Did you realize that you can monitor a Starlink dish using just Zabbix? The idea (or rather the need) to use Starlink came to me almost as soon as I moved to a fairly rural area. Local internet providers have not yet “provided” fiberoptic or stable mobile connectivity to places like this, and while searching for a solution I accidentally discovered that Starlink was already providing service to some local companies. As I later found out, they also offered service in my area for residential customers.
To make a long story short, since internet access is crucial in the IT field, I decided to acquire and then monitor my very own Starlink dish. At first, this proved challenging because regular user data access is quite limited. However, thanks to Zabbix browser monitoring, I managed to solve it fairly easily. In this post I will share my solution with you, including the template.
Table of Contents
Monitoring configuration
First, you need to make sure you have Zabbix installed (either a Zabbix proxy or server) on the same network that the Starlink dish and router are on. The next step is to configure Zabbix for browser monitoring.
Port 4444 will be the port on which the WebDriver will be listening, and port 7900 will be used by NoVNC, which allows us to observe browser behavior in case a browser with a GUI is used.
Zabbix server/proxy configuration
After WebDriver is installed, we need to set up the communication between Zabbix and the driver. This can be done by editing the Zabbix server/proxy configuration file and updating the following parameters:
### Option: WebDriverURL
# WebDriver interface HTTP[S] URL. For example http://localhost:4444 used with
# Selenium WebDriver standalone server.
#
# WebDriverURL=
WebDriverURL=http://localhost:4444
### Option: StartBrowserPollers
# Number of pre-forked instances of browser item pollers.
#
# Range: 0-1000
# StartBrowserPollers=1
StartBrowserPollers=5
With the configuration parameters in place, restart the Zabbix server/proxy to apply the changes:
systemctl restart zabbix-server
Creating a host
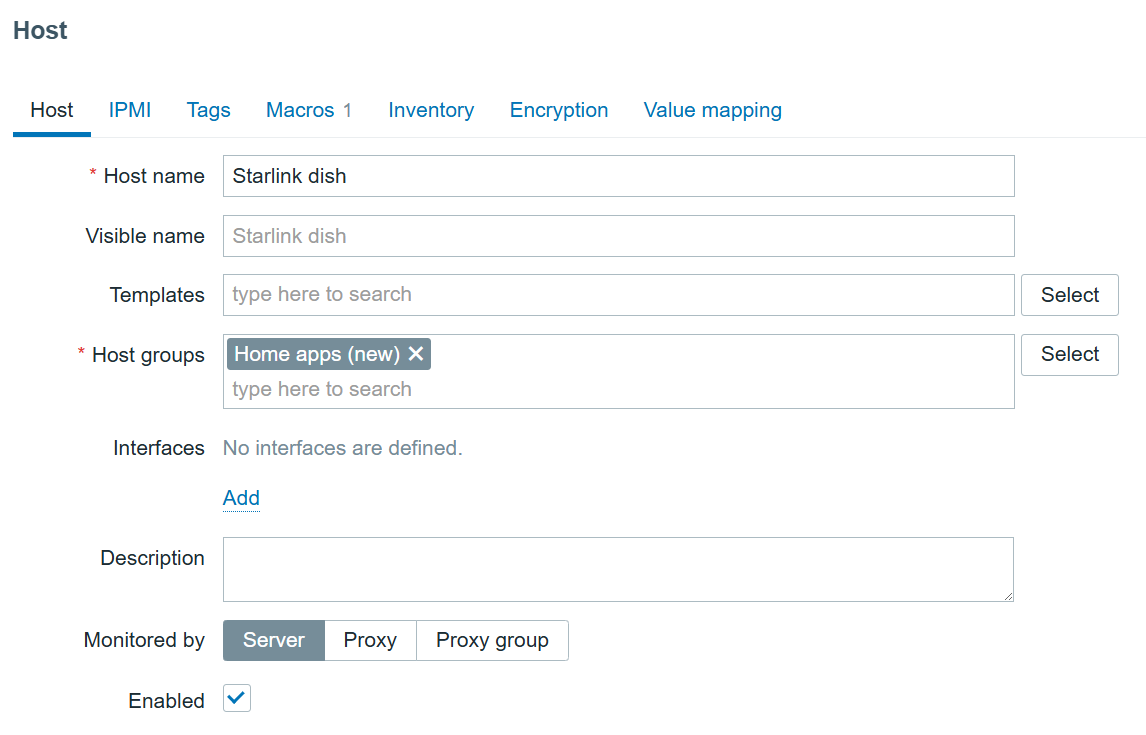
First, we need to navigate to the “Data collection” > “Hosts” section and create a host that represents our Starlink dish. The host in my example will look like this:
Starlink dish host
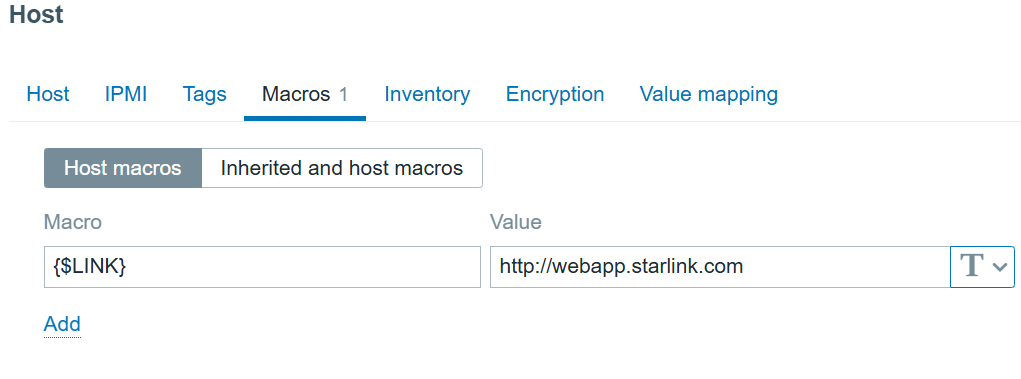
The host also has a user macro:
{$LINK} with value: http://webapp.starlink.com to point to the correct Starlink dish web app:
Link macro
Creating a browser item
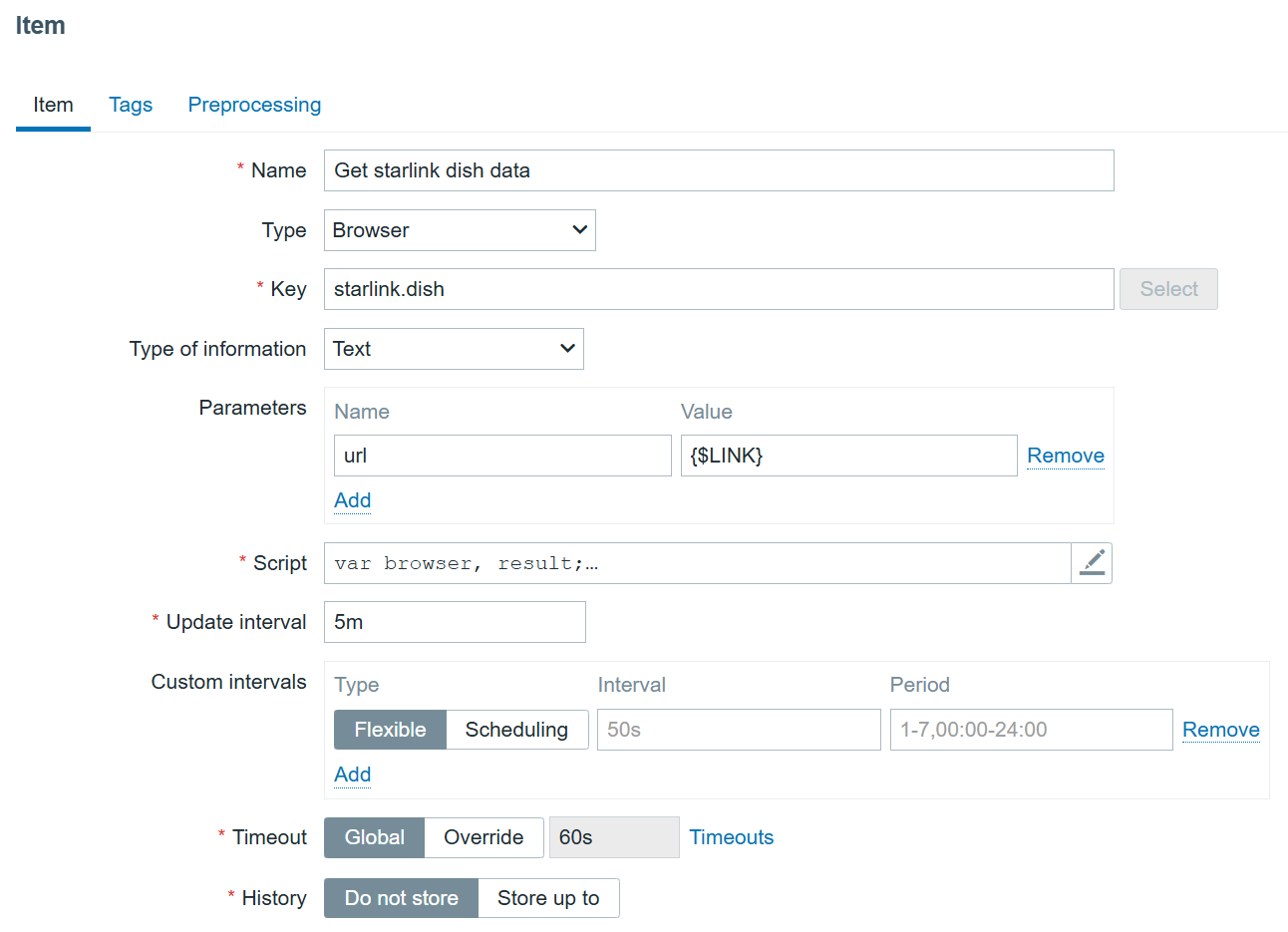
We will now configure our browser item to collect and monitor the list of metrics exposed in the Starlink browser app:
Starlink browser item
We are using the bare minimum here, so make sure the update intervals are as frequent as you need. However, I would not recommend updating it more frequently than every 5 minutes. It’s also not a good idea to store the history, since it is already stored trough dependent items.
The most important part of the item is the script itself:
var browser, result;
var opts = Browser.chromeOptions();
opts.capabilities.alwaysMatch['goog:chromeOptions'].args = [];
browser = new Browser(opts);
browser.setScreenSize(Number(1980), Number(1020));
try {
var params = JSON.parse(value);
browser.navigate(params.url);
// Wait for the dish to report status
Zabbix.sleep(2000);
// Find the JSON text element(s)
var jsonElements = browser.findElements("xpath", "//div[@id='root']/div[@class='App']/div[@class='Main']/div[2]/div[@class='Section'][2]/pre[@class='Json-Format']/div[@class='Json-Text']");
var extractedData = [];
for (var i = 0; i < jsonElements.length; i++) {
var text = jsonElements[i].getText();
// Try parsing JSON
try {
extractedData.push(JSON.parse(text));
} catch (e) {
// If not valid JSON, include raw text instead
extractedData.push({ raw: text, error: "Invalid JSON format" });
}
}
// Collect result
result = browser.getResult();
// Replace with parsed JSON data
result.extractedJsonData = extractedData.length === 1 ? extractedData[0] : extractedData;
}
catch (err) {
if (!(err instanceof BrowserError)) {
browser.setError(err.message);
}
result = browser.getResult();
}
finally {
// Return a clean JSON object
return JSON.stringify(result.extractedJsonData);
}
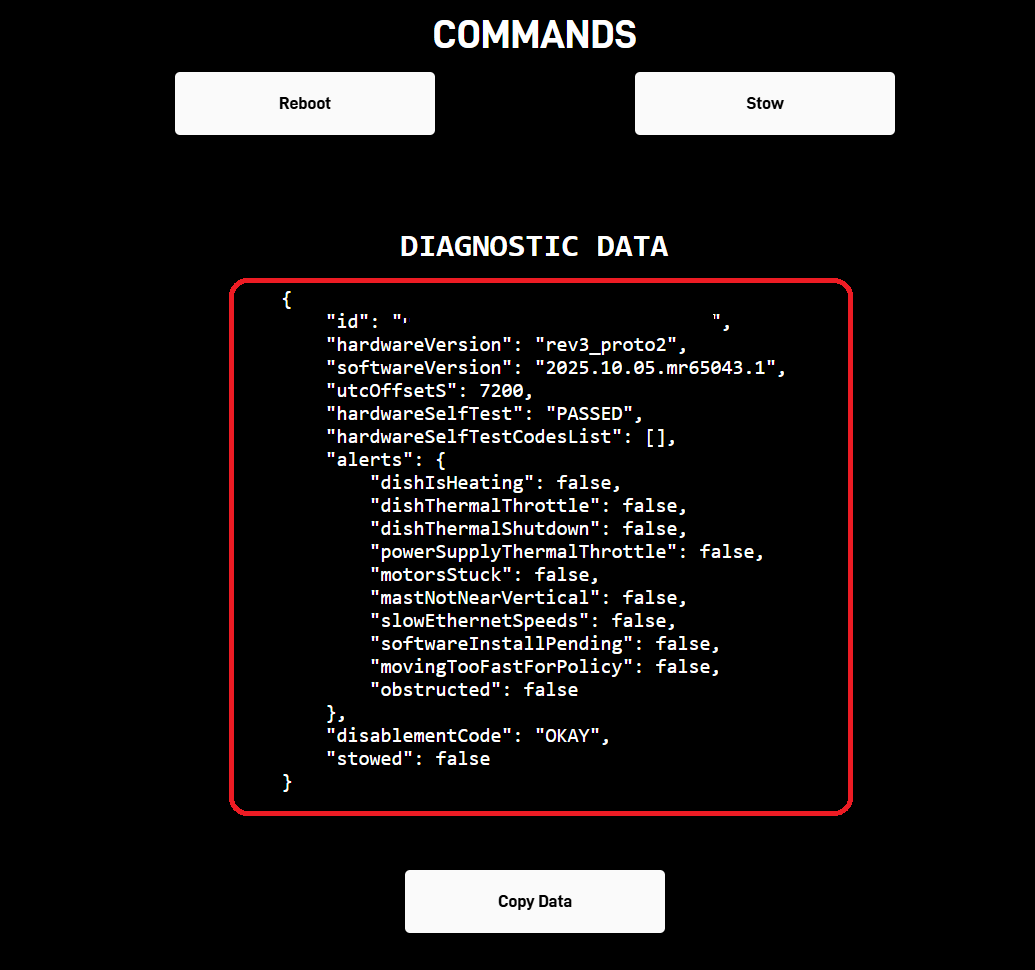
So what does this script do? It opens the Starlink web app, waits for the Starlink dish to output all the status data, and, after a bit of parsing, returns the data highlighted in the screenshot:
Starlink dish diagnostic data
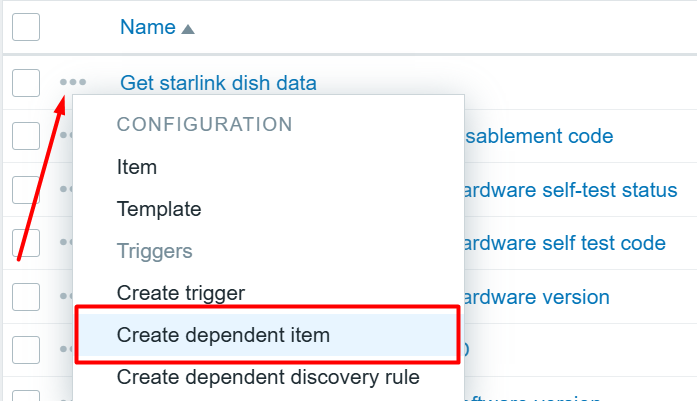
Now we can click on the three dots on the left of our newly created item in the items page and proceed to create dependent items for each value we are interested in!
Creating dependent items
Now we just click here:
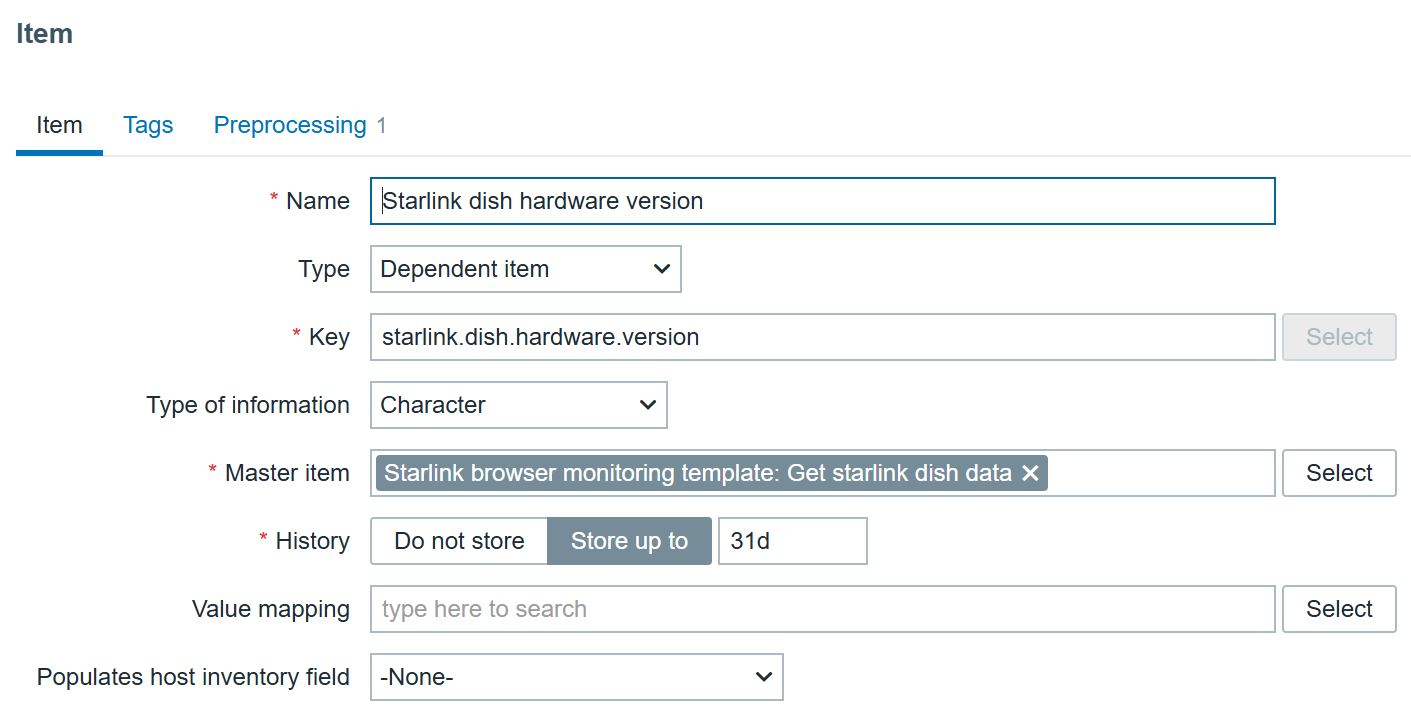
As an example, to create an item that monitors the hardware version we can create an item like this:
Hardware version dependent item
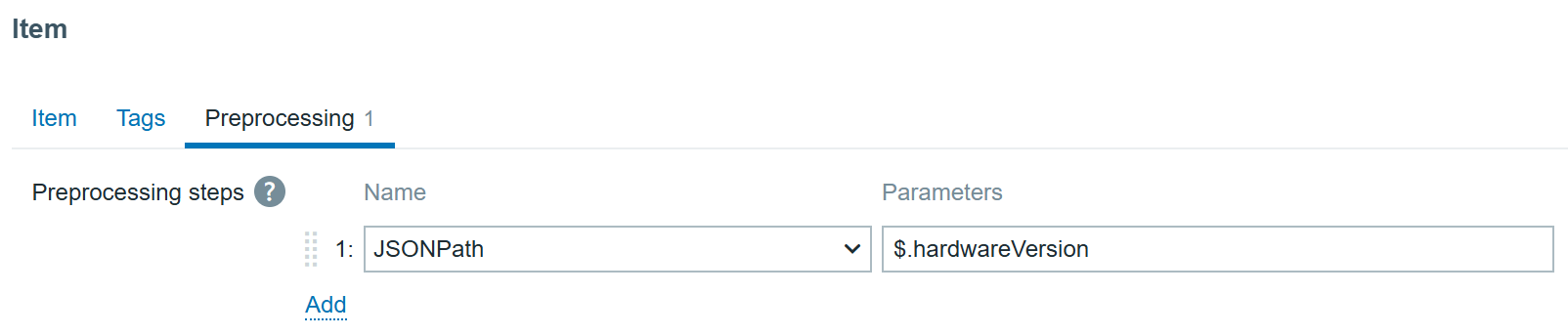
With JSONPath preprocessing:
Hardware version item preprocessing
In the end we get the data in Zabbix:
Starlink dish hardware version
All other items (except alerts) will follow the same logic – just update the item name, key, and JSONPath in preprocessing to extract the required values.
Creating dependent LLD item prototypes
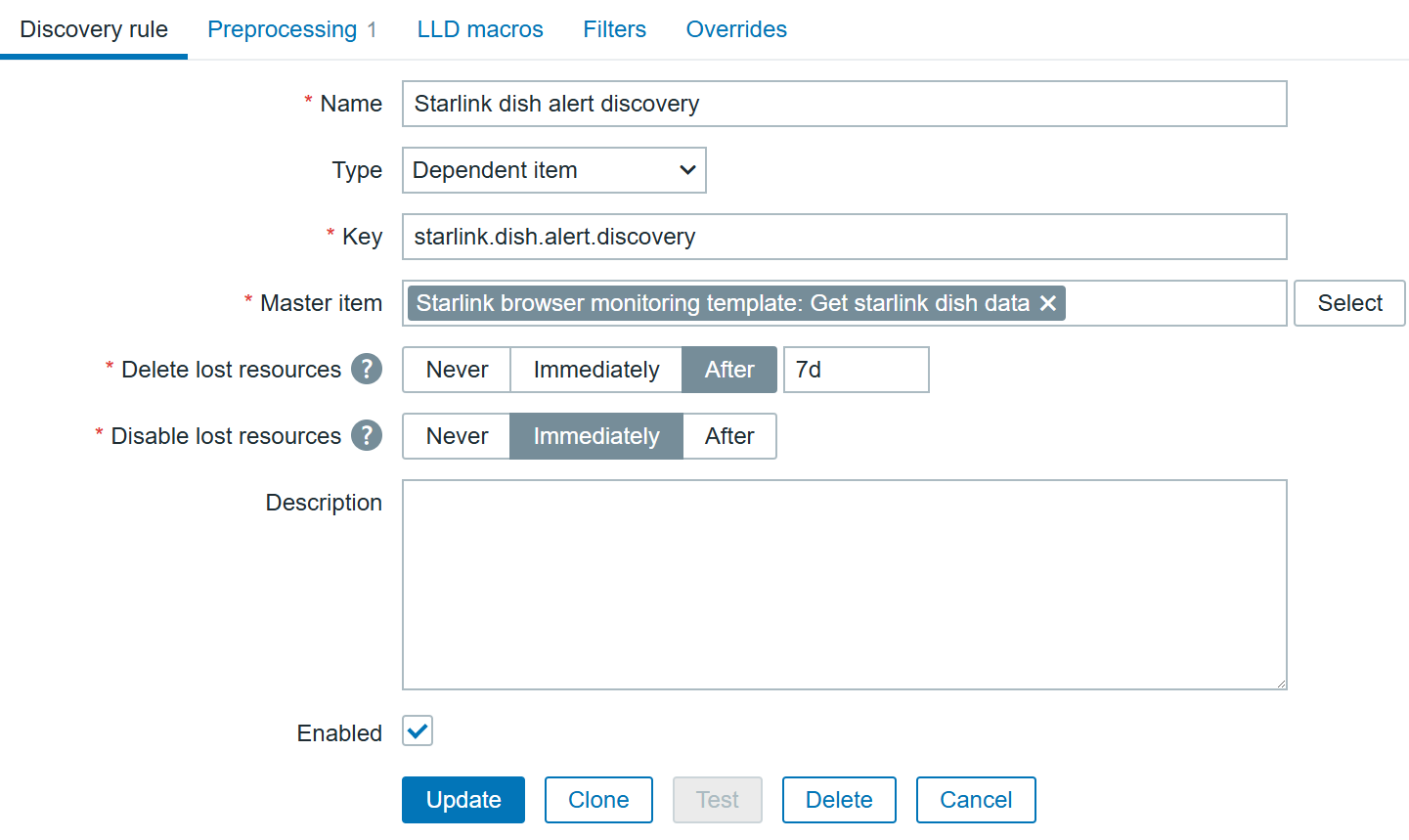
To automate the alerts items creation, we can create a dependent discovery rule. In the “Discovery” section, create a new discovery rule:
Starlink dish alerts discovery
With preprocessing using Java Script:
var data = JSON.parse(value);
var alerts = data.alerts;
var lld = [];
for (var key in alerts) {
if (alerts.hasOwnProperty(key)) {
lld.push({
"{#ALERT}": key
});
}
}
return JSON.stringify({ data: lld });
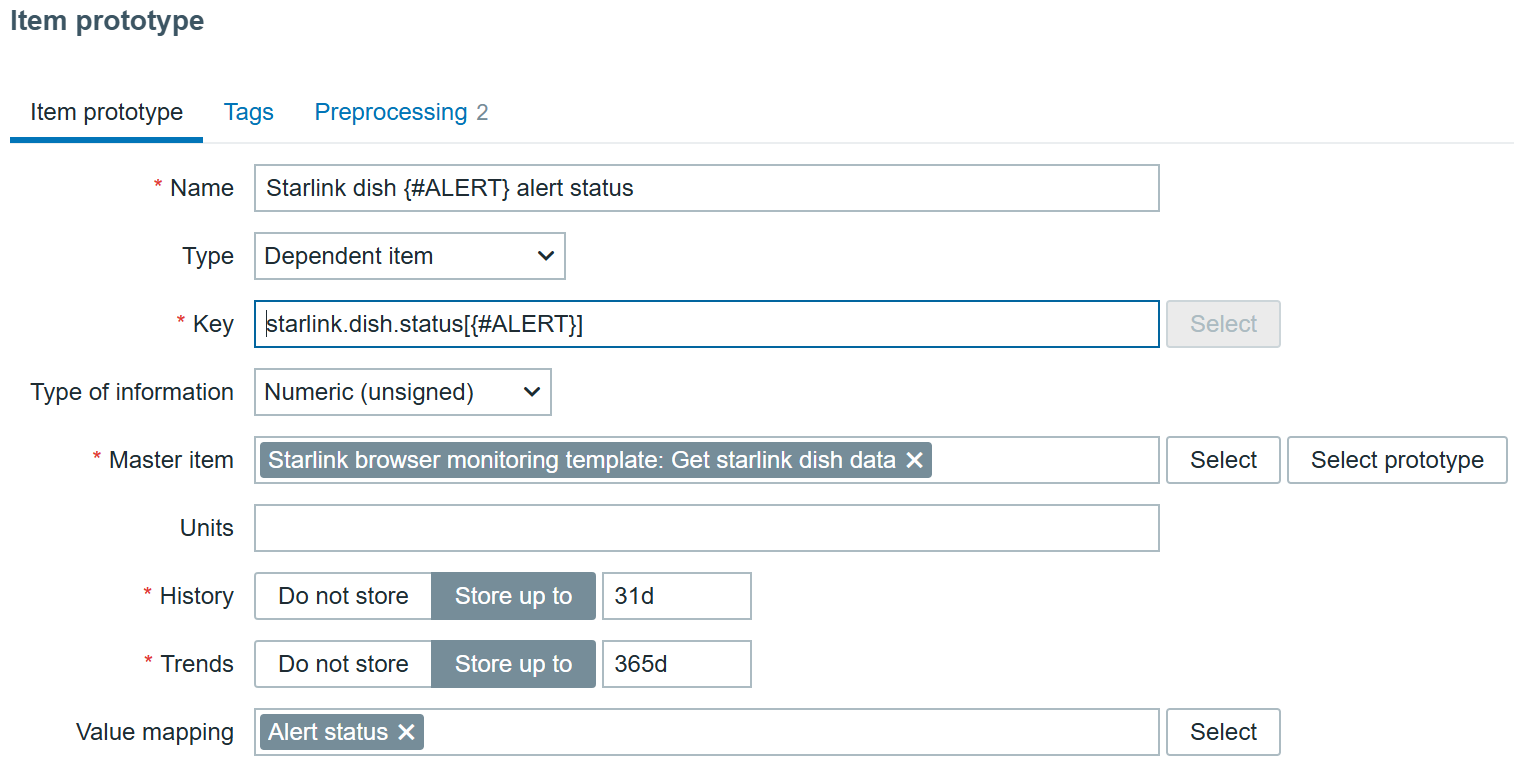
All that’s left ‘to do is to create a dependent item prototype:
Starlink dish alert prototype
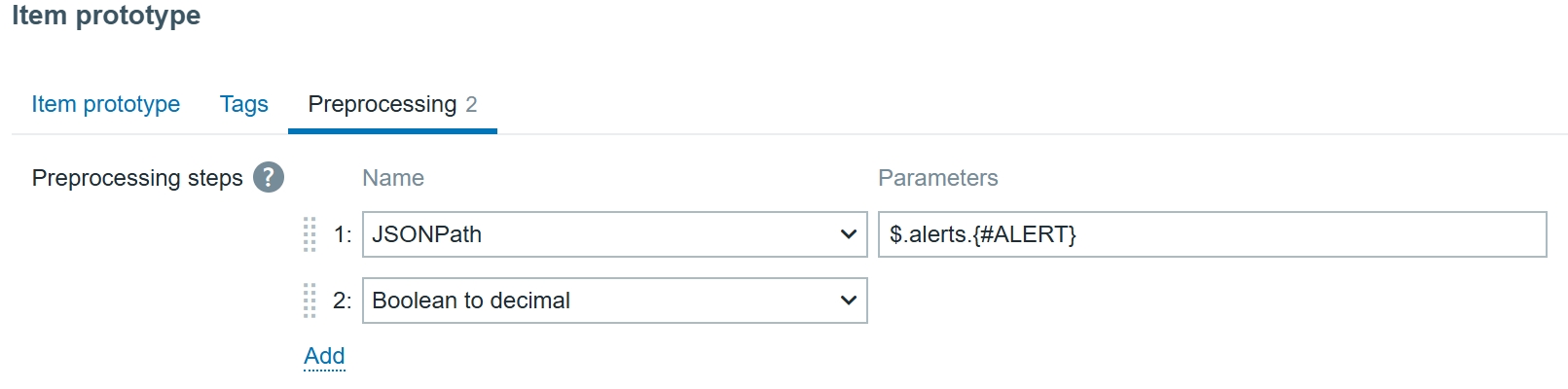
With preprocessing, of course:
JSONPath will transform to extract each specific alert and “Boolean to Decimal” will save us some space in the database by tranforming true/false booleans to digits.
Result
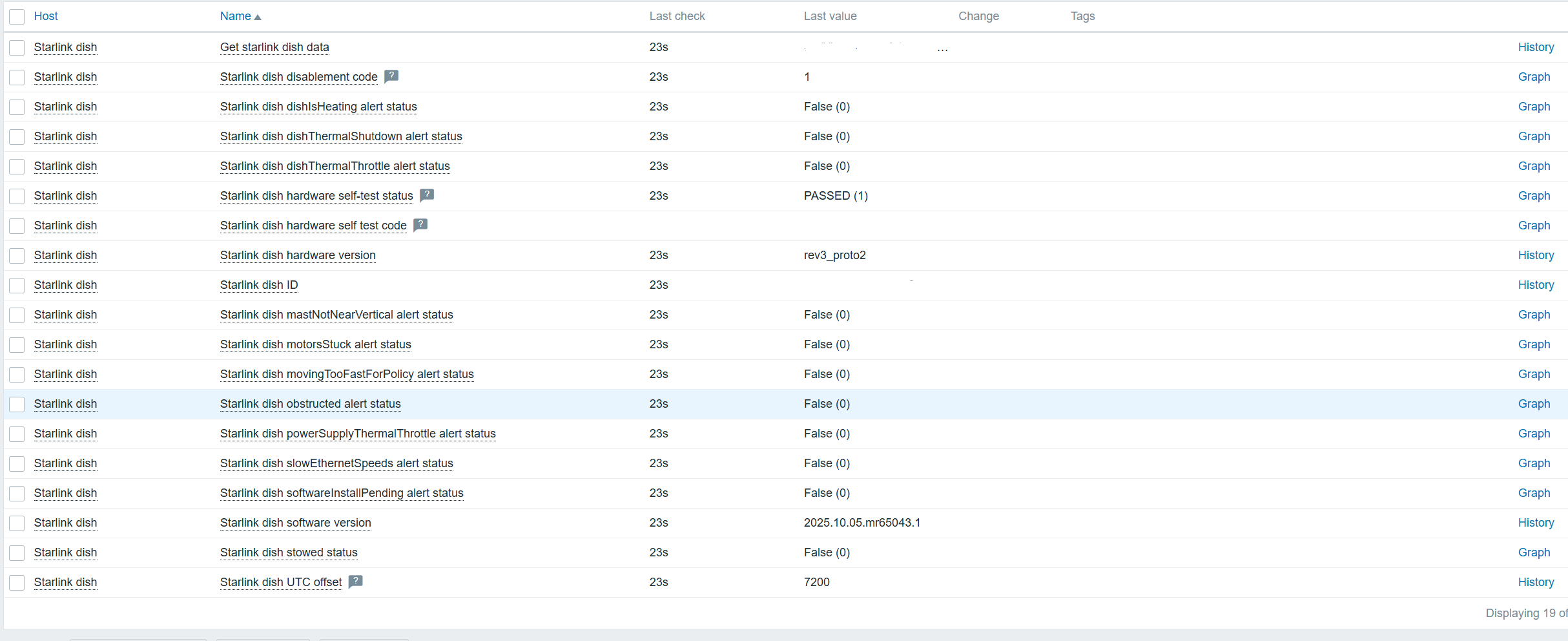
In the end, we can monitor all the data:
Starlink dish latest data
Even more data can be collected using exporters – if you are willing to do a bit of extra configuration, of course! Let me know if you are interested, and I will show you a completely different approach with a template.
Before I forget, the template used in this tutorial can be found here.
This post is cowritten by Danilo Tommasina and Lalit Kumar B from Thomson Reuters.
Large organizations often struggle with infrastructure management challenges including compliance issues, development bottlenecks and errors from inconsistent AWS resource creation across teams. Without standardized naming, tagging and policy enforcement, teams face repeated boilerplate code and difficulty accessing centrally-managed resources.
In this post, we will show you how Thomson Reuters developed an extension of the AWS Cloud Development Kit (CDK) to automate compliance, standardization and policy enforcement in Infrastructure as Code (IaC) scripts. We will explore the strategic reasoning behind this initiative, outline foundational design principles, and provide technical details on TR’s journey from concept to implementation. The solution accelerates and standardizes cloud infrastructure deployment and management through seamless integration between TR’s custom library and AWS CDK.
Thomson Reuters (TR) is one of the world’s leading information organizations for businesses and professionals. TR provides companies with the intelligence, technology, and human expertise they need to find trusted answers, enabling them to make better decisions more quickly. TR’s customers span the financial, risk, legal, tax, accounting, and media industries.
Overview
In a large organization that offers a variety of customer products, it is essential to manage numerous cloud resources effectively. This involves overseeing multiple AWS accounts, implementing access control or addressing financial tracking challenges. These tasks require the application of centrally defined standards and conventions, with additional requirements tailored to specific sub-organizations.
Infrastructure as Code (IaC) is an effective method for managing cloud resources. However, utilizing vanilla AWS CloudFormation for extensive and intricate infrastructure can pose challenges. It requires careful attention to naming conventions, tagging standards, security, and best practices for infrastructure deployments. Additionally, repeating infrastructure patterns across various services and products often leads to excessive use of copy-paste and dealing with boilerplate code. When projects require configurable and dynamic components – including conditionals, loops, repeatable patterns, and distribution to a large user base – delivering CloudFormation scripts can become quite cumbersome and prone to errors.
AWS CDK addresses these challenges by enabling IaC development in high-level programming languages like TypeScript, JavaScript, Python, Java. AWS CDK Level 2 and 3 constructs simplify and reduce the amount of code to be written to manage complex infrastructure. It allows TR to create custom libraries that extend the vanilla AWS CDK with additional patterns and utilities. The extension libraries can also be distributed for multiple programming languages and package managers thanks to JSII. JSII enables TypeScript libraries to be automatically compiled and packaged for native consumption in each target language, allowing CDK libraries to be written once but used in many different programming environments.
Solution to optimize the process
In a medium to large company, different teams provide the fundamental infrastructure services (e.g. authentication and authorization, networking, security, financial tracking and optimization, base infrastructure provisioning, etc.) to enable use of the cloud for a large community of developers.
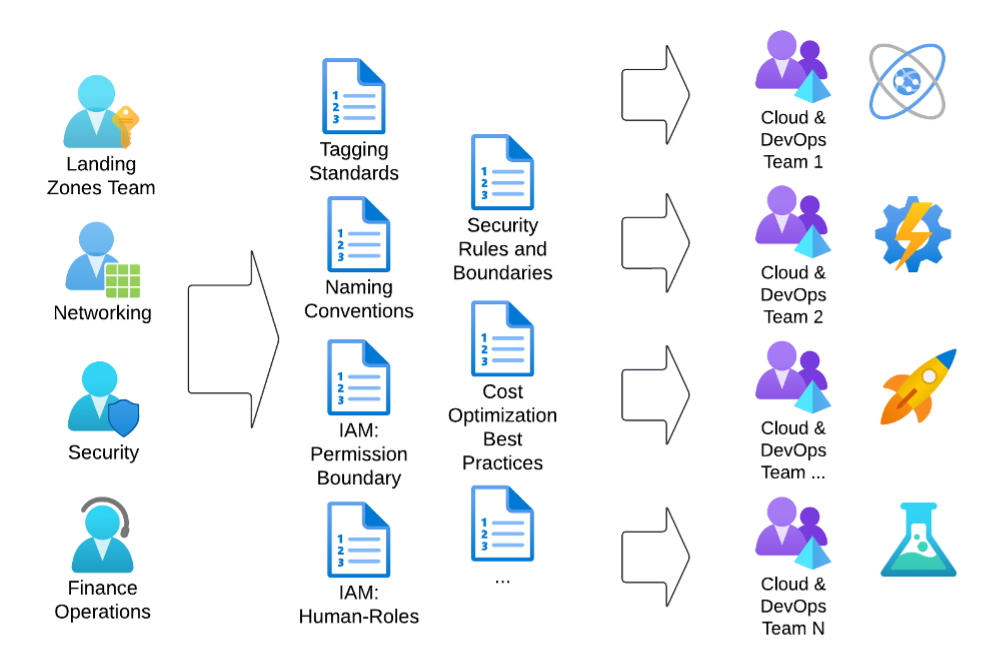
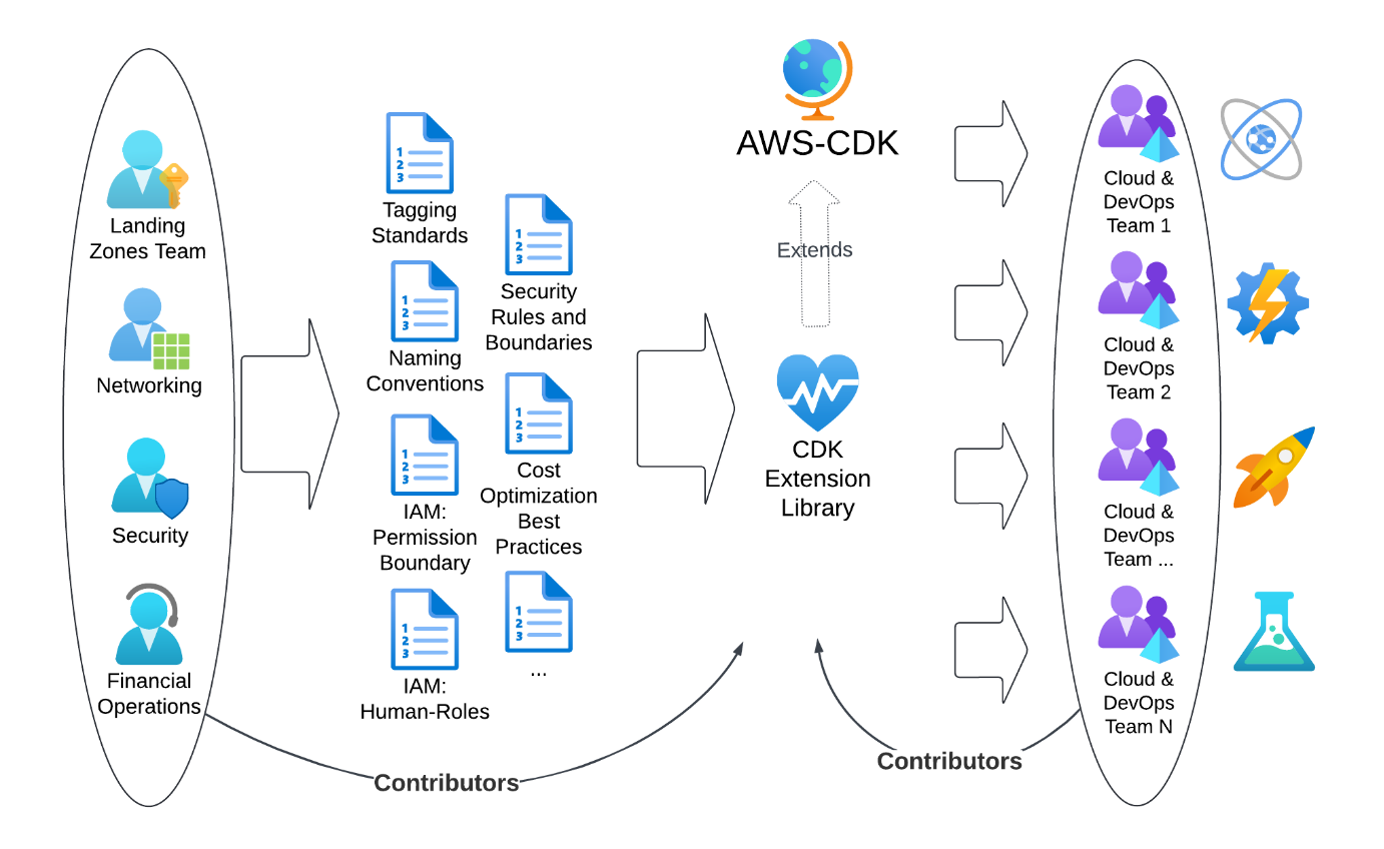
Figure 1 illustrates the conventional method involving teams producing documentation that outlines the usage of pre-deployed infrastructure. This includes naming and tagging standards, required security boundaries, default settings and other relevant guidelines. Subsequently, the implementation team reviews these documents and integrates the established rules into their tool chain consistently, often working in isolation. This results in inefficiencies, misinterpretation risks and maintenance challenges when specifications change.
Figure 1: The traditional approach
TR’s optimized approach replaces documentation with working code as shown in Figure 2.
Figure 2: The optimized approach
Infrastructure teams contribute their specifications into an extension library for AWS CDK, while the implementation teams can also contribute common patterns back into the central extension. The central extension library is released as polyglot packages allowing the implementation teams to pick the programming language that fits best to their knowledge.
With this approach, TR introduce a “shift-left” in the development and delivery lifecycle. Standards and best practices are introduced early, things are done right by default, and TR minimizes the risks of getting inappropriately configured resources to be deployed, which leads to a reduction in the number of governance and security incidents. Implementation delivery teams can share well architected patterns for re-use by other teams to improve overall effectiveness.
Implementation
Design principles
Key factors for the adoption of a framework are:
Simplicity, ease-of-use, self-service, and fast onboarding
Low maintenance effort and cost
Controlled roll-out, ability to quickly roll-back
With the above in mind, TR delivered a minimally invasive framework that can be enabled with a tiny set of custom code on top of vanilla AWS CDK code.
Using the TR-AWS CDK core library is straightforward – users simply import the package and adapt their entry point. From there, they can leverage standard AWS CDK code and documentation for most development tasks. There’s no need to learn custom construct classes or follow extensive specialized tutorials – vanilla AWS CDK knowledge is sufficient for most requirements. Additionally, developers can quickly incorporate open-source construct libraries through standard package managers. These third-party libraries integrate seamlessly with the TR implementation, automatically conforming to company standards without requiring additional configuration.
By managing distribution of the library following standard software packaging and release procedures TR enable consumers to adopt new capabilities in a controlled way, with the ability to roll-back to previous versions if something goes wrong during an update.
All this together allows TR to tick off the key factors listed above.
The monorepo approach
TR created a monorepo (monolithic repository) which is a version control strategy where multiple projects or packages are stored in a single repository. This approach offers several advantages over maintaining separate repositories for each package: unified versioning, simplified dependency management, consistent tooling, atomic changes across packages and improved collaboration.
This setup mirrors the configuration used by AWS CDK itself.
TR organized their monorepo following this structure:
repo/package.json: Defines dev dependencies and global scripts used by all packages
repo/packages: contains the different modules
repo/packages/core/package.json: deps of core module and scripts for core module
repo/packages/core/lib/*: typescript code that composes the core module
repo/packages/core/lib/augmentation/*: module augmentations for AWS CDK core components
repo/packages/constructs-pattern-X: define multiple reusable and independent level 3 constructs
repo/packages/tr-cdk-lib/package.json: assembly module that defines scripts to assemble the final mono package that will be shared via a npm repository
Figure 3: Repo structure
This structure enables TR to maintain a collection of related, but distinct CDK constructs while making sure they work together seamlessly.
The modules are assembled and released into one single versioned package which simplifies the end-user’s consumption.
The core module: Foundation of TR AWS CDK library
The core module is the foundation of TR’s CDK extension library, it consists of several key components that work together to “TR-ify” AWS resources and offer simplified access to centrally managed infrastructure resources that are provided by TR’s AWS landing zone teams.
TR refers to “TR-ification”, as the process of dynamically adapting AWS CDK constructs to meet their standards and best practices. From a user perspective, the process happens in a minimally invasive way, for most of the time the user is coding with vanilla AWS CDK components, while having access to short-cuts to a variety of TR specific resources.
The core module serves several critical purposes:
Standardization: makes sure the AWS resources follow TR naming conventions and tagging standards
Simplification: abstracts away complex configurations required for TR compliance
Integration: provides seamless access to TR-managed resources like VPCs, security groups, and Route53 hosted zones
Policy Enforcement: automatically applies custom security and financial optimization policies
The “TR-ification” process happens on every construct following a consistent order, for each construct it will:
If applicable, set a name following a consistent pattern
Apply custom initialization logic (e.g. set IAM permission boundary)
Apply security and financial optimization defaults (if not set)
Perform custom validations
Verify security and financial optimization policies
Tag resources
TR uses a single root-level Aspect instead of multiple Aspects to avoid complex resource type checking and improve maintainability:
// This is the entrypoint that triggers the trification process on all CDK constructs
// we apply all TR specific transformations at this point
Aspects.of(this).add({
visit: (node: IConstruct) => {
node.getTRifier().trify();
},
});
The careful readers at this point will scream: Wait a moment! node.getTRifier().trify() won’t compile!
Which is absolutely correct… unless you know a topic in TypeScript called module augmentation, in TR’s case, they augment the IConstruct interface and Construct class as follows:
/** Defines the set of functionality needed when trifying resources */
export interface ITRifier {
trify(): void;
readonly name: string | undefined;
readonly nameFromTree: string;
}
declare module 'constructs/lib/construct' {
interface IConstruct {
/** Obtain the ITRifier responsible to add TR specific features to this CDK IConstruct */
getTRifier(): ITRifier;
trContext(): AppContext | StageContext | StackContext;
}
interface Construct extends IConstruct {
/** Build the ITRifier responsible to add TR specific features to this CDK IConstruct */
buildTRifier(): ITRifier;
}
}
Then provide default implementations for the generic Construct:
Construct.prototype.getTRifier = function () {
// Lazy getter, build the TRifier only when needed and cache it
return ObjectUtils.lazyGetFrom(this, 'trifier', () => this.buildTRifier());
};
Construct.prototype.buildTRifier = function () {
return new ConstructTRifier(this); // Default dummy implementation
};
Construct.prototype.trContext = function (): StackContext {
return Stack.of(this).trContext() as StackContext;
};
Since AWS CDK constructs implement the IConstruct interface, respectively extend the Construct class automatically, the “TR-ification” process becomes available for many types of constructs. All you need to do now is inject your custom logic for all resources you need customization and make sure the module is loaded, e.g. in case of a Lambda function, it uses:
lambda.CfnFunction.prototype.buildTRifier = function () {
return new CfnResourceTRifierLambda.CfnFunction(
this,
() => { // Accessor for retrieving the lambda function name
return this.functionName;
},
(name: string) => { // Accessor for setting the lambda function name
this.functionName = name;
},
() => {
// Our own stuff to set defaults for financial optimizations
const policyChecker = FinOps.Lambda.Defaults.apply(this);
this.node.addValidation({
validate: () => {
// Inject a custom validation logic to check compliance with financial policies
return policyChecker.addErrorIfNotCompliant(this);
}
});
}
);
};
TR targets L1 (Cfn) constructs like CfnFunction because the higher-level L2 and L3 constructs internally create L1 constructs during synthesis. This architectural decision makes sure TR-ification is applied universally, whether users write new lambda.Function() or new lambda.CfnFunction(), both will be TR-ified. This approach provides complete coverage with a single implementation point while remaining completely transparent to library users who can continue using their preferred abstraction level without awareness of this internal mechanism.
Naming standardization
TR uses standardized naming to support IAM policy filtering and consistent resource management. In order to support a broad range of use-cases, TR defined the resource name pattern as follows: <segregationPrefix>[-appPrefix]-<resourceName>[-region]-<envSuffix> where the elements mean:
segregationPrefix: A prefix used for grouping resources for a specific asset, it implies that a segregated administrative group is responsible for this resource, where applicable it is used for ARN based IAM resource filtering.
appPrefix: Optional, a prefix used to map a resource to a specific application or service, this is shared across stacks within a CDK app.
resourceName: The name of a resource indicating its purpose.
region: Optional, applied only to resources that are global but are part of a CDK stack that is bound to a specific region.
envSuffix: A suffix used to segregate different deployment environments, e.g. development, continuous integration, quality assurance, production.
Traditional approaches require developers to manually construct these names, propagating prefixes and suffixes throughout their code:
new lambda.Function(stack, 'foo', {
runtime: lambda.Runtime.NODEJS_LATEST,
handler: 'index.handler',
code: new lambda.InlineCode('bar'),
functionName: `\${segregationPrefix}-\${appPrefix}-compute-stats-\${envSuffix}`,
});
With TR AWS CDK extension, the code is simplified to:
new lambda.Function(stack, 'MyFunction', {
runtime: lambda.Runtime.NODEJS_LATEST,
handler: 'index.handler',
code: new lambda.InlineCode('foo'),
functionName: 'compute-stats',
});
The functionName describes what the function does without “noise”, TR AWS CDK will transparently generate and inject the name into the synthetized CloudFormation script, matching the specification. Note that functionName is optional and TR-CDK will either TR-ify a provided name or automatically generate a valid one if the user omits it, making sure CloudFormation receives a properly formatted name.
Access to “Landing Zone” resources
TR’s central AWS Landing Zone team is responsible of inflating a set of standard resources (e.g. VPC, subnets, security groups, Route 53 zones, golden AMIs, etc.) into AWS accounts that are made available to application development teams.
Through module augmentation (shown earlier), the TR-ifier defines the function trContext() which provides access to a context-aware utility. When calling this function on a resource that resides within a Stack, it will return an object that implements StackContext interface.
export interface StackContext extends StageContext {
/** Get access to the TR IVpc */
readonly vpc: IVpc;
/** Provides access to standard security groups that are available in all TR accounts */
readonly securityGroups: trparams.ISecurityGroupsResolver;
/** Provides access to private and public hosted zones (with numeric digits) that are available in all TR accounts */
readonly route53: trparams.IRoute53Resolver;
/** Provides access to TR golden AMIs that are available in all TR accounts */
readonly goldenAMI: TRGoldenAMI;
}
The readonly attributes are accessors for the AWS Landing Zones resources listed above. With calls like the following examples, you have a simple way to obtain access to the standard VPC, subnets selections, route 53 private hosted zone, …
// Get the IVpc:
const trVpc: IVpc = stack.trContext().vpc;
// Get the private subnets as array
const privateSubnets: ISubnet[] = trVpc.privateSubnets;
// Get the private subnets as SubnetSelection
const privateSubSel: SubnetSelection = trVpc.selectSubnets({
subnetType: SubnetType.PRIVATE_WITH_EGRESS,
});
// Get the private Route53 hosted zone
const privateHZ = stack.trContext().route53.privateHostedZone;
You might now wonder how TR resolves the resources and obtain objects implementing IVpc, ISubnet, ISecurityGroup, …
Instead of using hard-coded resource attributes (e.g. Id, ARN, …) or complex lookups, TR uses CloudFormation’s ability to resolve Systems Manager parameters at execution time, as part of the AWS account initial inflation along with the resources, Systems Manager parameters are registered as well. The parameter names are the same across TR’s AWS accounts, the value contains e.g. the id of the matching AWS Landing Zone standard resource, e.g. /landing-zone/vpc/vpc-id, /landing-zone/vpc/subnets/private-1-id, /landing-zone/vpc/subnets/private-2-id, …
TR then defined custom IVpc, ISubnet, IHostedZone… implementations and for each function they implemented dynamic resolution of resource attributes via Systems Manager parameters. With this approach, TR obtains portable code that runs on AWS accounts initialized via TR inflation process. There are no hard-coded resource identifiers, and there is no need for lookups via AWS SDK during synthesis.
As a user of the TR AWS CDK library, TR developers interact with an object implementing the IVpc interface and do not have to care about how to obtain e.g. the VPC-id and subnet ids. The same principle applies to Route53 hosted zones, Golden AMI ids, etc.
Application initialization
As mentioned previously, one key design principle is to minimize the custom code that a user of TR AWS CDK is required to use compared to using vanilla AWS CDK. This approach leverages existing AWS CDK and reduces the learning curve for developers.
This is how TR developers initialize an App with vanilla CDK, compared to how they initialize it with TR AWS CDK.
From this point on, the developers can continue using vanilla AWS CDK code, the value returned by TRCdk.newApp(…) is an instance of an extension of CDK’s App class and is fully compatible with it. It, however, injects the TR-ification aspect, manages the tagging process, and initializes contextual information.
Here and there, e.g. when they need to pass the VPC into a construct, they will need to call TR AWS CDK code via the trContext() entry point that is exposed on CDK constructs through TypeScript’s module augmentation feature, but that’s it! 99% of the code is vanilla AWS CDK code.
The segregationId, namingProps, and deploymentEnv attributes are used for multiple purposes like formatting resource names and tagging resources.
Standardized Tagging
TR defines tagging standards, there are mandatory tags (e.g. for attribution to a specific product asset and for tracking resource ownership), and there are optional tags (e.g. for specifying resources that belong to different services within the same product asset).
The segregationId, the resourceOwner, and deploymentEnv attributes are used to set mandatory tags using CDK’s built-in functionality for tagging. TR also defines a standardized set of optional tags that can be passed into the application context or set ad-hoc on individual constructs.
This approach maintains consistency in the use of tag names and setting the values, it happens automatically behind the scenes and will be applied to the taggable constructs. No copy-pasting of tag definitions like in AWS CloudFormation, no issues dealing with CloudFormation’s inconsistent syntax for tag declarations, no forgetting of tagging resources.
Conclusion
In this post, we discussed how the monorepo approach to AWS CDK development, centered around the core module, has significantly improved the infrastructure management at Thomson Reuters. By providing well-architected L3 constructs, standardizing and simplifying AWS resource creation, they’ve reduced errors, enhanced governance, and accelerated development.
The core module’s ability to enforce policies, standardize naming and tagging, and provide access to TR-managed resources makes it an invaluable tool for teams working with AWS infrastructure at Thomson Reuters.
To get started with AWS CDK and build your CDK solutions, check out the AWS CDK Developer Guide.
Преди точно десет години в Moto Grand Prix (MotoGP) – най-високия клас от световните шампионати по мотоциклетизъм – се състоя може би най-спорната развръзка на борба за титлата, която този спорт е виждал. Испанецът Хорхе Лоренцо спечели последния кръг от шампионата за 2015 г. на пистата „Херес“. Младият шампион от предишната година Марк Маркес, известен с агресивното си управление на мотоциклета, този път кара пасивно зад него през цялата надпревара и го остави да спечели. Това позволи на сънародника му да събере необходимите точки, за да вземе титлата пред легендата Валентино Роси. По-рано през сезона между Роси и Маркес имаше няколко спорни ситуации, които доведоха до удар в предпоследния кръг за Голямата награда на Малайзия, а оттам – и до наказание за Роси, принуден да тръгне последен на пистата във Валенсия. Така италианецът изгуби последния си шанс за десета титла и в него остана горчивият вкус, че е бил измамен от съперник, намесил се в чужда битка.
В миналото подобни борби не са били рядкост. Формула 1 помни катастрофите между Ален Прост и Аертон Сена в края на 80-те, грозните обиди на Нелсон Пике по адрес на Найджъл Менсъл, ударите на Михаел Шумахер срещу Деймън Хил през 1994 г. и Жак Вилньов през 1997 г. През 2021 г. подобни искри прехвърчаха между Макс Верстапен и Люис Хамилтън, които се блъснаха свирепо два пъти – във Великобритания Люис изпрати Макс в болница, а в Италия колата на Верстапен се покатери върху автомобила на съперника си.
Тези сблъсъци не са нещо изненадващо.
Високите скорости са арена на свирепа битка между горди мъже, искрите от която понякога се разпалват до пожари. През последните години обаче се наблюдава отчетлива промяна в начина, по който пилотите се борят и общуват помежду си. Състезатели от ново поколение като Оскар Пиастри във Формула 1 и Хорхе Мартин в MotoGP реагират на конфликтните ситуации по различен начин, а примерът им изглежда заразителен и води до омекване дори у предишното поколение асове като Маркес и Верстапен.
Това е интересно по две причини. На първо място, стои въпросът за ролевите модели, които момчетата – основна аудитория на този тип състезания – получават. Доста се говори в последно време за лошия пример, даван от инфлуенсъри като братята Тейт – неонацисти, налагащи груб мачизъм, според който мъжете никога не плачат, а жените са само обект на желанието им. Но матрицата, залагана например в съвременни холивудски продукции, също не работи – мъжките образи системно изглеждат като кръгли глупаци. А съветът, че трябва да си чувствителен, да си позволяваш да плачеш и да показваш уязвимост, макар и правилен, може да предизвика т.нар. криндж сред много от момчетата. Да ги накара да се чувстват неловко, да блокират и в най-лошия случай – да бягат към другия модел.
Втората причина е, че дисциплини като Формула 1 и MotoGP са изключително конкурентни и в името на победата участниците в тях биха променили моделите си на поведение, които водят до влошаване на резултатите. Всяка десета от секундата е от значение, всеки излишен грам води до забавяне и заради това пилотите поддържат завидна спортна форма. Но през последните години става все по-ясно, че психическото състояние на участниците е също толкова важно. Пилот, който не е в добро емоционално състояние, ще губи време и увереност. Работа на отбора е да направи така, че състезателят да се чувства добре. Само тогава той може да изяви най-доброто, на което е способен.
Промяната
Важно е да се отбележи, че в първоначалната си форма моторните спортове са били арена на джентълмени и споменатите по-горе серии от инциденти са били немислими. Причината за взаимния респект е високата степен на опасност, при която и най-малката грешка може да завърши със смъртен случай. Ето защо нечистото каране на Сена предизвика потрес у сър Джеки Стюарт, чийто провокативен въпрос за техниката на бразилеца породи знаменития отговор, че ако един пилот не се възползва от пролука в защитата на съперника, значи не е състезател. Сена караше във време с подобрена сигурност – за съжаление, не толкова, че да предотврати гибелта му във фаталната катастрофа на пистата „Имола“ през 1994 г. Преди състезанието той е бил необичайно разстроен и в мрачно настроение заради смъртта на колегата си Роланд Ратценбергер в квалификацията – чувствал се е като в капан, който в крайна сметка се оказва смъртоносен.
Но по онова време не е съществувала грижа за емоционалното здраве. В спомените си световният шампион от 1996 г. Деймън Хил споделя, че след смъртта на баща си е получил като подкрепа половин час разговор в училище. През този период психологическа подкрепа за такива ситуации почти не се е предлагала. В резултат съпругата му споделя, че при запознанството им той ѝ се сторил един от най-тъжните хора на света. Да покажеш уязвимост, след като си се озовал в спорта, означава да си спечелиш подигравки; да си приятел с конкурента си на пистата е било трудно въобразимо. Чак след като Ален Прост се отказва от спорта, Сена разбира колко привързан е бил към своя съперник. Вечерта преди последния си старт той му се обажда по телефона, за да му каже, че липсва на всички.
В наши дни обаче спортът е променен. Ландо Норис и Макс Верстапен на няколко пъти имаха тежки удари помежду си, но въпреки това запазиха приятелството си, създадено покрай споделената им страст към виртуални състезания. Отношенията между Хорхе Мартин и Франческо Баная в MotoGP останаха топли въпреки оспорваните им битки за титлата. Нещо повече – пилотите са все по-склонни да споделят за трудностите, през които преминават, и получават съчувствие, а не присмех от колегите си.
Примерът на младите
През последните години Ландо Норис е смятан за един от най-бързите пилоти в своя спорт и редовно участва в битките за победата. Известен със силната си емоционалност, той често си казва всичко пред микрофоните. В случай на грешка е критичен към себе си, понякога стига до самобичуване. Дори харесва постове в социалните мрежи, в които е иронизиран или подиграван. Заради тези му особености световният шампион от 1980 г. Алън Джоунс казва, че той „няма качествата на шампион“. Ръководителят му в тима на „Макларън“ Зак Браун обаче не е съгласен. Той твърди, че е нормално за „мъжкар“ като Джоунс да разсъждава така, тъй като се е състезавал в друго време. Но според него Ландо просто изкарва от себе си негативните емоции и после става по-силен. Той не се срамува да покаже уязвимост, нито пък да се занимава с дейности, които се смятат за непривични за автомобилен състезател и му печелят подигравки онлайн. Норис не крие и интереса си към модата – наскоро участва във фотосесия, очевидно направена с мисъл и за момичетата, които е успял да привлече към публиката на Формула 1.
Съотборникът му Оскар Пиастри е също толкова интересен случай. Често е наричан Ледения и е сравняван с финландеца Кими Райконен, но спокойствието на австралийския състезател е от съвсем друг тип. Израснал в женско царство с няколко сестри, Оскар е смятан за човек, който е научил много от начина, по който жените се справят с кризисни моменти. Затова се въздържа от агресивни реакции дори когато нервите му са изопнати докрай. Пиастри споделя, че не е безчувствен – просто не вижда смисъл да се отдава на гнева и не смята, че това би му помогнало.
Ако Оскар е леден, то Хорхе Мартин – шампион за 2024 г. в MotoGP – е неговата огнена противоположност. Темпераментният испанец с гореща кръв признава открито как след първата си победа е направил грешката да се отдаде на пиене и купони – нещо, което много млади мъже правят, когато се главозамаят. Затова такъв положителен пример за откровеност има значение. Мартин не крие, че е приел много тежко загубата си от Баная през 2023 г. и буквално се е сринал психически, поради което е потърсил подкрепа от психолог, който му е помогнал да се изправи на крака и да спечели през следващата година.
Важно е да се отбележи, че гореспоменатото поведение не прави тези пилоти съвършени. По-скоро ги освобождава от очакването да бъдат такива. Те са признали, че са само хора, а емоциите са част от човешкото. Така оказват влияние дори върху „батковците“ си.
Омекването на големите шампиони
Макс Верстапен е пилотът, който на пръв поглед носи старомодната агресия на Сена и Шумахер. Това кара много фенове да му се възхищават и да смятат, че той е като вълк в кошара сред останалите си съперници. Нидерландецът наистина е безкомпромисен на пистата и избухва в гняв в радиовръзката с инженера, когато нещата не вървят добре. Но в същото време е внимателен с феновете си деца и се отнася с топлота и грижа към Пенелопе – детето на съпругата си Кели от предишния ѝ брак с друг състезател. Вярно е, че е прям и носи в себе си наследството на токсичния си баща Йос Верстапен, лежал в затвора за домашно насилие. В него обаче има и много от майка му Софи Кумпен, което смекчава характера му – може би затова Макс стана шампион във Формула 1, а Йос не стигна и до победа в състезание от най-престижния шампионат в света на високите скорости.
Верстапен-младши също така помага на млади геймъри, като Крис Лулъм, като им осигурява средства да пренесат уменията си и на истинската писта. Всъщност доброто отношение към по-младите колеги е запазена марка и на асове като Фернандо Алонсо и Люис Хамилтън. Вероятно то е съществувало и сред звездите на миналото, но акцентът върху него не е бил толкова силен, особено в медийното пространство.
Еволюция се наблюдава и при испанския ветеран Марк Маркес. След като доминира в спорта с мотоциклет на „Хонда“ и беше близо до рекордите на Роси, той се контузи тежко през 2020 г. и се възстановяваше дълги години, като отново и отново претърпяваше мъчителни падания, приближили го до отказване от състезаването. Едва през 2025 г. успя отново да се изкачи върха. При спечелването на титлата коленичи и се разплака пред видеоретроспекция, показваща огромните мъки, през които е преминал – операциите, рехабилитацията, провалите. Близките му споделиха колко сълзи е пролял през тези години, а и той не скри това. Може би най-красноречивият знак за промяната у него дойде след състезанието за Голямата награда на Индонезия, когато бе съборен на пистата от съперника си Марко Безеки (наричан още Без) и при инцидента отново получи тежка контузия. Скоро след това испанецът се обърна към феновете си с молба да не атакуват Без, защото никой не предизвиква такава катастрофа нарочно. Огромна разлика спрямо пилота, намесил се преди десет години в битката между Роси и Лоренцо заради наранена гордост.
Моторните спортове остават дисциплина, в която основна остава жаждата за победа.
Това вече се видя на няколко пъти през този сезон във Формула 1, където иначе примерните Ландо Норис и Оскар Пиастри допуснаха леки контакт между автомобилите си, нещо – което вероятно ще се случва отново, колкото повече наближава финалът на сезона. Но както и в случая с битката между Норис и Верстапен преди година, имаме основания да вярваме, че емоциите ще останат на пистата и около дните на състезанията, а няма да ескалират в трайните вражди, познати от миналото. Защото историите на тези състезатели показват, че днес мъжествеността не е това, което беше. Тя включва и умението да губиш, да приемаш помощ от съперниците си и да им предлагаш своята.
Тези неща впрочем не са запазена марка само на мъжете. И представляват, казано на езика на моторните спортове, смяна на една по-висока предавка.
This is part 3 in a series called “Behind the Streams”. Check out part 1 and part 2 to learn more.
Picture this: It’s seconds before the biggest fight night in Netflix history. Sixty-five million fans are waiting, devices in hand, hearts pounding. The countdown hits zero. What does it take to get everyone to the action on time, every time? At Netflix, we’re used to on-demand viewing where everyone chooses their own moment. But with live events, millions are eager to join in at once. Our job: make sure our members never miss a beat.
When Live events break streaming records ¹²³, our infrastructure faces the ultimate stress test. Here’s how we engineered a discovery experience for a global audience excited to see a knockout.
Why are Live Events Different?
Unlike Video on Demand (VOD), members want to catch live events as they happen. There’s something uniquely exciting about being part of the moment. That means we only have a brief window to recommend a Live event at just the right time. Too early, excitement fades; too late, the moment is missed. Every second counts.
To capture that excitement, we enhanced our recommendation delivery systems to serve real-time suggestions, providing members richer and more compelling signals to hit play in the moment when it matters most. The challenge? Sending dynamic, timely updates concurrently to over a hundred million devices worldwide without creating a thundering herd effect that would overwhelm our cloud services. Simply scaling up linearly isn’t efficient and reliable. For popular events, it could also divert resources from other critical services. We needed a smarter and more scalable solution than just adding more resources.
Orchestrating the moment: Real-time Recommendations
With millions of devices online and live event schedules that can shift in real time, the challenge was to keep everyone perfectly in sync. We set out to solve this by building a system that doesn’t just react, but adapts by dynamically updating recommendations as the event unfolds. We identified the need to balance three constraints:
Time: the duration required to coordinate an update.
Request throughput: the capacity of our cloud services to handle requests.
Compute cardinality: the variety of requests necessary to serve a unique update.
Visualizing constraints for real-time updates
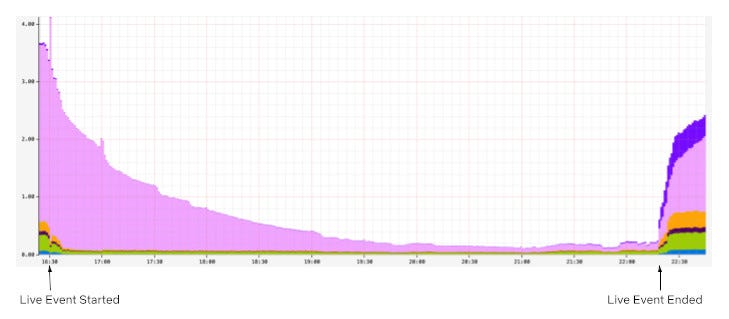
We solved this constraint optimization problem by splitting the real-time recommendations into two phases: prefetching and real-time broadcasting. First, we prefetch the necessary data ahead of time, distributing the load over a longer period to avoid traffic spikes. When the Live event starts or ends, we broadcast a low cardinality message to all connected devices, prompting them to use the prefetched data locally. The timing of the broadcast also adapts when event times shift to preserve accuracy with the production of the Live event. By combining these two phases, we’re able to keep our members’ devices in sync and solve the thundering herd problem. To maximize device reach, especially for those with unstable networks, we use “at least once” broadcasts to ensure every device gets the latest updates and can catch up on any previously missed broadcasts as soon as they’re back online.
The first phase optimizes request throughput and compute cardinality by prefetching materialized recommendations, displayed title metadata, and artwork for a Live event. As members naturally browse their devices before the event, this data is prepopulated and stored locally in device cache, awaiting the notification trigger to serve the recommendations instantaneously. By distributing these requests naturally over time ahead of the event, we can eliminate any related traffic spikes and avoid the need for large-scale, real-time system scaling.
A phased approach, smoothing traffic requests over time with a real-time low-cardinality broadcast
The second phase optimizes request throughput and time to updatedevices by broadcasting a low-cardinality, real-time message to all connected devices at critical moments in a Live event’s lifecycle. Each broadcast payload includes a state key and a timestamp. The state key indicates the current stage of the Live event, allowing devices to use their pre-fetched data to update cached responses locally without additional server requests. The timestamp ensures that if a device misses a broadcast due to network issues, it can catch up by replaying missed updates upon reconnecting. This mechanism guarantees devices receive updates at least once, significantly increasing delivery reliability even on unstable networks.
A phased approach optimizes each constraint to ensure we can deliver for the big moment!
Moment in Numbers: During peak load, we have successfully delivered updates at multiple stages of our events to over 100 million devices in under a minute.
Under the Hood: How It Works
With the big picture in mind, let’s examine how these pieces interact in practice.
In the diagram below, the Message Producer microservice centralizes all of the business logic. It continuously monitors live events for setup and timing changes. When it detects an update, it schedules broadcasts to be sent at precisely the right moment. The Message Producer also standardizes communication by providing a concise GraphQL schema for both device queries and broadcast payloads.
Rather than sending broadcasts directly to devices via WebSocket, the Message Producer hands them off to the Message Router. The Message Router is part of a robust two-tier pub/sub architecture built on proven technologies like Pushy (our WebSocket proxy), Apache Kafka, and Netflix’s KV key-value store. The Message Router tracks subscriptions at the Pushy node granularity, while Pushy nodes map the subscriptions to individual connections, creating a low-latency fanout that minimizes compute and bandwidth requirements.
Devices interface with our GraphQL Domain Graph Service (DGS). These schemas offer multiple query interfaces for prefetching, allowing devices to tailor their requests to the specific experience being presented. Each response adheres to a consistent API that resolves to a map of stage keys, enabling fast lookups and keeping business logic off the device. Our broadcast schema specifies WebSocket connection parameters, the current event stage, and the timestamp of the last broadcast message. When a device receives a broadcast, it injects the payload directly into its cache, triggering an immediate update and re-render of the interface.
Balancing the Moment: Throughput Management
In addition to building the new technology to support real-time recommendations, we also evaluated our existing systems for potential traffic hotspots. Using high-watermark traffic projections for live events, we generated synthetic traffic to simulate game-day scenarios and observed how our online services handled these bursts. Through this process, several common patterns emerged:
Breaking the Cache Synchrony
Our game-day simulations revealed that while our approach mitigated the immediate thundering herd risks driven by member traffic during the events, live events introduced unexpected mini thundering herds in our systems hours before and after the actual events. The surge of members joining just in time for these events led to concentrated cache expirations and recomputations, which created traffic spikes well outside the event window that we did not anticipate. This was not a problem for VOD content because the member traffic patterns are a lot smoother. We found that fixed TTLs caused cache expirations and refresh-traffic spikes to happen all at once. To address this, we added jitter to server and client cache expirations to spread out refreshes and smooth out traffic spikes.
Adaptive Traffic Prioritization
While our services already leverage traffic prioritization and partitioning based on factors such as request type and device type, live events introduced a distinct challenge. These events generated brief traffic bursts that were intensely spiky and placed significant strain on our systems. Through simulations, we recognized the need for an additional event-driven layer of traffic management.
To tackle this, we improved our traffic sharding strategies by using event-based signals. This enabled us to route live event traffic to dedicated clusters with more aggressive scaling policies. We also added a dynamic traffic prioritization ruleset that activates whenever we see high requests per second (RPS) to ensure our systems can handle the surge smoothly. During these peaks, we aggressively deprioritize non-critical server-driven updates so that our systems can devote resources to the most time-sensitive computations. This approach ensures smooth performance and reliability when demand is at its highest.
Snapshot of non-critical traffic volume decline (in %) for a member-facing service during a live event — achieved via aggressive de-prioritization
Looking Ahead
When we set out to build a seamlessly scalable scheduled viewing experience, our goal was to create a dynamic and richer member experience for live content. Popular live events like the Crawford v. Canelo fight and the NFL Christmas games truly put our systems to the test. Along the way, we also uncovered valuable learnings that continue to shape our work. Our attempts to deprioritize traffic to other non-critical services caused unexpected call patterns and spikes in traffic elsewhere. Similarly, in hindsight, we also learned that the high traffic volume from popular events caused excessive non-essential logging and was putting unnecessary pressure on our ingestion pipelines.
None of this work would have been possible without our stunning colleagues at Netflix who collaborated across multiple functions to architect, build, and test these approaches, ensuring members can easily access events at the right moment: UI Engineering, Cloud Gateway, Data Science & Engineering, Search and Discovery, Evidence Engineering, Member Experience Foundations, Content Promotion and Distribution, Operations and Reliability, Device Playback, Experience and Design and Product Management.
As Netflix’s content offering expands to include new formats like live titles, free-to-air linear content, and games, we’re excited to build on what we’ve accomplished and look ahead to even more possibilities. Our roadmap includes extending the capabilities we developed for scheduled live viewing to these emerging formats. We’re also focused on enhancing our engineering tooling for greater visibility into operations, message delivery, and error handling to help us continue to deliver the best possible experience for our members.
Join Us for What’s Next
We’re just scratching the surface of what’s possible as we bring new live experiences to members around the world. If you are looking to solve interesting technical challenges in a unique culture, then apply for a role that captures your curiosity.
Look out for future blog posts in our “Behind the Streams” series, where we’ll explore the systems that ensure viewers can watch live streams once they manage to find and play them.
Catwalk is Grab’s machine learning (ML) model serving platform, designed to enable data scientists and engineers in deploying production-ready inference APIs. Currently, Catwalk powers hundreds of ML models and online deployments. To accommodate this growth, the platform has adapted to the rapidly evolving machine learning technology landscape. This involved progressively integrating support for multiple frameworks such as ONNX, PyTorch, TensorFlow, and vLLM. While this approach initially worked for a limited number of frameworks, it soon became unsustainable as maintaining various inference engines, ensuring backward compatibility, and managing deprecated legacy components (such as the ONNX server) introduced significant technical debt. Over time, this resulted in degraded platform performance: with increased latency, reduced throughput, and escalating costs. These issues began to impact users, as larger models could no longer be served efficiently or cost-effectively by legacy components. Recognising the need for change, the team revisited the platform’s design to address these challenges.
Evaluation and implementation
After evaluating other industry-leading model serving platforms and studying best practices, we decided to conduct an in-depth analysis of NVIDIA Triton. Triton offers significant advantages as an inference engine, including:
Multi-framework support: Compatibility with major ML frameworks, including ONNX, PyTorch, and TensorFlow, ensuring versatility and broad applicability.
Unified inference interface: Provides a single, consistent API for various ML frameworks, simplifying user interaction and reducing overhead when switching between models or frameworks.
Hardware optimisation: Optimised for NVIDIA GPUs, Triton delivers strong performance on CPU-only environments and specialised instances like AWS Inferentia.
Up-to-date support: Continuously updated by upstream to support the latest optimisation and features from upstream ML frameworks, ensuring access to cutting-edge capabilities.
Advanced inference features: Includes capabilities like dynamic batching and model ensembling (model pipelining), which enhances throughput and efficiency for complex ML workflows.
Our extensive benchmarking demonstrated that NVIDIA Triton delivers substantial enhancements in both performance and service stability compared to our existing solutions.
We are now working towards consolidating the various inference engines we manage into a unified, all-in-one Triton engine, beginning with ONNX adoption as the first phase of implementation.
In this blog, we aim to share our journey of adopting Triton. From initial benchmarking results on one of Grab’s core models facing performance challenges, to the development of the “Triton manager”, a component designed to integrate Triton into our platform seamlessly and with minimal user disruption. Ultimately, more than 50% of online deployments were successfully migrated to Triton, with some of our critical systems achieving a 50% improvement in tail latency.
Exploratory benchmark results
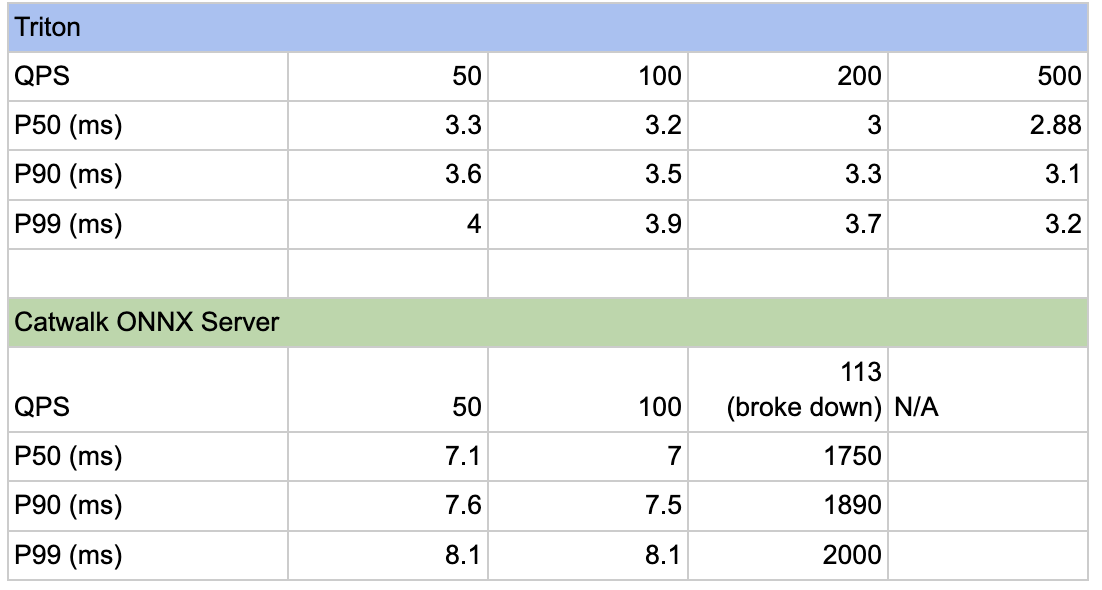
We conducted rigorous testing of Triton against our existing ONNX server under varying levels of request traffic.
Table 1: Benchmark results of Triton against Catwalk ONNX server.
During testing with a transformer-based model, Triton demonstrated the ability to handle at least 5 times the traffic while maintaining excellent latency. Additionally, its performance was further enhanced with features like batching enabled, and there is potential for even greater optimisation by converting the model to TensorRT, leveraging GPU support.
Through profiling, we learned that a handful of ONNX Runtime knobs have an outsized impact on throughput. One low-effort, high-return tweak is to set the intra-op thread count to match the number of physical CPU cores. In most cases, this single change yields a healthy performance lift, sparing us from time-consuming, model-by-model micro-optimisation.
Adopting Triton at scale
While the benchmark results clearly demonstrate Triton’s advantages, the primary challenge was ensuring a seamless migration, ideally with minimal user reactions. Given the high frequency of migrations within our company, even exceptional performance improvements are often insufficient to fully motivate internal users to adopt new systems. From our point of view, a successful migration required:
Maintaining API compatibility with existing systems.
Ensuring zero-downtime.
Preserving all existing functionality while adding new capabilities.
Minimising disruption to downstream services and users.
To streamline the migration process, we opted to manage it centrally within our platform, rather than relying on individual users to address the details themselves.
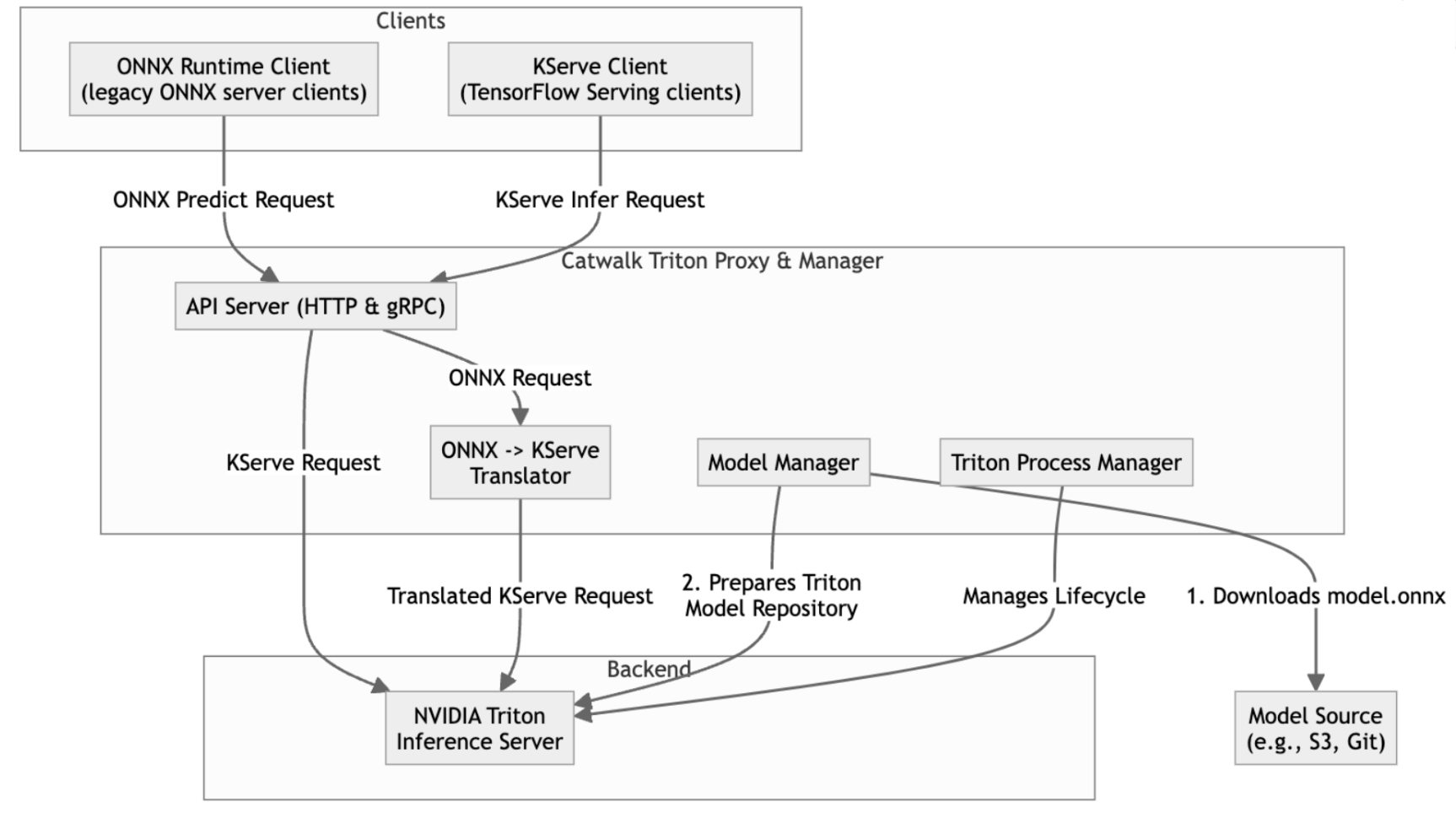
We landed on the idea of offering Triton to our users as a drop-in replacement for the old server, with the help of a new component, “Triton manager”. The Triton manager is a critical component that glues Triton to the Catwalk ecosystem. It consists of two major components: Triton server manager and Triton proxy.
Triton server manager is designed as the entry point of our Catwalk Triton. It downloads the model from remote storage, runs verification on the model files, prepares per-model configurations based on users’ customisation, and lastly it launches the Triton server. It also periodically checks the server’s health and provides observability overlooking the server’s status.
Triton proxy provides backward compatibility to the existing clients. It hosts endpoints that translate requests from the older API and forward them to the Triton server. The proxy layer plays a crucial role in facilitating a seamless transition from our legacy servers, eliminating the need for user code changes. The conversion logic is designed to prioritise performance, ensuring minimal overhead. Extensive benchmarks were conducted during development to validate and optimise its efficiency.
Figure 1: High-level architecture for Triton Inference Server (TIS) deployment at Catwalk.
Finally, a special mode in the Triton server manager is implemented to allow the Triton Inference Server (TIS) to be backward compatible with the command line interface of the existing ONNX runtime server used in Catwalk.
We plan to enhance the Triton Manager to ensure backward compatibility with other ML frameworks, as part of our efforts to onboard additional frameworks seamlessly.
Rollout result
Within just 10 days of Triton’s availability, we successfully rolled it out to over 50% of our online model deployments. Thanks to rigorous testing for backward compatibility, the rollout was seamless, with most users unaware of the transition while benefiting from the improved performance.
Triton’s impacts on critical models
Figure 2: Latency before and after rollout in ms. Blue line: XGBoost-based model. Orange line: transformer-based model. Solid line: average. Dashed line: p99
We’ve observed significant performance improvements in our business-critical models that have high demands for stability. Latency improvements were consistently observed in all models, especially in the models that suffered from highly volatile request traffic. For some larger transformer models, the p90 latency decreased dramatically from 120ms to 20ms, and the average latency remained steady at 4ms. Smaller XGBoost models maintained their average latency at 2ms across regions.
Figure 3: Number of pods, before (blue line) and after (purple line) rollout in another model.
Triton has delivered significant cost savings for certain models, with some achieving over 90% reductions due to its advanced optimisations. These improvements have come alongside enhanced performance and reliability.
It is worth noting that Triton was initially rolled out with limited capabilities to prioritise backward compatibility and ensure a seamless migration. However, we’ve noticed that higher tail latency still remains an issue when facing request spikes for larger models in production. To address this, we are working on enabling batching through Triton to minimise tail latency during traffic surges. This effort will involve close collaboration with model owners to optimise the capacity of each Triton instance further.
Early cost impact of the migration
To gauge the financial upside of migrating to Triton, we took a snapshot of 11 production ML services that had already completed the migration. For every ML service, we compared its infrastructure spend over the 14 days before the cut-over with the 14 days after.
Despite the staggered migration dates, the trend was uniform: average spend fell by ~ 20% across this small cohort within 14 days. As more models and applications migrate, we expect the absolute dollar savings to scale proportionally.
Takeaways
Initial results are aligned with our benchmarks for the Triton migration. With improved performance and cost reduction, we expect model owners to either upgrade their model sizes or allow for higher Queries Per Second (QPS). While making further progress with the overall Triton migration, the model serving platform team will continue to monitor cost differences and provide consultation to model owners who seek further optimisation for their deployments.
Another key takeaway is the painless migration of Triton for our internal users. Rather than asking internal users to make necessary code changes, our team dedicated significant time to providing Triton as a drop-in inference engine to minimise any inconvenience of migration.
Big appreciation to Shengwei Pang from the Geo team, Khai Hung Do, Nhat Minh Nguyen, and Siddharth Pandey from the Catwalk team, along with Richard Ryu from the PM team and Padarn George Wilson for the sponsorship.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
AWS had an outage today and Signal was unavailable for some users for a while. This has confused some people, including Elon Musk, who are concerned that having a dependency on AWS means that Signal could somehow be compromised by anyone with sufficient influence over AWS (it can’t). Which means we’re back to the richest man in the world recommending his own “X Chat”, saying The messages are fully encrypted with no advertising hooks or strange “AWS dependencies” such that I can’t read your messages even if someone put a gun to my head.
Elon is either uninformed about his own product, lying, or both.
As I wrote back in June, X Chat genuinely end-to-end encrypted, but ownership of the keys is complicated. The encryption key is stored using the Juicebox protocol, sharded between multiple backends. Two of these are asserted to be HSM backed – a discussion of the commissioning ceremony was recently posted here. I have not watched the almost 7 hours of video to verify that this was performed correctly, and I also haven’t been able to verify that the public keys included in the post were the keys generated during the ceremony, although that may be down to me just not finding the appropriate point in the video (sorry, Twitter’s video hosting doesn’t appear to have any skip feature and would frequently just sit spinning if I tried to seek to far and I should probably just download them and figure it out but I’m not doing that now). With enough effort it would probably also have been possible to fake the entire thing – I have no reason to believe that this has happened, but it’s not externally verifiable.
But let’s assume these published public keys are legitimately the ones used in the HSM Juicebox realms[1] and that everything was done correctly. Does that prevent Elon from obtaining your key and decrypting your messages? No.
On startup, the X Chat client makes an API call called GetPublicKeysResult, and the public keys of the realms are returned. Right now when I make that call I get the public keys listed above, so there’s at least some indication that I’m going to be communicating with actual HSMs. But what if that API call returned different keys? Could Elon stick a proxy in front of the HSMs and grab a cleartext portion of the key shards? Yes, he absolutely could, and then he’d be able to decrypt your messages.
(I will accept that there is a plausible argument that Elon is telling the truth in that even if you held a gun to his head he’s not smart enough to be able to do this himself, but that’d be true even if there were no security whatsoever, so it still says nothing about the security of his product)
The solution to this is remote attestation – a process where the device you’re speaking to proves its identity to you. In theory the endpoint could attest that it’s an HSM running this specific code, and we could look at the Juicebox repo and verify that it’s that code and hasn’t been tampered with, and then we’d know that our communication channel was secure. Elon hasn’t done that, despite it being table stakes for this sort of thing (Signal uses remote attestation to verify the enclave code used for private contact discovery, for instance, which ensures that the client will refuse to hand over any data until it’s verified the identity and state of the enclave). There’s no excuse whatsoever to build a new end-to-end encrypted messenger which relies on a network service for security without providing a trustworthy mechanism to verify you’re speaking to the real service.
We know how to do this properly. We have done for years. Launching without it is unforgivable.
[1] There are three Juicebox realms overall, one of which doesn’t appear to use HSMs, but you need at least two in order to obtain the key so at least part of the key will always be held in HSMs
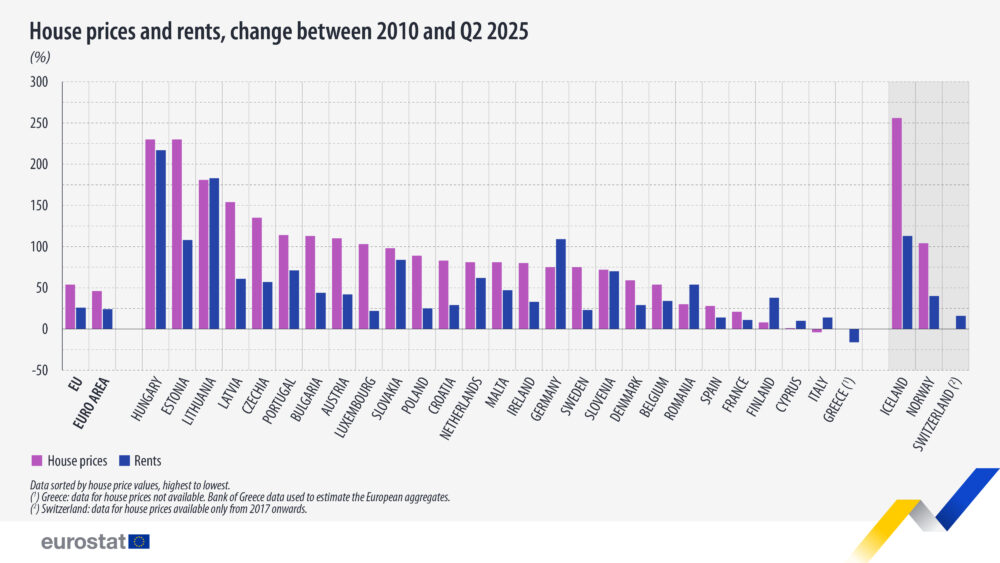
Покачващите се цени на имотите са основен елемент в няколко взаимносвързани обществени теми – има ли имотен балон, има ли презастрояване, финансова култура и инвестиции на домакинствата, демографска политика, сиви капитали и пране на пари. Описал съм позицията си, че имотния пазар не работи на пазарен принцип и защо въобще се говори за презастрояване макар да няма формална дефиниция.
Днес ще засегна друг аспект – статистиката за цените на имотите. Разделям я от данните за брой жилища пуснати на пазара, жилищна площ и отпуснати ипотеки. За тях препоръчвам да погледнете скорошната статия на Капитал и суровите данни от НСИ. Тук искам да погледнем това, което според мен е основен фактор в ценообразуването в сектора – следенето на т.н. „пазарни цени“.
Новини за покачването им навсякъде в България виждаме постоянно. Наскоро беше обявено, че България е сред рекордьорите по това отношение. Достатъчни са данните на Евростат, които ни поставят на 7-мо място по ръст за последните 15 години. 8-мо, ако включим Исландия. Тук ще намерите суровите данни по тримесечия.
За това, разбира се, има много фактори включително финансова култура, несигурност на инвестициите, влошен бизнес климат и липса на върховенство на закона, вътрешна миграция, пране на пари, ръст на доходите на част от населението та дори и обратна миграция от диаспорите.
Тезата ми обаче е, че има твърде много променливи в източниците на данни за цените на имотите, за които е практически невъзможно да контролираме и изчистим. Така според мен няма нито една оценка за пазара, която да може да твърди, че е вярна или дори, че може да следи динамика през времето. Разделям причините в четири категории.
Некоректни практики на брокери
Често изследвания и статистики за цените на имотите, особено що се отнася до разбивка по квартали, използват извадки от текущи обяви от сайтовете за имоти. Някои, включително най-известният imot.bg, включват дори историческа справка за избрания район. Взимайки квадратурата и параметрите на жилището лесно може да се изчисли средна цена на кв.м.
Проблемът с този подход е, че огромна част от обявите са фалшиви. Според брокери половината обяви, с които се свързват, се оказват на несъществуващи имоти и служат само като въдица за привличане на интерес след което се представят други жилища и сгради. Дори когато са истински оказва се, че параметри като квадратура, брой стаи, наличие на паркоместа и дори района на сградата са подменени.
Такива нелоялни практики са масови и затова много брокери призовават за регулиране на сектора. Като пример се дава Франция, където след 2-3 подобни измамни обяви или нарушения на кодекс лицето получава забрана да упражнява професията за дадено време. Доколкото искането за внасяне на ред се подкрепя от много фирми за недвижими имоти, брокери са ми споделяли, че най-големите и известни само формално са зад тази идея, но лобират да не види бял свят.
Друг източник на данни са самите комисионни на брокерите. Те знаят много добре кои обяви стигат до сделки, на каква цена се изповядват и колко реално е платено. В края на краищата на база именно платените пари получават комисионна. Тази информация обаче надали ще види бял свят, но дори да я получим, не може да се очаква, че ще е надеждна през времето, а и агенциите не покриват целия пазар на имоти – има много сделки директно със строител или без посредник.
Дори да изключим последното и дори оценката за 50% фалшиви обяви да е завишена, достатъчно е да са само една трета, за да прави тази вариация абсолютно неизползваеми публичните данни от подобни сайтове за оценка цената на жилищата.
Разлики в параметри на жилищата
Дори да можем да отсеем реалните обяви от публично достъпните, има разлики в самите имоти. Най-очевидна е квадратурата. Докато старите жилища се мерят по т.н. светла част или само видимия под на апартамент, например, при новите се броят вътрешни стени и целите балкони. Отделно на места включват общите части и понякога по различен начин. Когато се върнах от Германия се наложи в рамките на две седмици да огледам десетки апартаменти. Това ми даде възможност да сравня в кратък отрязък разликите между обявите и реалността. Квадратурата се разминаваше понякога с 50% от реалната жилищна площ.
Това непостоянство на това как се мери квадратурата означава, че не може да се сравняват имоти и цената им на кв.м. Тъй като в един район често се среща различни агенции да имат повече или по-малко обяви в зависимост от периода значи, че „динамиката“ на описанията се разминава и през времето и съвсем не може да сравняваме тримесечие за тримесечие или година.
Дори по-голям ефект има степента на завършване на сградата и жилището. Често сделки за жилища се правят на зелено, отделни обяви за които не се публикуват в сайтовете за имоти и не минават през агенции, т.н. там няма данни за тях. Цената им принципно е по-малка, но предвид, че жилището може да е готово след 2, 5 или 10 г. в зависимост от това колко е читав строителят, тези сделки не може да се слагат в една графа с препродажбата на жилища. В тази връзка, дори да получим данни за и да вкараме сделките на зелено в статистиката, нелоялни бизнес практики като късане на договор и прекомерни индексации означават, че за същото жилище получаваме две цени в различни години без дори да е предадено. Индексацията е параметър, за който също не научаваме и реално завишава значително платеното за едно жилище. Дори да научим за него кога го броим към статистиката – към годината на договора, кога се прехвърли или към годината на акт 16? А ако така и не получи такъв?
Доколкото агенциите за недвижими имоти и сайтовете с обяви посочват дали едно жилище е завършено, на мазилка или за ремонт, всеки търсил жилище знае, че тези също подвеждат силно и варират в широки граници. Покачващата се цена на майстори и материали именно заради огромния брой празни жилища и масовото вливане на пари в сектора води до допълнителен разход от 10 до 30% от цената на къща или апартамент за ремонт и обзавеждане. Оскъпяването на жилището след това е дори по-голямо.
Изброените широки граници са невъзможни да се изчистят в данните без да се посети всеки отделен апартамент и оцени по единни стандарти, което е практически невъзможно, но и не би било допуснато от самите брокери и продаващи.
Данъчни измами, сделки на сиво и други схеми
Тук може би може да се изпише най-много и затова ще гледам да маркирам основните. Най-очевидната е подписване на договор на занижени цени и даване на остатъка на ръка. Така се избягва от една страна плащането на данък, а от друга помага да се изперат незаконни или просто недекларирани пред НАП пари. По същия начин, но без доплащане на ръка, е документирано да се осъществява корупция, в които апартаменти (с и без асансьори) практически се подаряват на депутати, общински съветници, висши магистрати и техни роднини.
Така се зачерква друг източник на данни за сключените сделки – имотния регистър и нотариалните актове. Доколкото реалната цена на сделката е различна независимо дали се доплаща в кеш, в натура, с прокаран закон или с отсъждане по дело, няма как да я установим с точност. В някои случаи има вписани ипотеки, което помага. Тези обаче са едва една трета от сделките в последните тримесечия. Също така не гарантират, че няма пари или услуги под масата, защото често нотариуси и банки си затварят очите за подобни практики.
Не трябва да забравяме, че има немалко жилища в сгради без акт 16 или дори разрешения за строеж. Колко точно са всъщност никой не знае. Оказва се, че документите са пръснати между няколко институции в зависимост от типа сграда и почти никоя от тях не иска да ги дава или дори да сподели справка. Все още работя по това. ДНСК поне започна да сканира и публикува всички разрешения за строеж. Става бавно и е трудно да намери точно каквото му трябва човек, но може би ще се случи. Известни са обаче сгради, които имат тези проблеми и при оглед с неохота го признават, ако се сетите да питате. В такива случаи жилищата са обикновено с по-ниски цени, но следва ли да се включват в индексите при условие, че там не следва да живее никой и дори трябва да бъдат разрушени?
Вече стана дума за схемите с късане на договори на зелено и препродажба. Друга практика е да не се продава самият апартамент, а фирма, която държи собствеността и всеки купувач взима дялове в дружеството. Останалото се урежда с вътрешни договорки. Така реално продажба на имот няма, а от там се спестяват куп данъци. НАП санкционира Артекс преди години именно за това посочвайки очевидното, че сделките са фиктивни с цел избягване на данъци. Административният съд обаче взе страната на небезизвестният строител и дори отсъди да им платим от данъците си обезщетение. Това след като им опростиха 20 млн. лв. данъци, но преди според медиите ключови политици да получат евтини апартаменти. Идентична схема нашумя наскоро във връзка със Сарафов, където придобиване на имот на нелогично ниска цена беше разкрита и връзка с нелегалната фабрика за цигари свързана с Таки и Пеевски.
Доколкото изброеното и много други нелоялни и откровено незаконни практики прикриват други незаконни действия, за целите на статистиката за имотния пазар обезсмислят данните от държавни институции, официални документи или вътрешни извадки на самите агенции за имоти. В случая цените може да се занижават, но не може да се твърди дали и до колко това компенсира спекулативното завишаване от други фактори, както и че е постоянно през времето, което да позволява сравнението, което четем в медиите.
Вторичен пазар на имоти и ценообразуване
Тук се комбинират ефектите от няколко фактора, но като психологически ефект. Публичните данни и щедрите обещания на брокерите създават очаквания у продаващите и те съвсем очаквано залагат завишени цени.
Всъщност, нерядко се случва имоти да се слагат на неразумно висока цена въпреки предупрежденията дори на агенциите. Виждаме такива да престояват и да се публикуват отново и отново с месеци. Причината е, че собствениците нямат нужда от парите веднага, но оставят жилището „на пазара“ в случай, че някой се подлъже и получат цена доста над очакваното. В друг сектор би се нарекло limit sell order. Резултат е от „паркираните“ в имотите пари и неразумните очаквания към пазара. Вторичният ефект е още по-надута статистика от обявите за даден район.
Тук голямо влияние имат оценителите на имоти, за които ще стане дума след малко. Те се вглеждат по-дълбоко в състоянието на имота, сградата и обзавеждането, но в крайна сметка се влияят и придържат към същите метрики и изначално грешни източници за цени. Оценките се използват също като индикативни цени при препродажба или при пускане на нови жилища на зелено. Това затваря цикъла захранвайки същата мелница на фалшиви, неравномерно завишени, неправилно отчетени или неосъществени продажби.
Липса на данни, регулация и прозрачност
Тук някой би отправил критика, че привидно голяма част от тезата ми се базира на наблюдения върху пазара на имоти, обявите, разговори с архитекти и брокери, както и от собственото ми търсене на жилище. Този някой може би имал право доколкото не излизам с точни числа (или карти) на отклонение на цени, разминавания на оферти и сключени сделки. Същността на тази теза обаче е, че това са добре известни фактори и проблеми, за които се говори отдавна, но са проблем именно, защото не са измерими, предвидими и най-вече са непостоянни в ефекта си върху пазара.
Аналогично, когато писах за абортите в България, изписах надълго и широко защо не може да се вярва на данните на НЦОЗА. Разликата там обаче е, че освен, че са единственият наличен официален източник на информация, става дума за що-горе едно число с малко демографски променливи, които от своя страна са добре документирани и ясно определени – раждаемост, брой жени по възрастови групи и прочие. Не това е положението при данните за цените на имотите. Като антипример често давам данните на НЗОК за ражданията, които не само са неясни като методология, но и отчетливо непостоянни като неточност през времето.
За да имаме по-добри данни за имотите, трябват три неща. Първо, както стана дума по-рано, трябва да се регулира сектора на посредниците. Брокерите да носят отговорност за фалшиви или силно подвеждащи обяви. Трябва да има единна методология за описване, измерване и публикуване на имотите, за да не подвеждат и да може да се сравнява. Трябва всички документи покрай строителството и цени на вписване на имоти да бъдат публични, лесно и безплатно достъпни. Това ще заличи огромна част от несигурността, която описах до тук. Несигурност, която за пореден път твърдя, че прави практически всички сензационни заглавия в медии, оценки на агенции за недвижими имоти и индекси за цените на пазара най-малкото безпредметни.
Защо има значение отвъд заглавията?
Правилно е да се запитаме на този етап дали нещо от това има значение. Все пак, хората купуват и продават постоянно жилища на тези цени, видимо има търсене, което се среща с това предлагане. Идеята на пазарът все пак е именно тази и в самото начало започнах с това, че има рекорден брой сделки и ипотеки.
Първият проблем е, че има хора на пазара, които нямат особен избор. Задомяват се, раждат им се деца, връщат се от чужбина или си намират нова работа в друг град. Тогава въпросът е не дали да се вземе жилище, а какво и къде могат да си позволят и какъв дял от дохода им в следващите 20 години ще отделят. Изкуствено завишените цени на имотите означават, че ще ограничат финансовата си сигурност и икономическа активност в бъдеще, ще ограничат района, в който ще е удобно да търсят работа, градина и училище и в най-лошия според мен случай – ще повлияе на решението им да имат повече деца заради недостатъчно място. Именно жилищното пространство е сред основните рискови фактори, които се посочват от изследващите демографската криза в съвременния свят и има ясни белези за това от индустриалната революция до сега.
Стана въпрос обаче вече за оценителите и там се крие риск за банковата и застрахователната система. Зачетете се по-подробно в стандарта за оценка на сайта на Камарата на независимите оценители в България или дори в оценката на собствения си имот, ако имате такава. Ще откриете, че използват именно данните изброени до тук с всичките условности и неконтролируеми и измерими променили, които им влияят. С други думи, доколкото те се вглеждат по-добре в състоянието на жилището, в крайна сметка отново разчитат на поне 30% фалшиви обяви, други с нереалистични цени при сключени сделки на доста по-ниски цени, пари под масата или в магистратска натура.
Доколкото тези оценки влияят например на вноската ви за често задължителната застраховка живот към ипотеката води до оскъпяване за вас. Системно обаче те имат потенциално пагубен ефект върху активите на банките и дейността на застрахователните дружества. По всичко личи, че рисковите отдели на същите са съвсем наясно с този проблем, но предвид другите им практики, злоупотреби, проблеми с регулатори и дори съмнения за съдействие при пране на пари, надали трябва да ни учудва. Разчитат на видимо надути оценки в един откровено надут балон, за да не трябва да отписват активи и да покажат реалното състояние, до което нерентабилното отпускане на ипотеки ги е докарало.
Какво следва?
Ако вярваме на НСИ – още стотици хиляди кв. м. жилищна площ всяка година. Вече са разрешени милиони още за застрояване из страната. Националната асоциация на строителните предприемачи освен да настоява, че няма такова нещо като презастрояване, твърди, че решението за високите цени е леенето на много повече бетон. Т.е. повече предлагане. Предвид обсъденото вече ценообразуване, нелоялни практики и индексация, това бързо се разпознава като поредната подмяна.
Казах, че имотният пазар не работи на пазарен принцип, защото не е основан на нужда за дадената стока – в случая жилище, което да се обитава по един или друг начин, а на спекулативната му стойност. Доколкото има несъмнено много хора търсещи жилище, в което да живеят, вече между 20 и 40% в зависимост от града остават празни. Така същите разбираемо могат да се определят като нищо повече от бетонно крипто.
Постоянно се пита дали и кога ще се спука балонът. Истината е, че никой не знае. Това не значи, че междувременно щетата върху икономиката, прането на пари, финансовото състояние на населението и дори демографската криза не е истинска. В няколко интервюта наскоро споделих мнението си, че ще видим срив едва когато има значително намаление на доходите и свободните капитали най-вече в два сектора на обществото. Първият е IT индустрията, където сериозен и най-важното продължителен спад в позициите на IT специалисти ще накара много да се освобождават от инвестиции в такива имоти. Вторият е спиране на еврофондове и/или работеща прокуратура и регулаторни органи, които по един или друг начин спират краденето на обществен ресурс и изпирането му. И в двата случая пазарът ще бъде залят от до сега високо оценени жилища и ще се види липсата на търсене отвъд базовата жилищна нужда. Тогава вече ще имаме редица други проблеми в допълнение на тези, които природата ни донася.
Съгласни ли се с тезата ми? Ако не, ще се радвам да споделите в коментарите кои източници на данни за цените на имотите смятате за надеждни, защо и как се контролира за променливите и условностите, които изброих.
In September, a group of long-time maintainers of Ruby packaging tools
projects had their GitHub privileges for revoked by nonprofit corporation Ruby Central
in what many people are calling a
hostile takeover. Ruby Central and its board members have issued
several public statements that have, so far, failed to satisfy many in
the Ruby community. In response, some of the former contributors to
RubyGems are working on an alternative service called gem.coop. On October 17, ownership
of the RubyGems and Bundler
repositories was handed over to the Ruby core team, even though those projects had never been part of core Ruby
previously. The takeover and subsequent events have raised a number of
questions in the Ruby community.
Importing modules in Python is ubiquitous; most Python programs start
with at least a few import statements. But the performance impact
of those imports can be large—and may be entirely wasted effort if the
symbols imported end up being unused. There are multiple ways to lazily
import modules, including one in the standard library, but none of them are
part of the Python language itself. That
may soon change, if the recently proposed PEP 810 (“Explicit lazy
imports”) is approved.
I’ve been inspired by all the activities that tech communities around the world have been hosting and participating in throughout the year. Here in the southern hemisphere we’re starting to dream about our upcoming summer breaks and closing out on some of the activities we’ve initiated this year. The tech community in South Africa is participating in Amazon Q Developer coding challenges that my colleagues and I are hosting throughout this month as a fun way to wind down activities for the year. The first one was hosted in Johannesburg last Friday with Durban and Cape Town coming up next.
Last week’s launches These are the launches from last week that caught my attention:
Kiro is now available for every developer — Since its launch more than 90 days ago, more than 100,000 developers have joined the waitlist to try Kiro out. The waitlist is gone so if you want to try out this spec-driven approach to coding with AI, sign up now.
Amazon EBS Volume Clones — Sometimes you need production data to test a fix in a non-production environment before implementing it in production. Usually you’d take an EBS snapshot of this data and then create a new volume from that snapshot, meanwhile dealing with the operational overhead of this process. Learn about the availability of Amazon EBS Volume Clones, a new capability for you to create instant point-in-time copies of your EBS volumes within the same Availability Zone.
Additional updates I thought these projects, blog posts, and news items were also interesting:
AWS Transfer Family SFTP connectors now support VPC-based connectivity — AWS Transfer Family SFTP connectors now support connectivity to remote SFTP servers through Amazon Virtual Private Cloud (Amazon VPC) environments.
As your business evolves, you might need to migrate workloads between AWS Regions. Perhaps you’re looking to reduce latency for users in new geographic areas, meet Region-specific compliance requirements, or you’re an ISV expanding your product’s availability. Whatever your reason, cross-Region migration needs careful planning, especially when dealing with encrypted resources. Read how to migrate encrypted Amazon EC2 instances across AWS Regions without sharing AWS KMS keys.
Internet of Things (IoT) devices have transformed how we interact with our environments, from homes to industrial settings. However, as the number of connected devices grows, so does the complexity of managing them. Learn how to build a device management agent with Amazon Bedrock AgentCore.
Upcoming AWS events Keep a look out and be sure to sign up for these upcoming events:
AWS re:Invent 2025 (December 1-5, 2025, Las Vegas) — AWS flagship annual conference offering collaborative innovation through peer-to-peer learning, expert-led discussions, and invaluable networking opportunities.
Experience AI is a free educational programme that helps teachers and students learn about artificial intelligence (AI). It was developed by the Raspberry Pi Foundation in partnership with Google DeepMind and includes lessons, classroom resources, and hands-on activities to help students develop a foundational understanding of AI technologies, their social and ethical implications, and the role that AI can play in their lives.
It is based on original research into AI literacy and highlights real-world applications of AI technologies, including through videos featuring research scientists that help to bring the lessons to life for students.
A group of students and educators at the launch of Experience AI in Malaysia.
Since we launched the first Experience AI resources in April 2023, they have been used to teach over 2 million students, and that number is growing fast.
Experience AI was one of four laureates of the prestigious global Prize selected by the Director-General of UNESCO, based on recommendations from an independent, international jury. The jury commended the programme for its strong ethical foundation and wide international reach.
This year, marking its 20th anniversary, the Prize focused on the theme ‘Preparing learners and teachers for the ethical and responsible use of artificial intelligence’.
Romanian students in class during an Experience AI lesson.
The Prize was awarded at a ceremony at the University of Bahrain attended by the Director-General of UNESCO, Ministers of Education of the Gulf Cooperation Council, and members of the Raspberry Pi Foundation and Google DeepMind teams.
I want to say a heartfelt congratulations and thank you to everyone who has worked on Experience AI so far. It has been a fantastic, collaborative effort from colleagues across the Foundation, Google DeepMind, and all of our partner organisations.
I also want to pay tribute to all of the teachers — all over the world — who have engaged so enthusiastically with Experience AI, for helping us develop the materials, including testing them in your classrooms and providing such thoughtful feedback, and for everything you do, every day, to inspire your students. This recognition is for all of your hard work, diligence, and care. Congratulations and thank you.
Teachers in Kenya during an Experience AI teacher training event.
Experience AI is provided at no cost to schools, teachers, or students thanks to generous funding from Google.org. We are also very grateful to Broadcom Foundation, which has provided additional funding to support the programme.
What next for Experience AI?
We are exceptionally proud to have received this recognition for Experience AI, but we aren’t complacent. Equipping all young people, and their teachers, with a foundational understanding of AI technologies is one of the most urgent challenges facing all education systems.
We have made a great start, and we know there is much more to be done. That’s why we have lots of important updates and developments coming soon, including:
Updating and improving the current lessons: We are finalising an update to the resources to respond to feedback from teachers and students, including significant improvements to make them more accessible. These will be published early in 2026.
Expanding the range of lessons: Alongside the updates to the existing resources, we are developing new lessons. This will include lessons designed for both younger and older learners, as well as integrated lessons that enable teachers to bring AI concepts and skills into subjects such as science, language, and the arts.
Updated and improved professional development: We are also updating and improving the training that we offer to teachers, including both online courses and webinars, and in-person training delivered through the global network of education partners.
AI chatbot for educators: We recently integrated a chatbot into the Experience AI website. Powered by Gemini 2.5, this is intended as a tool to help teachers navigate and understand the concepts and lessons. This is an early experiment and we’d love to get your feedback, so please give it a try and let us know what you think.
Expanding the global network of partners: We currently have partners supporting teacher professional development in 25 countries, from Malaysia to Mexico. Over the coming year we will be launching partnerships in at least 15 more countries. If your organisation is interested in becoming a partner, you can let us know by filling in this form.
The OODA loop—for observe, orient, decide, act—is a framework to understand decision-making in adversarial situations. We apply the same framework to artificial intelligence agents, who have to make their decisions with untrustworthy observations and orientation. To solve this problem, we need new systems of input, processing, and output integrity.
Many decades ago, U.S. Air Force Colonel John Boyd introduced the concept of the “OODA loop,” for Observe, Orient, Decide, and Act. These are the four steps of real-time continuous decision-making. Boyd developed it for fighter pilots, but it’s long been applied in artificial intelligence (AI) and robotics. An AI agent, like a pilot, executes the loop over and over, accomplishing its goals iteratively within an ever-changing environment. This is Anthropic’s definition: “Agents are models using tools in a loop.”1
OODA Loops for Agentic AI
Traditional OODA analysis assumes trusted inputs and outputs, in the same way that classical AI assumed trusted sensors, controlled environments, and physical boundaries. This no longer holds true. AI agents don’t just execute OODA loops; they embed untrusted actors within them. Web-enabled large language models (LLMs) can query adversary-controlled sources mid-loop. Systems that allow AI to use large corpora of content, such as retrieval-augmented generation (https://en.wikipedia.org/wiki/Retrieval-augmented_generation), can ingest poisoned documents. Tool-calling application programming interfaces can execute untrusted code. Modern AI sensors can encompass the entire Internet; their environments are inherently adversarial. That means that fixing AI hallucination is insufficient because even if the AI accurately interprets its inputs and produces corresponding output, it can be fully corrupt.
In 2022, Simon Willison identified a new class of attacks against AI systems: “prompt injection.”2 Prompt injection is possible because an AI mixes untrusted inputs with trusted instructions and then confuses one for the other. Willison’s insight was that this isn’t just a filtering problem; it’s architectural. There is no privilege separation, and there is no separation between the data and control paths. The very mechanism that makes modern AI powerful—treating all inputs uniformly—is what makes it vulnerable. The security challenges we face today are structural consequences of using AI for everything.
Insecurities can have far-reaching effects. A single poisoned piece of training data can affect millions of downstream applications. In this environment, security debt accrues like technical debt.
AI security has a temporal asymmetry. The temporal disconnect between training and deployment creates unauditable vulnerabilities. Attackers can poison a model’s training data and then deploy an exploit years later. Integrity violations are frozen in the model. Models aren’t aware of previous compromises since each inference starts fresh and is equally vulnerable.
AI increasingly maintains state—in the form of chat history and key-value caches. These states accumulate compromises. Every iteration is potentially malicious, and cache poisoning persists across interactions.
Agents compound the risks. Pretrained OODA loops running in one or a dozen AI agents inherit all of these upstream compromises. Model Context Protocol (MCP) and similar systems that allow AI to use tools create their own vulnerabilities that interact with each other. Each tool has its own OODA loop, which nests, interleaves, and races. Tool descriptions become injection vectors. Models can’t verify tool semantics, only syntax. “Submit SQL query” might mean “exfiltrate database” because an agent can be corrupted in prompts, training data, or tool definitions to do what the attacker wants. The abstraction layer itself can be adversarial.
For example, an attacker might want AI agents to leak all the secret keys that the AI knows to the attacker, who might have a collector running in bulletproof hosting in a poorly regulated jurisdiction. They could plant coded instructions in easily scraped web content, waiting for the next AI training set to include it. Once that happens, they can activate the behavior through the front door: tricking AI agents (think a lowly chatbot or an analytics engine or a coding bot or anything in between) that are increasingly taking their own actions, in an OODA loop, using untrustworthy input from a third-party user. This compromise persists in the conversation history and cached responses, spreading to multiple future interactions and even to other AI agents. All this requires us to reconsider risks to the agentic AI OODA loop, from top to bottom.
Observe: The risks include adversarial examples, prompt injection, and sensor spoofing. A sticker fools computer vision, a string fools an LLM. The observation layer lacks authentication and integrity.
Orient: The risks include training data poisoning, context manipulation, and semantic backdoors. The model’s worldview—its orientation—can be influenced by attackers months before deployment. Encoded behavior activates on trigger phrases.
Decide: The risks include logic corruption via fine-tuning attacks, reward hacking, and objective misalignment. The decision process itself becomes the payload. Models can be manipulated to trust malicious sources preferentially.
Act: The risks include output manipulation, tool confusion, and action hijacking. MCP and similar protocols multiply attack surfaces. Each tool call trusts prior stages implicitly.
AI gives the old phrase “inside your adversary’s OODA loop” new meaning. For Boyd’s fighter pilots, it meant that you were operating faster than your adversary, able to act on current data while they were still on the previous iteration. With agentic AI, adversaries aren’t just metaphorically inside; they’re literally providing the observations and manipulating the output. We want adversaries inside our loop because that’s where the data are. AI’s OODA loops must observe untrusted sources to be useful. The competitive advantage, accessing web-scale information, is identical to the attack surface. The speed of your OODA loop is irrelevant when the adversary controls your sensors and actuators.
Worse, speed can itself be a vulnerability. The faster the loop, the less time for verification. Millisecond decisions result in millisecond compromises.
The Source of the Problem
The fundamental problem is that AI must compress reality into model-legible forms. In this setting, adversaries can exploit the compression. They don’t have to attack the territory; they can attack the map. Models lack local contextual knowledge. They process symbols, not meaning. A human sees a suspicious URL; an AI sees valid syntax. And that semantic gap becomes a security gap.
Prompt injection might be unsolvable in today’s LLMs. LLMs process token sequences, but no mechanism exists to mark token privileges. Every solution proposed introduces new injection vectors: Delimiter? Attackers include delimiters. Instruction hierarchy? Attackers claim priority. Separate models? Double the attack surface. Security requires boundaries, but LLMs dissolve boundaries. More generally, existing mechanisms to improve models won’t help protect against attack. Fine-tuning preserves backdoors. Reinforcement learning with human feedback adds human preferences without removing model biases. Each training phase compounds prior compromises.
This is Ken Thompson’s “trusting trust” attack all over again.3 Poisoned states generate poisoned outputs, which poison future states. Try to summarize the conversation history? The summary includes the injection. Clear the cache to remove the poison? Lose all context. Keep the cache for continuity? Keep the contamination. Stateful systems can’t forget attacks, and so memory becomes a liability. Adversaries can craft inputs that corrupt future outputs.
This is the agentic AI security trilemma. Fast, smart, secure; pick any two. Fast and smart—you can’t verify your inputs. Smart and secure—you check everything, slowly, because AI itself can’t be used for this. Secure and fast—you’re stuck with models with intentionally limited capabilities.
This trilemma isn’t unique to AI. Some autoimmune disorders are examples of molecular mimicry—when biological recognition systems fail to distinguish self from nonself. The mechanism designed for protection becomes the pathology as T cells attack healthy tissue or fail to attack pathogens and bad cells. AI exhibits the same kind of recognition failure. No digital immunological markers separate trusted instructions from hostile input. The model’s core capability, following instructions in natural language, is inseparable from its vulnerability. Or like oncogenes, the normal function and the malignant behavior share identical machinery.
Prompt injection is semantic mimicry: adversarial instructions that resemble legitimate prompts, which trigger self-compromise. The immune system can’t add better recognition without rejecting legitimate cells. AI can’t filter malicious prompts without rejecting legitimate instructions. Immune systems can’t verify their own recognition mechanisms, and AI systems can’t verify their own integrity because the verification system uses the same corrupted mechanisms.
In security, we often assume that foreign/hostile code looks different from legitimate instructions, and we use signatures, patterns, and statistical anomaly detection to detect it. But getting inside someone’s AI OODA loop uses the system’s native language. The attack is indistinguishable from normal operation because it is normal operation. The vulnerability isn’t a defect—it’s the feature working correctly.
Where to Go Next?
The shift to an AI-saturated world has been dizzying. Seemingly overnight, we have AI in every technology product, with promises of even more—and agents as well. So where does that leave us with respect to security?
Physical constraints protected Boyd’s fighter pilots. Radar returns couldn’t lie about physics; fooling them, through stealth or jamming, constituted some of the most successful attacks against such systems that are still in use today. Observations were authenticated by their presence. Tampering meant physical access. But semantic observations have no physics. When every AI observation is potentially corrupted, integrity violations span the stack. Text can claim anything, and images can show impossibilities. In training, we face poisoned datasets and backdoored models. In inference, we face adversarial inputs and prompt injection. During operation, we face a contaminated context and persistent compromise. We need semantic integrity: verifying not just data but interpretation, not just content but context, not just information but understanding. We can add checksums, signatures, and audit logs. But how do you checksum a thought? How do you sign semantics? How do you audit attention?
Computer security has evolved over the decades. We addressed availability despite failures through replication and decentralization. We addressed confidentiality despite breaches using authenticated encryption. Now we need to address integrity despite corruption.4
Trustworthy AI agents require integrity because we can’t build reliable systems on unreliable foundations. The question isn’t whether we can add integrity to AI but whether the architecture permits integrity at all.
AI OODA loops and integrity aren’t fundamentally opposed, but today’s AI agents observe the Internet, orient via statistics, decide probabilistically, and act without verification. We built a system that trusts everything, and now we hope for a semantic firewall to keep it safe. The adversary isn’t inside the loop by accident; it’s there by architecture. Web-scale AI means web-scale integrity failure. Every capability corrupts.
Integrity isn’t a feature you add; it’s an architecture you choose. So far, we have built AI systems where “fast” and “smart” preclude “secure.” We optimized for capability over verification, for accessing web-scale data over ensuring trust. AI agents will be even more powerful—and increasingly autonomous. And without integrity, they will also be dangerous.
End result: rc2 is on the bigger side, and we still have some of
the remaining regressions outstanding, but we should be making slow
progress. It’s fairly early days yet, so I’m not very
worried. Things on the whole look fairly normal.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.