Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=QJt-PEp6OCY
Zoom Exploit on MacOS
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/08/zoom-exploit-on-macos.html
This vulnerability was reported to Zoom last December:
The exploit works by targeting the installer for the Zoom application, which needs to run with special user permissions in order to install or remove the main Zoom application from a computer. Though the installer requires a user to enter their password on first adding the application to the system, Wardle found that an auto-update function then continually ran in the background with superuser privileges.
When Zoom issued an update, the updater function would install the new package after checking that it had been cryptographically signed by Zoom. But a bug in how the checking method was implemented meant that giving the updater any file with the same name as Zoom’s signing certificate would be enough to pass the test—so an attacker could substitute any kind of malware program and have it be run by the updater with elevated privilege.
It seems that it’s not entirely fixed:
Following responsible disclosure protocols, Wardle informed Zoom about the vulnerability in December of last year. To his frustration, he says an initial fix from Zoom contained another bug that meant the vulnerability was still exploitable in a slightly more roundabout way, so he disclosed this second bug to Zoom and waited eight months before publishing the research.
EDITED TO ADD: Disclosure works. The vulnerability seems to be patched now.
Target your customers with ML based on their interest in a product or product attribute.
Post Syndicated from Pavlos Ioannou Katidis original https://aws.amazon.com/blogs/messaging-and-targeting/use-machine-learning-to-target-your-customers-based-on-their-interest-in-a-product-or-product-attribute/
Customer segmentation allows marketers to better tailor their efforts to specific subgroups of their audience. Businesses who employ customer segmentation can create and communicate targeted marketing messages that resonate with specific customer groups. Segmentation increases the likelihood that customers will engage with the brand, and reduces the potential for communications fatigue—that is, the disengagement of customers who feel like they’re receiving too many messages that don’t apply to them. For example, if your business wants to launch an email campaign about business suits, the target audience should only include people who wear suits.
This blog presents a solution that uses Amazon Personalize to generate highly personalized Amazon Pinpoint customer segments. Using Amazon Pinpoint, you can send messages to those customer segments via campaigns and journeys.
Personalizing Pinpoint segments
Marketers first need to understand their customers by collecting customer data such as key characteristics, transactional data, and behavioral data. This data helps to form buyer personas, understand how they spend their money, and what type of information they’re interested in receiving.
You can create two types of customer segments in Amazon Pinpoint: imported and dynamic. With both types of segments, you need to perform customer data analysis and identify behavioral patterns. After you identify the segment characteristics, you can build a dynamic segment that includes the appropriate criteria. You can learn more about dynamic and imported segments in the Amazon Pinpoint User Guide.
Businesses selling their products and services online could benefit from segments based on known customer preferences, such as product category, color, or delivery options. Marketers who want to promote a new product or inform customers about a sale on a product category can use these segments to launch Amazon Pinpoint campaigns and journeys, increasing the probability that customers will complete a purchase.
Building targeted segments requires you to obtain historical customer transactional data, and then invest time and resources to analyze it. This is where the use of machine learning can save time and improve the accuracy.
Amazon Personalize is a fully managed machine learning service, which requires no prior ML knowledge to operate. It offers ready to use models for segment creation as well as product recommendations, called recipes. Using Amazon Personalize USER_SEGMENTATION recipes, you can generate segments based on a product ID or a product attribute.
About this solution
The solution is based on the following reference architectures:
Both of these architectures are deployed as nested stacks along the main application to showcase how contextual segmentation can be implemented by integrating Amazon Personalize with Amazon Pinpoint.
High level architecture

Once training data and training configuration are uploaded to the Personalize data bucket (1) an AWS Step Function state machine is executed (2). This state machine implements a training workflow to provision all required resources within Amazon Personalize. It trains a recommendation model (3a) based on the Item-Attribute-Affinity recipe. Once the solution is created, the workflow creates a batch segment job to get user segments (3b). The job configuration focuses on providing segments of users that are interested in action genre movies
{ "itemAttributes": "ITEMS.genres = \"Action\"" }When the batch segment job finishes, the result is uploaded to Amazon S3 (3c). The training workflow state machine publishes Amazon Personalize state changes on a custom event bus (4). An Amazon Event Bridge rule listens on events describing that a batch segment job has finished (5). Once this event is put on the event bus, a batch segment postprocessing workflow is executed as AWS Step Function state machine (6). This workflow reads and transforms the segment job output from Amazon Personalize (7) into a CSV file that can be imported as static segment into Amazon Pinpoint (8). The CSV file contains only the Amazon Pinpoint endpoint-ids that refer to the corresponding users from the Amazon Personalize recommendation segment, in the following format:
Id
hcbmnng30rbzf7wiqn48zhzzcu4
tujqyruqu2pdfqgmcgkv4ux7qlu
keul5pov8xggc0nh9sxorldmlxc
lcuxhxpqh/ytkitku2zynrqb2ceThe mechanism to resolve an Amazon Pinpoint endpoint id relies on the user id that is set in Amazon Personalize to be also referenced in each endpoint within Amazon Pinpoint using the user ID attribute.

The workflow ensures that the segment file has a unique filename so that the segments within Amazon Pinpoint can be identified independently. Once the segment CSV file is uploaded to S3 (7), the segment import workflow creates a new imported segment within Amazon Pinpoint (8).
Datasets
The solution uses an artificially generated movies’ dataset called Bingewatch for demonstration purposes. The data is pre-processed to make it usable in the context of Amazon Personalize and Amazon Pinpoint. The pre-processed data consists of the following:
- Interactions’ metadata created out of the Bingewatch ratings.csv
- Items’ metadata created out of the Bingewatch movies.csv
- users’ metadata created out of the Bingewatch ratings.csv, enriched with invented data about e-mail address and age
- Amazon Pinpoint endpoint data
Interactions’ dataset
The interaction dataset describes movie ratings from Bingewatch users. Each row describes a single rating by a user identified by a user id.
The EVENT_VALUE describes the actual rating from 1.0 to 5.0 and the EVENT_TYPE specifies that the rating resulted because a user watched this movie at the given TIMESTAMP, as shown in the following example:
USER_ID,ITEM_ID,EVENT_VALUE,EVENT_TYPE,TIMESTAMP
1,1,4.0,Watch,964982703
2,3,4.0,Watch,964981247
3,6,4.0,Watch,964982224
...Items’ dataset
The item dataset describes each available movie using a TITLE, RELEASE_YEAR, CREATION_TIMESTAMP and a pipe concatenated list of GENRES, as shown in the following example:
ITEM_ID,TITLE,RELEASE_YEAR,CREATION_TIMESTAMP,GENRES
1,Toy Story,1995,788918400,Adventure|Animation|Children|Comedy|Fantasy
2,Jumanji,1995,788918400,Adventure|Children|Fantasy
3,Grumpier Old Men,1995,788918400,Comedy|Romance
...Users’ dataset
The users dataset contains all known users identified by a USER_ID. This dataset contains artificially generated metadata that describe the users’ GENDER and AGE, as shown in the following example:
USER_ID,GENDER,E_MAIL,AGE
1,Female,[email protected],21
2,Female,[email protected],35
3,Male,[email protected],37
4,Female,[email protected],47
5,Agender,[email protected],50
...Amazon Pinpoint endpoints
To map Amazon Pinpoint endpoints to users in Amazon Personalize, it is important to have a consisted user identifier. The mechanism to resolve an Amazon Pinpoint endpoint id relies that the user id in Amazon Personalize is also referenced in each endpoint within Amazon Pinpoint using the userId attribute, as shown in the following example:
User.UserId,ChannelType,User.UserAttributes.Gender,Address,User.UserAttributes.Age
1,EMAIL,Female,[email protected],21
2,EMAIL,Female,[email protected],35
3,EMAIL,Male,[email protected],37
4,EMAIL,Female,[email protected],47
5,EMAIL,Agender,[email protected],50
...Solution implementation
Prerequisites
To deploy this solution, you must have the following:
- An AWS account
- The AWS CLI on your local machine. For more information see Installing the AWS CLI guide.
- The SAM CLI on your local machine. For more information, see Installing the SAM CLI in the AWS Serverless Application Model Developer Guide.
- The latest version of Boto3. For more information see Installation in the Boto3 Documentation.
Note: This solution creates an Amazon Pinpoint project with the name personalize. If you want to deploy this solution on an existing Amazon Pinpoint project, you will need to perform changes in the YAML template.
Deploy the solution
Step 1: Deploy the SAM solution
Clone the GitHub repository to your local machine (how to clone a GitHub repository). Navigate to the GitHub repository location in your local machine using SAM CLI and execute the command below:
sam deploy --stack-name contextual-targeting --guidedFill the fields below as displayed. Change the AWS Region to the AWS Region of your preference, where Amazon Pinpoint and Amazon Personalize are available. The Parameter Email is used from Amazon Simple Notification Service (SNS) to send you an email notification when the Amazon Personalize job is completed.
Configuring SAM deploy
======================
Looking for config file [samconfig.toml] : Not found
Setting default arguments for 'sam deploy' =========================================
Stack Name [sam-app]: contextual-targeting
AWS Region [us-east-1]: eu-west-1
Parameter Email []: [email protected]
Parameter PEVersion [v1.2.0]:
Parameter SegmentImportPrefix [pinpoint/]:
#Shows you resources changes to be deployed and require a 'Y' to initiate deploy
Confirm changes before deploy [y/N]:
#SAM needs permission to be able to create roles to connect to the resources in your template
Allow SAM CLI IAM role creation [Y/n]:
#Preserves the state of previously provisioned resources when an operation fails
Disable rollback [y/N]:
Save arguments to configuration file [Y/n]:
SAM configuration file [samconfig.toml]:
SAM configuration environment [default]:
Looking for resources needed for deployment:
Creating the required resources...
[...]
Successfully created/updated stack - contextual-targeting in eu-west-1
======================Step 2: Import the initial segment to Amazon Pinpoint
We will import some initial and artificially generated endpoints into Amazon Pinpoint.
Execute the command below to your AWS CLI in your local machine.
The command below is compatible with Linux:
SEGMENT_IMPORT_BUCKET=$(aws cloudformation describe-stacks --stack-name contextual-targeting --query 'Stacks[0].Outputs[?OutputKey==`SegmentImportBucket`].OutputValue' --output text)
aws s3 sync ./data/pinpoint s3://$SEGMENT_IMPORT_BUCKET/pinpointFor Windows PowerShell use the command below:
$SEGMENT_IMPORT_BUCKET = (aws cloudformation describe-stacks --stack-name contextual-targeting --query 'Stacks[0].Outputs[?OutputKey==`SegmentImportBucket`].OutputValue' --output text)
aws s3 sync ./data/pinpoint s3://$SEGMENT_IMPORT_BUCKET/pinpointStep 3: Upload training data and configuration for Amazon Personalize
Now we are ready to train our initial recommendation model. This solution provides you with dummy training data as well as a training and inference configuration, which needs to be uploaded into the Amazon Personalize S3 bucket. Training the model can take between 45 and 60 minutes.
Execute the command below to your AWS CLI in your local machine.
The command below is compatible with Linux:
PERSONALIZE_BUCKET=$(aws cloudformation describe-stacks --stack-name contextual-targeting --query 'Stacks[0].Outputs[?OutputKey==`PersonalizeBucketName`].OutputValue' --output text)
aws s3 sync ./data/personalize s3://$PERSONALIZE_BUCKETFor Windows PowerShell use the command below:
$PERSONALIZE_BUCKET = (aws cloudformation describe-stacks --stack-name contextual-targeting --query 'Stacks[0].Outputs[?OutputKey==`PersonalizeBucketName`].OutputValue' --output text)
aws s3 sync ./data/personalize s3://$PERSONALIZE_BUCKETStep 4: Review the inferred segments from Amazon Personalize
Once the training workflow is completed, you should receive an email on the email address you provided when deploying the stack. The email should look like the one in the screenshot below:

Navigate to the Amazon Pinpoint Console > Your Project > Segments and you should see two imported segments. One named endpoints.csv that contains all imported endpoints from Step 2. And then a segment named ITEMSgenresAction_<date>-<time>.csv that contains the ids of endpoints that are interested in action movies inferred by Amazon Personalize

You can engage with Amazon Pinpoint customer segments via Campaigns and Journeys. For more information on how to create and execute Amazon Pinpoint Campaigns and Journeys visit the workshop Building Customer Experiences with Amazon Pinpoint.
Next steps
Contextual targeting is not bound to a single channel, like in this solution email. You can extend the batch-segmentation-postprocessing workflow to fit your engagement and targeting requirements.
For example, you could implement several branches based on the referenced endpoint channel types and create Amazon Pinpoint customer segments that can be engaged via Push Notifications, SMS, Voice Outbound and In-App.
Clean-up
To delete the solution, run the following command in the AWS CLI.
The command below is compatible with Linux:
SEGMENT_IMPORT_BUCKET=$(aws cloudformation describe-stacks --stack-name contextual-targeting --query 'Stacks[0].Outputs[?OutputKey==`SegmentImportBucket`].OutputValue' --output text)
PERSONALIZE_BUCKET=$(aws cloudformation describe-stacks --stack-name contextual-targeting --query 'Stacks[0].Outputs[?OutputKey==`PersonalizeBucketName`].OutputValue' --output text)
aws s3 rm s3://$SEGMENT_IMPORT_BUCKET/ --recursive
aws s3 rm s3://$PERSONALIZE_BUCKET/ --recursive
sam deleteFor Windows PowerShell use the command below:
$SEGMENT_IMPORT_BUCKET=$(aws cloudformation describe-stacks --stack-name contextual-targeting --query 'Stacks[0].Outputs[?OutputKey==`SegmentImportBucket`].OutputValue' --output text)
$PERSONALIZE_BUCKET=$(aws cloudformation describe-stacks --stack-name contextual-targeting --query 'Stacks[0].Outputs[?OutputKey==`PersonalizeBucketName`].OutputValue' --output text)
aws s3 rm s3://$SEGMENT_IMPORT_BUCKET/ --recursive
aws s3 rm s3://$PERSONALIZE_BUCKET/ --recursive
sam deleteAmazon Personalize resources like Dataset groups, datasets, etc. are not created via AWS Cloudformation, thus you have to delete them manually. Please follow the instructions in the official AWS documentation on how to clean up the created resources.
About the Authors

Pavlos Ioannou Katidis
Pavlos Ioannou Katidis is an Amazon Pinpoint and Amazon Simple Email Service Specialist Solutions Architect at AWS. He loves to dive deep into his customer’s technical issues and help them design communication solutions. In his spare time, he enjoys playing tennis, watching crime TV series, playing FPS PC games, and coding personal projects.

Christian Bonzelet
Christian Bonzelet is an AWS Solutions Architect at DFL Digital Sports. He loves those challenges to provide high scalable systems for millions of users. And to collaborate with lots of people to design systems in front of a whiteboard. He uses AWS since 2013 where he built a voting system for a big live TV show in Germany. Since then, he became a big fan on cloud, AWS and domain driven design.
Gen Z
Post Syndicated from original https://xkcd.com/2660/
")
[$] From late-bound arguments to deferred computation, part 1
Post Syndicated from original https://lwn.net/Articles/904777/
Back in November, we looked at a Python proposal
to have function arguments with defaults that get
evaluated when the function is called, rather than when it is defined.
The article suggested that the discussion surrounding the proposal was
likely to continue on for a ways—which it did—but it had died down by the
end of last year. That all changed in mid-June, when the already voluminous
discussion of the feature picked up again; once again, some people thought that
applying the idea only to function arguments was too restrictive. Instead,
a more general mechanism to defer evaluation was touted as something that
could work for late-bound arguments while being useful for other use cases as
well.
Introducing AWS Glue interactive sessions for Jupyter
Post Syndicated from Zach Mitchell original https://aws.amazon.com/blogs/big-data/introducing-aws-glue-interactive-sessions-for-jupyter/
Interactive Sessions for Jupyter is a new notebook interface in the AWS Glue serverless Spark environment. Starting in seconds and automatically stopping compute when idle, interactive sessions provide an on-demand, highly-scalable, serverless Spark backend to Jupyter notebooks and Jupyter-based IDEs such as Jupyter Lab, Microsoft Visual Studio Code, JetBrains PyCharm, and more. Interactive sessions replace AWS Glue development endpoints for interactive job development with AWS Glue and offers the following benefits:
- No clusters to provision or manage
- No idle clusters to pay for
- No up-front configuration required
- No resource contention for the same development environment
- Easy installation and usage
- The exact same serverless Spark runtime and platform as AWS Glue extract, transform, and load (ETL) jobs
Getting started with interactive sessions for Jupyter
Installing interactive sessions is simple and only takes a few terminal commands. After you install it, you can run interactive sessions anytime within seconds of deciding to run. In the following sections, we walk you through installation on macOS and getting started in Jupyter.
To get started with interactive sessions for Jupyter on Windows, follow the instructions in Getting started with AWS Glue interactive sessions.
Prerequisites
These instructions assume you’re running Python 3.6 or later and have the AWS Command Line Interface (AWS CLI) properly running and configured. You use the AWS CLI to make API calls to AWS Glue. For more information on installing the AWS CLI, refer to Installing or updating the latest version of the AWS CLI.
Install AWS Glue interactive sessions on macOS and Linux
To install AWS Glue interactive sessions, complete the following steps:
- Open a terminal and run the following to install and upgrade Jupyter, Boto3, and AWS Glue interactive sessions from PyPi. If desired, you can install Jupyter Lab instead of Jupyter.
- Run the following commands to identify the package install location and install the AWS Glue PySpark and AWS Glue Spark Jupyter kernels with Jupyter:
- To validate your install, run the following command:
In the output, you should see both the AWS Glue PySpark and the AWS Glue Spark kernels listed alongside the default Python3 kernel. It should look something like the following:
Choose and prepare IAM principals
Interactive sessions use two AWS Identity and Access Management (IAM) principals (user or role) to function. The first is used to call the interactive sessions APIs and is likely the same user or role that you use with the AWS CLI. The second is GlueServiceRole, the role that AWS Glue assumes to run your session. This is the same role as AWS Glue jobs; if you’re developing a job with your notebook, you should use the same role for both interactive sessions and the job you create.
Prepare the client user or role
In the case of local development, the first role is already configured if you can run the AWS CLI. If you can’t run the AWS CLI, follow these steps for setting up. If you often use the AWS CLI or Boto3 to interact with AWS Glue and have full AWS Glue permissions, you can likely skip this step.
- To validate this first user or role is set up, open a new terminal window and run the following code:
You should see a response like the following. If not, you may not have permissions to call AWS Security Token Service (AWS STS), or you don’t have the AWS CLI set up properly. If you simply get access denied calling AWS STS, you may continue if you know your user or role and its needed permissions.
- Ensure your IAM user or role can call the AWS Glue interactive sessions APIs by attaching the
AWSGlueConsoleFullAccessmanaged IAM policy to your role.
If your caller identity returned a user, run the following:
If your caller identity returned a role, run the following:
Prepare the AWS Glue service role for interactive sessions
You can specify the second principal, GlueServiceRole, either in the notebook itself by using the %iam_role magic or stored alongside the AWS CLI config. If you have a role that you typically use with AWS Glue jobs, this will be that role. If you don’t have a role you use for AWS Glue jobs, refer to Setting up IAM permissions for AWS Glue to set one up.
To set this role as the default role for interactive sessions, edit the AWS CLI credentials file and add glue_role_arn to the profile you intend to use.
- With a text editor, open
~/.aws/credentials.
On Windows, useC:\Users\username\.aws\credentials. - Look for the profile you use for AWS Glue; if you don’t use a profile, you’re looking for [Default].
- Add a line in the profile for the role you intend to use like,
glue_role_arn=<AWSGlueServiceRole>. - I recommend adding a default Region to your profile if one is not specified already. You can do so by adding the line
region=us-east-1, replacingus-east-1with your desired Region.
If you don’t add a Region to your profile, you’re required to specify the Region at the top of each notebook with the%regionmagic.When finished, your config should look something like the following: - Save the config.
Start Jupyter and an AWS Glue PySpark notebook
To start Jupyter and your notebook, complete the following steps:
- Run the following command in your terminal to open the Jupyter notebook in your browser:
Your browser should open and you’re presented with a page that looks like the following screenshot.

- On the New menu, choose Glue PySpark.



A new tab opens with a blank Jupyter notebook using the AWS Glue PySpark kernel.

Configure your notebook with magics
AWS Glue interactive sessions are configured with Jupyter magics. Magics are small commands prefixed with % at the start of Jupyter cells that provide shortcuts to control the environment. In AWS Glue interactive sessions, magics are used for all configuration needs, including:
- %region – Region
- %profile – AWS CLI profile
- %iam_role – IAM role for the AWS Glue service role
- %worker_type – Worker type
- %number_of_workers – Number of workers
- %idle_timeout – How long to allow a session to idle before stopping it
- %additional_python_modules – Python libraries to install from pip
Magics are placed at the beginning of your first cell, before your code, to configure AWS Glue. To discover all the magics of interactive sessions, run %help in a cell and a full list is printed. With the exception of %%sql, running a cell of only magics doesn’t start a session, but sets the configuration for the session that starts next when you run your first cell of code. For this post, we use three magics to configure AWS Glue with version 2.0 and two G.2X workers. Let’s enter the following magics into our first cell and run it:
When you run magics, the output lets us know the values we’re changing along with their previous settings. Explicitly setting all your configuration in magics helps ensure consistent runs of your notebook every time and is recommended for production workloads.
Run your first code cell and author your AWS Glue notebook
Next, we run our first code cell. This is when a session is provisioned for use with this notebook. When interactive sessions are properly configured within an account, the session is completely isolated to this notebook. If you open another notebook in a new tab, it gets its own session on its own isolated compute. Run your code cell as follows:
When you ran the first cell containing code, Jupyter invoked interactive sessions, provisioned an AWS Glue cluster, and sent the code to AWS Glue Spark. The notebook was given a session ID, as shown in the preceding code. We can also see the properties used to provision AWS Glue, including the IAM role that AWS Glue used to create the session, the number of workers and their type, and any other options that were passed as part of the creation.
Interactive sessions automatically initialize a Spark session as spark and SparkContext as sc; having Spark ready to go saves a lot of boilerplate code. However, if you want to convert your notebook to a job, spark and sc must be initialized and declared explicitly.
Work in the notebook
Now that we have a session up, let’s do some work. In this exercise, we look at population estimates from the AWS COVID-19 dataset, clean them up, and write the results a table.
This walkthrough uses data from the COVID-19 data lake.
To make the data from the AWS COVID-19 data lake available in the Data Catalog in your AWS account, create an AWS CloudFormation stack using the following template.
If you’re signed in to your AWS account, deploy the CloudFormation stack by clicking the following Launch stack button:
![]()
It fills out most of the stack creation form for you. All you need to do is choose Create stack. For instructions on creating a CloudFormation stack, see Get started.
When I’m working on a new data integration process, the first thing I often do is identify and preview the datasets I’m going to work on. If I don’t recall the exact location or table name, I typically open the AWS Glue console and search or browse for the table then return to my notebook to preview it. With interactive sessions, there is a quicker way to browse the Data Catalog. We can use the %%sql magic to show databases and tables without leaving the notebook. For this example, the population table I want in is the COVID-19 dataset but I don’t recall its exact name, so I use the %%sql magic to look it up:
Looking through the returned list, we see a table named county_populations. Let’s select from this table, sorting for the largest counties by population:
Our query returned data but in an unexpected order. It looks like population estimate 2018 sorted lexicographically if the values were strings. Let’s use an AWS Glue DynamicFrame to get the schema of the table and verify the issue:
The schema shows population estimate 2018 to be a string, which is why our column isn’t sorting properly. We can use the apply_mapping transform in our next cell to correct the column type. In the same transform, we also clean up the column names and other column types: clarifying the distinction between id and id2, removing spaces from population estimate 2018 (conforming to Hive’s standards), and casting id2 as an integer for proper sorting. After validating the schema, we show the data with the new schema:
With the data sorting correctly, we can write it to Amazon Simple Storage Service (Amazon S3) as a new table in the AWS Glue Data Catalog. We use the mapped DynamicFrame for this write because we didn’t modify any data past that transform:
Finally, we run a query against our new table to show our table created successfully and validate our work:
Convert notebooks to AWS Glue jobs with nbconvert
Jupyter notebooks are saved as .ipynb files. AWS Glue doesn’t currently run .ipynb files directly, so they need to be converted to Python scripts before they can be uploaded to Amazon S3 as jobs. Use the jupyter nbconvert command from a terminal to convert the script.
- Open a new terminal or PowerShell tab or window.
cdto the working directory where your notebook is.
This is likely the same directory where you ran jupyter notebook at the beginning of this post.- Run the following bash command to convert the notebook, providing the correct file name for your notebook:
- Run
cat <Untitled-1>.ipynbto view your new file. - Upload the .py file to Amazon S3 using the following command, replacing the bucket, path, and file name as needed:
- Create your AWS Glue job with the following command.
Note that the magics aren’t automatically converted to job parameters when converting notebooks locally. You need to put in your job arguments correctly, or import your notebook to AWS Glue Studio and complete the following steps to keep your magic settings.
Run the job
After you have authored the notebook, converted it to a Python file, uploaded it to Amazon S3, and finally made it into an AWS Glue job, the only thing left to do is run it. Do so with the following terminal command:
Conclusion
AWS Glue interactive sessions offer a new way to interact with the AWS Glue serverless Spark environment. Set it up in minutes, start sessions in seconds, and only pay for what you use. You can use interactive sessions for AWS Glue job development, ad hoc data integration and exploration, or for large queries and audits. AWS Glue interactive sessions are generally available in all Regions that support AWS Glue.
To learn more and get started using AWS Glue Interactive Sessions visit our developer guide and begin coding in seconds.
About the author
 Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop data lakes and other data solutions on AWS analytics services.
Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop data lakes and other data solutions on AWS analytics services.
How Grillo Built a Low-Cost Earthquake Early Warning System on AWS
Post Syndicated from Marcia Villalba original https://aws.amazon.com/blogs/aws/how-grillo-built-a-low-cost-earthquake-early-warning-system-on-aws/
It is estimated that 50 percent of the injuries caused when a high magnitude earthquake affects an area are because of falls or falling hazards. This means that most of these injuries could have been prevented if the population had a few seconds of warning to take cover. Grillo, a social impact enterprise focused on seismology, created a low-cost solution using AWS that senses earthquakes and alerts the population in real time about the dangers in the area.
Earthquakes can happen at any time, and there are two actions cities can take to mitigate the damages. First is structural refitting, that is, building structures that can resist earthquakes. This solution doesn’t apply to many areas because they require big investments. The second solution is to send an alert to the affected population before the shaking reaches them. Ten to sixty seconds can be enough time for people to take action by getting out of a building, taking cover, or turning off a dangerous machine.
Earthquake Early Warning (EEW) systems provide rapid detection of earthquakes and alert people at risk. However, because of the hardware, infrastructure, and technology involved, traditional EEW systems can cost hundreds of millions of US dollars to deploy—a cost too high for most countries.
Andrés Meira was living in Haiti during the 2010 earthquake that claimed over 100,000 human lives and left many people homeless and injured. It is estimated that the earthquake affected three million people. He later moved to Mexico, where in 2017, he experienced another high-magnitude earthquake. As a result, Andrés founded Grillo to develop an accessible EEW system, and its solution has been operating successfully in Mexico since 2017.
Grillo developed a low-cost EEW system using sensors and cloud computing. This system uses off-the-shelf sensors that are placed in buildings near seismically active zones. Grillo sensors cost approximately $300 USD, compared to the traditional seismometers that cost around $10,000 USD. Because of these inexpensive sensors, Grillo can offer a higher density of sensors, which reduces the time needed to issue an alert and gives people more time for action. This benefits the population because higher density increases the accuracy of the location detection, reduces false positives, and reduces times to alert.

How Grillo sensors are placed
Grillo’s sensors transmit data to the cloud as the shaking is happening. The cloud platform Grillo built on AWS uses machine learning models that can determine and alert in almost real time, with an average latency of 2 to 3 seconds if an earthquake is happening, depending on the data sent by the different sensors. When the cloud platform detects earthquake risk, it sends alerts to nearby populations via a native phone application, IoT loudspeakers placed in populated areas, or by SMS.

How data flows from the shaking to the end users
OpenEEW
In addition, Grillo founded the OpenEEW initiative to enable EEW systems for millions of people who live in areas with earthquake risks. This features the sensor hardware schematics, firmware, dashboard, and other elements of the system as open source, with a permissive license for anyone to use freely.
In this initiative, they also share on the Registry of Open Data on AWS all the data produced from the sensors deployed in Mexico, Chile, Puerto Rico, and Costa Rica for different organizations to learn from it and also to train machine learning models.

Low-cost sensor
Grillo in Haiti
Haiti ranks among the countries with the highest seismic risk in the world. Large magnitude earthquakes hit Haiti in 2020 and 2021. Currently, Grillo is working to establish their low-cost EEW system in southern Haiti, where most of the large seismic events in the past decade have occurred. This area is home to over three million people.
Over the course of 2021, Grillo installed over 100 sensors in Puerto Rico. And during 2022, they have focused on deploying sensors in the nationwide cell tower network of Haiti. Also during this year, they will calibrate the machine learning models with data from the new sensors in order to correctly predict when there is earthquake risk. Finally, they will develop an SMS alert system with Digicel, a local telecommunication company. Grillo plans to complete the deployment of the south Haiti EEW system by the end of 2022.

School in southern Haiti where alarm systems are placed
Learn more
Grillo partnered with the AWS Disaster Response team to achieve their goals. AWS helped Grillo to migrate their initial system to AWS and provided expert technical assistance on how to use Amazon SageMaker and AWS IoT services. AWS also provided credits to run the system and financial help to build the sensors.
Check the AWS Disaster Response page to learn more about the projects they are currently working on. And visit the Grillo home page to learn more about their EEW system.
From centralized architecture to decentralized architecture: How data sharing fine-tunes Amazon Redshift workloads
Post Syndicated from Jingbin Ma original https://aws.amazon.com/blogs/big-data/from-centralized-architecture-to-decentralized-architecture-how-data-sharing-fine-tunes-amazon-redshift-workloads/
Amazon Redshift is a fully managed, petabyte-scale, massively parallel data warehouse that offers simple operations and high performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Today, Amazon Redshift has become the most widely used cloud data warehouse.
With the significant growth of data for big data analytics over the years, some customers have asked how they should optimize Amazon Redshift workloads. In this post, we explore how to optimize workloads on Amazon Redshift clusters using Amazon Redshift RA3 nodes, data sharing, and pausing and resuming clusters. For more cost-optimization methods, refer to Getting the most out of your analytics stack with Amazon Redshift.
Key features of Amazon Redshift
First, let’s review some key features:
- RA3 nodes – Amazon Redshift RA3 nodes are backed by a new managed storage model that gives you the power to separately optimize your compute power and your storage. They bring a few very important features, one of which is data sharing. RA3 nodes also support the ability to pause and resume, which allows you to easily suspend on-demand billing while the cluster is not being used.
- Data sharing – Amazon Redshift data sharing offers you to extend the ease of use, performance, and cost benefits of Amazon Redshift in a single cluster to multi-cluster deployments while being able to share data. Data sharing enables instant, granular, and fast data access across Redshift clusters without the need to copy or move it. You can securely share live data with Amazon Redshift clusters in the same or different AWS accounts, and across regions. You can share data at many levels, including schemas, tables, views, and user-defined functions. You can also share the most up-to-date and consistent information as it’s updated in Amazon Redshift Serverless. It also provides fine-grained access controls that you can tailor for different users and businesses that all need access to the data. However, data sharing in Amazon Redshift has a few limitations.
Solution overview
In this use case, our customer is heavily using Amazon Redshift as their data warehouse for their analytics workloads, and they have been enjoying the possibility and convenience that Amazon Redshift brought to their business. They mainly use Amazon Redshift to store and process user behavioral data for BI purposes. The data has increased by hundreds of gigabytes daily in recent months, and employees from departments continuously run queries against the Amazon Redshift cluster on their BI platform during business hours.
The company runs four major analytics workloads on a single Amazon Redshift cluster, because some data is used by all workloads:
- Queries from the BI platform – Various queries run mainly during business hours.
- Hourly ETL – This extract, transform, and load (ETL) job runs in the first few minutes of each hour. It generally takes about 40 minutes.
- Daily ETL – This job runs twice a day during business hours, because the operation team needs to get daily reports before the end of the day. Each job normally takes between 1.5–3 hours. It’s the second-most resource-heavy workload.
- Weekly ETL – This job runs in the early morning every Sunday. It’s the most resource-heavy workload. The job normally takes 3–4 hours.
The analytics team has migrated to the RA3 family and increased the number of nodes of the Amazon Redshift cluster to 12 over the years to keep the average runtime of queries from their BI tool within an acceptable time due to the data size, especially when other workloads are running.
However, they have noticed that performance is reduced while running ETL tasks, and the duration of ETL tasks is long. Therefore, the analytics team wants to explore solutions to optimize their Amazon Redshift cluster.
Because CPU utilization spikes appear while the ETL tasks are running, the AWS team’s first thought was to separate workloads and relevant data into multiple Amazon Redshift clusters with different cluster sizes. By reducing the total number of nodes, we hoped to reduce the cost of Amazon Redshift.
After a series of conversations, the AWS team found that one of the reasons that the customer keeps all workloads on the 12-node Amazon Redshift cluster is to manage the performance of queries from their BI platform, especially while running ETL workloads, which have a big impact on the performance of all workloads on the Amazon Redshift cluster. The obstacle is that many tables in the data warehouse are required to be read and written by multiple workloads, and only the producer of a data share can update the shared data.
The challenge of dividing the Amazon Redshift cluster into multiple clusters is data consistency. Some tables need to be read by ETL workloads and written by BI workloads, and some tables are the opposite. Therefore, if we duplicate data into two Amazon Redshift clusters or only create a data share from the BI cluster to the reporting cluster, the customer will have to develop a data synchronization process to keep the data consistent between all Amazon Redshift clusters, and this process could be very complicated and unmaintainable.
After more analysis to gain an in-depth understanding of the customer’s workloads, the AWS team found that we could put tables into four groups, and proposed a multi-cluster, two-way data sharing solution. The purpose of the solution is to divide the workloads into separate Amazon Redshift clusters so that we can use Amazon Redshift to pause and resume clusters for periodic workloads to reduce the Amazon Redshift running costs, because clusters can still access a single copy of data that is required for workloads. The solution should meet the data consistency requirements without building a complicated data synchronization process.
The following diagram illustrates the old architecture (left) compared to the new multi-cluster solution (right).

Dividing workloads and data
Due to the characteristics of the four major workloads, we categorized workloads into two categories: long-running workloads and periodic-running workloads.
The long-running workloads are for the BI platform and hourly ETL jobs. Because the hourly ETL workload requires about 40 minutes to run, the gain is small even if we migrate it to an isolated Amazon Redshift cluster and pause and resume it every hour. Therefore, we leave it with the BI platform.
The periodic-running workloads are the daily and weekly ETL jobs. The daily job generally takes about 1 hour and 40 minutes to 3 hours, and the weekly job generally takes 3–4 hours.
Data sharing plan
The next step is identifying all data (tables) access patterns of each category. We identified four types of tables:
- Type 1 – Tables are only read and written by long-running workloads
- Type 2 – Tables are read and written by long-running workloads, and are also read by periodic-running workloads
- Type 3 – Tables are read and written by periodic-running workloads, and are also read by long-running workloads
- Type 4 – Tables are only read and written by periodic-running workloads
Fortunately, there is no table that is required to be written by all workloads. Therefore, we can separate the Amazon Redshift cluster into two Amazon Redshift clusters: one for the long-running workloads, and the other for periodic-running workloads with 20 RA3 nodes.
We created a two-way data share between the long-running cluster and the periodic-running cluster. For type 2 tables, we created a data share on the long-running cluster as the producer and the periodic-running cluster as the consumer. For type 3 tables, we created a data share on the periodic-running cluster as the producer and the long-running cluster as the consumer.
The following diagram illustrates this data sharing configuration.

Build two-way data share across Amazon Redshift clusters
In this section, we walk through the steps to build a two-way data share across Amazon Redshift clusters. First, let’s take a snapshot of the original Amazon Redshift cluster, which became the long-running cluster later.

Now, let’s create a new Amazon Redshift cluster with 20 RA3 nodes for periodic-running workloads. Then we migrate the type 3 and type 4 tables to the periodic-running cluster. Make sure you choose the ra3 node type. (Amazon Redshift Serverless supports data sharing too, and it becomes generally available in July 2022, so it is also an option now.)

Create the long-to-periodic data share
The next step is to create the long-to-periodic data share. Complete the following steps:
- On the
periodic-runningcluster, get the namespace by running the following query:
Make sure record the namespace.
- On the
long-runningcluster, we run queries similar to the following:
- We can validate the long-to-periodic data share using the following command:
- After we validate the data share, we get the long-running cluster namespace with the following query:
Make sure record the namespace.
- On the
periodic-runningcluster, run the following command to load the data from the long-to-periodic data share with the long-running cluster namespace:
- Confirm that we have read access to tables in the long-to-periodic data share.
Create the periodic-to-long data share
The next step is to create the periodic-to-long data share. We use the namespaces of the long-running cluster and the periodic-running cluster that we collected in the previous step.
- On the
periodic-runningcluster, run queries similar to the following to create the periodic-to-long data share:
- Validate the data share using the following command:
- On the
long-runningcluster, run the following command to load the data from the periodic-to-long data using the periodic-running cluster namespace:
- Check that we have read access to the tables in the periodic-to-long data share.
At this stage, we have separated workloads into two Amazon Redshift clusters and built a two-way data share across two Amazon Redshift clusters.
The next step is updating the code of different workloads to use the correct endpoints of two Amazon Redshift clusters and perform consolidated tests.
Pause and resume the periodic-running Amazon Redshift cluster
Let’s update the crontab scripts, which run periodic-running workloads. We make two updates.
- When the scripts start, call the Amazon Redshift check and resume cluster APIs to resume the periodic-running Amazon Redshift cluster when the cluster is paused:
- After the workloads are finished, call the Amazon Redshift pause cluster API with the cluster ID to pause the cluster:
Results
After we migrated the workloads to the new architecture, the company’s analytics team ran some tests to verify the results.
According to tests, the performance of all workloads improved:
- The BI workload is about 100% faster during the ETL workload running periods
- The hourly ETL workload is about 50% faster
- The daily workload duration reduced to approximately 40 minutes, from a maximum of 3 hours
- The weekly workload duration reduced to approximately 1.5 hours, from a maximum of 4 hours
All functionalities work properly, and cost of the new architecture only increased approximately 13%, while over 10% of new data had been added during the testing period.
Learnings and limitations
After we separated the workloads into different Amazon Redshift clusters, we discovered a few things:
- The performance of the BI workloads was 100% faster because there was no resource competition with daily and weekly ETL workloads anymore
- The duration of ETL workloads on the periodic-running cluster was reduced significantly because there were more nodes and no resource competition from the BI and hourly ETL workloads
- Even when over 10% new data was added, the overall cost of the Amazon Redshift clusters only increased by 13%, due to using the cluster pause and resume function of the Amazon Redshift RA3 family
As a result, we saw a 70% price-performance improvement of the Amazon Redshift cluster.
However, there are some limitations of the solution:
- To use the Amazon Redshift pause and resume function, the code for calling the Amazon Redshift pause and resume APIs must be added to all scheduled scripts that run ETL workloads on the periodic-running cluster
- Amazon Redshift clusters require several minutes to finish pausing and resuming, although you’re not charged during these processes
- The size of Amazon Redshift clusters can’t automatically scale in and out depending on workloads
Next steps
After improving performance significantly, we can explore the possibility of reducing the number of nodes of the long-running cluster to reduce Amazon Redshift costs.
Another possible optimization is using Amazon Redshift Spectrum to reduce the cost of Amazon Redshift on cluster storage. With Redshift Spectrum, multiple Amazon Redshift clusters can concurrently query and retrieve the same structured and semistructured dataset in Amazon Simple Storage Service (Amazon S3) without the need to make copies of the data for each cluster or having to load the data into Amazon Redshift tables.
Amazon Redshift Serverless was announced for preview in AWS re:Invent 2021 and became generally available in July 2022. Redshift Serverless automatically provisions and intelligently scales your data warehouse capacity to deliver best-in-class performance for all your analytics. You only pay for the compute used for the duration of the workloads on a per-second basis. You can benefit from this simplicity without making any changes to your existing analytics and BI applications. You can also share data for read purposes across different Amazon Redshift Serverless instances within or across AWS accounts.
Therefore, we can explore the possibility of removing the need to script for pausing and resuming the periodic-running cluster by using Redshift Serverless to make the management easier. We can also explore the possibility of improving the granularity of workloads.
Conclusion
In this post, we discussed how to optimize workloads on Amazon Redshift clusters using RA3 nodes, data sharing, and pausing and resuming clusters. We also explored a use case implementing a multi-cluster two-way data share solution to improve workload performance with a minimum code change. If you have any questions or feedback, please leave them in the comments section.
About the authors

Jingbin Ma is a Sr. Solutions Architect at Amazon Web Services. He helps customers build well-architected applications using AWS services. He has many years of experience working in the internet industry, and his last role was CTO of a New Zealand IT company before joining AWS. He is passionate about serverless and infrastructure as code.
 Chao Pan is a Data Analytics Solutions Architect at Amazon Web Services. He’s responsible for the consultation and design of customers’ big data solution architectures. He has extensive experience in open-source big data. Outside of work, he enjoys hiking.
Chao Pan is a Data Analytics Solutions Architect at Amazon Web Services. He’s responsible for the consultation and design of customers’ big data solution architectures. He has extensive experience in open-source big data. Outside of work, he enjoys hiking.
Configure Hadoop YARN CapacityScheduler on Amazon EMR on Amazon EC2 for multi-tenant heterogeneous workloads
Post Syndicated from Suvojit Dasgupta original https://aws.amazon.com/blogs/big-data/configure-hadoop-yarn-capacityscheduler-on-amazon-emr-on-amazon-ec2-for-multi-tenant-heterogeneous-workloads/
Apache Hadoop YARN (Yet Another Resource Negotiator) is a cluster resource manager responsible for assigning computational resources (CPU, memory, I/O), and scheduling and monitoring jobs submitted to a Hadoop cluster. This generic framework allows for effective management of cluster resources for distributed data processing frameworks, such as Apache Spark, Apache MapReduce, and Apache Hive. When supported by the framework, Amazon EMR by default uses Hadoop YARN. Please note that not all frameworks offered by Amazon EMR use Hadoop YARN, such as Trino/Presto and Apache HBase.
In this post, we discuss various components of Hadoop YARN, and understand how components interact with each other to allocate resources, schedule applications, and monitor applications. We dive deep into the specific configurations to customize Hadoop YARN’s CapacityScheduler to increase cluster efficiency by allocating resources in a timely and secure manner in a multi-tenant cluster. We take an opinionated look at the configurations for CapacityScheduler and configure them on Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2) to solve for the common resource allocation, resource contention, and job scheduling challenges in a multi-tenant cluster.
We dive deep into CapacityScheduler because Amazon EMR uses CapacityScheduler by default, and CapacityScheduler has benefits over other schedulers for running workloads with heterogeneous resource consumption.
Solution overview
Modern data platforms often run applications on Amazon EMR with the following characteristics:
- Heterogeneous resource consumption patterns by jobs, such as computation-bound jobs, I/O-bound jobs, or memory-bound jobs
- Multiple teams running jobs with an expectation to receive an agreed-upon share of cluster resources and complete jobs in a timely manner
- Cluster admins often have to cater to one-time requests for running jobs without impacting scheduled jobs
- Cluster admins want to ensure users are using their assigned capacity and not using others
- Cluster admins want to utilize the resources efficiently and allocate all available resources to currently running jobs, but want to retain the ability to reclaim resources automatically should there be a claim for the agreed-upon cluster resources from other jobs
To illustrate these use cases, let’s consider the following scenario:
user1anduser2don’t belong to any team and use cluster resources periodically on an ad hoc basis- A data platform and analytics program has two teams:
- A
data_engineeringteam, containinguser3 - A
data_scienceteam, containinguser4
- A
user5anduser6(and many other users) sporadically use cluster resources to run jobs
Based on this scenario, the scheduler queue may look like the following diagram. Take note of the common configurations applied to all queues, the overrides, and the user/groups-to-queue mappings.

In the subsequent sections, we will understand the high-level components of Hadoop YARN, discuss the various types of schedulers available in Hadoop YARN, review the core concepts of CapacityScheduler, and showcase how to implement this CapacityScheduler queue setup on Amazon EMR (on Amazon EC2). You can skip to Code walkthrough section if you are already familiar with Hadoop YARN and CapacityScheduler.
Overview of Hadoop YARN
At a high level, Hadoop YARN consists of three main components:
- ResourceManager (one per primary node)
- ApplicationMaster (one per application)
- NodeManager (one per node)
The following diagram shows the main components and their interaction with each other.

Before diving further, let’s clarify what Hadoop YARN’s ResourceContainer (or container) is. A ResourceContainer represents a collection of physical computational resources. It’s an abstraction used to bundle resources into distinct, allocatable unit.
ResourceManager
The ResourceManager is responsible for resource management and making allocation decisions. It’s the ResourceManager’s responsibility to identify and allocate resources to a job upon submission to Hadoop YARN. The ResourceManager has two main components:
- ApplicationsManager (not to be confused with ApplicationMaster)
- Scheduler
ApplicationsManager
The ApplicationsManager is responsible for accepting job submissions, negotiating the first container for running ApplicationMaster, and providing the service for restarting the ApplicationMaster on failure.
Scheduler
The Scheduler is responsible for scheduling allocation of resources to the jobs. The Scheduler performs its scheduling function based on the resource requirements of the jobs. The Scheduler is a pluggable interface. Hadoop YARN currently provides three implementations:
- CapacityScheduler – A pluggable scheduler for Hadoop that allows for multiple tenants to securely share a cluster such that jobs are allocated resources in a timely manner under constraints of allocated capacities. The implementation is available on GitHub. The Java concrete class is
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler. In this post, we primarily focus on CapacityScheduler, which is the default scheduler on Amazon EMR (on Amazon EC2). - FairScheduler – A pluggable scheduler for Hadoop that allows Hadoop YARN applications to share resources in clusters fairly. The implementation is available on GitHub. The Java concrete class is
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler. - FifoScheduler – A pluggable scheduler for Hadoop that allows Hadoop YARN applications share resources in clusters in a first-in-first-out basis. The implementation is available on GitHub. The Java concrete class is
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fifo.FifoScheduler.
ApplicationMaster
Upon negotiating the first container by ApplicationsManager, the per-application ApplicationMaster has the responsibility of negotiating the rest of the appropriate resources from the Scheduler, tracking their status, and monitoring progress.
NodeManager
The NodeManager is responsible for launching and managing containers on a node.
Hadoop YARN on Amazon EMR
By default, Amazon EMR (on Amazon EC2) uses Hadoop YARN for cluster management for the distributed data processing frameworks that support Hadoop YARN as a resource manager, like Apache Spark, Apache MapReduce, and Apache Hive. Amazon EMR provides multiple sensible default settings that work for most scenarios. However, every data platform is different and has specific needs. Amazon EMR provides the ability to customize the setting at cluster creation using configuration classifications . You can also reconfigure Amazon EMR cluster applications and specify additional configuration classifications for each instance group in a running cluster using AWS Command Line Interface (AWS CLI), or the AWS SDK.
CapacityScheduler
CapacityScheduler depends on ResourceCalculator to identify the available resources and calculate the allocation of the resources to ApplicationMaster. The ResourceCalculator is an abstract Java class. Hadoop YARN currently provides two implementations:
- DefaultResourceCalculator – In
DefaultResourceCalculator, resources are calculated based on memory alone. - DominantResourceCalculator –
DominantResourceCalculatoris based on the Dominant Resource Fairness (DRF) model of resource allocation. The paper Dominant Resource Fairness: Fair Allocation of Multiple Resource Types, Ghodsi et al. [2011] describes DRF as follows: “DRF computes the share of each resource allocated to that user. The maximum among all shares of a user is called that user’s dominant share, and the resource corresponding to the dominant share is called the dominant resource. Different users may have different dominant resources. For example, the dominant resource of a user running a computation-bound job is CPU, while the dominant resource of a user running an I/O-bound job is bandwidth. DRF simply applies max-min fairness across users’ dominant shares. That is, DRF seeks to maximize the smallest dominant share in the system, then the second-smallest, and so on.”
Because of DRF, DominantResourceCalculator is a better ResourceCalculator for data processing environments running heterogeneous workloads. By default, Amazon EMR uses DefaultResourceCalculator for CapacityScheduler. This can be verified by checking the value of yarn.scheduler.capacity.resource-calculator parameter in /etc/hadoop/conf/capacity-scheduler.xml.
Code walkthrough
CapacityScheduler provides multiple parameters to customize the scheduling behavior to meet specific needs. For a list of available parameters, refer to Hadoop: CapacityScheduler.
Refer to the configurations section in cloudformation/templates/emr.yaml to review all the CapacityScheduler parameters set as part of this post. In this example, we use two classifiers of Amazon EMR (on Amazon EC2):
- yarn-site – The classification to update
yarn-site.xml - capacity-scheduler – The classification to update
capacity-scheduler.xml
For various types of classification available in Amazon EMR, refer to Customizing cluster and application configuration with earlier AMI versions of Amazon EMR.
In the AWS CloudFormation template, we have modified the ResourceCalculator of CapacityScheduler from the defaults, DefaultResourceCalculator to DominantResourceCalculator. Data processing environments tends to run different kinds of jobs, for example, computation-bound jobs consuming heavy CPU, I/O-bound jobs consuming heavy bandwidth, and memory-bound jobs consuming heavy memory. As previously stated, DominantResourceCalculator is better suited for such environments due to its Dominant Resource Fairness model of resource allocation. If your data processing environment only runs memory-bound jobs, then modifying this parameter isn’t necessary.
You can find the codebase in the AWS Samples GitHub repository.
Prerequisites
For deploying the solution, you should have the following prerequisites:
- An AWS account
- The AWS Command Line Interface (AWS CLI) installed
- The GIT Command Line Interface (GIT CLI) installed
- Permission to create AWS resources
- Familiarity with AWS CloudFormation and Amazon EMR
Deploy the solution
To deploy the solution, complete the following steps:
- Download the source code from the AWS Samples GitHub repository:
- Create an Amazon Simple Storage Service (Amazon S3) bucket:
- Copy the cloned repository to the Amazon S3 bucket:
- Update the amazon-emr-yarn-capacity-scheduler/cloudformation/parameters/parameters.json file with appropriate values for the following keys. We have provided sensible defaults wherever possible. You should update the values to fit your specific requirements.
-
- ArtifactsS3Repository – The S3 bucket name that was created in the previous step (
emr-yarn-capacity-scheduler-<AWS_ACCOUNT_ID>-<AWS_REGION>). - emrKeyName – An existing EC2 key name. If you don’t have an existing key and want to create a new key, refer to Use an Amazon EC2 key pair for SSH credentials.
- clientCIDR – The CIDR range of the client machine for accessing the EMR cluster via SSH. You can run the following command to identify the IP of the client machine:
echo "$(curl -s http://checkip.amazonaws.com)/32"
- ArtifactsS3Repository – The S3 bucket name that was created in the previous step (
- Deploy the AWS CloudFormation templates:
- On the AWS CloudFormation console, check for the successful deployment of the following stacks.
- On the Amazon EMR console, check for the successful creation of the
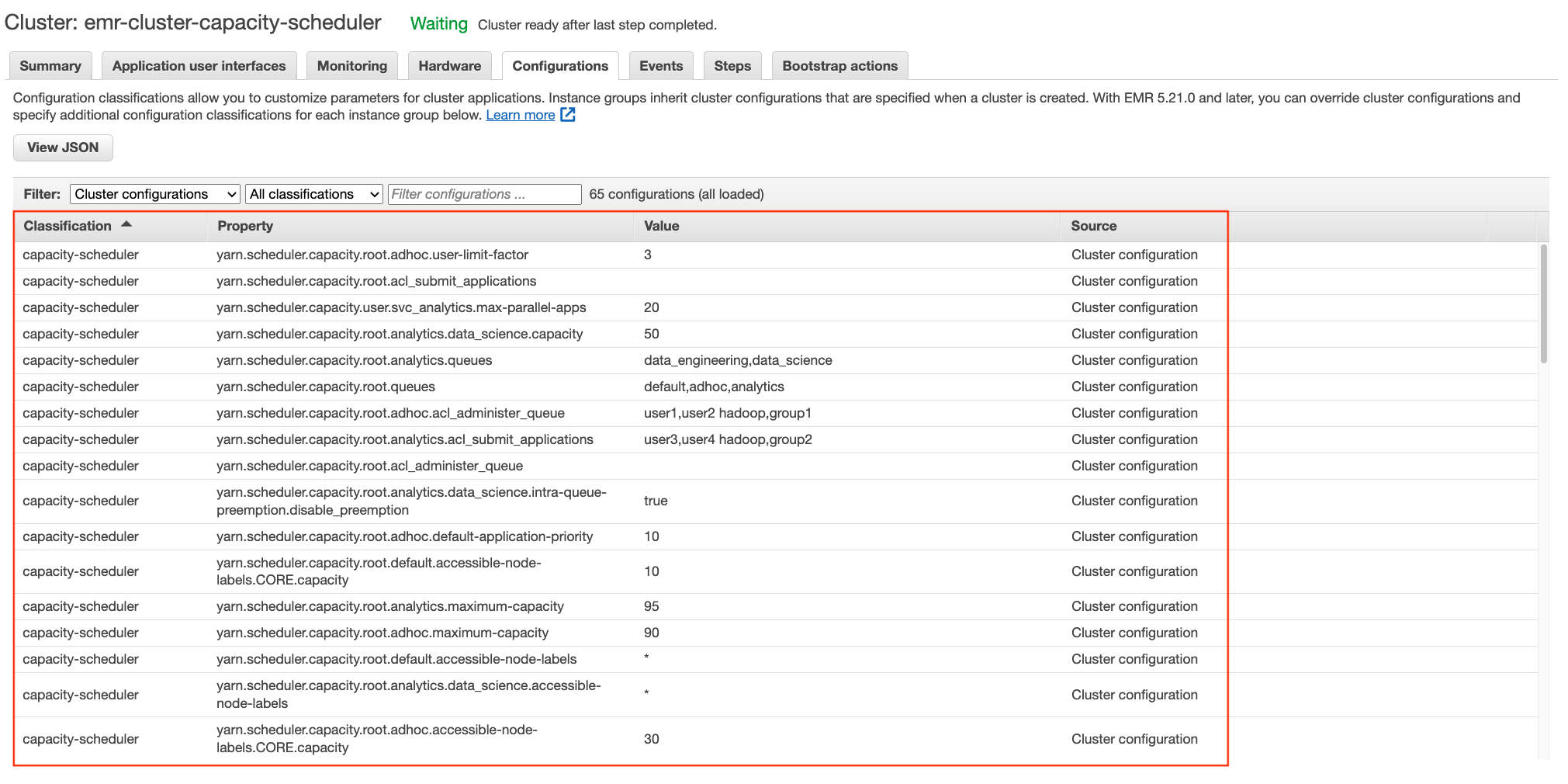
emr-cluster-capacity-schedulercluster. - Choose the cluster and on the Configurations tab, review the properties under the
capacity-schedulerandyarn-siteclassification labels.
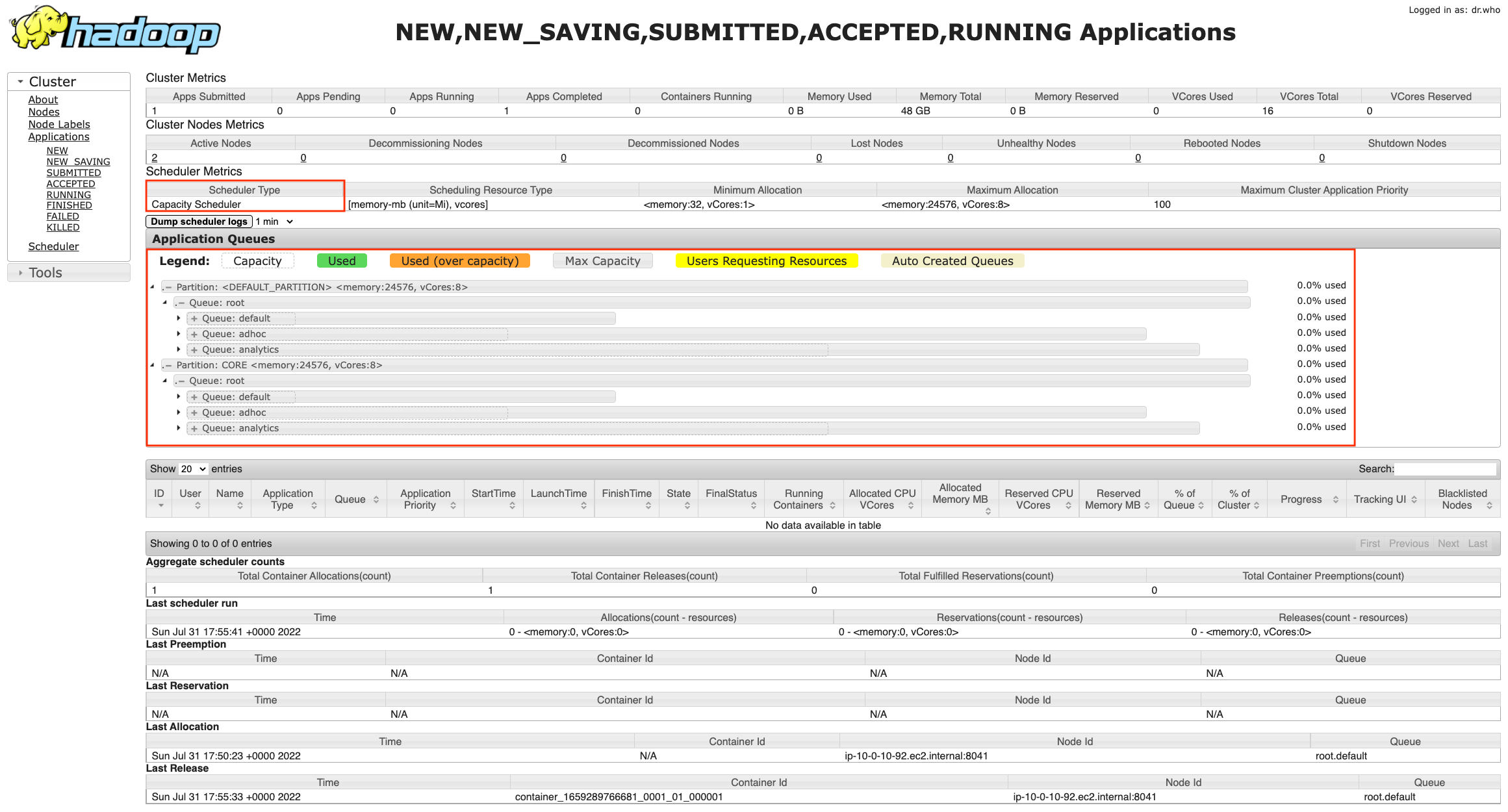
- Access the Hadoop YARN resource manager UI on the
emr-cluster-capacity-schedulercluster to review the CapacityScheduler setup. For instructions on how to access the UI on Amazon EMR, refer to View web interfaces hosted on Amazon EMR clusters.
- SSH into the
emr-cluster-capacity-schedulercluster and review the following files.For instructions on how to SSH into the EMR primary node, refer to Connect to the master node using SSH.
-
/etc/hadoop/conf/yarn-site.xml/etc/hadoop/conf/capacity-scheduler.xml
All the parameters set using the yarn-site and capacity-scheduler classifiers are reflected in these files. If an admin wants to update CapacityScheduler configs, they can directly update capacity-scheduler.xml and run the following command to apply the changes without interrupting any running jobs and services:
Changes to yarn-site.xml require the ResourceManager service to be restarted, which interrupts the running jobs. As a best practice, refrain from manual modifications and use version control for change management.
The CloudFormation template adds a bootstrap action to create test users (user1, user2, user3, user4, user5 and user6) on all the nodes and adds a step script to create HDFS directories for the test users.
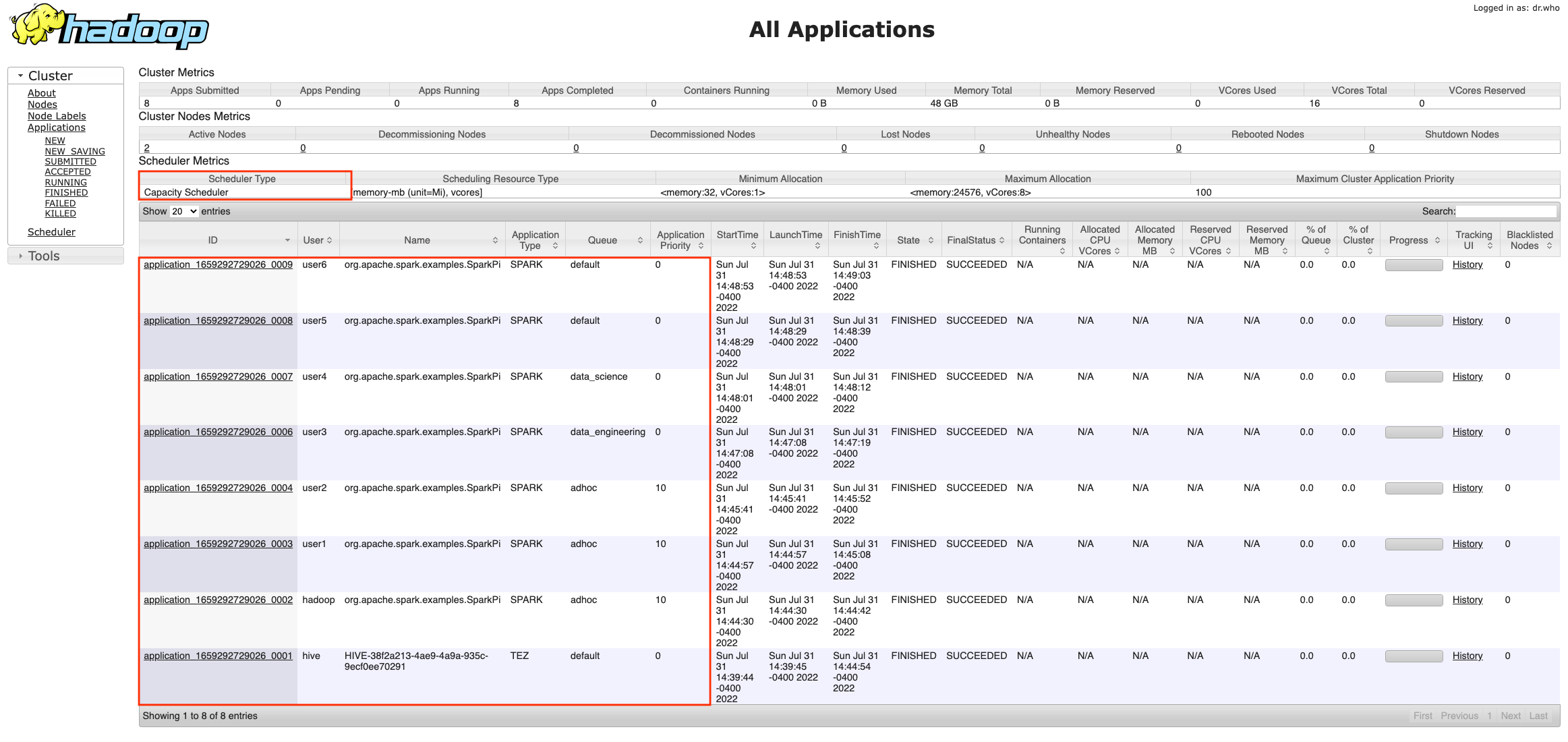
Users can SSH into the primary node, sudo as different users and submit Spark jobs to verify the job submission and CapacityScheduler behavior:
You can validate the results from the resource manager web UI.
Clean up
To avoid incurring future charges, delete the resources you created.
- Delete the CloudFormation stack:
- Delete the S3 bucket:
The command deletes the bucket and all files underneath it. The files may not be recoverable after deletion.
Conclusion
In this post, we discussed Apache Hadoop YARN and its various components. We discussed the types of schedulers available in Hadoop YARN. We dived deep in to the specifics of Hadoop YARN CapacityScheduler and the use of Dominant Resource Fairness to efficiently allocate resources to submitted jobs. We also showcased how to implement the discussed concepts using AWS CloudFormation.
We encourage you to use this post as a starting point to implement CapacityScheduler on Amazon EMR (on Amazon EC2) and customize the solution to meet your specific data platform goals.
About the authors
![]() Suvojit Dasgupta is a Sr. Lakehouse Architect at Amazon Web Services. He works with customers to design and build data solutions on AWS.
Suvojit Dasgupta is a Sr. Lakehouse Architect at Amazon Web Services. He works with customers to design and build data solutions on AWS.
![]() Bharat Gamini is a Data Architect focused on big data and analytics at Amazon Web Services. He helps customers architect and build highly scalable, robust, and secure cloud-based analytical solutions on AWS.
Bharat Gamini is a Data Architect focused on big data and analytics at Amazon Web Services. He helps customers architect and build highly scalable, robust, and secure cloud-based analytical solutions on AWS.
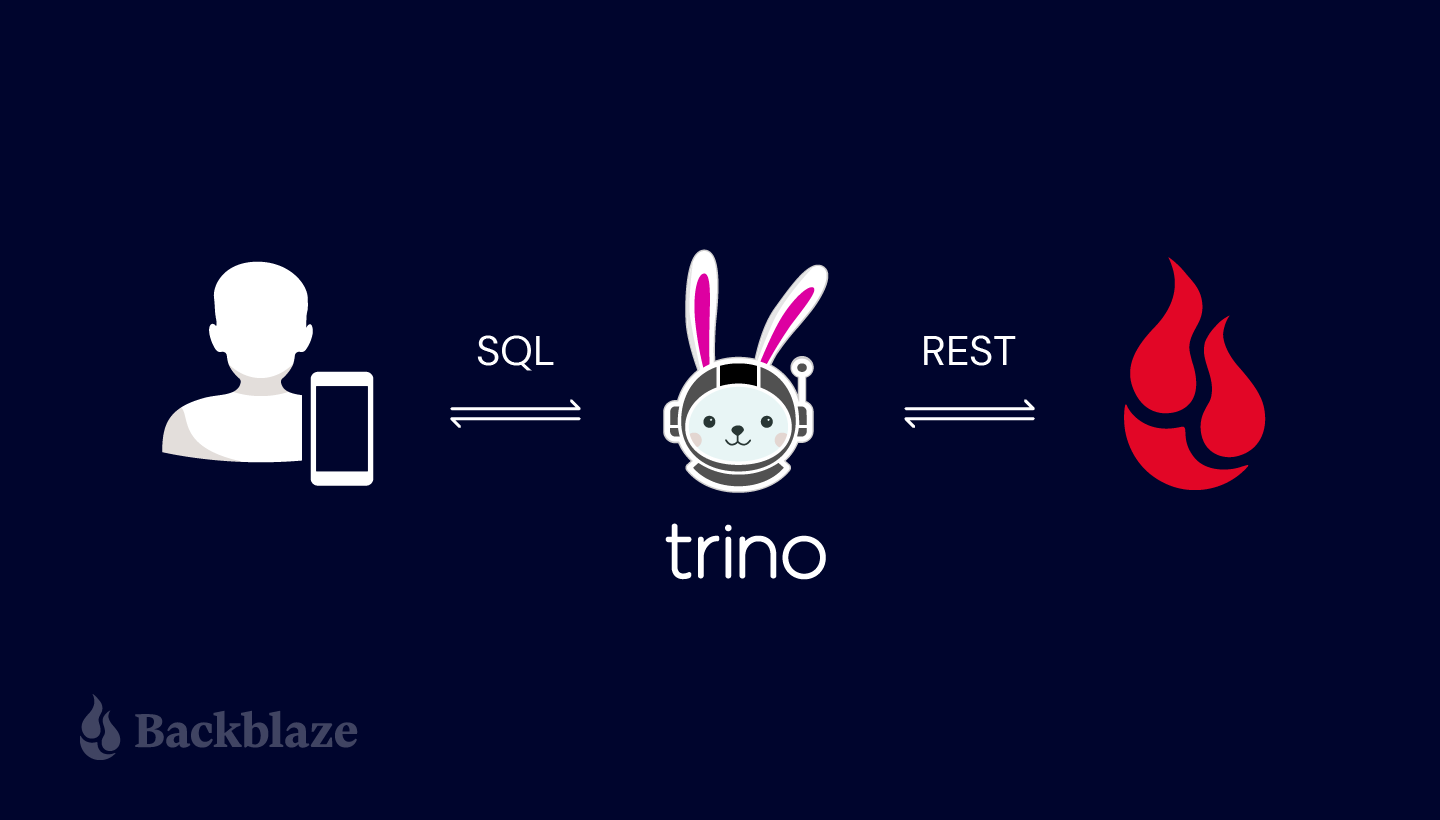
Storing and Querying Analytical Data in Backblaze B2
Post Syndicated from Greg Hamer original https://www.backblaze.com/blog/storing-and-querying-analytical-data-in-backblaze-b2/
Note: This blog is the result of a collaborative effort of the Backblaze Evangelism team members Andy Klein, Pat Patterson and Greg Hamer.
Have You Ever Used Backblaze B2 Cloud Storage for Your Data Analytics?
Backblaze customers find that Backblaze B2 Cloud Storage is optimal for a wide variety of use cases. However, one application that many teams might not yet have tried is using Backblaze B2 for data analytics. You may find that having a highly reliable pre-provisioned storage option like Backblaze B2 Cloud Storage for your data lakes can be a useful and very cost-effective alternative for your data analytic workloads.
This article is an introductory primer on getting started using Backblaze B2 for data analytics that uses our Drive Stats as the example of the data being analyzed. For readers new to data lakes, this article can help you get your own data lake up and going on Backblaze B2 Cloud Storage.
As you probably know, a commonly used technology for data analytics is SQL (Structured Query Language). Most people know SQL from databases. However, SQL can be used against collections of files stored outside of databases, now commonly referred to as data lakes. We will focus here on several options using SQL for analyzing Drive Stats data stored on Backblaze B2 Cloud Storage.
It should be noted that data lakes most frequently prove optimal for read-only or append-only datasets. Whereas databases often remain optimal for “hot” data with active insert, update and delete of individual rows, and especially updates of individual column values on individual rows.
We can only scratch the surface of storing, querying, and analyzing tabular data in a single blog post. So for this introductory article, we will:
- Briefly explain the Drive Stats data.
- Introduce open-source Trino as one option for executing SQL against the Drive Stats data.
- Query Drive Stats data both in raw CSV format versus enhanced performance after transforming the data into the open-source Apache Parquet format.
The sections below take a step-by-step approach including details on the performance improvements realized when implementing recommended data engineering options. We start with a demonstration of analysis of raw data. Then progress through “data engineering” that transforms the data into formats that are optimal for accelerating repeated queries of the dataset. We conclude by highlighting our hosted, consolidated, complete Drive Stats dataset.
As mentioned earlier, this blog post is intended only as an introductory primer. In future blog posts, we will detail additional best practices and other common issues and opportunities with data analysis using Backblaze B2.
Backblaze Hard Drive Data and Stats (aka Drive Stats)
Drive Stats is an open-source data set of the daily metrics on the hard drives in Backblaze’s cloud storage infrastructure that Backblaze has open-sourced starting with April 2013. Currently, Drive Stats comprises nearly 300 million records, occupying over 90GB of disk space in raw comma-separated values (CSV) format, rising by over 200,000 records, or about 75MB of CSV data, per day. Drive Stats is an append-only dataset effectively logging daily statistics that once written are never updated or deleted.
The Drive Stats dataset is not quite “big data,” where datasets range from a few dozen terabytes to many zettabytes, but enough that physical data architecture starts to have a significant effect in both the amount of space that the data occupies and how the data can be accessed.
At the end of each quarter, Backblaze creates a CSV file for each day of data, ZIP those 90 or so files together, and make the compressed file available for download from a Backblaze B2 Bucket. While it’s easy to download and decompress a single file containing three months of data, this data architecture is not very flexible. With a little data engineering, though, it’s possible to make analytical data, such as the Drive Stats data set, available for modern data analysis tools to directly access from cloud storage, unlocking new opportunities for data analysis and data science.
Later, for comparison, we include a brief demonstration of performance of the data lake versus a traditional relational database. Architecturally, a difference between a data lake and a database is that databases integrate together both the query engine and the data storage. When data is either inserted or loaded into a database, the database has optimized internal storage structures it uses. Alternatively, with a data lake, the query engine and the data storage are separate. What we highlight below are basics for optimizing data storage in a data lake to enable the query engine to deliver the fastest query response times.
As with all data analysis, it is helpful to understand details of what the data represents. Before showing results, let’s take a deeper dive into the nature of the Drive Stats data. (For readers interested in first reviewing outcomes and improved query performance results, please skip ahead to the later sections “Compressed CSV” and “Enter Apache Parquet.”)
Navigating the Drive Stats Data
At Backblaze we collect a Drive Stats record from each hard drive, each day, containing the following data:
- date: the date of collection.
- serial_number: the unique serial number of the drive.
- model: the manufacturer’s model number of the drive.
- capacity_bytes: the drive’s capacity, in bytes.
- failure: 1 if this was the last day that the drive was operational before failing, 0 if all is well.
- A collection of SMART attributes. The number of attributes collected has risen over time; currently we store 87 SMART attributes in each record, each one in both raw and normalized form, with field names of the form smart_n_normalized and smart_n_raw, where n is between 1 and 255.
In total, each record currently comprises 179 fields of data describing the state of an individual hard drive on a given day (the number of SMART attributes collected has risen over time).
Comma-Separated Values, a Lingua Franca for Tabular Data
A CSV file is a delimited text file that, as its name implies, uses a comma to separate values. Typically, the first line of a CSV file is a header containing the field names for the data, separated by commas. The remaining lines in the file hold the data: one line per record, with each line containing the field values, again separated by commas.
Here’s a subset of the Drive Stats data represented as CSV. We’ve omitted most of the SMART attributes to make the records more manageable.
date,serial_number,model,capacity_bytes,failure, smart_1_normalized,smart_1_raw 2022-01-01,ZLW18P9K,ST14000NM001G,14000519643136,0,73,20467240 2022-01-01,ZLW0EGC7,ST12000NM001G,12000138625024,0,84,228715872 2022-01-01,ZA1FLE1P,ST8000NM0055,8001563222016,0,82,157857120 2022-01-01,ZA16NQJR,ST8000NM0055,8001563222016,0,84,234265456 2022-01-01,1050A084F97G,TOSHIBA MG07ACA14TA,14000519643136,0,100,0
Currently, we create a CSV file for each day’s data, comprising a record for each drive that was operational at the beginning of that day. The CSV files are each named with the appropriate date in year-month-day order, for example, 2022-06-28.csv. As mentioned above, we make each quarter’s data available as a ZIP file containing the CSV files.
At the beginning of the last Drive Stats quarter, Jan 1, 2022, we were spinning over 200,000 hard drives, so each daily file contained over 200,000 lines and occupied nearly 75MB of disk space. The ZIP file containing the Drive Stats data for the first quarter of 2022 compressed 90 files totaling 6.63GB of CSV data to a single 1.06GB file made available for download here.
Big Data Analytics in the Cloud with Trino
Zipped CSV files allow users to easily download, inspect, and analyze the data locally, but a new generation of tools allows us to explore and query data in situ on Backblaze B2 and other cloud storage platforms. One example is the open-source Trino query engine (formerly known as Presto SQL). Trino can natively query data in Backblaze B2, Cassandra, MySQL, and many other data sources without copying that data into its own dedicated store.
A powerful capability of Trino is that it is a distributed query engine and offers what is sometimes referred to as massively parallel processing (MPP). Thus, adding more nodes in your Trino compute cluster consistently delivers dramatically shorter query execution times. Faster results are always desirable. We achieved the results we report below running Trino on only a single node.
Note: If you are unfamiliar with Trino, the open-source project was previously known as Presto and leverages the Hadoop ecosystem.
In preparing this blog post, our team used Brian Olsen’s excellent Hive connector over MinIO file storage tutorial as a starting point for integrating Trino with Backblaze B2. The tutorial environment includes a preconfigured Docker Compose environment comprising the Trino Docker image and other required services for working with data in Backblaze B2. We brought up the environment in Docker Desktop; alternately on ThinkPads and MacBook Pros.
As a first step, we downloaded the data set for the most recent quarter, unzipped it to our local disks, and then finally reuploaded the unzipped CSV into Backblaze B2 buckets. As mentioned above, the uncompressed CSV data occupies 6.63GB of storage, so we confined our initial explorations to just a single day’s data: over 200,000 records, occupying 72.8MB.
A Word About Apache Hive
Trino accesses analytical data in Backblaze B2 and other cloud storage platforms via its Hive connector. Quoting from the Trino documentation:
The Hive connector allows querying data stored in an Apache Hive data warehouse. Hive is a combination of three components:
- Data files in varying formats, that are typically stored in the Hadoop Distributed File System (HDFS) or in object storage systems such as Amazon S3.
- Metadata about how the data files are mapped to schemas and tables. This metadata is stored in a database, such as MySQL, and is accessed via the Hive metastore service.
- A query language called HiveQL. This query language is executed on a distributed computing framework such as MapReduce or Tez.
Trino only uses the first two components: the data and the metadata. It does not use HiveQL or any part of Hive’s execution environment.
The Hive connector tutorial includes Docker images for the Hive metastore service (HMS) and MariaDB, so it’s a convenient way to explore this functionality with Backblaze B2.
Configuring Trino for Backblaze B2
The tutorial uses MinIO, an open-source implementation of the Amazon S3 API, so it was straightforward to adapt the sample MinIO configuration to Backblaze B2’s S3 Compatible API by just replacing the endpoint and credentials. Here’s the b2.properties file we created:
connector.name=hive hive.metastore.uri=thrift://hive-metastore:9083 hive.s3.path-style-access=true hive.s3.endpoint=https://s3.us-west-004.backblazeb2.com hive.s3.aws-access-key= hive.s3.aws-secret-key= hive.non-managed-table-writes-enabled=true hive.s3select-pushdown.enabled=false hive.storage-format=CSV hive.allow-drop-table=true
Similarly, we edited the Hive configuration files, again replacing the MinIO configuration with the corresponding Backblaze B2 values. Here’s a sample core-site.xml:
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>s3a://b2-trino-getting-started</value>
</property>
<!-- B2 properties -->
<property>
<name>fs.s3a.connection.ssl.enabled</name>
<value>true</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>https://s3.us-west-004.backblazeb2.com</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<value><my b2 application key id></value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value><my b2 application key id></value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
<property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
</property>
</configuration>
We made a similar set of edits to metastore-site.xml and restarted the Docker instances so our changes took effect.
Uncompressed CSV
Our first test validated creating a table and running a query on a single-day CSV data set. Hive tables are configured with the directory containing the actual data files, so we uploaded 2020-01-01.csv from a local disk to data_20220101_csv/2020-01-01.csv in a Backblaze B2 bucket, opened the Trino CLI, and created a schema and a table:
CREATE SCHEMA b2.ds
WITH (location = 's3a://b2-trino-getting-started/');
USE b2.ds;
CREATE TABLE jan1_csv (
date VARCHAR,
serial_number VARCHAR,
model VARCHAR,
capacity_bytes VARCHAR,
failure VARCHAR,
smart_1_normalized VARCHAR,
smart_1_raw VARCHAR,
...
smart_255_normalized VARCHAR,
smart_255_raw VARCHAR)
WITH (format = 'CSV',
skip_header_line_count = 1,
external_location = '
s3a://b2-trino-getting-started/data_20220101_csv');
Unfortunately, the Trino Hive connector only supports the VARCHAR data type when accessing CSV data, but, as we’ll see in a moment, we can use the CAST function in queries to convert character data to numeric and other types.
Now to run some queries! A good test is to check if all the data is there:
trino:ds> SELECT COUNT(*) FROM jan1_csv; _col0 -------- 206954 (1 row) Query 20220629_162533_00024_qy4c6, FINISHED, 1 node Splits: 8 total, 8 done (100.00%) 8.23 [207K rows, 69.4MB] [25.1K rows/s, 8.43MB/s]
Note: If you’re wondering about the discrepancy between the size of the CSV file–72.8MB–and the amount of data read by Trino–69.4MB–it’s accounted for in the different usage of the ‘MB’ abbreviation. For instance Mac interprets MB as a megabyte, 1,000,000 bytes, while Trino is reporting mebibytes, 1,048,576 bytes. Strictly speaking, Trino should use the abbreviation MiB. Pat opened an issue for this (with a goal of fixing it and submitting a pull request to the Trino project).
Now let’s see how many drives failed that day, grouped by the drive model:
trino:ds> SELECT model, COUNT(*) as failures
-> FROM jan1_csv
-> WHERE failure = 1
-> GROUP BY model
-> ORDER BY failures DESC;
model | failures
--------------------+----------
TOSHIBA MQ01ABF050 | 1
ST4000DM005 | 1
ST8000NM0055 | 1
(3 rows)
Query 20220629_162609_00025_qy4c6, FINISHED, 1 node
Splits: 17 total, 17 done (100.00%)
8.23 [207K rows, 69.4MB] [25.1K rows/s, 8.43MB/s]
Notice that the query execution time is identical between the two queries. This makes sense–the time taken to run the query is dominated by the time required to download the data from Backblaze B2.
Finally, we can use the CAST function with SUM and ROUND to see how many exabytes of storage we were spinning on that day:
trino:ds> SELECT ROUND(SUM(CAST(capacity_bytes AS bigint))/1e+18, 2) FROM jan1_csv; _col0 ------- 2.25 (1 row) Query 20220629_172703_00047_qy4c6, FINISHED, 1 node Splits: 12 total, 12 done (100.00%) 7.83 [207K rows, 69.4MB] [26.4K rows/s, 8.86MB/s]
Although this performance may seem too long running, please note that this is against raw data. What we are highlighting here with Drive Stats data can also be used for querying data in log files. As new records are written on this append-only dataset they immediately appear as new rows in the query. This is very powerful for both real-time and near real-time analysis, and faster performance is easily achieved by scaling out the Trino cluster. Remember, Trino is a distributed query engine. For this demonstration, we have limited Trino to running on just a single node.
Compressed CSV
This is pretty neat, but not exactly fast. Extrapolating, we might expect it to take about 12 minutes to run a query against a whole quarter of Drive Stats data.
Can we improve performance? Absolutely–we simply need to reduce the amount of data that needs to be downloaded for each query!
Commonplace in the world of data analytics are data pipelines, often known as ETL for Extract, Transform, and Load. Where data is repeatedly queried, it is often advantageous to “transform” data from the raw form that it originates in into some format more optimized for the repeated queries that follow through the next stages of that data’s life cycle.
For our next test we will perform an elementary transformation of the data using a lossless compression of the CSV data with Hive’s preferred gzip format, resulting in an 11.7 MB file, 2020-01-01.csv.gz. After uploading the compressed file to data_20220101_csv_gz/2020-01-01.csv.gz, we created a second table, copying the schema from the first:
CREATE TABLE jan1_csv_gz (
LIKE jan1_csv
)
WITH (FORMAT = 'CSV',
EXTERNAL_LOCATION = 's3a://b2-trino-getting-started/data_20220101_csv_gz');
Trying the failure count query:
trino:ds> SELECT model, COUNT(*) as failures
-> FROM jan1_csv_gz
-> WHERE failure = 1
-> GROUP BY model
-> ORDER BY failures DESC;
model | failures
--------------------+----------
TOSHIBA MQ01ABF050 | 1
ST8000NM0055 | 1
ST4000DM005 | 1
(3 rows)
Query 20220629_162713_00027_qy4c6, FINISHED, 1 node
Splits: 15 total, 15 done (100.00%)
2.71 [207K rows, 11.1MB] [76.4K rows/s, 4.1MB/s]
As you might expect, given that Trino has to download less than ⅙ as much data as previously, the query time fell dramatically–from just over 8 seconds to under 3 seconds. Can we do even better than this?
Enter Apache Parquet
The issue with running this kind of analytical query is that it often results in a “full table scan”–Trino has to read the model and failure fields from every record to execute the query. The row-oriented layout of CSV data means that Trino ends up reading the entire file. We can get around this by using a file format designed specifically for analytical workloads.
While CSV files comprise a line of text for each record, Parquet is a column-oriented, binary file format, storing the binary values for each column contiguously. Here’s a simple visualization of the difference between row and column orientation:
Table representation:
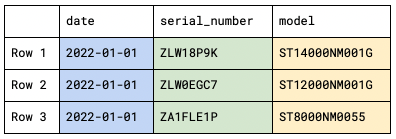
Row orientation:

Column Orientation:

Parquet also implements run-length encoding and other compression techniques. Where a series of records have the same value for a given field the Parquet file need only store the value and the number of repetitions:

The result is a compact file format well suited for analytical queries.
There are many tools to manipulate tabular data from one format to another. In this case, we wrote a very simple Python script that used the pyarrow library to do the job:
import pyarrow.csv as csv
import pyarrow.parquet as parquet
filename = '2022-01-01.csv'
parquet.write_table(csv.read_csv(filename),
filename.replace('.csv', '.parquet'))
The resulting Parquet file occupies 12.8MB–only 1.1MB more than the gzip file. Again, we uploaded the resulting file and created a table in Trino.
CREATE TABLE jan1_parquet (
date DATE,
serial_number VARCHAR,
model VARCHAR,
capacity_bytes BIGINT,
failure TINYINT,
smart_1_normalized BIGINT,
smart_1_raw BIGINT,
...
smart_255_normalized BIGINT,
smart_255_raw BIGINT)
WITH (FORMAT = 'PARQUET',
EXTERNAL_LOCATION =
's3a://b2-trino-getting-started/data_20220101_parquet);
Note that the conversion to Parquet automatically formatted the data using appropriate types, which we used in the table definition.
Let’s run a query and see how Parquet fares against compressed CSV:
trino:ds> SELECT model, COUNT(*) as failures
-> FROM jan1_parquet
-> WHERE failure = 1
-> GROUP BY model
-> ORDER BY failures DESC;
model | failures
--------------------+----------
TOSHIBA MQ01ABF050 | 1
ST4000DM005 | 1
ST8000NM0055 | 1
(3 rows)
Query 20220629_163018_00031_qy4c6, FINISHED, 1 node
Splits: 15 total, 15 done (100.00%)
0.78 [207K rows, 334KB] [265K rows/s, 427KB/s]
The test query is executed in well under a second! Looking at the last line of output, we can see that the same number of rows were read, but only 334KB of data was retrieved. Trino was able to retrieve just the two columns it needed, out of the 179 columns in the file, to run the query.
Similar analytical queries execute just as efficiently. Calculating the total amount of storage in exabytes:
trino:ds> SELECT ROUND(SUM(capacity_bytes)/1e+18, 2) FROM jan1_parquet; _col0 ------- 2.25 (1 row) Query 20220629_163058_00033_qy4c6, FINISHED, 1 node Splits: 10 total, 10 done (100.00%) 0.83 [207K rows, 156KB] [251K rows/s, 189KB/s]
What was the capacity of the largest drive in terabytes?
trino:ds> SELECT max(capacity_bytes)/1e+12 FROM jan1_parquet;
_col0
-----------------
18.000207937536
(1 row)
Query 20220629_163139_00034_qy4c6, FINISHED, 1 node
Splits: 10 total, 10 done (100.00%)
0.80 [207K rows, 156KB] [259K rows/s, 195KB/s]
Parquet’s columnar layout excels with analytical workloads, but if we try a query more suited to an operational database, Trino has to read the entire file, as we would expect:
trino:ds> SELECT * FROM jan1_parquet WHERE serial_number = 'ZLW18P9K';
date | serial_number | model | capacity_bytes | failure
------------+---------------+---------------+----------------+--------
2022-01-01 | ZLW18P9K | ST14000NM001G | 14000519643136 | 0
(1 row)
Query 20220629_163206_00035_qy4c6, FINISHED, 1 node
Splits: 5 total, 5 done (100.00%)
2.05 [207K rows, 12.2MB] [101K rows/s, 5.95MB/s]
Scaling Up
After validating our Trino configuration with just a single day’s data, our next step up was to create a Parquet file containing an entire quarter. The file weighed in at 1.0GB, a little smaller than the zipped CSV.
Here’s the failed drives query for the entire quarter, limited to the top 10 results:
trino:ds> SELECT model, COUNT(*) as failures
-> FROM q1_2022_parquet
-> WHERE failure = 1
-> GROUP BY model
-> ORDER BY failures DESC
-> LIMIT 10;
model | failures
----------------------+----------
ST4000DM000 | 117
TOSHIBA MG07ACA14TA | 88
ST8000NM0055 | 86
ST12000NM0008 | 73
ST8000DM002 | 38
ST16000NM001G | 24
ST14000NM001G | 24
HGST HMS5C4040ALE640 | 21
HGST HUH721212ALE604 | 21
ST12000NM001G | 20
(10 rows)
Query 20220629_183338_00050_qy4c6, FINISHED, 1 node
Splits: 43 total, 43 done (100.00%)
3.38 [18.8M rows, 15.8MB] [5.58M rows/s, 4.68MB/s]
Of course, those are absolute failure numbers; they don’t take account of how many of each drive model are in use. We can construct a more complex query that tells us the percentages of failed drives, by model:
trino:ds> SELECT drives.model AS model, drives.drives AS drives,
-> failures.failures AS failures,
-> ROUND((CAST(failures AS double)/drives)*100, 6) AS percentage
-> FROM
-> (
-> SELECT model, COUNT(*) as drives
-> FROM q1_2022_parquet
-> GROUP BY model
-> ) AS drives
-> RIGHT JOIN
-> (
-> SELECT model, COUNT(*) as failures
-> FROM q1_2022_parquet
-> WHERE failure = 1
-> GROUP BY model
-> ) AS failures
-> ON drives.model = failures.model
-> ORDER BY percentage DESC
-> LIMIT 10;
model | drives | failures | percentage
----------------------+--------+----------+------------
ST12000NM0117 | 873 | 1 | 0.114548
ST10000NM001G | 1028 | 1 | 0.097276
HGST HUH728080ALE604 | 4504 | 3 | 0.066607
TOSHIBA MQ01ABF050M | 26231 | 13 | 0.04956
TOSHIBA MQ01ABF050 | 24765 | 12 | 0.048455
ST4000DM005 | 3331 | 1 | 0.030021
WDC WDS250G2B0A | 3338 | 1 | 0.029958
ST500LM012 HN | 37447 | 11 | 0.029375
ST12000NM0007 | 118349 | 19 | 0.016054
ST14000NM0138 | 144333 | 17 | 0.011778
(10 rows)
Query 20220629_191755_00010_tfuuz, FINISHED, 1 node
Splits: 82 total, 82 done (100.00%)
8.70 [37.7M rows, 31.6MB] [4.33M rows/s, 3.63MB/s]
This query took twice as long as the last one! Again, data transfer time is the limiting factor–Trino downloads the data for each subquery. A real-world deployment would take advantage of the Hive Connector’s storage caching feature to avoid repeatedly retrieving the same data.
Picking the Right Tool for the Job
You might be wondering how a relational database would stack up against the Trino/Parquet/Backblaze B2 combination. As a quick test, we installed PostgreSQL 14 on a MacBook Pro, loaded the same quarter’s data into a table, and ran the same set of queries:
Count Rows
sql_stmt=# \timing Timing is on. sql_stmt=# SELECT COUNT(*) FROM q1_2022; count ---------- 18845260 (1 row) Time: 1579.532 ms (00:01.580)
Absolute Number of Failures
sql_stmt=# SELECT model, COUNT(*) as failures FROM q1_2022 WHERE failure = 't' GROUP BY model ORDER BY failures DESC LIMIT 10;
model | failures
----------------------+----------
ST4000DM000 | 117
TOSHIBA MG07ACA14TA | 88
ST8000NM0055 | 86
ST12000NM0008 | 73
ST8000DM002 | 38
ST14000NM001G | 24
ST16000NM001G | 24
HGST HMS5C4040ALE640 | 21
HGST HUH721212ALE604 | 21
ST12000NM001G | 20
(10 rows)
Time: 2052.019 ms (00:02.052)
Relative Number of Failures
sql_stmt=# SELECT drives.model AS model, drives.drives AS drives, failures.failures, ROUND((CAST(failures AS numeric)/drives)*100, 6) AS percentage FROM ( SELECT model, COUNT(*) as drives FROM q1_2022 GROUP BY model ) AS drives RIGHT JOIN ( SELECT model, COUNT(*) as failures FROM q1_2022 WHERE failure = 't' GROUP BY model ) AS failures ON drives.model = failures.model ORDER BY percentage DESC LIMIT 10;
model | drives | failures | percentage
----------------------+--------+----------+------------
ST12000NM0117 | 873 | 1 | 0.114548
ST10000NM001G | 1028 | 1 | 0.097276
HGST HUH728080ALE604 | 4504 | 3 | 0.066607
TOSHIBA MQ01ABF050M | 26231 | 13 | 0.049560
TOSHIBA MQ01ABF050 | 24765 | 12 | 0.048455
ST4000DM005 | 3331 | 1 | 0.030021
WDC WDS250G2B0A | 3338 | 1 | 0.029958
ST500LM012 HN | 37447 | 11 | 0.029375
ST12000NM0007 | 118349 | 19 | 0.016054
ST14000NM0138 | 144333 | 17 | 0.011778
(10 rows)
Time: 3831.924 ms (00:03.832)
Retrieve a Single Record by Serial Number and Date
Modifying the query, since we have an entire quarter’s data:
sql_stmt=# SELECT * FROM q1_2022 WHERE serial_number = 'ZLW18P9K' AND date = '2022-01-01';
date | serial_number | model | capacity_bytes | failure
------------+---------------+---------------+----------------+--------
2022-01-01 | ZLW18P9K | ST14000NM001G | 14000519643136 | f (1 row)
Time: 1690.091 ms (00:01.690)
For comparison, we tried to run the same query against the quarter’s data in Parquet format, but Trino crashed with an out of memory error after 58 seconds. Clearly some tuning of the default configuration is required!
Bringing the numbers together for the quarterly data sets. All times are in seconds.
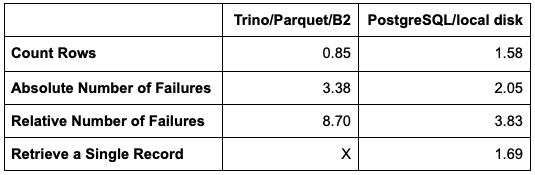
PostgreSQL is faster for most operations, but not by much, especially considering that its data is on the local SSD, rather than Backblaze B2!
It’s worth mentioning that there are yet more tuning optimizations that we have not demonstrated in this exercise. For instance, the Trino Hive connector supports storage caching. Implementing a cache yields further performance gains by avoiding repeatedly retrieving the same data from Backblaze B2. Further, Trino is a distributed query engine. Trino’s architecture is horizontally scalable. This means that Trino can also deliver shorter query run times by adding more nodes in your Trino compute cluster. We have limited all timings in this demonstration to Trino running on just a single node.
Partitioning Your Data Lake
Our final exercise was to create a single Drive Stats dataset containing all nine years of Drive Stats data. As stated above, at the time of writing the full Drive Stats dataset comprises nearly 300 million records, occupying over 90GB of disk space when in raw CSV format, rising by over 200,000 records per day, or about 75MB of CSV data.
As the dataset grows in size, an additional data engineering best practice is to include partitions.
In the introduction we mentioned that databases use optimized internal storage structures. Foremost among these are indexes. Data lakes have limited support for indexes. Data lakes do, however, support partitions. Data lake partitions are functionally similar to what databases alternately refer to as either a primary key index or index-organized tables. Regardless of the name, they effectively achieve faster data retrieval by having the data itself physically sorted. Since Drive Stats is append-only, when sorting on a date field, new records are appended to the dataset.
Having the data physically sorted greatly aids retrieval in cases that are known as range queries. To achieve fastest retrieval on a given query, it is important to only retrieve data that resolves true on the predicate in the WHERE clause. In the case of Drive Stats, for a query on only a single month or several consecutive months we get the fastest time to the result if we can read only the data for these months. Without partitioning Trino would need to do a full table scan, resulting in slower response due to the overhead of reading records for which the WHERE clause logic resolves to false. Organizing the Drive Stats data into partitions enables Trino to efficiently skip records that resolve the WHERE clause to false. Thus with partitions, many queries are far more efficient and incur the read cost only of those records whose WHERE clause logic resolves to true.
Our final transformation required a tweak to the Python script to iterate over all of the Drive Stats CSV files, writing Parquet files partitioned by year and month, so the files have prefixes of the form.
/drivestats/year={year}/month={month}/
For example:
/drivestats/year=2021/month=12/
The number of SMART attributes reported can change from one day to the next, and a single Parquet file can have only one schema, so there are one or more files with each prefix, named
{year}-{month}-{index}.parquet
For example:
2021-12-1.parquet
Again, we uploaded the resulting files and created a table in Trino.
CREATE TABLE drivestats (
serial_number VARCHAR,
model VARCHAR,
capacity_bytes BIGINT,
failure TINYINT,
smart_1_normalized BIGINT,
smart_1_raw BIGINT,
...
smart_255_normalized BIGINT,
smart_255_raw BIGINT,
day SMALLINT,
year SMALLINT,
month SMALLINT
)
WITH (format = 'PARQUET',
PARTITIONED_BY = ARRAY['year', 'month'],
EXTERNAL_LOCATION = 's3a://b2-trino-getting-started/drivestats-parquet');
Note that the conversion to Parquet automatically formatted the data using appropriate types, which we used in the table definition.
This command tells Trino to scan for partition files.
CALL system.sync_partition_metadata('ds', 'drivestats', 'FULL');
Let’s run a query and see the performance against the full Drive Stats dataset in Parquet format, partitioned by month:
trino:ds> SELECT COUNT(*) FROM drivestats; _col0 ----------- 296413574 (1 row) Query 20220707_182743_00055_tshdf, FINISHED, 1 node Splits: 412 total, 412 done (100.00%) 15.84 [296M rows, 5.63MB] [18.7M rows/s, 364KB/s]
It takes 16 seconds to count the total number of records, reading only 5.6MB of the 15.3GB total data.
Next, let’s run a query against just one month’s data:
trino:ds> SELECT COUNT(*) FROM drivestats WHERE year = 2022 AND month = 1; _col0 --------- 6415842 (1 row) Query 20220707_184801_00059_tshdf, FINISHED, 1 node Splits: 16 total, 16 done (100.00%) 0.85 [6.42M rows, 56KB] [7.54M rows/s, 65.7KB/s]
Counting the records for a given month takes less than a second, retrieving just 56KB of data–partitioning is working!
Now we have the entire Drive Stats data set loaded into Backblaze B2 in an efficient format and layout for running queries. Our next blog post will look at some of the queries we’ve run to clean up the data set and gain insight into nine years of hard drive metrics.
Conclusion
We hope that this article inspires you to try using Backblaze for your data analytics workloads if you’re not already doing so, and that it also serves as a useful primer to help you set up your own data lake using Backblaze B2 Cloud Storage. Our Drive Stats data is just one example of the type of data set that can be used for data analytics on Backblaze B2.
Hopefully, you too will find that Backblaze B2 Cloud Storage can be a useful, powerful, and very cost effective option for your data lake workloads.
If you’d like to get started working with analytical data in Backblaze B2, sign up here for 10 GB storage, free of charge, and get to work. If you’re already storing and querying analytical data in Backblaze B2, please let us know in the comments what tools you’re using and how it’s working out for you!
If you already work with Trino (or other data lake analytic engines), and would like connection credentials for our partitioned, Parquet, complete Drive Stats data set that is now hosted on Backblaze B2 Cloud Storage, please contact us at [email protected].
Future blog posts focused on Drive Stats and analytics will be using this complete Drive Stats dataset.
Similarly, please let us know if you would like to run a proof of concept hosting your own data in a Backblaze B2 data lake and would like the assistance of the Backblaze Developer Evangelism team.
And lastly, if you think this article may be of interest to your colleagues, we’d very much appreciate you sharing it with them.
The post Storing and Querying Analytical Data in Backblaze B2 appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
UniFi Teleport – Easy Setup VPN
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=v_NrTVbO9oE
Charles Clover | Rewilding the Sea: How to Save Our Oceans | Talks at Google
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=Ci_vTJNTBjE
Are Your Apps Exposed? Know Faster With Application Discovery in InsightAppSec
Post Syndicated from Ronan McCrory original https://blog.rapid7.com/2022/08/16/are-your-apps-exposed-know-faster-with-application-discovery-in-insightappsec/

“Yes, I know what applications we have publicly exposed.”
How many times have you said that with confidence? I bet not too many. With the rapid pace of development that engineering teams can work at, it is becoming increasingly difficult to know what apps you have exposed to the internet, adding potential security risks to your organization.
This is where InsightAppSec’s new application discovery feature, powered by Rapid7’s Project Sonar, can help to fill in these gaps.
What exactly is application discovery?
Using the data supplied by Project Sonar — which was started almost a decade ago and conducts internet-wide surveys across more than 70 different services and protocols — you can enter a domain within InsightAppSec and run a discovery search. You will get back a list of results that are linked to that initial domain, along with some useful metadata.
We have had this feature open as a beta for various customers and received real-world examples of how they used it. Here are two key use cases for this functionality.
Application ports
After running a discovery scan, one customer noticed that a “business-critical web application was found on an open port that it shouldn’t have been on.” After getting this data, they were able to work with that application team and get it locked down.
App inventory
Various customers noted that running a discovery scan helped them to get a better sense of their public-facing app inventory. From this, they were able to carry out various tasks, including “checking the list against their own list for accountability purposes” and “having relevant teams review the list before attacking.” They did this by exporting the discovery results to a CSV file and reviewing them outside of InsightAppSec.
How exactly does it work?
Running a discovery search shouldn’t be difficult, so we’ve made the process as easy as possible. Start by entering a domain that you own, and hit “Discover.” This will bring back a list of domains, along with their IP, Port, and Last Seen date (based on the last time a Sonar scan has found it.)
From here, you could add a domain to your allow list and then run a scan against it, using the scan config setup process.

If you see some domains that you are not sure about, you might decide that you need to know more about the domains before you run a scan. You can do this by exporting the data as a CSV and then running your own internal process on these before taking any next steps.
How do I access application discovery?
Running a discovery scan is currently available to all InsightAppSec Admins, but Admins can grant other users or sets of users access to the feature using the InsightPlatform role-based access control feature.
Additional reading:
Security updates for Tuesday
Post Syndicated from original https://lwn.net/Articles/904842/
Security updates have been issued by CentOS (kernel), Debian (kernel), Fedora (webkit2gtk3), Oracle (.NET 6.0, .NET Core 3.1, kernel, and kernel-container), Slackware (rsync), and SUSE (canna, ceph, chromium, curl, kernel, opera, python-Twisted, and seamonkey).
Cloudflare Support Portal gets an overhaul
Post Syndicated from Meghan Bevill original https://blog.cloudflare.com/cloudflare-support-portal-gets-an-overhaul/


The Cloudflare Support team is excited to announce the launch of our brand-new Customer Support Portal. When our customers open support tickets, we understand that they want quick and accurate responses from us. For those of you who have opened a support ticket in the past, we are certain you will notice the improvements we’ve made! The new Support Portal lives where our ticket submission form has always been, dash.cloudflare.com/support, but that’s where the similarities between the old and the new one end.
What can you expect in the new portal?
The new Support Portal will help you solve your problems quickly and effectively, by getting you on the fastest path to resolution. In some cases, the most efficient way to resolve your issue will be to use our self-help resources or our machine learning-trained Support Bot. Other times, the most efficient way to resolve your issue will be by working with one of our Support Engineers via ticket, phone or chat, depending on your plan type. Regardless of how we help you solve your issue, we will have more context about the products you are using and your issue up front, reducing time-consuming back and forth.
The new portal has several features that will make it easier for you to access the support you need, including:
- Fast and secure ticket submission for verified Cloudflare users
- An easier-to-use interface that serves relevant resources based on your issue summary
- Machine learning-powered Support Bot to run diagnostics and serve targeted help guides
Everyone is encouraged to begin using our new portal. Tickets submitted through our legacy form are typically solved faster than tickets emailed to us, and we expect the updates in our new form to help us resolve your issues even faster!
If you are ready to be one of the first people to take advantage of our new Support Portal, you can now opt in and begin using the new experience to access resources and submit tickets. Just hit the Support dropdown in your dashboard and click Contact Support.
Below is a preview of what you can expect with the new experience.
Relevant self-help resources at your fingertips
The biggest change you’ll notice from our old ticket submission form is that we’ve made it easier to get help. First, we link you directly to relevant resources and the ticket submission form immediately upon clicking “Contact Support”. You no longer have to navigate through multiple steps to get your problem resolved. Second, we’ve moved to a full-page experience allowing us to curate a selection of support articles and help guides targeting your specific problem, making it easier for you to find answers to your questions. Of course, there will still be times when you need to submit a support ticket, but if we have resources that address your problem, we want you to be able to find that information easily.
All the details you provide when searching for articles in the portal will be captured and added to your ticket if you are not able to find the answers to your questions.

Take advantage of our Support Bot
Our machine learning-powered Support Bot has been integrated into the new portal to deliver a customized experience that identifies your specific problem. Support Bot has been helping our Support Engineers work more efficiently for years, and now we’re making some of this functionality customer-facing so that you can benefit from these efficiencies as well.
Within the portal, the Support Bot will run diagnostics (if your issue is domain-related), assess the issue summary you entered, and provide you with help guides to address the root cause of your problem. The more information you are able to provide, the better our bot can direct you to the resources most pertinent to your issue. This gives you the chance to solve your issue on the spot, rather than waiting for a response to your ticket.
For each issue submitted through the portal, our Support Bot can perform one of two actions. If your issue is domain-specific, the bot will run a set of diagnostics against your domain that check for common configuration issues. If any issue is detected, the bot will display the issue and a suggested solution. Regardless of whether your issue is domain-specific, the bot will also analyze the issue summary you’ve entered against our ensemble of Natural Language Processing models and keyword searches. The bot is trained on thousands of historic customer tickets to differentiate between specific customer issues. We retrain the model on a regular basis to ensure it is consistently learning from new and emerging issues. If the bot detects keywords in your summary that map to a relevant issue, it will present a known solution for that issue.
The solutions the bot surfaces are based on how successfully these resources resolved issues previously, and we will continue to refine the bot’s responses and solutions based on a couple of key success metrics. We consider a recommendation successful if a customer doesn’t need to ultimately open a ticket or if they acknowledge that a resource was helpful by voting on the page. We will evaluate this data along with any information you provide on why specific content wasn’t helpful, and make iterative improvements to the bot every time we retrain it.
Fast and secure ticket submission
While we have a ton of helpful content for a wide range of problems, we know there will be instances where you need to speak to one of our very experienced Support Engineers. For plan types that include ticket support, we have built our ticket submission flow into the portal and introduced new features to make the experience more efficient. The first step for our Support Engineers in resolving most issues is for us to verify the identity of account users and admins. The new process ensures that tickets are only submitted by verified account users and admins, reducing some back and forth and allowing us to start working on your issue right away.
Along with this verification step, the new portal will collect detailed information about your problem up front, including issue category and impact level. These details will help route your ticket to the Support Engineer most knowledgeable in the area of your issue and enable that engineer to begin work on your ticket more quickly and without having to come to you with additional questions.
How to try the new experience
To take advantage of these improvements, we encourage everyone to use the new Support Portal as the starting point for troubleshooting your issues.
Over the next few months, we will be rolling out the new portal to all plan types, starting with an opt-in period where you can pilot the new experience. Once we are satisfied the portal is working as intended, we will close the opt-in phase and release the portal to all customers. At that point, we will begin redirecting emails received at our main support email addresses (support at cloudflare.com and billing at cloudflare.com) to the Support Portal so that they can be triaged, and resolved quicker and more efficiently. We are excited to start implementing these changes and are confident that these steps are the first of many planned in making your support experience as efficient and effective as possible. We can’t wait for you to check it out!
To start using the new portal today, you can opt in from your dashboard. Let us know what you think with the feedback form included at the top of the new portal.
THG Podcast: Border Wars
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=z3ug69Foh4Q
Remotely Controlling Touchscreens
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/08/remotely-controlling-touchscreens-2.html
This is more of a demonstration than a real-world vulnerability, but researchers can use electromagnetic interference to remotely control touchscreens.
From a news article:
It’s important to note that the attack has a few key limitations. Firstly, the hackers need to know the target’s phone passcode, or launch the attack while the phone is unlocked. Secondly, the victim needs to put the phone face down, otherwise the battery and motherboard will block the electromagnetic signal. Thirdly, the antenna array has to be no more than four centimeters (around 1.5 inches) away. For all these reasons the researchers themselves admit that the “invisible finger” technique is a proof of concept that at this point is far from being a threat outside of a university lab.
A Decade of Ever-Increasing Provisioned IOPS for Amazon EBS
Post Syndicated from Jeff Barr original https://aws.amazon.com/blogs/aws/a-decade-of-ever-increasing-provisioned-iops-for-amazon-ebs/
Progress is often best appreciated in retrospect. It is often the case that a steady stream of incremental improvements over a long period of time ultimately adds up to a significant level of change. Today, ten years after we first launched the Provisioned IOPS feature for Amazon Elastic Block Store (EBS), I strongly believe that to be the case.
All About the IOPS
Let’s start with a quick review of IOPS, which is short for Input/Output Operations per Second. This is a number which is commonly used to characterize the performance of a storage device, and higher numbers mean better performance. In many cases, applications that generate high IOPS values will use threads, asynchronous I/O operations, and/or other forms of parallelism.
The Road to Provisioned IOPS
When we launched Amazon Elastic Compute Cloud (Amazon EC2) back in 2006 (Amazon EC2 Beta), the m1.small instances had a now-paltry 160 GiB of local disk storage. This storage had the same lifetime as the instance, and disappeared if the instance crashed or was terminated. In the run-up to the beta, potential customers told us that they could build applications even without persistent storage. During the two years between the EC2 beta and the 2008 launch of Amazon EBS, those customers were able to gain valuable experience with EC2 and to deploy powerful, scalable applications. As a reference point, these early volumes were able to deliver an average of about 100 IOPS, with bursting beyond that on a best-effort basis.
Evolution of Provisioned IOPS
As our early customers gained experience with EC2 and EBS, they asked us for more I/O performance and more flexibility. In my 2012 post (Fast Forward – Provisioned IOPS for EBS Volumes), I first told you about the then-new Provisioned IOPS (PIOPS) volumes and also introduced the concept of EBS-Optimized instances. These new volumes found a ready audience and enabled even more types of applications.
Over the years, as our customer base has become increasingly diverse, we have added new features and volume types to EBS, while also pushing forward on performance, durability, and availability. Here’s a family tree to help put some of this into context:
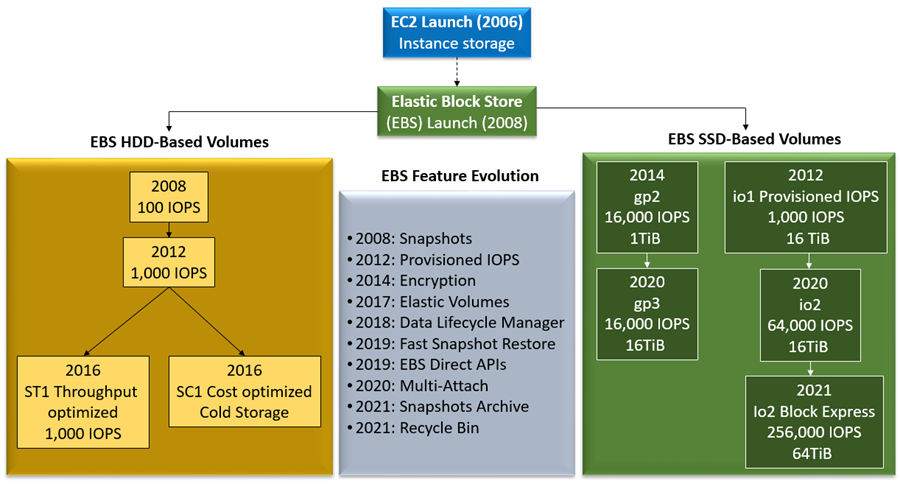
Today, EBS handles trillions of input/output operations daily, and supports seven distinct volume types each with a specific set of performance characteristics, maximum volume sizes, use cases, and prices. From that 2012 starting point where a single PIOPS volume could deliver up to 1000 IOPS, today’s high-end io2 Block Express volumes can deliver up to 256,000 IOPS.
Inside io2 Block Express
Let’s dive in a bit and take a closer look at io2 Block Express. These volumes make use of multiple Nitro System components including AWS Nitro SSD storage and the Nitro Card for EBS. The io2 Block Express volumes can be as large as 64 TiB, and can deliver up to 256,000 IOPS with 99.999% durability and up to 4,000 MiB/s of throughput. This performance makes them suitable for the most demanding mission-critical workloads, those that require sustained high performance and sub-millisecond latency. On the network side, the io2 Block Express volumes make use of a Scalable Reliable Datagram (SRD) protocol that is designed to deliver consistent high performance on complex, multipath networks (read A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC to learn a lot more). You can use these volumes with X2idn, X2iedn, R5b, and C7g instances today, with support for additional instance types in the works.
Your Turn
Here are some resources to help you to learn more about EBS and Provisioned IOPS:
- EBS Home Page
- Provisioned IOPS Home Page
- AWS Free Tier – 30 GB of EBS storage for the first 12 months
I can’t wait to see what the second decade holds for EBS and Provisioned IOPS!
— Jeff;
New – HTTP/3 Support for Amazon CloudFront
Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/new-http-3-support-for-amazon-cloudfront/
Amazon CloudFront is a content delivery network (CDN) service, a network of interconnected servers that is geographically closer to the users and reaches their computers much faster. Amazon CloudFront reduces latency by delivering data through 410+ globally dispersed Points of Presence (PoPs) with automated network mapping and intelligent routing.
With Amazon CloudFront, content, API requests and responses or applications can be delivered over Hypertext Transfer Protocol (HTTP) version 1.1, and 2.0 over the latest version of Transport Layer Security (TLS) to encrypt and secure communication between the user client and CloudFront.
Today we are adding HTTP version 3.0 (HTTP/3) support for Amazon CloudFront. HTTP/3 uses QUIC, a user datagram protocol-based, stream-multiplexed, and secure transport protocol that combines and improves upon the capabilities of existing transmission control protocol (TCP), TLS, and HTTP/2. Now, you can enable HTTP/3 for end user connections in all new and existing CloudFront distributions on all edge locations worldwide, and there is no additional charge for using this feature.
What is HTTP/3?
HTTP/3 uses QUIC and overcomes many of TCP’s limitations and bring those benefits to HTTP. When using existing HTTP/2 over TCP and TLS, TCP needs a handshake to establish a session between a client and server, and TLS also needs its own handshake to ensure that the session is secured. Each handshake has to make the full round trip between client and server, which can take a long time when client and server and far apart, network-wise. But, QUIC only needs a single handshake to establish a secure session.
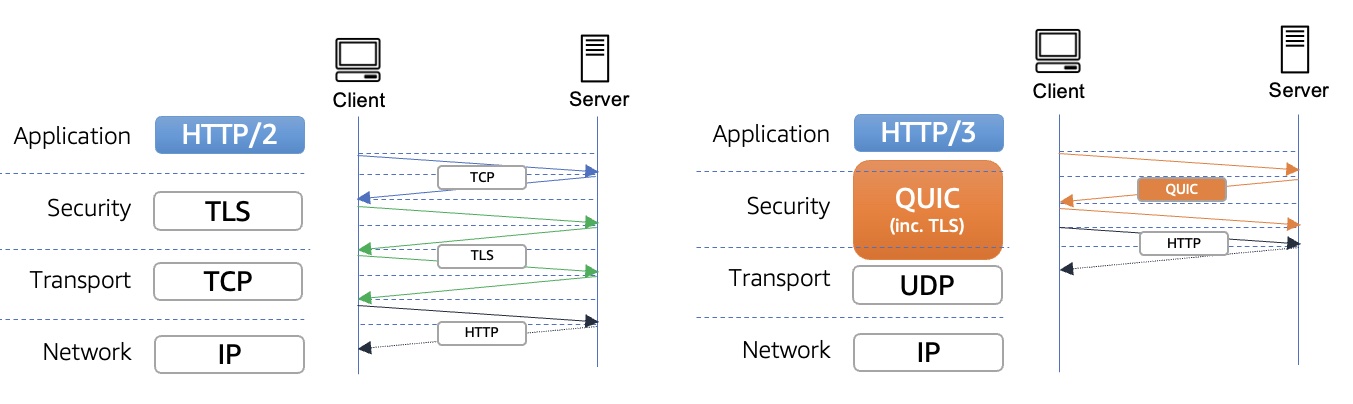
Also, TCP is understood and manipulated by a myriad of different middleboxes, such as firewalls and network address translation (NAT) devices. QUIC uses UDP as its basis to allow packet flows in an enterprise or public network and is fully encrypted, including the metadata, which makes middleboxes unable to inspect or manipulate its details.
HTTP/3 streams are multiplexed independently to eliminate head-of-line blocking between requests and responses. This is possible because stream multiplexing occurs in the transport layer as opposed to the application layer like HTTP/2 over TCP. This enables web applications to perform faster, especially over slow networks and latency-sensitive connections.
Benefits of HTTP/3 on CloudFront
Our customers always want to provide faster, more responsive and secure experience on the web for end users. HTTP/3 provides benefits to all CloudFront customers in the form of faster connection times, stream multiplexing, client-side connection migration, and fewer round trips in the handshake process to reduce error rates.
QUIC connections over UDP support connection reuse with a connection ID independent from IP address/port tuples so users have no interruption or impact. Customers operating in countries with low network connectivity will see improved performance from their applications.
CloudFront’s HTTP/3 support provides enhanced security built on top of s2n-quic, an open-source Rust implementation of the QUIC protocol added to our set of AWS encryption open-source libraries, both with a strong emphasis on efficiency and performance.
If you enable HTTP/3 in CloudFront distributions, the users can make HTTP/3 viewer request to CloudFront edge locations. Past the edge location, we have highly reliable networks within AWS Cloud and CloudFront will continue to use HTTP/1.1 for origin fetches. So, you don’t need to make any server-side changes in order to make your content accessible via HTTP/3.
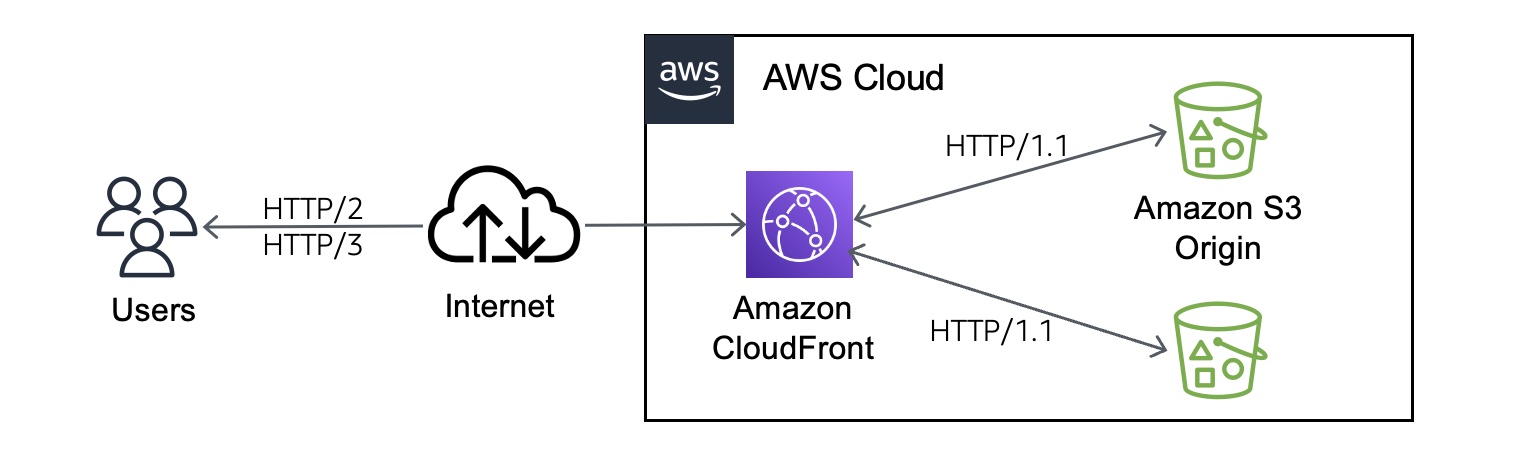
For some types of applications, like those requiring an HTTP client library to make HTTP requests, customers may need to update their HTTP client library to a version that supports HTTP/3. But if for some operational reason clients cannot establish a QUIC connection, they can fall back to another supported protocol such as HTTP/1.1 or HTTP/2.
How to Enable HTTP/3
To enable HTTP/3 connection, you can edit the distribution configuration through the CloudFront console. You can select HTTP/3 in Supported HTTP versions on an existing distribution or create a new distribution without any changes to origin. You can use the UpdateDistribution API or use the CloudFormation template.
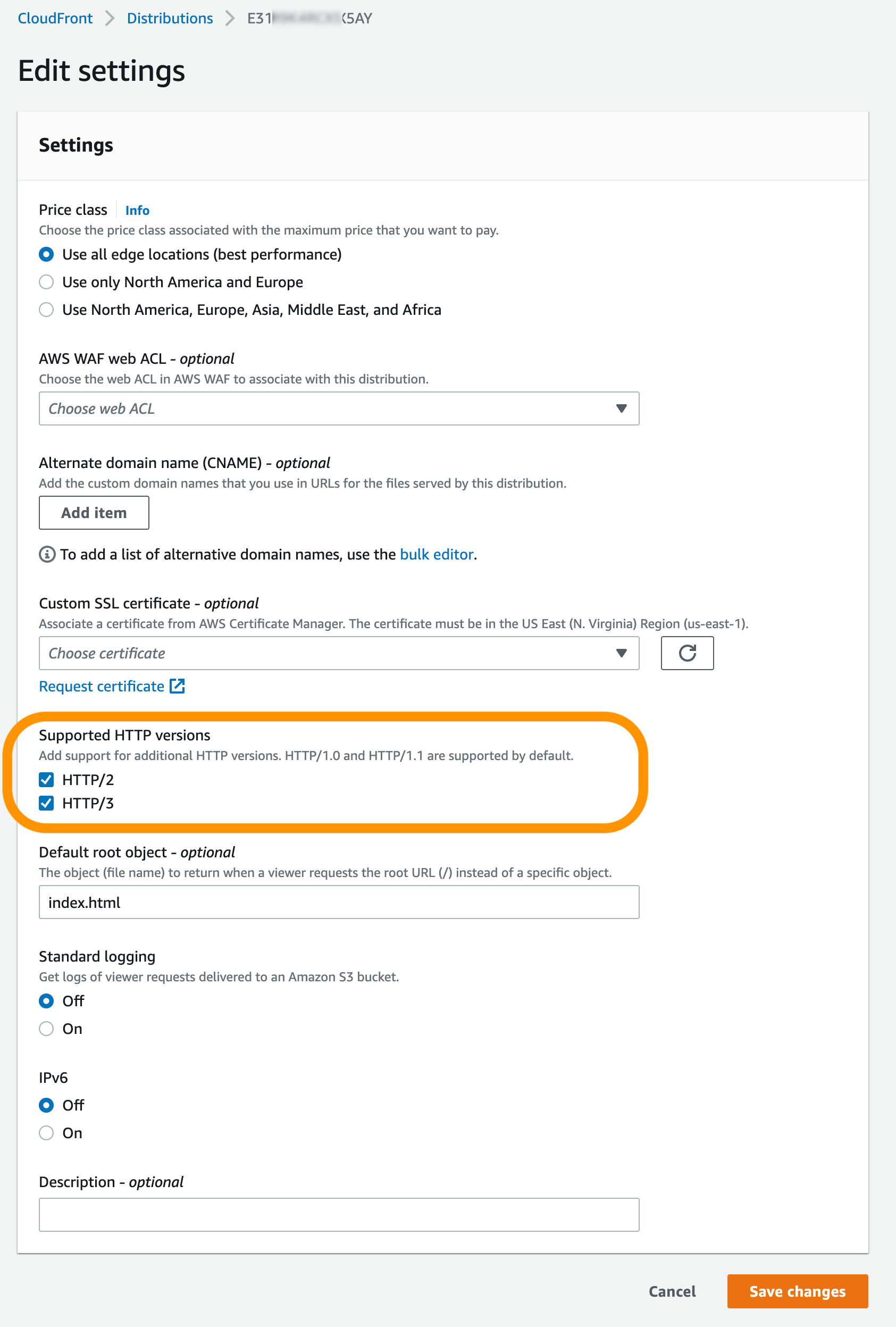
After deploying your distribution, you can connect with a browser that supports HTTP/3, such as the latest version of Google Chrome, Mozilla Firefox, and Microsoft Edge, and Apple Safari after turning it on manually. To learn more about web browser support, see the Can I Use – HTTP/3 Support page.
From web developer tools in your browser, you can see the HTTP/3 requests made when a page is loaded from the CloudFront. The image below is an example of Mozilla Firefox.
You can also add HTTP/3 support to Curl and test from the command line:
$ curl --http3 -i https://d1e0fmnut9xxxxx.cloudfront.net/speed.html
HTTP/3 200
content-type: text/html
content-length: 9286
date: Fri, 05 Aug 2022 15:49:52 GMT
last-modified: Thu, 28 Jul 2022 00:50:38 GMT
etag: "d928997023f6479537940324aeddabb3"
x-amz-version-id: mdUmFuUfVaSHPseoVPRoOKGuUkzWeUhK
accept-ranges: bytes
server: AmazonS3
vary: Origin
x-cache: Miss from cloudfront
via: 1.1 6e4f43c5af08f740d02d21f990dfbe80.cloudfront.net (CloudFront)
x-amz-cf-pop: ICN54-C2
alt-svc: h3=":443"; ma=86400
x-amz-cf-id: 6fy8rrUrtqDMrgoc7iJ73kzzXzHz7LQDg73R0lez7_nEXa3h9uAlCQ==Customer Stories
Several AWS customers including Snap, Zillow, AC3/Movember, Audible, Skyscanner have already enabled HTTP/3 on their CloudFront distributions. Here are some of their voices:
Snap Inc is a social media company that offers Snapchat, an app that offers a fast and fun way to connect with close friends to its community around the world. On AWS, Snap now supports more than 306 million Snapchat users sending over 5.4 billion Snaps daily with 20 percent less latency than its prior architecture.
Mahmoud Ragab, Software Engineering Manager at Snapchat said:
“Snapchat helps millions of people around the world to share moments with friends. At Snapchat, we strive to be the fastest way to communicate. This is why we have been partnering with Amazon Cloudfront for fast, high-performance, low latency content delivery, leveraging QUIC on Cloudfront.
It offers significant advantages while sending and receiving content, especially in networks with lossy signals and intermittent connectivity. Improvements offered by QUIC, like zero round-trip time (0-RTT) connection setup and improved congestion control enables an average of 10% reduction in time to first byte (TTFB) while lowering overall error rates. Lower network latencies and errors make Snapchat better for people all over the world.
With early access to QUIC, we’ve been able to experiment and quickly iterate and improve server-side implementation and optimize integration between the client and the server. Both companies will continue to collaborate together as QUIC is made more widely available.”
Zillow is a real estate tech company that offer its customers an on-demand experience for selling, buying, renting and financing with transparency and nearly seamless end-to-end service. Since 2015, Zillow has increased the availability of its imaging system by using Amazon S3 and Amazon CloudFront.
Craig Link, Chief Cloud Architect at Zillow said:
“We are excited about the launch of HTTP/3 support for Amazon CloudFront. Enabling HTTP/3 on CloudFront was a seamless transition and our synthetic test and ad-hoc usage continued working without issue.”
AC3 is an Australia-based AWS Managed Services partner and has supported our customer, Movember Foundation, one of the leading charities for men’s health. Running an international charity that handles donations, data, events, and localized websites in 21 countries can pose some technical challenges. Born in the cloud, Movember has leveraged AWS technology in adopting new working models, ensuring a flexible IT platform, and innovating faster.
Greg Cockburn, Head of Hyperscale Cloud at AC3 said:
“AC3 is excited to work with their longtime partner Movember enabling HTTP3 on their CloudFront distributions serving web and API frontends and is encouraged by the performance improvements seen in the initial results.”
Now Available
The HTTP/3 support for Amazon CloudFront is now available in all 410+ CloudFront edge locations worldwide with no additional charge for using this feature. To learn more, see the FAQ and Developer Guide of Amazon CloudFront. Please send feedback to AWS re:Post for Amazon CloudFront or through your usual AWS support contacts.
– Channy
How to use customer managed policies in AWS IAM Identity Center for advanced use cases
Post Syndicated from Ron Cully original https://aws.amazon.com/blogs/security/how-to-use-customer-managed-policies-in-aws-single-sign-on-for-advanced-use-cases/
Are you looking for a simpler way to manage permissions across all your AWS accounts? Perhaps you federate your identity provider (IdP) to each account and divide permissions and authorization between cloud and identity teams, but want a simpler administrative model. Maybe you use AWS IAM Identity Center (successor to AWS Single Sign-On) but are running out of room in your permission set policies; or need a way to keep the role models you have while tailoring the policies in each account to reference their specific resources. Or perhaps you are considering IAM Identity Center as an alternative to per-account federation, but need a way to reuse the customer managed policies that you have already created. Great news! Now you can use customer managed policies (CMPs) and permissions boundaries (PBs) to help with these more advanced situations.
In this blog post, we explain how you can use CMPS and PBs with IAM Identity Center to address these considerations. We describe how IAM Identity Center works, how these types of policies work with IAM Identity Center, and how to best use CMPs and PBs with IAM Identity Center. We also show you how to configure and use CMPs in your IAM Identity Center deployment.
IAM Identity Center background
With IAM Identity Center, you can centrally manage access to multiple AWS accounts and business applications, while providing your workplace users a single sign-on experience with your choice of identity system. Rather than manage identity in each account individually, IAM Identity Center provides one place to connect an existing IdP, Microsoft Active Directory Domain Services (AD DS), or workforce users that you create directly in AWS. Because IAM Identity Center integrates with AWS Organizations, it also provides a central place to define your roles, assign them to your users and groups, and give your users a portal where they can access their assigned accounts.
With AWS Identity Center, you manage access to accounts by creating and assigning permission sets. These are AWS Identity and Access Management (IAM) role templates that define (among other things) which policies to include in a role. If you’re just getting started, you can attach AWS managed policies to the permission set. These policies, created by AWS service teams, enable you to get started without having to learn how to author IAM policies in JSON.
For more advanced cases, where you are unable to express policies sufficiently using inline policies, you can create a custom policy in the permission set. When you assign a permission set to users or groups in a specified account, IAM Identity Center creates a role from the template and then controls single sign-on access to the role. During role creation, IAM Identity Center attaches any specified AWS managed policies, and adds any custom policy to the role as an inline policy. These custom policies must be within the 10,240 character IAM quota of inline policies.
IAM provides two other types of custom policies that increase flexibility when managing access in AWS accounts. Customer managed policies (CMPs) are standalone policies that you create and can attach to roles in your AWS accounts to grant or deny access to AWS resources. Permissions boundaries (PBs) provide an advanced feature that specifies the maximum permissions that a role can have. For both CMPs and PBs, you create the custom policy in your account and then attach it to roles. IAM Identity Center now supports attaching both of these to permission sets so you can handle cases where AWS Managed Policies and inline policies may not be enough.
How CMPs and PBs work with IAM Identity Center
Although you can create IAM users to manage access to AWS accounts and resources, AWS recommends that you use roles instead of IAM users for this purpose. Roles act as an identity (sometimes called an IAM principal), and you assign permissions (identity-based policies) to the role. If you use the AWS Management Console or the AWS Command Line Interface to assume a role, you get the permissions of the role that you assumed. With its simpler way to maintain your users and groups in one AWS location and its ability to centrally manage and assign roles, AWS recommends that you use IAM Identity Center to manage access to your AWS accounts.
With this new IAM Identity Center release, you have the option to specify the names of CMPs and one PB in your permission set (role definition). Doing so modifies how IAM Identity Center provisions roles into accounts. When you assign a user or group to a permission set, IAM Identity Center checks the target account to verify that all specified CMPs and the PB are present. If they are all present, IAM Identity Center creates the role in the account and attaches the specified policies. If any of the specified CMPs or the PB are missing, IAM Identity Center fails the role creation.
This all sounds simple enough, but there are important implications to consider.
If you modify the permission set, IAM Identity Center updates the corresponding roles in all accounts to which you assigned the permission set. What is different when using CMPs and PBs is that IAM Identity Center is uninvolved in the creation or maintenance of the CMPs or PBs. It’s your responsibility to make sure that the CMPs and PBs are created and managed in all of the accounts to which you assign permission sets that use the CMPs and PBs. This means that you must be careful in how you name, create, and maintain these policies in your accounts, to avoid unintended consequences. For example, if you do not apply changes to CMPs consistently across all your accounts, the behavior of an IAM Identity Center created role will vary between accounts.
What CMPs do for you
By using CMPs with permission sets, you gain four main benefits:
- If you federate to your accounts directly and have CMPs already, you can reuse your CMPs with permission sets in IAM Identity Center. We describe exceptions later in this post.
- If you are running out of space in your permission set inline policies, you can add permission sets to increase the aggregate size of your policies.
- Policies often need to refer to account-specific resources by Amazon Resource Name (ARN). Designing an inline policy that does this correctly across all your accounts can be challenging and, in some cases, may not be possible. By specifying a CMP in a permission set, you can tailor the CMPs in each of your accounts to reference the resources of the account. When IAM Identity Center creates the role and attaches the CMPs of the account, the policies used by the IAM Identity Center–generated role are now specific to the account. We highlight this example later in this post.
- You get the benefit of a central location to define your roles, which gives you visibility of all the policies that are in use across the accounts where you assigned permission sets. This enables you to have a list of CMP and PB names that you should monitor for change across your accounts. This helps you ensure that you are maintaining your policies correctly.
Considerations and best practices
Start simple, avoid complex – If you’re just starting out, try using AWS managed policies first. With managed policies, you don’t need to know JSON policy to get started. If you need more advanced policies, start by creating identity-based inline custom policies in the permission set. These policies are provisioned as inline policies, and they will be identical in all your accounts. If you need larger policies or more advanced capabilities, use CMPs as your next option. In most cases, you can accomplish what you need with inline and customer managed policies. When you can’t achieve your objective using CMPs, use PBs. For information about intended use cases for PBs, see the blog post When and where to use IAM permissions boundaries.
Permissions boundaries don’t constrain IAM Identity Center admins who create permission sets – IAM Identity Center administrators (your staff) that you authorize to create permission sets can create inline policies and attach CMPs and PBs to permission sets, without restrictions. Permissions boundary policies set the maximum permissions of a role and the maximum permissions that the role can grant within an account through IAM only. For example, PBs can set the maximum permissions of a role that uses IAM to create other roles for use by code or services. However, a PB doesn’t set maximum permissions of the IAM Identity Center permission set creator. What does that mean? Suppose you created an IAM Identity Center Admin permission set that has a PB attached, and you assigned it to John Doe. John Doe can then sign in to IAM Identity Center and modify permission sets with any policy, regardless of what you put in the PB. The PB doesn’t restrict the policies that John Doe can put into a permission set.
In short, use PBs only for roles that need to create IAM roles for use by code or services. Don’t use PBs for permission sets that authorize IAM Identity Center admins who create permission sets.
Create and use a policy naming plan – IAM Identity Center doesn’t consider the content of a named policy that you attach to a permission set. If you assign a permission set in multiple accounts, make sure that all referenced policies have the same intent. Failure to do this will result in unexpected and inconsistent role behavior between different accounts. Imagine a CMP named “S3” that grants S3 read access in account A, and another CMP named “S3” that grants S3 administrative permissions over all S3 buckets in account B. A permission set that attaches the S3 policy and is assigned in accounts A and B will be confusing at best, because the level access is quite different in each of the accounts. It’s better to have more specific names, such as “S3Reader” and “S3Admin,” for your policies and ensure they are identical except for the account-specific resource ARNs.
Use automation to provision policies in accounts – Using tools such as AWS CloudFormation stacksets, or other infrastructure-as-code tools, can help ensure that naming and policies are consistent across your accounts. It also helps reduce the potential for administrators to modify policies in undesirable ways.
Policies must match the capabilities of IAM Identity Center – Although IAM Identity Center supports most IAM semantics, there are exceptions:
- If you use an identity provider as your identity source, IAM Identity Center passes only PrincipalTag attributes that come through SAML assertions to IAM. IAM Identity Center doesn’t process or forward other SAML assertions to IAM. If you have CMPs or PBs that rely on other information from SAML assertions, they won’t work. For example, IAM Identity Center doesn’t provide multi-factor authentication (MFA) context keys or SourceIdentity.
- Resource policies that reference role names or tags as part of trust policies don’t work with IAM Identity Center. You can use resource policies that use attribute-based access control (ABAC). IAM Identity Center role names are not static, and you can’t tag the roles that IAM Identity Center creates from its permission sets.
How to use CMPs with permission sets
Now that you understand permission sets and how they work with CMPs and PBs, let’s take a look at how you can configure a permission set to use CMPs.
In this example, we show you how to use one or more permission sets that attach a CMP that enables Amazon CloudWatch operations to the log group of specified accounts. Specifically, the AllowCloudWatch_permission set attaches a CMP named AllowCloudWatchForOperations. When we assign the permission set in two separate accounts, the assigned users can perform CloudWatch operations against the log groups of the assigned account only. Because the CloudWatch operations policies are in CMPs rather than inline policies, the log groups can be account specific, and you can reuse the CMPs in other permission sets if you want to have CloudWatch operations available through multiple permission sets.
Note: For this blog post, we demonstrate using CMPs by utilizing the IAM Management Console to create policies and assignments. We recommend that after you learn how to do this, you create your policies through automation for production environments. For example, use AWS CloudFormation. The intent of this example is to demonstrate how you can have a policy in two separate accounts that refer to different resources; something that is harder to accomplish using inline policies. The use case itself is not that advanced, but the use of CMPs to have different resources referenced in each account is a more advanced idea. We kept this simple to make it easier to focus on the feature than the use case.
Prerequisites
In this example, we assume that you know how to use the AWS Management Console, create accounts, navigate between accounts, and create customer managed policies. You also need administrative privileges to enable IAM Identity Center and to create policies in your accounts.
Before you begin, enable IAM Identity Center in your AWS Organizations management account in an AWS Region of your choice. You need to create at least two accounts within your AWS Organization. In this example, the account names are member-account and member-account-1. After you set up the accounts, you can optionally configure IAM Identity Center for administration in a delegated member account.
Configure an IAM Identity Center permission set to use a CMP
Follow these four procedures to use a CMP with a permission set:
- Create CMPs with consistent names in your target accounts
- Create a permission set that references the CMP that you created
- Assign groups or users to the permission set in accounts where you created CMPs
- Test your assignments
Step 1: Create CMPs with consistent names in your target accounts
In this step, you create a customer managed policy named AllowCloudWatchForOperations in two member accounts. The policy allows your cloud operations users to access a predefined CloudWatch log group in the account.
To create CMPs in your target accounts
- Sign into AWS.
Note: You can sign in to IAM Identity Center if you have existing permission sets that enable you to create policies in member accounts. Alternatively, you can sign in using IAM federation or as an IAM user that has access to roles that enable you to navigate to other accounts where you can create policies. Your sign-in should also give you access to a role that can administer IAM Identity Center permission sets.
- Navigate to an AWS Organizations member account.
Note: If you signed in through IAM Identity Center, use the user portal page to navigate to the account and role. If you signed in by using IAM federation or as an IAM user, choose your sign-in name that is displayed in the upper right corner of the AWS Management Console and then choose switch role, as shown in Figure 1.

Figure 1: Switch role for IAM user or IAM federation
- Open the IAM console.
- In the navigation pane, choose Policies.
- In the upper right of the page, choose Create policy.
- On the Create Policy page, choose the JSON tab.
- Paste the following policy into the JSON text box. Replace <account-id> with the ID of the account in which the policy is created.
Tip: To copy your account number, choose your sign-in name that is displayed in the upper right corner of the AWS Management Console, and then choose the copy icon next to the account ID, as shown in Figure 2.

Figure 2: Copy account number
- Choose Next:Tags, and then choose Next:Review.
- On the Create Policy/Review Policy page, in the Name field, enter AllowCloudWatchForOperations. This is the name that you will use when you attach the CMP to the permission set in the next procedure (Step 2).
- Repeat steps 1 through 7 in at least one other member account. Be sure to replace the <account-id> element in the policy with the account ID of each account where you create the policy. The only difference between the policies in each account is the <account-id> in the policy.


Step 2: Create a permission set that references the CMP that you created
At this point, you have at least two member accounts containing the same policy with the same policy name. However, the ResourceARN in each policy refers to log groups that belong to the respective accounts. In this step, you create a permission set and attach the policy to the permission set. Importantly, you attach only the name of the policy to the permission set. The actual attachment of the policy to the role that IAM Identity Center creates, happens when you assign the permission set to a user or group in Step 3.
To create a permission set that references the CMP
- Sign in to the Organizations management account or the IAM Identity Center delegated administration account.
- Open the IAM Identity Center console.
- In the navigation pane, choose Permission Sets.
- On the Select Permission set type screen, select Custom permission Set and choose Next.

Figure 3: Select custom permission set
- On the Specify policies and permissions boundary page, expand the Customer managed policies option, and choose Attach policies.
Figure 4: Specify policies and permissions boundary
- For Policy names, enter the name of the policy. This name must match the name of the policy that you created in Step 1. In our example, the name is AllowCloudWatchForOperations. Choose Next.
- On the Permission set details page, enter a name for your permission set. In this example, use AllowCloudWatch_PermissionSet. You can alspecify additional details for your permission sets, such as session duration and relay state (these are a link to a specific AWS Management Console page of your choice).

Figure 5: Permission set details
- Choose Next, and then choose Create.



Step 3: Assign groups or users to the permission set in accounts where you created your CMPs
In the preceding steps, you created a customer managed policy in two or more member accounts, and a permission set with the customer managed policy attached. In this step, you assign users to the permission set in your accounts.
To assign groups or users to the permission set
- Sign in to the Organizations management account or the IAM Identity Center delegated administration account.
- Open the IAM Identity Center console.
- In the navigation pane, choose AWS accounts.
Figure 6: AWS account
- For testing purposes, in the AWS Organization section, select all the accounts where you created the customer managed policy. This means that any users or groups that you assign during the process will have access to the AllowCloudWatch_PermissionSet role in each account. Then, on the top right, choose Assign users or groups.
- Choose the Users or Groups tab and then select the users or groups that you want to assign to the permission set. You can select multiple users and multiple groups in this step. For this example, we recommend that you select a single user for which you have credentials, so that you can sign in as that user to test the setup later. After selecting the users or groups that you want to assign, choose Next.
Figure 7: Assign users and groups to AWS accounts
- Select the permission set that you created in Step 2 and choose Next.
- Review the users and groups that you are assigning and choose Submit.
- You will see a message that IAM Identity Center is configuring the accounts. In this step, IAM Identity Center creates roles in each of the accounts that you selected. It does this for each account, so it looks in the account for the CMP that you specified in the permission set. If the name of the CMP that you specified in the permission set matches the name that you provided when creating the CMP, IAM Identity Center creates a role from the permission set. If the names don’t match or if the CMP isn’t present in the account to which you assigned the permission set, you see an error message associated with that account. After successful submission, you will see the following message: We reprovisioned your AWS accounts successfully and applied the updated permission set to the accounts.


Step 4: Test your assignments
Congratulations! You have successfully created CMPs in multiple AWS accounts, created a permission set and attached the CMPs by name, and assigned the permission set to users and groups in the accounts. Now it’s time to test the results.
To test your assignments
- Go to the IAM Identity Center console.
- Navigate to the Settings page.
- Copy the user portal URL, and then paste the user portal URL into your browser.
- At the sign-in prompt, sign in as one of the users that you assigned to the permission set.
- The IAM Identity Center user portal shows the accounts and roles that you can access. In the example shown in Figure 8, the user has access to the AllowCloudWatch_PermissionSet created in two accounts.
Figure 8: User portal
If you choose AllowCloudWatch_PermissionSet in the member-account, you will have access to the CloudWatch log group in the member-account account. If you choose the role in member-account-1, you will have access to CloudWatch Log group in member-account-1.
- Test the access by choosing Management Console for the AllowCloudWatch_PermissionSet in the member-account.
- Open the CloudWatch console.
- In the navigation pane, choose Log groups. You should be able to access log groups, as shown in Figure 9.
Figure 9: CloudWatch log groups
- Open the IAM console. You shouldn’t have permissions to see the details on this console, as shown in figure 10. This is because AllowCloudWatch_PermissionSet only provided CloudWatch log access.
Figure 10: Blocked access to the IAM console
- Return to the IAM Identity Center user portal.
- Repeat steps 4 through 8 using member-account-1.



Answers to key questions
What happens if I delete a CMP or PB that is attached to a role that IAM Identity Center created?
IAM prevents you from deleting policies that are attached to IAM roles.
How can I delete a CMP or PB that is attached to a role that IAM Identity Center created?
Remove the CMP or PB reference from all your permission sets. Then re-provision the roles in your accounts. This detaches the CMP or PB from IAM Identity Center–created roles. If the policies are unused by other IAM roles in your account or by IAM users, you can delete the policy.
What happens if I modify a CMP or PB that is attached to an IAM Identity Center provisioned role?
The IAM Identity Center role picks up the policy change the next time that someone assumes the role.
Conclusion
In this post, you learned how IAM Identity Center works with customer managed policies and permissions boundaries that you create in your AWS accounts. You learned different ways that this capability can help you, and some of the key considerations and best practices to succeed in your deployments. That includes the principle of starting simple and avoiding unnecessarily complex configurations. Remember these four principles:
- In most cases, you can accomplish everything you need by starting with custom (inline) policies.
- Use customer managed policies for more advanced cases.
- Use permissions boundary policies only when necessary.
- Use CloudFormation to manage your customer managed policies and permissions boundaries rather than having administrators deploy them manually in accounts.
To learn more about this capability, see the IAM Identity Center User Guide. If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS IAM re:Post or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.