Post Syndicated from Antoine Boucherie original https://aws.amazon.com/blogs/architecture/pilot-light-with-reserved-capacity-how-to-optimize-dr-cost-using-on-demand-capacity-reservations/
For digital enterprises to remain competitive, resilience is essential for maintaining reliability and building customer trust. End users expect applications to be available 24 hours a day, leading companies to develop increasingly sophisticated methods to provide continuous operation of critical services. Some companies, such as financial services companies, have to meet regulatory requirements such as Digital Operational Resilience Act (DORA) and are expected to manage the risk of outsourcing critical applications. They must design for high availability and plan for potential impairments. By proactively planning for potential disruptions, they’re not just mitigating risks – they’re building trust and delivering unparalleled value to their customers.
When assessing your own applications, you should define a set of objectives, perform a business impact analysis and a risk assessment. This way, you can estimate the impact to the business if the application isn’t available. This results in categorization of the applications and influence their design according to the AWS resilience lifecycle framework. Each application is given a specific Recovery Point Objective (RPO) and Recovery Time Objective (RTO), depending on its criticality for the business.
Not all applications fall in the most critical category. You allocate resources according to the results of the assessment and make trade-offs when designing applications. For example, you’ll have a more stringent RTO and RPO for—and be willing to spend more time and money on—a critical application than on a less critical application. The challenge becomes how to minimize the risk of breaching a specific RTO while optimizing for resources, such as cost and operational complexity.
At AWS, we provide guidance through the Well-Architected Framework and specifically within the Reliability pillar. Disruption can happen at several levels, and we recommend that you explore and prepare for four types of disruptions in the AWS Resilience Hub: application, infrastructure, Availability Zone, and AWS Region.
We recommend that you use managed services and make sure that all production workloads are designed to take advantage of multiple Availability Zones in AWS Regions. If your application also needs to be protected against the unlikely risk of Regional impairment, you should consider a multi-Region disaster recovery (DR) strategy.
You can select from several DR strategies: backup and restore, pilot light, warm standby, and multi-site active-active:
- Backup and restore – This strategy might not provide the necessary RPO or RTO required for a highly critical application.
- Multi-site active-active – This strategy increases significantly the cost and operational complexity of your application.
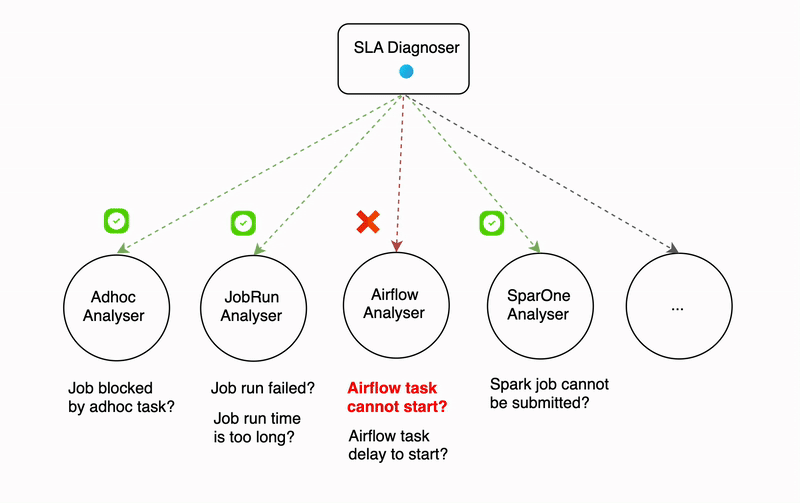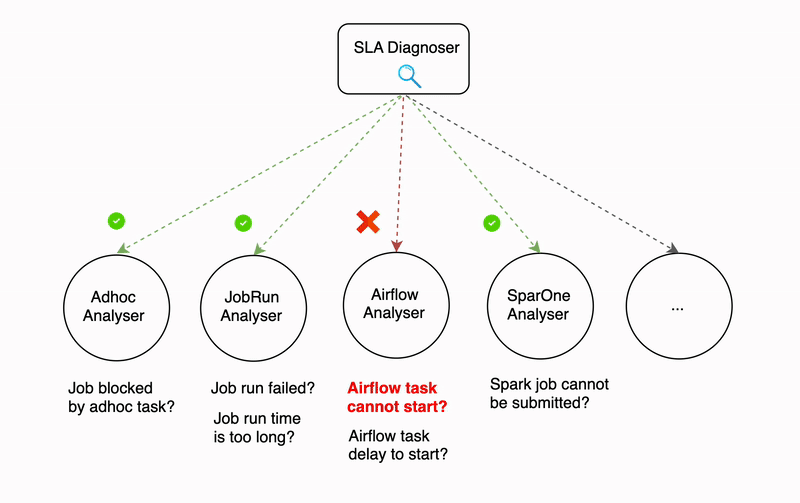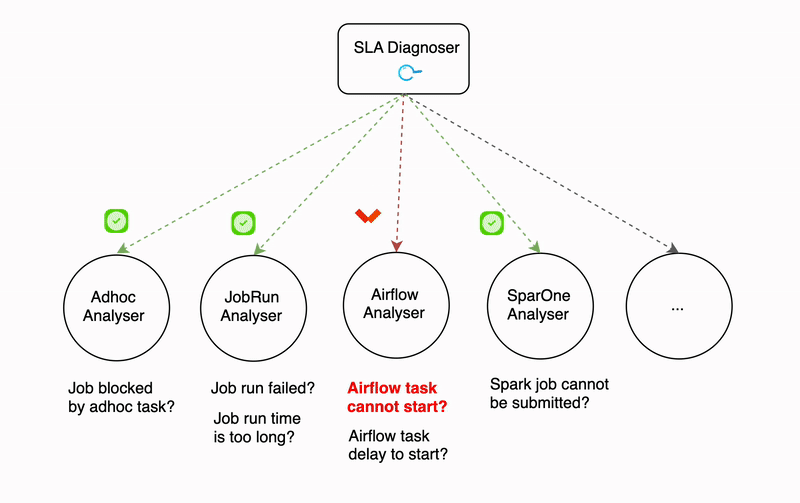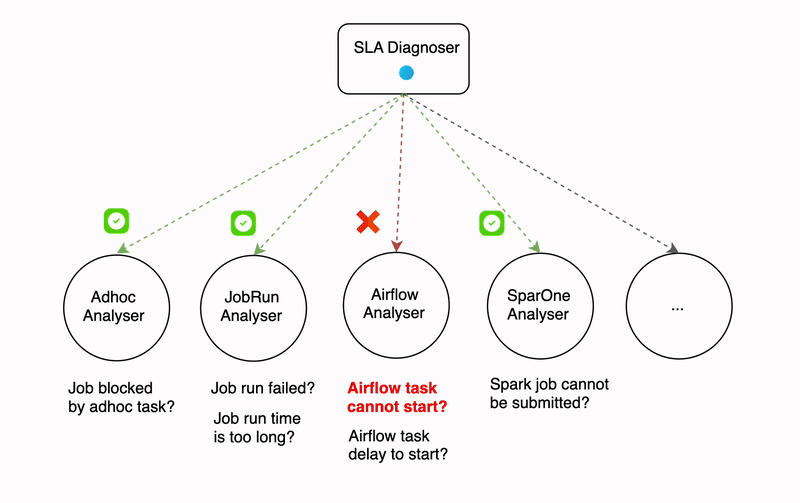
- Pilot light – This strategy allows for a RPO or RTO in the tens of minutes by having the data asynchronously copied to the secondary Region and ready to be accessed. However, unlike a warm standby, the application servers aren’t deployed and aren’t ready to serve traffic. The pilot light strategy allows for a lower cost but brings a risk that you might not be able to provision the compute capacity you need when you want to fail over to the secondary Region, especially if you require a specific instance type.
In this post, we explore an intermediate strategy between the pilot light and the warm standby strategies: pilot light with reserved capacity. You can use this strategy to reserve compute capacity in a secondary Region while also limiting cost.
The following diagram illustrates where the pilot light with reserved capacity solution lies in the spectrum of disaster recovery strategies.

Reserving capacity, on demand
On-Demand Capacity Reservations were launched in 2018. They make it possible to reserve capacity in the Availability Zone of your choice without a long-term contract. You have the flexibility to create, modify, or cancel reservations at your discretion. It’s especially well-suited if your application is dependent on a specific instance type or size.
Optimizing the cost of On-Demand Capacity Reservations with a Savings Plan
On-Demand Capacity Reservations is a reservation mechanism and doesn’t require a commitment. However, you can optimize your spending by combining the capacity reservation with an AWS Savings Plan. By using Savings Plans, you can achieve up to a 72% discount, a very significant cost reduction for DR instances that have to stay available all year long.
Optimizing the cost of On-Demand Capacity Reservations by sharing Capacity Reservations
To further optimize the cost, you can use your reserved capacity in another account when you don’t need it for DR.
Here’s an example in which we share On-Demand Capacity Reservations with our development and test account:
We have a three-tier application running in production in a primary AWS Region. This application is composed of a load balancer forwarding traffic to a fleet of application servers running on Amazon Elastic Compute Cloud (Amazon EC2) instances, backed by an Amazon Relational Database Service (Amazon RDS) database. All services used by this application are configured to use multiple Availability Zones in this primary Region.
We use the pilot light strategy, so the application data is being replicated to the disaster recovery environment in a secondary Region using Amazon RDS cross-Region read replicas. However, the load balancer and EC2 services aren’t running in DR to limit cost and operational complexity. Following best practices, each environment is running in a different AWS account.
The following diagram illustrates the pilot light strategy setup for our example.

To reserve capacity in case of failover to the secondary Region, we create an On-Demand Capacity Reservation in the DR account, according to our baseline compute capacity. Because we don’t need this capacity until we fail over the application from the primary to the secondary Region, we share those On-Demand Capacity Reservations with a development and test account hosting our nonproduction environment in the secondary Region. On-Demand Capacity Reservations are Availability Zone specific (and hence Region specific) and can be shared with either AWS accounts or AWS Organizations using AWS Resource Access Manager (AWS RAM).
Best practices are to share those On-Demand Capacity Reservations with a nonproduction organizational unit (OU) within an organization or to directly share with the account(s) hosting the testing environments (for example, user acceptance testing or preproduction). Those environments are usually very similar to the production account in baseline sizing, in order to perform load and performance testing. This is an important point: you want to be able to retrieve those On-Demand Capacity Reservations when needed without impacting other critical applications.
The following diagram illustrates the Capacity Reservations sharing with the development and test account.

If an impairment affects our production environment in the primary Region, we can trigger failover to the secondary Region. To reclaim capacity, we need to terminate the EC2 instances running in our development and test account. Capacity becomes available nearly immediately after these instances are successfully terminated. Separately, we can also stop the sharing of On-Demand Capacity Reservations to make sure that the development and test account can’t consume that capacity again. Know that merely unsharing your reservation without terminating development and test instances might not result in complete or immediate capacity retrieval. This is because when you unshare an On-Demand Capacity Reservation, the instances in the consumer account continue to run, and capacity is only returned to the owner account if additional capacity is available in the Amazon EC2 service on-demand pool.
The following diagram illustrates the failover to the DR environment in a secondary Region.

Steps
Here is a possible approach to take advantage of On-Demand Capacity Reservations to reduce the application’s total infrastructure cost:
- Calculate the baseline compute capacity necessary for the DR environment in the secondary Region in the event of failover, including the compute that might already be running in this secondary Region for data stores (for example, a Kafka broker running on Amazon EC2). How much vCPU and RAM is required or what are the exact EC2 instances necessary to host the whole application in case of failover of the production from the primary to the secondary Region.
- Create an On-Demand Capacity Reservation for the exact EC2 instances that the application need as a baseline in the DR account. Capacity Reservation Fleet is also a possible choice to reserve capacity across multiple instance types, which is often the case for Amazon Elastic Kubernetes Service (Amazon EKS) or Amazon Elastic Container Service (Amazon ECS) clusters, for example. Creating a Capacity Reservation Fleet will create multiple Capacity Reservations that can be shared independently. It’s also recommended to apply for Savings Plans on those On-Demand Capacity Reservations to save up to 72%.
- Share those On-Demand Capacity Reservations from the DR account to one or several accounts, depending on your need. In our example, we share the On-Demand Capacity Reservations with the development and test account, effectively allowing the development and test environment to use compute capacity that has already been reserved.
- In case of impairment in the primary Region, terminate the development and test instances first and then stop the On-Demand Capacity Reservation sharing The DR account will recover those reservations. If you want to keep the development and test instances, you will be charged at the on-demand rate.
- Redeploy in an automated manner the application in the DR account on new EC2 instances behind a load balancer.
Benefits
By purchasing On-Demand Capacity Reservations in the DR account, you make sure that you always have Amazon EC2 capacity access when required and for as long as you need it. By sharing those On-Demand Capacity Reservations with another AWS account or organization, you can share the cost of the application’s compute capacity with other environments, reducing your application’s total cost of ownership. The additional cost of the DR instances can even reach zero, if your instances are completely consumed by nonproduction environments such as development and testing.
| DR savings over On-Demand | |
| Compute Savings Plan – 1 year, no upfront | Around 27% (for example, for m7i instance) |
| Compute Savings Plan – 3 years, all upfront | Up to 66% |
| Instance Savings Plan – 3 years, all upfront | Up to 72% |
| Reservation shared and consumed 100% by development and test environment | Up to 100% |
Limits
Although you can reserve DR capacity at a minimal cost using the pilot light with reserved capacity solution, there are some limits to keep in mind.
Firstly, we advise looking at this solution only if the Recovery Time Objective of the application, in case of Regional disruption, is in hours because you need to take into account the time needed to:
- Detect the impairment in the primary Region.
- Trigger the failover procedure.
- Terminate the used instances to retrieve capacity (estimated time in minutes)
- Stop the On-Demand Capacity Reservations sharing and automatically retrieve them in the DR account (estimated time in minutes).
- Launch the compute infrastructure with the necessary application software in the DR account. You need to make sure that it matches the On-Demand Capacity Reservations according to the criteria used (open or targeted)
If your application requires a lower RTO, we recommend exploring the warm standby strategy.
Secondly, this strategy can only be used for application servers running EC2 instances and ECS or EKS clusters on EC2 because On-Demand Capacity Reservations aren’t available for managed services such as AWS Fargate or AWS Lambda. For those managed services, we recommend having them up and running like in a warm standby strategy, with a minimum baseline capacity that you’re comfortable with.
Thirdly, it requires some nonproduction development and test usage in the selected secondary Region to use the shared On-Demand Capacity Reservation.
Finally, it’s important to consider that this solution brings some complexity and extra operational work. You should plan well ahead, automate the operational tasks where possible, but most importantly, regularly test that the failover of the application works according to plan. We encourage you to perform your own game days to support your operational resilience.
Deciding whether this strategy is a good fit for your application will ultimately be a decision based on your business and regulatory requirements.
Conclusion
In this post, we explained how to reserve capacity in a secondary Region using On-Demand Capacity Reservations. We highlighted how cost can be optimized using Savings Plans and by sharing reserved capacity with noncritical workloads. We saw how we can recover that capacity for the DR environment, in the event of a disaster, to allow the application to continue to serve end users. We looked at the benefits and limits of the pilot light with reserved capacity solution and the necessary steps to put it in place.