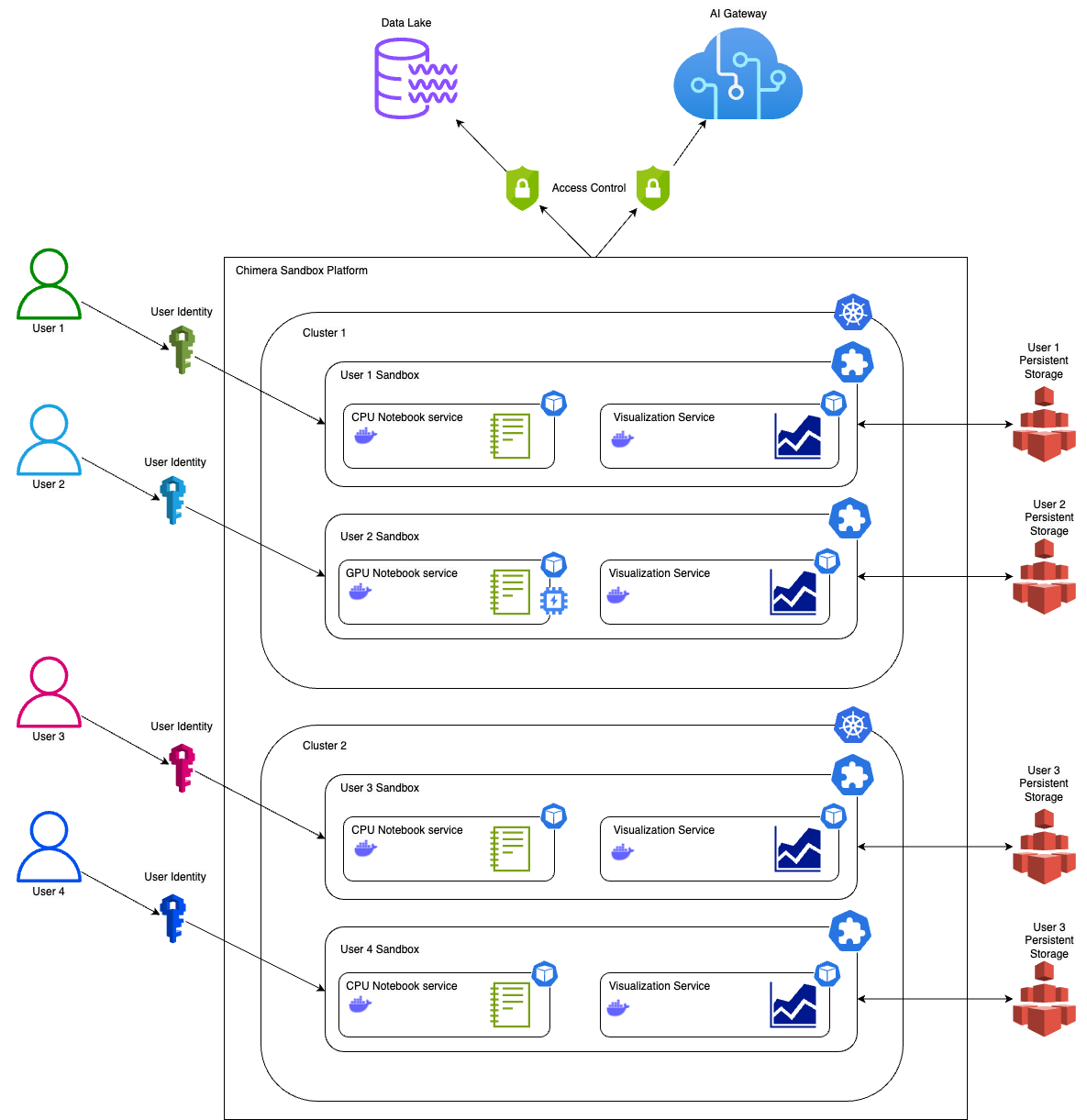
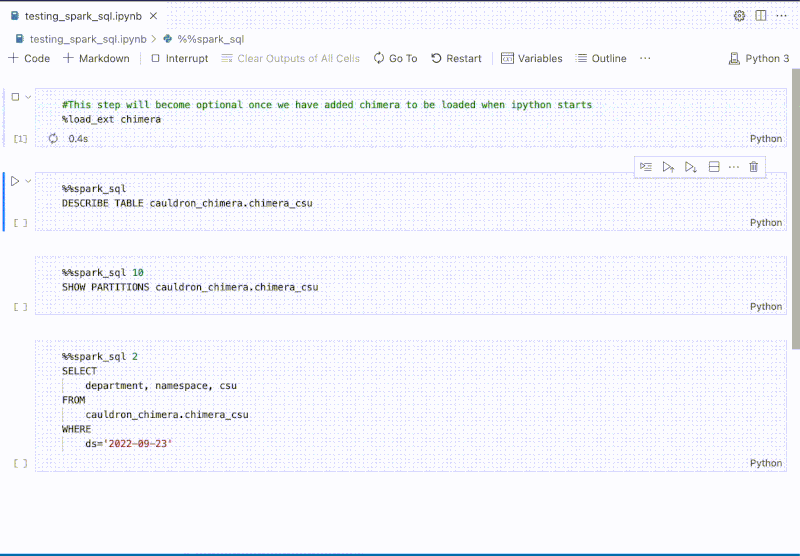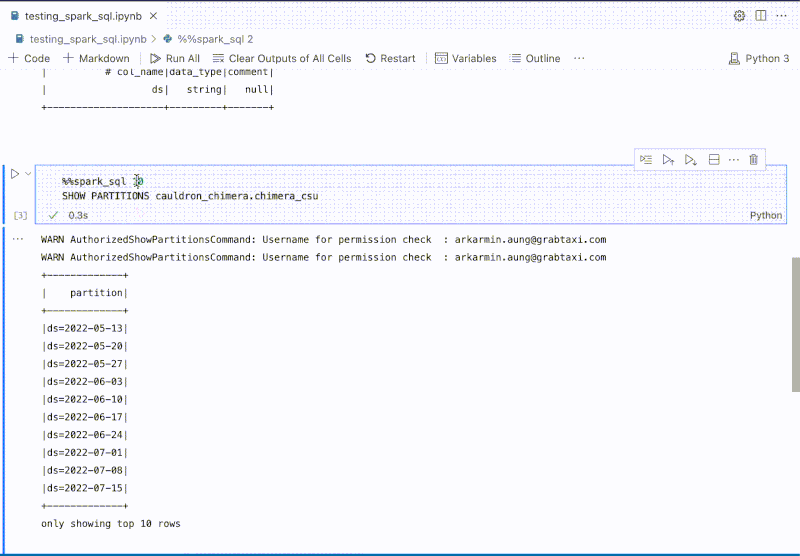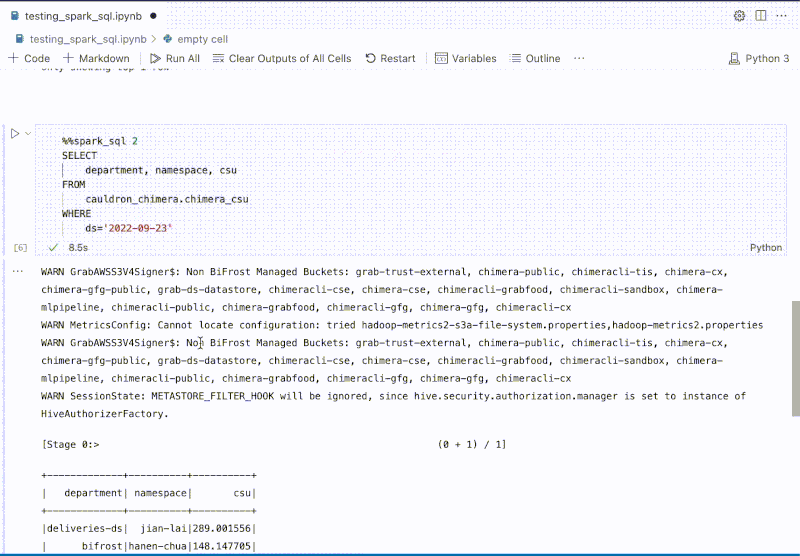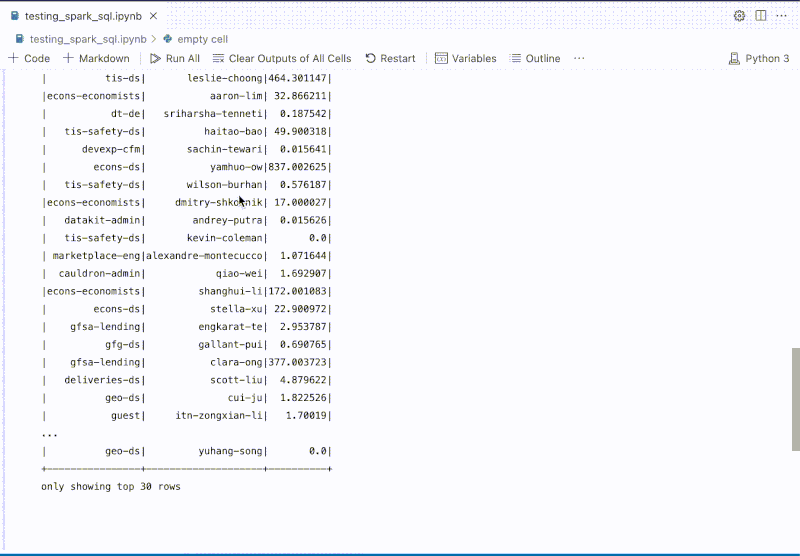
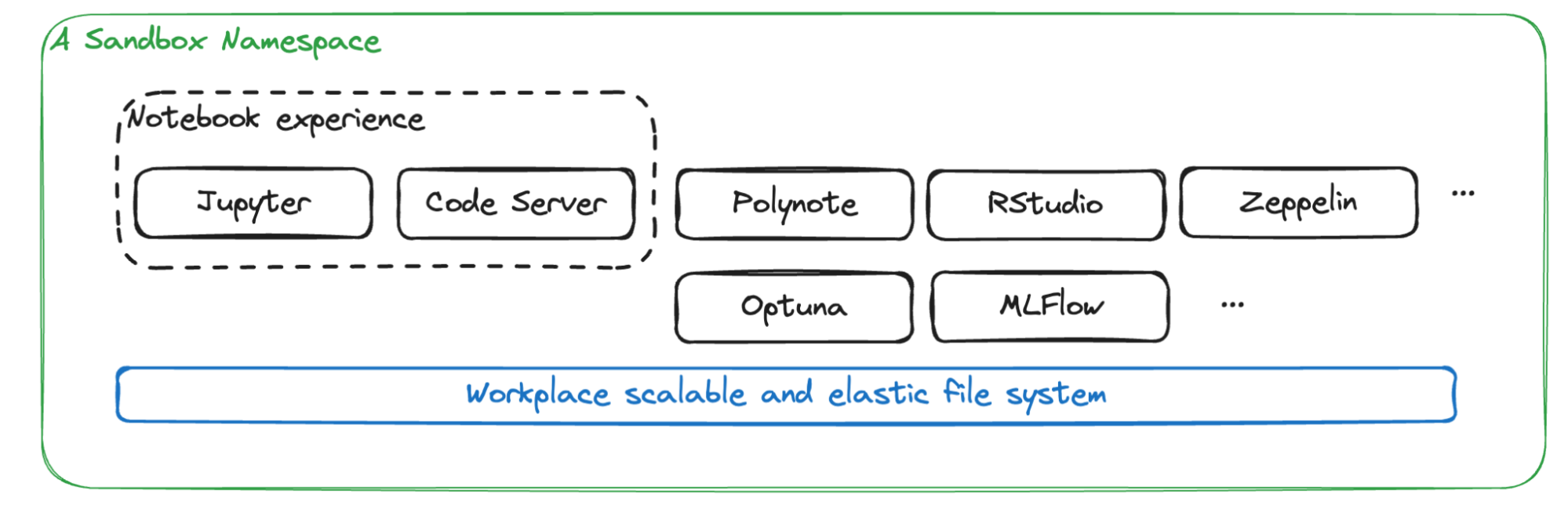
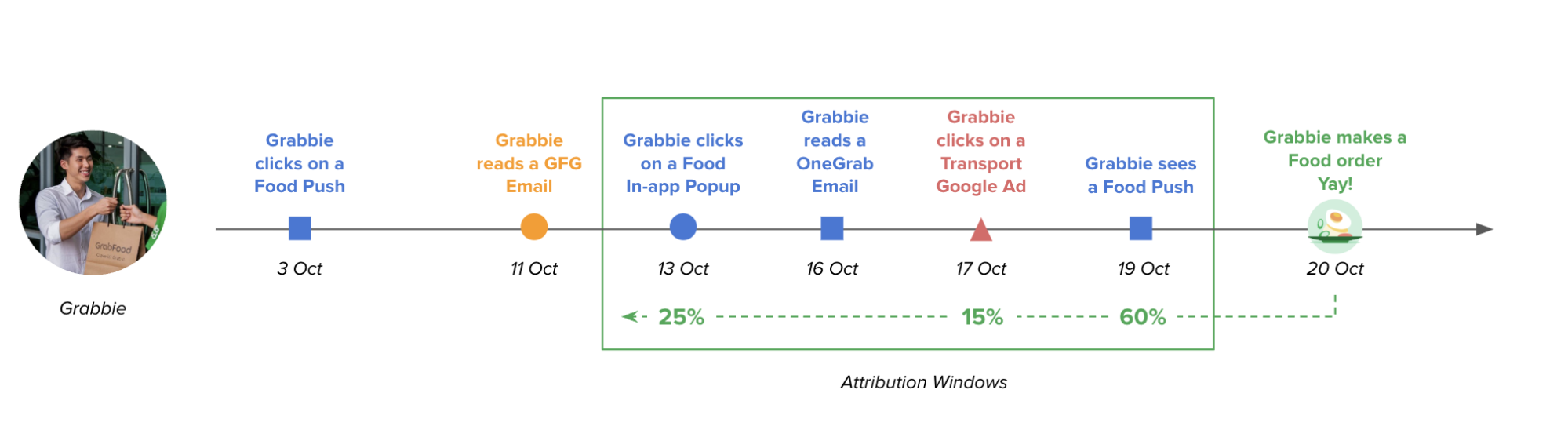
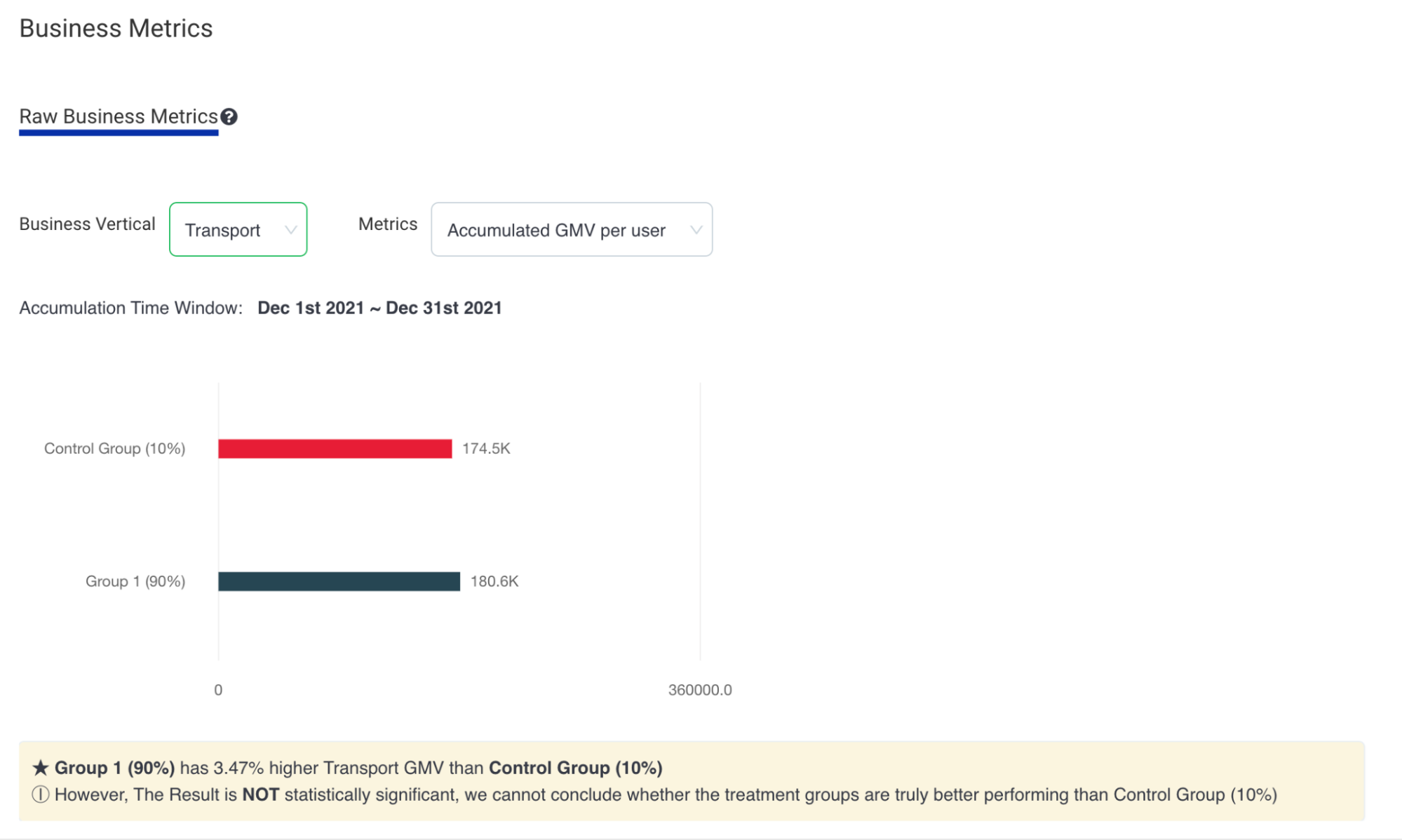
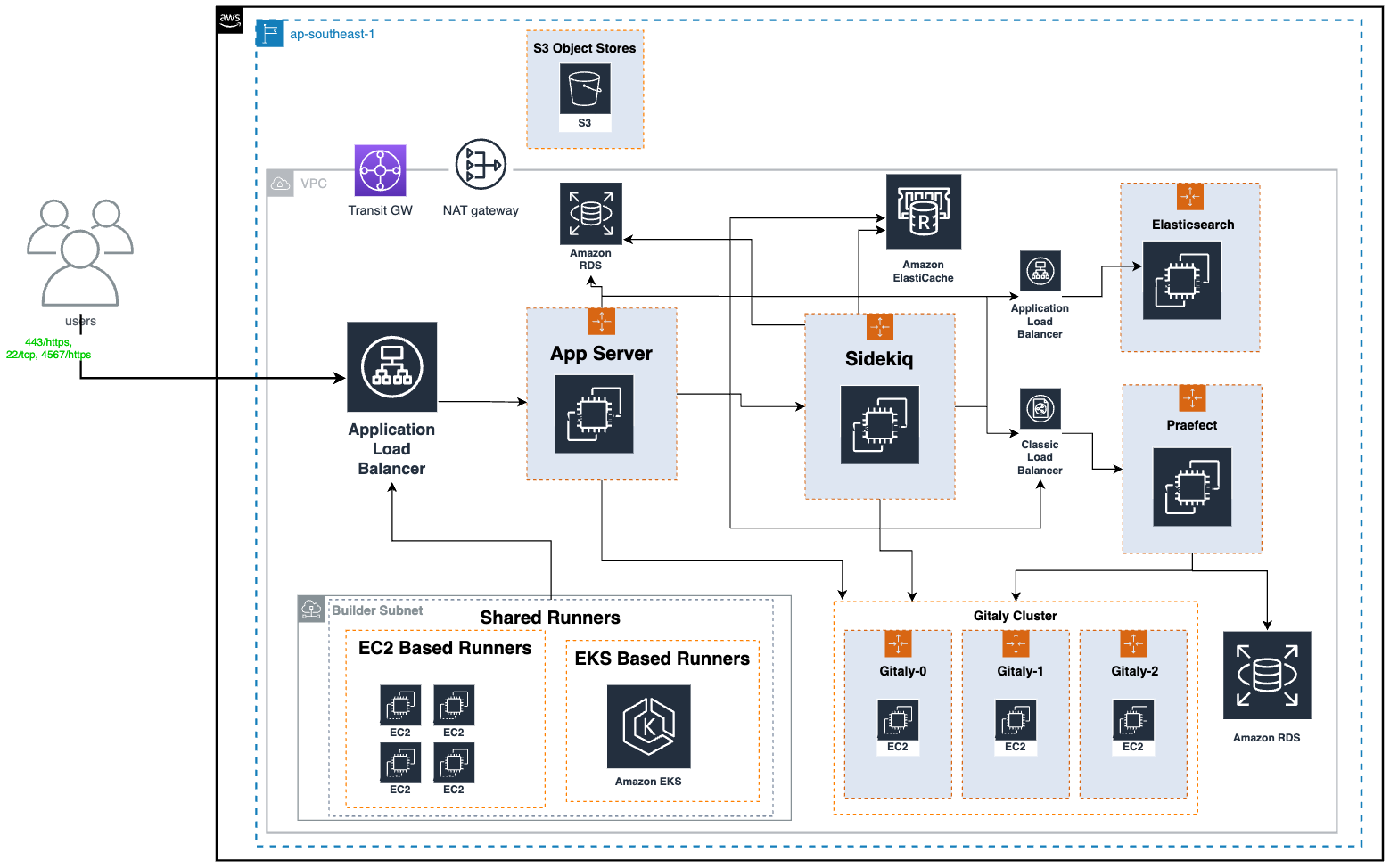
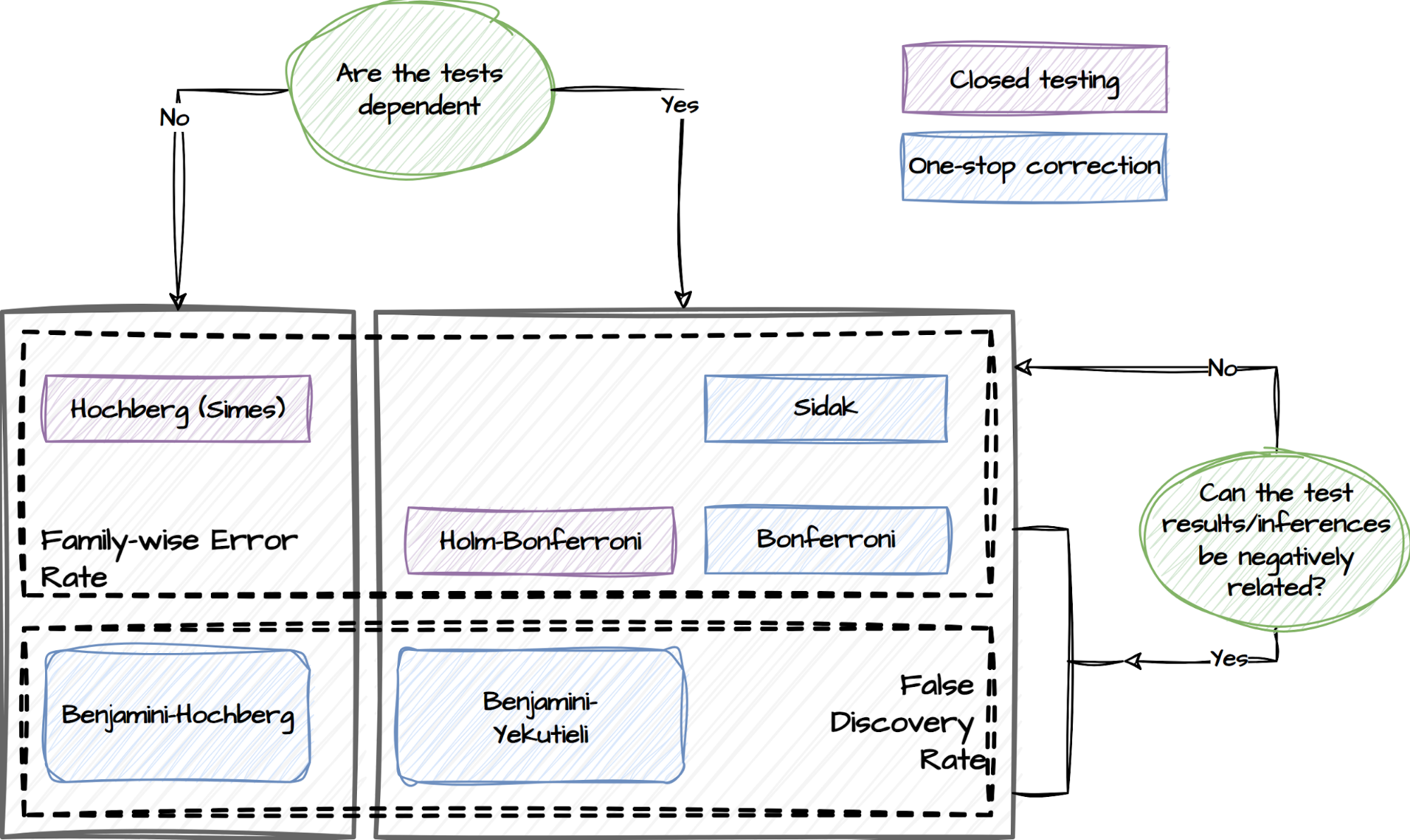
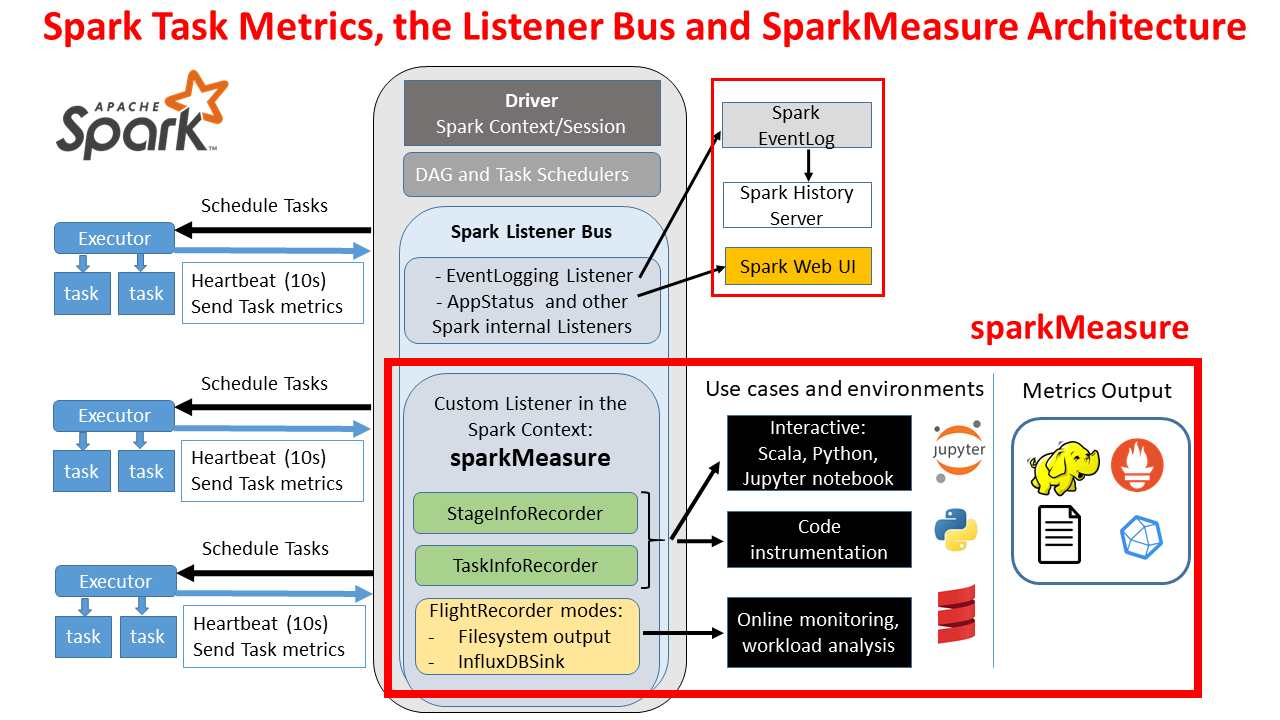
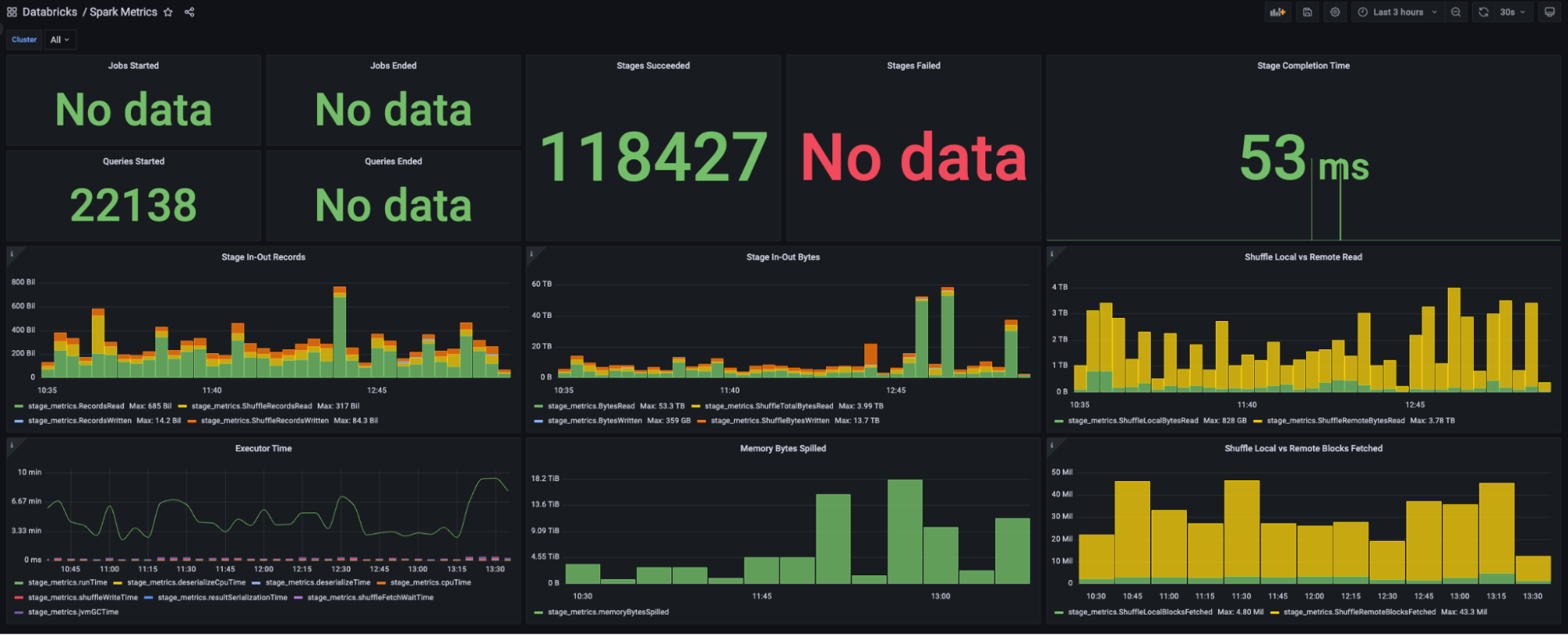
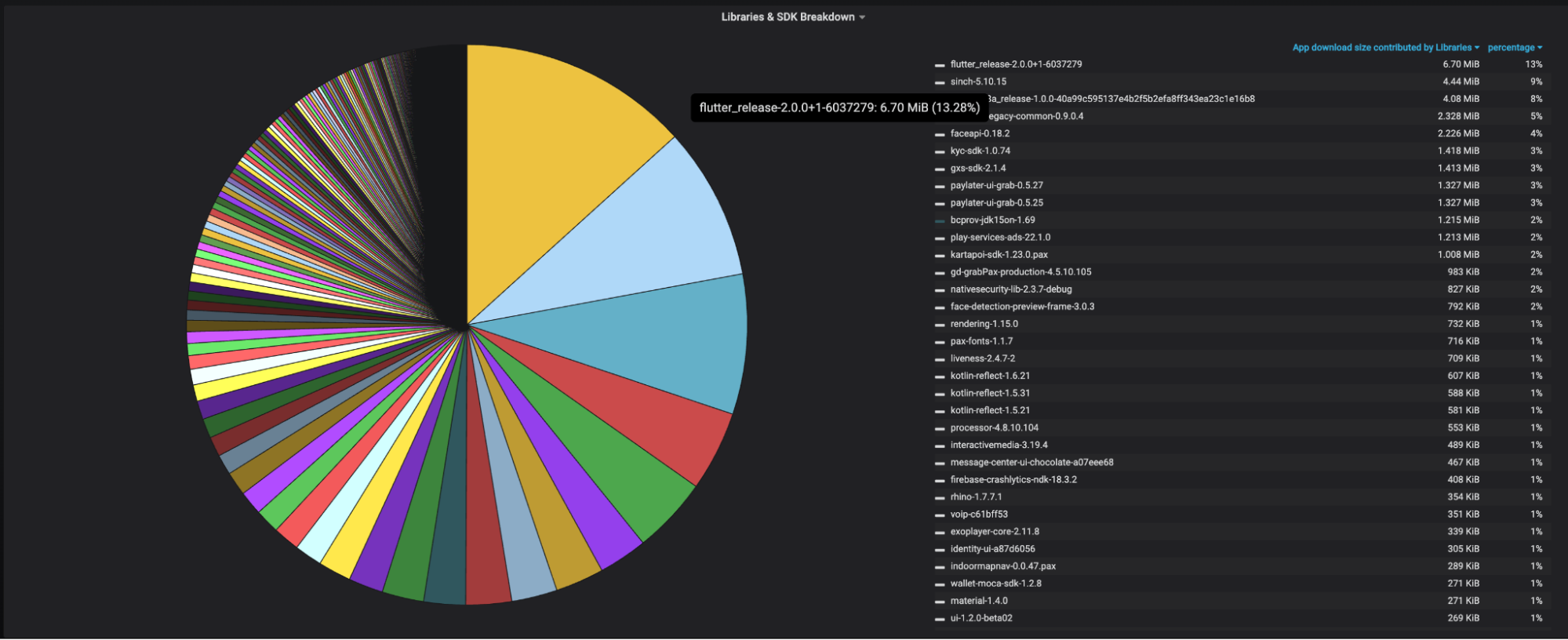
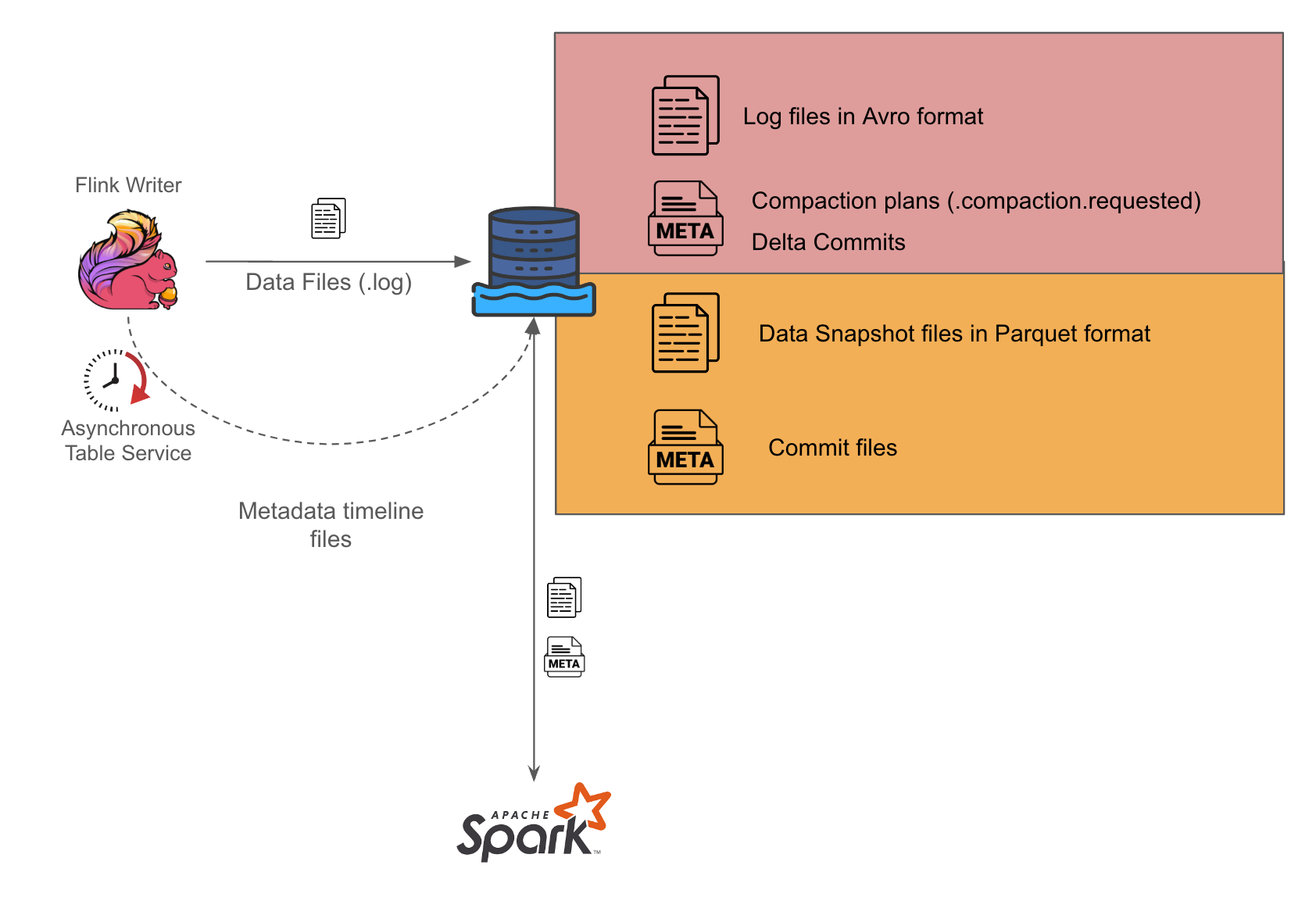
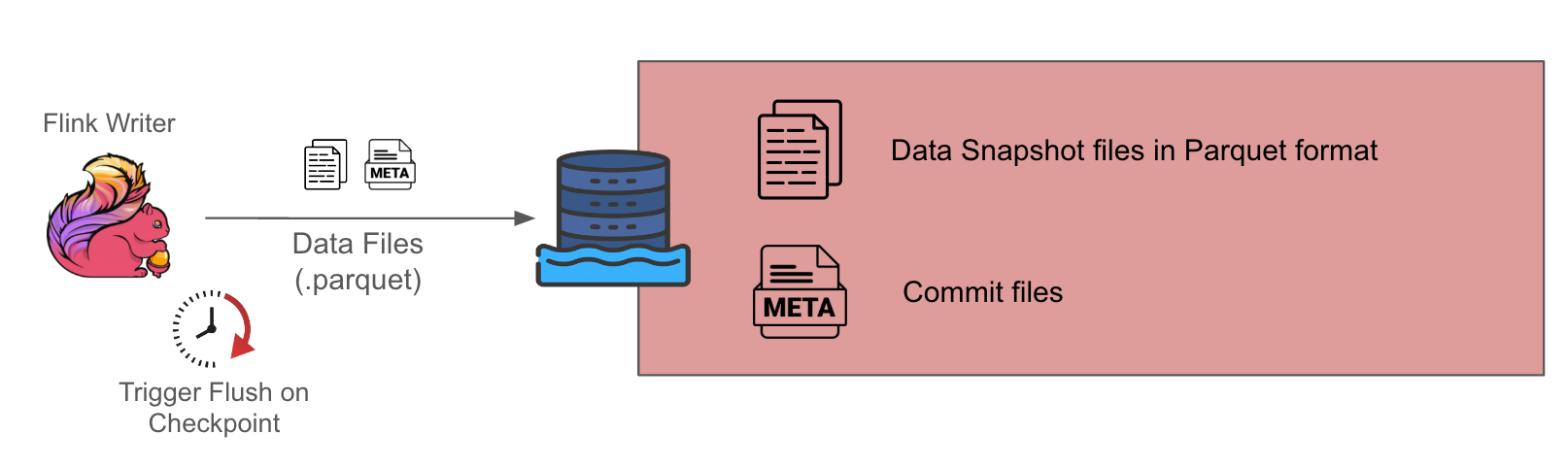
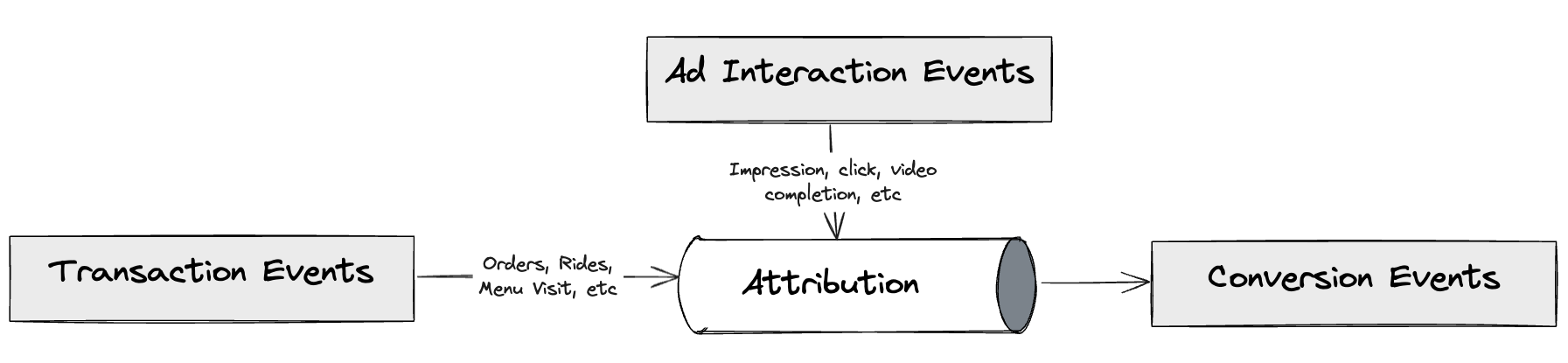
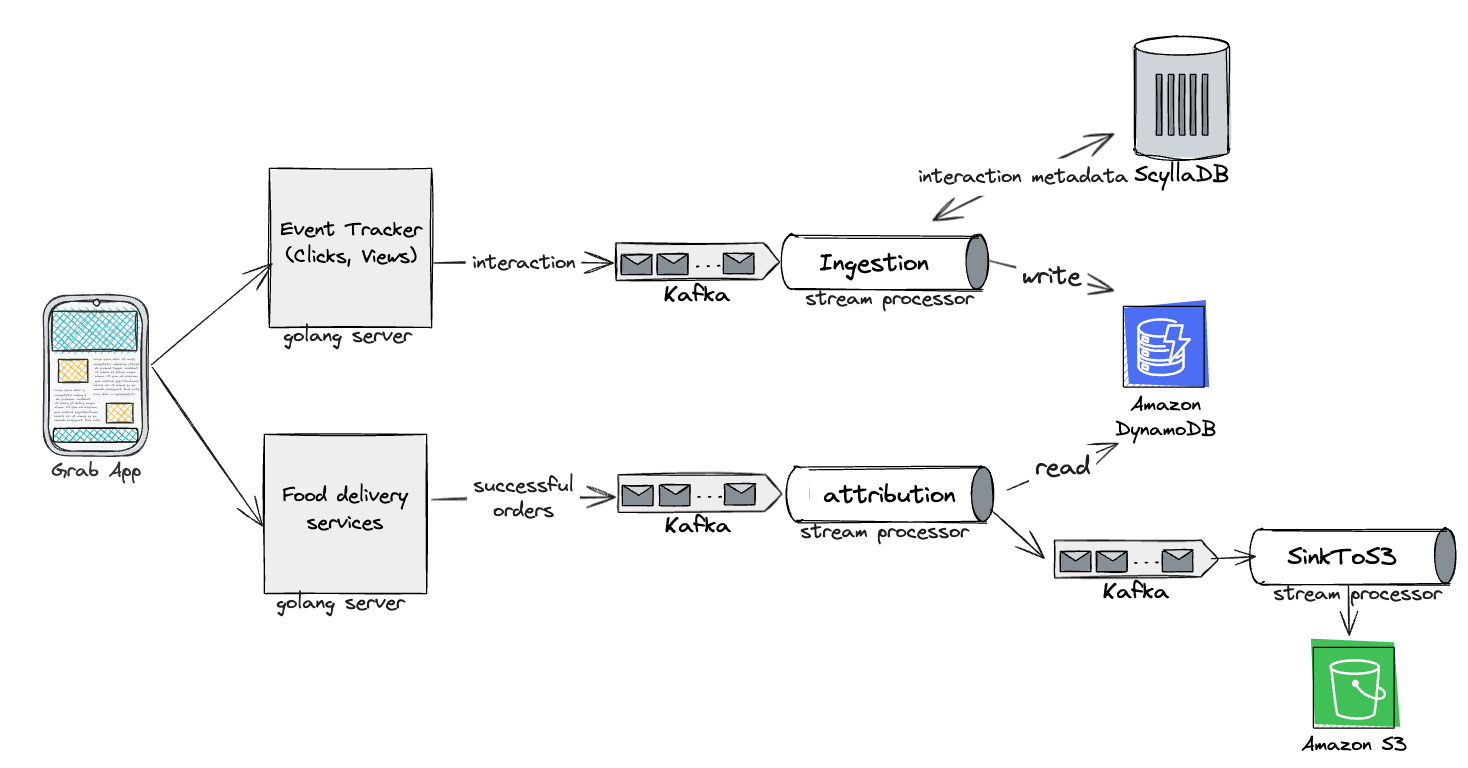
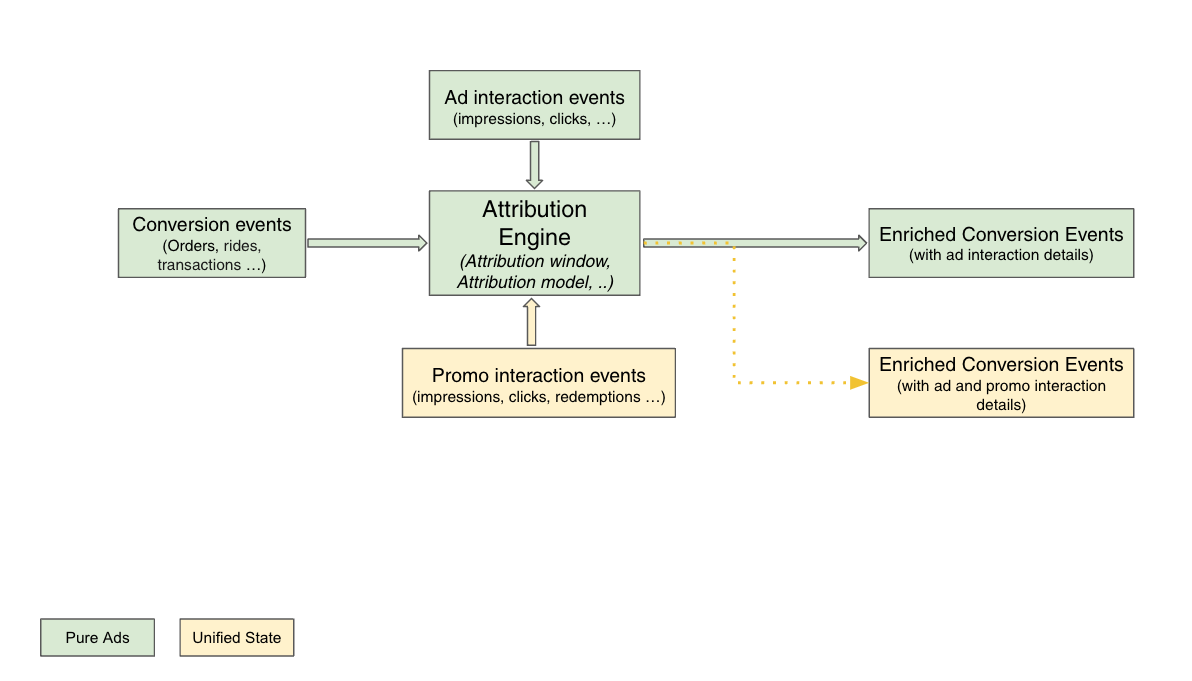
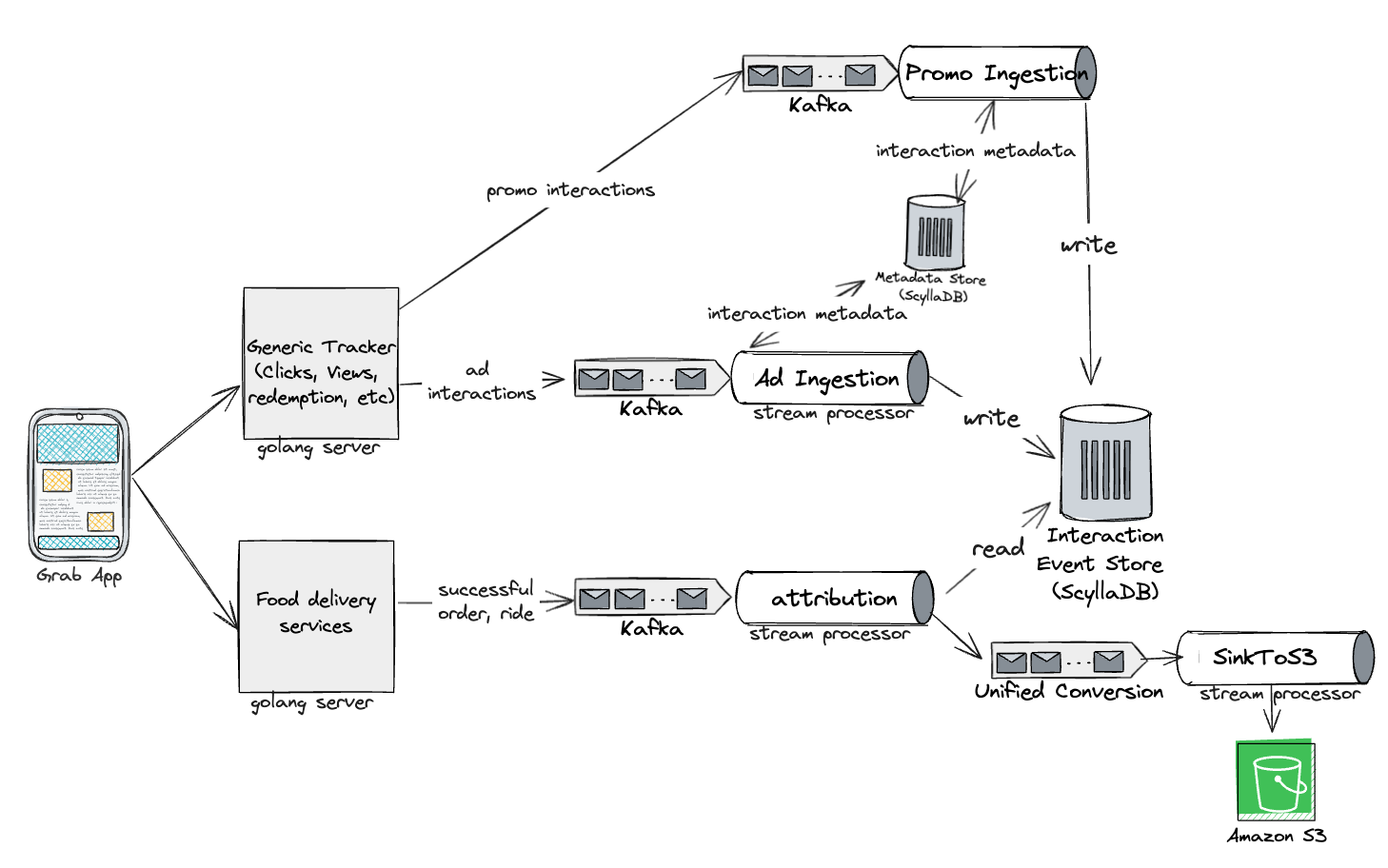
GrabX is Grab’s central platform for product configuration management. It has the capacity to control any component within Grab’s backend systems through configurations that are hosted directly on GrabX.
GrabX clients read these configurations through an SDK, which reads the configurations in a way that’s asynchronous and eventually consistent. As a result, it takes about a minute for any updates to the configurations to reach the client SDKs.
In this article, we discuss our analysis and the steps we took to reduce the peak memory and CPU usage of the SDK.
Observations on potential SDK improvements
Our GrabX clients noticed that the GrabX SDK tended to require high memory and CPU usage. From this, we saw opportunities for further improvements that could:
Optimise the tail latencies of client services.
Enable our clients to use their resources more effectively.
Reduce operation costs and improve the efficiency of using the GrabX SDK.
Accelerate the adoption of GrabX by Grab’s internal services.
SDK design
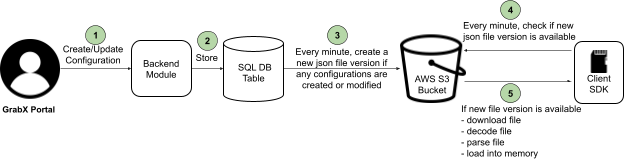
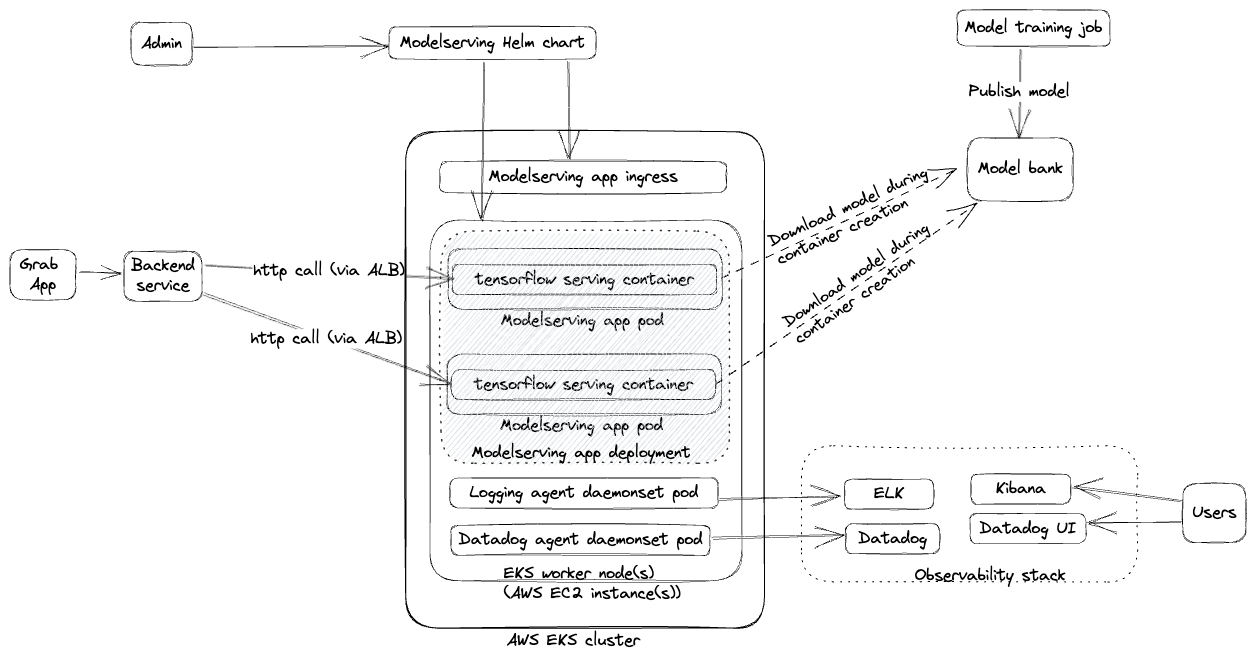
At a high-level, creating, updating, and serving configuration values via the GrabX SDK involved the following process:
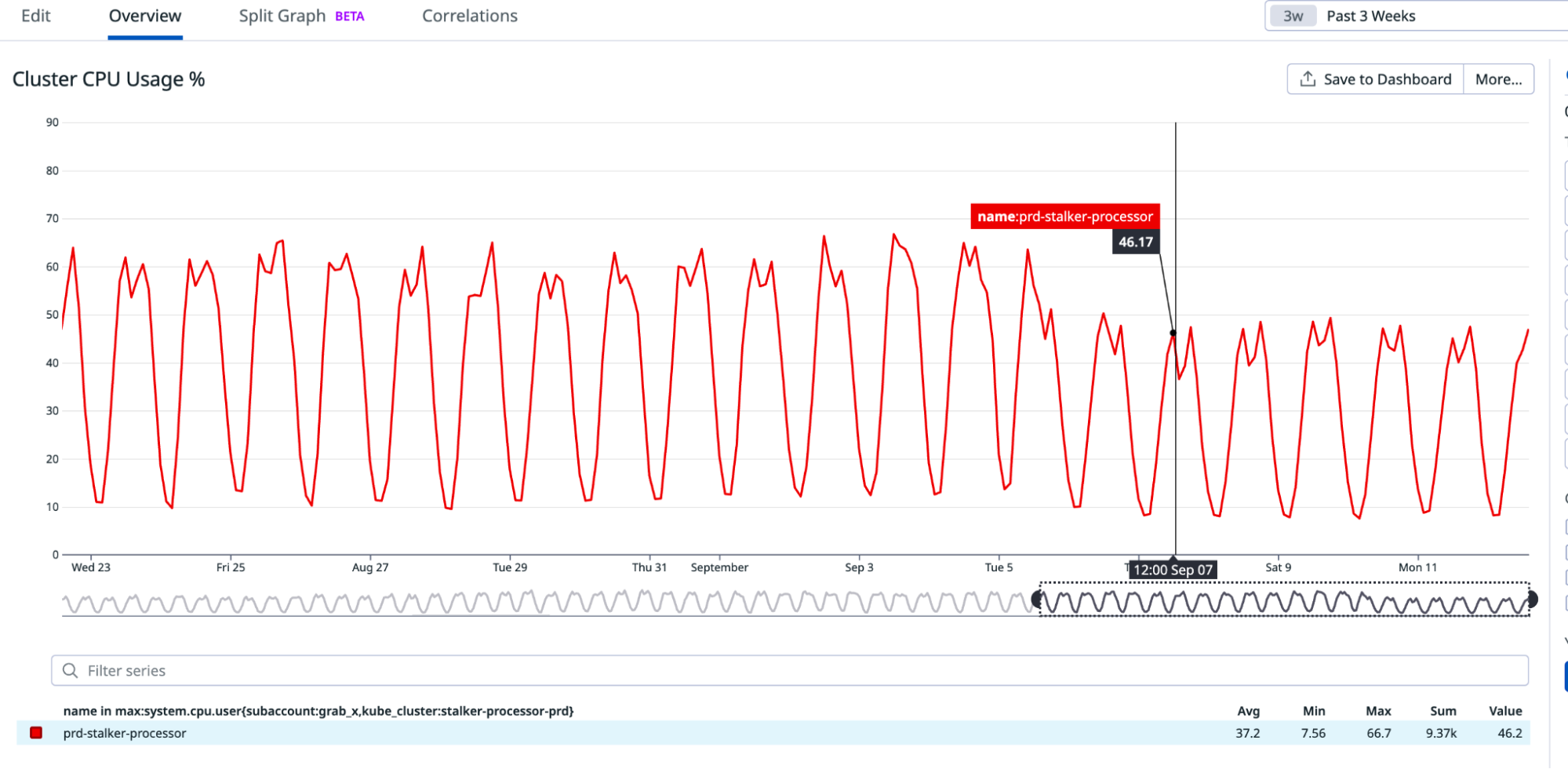
Figure 1. Previous GrabX SDK design.
The process begins when GrabX clients either create or update configurations. This is done through the GrabX web portal or by making an API call.
Once the configurations are created or updated, the GrabX backend module takes over. It stores the new configuration into an SQL database table.
The GrabX backend ensures that the latest configuration data is available to client SDKs.
a. The GrabX backend checks every minute for any newly created or updated configurations.
b. If there are new or updated configurations, GrabX backend creates a new JSON file. This file contains all existing and newly created configurations. It’s important to note that all configurations across all services are stored in a single JSON file.
c. The backend module uploads this newly created JSON file to an AWS S3 bucket.
d. The backend module assigns a version number to the new JSON file and updates a text file in the AWS S3 bucket. This text file stores the latest JSON file version number. The client SDK refers to this version file to check if a newer version of the configuration data is available.
The client SDK performs a check on the version file every minute to determine if a newer version is available. This mechanism is crucial to maintain data consistency across all instances of a service. If any instance fell out of sync, it would be brought back in sync within a minute.
If a new version of the configuration JSON file is available, the client SDK downloads this new file. Following the download, it loads the configuration data into memory. Storing the configuration data in memory reduces the read latency for the configurations.
Areas of improvement for existing SDK design
In this section we outline the areas of improvement we identified within the SDK design.
Service-based data partitioning
We saw an opportunity for service-based data partitioning. The configuration data for all services was consolidated into a single JSON file. Upon studying the data read patterns of client services, we observed that most services primarily needed to access configuration data specific to their own service. However, the present design required storing configuration data for all other services. This resulted in unnecessary memory consumption.
Retaining only new version of configuration in the same file
By using a single JSON file for storing old and new configuration data, we saw a significant increase in the size of the JSON file.
The SDK only needs the full data when it starts; the more common case is that it needs to stay updated with the latest configuration. Even in that scenario, the SDK needed to fetch a complete new JSON file every minute no matter the size of the updates. Consequently, the process of downloading, decoding, and loading high volumes of data at a high frequency (every minute) caused the client SDK to spike in memory and CPU usage.
More efficient JSON decoding
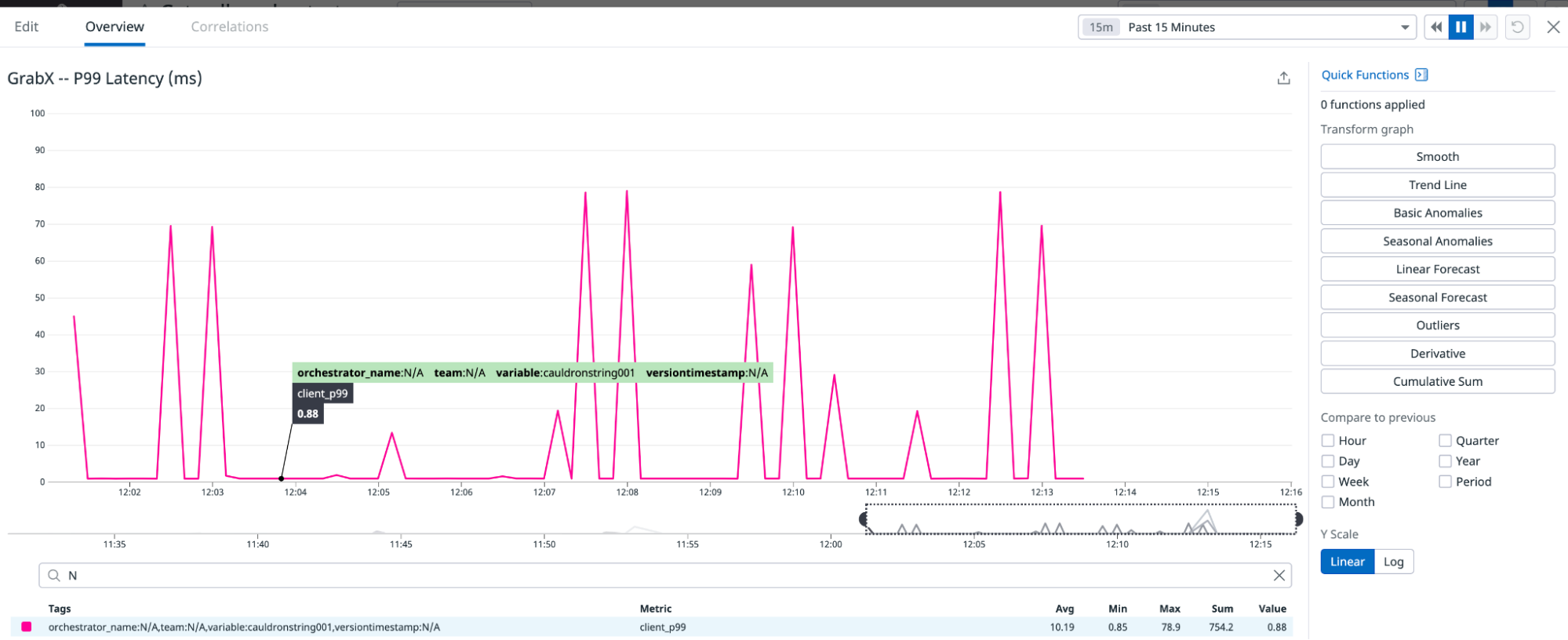
An additional factor which contributed to memory and CPU usage during the decoding phase was the inefficiency of the default JSON decode library to decode this large (>100MB) JSON file. Decoding this JSON file was heavy on available CPU resources, which tended to starve the service of its ability to handle incoming requests. This manifested as increasing the P99 latency of the service.
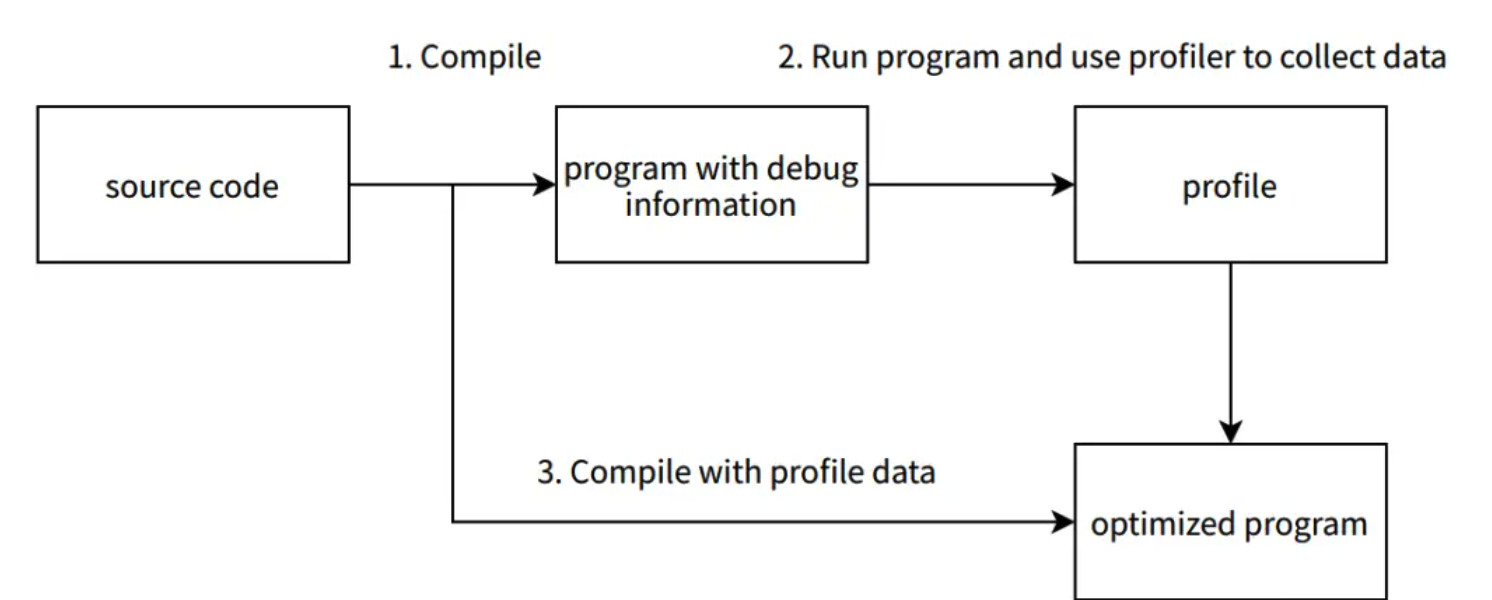
Figure 2. Graph illustrating the increased P99 latency due to CPU throttling for a service.
Implemented solution
We proposed modifications to the existing SDK design, which we discuss in this section.
Partition data by service
The proposed solution involved partitioning the data based on services. We chose this approach because a single configuration typically belonged to a single service, and most services primarily needed to read configurations that pertained to their own service.
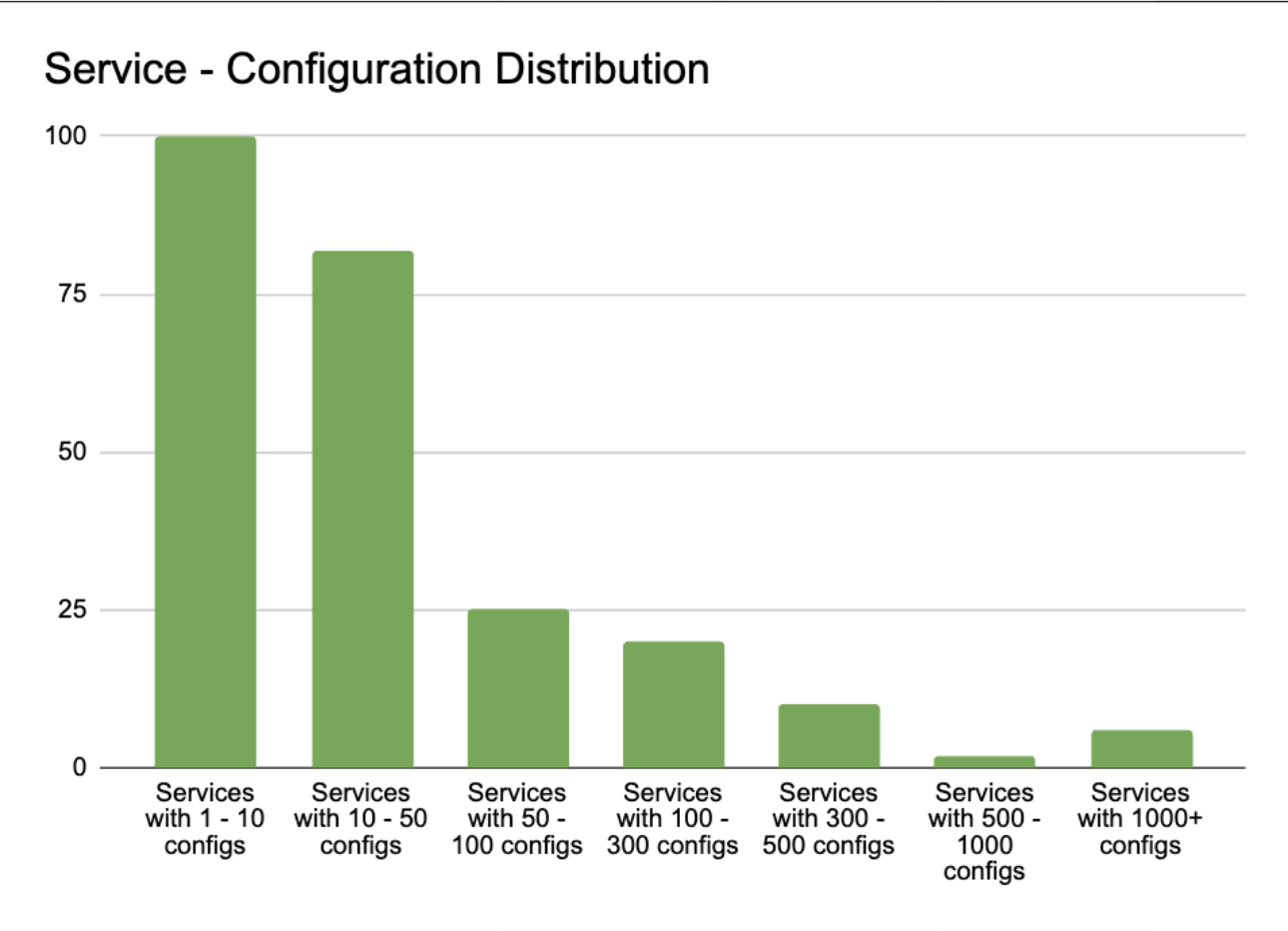
Upon analysing the distribution of service-configuration, we discovered that 98% of client services required less than 1% of the total configuration data. Despite this, they were required to maintain and reload 100% of the configuration data. Furthermore, the service with the largest number of configurations only required 20% of the total configuration data.
Therefore, we proposed a shift towards service-based partitioning of configuration data. This allowed individual client services to access only the data they needed to read.
Figure 3. Graph showing the number of services with varying amounts of configurations.
Create separate JSON files for each configuration
Our proposal also included creating a separate JSON file for each configuration in a service. Previously, all data was stored in a single JSON file housed in an AWS S3 bucket, which supported a maximum of 3,500 write/update requests and 5,500 read requests per second.
By storing each configuration in a separate JSON file, we were able to create a different S3 prefix for each configuration file. These S3 prefixes helped us to maximise S3 throughput by enhancing the read/write performance for each configuration. AWS S3 can handle at least 3,500 PUT/COPY/POST/DELETE requests or 5,500 GET/HEAD requests per second for each partitioned Amazon S3 prefix.
Therefore, with each configuration’s data stored in a separate S3 file with a different prefix, the GrabX platform could achieve a throughput of 5,500 read requests and 3,500 write/update requests per second per configuration. This was beneficial for boosting read/write capacity when needed.
Implement a service-level changelog
We proposed to create a changelog file at the service level. In other words, a changelog file was created for each service. This file was used to keep track of the latest update version, as well as previous service configuration update versions. This file also recorded the configurations which were created or updated in each version. This enables the SDK to accurately identify the configurations that were created or updated in each update version. This was useful to update the specific configurations belonging to a service on the client side.
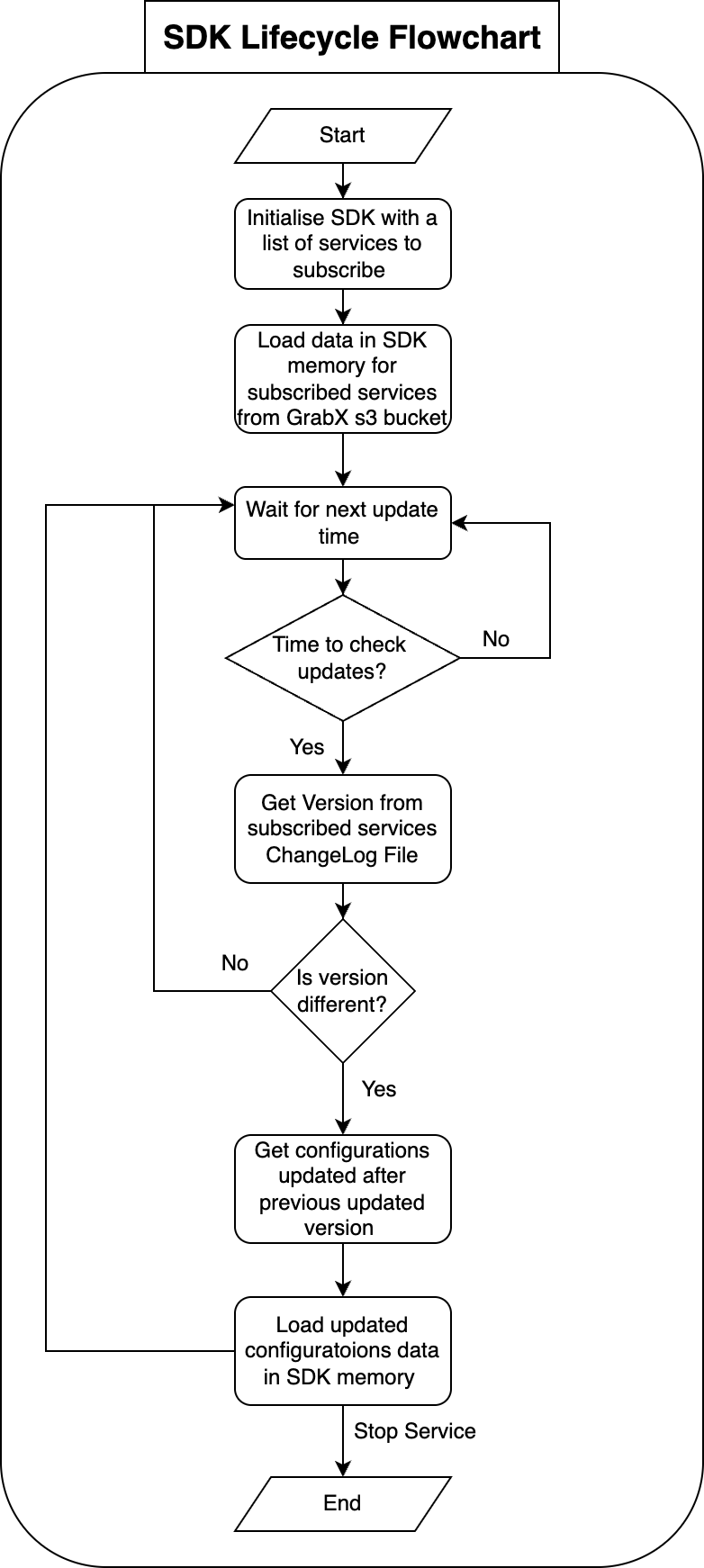
Implement service-based SDK
We proposed that SDK client services should be allowed to subscribe to a list of services for which they need to read configuration data. The SDK was initialised with data of the subscribed services and received updates only for configurations corresponding to the subscribed services.
Figure 4. This flowchart shows our proposed service-based SDK implementation.
The SDK only sought updates for the subscribed services. The client SDK needed to read the changelog file for each of the subscribed services, comparing the latest changelog version against the SDK version number. Whenever a newer changelog version was available, the SDK updated the variables with the latest version.
This approach significantly reduced the volume of data that the SDK needed to download, decode, and load into memory during both initialisation and each subsequent update.
Conclusion
In summary, we identified ways to optimise CPU and memory usage in the GrabX SDK. Our analysis revealed that frequent high resource consumption hindered the wider adoption of GrabX. We proposed a series of modifications, including partitioning data by service and creating separate JSON files for each configuration.
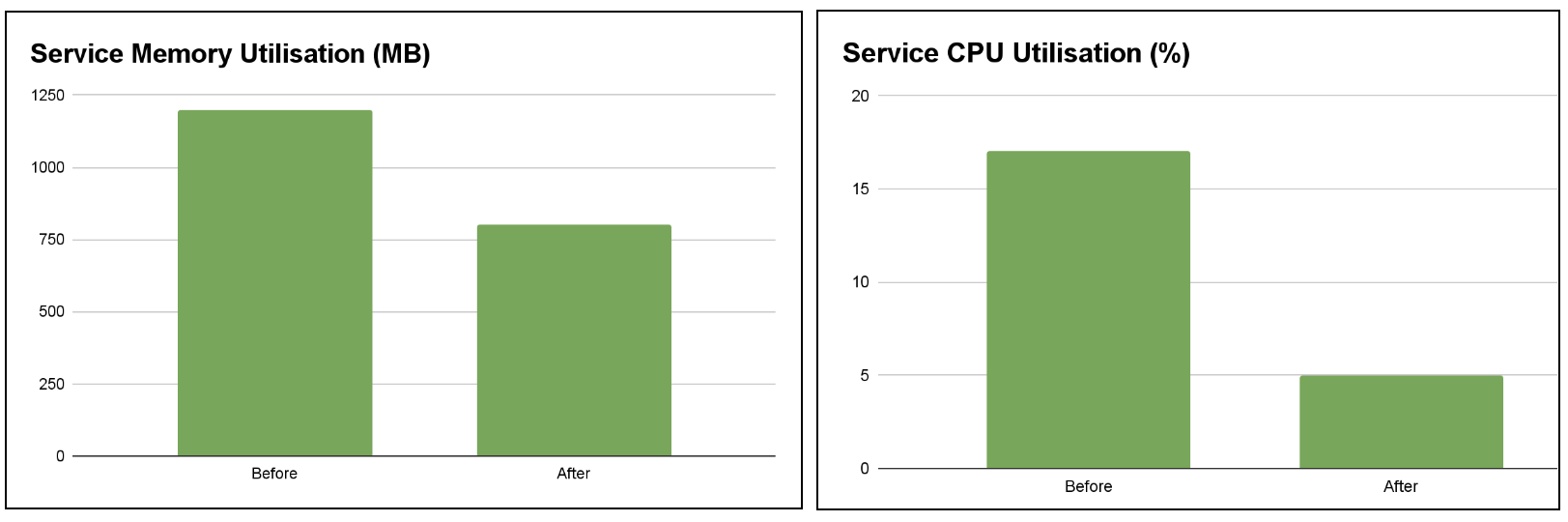
After benchmarking the proposed solution with a variety of configuration data sizes, we found that the solution has the potential to reduce memory utilisation by up to 70% and decrease the maximum CPU utilisation by more than 50%. These improvements significantly enhance the performance and scalability of the GrabX SDK.
Figure 5. Bar charts showcasing memory(MB) & CPU(%) utilisation for Service A before and after using the discussed solution.
Moving forward, we plan to continue optimising the GrabX SDK by exploring additional improvements, such as reducing its initialisation time. These efforts aim to make GrabX an even more robust and reliable solution for product configuration management within Grab’s ecosystem.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
As the complexity of data retrieval requirements continue to grow, traditional search methods often struggle to provide relevant and accurate results, especially for nuanced or conceptual queries. Vector similarity search has emerged as a powerful technique for finding semantically similar information. It refers to finding vectors in a large dataset that are most similar to a given query vector, typically using some distance or similarity measure. The concept originated in the 1960s with the work by Minsky and Papert on nearest neighbour search 1. Since then, the idea has evolved substantially with modern approaches often using approximate methods to enable fast search in high-dimensional spaces, such as locality-sensitive hashing 2 and graph-based indexing 3.
Recently, vector similarity search has become a crucial component in many machine learning and information retrieval applications. It is one of the key technologies that popularised the idea of Retrieval Augmented Generation (RAG) 4 which increased the applicability of Transformer 5 based Generative Large Language Models (LLMs) 6 in domain-specific tasks without requiring any further training or fine-tuning. However, the effectiveness of the vector search can be limited when dealing with intricate queries or contextual nuances. For example, from a typical vector similarity search perspective, “I like fishing” and “I do not like fishing” may be quite close to each other, while in reality, they are the exact opposite. In this blog post, we discuss an approach that we experimented with that combines vector similarity search with LLMs to enhance the relevance and accuracy of search results for such complex and nuanced queries. We leverage the strengths of both techniques: vector similarity search for efficient shortlisting of potential matches, and LLMs for their ability to understand natural language queries and rank the shortlisted results based on their contextual relevance.
Proposed solution
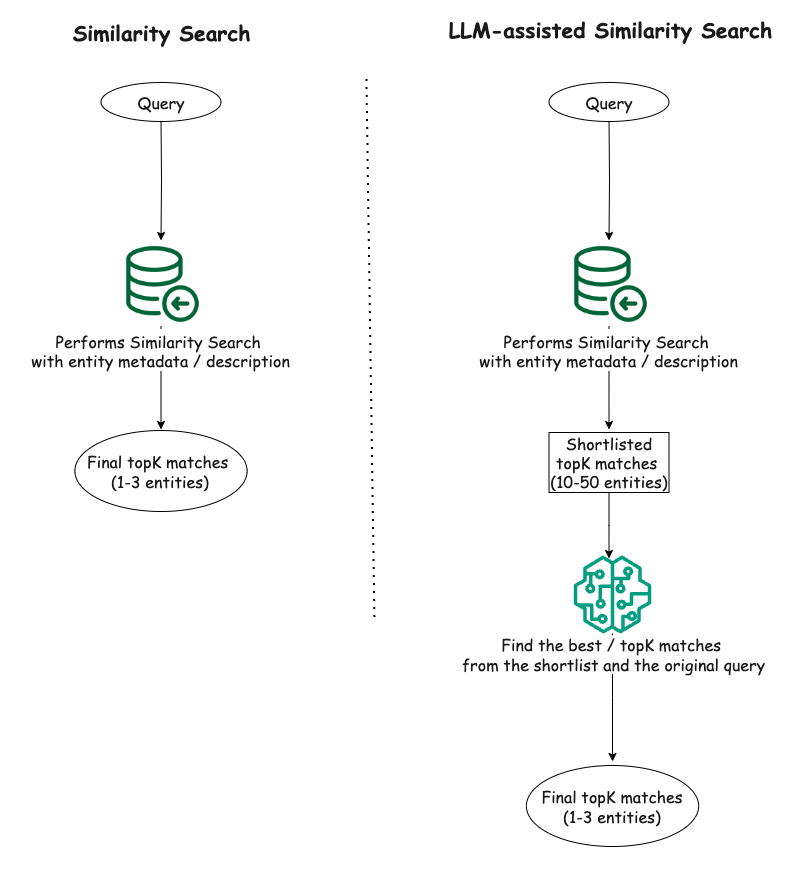
The proposed solution involves a two-step process:
Vector similarity search: We first perform a vector similarity search on the dataset to obtain a shortlist of potential matches (e.g., top 10-50 results) for the given query. This step leverages the efficiency of vector similarity search to quickly narrow down the search space.
LLM-assisted ranking: The shortlisted results from the vector similarity search are then fed into an LLM, which ranks the results based on their relevance to the original query. The LLM’s ability to understand natural language queries and contextual information helps in identifying the most relevant results from the shortlist.
By combining these two steps, we aim to achieve the best of both worlds: the efficiency of vector similarity search for initial shortlisting, and the contextual understanding and ranking capabilities of LLMs for refining the final results.
Figure 1. Similarity search and the proposed LLM-assisted similarity search.
Experiment
Datasets
To evaluate the effectiveness of our proposed solution, we conducted experiments on two small synthetic datasets in CSV format that we curated using GPT-4o 7.
Food dataset: A collection of 100 dishes with their titles and descriptions.
Tourist spots dataset: A collection of 100 tourist spots in Asia, including their names, cities, countries, and descriptions.
It is important to note that we primarily focus on performing similarity search on structured data such as description of various entities in a relational database.
Setup
Our experimental setup included a Python script for vector similarity search leveraging Facebook AI Similarity Search (FAISS) 8, a library developed by Facebook that offers efficient similarity search, and OpenAI’s embeddings (i.e., text-embedding-ada-002) 9 to generate the vector embeddings needed for facilitating the vector search. For our proposed solution, an LLM component (i.e., GPT-4o) was included in the setup in addition to the FAISS-based similarity search component.
Observations
To compare the performance of the proposed approach of LLM-assisted vector similarity search as outlined in the “Proposed solution” section with the raw vector similarity search, we conducted both techniques on our two synthetic datasets. With the raw vector search, we get the top three matches for a given query. For our proposed technique, we first get a shortlist of 15 entity matches from FAISS for the same query, and supply the shortlist and the original query to LLM with some descriptive instructions in the prompt to find the top three matches from the provided shortlist.
From the experiments, in simpler cases where the queries were straightforward and directly aligned with the textual content of the data, both the raw similarity search and the LLM-assisted similarity search demonstrated comparable performance. However, as the queries became more complex, involving additional constraints, negations, or conceptual requirements, the LLM-assisted search exhibited a clear advantage over the raw similarity search. The LLM’s ability to understand context and capture subtleties in the queries allowed it to filter out irrelevant results and rank the most appropriate ones higher, leading to improved accuracy.
Here are a few examples where the LLM-assisted similarity search performed better:
Food dataset
Query: “food with no fish or shrimp”
Raw similarity search result:
- title: Tempura, description: A Japanese dish of seafood or vegetables that have been battered and deep fried.
- title: Ceviche, description: A seafood dish popular in Latin America, made from fresh raw fish cured in citrus juices.
- title: Sushi, description: A Japanese dish consisting of vinegared rice accompanied by various ingredients such as seafood and vegetables.
LLM-assisted similarity search result:
- title: Chicken Piccata, description: Chicken breasts cooked in a sauce of lemon, butter, and capers.
- title: Chicken Alfredo, description: An Italian-American dish of pasta in a creamy sauce made from butter and Parmesan cheese.
- title: Chicken Satay, description: Grilled chicken skewers served with peanut sauce.
Observation: The LLM correctly filtered out dishes containing fish or shrimp, while the raw similarity search failed to do so, presumably due to the presence of negation in the query.
Tourist spots dataset
Query: “exposure to wildlife”
Raw similarity search result:
- name: Ocean Park, city: Hong Kong, country: Hong Kong, description: Marine mammal park and oceanarium.
- name: Merlion Park, city: Singapore, country: Singapore, description: Iconic statue with the head of a lion and body of a fish.
- name: Manila Bay, city: Manila, country: Philippines, description: A natural harbor known for its sunset views.
LLM-assisted similarity search result:
- name: Ocean Park, city: Hong Kong, country: Hong Kong, description: Marine mammal park and oceanarium.
- name: Chengdu Research Base, city: Chengdu, country: China, description: A research center for giant panda breeding.
- name: Mount Hua, city: Shaanxi, country: China, description: Mountain known for its dangerous hiking trails.
Observation: Two out of the top three matches by the LLM-assisted technique seem relevant to the query while only one result from the raw similarity search is relevant and the other two being somewhat irrelevant to the query. The LLM identified the relevance of a research base for giant panda breeding to the “exposure to wildlife”, which the raw similarity search ignored in its ranking.
These examples provide a glimpse into the utility of LLMs in finding more relevant matches in scenarios where the queries involved additional context, constraints, or conceptual requirements beyond simple keyword matching. On the other hand, when the queries were more straightforward and focused on specific keywords or phrases present in the data, both approaches demonstrated comparable performance. For instance, queries like “Japanese food” or “beautiful mountains” yielded similar results from both the raw similarity search and the proposed LLM-assisted approach.
Overall, the LLM-assisted vector search exhibited a clear advantage in handling complex queries, leveraging its ability to understand natural language and contextual information. However, for simpler queries, the raw similarity search remained a viable option, especially when computational efficiency is a concern.
Conclusion
The experiments demonstrated the potential of combining vector similarity search with LLMs to enhance the relevance and accuracy of search results, particularly for complex and nuanced queries. While vector similarity search alone can provide reasonable results for straightforward queries, the LLM-assisted approach shines when dealing with queries that require a deeper understanding of context, nuances, and conceptual relationships. By leveraging the natural language understanding capabilities of LLMs, this approach can better capture the intent behind complex queries and provide more relevant search results.
Our experiment was limited to using a small volume of structured data (100 data points in each dataset) with a limited number of queries. However, we have witnessed similar enhancement in search result relevance when we deployed this solution internally within Grab for larger datasets, for example, 4500+ rows of data stored in a relational database.
Nevertheless, it is important to note that the effectiveness of this approach may still depend on the quality and complexity of the data, as well as the specific use case and query patterns. We believe it is still worthwhile to evaluate the proposed approach for more diverse (e.g., beyond CSV) and larger datasets. An interesting future work can be varying the size of the shortlist from the similarity search and observing how it impacts the overall search relevance when using the proposed approach. In addition, for real world applications, the performance implications in terms of additional latency introduced by the additional LLM query must also be considered.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
References
M. Minsky and S. Papert, Perceptrons: An Introduction to Computational Geometry. MIT Press, 1969. ↩
P. Indyk and R. Motwani, “Approximate nearest neighbors: Towards removing the curse of dimensionality,” in Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, 1998. ↩
Y. Malkov and D. Yashunin, “Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020. ↩
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Advances in Neural Information Processing Systems, 2020. ↩
A. Vaswani, “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017. ↩
A. Radford, “Improving language understanding by generative pre-training,” 2018. ↩
Retrieval-Augmented Generation (RAG) is a powerful process that is designed to integrate direct function calling to answer queries more efficiently by retrieving relevant information from a broad database. In the rapidly evolving business landscape, Data Analysts (DAs) are struggling with the growing number of data queries from stakeholders. The conventional method of manually writing and running similar queries repeatedly is time-consuming and inefficient. This is where RAG-powered Large Language Models (LLMs) step in, offering a transformative solution to streamline the analytics process and empower DAs to focus on higher value tasks.
In this article, we will share how the Integrity Analytics team has built out a data solution using LLMs to help automate tedious analytical tasks like generating regular metric reports and performing fraud investigations.
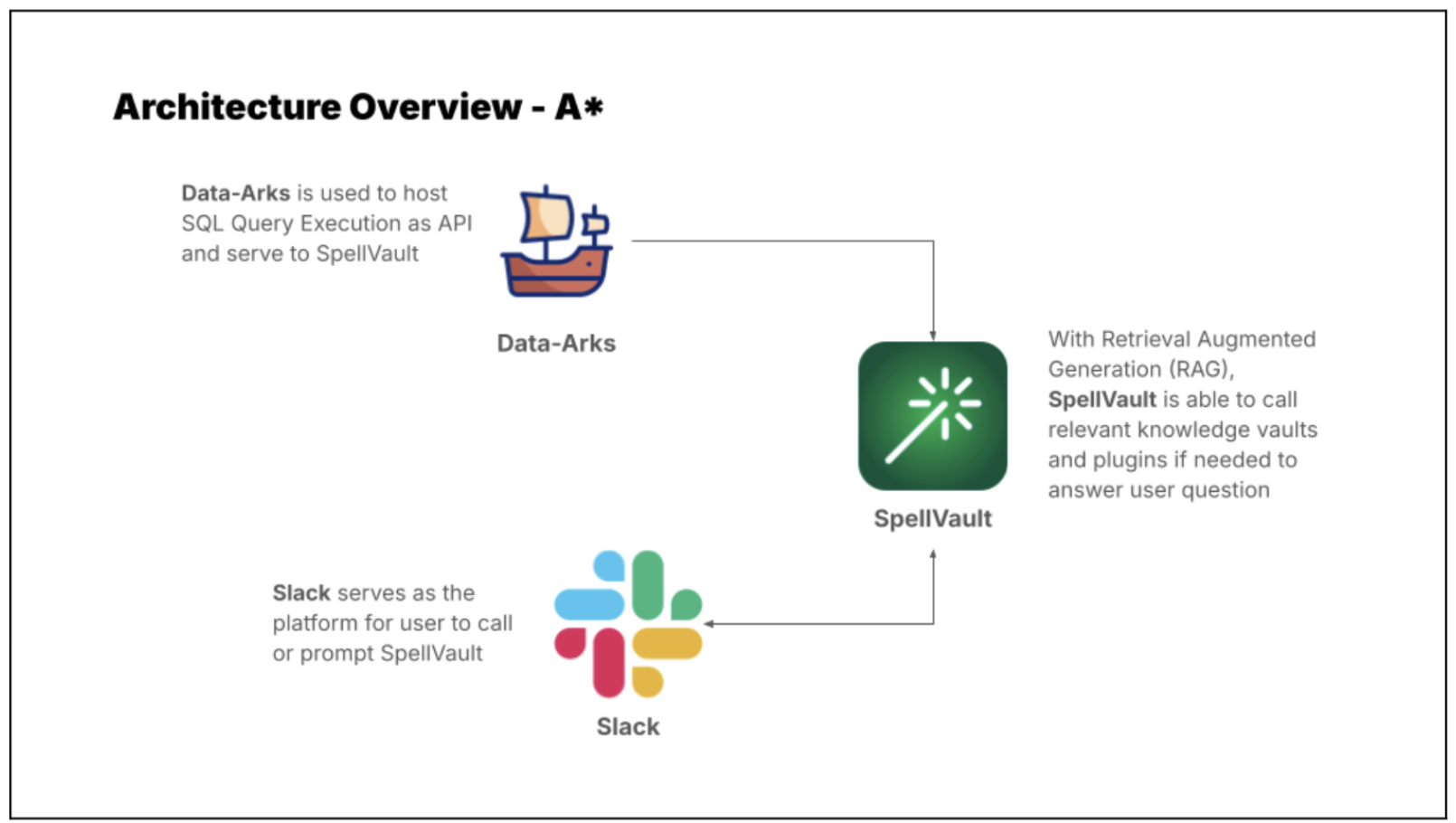
While LLMs are known for their proficiency in data interpretation and insight generation, they represent just a fragment of the entire solution. For a comprehensive solution, LLMs must be integrated with other essential tools. The following is required in assembling a solution:
Internally facing LLM tool – Spellvault is a platform within Grab that stores, shares, and refines LLM prompts. It features low/no-code RAG capabilities that lower the barrier of entry for people to create LLM applications.
Data – with real time or close to real-time latency to ensure accuracy. It has to be in a standardised format to ensure that all LLM data inputs are accurate.
Scheduler – runs LLM applications at regular intervals. Useful for automating routine tasks.
Messaging Tool – a user interface where users can interact with LLM by entering a command to receive reports and insights.
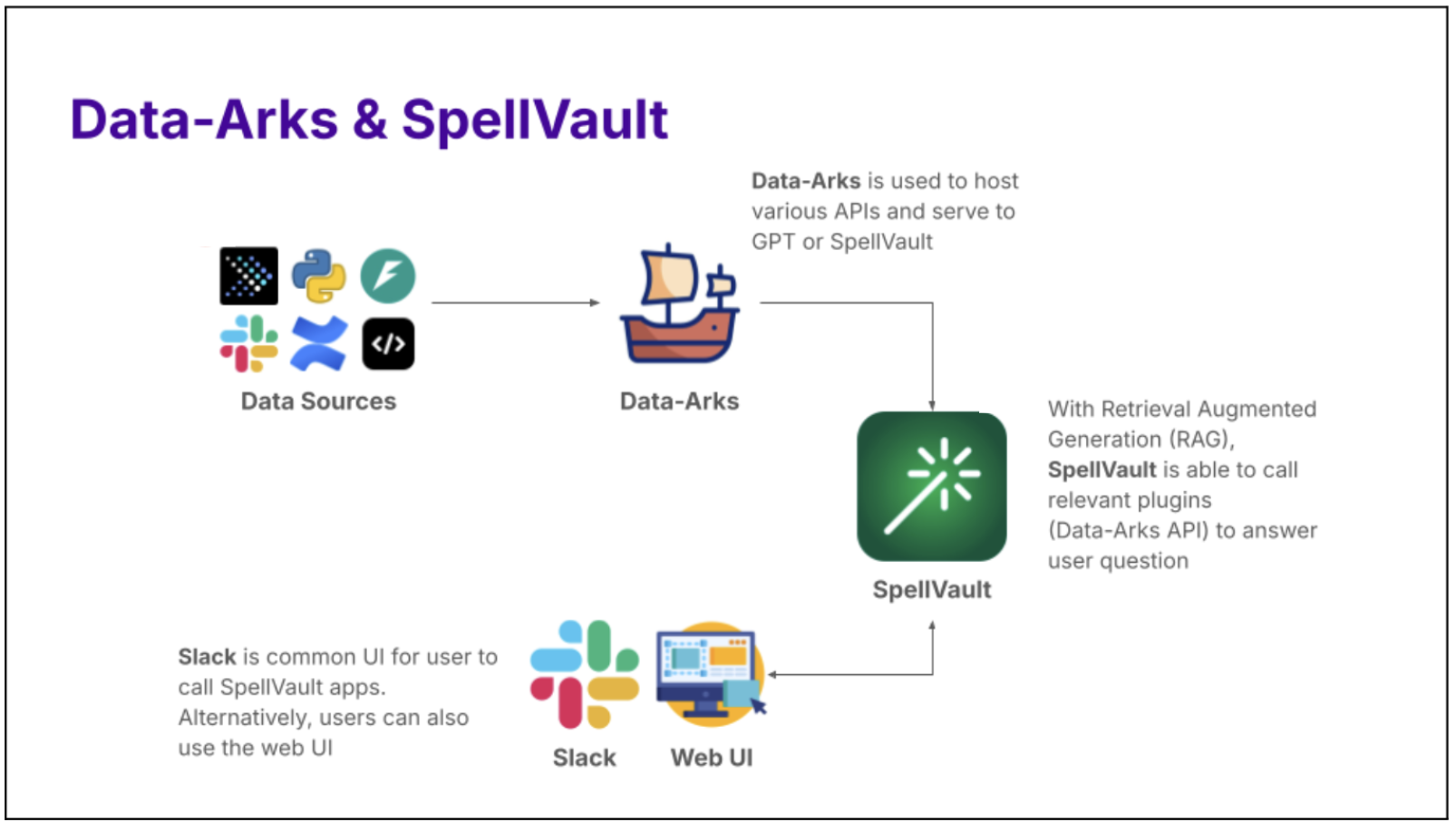
Introducing Data-Arks, the data middleware serving up relevant data to the LLM agents
For most data use cases, DAs are usually running the same set of SQL queries with minor changes to parameters like dates, age or other filter conditions. In most instances, we already have a clear understanding of the required data and format to accomplish a task. Therefore, we need a tool that can execute the exact SQL query and channel the data output to the LLM.
Figure 1. Data-Arks hosts various APIs which can be called to serve data to applications like SpellVault.
What is Data-Arks?
Data-Arks is an in-house Python-based API platform housing several frequently used SQL queries and python functions packaged into individual APIs. Data-Arks is also integrated with Slack, Wiki, and JIRA APIs, allowing users to parse and fetch information and data from these tools as well. The benefits of Data-Arks are summarised as follows:
Integration: Data-Arks service allows users to upload any SQL query or Python script on the platform. These queries are then surfaced as APIs, which can be called to serve data to the LLM agent.
Versatility: Data-Arks can be extended to everyone. Employees from various teams and functions at Grab can self-serve to upload any SQL query that they want onto the platform, allowing this tool to be used for different teams’ use cases.
Automating regular report generation and summarisation using Data-Arks and Spellvault
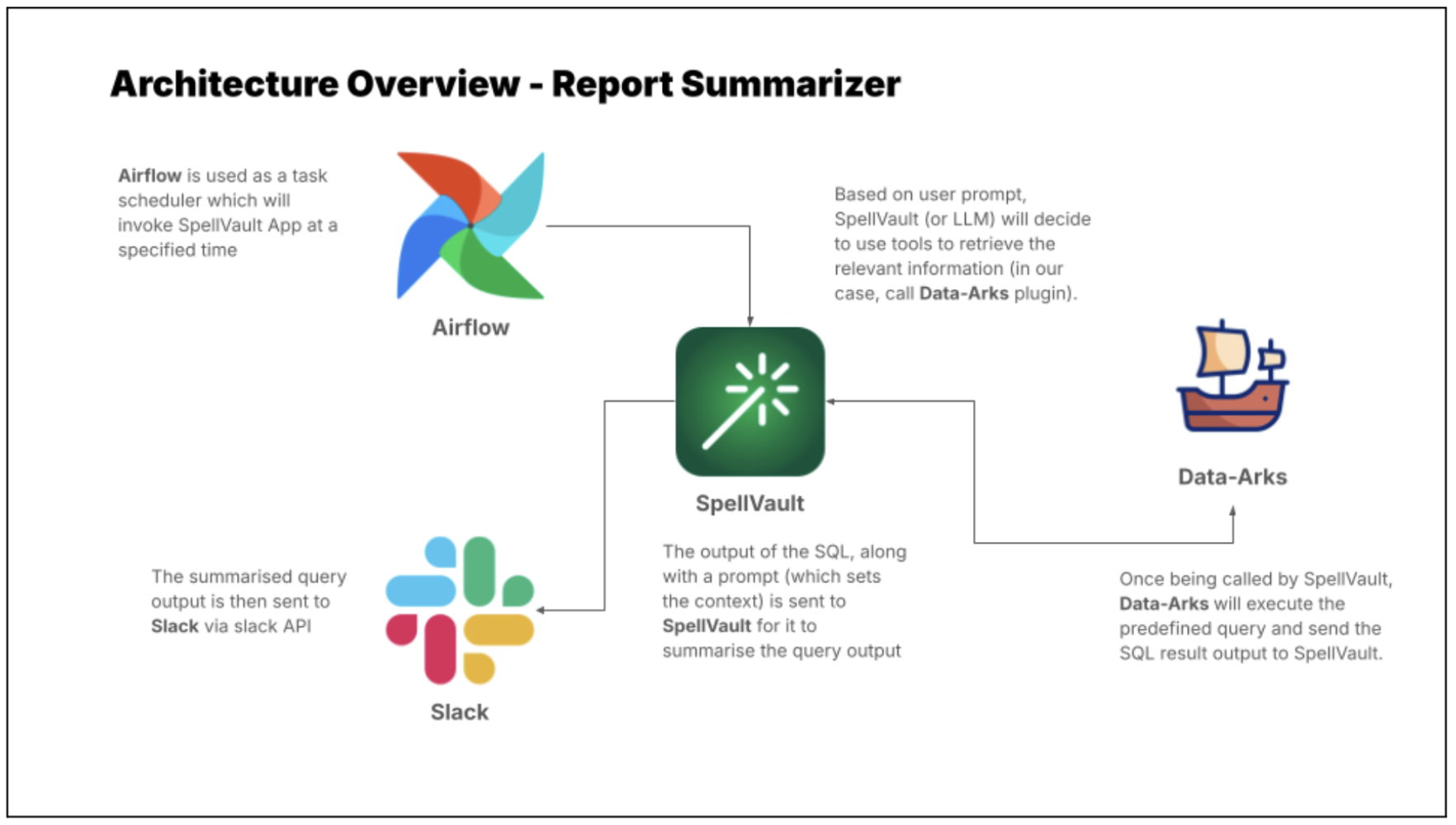
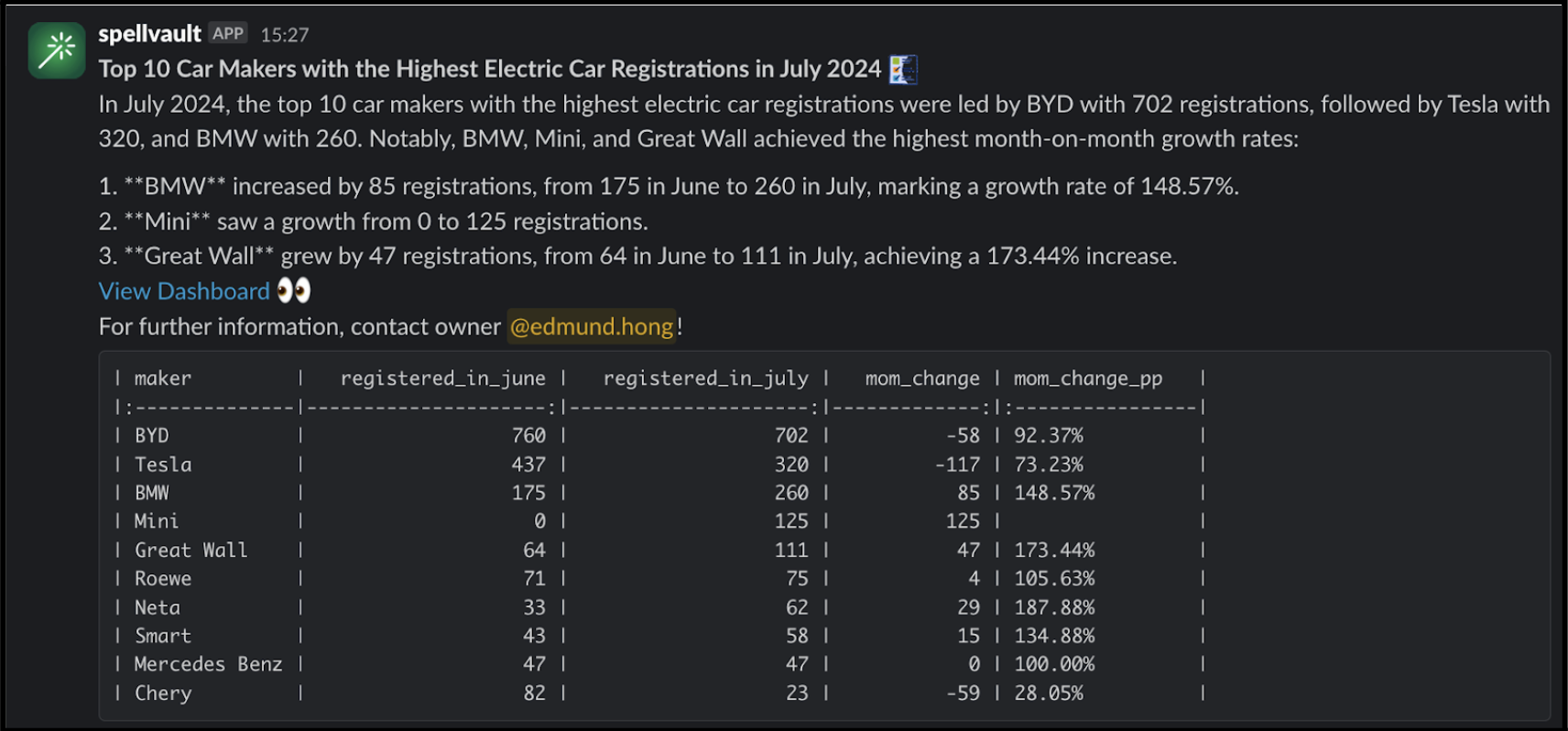
LLMs are just one piece of the puzzle, to build a comprehensive solution, they must be integrated with other tools. Figure 2 shows how different tools are used in executing report summaries in Slack.
Figure 2 shows how different tools are used in executing report summaries in Slack.
Figure 2. Report Summarizer uses various tools to summarise queries and deliver a summarised report through Slack.
Figure 3 is an example of a summarised report generated by the Report Summarizer using dummy data. Report Summarizer calls a Data-Arks API to generate the data in a tabular format and LLM helps summarise and generate a short paragraph of key insights. This automated report generation has helped save an estimated 3-4 hours per report.
Figure 3. Sample of a report generated using dummy data extracted from [https://data.gov.my/](https://data.gov.my/).
LLM bots for fraud investigations
LLMs also excel in helping to streamline fraud investigations, as LLMs are able to contextualise several different data points and information and derive useful insights from them.
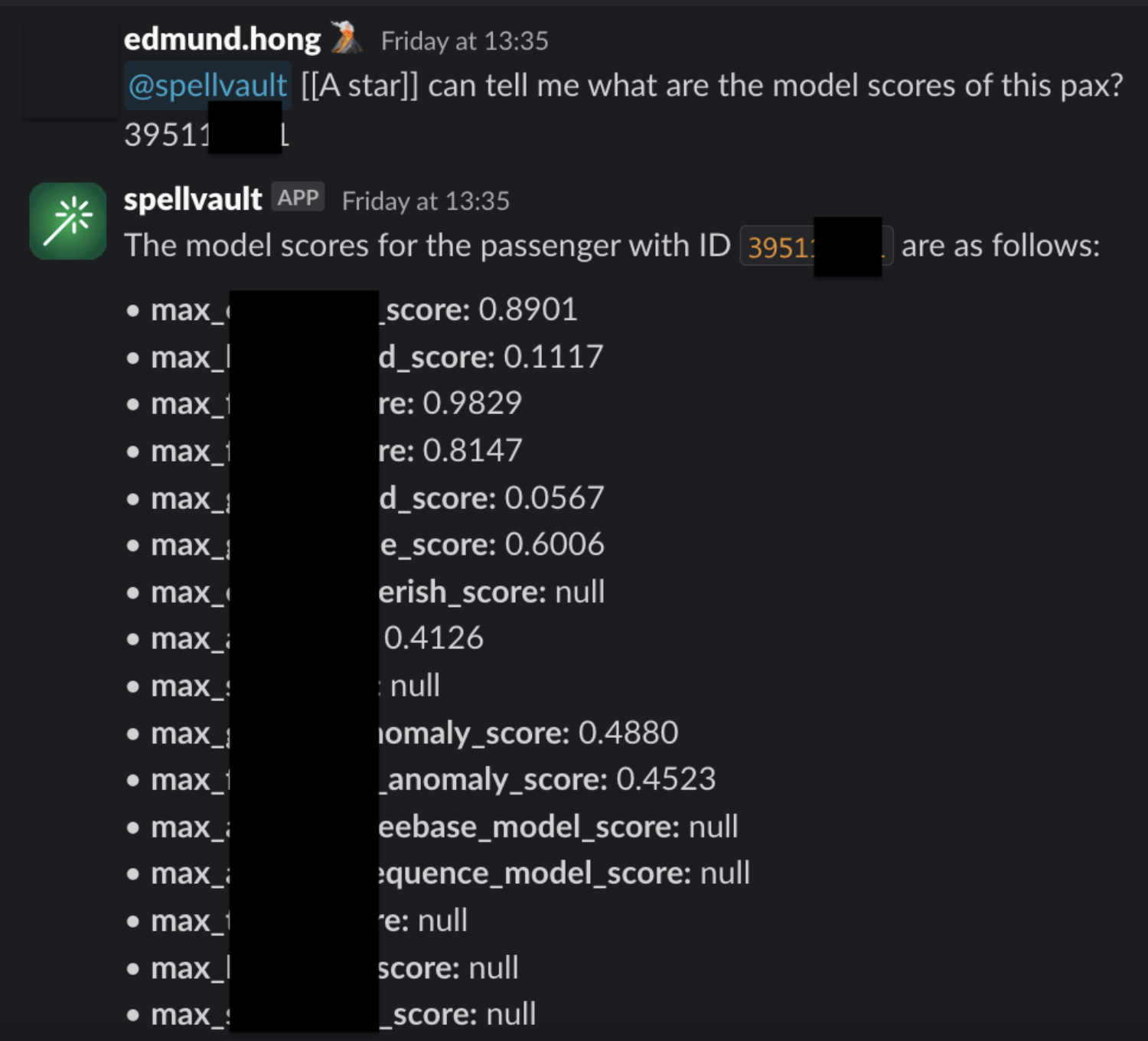
Introducing A* bot, the team’s very own LLM fraud investigation helper.
A set of frequently used queries for fraud investigation is made available as Data-Arks APIs. Upon a user prompt or query, SpellVault selects the most relevant queries using RAG, executes them and provides a summary of the results to users through Slack.
Figure 4. A* bot uses Data-Arks and Spellvault to get information for fraud investigations.
Figure 5 shows a sample of fraud investigation responses from A* bot. Scaling to multiple queries for a fraud investigation process, what was once a time-consuming fraud investigation can now be reduced to a matter of minutes, as the A* bot is capable of providing all the necessary information simultaneously.
Figure 5. Sample of fraud investigation responses.
RAG vs fine-tuning
On deciding between RAG or fine-tuning to improve LLM accuracy, three key factors tipped the scales in favour of the RAG approach:
Effort and cost considerations
Fine-tuning requires significant computational cost as it involves taking a base model and further training it with smaller, domain specific data and context. RAG is computationally less expensive as it relies on retrieving only relevant data and context to augment a model’s response. As the same base model can be used for different use cases, RAG is the preferred choice due to its flexibility and cost efficiency.
Ability to respond with the latest information
Fine-tuning requires model re-training with each new information update, whereas RAG simply retrieves required context and data from a knowledge base to enhance its response. Thus, by using RAG, LLM is able to answer questions using the most current information from our production database, eliminating the need for model re-training.
Speed and scalability
Without the burden of model re-training, the team can rapidly scale and build out new LLM applications with a well managed knowledge base.
What’s next?
The potential of using RAG-powered LLM can be limitless as the ability of GPT is correlated with the tools it equips. Hence, the process does not stop here and we will try to onboard more tools or integration to GPT. In the near future, we plan to utilise Data-Arks to provide images to GPT as GPT-4o is a multimodal model that has vision capabilities. We are committed to pushing the boundaries of what’s possible with RAG-powered LLM, and we look forward to unveiling the exciting advancements that lie ahead.
Figure 6. What’s next?
We would like to express our sincere gratitude to the following individuals and teams whose invaluable support and contributions have made this project a reality: – Meichen Lu, a senior data scientist at Grab, for her guidance and assistance in building the MVP and testing the concept. – The data engineering team, particularly Jia Long Loh and Pu Li, for setting up the necessary services and infrastructure.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Retrieval-Augmented Generation (RAG) is a powerful process that is designed to integrate direct function calling to answer queries more efficiently by retrieving relevant information from a broad database. In the rapidly evolving business landscape, Data Analysts (DAs) are struggling with the growing number of data queries from stakeholders. The conventional method of manually writing and running similar queries repeatedly is time-consuming and inefficient. This is where RAG-powered Large Language Models (LLMs) step in, offering a transformative solution to streamline the analytics process and empower DAs to focus on higher value tasks.
In this article, we will share how the Integrity Analytics team has built out a data solution using LLMs to help automate tedious analytical tasks like generating regular metric reports and performing fraud investigations.
While LLMs are known for their proficiency in data interpretation and insight generation, they represent just a fragment of the entire solution. For a comprehensive solution, LLMs must be integrated with other essential tools. The following is required in assembling a solution:
Internally facing LLM tool – Spellvault is a platform within Grab that stores, shares, and refines LLM prompts. It features low/no-code RAG capabilities that lower the barrier of entry for people to create LLM applications.
Data – with real time or close to real-time latency to ensure accuracy. It has to be in a standardised format to ensure that all LLM data inputs are accurate.
Scheduler – runs LLM applications at regular intervals. Useful for automating routine tasks.
Messaging Tool – a user interface where users can interact with LLM by entering a command to receive reports and insights.
Introducing Data-Arks, the data middleware serving up relevant data to the LLM agents
For most data use cases, DAs are usually running the same set of SQL queries with minor changes to parameters like dates, age or other filter conditions. In most instances, we already have a clear understanding of the required data and format to accomplish a task. Therefore, we need a tool that can execute the exact SQL query and channel the data output to the LLM.
Figure 1. Data-Arks hosts various APIs which can be called to serve data to applications like SpellVault.
What is Data-Arks?
Data-Arks is an in-house Python-based API platform housing several frequently used SQL queries and python functions packaged into individual APIs. Data-Arks is also integrated with Slack, Wiki, and JIRA APIs, allowing users to parse and fetch information and data from these tools as well. The benefits of Data-Arks are summarised as follows:
Integration: Data-Arks service allows users to upload any SQL query or Python script on the platform. These queries are then surfaced as APIs, which can be called to serve data to the LLM agent.
Versatility: Data-Arks can be extended to everyone. Employees from various teams and functions at Grab can self-serve to upload any SQL query that they want onto the platform, allowing this tool to be used for different teams’ use cases.
Automating regular report generation and summarisation using Data-Arks and Spellvault
LLMs are just one piece of the puzzle, to build a comprehensive solution, they must be integrated with other tools. Figure 2 shows how different tools are used in executing report summaries in Slack.
Figure 2 shows how different tools are used in executing report summaries in Slack.
Figure 2. Report Summarizer uses various tools to summarise queries and deliver a summarised report through Slack.
Figure 3 is an example of a summarised report generated by the Report Summarizer using dummy data. Report Summarizer calls a Data-Arks API to generate the data in a tabular format and LLM helps summarise and generate a short paragraph of key insights. This automated report generation has helped save an estimated 3-4 hours per report.
Figure 3. Sample of a report generated using dummy data extracted from [https://data.gov.my/](https://data.gov.my/).
LLM bots for fraud investigations
LLMs also excel in helping to streamline fraud investigations, as LLMs are able to contextualise several different data points and information and derive useful insights from them.
Introducing A* bot, the team’s very own LLM fraud investigation helper.
A set of frequently used queries for fraud investigation is made available as Data-Arks APIs. Upon a user prompt or query, SpellVault selects the most relevant queries using RAG, executes them and provides a summary of the results to users through Slack.
Figure 4. A* bot uses Data-Arks and Spellvault to get information for fraud investigations.
Figure 5 shows a sample of fraud investigation responses from A* bot. Scaling to multiple queries for a fraud investigation process, what was once a time-consuming fraud investigation can now be reduced to a matter of minutes, as the A* bot is capable of providing all the necessary information simultaneously.
Figure 5. Sample of fraud investigation responses.
RAG vs fine-tuning
On deciding between RAG or fine-tuning to improve LLM accuracy, three key factors tipped the scales in favour of the RAG approach:
Effort and cost considerations
Fine-tuning requires significant computational cost as it involves taking a base model and further training it with smaller, domain specific data and context. RAG is computationally less expensive as it relies on retrieving only relevant data and context to augment a model’s response. As the same base model can be used for different use cases, RAG is the preferred choice due to its flexibility and cost efficiency.
Ability to respond with the latest information
Fine-tuning requires model re-training with each new information update, whereas RAG simply retrieves required context and data from a knowledge base to enhance its response. Thus, by using RAG, LLM is able to answer questions using the most current information from our production database, eliminating the need for model re-training.
Speed and scalability
Without the burden of model re-training, the team can rapidly scale and build out new LLM applications with a well managed knowledge base.
What’s next?
The potential of using RAG-powered LLM can be limitless as the ability of GPT is correlated with the tools it equips. Hence, the process does not stop here and we will try to onboard more tools or integration to GPT. In the near future, we plan to utilise Data-Arks to provide images to GPT as GPT-4o is a multimodal model that has vision capabilities. We are committed to pushing the boundaries of what’s possible with RAG-powered LLM, and we look forward to unveiling the exciting advancements that lie ahead.
Figure 6. What’s next?
We would like to express our sincere gratitude to the following individuals and teams whose invaluable support and contributions have made this project a reality: – Meichen Lu, a senior data scientist at Grab, for her guidance and assistance in building the MVP and testing the concept. – The data engineering team, particularly Jia Long Loh and Pu Li, for setting up the necessary services and infrastructure.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
As Southeast Asia’s leading super app, Grab serves millions of users across multiple countries every day. Our services range from ride-hailing and food delivery to digital payments and much more. The backbone of our operations? Machine Learning (ML) models. They power our real-time decision-making capabilities, enabling us to provide a seamless and personalised experience to our users. Whether it’s determining the most efficient route for a ride, suggesting a food outlet based on a user’s preference, or detecting fraudulent transactions, ML models are at the forefront.
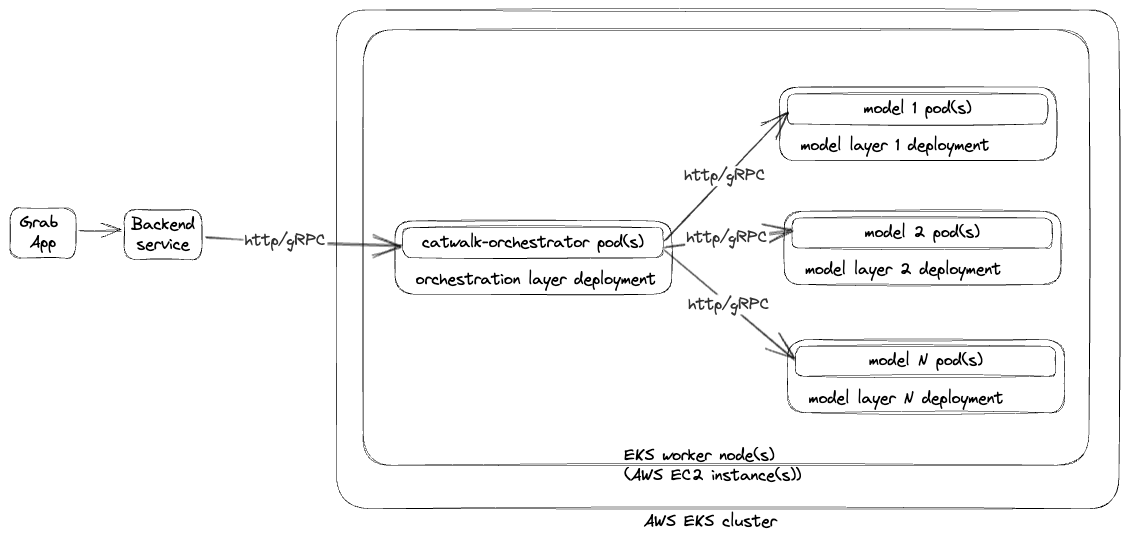
However, serving these ML models at Grab’s scale is no small feat. It requires a robust, efficient, and scalable model serving platform, which is where our ML model serving platform, Catwalk, comes in.
Catwalk has evolved over time, adapting to the growing needs of our business and the ever-changing tech landscape. It has been a journey of continuous learning and improvement, with each step bringing new challenges and opportunities.
Evolution of the platform
Phase 0: The need for a model serving platform
Before Catwalk’s debut as our dedicated model serving platform, data scientists across the company employed various ad-hoc approaches to serve ML models. These included:
Shipping models online using custom solutions.
Relying on backend engineering teams to deploy and manage trained ML models.
Embedding ML logic within Go backend services.
These methods, however, led to several challenges, undercovering the need for a unified, company-wide platform for serving machine learning models:
Operational overhead: Data scientists often lacked the necessary expertise to handle the operational aspects of their models, leading to service outages.
Resource wastage: There was frequently low resource utilisation (e.g., 1%) for data science services, leading to inefficient use of resources.
Friction with engineering teams: Differences in release cycles and unclear ownership when code was embedded into backend systems resulted in tension between data scientists and engineers.
Reinventing the wheel: Multiple teams independently attempted to solve model serving problems, leading to a duplication of effort.
These challenges highlighted the need for a company-wide, centralised platform for serving machine learning models.
Phase 1: No-code, managed platform for TensorFlow Serving models
Our initial foray into model serving was centred around creating a managed platform for deploying TensorFlow Serving models. The process involved data scientists submitting their models to the platform’s engineering admin, who could then deploy the model with an endpoint. Infrastructure and networking were managed using Amazon Elastic Kubernetes Service (EKS) and Helm Charts as illustrated below.
This phase of our platform, which we also detailed in our previous article, was beneficial for some users. However, we quickly encountered scalability challenges:
Codebase maintenance: Applying changes to every TensorFlow Serving (TFS) version was cumbersome and difficult to maintain.
Limited scalability: The fully managed nature of the platform made it difficult to scale.
Admin bottleneck: The engineering admin’s limited bandwidth became a bottleneck for onboarding new models.
Limited serving types: The platform only supported TensorFlow, limiting its usefulness for data scientists using other frameworks like LightGBM, XGBoost, or PyTorch.
After a year of operation, only eight models were onboarded to the platform, highlighting the need for a more scalable and flexible solution.
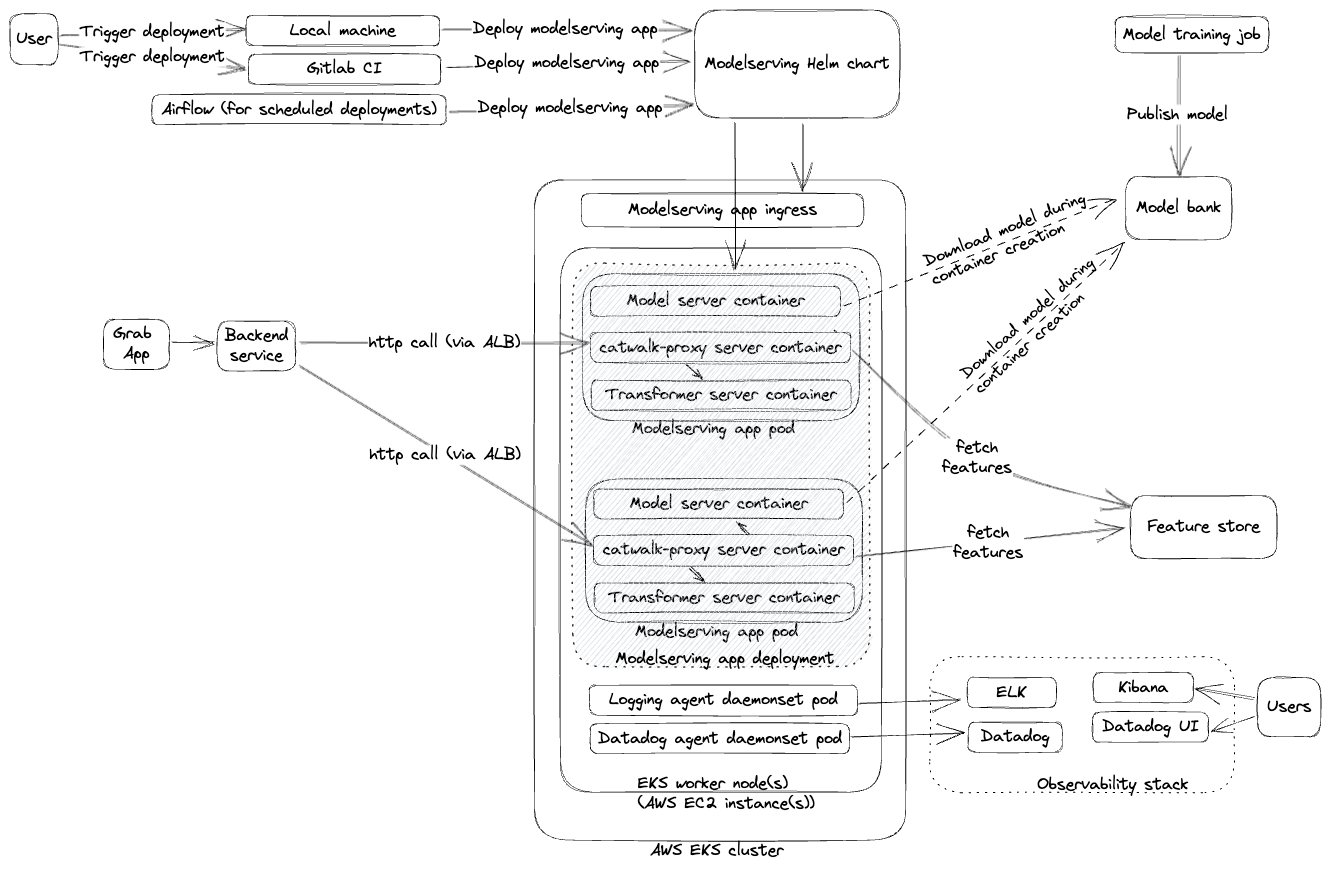
Phase 2: From models to model serving applications
To address the limitations of Phase 1, we transitioned from deploying individual models to self-contained model serving applications. This “low-code, self-serving” strategy introduced several new components and changes as illustrated in the points and diagram below:
Support for multiple serving types: Users gained the ability to deploy models trained with a variety of frameworks like Open Neural Network Exchange (ONNX), PyTorch, and TensorFlow.
Self-served platform through CI/CD pipelines: Data scientists could self-serve and independently manage their model serving applications through CI/CD pipelines.
New components: We introduced these new components to support the self-serving approach:
Catwalk proxy, a managed reverse proxy to various serving types.
Catwalk transformer, a low-code component to transform input and output data.
Amphawa, a feature fetching component to augment model inputs.
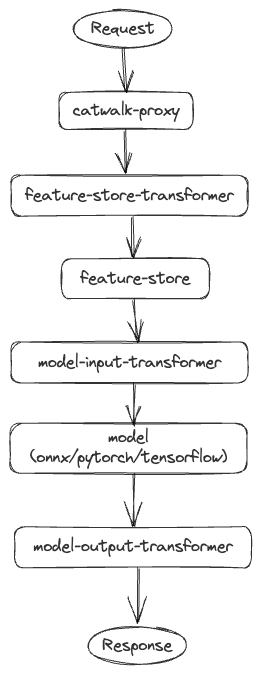
API request flow
The Catwalk proxy acts as the orchestration layer. Clients send requests to Catwalk proxy then it orchestrates calls to different components like transformers, feature-store, and so on. A typical end to end request flow is illustrated below.
Within a year of implementing these changes, the number of models on the platform increased from 8 to 300, demonstrating the success of this approach. However, new challenges emerged:
Complexity of maintaining Helm chart: As the platform continued to grow with new components and functionalities, maintaining the Helm chart became increasingly complex. The readability and flow control became more challenging, making the helm chart updating process prone to errors.
Process-level mistakes: The self-serving approach led to errors such as pushing empty or incompatible models to production, setting too few replicas, or allocating insufficient resources, which resulted in service crashes.
We knew that our work was nowhere near done. We had to keep iterating and explore ways to address the new challenges.
Phase 3: Replacing Helm charts with Kubernetes CRDs
To tackle the deployment challenges and gain more control, we made the significant decision to replace Helm charts with Kubernetes Custom Resource Definitions (CRDs). This required substantial engineering effort, but the outcomes have been rewarding. This transition gave us improved control over deployment pipelines, enabling customisations such as:
Smart defaults for AutoML
Blue-green deployments
Capacity management
Advanced scaling
Application set groupings
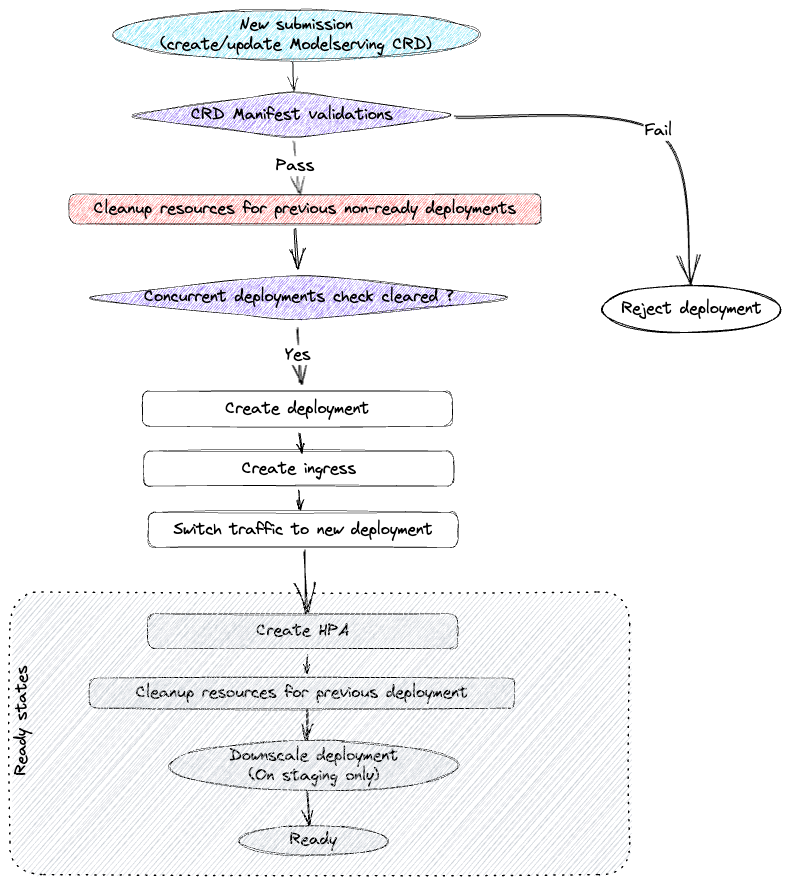
Below is an example of a simple model serving CRD manifest:
Every model serving CRD submission follows a sequence of steps. If there are failures at any step, the controller keeps retrying after small intervals. The major steps on the deployment cycle are described below:
Validate whether the new CRD specs are acceptable. Along with sanity checks, we also enforce a lot of platform constraints through this step.
Clean up previous non-ready deployment resources. Sometimes a deployment submission might keep crashing and hence it doesn’t proceed to a ready state. On every submission, it’s important to check and clean up such previous deployments.
Create resources for the new deployment and ensure that the new deployment is ready.
Switch traffic from old deployment to the new deployment.
Clean up resources for old deployment. At this point, traffic is already being served by the new deployment resources. So, we can clean up the old deployment.
Phase 4: Transition to a high-code, self-served, process-managed platform
As the number of model serving applications and use cases multiplied, clients sought greater control over orchestrations between different models, experiment executions, traffic shadowing, and responses archiving. To cater to these needs, we introduced several changes and components with the Catwalk Orchestrator, a high code orchestration solution, leading the pack.
Catwalk orchestrator
The Catwalk Orchestrator is a highly abstracted framework for building ML applications that replaced the catwalk-proxy from previous phases. The key difference is that users can now write their own business/orchestration logic. The orchestrator offers a range of utilities, reducing the need for users to write extensive boilerplate code. Key components of the Catwalk Orchestrator include HTTP server, gRPC server, clients for different model serving flavours (TensorFlow, ONNX, PyTorch, etc), client for fetching features from the feature bank, and utilities for logging, metrics, and data lake ingestion.
The Catwalk Orchestrator is designed to streamline the deployment of machine learning models. Here’s a typical user journey:
Scaffold a model serving application: Users begin by scaffolding a model serving application using a command-line tool.
Write business logic: Users then write the business logic for the application.
Deploy to staging: The application is then deployed to a staging environment for testing.
Complete load testing: Users test the application in the staging environment and complete load testing to ensure it can handle the expected traffic.
Deploy to production: Once testing is completed, the application is deployed to the production environment.
Bundled deployments
To support multiple ML models as part of a single model serving application, we introduced the concept of bundled deployments. Multiple Kubernetes deployments are bundled together as a single model serving application deployment, allowing each component (e.g., models, catwalk-orchestrator, etc) to have its own Kubernetes deployment and to scale independently.
In addition to the major developments, we implemented other changes to enhance our platform’s efficiency. We made load testing mandatory for all ML application updates to ensure robust performance. This testing process was streamlined with a single command that runs the load test in the staging environment, with the results directly shared with the user.
Furthermore, we boosted deployment transparency by sharing deployment details through Slack and Datadog. This empowered users to diagnose issues independently, reducing the dependency on on-call support. This transparency not only improved our issue resolution times but also enhanced user confidence in our platform.
The results of these changes speak for themselves. The Catwalk Orchestrator has evolved into our flagship product. In just two years, we have deployed 200 Catwalk Orchestrators serving approximately 1,400 ML models.
What’s next?
As we continue to innovate and enhance our model serving platform, we are venturing into new territories:
Catwalk serverless: We aim to further abstract the model serving experience, making it even more user-friendly and efficient.
Catwalk data serving: We are looking to extend Catwalk’s capabilities to serve data online, providing a more comprehensive service.
LLM serving: In line with the trend towards generative AI and large language models (LLMs), we’re pivoting Catwalk to support these developments, ensuring we stay at the forefront of the AI and machine learning field.
Stay tuned as we continue to advance our technology and bring these exciting developments to life.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
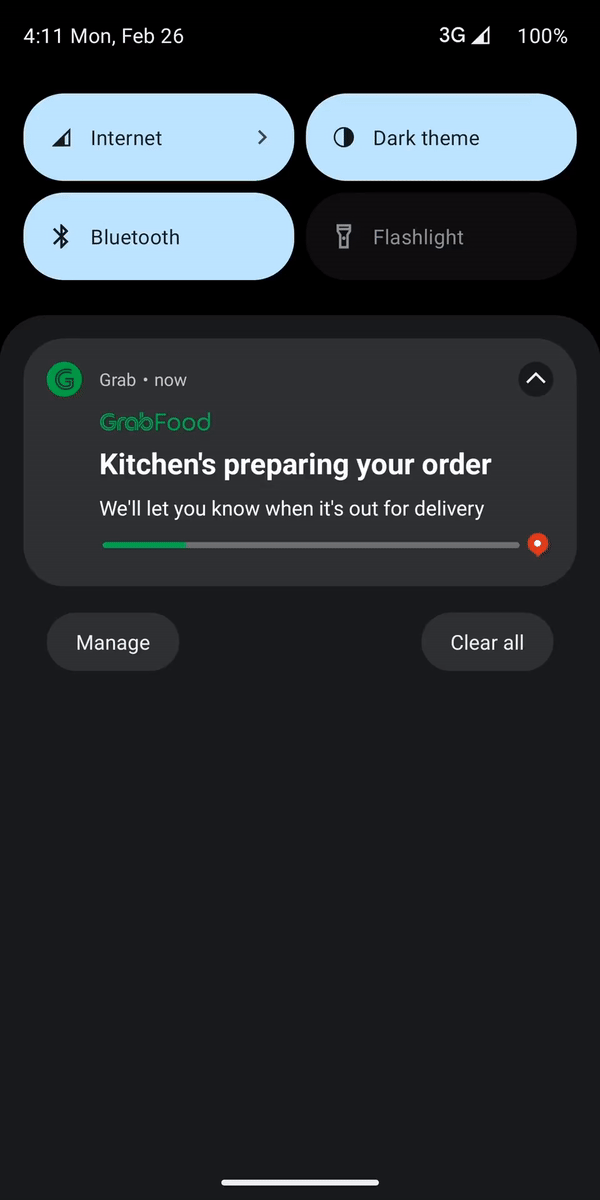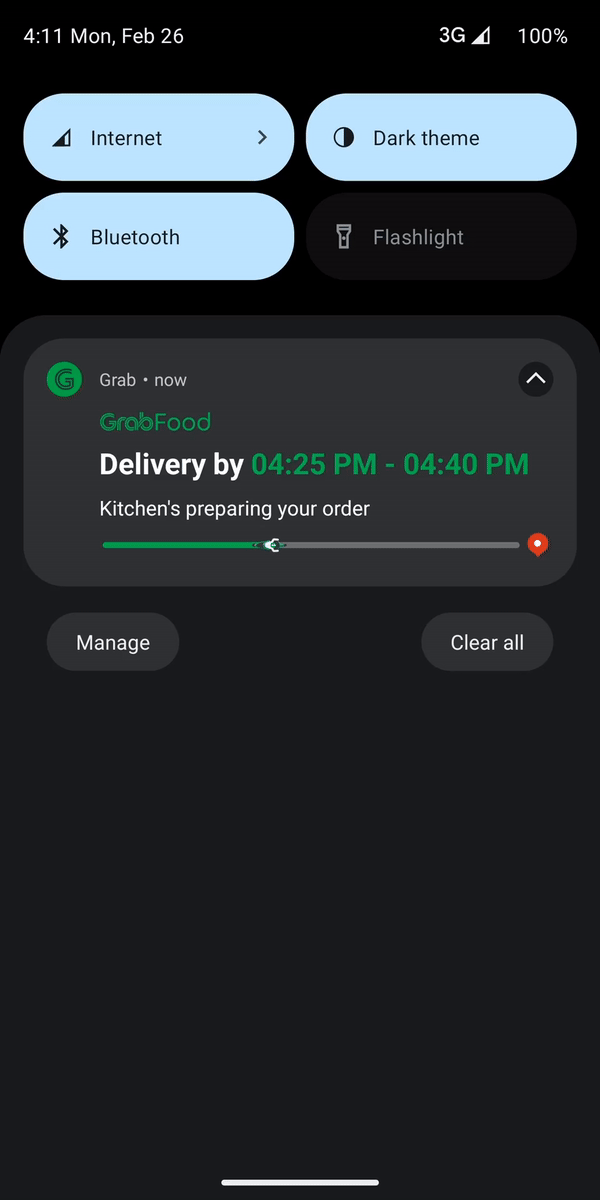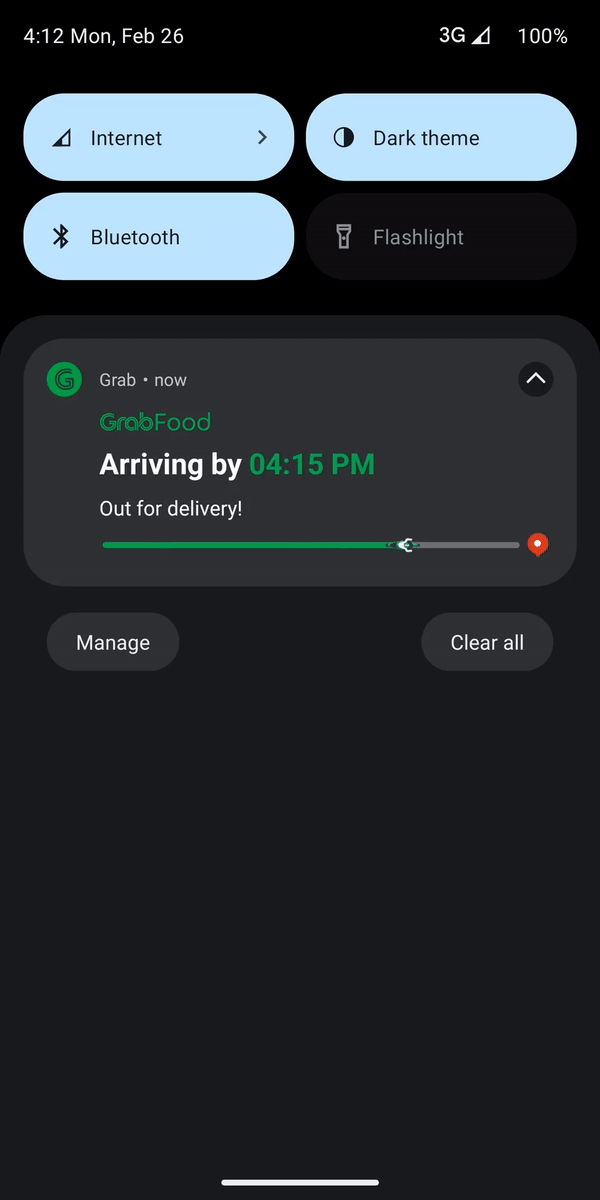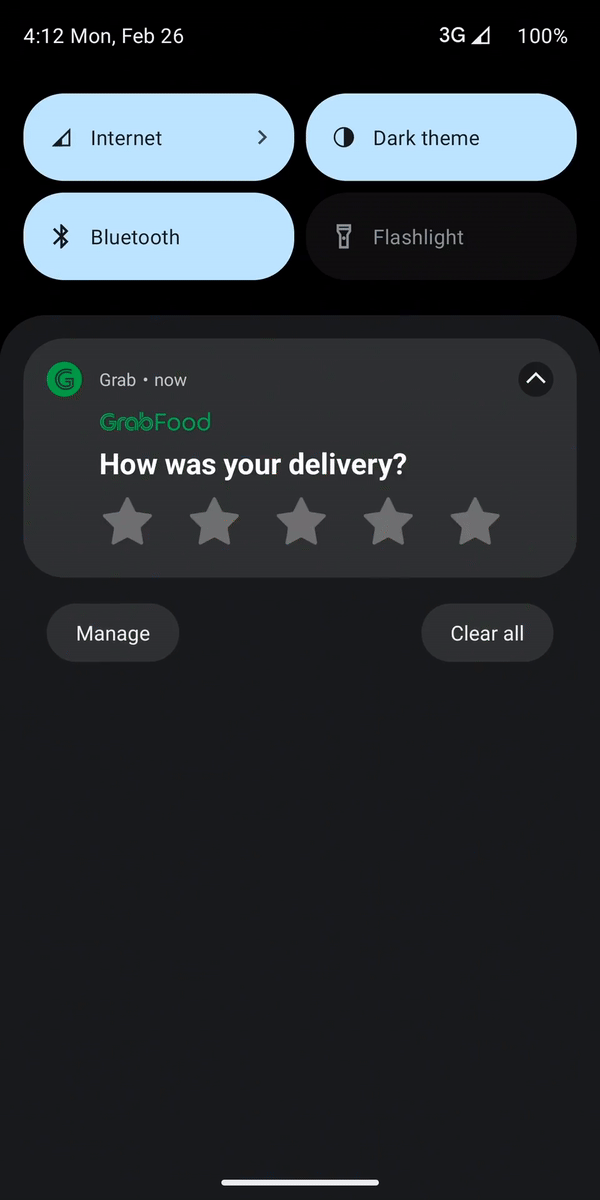
In May 2023, Grab unveiled the Live Activity feature for iOS, which received positive feedback from users. Live Activity is a feature that enhances user experience by displaying a user interface (UI) outside of the app, delivering real-time updates and interactive content. At Grab, we leverage this feature to keep users informed about their order updates without requiring them to manually open the app.
While Live Activity is a native iOS feature provided by Apple, there is currently no official Android equivalent. However, we are determined to bring this immersive experience to Android users. Inspired by the success of Live Activity on iOS, we have embarked on design explorations and feasibility studies to ensure the seamless integration of Live Activity into the Android platform. Our ultimate goal is to provide Android users with the same level of convenience and real-time updates, elevating their Grab experience.
Product Exploration
In July 2023, we took a proactive step by forming a dedicated working group with the specific goal of exploring Live Activity on the Android platform. Our mindset was focused on quickly enabling the MVP (Minimum Viable Product) of this feature for Android users. We focused on enabling Grab users to track food and mart orders on Live Activity as our first use-case. We also designed the Live Activity module as an extendable platform, allowing easy adoption by other Grab internal verticals such as the Express and Transport teams.
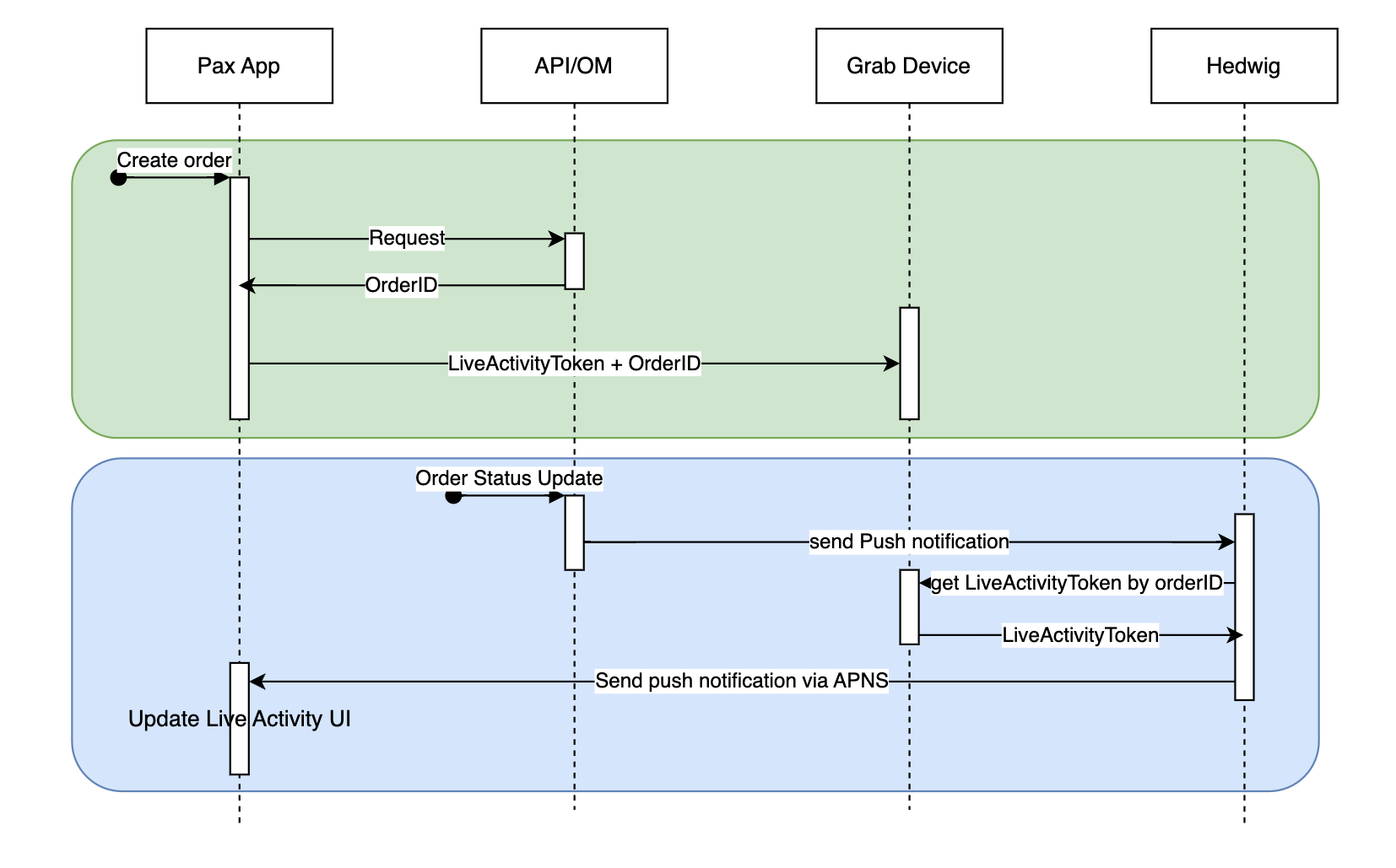
The team kicked off by analysing the current solution and end-to-end flow of Live Activity on iOS. The objective was to uncover opportunities on how we could leverage the existing platform approach.
Figure 1. Grab iOS Live Activity flow.
The first thing that caught our attention was that there is no Live Activity Token (also known as Push Token) concept on Android. Push Token is a token generated from the ActivityKit framework and used to remotely start, update, and end Live Activity notifications on iOS.
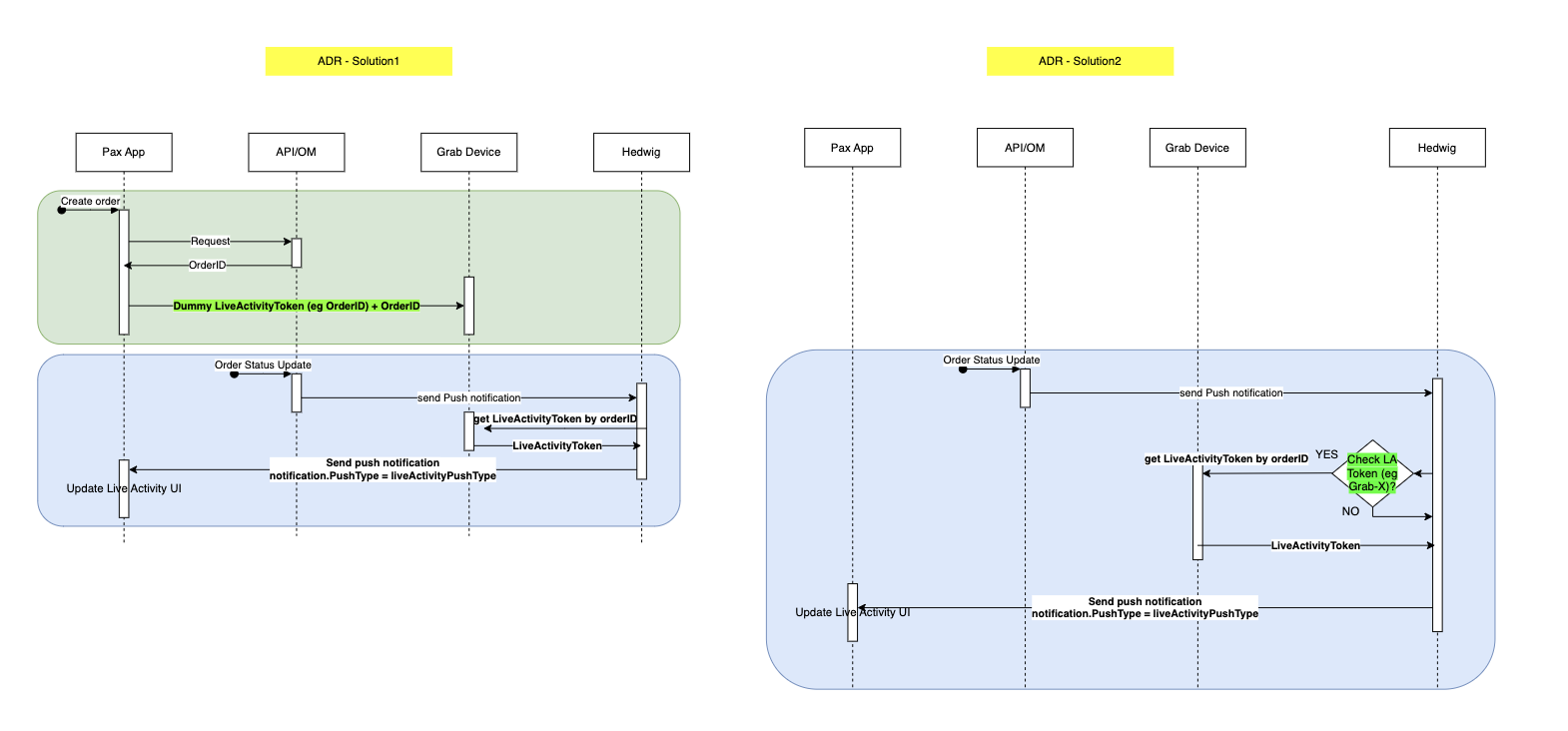
Our goal was to match the Live Activity set-up of iOS in Android, which was a challenge due to the missing Push Token. This required us to think outside the box and develop an innovative workaround. After multiple brainstorming sessions, the team developed two potential solutions, Solution 1 and Solution 2, as illustrated below:
Figure 2. Proposed solutions for Live Activity for Android.
We evaluated the two solutions. The first solution is to substitute the Push Token with a placeholder value, serving as a distinctive notification identifier. Whereas, the second solution involves the Hedwig service, our in-house message delivery service. We proposed to bypass the Live Activity token check process specifically for Android devices. Following extensive discussions, we decided to proceed with the first solution, which ensures consistency in the technical approach between Android and iOS platforms. Additionally, this solution allows us to ensure that notifications are only pushed to the devices that support the Live Activity feature. This decision strikes a good balance between efficiency and compatibility.
UI Components
Starting with a kick-off project meeting where we showcased our plans and proposed solutions to our stakeholders, the engineering team presented two native Android UI components that could be utilised to replicate Live Activity: the Notification View and the Floating View.
The Notification View is a component located in the notification drawer (and potentially on the Lock Screen) that fulfils the most basic use-case of the Live Activity feature. It enables Android users to access information without the need to open the app. Since the standard notification template only allows developers to display a single content title, a content subtitle, and one image, it falls short of meeting our Live Activity UI requirements. To overcome this limitation, custom notifications with custom layouts are needed.
Figure 3. Early design spec of Grab’s LA using custom notification.
One of the key advantages of custom notifications is that they do not require any additional new permissions, ensuring a smooth user experience. Additionally, Android users are accustomed to checking their notifications from the notification tray, making it a familiar and intuitive interaction. However, it is important to acknowledge that custom notifications rely on a remote view, which can pose restrictions on rendering only specific views. On top of that, custom notifications provide a limited space for content – limited to 48dp when collapsed and 252dp when expanded.
The Floating View is a component that will appear above all the applications in Android. It adds the convenience of accessing the information when the device is unlocked or when the user is on another app.
Figure 4. Early design spec of Grab’s LA using floating view.
The use of a Floating View offers greater flexibility to the view by eliminating the reliance on a remote view. However, it’s important to be aware of the potential limitations associated with this approach. These limitations include the requirement for screen space, which can potentially impact other app functionalities and cause frustration for users. Additionally, if we intend to display multiple order updates, we may require even more space, taking into account that Grab allows users to place multiple orders. Furthermore, the Floating View feature requires an extra “Draw over other apps” permission, a setting that allows an app to display information on top of other apps on your screen.
After thoughtful deliberation, we concluded that custom notifications provide a more consistent and user-friendly solution for implementing Grab’s Live Activity feature on Android. They offer compatibility, non-intrusiveness, no extra permissions, and the flexibility of silent notifications, ensuring an optimised user experience.
Building Grab Android’s “Live Activity”
We began developing the Live Activity feature by focusing on Food and Mart for the MVP. However, we prioritised potential future use cases for other verticals by examining the existing functionality of the Grab iOS Live Activity feature. By considering these factors from the start, we need to make sure that we build an extendable and flexible solution that caters to different verticals and their various use-cases.
Figure 5. Grab’s Android Live Activity.
As we set out to design Grab’s Android Live Activity module, we broke down the task into three key components:
Registering Live Activity Token
In order to enable Hedwig services to send Live Activity notifications to devices, it is necessary to register a Live Activity Token for a specific order to Grab Devices services (refer to figure 1 for the iOS flow). As this use-case is applicable across various verticals in iOS, we have designed a LiveActivityIntegrationManager class specifically to handle this functionality.
interface LiveActivityIntegrationManager {
/\*\*
\* To start live activity journey
\* @param vertical refers to vertical name
\* @param id refers to unique id which is used to differentiate live activity UI instances
\* eg: Food will use orderID as id, transport can pass rideID
\*\*/
fun startLiveActivity(vertical: Vertical, id: String): Completable
fun updateLiveActivity(id: String, attributes: LiveActivityAttributes)
fun cancelLiveActivity(id: String)
}
Our goal is to provide developers with an easy implementation of Live Activity in the Grab app. Developers can simply utilize the startLiveActivity() function to register the token to Grab Devices by passing the vertical name and unique ID as parameters.
Notification Listener and Payload Mapping
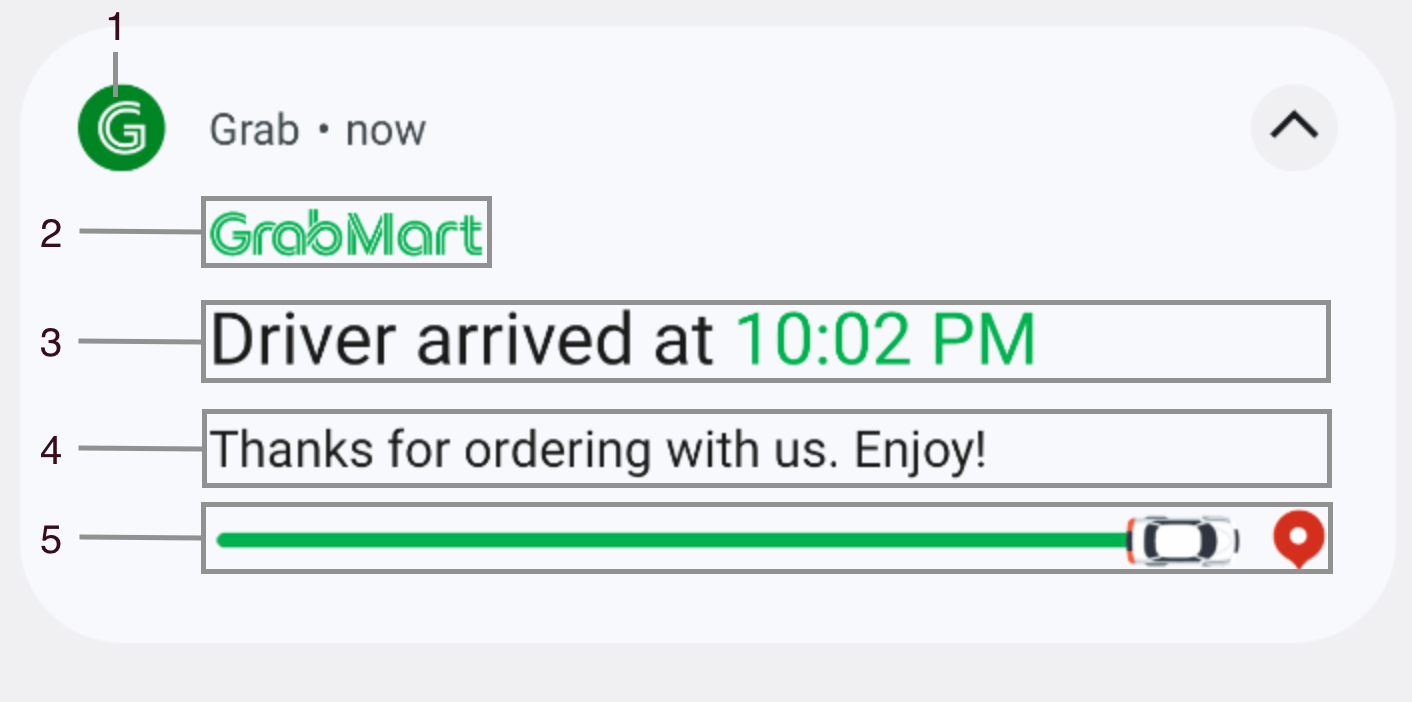
To handle Live Activity notifications in Android, it is necessary to listen to the Live Activity notification payload and map it to LiveActivityAttributes. Taking into consideration the initial Live Activity design (refer to figure 3), we need to analyse the variables necessary for this process. As a result, we break down the Live Activity UI into different UI elements and layouts, as follows:
Figure 6. Android Live Activity view breakdown.
App Icon – labeled as 1 in Figure 6.
This view always shows the Grab app icon.
Header Icon – labeled as 2 in Figure 6.
This view is an image view that could be set with icon resources.
Content Title View – labeled as 3 in Figure 6.
This view is a placeholder that could be set with a text or custom remote view.
Content Text View – labeled as 4 in Figure 6.
This view is a placeholder that could be set with a text or custom remote view.
Footer View – labeled as 5 in Figure 6.
This view is a placeholder that could be set with icon resources, bitmap, or custom remote view.
Decomposing the UI into different parts allows us to clearly understand of the UI components that need to maintain consistency across different use-cases, as well as the elements that can be easily customised and configured based on specific requirements. As a result, we have designed the LiveActivityAttributes class that serves as a container that encompasses all the necessary configurations required for rendering the Live Activity.
class LiveActivityAttributes private constructor(
val iconRes: Int?,
val headerIconRes: Int?,
val contentTitle: CharSequence?,
val contentTitleStyle: ContentStyle.TitleStyle?,
val customContentTitleView: LiveActivityCustomView?,
val contentText: CharSequence?,
val contentTextStyle: ContentStyle.TextStyle?,
val customContentTextView: LiveActivityCustomView?,
val footerIconRes: Int?,
val footerBitmap: Bitmap?,
val footerProgressBarProgress: Float?,
val footerProgressBarStyle: ProgressBarStyle?,
val footerRatingBarAttributes: RatingBarAttributes?,
val customFooterView: LiveActivityCustomView?,
val contentIntent: PendingIntent?,
…
)
Payload Rendering
To ensure a clear separation of responsibilities, we have designed a separate class called LiveActivityManager. This dedicated class is responsible for the mapping of LiveActivityAttributes to Notifications. The generated notifications are then utilised by Android’s NotificationManager class to be posted and displayed accordingly.
interface LiveActivityManager {
/\*\*
\* Post a Live Activity to be shown in the status bar, stream, etc.
\*
\* @param id the ID of the Live Activity
\* @param attributes the LiveActivity to post to the system
\*/
fun notify(id: Int, attributes: LiveActivityAttributes)
fun cancel(id: Int)
}
What’s Next?
We are delighted to announce that we have successfully implemented Grab’s Android version of the Live Activity feature for Express and Transport products. Furthermore, we plan to extend this feature to the Driver and Merchant applications as well. We understand the value this feature brings to our users and are committed to enhancing it further. Stay tuned for upcoming updates and enhancements to the Live Activity feature as we continue to improve and expand its capabilities across various verticals.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Imagine a world where finding the right data is like searching for a needle in a haystack. In today’s data-driven landscape, companies are drowning in a sea of information, struggling to navigate through countless datasets to uncover valuable insights. At Grab, we faced a similar challenge. With over 200,000 tables in our data lake, along with numerous Kafka streams, production databases, and ML features, locating the most suitable dataset for our Grabber’s use cases promptly has historically been a significant hurdle.
Problem Space
Our internal data discovery tool, Hubble, built on top of the popular open-source platform Datahub, was primarily used as a reference tool. While it excelled at providing metadata for known datasets, it struggled with true data discovery due to its reliance on Elasticsearch, which performs well for keyword searches but cannot accept and use user-provided context (i.e., it can’t perform semantic search, at least in its vanilla form). The Elasticsearch parameters provided by Datahub out of the box also had limitations: our monthly average click-through rate was only 82%, meaning that in 18% of sessions, users abandoned their searches without clicking on any dataset. This suggested that the search results were not meeting their needs.
Another indispensable requirement for efficient data discovery that was missing at Grab was documentation. Documentation coverage for our data lake tables was low, with only 20% of the most frequently queried tables (colloquially referred to as P80 tables) having existing documentation. This made it difficult for users to understand the purpose and contents of different tables, even when browsing through them on the Hubble UI.
Consequently, data consumers heavily relied on tribal knowledge, often turning to their colleagues via Slack to find the datasets they needed. A survey conducted last year revealed that 51% of data consumers at Grab took multiple days to find the dataset they required, highlighting the inefficiencies in our data discovery process.
To address these challenges and align with Grab’s ongoing journey towards a data mesh architecture, the Hubble team recognised the importance of improving data discovery. We embarked on a journey to revolutionise the way our employees find and access the data they need, leveraging the power of AI and Large Language Models (LLMs).
Vision
Given the historical context, our vision was clear: to remove humans in the data discovery loop by automating the entire process using LLM-powered products. We aimed to reduce the time taken for data discovery from multiple days to mere seconds, eliminating the need for anyone to ask their colleagues data discovery questions ever again.
Goals
To achieve our vision, we set the following goals for ourselves for the first half of 2024:
Build HubbleIQ: An LLM-based chatbot that could serve as the equivalent of a Lead Data Analyst for data discovery. Just as a lead is an expert in their domain and can guide data consumers to the right dataset, we wanted HubbleIQ to do the same across all domains at Grab. We also wanted HubbleIQ to be accessible where data consumers hang out the most: Slack.
Improve documentation coverage: A new Lead Analyst joining the team would require extensive documentation coverage of very high quality. Without this, they wouldn’t know what data exists and where. Thus, it was important for us to improve documentation coverage.
Enhance Elasticsearch: We aimed to tune our Elasticsearch implementation to better meet the requirements of Grab’s data consumers.
A Systematic Path to Success
Step 1: Enhance Elasticsearch
Through clickstream analysis and user interviews, the Hubble team identified four categories of data search queries that were seen either on the Hubble UI or in Slack channels:
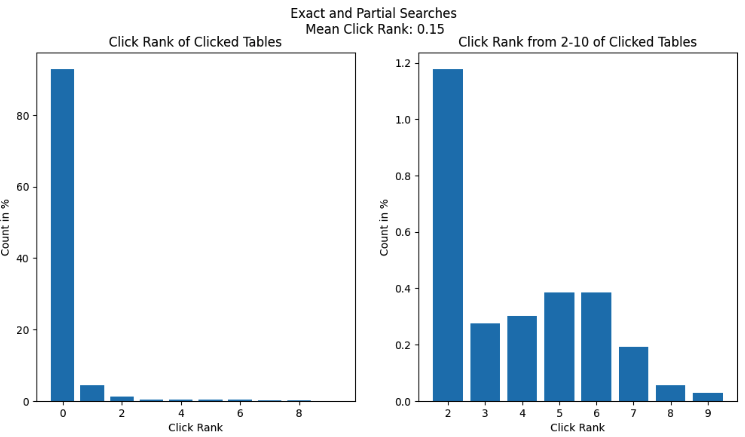
Exact search: Queries belonging to this category were a substring of an existing dataset’s name at Grab, with the query length being at least 40% of the dataset’s name.
Partial search: The Levenshtein distance between a query in this category and any existing dataset’s name was greater than 80. This category usually comprised queries that closely resembled an existing dataset name but likely contained spelling mistakes or were shorter than the actual name.
Exact and partial searches accounted for 75% of searches on Hubble (and were non-existent on Slack: as a human, receiving a message that just had the name of a dataset would feel rather odd). Given the effectiveness of vanilla Elasticsearch for these categories, the click rank was close to 0.
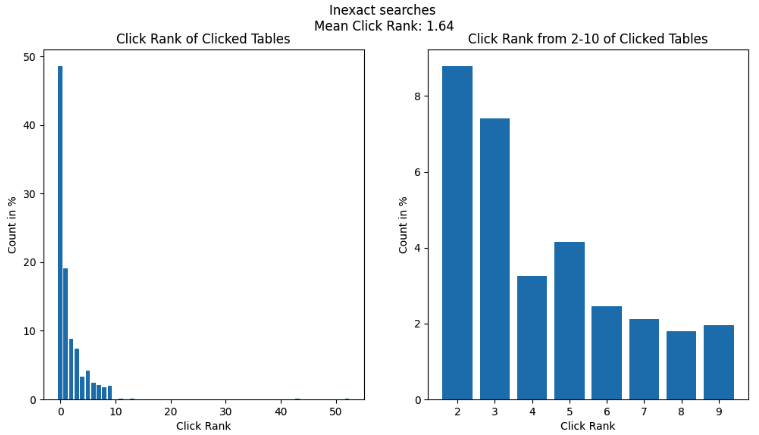
Inexact search: This category comprised queries that were usually colloquial keywords or phrases that may be semantically related to a given table, column, or piece of documentation (e.g., “city” or “taxi type”). Inexact searches accounted for the remaining 25% of searches on Hubble. Vanilla Elasticsearch did not perform well in this category since it relied on pure keyword matching and did not consider any additional context.
Semantic search: These were free text queries with abundant contextual information supplied by the user. Hubble did not see any such queries as users rightly expected that Hubble would not be able to fulfil their search needs. Instead, these queries were sent by data consumers to data producers via Slack. Such queries were numerous, but usually resulted in data hunting journeys that spanned multiple days – the root of frustration amongst data consumers.
The first two search types can be seen as “reference” queries, where the data consumer already knows what they are looking for. Inexact and contextual searches are considered “discovery” queries. The Hubble team noticed drop-offs in inexact searches because users learned that Hubble could not fulfil their discovery needs, forcing them to search for alternatives.
Through user interviews, the team discovered how Elasticsearch should be tuned to better fit the Grab context. They implemented the following optimisations:
Tagging and boosting P80 tables
Boosting the most relevant schemas
Hiding irrelevant datasets like PowerBI dataset tables
Deboosting deprecated tables
Improving the search UI by simplifying and reducing clutter
Adding relevant tags
Boosting certified tables
As a result of these enhancements, the click-through rate rose steadily over the course of the half to 94%, a 12 percentage point increase.
While this helped us make significant improvements to the first three search categories, we knew we had to build HubbleIQ to truly automate the last category – semantic search.
Step 2: Build a Context Store for HubbleIQ
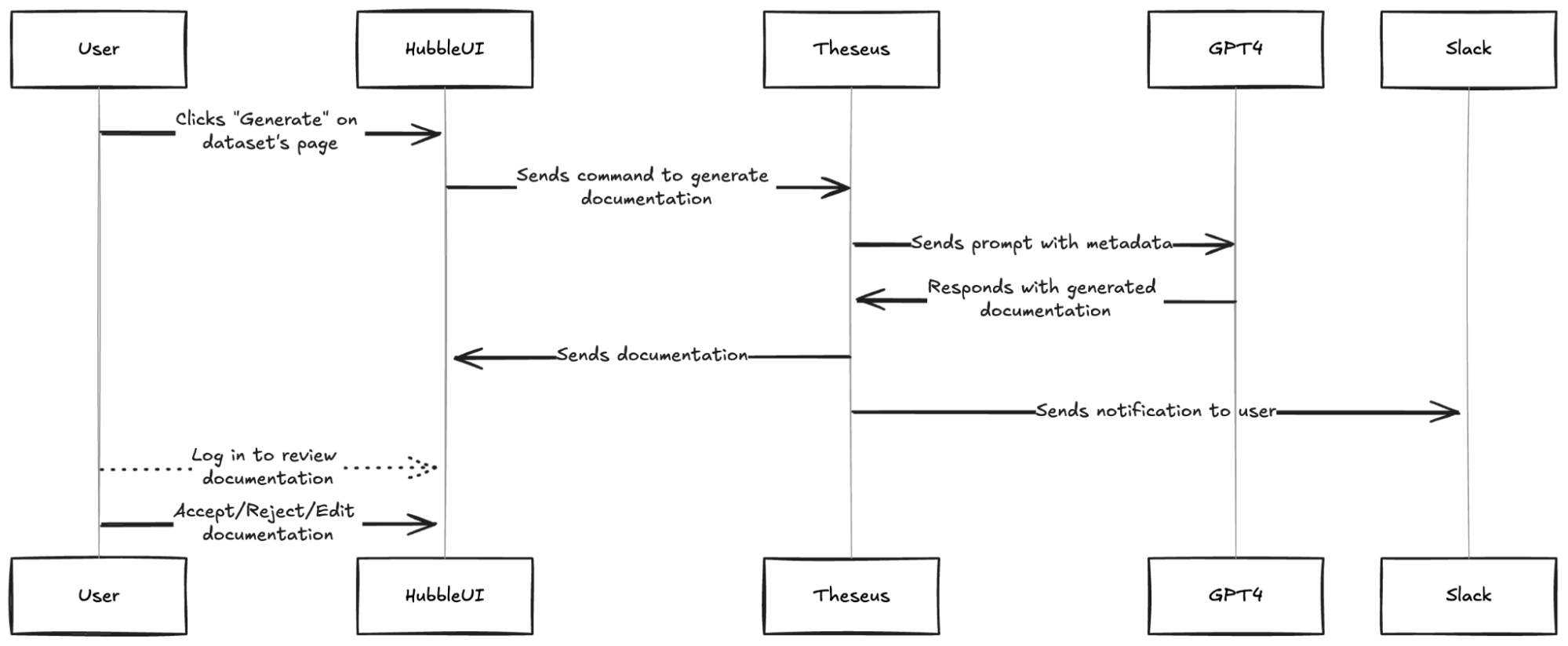
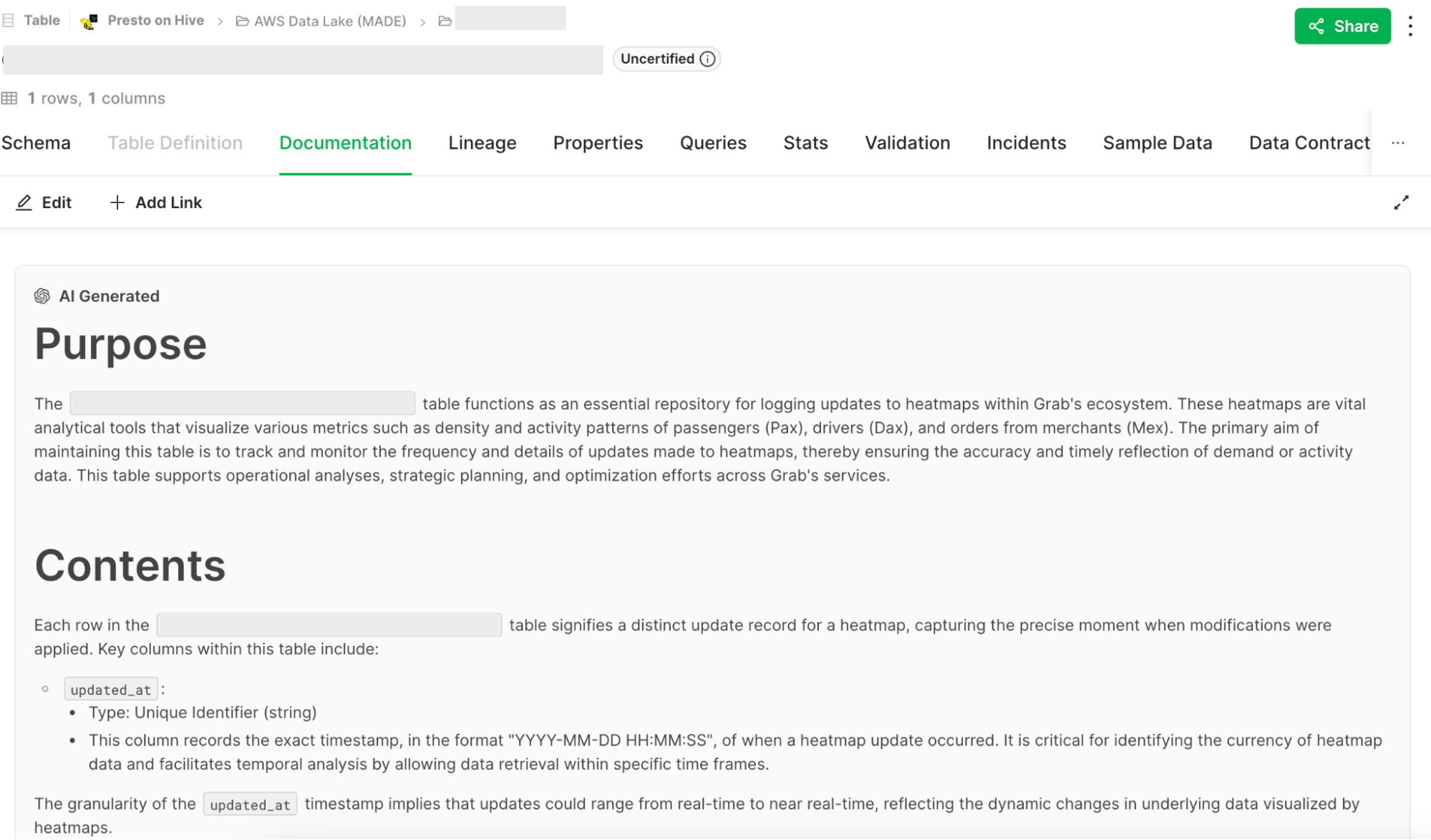
To support HubbleIQ, we built a documentation generation engine that used GPT-4 to generate documentation based on table schemas and sample data. We refined the prompt through multiple iterations of feedback from data producers.
We added a “generate” button on the Hubble UI, allowing data producers to easily generate documentation for their tables. This feature also supported the ongoing Grab-wide initiative to certify tables.
In conjunction, we took the initiative to pre-populate docs for the most critical tables, while notifying data producers to review the generated documentation. Such docs were visible to data consumers with an “AI-generated” tag as a precaution. When data producers accepted or edited the documentation, the tag was removed.
As a result, documentation coverage for P80 tables increased by 70 percentage points to ~90%. User feedback showed that ~95% of users found the generated docs useful.
Step 3: Build and Launch HubbleIQ
With high documentation coverage in place, we were ready to harness the power of LLMs for data discovery. To speed up go-to-market, we decided to leverage Glean, an enterprise search tool used by Grab.
First, we integrated Hubble with Glean, making all data lake tables with documentation available on the Glean platform. Next, we used Glean Apps to create the HubbleIQ bot, which was essentially an LLM with a custom system prompt that could access all Hubble datasets that were catalogued on Glean. Finally, we integrated this bot into Hubble search, such that for any search that is likely to be a semantic search, HubbleIQ results are shown on top, followed by regular search results.
Recently, we integrated HubbleIQ with Slack, allowing data consumers to discover datasets without breaking their flow. Currently, we are working with analytics teams to add the bot to their “ask” channels (where data consumers come to ask contextual search queries for their domains). After integration, HubbleIQ will act as the first line of defence for answering questions in these channels, reducing the need for human intervention.
The impact of these improvements was significant. A follow-up survey revealed that 73% of respondents found it easy to discover datasets, marking a substantial 17 percentage point increase from the previous survey. Moreover, Hubble reached an all-time high in monthly active users, demonstrating the effectiveness of the enhancements made to the platform.
Next Steps
We’ve made significant progress towards our vision, but there’s still work to be done. Looking ahead, we have several exciting initiatives planned to further enhance data discovery at Grab.
On the documentation generation front, we aim to enrich the generator with more context, enabling it to produce even more accurate and relevant documentation. We also plan to streamline the process by allowing analysts to auto-update data docs based on Slack threads directly from Slack. To ensure the highest quality of documentation, we will develop an evaluator model that leverages LLMs to assess the quality of both human and AI-written docs. Additionally, we will implement Reflexion, an agentic workflow that utilises the outputs from the doc evaluator to iteratively regenerate docs until a quality benchmark is met or a maximum try-limit is reached.
As for HubbleIQ, our focus will be on continuous improvement. We’ve already added support for metric datasets and are actively working on incorporating other types of datasets as well. To provide a more seamless user experience, we will enable users to ask follow-up questions to HubbleIQ directly on the HubbleUI, with the system intelligently pulling additional metadata when a user mentions a specific dataset.
Conclusion
By harnessing the power of AI and LLMs, the Hubble team has made significant strides in improving documentation coverage, enhancing search capabilities, and drastically reducing the time taken for data discovery. While our efforts so far have been successful, there are still steps to be taken before we fully achieve our vision of completely replacing the reliance on data producers for data discovery. Nonetheless, with our upcoming initiatives and the groundwork we have laid, we are confident that we will continue to make substantial progress in the right direction over the next few production cycles.
As we forge ahead, we remain dedicated to refining and expanding our AI-powered data discovery tools, ensuring that Grabbers have every dataset they need to drive Grab’s success at their fingertips. The future of data discovery at Grab is brimming with possibilities, and the Hubble team is thrilled to be at the forefront of this exciting journey.
To our readers, we hope that our journey has inspired you to explore how you can leverage the power of AI to transform data discovery within your own organisations. The challenges you face may be unique, but the principles and strategies we have shared can serve as a foundation for your own data discovery revolution. By embracing innovation, focusing on user needs, and harnessing the potential of cutting-edge technologies, you too can unlock the full potential of your data and propel your organisation to new heights. The future of data-driven innovation is here, and we invite you to join us on this exhilarating journey.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
In a previous blog, we introduced Trident, Grab’s internal marketing campaign platform. Trident empowers our marketing team to configure If This, Then That (IFTTT) logic and processes real-time events based on that.
While we mainly covered how we scaled up the system to handle large volumes of real-time events, we did not explain the implementation of the event processing mechanism. This blog will fill up this missing piece. We will walk you through the various processing mechanisms supported in Trident and how they were built.
Base building block: Treatment
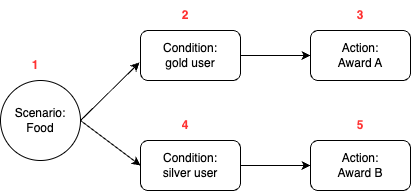
In our system, we use the term “treatment” to refer to the core unit of a full IFTTT data structure. A treatment is an amalgamation of three key elements – an event, conditions (which are optional), and actions. For example, consider a promotional campaign that offers “100 GrabPoints for completing a ride paid with GrabPay Credit”. This campaign can be transformed into a treatment in which the event is “ride completion”, the condition is “payment made using GrabPay Credit”, and the action is “awarding 100 GrabPoints”.
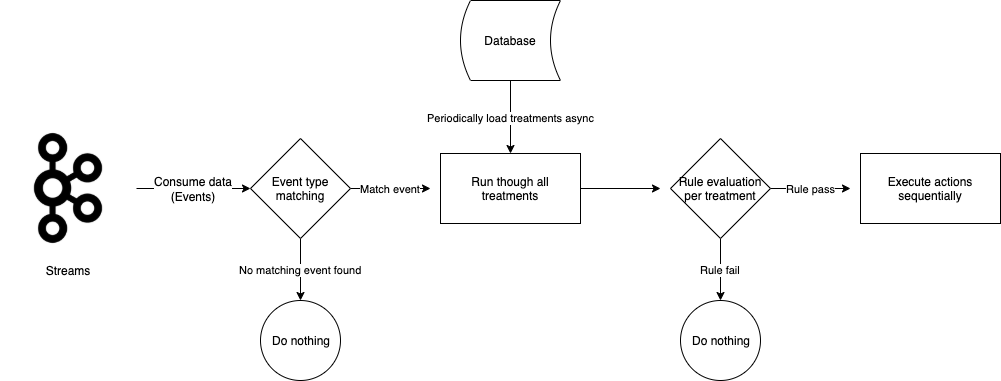
Data generated across various Kafka streams by multiple services within Grab forms the crux of events and conditions for a treatment. Trident processes these Kafka streams, treating each data object as an event for the treatments. It evaluates the set conditions against the data received from these events. If all conditions are met, Trident then executes the actions.
Figure 1. Trident processes Kafka streams as events for treatments.
When the Trident user interface (UI) was first established, campaign creators had to grasp the treatment concept and configure the treatments accordingly. As we improved the UI, it became more user-friendly.
Building on top of treatment
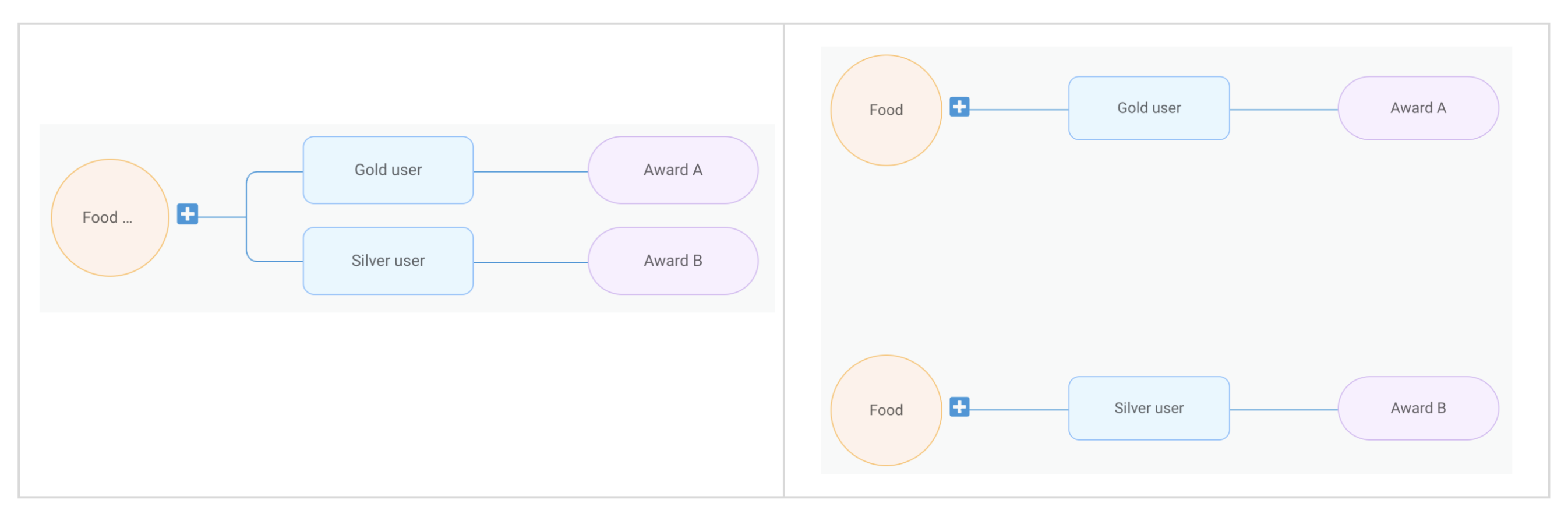
Campaigns can be more complex than the example we provided earlier. In such scenarios, a single campaign may need transformation into several treatments. All these individual treatments are categorised under what we refer to as a “treatment group”. In this section, we discuss features that we have developed to manage such intricate campaigns.
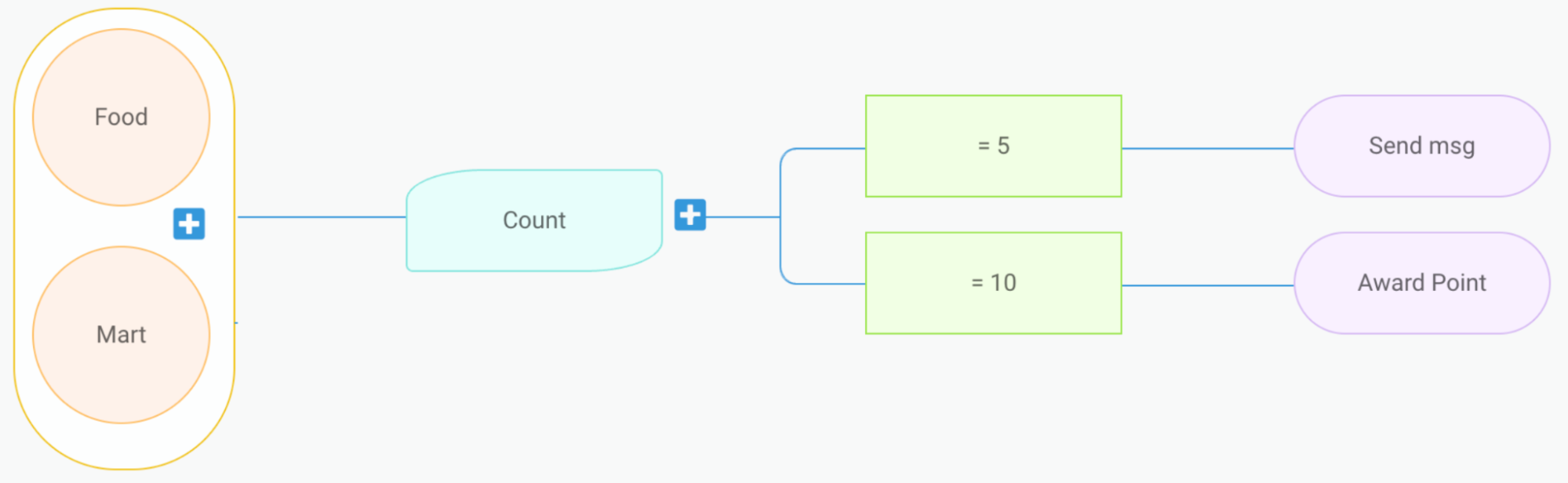
Counter
Let’s say we have a marketing campaign that “rewards users after they complete 4 rides”. For this requirement, it’s necessary for us to keep track of the number of rides each user has completed. To make this possible, we developed a capability known as counter.
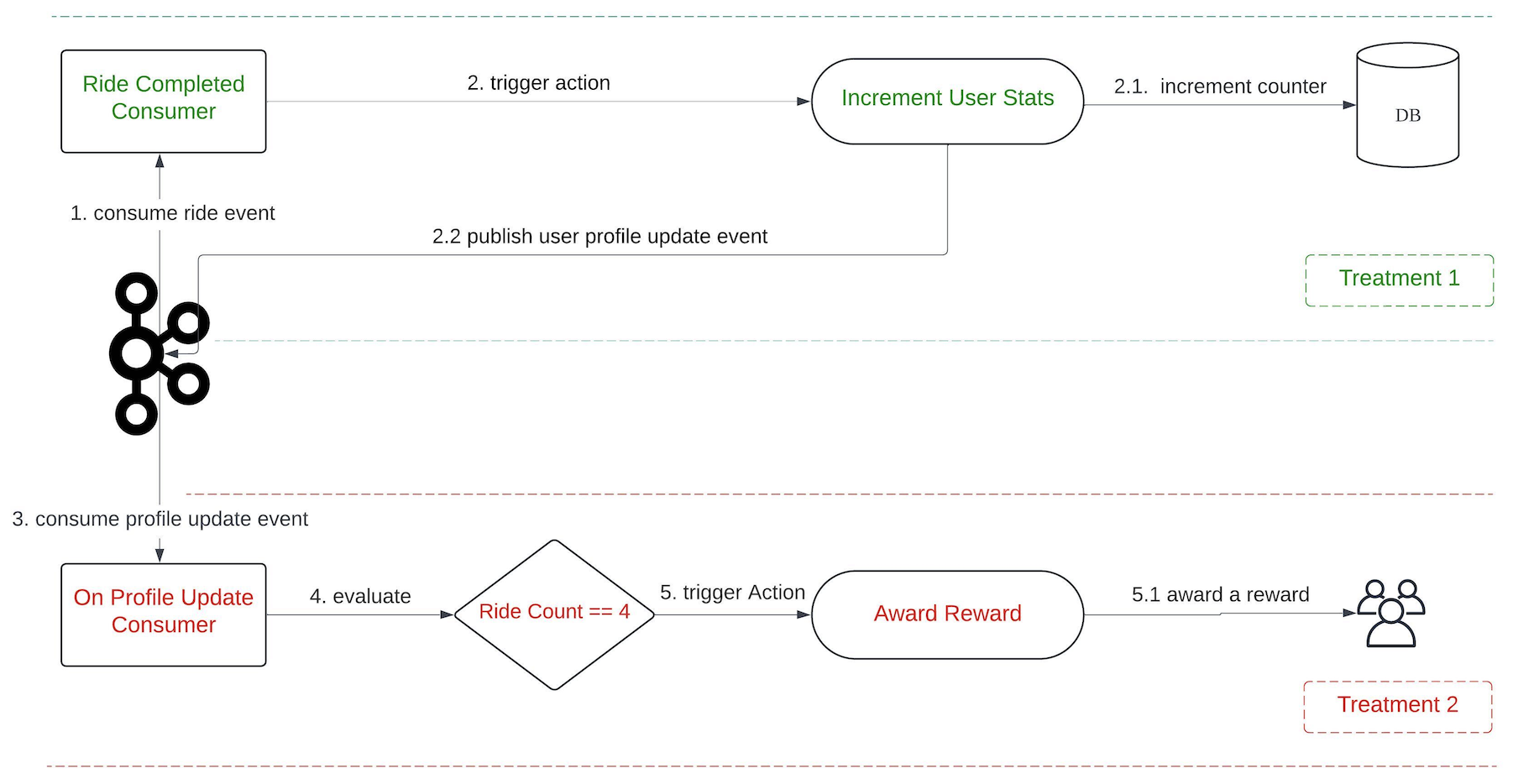
On the backend, a single counter setup translates into two treatments.
Treatment 1:
Event: onRideCompleted
Condition: N/A
Action: incrementUserStats
Treatment 2:
Event: onProfileUpdate
Condition: Ride Count == 4
Action: awardReward
In this feature, we introduce a new event, onProfileUpdate. The incrementUserStats action in Treatment 1 triggers the onProfileUpdate event following the update of the user counter. This allows Treatment 2 to consume the event and perform subsequent evaluations.
Figure 2. The end-to-end evaluation process when using the Counter feature.
When the onRideCompleted event is consumed, Treatment 1 is evaluated which then executes the incrementUserStat action. This action increments the user’s ride counter in the database, gets the latest counter value, and publishes an onProfileUpdate event to Kafka.
There are also other consumers that listen to onProfileUpdate events. When this event is consumed, Treatment 2 is evaluated. This process involves verifying whether the Ride Count equals to 4. If the condition is satisfied, the awardReward action is triggered.
This feature is not limited to counting the number of event occurrences only. It’s also capable of tallying the total amount of transactions, among other things.
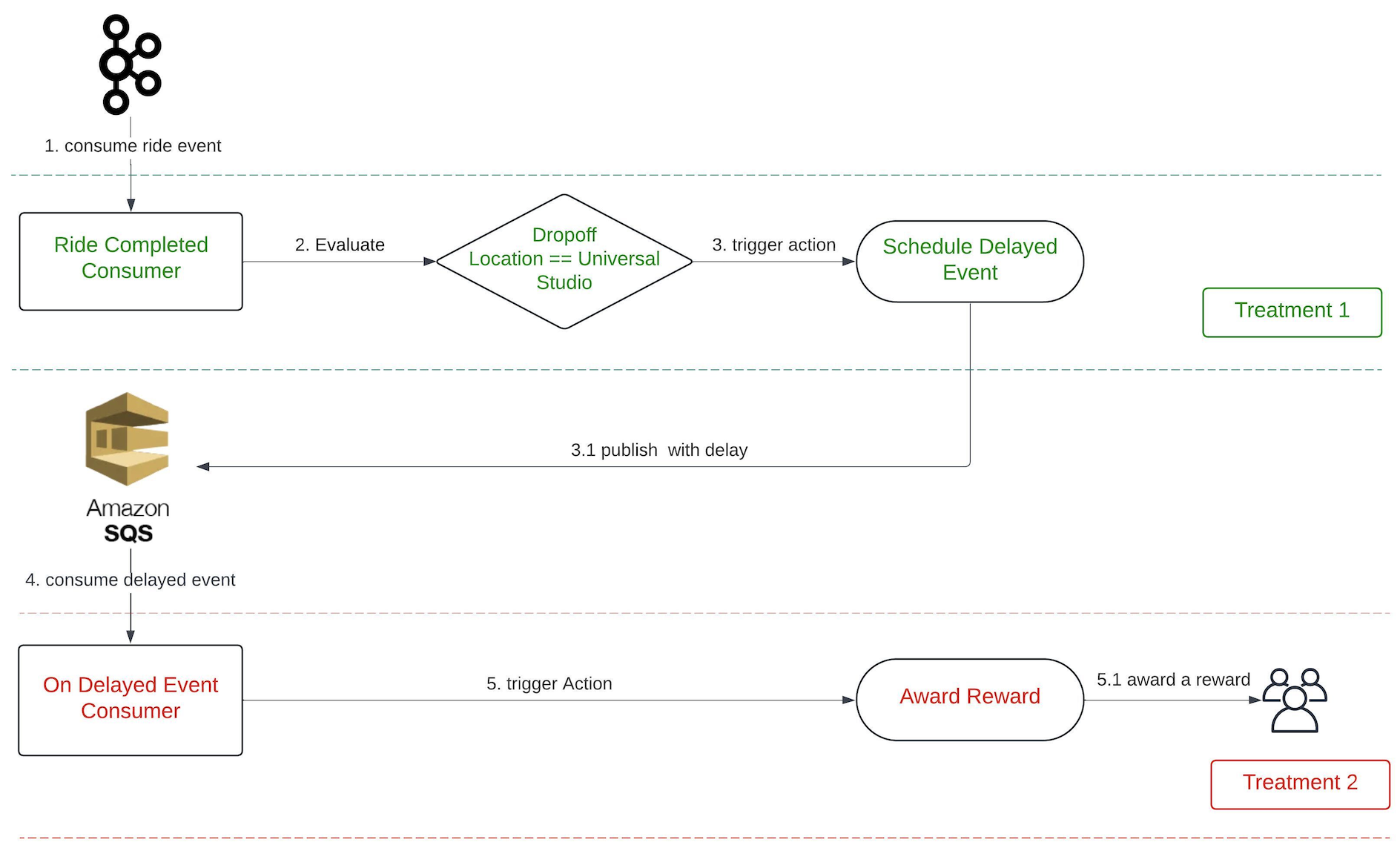
Delay
Another feature available on Trident is a delay function. This feature is particularly beneficial in situations where we want to time our actions based on user behaviour. For example, we might want to give a ride voucher to a user three hours after they’ve ordered a ride to a theme park. The intention for this is to offer them a voucher they can use for their return trip.
On the backend, a delay setup translates into two treatments. Given the above scenario, the treatments are as follows:
Treatment 1:
Event: onRideCompleted
Condition: Dropoff Location == Universal Studio
Action: scheduleDelayedEvent
Treatment 2:
Event: onDelayedEvent
Condition: N/A
Action: awardReward
We introduce a new event, onDelayedEvent, which Treatment 1 triggers during the scheduleDelayedEvent action. This is made possible by using Simple Queue Service (SQS), given its built-in capability to publish an event with a delay.
Figure 3. The end-to-end evaluation process when using the Delay feature.
The maximum delay that SQS supports is 15 minutes; meanwhile, our platform allows for a delay of up to x hours. To address this limitation, we publish the event multiple times upon receiving the message, extending the delay by another 15 minutes each time, until it reaches the desired delay of x hours.
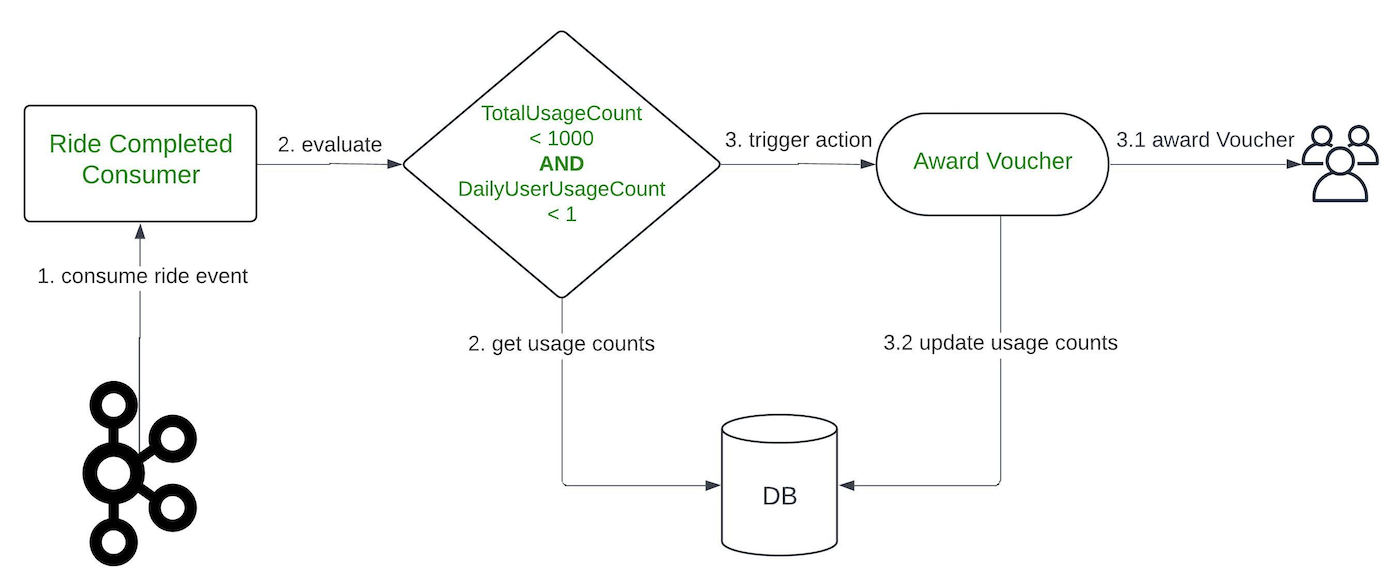
Limit
The Limit feature is used to restrict the number of actions for a specific campaign or user within that campaign. This feature can be applied on a daily basis or for the full duration of the campaign.
For instance, we can use the Limit feature to distribute 1000 vouchers to users who have completed a ride and restrict it to only one voucher for one user per day. This ensures a controlled distribution of rewards and prevents a user from excessively using the benefits of a campaign.
In the backend, a limit setup translates into conditions within a single treatment. Given the above scenario, the treatment would be as follows:
Event: onRideCompleted
Condition: TotalUsageCount <= 1000 AND DailyUserUsageCount <= 1
Action: awardReward
Similar to the Counter feature, it’s necessary for us to keep track of the number of completed rides for each user in the database.
Figure 4. The end-to-end evaluation process when using the Limit feature.
A better campaign builder
As our campaigns grew more and more complex, the treatment creation quickly became overwhelming. A complex logic flow often required the creation of many treatments, which was cumbersome and error-prone. The need for a more visual and simpler campaign builder UI became evident.
Our design team came up with a flow-chart-like UI. Figure 5, 6, and 7 show examples of how certain imaginary campaign setup would look like in the new UI.
Figure 5. When users complete a food order, if they are a gold user, award them with A. However, if they are a silver user, award them with B.
Figure 6. When users complete a food or mart order, increment a counter. When the counter reaches 5, send them a message. Once the counter reaches 10, award them with points.
Figure 7. When a user confirms a ride booking, wait for 1 minute, and then conduct A/B testing by sending a message 50% of the time.
The campaign setup in the new UI can be naturally stored as a node tree structure. The following is how the example in figure 5 would look like in JSON format. We assign each node a unique number ID, and store a map of the ID to node content.
The question then arises, how do we execute this node tree as treatments? This requires a conversion process. We then developed the following algorithm for converting the node tree into equivalent treatments:
// convertToTreatments is the main function
func convertToTreatments(rootNode) -> []Treatment:
output = []
for each scenario in rootNode.scenarios:
// traverse down each branch
context = createConversionContext(scenario)
for child in rootNode.children:
treatments = convertHelper(context, child)
output.append(treatments)
return output
// convertHelper is a recursive helper function
func convertHelper(context, node) -> []Treatment:
output = []
f = getNodeConverterFunc(node.type)
treatments, updatedContext = f(context, node)
output.append(treatments)
for child in rootNode.children:
treatments = convertHelper(updatedContext, child)
output.append(treatments)
return output
The getNodeConverterFunc will return different handler functions according to the node type. Each handler function will either update the conversion context, create treatments, or both.
Table 1. The handler logic mapping for each node type.
Node type
Logic
condition
Add conditions into the context and return the updated context.
action
Return a treatment with the event type, condition from the context, and the action itself.
delay
Return a treatment with the event type, condition from the context, and a scheduleDelayedEvent action.
count
Return a treatment with the event type, condition from the context, and an incrementUserStats action.
count condition
Form a condition with the count key from the context, and return an updated context with the condition.
It is important to note that treatments cannot always be reverted to their original node tree structure. This is because different node trees might be converted into the same set of treatments.
The following is an example where two different node trees setups correspond to the same set of treatments:
Food order complete -> if gold user -> then award A
Food order complete -> if silver user -> then award B
Figure 8. An example of two node tree setups corresponding to the the same set of treatments.
Therefore, we need to store both the campaign node tree JSON and treatments, along with the mapping between the nodes and the treatments. Campaigns are executed using treatments, but displayed using the node tree JSON.
Figure 9. For each campaign, we store both the node tree JSON and treatments, along with their mapping.
How we handle campaign updates
There are instances where a marketing user updates a campaign after its creation. For such cases we need to identify:
Which existing treatments should be removed.
Which existing treatments should be updated.
What new treatments should be added.
We can do this by using the node-treatment mapping information we stored. The following is the pseudocode for this process:
func howToUpdateTreatments(oldTreatments []Treatment, newTreatments []Treatment):
treatmentsUpdate = map[int]Treatment // treatment ID -> updated treatment
treatmentsRemove = []int // list of treatment IDs
treatmentsAdd = []Treatment // list of new treatments to be created
matchedOldTreamentIDs = set()
for newTreatment in newTreatments:
matched = false
// see whether the nodes match any old treatment
for oldTreatment in oldTreatments:
// two treatments are considered matched if their linked node IDs are identical
if isSame(oldTreatment.nodeIDs, newTreatment.nodeIDs):
matched = true
treatmentsUpdate[oldTreament.ID] = newTreatment
matchedOldTreamentIDs.Add(oldTreatment.ID)
break
// if no match, that means it is a new treatment we need to create
if not matched:
treatmentsAdd.Append(newTreatment)
// all the non-matched old treatments should be deleted
for oldTreatment in oldTreatments:
if not matchedOldTreamentIDs.contains(oldTreatment.ID):
treatmentsRemove.Append(oldTreatment.ID)
return treatmentsAdd, treatmentsUpdate, treatmentsRemove
For a visual illustration, let’s consider a campaign that initially resembles the one shown in figure 10. The node IDs are highlighted in red.
Figure 10. A campaign in node tree structure.
This campaign will generate two treatments.
Table 2. The campaign shown in the figure 10 will generated two treatments.
ID
Treatment
Linked node IDs
1
Event: food order complete Condition: gold user Action: award A
1, 2, 3
2
Event: food order complete Condition: silver user Action: award B
1, 4, 5
After creation, the campaign creator updates the upper condition branch, deletes the lower branch, and creates a new branch. Note that after node deletion, the deleted node ID will not be reused.
Figure 11. An updated campaign in node tree structure.
According to our logic in figure 11, the following update will be performed:
Update action for treatment 1 to “award C”.
Delete treatment 2
Create a new treatment: food -> is promo used -> send push
Conclusion
This article reveals the workings of Trident, our bespoke marketing campaign platform. By exploring the core concept of a “treatment” and additional features like Counter, Delay and Limit, we illustrated the flexibility and sophistication of our system.
We’ve explained changes to the Trident UI that have made campaign creation more intuitive. Transforming campaign setups into executable treatments while preserving the visual representation ensures seamless campaign execution and adaptation.
Our devotion to improving Trident aims to empower our marketing team to design engaging and dynamic campaigns, ultimately providing excellent experiences to our users.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Key to innovation and improvement in machine learning (ML) models is the ability for rapid iteration. Our team, Chimera, part of the Artificial Intelligence (AI) Platform team, provides the essential compute infrastructure, ML pipeline components, and backend services. This support enables our ML engineers, data scientists, and data analysts to efficiently experiment and develop ML solutions at scale.
With a commitment to leveraging the latest Generative AI (GenAI) technologies, Grab is enhancing productivity tools for all Grabbers. Our Chimera Sandbox, a scalable Notebook platform, facilitates swift experimentation and development of ML solutions, offering deep integration with our AI Gateway. This enables easy access to various Large Language Models (LLMs) (both proprietary and open source), ensuring scalability, compliance, and access control are managed seamlessly.
What is Chimera Sandbox?
Chimera Sandbox is a Notebook service platform. It allows users to launch multiple notebook and visualisation services for experimentation and development. The platform offers an extremely quick onboarding process enabling any Grabber to start learning, exploring and experimenting in just a few minutes. This inclusivity and ease of use have been key in driving the adoption of the platform across different teams within Grab and empowering all Grabbers to be GenAI-ready.
One significant challenge in harnessing ML for innovation, whether for technical experts or non-technical enthusiasts, has been the accessibility of resources. This includes GPU instances and specialised services for developing LLM-powered applications. Chimera Sandbox addresses this head-on by offering an extensive array of compute instances, both with and without GPU support, thus removing barriers to experimentation. Its deep integration with Grab’s suite of internal ML tools transforms the way users approach ML projects. Users benefit from features like hyperparameter tuning, tracking ML training metadata, accessing diverse LLMs through Grab’s AI Gateway, and experimenting with rich datasets from Grab’s data lake. Chimera Sandbox ensures that users have everything they need at their fingertips. This ecosystem not only accelerates the development process but also encourages innovative approaches to solving complex problems.
The underlying compute infrastructure of the Chimera Sandbox platform is Grab’s very own battle-tested, highly scalable ML compute infrastructure running on multiple Kubernetes clusters. Each cluster can scale up to thousands of nodes at peak times gracefully. This scalability ensures that the platform can handle the high computational demands of ML tasks. The robustness of Kubernetes ensures that the platform remains stable, reliable, and highly available even under heavy load. At any point in time, there can be hundreds of data scientists, ML engineers and developers experimenting and developing on the Chimera Sandbox platform.
Figure 1. Chimera Sandbox Platform.
Figure 2. UI for Starting Chimera Sandbox.
Best of both worlds
Chimera Sandbox is suitable for both new users who want to explore and experiment ML solutions and advanced users who want to have full control over the Notebook services they run. Users can launch Notebook services using default Docker images provided by the Chimera Sandbox platform. These images come pre-loaded with popular data science and ML libraries and various Grab internal systems integrations. Chimera also provides basic Docker images from which the users can use as base images to build their own customised Notebook service Docker images. Once the images are built, the users can configure their Notebook services to use their custom Docker images. This ensures their Notebook environment can be exactly the way they want them to be.
Figure 3. Users are able to customise their Notebook service with additional packages.
Real-time collaboration
The Chimera Sandbox platform also features a real-time collaboration feature. This feature fosters a collaborative environment where users can exchange ideas and work together on projects.
CPU and GPU choices
Chimera Sandbox offers a wide variety of CPU and GPU choices to cater to specific needs, whether it is a CPU, memory, or GPU intensive experimentation. This flexibility allows users to choose the most suitable computational resources for their tasks, ensuring optimal performance and efficiency.
Deep integration with Spark
The platform is deeply integrated with internal Spark engines, enabling users to experiment building extract, transform, and load (ETL) jobs with data from Grab’s data lake. Integrated helpers such as SparkConnect Kernel and %%spark_sql magic cell, provide a faster developer experience, which can execute Spark SQL queries without needing to write additional code to start a Spark session and query.
Figure 4. %%spark_sql magic cell enables users to quickly explore data with Spark.
In addition to Magic Cell, the Chimera Sandbox offers advanced Spark functionalities. Users can write PySpark code using pre-configured and configurable Spark clients in the runtime environment. The underlying computation engine leverages Grab’s custom Spark-on-Kubernetes operator, enabling support for large-scale Spark workloads. This high-code capability complements the low-code Magic Cell feature, providing users with a versatile data processing environment.
AI Gallery
Chimera Sandbox features an AI Gallery to guide and accelerate users to start experimenting with ML solutions or building GenAI-powered applications. This is especially useful for new or novice users who are keen to explore what they can do on the Chimera Sandbox platform. With Chimera Sandbox, users are not just presented with a bare bones compute solution but rather are provided with ways to do ML tasks right from Chimera Sandbox Notebooks. This approach saves users from the hassle of having to piece together the examples from the public internet, which may not work on the platform. These ready-to-run and comprehensive notebooks in the AI Gallery assure users that they can run end-to-end examples without a hitch. Based on these examples, the users can only extend their experimentations and development for their specific needs. Not only that, these tutorials and notebooks exhibit the platform capabilities and integrations available on the platform in an interactive manner rather than having the users refer to a separate documentation.
Lastly, the AI Gallery encourages contributions from other Grabbers, fostering a collaborative environment. Users who are enthusiastic about creating educational contents on Chimera Sandbox can effectively share their work with other Grabbers.
Figure 5. Including AI Gallery in user specified sandbox images.
Integration with various LLM services
Notebook users on Chimera Sandbox can easily tap into a plethora of LLMs, both open source and proprietary models, without any additional setup via our AI Gateway. The platform takes care of access mechanisms and endpoints for various LLM services so that the users can easily use their favourite libraries to create LLM-powered applications and conduct experimentations. This seamless integration with LLMs enables users to focus on their GAI-powered ideas rather than having to worry about underlying logistics and technicalities of using different LLMs.
More than a notebook service
While Notebook is the most popular service on the platform, Chimera Sandbox offers much more than just notebook capabilities. It serves as a comprehensive namespace workspace equipped with a suite of ML/AI tools. Alongside notebooks, users can access essential ML tools such as Optuna for hyperparameter tuning, MLflow for experiment tracking, and other tools including Zeppelin, RStudio, Spark history, Polynote, and LabelStudio. All these services use a shared storage system, creating a tailored workspace for ML and AI tasks.
Figure 6. A Sandbox namespace with its out-of-the-box services.
Additionally, the Sandbox framework allows for the seamless integration of more services into personal workspaces. This high level of flexibility significantly enhances the capabilities of the Sandbox platform, making it an ideal environment for diverse ML and AI applications.
Cost attribution
For a multi-tenanted platform such as Chimera Sandbox, it is crucial to provide users information on how much they have spent with their experimentations. Cost showback and chargeback capabilities are of utmost importance for a platform on which users can launch Notebook services that use accelerated instances with GPUs. The platform provides cost attribution to individual users, so each user knows exactly how much they are spending on their experimentations and can make budget-conscious decisions. This transparency in cost attribution encourages responsible usage of resources and helps users manage their budgets effectively.
Growth and future plans
In essence, Chimera Sandbox is more than just a tool; it’s a catalyst for innovation and growth, empowering Grabbers to explore the frontiers of ML and AI. By providing an inclusive, flexible, and powerful platform, Chimera Sandbox is helping shape the future of Grab, making every Grabber not just ready but excited to contribute to the AI-driven transformation of our products and services.
In July and August of this year, teams were given the opportunity to intensively learn and experiment with AI. Since then, we have observed hockey stick growth on the Chimera Sandbox platform. We are enabling massive experimentation across different teams at Grab to experiment and work on different GAI-powered applications.
Figure 7. Chimera Sandbox daily active users.
Our future plans include mechanisms for better notebook discovery, collaboration and usability, and the ability to enable users to schedule their notebooks right from Chimera Sandbox. These enhancements aim to improve the user experience and make the platform even more versatile and powerful.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 700 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
As COVID restrictions were fully lifted in 2023, the number of tourists grew dramatically. People began to explore the world again, frequently using the Grab app to make bookings outside of their home country. However, we noticed that communication posed a challenge for some users. Despite our efforts to integrate an auto-translation feature in the booking chat, we received feedback about occasional missed or inaccurate translations. You can refer to this blog for a better understanding of Grab’s chat system.
An example of a bad translation. The correct translation is: ‘ok sir’.
In an effort to enhance the user experience for travellers using the Grab app, we formed an engineering squad to tackle this problem. The objectives are as follows:
Ensure translation is provided when it’s needed.
Improve the quality of translation.
Maintain the cost of this service within a reasonable range.
Ensure translation is provided when it’s needed
Originally, we relied on users’ device language settings to determine if translation is needed. For example, if both the passenger and driver’s language setting is set to English, translation is not needed. Interestingly, it turned out that the device language setting did not reliably indicate the language in which a user would send their messages. There were numerous cases where despite having their device language set to English, drivers sent messages in another language.
Therefore, we needed to detect the language of user messages on the fly to make sure we trigger translation when it’s needed.
Language detection
Simple as it may seem, language detection is not that straightforward a task. We were unable to find an open-source language detector library that covered all Southeast Asian languages. We looked for Golang libraries as our service was written in Golang. The closest we could find were the following:
Whatlang: unable to detect Malay
Lingua: unable to detect Burmese and Khmer
We decided to choose Lingua over Whatlang as the base detector due to the following factors:
Overall higher accuracy.
Capability to provide detection confidence level.
We have more users using Malay than those using Burmese or Khmer.
When a translation request comes in, our first step is to use Lingua for language detection. If the detection confidence level falls below a predefined threshold, we fall back to call the third-party translation service as it can detect all Southeast Asian languages.
You may ask, why don’t we simply use the third-party service in the first place. It’s because:
The third-party service only has a translate API that also does language detection, but it does not provide a standalone language detection API.
Using the translate API is costly, so we need to avoid calling it when it’s unnecessary. We will cover more on this in a later section.
Another challenge we’ve encountered is the difficulty of distinguishing between Malay and Indonesian languages due to their strong similarities and shared vocabulary. The identical text might convey different meanings in these two languages, which the third-party translation service struggles to accurately detect and translate.
Differentiating Malay and Indonesian is a tough problem in general. However, in our case, the detection has a very specific context, and we can make use of the context to enhance our detection accuracy.
Making use of translation context
All our translations are for the messages sent in the context of a booking or order, predominantly between passenger and driver. There are two simple facts that can aid in our language detection:
Booking/order happens in one single country.
Drivers are almost always local to that country.
So, for a booking that happens in an Indonesian city, if the driver’s message is detected as Malay, it’s highly likely that the message is actually in Bahasa Indonesia.
Improve quality of translation
Initially, we were entirely dependent on a third-party service for translating our chat messages. While overall powerful, the third-party service is not perfect, and it does generate weird translations from time to time.
An example of a weird translation from a third-party service recorded on 19 Dec 2023.
Then, it came to us that we might be able to build an in-house translation model that could translate chat messages better than the third-party service. The reasons being:
The scope of our chat content is highly specific. All the chats are related to bookings or orders. There would not be conversations about life or work in the chat. Maybe a small Machine Learning (ML) model would suffice to do the job.
The third-party service is a general translation service. It doesn’t know the context of our messages. We, however, know the whole context. Having the right context gives us a great edge on generating the right translation.
Training steps
To create our own translation model, we took the following steps:
Perform topic modelling on Grab chat conversations.
Worked with the localisation team to create a benchmark set of translations.
Measured existing translation solutions against benchmarks.
Used an open source Large Language Model (LLM) to produce synthetic training data.
Used synthetic data to train our lightweight translation model.
Topic modelling
In this step, our aim was to generate a dataset which is both representative of the chat messages sent by our users and diverse enough to capture all of the nuances of the conversations. To achieve this, we took a stratified sampling approach. This involved a random sample of past chat conversation messages stratified by various topics to ensure a comprehensive and balanced representation.
Developing a benchmark
For this step we engaged Grab’s localisation team to create a benchmark for translations. The intention behind this step wasn’t to create enough translation examples to fully train or even finetune a model, but rather, it was to act as a benchmark for translation quality, and also as a set of few-shot learning examples for when we generate our synthetic data.
This second point was critical! Although LLMs can generate good quality translations, LLMs are highly susceptible to their training examples. Thus, by using a set of handcrafted translation examples, we hoped to produce a set of examples that would teach the model the exact style, level of formality, and correct tone for the context in which we plan to deploy the final model.
Benchmarking
From a theoretical perspective there are two ways that one can measure the performance of a machine translation system. The first is through the computation of some sort of translation quality score such as a BLEU or CHRF++ score. The second method is via subjective evaluation. For example, you could give each translation a score from 1 to 5 or pit two translations against each other and ask someone to assess which they prefer.
Both methods have their relative strengths and weaknesses. The advantage of a subjective method is that it corresponds better with what we want, a high quality translation experience for our users. The disadvantage of this method is that it is quite laborious. The opposite is true for the computed translation quality scores, that is to say that they correspond less well to a human’s subjective experience of our translation quality, but that they are easier and faster to compute.
To overcome the inherent limitations of each method, we decided to do the following:
Set a benchmark score for the translation quality of various translation services using a CHRF++ score.
Train our model until its CHRF++ score is significantly better than the benchmark score.
Perform a manual A/B test between the newly trained model and the existing translation service.
Synthetic data generation
To generate the training data needed to create our model, we had to rely on an open source LLM to generate the synthetic translation data. For this task, we spent considerable effort looking for a model which had both a large enough parameter count to ensure high quality outputs, but also a model which had the correct tokenizer to handle the diverse sets of languages which Grab’s customers speak. This is particularly important for languages which use non-standard character sets such as Vietnamese and Thai. We settled on using a public model from Hugging Face for this task.
We then used a subset of the previously mentioned benchmark translations to input as few-shot learning examples to our prompt. After many rounds of iteration, we were able to generate translations which were superior to the benchmark CHRF++ scores which we had attained in the previous section.
Model fine tuning
We now had one last step before we had something that was production ready! Although we had successfully engineered a prompt capable of generating high quality translations from the public Hugging Face model, there was no way we’d be able to deploy such a model. The model was far too big for us to deploy it in a cost efficient manner and within an acceptable latency. Our solution to this was to fine-tune a smaller bespoke model using the synthetic training data which was derived from the larger model.
These models were language specific (e.g. English to Indonesian) and built solely for the purpose of language translation. They are 99% smaller than the public model. With approximately 10 Million synthetic training examples, we were able to achieve performance which was 98% as effective as our larger model.
We deployed our model and ran several A/B tests with it. Our model performed pretty well overall, but we noticed a critical problem: sometimes, numbers got mutated in the translation. These numbers can be part of an address, phone number, price etc. Showing the wrong number in a translation can cause great confusion to the users. Unfortunately, an ML model’s output can never be fully controlled; therefore, we added an additional layer of programmatic check to mitigate this issue.
Post-translation quality check
Our goal is to ensure non-translatable content such as numbers, special symbols, and emojis in the original message doesn’t get mutated in the translation produced by our in-house model. We extract all the non-translatable content from the original message, count the occurrences of each, and then try to match the same in the translation. If it fails to match, we discard the in-house translation and fall back to using the third-party translation service.
Keep cost low
At Grab, we try to be as cost efficient as possible in all aspects. In the case of translation, we tried to minimise cost by avoiding unnecessary on-the-fly translations.
As you would have guessed, the first thing we did was to implement caching. A cache layer is placed before both the in-house translation model and the third-party translation. We try to serve translation from the cache first before hitting the underlying translation service. However, given that translation requests are in free text and can be quite dynamic, the impact of caching is limited. There’s more we need to do.
For context, in a booking chat, other than the users, Grab’s internal services can also send messages to the chat room. These messages are called system messages. For example,our food service always sends a message with information on the food order when an order is confirmed.
System messages are all fairly static in nature, however, we saw a very high amount of translation cost attributed to system messages. Taking a deeper look, we noticed the following:
Many system messages were not sent in the recipient’s language, thus requiring on-the-fly translation.
Many system messages, though having the same static structure, contain quite a few variants such as passenger’s name and food order item name. This makes it challenging to utilise our translation cache effectively as each message is different.
Since all system messages are manually prepared, we should be able to get them all manually translated into all the required languages, and avoid on-the-fly translations altogether.
Therefore, we launched an internal campaign, mandating all internal services that send system messages to chat rooms to get manual translations prepared, and pass in the translated contents. This alone helped us save roughly US$255K a year!
Next steps
At Grab, we firmly believe that our proprietary in-house translation models are not only more cost-effective but cater more accurately to our unique use cases compared to third-party services. We will focus on expanding these models to more languages and countries across our operating regions.
Additionally, we are exploring opportunities to apply learnings of our chat translations to other Grab content. This strategy aims to guarantee a seamless language experience for our rapidly expanding user base, especially travellers. We are enthusiastically looking forward to the opportunities this journey brings!
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Profile-guided optimisation (PGO) is a technique where CPU profile data for an application is collected and fed back into the next compiler build of Go application. The compiler then uses this CPU profile data to optimise the performance of that build by around 2-14% currently (future releases could likely improve this figure further).
High level view of how PGO works
PGO is a widely used technique that can be implemented with many programming languages. When it was released in May 2023, PGO was introduced as a preview in Go 1.20.
Enabling PGO on a service
Profile the service to get pprof file
First, make sure that your service is built using Golang version v1.20 or higher, as only these versions support PGO.
TalariaDB: TalariaDB is a distributed, highly available, and low latency time-series database for Presto open sourced by Grab.
It is a service that runs on an EKS cluster and is entirely managed by our team, we will use it as an example here.
Since the cluster deployment relies on a Docker image, we only need to update the Docker image’s go build command to include -PGO=./talaria.PGO. The talaria.PGO file is a pprof profile collected from production services over a span of 360 seconds.
If you’re utilising a go plugin, as we do in TalariaDB, it’s crucial to ensure that the PGO is also applied to the plugin.
Here’s our Dockerfile, with the additions to support PGO.
FROM arm64v8/golang:1.21 AS builder
ARG GO111MODULE="on"
ARG GOOS="linux"
ARG GOARCH="arm64"
ENV GO111MODULE=${GO111MODULE}
ENV GOOS=${GOOS}
ENV GOARCH=${GOARCH}
RUN mkdir -p /go/src/talaria
COPY . src/talaria
#RUN cd src/talaria && go mod download && go build && test -x talaria
RUN cd src/talaria && go mod download && go build -PGO=./talaria.PGO && test -x talaria
RUN mkdir -p /go/src/talaria-plugin
COPY ./talaria-plugin src/talaria-plugin
RUN cd src/talaria-plugin && make plugin && test -f talaria-plugin.so
FROM arm64v8/debian:latest AS base
RUN apt-get update && apt-get install -y ca-certificates && rm -rf /var/cache/apk/*
WORKDIR /root/
ARG GO_BINARY=talaria
COPY --from=builder /go/src/talaria/${GO_BINARY} .
COPY --from=builder /go/src/talaria-plugin/talaria-plugin.so .
ADD entrypoint.sh .
RUN mkdir /etc/talaria/ && chmod +x /root/${GO_BINARY} /root/entrypoint.sh
ENV TALARIA_RC=/etc/talaria/talaria.rc
EXPOSE 8027
ENTRYPOINT ["/root/entrypoint.sh"]
Result on enabling PGO on one GrabX service
It’s important to mention that the pprof utilised for PGO was not captured during peak hours and was limited to a duration of 360 seconds.
Service TalariaDB has three clusters and the time we enabled PGO for these clusters are:
We enabled PGO on cluster 0, and deployed on 4 Sep 11.16 AM.
We enabled PGO on cluster 1, and deployed on 5 Sep 15:00 PM.
We enabled PGO on cluster 2, and deployed on 6 Sep 16:00 PM.
The size of the instances, their quantity, and all other dependencies remained unchanged.
CPU metrics on cluster
Cluster CPU usage before enabling PGO
Cluster CPU usage after enabling PGO
It’s evident that enabling PGO resulted in at least a 10% reduction in CPU usage.
Memory metrics on cluster
Memory usage of the cluster before enabling PGO
Percentage of free memory after enabling PGO
It’s clear that enabling PGO led to a reduction of at least 10GB (30%) in memory usage.
Volume metrics on cluster
Persistent volume usage on cluster before enabling PGO
Volume usage after enabling PGO
Enabling PGO resulted in a reduction of at least 7GB (38%) in volume usage. This volume is utilised for storing events that are queued for ingestion.
Ingested event count/CPU metrics on cluster
To gauge the enhancements, I employed the metric of ingested event count per CPU unit (event count / CPU). This approach was adopted to account for the variable influx of events, which complicates direct observation of performance gains.
Count of ingested events on cluster after enabling PGO
Upon activating PGO, there was a noticeable increase in the ingested event count per CPU, rising from 1.1 million to 1.7 million, as depicted by the blue line in the cluster screenshot.
How we enabled PGO on a Catwalk service
We also experimented with enabling PGO on certain orchestrators in a Catwalk service. This section covers our findings.
Enabling PGO on the test-golang-orch-tfs orchestrator
Attempt 1: Take pprof for 59 seconds
Just 1 pod running with a constant throughput of 420 QPS.
Load test started with a non-PGO image at 5:39 PM SGT.
Take pprof for 59 seconds.
Image with PGO enabled deployed at 5:49 PM SGT.
Observation: CPU usage increased after enabling PGO with pprof for 59 seconds.
We suspected that taking pprof for just 59 seconds may not be sufficient to collect accurate metrics. Hence, we extended the duration to 6 minutes in our second attempt.
Attempt 2 : Take pprof for 6 minutes
Just 1 pod running with a constant throughput of 420 QPS.
Deployed non PGO image with custom pprof server at 6:13 PM SGT.
pprof taken at 6:19 PM SGT for 6 minutes.
Image with PGO enabled deployed at 6:29 PM SGT.
Observation: CPU usage decreased after enabling PGO with pprof for 6 minutes.
CPU usage after enabling PGO on Catwalk
Container memory utilisation after enabling PGO on Catwalk
Based on this experiment, we found that the impact of PGO is around 5% but the effort involved to enable PGO outweighs the impact. To enable PGO on Catwalk, we would need to create Docker images for each application through CI pipelines.
Additionally, the Catwalk team would require a workaround to pass the pprof dump, which is not a straightforward task. Hence, we decided to put off the PGO application for Catwalk services.
Looking into PGO for monorepo services
From the information provided above, enabling PGO for a service requires the following support mechanisms:
A pprof service, which is currently facilitated through Jenkins.
A build process that supports PGO arguments and can attach or retrieve the pprof file.
For services that are hosted outside the monorepo and are self-managed, the effort required to experiment is minimal. However, for those within the monorepo, we will require support from the build process, which is currently unable to support this.
Conclusion/Learnings
Enabling PGO has proven to be highly beneficial for some of our services, particularly TalariaDB. By using PGO, we’ve observed a clear reduction in both CPU usage and memory usage to the tune of approximately 10% and 30% respectively. Furthermore, the volume used for storing queued ingestion events has been reduced by a significant 38%. These improvements definitely underline the benefits and potential of utilising PGO on services.
Interestingly, applying PGO resulted in an increased rate of ingested event count per CPU unit on TalariaDB, which demonstrates an improvement in the service’s efficiency.
Experiments with the Catwalk service have however shown that the effort involved to enable PGO might not always justify the improvements gained. In our case, a mere 5% improvement did not appear to be worth the work required to generate Docker images for each application via CI pipelines and create a solution to pass the pprof dump.
On the whole, it is evident that the applicability and benefits of enabling PGO can vary across different services. Factors such as application characteristics, current architecture, and available support mechanisms can influence when and where PGO optimisation is feasible and beneficial.
Moving forward, further improvements to go-build and the introduction of PGO support for monorepo services may drive greater adoption of PGO. In turn, this has the potential to deliver powerful system-wide gains that translate to faster response times, lower resource consumption, and improved user experiences. As always, the relevance and impact of adopting new technologies or techniques should be considered on a case-by-case basis against operational realities and strategic objectives.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
In a previous post, we introduced our systems for running marketing campaigns. Although we sent millions of messages daily, we had little insight into their effectiveness. Did they engage our users with our promotions? Did they encourage more transactions and bookings?
As Grab’s business expanded and the number of marketing campaigns increased, understanding the impact of these campaigns became crucial. This knowledge enables campaign managers to design more effective campaigns and avoid wasteful ones that degrade user experience.
Initially, campaign managers had to consult marketing analysts to gauge the impact of campaigns. However, this approach soon proved unsustainable:
Manual analysis doesn’t scale with an increasing number of campaigns.
Different analysts might assess the business impact in slightly different ways, leading to inconsistent results over time.
Thus, we recognised the need for a centralised solution allowing campaign managers to view their campaign impact analyses.
Marketing attribution model
The marketing analyst team designed a Marketing attribution model (MAM) for estimating the business impact of any campaign that sends messages to users. It quantifies business impact in terms of generated gross merchandise value (GMV), revenue, etc.
Unlike traditional models that only credit the last touchpoint (i.e. the last message user reads before making a transaction), MAM offers a more nuanced view. It recognises that users are exposed to various marketing messages (emails, pushes, feeds, etc.) throughout their decision-making process. As shown in Fig 1, MAM assigns credit to each touchpoint that influences a conversion (e.g., Grab usage) based on two key factors:
Relevance: Content directly related to the conversion receives a higher weightage. Imagine a user opening a GrabFood push notification before placing a food order. This push would be considered highly relevant and receive significant credit.
Recency: Touchpoints closer in time to the conversion hold more weight. For instance, a brand awareness email sent weeks before the purchase would be less impactful than a targeted GrabFood promotion right before the order.
By factoring in both relevance and recency, MAM avoids crediting the same touchpoint twice and provides a more accurate picture of which marketing campaigns are driving higher conversions.
Fig 1. How MAM does business attribution
While MAM is effective for comparing the impacts of different campaigns, it struggles with the assessment of a single campaign because it does not account for negative impacts. For example, consider a message stating, “Hey, don’t use Grab.” Clearly, not all messages positively impact business.
Hold-out group
To better evaluate the impact of a single campaign, we divide targeted users into two groups:
Hold-out (control): do not send any message
Treatment: send the message
Fig 2. Campaign setup with hold-out group
We then compare the business performance of sending versus not sending messages. For the treatment group, we ideally count only the user transactions potentially linked to the message (i.e., transactions occurring within X days of message receipt). However, since the hold-out group receives no messages, there are no equivalent metrics for comparison.
The only business metrics available for the hold-out group are the aggregated totals of GMV, revenue, etc., over a given time, divided by the number of users. We must calculate the same for the treatment group to ensure a fair comparison.
Fig 3. Metrics calculation for both hold-out and treatment group
The comparison might seem unreliable due to:
The metrics are raw aggregations, lacking attribution logic.
The aggregated GMV and revenue might be skewed by other simultaneous campaigns involving the same users.
Here, we have to admit that figuring out true business impact is difficult. All we can do is try our best to get as close to the truth as possible. To make the comparison more precise, we employed the following strategies:
Stratify the two groups, so that both groups contain roughly the same distribution of users.
Calculate statistical significance to rule out the difference caused by random factors.
Allow users to narrow down the business metrics to compare according to campaign set-up. For example, we don’t compare ride bookings if the campaign is promoting food.
Statistical significance is a common, yet important technique for evaluating the result of controlled experiments. Let’s see how it’s used in our case.
Statistical significance
When we do an A/B testing, we cannot simply conclude that A is better than B when A’s result is better than B. The difference could be due to other random factors. If you did an A/A test, you will still see differences in the results even without doing anything different to the two groups.
Statistical significance is a method to calculate the probability that the difference between two groups is really due to randomness. The lower the probability, the more confidently we can say our action is truly making some impact.
In our case, to derive statistical significance, we assume:
Our hold-out and treatment group are two sets of samples drawn from two populations, A and B.
A and B are the same except that B received our message. We can’t 100% prove this, but can reasonably guess this is close to true, since we split with stratification.
Assuming the business metrics we are comparing is food GMV, the base numbers can be formulated as shown in Fig 4.
Fig 4. Formulation for calculating statistical significance
To calculate the probability, we then use a formula derived from the central limit theorem (CLT). The mathematical derivation of the formula is beyond the scope of this post. Programmatically, we use the popular jStat library for the calculation.
The calculation result of statistical significance as a special notice to the campaign owners is shown in Fig 5.
Fig 5. Display of business impact analysis with statistical significance
What’s next
Evaluating the true business impact remains challenging. We continue to refine our methodology and address potential biases, such as the assumption that both groups are of the same distribution, which might not hold true, especially in smaller group sizes. Furthermore, consistently reserving a 10% hold-out in each campaign is impractical for some campaigns, as sometimes campaign owners require messages to reach all targeted users.
We are committed to advancing our business impact evaluation solutions and will continue improving our existing solutions. We look forward to sharing more insights in future blogs.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
In a tech-driven field, staying updated isn’t an option—it’s essential. At Grab, we’re committed to providing top-notch technology services. However, keeping pace can be demanding. At one point in time, our GitLab instance was trailing by roughly 14 months of releases. This blog post recounts our experience updating and formulating a consistent upgrade routine.
Recognising the need to upgrade
Our team, while skilled, was still learning GitLab’s complexities. Regular stability issues left us little time for necessary upgrades. Understanding the importance of upgrades for our operations to get latest patches for important security fixes and vulnerabilities, we started preparing for GitLab updates while managing system stability. This meant a quick learning and careful approach to updates.
The following image illustrates the version discrepancy between our self-hosted GitLab instance and the official most recent release of GitLab as of July 2022. GitLab follows a set release schedule, issuing one minor update monthly and rolling out a major upgrade annually.
Fig 1. The difference between our hosted version and the latest available GitLab version by 22 July 2022
Addressing fears and concerns
We were concerned about potential downtime, data integrity, and the threat of encountering unforeseen issues. GitLab is critical for the daily activities of Grab engineers. It serves a critical user base of thousands of engineers actively using it, hosting multiple mono repositories with code bases ranging in size from 1GB to a sizable 15GB. When taking into account all its artefacts, the overall imprint of a monorepo can extend to an impressive 39TB.
Our self-hosted GitLab firmly intertwines with multiple critical components. We’ve aligned our systems with GitLab’s official reference architecture for 5,000 users. We use Terraform to configure complete infrastructure with immutable Amazon Machine Images (AMIs) built using Packer and Ansible. Our efficient GitLab setup is designed for reliable performance to serve our wide user base. However, any fault leading to outages can disrupt our engineers, resulting in a loss of productivity for hundreds of teams.
High-level GitLab Architecture Diagram
The above is the top level architecture diagram of our GitLab infrastructure. Here are the major components of the GitLab architecture and their functions:
Gitaly: Handles low-level Git operations for GitLab, such as interacting directly with the code repository present on disk. It’s important to mention that these code repositories are also stored on the same Gitaly nodes, using the attached Amazon Elastic Block Store (Amazon EBS) disks.
Praefect: Praefect in GitLab acts as a manager, coordinating Gitaly nodes to maintain data consistency and high availability.
Sidekiq: The background processing framework for GitLab written in Ruby. It handles asynchronous tasks in GitLab, ensuring smooth operation without blocking the main application.
App Server: The core web application server that serves the GitLab user interface and interacts with other components.
The importance of preparation
Recognising the complexity of our task, we prioritised careful planning for a successful upgrade. We studied GitLab’s documentation, shared insights within the team, and planned to prevent data losses.
To minimise disruptions from major upgrades or database migrations, we scheduled these during weekends. We also developed a checklist and a systematic approach for each upgrade, which include the following:
Diligently go through the release notes for each version of GitLab that falls within the scope of our upgrade.
Read through all dependencies like RDS, Redis, and Elasticsearch to ensure version compatibility.
Create documentation outlining new features, any deprecated elements, and changes that could potentially impact our operations.
Generate immutable AMIs for various components reflecting the new version of GitLab.
Revisit and validate all the backup plans.
Refresh staging environment with production data for accurate, realistic testing and performance checks, and validation of migration scripts under conditions similar to the actual setup.
Upgrade the staging environment.
Conduct extensive testing, incorporating both automated and manual functional testing, as well as load testing.
Conduct rollback tests on the staging environment to the previous version to confirm the rollback procedure’s reliability.
Inform all impacted stakeholders, and provide a defined timeline for upcoming upgrades.
We systematically follow GitLab’s official documentation for each upgrade, ensuring compatibility across software versions and reviewing specific instructions and changes, including any deprecations or removals.
The first upgrade
Equipped with knowledge, backup plans, and a robust support system, we embarked on our first GitLab upgrade two years ago. We carefully followed our checklist, handling each important part systematically. GitLab comprises both stateful (Gitaly) and stateless (Praefect, Sidekiq, and App Server) components, all managed through auto-scaling groups. We use a ‘create before destroy’ strategy for deploying stateless components and an ‘in-place node rotation’ method via Terraform for stateful ones.
We deployed key parts like Gitaly, Praefect, Sidekiq, App Servers, Network File System (NFS) server, and Elasticsearch in a specific sequence. Starting with Gitaly, followed by Praefect, then Sidekiq and App Servers, and finally NFS and Elasticsearch. Our thorough testing showed this order to be the most dependable and safe.
However, the journey was full of challenges. For instance, we encountered issues such as the Gitaly cluster falling out of sync for monorepo and the Praefect server failing to distribute the load effectively. Praefect assigns a primary Gitaly node for each repository to host it. All write operations are sent to the repository’s primary node, while read requests are spread across all synced nodes in the Gitaly cluster. If the Gitaly nodes aren’t synced, Praefect will redirect all write and read operations to the repository’s primary node.
Gitaly is a stateful application, we upgraded each Gitaly node with the latest AMI using an in-place node rotation strategy. In older versions of GitLab (up to v14.0), if a Gitaly node is unhealthy, Praefect would immediately update the primary node for the repository to any healthy Gitaly node. After the rolling upgrade for a 3-node Gitaly cluster, repositories were mainly concentrated on only one Gitaly node.
In our situation, a very busy monorepo was assigned to a Gitaly node that was also the main node for many other repositories. When real traffic began after deployment, the Gitaly node had trouble syncing the monorepo with the other nodes in the cluster.
Because the Gitaly node was out of sync, Praefect started sending all changes and access requests for monorepo to this struggling Gitaly node. This increased the load on the Gitaly server, causing it to fail. We found this to be the main issue and decided to manually move our monorepo to a Gitaly node that was less crowded. We also added a step to validate primary node distribution to our deployment checklist.
This immediate failover behaviour changed in GitLab version 14.1. Now, a primary is only elected lazily when a write request arrives for any repository. However, since we enabled maintenance mode before the Gitaly deployment, we didn’t receive any write requests. As a result, we did not see a shift in the primary node of the monorepo with new GitLab versions.
Regular upgrades: Our new normal
Embracing the practice of consistent upgrades dramatically transformed the way we operate. We initiated frequent upgrades and implemented measures to reduce the actual deployment time.
Perform all major testing in one day before deployment.
Prepare a detailed checklist to follow during the deployment activity.
Reduce the minimum number of App Server and Sidekiq Servers required just after we start the deployment.
Upgrade components like App Server and Sidekiq in parallel.
Automate smoke testing to examine all major workflows after deployment.
Leveraging the lessons learned and the experience gained with each upgrade, we successfully cut the time spent on the entire operation by 50%. The image-3 shows how we reduced our deployment time for major upgrades from 6 hours to 3 hours and our deployment time for minor upgrades from 4 to 1.5 hours.
Each upgrade enriched our comprehensive knowledge base, equipping us with insights into the possible behaviours of each component under varying circumstances. Our growing experience and enhanced knowledge helped us achieve successful upgrades with less downtime with each deployment.
Rather than moving up one minor version at a time, we learned about the feasibility of skipping versions. We began using the GitLab Upgrade Path. This method allowed us to skip several versions, closing the distance to the latest version with fewer deployments. This approach enabled us to catch up on 24 months’ worth of upgrades in just 11 months, even though we started 14 months behind.
Time taken in hrs for each upgrade. The blue line depicts major and the red line is for minor upgrades
Overcoming challenges
Our journey was not without hurdles. We faced challenges in maintaining system stability during upgrades, navigating unexpected changes in functionality post upgrades, and ensuring data integrity.
However, these challenges served as an opportunity for our team to innovate and create robust workarounds. Here are a few highlights:
Unexpected project distribution: During upgrades and Gitaly server restarts, we observed unexpected migration of the monorepo to a crowded Gitaly server, resulting in higher rate limiting. We manually updated primary nodes for the monorepo and made this validation as a part of our deployment checklist.
NFS deprecation: We migrated all required data to S3 buckets and deprecated NFS to become more resilient and independent of Availability Zone (AZ).
Handling unexpected Continuous Integration (CI) operations: A sudden surge in CI operations sometimes resulted in rate limiting and interrupted more essential Git operations for developers. This is because GitLab uses different RPC calls and their concurrency for SSH and HTTP operations. We encouraged using HTTPS links for GitLab CI and automation script and SSH links for regular Git operations.
Right-sizing resources: We countered resource limitations by right-sizing our infrastructure, ensuring each component had optimal resources to function efficiently.
Performance testing: We conducted performance testing of our GitLab using the GitLab Performance Tool (GPT). In addition, we used our custom scripts to load test Grab specific use cases and mono repositories.
Limiting maintenance windows: Each deployment required a maintenance window or downtime. To minimise this, we structured our deployment processes more efficiently, reducing potential downtime and ensuring uninterrupted service for users.
Dependency on GitLab.com image registry: We introduced measures to host necessary images internally, which increased our resilience and allowed us to cut ties with external dependencies.
The results
Through careful planning, we’ve improved our upgrade process, ensuring system stability and timely updates. We’ve also reduced the delay in aligning with official GitLab releases. The image below displays how the time delay between release date and deployment has been reduced with each upgrade. It sharply brought down from 396 days (around 14 months) to 35 days.
At the time of this article, we’re just two minor versions behind the latest GitLab release, with a strong focus on security and resilience. We are also seeing a reduced number of reported issues after each upgrade.
Our refined process has allowed us to perform regular updates without any service disruptions. We aim to leverage these learnings to automate our upgrade deployments, painting a positive picture for our future updates, marked by efficiency and stability.
Time delay between official release date and date of deployment
Looking ahead
Our dedication extends beyond staying current with the most recent GitLab versions. With stabilised deployment, we are now focusing on:
Automated upgrades: Our efforts extend towards bringing in more automation to enhance efficiency. We’re already employing zero-downtime automated upgrades for patch versions involving no database migrations, utilising GitLab pipelines. Looking forward, we plan to automate minor version deployments as well, ensuring minimal human intervention during the upgrade process.
Automated runner onboarding for service teams: We’ve developed a ‘Runner as a Service’ solution for our service teams. Service teams can create their dedicated runners by providing minimal details, while we manage these runners centrally. This setup allows the service team to stay focused on development, ensuring smooth operations.
Improved communication and data safety: We’re regularly communicating new features and potential issues to our service teams. We also ensure targeted solutions for any disruptions. Additionally, we’re focusing on developing automated data validation via our data restoration process.
Focus on development: With stabilised updates, we’ve created an environment where our development teams can focus more on crafting new features and supporting ongoing work, rather than handling upgrade issues.
Key takeaways
The upgrade process taught us the importance of adaptability, thorough preparation, effective communication, and continuous learning. Our ‘No Version Left Behind’ motto underscores the critical role of regular tech updates in boosting productivity, refining processes, and strengthening security. These insights will guide us as we navigate ongoing technological advancements.
Below are the key areas in which we improved:
Enhanced testing procedures: We’ve fine-tuned our testing strategies, using both automated and manual testing for GitLab, and regularly conducting performance tests before upgrades.
Approvals: We’ve designed approval workflows that allow us to obtain necessary clearances or approvals before each upgrade efficiently, further ensuring the smooth execution of our processes.
Improved communication: We’ve improved stakeholder communication, regularly sharing updates and detailed documents about new features, deprecated items, and significant changes with each upgrade.
Streamlined planning: We’ve improved our upgrade planning, strictly following our checklist and rotating the role of Upgrade Ownership among team members.
Optimised activity time: We’ve significantly reduced the time for production upgrade activity through advanced planning, automation, and eliminating unnecessary steps.
Efficient issue management: We’ve improved our ability to handle potential GitLab upgrade issues, with minimal to no issues occurring. We’re prepared to handle any incidents that could cause an outage.
Knowledge base creation and automation: We’ve created a GitLab knowledge base and continuously enhanced it with rich content, making it even more invaluable for training new team members and for reference during unexpected situations. We’ve also automated routine tasks to improve efficiency and reduce manual errors.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Grab has an in-house Risk Management platform called GrabDefence which relies on ingesting large amounts of data gathered from upstream services to power our heuristic risk rules and data science models in real time.
Fig 1. GrabDefence aggregates data from different upstream services
As Grab’s business grows, so does the amount of data. It becomes imperative that the data which fuels our risk systems is of reliable quality as any data discrepancy or missing data could impact fraud detection and prevention capabilities.
We need to quickly detect any data anomalies, which is where data observability comes in.
Data observability as a solution
Data observability is a type of data operation (DataOps; similar to DevOps) where teams build visibility over the health and quality of their data pipelines. This enables teams to be notified of data quality issues, and allows teams to investigate and resolve these issues faster.
We needed a solution that addresses the following issues:
Alerts for any data quality issues as soon as possible – so this means the observability tool had to work in real time.
With hundreds of data points to observe, we needed a neat and scalable solution which allows users to quickly pinpoint which data points were having issues.
A consistent way to compare, analyse, and compute data that might have different formats.
Hence, we decided to use Flink to standardise data transformations, compute, and observe data trends quickly (in real time) and scalably.
Utilising Flink for real-time computations at scale
What is Flink?
Flink SQL is a powerful, flexible tool for performing real-time analytics on streaming data. It allows users to query continuous data streams using standard SQL syntax, enabling complex event processing and data transformation within the Apache Flink ecosystem, which is particularly useful for scenarios requiring low-latency insights and decisions.
How we used Flink to compute data output
In Grab, data comes from multiple sources and while most of the data is in JSON format, the actual JSON structure differs between services. Because of JSON’s nested and dynamic data structure, it is difficult to consistently analyse the data – posing a significant challenge for real-time analysis.
To help address this issue, Apache Flink SQL has the capability to manage such intricacies with ease. It offers specialised functions tailored for parsing and querying JSON data, ensuring efficient processing.
Another standout feature of Flink SQL is the use of custom table functions, such as JSONEXPLOAD, which serves to deconstruct and flatten nested JSON structures into tabular rows. This transformation is crucial as it enables subsequent aggregation operations. By implementing a 5-minute tumbling window, Flink SQL can easily aggregate these now-flattened data streams. This technique is pivotal for monitoring, observing, and analysing data patterns and metrics in near real-time.
Now that data is aggregated by Flink for easy analysis, we still needed a way to incorporate comprehensive monitoring so that teams could be notified of any data anomalies or discrepancies in real time.
How we interfaced the output with Datadog
Datadog is the observability tool of choice in Grab, with many teams using Datadog for their service reliability observations and alerts. By aggregating data from Apache Flink and integrating it with Datadog, we can harness the synergy of real-time analytics and comprehensive monitoring. Flink excels in processing and aggregating data streams, which, when pushed to Datadog, can be further analysed and visualised. Datadog also provides seamless integration with collaboration tools like Slack, which enables teams to receive instant notifications and alerts.
With Datadog’s out-of-the-box features such as anomaly detection, teams can identify and be alerted to unusual patterns or outliers in their data streams. Taking a proactive approach to monitoring is crucial in maintaining system health and performance as teams can be alerted, then collaborate quickly to diagnose and address anomalies.
This integrated pipeline—from Flink’s real-time data aggregation to Datadog’s monitoring and Slack’s communication capabilities—creates a robust framework for real-time data operations. It ensures that any potential issues are quickly traced and brought to the team’s attention, facilitating a rapid response. Such an ecosystem empowers organisations to maintain high levels of system reliability and performance, ultimately enhancing the overall user experience.
Organising monitors and alerts using out-of-the-box solutions from Datadog
Once we integrated Flink data into Datadog, we realised that it could become unwieldy to try to identify the data point with issues from hundreds of other counters.
Fig 2. Hundreds of data points on a graph make it hard to decipher which ones have issues
We decided to organise the counters according to the service stream it was coming from, and create individual monitors for each service stream. We used Datadog’s Monitor Summary tool to help visualise the total number of service streams we are reading from and the number of underlying data points within each stream.
Fig 3. Data is grouped according to their source stream
Within each individual stream, we used Datadog’s Anomaly Detection feature to create an alert whenever a data point from the stream exceeds a predefined threshold. This can be configured by the service teams on Datadog.
Fig 4. Datadog’s built-in Anomaly Detection function triggers alerts whenever a data point exceeds a threshold
These alerts are then sent to a Slack channel where the Data team is informed when a data point of interest starts throwing anomalous values.
Fig 5. Datadog integration with Slack to help alert users
Impact
Since the deployment of this data observability tool, we have seen significant improvement in the detection of anomalous values. If there are any anomalies or issues, we now get alerts within the same day (or hour) instead of days to weeks later.
Organising the alerts according to source streams have also helped simplify the monitoring load and allows users to quickly narrow down and identify which pipeline has failed.
What’s next?
At the moment, this data observability tool is only implemented on selected checkpoints in GrabDefence. We plan to expand the observability tool’s coverage to include more checkpoints, and continue to refine the workflows to detect and resolve these data issues.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
This article introduces the GrabX Decision Engine, an internal open-source package that offers a comprehensive framework for designing and analysing experiments conducted on online experiment platforms. The package encompasses a wide range of functionalities, including a pre-experiment advisor, a post-experiment analysis toolbox, and other advanced tools. In this article, we explore the motivation behind the development of these functionalities, their integration into the unique ecosystem of Grab’s multi-sided marketplace, and how these solutions strengthen the culture and calibre of experimentation at Grab.
Background
Today, Grab’s Experimentation (GrabX) platform orchestrates the testing of thousands of experimental variants each week. As the platform continues to expand and manage a growing volume of experiments, the need for dependable, scalable, and trustworthy experimentation tools becomes increasingly critical for data-driven and evidence-based
decision-making.
In our previous article, we presented the Automated Experiment Analysis application, a tool designed to automate data pipelines for analyses. However, during the development of this application for Grab’s experimenter community, we noticed a prevailing trend: experiments were predominantly analysed on a one-by-one, manual basis. While such a federated approach may be needed in a few cases, it presents numerous challenges at
the organisational level:
Lack of a contextual toolkit: GrabX facilitates executing a diverse range of experimentation designs, catering to the varied needs and contexts of different tech teams across the organisation. However, experimenters may often rely on generic online tools for experiment configurations (e.g. sample size calculations), which were not specifically designed to cater to the nuances of GrabX experiments or the recommended evaluation method, given the design. This is exacerbated by the fact
that most online tutorials or courses on experimental design do not typically address the nuances of multi-sided marketplaces, and cannot consider the nature or constraints of specific experiments.
Lack of standards: In this federated model, the absence of standardised and vetted practices can lead to reliability issues. In some cases, these can include poorly designed experiments, inappropriate evaluation methods, suboptimal testing choices, and unreliable inferences, all of which are difficult to monitor and rectify.
Lack of scalability and efficiency: Experimenters, coming from varied backgrounds and possessing distinct skill sets, may adopt significantly different approaches to experimentation and inference. This diversity, while valuable, often impedes the transferability and sharing of methods, hindering a cohesive and scalable experimentation framework. Additionally, this variance in methods can extend the lifecycle of experiment analysis, as disagreements over approaches may give rise to
repeated requests for review or modification.
Solution
To address these challenges, we developed the GrabX Decision Engine, a Python package open-sourced internally across all of Grab’s development platforms. Its central objective is to institutionalise best practices in experiment efficiency and analytics, thereby ensuring the derivation of precise and reliable conclusions from each experiment.
In particular, this unified toolkit significantly enhances our end-to-end experimentation processes by:
Ensuring compatibility with GrabX and Automated Experiment Analysis: The package is fully integrated with the Automated Experiment Analysis app, and provides analytics and test results tailored to the designs supported by GrabX. The outcomes can be further used for other downstream jobs, e.g. market modelling, simulation-based calibrations, or auto-adaptive configuration tuning.
Standardising experiment analytics: By providing a unified framework, the package ensures that the rationale behind experiment design and the interpretation of analysis results adhere to a company-wide standard, promoting consistency and ease of review across different teams.
Enhancing collaboration and quality: As an open-source package, it not only fosters a collaborative culture but also upholds quality through peer reviews. It invites users to tap into a rich pool of features while encouraging contributions that refine and expand the toolkit’s capabilities.
The package is designed for everyone involved in the experimentation process, with data scientists and product analysts being the primary users. Referred to as experimenters in this article, these key stakeholders can not only leverage the existing capabilities of the package to support their projects, but can also contribute their own innovations. Eventually, the experiment results and insights generated from the package via the Automated Experiment Analysis app have an even wider reach to stakeholders across all functions.
In the following section, we go deeper into the key functionalities of the package.
Feature details
The package comprises three key components:
An experimentation trusted advisor
A comprehensive post-experiment analysis toolbox
Advanced tools
These have been built taking into account the type of experiments we typically run at Grab. To understand their functionality, it’s useful to first discuss the key experimental designs supported by GrabX.
A note on experimental designs
While there is a wide variety of specific experimental designs implemented, they can be bucketed into two main categories: a between-subject design and a within-subject design.
In a between-subject design, participants — like our app users, driver-partners, and merchant-partners — are split into experimental groups, and each group gets exposed to a distinct condition throughout the experiment. One challenge in this design is that each participant may provide multiple observations to our experimental analysis sample, causing a high within-subject correlation among observations and deviations between the randomisation and session unit. This can affect the accuracy of
pre-experiment power analysis, and post-experiment inference, since it necessitates adjustments, e.g. clustering of standard errors when conducting hypothesis testing.
Conversely, a within-subject design involves every participant experiencing all conditions. Marketplace-level switchback experiments are a common GrabX use case, where a timeslice becomes the experimental unit. This design not only faces the aforementioned challenges, but also creates other complications that need to be accounted for, such as spillover effects across timeslices.
Designing and analysing the results of both experimental approaches requires careful nuanced statistical tools. Ensuring proper duration, sample size, controlling for confounders, and addressing potential biases are important considerations to enhance the validity of the results.
Trusted Advisor
The first key component of the Decision Engine is the Trusted Advisor, which provides a recommendation to the experimenter on key experiment attributes to be considered when preparing the experiment. This is dependent on the design; at a minimum, the experimenter needs to define whether the experiment design is between- or within-subject.
The between-subject design: We strongly recommend that experimenters utilise the “Trusted Advisor” feature in the Decision Engine for estimating their required sample size. This is designed to account for the multiple observations per user the experiment is expected to generate and adjusts for the presence of clustered errors (Moffatt, 2020; List, Sadoff, & Wagner, 2011). This feature allows users to input their data, either as a PySpark or Pandas dataframe. Alternatively, a function is
provided to extract summary statistics from their data, which can then be inputted into the Trusted Advisor. Obtaining the data beforehand is actually not mandatory; users have the option to directly query the recommended sample size based on common metrics derived from a regular data pipeline job. These functionalities are illustrated in the flowchart below.
Trusted Advisor functionalities
Furthermore, the Trusted Advisor feature can identify the underlying characteristics of the data, whether it’s passed directly, or queried from our common metrics database. This enables it to determine the appropriate power analysis for the experiment, without further guidance. For instance, it can detect if the target metric is a binary decision variable, and will adapt the power analysis to the correct context.
The within-subject design: In this case, we instead provide a best practices guideline to follow. Through our experience supporting various Tech Families running switchback experiments, we have observed various challenges highly dependent on the use case. This makes it difficult to create a one-size-fits-all solution.
For instance, an important factor affecting the final sample size requirement is how frequently treatments switch, which is also tied to what data granularity is appropriate to use in the post-experiment analysis. These considerations are dependent on, among other factors, how quickly a given treatment is expected to cause an effect. Some treatments may take effect relatively quickly (near-instantly, e.g. if applied to price checks), while others may take significantly longer (e.g. 15-30 minutes because they may require a trip to be completed). This has further consequences, e.g. autocorrelation between observations within a treatment window, spillover effects between different treatment windows, requirements for cool-down windows when treatments switch, etc.
Another issue we have identified from analysing the history of experiments on our platform is that a significant portion is prone to issues related to sample ratio mismatch (SRM). We therefore also heavily emphasise the post-experiment analysis corrections and robustness checks that are needed in switchback experiments, and do not simply rely on pre-experiment guidance such as power analysis.
Post-experiment analysis
Upon completion of the experiment, a comprehensive toolbox for post-experiment analysis is available. This toolbox consists of a wide range of statistical tests, ranging from normality tests to non-parametric and parametric tests. Here is an overview of the different types of tests included in the toolbox for different experiment setups:
Tests supported by the post-experiment analysis component
Though we make all the relevant tests available, the package sets a default list of output. With just two lines of code specifying the desired experiment design, experimenters can easily retrieve the recommended results, as summarised in the following table.
Types
Details
Basic statistics
The mean, variance, and sample size of Treatment and Control
Uplift tests
Welch’s t-test; Non-parametric tests, such as Wilcoxon signed-rank test and Mann-Whitney U Test
Misc tests
Normality tests such as the Shapiro-Wilk test, Anderson-Darling test, and Kolmogorov-Smirnov test; Levene test which assesses the equality of variances between groups
Regression models
A standard OLS/Logit model to estimate the treatment uplift; Recommended regression models
Warning
Provides a warning or notification related to the statistical analysis or results, for example: – Lack of variation in the variables – Sample size is too small – Too few randomisation units which will lead to under-estimated standard errors
Recommended regression models
Besides reporting relevant statistical test results, we adopt regression models to leverage their flexibility in controlling for confounders, fixed effects and heteroskedasticity, as is commonly observed in our experiments. As mentioned in the section “A note on experimental design”, each approach has different implications on the achieved randomisation, and hence requires its own customised regression models.
Between-subject design: the observations are not independent and identically distributed (i.i.d) but clustered due to repeated observations of the same experimental units. Therefore, we set the default clustering level at the participant level in our regression models, considering that most of our between-subject experiments only take a small portion of the population (Abadie et al., 2022).
Within-subject design: this has further challenges, including spillover effects and randomisation imbalances. As a result, they often require better control of confounding factors. We adopt panel data methods and impose time fixed effects, with no option to remove them. Though users have the flexibility to define these themselves, we use hourly fixed effects as our default as we have found that these match the typical seasonality we observe in marketplace metrics. Similar to between-subject
designs, we use standard error corrections for clustered errors, and small number of clusters, as the default. Our API is flexible for users to include further controls, as well as further fixed effects to adapt the estimator to geo-timeslice designs.
Advanced tools
Apart from the pre-experiment Trusted Advisor and the post-experiment Analysis Toolbox, we have enriched this package by providing more advanced tools. Some of them are set as a default feature in the previous two components, while others are ad-hoc capabilities which the users can utilise via calling the functions directly.
Variance reduction
We bring in multiple methods to reduce variance and improve the power and sensitivity of experiments:
Stratified sampling: recognised for reducing variance during assignment
Post stratification: a post-assignment variance reduction technique
MLRATE: an extension of CUPED that allows for the use of non-linear / machine learning models
These approaches offer valuable ways to mitigate variance and improve the overall effectiveness of experiments. The experimenters can directly access these ad hoc capabilities via the package.
Multiple comparisons problem
A multiple comparisons problem occurs when multiple hypotheses are simultaneously tested, leading to a higher likelihood of false positives. To address this, we implement various statistical correction techniques in this package, as illustrated below.
Statistical correction techniques
Experimenters can specify if they have concerns about the dependency of the tests and whether the test results are expected to be negatively related. This capability will adopt the following procedures and choose the relevant tests to mitigate the risk of false positives accordingly:
False Discovery Rate (FDR) procedures, which control the expected rate of false discoveries.
Family-wise Error Rate (FWER) procedures, which control the probability of making at least one false discovery within a set of related tests referred to as a family.
Multiple treatments and unequal treatment sizes
We developed a capability to deal with experiments where there are multiple treatments. This capability employs a conservative approach to ensure that the size reaches a minimum level where any pairwise comparison between the control and treatment groups has a sufficient sample size.
Heterogeneous treatment effects
Heterogeneous treatment effects refer to a situation where the treatment effect varies across different groups or subpopulations within a larger population. For instance, it may be of interest to examine treatment effects specifically on rainy days compared to non-rainy days. We have incorporated this functionality into the tests for both experiment designs. By enabling this feature, we facilitate a more nuanced analysis that accounts for potential variations in treatment effects based on different factors or contexts.
Maintenance and support
The package is available across all internal DS/Machine Learning platforms and individual local development environments within Grab. Its source code is openly accessible to all developers within Grab and its release adheres to a semantic release standard.
In addition to the technical maintenance efforts, we have introduced a dedicated committee and a workspace to address issues that may extend beyond the scope of the package’s current capabilities.
Experiment Council
Within Grab, there is a dedicated committee known as the ‘Experiment Council’. This committee includes data scientists, analysts, and economists from various functions. One of their responsibilities is to collaborate to enhance and maintain the package, as well as guide users in effectively utilising its functionalities. The Experiment Council plays a crucial role in enhancing the overall operational excellence of conducting experiments and deriving meaningful insights from them.
GrabCausal Methodology Bank
Experimenters frequently encounter challenges regarding the feasibility of conducting experiments for causal problems. To address this concern, we have introduced an alternative workspace called GrabCausal Methodology Bank. Similar to the internal open-source nature of this project, the GrabCausal Methodology bank is open to contributions from all users within Grab. It provides a collaborative space where users can readily share their code, case studies, guidelines, and suggestions related to
causal methodologies. By fostering an open and inclusive environment, this workspace encourages knowledge sharing and promotes the advancement of causal research methods.
The workspace functions as a platform, which now exhibits a wide range of commonly used methods, including Diff-in-Diff, Event studies, Regression Discontinuity Designs (RDD), Instrumental Variables (IV), Bayesian structural time series, and Bunching. Additionally, we are dedicated to incorporating more, such as Synthetic control, Double ML (Chernozhukov et al. 2018), DAG discovery/validation, etc., to further enhance our offerings in this space.
Learnings
Over the past few years, we have invested in developing and expanding this package. Our initial motivation was humble yet motivating – to contribute to improving the quality of experimentation at Grab, helping it develop from its initial start-up modus operandi to a more consolidated, rigorous, and guided approach.
Throughout this journey, we have learned that prioritisation holds the utmost significance in open-source projects of this nature; the majority of user demands can be met through relatively small yet pivotal efforts. By focusing on these core capabilities, we avoid spreading resources too thinly across all areas at the initial stage of planning and development.
Meanwhile, we acknowledge that there is still a significant journey ahead. While the package now focuses solely on individual experiments, an inherent challenge in online-controlled experimentation platforms is the interference between experiments (Gupta, et al, 2019). A recent development in the field is to embrace simultaneous tests (Microsoft, Google, Spotify and booking.com and Optimizely), and to carefully consider the tradeoff between accuracy and velocity.
The key to overcoming this challenge will be a close collaboration between the community of experimenters, the teams developing this unified toolkit, and the GrabX platform engineers. In particular, the platform developers will continue to enrich the experimentation SDK by providing diverse assignment strategies, sampling mechanisms, and user interfaces to manage potential inference risks better. Simultaneously, the community of experimenters can coordinate among themselves effectively to
avoid severe interference, which will also be monitored by GrabX. Last but not least, the development of this unified toolkit will also focus on monitoring, evaluating, and managing inter-experiment interference.
In addition, we are committed to keeping this package in sync with industry advancements. Many existing tools in this package, despite being labelled as “advanced” in the earlier discussions, are still relatively simplified. For instance,
Incorporating standard errors clustering based on the diverse assignment and sampling strategies requires attention (Abadie, et al, 2023).
Sequential testing will play a vital role in detecting uplifts earlier and safely, avoiding p-hacking. One recent innovation is the “always valid inference” (Johari, et al., 2022)
The advancements in investigating heterogeneous effects, such as Causal Forest (Athey and Wager, 2019), have extended beyond linear approaches, now incorporating nonlinear and more granular analyses.
Estimating the long-term treatment effects observed from short-term follow-ups is also a long-term objective, and one approach is using a Surrogate Index (Athey, et al 2019).
Continuous effort is required to stay updated and informed about the latest advancements in statistical testing methodologies, to ensure accuracy and effectiveness.
This article marks the beginning of our journey towards automating the experimentation and product decision-making process among the data scientist community. We are excited about the prospect of expanding the toolkit further in these directions. Stay tuned for more updates and posts.
References
Abadie, Alberto, et al. “When should you adjust standard errors for clustering?.” The Quarterly Journal of Economics 138.1 (2023): 1-35.
Athey, Susan, et al. “The surrogate index: Combining short-term proxies to estimate long-term treatment effects more rapidly and precisely.” No. w26463. National Bureau of Economic Research, 2019.
Athey, Susan, and Stefan Wager. “Estimating treatment effects with causal forests: An application.” Observational studies 5.2 (2019): 37-51.
Chernozhukov, Victor, et al. “Double/debiased machine learning for treatment and structural parameters.” (2018): C1-C68.
Facure, Matheus. Causal Inference in Python. O’Reilly Media, Inc., 2023.
Gupta, Somit, et al. “Top challenges from the first practical online controlled experiments summit.” ACM SIGKDD Explorations Newsletter 21.1 (2019): 20-35.
Huntington-Klein, Nick. The Effect: An Introduction to Research Design and Causality. CRC Press, 2021.
Imbens, Guido W. and Donald B. Rubin. Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction. Cambridge University Press, 2015.
Johari, Ramesh, et al. “Always valid inference: Continuous monitoring of a/b tests.” Operations Research 70.3 (2022): 1806-1821.
List, John A., Sally Sadoff, and Mathis Wagner. “So you want to run an experiment, now what? Some simple rules of thumb for optimal experimental design.” Experimental Economics 14 (2011): 439-457.
Moffatt, Peter. Experimetrics: Econometrics for Experimental Economics. Bloomsbury Publishing, 2020.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Iris (/ˈaɪrɪs/), a name inspired by the Olympian mythological figure who personified the rainbow and served as the messenger of the gods, is a comprehensive observability platform for Extract, Transform, Load (ETL) jobs. Just as the mythological Iris connected the gods to humanity, our Iris platform bridges the gap between raw data and meaningful insights, serving the needs of data-driven organisations. Specialising in meticulous monitoring and tracking of Spark and Presto jobs, Iris stands as a transformative tool for peak observability and effective decision-making.
Iris captures critical job metrics right at the Java Virtual Machine (JVM) level, including but not limited to runtime, CPU and memory utilisation rates, garbage collection statistics, stage and task execution details, and much more.
Iris not only regularly records these metrics but also supports real-time monitoring and offline analytics of metrics in the data lake. This gives you multi-faceted control and insights into the operational aspects of your workloads.
Iris gives you an overview of your jobs, predicts if your jobs are over or under-provisioned, and provides suggestions on how to optimise resource usage and save costs.
Understanding the needs
When examining ETL job monitoring across various platforms, a common deficiency became apparent. Existing tools could only provide CPU and memory usage data at the instance level, where an instance could refer to an EC2 unit or a Kubernetes pod with resources bound to the container level.
However, this CPU and memory usage data included usage from the operating system and other background tasks, making it difficult to isolate usage specific to Spark jobs (JVM level). A sizeable fraction of resource consumption, thus, could not be attributed directly to our ETL jobs. This lack of granularity posed significant challenges when trying to perform effective resource optimisation for individual jobs.
Gap between total instance and JVM provisioned resources
The situation was further complicated when compute instances were shared among various jobs. In such cases, determining the precise resource consumption for a specific job became nearly impossible. This made in-depth analysis and performance optimisation of specific jobs a complex and often ineffective process.
In the initial stages of my career in Spark, I took the reins of handling SEGP ETL jobs deployed in Chimera. Then, Chimera did not possess any tool for observing and understanding SEGP jobs. The lack of an efficient tool for close-to-real-time visualisation of Spark cluster/job metrics, profiling code class/function runtime durations, and investigating deep-level job metrics to assess CPU and memory usage, posed a significant challenge even back then.
In the quest for solutions within Grab, I found no tool that could fulfill all these needs. This prompted me to extend my search beyond the organisation, leading me to discover that Uber had an exceptional tool known as the JVM Profiler. This tool could collect JVM metrics and profile the job. Further research also led me to sparkMeasure, a standalone tool known for its ability to measure Spark metrics on-the-fly without any code changes.
This personal research and journey highlights the importance of a comprehensive, in-depth observability tool – emphasising the need that Iris aims to fulfill in the world of ETL job monitoring. Through this journey, Iris was ideated, named after the Greek deity, encapsulating the mission to bridge the gap between the realm of raw ETL job metrics and the world of actionable insights.
Observability with Iris
Platform architecture
Platform architecture of Iris
Iris’s robust architecture is designed to smartly deliver observability into Spark jobs with high reliability. It consists of three main modules: Metrics Collector, Kafka Queue, and Telegraf, InfluxDB, and Grafana (TIG) Stack.
Metrics Collector: This module listens to Spark jobs, collects metrics, and funnels them to the Kafka queue. What sets this apart is its unobstructive nature – there is no need for end-users to update their application code or notebook.
Kafka Queue: Serving as an asynchronous deliverer of metrics messages, Kafka is leveraged to prevent Iris from becoming another bottleneck slowing down user jobs. By functioning as a message queue, it enables the efficient processing of metric data.
TIG Stack: This component is utilised for real-time monitoring, making visualising performance metrics a cinch. The TIG stack proves to be an effective solution for real-time data visualisation.
For offline analytics, Iris pushes metrics data from Kafka into our data lake. This creates a wealth of historical data that can be utilised for future research, analysis, and predictions. The strategic combination of real-time monitoring and offline analysis forms the basis of Iris’s ability to provide valuable insights.
Next, we will delve into how Iris collects the metrics.
Data collection
Iris’s metrics is now primarily driven by two tools that operate under the Metrics Collector module: JVM Profiler and sparkMeasure.
JVM Profiler
As mentioned earlier, JVM Profiler is an exceptional tool that helps to collect and profile metrics at JVM level.
Java process for the JVM Profiler tool
Uber JVM Profiler supports the following features:
Debug memory usage for all your Spark application executors, including java heap memory, non-heap memory, native memory (VmRSS, VmHWM), memory pool, and buffer pool (directed/mapped buffer).
Debug CPU usage, garbage collection time for all Spark executors.
Debug arbitrary Java class methods (how many times they run, how long they take), also called Duration Profiling.
Debug arbitrary Java class method call and trace its argument value, also known as Argument Profiling.
Do Stacktrack Profiling and generate flamegraph to visualise CPU time spent for the Spark application.
Debug I/O metrics (disk read/write bytes for the application, CPU iowait for the machine).
Debug JVM Thread Metrics like Count of Total Threads, Peak Threads, Live/Active Threads, and newThreads.
A list of all metrics and information corresponding to them can be found here.
sparkMeasure
Complementing the JVM Profiler is sparkMeasure, a standalone tool that was built to robustly capture Spark job-specific metrics.
Architecture of Spark Task Metrics, Listener Bus, and sparkMeasure (Source)
It is registered as a custom listener and operates by collection built-in metrics that Spark exchanges between the driver node and executor nodes. Its standout feature is the ability to collect all metrics supported by Spark, as defined in Spark’s official documentation here.
Example stage metrics collected by sparkMeasure (Source code)
The architecture of Iris is designed to efficiently route metrics to two key destinations:
Real-time datasets: InfluxDB
Offline datasets: GrabTech Datalake in AWS
Real-time dataset
Freshness/latency: 5 to 10 seconds
All metrics flowing in through Kafka topics are instantly wired into InfluxDB. A crucial part of this process is accomplished by Telegraf, a plugin-driven server agent used for collecting and sending metrics. Acting as a Kafka consumer, Telegraf listens to each Kafka topic according to its corresponding metrics profiling. It parses the incoming JSON messages and extracts crucial data points (such as role, hostname, jobname, etc.). Once the data is processed, Telegraf writes it into the InfluxDB.
InfluxDB organises the stored data in what we call ‘measurements’, which could analogously be considered as tables in traditional relational databases.
In Iris’s context, we have structured our real-time data into the following crucial measurements:
CpuAndMemory: This measures CPU and memory-related metrics, giving us insights into resource utilisation by Spark jobs.
I/O: This records input/output metrics, providing data on the reading and writing operations happening during the execution of jobs.
ThreadInfo: This measurement holds data related to job threading, allowing us to monitor concurrency and synchronisation aspects.
application_started and application_ended: These measurements allow us to track Spark application lifecycles, from initiation to completion.
executors_started and executors_removed: These measurements give us a look at the executor dynamics during Spark application execution.
jobs_started and jobs_ended: These provide vital data points relating to the lifecycle of individual Spark jobs within applications.
queries_started and queries_ended: These measurements are designed to track the lifecycle of individual Spark SQL queries.
stage_metrics, stages_started, and stages_ended: These measurements help monitor individual stages within Spark jobs, a valuable resource for tracking the job progress and identifying potential bottlenecks.
The real-time data collected in these measurements form the backbone of the monitoring capabilities of Iris, providing an accurate and current picture of Spark job performances.
Offline dataset
Freshness/latency: 1 hour
In addition to real-time data management with InfluxDB, Iris is also responsible for routing metrics to our offline data storage in the Grab Tech Datalake for long-term trend studies, pattern analysis, and anomaly detection.
The metrics from Kafka are periodically synchronised to the Amazon S3 tables under the iris schema in the Grab Tech AWS catalogue. This valuable historical data from Kafka is meticulously organised with a one-to-one mapping between the platform or Kafka topic to the table in the iris schema. For example: iris.chimera_jvmprofiler_cpuandmemory map with prd-iris-chimera-jvmprofiler-cpuandmemory Kafka topic.
This streamlined organisation means you can write queries to retrieve information from the AWS dataset very similarly to how you would do it from InfluxDB. Whether it’s CPU and memory usage, I/O, thread info, or spark metrics, you can conveniently fetch historical data for your analysis.
Data visualisation
A well-designed visual representation makes it easier to see patterns, trends, and outliers in groups of data. Iris employs different visualisation tools based on whether the data is real-time or historical.
Real-Time data visualisation – Grafana
Iris uses Grafana for showcasing real-time data. For each platform, two primary dashboards have been set up: JVM metrics and Spark metrics.
JVM metrics dashboard: This dashboard is designed to display information related to the JVM.
Spark metrics dashboard: This dashboard primarily focuses on visualising Spark-specific elements.
Offline data visualisation
While real-time visualisation is crucial for immediate awareness and decision-making, visualising historical data provides invaluable insights about long-term trends, patterns, and anomalies. Developers can query the raw or aggregated data from the Iris tables for their specific analyses.
Moreover, to assist platform owners and end-users in obtaining a quick summary of their job data, we provide built-in dashboards with pre-aggregated visuals. These dashboards contain a wealth of information expressed in an easy-to-understand format. Key metrics include:
Total instances
Total CPU cores
Total memory
CPU and memory utilisation
Total machine runtimes
Besides visualisations for individual jobs, we have designed an overview dashboard providing a comprehensive summary of all resources consumed by all ETL jobs. This is particularly useful for platform owners and tech leads, allowing them to have an all-encompassing visibility of the performance and resource usage across the ETL jobs.
Dashboard for monitoring ETL jobs
These dashboards’ visuals effectively turn the historical metrics data into clear, comprehensible, and insightful information, guiding users towards objective-driven decision-making.
Transforming observations into insights
While our journey with Iris is just in the early stages, we’ve already begun harnessing its ability to transform raw data into concrete insights. The strength of Iris lies not just in its data collection capabilities but also in its potential to analyse and infer patterns from the collated data.
Currently, we’re experimenting with a job classification model that aims to predict resource allocation efficiency (i.e. identifying jobs as over or under-provisioned). This information, once accurately predicted, can help optimise the usage of resources by fine-tuning the provisions for each job. While this model is still in its early stages of testing and lacks sufficient validation data, it exemplifies the direction we’re heading – integrating advanced analytics with operational observability.
As we continue to refine Iris and develop more models, our aim is to empower users with deep insights into their Spark applications. These insights can potentially identify bottlenecks, optimise resource allocation and ultimately, enhance overall performance. In the long run, we see Iris evolving from being a data collection tool to a platform that can provide actionable recommendations and enable data-driven decision-making.
Job classification feature set
At the core of our job classification model, there are two carefully selected metrics:
CPU cores per hour: This represents the number of tasks a job can handle concurrently in a given hour. A higher number would mean more tasks being processed simultaneously.
Total Terabytes of data input per core: This considers only the input from the underlying HDFS/S3 input, excluding shuffle data. It represents the volume of data one CPU core needs to process. A larger input would mean more CPUs are required to complete the job in a reasonable timeframe.
The choice of these two metrics for building feature sets is based on a nuanced understanding of Spark job dynamics:
Allocating the right CPU cores is crucial as a higher number of cores means more tasks being processed concurrently. This is especially important for jobs with larger input data and more partitioned files, as they often require more concurrent processing capacity, hence, more CPU cores.
The total data input helps to estimate the data processing load of a job. A job tasked with processing a high volume of input data but assigned low CPU cores might be under-provisioned and result in an extended runtime.
As for CPU and memory utilisation, while it could offer useful insights, we’ve found it may not always contribute to predicting if a job is over or under-provisioned because utilisation can vary run-to-run. Thus, to keep our feature set robust and consistent, we primarily focus on CPU cores per hour and total terabytes of input data.
With these metrics as our foundation, we are developing models that can classify jobs into over-provisioned or under-provisioned, helping us optimise resource allocation and improve job performance in the long run.
As always, treat any information related to our job classification feature set and the insights derived from it with utmost care for data confidentiality and integrity.
We’d like to reiterate that these models are still in the early stages of testing and we are constantly working to enhance their predictive accuracy. The true value of this model will be unlocked as it is refined and as we gather more validation data.
Model training and optimisation
Choosing the right model is crucial for deriving meaningful insights from datasets. We decided to start with a simple, yet powerful algorithm – K-means clustering, for job classification. K-means is a type of unsupervised machine learning algorithm used to classify items into groups (or clusters) based on their features.
Here is our process:
Model exploration: We began by exploring the K-means algorithm using a small dataset for validation.
Platform-specific cluster numbers: To account for the uniqueness of every platform, we ran a Score Test (an evaluation method to determine the optimal number of clusters) for each platform. The derived optimal number of clusters is then used in the monthly job for that respective platform’s data.
Set up a scheduled job: After ensuring the code was functioning correctly, we set up a job to run the model on a monthly schedule. Monthly re-training was chosen to encapsulate possible changes in the data patterns over time.
Model saving and utilisation: The trained model is saved to our S3 bucket and used to classify jobs as over-provisioned or under-provisioned based on the daily job runs.
This iterative learning approach, through which our model learns from an ever-increasing pool of historical data, helps maintain its relevance and improve its accuracy over time.
Here is an example output from Databricks train run:
Blue green group: Input per core is too large but the CPU per hour is small, so the job may take a lot of time to complete.
Purple group: Input per core is too small but the CPU per hour is too high. There may be a lot of wasted CPU here.
Yellow group: I think this is the ideal group where input per core and CPU per hour is not high.
Keep in mind that classification insights provided by our K-means model are still in the experimental stage. As we continue to refine the approach, the reliability of these insights is expected to grow, providing increasingly valuable direction for resource allocation optimisation.
Seeing Iris in action
This section provides practical examples and real-case scenarios that demonstrate Iris’s capacity for delivering insights from ETL job observations.
Case study 1: Spark benchmarking
From August to September 2023, we carried out a Spark benchmarking exercise to measure and compare the cost and performance of Grab’s Spark platforms: Open Source Spark on Kubernetes (Chimera), Databricks and AWS EMR. Since each platform has its own way to measure a job’s performance and cost, Iris was used to collect the necessary Spark metrics in order to calculate the cost for each job. Furthermore, many other metrics were collected by Iris in order to compare the platforms’ performances like CPU and memory utilisation, runtime, etc.
Case study 2: Improving Databricks Infra Cost Unit (DBIU) Accuracy with Iris
Being able to accurately calculate and fairly distribute Databricks infrastructure costs has always been a challenge, primarily due to difficulties in distinguishing between on-demand and Spot instance usage. This was further complicated by two conditions:
Fallback to on-demand instances: Databricks has a feature that automatically falls back to on-demand instances when Spot instances are not readily available. While beneficial for job execution, this feature has traditionally made it difficult to accurately track per-job Spot vs. on-demand usage.
User configurable hybrid policy: Users can specify a mix of on-demand and Spot instances for their jobs. This flexible, hybrid approach often results in complex, non-uniform usage patterns, further complicating cost categorisation.
Iris has made a key difference in resolving these dilemmas. By providing granular, instance-level metrics including whether each instance is on-demand or Spot, Iris has greatly improved our visibility into per-job instance usage.
This precise data enables us to isolate the on-demand instance usage, which was previously bundled in the total cost calculation. Similarly, it allows us to accurately gauge and consider the usage ratio of on-demand instances in hybrid policy scenarios.
The enhanced transparency provided by Iris metrics allows us to standardise DBIU cost calculations, making them fairer for users who majorly or only use Spot instances. In other words, users need to pay more if they intentionally choose or fall back to on-demand instances for their jobs.
The practical application of Iris in enhancing DBIU accuracy illustrates its potential in driving data-informed decisions and fostering fairness in resource usage and cost distribution.
Case study 3: Optimising job configuration for better performance and cost efficiency
One of the key utilities of iris is its potential to assist with job optimisation. For instance, we have been able to pinpoint jobs that were consistently over-provisioned and work with end-users to tune their job configurations.
Through this exercise and continuous monitoring, we’ve seen substantial results from the job optimisations:
Cost reductions ranging from 20% to 50% for most jobs.
Positive feedback from users about improvements in job performance and cost efficiency.
By the way, interestingly, our analysis led us to identify certain the following patterns. These patterns could be leveraged to widen the impact of our optimisation efforts across multiple use-cases in our platforms:
Pattern
Recommendation
Job duration < 20 minutes
Input per core < 1GB
Total used instance is 2x/3x of max worker nodes
Use fixed number of workers nodes potentially speeding up performance and certainly reducing costs.
CPU utilisation < 25%
Cut max worker in half. E.g: 10 to 5 workers
Downgrade instance size a half. E.g: 4xlarge -> 2xlarge
Job has much shuffle
Bump the instance size and reduce the number of workers. E.g. bump 2xlarge -> 4xlarge and reduce number of workers from 100 -> 50
However, we acknowledge that these findings may not apply uniformly to every instance. The optimisation recommendations derived from these patterns might not yield the desired outcomes in all cases.
The future of Iris
Building upon its firm foundation as a robust Spark observability tool, we envision a future for Iris wherein it not only monitors metrics but provides actionable insights, discerns usage patterns, and drives predictions.
Our plans to make Iris more accessible include developing APIs endpoint for platform teams to query performance by job names. Another addition we’re aiming for is the ability for Iris to provide resource tuning recommendations. By making platform-specific and job-specific recommendations easily accessible, we hope to assist platform teams in making informed, data-driven decisions on resource allocation and cost efficiency.
We’re also looking to expand Iris’s capabilities with the development of a listener for Presto jobs, similar to the sparkMeasure tool currently used for Spark jobs. The listener would provide valuable metrics and insights into the performance of Presto jobs, opening up new avenues for optimisation and cost management.
Another major focus will be building a feedback loop for Iris to further enhance accuracy, continually refine its models, and improve insights provided. This effort would greatly benefit from the close collaboration and inputs from platform teams and other tech leads, as their expertise aids in interpreting Iris’s metrics and predictions and validating its meaningfulness.
In conclusion, as Iris continues to develop and mature, we foresee it evolving into a crucial tool for data-driven decision-making and proactive management of Spark applications, playing a significant role in the efficient usage of cloud computing resources.
Conclusion
The role of Iris as an observability tool for Spark jobs in the world of Big Data is rapidly evolving. Iris has proven to be more than a simple data collection tool; it is a platform that integrates advanced analytics with operational observability.
Even though Iris is in its early stages, it’s already been instrumental in creating detailed visualisations of both real-time and historical data from varied platforms. Besides that, Iris has started making strides in its journey towards using machine learning models like K-means clustering to classify jobs, demonstrating its potential in helping operators fine-tune resource allocation.
Using instance-level metrics, Iris is helping improve cost distribution fairness and accuracy, making it a potent tool for resource optimisation. Furthermore, the successful case study of reducing job costs and enhancing performance through resource reallocation provides a promising outlook into Iris’s future applicability.
With ongoing development plans, such as the Presto listener and the creation of endpoints for broader accessibility, Iris is poised to become an integral tool for data-informed decision-making. As we strive to enhance Iris, we will continue to collaborate with platform teams and tech leads whose feedback is invaluable in fulfilling Iris’s potential.
Our journey with Iris is a testament to Grab’s commitment to creating a data-informed and efficient cloud computing environment. Iris, with its observed and planned capabilities, is on its way to revolutionising the way resource allocation is managed and optimised.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Grab is Southeast Asia’s leading superapp, providing a suite of services that brings essential needs to users throughout the region. Its offerings include ride-hailing, food delivery, parcel delivery, mobile payments, and more. With safety, efficiency, and user-centered design at heart, Grab remains dedicated to solving everyday issues and improving the lives of millions.
As the app continues to expand with more features, Grab identified the need for a consistent, high-quality experience for new users who may have limited storage space or restricted internet bandwidth. Read to find out more about Project Bonsai and how it reduced app download size and app disk size.
Introduction
In 2020, Google conducted research that highlighted the negative impact of app sizes on conversion rates, revealing a 1% decrease for every 6MB expansion of the app APK size. This finding prompted Grab to ensure new and existing users had a consistently excellent Grab superapp experience, given the prevalence of low-end devices and disparate internet infrastructure in Southeast Asian regions. As a result, Grab initiated Project Bonsai in Q3 2021, with the goal of reducing and optimising the app size while enhancing user experience, reducing installation barriers, and boosting user acquisition.
Understanding the problem
The Grab superapp, with over 4 million lines of code and integration with hundreds of third-party libraries, had a significant app size. Given the prevalence of low-end devices and disparate internet infrastructure in our target region, it is crucial for us to proactively and constantly ensure we are delivering excellence in app-based user experience.
Objectives of the Bonsai project
The Bonsai project focused on these two key metrics:
App Download Size: This represents the total size of the compressed APK file that users need to download from Google Play when performing a fresh installation.
App Disk Size: This encompasses the total storage space occupied by the app on user devices, including both the binary and data generated by the app.
In this article, we will share the strategy and solutions that resulted in a successful 26% reduction in App Download Size, while also reducing the App Disk Size.
Status quo
Prior to the Bonsai project, the Grab app project had implemented various measures to achieve optimal app size. Here are some notable highlights:
Leveraging App Bundle: Since 2019, Grab has been using the app bundle approach to optimise app delivery. This approach generates smaller APKs tailored to specific device configurations, ensuring users receive optimised APKs. This helps reduce the overall app size and improve installation efficiency.
Monitoring: With a team of over 100 Android engineers and multiple collaborative teams, the Grab app undergoes a weekly release process involving hundreds of commits for each release. Closely monitoring app size changes with every commit is essential for our team. The team established debug build (APK file size) monitoring for every commit merged to the master branch. Regular weekly reviews are conducted to stay updated on the app size and identify commits that might lead to changes in app size. However, occasional mismatches may occur due to discrepancies between the debug and release builds.
Monitoring the changes in APK size
R8 Integration: R8/Proguard, known as the code shrinker, obfuscator, and optimiser, has been enabled since the beginning. This powerful tool helps reduce the app’s bytecode and resources, leading to further size optimisation and improved app performance.
Resource Optimisation: The team diligently pursued resource optimisation strategies, including:
Images: Engineers were encouraged to use vector images whenever possible, as they usually have smaller file sizes than raster images. In exceptional cases where raster images were necessary, Grab adopted the webp format instead of png, utilising better image compression to minimise app size.
Language ResourceConfig: Grab enabled resourceConfig to support only the languages actively used by the Grab app, reducing unnecessary resource overhead and enhancing app efficiency.
Third-Party Libraries Review: The team established a review process for third-party libraries, assessing their size impact on the app. This practice ensured that only essential libraries were included, preventing unnecessary bloating of the app size.
Despite the application of these measures and solutions aimed at managing the app size, there was still the potential of significant expansion in magnitude.
Strategy
The Bonsai project revolves around strategic pillars, namely Measurement, Reduction, and Containment.
Project Bonsai’s three strategic pillars for continuous app size reduction
In the Measurement phase, the focus is on providing accurate information on the app’s binary composition and how individual features, modules, libraries impact the overall app size. This allows teams to make informed decisions and gain insights into their components’ influence on the app’s size.
The insights from the Measure phase provided us with a list of actionable items for our backlog. In the Reduction phase, we employ strategic action to tackle this backlog to constantly achieve optimal app size.
Optimising the app size is not a one-time endeavour, especially as more features are added over time, potentially increasing the project’s size. While there may be limited solutions to manage app size, it’s important to find a balance between size and functionality. Else, the effort and trade-offs required may become overwhelming. Therefore, in the Containment phase, we intend to introduce effective long-term strategies and solutions designed to manage the app’s size.
In the remainder of this blog post, we explore the strategic pillars and actions taken to contain the download size.
Measure
The Grab Passenger App Core team actively engages in optimisation projects and recognised the importance of measurement as the foundation for improvement. For example, enhancing the app startup time, pipeline time, build time, and more.
In every optimisation endeavour, we adhere to a crucial principle: “MEASURE” – the first and most critical step for any improvement project. As the famous quote goes, “If you can’t measure it, you can’t improve it.” This emphasises the significance of accurate and comprehensive measurement as the foundation for driving successful optimisation efforts.
In the third quarter of 2021, our team initiated an investigation into existing tools provided by both Google and the broader community. The intention was to employ tools such as APK Analyzer or Android Studio to conduct a thorough analysis of the app binary. However, it soon became evident that these tools were not well-suited to accommodate the extensive scope of our project.
In order to accommodate our discovery, we developed a custom analytics tool called App Sizer. This tool is specifically designed to analyse app binaries from bundle files. Our primary goal was to construct a solution that adheres effectively to our unique needs.
The tool was seamlessly integrated into Grab’s CI system and sends data to a Grafana instance. As a result, the tool collates and transmits daily analytics data from the release candidate branch. It offers the following key functionalities and monitors important aspects such as:
Device-specific App Download Size: Precise information about the app download size for specific devices, focusing on optimising the App Download Size.
Trends for app download size by device type
Comprehensive Size Breakdown: A breakdown of the app’s size, including the proportion attributed to the codebase Kotlin/Java, Kotlin/Java-based libraries, native libraries, resources, and other relevant factors.
Comprehensive breakdown of app download size by component
Size Contribution by Teams: Insights into the size contributed by each individual team within the project’s scope.
Breakdown of Grab’s codebase by TF
Module-wise Size Contribution: Insights into the size impacted by each module, categorised by team.
Breakdown of the codebase by TF modules
Size Contribution by Third-Party Libraries: Information about the size attributed to each third-party library incorporated within the app.
App download size contribution by external libraries and SDK breakdown
List of Large Files: A categorised list of large files (file size exceeding X value), organised by each respective team.
Large file categories broken down by TF
It’s important to note that all the size values presented within these dashboards specifically pertain to the download size, representing the contribution of each item to the overall app download size.
As part of our commitment to the developer community, we plan to open-source this tool in the near future, allowing others to benefit from its capabilities as well.
Reduce
To optimise the app based on the analysis data obtained from the measuring step, we focused on applying common solutions from Google and the suggestions from the community. There were no fancy solutions that we invented. Our concentration centered on optimising the dex file size, refining resources, and eliminating duplication and redundancy.
dex file optimisation (Java/Kotlin)
In our initial findings, it became evident that Java/Kotlin code was the major contributor of app size. Recognising this, we made it our top priority for optimisation.
R classes
During our investigation, we discovered that a proportion of the overall app size was attributable to R classes. Further research unveiled two primary reasons behind this phenomenon:
Transitive R classes: R classes contained ID references not only to their own resources but also to resources from their transitive dependencies. This meant that if Module A depended on Module B, and Module B in turn, depended on Module C (Module A -> Module B -> Module C), then Module A’s R class included IDs references to resources from Modules B and C, even if Module A didn’t directly utilise these resources. This explained why R classes in a modularised project could accumulate millions of lines of code.
A spread of Modules and Third-Party Libraries: Our Grab project comprised over 1,500 modules and integrates hundreds of third-party libraries, leading to the generation of significantly large R classes within the project. Furthermore, this discovery also explained instances where our app size monitor exhibited spikes during certain commits despite no significant additions of resources, libraries, or code within those commits. These fluctuations were linked to changes in the dependency graph, further emphasising the impact of Transitive R classes.
It is worth noting that the team had long been cognisant of the challenges posed by Transitive R classes, especially in terms of optimising build times. Consequently, we had already undertaken various initiatives to address this specific challenge related to build times.
However, it wasn’t long before we started wondering why R8 wasn’t removing unused fields from the R classes, which would have resulted in a size reduction for these classes. It turned out that back in mid-2021, we were using Android Gradle Plugin 4.0 along with the default R8 rules. One of these rules was preserving all fields in the R classes:
-keepclassmembers class **.R$* {
public static <fields>;
}
This rule was the root cause of why unused fields in the R classes were persisting. Google removed this rule in AGP 4.1, and the solution was straightforward: updating AGP to version 4.1.1 (or newer) helped us resolve the issue.
However, due to the project’s unusual size, there was a risk of inadvertently removing non-used R class fields if there were any instances of code accessing R classes through reflection within the codebase or third-party libraries. Since our automation testing did not yet support R8, conducting a full test of the entire project was possible, but would have demanded significant effort from the team. To avoid this substantial effort, we developed a script to search the entire codebase and identify instances where reflections were used, allowing us to assess their usage. For third-party libraries, we decompiled the libraries and applied the same script to the decompiled code.
Fix & Optimise R8 Rules
Subsequently, we conducted a revision of the R8 configuration rules. This involved assessing the compiled R8 configuration file and paying specific attention to any ‘keep’ rules that contained package wildcards. It is crucial to decipher the purpose behind each rule and its reason for existence. Any rules identified as redundant were recommended for removal. Post the thorough scrutiny of the R8 rules, we initiated request tickets urging the respective teams to work on the elimination and optimisation of these rules.
Enable more aggressive optimisations
In 2019, Google began recommending the utilisation of the proguard-android-optimise.txt configuration with code optimisation enabled. However, our project’s origins predate the introduction of Google’s R8, a time when Proguard was the primary tool for code obfuscation and size reduction. Prior to the release of Android Gradle Plugin 3.4.0, there were no explicit recommendations for enabling code optimisations during the minification process. As a result, our project has persisted in using the proguard-android.txt configuration without activating the code optimisation feature.
Our team has considered adopting a more aggressive approach towards optimisation. This approach spans from exploring the optimisation mode to incorporating the R8 full mode. This includes substantial effort required for testing and addressing issues arising from the introduction of these new modes. We encountered a particular challenge wherein the R8 optimisation exhibits instability, an issue that has been reported to Google. A definitive solution remains a work-in-progress.
At present, we have decided to postpone the implementation of a more aggressive R8 mode. However, this remains a high-priority item on our agenda, and we intend to address it in the near future.
Resources optimisation
In addition to optimising the dex file, we also address resource optimisation.
Handling large resources
During the Measure phase, we use the List Of Large Files dashboard to identify large files categorised by teams. For each team, we create request tickets with straightforward guidance. These guidelines encourage the following actions:
Explore the possibility of removing unnecessary resources.
Consider offloading the resource to the Internet (server) when feasible. Within Grab, we have the Asset Delivery Kit, which facilitates hosting and downloading resources on the client side.
Optimise files by converting them to alternative formats or reducing their size. For instance, for images, we recommend utilising vector images and the Webp format, among other optimisations.
Convert PNG to Webp
The Grab app project has a long history, and while the team has recently established guidelines and implemented CI processes to promote the use of vector and Webp images, there are still existing images that have not been optimised. The team has undertaken an initiative to address these images and has converted all PNG images to Webp format wherever a reduction in file size is achievable.
Fonts
Fonts are another group of files that have a notable impact on the project’s size. We collaborate with the teams to:
Remove fonts that are rarely used in the project.
Eliminate duplicate fonts.
While the project still contains numerous fonts, we have a project to unify all features and transition to using a single font. Our recommendation is to explore the use of one primary font style, with the flexibility to incorporate different typeface variations in your programming to achieve various typefaces using the same font.
Remove stale features and replace large library
Based on the data, it was discovered that a specific library, which was contributing approximately 8% to the overall app size, had an adverse impact. This library has since been removed from the project. Moreover, through analysing the Size Contribution by Third-Party Libraries dashboard, we identified duplicates in functions and have made efforts to eliminate these redundancies.
Moreover, in Grab, we are using the feature toggle to enable or disable a feature. The feature flags are controlled remotely. It’s very useful for running an experiment or turning off if a feature causes us any problems. So, many features in the project are controlled under a feature flag. In certain cases, even when some features are deactivated, the corresponding code remains included in the binary. We identify these cases and collaborate with teams to remove the redundant code.
After six months of working on the above initiatives, the Bonsai team managed to reduce the Grab app download size by 26%. This is particularly noteworthy, considering that prior to the commencement of the Bonsai Project, the average app size exhibited a monthly increase of approximately 1%.
Containment
After dedicating over a semester to the Reduce phase, we started the transition to the Containment phase. The first step for this phase involved setting up an App Growth Rate dashboard that presents the growth rate of app download size per release. Our goal is to keep this rate as low as possible.
The team has been discovering a few solutions, such as introducing the common UI design components to prevent duplication, and experimenting with Dynamic Delivery Feature. This phase of exploration is still ongoing and we are optimistic that it will help maintain a manageable app download size, or perhaps even contribute to further optimization.
Considering alternative initiatives, the team is contemplating recognising app size as a confined resource of our application. We believe it should be the responsibility of every team to maintain an optimal app size. Based on the measurements we have, which provide an insight into each team’s impact on the total app download size, it could be advantageous to allocate an ‘app size budget’ to each team. This would entail each team taking responsibility for managing and maintaining the size influenced by their work.
Conclusion
Grab’s Project Bonsai demonstrated the company’s commitment to optimising the app experience for users in Southeast Asia. By prioritising code optimisation, resource management, modularisation, and asset bundling, we achieved substantial optimisations in app size while enhancing user experience. These efforts not only addressed the challenges we outlined, but also contributed to increased user acquisition and improved user retention rates.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
In the domain of data processing, data analysts run their ad hoc queries on the data lake. The lake serves as an interface between our analytics and production environment, preventing downstream queries from impacting upstream data ingestion pipelines. To ensure efficient data processing in the data lake, choosing appropriate storage formats is crucial.
The vanilla data lake solution is built on top of cloud object storage with Hive metastore, where data files are written in Parquet format. Although this setup is optimised for scalable analytics query patterns, it struggles to handle frequent updates to the data due to two reasons:
The Hive table format requires us to rewrite the Parquet files with the latest data. For instance, to update one record in a Hive unpartitioned table, we would need to read all the data, update the record, and write back the entire data set.
Writing Parquet files is expensive due to the overhead of organising the data to a compressed columnar format, which is more complex than a row format.
The issue is further exacerbated by the scheduled downstream transformations. These necessary steps, which clean and process the data for use, increase the latency because the total delay now includes the combined scheduled intervals of these processing jobs.
Fortunately, the introduction of the Hudi format, which supports fast writes by allowing Avro and Parquet files to co-exist on a Merge On Read (MOR) table, opens up the possibility of having a data lake with minimal data latency. The concept of a commit timeline further allows data to be served with Atomicity, Consistency, Isolation, and Durability (ACID) guarantees.
We employ different sets of configurations for the different characteristics of our input sources:
High or low throughput. A high-throughput source refers to one that has a high level of activity. One example of this can be our stream of booking events generated from each customer transaction. On the other hand, a low-throughput source would be one that has a relative low level of activity. An example of this can be transaction events generated from reconciliation happening on a nightly basis.
Kafka (unbounded) or Relational Database Sources (bounded). Our sinks have sources that can be broadly categorised into unbounded and bounded sources. Unbounded sources are usually related to transaction events materialised as Kafka topics, representing user-generated events as they interact with the Grab superapp. Bounded sources usually refer to Relational Database (RDS) sources, whose size is bound to storage provisioned.
The following sections will delve into the differences between each source and our corresponding configurations optimised for them.
High throughput source
For our data sources with high throughput, we have chosen to write the files in MOR format since the writing of files in Avro format allows for fast writes to meet our latency requirements.
Figure 1 Architecture for MOR tables
As seen in Figure 1, we use Flink to perform the stream processing and write out log files in Avro format in our setup. We then set up a separate Spark writer which periodically converts the Avro files into Parquet format in the Hudi compaction process.
We have further simplified the coordination between the Flink and Spark writers by enabling asynchronous services on the Flink writer so it can generate the compaction plans for Spark writers to act on. During the Spark job runs, it checks for available compaction plans and acts on them, placing the burden of orchestrating the writes solely on the Flink writer. This approach could help minimise potential concurrency problems that might otherwise arise, as there would be a single actor
orchestrating the associated Hudi table services.
Low throughput source
Figure 2 Architecture for COW tables
For low throughput sources, we gravitate towards the choice of Copy On Write (COW) tables given the simplicity of its design, since it only involves one component, which is the Flink writer. The downside is that it has higher data latency because this setup only generates Parquet format data snapshots at each checkpoint interval, which is typically about 10-15 minutes.
Connecting to our Kafka (unbounded) data source
Grab uses Protobuf as our central data format in Kafka, ensuring schema evolution compatibility. However, the derivation of the schema of these topics still requires some transformation to make it compatible with Hudi’s accepted schema. Some of these transformations include ensuring that Avro record fields do not contain just a single array field, and handling logical decimal schemas to transform them to fixed byte schema for Spark compatibility.
Given the unbounded nature of the source, we decided to partition it by Kafka event time up to the hour level. This ensured that our Hudi operations would be faster. Parquet file writes would be faster since they would only affect files within the same partition, and each Parquet file within the same event time partition would have a bounded size given the monotonically increasing nature of Kafka event time.
By partitioning tables by Kafka event time, we can further optimise compaction planning operations, since the amount of file lookups required is now reduced with the use of BoundedPartitionAwareCompactionStrategy. Only log files in recent partitions would be selected for compaction and the job manager need not list every partition to figure out which log files to select for compaction during the planning phase anymore.
Connecting to our RDS (bounded) data source
For our RDS, we decided to use the Flink Change Data Capture (CDC) connectors by Veverica to obtain the binlog streams. The RDS would then treat the Flink writer as a replication server and start streaming its binlog data to it for each MySQL change. The Flink CDC connector presents the data as a Kafka Connect (KC) Source record, since it uses the Debezium connector under the hood. It is then a straightforward task to deserialise these records and transform them into Hudi records, since
the Avro schema and associated data changes are already captured within the KC source record.
The obtained binlog timestamp is also emitted as a metric during consumption for us to monitor the observed data latency at the point of ingestion.
Optimising for these sources involves two phases:
First, assigning more resources for the cold start incremental snapshot process where Flink takes a snapshot of the current data state in the RDS and loads the Hudi table with that snapshot. This phase is usually resource-heavy as there are a lot of file writes and data ingested during this process.
Once the snapshotting is completed, Flink would then start to process the binlog stream and the observed throughput would drop to a level similar to the DB write throughput. The resources required by the Flink writer at this stage would be much lower than in the snapshot phase.
Indexing for Hudi tables
Indexing is important for upserting Hudi tables when the writing engine performs updates, allowing it to efficiently locate the file groups of the data to be updated.
As of version 0.14, the Flink engine only supports Bucket Index or Flink State Index. Bucket Index performs indexing of the file record by hashing the record key and matching it to a specific bucket of files indicated by the naming convention of the written data files. Flink State Index on the other hand stores the index map of record keys to files in memory.
Given that our tables include unbounded Kafka sources, there is a possibility for our state indexes to grow indefinitely. Furthermore, the requirement of state preservation for Flink State Index across version deployments and configuration updates adds complexity to the overall solution.
Thus, we opted for the simple Bucket Index for its simplicity and the fact that our Hudi table size per partition does not change drastically across the week. However, this comes with a limitation whereby the number of buckets cannot be updated easily and imposes a parallelism limit at which our Flink pipelines can scale. Thus, as traffic grows organically, we would find ourselves in a situation whereby our configuration grows obsolete and cannot handle the increased load.
To resolve this going forward, using consistent hashing for the Bucket Index would be something to explore to optimise our Parquet file sizes and allow the number of buckets to grow seamlessly as traffic grows.
Impact
Fresh business metrics
Post creation of our Hudi Data Ingestion solution, we have enabled various users such as our data analysts to perform ad hoc queries much more easily on data that has lower latency. Furthermore, Hudi tables can be seamlessly joined with Hive tables in Trino for additional context. This enabled the construction of operational dashboards reflecting fresh business metrics to our various operators, empowering them with the necessary information to quickly respond to any abnormalities (such as high-demand events like F1 or seasonal holidays).
Quicker fraud detection
Another significant user of our solution is our fraud detection analysts. This enabled them to rapidly access fresh transaction events and analyse them for fraudulent patterns, particularly during the emergence of a new attack pattern that hadn’t been detected by their rules engine. Our solution also allowed them to perform multiple ad hoc queries that involve lookbacks of various days’ worth of data without impacting our production RDS and Kafka clusters by using the data lake as the data interface, reducing the data latency to the minute level and, in turn, empowering them to respond more quickly to attacks.
What’s next?
As the landscape of data storage solutions evolves rapidly, we are eager to test and integrate new features like Record Level Indexing and the creation of Pre Join tables. This evolution extends beyond the Hudi community to other table formats such as IceBerg and DeltaLake. We remain ready to adapt ourselves to these changes and incorporate the advantages of each format into our data lake within Grab.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
The Grab superapp offers a comprehensive array of services from ride-hailing and food delivery to financial services. This creates multifaceted user journeys, traversing homepages, product pages, checkouts, and interactions with diverse content, including advertisements and promo codes.
Background: Why ads and attribution matter in our superapp
Ads are crucial for Grab in driving user engagement and supporting our ecosystem by seamlessly connecting users with our services. In the ever-evolving world of advertising, the ability to gauge the impact of marketing investments takes on pivotal significance. Advertisers dedicate substantial resources to promote their businesses, necessitating a clear understanding of the return on AdSpend (ROAS) for each campaign. In this context, attribution plays a central role, serving as the guiding compass for advertisers and marketers, elucidating the effectiveness of touchpoints within campaigns.
For instance, a merchant-partner seeks to enhance its reach by advertising on the Grab food delivery homepage. With the assistance of our attribution system, the merchant-partner can now precisely gauge the impact of their homepage ads on Grab. This involves tracking user engagement and monitoring the resulting orders that stem from these interactions. This level of granularity not only highlights the value of attribution but also demonstrates its capability in providing detailed insights into the effectiveness of advertising campaigns and enabling merchant-partners to optimise their campaigns with more precision.
In this blog, we delve into the technical intricacies, software architecture, challenges, and solutions involved in crafting a state-of-the-art engineering solution for the attribution platform.
Genesis: Pre-project landscape
When our journey began in 2020, Grab’s marketing efforts had limited attribution capabilities and data analytics was predominantly reliant on ad hoc queries conducted by business and data analysts. Before the introduction of a standardised approach, we had to manage discrepant results and a time-consuming manual process of data preparation, cleansing, and storage across teams. When issues arose in the analytical pipeline, resolution efforts took relatively longer and were reoccurring. We needed a comprehensive engineering solution that would address the identified gaps, and significantly enhance metrics related to ROI, attribution accuracy, and data-handling efficiency.
Inception: The pure ads attribution engine (Kappa architecture)
We chose Kappa architecture due to its imperative role in achieving near real-time attribution, especially in support of our new pricing model, cost per order (CPO). With this solution, we aimed to drastically reduce data latency from 2-3 days to just a few minutes. Traditional ETL (Extract, Transform, and Load) based batch processing methods were evaluated but quickly found to be inadequate for our purposes, mainly due to their speed.
In the advertising industry, rapid decision-making is critical. Traditional batch processing solutions would introduce significant latency, hampering our ability to make real-time, data-driven decisions. With its architecture’s inherent capability for real-time stream processing, Kappa emerged as the logical choice. Additionally, Kappa offers the agility required to empower our ad-serving team for real-time decision support, and better ad ranking and selection, enabling dynamic and effective targeting decisions without delay.
The first step on this journey was to create a pure and near real-time stream processing Ads Attribution Engine. This engine was based on the Kappa architecture to provide advertisers with quick insights into their ROAS offering real-time attribution, enabling advertisers to optimise their campaigns efficiently.
High-level workflow of the Ads Attribution Engine
In this solution, we used the following tools in our tech stack:
Kafka for event streams
DDB for events storage
Amazon S3 as the data lake
An in-house stream processing framework similar to Keystone
Redis for caching events
ScyllaDB for storing ad metadata
Amazon relational database service (RDS) for analytics
Architecture of the near real-time stream processing Ads Attribution Engine
Evolution: Merging marketing levers – Ads and promos
We began to envision a world where we could merge various marketing levers into a unified Attribution Engine, starting with ads and promos. This evolved vision also aimed to prevent order double counting (when a user interacts with both ads and promos in the same checkout), which would provide a more holistic attribution solution.
With the unified Attribution Engine, we would also enable more sophisticated personalisation through machine learning models and drive higher conversions.
The unified Attribution Engine workflow, which included Promo touch points
The unified attribution engine used mostly the same tech stack, except for analytics where Druid was used instead of RDS.
Architecture of the unified Attribution Engine
Introspection: Identifying shortcomings and the path to improvement
While the unified attribution engine was a step in the right direction, it wasn’t without its challenges. There were challenges related to real-time data processing costs, scalability for longer attribution windows, latency and lag issues, out-of-order events leading to misattribution, and the complexity of implementing multi-touch attribution models. To truly empower advertisers and enhance the attribution process, we knew we needed to evolve further.
Rebirth: The birth of a full-fledged attribution platform (Lambda architecture)
This journey eventually led us to build a full-fledged attribution platform using Lambda architecture, which blended both batch and real-time stream processing methods. With this change, our platform could rapidly and accurately process data and attribute the impact of ads and promos on user behaviour.
Why Lambda architecture?
This choice was a strategic one – real-time processing is vital for tracking events as they occur, but it offers only a current snapshot of user behaviour. This means we would not be able to analyse historical data, which is a crucial aspect of accurate attribution and exploring multiple attribution models. Historical data allows us to identify trends, patterns, and correlations not evident in real-time data alone.
High level workflow for the full-fledged attribution platform with Lambda architecture
In this system’s tech stack, the key components are:
Coban, an in-house stream processing framework used for real-time data processing
Spark-based ETL jobs for batch processing
Amazon S3 as the data warehouse
An offline layer that is capable of providing historical context, handling large data volumes, performing complex analytics, and so on.
Key benefits of the offline layer
Provides historical context: The offline layer enriches the attribution process by providing a historical perspective on user interactions, essential for precise attribution analysis spanning extended time periods.
Handles enormous data volumes: This layer efficiently manages and processes extensive data generated by advertising campaigns, ensuring that attribution seamlessly accommodates large-scale data sets.
Performs complex analytics: Enables more intricate computations and data analysis than real-time processing alone, the offline layer is instrumental in fine-tuning attribution models and enhancing their accuracy.
Ensures reliability in the face of challenges: By providing fault tolerance and resilience against system failures, the offline layer ensures the continuous and dependable operation of the attribution system, even during unexpected events.
Optimises data storage and serving: Relying on Amazon S3, the storage layer for raw data optimises storage by building interactive reporting APIs.
Architecture of our comprehensive offline attribution platform
Challenges with Lambda and mitigation
Lambda architecture allows us to have the accuracy and robustness of batch processing along with real-time stream processing. However, we noticed some drawbacks that may lead to complexity due to maintaining both batch and stream processing:
Operating two parallel systems for batch and stream processing can lead to increased complexity in production environments.
Lambda architecture requires two sets of business logic – one for the batch layer and another for the stream layer.
Synchronisation across both layers can make system alterations more challenging.
This dual implementation could also allude to inconsistencies and introduce potential bugs into the system.
To mitigate these complications, we’re establishing an optimisation strategy for our current system. By distinctly separating the responsibilities of our real-time pipelines from those of our offline jobs, we intend to harness the full potential of each approach, while simultaneously curbing the added complexity.
Hence, redefining the way we utilise Lambda architecture, striking an efficient balance between real-time responsiveness and sturdy accuracy with the below proposal.
Vanguard: Enhancements in the future
In the coming months, we will be implementing the optimisation strategy and improving our attribution platform solution. This strategy can be broken down into the following sections.
Real-time pipeline handling time-sensitive data: Real-time pipelines can process and deliver time-sensitive metrics like CPO-related data in near real-time, allowing for budget capping and immediate adjustments to marketing spend. This can provide us with actionable insights that can help with areas like real-time bidding, real-time marketing, or dynamic pricing. By limiting the volume of data through the real-time path, we can ensure it’s more manageable and focused on immediate actionable data.
Batch jobs handling all other reporting data: Batch processing is best suited for computations that are not time-bound and where completeness is more important. By dedicating more time to the processing phase, batch processing can handle larger volumes and more complex computations, providing more comprehensive and accurate reporting.
This approach will simplify our Lambda architecture, as the batch and real-time pipelines will have clear separation of duties. It may also reduce the chance of discrepancies between the real-time and batch-processing datasets and lower the operational load of our real-time system.
Conclusion: A holistic attribution picture
Through our journey of building a comprehensive attribution platform, we can now deliver a holistic and dependable view of user behaviour and empower merchant-partners to use insights from advertisements and promotions. This journey has been a long one, but we were able to improve our attribution solution in several ways:
Attribution latency: Successfully reduced attribution latency from 2-3 days to just a few minutes, ensuring that advertisers can access real-time insights and feedback.
Data accuracy: Through improved data collection and processing, we achieved data discrepancies of less than 1%, enhancing the accuracy and reliability of attribution data.
Conversion rate: Advertisers witnessed a significant increase in conversion rates, a direct result of our real-time attribution capabilities.
Cost efficiency: Embracing the Lambda architecture led to a ~25% reduction in real-time data processing costs, allowing for more efficient campaign optimisations.
Operational resilience: Building an offline layer provided fault tolerance and resilience against system failures, ensuring that our attribution system continued to operate seamlessly, even during unexpected events.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
In the fast-paced world of on-demand delivery, maintaining safe marketplaces is a complex undertaking. Grab, a leading superapp in Southeast Asia, operates GrabFood and GrabMart, two popular marketplaces that connect consumers with a wide range of food and daily necessities. With more than 100k listings for different items updated daily by our merchants across eight different countries, Grab is rising to the challenge of ensuring that its marketplaces remain compliant with its own policies, government regulations as well as platform policies.
This article provides an overview of how Grab employs a combination of automated and manual content moderation to manage its dynamic marketplace content efficiently, while also collaborating with Google to ensure marketplace safety. Stay tuned for future articles that will delve deeper into the technology and solutions used for content moderation.
Dynamic Marketplace Landscape
Marketplaces like GrabFood and GrabMart are at the forefront of connecting merchants and consumers. These marketplaces provide an avenue for merchants to showcase their offerings, enabling consumers to conveniently access a plethora of on-demand options. However, in an environment characterized by rapid changes as well as evolving regulatory frameworks, maintaining the integrity of these marketplaces becomes a formidable task.
Scale and Flexibility: A Dual Challenge
The cornerstone of Grab’s success lies in its ability to adapt to the unique regulations and requirements of each country it operates in. This necessitates a nuanced and multifaceted approach to content moderation. To achieve both scale and flexibility, Grab employs a proactive strategy that combines and leverages automated and manual moderation processes.
Automated Moderation
Automated moderation plays a pivotal role in efficiently managing the high volume of listings that undergo daily updates. Grab utilises advanced algorithms and machine learning technologies, built in-house, to scan listings everyday for potential violations of its own policies, government regulations and platform policies. This automation not only speeds up the process to put eligible listings on the Grab platform, but also ensures consistent adherence to predefined guidelines. However, automated moderation is not without its limitations, as contextual understanding and subjective judgment often require human intervention.
Manual Moderation
Recognising the nuanced nature of content moderation, Grab employs a team of human moderators who possess the cultural awareness and contextual understanding necessary to assess complex cases. These moderators review listings flagged by algorithms and machine learning technologies that require human judgment, ensuring that content aligns with Grab’s policies, local regulations as well as platform policies. Manual moderation adds a layer of human insight that automated systems may lack, contributing to a more accurate and contextually sensitive approach.
In its commitment to ensuring marketplace safety, Grab has also established a strong collaboration with Google. Grab works hand in hand with Google to collectively ensure adherence to Play Store policies and guidelines.
Grab
Programme Management: Poonam Gambhire, Shuyang Sun
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.