Post Syndicated from Richard "RichiH" Hartmann original https://prometheus.io/blog/2021/10/14/prometheus-conformance-results/
Prometheus Conformance Program: First round of results
Post Syndicated from Richard "RichiH" Hartmann original https://prometheus.io/blog/2021/10/14/prometheus-conformance-results/
Today, we’re launching the Prometheus Conformance Program with the goal of ensuring interoperability between different projects and vendors in the Prometheus monitoring space. While the legal paperwork still needs to be finalized, we ran tests, and we consider the below our first round of results. As part of this launch Julius Volz updated his PromQL test results.
As a quick reminder: The program is called Prometheus Conformance, software can be compliant to specific tests, which result in a compatibility rating. The nomenclature might seem complex, but it allows us to speak about this topic without using endless word snakes.
Preamble
New Categories
We found that it’s quite hard to reason about what needs to be applied to what software. To help sort my thoughts, we created an overview, introducing four new categories we can put software into:
- Metrics Exposers
- Agents/Collectors
- Prometheus Storage Backends
- Full Prometheus Compatibility
Call for Action
Feedback is very much welcome. Maybe counter-intuitively, we want the community, not just Prometheus-team, to shape this effort. To help with that, we will launch a WG Conformance within Prometheus. As with WG Docs and WG Storage, those will be public and we actively invite participation.
As we alluded to recently, the maintainer/adoption ratio of Prometheus is surprisingly, or shockingly, low. In different words, we hope that the economic incentives around Prometheus Compatibility will entice vendors to assign resources in building out the tests with us. If you always wanted to contribute to Prometheus during work time, this might be the way; and a way that will have you touch a lot of highly relevant aspects of Prometheus. There’s a variety of ways to get in touch with us.
Register for being tested
You can use the same communication channels to get in touch with us if you want to register for being tested. Once the paperwork is in place, we will hand contact information and contract operations over to CNCF.
Test results
Full Prometheus Compatibility
We know what tests we want to build out, but we are not there yet. As announced previously, it would be unfair to hold this against projects or vendors. As such, test shims are defined as being passed. The currently semi-manual nature of e.g. the PromQL tests Julius ran this week mean that Julius tested sending data through Prometheus Remote Write in most cases as part of PromQL testing. We’re reusing his results in more than one way here. This will be untangled soon, and more tests from different angles will keep ratcheting up the requirements and thus End User confidence.
It makes sense to look at projects and aaS offerings in two sets.
Projects
Passing
- Cortex 1.10.0
- M3 1.3.0
- Promscale 0.6.2
- Thanos 0.23.1
Not passing
VictoriaMetrics 1.67.0 is not passing and does not intend to pass. In the spirit of End User confidence, we decided to track their results while they position themselves as a drop-in replacement for Prometheus.
aaS
Passing
- Chronosphere
- Grafana Cloud
Not passing
- Amazon Managed Service for Prometheus
- Google Cloud Managed Service for Prometheus
- New Relic
- Sysdig Monitor
NB: As Amazon Managed Service for Prometheus is based on Cortex just like Grafana Cloud, we expect them to pass after the next update cycle.
Agent/Collector
Passing
- Grafana Agent 0.19.0
- OpenTelemetry Collector 0.37.0
- Prometheus 2.30.3
Not passing
- Telegraf 1.20.2
- Timber Vector 0.16.1
- VictoriaMetrics Agent 1.67.0
NB: We tested Vector 0.16.1 instead of 0.17.0 because there are no binary downloads for 0.17.0 and our test toolchain currently expects binaries.
Prometheus Conformance Program: First round of results
Post Syndicated from Richard "RichiH" Hartmann original https://prometheus.io/blog/2021/05/14/prometheus-conformance-results/
Today, we’re launching the Prometheus Conformance Program. While the legal paperwork still needs to be finalized, we ran tests, and we consider the below our first round of results. As part of this launch Julius Volz updated his PromQL test results.
As a quick reminder: The program is called Prometheus Conformance, software can be compliant to specific tests, which result in a compatibility rating. The nomenclature might seem complex, but it allows us to speak about this topic without using endless word snakes.
Preamble
New Categories
We found that it’s quite hard to reason about what needs to be applied to what software. To help sort my thoughts, we created an overview, introducing four new categories we can put software into:
* Metrics Exposers
* Agent/Collector
* Prometheus Storage Backends
* Full Prometheus Compatibility
Call for Action
Feedback is very much welcome. Maybe counter-intuitively, we want the community, not just Prometheus-team, to shape this effort. To help with that, we will launch a WG Conformance within Prometheus. As with WG Docs and WG Storage, those will be public and we actively invite participation.
As we alluded to recently, the maintainer/adoption ratio of Prometheus is surprisingly, or shockingly, low. In different words, we hope that the economic incentives around Prometheus Compatibility will entice vendors to assign resources in building out the tests with us. If you always wanted to contribute to Prometheus during work time, this might be the way; and a way that will have you touch a lot of highly relevant aspects of Prometheus. There’s a variety of ways to get in touch with us.
Register for being tested
You can use the same communication channels to get in touch with us if you want to register for being tested. Once the paperwork is in place, we will hand contact information and contract operations over to CNCF.
Test results
Full Prometheus Compatibility
We know what tests we want to build out, but we are not there yet. As announced previously, it would be unfair to hold this against projects or vendors. As such, test shims are defined as being passed. The currently semi-manual nature of e.g. the PromQL tests Julius ran this week mean that Julius tested sending data through Prometheus Remote Write in most cases as part of PromQL testing. We’re reusing his results in more than one way here. This will be untangled soon, and more tests from different angles will keep ratcheting up the requirements and thus End User confidence.
It makes sense to look at projects and aaS offerings in two sets.
Projects
Passing
- Cortex 1.10.0
- M3 1.3.0
- Promscale 0.6.2
- Thanos 0.23.1
Not passing
VictoriaMetrics 1.67.0 is not passing and does not intend to pass. In the spirit of End User confidence, we decided to track their results while they position themselves as a drop-in replacement for Prometheus.
aaS
Passing
- Chronosphere
- Grafana Cloud
Not passing
- Amazon Managed Service for Prometheus
- Google Cloud Managed Service for Prometheus
- New Relic
- Sysdig Monitor
NB: As Amazon Managed Service for Prometheus is based on Cortex just like Grafana Cloud, we expect them to pass after the next update cycle.
Agent/Collector
Passing
- Grafana Agent 0.19.0
- OpenTelemetry Collector 0.37.0
- Prometheus 2.30.3
Not passing
- Telegraf 1.20.2
- Timber Vector 0.16.1
- VictoriaMetrics Agent 1.67.0
NB: We tested Vector 0.16.1 instead of 0.17.0 because there are no binary downloads for 0.17.0 and our test toolchain currently expects binaries.
[$] Scrutinizing bugs found by syzbot
Post Syndicated from original https://lwn.net/Articles/872649/rss
The syzbot
kernel-fuzzing system finds an enormous number of bugs, but, since many
of them may seem to be of a relatively low severity, they have a lower priority
when contending for the attention of developers. A talk
at the recent Linux
Security Summit North America reported on some research that
dug further into the bugs that syzbot has
found; the results are rather worrisome. Rather than a pile of
difficult- or impossible-to-exploit bugs, there are numerous, more serious
problems lurking within.
Optimize performance and reduce costs for network analytics with VPC Flow Logs in Apache Parquet format
Post Syndicated from Radhika Ravirala original https://aws.amazon.com/blogs/big-data/optimize-performance-and-reduce-costs-for-network-analytics-with-vpc-flow-logs-in-apache-parquet-format/
VPC Flow Logs help you understand network traffic patterns, identify security issues, audit usage, and diagnose network connectivity on AWS. Customers often route their VPC flow logs directly to Amazon Simple Storage Service (Amazon S3) for long-term retention. You can then use a custom format conversion application to convert these text files into an Apache Parquet format to optimize the analytical processing of the log data and reduce the cost of log storage. This custom format conversion step added complexity, time to insight, and costs to the VPC flow log traffic analytics. Until today, VPC flow logs were delivered to Amazon S3 as raw text files in GZIP format.
Today, we’re excited to announce a new feature that delivers VPC flow logs in the Apache Parquet format, making it easier, faster, and more cost-efficient to analyze your VPC flow logs stored in Amazon S3. You can also deliver VPC flow logs to Amazon S3 with Hive-compatible S3 prefixes partitioned by the hour.
Apache Parquet is an open-source file format that stores data efficiently in columnar format, provides different encoding types, and supports predicate filtering. With good compression ratios and efficient encoding, VPC flow logs stored in Parquet reduce your Amazon S3 storage costs. When querying flow logs persisted in Parquet format with analytic frameworks, non-relevant data is skipped, requiring fewer reads on Amazon S3 and thereby improving query performance. To reduce query running time and cost with Amazon Athena and Amazon Redshift Spectrum, Apache Parquet is often the recommended file format.
In this post, we explore this new feature and how it can help you run performant queries on your flow logs with Athena.
Create flow logs with Parquet file format
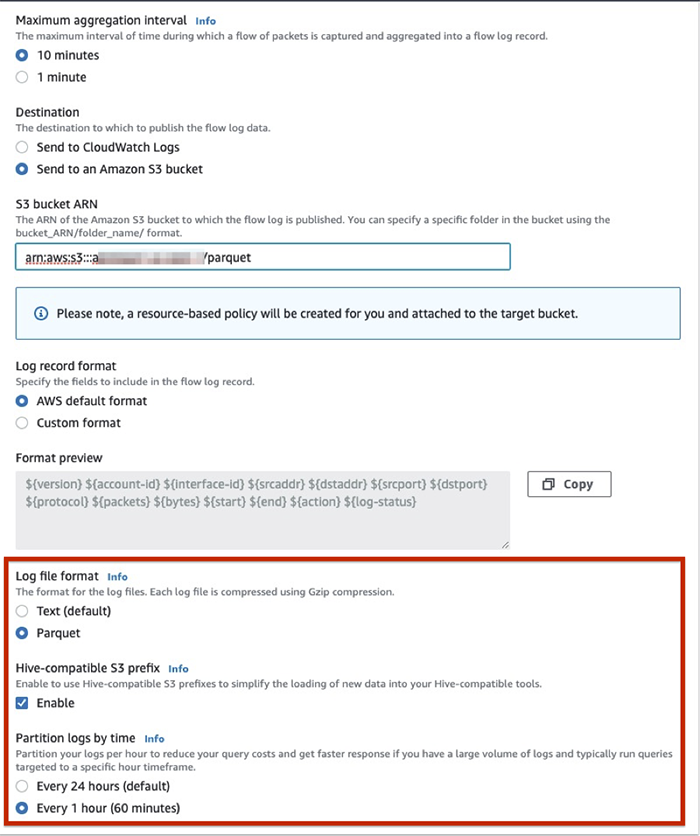
To take advantage of this feature, simply create a new VPC flow log subscription with Amazon S3 as the destination using the AWS Management Console, AWS Command Line Interface (AWS CLI), or API. On the console, when creating new a VPC flow log subscription with Amazon S3, you can select one or more of the following options:
- Log file format
- Hive-compatible S3 prefixes
- Partition logs by time
We now explore how each of these options can make processing and storage of flow logs more efficient
Apache Parquet formatted files
By default, your logs are delivered in text format. To change to Parquet, for Log file format, select Parquet. This delivers your VPC flow logs to Amazon S3 in the Apache Parquet format.
Note the following considerations:
- You can’t change existing flow logs to deliver logs in Parquet format. You need to create a new VPC flow log subscription with Parquet as the log file format.
- Consider using a higher maximum aggregation interval (10 minutes) when aggregating flow packets to ensure larger Parquet files on Amazon S3.
- Refer to Amazon CloudWatch pricing for pricing of log delivery in Apache Parquet format for VPC flow logs
Hive-compatible partitions
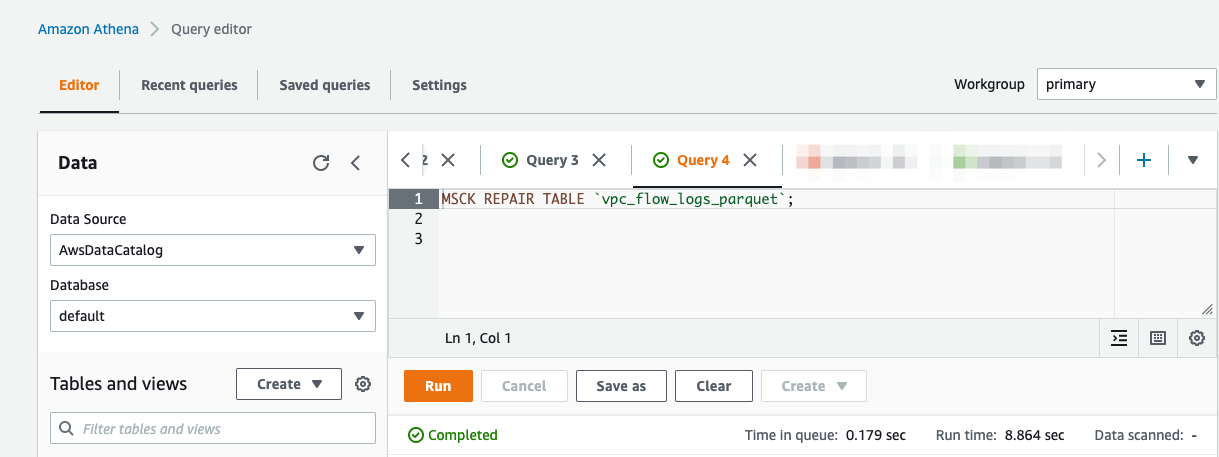
Partitioning is a technique to organize your data to improve the efficiency of your query engine. Partitions aligned with the columns that are frequently used in the query filters can significantly lower your query response time. You can now specify that your flow logs be organized in Hive-compatible format. This allows you to run the MSCK REPAIR command in Athena to quickly and easily add new partitions as they get delivered into Amazon S3. Simply select Enable for Hive-compatible S3 prefix to set this up. This delivers the flow logs to Amazon S3 in the following path:
Per-hour partitions
You can also organize your flow logs at a much more granular level by adding per-hour partitions. You should enable this feature if you constantly need to query large volumes of logs with a specific time frame as the predicate. Querying logs only during certain hours results in less data scanned, which translates to lower cost per query with engines such as Athena and Redshift Spectrum.
You can also set per-hour partitions via an API or the AWS CLI using the --destination-options parameter in create-flow-logs:
The following is a sample flow log file deposited into an hourly bucket. By default, the flow logs in Parquet are compressed using Gzip format, which has the highest compression ratio compared to other compression formats.
Query with Athena
You can use the Athena integration for VPC Flow Logs from the Amazon VPC console to automate the Athena setup and query VPC flow logs in Amazon S3. This integration has now been extended to support these new flow log delivery options to Amazon S3.
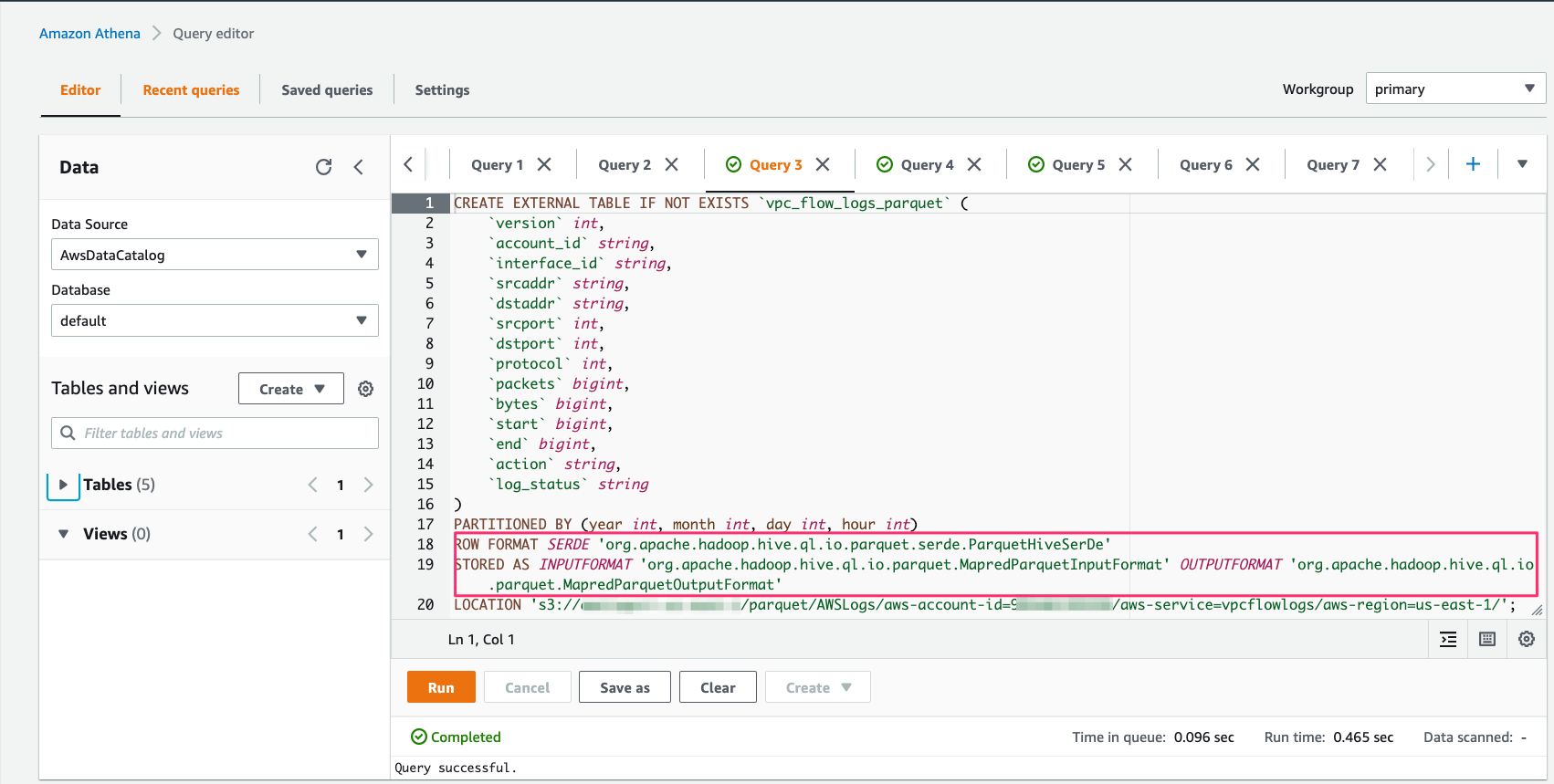
To demonstrate querying flow logs in Parquet and in plain text in this blog, let’s start from the Amazon Athena console. We begin by creating an external table pointing to flow logs in Parquet.
Note that this feature supports specifying flow logs fields in Parquet’s native data types. This eliminates the need for you to cast your fields when querying the traffic logs.
Then run MSCK REPAIR TABLE.
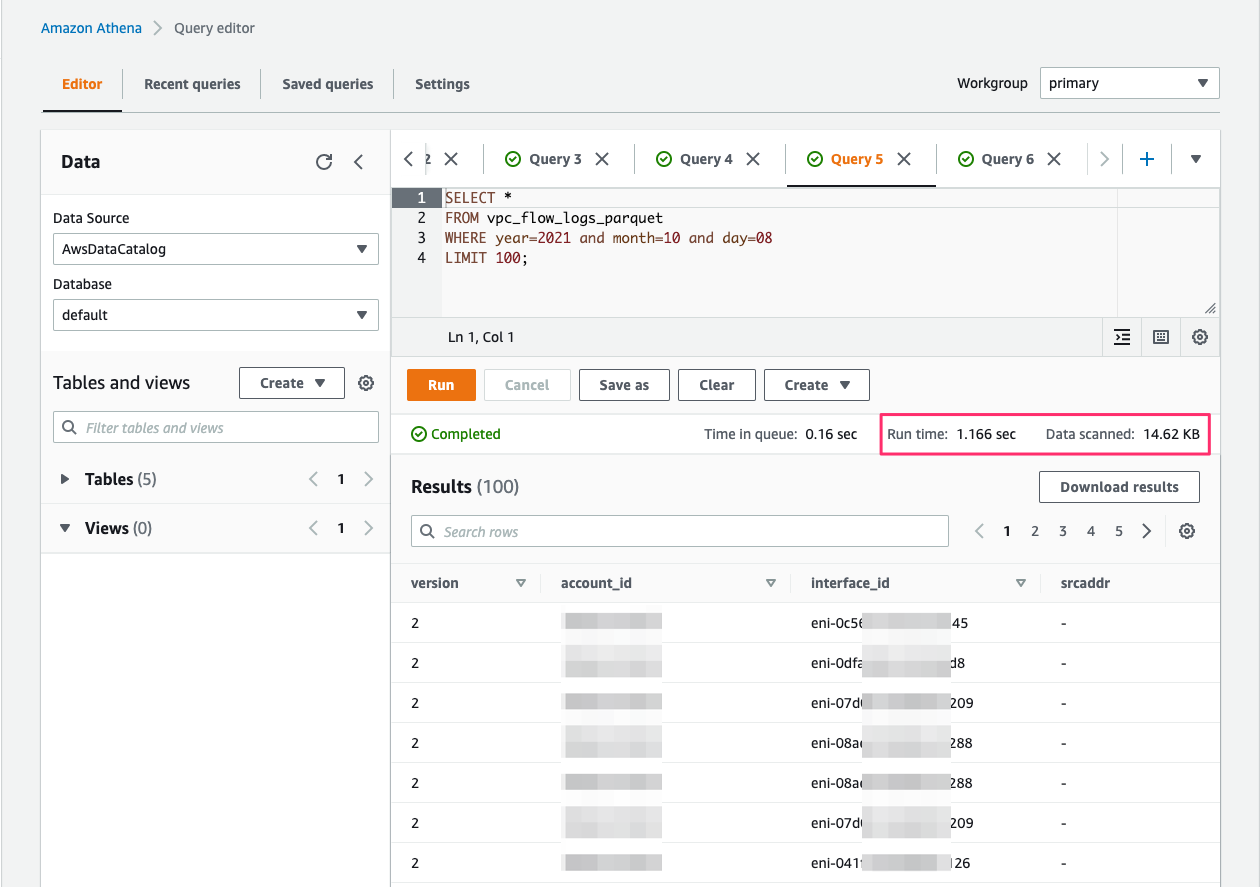
Let’s run a sample query on these Parquet-based flow logs.
Now, let’s create a table for flow logs delivered in plain text.

We add the partitions using the ALTER TABLE statement in Athena.
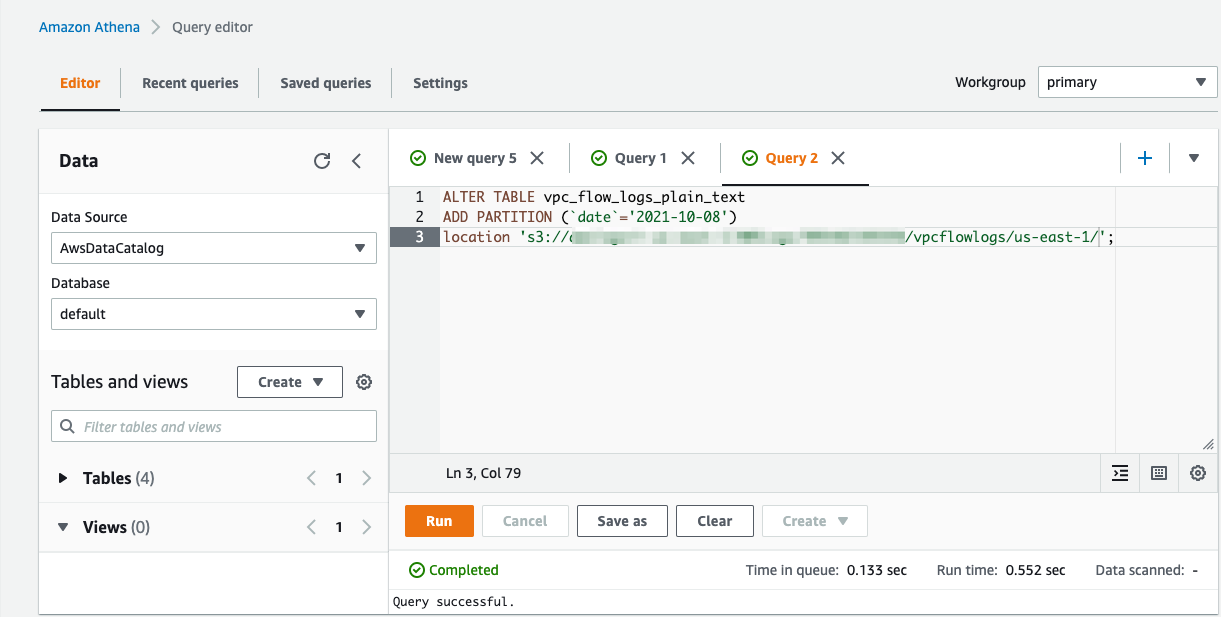
Run a simple flow logs query and note the time it took to run the query.
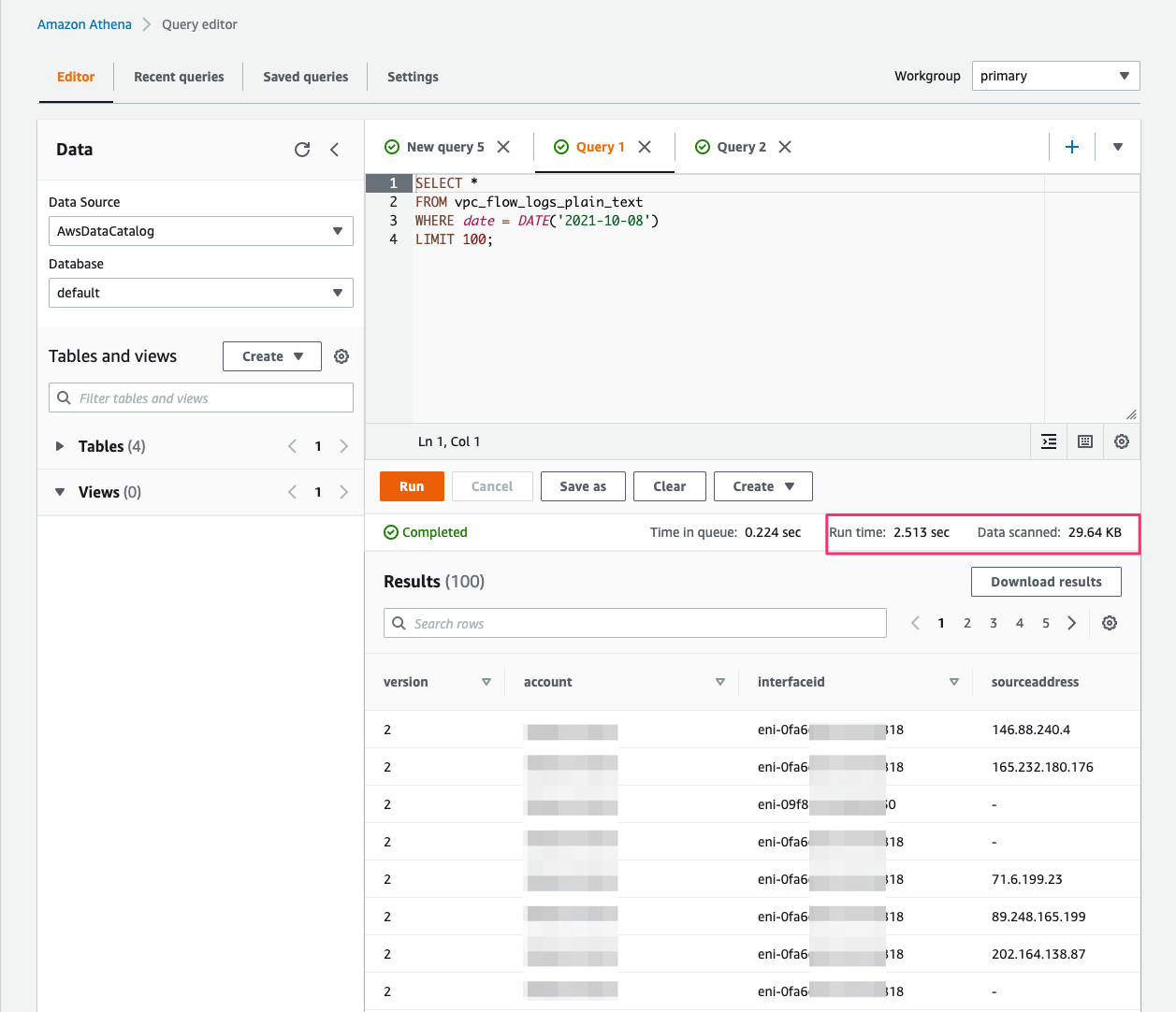
The Athena query run time with flow logs in Parquet (1.16 seconds) is much faster than the run time with flow logs in plain text (2.51 seconds).
For benchmarks that further describe the cost savings and performance improvements from persisting data in Parquet in granular partitions, see Top 10 Performance Tuning Tips for Amazon Athena.
Summary
You can now deliver your VPC flow logs to Amazon S3 with three new options:
- In Apache Parquet formatted files
- With Hive-compatible S3 prefixes
- In hourly partitioned files
These delivery options make it faster, easier, and more cost-efficient to store and run analytics on your VPC flow logs. To learn more, visit VPC Flow Logs documentation. We hope you will give this feature a try and share your experience with us. Please send feedback to the AWS forum for Amazon VPC or through your usual AWS support contacts.
About the Authors
 Radhika Ravirala is a Principal Streaming Architect at Amazon Web Services, where she helps customers craft distributed streaming applications using Amazon Kinesis and Amazon MSK. In her free time, she enjoys long walks with her dog, playing board games, and reading widely.
Radhika Ravirala is a Principal Streaming Architect at Amazon Web Services, where she helps customers craft distributed streaming applications using Amazon Kinesis and Amazon MSK. In her free time, she enjoys long walks with her dog, playing board games, and reading widely.
 Vaibhav Katkade is a Senior Product Manager in the Amazon VPC team. He is interested in areas of network security and cloud networking operations. Outside of work, he enjoys cooking and the outdoors.
Vaibhav Katkade is a Senior Product Manager in the Amazon VPC team. He is interested in areas of network security and cloud networking operations. Outside of work, he enjoys cooking and the outdoors.
Introducing the new AWS Well-Architected Machine Learning Lens
Post Syndicated from Haleh Najafzadeh original https://aws.amazon.com/blogs/architecture/introducing-the-new-aws-well-architected-machine-learning-lens/
The AWS Well-Architected Framework provides you with a formal approach to compare your workloads against best practices. It also includes guidance on how to make improvements.
Machine learning (ML) algorithms discover and learn patterns in data, and construct mathematical models to predict future data. These solutions can revolutionize lives through better diagnoses of diseases, environmental protections, products and services transformation, and more.
Your ML models depend on the quality of input data to generate accurate results. As data changes over time, monitoring is required to continuously detect, correct, and mitigate issues. This improves accuracy and performance. It also may require you to retrain your model with the latest refined data.
Application workloads rely on step-by-step instructions to solve a problem. ML workloads enable algorithms to learn from data through an iterative and continuous cycle. We are announcing a brand-new version of the AWS Well-Architected Machine Learning Lens whitepaper. It complements and builds upon the Well-Architected Framework to address this difference between these two types of workloads.
The whitepaper provides you with a set of established cloud and technology agnostic best practices. You can apply this guidance and architectural principles when designing your ML workloads, or after your workloads have entered production as part of continuous improvement. The paper includes guidance and resources to help you implement these best practices on AWS.
The Well-Architected Machine Learning Lens components
The Lens includes four focus areas:
1. The Well-Architected Machine Learning Design Principles — A set of considerations that are used as the basis for a Well-Architected ML workload. These design principles are the guiding light for the collection of the best practices in the ML Lens.
2. The Well-Architected Machine Learning Lifecycle — This integrates the Well-Architected Framework into the Machine Learning Lifecycle as can be seen in figure 1.
-
- The Well-Architected Framework pillars includes:
-
-
- Operational Excellence
- Security
- Reliability
- Performance Efficiency
- Cost Optimization
-
-
- The Machine Learning Lifecycle phases referenced in the ML Lens include:
-
-
- Business goal identification
- ML problem framing
- Data processing (data collection, data pre-processing, feature engineering)
- Model development (training, tuning, evaluation)
- Model deployment (prediction, inference)
- Model monitoring
-

Figure 1. Well-Architected Machine Learning Lifecycle
In the Well-Architected ML Lens whitepaper, the Well-Architected Machine Learning Lifecycle applies the Well-Architected Framework pillars to each of the lifecycle phases.
3. Cloud and technology agnostic best practices — These are best practices for each ML lifecycle phase across the Well-Architected Framework pillars. Best practices are accompanied by:
-
- Implementation guidance that provides AWS implementation plans for each best practice with references to AWS technologies and resources.
- Resources as a set of links to AWS documents, blogs, videos, and code examples as supporting resources to the best practices and their implementation plans.
4. ML Lifecycle architecture diagrams — These illustrate processes, technologies, and components that support many of the best practices, shown in Figure 2. They include: Feature stores, Model Registry, lineage tracker, alarm manager, scheduler, and more. Different pipeline technologies are illustrated using these architecture diagrams.
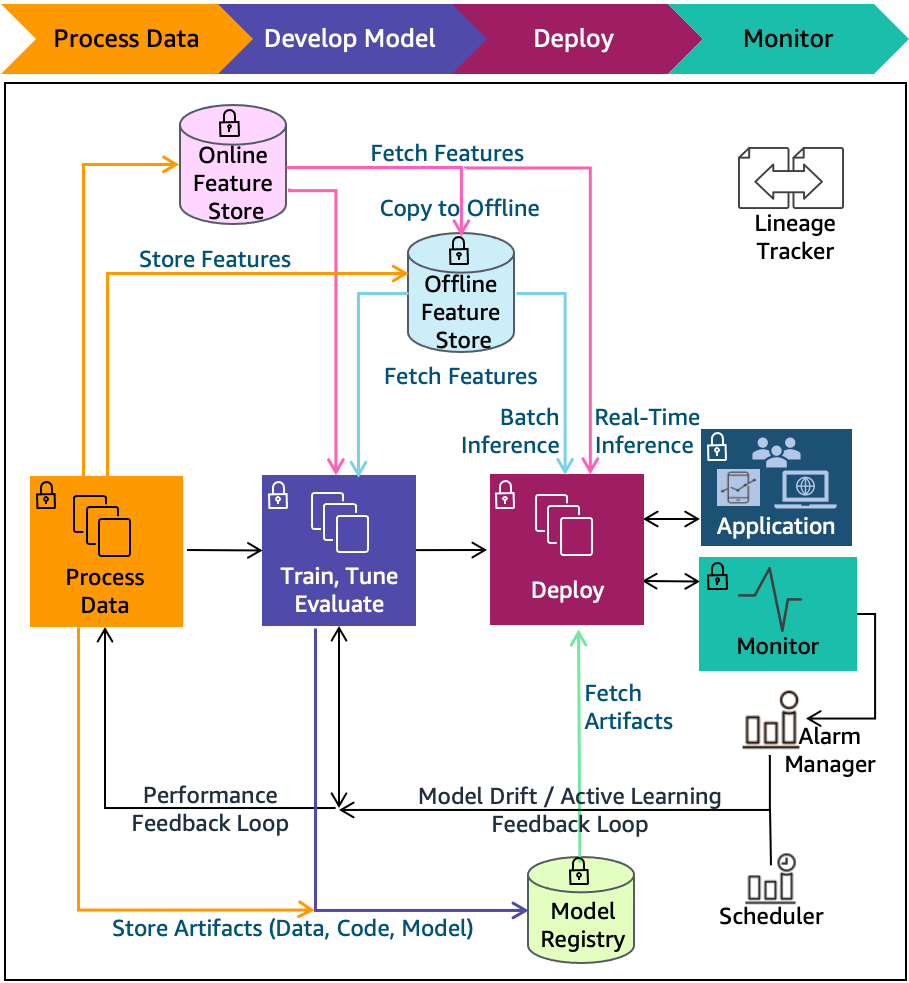
Figure 2. Machine Learning Lifecycle phases with expanded components
Where should you apply the Well-Architected Machine Learning Lens?
Use the Well-Architected ML Lens to:
- Make informed decisions — Plan early and make informed decisions by reviewing best practices before a new workload design begins.
- Build and deploy faster — Use the best practices to guide you through building new Well-Architected workloads across the ML lifecycle.
- Lower or mitigate risks — Evaluate existing workloads regularly to identify, mitigate, and address potential issues early.
- Learn AWS best practices — Use the provided implementation plans as guidance on implementing the best practices on AWS.
Conclusion
The new Well-Architected Machine Learning Lens whitepaper is available now. Use the Lens to help ensure that your ML workloads are architected with operational excellence, security, reliability, performance efficiency, and cost optimization in mind.
Special thanks to everyone across the AWS Solution Architecture and Machine Learning communities. These contributions encompassed diverse perspectives, expertise, and experiences in developing the new AWS Well-Architected Machine Learning Lens.
[Security Nation] Michael Daniel on the Cyber Threat Alliance
Post Syndicated from Rapid7 original https://blog.rapid7.com/2021/10/13/security-nation-michael-daniel-on-the-cyber-threat-alliance/
![]()
In this episode of Security Nation, Jen and Tod chat with Michael Daniel, president and CEO of the Cyber Threat Alliance (CTA), as well as a co-chair on the IST’s Ransomware Task Force. After discussing Michael’s career in cybersecurity with the US government, they talk about what makes information sharing so hard in the security space and how the CTA has addressed this challenge in its efforts to promote better threat intelligence.
Stick around for the Rapid Rundown – with Tod on holiday (AKA vacation), Jen brings on Rapid7’s public policy guru Harley Geiger. They chat about the Cyber Incident Reporting Act, which is likely headed to a Senate floor vote and, if passed, would bring major changes to the reporting requirements around cybersecurity events for owners and operators of critical infrastructure.
Michael Daniel
![[Security Nation] Michael Daniel on the Cyber Threat Alliance](https://blog.rapid7.com/content/images/2021/10/Michael-Daniel--2400-px-.jpg)
Michael Daniel serves as the President and CEO of the Cyber Threat Alliance (CTA), a not-for-profit that enables high-quality cyber threat information sharing among cybersecurity organizations. Prior to CTA, Michael served for four years as US Cybersecurity Coordinator, leading US cybersecurity policy development, facilitating US government partnerships with the private sector and other nations, and coordinating significant incident response activities. From 1995 to 2012, Michael worked for the Office of Management and Budget, overseeing funding for the US Intelligence Community. Michael also works with the Aspen Cybersecurity Group, the World Economic Forum’s Partnership Against Cybercrime, and other organizations improving cybersecurity in the digital ecosystem. In his spare time, he enjoys running and martial arts.
Show notes
Interview links
- Follow Michael on Twitter @CyAlliancePrez
- Learn more about the Cyber Threat Alliance
- Check out the Ransomware Task Force, which Michael co-chairs
- Read Jen’s position piece on hack back
Rapid Rundown links
- Read the full text of the Cyber Incident Reporting Act
- Refresh your memory on the SolarWinds data breach
- See who’s on the House Homeland Security Committee
Want More Inspiring Stories From the Security Community?
Offloading SQL for Amazon RDS using the Heimdall Proxy
Post Syndicated from Antony Prasad Thevaraj original https://aws.amazon.com/blogs/architecture/offloading-sql-for-amazon-rds-using-the-heimdall-proxy/
Getting the maximum scale from your database often requires fine-tuning the application. This can increase time and incur cost – effort that could be used towards other strategic initiatives. The Heimdall Proxy was designed to intelligently manage SQL connections to help you get the most out of your database.
In this blog post, we demonstrate two SQL offload features offered by this proxy:
- Automated query caching
- Read/Write split for improved database scale
By leveraging the solution shown in Figure 1, you can save on development costs and accelerate the onboarding of applications into production.

Figure 1. Heimdall Proxy distributed, auto-scaling architecture
Why query caching?
For ecommerce websites with high read calls and infrequent data changes, query caching can drastically improve your Amazon Relational Database Sevice (RDS) scale. You can use Amazon ElastiCache to serve results. Retrieving data from cache has a shorter access time, which reduces latency and improves I/O operations.
It can take developers considerable effort to create, maintain, and adjust TTLs for cache subsystems. The proxy technology covered in this article has features that allow for automated results caching in grid-caching chosen by the user, without code changes. What makes this solution unique is the distributed, scalable architecture. As your traffic grows, scaling is supported by simply adding proxies. Multiple proxies work together as a cohesive unit for caching and invalidation.
View video: Heimdall Data: Query Caching Without Code Changes
Why Read/Write splitting?
It can be fairly straightforward to configure a primary and read replica instance on the AWS Management Console. But it may be challenging for the developer to implement such a scale-out architecture.
Some of the issues they might encounter include:
- Replication lag. A query read-after-write may result in data inconsistency due to replication lag. Many applications require strong consistency.
- DNS dependencies. Due to the DNS cache, many connections can be routed to a single replica, creating uneven load distribution across replicas.
- Network latency. When deploying Amazon RDS globally using the Amazon Aurora Global Database, it’s difficult to determine how the application intelligently chooses the optimal reader.
The Heimdall Proxy streamlines the ability to elastically scale out read-heavy database workloads. The Read/Write splitting supports:
- ACID compliance. Determines the replication lag and know when it is safe to access a database table, ensuring data consistency.
- Database load balancing. Tracks the status of each DB instance for its health and evenly distribute connections without relying on DNS.
- Intelligent routing. Chooses the optimal reader to access based on the lowest latency to create local-like response times. Check out our Aurora Global Database blog.
View video: Heimdall Data: Scale-Out Amazon RDS with Strong Consistency
Customer use case: Tornado
Hayden Cacace, Director of Engineering at Tornado
Tornado is a modern web and mobile brokerage that empowers anyone who aspires to become a better investor.
Our engineering team was tasked to upgrade our backend such that it could handle a massive surge in traffic. With a 3-month timeline, we decided to use read replicas to reduce the load on the main database instance.
First, we migrated from Amazon RDS for PostgreSQL to Aurora for Postgres since it provided better data replication speed. But we still faced a problem – the amount of time it would take to update server code to use the read replicas would be significant. We wanted the team to stay focused on user-facing enhancements rather than server refactoring.
Enter the Heimdall Proxy: We evaluated a handful of options for a database proxy that could automatically do Read/Write splits for us with no code changes, and it became clear that Heimdall was our best option. It had the Read/Write splitting “out of the box” with zero application changes required. And it also came with database query caching built-in (integrated with Amazon ElastiCache), which promised to take additional load off the database.
Before the Tornado launch date, our load testing showed the new system handling several times more load than we were able to previously. We were using a primary Aurora Postgres instance and read replicas behind the Heimdall proxy. When the Tornado launch date arrived, the system performed well, with some background jobs averaging around a 50% hit rate on the Heimdall cache. This has really helped reduce the database load and improve the runtime of those jobs.
Using this solution, we now have a data architecture with additional room to scale. This allows us to continue to focus on enhancing the product for all our customers.
Download a free trial from the AWS Marketplace.
Resources
- Blog: Read/Write Split with ACID Compliance
- Blog: Automated Query Caching
- Blog: Advanced Connection Pooling
- Heimdall Data technical documentation
- Contact: [email protected]
Heimdall Data, based in the San Francisco Bay Area, is an AWS Advanced Tier ISV partner. They have Amazon Service Ready designations for Amazon RDS and Amazon Redshift. Heimdall Data offers a database proxy that offloads SQL improving database scale. Deployment does not require code changes. For other proxy options, consider the Amazon RDS Proxy, PgBouncer, PgPool-II, or ProxySQL.
How Viasat scaled their big data applications by migrating to Amazon EMR
Post Syndicated from Manoj Gundawar original https://aws.amazon.com/blogs/big-data/how-viasat-scaled-their-big-data-applications-by-migrating-to-amazon-emr/
This post is co-written with Manoj Gundawar from Viasat.
Viasat is a satellite internet service provider based in Carlsbad, CA, with operations across the United States and worldwide. Viasat’s ambition is to be the first truly global, scalable, broadband service provider with a mission to deliver connections that can change the world. Viasat operates across three main business segments: satellite services, commercial networks, and government systems, providing high-speed satellite broadband services and secure networking systems.
In this post, we discuss how migrating our on-premises big data workloads to Amazon EMR helped us achieve a fully managed cloud-native solution and freed us from the constraints of our legacy on-premises solution, so we can focus on business innovation with a lower TCO.
Challenge with the legacy big data environment
Viasat’s big data application, Usage Data Mart, is a high-volume, low-latency Hadoop-based solution that ingests internet usage data from a multitude of source systems. It curates and aggregates with data from other sources, and provides the data in an optimized system to support high-volume access to reporting and web interfaces. This critical application processes over 1.3 billion internet usage records per day, sourced from various upstream systems. Viasat customer support representatives use this data through APIs and reports to assist end-users on any queries regarding their internet usage. Various internal teams and customers also use data for usage accounting, tracking, compliance, and billing purposes.
The Usage Data Mart was previously implemented in an on-premises footprint of over 40 nodes with three independent clusters all running a commercial distribution of Hadoop to process our big data work load. The legacy Hadoop environment required three times the data replication to achieve high availability, which resulted in a large infrastructure footprint. In this architecture, we had a data ingestion cluster to ingest data from a Kafka streaming service, MySQL, and Oracle databases. We had extract, transform, and load (ETL) jobs for each data source and data domains or models, and most of the ETL jobs filter, curate, canonicalize, and aggregate data (by specific keys) using MapReduce framework and load in HBase as well as in HDFS or Amazon Simple Storage Service (Amazon S3) in Apache Parquet format. We used HBase to provide on-demand query and aggregation of data via REST APIs that used HBase coprocessors to apply aggregation and other business logic. Our independent reporting cluster queried Parquet files on HDFS and Amazon S3 with Apache Drill to generate a few dozen periodic reports. We had separated HBase and ETL clusters from reporting clusters to avoid any resource contention.
Our legacy environment had challenges at various levels:
- Hardware – As the hardware aged, we encountered hardware failures on a regular basis. Expiring warranties on hardware and faulty component replacement increased operational risk. The burden of managing the hardware replacement and servers failing to restart after maintenance imposed a serious risk to the business, which made maintenance unpredictable and time-consuming.
- Software – Yearly software license renewal costs and engineering efforts involved with software version upgrades to keep it on a supported version added operational complexity. Moreover, the commercial Hadoop distribution that we were running reached end of life in 2020.
- Scaling – We needed to scale on-premises hardware to meet growing business needs during additional satellite launches that required forecasting and capacity planning. Delays in procurement and shipment of hardware affected project timelines. Finally, increasing data usage and customer adoption of this portal presented serious scaling challenges for Viasat.
How migration to Amazon EMR helped solve this challenge
Viasat evaluated a few alternatives to modernize big data applications and determined that Amazon EMR would be the right platform for our requirements. The separate compute and storage architecture of Amazon EMR helped us address our challenges. The following are some of the key benefits we realized with migration to AWS:
- Storage – Amazon EMR supports HBase on Amazon S3, where Amazon S3 is used as persistent storage for the HBase cluster and allows us to scale our compute needs independently of storage. It also allows us to easily decommission HBase clusters, test upgrades, and optimizes our total cost of ownership. For guidelines and best practices, see Migrating to Apache HBase on Amazon S3 on Amazon EMR.
- DNS records – Because it’s so easy for us to provision new HBase clusters, we needed a way to maintain DNS records to make the cluster easily accessible. We use a simple AWS Lambda function to update DNS records during EMR cluster boot up. The DNS records are stored in our custom DNS service and we use a custom API to update the records.
- Customization – Amazon EMR allows you to customize existing software on the cluster as well as install additional software. We use Apache Drill for reporting and, with EMR bootstrap actions, we were able to install Apache Drill on all the nodes of the reporting cluster to provide us with distributed reporting using Parquet files generated with a MapReduce job. Because our reporting uses different query patterns than the data in the HBase cluster, the Parquet files are written with a different partition optimized for reporting. We increased the default bucket size from approximately 8 MB to 16 MB and pointed Amazon EMR to private Amazon S3 endpoints to avoid traffic going through an external firewall, which increased performance.
The following diagram depicts the process we followed for migration to Amazon EMR.

Viasat successfully migrated our on-premises big data applications to Amazon EMR in May 2021, following a lift-and-shift approach to move the big data workload to the cloud with minimal changes. Although we have an experienced big data team, we used AWS Infrastructure Event Management (IEM) to support queries on fine-tuning the Amazon EMR infrastructure within the migration timeline.
The following diagram outlines our new architecture. With this new architecture, we can process the same workloads with 50% of the compute footprint and approximately 50% of the costs compared to our on-premises clusters and still meet our SLAs.
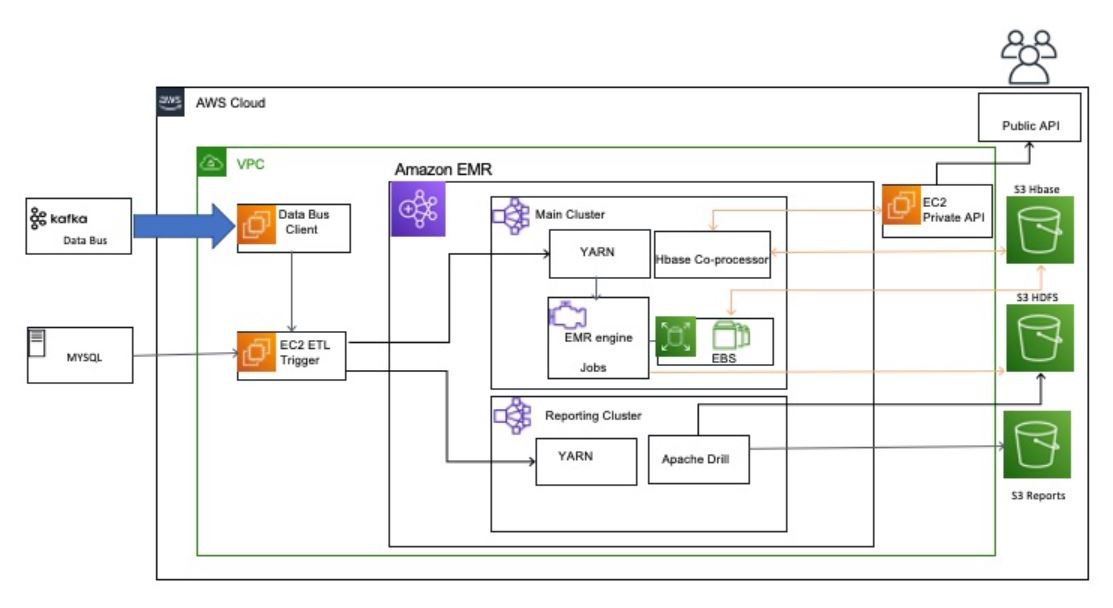
Conclusion
With the new data platform, we can ingest additional data sources so that our analysts and customer service teams can gain insights and improve customer experience. As Viasat is launching new satellites and growing business in multiple new countries, we’re looking to stand up this solution in new AWS Regions (closest to the host country) and scale it as needed.
Questions or feedback? Send an email to [email protected].
About the Authors
 Manoj Gundawar is a product owner at Viasat. He builds product roadmap, provides architecture guidance and manages full software development life cycle to build high quality product/software with minimal TCO. He is passionate about delighting the customers by providing innovating solutions, leveraging technology, agile methodology and continues improvement mindset.
Manoj Gundawar is a product owner at Viasat. He builds product roadmap, provides architecture guidance and manages full software development life cycle to build high quality product/software with minimal TCO. He is passionate about delighting the customers by providing innovating solutions, leveraging technology, agile methodology and continues improvement mindset.
 Archana Srinivasan is a Technical Account Manager within Enterprise Support at Amazon Web Services. Archana helps AWS customers leverage Enterprise Support entitlements to solve complex operational challenges and accelerate their cloud adoption.
Archana Srinivasan is a Technical Account Manager within Enterprise Support at Amazon Web Services. Archana helps AWS customers leverage Enterprise Support entitlements to solve complex operational challenges and accelerate their cloud adoption.
 Kiran Guduguntla is a WW Go-to-Market Specialist for Amazon EMR at AWS. He works with AWS customers across the globe to strategize, build, develop and deploy modern Big Data solutions. He is passionate about working with customers and helping them in their cloud journey. Kiran loves music, travel, food and watching football.
Kiran Guduguntla is a WW Go-to-Market Specialist for Amazon EMR at AWS. He works with AWS customers across the globe to strategize, build, develop and deploy modern Big Data solutions. He is passionate about working with customers and helping them in their cloud journey. Kiran loves music, travel, food and watching football.
The Trevor Project: Leveraging AI to Help LGBTQ Youth in Crisis | Talks at Google
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=N6UDuR51hJQ
Folder Watcher for Home Assistant
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=Rs63cYoRQUw
Four stable kernels
Post Syndicated from original https://lwn.net/Articles/872845/rss
Stable kernels 5.14.12, 5.10.73, 5.4.153, and 4.19.211 have been released with important
fixes. Users of those series should upgrade.
[$] Digging into Julia’s package system
Post Syndicated from original https://lwn.net/Articles/871490/rss
We recently looked at
some of the changes and new features arriving with the upcoming
version 1.7 release of the Julia programming language.
The package system provided by the language makes it easier to
explore new language versions, while still preserving
multiple versions of various parts of the ecosystem. This flexible system
takes care of dependency management, both
for writing exploratory code in the REPL and for
developing projects or libraries.
Security updates for Wednesday
Post Syndicated from original https://lwn.net/Articles/872843/rss
Security updates have been issued by Debian (flatpak and ruby2.3), Fedora (flatpak, httpd, mediawiki, redis, and xstream), openSUSE (kernel, libaom, libqt5-qtsvg, systemd, and webkit2gtk3), Red Hat (.NET 5.0, 389-ds-base, httpd:2.4, kernel, kernel-rt, libxml2, openssl, and thunderbird), Scientific Linux (389-ds-base, kernel, libxml2, and openssl), SUSE (apache2-mod_auth_openidc, curl, glibc, kernel, libaom, libqt5-qtsvg, systemd, and webkit2gtk3), and Ubuntu (squashfs-tools).
Suing Infrastructure Companies for Copyright Violations
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2021/10/suing-infrastructure-companies-for-copyright-violations.html
It’s a matter of going after those with deep pockets. From Wired:
Cloudflare was sued in November 2018 by Mon Cheri Bridals and Maggie Sottero Designs, two wedding dress manufacturers and sellers that alleged Cloudflare was guilty of contributory copyright infringement because it didn’t terminate services for websites that infringed on the dressmakers’ copyrighted designs….
[Judge] Chhabria noted that the dressmakers have been harmed “by the proliferation of counterfeit retailers that sell knock-off dresses using the plaintiffs’ copyrighted images” and that they have “gone after the infringers in a range of actions, but to no avail — every time a website is successfully shut down, a new one takes its place.” Chhabria continued, “In an effort to more effectively stamp out infringement, the plaintiffs now go after a service common to many of the infringers: Cloudflare. The plaintiffs claim that Cloudflare contributes to the underlying copyright infringement by providing infringers with caching, content delivery, and security services. Because a reasonable jury could not — at least on this record — conclude that Cloudflare materially contributes to the underlying copyright infringement, the plaintiffs’ motion for summary judgment is denied and Cloudflare’s motion for summary judgment is granted.”
I was an expert witness for Cloudflare in this case, basically explaining to the court how the service works.
Cloudflare and the IETF
Post Syndicated from Jonathan Hoyland original https://blog.cloudflare.com/cloudflare-and-the-ietf/
The Internet, far from being just a series of tubes, is a huge, incredibly complex, decentralized system. Every action and interaction in the system is enabled by a complicated mass of protocols woven together to accomplish their task, each handing off to the next like trapeze artists high above a virtual circus ring. Stop to think about details, and it is a marvel.
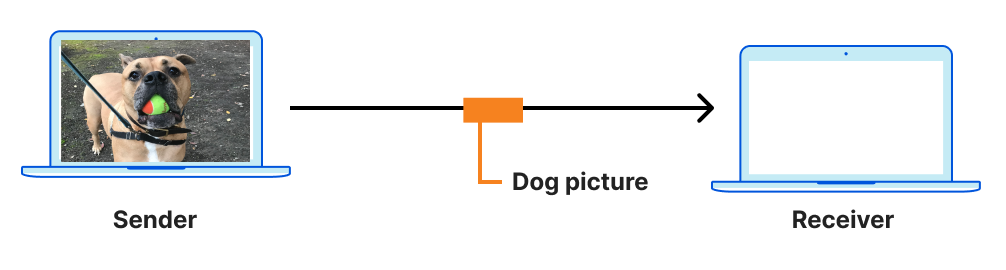
Consider one of the simplest tasks enabled by the Internet: Sending a message from sender to receiver.
The location (address) of a receiver is discovered using DNS, a connection between sender and receiver is established using a transport protocol like TCP, and (hopefully!) secured with a protocol like TLS. The sender’s message is encoded in a format that the receiver can recognize and parse, like HTTP, because the two disparate parties need a common language to communicate. Then, ultimately, the message is sent and carried in an IP datagram that is forwarded from sender to receiver based on routes established with BGP.
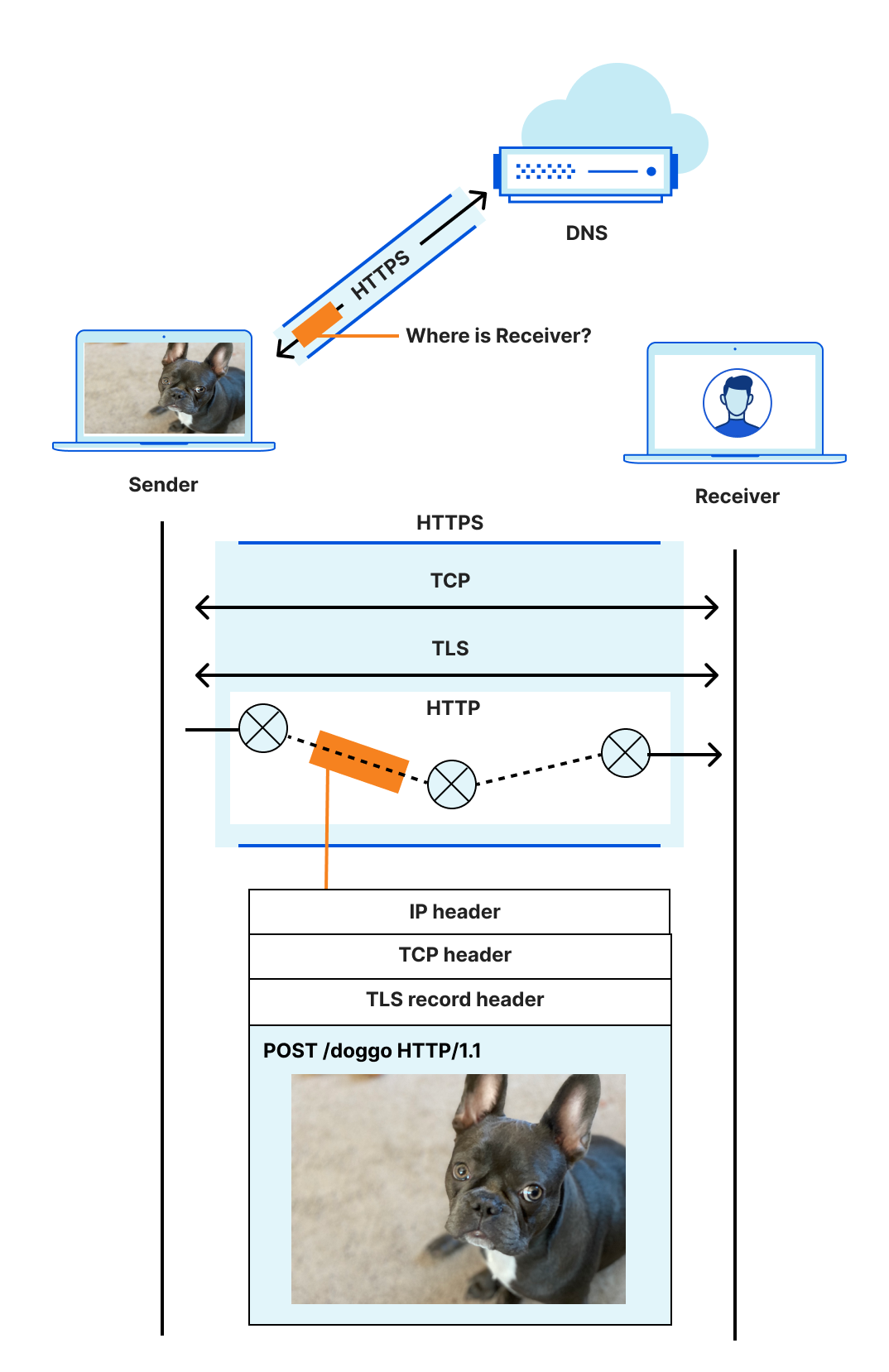
Even an explanation this dense is laughably oversimplified. For example, the four protocols listed are just the start, and ignore many others with acronyms of their own. The truth is that things are complicated. And because things are complicated, how these protocols and systems interact and influence the user experience on the Internet is complicated. Extra round trips to establish a secure connection increase the amount of time before useful work is done, harming user performance. The use of unauthenticated or unencrypted protocols reveals potentially sensitive information to the network or, worse, to malicious entities, which harms user security and privacy. And finally, consolidation and centralization — seemingly a prerequisite for reducing costs and protecting against attacks — makes it challenging to provide high availability even for essential services. (What happens when that one system goes down or is otherwise unavailable, or to extend our earlier metaphor, when a trapeze isn’t there to catch?)
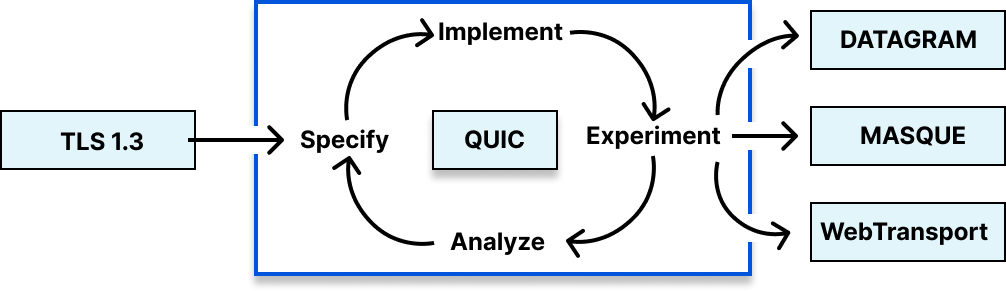
These four properties — performance, security, privacy, and availability — are crucial to the Internet. At Cloudflare, and especially in the Cloudflare Research team, where we use all these various protocols, we’re committed to improving them at every layer in the stack. We work on problems as diverse as helping network security and privacy with TLS 1.3 and QUIC, improving DNS privacy via Oblivious DNS-over-HTTPS, reducing end-user CAPTCHA annoyances with Privacy Pass and Cryptographic Attestation of Personhood (CAP), performing Internet-wide measurements to understand how things work in the real world, and much, much more.
Above all else, these projects are meant to do one thing: focus beyond the horizon to help build a better Internet. We do that by developing, advocating, and advancing open standards for the many protocols in use on the Internet, all backed by implementation, experimentation, and analysis.
Standards
The Internet is a network of interconnected autonomous networks. Computers attached to these networks have to be able to route messages to each other. However, even if we can send messages back and forth across the Internet, much like the storied Tower of Babel, to achieve anything those computers have to use a common language, a lingua franca, so to speak. And for the Internet, standards are that common language.
Many of the parts of the Internet that Cloudflare is interested in are standardized by the IETF, which is a standards development organization responsible for producing technical specifications for the Internet’s most important protocols, including IP, BGP, DNS, TCP, TLS, QUIC, HTTP, and so on. The IETF’s mission is:
> to make the Internet work better by producing high-quality, relevant technical documents that influence the way people design, use, and manage the Internet.
Our individual contributions to the IETF help further this mission, especially given our role on the Internet. We can only do so much on our own to improve the end-user experience. So, through standards, we engage with those who use, manage, and operate the Internet to achieve three simple goals that lead to a better Internet:
1. Incrementally improve existing and deployed protocols with innovative solutions;
2. Provide holistic solutions to long-standing architectural problems and enable new use cases; and
3. Identify key problems and help specify reusable, extensible, easy-to-implement abstractions for solving them.
Below, we’ll give an example of how we helped achieve each goal, touching on a number of important technical specifications produced in recent years, including DNS-over-HTTPS, QUIC, and (the still work-in-progress) TLS Encrypted Client Hello.
Incremental innovation: metadata privacy with DoH and ECH
The Internet is not only complicated — it is leaky. Metadata seeps like toxic waste from nearly every protocol in use, from DNS to TLS, and even to HTTP at the application layer.
One critically important piece of metadata that still leaks today is the name of the server that clients connect to. When a client opens a connection to a server, it reveals the name and identity of that server in many places, including DNS, TLS, and even sometimes at the IP layer (if the destination IP address is unique to that server). Linking client identity (IP address) to target server names enables third parties to build a profile of per-user behavior without end-user consent. The result is a set of protocols that does not respect end-user privacy.
Fortunately, it’s possible to incrementally address this problem without regressing security. For years, Cloudflare has been working with the standards community to plug all of these individual leaks through separate specialized protocols:
- DNS-over-HTTPS encrypts DNS queries between clients and recursive resolvers, ensuring only clients and trusted recursive resolvers see plaintext DNS traffic.
- TLS Encrypted Client Hello encrypts metadata in the TLS handshake, ensuring only the client and authoritative TLS server see sensitive TLS information.
These protocols impose a barrier between the client and server and everyone else. However, neither of them prevent the server from building per-user profiles. Servers can track users via one critically important piece of information: the client IP address. Fortunately, for the overwhelming majority of cases, the IP address is not essential for providing a service. For example, DNS recursive resolvers do not need the full client IP address to provide accurate answers, as is evidenced by the EDNS(0) Client Subnet extension. To further reduce information exposure on the web, we helped push further with two more incremental improvements:
- Oblivious DNS-over-HTTPS (ODoH) uses cryptography and network proxies to break linkability between client identity (IP address) and DNS traffic, ensuring that recursive resolvers have only the minimal amount of information to provide DNS answers — the queries themselves, without any per-client information.
- MASQUE is standardizing techniques for proxying UDP and IP protocols over QUIC connections, similar to the existing HTTP CONNECT method for TCP-based protocols. Generally, the CONNECT method allows clients to use services without revealing any client identity (IP address).
While each of these protocols may seem only an incremental improvement over what we have today, together, they raise many possibilities for the future of the Internet. Are DoH and ECH sufficient for end-user privacy, or are technologies like ODoH and MASQUE necessary? How do proxy technologies like MASQUE complement or even subsume protocols like ODoH and ECH? These are questions the Cloudflare Research team strives to answer through experimentation, analysis, and deployment together with other stakeholders on the Internet through the IETF. And we could not ask the questions without first laying the groundwork.
Architectural advancement: QUIC and HTTP/3
QUIC and HTTP/3 are transformative technologies. Whilst the TLS handshake forms the heart of QUIC’s security model, QUIC is an improvement beyond TLS over TCP, in many respects, including more encryption (privacy), better protection against active attacks and ossification at the network layer, fewer round trips to establish a secure connection, and generally better security properties. QUIC and HTTP/3 give us a clean slate for future innovation.
Perhaps one of QUIC’s most important contributions is that it challenges and even breaks many established conventions and norms used on the Internet. For example, the antiquated socket API for networking, which treats the network connection as an in-order bit pipe is no longer appropriate for modern applications and developers. Modern networking APIs such as Apple’s Network.framework provide high-level interfaces that take advantage of the new transport features provided by QUIC. Applications using this or even higher-level HTTP abstractions can take advantage of the many security, privacy, and performance improvements of QUIC and HTTP/3 today with minimal code changes, and without being constrained by sockets and their inherent limitations.
Another salient feature of QUIC is its wire format. Nearly every bit of every QUIC packet is encrypted and authenticated between sender and receiver. And within a QUIC packet, individual frames can be rearranged, repackaged, and otherwise transformed by the sender.

Together, these are powerful tools to help mitigate future network ossification and enable continued extensibility. (TLS’s wire format ultimately led to the middlebox compatibility mode for TLS 1.3 due to the many middlebox ossification problems that were encountered during early deployment tests.)
Exercising these features of QUIC is important for the long-term health of the protocol and applications built on top of it. Indeed, this sort of extensibility is what enables innovation.
In fact, we’ve already seen a flurry of new work based on QUIC: extensions to enable multipath QUIC, different congestion control approaches, and ways to carry data unreliably in the DATAGRAM frame.
Beyond functional extensions, we’ve also seen a number of new use cases emerge as a result of QUIC. DNS-over-QUIC is an upcoming proposal that complements DNS-over-TLS for recursive to authoritative DNS query protection. As mentioned above, MASQUE is a working group focused on standardizing methods for proxying arbitrary UDP and IP protocols over QUIC connections, enabling a number of fascinating solutions and unlocking the future of proxy and VPN technologies. In the context of the web, the WebTransport working group is standardizing methods to use QUIC as a “supercharged WebSocket” for transporting data efficiently between client and server while also depending on the WebPKI for security.
By definition, these extensions are nowhere near complete. The future of the Internet with QUIC is sure to be a fascinating adventure.
Specifying abstractions: Cryptographic algorithms and protocol design
Standards allow us to build abstractions. An ideal standard is one that is usable in many contexts and contains all the information a sufficiently skilled engineer needs to build a compliant implementation that successfully interoperates with other independent implementations. Writing a new standard is sort of like creating a new Lego brick. Creating a new Lego brick allows us to build things that we couldn’t have built before. For example, one new “brick” that’s nearly finished (as of this writing) is Hybrid Public Key Encryption (HPKE). HPKE allows us to efficiently encrypt arbitrary plaintexts under the recipient’s public key.
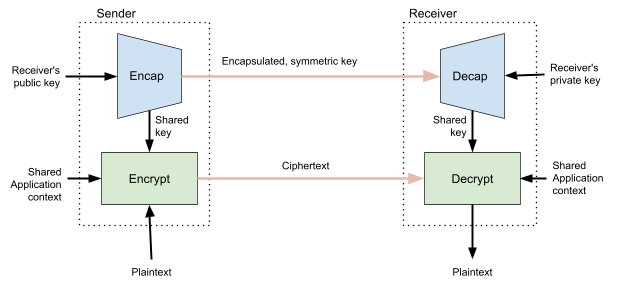
Mixing asymmetric and symmetric cryptography for efficiency is a common technique that has been used for many years in all sorts of protocols, from TLS to PGP. However, each of these applications has come up with their own design, each with its own security properties. HPKE is intended to be a single, standard, interoperable version of this technique that turns this complex and technical corner of protocol design into an easy-to-use black box. The standard has undergone extensive analysis by cryptographers throughout its development and has numerous implementations available. The end result is a simple abstraction that protocol designers can include without having to consider how it works under-the-hood. In fact, HPKE is already a dependency for a number of other draft protocols in the IETF, such as TLS Encrypted Client Hello, Oblivious DNS-over-HTTPS, and Message Layer Security.
Modes of Interaction
We engage with the IETF in the specification, implementation, experimentation, and analysis phases of a standard to help achieve our three goals of incremental innovation, architectural advancement, and production of simple abstractions.
Our participation in the standards process hits all four phases. Individuals in Cloudflare bring a diversity of knowledge and domain expertise to each phase, especially in the production of technical specifications. This week, we’ll have a blog about an upcoming standard that we’ve been working on for a number of years and will be sharing details about how we used formal analysis to make sure that we ruled out as many security issues in the design as possible. We work in close collaboration with people from all around the world as an investment in the future of the Internet. Open standards mean that everyone can take advantage of the latest and greatest in protocol design, whether they use Cloudflare or not.
Cloudflare’s scale and perspective on the Internet are essential to the standards process. We have experience rapidly implementing, deploying, and experimenting with emerging technologies to gain confidence in their maturity. We also have a proven track record of publishing the results of these experiments to help inform the standards process. Moreover, we open source as much of the code we use for these experiments as possible to enable reproducibility and transparency. Our unique collection of engineering expertise and wide perspective allows us to help build standards that work in a wide variety of use cases. By investing time in developing standards that everyone can benefit from, we can make a clear contribution to building a better Internet.
One final contribution we make to the IETF is more procedural and based around building consensus in the community. A challenge to any open process is gathering consensus to make forward progress and avoiding deadlock. We help build consensus through the production of running code, leadership on technical documents such as QUIC and ECH, and even logistically by chairing working groups. (Working groups at the IETF are chaired by volunteers, and Cloudflare numbers a few working group chairs amongst its employees, covering a broad spectrum of the IETF (and its related research-oriented group, the IRTF) from security and privacy to transport and applications.) Collaboration is a cornerstone of the standards process and a hallmark of Cloudflare Research, and we apply it most prominently in the standards process.
If you too want to help build a better Internet, check out some IETF Working Groups and mailing lists. All you need to start contributing is an Internet connection and an email address, so why not give it a go? And if you want to join us on our mission to help build a better Internet through open and interoperable standards, check out our open positions, visiting researcher program, and many internship opportunities!
Pairings in CIRCL
Post Syndicated from Armando Faz-Hernández original https://blog.cloudflare.com/circl-pairings-update/


In 2019, we announced the release of CIRCL, an open-source cryptographic library written in Go that provides optimized implementations of several primitives for key exchange and digital signatures. We are pleased to announce a major update of our library: we have included more packages for elliptic curve-based cryptography (ECC), pairing-based cryptography, and quantum-resistant algorithms.
All of these packages are the foundation of work we’re doing on bringing the benefits of cutting edge research to Cloudflare. In the past we’ve experimented with post-quantum algorithms, used pairings to keep keys safe around the world, and implemented advanced elliptic curves. Now we’re continuing that work, and sharing the foundation with everyone.
In this blog post we’re going to focus on pairing-based cryptography and give you a brief overview of some properties that make this topic so pleasant. If you are not so familiar with elliptic curves, we recommend this primer on ECC.
Otherwise, let’s get ready, pairings have arrived!
What are pairings?
Elliptic curve cryptography enables an efficient instantiation of several cryptographic applications: public-key encryption, signatures, zero-knowledge proofs, and many other more exotic applications like oblivious transfer and OPRFs. With all of those applications you might wonder what is the additional value that pairings offer? To see that, we need first to understand the basic properties of an elliptic curve system, and from that we can highlight the big gap that pairings have.
Conventional elliptic curve systems work with a single group $\mathbb{G}$: the points of an elliptic curve $E$. In this group, usually denoted additively, we can add the points $P$ and $Q$ and get another point on the curve $R=P+Q$; also, we can multiply a point $P$ by an integer scalar $k$ and by repeatedly doing
$$ kP = \underbrace{P+P+\dots+P}_{k \text{ terms}} $$
This operation is known as scalar multiplication, which resembles exponentiation, and there are efficient algorithms for this operation. But given the point $Q=kP$, and $P$, it is very hard for an adversary that doesn’t know $k$ to find it. This is the Elliptic Curve Discrete Logarithm problem (ECDLP).
Now we show a property of scalar multiplication that can help us to understand the properties of pairings.
Scalar Multiplication is a Linear Map
Note the following equivalences:
$ (a+b)P = aP + bP $
$ b (aP) = a (bP) $.
These are very useful properties for many protocols: for example, the last identity allows Alice and Bob to arrive at the same value when following the Diffie-Hellman key-agreement protocol.
But while point addition and scalar multiplication are nice, it’s also useful to be able to multiply points: if we had a point $P$ and $aP$ and $bP$, getting $abP$ out would be very cool and let us do all sorts of things. Unfortunately Diffie-Hellman would immediately be insecure, so we can’t get what we want.
Guess what? Pairings provide an efficient, useful sort of intermediary point multiplication.
It’s intermediate multiplication because although the operation takes two points as operands, the result of a pairing is not a point, but an element of a different group; thus, in a pairing there are more groups involved and all of them must contain the same number of elements.
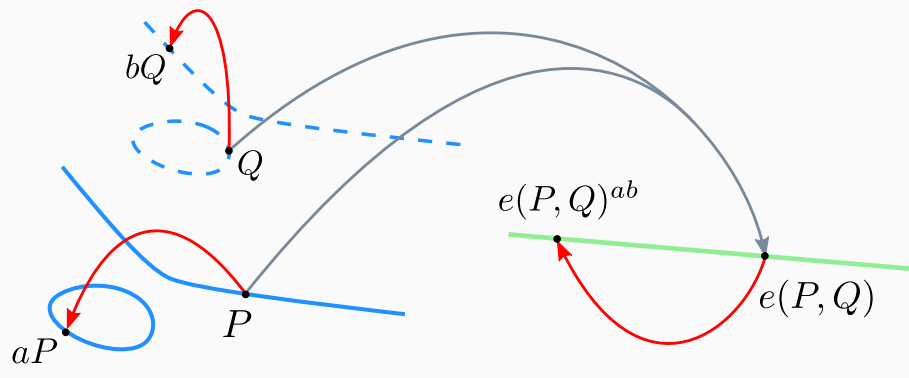
Pairing is denoted as $$ e \colon\; \mathbb{G}_1 \times \mathbb{G}_2 \rightarrow \mathbb{G}_T $$
Groups $\mathbb{G}_1$ and $\mathbb{G}_2$ contain points of an elliptic curve $E$. More specifically, they are the $r$-torsion points, for a fixed prime $r$. Some pairing instances fix $\mathbb{G}_1=\mathbb{G}_2$, but it is common to use disjoint sets for efficiency reasons. The third group $\mathbb{G}_T$ has notable differences. First, it is written multiplicatively, unlike the other two groups. $\mathbb{G}_T$ is not the set of points on an elliptic curve. It’s instead a subgroup of the multiplicative group over some larger finite field. It contains the elements that satisfy $x^r=1$, better known as the $r$-roots of unity.
While every elliptic curve has a pairing, very few have ones that are efficiently computable. Those that do, we call them pairing-friendly curves.
The Pairing Operation is a Bilinear Map
What makes pairings special is that \(e\) is a bilinear map. Yes, the linear property of the scalar multiplication is present twice, one per group. Let’s see the first linear map.
For points $P, Q, R$ and scalars $a$ and $b$ we have:
$ e(P+Q, R) = e(P, R) * e(Q, R) $
$ e(aP, Q) = e(P, Q)^a $
So, a scalar $a$ acting in the first operand as $aP$, finds its way out and escapes from the input of the pairing and appears in the output of the pairing as an exponent in $\mathbb{G}_T$. The same linear map is observed for the second group:
$ e(P, Q+R) = e(P, Q) * e(P, R) $
$ e(P, bQ) = e(P, Q)^b $
Hence, the pairing is bilinear. We will see below how this property becomes useful.
Can bilinear pairings help solving ECDLP?
The MOV (by Menezes, Okamoto, and Vanstone) attack reduces the discrete logarithm problem on elliptic curves to finite fields. An attacker with knowledge of $kP$ and public points $P$ and $Q$ can recover $k$ by computing:
$ g_k = e(kP, Q) = e(P, Q)^k $,
$ g = e(P, Q) $
$ k = \log_g(g_k) $
Note that the discrete logarithm to be solved was moved from $\mathbb{G}_1$ to $\mathbb{G}_T$. So an attacker must ensure that the discrete logarithm is easier to solve in $\mathbb{G}_T$, and surprisingly, for some curves this is the case.
Fortunately, pairings do not present a threat for standard curves (such as the NIST curves or Curve25519) because these curves are constructed in such a way that $\mathbb{G}_T$ gets very large, which makes the pairing operation not efficient anymore.
This attacking strategy was one of the first applications of pairings in cryptanalysis as a tool to solve the discrete logarithm. Later, more people noticed that the properties of pairings are so useful, and can be used constructively to do cryptography. One of the fascinating truisms of cryptography is that one person’s sledgehammer is another person’s brick: while pairings yield a generic attack strategy for the ECDLP problem, it can also be used as a building block in a ton of useful applications.
Applications of Pairings
In the 2000s decade, a large wave of research works were developed aimed at applying pairings to many practical problems. An iconic pairing-based system was created by Antoine Joux, who constructed a one-round Diffie-Hellman key exchange for three parties.
Let’s see first how a three-party Diffie-Hellman is done without pairings. Alice, Bob and Charlie want to agree on a shared key, so they compute, respectively, $aP$, $bP$ and $cP$ for a public point P. Then, they send to each other the points they computed. So Alice receives $cP$ from Charlie and sends $aP$ to Bob, who can then send $baP$ to Charlie and get $acP$ from Alice and so on. After all this is done, they can all compute $k=abcP$. Can this be performed in a single round trip?
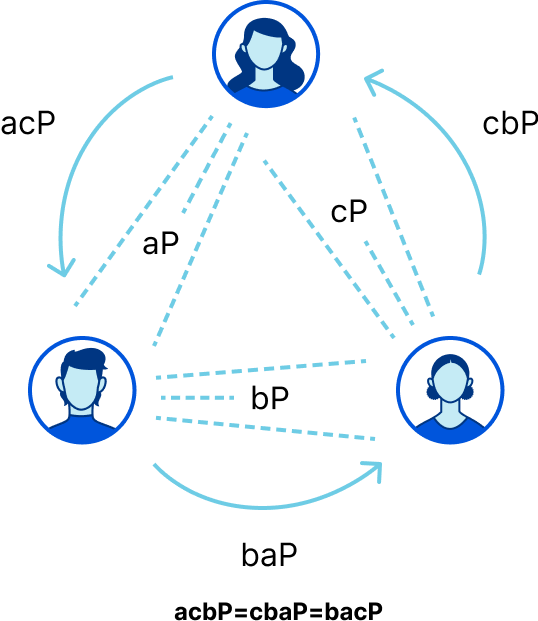

The 3-party Diffie-Hellman protocol needs two communication rounds (on the top), but with the use of pairings a one-round trip protocol is possible.
Affirmative! Antoine Joux showed how to agree on a shared secret in a single round of communication. Alice announces $aP$, gets $bP$ and $cP$ from Bob and Charlie respectively, and then computes $k= (bP, cP)^a$. Likewise Bob computes $e(aP,cP)^b$ and Charlie does $e(aP,bP)^c$. It’s not difficult to convince yourself that all these values are equivalent, just by looking at the bilinear property.
$e(bP,cP)^a = e(aP,cP)^b = e(aP,bP)^c = e(P,P)^{abc}$
With pairings we’ve done in one round what would otherwise take two.
Another application in cryptography addresses a problem posed by Shamir in 1984: does there exist an encryption scheme in which the public key is an arbitrary string? Imagine if your public key was your email address. It would be easy to remember and certificate authorities and certificate management would be unnecessary.
A solution to this problem came some years later, in 2001, and is the Identity-based Encryption (IBE) scheme proposed by Boneh and Franklin, which uses bilinear pairings as the main tool.
Nowadays, pairings are used for the zk-SNARKS that make Zcash an anonymous currency, and are also used in drand to generate public-verifiable randomness. Pairings and the compact, aggregatable BLS signatures are used in Ethereum. We have used pairings to build Geo Key Manager: pairings let us implement a compact broadcast and negative broadcast scheme that together make Geo Key Manager work.
In order to make these schemes, we have to implement pairings, and to do that we need to understand the mathematics behind them.
Where do pairings come from?
In order to deeply understand pairings we must understand the interplay of geometry and arithmetic, and the origins of the group’s law. The starting point is the concept of a divisor, a formal combination of points on the curve.
$D = \sum n_i P_i$
The sum of all the coefficients $n_i$ is the degree of the divisor. If we have a function on the curve that has poles and zeros, we can count them with multiplicity to get a principal divisor. Poles are counted as negative, while zeros as positive. For example if we take the projective line, the function $x$ has the divisor $(0)-(\infty)$.
The degree of a divisor is the sum of its coefficients. All principal divisors have degree $0$. The group of degree zero divisors modulo the principal divisors is the Jacobian. This means that we take all the degree zero divisors, and freely add or subtract principle divisors, constructing an abelian variety called the Jacobian.
Until now our constructions have worked for any curve. Elliptic curves have a special property: since a line intersects the curve in three points, it’s always possible to turn an element of the Jacobian into one of the form $(P)-(O)$ for a point $P$. This is where the addition law of elliptic curves comes from.

{kind=link}
Given a function $f$ we can evaluate it on a divisor $D=\sum n_i P_i$ by taking the product $\prod f(P_i)^{n_i}$. And if two functions $f$ and $g$ have disjoint divisors, we have the Weil duality:
$ f(\text{div}(g)) = g(\text{div}(f)) $,
The existence of Weil duality is what gives us the bilinear map we seek. Given an $r$-torsion point $T$ we have a function $f$ whose divisor is $r(T)-r(O)$. We can write down an auxiliary function $g$ such that $f(rP)=g^r(P)$ for any $P$. We then get a pairing by taking.
$e_r(S,T)=\frac{g(X+S)}{g(X)}$.
The auxiliary point $X$ is any point that makes the numerator and denominator defined.
In practice, the pairing we have defined above, the Weil pairing, is little used. It was historically the first pairing and is extremely important in the mathematics of elliptic curves, but faster alternatives based on more complicated underlying mathematics are used today. These faster pairings have different $\mathbb{G}_1$ and $\mathbb{G}_2$, while the Weil pairing made them the same.
Shift in parameters
As we saw earlier, the discrete logarithm problem can be attacked either on the group of elliptic curve points or on the third group (an extension of a prime field) whichever is weaker. This is why the parameters that define a pairing must balance the security of the three groups.
Before 2015 a good balance between the extension degree, the size of the prime field, and the security of the scheme was achieved by the family of Barreto-Naehrig (BN) curves. For 128 bits of security, BN curves use an extension of degree 12, and have a prime of size 256 bits; as a result they are an efficient choice for implementation.
A breakthrough for pairings occurred in 2015 when Kim and Barbescu published a result that accelerated the attacks in finite fields. This resulted in increasing the size of fields to comply with standard security levels. Just as short hashes like MD5 got depreciated as they became insecure and $2^{64}$ was no longer enough, and RSA-1024 was replaced with RSA-2048, we regularly change parameters to deal with improved attacks.
For pairings this implied the use of larger primes for all the groups. Roughly speaking, the previous 192-bit security level becomes the new 128-bit level after this attack. Also, this shift in parameters brings the family of Barreto-Lynn-Scott (BLS) curves to the stage because pairings on BLS curves are faster than BN in this new setting. Hence, currently BLS curves using an extension of degree 12, and primes of around 384 bits provide the equivalent to 128 bit security.
The IETF draft (currently in preparation) draft-irtf-cfrg-pairing-friendly-curves specifies secure pairing-friendly elliptic curves. It includes parameters for BN and BLS families of curves. It also targets different security levels to provide crypto agility for some applications relying on pairing-based cryptography.
Implementing Pairings in Go
Historically, notable examples of software libraries implementing pairings include PBC by Ben Lynn, Miracl by Michael Scott, and Relic by Diego Aranha. All of them are written in C/C++ and some ports and wrappers to other languages exist.
In the Go standard library we can find the golang.org/x/crypto/bn256 package by Adam Langley, an implementation of a pairing using a BN curve with 256-bit prime. Our colleague Brendan McMillion built github.com/cloudflare/bn256 that dramatically improves the speed of pairing operations for that curve. See the RWC-2018 talk to see our use case of pairing-based cryptography. This time we want to go one step further, and we started looking for alternative pairing implementations.
Although one can find many libraries that implement pairings, our goal is to rely on one that is efficient, includes protection against side channels, and exposes a flexible API oriented towards applications that permit generality, while avoiding common security pitfalls. This motivated us to include pairings in CIRCL. We followed best practices on secure code development and we want to share with you some details about the implementation.
We started by choosing a pairing-friendly curve. Due to the attack previously mentioned, the BN256 curve does not meet the 128-bit security level. Thus there is a need for using stronger curves. Such a stronger curve is the BLS12-381 curve that is widely used in the zk-SNARK protocols and short signature schemes. Using this curve allows us to make our Go pairing implementation interoperable with other implementations available in other programming languages, so other projects can benefit from using CIRCL too.
This code snippet tests the linearity property of pairings and shows how easy it is to use our library.
import ( "crypto/rand" "fmt" e "github.com/cloudflare/circl/ecc/bls12381" ) func ExamplePairing() { P, Q := e.G1Generator(), e.G2Generator() a, b := new(e.Scalar), new(e.Scalar) aP, bQ := new(e.G1), new(e.G2) ea, eb := new(e.Gt), new(e.Gt) a.Random(rand.Reader) b.Random(rand.Reader) aP.ScalarMult(a, P) bQ.ScalarMult(b, Q) g := e.Pair( P, Q) ga := e.Pair(aP, Q) gb := e.Pair( P,bQ) ea.Exp(g, a) eb.Exp(g, b) linearLeft := ea.IsEqual(ga) // e(P,Q)^a == e(aP,Q) linearRight:= eb.IsEqual(gb) // e(P,Q)^b == e(P,bQ) fmt.Print(linearLeft && linearRight) // Output: true }
We applied several optimizations that allowed us to improve on performance and security of the implementation. In fact, as the parameters of the curve are fixed, some other optimizations become easier to apply; for example, the code for prime field arithmetic and the towering construction for extension fields as we detail next.
Formally-verified arithmetic using fiat-crypto
One of the more difficult parts of a cryptography library to implement correctly is the prime field arithmetic. Typically people specialize it for speed, but there are many tedious constraints on what the inputs to operations can be to ensure correctness. Vulnerabilities have happened when people get it wrong, across many libraries. However, this code is perfect for machines to write and check. One such tool is fiat-crypto.
Using fiat-crypto to generate the prime field arithmetic means that we have a formal verification that the code does what we need. The fiat-crypto tool is invoked in this script, and produces Go code for addition, subtraction, multiplication, and squaring over the 381-bit prime field used in the BLS12-381 curve. Other operations are not covered, but those are much easier to check and analyze by hand.
Another advantage is that it avoids relying on the generic big.Int package, which is slow, frequently spills variables to the heap causing dynamic memory allocations, and most importantly, does not run in constant-time. Instead, the code produced is straight-line code, no branches at all, and relies on the math/bits package for accessing machine-level instructions. Automated code generation also means that it’s easier to apply new techniques to all primitives.
Tower Field Arithmetic
In addition to prime field arithmetic, say integers modulo a prime number p, a pairing also requires high-level arithmetic operations over extension fields.
To better understand what an extension field is, think of the analogous case of going from the reals to the complex numbers: the operations are referred as usual, there exist addition, multiplication and division $(+, -, \times, /)$, however they are computed quite differently.
The complex numbers are a quadratic extension over the reals, so imagine a two-level house. The first floor is where the real numbers live, however, they cannot access the second floor by themselves. On the other hand, the complex numbers can access the entire house through the use of a staircase. The equation $f(x)=x^2+1$ was not solvable over the reals, but is solvable over the complex numbers, since they have the number $i^2=1$. And because they have the number $i$, they also have to have numbers like $3i$ and $5+i$ that solve other equations that weren’t solvable over the reals either. This second story has given the roots of the polynomials a place to live.
Algebraically we can view the complex numbers as $\mathbb{R}[x]/(x^2+1)$, the space of polynomials where we consider $x^2=-1$. Given a polynomial like $x^3+5x+1$, we can turn it into $4x+1$, which is another way of writing $1+4i$. In this new field $x^2+1=0$ holds automatically, and we have added both $x$ as a root of the polynomial we picked. This process of writing down a field extension by adding a root of a polynomial works over any field, including finite fields.
Following this analogy, one can construct not a house but a tower, say a $k=12$ floor building where the ground floor is the prime field $\mathbb{F}_p$. The reason to build such a large tower is because we want to host VIP guests: namely a group called $\mu_r$, the $r$-roots of unity. There are exactly $r$ members and they behave as an (algebraic) group, i.e. for all $x,y \in \mu_r$, it follows $x*y \in \mu_r$ and $x^r = 1$.
One particularity is that making operations on the top-floor can be costly. Assume that whenever an operation is needed in the top-floor, members who live on the main floor are required to provide their assistance. Hence an operation on the top-floor needs to go all the way down to the ground floor. For this reason, our tower needs more than a staircase, it needs an efficient way to move between the levels, something even better than an elevator.
What if we use portals? Imagine anyone on the twelfth floor using a portal to go down immediately to the sixth floor, and then use another one connecting the sixth to the second floor, and finally another portal connecting to the ground floor. Thus, one can get faster to the first floor rather than descending through a long staircase.
The building analogy can be used to understand and construct a tower of finite fields. We use only some extensions to build a twelfth extension from the (ground) prime field $\mathbb{F}_p$.
$\mathbb{F}_{p}$ ⇒ $\mathbb{F}_{p^2}$ ⇒ $\mathbb{F}_{p^4}$ ⇒ $\mathbb{F}_{p^{12}}$
In fact, the extension of finite fields is as follows:
- $\mathbb{F}_{p^2}$ is built as polynomials in $\mathbb{F}_p[u]$ reduced modulo $u^2+1=0$.
- $\mathbb{F}_{p^6}$ is built as polynomials in $\mathbb{F}_{p^2}[v]$ reduced modulo $v^2+u+1=0$.
- $\mathbb{F}_{p^{12}}$ is built as polynomials in $\mathbb{F}_{p^6}[w]$ reduced modulo $w^2+v=0$, or as polynomials in $\mathbb{F}_{p^4}[w]$ reduced modulo $w^3+v=0$.
The portals here are the polynomials used as modulus, as they allow us to move from one extension to the other.
Different constructions for higher extensions have an impact on the number of operations performed. Thus, we implemented the latter tower field for $\mathbb{F}_{p^{12}}$ as it results in a lower number of operations. The arithmetic operations are quite easy to implement and manually verify, so at this level formal verification is not as effective as in the case of prime field arithmetic. However, having an automated tool that generates code for this arithmetic would be useful for developers not familiar with the internals of field towering. The fiat-crypto tool keeps track of this idea [Issue 904, Issue 851].
Now, we describe more details about the main core operations of a bilinear pairing.
The Miller loop and the final exponentiation
The pairing function we implemented is the optimal r-ate pairing, which is defined as:
$ e(P,Q) = f_Q(P)^{\text{exp}} $
That is the construction of a function $f$ based on $Q$, then evaluated on a point $P$, and the result of that is raised to a specific power. The efficient function evaluation is performed using “the Miller loop”, which is an algorithm devised by Victor Miller and has a similar structure to a double-and-add algorithm for scalar multiplication.
After having computed $f_Q(P)$ this value is an element of $\mathbb{F}_{p^{12}}$, however it is not yet an $r$-root of unity; in order to do so, the final exponentiation accomplishes this task. Since the exponent is constant for each curve, special algorithms can be tuned for it.
One interesting acceleration opportunity presents itself: in the Miller loop the elements of $\mathbb{F}_{p^{12}}$ that we have to multiply by are special — as polynomials, they have no linear term and their constant term lives in $\mathbb{F}_{p^{2}}$. We created a specialized multiplication that avoids multiplications where the input has to be zero. This specialization accelerated the pairing computation by 12%.
So far, we have described how the internal operations of a pairing are performed. There are still some other functions floating around regarding the use of pairings in cryptographic protocols. It is also important to optimize these functions and now we will discuss some of them.
Product of Pairings
Often protocols will want to evaluate a product of pairings, rather than a single pairing. This is the case if we’re evaluating multiple signatures, or if the protocol uses cancellation between different equations to ensure security, as in the dual system encoding approach to designing protocols. If each pairing was evaluated individually, this would require multiple evaluations of the final exponentiation. However, we can evaluate the product first, and then evaluate the final exponentiation once. This requires a different interface that can take vectors of points.
Occasionally, there is a sign or an exponent in the factors of the product. It’s very easy to deal with a sign explicitly by negating one of the input points, almost for free. General exponents are more complicated, especially when considering the need for side channel protection. But since we expose the interface, later work on the library will accelerate it without changing applications.
Regarding API exposure, one of the trickiest and most error prone aspects of software engineering is input validation. So we must check that raw binary inputs decode correctly as the points used for a pairing. Part of this verification includes subgroup membership testing which is the topic we discuss next.
Subgroup Membership Testing
Checking that a point is on the curve is easy, but checking that it has the right order is not: the classical way to do this is an entire expensive scalar multiplication. But implementing pairings involves the use of many clever tricks that help to make things run faster.
One example is twisting: the $\mathbb{G}_2$ group are points with coordinates in $\mathbb{F}_{p^{12}}$, however, one can use a smaller field to reduce the number of operations. The trick here is using an associated curve $E’$, which is a twist of the original curve $E$. This allows us to work on the subfield $\mathbb{F}_{p^{2}}$ that has cheaper operations.
Additionally, twisting the curve over $\mathbb{G}_2$ carries some efficiently computable endomorphisms coming from the field structure. For the cost of two field multiplications, we can compute an additional endomorphism, dramatically decreasing the cost of scalar multiplication.
By searching for the smallest combination of scalars that could zero out the $r$-torsion points, Sean Bowe came up with a much more efficient way to do subgroup checks. We implement his trick, with a big reduction in the complexity of some applications.
As can be seen, implementing a pairing is full of subtleties. We just saw that point validation in the pairing setting is a bit more challenging than in the conventional case of elliptic curve cryptography. This kind of reformulation also applies to other operations that require special care on their implementation. One another example is how to encode binary strings as elements of the group $\mathbb{G}_1$ (or $\mathbb{G}_2$). Although this operation might sound simple, implementing it securely needs to take into consideration several aspects; thus we expand more on this topic.
Hash to Curve
An important piece on the Boneh-Franklin Identity-based Encryption scheme is a special hash function that maps an arbitrary string — the identity, e.g., an email address — to a point on an elliptic curve, and that still behaves as a conventional cryptographic hash function (such as SHA-256) that is hard to invert and collision-resistant. This operation is commonly known as hashing to curve.
Boneh and Franklin found a particular way to perform hashing to curve: apply a conventional hash function to the input bitstring, and interpret the result as the $y$-coordinate of a point, then from the curve equation $y^2=x^3+b$, find the $x$-coordinate as $x=\sqrt[3]{y^2-b}$. The cubic root always exists on fields of characteristic $p\equiv 2 \bmod{3}$. But this algorithm does not apply to other fields in general restricting the parameters to be used.
Another popular algorithm, but since now we need to remark it is an insecure way for performing hash to curve is the following. Let the hash of the input be the $x$-coordinate, and from it find the $y$-coordinate by computing a square root $y= \sqrt{x^3+b}$. Note that not all $x$-coordinates lead that the square root exists, which means the algorithm may fail; thus, it’s a probabilistic algorithm. To make sure it works always, a counter can be added to $x$ and increased everytime the square root is not found. Although this algorithm always finds a point on the curve, this also makes the algorithm run in variable time i.e., it’s a non-constant time algorithm. The lack of this property on implementations of cryptographic algorithms makes them susceptible to timing attacks. The DragonBlood attack is an example of how a non-constant time hashing algorithm resulted in a full key recovery of WPA3 Wi-Fi passwords.
Secure hash to curve algorithms must guarantee several properties. It must be ensured that any input passed to the hash produces a point on the targeted group. That is no special inputs must trigger exceptional cases, and the output point must belong to the correct group. We make emphasis on the correct group since in certain applications the target group is the entire set of points of an elliptic curve, but in other cases, such as in the pairing setting, the target group is a subgroup of the entire curve, recall that $\mathbb{G}_1$ and $\mathbb{G}_2$ are $r$-torsion points. Finally, some cryptographic protocols are proven secure provided that the hash to curve function behaves as a random oracle of points. This requirement adds another level of complexity to the hash to curve function.
Fortunately, several researchers have addressed most of these problems and some other researchers have been involved in efforts to define a concrete specification for secure algorithms for hashing to curves, by extending the sort of geometric trick that worked for the Boneh-Franklin curve. We have participated in the Crypto Forum Research Group (CFRG) at IETF on the work-in-progress Internet draft-irtf-cfrg-hash-to-curve. This document specifies secure algorithms for hashing targeting several elliptic curves including the BLS12-381 curve. At Cloudflare, we are actively collaborating in several working groups of IETF, see Jonathan Hoyland’s post to know more about it.
Our implementation complies with the recommendations given in the hash to curve draft and also includes many implementation techniques and tricks derived from a vast number of academic research articles in pairing-based cryptography. A good compilation of most of these tricks is delightfully explained by Craig Costello.
We hope this post helps you to shed some light and guidance on the development of pairing-based cryptography, as it has become much more relevant these days. We will share with you soon an interesting use case in which the application of pairing-based cryptography helps us to harden the security of our infrastructure.
What’s next?
We invite you to use our CIRCL library, now equipped with bilinear pairings. But there is more: look at other primitives already available such as HPKE, VOPRF, and Post-Quantum algorithms. On our side, we will continue improving the performance and security of our library, and let us know if any of your projects uses CIRCL, we would like to know your use case. Reach us at research.cloudflare.com.
You’ll soon hear more about how we’re using CIRCL across Cloudflare.
Exported Authenticators: The long road to RFC
Post Syndicated from Jonathan Hoyland original https://blog.cloudflare.com/exported-authenticators-the-long-road-to-rfc/
Our earlier blog post talked in general terms about how we work with the IETF. In this post we’re going to talk about a particular IETF project we’ve been working on, Exported Authenticators (EAs). Exported Authenticators is a new extension to TLS that we think will prove really exciting. It unlocks all sorts of fancy new authentication possibilities, from TLS connections with multiple certificates attached, to logging in to a website without ever revealing your password.
Now, you might have thought that given the innumerable hours that went into the design of TLS 1.3 that it couldn’t possibly be improved, but it turns out that there are a number of places where the design falls a little short. TLS allows us to establish a secure connection between a client and a server. The TLS connection presents a certificate to the browser, which proves the server is authorised to use the name written on the certificate, for example blog.cloudflare.com. One of the most common things we use that ability for is delivering webpages. In fact, if you’re reading this, your browser has already done this for you. The Cloudflare Blog is delivered over TLS, and by presenting a certificate for blog.cloudflare.com the server proves that it’s allowed to deliver Cloudflare’s blog.
When your browser requests blog.cloudflare.com you receive a big blob of HTML that your browser then starts to render. In the dim and distant past, this might have been the end of the story. Your browser would render the HTML, and display it. Nowadays, the web has become more complex, and the HTML your browser receives often tells it to go and load lots of other resources. For example, when I loaded the Cloudflare blog just now, my browser made 73 subrequests.
As we mentioned in our connection coalescing blog post, sometimes those resources are also served by Cloudflare, but on a different domain. In our connection coalescing experiment, we acquired certificates with a special extension, called a Subject Alternative Name (SAN), that tells the browser that the owner of the certificate can act as two different websites. Along with some further shenanigans that you can read about in our blog post, this lets us serve the resources for both the domains over a single TLS connection.
Cloudflare, however, services millions of domains, and we have millions of certificates. It’s possible to generate certificates that cover lots of domains, and in fact this is what Cloudflare used to do. We used to use so-called “cruise-liner” certificates, with dozens of names on them. But for connection coalescing this quickly becomes impractical, as we would need to know what sub-resources each webpage might request, and acquire certificates to match. We switched away from this model because issues with individual domains could affect other customers.
What we’d like to be able to do is serve as much content as possible down a single connection. When a user requests a resource from a different domain they need to perform a new TLS handshake, costing valuable time and resources. Our connection coalescing experiment showed the benefits when we know in advance what resources are likely to be requested, but most of the time we don’t know what subresources are going to be requested until the requests actually arrive. What we’d rather do is attach extra identities to a connection after it’s been established, and we know what extra domains the client actually wants. Because the TLS connection is just a transport mechanism and doesn’t understand the information being sent across it, it doesn’t actually know what domains might subsequently be requested. This is only available to higher-layer protocols such as HTTP. However, we don’t want any website to be able to impersonate another, so we still need to have strong authentication.
Exported Authenticators
Enter Exported Authenticators. They give us even more than we asked for. They allow us to do application layer authentication that’s just as strong as the authentication you get from TLS, and then tie it to the TLS channel. Now that’s a pretty complicated idea, so let’s break it down.
To understand application layer authentication we first need to explain what the application layer is. The application layer is a reference to the OSI model. The OSI model describes the various layers of abstraction we use, to make things work across the Internet. When you’re developing your latest web application you don’t want to have to worry about how light is flickered down a fibre optic cable, or even how the TLS handshake is encoded (although that’s a fascinating topic in its own right, let’s leave that for another time.)
All you want to care about is having your content delivered to your end-user, and using TLS gives you a guaranteed in-order, reliable, authenticated channel over which you can communicate. You just shove bits in one end of the pipe, and after lots of blinky lights, fancy routing, maybe a touch of congestion control, and a little decoding, *poof*, your data arrives at the end-user.
The application layer is the top of the OSI stack, and contains things like HTTP. Because the TLS handshake is lower in the stack, the application is oblivious to this process. So, what Exported Authenticators give us is the ability for the very top of the stack to reliably authenticate their partner.
Now let’s jump back a bit, and discuss what we mean when we say that EAs give us authentication that’s as strong as TLS authentication. TLS, as we know, is used to create a secure connection between two endpoints, but lots of us are hazy when we try and pin down exactly what we mean by “secure”. The TLS standard makes eight specific promises, but rather than get buried in that particular ocean of weeds, let’s just pick out the one guarantee that we care about most: Peer Authentication.
Peer authentication: The client's view of the peer identity should reflect the server's identity. [...]
In other words, if the client thinks that it’s talking to example.com then it should, in fact, be talking to example.com.
What we want from EAs is that if I receive an EA then I have cryptographic proof that the person I’m talking to is the person I think I’m talking to. Now at this point you might be wondering what an EA actually looks like, and what it has to do with certificates. Well, an EA is actually a trio of messages, the first of which is a Certificate. The second is a CertificateVerify, a cryptographic proof that the sender knows the private key for the certificate. Finally there is a Finished message, which acts as a MAC, and proves the first two parts of the message haven’t been tampered with. If this structure sounds familiar to you, it’s because it’s the same structure as used by the server in the TLS handshake to prove it is the owner of the certificate.
The final piece of unpacking we need to do is explaining what we mean by tying the authentication to the TLS channel. Because EAs are an application layer construct they don’t provide any transport mechanism. So, whilst I know that the EA was created by the server I want to talk to, without binding the EA to a TLS connection I can’t be sure that I’m talking directly to the server I want.

For all I know, the TLS server I’m talking to is creating a new TLS connection to the EA Server, and relaying my request, and then returning the response. This would be very bad, because it would allow a malicious server to impersonate any server that supports EAs.

EAs therefore have an extra security feature. They use the fact that every TLS connection is guaranteed to produce a unique set of keys. EAs take one of these keys and use it to construct the EA. This means that if some malicious third-party copies an EA from one TLS session to another, the recipient wouldn’t be able to validate it. This technique is called channel binding, and is another fascinating topic, but this post is already getting a bit long, so we’ll have to revisit channel binding in a future blog post.
How the sausage is made
OK, now we know what EAs do, let’s talk about how they were designed and built. EAs are going through the IETF standardisation process. Draft standards move through the IETF process starting as Internet Drafts (I-Ds), and ending up as published Requests For Comment (RFCs). RFCs are voluntary standards that underpin much of the global Internet plumbing, and not just for security protocols like TLS. RFCs define DNS, UDP, TCP, and many, many more.
The first step in producing a new IETF standard is coming up with a proposal. Designing security protocols is a very conservative business, firstly because it’s very easy to introduce really subtle bugs, and secondly, because if you do introduce a security issue, things can go very wrong, very quickly. A flaw in the design of a protocol can be especially problematic as it can be replicated across multiple independent implementations — for example the TLS renegotiation vulnerabilities reported in 2009 and the custom EC(DH) parameters vulnerability from 2012. To minimise the risks of design issues, EAs hew closely to the design of the TLS 1.3 handshake.
Security and Assurance
Before making a big change to how authentication works on the Internet, we want as much assurance as possible that we’re not going to break anything. To give us more confidence that EAs are secure, they reuse parts of the design of TLS 1.3. The TLS 1.3 design was carefully examined by dozens of experts, and underwent multiple rounds of formal analysis — more on that in a moment. Using well understood design patterns is a super important part of security protocols. Making something secure is incredibly difficult, because security issues can be introduced in thousands of ways, and an attacker only needs to find one. By starting from a well understood design we can leverage the years of expertise that went into it.
Another vital step in catching design errors early is baked into the IETF process: achieving rough consensus. Although the ins and outs of the IETF process are worthy of their own blog post, suffice it to say the IETF works to ensure that all technical objections get addressed, and even if they aren’t solved they are given due care and attention. Exported Authenticators were proposed way back in 2016, and after many rounds of comments, feedback, and analysis the TLS Working Group (WG) at the IETF has finally reached consensus on the protocol. All that’s left before the EA I-D becomes an RFC is for a final revision of the text to be submitted and sent to the RFC Editors, leading hopefully to a published standard very soon.
As we just mentioned, the WG has to come to a consensus on the design of the protocol. One thing that can hold up achieving consensus are worries about security. After the Snowden revelations there was a barrage of attacks on TLS 1.2, not to mention some even earlier attacks from academia. Changing how trust works on the Internet can be pretty scary, and the TLS WG didn’t want to be caught flat-footed. Luckily this coincided with the maturation of some tools and techniques we can use to get mathematical guarantees that a protocol is secure. This class of techniques is known as formal methods. To help ensure that people are confident in the security of EAs I performed a formal analysis.
Formal Analysis
Formal analysis is a special technique that can be used to examine security protocols. It creates a mathematical description of the protocol, the security properties we want it to have, and a model attacker. Then, aided by some sophisticated software, we create a proof that the protocol has the properties we want even in the presence of our model attacker. This approach is able to catch incredibly subtle edge cases, which, if not addressed, could lead to attacks, as has happened before. Trotting out a formal analysis gives us strong assurances that we haven’t missed any horrible issues. By sticking as closely as possible to the design of TLS 1.3 we were able to repurpose much of the original analysis for EAs, giving us a big leg up in our ability to prove their security. Our EA model is available in Bitbucket, along with the proofs. You can check it out using Tamarin, a theorem prover for security protocols.
Formal analysis, and formal methods in general, give very strong guarantees that rule out entire classes of attack. However, they are not a panacea. TLS 1.3 was subject to a number of rounds of formal analysis, and yet an attack was still found. However, this attack in many ways confirms our faith in formal methods. The attack was found in a blind spot of the proof, showing that attackers have been pushed to the very edges of the protocol. As our formal analyses get more and more rigorous, attackers will have fewer and fewer places to search for attacks. As formal analysis has become more and more practical, more and more groups at the IETF have been asking to see proofs of security before standardising new protocols. This hopefully will mean that future attacks on protocol design will become rarer and rarer.
Once the EA I-D becomes an RFC, then all sorts of cool stuff gets unlocked — for example OPAQUE-EAs, which will allow us to do password-based login on the web without the server ever seeing the password! Watch this space.

Coalescing Connections to Improve Network Privacy and Performance
Post Syndicated from Talha Paracha original https://blog.cloudflare.com/connection-coalescing-experiments/
Web pages typically have a large number of embedded subresources (e.g., JavaScript, CSS, image files, ads, beacons) that are fetched by a browser on page loads. Requests for these subresources can prompt browsers to perform further DNS lookups, TCP connections, and TLS handshakes, which can have a significant impact on how long it takes for the user to see the content and interact with the page. Further, each additional request exposes metadata (such as plaintext DNS queries, or unencrypted SNI in TLS handshake) which can have potential privacy implications for the user. With these factors in mind, we carried out a measurement study to understand how we can leverage Connection Coalescing (aka Connection Reuse) to address such concerns, and study its feasibility.
Background
The web has come a long way and initially consisted of very simple protocols. One of them was HTTP/1.0, which required browsers to make a separate connection for every subresource on the page. This design was quickly recognized as having significant performance bottlenecks and was extended with HTTP pipelining and persistent connections in HTTP/1.1 revision, which allowed HTTP requests to reuse the same TCP connection. But, yet again, this was no silver bullet: while multiple requests could share the same connection, they still had to be serialized one after the other, so a client and server could only execute a single request/response exchange at any given time for each connection. As time passed, websites became more complex in structure and dynamic in nature, and HTTP/1.1 was identified as a major bottleneck. The only way to gain concurrency at the network layer was to use multiple TCP connections to the same origin in parallel, but this meant losing most benefits of persistent connections and ended up overloading the origin servers which were unable to meet the concurrency demand.
To address these performance limitations, the SPDY protocol was introduced over a decade later. SPDY supported stream multiplexing, where requests to and responses from the server used a single interleaved TCP connection, and allowed browsers to prioritize requests for critical subresources first — that were blocking page rendering. A modified variant of SPDY was standardized by the IETF as HTTP/2 in 2012 and published as RFC 7540 in 2015.
HTTP/2 and onwards retained this new standard for connection reuse. More specifically, all subresources on the same domain were able to reuse the same TCP/TLS (or UDP/QUIC) connection without any head-of-line blocking (at least on the application layer). This resulted in a single connection for all the subresources — reducing extraneous requests on page loads — potentially speeding up some websites and applications.
Interestingly, the protocol has a lesser-known feature to also enable subresources at different hostnames to be fetched over the same connection. We studied the real-world feasibility and benefits of this technique as an effort to improve users’ experience for websites across our network.
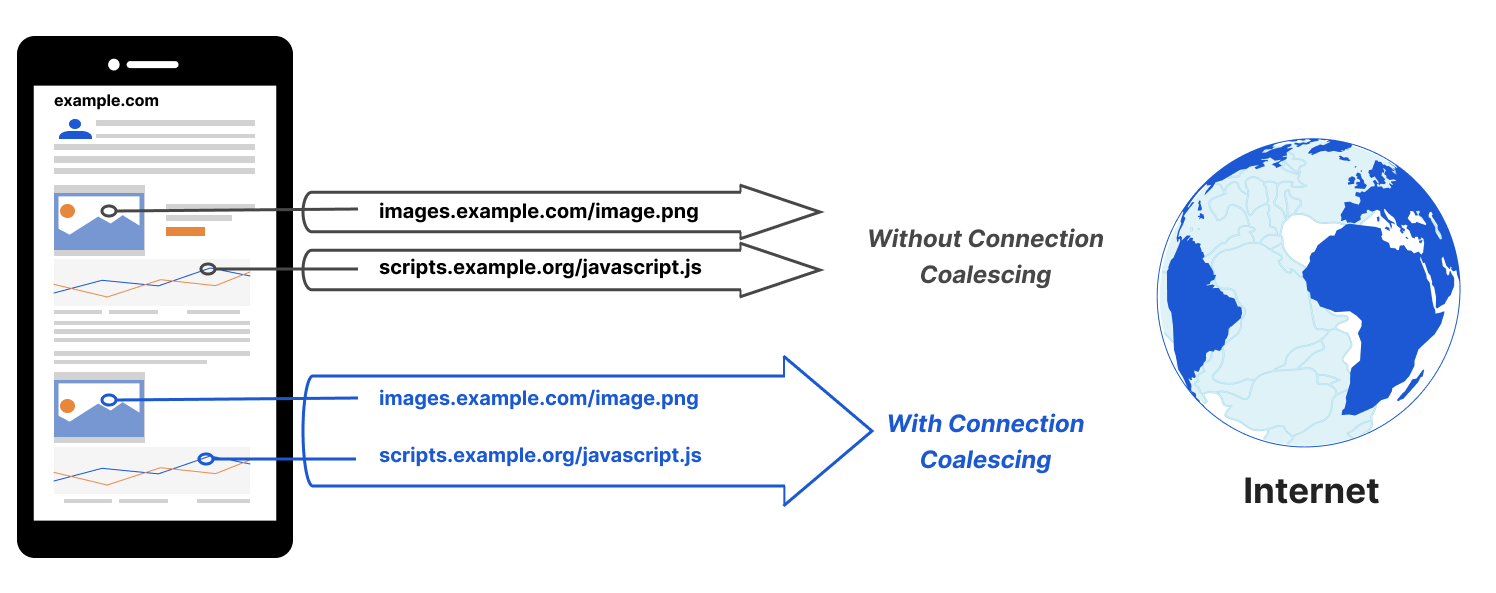
Connection Coalescing
The technique is often referred to as Connection Coalescing and, to put it simply, is a way to access resources from different hostnames that are accessible from the same web server.
There are several reasons for why a single server could handle requests for different hosts, ranging from low-cost virtual hosting to the usage of CDNs and cloud providers (including Cloudflare, that acts as a reverse proxy for approximately 25 million Internet properties). Before going into the technical conditions required to enable connection coalescing, we should take a look at some benefits such a strategy can provide.
- Privacy. When resources at different hostnames are loaded via separate TLS connections, those connections expose metadata to ISPs and other observers via the Server Name Indicator (SNI) field about the destinations that are being contacted (i.e., in the absence of encrypted SNI). This set of exposed SNI’s can allow an on-path adversary to fingerprint traffic and possibly determine user interactions on the webpage. On the other hand, coalesced requests for more than one hostname on a single connection exposes only one destination, and helps avoid such threats.
- Performance. Additional TLS handshakes and TCP connections can incur significant costs in terms of cpu, memory and other resources. Thus, coalescing requests to use the same connection can optimize resource utilization.
- Resource Prioritization. Multiplexing requests on a single connection means that applications have better visibility and more direct control over how related resources are prioritized and scheduled. In the absence of coalescing, the network properties (for example, route congestion) can interfere with the intended order of delivery for resources. This reliability gained through connection coalescing opens up new optimization opportunities to improve web page load times, among other things.
However, along with all these potential benefits, connection coalescing also has some associated risk factors that need to be considered in practice. First, TCP incorporates “fair” congestion control mechanisms — if there are ten connections on the same route, each gets approximately 1/10th of the total bandwidth. So with a route congested and bandwidth restricted, a client relying on multiple connections might be better off (for example, if they have five of the ten connections, their total share of bandwidth would be half). Second, browsers will use different parallelization routines for scheduling requests on multiple connections versus the same connection — it is not immediately clear whether the former or latter would perform better. Third, multiple connections exhibit an inherent form of load balancing for TLS-termination processes. That’s because multiple requests on the same connection must be answered by the same TLS-termination process that holds the session keys (often on the same physical server). So, it is important to study connection coalescing carefully before rolling it out widely.
With this context in mind, we studied the feasibility of connection coalescing on real-world traffic. More specifically, the two questions we wanted to answer were
(a) can we empirically demonstrate and quantify the theoretical benefits of connection coalescing?, and (b) could coalescing cause unintended side effects, such as performance degradation, due to the risks highlighted above?
In order to answer these questions, we first made the observation that a large number of Cloudflare customers request subresources from cdnjs — which is also powered by Cloudflare. For context, cdnjs has public JavaScript and CSS libraries (like jQuery), and is used by more than 12% of all websites on the Internet. One popular way these websites include resources from cdnjs is by using <script src="https://cdnjs.cloudflare.com/..." ></script> HTML tags. But there are other ways as well, such as the usage of XMLHttpRequest or Fetch APIs. Regardless of the way these resources are included, browsers will need to fetch them for completely loading a website.
We then identified a list of approximately four thousand websites using Cloudflare (on the Free plan) that likely used cdnjs. We divided this list of sites into evenly-sized and randomly-picked control and experiment groups. Our plan was to enable coalescing only for the experiment group, so that subresource requests generated from their web pages for cdnjs could reuse existing connections. In this way, we were able to compare results obtained on the experiment group, with the ones for the control group, and attribute any differences observed to connection coalescing.
In order to signal browsers that the requests can be coalesced, we served cdnjs and the sites from the same IP address in a few regions around the world. This meant the same DNS responses for all the zones that were part of the study — eventually load balanced by our Anycast network. These sites also had TLS certificates that included cdnjs.
The above two conditions (same IP and compatible certificate) are required to achieve coalescing as per the HTTP/2 spec. However, the QUIC spec allows coalescing even if only the second condition is met. Major web browsers are yet to adopt the QUIC coalescing mechanism, and currently use only the HTTP/2 coalescing logic for both protocols.

Results
We started noticing evidence of real-world coalescing from the day our experiment was launched. The following graph shows that approximately 50% of requests to cdnjs from our experiment group sites are coalesced (i.e., their TLS SNI does not equal cdnjs) as compared to 0% of requests from the control group sites.
In addition, we conducted active measurements using our private WebPageTest instances at the landing pages of experiment and control sites — using the two well-supported browsers: Google Chrome and Firefox. From our results, Chrome created about 78% fewer TLS connections to cdnjs for our experiment group sites, as compared to the control group. But surprisingly, Firefox created just roughly 22% fewer connections. As TLS handshakes are computationally expensive because they involve cryptographic signatures and key exchange algorithms, fewer handshakes meant less CPU cycles spent by both the client and the server.
Upon further analysis, we were able to make two observations from the data:
- A fraction of sites that never coalesced connections with either browser appeared to load subresources with CORS enabled (i.e.,
<script src="https://cdnjs.cloudflare.com/..." integrity="sha512-894Y..." crossorigin="anonymous">). This is the default way cdnjs recommends inclusion of subresources, as CORS is needed for integrity checks that provide substantial mitigations against script-manipulation attacks. We do not recommend removing this attribute. Our testing also revealed that using XMLHttpRequest or Fetch APIs to load subresources disabled coalescing as well. It is unclear why browsers choose to not coalesce such connections, and we are in contact with the vendors to find out. - Although both Firefox and Chrome coalesced requests for cdnjs on existing connections, the reason for the discrepancy in the number of TLS connections to cdnjs (approximately 78% vs roughly 22%) is because Firefox appears to open new connections even if it does not end up using them.
After evaluating the potential benefits of coalescing, we wanted to understand if coalescing caused any unintended side effects. Hence, the final measurement we conducted was to check whether our experiments were detrimental to a website’s performance. We tracked Page Load Times (PLT) and Largest Contentful Paint (LCP) across a variety of stimulated network conditions using both Chrome and Firefox and found the results for experiment vs control group to not be statistically significant.
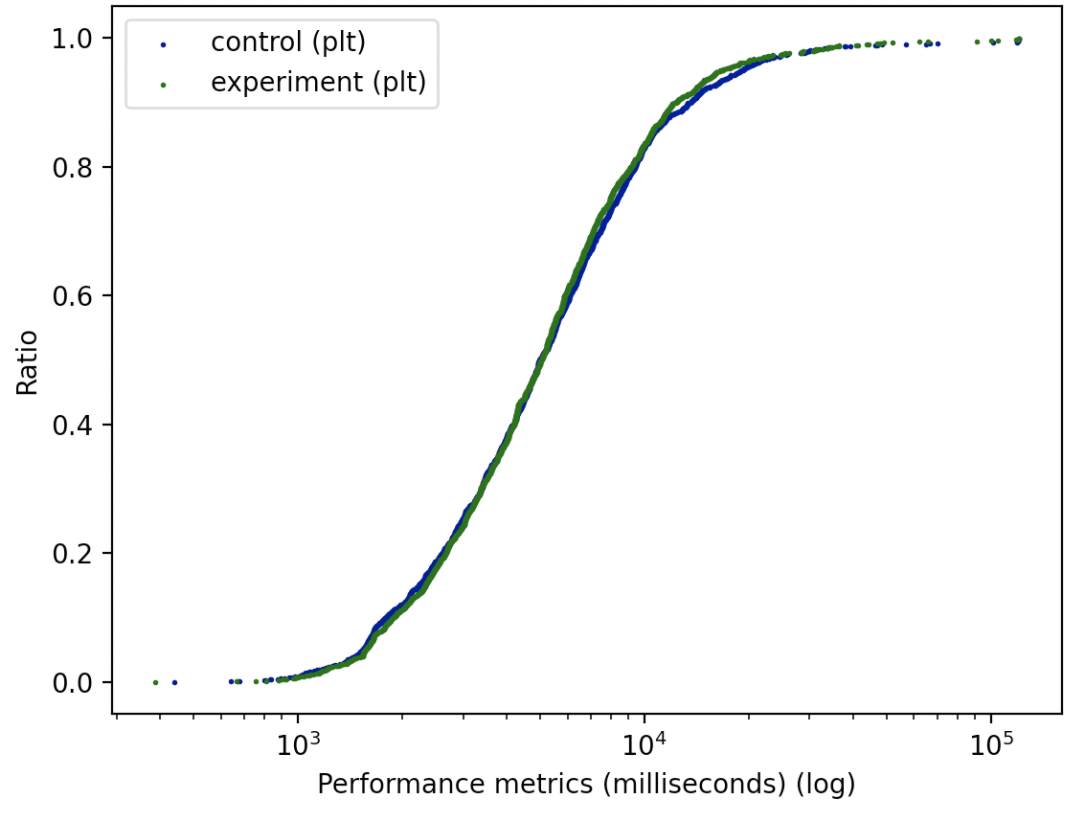
Conclusion
We consider our experimentation successful in determining the feasibility of connection coalescing and highlighting its potential benefits in terms of privacy and performance. More specifically, we observed the privacy benefits of coalescing in more than 50% of requests to cdnjs from real-world traffic. In addition, our active testing demonstrated that browsers create fewer TLS connections with coalescing enabled. Interestingly, our results also revealed that the benefits might not always occur (i.e., CORS-enabled requests, Firefox creating additional TLS connections despite coalescing). Finally, we did not find any evidence that coalescing can cause harm to real-world users’ experience on the Internet.
Some future directions we would like to explore include:
- More aggressive connection reuse with multiple hostnames, while identifying conditions most suitable for coalescing.
- Understanding how different connection reuse methods compare, e.g., IP-based coalescing vs. use of Origin Frames, and what effects do they have on user experience over the Internet.
- Evaluating coalescing support among different browser vendors, and encouraging adoption of HTTP/3 QUIC based coalescing.
- Reaping the full benefits of connection coalescing by experimenting with custom priority schemes for requests within the same connection.
Please send questions and feedback to [email protected]. We’re excited to continue this line of work in our effort to help build a better Internet! For those interested in joining our team please visit our Careers Page.
Inspiring learners about computing through health and well-being projects | Hello World #17
Post Syndicated from Gemma Coleman original https://www.raspberrypi.org/blog/inspiring-learners-computing-health-well-being-projects-hello-world-17/
Your brand-new issue of the free Hello World magazine for computing educators focuses on all things health and well-being, featuring useful tools for educators, great ideas for schools, and inspiring projects, ideas, and resources from teachers around the world!

One such project was created by the students of James Abela, Head of Computing at Garden International School in Kuala Lumpur, Raspberry Pi Certified Educator, founder of the South East Asian Computer Science Teachers Association, and author of The Gamified Classroom:
Protecting children from breathing hazardous air
In 2018, Indonesia burned approximately 529,000 hectares of land. That’s an area more than three times the size of Greater London, or almost the size of Brunei. With so much forest being burned, the whole region felt the effects of the pollution. Schools frequently had to ban outdoor play and PE lessons, and on some days schools were closed completely. Many schools in the region had an on-site CO2 detector to know when pollution was bad, but by the time the message could get out, children had already been breathing in the polluted air for several minutes.

My Year 12 students (aged 16–17) followed the news and weather forecasts intently, and we all started to see how the winds from Singapore and Sumatra were sending pollution to us in Kuala Lumpur. We also realised that if we had measurements from around the city, we might have some visibility as to when pollution was likely to affect our school.
Making room for student-led projects
I’ve always encouraged my students to do their own projects, because it gives programming tasks meaning and creates something that they can be genuinely proud of. The other benefit is that it is something to talk about in university essays and interviews, especially as they often need to do extensive research to solve the problems central to their projects.
This project was […] a genuine passion project in every sense of the word.
James Abela
This project was much more than this: it was a genuine passion project in every sense of the word. Three of my students approached me with the idea of tracking CO2 to give schools a better idea of when there was pollution and which way it was going. They had had some experience of using Raspberry Pi computers, and knew that it was possible to use them to make weather stations, and that the latest versions had wireless LAN capability that they could use. I agreed to support them during allocated programming time, and to help them reach out to other schools.
I was able to offer students support with this project because I flip quite a lot of the theory in my class. Flipped learning is a teaching approach in which some direct instruction, for example reading articles or watching specific videos, is done at home. This enables more class time to be used to answer questions, work through higher-order tasks, or do group work, and it creates more supervised coding time.
I was able to offer students support with this project because I flip quite a lot of the theory in my class.
James Abela
I initially started doing this because when I set coding challenges for homework, I often had students who confessed they spent all night trying to solve it, only for me to glance at the code and notice a missing colon or indentation issue. I began flipping the less difficult theory for students to do as homework, to create more programming time in class where we could resolve issues more quickly. This then evolved into a system where students could work much more at their own pace and eventually led to a point at which older students could, in effect, learn through their own projects, such as the pollution monitor.
Building the pollution monitor
The students started by looking at existing weather station projects — for example, there is an excellent tutorial on the Raspberry Pi Foundation’s projects site. Students discovered that wind data is relatively easy to get over a larger area, but the key component would be something to measure CO2. […]
Check out issue 17 of Hello World to read the rest of James’s article and find out all the details about the hardware and software his students used for this passion project. He says:
This project really helped these students to decide whether they enjoyed the hardware side of computing, and solving real-world issues really encouraged them to see computing as a practical subject. This is a message that has really resonated with other students, and we’ve since doubled the number of students taking A level computer science.
James Abela
Download the new Hello World for free!
Issue 17 of Hello World is bursting with inspiring ideas for teaching your learners about computing in the context of health and well-being. And you’ll find lots more great content in its 100 pages!
James’s article is also a wonderful example of an educator empowering their students to build a tech project they care about. You’ll discover more insights and practical tips on making computing relevant to all your learners in the following articles of the new Hello World issue:
- Inspiring Young People With Contexts They Care About
- Computing for all: Designing a Culturally Relevant Curriculum
- Going Back to Basics: Part 2 — a follow-on from issue 16 about how to take beginner digital makers through their first physical computing projects
Download the new issue of Hello World for free today:
If you’re an educator based in the UK, you can subscribe to receive each new issue in print completely free! And wherever you are in the world, don’t forget to listen to the Hello World podcast, where each episode we dive into a new topic from the magazine with some of the computing educators who’ve written for us.
The post Inspiring learners about computing through health and well-being projects | Hello World #17 appeared first on Raspberry Pi.