In today’s rapidly evolving digital landscape, the decision to join a company is not just about making a career move. Instead, it’s about finding a mission, a community, and a platform to make a meaningful impact. Cloudflare’s remarkable technology and incredibly driven teams are two reasons why I’m excited to join the team.
Joining Cloudflare as the Chief Partner Officer is my commitment to driving innovation and impact across the Internet through our channel partnerships. In each conversation throughout the interview process, I found myself getting more and more excited about the opportunity. Several former trusted colleagues who have recently joined Cloudflare repeatedly told me how amazing the people and company culture are. A positive culture driven by people that are passionate about their work is key. We work too hard not to have fun while doing it.
When it comes to partnerships, I see the immense value that partners can provide. My philosophy revolves around fostering collaborative, value-driven partnerships. It is about building ecosystems where we jointly navigate challenges, innovate together, and collectively thrive in a rapidly evolving global marketplace where the success of our channel partners directly influences our collective achievements. It also involves investing in their growth through tailored programs and providing strategic guidance and ongoing support. In doing so, we strengthen our most competitive advantage: our partners.
Partners are integral to our success in extending critical solutions to our customers, to fully connect and secure businesses, and in turn, the Internet at large. There are unique aspects to Cloudflare that I believe will be especially appealing as we grow this part of our business.
Innovation at the forefront
From edge computing to cybersecurity solutions, Cloudflare is renowned for its innovative technologies that are reshaping the Internet itself. As someone who is deeply passionate about pushing the boundaries of technology and driving innovation, joining a company like Cloudflare was a clear choice. I am eager to be part of a team that is at the forefront of technological advancements, constantly striving to make the Internet faster, safer, and more reliable for its billions of users worldwide.
Impactful mission
Cloudflare’s mission of helping to build a better Internet resonates deeply with me. In an age where digital connectivity is more crucial than ever, Cloudflare’s commitment to helping make the Internet more secure, accessible, and resilient is both inspiring and necessary. By joining Cloudflare, I see an opportunity to contribute to a larger cause by empowering our partner ecosystem to help with this mission.
Culture of collaboration
One of the most compelling aspects of Cloudflare is its culture of collaboration and inclusivity. From my first conversation, I have been impressed by the genuine sense of camaraderie and teamwork that permeates the organization. In all my conversations, both internally and externally, I get a real sense that Cloudflare fosters an environment where diverse perspectives are celebrated, and where every individual is empowered to make a difference. I am excited to be part of a community that values transparency, empathy, and continuous learning.
Global reach and impact
With a global network that puts it within 50 milliseconds of around 95% of the online population, Cloudflare has a far-reaching impact on the digital economy. Joining Cloudflare means being part of a truly global team, working with all different partners from all corners of the world. This global perspective not only presents exciting opportunities for collaboration and growth but also underscores the significance of Cloudflare’s mission on a global scale.
Endless opportunities for growth
Cloudflare’s tried and tested technology delivers value at massive scale. This presents immense opportunities for partners to achieve significant growth and foster a true partnership together to better serve our customers.
What’s ahead
Working with channel partners over the years, fostering meaningful relationships, and gaining insights into unique perspectives is what I find the most enjoyment in. The constant exchange of ideas and learning within these relationships acts as a catalyst for innovation and continuous improvement.
Since my early days as a sales account manager, I experienced the immense value partners provide first-hand, and leaned into this. As an integral part of my success, I found myself crafting comprehensive sales strategies that aligned our partners’ capabilities with my business objectives. I focused on developing value-driven partnerships that transcend a purely transactional mindset, which led me to a role managing partners and eventually leading channel sales and distribution teams.
Cloudflare embodies everything I personally look for in a company. I am eager to be part of the talented team here and partner with organizations around the world to drive meaningful change by contributing to the mission of helping build a better Internet for all. The future is bright, and I couldn’t be more thrilled to be a part of it.
We continue to listen to our customers, regulators, and stakeholders to understand their needs regarding audit, assurance, certification, and attestation programs at Amazon Web Services (AWS). We are pleased to announce that for the first time an AWS System and Organization Controls (SOC) 1 report is now available in Japanese and Korean, along with Spanish. This translated report will help drive greater engagement and alignment with customer and regulatory requirements across Japan, Korea, Latin America, and Spain.
The Japanese, Korean, and Spanish language versions of the report do not contain the independent opinion issued by the auditors, but you can find this information in the English language version. Stakeholders should use the English version as a complement to the Japanese, Korean, or Spanish versions.
Going forward, the following reports in each quarter will be translated. Because the SOC 1 controls are included in the Spring and Fall SOC 2 reports, this schedule provides year-round coverage in all translated languages when paired with the English language versions.
The Winter 2023 SOC 1 report includes a total of 171 services in scope. For up-to-date information, including when additional services are added, visit the AWS Services in Scope by Compliance Program webpage and choose SOC.
AWS strives to continuously bring services into scope of its compliance programs to help you meet your architectural and regulatory needs. Please reach out to your AWS account team if you have questions or feedback about SOC compliance.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us onX.
Japanese version
冬季 2023 SOC 1 レポートの日本語、韓国語、スペイン語版の提供を開始
当社はお客様、規制当局、利害関係者の声に継続的に耳を傾け、Amazon Web Services (AWS) における監査、保証、認定、認証プログラムに関するそれぞれのニーズを理解するよう努めています。この度、AWS System and Organization Controls (SOC) 1 レポートが今回初めて、日本語、韓国語、スペイン語で利用可能になりました。この翻訳版のレポートは、日本、韓国、ラテンアメリカ、スペインのお客様および規制要件との連携と協力体制を強化するためのものです。
Amazon은 고객, 규제 기관 및 이해 관계자의 의견을 지속적으로 경청하여 Amazon Web Services (AWS)의 감사, 보증, 인증 및 증명 프로그램과 관련된 요구 사항을 파악하고 있습니다. 이제 처음으로 스페인어와 함께 한국어와 일본어로도 AWS System and Organization Controls(SOC) 1 보고서를 이용할 수 있게 되었음을 알려드립니다. 이 번역된 보고서는 일본, 한국, 중남미, 스페인의 고객 및 규제 요건을 준수하고 참여도를 높이는 데 도움이 될 것입니다.
보고서의 일본어, 한국어, 스페인어 버전에는 감사인의 독립적인 의견이 포함되어 있지 않지만, 영어 버전에서는 해당 정보를 확인할 수 있습니다. 이해관계자는 일본어, 한국어 또는 스페인어 버전을 보완하기 위해 영어 버전을 사용해야 합니다.
앞으로 매 분기마다 다음 보고서가 번역본으로 제공됩니다. SOC 1 통제 조치는 춘계 및 추계 SOC 2 보고서에 포함되어 있으므로, 이 일정은 영어 버전과 함께 모든 번역된 언어로 연중 내내 제공됩니다.
AWS는 고객이 아키텍처 및 규제 요구 사항을 충족할 수 있도록 지속적으로 서비스를 규정 준수 프로그램의 범위에 포함시키기 위해 노력하고 있습니다. SOC 규정 준수에 대한 질문이나 피드백이 있는 경우 AWS 계정 팀에 문의하시기 바랍니다.
규정 준수 및 보안 프로그램에 대한 자세한 내용은 AWS 규정 준수 프로그램을 참조하세요. 언제나 그렇듯이 AWS는 여러분의 피드백과 질문을 소중히 여깁니다. 문의하기 페이지를 통해 AWS 규정 준수 팀에 문의하시기 바랍니다.
이 게시물에 대한 피드백이 있는 경우, 아래의 의견 섹션에 의견을 제출해 주세요.
더 많은 AWS 보안 방법 콘텐츠, 뉴스 및 기능 발표를 원하시나요? X 에서 팔로우하세요.
Spanish version
El informe SOC 1 invierno 2023 se encuentra disponible actualmente en japonés, coreano y español
Seguimos escuchando a nuestros clientes, reguladores y partes interesadas para comprender sus necesidades en relación con los programas de auditoría, garantía, certificación y acreditación en Amazon Web Services (AWS). Nos enorgullece anunciar que, por primera vez, un informe de controles de sistema y organización (SOC) 1 de AWS se encuentra disponible en japonés y coreano, junto con la versión en español. Estos informes traducidos ayudarán a impulsar un mayor compromiso y alineación con los requisitos normativos y de los clientes en Japón, Corea, Latinoamérica y España.
Estas versiones del informe en japonés, coreano y español no contienen la opinión independiente emitida por los auditores, pero se puede acceder a esta información en la versión en inglés del documento. Las partes interesadas deben usar la versión en inglés como complemento de las versiones en japonés, coreano y español.
De aquí en adelante, los siguientes informes trimestrales estarán traducidos. Dado que los controles SOC 1 se incluyen en los informes de primavera y otoño de SOC 2, esta programación brinda una cobertura anual para todos los idiomas traducidos cuando se la combina con las versiones en inglés.
SOC 1 invierno (del 1/1 al 31/12)
SOC 2 primavera (del 1/4 al 31/3)
SOC 1 verano (del 1/7 al 30/6)
SOC 2 otoño (del 1/10 al 30/9)
Los clientes pueden descargar los informes SOC 1 invierno 2023 traducidos al japonés, coreano y español a través de AWS Artifact, un portal de autoservicio para el acceso bajo demanda a los informes de conformidad de AWS. Inicie sesión en AWS Artifact mediante la Consola de administración de AWS u obtenga más información en Introducción a AWS Artifact.
El informe SOC 1 invierno 2023 incluye un total de 171 servicios que se encuentran dentro del alcance. Para acceder a información actualizada, que incluye novedades sobre cuándo se agregan nuevos servicios, consulte los Servicios de AWS en el ámbito del programa de conformidad y seleccione SOC.
AWS se esfuerza de manera continua por añadir servicios dentro del alcance de sus programas de conformidad para ayudarlo a cumplir con sus necesidades de arquitectura y regulación. Si tiene alguna pregunta o sugerencia sobre la conformidad de los SOC, no dude en comunicarse con su equipo de cuenta de AWS.
Para obtener más información sobre los programas de conformidad y seguridad, consulte los Programas de conformidad de AWS. Como siempre, valoramos sus comentarios y preguntas; de modo que no dude en comunicarse con el equipo de conformidad de AWS a través de la página Contacte con nosotros.
Si tiene comentarios sobre esta publicación, envíelos a través de la sección de comentarios que se encuentra a continuación.
¿Quiere acceder a más contenido instructivo, novedades y anuncios de características de seguridad de AWS? Síganos en X.
AWS Community Days conferences are in full swing with AWS communities around the globe. The AWS Community Day Poland was hosted last week with more than 600 cloud enthusiasts in attendance. Community speakers Agnieszka Biernacka, Krzysztof Kąkol, and more, presented talks which captivated the audience and resulted in vibrant discussions throughout the day. My teammate, Wojtek Gawroński, was at the event and he’s already looking forward to attending again next year!
Last week’s launches Here are some launches that got my attention during the previous week.
These two announcements related to Knowledge Bases for Amazon Bedrock caught my eye:
Metadata filtering to improve retrieval accuracy – With metadata filtering, you can retrieve not only semantically relevant chunks but a well-defined subset of those relevant chunks based on applied metadata filters and associated values.
For a full list of AWS announcements, be sure to keep an eye on the What’s New at AWS page.
Other AWS news AWS open source news and updates – My colleague Ricardo writes this weekly open source newsletter in which he highlights new open source projects, tools, and demos from the AWS Community.
Upcoming AWS events AWS Summits – These are free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. Whether you’re in the Americas, Asia Pacific & Japan, or EMEA region, learn here about future AWS Summit events happening in your area.
AWS Community Days – Join an AWS Community Day event just like the one I mentioned at the beginning of this post to participate in technical discussions, workshops, and hands-on labs led by expert AWS users and industry leaders from your area. If you’re in Kenya, or Nepal, there’s an event happening in your area this coming weekend.
Kumar Kartikeya Dwivedi has been working to add support for exceptions to BPF
since mid-2023. In July, Dwivedi posted
the first patch set in this effort, which adds support for basic stack unwinding.
In February 2024, he posted
the second patch set
aimed at letting the kernel release resources held by the BPF program when an
exception occurs. This makes exceptions usable in many more contexts.
Security updates have been issued by AlmaLinux (bind, bind and dhcp, bind9.16, gnutls, httpd:2.4/mod_http2, squid:4, and unbound), Debian (kernel, trafficserver, and xorg-server), Fedora (chromium, kernel, libopenmpt, and rust-h2), Mageia (apache-mod_jk, golang, indent, openssl, perl-HTTP-Body, php, rear, ruby-rack, squid, varnish, and xfig), Oracle (bind, squid, unbound, and X.Org server), Red Hat (bind and dhcp and unbound), Slackware (less and php), SUSE (gnutls, python-Pillow, webkit2gtk3, xen, xorg-x11-server, and xwayland), and Ubuntu (yard).
In an ever-changing security landscape, teams must be able to quickly remediate security risks. Many organizations look for ways to automate the remediation of security findings that are currently handled manually. Amazon CodeWhisperer is an artificial intelligence (AI) coding companion that generates real-time, single-line or full-function code suggestions in your integrated development environment (IDE) to help you quickly build software. By using CodeWhisperer, security teams can expedite the process of writing security automation scripts for various types of findings that are aggregated in AWS Security Hub, a cloud security posture management (CSPM) service.
In this post, we present some of the current challenges with security automation and walk you through how to use CodeWhisperer, together with Amazon EventBridge and AWS Lambda, to automate the remediation of Security Hub findings. Before reading further, please read the AWS Responsible AI Policy.
Current challenges with security automation
Many approaches to security automation, including Lambda and AWS Systems Manager Automation, require software development skills. Furthermore, the process of manually writing code for remediation can be a time-consuming process for security professionals. To help overcome these challenges, CodeWhisperer serves as a force multiplier for qualified security professionals with development experience to quickly and effectively generate code to help remediate security findings.
Security professionals should still cultivate software development skills to implement robust solutions. Engineers should thoroughly review and validate any generated code, as manual oversight remains critical for security.
Solution overview
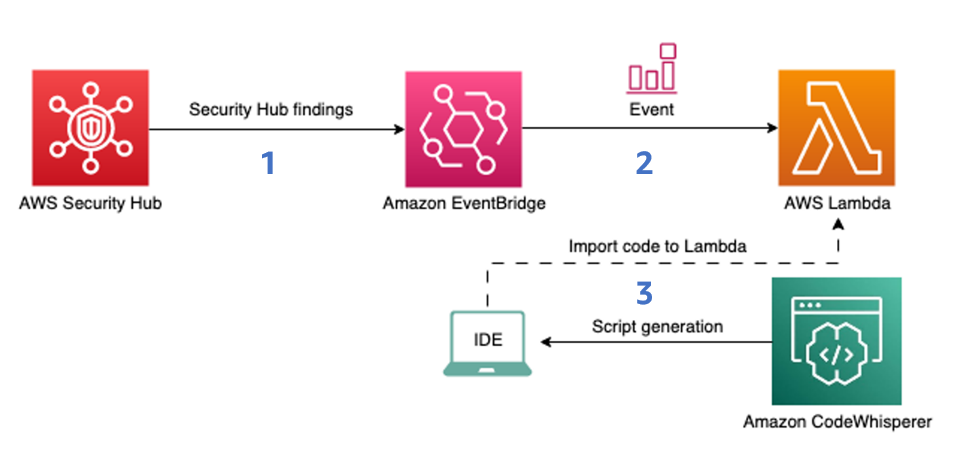
Figure 1 shows how the findings that Security Hub produces are ingested by EventBridge, which then invokes Lambda functions for processing. The Lambda code is generated with the help of CodeWhisperer.
Figure 1: Diagram of the solution
Security Hub integrates with EventBridge so you can automatically process findings with other services such as Lambda. To begin remediating the findings automatically, you can configure rules to determine where to send findings. This solution will do the following:
Ingest an Amazon Security Hub finding into EventBridge.
Use an EventBridge rule to invoke a Lambda function for processing.
Use CodeWhisperer to generate the Lambda function code.
It is important to note that there are two types of automation for Security Hub finding remediation:
Partial automation, which is initiated when a human worker selects the Security Hub findings manually and applies the automated remediation workflow to the selected findings.
End-to-end automation, which means that when a finding is generated within Security Hub, this initiates an automated workflow to immediately remediate without human intervention.
Important: When you use end-to-end automation, we highly recommend that you thoroughly test the efficiency and impact of the workflow in a non-production environment first before moving forward with implementation in a production environment.
Prerequisites
To follow along with this walkthrough, make sure that you have the following prerequisites in place:
In this scenario, you have been tasked with making sure that versioning is enabled across all Amazon Simple Storage Service (Amazon S3) buckets in your AWS account. Additionally, you want to do this in a way that is programmatic and automated so that it can be reused in different AWS accounts in the future.
To do this, you will perform the following steps:
Generate the remediation script with CodeWhisperer
Create the Lambda function
Integrate the Lambda function with Security Hub by using EventBridge
Create a custom action in Security Hub
Create an EventBridge rule to target the Lambda function
Run the remediation
Generate a remediation script with CodeWhisperer
The first step is to use VS Code to create a script so that CodeWhisperer generates the code for your Lambda function in Python. You will use this Lambda function to remediate the Security Hub findings generated by the [S3.14] S3 buckets should use versioning control.
Note: The underlying model of CodeWhisperer is powered by generative AI, and the output of CodeWhisperer is nondeterministic. As such, the code recommended by the service can vary by user. By modifying the initial code comment to prompt CodeWhisperer for a response, customers can change the corresponding output to help meet their needs. Customers should subject all code generated by CodeWhisperer to typical testing and review protocols to verify that it is free of errors and is in line with applicable organizational security policies. To learn about best practices on prompt engineering with CodeWhisperer, see this AWS blog post.
To generate the remediation script
Open a new VS Code window, and then open or create a new folder for your file to reside in.
Create a Python file called cw-blog-remediation.py as shown in Figure 2.
Figure 2: New VS Code file created called cw-blog-remediation.py
Add the following imports to the Python file.
import json
import boto3
Because you have the context added to your file, you can now prompt CodeWhisperer by using a natural language comment. In your file, below the import statements, enter the following comment and then press Enter.
# Create lambda function that turns on versioning for an S3 bucket after the function is triggered from Amazon EventBridge
Accept the first recommendation that CodeWhisperer provides by pressing Tab to use the Lambda function handler, as shown in Figure 3. &ngsp;
Figure 3: Generation of Lambda handler
To get the recommendation for the function from CodeWhisperer, press Enter. Make sure that the recommendation you receive looks similar to the following. CodeWhisperer is nondeterministic, so its recommendations can vary.
import json
import boto3
# Create lambda function that turns on versioning for an S3 bucket after function is triggered from Amazon EventBridgedef lambda_handler(event, context):
s3 = boto3.client('s3')
bucket = event['detail']['requestParameters']['bucketName']
response = s3.put_bucket_versioning(
Bucket=bucket,
VersioningConfiguration={
'Status': 'Enabled'
}
)
print(response)
return {
'statusCode': 200,
'body': json.dumps('Versioning enabled for bucket ' + bucket)
}
You can change the function body to fit your use case. To get the Amazon Resource Name (ARN) of the S3 bucket from the EventBridge event, replace the bucket variable with the following line:
To prompt CodeWhisperer to extract the bucket name from the bucket ARN, use the following comment:
# Take the S3 bucket name from the ARN of the S3 bucket
Your function code should look similar to the following:
import json
import boto3
# Create lambda function that turns on versioning for an S3 bucket after function is triggered from Amazon EventBridgedef lambda_handler(event, context):
s3 = boto3.client('s3')
bucket = event['detail']['findings'][0]['Resources'][0]['Id']
# Take the S3 bucket name from the ARN of the S3 bucket
bucket = bucket.split(':')[5]
response = s3.put_bucket_versioning(
Bucket=bucket,
VersioningConfiguration={
'Status': 'Enabled'
}
)
print(response)
return {
'statusCode': 200,
'body': json.dumps('Versioning enabled for bucket ' + bucket)
}
Create a .zip file for cw-blog-remediation.py. Find the file in your local file manager, right-click the file, and select compress/zip. You will use this .zip file in the next section of the post.
Create the Lambda function
The next step is to use the automation script that you generated to create the Lambda function that will enable versioning on applicable S3 buckets.
In the left navigation pane, choose Functions, and then choose Create function.
Select Author from Scratch and provide the following configurations for the function:
For Function name, select sec_remediation_function.
For Runtime, select Python 3.12.
For Architecture, select x86_64.
For Permissions, select Create a new role with basic Lambda permissions.
Choose Create function.
To upload your local code to Lambda, select Upload from and then .zip file, and then upload the file that you zipped.
Verify that you created the Lambda function successfully. In the Code source section of Lambda, you should see the code from the automation script displayed in a new tab, as shown in Figure 4.
Figure 4: Source code that was successfully uploaded
Choose the Code tab.
Scroll down to the Runtime settings pane and choose Edit.
For Handler, enter cw-blog-remediation.lambda_handler for your function handler, and then choose Save, as shown in Figure 5.
Figure 5: Updated Lambda handler
For security purposes, and to follow the principle of least privilege, you should also add an inline policy to the Lambda function’s role to perform the tasks necessary to enable versioning on S3 buckets.
In the Lambda console, navigate to the Configuration tab and then, in the left navigation pane, choose Permissions. Choose the Role name, as shown in Figure 6.
Figure 6: Lambda role in the AWS console
In the Add permissions dropdown, select Create inline policy.
Figure 7: Create inline policy
Choose JSON, add the following policy to the policy editor, and then choose Next.
In the left navigation pane, choose Settings, and then choose Custom actions.
Choose Create custom action.
Provide the following information, as shown in Figure 8:
For Name, enter TurnOnS3Versioning.
For Description, enter Action that will turn on versioning for a specific S3 bucket.
For Custom action ID, enter TurnOnS3Versioning.
Figure 8: Create a custom action in Security Hub
Choose Create custom action.
Make a note of the Custom action ARN. You will need this ARN when you create a rule to associate with the custom action in EventBridge.
Create an EventBridge rule to target the Lambda function
The next step is to create an EventBridge rule to capture the custom action. You will define an EventBridge rule that matches events (in this case, findings) from Security Hub that were forwarded by the custom action that you defined previously.
On the Define rule detail page, give your rule a name and description that represents the rule’s purpose—for example, you could use the same name and description that you used for the custom action. Then choose Next.
Scroll down to Event pattern, and then do the following:
For Event source, make sure that AWS services is selected.
For AWS service, select Security Hub.
For Event type, select Security Hub Findings – Custom Action.
Select Specific custom action ARN(s) and enter the ARN for the custom action that you created earlier.
Figure 9: Specify the EventBridge event pattern for the Security Hub custom action workflow
As you provide this information, the Event pattern updates.
Choose Next.
On the Select target(s) step, in the Select a target dropdown, select Lambda function. Then from the Function dropdown, select sec_remediation_function.
Choose Next.
On the Configure tags step, choose Next.
On the Review and create step, choose Create rule.
Run the automation
Your automation is set up and you can now test the automation. This test covers a partial automation workflow, since you will manually select the finding and apply the remediation workflow to one or more selected findings.
Important: As we mentioned earlier, if you decide to make the automation end-to-end, you should assess the impact of the workflow in a non-production environment. Additionally, you may want to consider creating preventative controls if you want to minimize the risk of event occurrence across an entire environment.
To run the automation
In the Security Hub console, on the Findings tab, add a filter by entering Title in the search box and selecting that filter. Select IS and enter S3 general purpose buckets should have versioning enabled (case sensitive). Choose Apply.
In the filtered list, choose the Title of an active finding.
Before you start the automation, check the current configuration of the S3 bucket to confirm that your automation works. Expand the Resources section of the finding.
Under Resource ID, choose the link for the S3 bucket. This opens a new tab on the S3 console that shows only this S3 bucket.
In your browser, go back to the Security Hub tab (don’t close the S3 tab—you will need to return to it), and on the left side, select this same finding, as shown in Figure 10.
Figure 10: Filter out Security Hub findings to list only S3 bucket-related findings
In the Actions dropdown list, choose the name of your custom action.
Figure 11: Choose the custom action that you created to start the remediation workflow
When you see a banner that displays Successfully started action…, go back to the S3 browser tab and refresh it. Verify that the S3 versioning configuration on the bucket has been enabled as shown in figure 12.
Figure 12: Versioning successfully enabled
Conclusion
In this post, you learned how to use CodeWhisperer to produce AI-generated code for custom remediations for a security use case. We encourage you to experiment with CodeWhisperer to create Lambda functions that remediate other Security Hub findings that might exist in your account, such as the enforcement of lifecycle policies on S3 buckets with versioning enabled, or using automation to remove multiple unused Amazon EC2 elastic IP addresses. The ability to automatically set public S3 buckets to private is just one of many use cases where CodeWhisperer can generate code to help you remediate Security Hub findings.
To sum up, CodeWhisperer acts as a tool that can help boost the productivity of security experts who have coding abilities, assisting them to swiftly write code to address security issues. However, security specialists should continue building their software development capabilities to implement robust solutions. Engineers should carefully review and test any generated code, since human oversight is still vital for security.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Backblaze Event Notifications is now in public preview. If you’re interested in joining the waitlist, feel free to sign up here.
Backblaze believes companies should be able to store, use, and protect their data in whatever way is best for their business—and that doing so should be easy. That’s why we’re such fierce advocates for the open cloud and why today’s announcement is so exciting.
Event Notifications—available in public preview—gives businesses the freedom to build automated workloads across the different best-of-breed cloud platforms they use or want to use, saving time and money and improving end user experiences.
Here’s how: With Backblaze Event Notifications, any data changes within Backblaze B2 Cloud Storage—like uploads, updates, or deletions—can automatically trigger actions in a workflow, including transcoding video files, spooling up data analytics, delivering finished assets to end users, and many others. Importantly, unlike many other solutions currently available, Backblaze’s service doesn’t lock you into one platform or require you to use legacy tools from AWS.
So, to businesses that want to create an automated workflow that combines different compute, content delivery networks (CDN), data analytics, and whatever other cloud service: Now you can, with the bonus of cloud storage at a fifth of the rates of other solutions and free egress.
If you’re already a Backblaze customer, you can join the waiting list for the Event Notifications preview by signing up here. Once you’re admitted to the preview, the Event Notifications option will become visible in your Backblaze B2 account.
Not a Backblaze customer yet? Sign up for a free Backblaze B2 account and join the waitlist. Read on for more details on how Event Notifications can benefit you.
With Event Notifications, we can eliminate the final AWS component, Simple Queue Service (SQS), from our infrastructure. This completes our transition to a more streamlined and cost-effective tech stack. It’s not just about simplifying operations—it’s about achieving full independence from legacy systems and future-proofing our infrastructure.
— Oleh Aleynik, Senior Software Engineer and Co-Founder at CloudSpot.
A Deeper Dive on Backblaze’s Event Notifications Service
Event Notifications is a service designed to streamline and automate data workflows for Backblaze B2 customers. Whether it’s compressing objects, transcoding videos, or transforming data files, Event Notifications empowers you to orchestrate complex, multistep processes seamlessly.
The top line benefit of Event Notifications is its ability to trigger processing workflows automatically whenever data changes on Backblaze B2. This means that as soon as new data is uploaded, changed, or deleted, the relevant processing steps can be initiated without manual intervention. This automation not only saves time and resources, but it also ensures that workflows are consistently executed with precision, free from human errors.
What sets Event Notifications apart is its flexibility. Unlike some other solutions that are tied to specific target services, Event Notifications allows customers the freedom to choose the target services that best suit their needs. Whether it’s integrating with third-party applications, cloud services, or internal systems, Event Notifications seamlessly integrates into existing workflows, offering unparalleled versatility.
Finally, Event Notifications doesn’t only bring greater ease and efficiency to workflows, it is also designed for very easy enablement. Whether via browser UI or SDKs or APIs or CLI, it is incredibly simple to set up a notification rule and integrate it with your preferred target service. Simply choose your event type, set the criteria, and input your endpoint URL, and a new workflow can be configured in minutes.
Public Preview Update: July 31, 2024
Additional capabilities offered in the public preview include:
Retries: Event Notifications are automatically re-sent if the initial delivery attempt fails. This feature increases the reliability of Event Notifications by ensuring that temporary issues do not result in missed events, thus maintaining the integrity of your event-driven workflows.
Delivery: Event Notifications are designed for the at-least-once delivery guarantee to ensure Event Notifications are delivered reliably, even in the presence of network or system failures.
What Is Backblaze B2 Event Notifications Good For?
By leveraging Event Notifications, Backblaze B2 customers can simplify their data processing pipelines, reduce manual effort, and increase operational efficiency. With the ability to automate repetitive tasks and handle millions of objects per day, businesses can focus on extracting insights from their data rather than managing the logistics of data processing.
Automating tasks: Event Notifications allows users to trigger automated actions in response to changes in stored objects like upload, delete, and hide actions, streamlining complex data processing tasks.
Orchestrating workflows: Users can orchestrate multi-step workflows, such as compressing files, transcoding videos, or transforming data formats, based on specific object events.
Integrating with services: The feature offers flexible integration capabilities, enabling seamless interaction with various services and tools to enhance data processing and management.
Monitoring changes: Users can efficiently monitor and track changes to stored objects, ensuring timely responses to evolving data requirements and faster security response to safeguard critical assets.
What Are Some of the Key Capabilities of Backblaze B2 Event Notifications?
Flexible Implementation: Event Notifications are sent as HTTP POST requests to the desired service or endpoint within your infrastructure or any other cloud service. This flexibility ensures seamless integration with your existing workflows. For instance, your endpoint could be Fastly Compute, AWS Lambda, Azure Functions, or Google Cloud Functions, etc.
Event Categories: Specify the types of events you want to be notified about, such as when files are uploaded and deleted. This allows you to receive notifications tailored to your specific needs. For instance, you have the flexibility to specify different methods of object creation, such as copying, uploading, or multipart replication, to trigger event notifications. You can also manage Event Notification rules through UI or API.
Filter by Prefix: Define prefixes to filter events, enabling you to narrow down notifications to specific sets of objects or directories within your storage on Backblaze B2. For instance, if your bucket contains audio, video, and text files organized into separate prefixes, you can specify the prefix for audio files to receive event notifications exclusively for audio files.
Custom Headers: Include personalized HTTP headers in your event notifications to provide additional authentication or contextual information when communicating with your target endpoint. For example, you can use these headers to add necessary authentication tokens or API keys for your target endpoint, or include any extra metadata related to the payload to offer contextual information to your webhook endpoint, and more.
Signed Notification Messages: You can configure outgoing messages to be signed by the Event Notifications service, allowing you to validate signatures and verify that each message was generated by Backblaze B2 and not tampered with in transit.
Test Rule Functionality: Validate the functionality of your target endpoint by testing event notifications before deploying them into action. This allows you to ensure that your integration with your target endpoint is set up correctly and functioning as expected.
Event Notifications represents a significant advancement in data management and automation for Backblaze B2 users. By providing a flexible and powerful capability for orchestrating data processing workflows, Backblaze continues to empower businesses to unlock the full potential of their data with ease and efficiency.
A new paper presents a polynomial-time quantum algorithm for solving certain hard lattice problems. This could be a big deal for post-quantum cryptographic algorithms, since many of them base their security on hard lattice problems.
A few things to note. One, this paper has not yet been peer reviewed. As this comment points out: “We had already some cases where efficient quantum algorithms for lattice problems were discovered, but they turned out not being correct or only worked for simple special cases.” I expect we’ll learn more about this particular algorithm with time. And, like many of these algorithms, there will be improvements down the road.
Two, this is a quantum algorithm, which means that it has not been tested. There is a wide gulf between quantum algorithms in theory and in practice. And until we can actually code and test these algorithms, we should be suspicious of their speed and complexity claims.
And three, I am not surprised at all. We don’t have nearly enough analysis of lattice-based cryptosystems to be confident in their security.
EDITED TO ADD (4/20): The paper had a significant error, and has basically been retracted. From the new abstract:
Note: Update on April 18: Step 9 of the algorithm contains a bug, which I don’t know how to fix. See Section 3.5.9 (Page 37) for details. I sincerely thank Hongxun Wu and (independently) Thomas Vidick for finding the bug today. Now the claim of showing a polynomial time quantum algorithm for solving LWE with polynomial modulus-noise ratios does not hold. I leave the rest of the paper as it is (added a clarification of an operation in Step 8) as a hope that ideas like Complex Gaussian and windowed QFT may find other applications in quantum computation, or tackle LWE in other ways.
(UPDATED on April 15, 2024, with information regarding the Palestinian territories.)
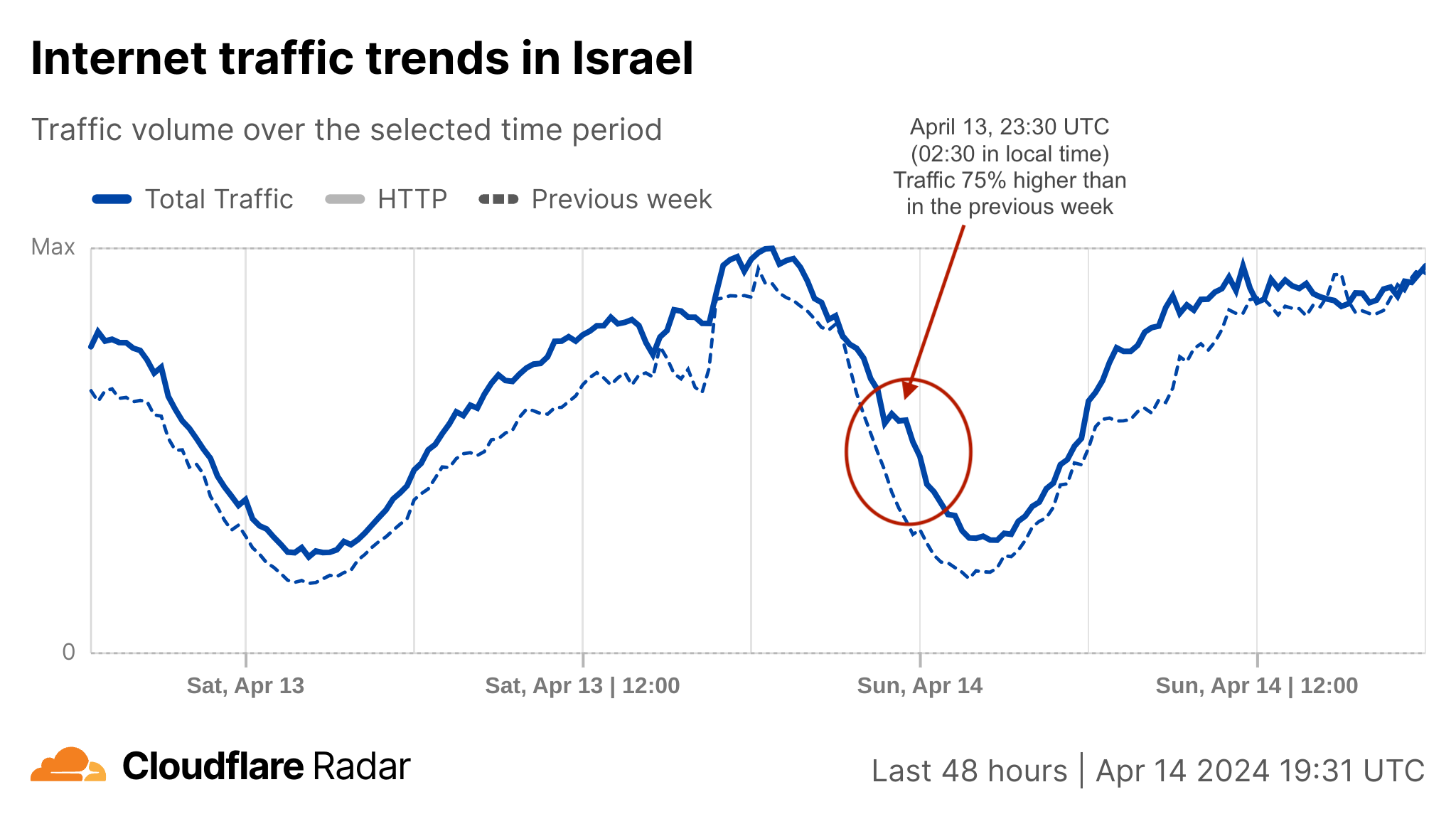
As news came on Saturday, April 13, 2024, that Iran was launching a coordinated retaliatory attack on Israel, we took a closer look at the potential impact on Internet traffic and attacks. So far, we have seen some traffic shifts in both Israel and Iran, but we haven’t seen a coordinated large cyberattack on Israeli domains protected by Cloudflare.
First, let’s discuss general Internet traffic patterns. Following reports of attacks with drones, cruise missiles, and ballistic missiles, confirmed by Israeli and US authorities, Internet traffic in Israel surged after 02:00 local time on Saturday, April 13 (23:00 UTC on April 12), peaking at 75% higher than in the previous week around 02:30 (23:30 UTC) as people sought news updates. This traffic spike was predominantly driven by mobile device usage, accounting for 62% of all traffic from Israel at that time. Traffic remained higher than usual during Sunday.
Around that time, at 02:00 local time (23:00 UTC), the IDF (Israel Defense Forces) posted on X that sirens were sounding across Israel because of an imminent attack from Iran.
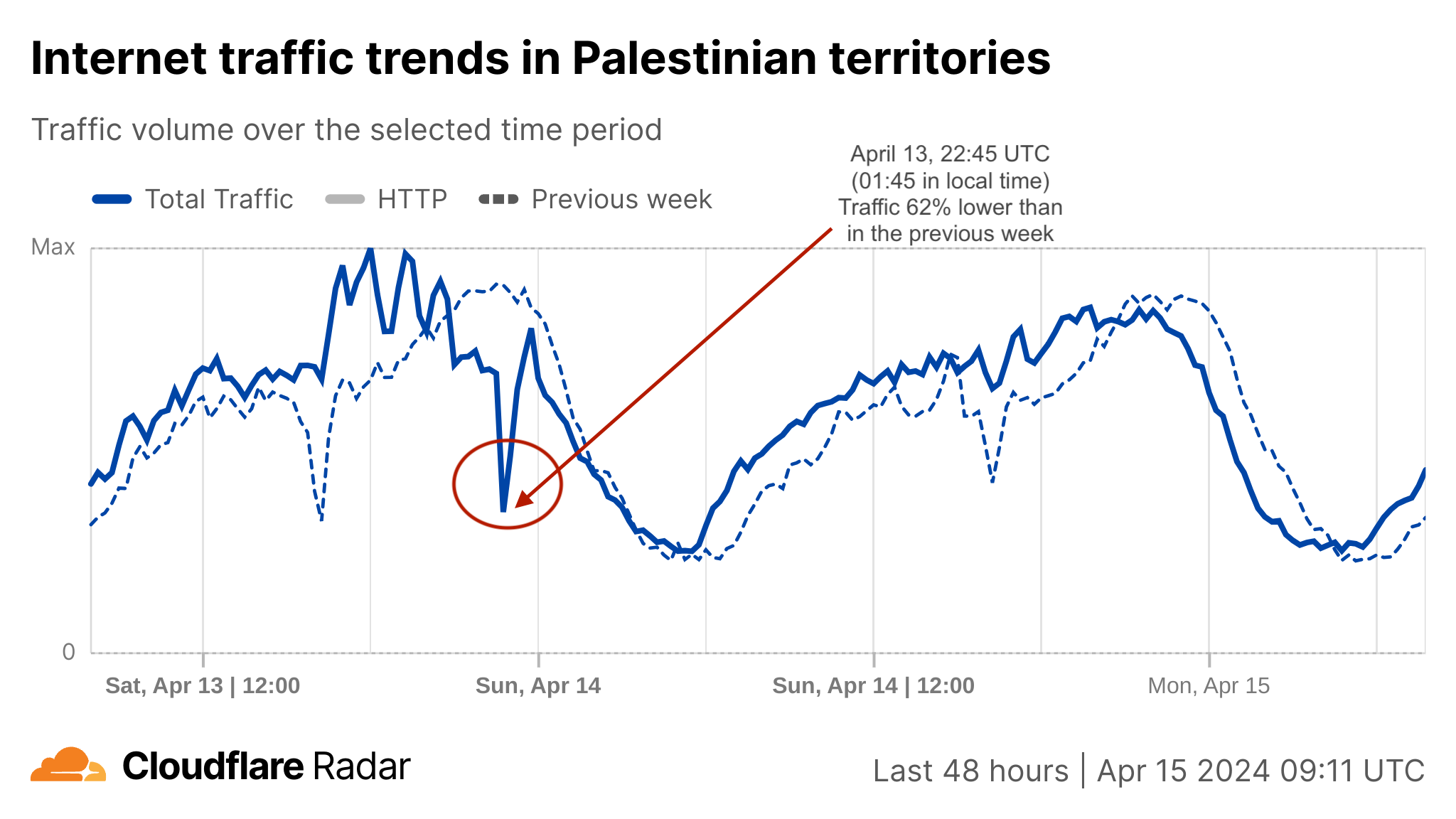
(April 15 UPDATE: the Palestinian territories related part). At around the same time, 01:25 local time (22:45 UTC), when the sirens were sounding in Israel, we observed not an increase, but a clear drop in traffic in Palestinian territories. The noticeable drop was seen in all of the Palestinian governorates, although it was a bigger drop in the West Bank, than in the Gaza Strip.
Usually, based on our past observations, drops in traffic unrelated to connectivity issues can occur when people pause their online activities for some reason (an eclipse or war, for example) or turn to television for news updates instead of the Internet (common during election days when TVs broadcast the latest exit polls).
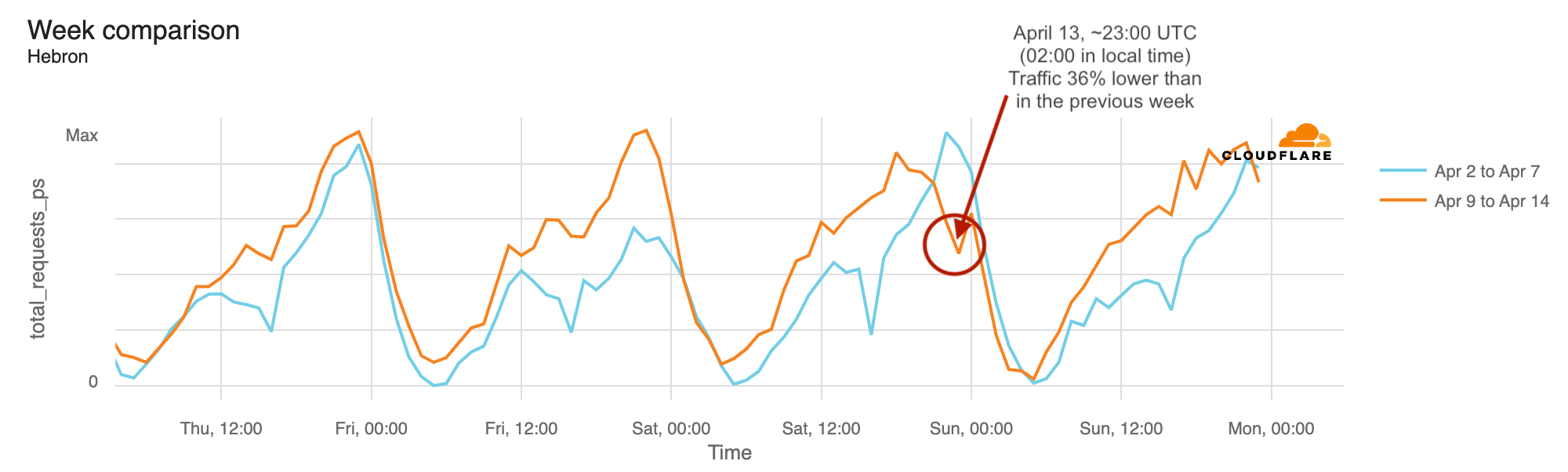
Here’s the noticeable HTTP requests drop in Hebron, one of the most populated states of the Palestinian territories, part of the West Bank. The noticeable drops in the blue line from the previous week are related to the Ramadan, and the Iftar, the first meal after sunset that breaks the fast and often also a family or community event. Ramadan ended on Tuesday, April 9, 2024.
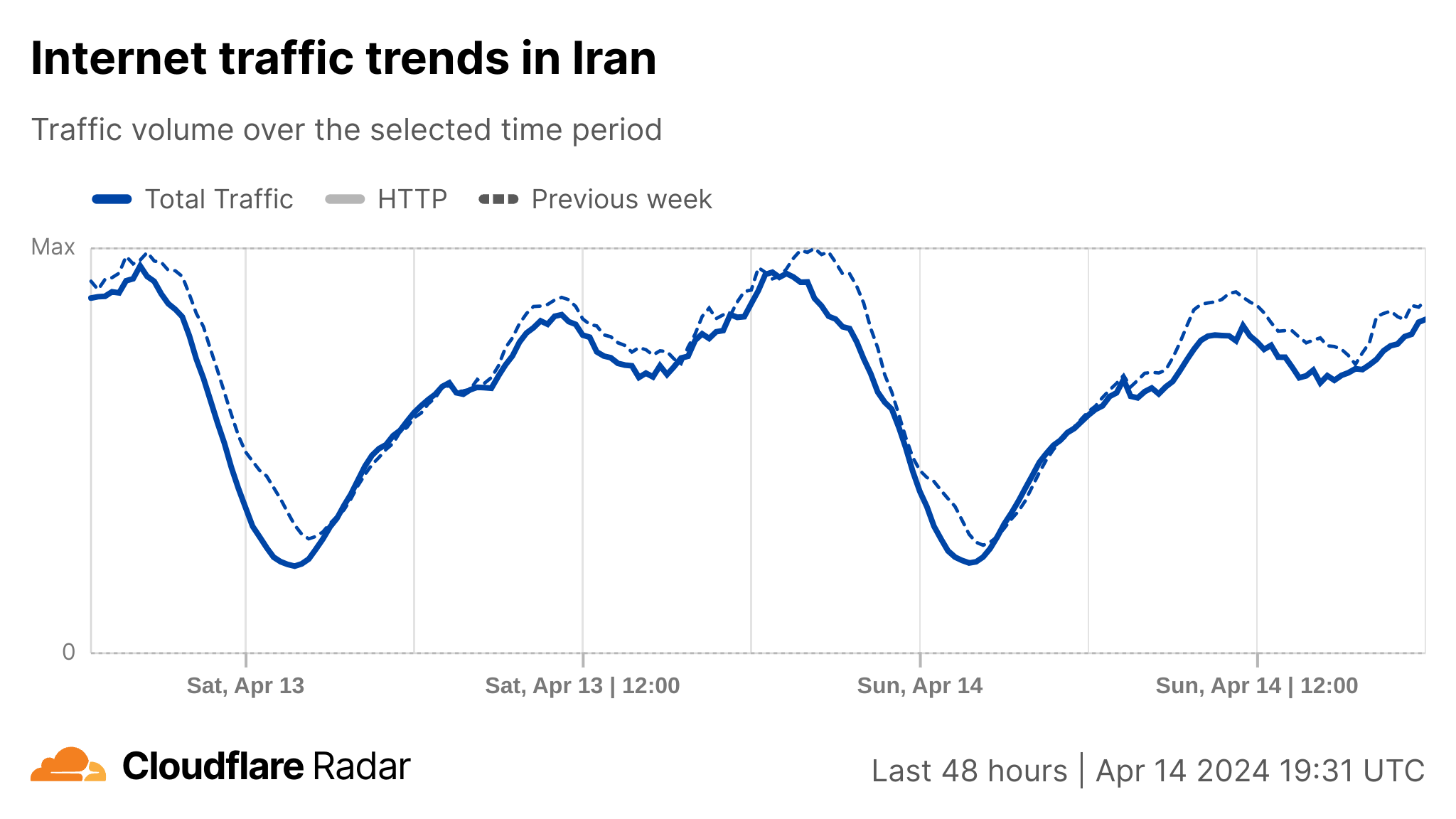
Meanwhile, in Iran, there has been a noticeable decline in traffic over the past few days in the early morning hours, around 04:30 local time (01:00 UTC), as compared to the previous week. However, this decline appears to be linked to the conclusion of Ramadan, which ended April 9. As we have writtenbefore, during Ramadan, there is typically an increase in traffic around 04:00 in most Muslim countries for Suhur, the pre-dawn meal. Nevertheless, traffic was higher in Iran early in the morning of Sunday, April 14 than the previous day, between 02:30 local time (23:00 UTC on April 13) and 07:00 (03:30 UTC).
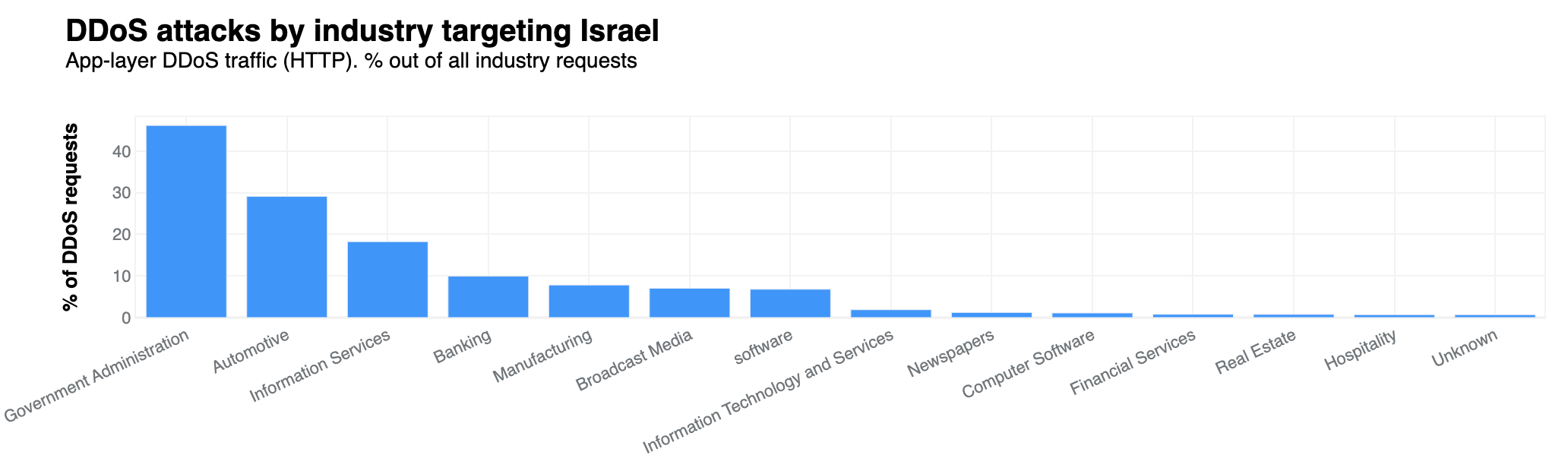
When analyzing application layer attacks, we haven’t observed any significant changes in those targeting Israel over the past few days. However, over the past month, the Government Administration sector emerged as the most targeted industry, with blocked DDoS requests accounting for 46% of all traffic directed towards it.
Based on Cloudflare data, we have not yet seen a coordinated cyberattack campaign targeting Israel. However, we saw a clear uptick in attacks back in October 2023, after the Israel-Hamas war started, as we noted in a blog post at that time.
The 6.9-rc4 kernel prepatch is out for
testing. “Nothing particularly unusual going on this week – some new hw
mitigations may stand out, but after a decade of this I can’t really call
it ‘unusual’ any more, can I?“
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.