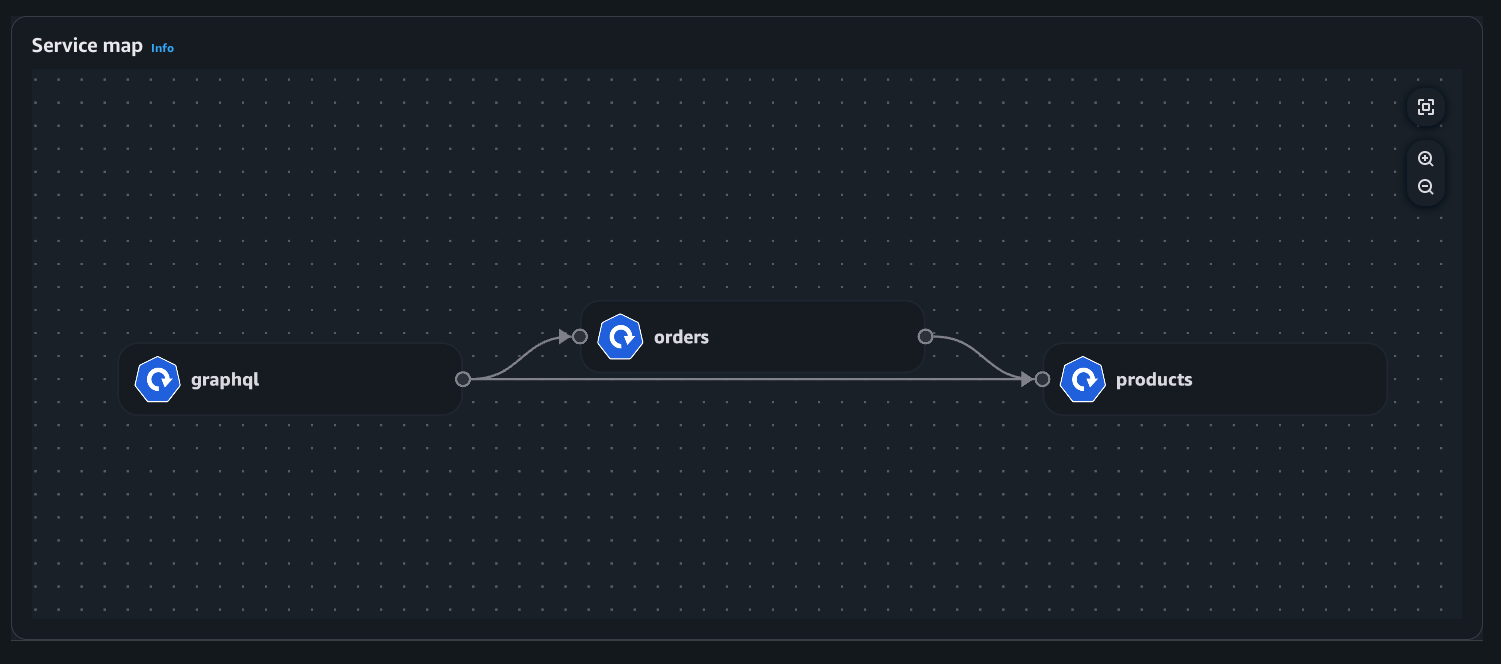
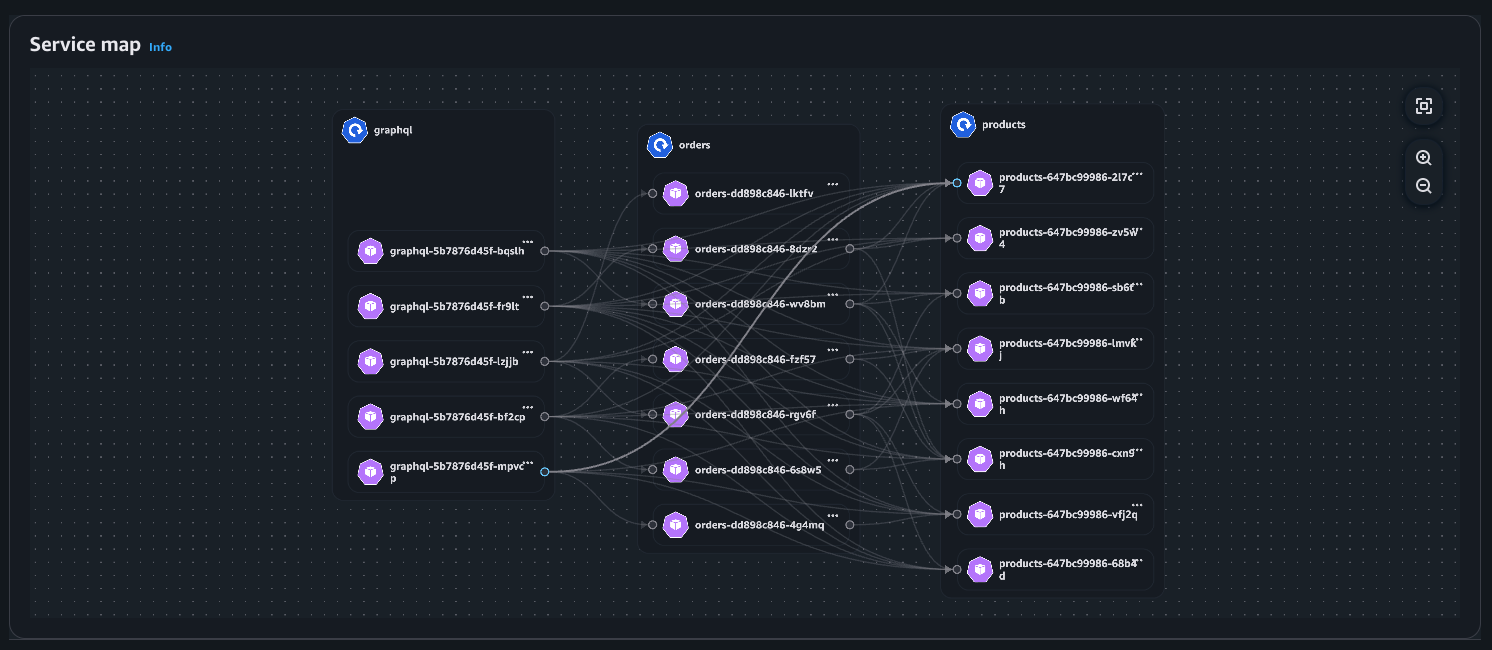
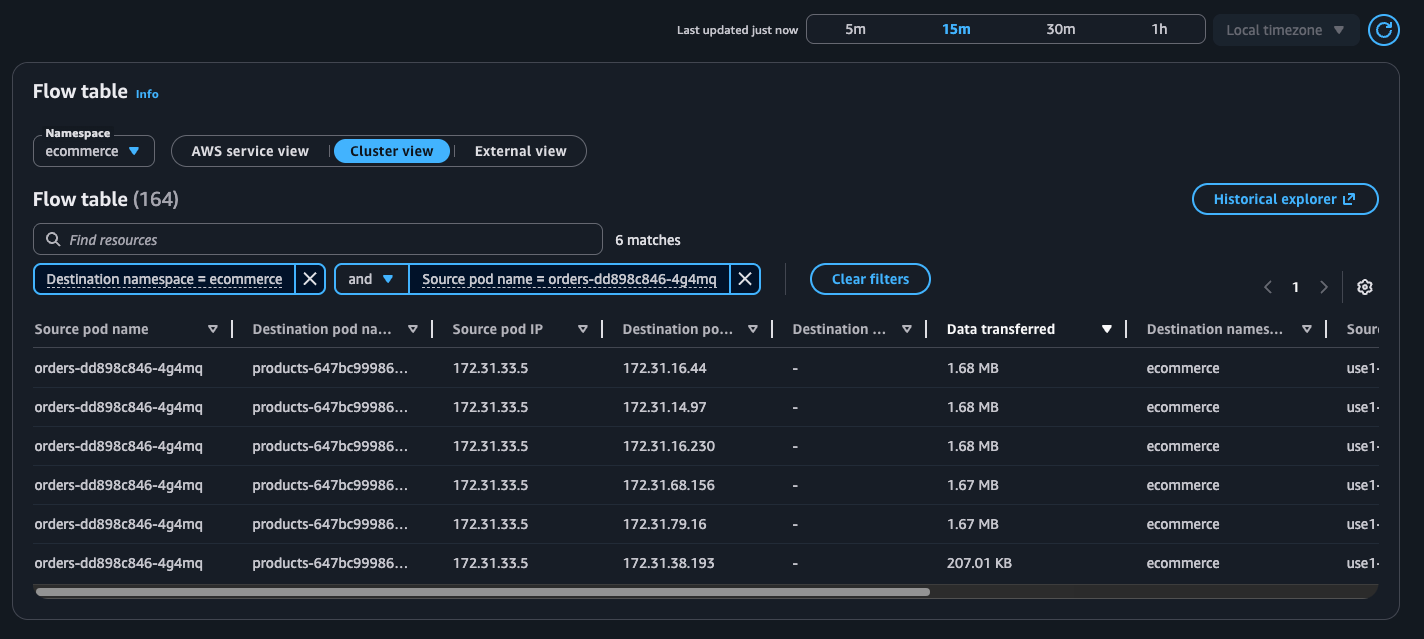



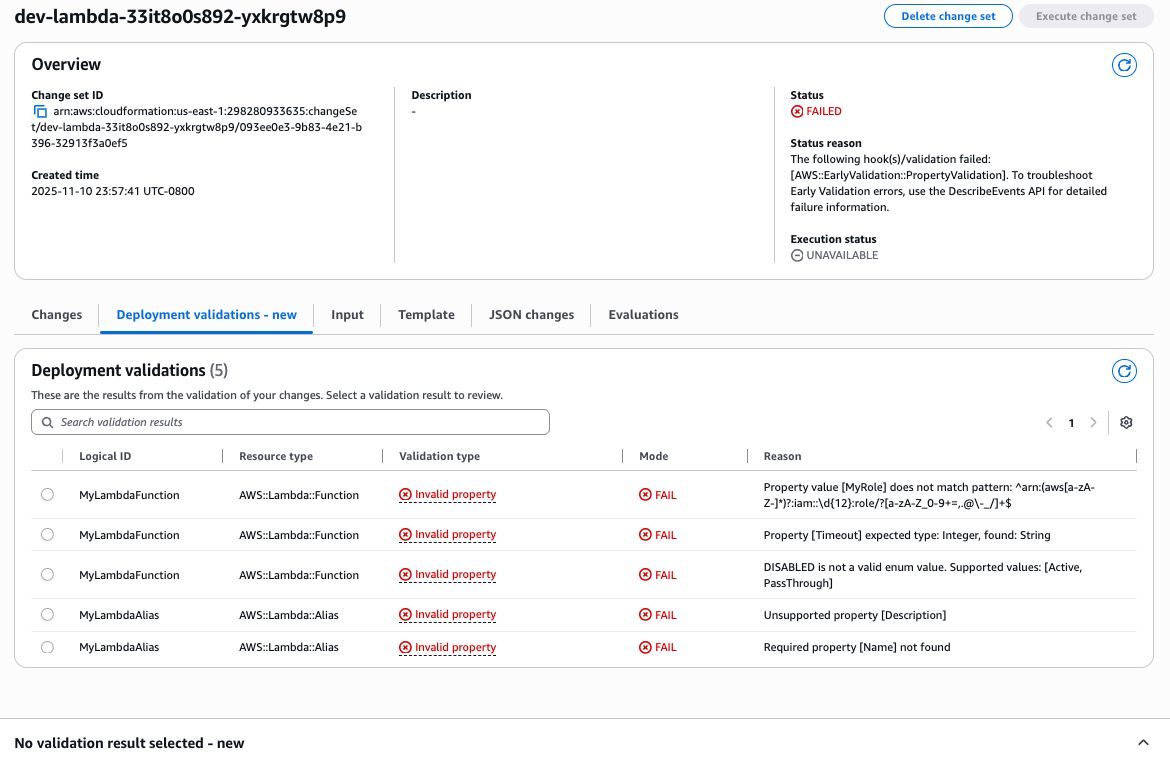
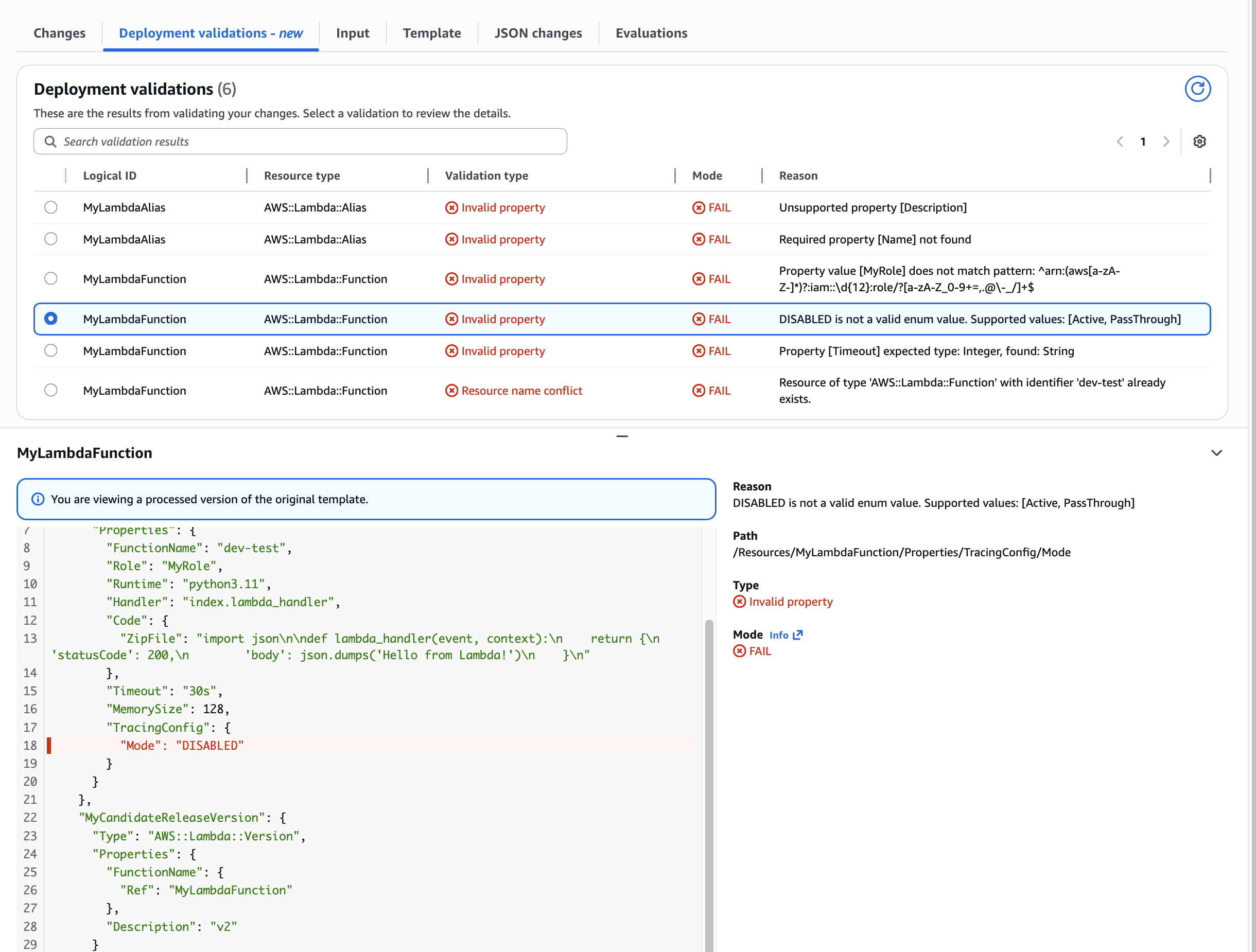
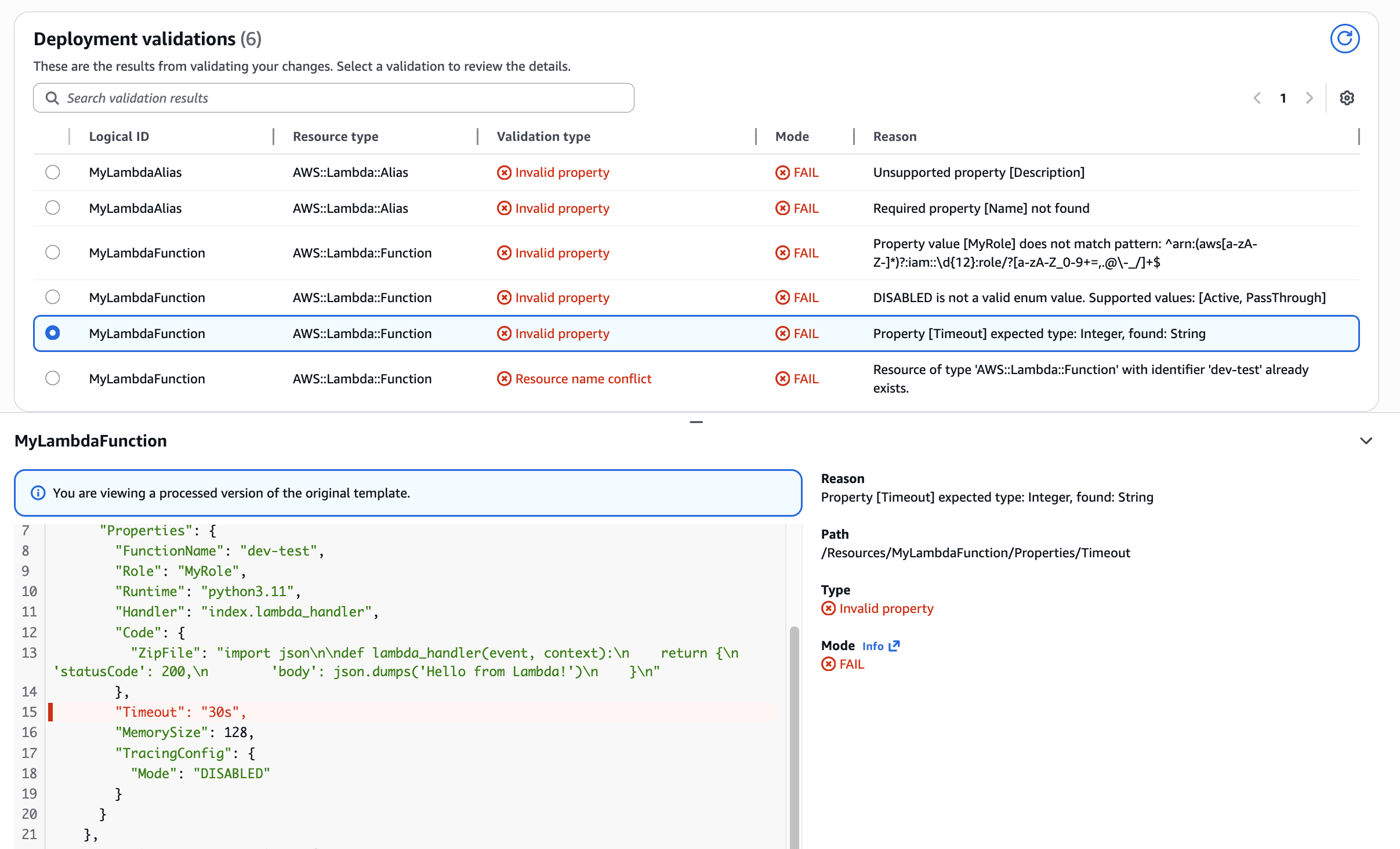
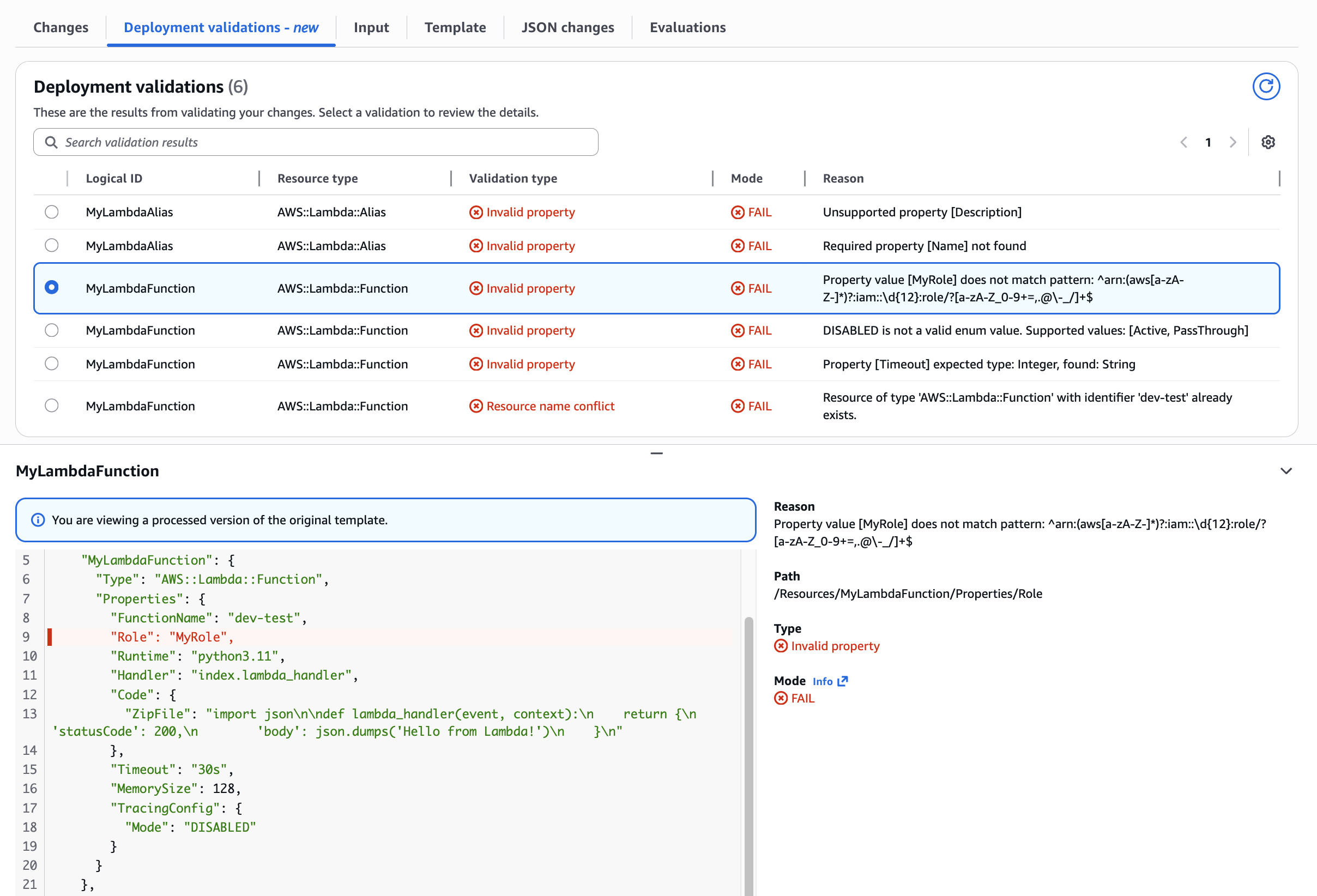
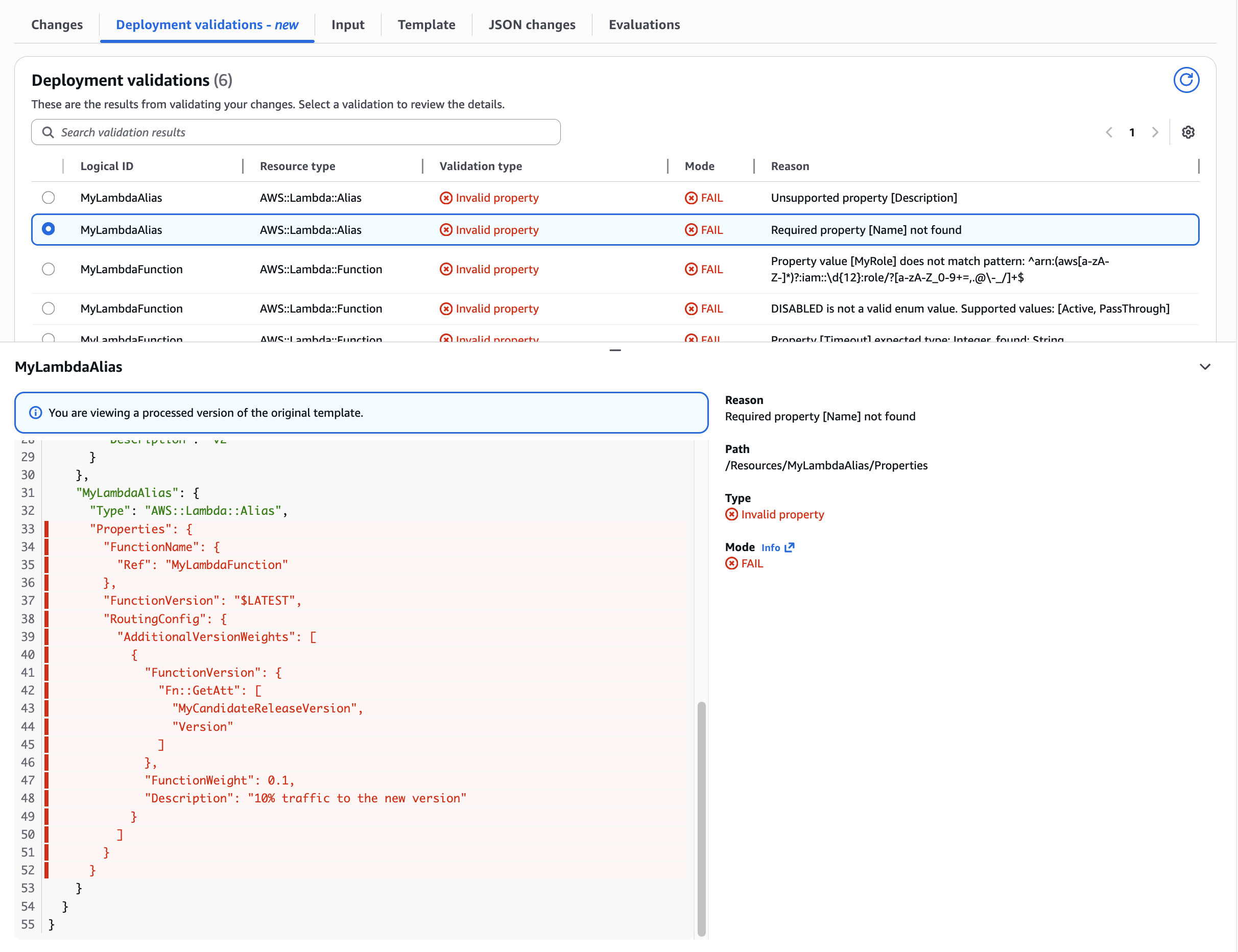
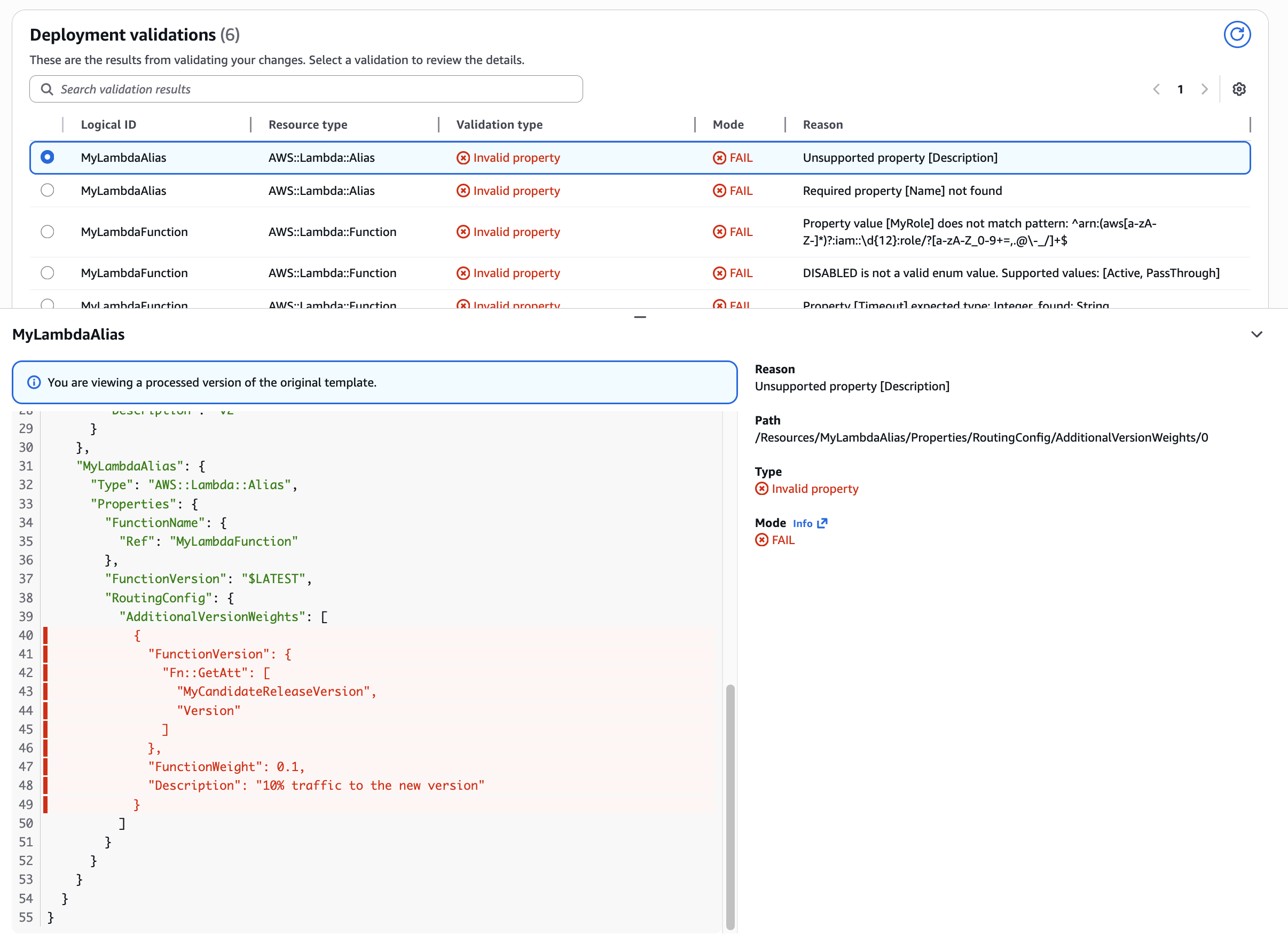
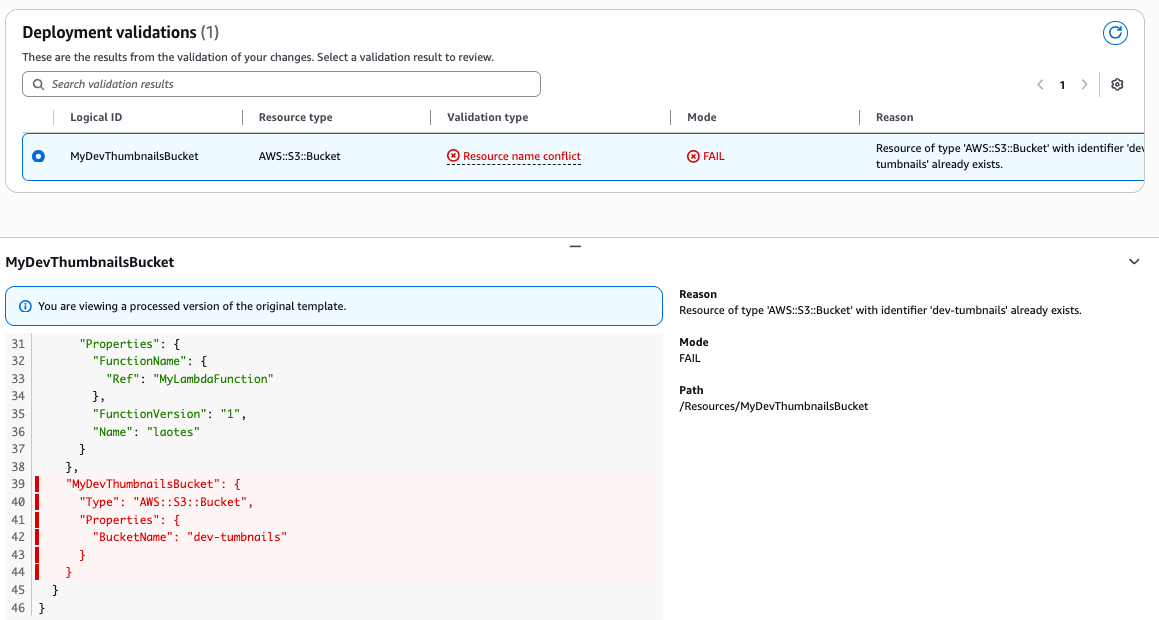
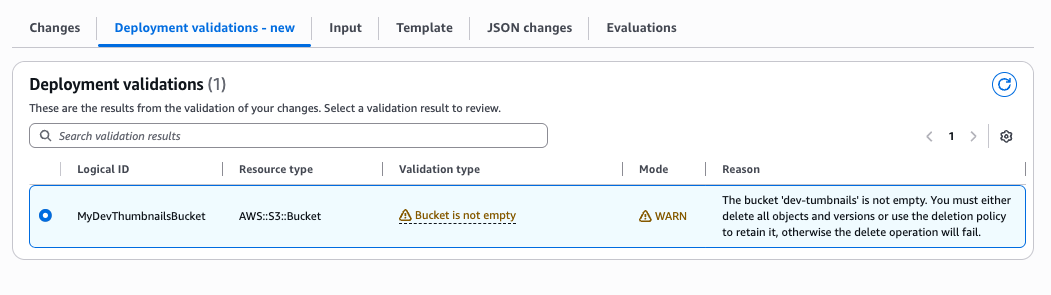
 Figure 12: New CloudFormation stack operation page
Figure 12: New CloudFormation stack operation page