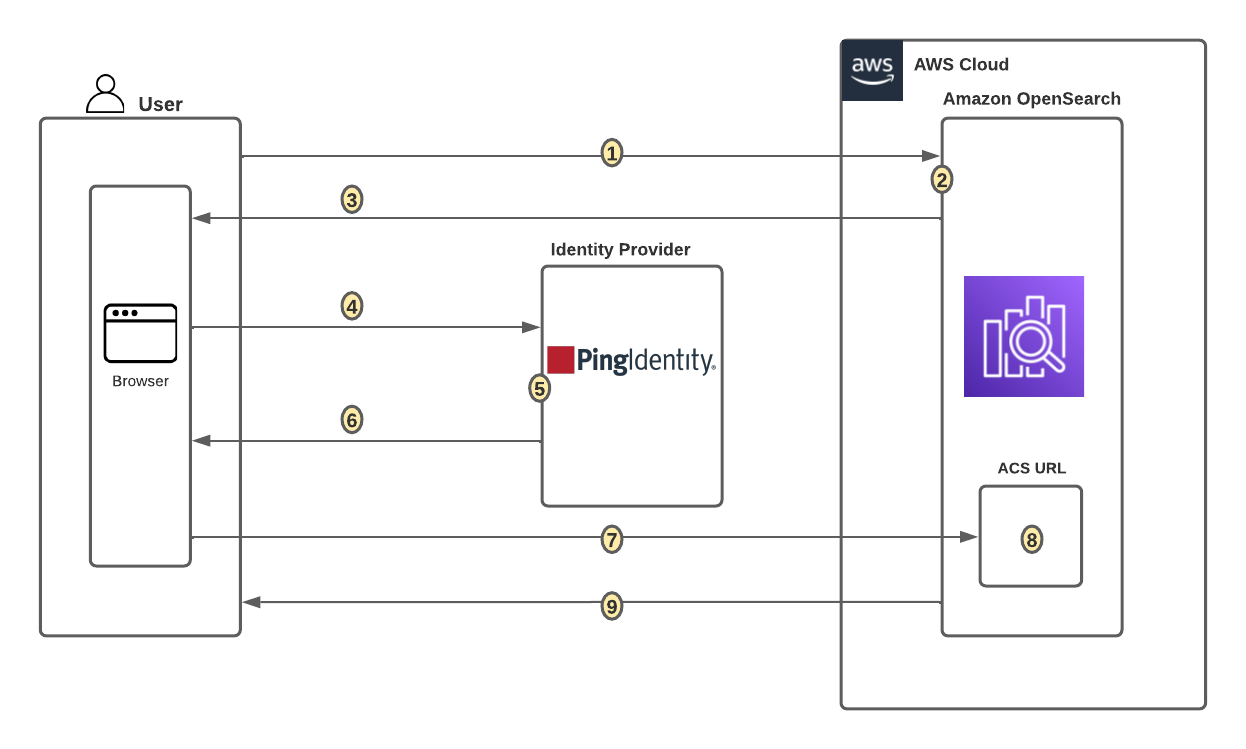
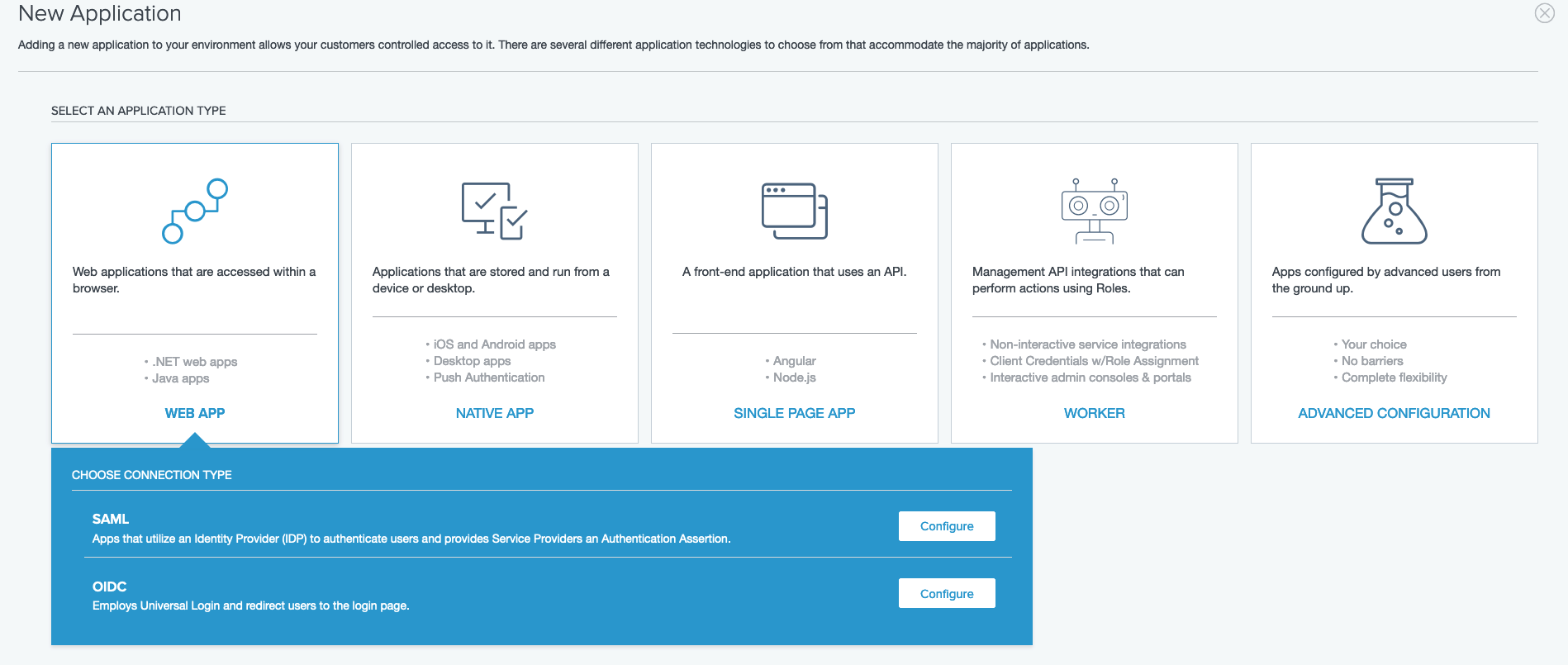
Post Syndicated from Jerome Van Der Linden original https://aws.amazon.com/blogs/architecture/use-direct-service-integrations-to-optimize-your-architecture/
When designing an application, you must integrate and combine several AWS services in the most optimized way for an effective and efficient architecture:
- Optimize for performance by reducing the latency between services
- Optimize for costs operability and sustainability, by avoiding unnecessary components and reducing workload footprint
- Optimize for resiliency by removing potential point of failures
- Optimize for security by minimizing the attack surface
As stated in the Serverless Application Lens of the Well-Architected Framework, “If your AWS Lambda function is not performing custom logic while integrating with other AWS services, chances are that it may be unnecessary.” In addition, Amazon API Gateway, AWS AppSync, AWS Step Functions, Amazon EventBridge, and Lambda Destinations can directly integrate with a number of services. These optimizations can offer you more value and less operational overhead.
This blog post will show how to optimize an architecture with direct integration.
Workflow example and initial architecture
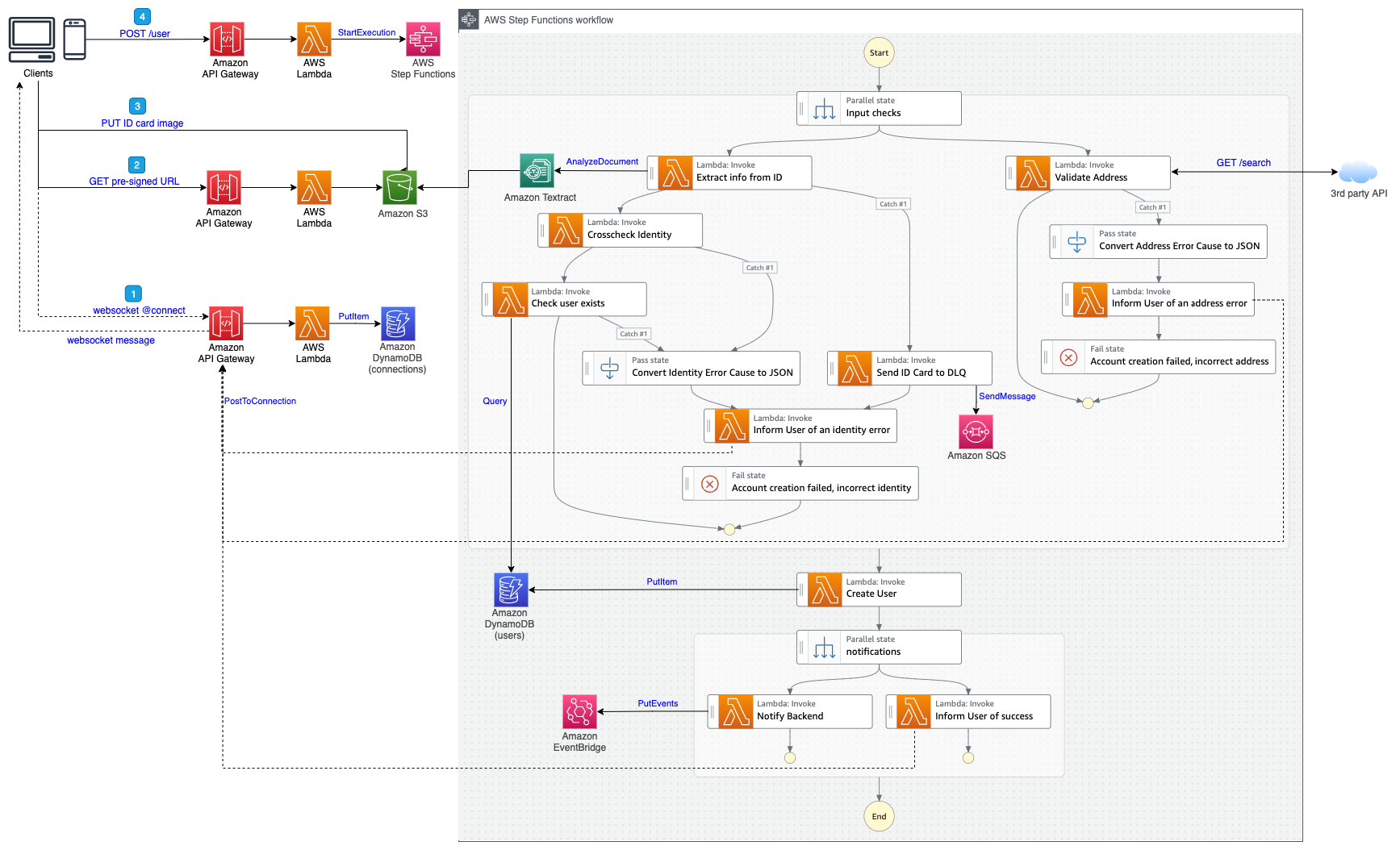
Figure 1 shows a typical workflow for the creation of an online bank account. The customer fills out a registration form with personal information and adds a picture of their ID card. The application then validates ID and address, and scans if there is already an existing user by that name. If everything checks out, a backend application will be notified to create the account. Finally, the user is notified of successful completion.

Figure 1. Bank account application workflow
The workflow architecture is shown in Figure 2 (click on the picture to get full resolution).

Figure 2. Initial account creation architecture
This architecture contains 13 Lambda functions. If you look at the code on GitHub, you can see that:
Five of these Lambda functions are basic and perform simple operations:
Additional Lambda functions perform other tasks, such as verification and validation:
- One function generates a presigned URL to upload ID card pictures to Amazon Simple Storage Service (Amazon S3)
- One function uses the Amazon Textract API to extract information from the ID card
- One function verifies the identity of the user against the information extracted from the ID card
- One function performs simple HTTP request to a third-party API to validate the address
Finally, four functions concern the websocket (connect, message, and disconnect) and notifications to the user.
Opportunities for improvement
If you further analyze the code of the five basic functions (see startWorkflow on GitHub, for example), you will notice that there are actually three lines of fundamental code that start the workflow. The others 38 lines involve imports, input validation, error handling, logging, and tracing. Remember that all this code must be tested and maintained.
import os
import json
import boto3
from aws_lambda_powertools import Tracer
from aws_lambda_powertools import Logger
import re
logger = Logger()
tracer = Tracer()
sfn = boto3.client('stepfunctions')
PATTERN = re.compile(r"^arn:(aws[a-zA-Z-]*)?:states:[a-z]{2}((-gov)|(-iso(b?)))?-[a-z]+-\d{1}:\d{12}:stateMachine:[a-zA-Z0-9-_]+$")
if ('STATE_MACHINE_ARN' not in os.environ
or os.environ['STATE_MACHINE_ARN'] is None
or not PATTERN.match(os.environ['STATE_MACHINE_ARN'])):
raise RuntimeError('STATE_MACHINE_ARN env var is not set or incorrect')
STATE_MACHINE_ARN = os.environ['STATE_MACHINE_ARN']
@logger.inject_lambda_context
@tracer.capture_lambda_handler
def handler(event, context):
try:
event['requestId'] = context.aws_request_id
sfn.start_execution(
stateMachineArn=STATE_MACHINE_ARN,
input=json.dumps(event)
)
return {
'requestId': event['requestId']
}
except Exception as error:
logger.exception(error)
raise RuntimeError('Internal Error - cannot start the creation workflow') from error
After running this workflow several times and reviewing the AWS X-Ray traces (Figure 3), we can see that it takes about 2–3 seconds when functions are warmed:

Figure 3. X-Ray traces when Lambda functions are warmed
But the process takes around 10 seconds with cold starts, as shown in Figure 4:

Figure 4. X-Ray traces when Lambda functions are cold
We use an asynchronous architecture to avoid waiting time for the user, as this can be a long process. We also use WebSockets to notify the user when it’s finished. This adds some complexity, new components, and additional costs to the architecture. Now let’s look at how we can optimize this architecture.
Improving the initial architecture
Direct integration with Step Functions
Step Functions can directly integrate with some AWS services, including DynamoDB, Amazon SQS, and EventBridge, and more than 10,000 APIs from 200+ AWS services. With these integrations, you can replace Lambda functions when they do not provide value. We recommend using Lambda functions to transform data, not to transport data from one service to another.
In our bank account creation use case, there are four Lambda functions we can replace with direct service integrations (see large arrows in Figure 5):
- Query a DynamoDB table to search for a user
- Send a message to an SQS queue when the extraction fails
- Create the user in DynamoDB
- Send an event on EventBridge to notify the backend

Figure 5. Lambda functions that can be replaced
It is not as clear that we need to replace the other Lambda functions. Here are some considerations:
- To extract information from the ID card, we use Amazon Textract. It is available through the SDK integration in Step Functions. However, the API’s response provides too much information. We recommend using a library such as amazon-textract-response-parser to parse the result. For this, you’ll need a Lambda function.
- The identity cross-check performs a simple comparison between the data provided in the web form and the one extracted in the ID card. We can perform this comparison in Step Functions using a
Choice state and several conditions. If the business logic becomes more complex, consider using a Lambda function.
- To validate the address, we query a third-party API. Step Functions cannot directly call a third-party HTTP endpoint, but because it’s integrated with API Gateway, we can create a proxy for this endpoint.
If you only need to retrieve data from an API or make a simple API call, use the direct integration. If you need to implement some logic, use a Lambda function.
Direct integration with API Gateway
API Gateway also provides service integrations. In particular, we can start the workflow without using a Lambda function. In the console, select the integration type “AWS Service”, the AWS service “Step Functions”, the action “StartExecution”, and “POST” method, as shown in Figure 6.

Figure 6. API Gateway direct integration with Step Functions
After that, use a mapping template in the integration request to define the parameters as shown here:
{
"stateMachineArn":"arn:aws:states:eu-central-1:123456789012:stateMachine: accountCreationWorkflow",
"input":"$util.escapeJavaScript($input.json('$'))"
}
We can go further and remove the websockets and associated Lambda functions connect, message, and disconnect. By using Synchronous Express Workflows and the StartSyncExecution API, we can start the workflow and wait for the result in a synchronous fashion. API Gateway will then directly return the result of the workflow to the client.
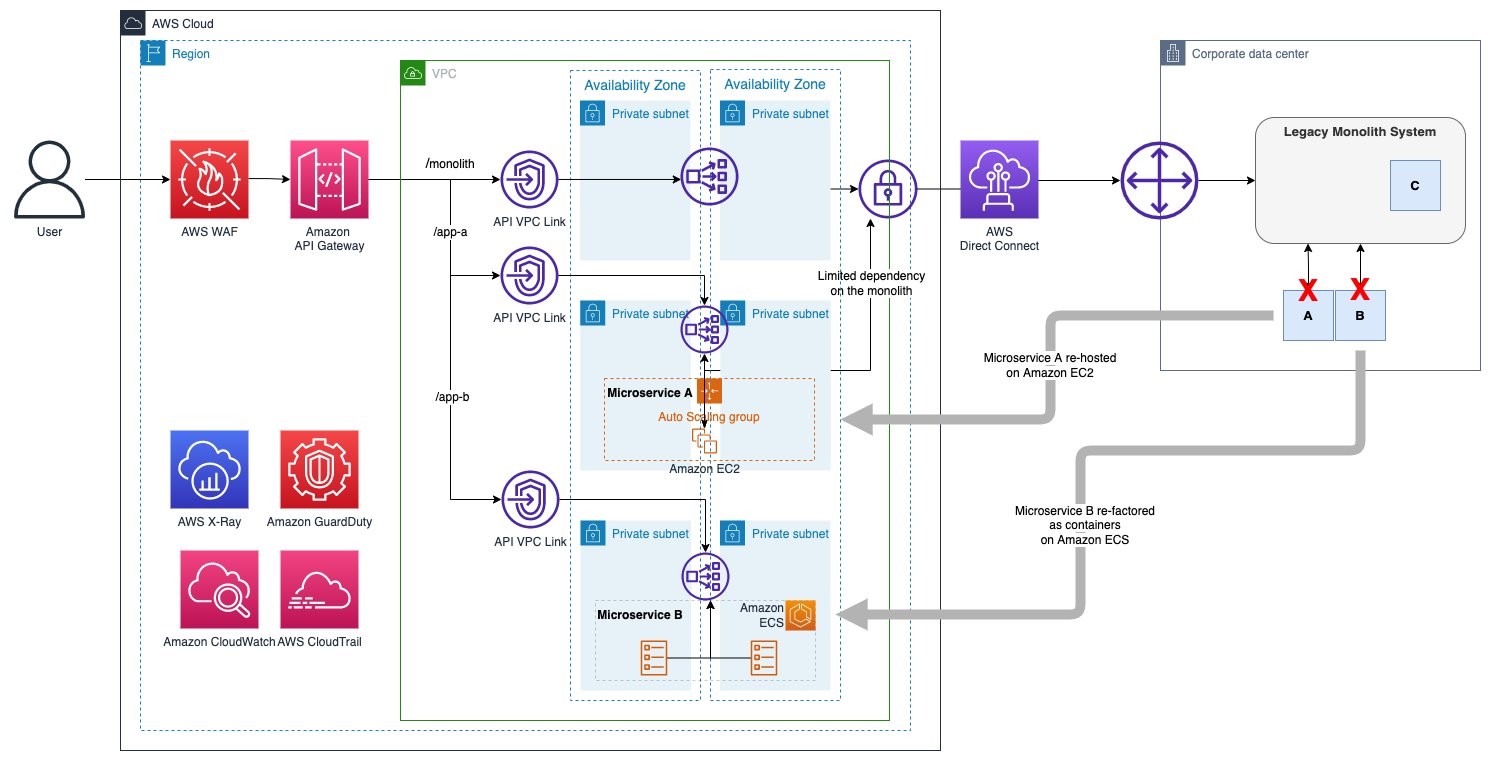
Final optimized architecture
After applying these optimizations, we have the updated architecture shown in Figure 7. It uses only two Lambda functions out of the initial 13. The rest have been replaced by direct service integrations or implemented in Step Functions.

Figure 7. Final optimized architecture
We were able to remove 11 Lambda functions and their associated fees. In this architecture, the cost is mainly driven by Step Functions, and the main price difference will be your use of Express Workflows instead of Standard Workflows. If you need to keep some Lambda functions, use AWS Lambda Power Tuning to configure your function correctly and benefit from the best price/performance ratio.
One of the main benefits of this architecture is performance. With the final workflow architecture, it now takes about 1.5 seconds when the Lambda function is warmed and 3 seconds on cold starts (versus up to 10 seconds previously), see Figure 8:

Figure 8. X-Ray traces for the final architecture
The process can now be synchronous. It reduces the complexity of the architecture and vastly improves the user experience.
An added benefit is that by reducing the overall complexity and removing the unnecessary Lambda functions, we have also reduced the risk of failures. These can be errors in the code, memory or timeout issues due to bad configuration, lack of permissions, network issues between components, and more. This increases the resiliency of the application and eases its maintenance.
Testing
Testability is an important consideration when building your workflow. Unit testing a Lambda function is straightforward, and you can use your preferred testing framework and validate methods. Adopting a hexagonal architecture also helps remove dependencies to the cloud.
When removing functions and using an approach with direct service integrations, you are by definition directly connected to the cloud. You still must verify that the overall process is working as expected, and validate these integrations.
You can achieve this kind of tests locally using Step Functions Local, and the recently announced Mocked Service Integrations. By mocking service integrations, for example, retrieving an item in DynamoDB, you can validate the different paths of your state machine.
You also have to perform integration tests, but this is true whether you use direct integrations or Lambda functions.
Conclusion
This post describes how to simplify your architecture and optimize for performance, resiliency, and cost by using direct integrations in Step Functions and API Gateway. Although many Lambda functions were reduced, some remain useful for handling more complex business logic and data transformation. Try this out now by visiting the GitHub repository.
For further reading: