Post Syndicated from Marcia Villalba original https://aws.amazon.com/blogs/aws/amazon-kinesis-data-streams-on-demand-stream-data-at-scale-without-managing-capacity/
Today we are launching Amazon Kinesis Data Streams On-demand, a new capacity mode. This capacity mode eliminates capacity provisioning and management for streaming workloads.
Kinesis Data Streams is a fully-managed, serverless service for real-time processing of streamed data at a massive scale. Kinesis Data Streams can take any amount of data, from any number of sources, and scale up and down as needed. Creating a new data stream is easy, since we announced Kinesis Data Streams in November 2013. To get started, you only need to specify the number of shards with which you must provision your stream.
Shards are the way to define capacity in Kinesis Data Streams. Each shard can ingest 1 MB/s and 1,000 records/second and egress up to 2 MB/s. You can add or remove shards of the stream using Kinesis Data Streams APIs to adjust the stream capacity according to the throughout needs of their workloads. This lets you make sure that producer and consumer applications don’t experience any throttling.
As customers adopt data streaming broadly, workloads with data traffic that can increase by millions of events in a few minutes are becoming more common. For these volatile traffic patterns, customers carefully plan capacity, monitor throughput, and in some cases develop processes that automatically change the Kinesis Data Streams stream capacity.
Kinesis Data Streams On-Demand Mode
That is why today we are announcing Kinesis Data Streams On-demand. This new capacity mode eliminates the need for provisioning and managing the capacity for streaming data. Using Kinesis Data Streams On-demand automatically scales the capacity in response to varying data traffic. Customers are charged per gigabyte of data written, read, and stored in the stream, in a pay-per-throughput fashion.
Data streams in the on-demand mode have the same high durability, high availability, low latency, security, and deep AWS integrations that Kinesis Data Streams already provides. Moreover, there are no new APIs to write or read data. All existing Kinesis Data Streams integrations work in the on-demand mode.
Kinesis Data Streams uses the partition key to distribute data across shards. That is why when using Kinesis Data Streams On-demand, you still must specify a partition key for each record to write data into a data stream, as you do today in Kinesis Data Streams using the provisioned mode. In Kinesis Data Streams On-demand, the data stream automatically adapts to handle uneven data distribution patterns. But you must be careful that no partition key exceeds a shard’s limits. If this happens, then you will receive write throttles, and then you can retry these requests.
When a new data stream is created using Kinesis Data Streams On-demand, it gets created with the default capacity of 4 MB/s and 4,000 records per second for writes. Kinesis Data Streams On-demand can automatically scale up to 200 MB/s and 200,000 records per second for writes.
Kinesis Data Streams On-demand accommodates up to double its previous peak write throughput observed in the last 30 days. As your data stream’s write throughput hits a new peak, Kinesis Data Streams automatically scales the stream’s capacity.
For example, if your data stream has a write throughput that varies between 10 MB/s and 40 MB/s, Kinesis Data Streams will make sure that you can easily burst to double the peak—80 MB/s. And, if later on that same data stream reaches a new peak of 50 MB/s, then Kinesis Data Streams will make sure that there is enough capacity to ingest 100 MB/s. However, write throttling can occur if your traffic grows more than double the previous peak in less than 15 minutes.
When to Use Kinesis Data Streams On-demand
On-demand mode is great for customers that have an unknown or variable workload, or who simply don’t want to deal with capacity management. On-demand mode works best for workloads that have even partition key distribution. For example, you run a mobile game that has variable traffic through the week or day, as customers play mostly on nights or weekends. Or, you run a streaming platform that hosts live shows, and you see a sudden increase in demand depending on the guests you have.
In addition, you can switch between on-demand and provision mode twice a day. For example, you run an e-commerce site with predictable traffic. But, starting next month, there will be many marketing campaigns launched globally. You don’t know the impact that those will have on the site traffic. Switch your Kinesis Data Streams to on-demand mode, and now you can enjoy the automated capacity planning and management for your data streams.
Get Started with Kinesis Data Streams On-demand
Create a new data stream with Kinesis Data Streams On-demand from the AWS console, AWS SDKs, AWS Command Line Interface (CLI), and AWS CloudFormation.
To create one from the console, visit the Kinesis console and Create data stream. When selecting the capacity mode, select On-demand.

At the end of the page, all of the settings for the new data stream are presented. These settings can be changed after the data stream has been created.

Let’s See This in Action!
For this demo, I want to show you how the new Kinesis Data Streams capability works. This situation is best described if you at look at the following Amazon CloudWatch graphs. The green line represents the bytes ingested successfully into the stream, and the red line shows the percentage of traffic that is throttled.
First, we will start with a stream provisioned with five shards. For the first three minutes, we are sending a load of 4 MB/s. You can see that the stream can handle the load.
At the time stamp 21:19, we increase the load to 12 MB/s. Now the stream cannot handle the load, and the throttles start (the red line starts climbing up to 60 percent of request being throttled).
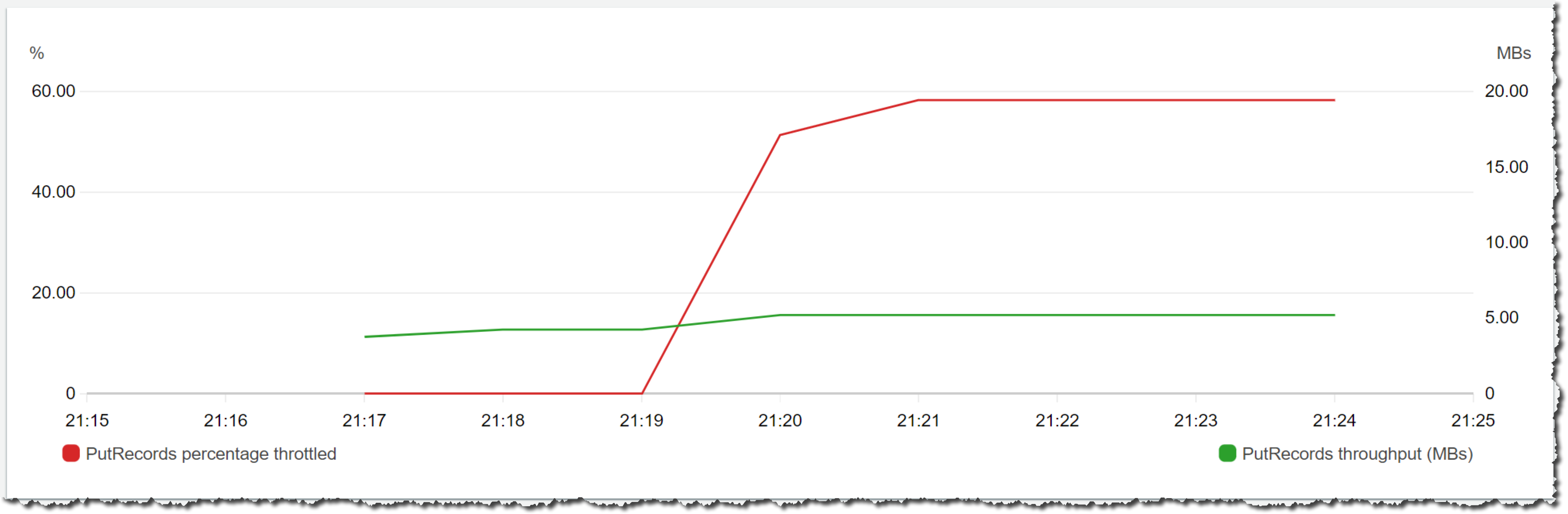
At the time stamp 21:23, we change the stream capacity from provisioned to on-demand. You can do that on-the-fly without affecting the stream. See that it takes a very short time for the stream to handle the load when converting from one capacity mode to the other.
In a few minutes (time stamp 21:24) the throttles start to drop as the stream starts scaling up. The stream capacity doubles to 10 shards first (time stamp 21:26), and the stream keeps scaling up until each shard has a load of less than 0.5 MB/s. In this way, if the stream suddenly receives double the amount of load, then it has the capacity ready to handle it.

At the time stamp 21:26, the load in the stream is increased to 18 MB/s. You can see the green line climbing to 350,000 records – there are no throttles, and the stream ends this demo with 40 open shards. This means that if suddenly the stream receives a load of 40 MB/s, then it could handle it with no problem.

Available Now!
The Amazon Kinesis Data Streams On-demand is available globally in all commercial Regions.
You can learn more about the capacity modes in the Amazon Kinesis Data Streams Developer Guide.
— Marcia



 Damon Cortesi is a Principal Developer Advocate with Amazon Web Services.
Damon Cortesi is a Principal Developer Advocate with Amazon Web Services. Mehul Y. Shah is the GM for Amazon EMR.
Mehul Y. Shah is the GM for Amazon EMR. Abhishek Sinha is a Principal Product Manager at Amazon Web Services.
Abhishek Sinha is a Principal Product Manager at Amazon Web Services.




















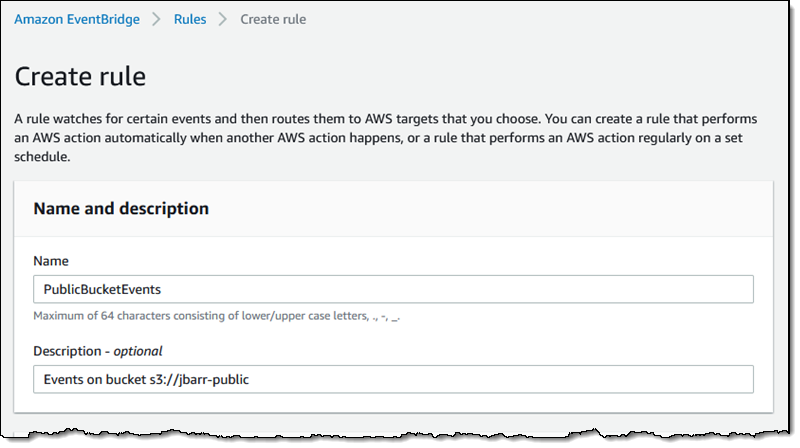 Then I define a pattern that matches the bucket and the events of interest:
Then I define a pattern that matches the bucket and the events of interest: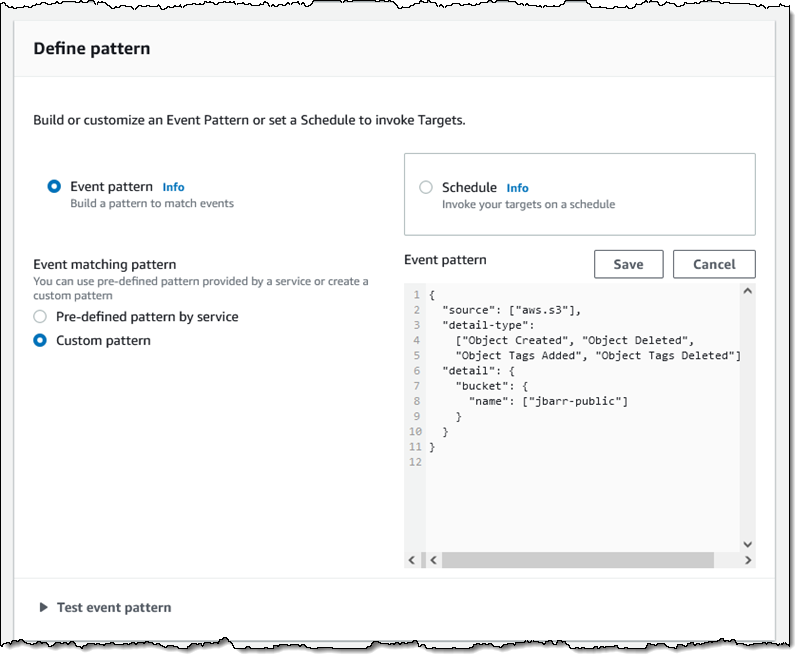 One pattern can match one or more buckets and one or more events; the following events are supported:
One pattern can match one or more buckets and one or more events; the following events are supported: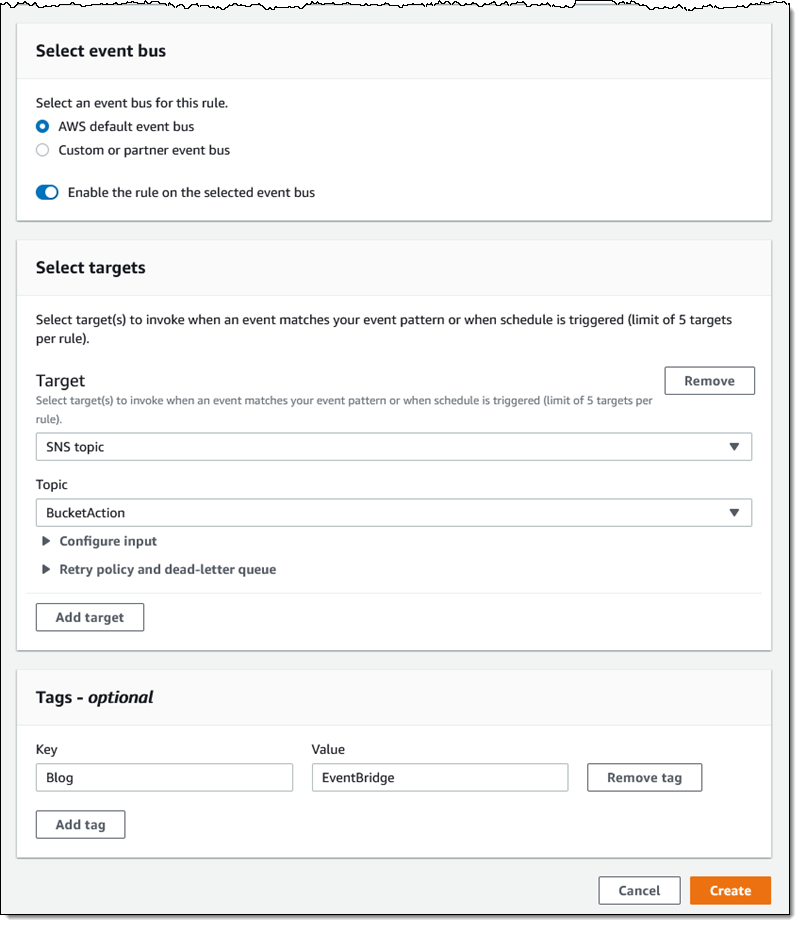


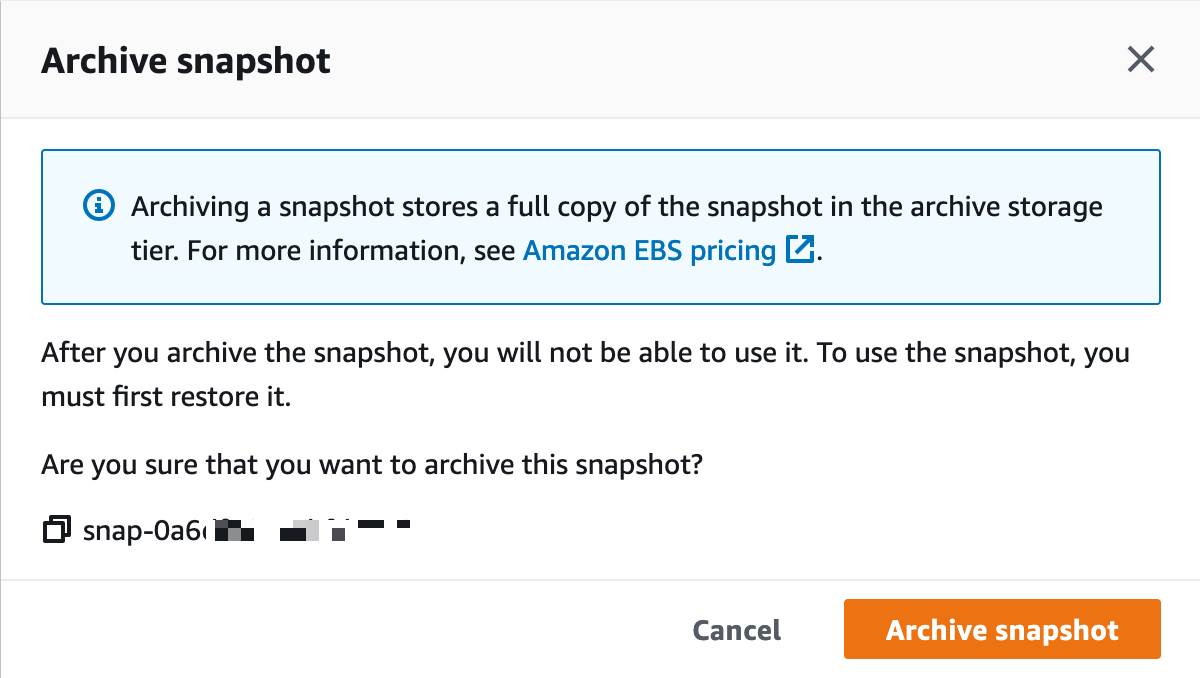
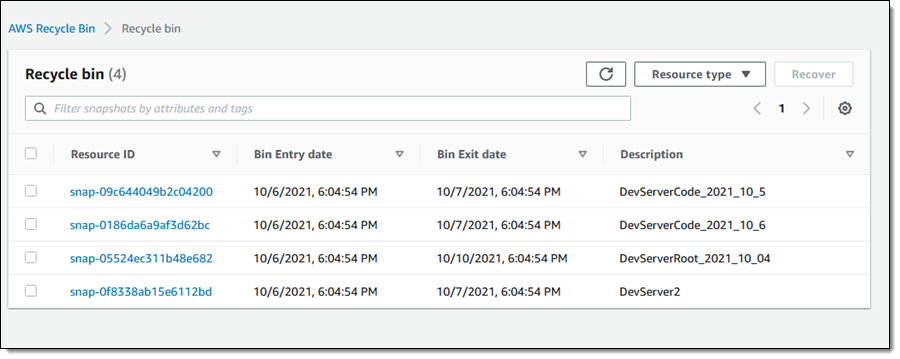
 Archival completed.
Archival completed.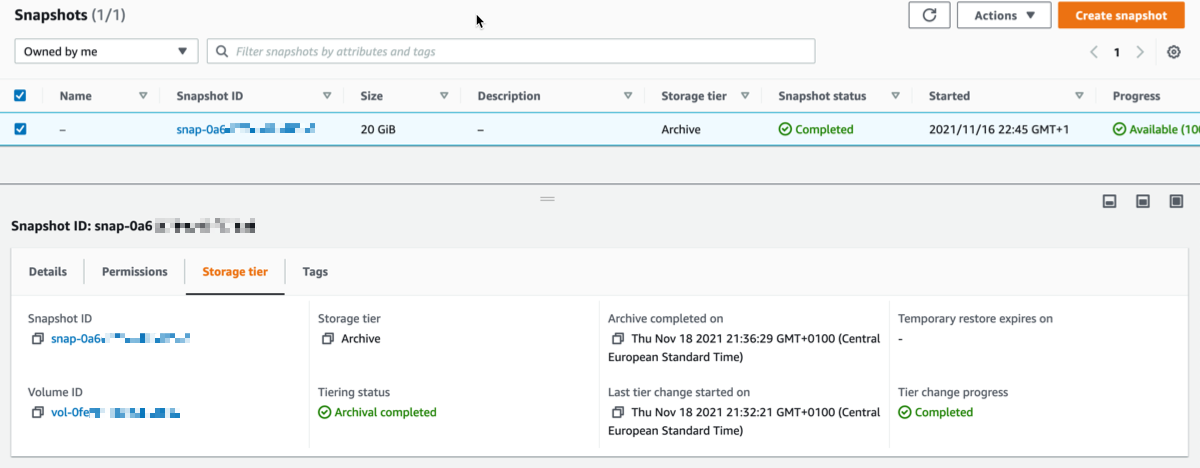


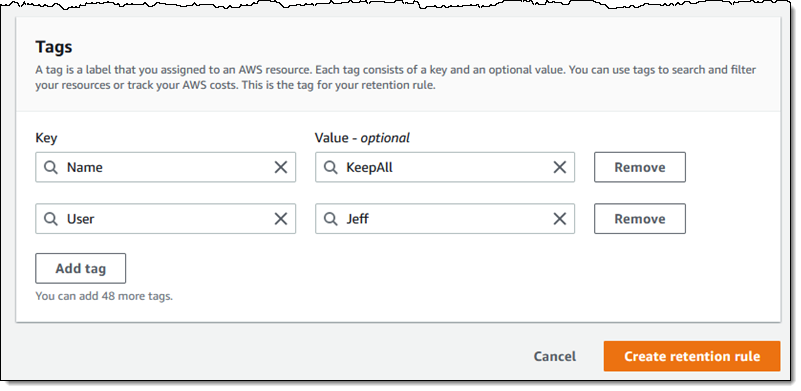
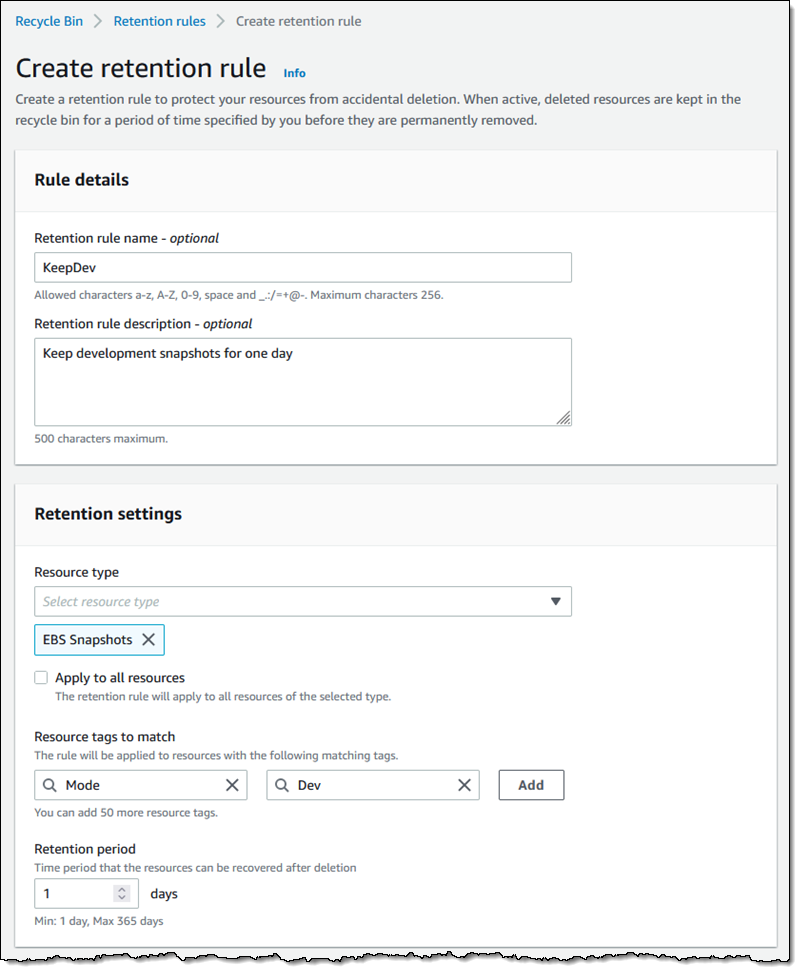
 I add a tag (User) to the rule, and click Create retention rule:
I add a tag (User) to the rule, and click Create retention rule: